{kind=link}
- ↑ Forrer Е. Neue Probleme zum Ursprung der indogermanichen Sprachen. «Mannus», B. 26, 1934.
- ↑ Горнунг Б. В. К вопросу об образовании индоевропейской языковой общности. Доклад на VII международном конгрессе антропологических и этнографических наук. — Μ., 1964.
- ↑ 1 2 J. C. Kerns. Eurasiatic Pronouns and the Indo-Uralic Question. Fairborn, Ohio, 1967.
- ↑ Хелимский Е. А. Труды В. М. Иллич-Свитыча и развитие ностратических исследований за рубежом // Зарубежная историография славяноведения и балканистики / Отв. ред.: А. С. Мыльников, АН СССР, Ин-т славяноведения и балканистики. — М. : Наука, 1986. — С. 269.
N. KisamovTürkic Substrate in English
http://s155239215.onlinehome.us/turkic/41TurkicInEnglish/EnglishTurkicLexiconEn.htm
Journal of Eurasian Studies,
October-December 2013, Volume V, Issue 4
Mikes International, The Hague, Holland, 2013, ISSN 1877-4199
http://www.federatio.org/joes/EurasianStudies_0413s1.pdf
http://www.federatio.org/joes/EurasianStudies_0413.pdf
© Copyright Mikes International 2001-2013, All Rights Reserved
Russian text
Тюркский Субстрат в Английском
в сборнике
Вопросы этногенеза и этнической истории народов Средней Азии, Шамсиддин Камолиддин (ред.), Вып. 1, 2016, стр. 191-240
LAP LAMBERT Academic Publishing, Saarbrucken, Deutschland, ISBN 978-3-659-95130-5
Links
https://web.archive.org/web/20130914022422/
Web Archive
For
Germanic substrate hypothesis
refer to that Wikipedia article, which suffers a major bout of blindness indirectly addressed on
this page.
For a complete Irek Bikkinin's article “Turkic Borrowings In English”, 1994, click here:
http://www.tatarica.narod.ru/world/language/tat_eng.htm
(in Russian),
Turkic Borrowings In English (in
English).
Valentyn Stetsyuk, 2003,
Research of Prehistoric Ethnogenetic
Processes in Eastern Europe
Comments on Indo-European linguistics are here:
http://www.ece.lsu.edu/kak/ary2.pdf
![]()
![]()
http://www.danshort.com/ie/grafx/timeline.gif
The graph is a simplified draft. Etymological panorama needs to show contribution of each component,
including missing ones, and their real fractional contribution to modern live language.
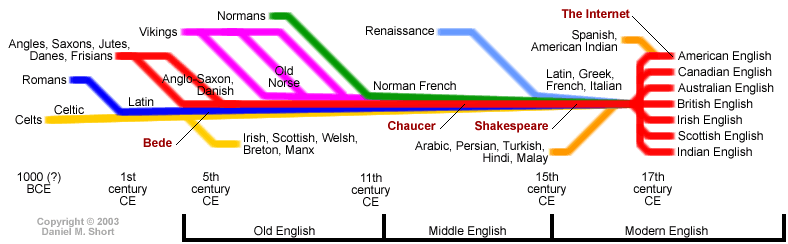
Since the initial publication of the article in 2013, the substrate word list has steadily grown by about doubling, along with expanded narrative part.
Türkic Substrate in English
Author’s Foreword. The objective of this book is history, a language is no more than its ocular. To the curious, the work demonstrates the tangible origin of a good portion of the European languages from historic and genetic perspective. I have a very rudimentary familiarity with any live Türkic language, and for the linguistic contents, this compendium relied on attestations found in literature and dictionaries, and not in a small degree on insights and kind help of native speakers, Türkic and non-Türkic. The fundamental facts supporting this work are altered neither by the want of linguistic competence, nor by the want of unflawed presentation. The scrutiny is useless to those who already know it all. The work consists of two parts; the first part contains an overview of the history, methods, aspects of the problem, premises, and broad observations in the form of mini essays. The second part contains a catalogue of the lexical material under a heading Etymological Notes. With a vast measure of translations, quotations, references, and comparisons, such a mass is apt to accrete mistakes, misunderstandings, and misinterpretations. The father of linguistics M. Kashgari said a millennium ago, Yazmas atım yağmur, yañılmas bilge yañku “only rain shoots without misses, only echo is a sage without mistakes”. The surface of the historical canvas has been barely scratched. There is plenty of room for kind advice and improvement. A spectrum of averted subjects are ready for examination.
3
Kim ol jolsuz ersä aŋa keŋrü jol
Who does not trod a beaten path has his course wide open
(Proverb)
Turkism (or Turkizm) is a word in any language that comes from Türkic languages, directly or indirectly. The adjective Turkic (or Türkic) applies not to an individual language, but to the entire linguistic family numbering some 40+ languages with various degree of mutual understandability. Unlike the structured pairs Celtic/Celt, Turkish/Turk, British/Brit, the collective adjective Turkic (Türkic) does not have a standard counterpart noun in English, since the word “Turk” is already used as a concrete noun counterpart for “Turkish”. Very few names of the Turkic ethnoses and languages contain the part “Türk”. Most linguists know the difference between Turkish and Turkic/Türkic, and do not confuse them. In this book, for clarity, the complementary terms Türkic and Türk are used as collective designations.
The term “Proto-Türkic” refers to a continuum of languages with similar syntactic typologies that
formed a lingua franca Sprachbund. The use of the term “Proto-Türkic” is better avoided since
it is inaccurately used as a formed seed language under inapplicable Family Tree linguistic model.
As a result of diverse linguistic amalgamations, its functional designation is better defined with
the unconventional term “Türkic Sprachbund”. Following N.Trubetzkoy (N.Trubetzkoy 1923,
1928), the Türkic linguistic family belongs to the
Sprachbund language union formed between language families consisting of unrelated Türkic,
Uralic, Mongolian, and Manchurian families, dubbed “Union of Uralo-Altaic language families”. A
language or language family can at the same time belong, or fluctuate between, two different
Sprachbunds, such as Indo-European fluctuating between the Mediterranean and Uralo-Altaic
Sprachbunds. A
Sprachbund is defined as an areal group of languages with common traits:
1. considerable similarity in syntax;
2. similarity in principles of morphological structure;
3. a large number of common cultural words, and optionally
4. a surface similarity in sound systems, lacking however any systematic sound correspondences,
correspondences in morphological elements, and common elementary vocabulary.
In contrast to the Family Tree model, amalgamation occurs on a case-by-case basis, it does not follow any particular “linguistic law”. Amalgamation is always unique, even when it occurs in nearly the same linguistic, economic, and environmental circumstances. It is a result of stochastic human interactions, environmental events, and very stochastic human whims. It follows the rule that there are no rules, only some tendencies with uncertain statistic frequencies. In that, amalgamation agrees with the Family Tree model and in particular with the Indo-European linguistic hypothesis where they accept a premise of statistical probability for tendencies inaccurately named “linguistic laws”. The Turkish language, for example, is amalgamated of dozens of languages, each with its own history and idiosyncrasies, not all of them entirely Türkic, with a substantial influence of the local, Arabic and Persian cultural layers. Just the Islamic segment of the M. Kashgari’s work of the 11th c. lists 8 Oguz and 2 Ogur monolingual Türkic communities, and 10 bilingual Türkic communities, neither of those accounted for the Arabic and Persian cultural influence. Nearly completely outside of the M. Kashgari’s orbit were the huge western and eastern segments of the Turkic phylum, many of which over the last millennium also contributed to the Turkish language. In the last two centuries, many languages experienced profound changes under unification, division, cleansing, reforms, leveling, and increasing influx from culturally and geographically domineering languages. All “IE” languages passed through a similar agglomeration that affected many linguistic aspects including typology and phonetics.
Typological features of the Türkic languages include an agglutinative and exclusively suffixing word structure, sound harmony, verb-final word order, with dependents preceding their head, and use of numerous nonfinite verb constructions. The Türkic long vowels disappeared way back, they only remain in some geographically and phonetically scattered dialects (Kyzyl and tribal Türkic languages of the southwestern Turkey). The clay of the Türkic languages is extremely malleable, while the clay granules and the affinity of different granules are fairly firm. This combination of properties allows smooth reuse of the same granules in very different functions, similar to the economy of English, where for example crossing a crossing at a crossing point recycles a three-phoneme stem and a three-phoneme suffix as a noun, verb, and an adjective. Agglutinative languages, like Turkic, Finnish, Sumerian, do not use articles, since suffixes serve as discriminators between verbs and nouns, and articles need not to be borrowed, unless a language is creolized and had lost its functional suffixes. Typically, articles are borrowed from а lingua franca or amalgamating languages, like the Hungarian the is a borrowed that, at times in a form of a calque, like the Türkic bir is a calque of one. In most cases such cultural exchanges are transparent and traceable. These typological features are largely shared by the “Union of Uralo-Altaic language families”, and their elements are shared by a wide spectrum of the Eurasian and Native American languages. The commonalities between the Eurasian and Native American languages attest to the existence of the “Union of Uralo-Altaic language families” prior to the peopling of Americas approximately 15,000 years ago. The word “Union” in this context is as stochastic as a stratified by elevation mountain forest with some species randomly scattered along the slopes.
The term “substrate” in linguistics refers to an indigenous language that in the process of diffusion and convergence contributes features to the language of the later migrants, it presupposes distinct layering of the language, defines the temporal sequence, and the direction of convergence. The term “substrate” implies a distinct formed local language at the time of its encounter with a distinct formed alien language. By definition, the English being a Germanic language, the substrate of English was overlaid and supplanted by Germanic, making it a Germanic language, and then by the Old French, it was gradually enriched by Celtic, Danish, Latin, and other lexicons that also carried numerous Turkisms. The term “substrate” presupposes a linear development, a particular case of an amalgamation. Amalgamation is a layered process. Where amalgamation processes are not linear, the term “substrate” from an absolute becomes a conditional term, changing its content to suit a specific situation. That is the case with English, where the amalgamation process is far from being clear, is an object of the research, and the term “substrate” is a conditional convention to name one of the basic components.
To recognize substrate words within a mixed lexicon was proposed a complex of logical diagnostic
criteria arranged in an order of relative importance:
1. candidate word with dubious or no etymology in the host family
2. candidate word with a base root within the substrate family
3. wide distribution (>50%) of the compared words in the substrate and host families
4. semantic affinity
5. phonetic affinity
Each substrate candidate should be examined along the minimal, but largely insufficient criteria, to validate a candidate and at least to reveal additional factors supporting or contravening a substrate affinity. Frequently, applicability of individual criteria is hindered by a paucity of sources, especially in the temporal aspect. The criteria of a comparatively later appearance of a word in a host language (e.g. Lat. vs. LLat.) vesus an earliest attestation help to come to a reasonable conclusion. Given that just to be rated a candidate a substrate candidate satisfies criteria 1, a bias in the prior evaluations may flag a preference for attribution of the cognates to an advocated linguistic group, with a support from a circular logics. The only objective path to a reasonable conclusion is an equitable comparison of attested base roots, without appeal to “reconstructed” unattested models.
Languages are bio-cultural hybrids, products of evolution and hybridization. Linguistic process, like all processes in universe, are cyclical. Processes emerge, run, and decay. Processes are controlled by obstructions. Processes run as interactions between the energy of the process and sturdiness of the obstruction. Processes drug chunks of obstructions forward, carried by the process flow, drop them off as some barriers built of various obstacles. They continue in a new quality, resuming anew after some equilibrium point, embarking on a new cycle under new conditions. Regular patterns arise from random starting conditions, and end with the rise of the new random conditions. In linguistics, little is known of the cycles preceding the advent of our era, save for few known cycles that happened on the European peninsula at the end of the western Eurasia. The most powerful processes were connected with the expansion of the Greek and Latin languages, which in the process of Europeanization, later called Indo-Europeanization, overcame the resistance of the local languages. The advent of the Classical languages waned with Industrial Revolution, opening an era of cultural and technological languages: French, German, and nowadays English. In the 2nd mill. BC, long before the run-up to our era, the Türkic languages of the Kurgans were on the wane, supplanted by the resurgence of the local European languages. Before that, the Türkic languages were widespread, in lieu of historical records that is attested by the Türkic substrates in the European languages. Some languages consist largely of obstructions, others are a robust mix of obstructions and sediments. Of the pre-historic processes, we can only get a glance using the imprecise measurements of archeology and genetic part of the biology, and some fragments of the early writing. Prior to the scientific archeology and genetics, the paucity of the knowledge allowed any fancy to steady and bloom, alternating between predominant and counter-culture story.
The term “cognate” in linguistics refers to the words derived from the same word in an ancestral language: if a word exists, it has to come from somewhere. Examination of cognates is the method of historical linguistics, it seemed to fit well into a Family Tree model, and is complemented by the concept of the loanwords. The model, however, drives the examination of the cognates, instead of the other way around, in the process creating discrepancies and grounds for critical re-examinations. The developing of the Sprachbund concept and the Wave model was a consequence of the misuse of the Family Tree model far outside its range of applicability. It is, however, impossible to define the range for something lacking a definition and identified by individual gut feelings. Once a hypothesis coagulates into a theory, there is a specific domain where a theory is applicable. Beyond that domain a theory is false, and a viable theory validated by its predictive capability has to supersede it.
As a means of communication, language is not tied to a location, it migrates with the people, and can superimpose on the local languages (adstrate) or, in the case of replacement of the local languages, serve as a basis (substrate), incorporating elements of the local languages. The idea of migration was already seeded in the William Jones' discovery of the kinship between classical Sanskrit and European languages. That kinship could only come with migration, hence the start of the endless Urheimat odyssey in search for a single focal point chimera. All languages that surround linguists are a result of amalgamation. A chimera of a proto-language had to be contrived like a creation mythology, it could not hail from the linguistic experience. Migrations created mixed populations that were creating their languages in a convoluted reciprocal evolution of many individual streams. They were intertwined into a continuously changing web of overlapping Sprachbunds delineated by physical or cultural barriers. Individual streams formed and dissolved randomly, feeding back on the societies and their languages in endless cycles of creation and attrition of the speech and its facets.
An ability to discern the inner skeleton of a word parsed from the barnacles enveloping it is like using an optical magnification. A word reveals its inner core, a core of a living reef enveloped by layer upon a layer of sediments leading to its present appearance. The core skeleton survives largely intact, like a fossil bone. A concept of a word root is a part of the comparative linguistics method that routinely invents new “reconstructed” roots when one is needed to fill a gap between the reality and a mystical “proto-world”. In practice, the invented “IE” “proto-world” is frequently a phantom clone of a real attested root from a linguistic family outside the students’ mental horizon. That is the case, for example, with the notion “stay” and its immediate derivatives, an allophone of the Türkic üstü “stay”, lit. “on feet, standing”, from the root üst “get up”, “standing on feet”, lit. “atop, aloft, upward” formed with a locative suffix -t/-d “up, upward movement”. The words “stay, stand”, etc. elided the initial vowel, hence the unattested “IE” phantom clone *sta- in lieu of the attested üst. Both elision and prosthemia, so regular within the bounds of the “IE” etymology, appear to run into a mental block outside its bounds, where mechanical deduction takes over.
A distinct source for English was the Anglo-Saxon language, it was a backbone and a main vehicle that carried substrate language to the Old English and eventually to the modern English. A good portion of the substrate language, albeit quite late in time, is recorded in the Anglo-Saxon dictionaries and grammars. Numerous lexemes that escaped a contemporary record but found their way into English without direct borrowing from the neighboring languages may have also come from the Anglo-Saxon and its siblings, and absent counterindicators thus accepted as belonging to the substrate. Anglo-Saxon was a member of a distinct cluster of languages in a loosely-knit body of mutually comprehensible dialects, fairly far removed from Gothic and other Germanic languages.
A very considerable uniquely English lexical portion appears late and apparently from nowhere, with cognates known only from Türkic languages; that type of words can also be deemed to be a part of the undocumented substrate layer. A conspicuous lexical portion is shared by many archaic languages in the area, affording a good possibility that it was also shared by the substrate of English. Since Türkic languages were developing in mobile and open societies noted for their coexistence with alien peoples, at least some of the English substrate may be re-borrowing of the local lexemes.
In the context of this compendium, the term “linguistics” refers specifically to the theory and practice of historical linguistics, a narrow branch of the entire philological field which studies lingual evidence of the past. The term “IE etymology” refers to the self-contained circular version of the historical linguistics with etymological studies focused solely on languages viscerally postulated to be Indo-European (IE). The “IE” linguistics is not a parcel of philology that represents the full universe of communications, it is rather an isolated parochial interpretation of a confined domain. To not appear to be built to order, linguistic reconstructions, and especially etymologies, must be based on plentiful actual material independent of the research method, they should reflect realities of time, space, and social world, and withstand critical analysis in any aspect. Unlike a science, where asserting irreproducible findings falls to ostracism, the “IE” practitioners are lauded when their tentative proposition looks convincing enough to be held for a mighty fact. Its not unlike any other etiology in the practice of promotional propaganda. Otherwise, etymology is a study of the sources and development of words, to find the sources wherever they may be found in our full universe.
The term “IE languages” refers to a theoretical construct that presupposes a linear evolution of a single linguistic kernel, deemed theoretical or real, into a huge branch, defined by a spectrum of intuitive perceptions of a “common knowledge”-type conceptualization. Unlike any other scientific discipline, it does not rely on its mathematical apparatus. For now, there is no definition of the “IE languages” other than the trade practitioners' personal intuitive perceptions. While some practitioners believe that the Proto-Indo-European (PIE) language existed as a formed language used by real people, others believe that it is a theoretical construct like the one time ether, useful for canvassing a model but that never existed in reality. In practice, both sides treat the hypothetical construct as a proven reality. Omission of material contravening concept is driven by confirmation bias that ignores disconfirming evidence, a propensity to seek only suitable examples whilst flouting those confounding. Excluded exceptions undermine the concept to a useless subjective speculation. The subject of the PIE and “IE” languages remains, historically and hence on, prone to patriotic approaches of all suits, marked by systemic disregard of annoying contrary evidence and fabrication of faux scenarios. And, the same fuzzy concept was mechanically applied to other languages, at times against all contraindications.
Genetic studies have broken the glass wall that separated and counterposed the “Indo-European” and Türkic worlds. A significant part of the Europeans turned out to be descendents of the Kurgan people, marked by the inheritance of the Y-DNA haplogroups R1a and R1b. From the standpoint of the parochial “Indo-European” linguistics, that would compel inclusion of the Türkic family into the “Indo-European” superfamily, ostensibly consistent with the contents of this work. That expansion, however, would clash with the historical reality outside of the linguistics’ control. The “Indo-European” languages became “Indo-European” during the Corded Ware period, in contact with the nomadic Kurganians, and the Kurgan culture not only precedes by far the Corded Ware period, but its migrational waves were the immediate cause for the formation of the distinct Corded Ware communities. The “Indo-European” languages were formed in the presence and under repeated influence of the Kurganians’ languages.
The Türkic linguistic map is uniquely broad in its Eurasian extent. It extends in the Southwest from Near and Middle East on the Atlantic Ocean's fringes to the Southeast, to Eastern Turkistan and on into China toward Pacific Ocean. Then it stretches to the Northeast covering Southern and Northern Siberia to the Arctic Ocean, and Northwestward across Western Siberia and Eastern Europe. The Türkic languages are fascinating with their vast geographical distribution, their contacts with many different linguistic zones, their peculiar stability over time, their morphological and syntactical regularity. Their spread represents a great number of different peoples and languages, most of them politically and scientifically reduced to a vanishing point. Currently, there are about twenty Türkic codified languages, about 42+ acknowledged languages, and about the same number of unacknowledged, amalgamated, vanishing, unexplored, and trace languages. This was actually the beginning of a Western European front against Russian Turkology that came to dominate for decades. Across Eurasia, Türkic languages lived through the periods of expansion, blossoming, migration, contraction, devastation, mutilation, genocide, prohibition, and prejudicial, cultural, political, and scientific bans. Currently, except for the lingering prejudices, most of the previous severe restrictions on studies the life of the Türkic folks have abated.
Türkic languages, from the time of M. Kashgari, are divided into Western and Eastern languages. The M. Kashgari's notion of language is not known, probably it differs significantly from the modern interpretations. Probably, his definition was a common perception based on identical typology and morphological and lexical similarities; his notion of Western and Eastern languages probably saw Kashgar as a central point. M. Kashgari could not have known of the nomadic migrations beyond his temporal and spatial horizons, nor of the Türkic languages that diverged too much to be comprehensible to the speakers of Türkic languages of his interpretation. Today, the M. Kashgari's Western languages can be roughly associated with the Oguric languages, and his Eastern languages can be roughly associated with the Oguzic languages; the h- languages of the Caspian-Aral area do not figure at all in the Oguric/Oguzic classification. The term “Common Turkic” (CT) or “Shaz Turkic” refers to one of the taxa in some classifications of the Turkic languages, in practice it is a euphemism for the Oguz-type languages. It stands in opposition to the Ogur-type “r” or the Chuvash “l” languages. Taxonomy does not cover all languages, since none of the Turkic languages escaped numerous amalgamations with linguistic varieties found across Eurasia, and the linguistic variety exceeds by far the suggested simple taxonomic criteria. Debate on the place and chronology of Oguric within Türkic continues, the differences are studied predominately through the shreds of Danube and Itil Chuvash Bulgar, without a benefit of the languages like the Hunnic that historically were connected with the Ogur languages.
However, the Western-Eastern association is period-dependent: Oguric languages in the historical time expanded from the Mesopotamian-Caspian-Aral basin to the Ordos, reverted back to the Caspian-Aral basin, and expanded westward to the Eastern and northwestern Europe. Nomadic communities used to leapfrog over occupied territories, and spread over remote defenseless sedentary populations, thus the once western languages could become extreme eastern languages, vice-versa, and anything in-between. M. Kashgari could not have known of the Oguric languages much outside of the Moslem world. Similar swings happened to the M. Kashgari's Eastern languages that during the historical time traversed Eurasia from Mongolia to Balkans and beyond. The genetic pallets of the Türkic ethnicities, drawn starting from the last decades of the 20th c., provide a good illustration of the admixtures that compose each ethnicity. Genetic pallets of the nation-states and nations united within a common linguistic family also provide a good graphic illustration of the fallacy of the Family Tree models.
In the context of this compendium, the term Western Türkic languages refers to the pre-historic languages of the Kurgan western waves plus the Western languages of M. Kashgari, and the term Eastern Türkic languages refers to the pre-historic languages of the Kurgan eastern waves plus the Eastern languages of M. Kashgari. Under that hazy definition, the Türkic language dictionaries compiled in the Muslim world largely cover the Eastern Türkic languages, with accidental elements of the Western Türkic languages spilled to the Muslim areas. The multi-ethnic composition of all Türkic confederations, always based on a system of marital unions between non-blood related and largely alien members, precluded formation of a single common language that can be identified with a single ethnic or political entity; any lingua franca of any confederation inevitably was a blend of few, at times very diverse, languages.
Although the first written evidence of the Türkic languages comes from Mesopotamia (5th-3rd mill BC), archeological evidence shows that Mesopotamia was a fringe finger much to the south of the bulk of the eneolithic Kurgan people, whose expanse of the Khvalynsk and Sredny Stog cultures (5th mill. BC) were focal points for the coming expansions. The first written attestations came with the very first inscriptions in the history of the mankind, the Sumerian and Türkic yer, English “earth”; the Sumerian sig-, Türkic sok, English “sock” (beat); the Sumerian akka, Türkic aga, English “age”, and numerous others. Such cognates have not deserved the attention of those who declared Sumerian to be a “language isolate”. Not the typology and grammar instigated the assertion, since European philology holds those as malleable. These cognates testify that not only the Sumerian was a flourishing amalgamation of the Türkic and a local language, but that it is still an essential component of the undoubtedly agile modern Türkic and English languages. Türkic vernaculars were settling in the Middle East for about 6 thousand years with each influx of the mounted nomads, at least 3 thousand years before the Indo-Aryan arrival there ca 1500 BC, and many times after that. The Türkic component found its way in all three stages of the Persian language, contributing to its complexity as a blend of primarily local, overlaying migrant vernaculars, and multi-stage vernacular amalgamations, and to the drastic changes between stages. With such complicated history, outside of the late Islamic innovations, any presumption asserted in attributing to the Persian language as an ultimate source is jeopardizing credibility. Etymological data shows way less Persianisms in the Old Türkic (10th c.) than the Turkisms in the Persian. Historical processes outside of the contemporary Moslem world nearly completely escaped attention of M. Kashgari.
| M.Kashgari AD 1072 Map of the World |
|---|
 |
Language abbreviations
| Alb. | Albanian | Fin. | Finnish | Lat. | Latin | Sax. | Saxon | ||||
| Ang. | Anglian | Flem. | Flemish | Luz. | Luzian | Scand. | Scandinavia | ||||
| Ar. | Arabic | Fr. | French | M | Middle | Serb. | Serbian | ||||
| Arm. | Armenian | Fris. | Frisian | MHG | Middle High German | Skt. | Sanskrit | ||||
| A.-Sax. | Anglo-Saxon | 811 | Gael. | Gaelic | 13 | MLG | Middle Low German | Sl. | Slavic | ||
| Av. | Avesta | Gaul. | Gaulic | 6 | MM | Middle Mongol | Sloven. | Slovenian | 158 | ||
| Az. | Azeri | Gk. | Greek | Mod. | modern | Slvt. | Slovak | ||||
| Balt. | Baltic | Gmc. | Germanic | Mong. | Mongol | Sp. | Spanish | ||||
| Beng. | Bengal | Gmn. | German | N | North | Sum. | Sumerian | ||||
| Blr. | Belarusian | Goth. | Gothic | Norw. | Norwegian | Sw. | Swedish | ||||
| Boh. | Bohemian | Gujr. | Gujrat | O | Old | Tat. | Tatar | ||||
| Bosn. | Bosnian | Hebr. | Hebrew | OCS | Old Church Slavonic | Taj. | Tajik | ||||
| Bulg. | Bulgarian Slavic | Hitt. | Hittite | OE | Old English (Anglo-Saxon) | Tr. | Türkic | ||||
| Cat. | Catalonian | Hu. | Hungarian | OHG | Old High German | Turk. | Turkish | ||||
| Ch. | Chinese | 60 | Icl. | Icelandic | OT | Old Türkic | Turkm. | Turkmen | |||
| Chuv. | Chuvash | IE | Indo-European | P | Proto- | 244 | Tuv. | Tuvinian | |||
| Cimr. | Cimbrian | Ir. | Irish | Pers. | Persian | Ukr. | Ukrainian | ||||
| Croat. | Croatian | It. | Italian | 146 | Phryg. | Phrygian | V | vulgar | |||
| CT | Common Türkic | Khak. | Khakass | Pol. | Polish | W | West | ||||
| Cz. | Czech | Khal. | Khalka Mongol | Pruss. | Prussian | Welsh | Welsh | ||||
| Dag. | Dagur | Kirg. | Kirgiz | Rum. | Rumanian | Yak. | Sakha | 118 | |||
| Dan. | Danish | Kor. | Korean | Rus. | Russian | Yid. | Yiddish | 5 | |||
| Du | Dutch | L | Late | ||||||||
| Eng. | English | Latv. | Latvian | ||||||||
| Est. | Estonian | Lith. | Lithuanian |
Archeological and genetic works demonstrated migrations, amalgamations, and replacement of
populations in the Western Europe, where the Germanic branch of the Indo-European (IE) languages
occupies a prominent place. Linguistic works demonstrated that Germanic branch contains a
substantial layer of non-Indo-European substrate. The English language is a prominent member of the
Germanic branch. The sources of the Germanic substrate remain debatable, with numerous candidates
explored and rejected. With the insights provided by archeology and genetics, and based on their
converging contention that from the time of the population replacement in the 3rd millennium BC
until the middle of the 1st millennium BC, the Türkic (Proto-Türkic) linguistic field dominated the
whole Eurasia reaching the Atlantic Ocean on one end and Pacific Ocean on another end, a concept was
formulated and substantiated that the non-Indo-European substrate of the Germanic branch was rooted
in the Türkic (Proto-Türkic) linguistic field. The groundwork for this linguistic concept has
already been established, the concept is a necessary corollary of the positively attested migratory
flows. The concept explores the Türkic–English morphological and lexical correspondences, and finds
substantial traces of the Türkic substrate in English, potentially exceeding 30-40% of the English
words used in the daily life. Of the English suffixes, 63% descend from the Türkic origin and remain
morphologically active in forming English words. The concept touches on the substantial trace of the
Türkic–Latin–English correspondences, linguistically corroborating the thesis that the Kurgans'
circum-Mediterranean path via the Pyrenees to the Continental Europe brought about the Beaker
Culture, ancestral to the Pra-Celts and Pra-Italics. The Beaker Culture's language in terms of the
Celtic archeology is called Celtic, but is meant to name that ancestral language.
4
The results of the study corroborate archeological and genetic conclusions, on the example of the English and Latin languages providing a salient amount of linguistic evidence in their favor. The results introduce solutions for lingering questions, raise questions about adopted dogmas, and open gates for multi-discipline studies of the questions raised. Far from exhaustive treatment of the subject, the study attempts to follow a holistic view on the Eurasian history with languages being one of the major human attributes where the past instigated the present. It explores a portion of relevant information where neglected evidence is disproportionally substantial in relation to the attention it has been receiving. The study leaves much material unexplored, it only extends to a degree sufficient to substantiate the proposed concept and illustrate stochastic nature of the past linguistic dynamics. In the world where observation, not preconception, describes the reality, preconception is fleeting. The study draws attention to the perspective research in this field in a diachronic typological approach, which, in my opinion, may shed light on reconstruction of the linguistic prehistory of Eurasia.
The concept fits in well with the theoretical and experimental facts. It fits well with the fact that nobody could ever substantiate the location of the “IE” Urheimat, the area where the “IE” languages were born, that some people had thought existed. It fits well with the assertion that the Scytho-Iranian Theory was a poorly executed hoax concocted for political ends at a certain apex of the late colonial mentality. It fits well with five dozens or so counterindicators that demonstrate impossibility of the said Theory. Some counterindicators are as weighty as the genetic conflict between the predominantly Kurgans’ R1b Y-DNA haplogroup and the predominantly Iranian J2 haplogroup, the biological conflict between the milk-based diet of Kurgans and the general lactose intolerance of the Iranians, and the conflicts of the literary, ethnologic, linguistic, and ethnic appellations’ nature. It fits well with the archeological conclusions on the Kurgan migrations, with the genetic dating of the Kurgan migratory paths, with the genetic composition of the North-Western European population, with the existence of the substrate language underlying Germanic languages, with the European geography of the Classical period, with the abundance of Turkisms in the Anglo-Saxon, Gothic, Latin, and other documented languages of the Classical and Late Classical period. The predictive capability is well beyond serendipity at a random examination of Proto-Germanic *prototypes where the “IE etymology” stops dead at the *PG model. Random experiments with random sets of suspected Turkisms in English found that in about one-half of the cases the suspicion was justified, depending on physical or abstract notion, by direct or readily apparent metaphoric concordance. Moreover, in many cases both literal and metaphorical semantics of a word constitute instances of paradigmatic transfer. Random statistical testing demonstrates the reality of the Türkic-Germanic link. Finally, the concept is supported by the incompatibly potent explanatory capacity, and a viable predictive capability for minor and crucial indicators.
A number of the Scytho-Iranian Theory counterindicators have a predictive capability, they have already accurately forecasted the future genetic findings before they became confirmed by facts. They have already accurately forecasted the salient presence of Turkisms in the archaic European dictionaries. They open a gate for future discoveries. Combined altogether, the various facets of the concept are weighty enough to inspire confidence that the concept is well substantiated.
Attention to the Germanic-Türkic commonalities must have arisen many times over on various levels. Probably, it far predates the discovery of the “IE” connections. Over the centuries, many word lists may have been produced impromptu, and they circulated in the Internet Age, primarily for the German language due to historical exposure. Typically, a closer look at such listings related to English produces a high degree of etymological misfires, the remaining small minority tend to be repetitive, inevitably inclusive of a standard complement of obvious clones, mostly nouns: ace, dawn, do, earth, guest, eat, say, son, and the like. On the other hand, about every tenth word turns out not to be a false lead, and a few more appear plausible but on inspection lacking a preponderance of evidence.
E.Forrer (1934) raised to a scientific discussion the observation that Germanic languages have a non-Indo-European substrate. Before that, the linguistic terrain belonged exclusively to the “IE” studies, based solely on the Family Tree model. All apples were falling at the root of the mama tree, and all saplings were its kids. The concept of substrate had infringed on that idyllic cartoon. Not only the mamma could grow in a distant banana grove, but the saplings could be various kinds of hybrids. The “IE” Theory was incessantly criticized and adjusted since its inception two centuries ago, and it is still lacking its fundamentals, such as a basic definition of what is and what is not Indo-European. An archaic notion that at some time there existed the PIE Adam and Eve speaking PIE language has been shelved long ago, pulling the rug from under a stipulation that at some time, somewhere, existed a community that used to speak the PIE language, that the PIE is not a chimera. An evidence that PIE was not a compact language, and even not a language at all, pops up everywhere. Either lexically, phonologically, or morphologically, the “IE” Family Tree is perplexing.
Perpetuation of the obvious etymological manipulations in support of the “IE” Theory has an opposite effect of seeding discontent. To account for the contraventions, the model has to be disfigured with areal and contact interpretations fused into a single-dimension paradigm, with optative inspiration that a three-dimensional amalgamation of Family Tree and a Wave models may putatively address the nature and distribution of the correlations found among the “IE” languages. A few core languages provide well attested “IE” correlations, while the optimistic attribution of other languages to the family rests on statistically insignificant spotty evidence carried by mounds of interpretations. Aside from notoriously circular argumentation, the Family Tree model is bound with fluid interpretations of undefined parameters. Beyond a fuzzy notion that a majority (dubbed “consensus”) of some particular scholar community should be convinced on attribution of a language to a particular linguistic group, no defined criteria requires to meet any evidentiary specifications neither for pro nor for the con position. Conclusions are driven more by embedded ideological trends than by analysis. In the end, the PIE comes out as a clash of beliefs, rather than a clash of evidence. The problem remains a tag-of-war between competing opinions of the “IE” linguists.
Genetic evidence shows a massive demographic imprint of the R1b haplogroup in the Western Europe and in the Inner Asia. In Western Europe this demographic imprint is connected with the Germanic languages, in Inner Asia it is connected with the Türkic languages. Another unique for the mankind common biological adaptation is the lactose tolerance that could only germinate and survive in a pastoral economy dependent on dairy products for subsisting and successful reproduction. Biological connection is independent of nationalistic notions, ideological biases, religious affiliations, dress codes, and other curses of the New Era civilizations. Instead, that connection carries common nomadic societal traits atypical for the Classical Europe: respect for individual liberties, autonomous parliamentary organization, respect for women, and spirit of mobility. Logics bears to seek demographic commonalities in the fields beyond the innate biological and societal domains. Language, being a major human demographic attribute, can't escape from demographicly carrying its uniqueness form generation to generation, and across all kinds of societal and demographic perturbations. As objects of cultural exchange, linguistic elements permeate incompatible languages, living linguistic clues everywhere. Inescapably, linguistic elements are passed along across generations, millenniums and populations. Unlike the strands of DNA revealing the story of human migrations, theoretic linguistic strands live their own life of abstruse and denial, obfuscating rather than attesting linguistic flows across our small globe. In the surrounding richly amalgamated world, linguistics of the past had created its own closet world of linear surrealism little permeable to the rest. Linguistic clues sloth about, unneeded to divine past wanderlust behind sundry present.
An unexpected development came from the genetic studies that confirmed nearly complete wipe-out of the “Old Europe” population by the 3rd mill. BC, and its replacement by the mounted Kurgan nomads, long stipulated by the archeologists. A corollary of the population replacement by the waves of the pastoral Kurgans is that the Türkic languages of the Kurgans replaced, penetrated, and amalgamated with various European languages still in the 3rd mill. BC. In one form or another, the Türkic languages dominated most of the Europe as lingua franca, although demographically, the pastoral populations are always sparse. The “Old Europe” populations found a refuge in the Eastern Europe, from where in the 2nd mill. BC their descendants migrated to the South-Central Asia, and in the 1st mill. BC their other descendants bounced back to the Western Europe. The “IE” migration to the South-Central Asia from the Eastern Europe is reflected in the diminished “IE” element in comparison with the Germanic languages (Prokosch 1939). After some wild excursions in space and time, the PIE theory is about to curdle down to the N.Pontic geographically and 3,500 BC temporally. Conceptually, that puts it right next to, and thus intersperced, with the real Kurganians, and enables it to at least discursively to accept the iniquity of amalgamation.
Domestication of animals for food was a first step in liberating people from the burden of daily provisioning. Domestication of horses vastly increased that benefit, it made provisioning portable. A feedback was revolutionary. It initiated a self-perpetuating technological revolution that extends to our days. Pastoralism sparked a mass of inventions that crucially changed the human society. Just the invention of a portable home and a wheeled mobile home required a creation of a technological complex spanning numerous engineering fields. Pastoralism freed societies from the constraints of immobility and torpidity. It required daily ingenuity, cultural openness, flexibility, and providence. It removed constraints of climate, distance, areal containment, and stewing in its own juice. It opened a path to flourishing societies, to continent-wide cultural and technological exchange. It shared its knowledge far and wide with the sedentary neighbors, both of agricultural and hunting economies. That did not get unnoticed, news of the pleiad of the nomadic teachers is found in classical literature of literal nations, Greek, Indian, Chinese, etc. Nomadic societies were on the move and evolving, and facilitated explosive evolution among their static neighbors. They either spawned or spread totally unforeseen novelties, like parliamentarism, religion, and personal freedom.
Genetics corroborates independently migratory flows marked by distinct archeological traces. Their corollary defines linguistic situation in the Eastern and Western Europe in the course of the 5th – 1st mill. BC. Earlier migrations set up conditions for the following migrations preceding to and during the period of the Great Migration of People in the 1st mill. AD. Genetics helped to clarify the phenomenon of the Celtic migration, it corroborated archeological understanding of the Celts coming from Africa to Iberia at about 2800 BC, and traced their migration in a circum-Mediterranean movement to its source in the Eastern Europe of the 6th-5th mill. BC. Some linguistic elements, shared by the Eastern European languages in the 6th-5th mill. BC, survived both the overland and circum-Mediterranean movements of the Kurgans, and along with the later migrations and local vernaculars, they formed the Germanic substrate now found as linguistic vestiges.
Among potential Germanic substrate donors were suggested Fennic, Uralic (Wiik, 2002), Semitic (Vennemann, 2003), Tyrsenian (Steinbauer, 1999), but due to the episodic nature of the linguistic parallels, none of them gained an acceptance. Consensus remains with the S.Feist's assessment of about one third of the Proto-Germanic lexemes originating from a non-Indo-European substrate, and that the Germanic languages were a result of pidginization and creolization or koineization of that substrate with the later adstrate. Pidgins are simplified conflated languages with trimmed grammar and limited vocabulary; a pidginated language is stripped down to the roots of nouns, verbs, and adjectives, with vestigial morphology and inflection, a fluid word order with prime accent on action, and a use of uncoupled vestigial elements as modal semantic determinants. Within a single or few generations pidgins develop into viable creole languages with fairly fixed syntax, grammar, morphology, and syntactic clauses. Any semantic gaps are filled in with local innovations that replace the lost conventions of the parent languages. A pidgin stage is an innate part of the human development starting from the moment of birth. The pidgin processes are fairly uniform. The most rudimentary SVO syntax, not burdened with convoluted conventions, tends to tarry on in the formed language. Here again, the northwestern Baltic, Slavic and Germanic languages differ by inconsistent syntactic preference attributable to contacts with SOV-type languages, in our case specifically with the Türkic languages of the steppe Kurgans.
The spread of the European languages during the era of the global colonization had created numerous pidgin islands across the globe, spreading Indo-European languages to all kinds of natives, and promoting Indo-European languages to become a predominant linguistic family of the entire world. Nowadays, computers and English, with a twist of exploding literacy, do the same, creating vernacular English creoles across the globe. The process, started by the first waves of the mounted Kurgans to the Europe and Far East, continues unabated.
Based on the combination of the archeological, genetic, and linguistic indicators, the present concept was formulated and substantiated that the substrate of the Germanic languages was or were languages of the Türkic linguistic family, whose male speakers had a frequent marker of the haplogroup R1b, and who amalgamated with the local populations marked by the predominant male haplogroups I and N. The haplogroup I is identified with the native European populations, in particular the Balkans and Scandinavia, noted for their sedentary lifestyle, cereal farming, and military vulnerability. The haplogroup N is identified with the northern Eurasian Fennic populations, noted for their sedentary lifestyle, hunter-gatherer economy, sparseness, and military vulnerability. The haplogroup R1b is identified with the Kurgan cultures, noted for their horse nomadic husbandry, high mobility, and high military aptitude.
The proposed concept disbands unsustainable “IE” etymologies, analyzes and explains the peculiar
geographical linguistic distribution stretching from Northwest India up to the Pontic Steppe and on
to the North Sea, corroborates archeological and genetic evidence of migrations and amalgamations,
is in concordance with the documented history of the Eurasian Steppe and Northern European people,
is in concert with historically attested ethnological and cultural distinctions, and is
constructively helping to rid the swollen “IE” paradigm from unrelated burdens. It allows to discern
particular groups and distinctions that contributed to the evolution of the English language. It
uses hard statistical probability in lieu of warm linguistic feelings to discern correspondences
from similarities, disbanding speculative justifications and accounting for wide distribution of
similarities across Eurasia to the significant exclusion of the Near East that muddles the “IE” paradigm. It demonstrates partial adoption of an entire lexical, morphological and script paradigms
that can be accounted for only through borrowing, attesting to demographic fusion. The material that
forms the concept is not amenable to a flawless reverse interpretation. Impervious to the evidence
and testimony the faux etymologies fall flat. The circular logics, endemic in general linguistics
and particularly universal in the “IE” methodology, is eschewed as counterproductive. It demonstrates
futility of limiting the field to poorly substantiated and arbitrarily applied phonetic processes,
to a reflexive exclusion of all other indicators. The concept illustrates mechanisms of the
typological change, replacing habitually postulated miraculous conversions with
demographically-driven and component-specific mechanisms, like a pidginization leading to a
linguistic analyticity, Cf. English and Bulgar among the European “IE” languages. The concept strives
to avoid elastic definitions drafted to include diverse material, it seeks to rely on attested
evidence in lieu of theoretical concoctions. It allows to place the few core languages in a
historical perspective, stripping them of a special ancestral status without throwing the baby with
the water.
5
The converging genetic dating allowed to trace genetic markers in space and time, and draw observations about their migration, spread, and timing. According to Klyosov 2010, “The modern Uigurs, Kazakhs, Bashkirs, and some other peoples of Siberia, Central Asia and the Urals descend in part from the ancient R1b1 branch, and by now retain the same haplogroup for 16,000 years. The “Türkic-lingual” haplogroup R1b expanded from the South Siberia, where it formed 16,000 years ago, across the territories of the Middle Volga, Samara, Khvalynsk (in the middle course of river Volga) and the Ancient Pit Grave (“Kurgan”) archaeological cultures and historical-cultural complexes (8-6 thousand years ago and later, the common ancestor of the ethnic Russians with the haplogroup R1b1 lived 6,775 ± 830 years ago), northern Kazakhstan (for example Botai culture dated by the archaeologists 5,700 - 5,100 years before present (BP), in reality much older), passed through the Caucasus to Anatolia (6,000 ± 800 BP by the dating of R1b1b2 haplogroup of the modern Caucasians), and through the Middle East (Lebanon, 5,300 ± 700 BP; the ancient ancestors of the modern Jews, 5,150 ± 620 BP), and Northern Africa (Berbers of the R1b haplogroup, 3,875 ± 670 BP), crossed over to the Iberian Peninsula (around 4,800-4,500 BP, present day Basques 3625 ± 370 BP) and further on to the British Isles (in the Ireland 3,800 ± 380 and 3,350 ± 360 BP for different populations), and to the continental Europe (Flanders, 4,150 ± 500 BP, Sweden 4,225 ± 520 BP).” The trace is seen as linear, while its object is turbulent, consisting of eddies and vortices of local and global dimensions. The exponential increase in the accumulated quality and quantity of the available genetic analyses tends to advance precision of the early dating, adding sharpness and geographical detail to the temporal assessment without substantial challenge to its topography.
According to the archeological evidence systemized by M. Gimbutas, 1994, Europe also experienced three major Kurgan overland migration waves, some of them were repeat migrations into the same areas. The dating of the Kurgan migration waves, produced by archeologists using radiocarbon analysis, is in concert with the genetic dating: wave 1 at c. 4400-4300 BC, wave 2 at c. 3500 BC or somewhat later, and wave 3 soon after 3000 BC; the circum-Mediterranean Celtic Kurgan wave reached Europe independently at 2800 BC. Along its route, the circum-Mediterranean wave remains archeologically unexplored. Between the 3000 BC wave and Sarmatian migrations of the 2nd c. BC, there is a historiographical lacuna, but considering the sequential waves of the Huns, Bulgars, Avars, Kangars-Bechens, and Oguzes of the 1st mill. AD, there is no reason to suspect an absence of the Kurgan migrations during the lacuna period. It is reasonably expected that the waves, separated by the timespans on the order of millenniums, were likely composed of linguistically differing tribes of the same linguistic family but complemented by different allies, were impacted by the specifics of their migration routes and their durations, and were bringing to the new territories their particularly distinct vernaculars. Although belonging to the same nomadic horse-breeding Kurgan historical-cultural complex, they possessed different technologies, starting with the Neolithic, and ending with the metals.
The notion of the Türkic languages underlying European languages is nothing new. At the time preceding the emergence of the Scytho-Iranian Theory by two and a half centuries, as far back as 1653, M. Van Boxhorn suggested that a Scythian language was the Family Tree's proto-language of Baltic, Celtic, Germanic, Greek, Iranian, Romance, and Slavic languages. At the time, in the 17th century, following the heritage from the Antique period, the old collective name Scythians was vaguely synonymous with the Türkic people, at the time known as undifferentiated Turks or Tatars. The vagueness of the term was predicated by the vagueness of the European knowledge about people further east, and especially the pastoral nomads; practically nothing was known of the pre-Islamic northern Eurasians, their kurgans, their cultures and scripts. The Van Boxhorn's suggestion was numerously modified by later scholars as new studies filled in the scholarly gaps, and survived in the crevices left out by the rise of the nation-states with their reinvented and politicized histories. According to the Türkic substrate concept, Van Boxhorn's suggestion is solidly corroborated, especially in respect to the English language, and to the Germanic languages in general. Some other European languages do not lag too far behind, each with its own historical and linguistic peculiarity.
The breakthrough afforded by the genetics helped in dislodging interpretations based on simplistic presumptions, it allowed to correlate migration of the genetic markers with migration of certain archeological cultures and people. The R1a and R1b haplogroup markers were felled from their “European” pedestal, they were found to originate in the South Siberia - Northern India area, and being dispersed west and east in a sequence of numerous migrations. Paleogenetic studies allow to peek into genetic composition of long-gone cultures and people, either bridging the past and present or demonstrating a demographic disconnect between them That is best illustrated by the western European peninsula, where the modern predominance of the marker R1b contrasts with the paleogenetic predominance of the markers I and G. The gullible presumption of the genetic continuity was felled, the realization that the Western Europe is largely populated by the Asian migrants has taken over. After many migrational waves, the marker R1b has survived and blossomed, while their companion markers R, R1, R1a, and many others, present in the past migration flows, have faded.
That does not negate their value in the genetic studies, not only to better describe the past populations, but also to cross-correlate genetic dating for the populations' samples. An asymmetry of the male Y-DNA and female mt-DNA markers, with fast-changing Y-DNA and slow-changing mt-DNA, may fairly well reflect a demographic picture (changing males and stable local females), but provide a skewed linguistic picture, with languages propagated on the maternal side playing a relatively larger role than the ones propagated on the paternal side. These correlations affect dissemination of linguistic traits, and our perceptions of the mechanics of the linguistic development.
Reverse tracing the Indo-European languages, before their partial migration from the N.Pontic to the South-Central Asia in the 2nd mill. BC, and a back migration to the Western Europe in the 1st mill. BC, tells that the bulk of the linguistically European population lived in the Eastern European refuge, with dispersed linguistic isles of the “Old Europe” surviving across Western Europe and with a considerable isle in Scandinavia. The European refugees of the “Old Europe” camped in the Eastern Europe from the beginning of the 3rd mill. BC. Before that, they were the “Old Europeans” and the future Indo-Europeans of the Western and Central Europe, they were farmers, and many of them amalgamated with the pastoral people of the Kurgan wave 1. The linguistic traces of the “Old Europeans” are still with us, the Balto-Slavic and Indo-Aryan/Sanskrit daughter languages.
The Kurgan wave 1 of the mid 5th mill. BC was neither peaceful, nor destructive, it replaced the
rustic social organization of the “Old Europe” with culturally alien elite, with demographic and
linguistic situation largely left intact. It was the old Neolithic “Old Europe” under a new
management. The new world order lasted for 15 centuries, or 60 generations, till the destructive
Kurgan wave 2. Before the Kurgan wave 1, the Neolithic “Old Europe” was peaceful and happy for
millennia, from the time of the introduction and spread of farming, which supplanted the rare
scattered hunter-gatherers and greatly affected their demography by boosting their fecundity. The
few members of the “Old Europe”, excavated from the Central European “killing fields”, belonged to
the Y-DNA Hg I and G. The genetic picture is regularly improved by new paleogenetic data.
6
(background R.R.Sokal et al. 1992 and M. Gimbutas 1994)
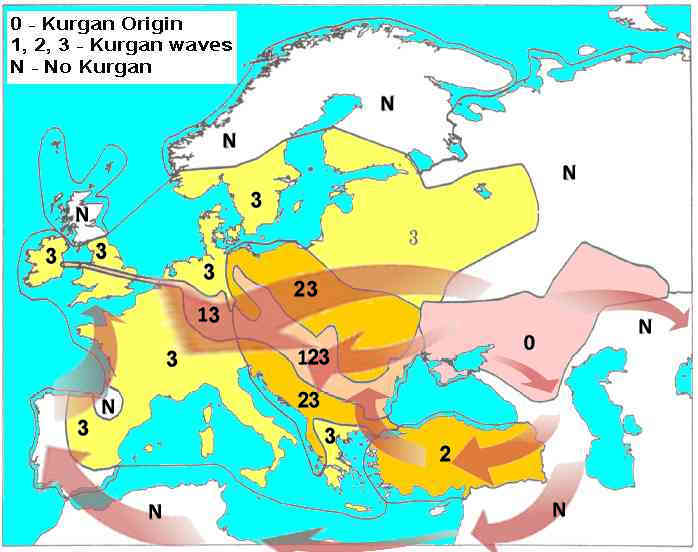
This detailed genetic picture provides an impetus for linguistic studies. Presently, English is credited with approximately 800 Türkic cultural loanwords of mostly medieval Ottoman and Kipchak origin (Bikkinin I., 1998), of them about 250 are found in common English dictionaries, and are listed in the Wikipedia “List of English words of Turkic origin”. According to the Türkic substrate concept, a deeper linguistic layer forms the substrate layer of the Germanic languages, and particularly of the English language. The fresh approach would not change the body of the factual evidence, it would bring out new connections instead of trying to trod the same path and expect different results. Fresh approach either challenges the standing theories and hypotheses, or confirms them till an emergence of a new challenge.
For the sedentary societies, the Kurgan expansion and population replacement, attested by the “killing fields” of the period between 4500 and 4000 ybp, would overlay a continuous chain of mutually incomprehensible vernaculars every 200 km. This value would not apply to the mobile nomadic society, where the linkages are much longer and alien encounters are much more frequent, resulting in more pronounced effect of linguistic leveling. Still, with the longitudinal distance of 55°, as depicted on the Conceptual map of Kurgan westward waves above, and the timespan of 2,500 years, the development of local Sprachbunds is unavoidable. Allowing a theoretical 5-fold increase in the linear spacing would divide the European theater into 10 conceptual Sprachbund areas, 5 areas wide and 2 areas across. Given the relative stability of the roots in the agglutinative languages, the interplay between these European Türkic Sprachbunds and later historical events that shaped various European languages would create a raster of allophones for each word, at times barely recognizable, united by their origin from a small group of relatively close vernaculars.
The last Kurgan waves belong to the Iron Age, they are connected, in sequence, with the last northward movements of the Scythians coinciding with the formation and rise of the Roman Empire and with Kurgan migration from the Central Asia to the Urals. The Uralian Sarmat men were supplanted by the migrants, who inaugurated the Late Sarmatian Age. Retreating Sarmats overrun the N. Pontic Scythians, and expanded into the Central Europe, turning it into European Sarmatia described by Ptolemy and Strabo. In the process, Europe gained theretofore unknown nomadic people called Wendeln and Goths, Burgunds and Turings, and others that pushed out the old Scythian nomadic tribes into inaccessible Netherlands and Jutland. With the newcomers came their vernaculars, mixing, and amalgamation.
The next Kurgan wave is known under the name of the Huns, although its bulk consisted of the Early and Late Sarmatians known under variety of names. With the Hunnic wave came more vernaculars, mixing, and amalgamation. From the Hunnic wave arose Anglo-Saxons, history becomes much less blurred, and we receive the first records on the languages of amalgamated nomadic peoples, in case of Anglo-Saxons and Goths a blend of recognizably Türkic and unrecognized local European languages that become known as Germanic languages. From the same milieu of the Türkic and local vernaculars rose the Slavic languages.
The next Kurgan wave was already termed Türkic, it brought along Avar, Bulgar, and Suvar Türks, and numerous tribal names, but their western influence did not extend much beyond the Slavic linguistic area. All subsequent Kurgan waves, those of the Bechens (aka Pecheneg), Oguzes (aka Torks and Türks), and Kipchaks (aka Polovetses) did not extend beyond Balkans. The last Kurgans that reached central Europe were a branch of Bulgar Onogurs with their allied Ugro-Finnic allies who took over Pannonia and formed the Magna Hungaria. The last Kurgan wave was that of the Chingizids, it was stopped at Adriatic and barely affected the Balkans. The Hunnic wave was the last one connected with the Türkic substrate of the English language.
The eventful life of the Kurgans shaped their languages. According to Turkologist S.E. Malov 1952, “Western Türkic languages show that they had very rich and long life, they experienced many different influences and other exposures. That could not have happened in a very short period. In the west, all settling of Türkic people from Central Asia that we know of (for example, the Huns, Mongols and Tatars, Kyrgyz) did not exert influence and shift toward Eastern Türkic linguistic elements that could be expected if here in the West have not been established the steady and well-ossified Western Türkic languages”. The western traces of the Türkic languages are deep and wide, so deep that they continue their active and productive life in the languages across much of the Europe, so wide that they could not have been wiped out by the pre-Industrial Age extermination campaigns. The traces are neither erasable nor untestable.
Long before the horse nomadic Scythians brought their kurgans from Siberia to the N. Pontic (ca 8th c. BC), kurgans were already ubiquitous across much of the Europe. The first kurgans came to Europe with the wave 1 of the pastoral horse-riders ca 44 c. BC, by that time the Kurgan Culture of the Eastern Europe was about 3 millennia old. Wave 1 established a European forepost, wave 2 fortified the revolving east-west links, and the wave 3 drastically changed the European demography and culture. In turn, Europe was changing the nomads. A major factor was the transition from the severe continental climate to the oceanic climate, with its mild winters and cool summers. Instead of subsisting on under-the-snow winter forage, herds had a continuous round-the-year access to fresh grass. Sedentary hunter-gatherer and farming populations were defenseless against the mounted nomads, they could easily be levied for labor-intensive supplies. The long-range meridional and mountain elevation migrations, and migrations to the winter refuge became unnecessary. Herds of horses could remain in situ, and be complemented by incapable of the long-range migrations cows and sheep. Compared with horses, cows and sheep produced an abundance of milk and meat. The technology of mobile homes waned in favor of the permanent settlements. An abundance of waterways reduced the need for overland travel that faded to became a secondary option. The extent of the year-around pastures allowed to bring pastoralism into the theretofore inhospitable latitudes, particularly to Scandinavia and the Isles with their pastoral economies surviving to this day. Economic adaptations turned once perilous and isolated pasturing routs into communal ventures that involved diverse ethnicities and social strata. They were a medium which grew cultural, syncretistic, linguistic, etiological, social, and technological adaptations. The hallmark of the adaptations was expressed by the Central Europe's regional Tumulus culture (Gmn. Hügelgräberkulturca, 16th - 12th cc. BC), another name for the Kurgan culture, from the Türkic tumlu “tomb”. Germanic and other European tribes were “Huns” long before the coming of the Western Huns to Europe in the 4th c. AD.
After some unknown prehistorical events, ca 8th c. BC, masses of the European nomads migrated northward with their minions, to the Scandinavian area. Climate-wise, the area afforded the same favorable conditions, but otherwise it was an area reliably secured from attacks by the wide bodies of water. That probably was a reason for migrations. The following two thousand years saw plenty of demographic activity, little known initially, but well documented for the later literate period. The events of that period attest to all kinds of amalgamations, diffusions, and divergency. There are indications that on the way, Denmark accepted Cimmerian and Scythian refugees who established their own enclaves behind the safety of marches and water barriers. Ethnically distinct, these nomadic migrants had enough commonalities with the Scandinavian pastoralists to coexist and amalgamate. These processes are fairly well known, up to the specific name of Ases of the Norse sagas, but lightly studied for historical reasons, the nomadic pastoral culture fell by wayside in comparison with unduly glorified culture of the farming population and the Viking glory. On one hand, the skewed science brings skewed results, but on the other hand it leaves plenty of room for historical explorations that would right aberrations in many involved disciplines, not the least, and probably most heavily, in linguistics.
Available dictionaries cover Anglo-Saxon and Old Saxon from the 7th c., the Old German from the 8th c., the Old Frisian from the 13th c. copies of the older material, and the Jute that combined Jute and Cimbri (the Classical Cimmerians) from the 13th c. The Angles, Saxes, and Jutes were the most important initial contributors to the development of the English. The Anglo-Saxon lexis remains a solid backbone of the English, it formed in the Central Europe before the 5th c. migrations to the British Isle. English was greatly transformed in two periods of fast and cardinal changes, the first in the 11th c., the second in the 15th c. The first transition from the Anglo-Saxon or Old English to Middle English was connected with the Norman conquest, the second transition from the Middle English to New English was technologically driven by the introduction of typography.
English has estimated 500,000 words, absorbed from every imaginable language; about 30% of the lexicon ascend to the Germanic, Celtic, and substrate portions; the unique words shared by English and individual Germanic languages serve as indicators of the colorful blend: 120 Anglo-Frisian words vs. 40 Friso-Scandinavian words. Thus, for example, the particular form sin “sinful” came from the Türkic exclusively via Frisian. Only a portion of the Türkic lexicon in the Anglo-Saxon vocabulary survived into English, numerous Anglo-Saxon Türkic words are absent in English, but at the same time English is endowed with numerous Türkic words not documented in the Anglo-Saxon lexicon.
The layer of the Türkic origin may number only few hundred words, but they are the most important words: I, do, this, my, make, give, talk, eat, write, tell, kill, earth, time, day, dawn, body, and the little suffixes that make English the English. They are also the most necessary and endearing household words: mommy, papa, daddy, baby, puppy, doll, lullaby, cry, hash, wake, fart, butt, son, girl, brother, cousin, kin, guest, say, tell, candle, loaf. In the G.Doerfer's classification, these words are “essential basic words”, essential for the daily life and for the substrate concept. Of the Swadesh list of 207 “basic” words, about 62 words or exactly 30% correspond to this study’s entries on the 800-word listing of the English Turkisms. Pointedly, the study did not pursue a targeted examination of the Swadesh-207 list, and the results are random coincidences between two independent tabulations. That allows to predict that a complete examination would produce a number somewhat closer to 40%. In reality, since the Swadesh list is tailored to the specifics of the English with its absence of locative suffixes and similar inflectional markers, the English words indicating inflection can’t be classed as“basic words contained in any language”, making the Swadesh-207 list somewhat smaller, and even in this random examination the actual proportion of the 62 words stands higher than the pedantic 30%.
So far, most of the Türkic words meet etymologists' blank eye, many appear from nowhere in the records of the late Middle Ages as a “folk speech”, which what they precisely were, the speech of the ingenious English folk little affected by the Lat. influence. Quite remarkably, some of these basic words echo in the Chinese and Korean, demonstrating their spread from one end of the Eurasia to another, which only the horse-mounted Kurgan nomads could feasibly achieve. That common thread once propelled, under a spell of the Family Tree model, a suggestion of Sino-Caucasian superfamily.
A study of English Turkisms may be helpful in understanding development of the Türkic languages. The portion of the Turkisms brought to English by the Anglo-Saxons and other concomitant ethnicities may illuminate semantic nuances and extensions that did not survive to the 13th c. late records for the eastern languages. For example, the Anglo-Saxon word sink in the compound naegledsink “studded vessel”, lit. “nail-adorned vessel” uses the word sink for a an object translated as “vessel”, but could be a funeral casket made of a watercraft, or a watercraft used in funerals, or a casket patterned as a watercraft, while the recorded Türkic stem siŋ-/sı:n carries notions of submergence into water instead of floating on the water, a sink basin, and a tomb, i.e. the objects that can't be imagined studded. The older records of the Anglo-Saxon language may also elucidate the apparently unconnected derivatives and concrete nouns. Some basic Turkisms came to us practically unchanged, they may be as old as the parental haplogroup NOP, Cf. earth, don, tell, sink, sail. Other basic words stratified into clusters of barely compatible allophones with very different degrees of recognisability.
We do not know the names of the Kurgan nomads before 2200 BC, we know some names of these nomads
from the Assyrian tablets ca 2200 BC: Guties, Turuks, Komans, Kangars; ca 1600 BC in China they are
called Juns (Rongs) and Jous (Zhou); at approx. 800 BC in N.Pontic and Asia Minor they are called
Cimmerians and Scythians; ca. 200 BC north of China they are called Huns, Juns, Tokhars (Yuezhi),
Usuns, Saka, Kangars, and Tele; and in 200-400 AD they are called Huns in the west, in India, and
across the eastern Eurasia, and Kangars and Usuns in the center of the Asia. After that, they
continue to rush around Eurasia and build kurgans for their deceased for another 1,000 years, coming
into the present.
7
Contrary to the evidence and testimonies, Germanic peoples are held as autochthons of the Scandinavia. Jordanes (6th c., Getica) introduced an opinion that most of the European peoples originated in Scandinavia. At the same time, Jordanes knew of the Goths' “Scythian” origin: “the Goths dwelt in the land of Scythia near Lake Maeotis. On the second migration they went to Moesia, Thrace and Dacia, and after their third they dwelt again in Scythia, above the Sea of Pontus” (Jordanes V.38). The Gothic origins are relayed in the initial legendary part, the non-fictional part of the Jordanes' work starts in the 3rd c. AD with Roman clash with the Goths.
Toponymic research demonstrated a paucity of native German place names in Germany, corroborating that Germans came to Germany in the last centuries BC (Chemodanov, 1962, 79). The south Scandinavia, reputedly the original homeland of the Germans, definitely could not populate the whole of the Europe. It has a gap between the cultures of the Bronze and Iron Ages (Mongait, 1974, 324), when sometime during the Sub-Atlantic climatic phase (cold wave, 5th c. BC - 50 BC) it was completely deserted, and then re-populated with a reverse flow. Evacuation of the farming population rolled out within a period of less than a century. Then enter the Classical writers, who found Germanic tribes in Gaul and Germany. In the first centuries AD the names Suebi and Germans had an equal currency. Apparently, both the names Germani and Suebi are exonyms, the first means “manly, brave” in Türkic, the second means “vagabond, vandal, wendeln (Wanderers)” in Celtic. The Germanic form wendeln is a calque of the Celtic word. The names Suebi and Germani are umbrella terms like the names Scythians, Saka, Sarmats, Alans, Ases, Goths, Huns, Türks, or Tatars, and like the names Celts, Greeks, and Romans. They refer to horse nomadic pastoral societies, mobile and perilous for sedentary farming peoples. From around 58 BC on, the fragmentary information on Germans becomes fairly continuous. Strabo (1st c. BC) described the category of the Suebi nomads as peoples living off their flocks on meat and milk, with “small huts” yurts and wagons, driving their herds from pasture to pasture, and opposite to the settled farming. The description of Suebi is indistinguishable from the description of the Scythians and their variety. As a number of distinct tribes with their own distinct names, the Suebi tribes occupied more than a half of Germania. The nomads and local farmers coexisted, occupying different interspersed niches. The nomadic part of Europe must have been very sparsely populated, because the pastoral economy is highly manpower-efficient but needs huge pastoral tracts to sustain large herds. East of Germania was the endless European Sarmatia, populated by the Sarmat Scythians, and nobody knew where one ends and another starts. A number of Suebi tribes have transparent Türkic names, Cf. Goths that stands for generic Guz (and gur) “tribe”, Alamanni that stands for generic alaman “raid” (Vorontsov, 2009, 65), Hercyni (as in Hercynian forest) that stands for generic “nomad” lit. “kindred (hence the appellative Hun) people”, As that stands for “plain (people)”, its Slavic calque is pole “field”, Polyan “field-man”.
The Normans' genealogical legends also recall that they “came from Asia”, they lived there in an ever flourishing country, richer than the cold Scandinavian coasts. The description of the “old country” echoes that of the Cockney, in Türkic köken “motherland, native place, ancestral land”, a “mythical luxurious country”. The Old Norse Prose Edda provides numerous parallels with the Türkic mythology, etiology, and ethnology. It links the Norman-Germanic genealogy with the god-ancestor Thor (Þor, Þorr), the Tengri of Tengriism and the Chinese Tian “heaven”. Following a prophecy, a legendary leader Odin led a “multitude of Ases” to the country of Saxes, and then on to other regions of the Germany. The Türkic term yazï “steppe, plain, flatland” is almost synonymous with the word alan “plain, flatland”, the names As and Alan were used interchangeably. The confusing parallelism of these two terms in the historical records and in Türkic attests to their common source, it is a salient case of paradigmatic transfer. Under the leadership of Odin, Ases triumphed everywhere over the local population, and in the end “the tongue of these Asiamen was the true tongue over all these lands;... and (that) the Asa brought the tongue hither into the north country; into Norway and into SviÞiod, into Denmark and into Saxland; but in England there are old names of the land and towns, which one may skill to know that they have been given in another tongue than this.” (Snorri Sturluson (ca 1220), 1842, 111). Of the nomadic Scythians, Strabo singled out the “best known of the nomads are those who took away Bactriana from the Greeks,... Asii or Asians, Tochari,... who originally came from the country on the other side of the Iaxartes River (Syrdarya) that adjoins that of the Sacae and the Sogdiani and was occupied by the Sacae.” The sources trace Ases and Saxes (Saka, Sacae) from the 140 BC Horezm to Bactria, to the N. Pontic Scythians, and to the vicinities of the Baltic Sea. Before that, in the 3rd c. BC, the Asii-Yuezhi controlled Ordos. The migrants had to carry not only their spoken language, but also their written language, the traditional titles, social and state organization, and a myriad of other cultural and societal traits. The Germanic Normans have a glorious obfuscated pedigree. The Normanic Vikings used to intimidate their neighbors a millennium before they turned to consummate the sitting ducks across Europe.
Snippets of the nomadic traces are scattered in the lexicon, morphology, semantic links, distinct phonetics, and regular phonetic shifts throughout the body of the examined English Turkisms. The body of knowledge inherited from the early days of the Germanic people had to suffer from a cognitive dissonance on the institutional level, when the uncivilized nomadic ancestry was first minimized in favor of the civilized agricultural traditions, then in favor of the civilized religion, then in favor of the civilized wars and colonization, and finally in favor of the civilized parochial patriotism. Linguistics is but one facet of the discrepant humanities; not only matters like earth/erde “earth” is unrelated to the Türkic yer “earth”, but the Germanic runes are unrelated to the Türkic runes, the European jurisprudence is unrelated to the nomadic jurisprudence, the European parliamentarism is unrelated to the nomadic parliamentarism, and so on in the department of new mythology of the European humanities. No applied science discipline can be institutionalized with one blinder on, rather, a minutest discrepancy is mercilessly massaged and studied till it is resolved, exhaustively tested, and applied for practical needs. No applied science discipline can exist without crisp definitions of its basics and effects. No applied science discipline can exist with two sets of contradictory textbooks. Humanities, in contrast, can have three Saxonias, one in Horezm bordering on the Asii, the other the Sakacena in Azerbaijan in the Caucasus, another one in the center of the Europe, and any contiguity is in a state of denial. Or have the two Asii folks, one in Bactria and Horezm, the other by the Baltic, and no contiguity in language or script. Science searches for quark entanglement, the humanities in contrast, in conflict with all counterindicators, postulate a disentangled egression. Instead of amalgamation, is firmly postulated an internal development.
A Zoroastrian source (speculatively dated by 1200 BC, on the events of the 7th c. BC, if that makes any sence) recites the As-related events: “Some Turanians, expelled from the Media country by (the legendary) Kai Khosrow, settled in the northwest karshvar (province) of the known inhabited earth. They crossed the river Erehsh (Arax) and Kurush (Kura), and lived on both sides of the mountain Erezur (Caucasian Elbrus) of the Hara Berezati ridge. These Turanians were also called by the name Ihkuzu (As Scythians). Later, they moved into the vast plain north of the ridge High Hara to the rivers Ranh and Danush (Itil and Don)... The Saka living by Danush (Don) were also called Danavas Turs (Danavo Turs) because in their country flows the river Danush, the longest and most dangerous of the rivers” (Zarathustra, 2002, 29). The name Scandinavia may be an echo of the name Saka-Danavo.
In Turkic languages tur/tura means “live, dwell”, “stopover, layover”, “settlement, dwelling”, toručï “inhabitants, population”. The names Tur and Turan are popular with Avesta, in the Iranian languages the names are not etymologized, etymologized, they attest to the Türkic linguistic influence on the Iranian languages of the time. As a specific toponym, Turan persevered for 3 millenniums, predating both Persia and the Han China.
Although the Old Norse sagas clearly depict Odin as a leader of the Asparukh type, who at a time of trouble leads his people to safety, the European historiography presents Odin as a head of a religious pantheon. There is no need to confuse the issue, since the Almighty is Thor. Attempts to re-christen Odin as a supreme being were not successful, under any dressing Odin could not replace the Almighty Thor. The mythological Odin may have been treated as a deified figure, but he remained a figure of flesh and blood, an eponymic tribal ancestor of the Nordic royalty. His name appears to be a title-name, like Attila (Father of Country) and Ataturk (Father of Türks), consistent with the pre-Islamic, pre-Christian Türkic naming tradition. The god-like qualities of Odin are consistent with the properties of the boyar class, who were held in reverence for their foresight, wisdom, knowledge of omens, foreboding, and even magic powers. The prosthetic initial w- in his name is of the same nature as the prosthetic f- in “father”, an allophone of the Türkic ata “father” (Gothic atta) with a pl. suffix to express a notion of respect. The title is a straightforward epithet, an allophone of the ata-ani “ancestor” (lit. “father-mother”), with some dialectal peculiarities. In Slavic languages, the title Odin has a form otchina/votchina (отчина/вотчина), from otets (отец) “father”, an allophone of ata that also has a variant with a prosthetic initial v-, specific for Slavic languages. It goes without a saying that a mortal, even if deified, can't head a religious pantheon. However, as a deceased fatherly figure, he can provide some occult protection, along the line of the dependable Catholic saints and the time-tested Roman/Greek gods. The name Odin is another relict of the Asian ancestry.
Huns play a major role in the German genealogical legends, an especial place occupies Etzel Attila (Nibelungenlied). The western Hunnic state operated on the model of the prior and later Türkic states, as a confederation of kindred tribes and their sedentary dependents. Attila inherited a state with a long-ingrained notion of the Türkic-Germanic kinship. The blurred footprint prevented Classical authors from delineating where the European Sarmatia ends and the Germania starts. The tribal composition of the Attila's forces at the Chalons (Catalaun) battle and the rise of the Germanic states after the split of the Western Hunnic Empire present a vivid attestation of the confederation membership. In a genetic bird's-eye view, the Roman-Hunnic confrontation and the succeeding melees were a conflict of the R1 haplogroup (R1a and R1b varieties) with the native European haplogroups, a replay of the millenniums-old confrontations during the previous Kurgan waves, including the last Sarmat wave of the 2nd c. BC. Huns left a sizable trace in the European culture and social organization, it took a millennium to suppress the last vestiges of the Türkic religion (in the forms of Arianism, Bogomilism, and other monikers), but the will for freedoms and the social canons have survived as the modern canons. Except for the eastern fringes, the European civilized slavery system did not survive the Hunnic period. Unlike the sedentary civilized societies, barbarians practiced confederations, not enslavement. The individual freedoms and parliamentary system are the vestiges of the steppe societal traditions.
To establish in a systematic fashion a conjectural genetical link between English and Türkic, suggested by history, archeology, ethnology, and biology, comparisons must be made between all linguistic aspects, namely typology, syntax, morphology, lexis, phonetics, distribution, script, and statistical significance. All these aspects must corroborate, or at least not contradict, the proposed concept. The historical background, and the parent and kindred languages systemically infused with Türkic elements, must be a canvas over which the linguistic aspects are drawn.
The discipline that pursues in that direction is called comparative historical linguistics, and that term should be used for the task of identifying Türkic-type layer in English. However, due to self-imposed preconceptions and limitations, that task can be called comparative historical linguistics only with major caveats. From its inception, the discipline of comparative historical linguistics emerged and was defined as a linguistic analysis of the Family Tree model, it is a “normal”, “accepted”, or “established, traditional” discipline; deviations from the “norm” are held abnormal and peripheral. Whatever linguistic classification scheme is selected, it is the Family Tree model, to the deliberate exclusion of other models, like the Wave model, by the very essence of the “normal” comparative procedure. Atomistic in method, the “normal” comparative historical linguistics behaved as an interpretive discipline-isolate, short-circuited on itself, and opposed to a holistic approach.
Historically, ethnic depictions described typical appearances of the alien peoples. In the “them” vs. “us” descriptions, the part “us” is omitted as well known to the reader. For the later students that part was understood as implied opposite: “they” are swarthy, then “us” are “white”, “they” are nomadic or sea-fairing, then “us” are stationary, “they” are blonds, then “us” are brunettes, etc. For centuries. the notion of race underlain and tainted all aspects of ethnic studies, including linguistics. The understanding of the origin and propagation paths of the typological traits is a newer development. The Indo-Arian “blond beast” turned out to be a trait alien to the Mediterranean “us”, it is carried by the genes originated in the northern Eurasians, the Finns and their genetic kins, the carriers and descendants of the Y-DNA haplogroup NO with that unique mutation. In the age of genetics, not once a discovery of light-haired dead was still hailed as an evidence of linguistic Indo-Europeanism. Similar misconceptions in respect to Mongoloidness and other acquired appearances covertly underlain the fundamentals of the comparative linguistics.
In reality, very few societies and their languages fall under the essence of such “comparative” procedure. A test of such peculiar comparative historical linguistics built on the Family Tree model, applied to any language in Europe from the Noah-equivalent point for the historical period, with terminal points from when it was documented for the first time to the modern language, would fail to reconstruct the modern language from the initial one, and vice-versa. That failure would be predicated by the deficiency of the model that neglects the most important factors in development of any European language, those of the Sprachbund effect, demographic effects of amalgamation and migration, demic cultural impact, and impact of mass media that started with introduction of mass print and spread of literacy. In pursuit of the proposed concept, no developmental model should be presumed, it should be a conclusion of the exploration, not its premise or precondition, nor a target nor a guiding star.
A similar position should be taken toward all other linguistic aspects, directed toward examination of the factual material without pre-imposed targets and limitations. Personal beliefs on what is possible and impossible must be dispensed with beforehand. Elementary justice demands a search for, introduction, and examination of every relevant evidence and every testimony for every etymological investigation, with unmitigated attention to counterevidence and wanton presumptions. Instead of being dispensed with as malleable variables to justify diversity within the “IE” family conglomerate, the subjects of typology and syntax, completely ignored by the “normal” comparative procedure, need to take their proper place as the leading and most conservative properties. The statistical significance stepdaughter of linguistics, which the “normal” comparative procedure knows only from citations of few selected luminaries, need to be a common and productive tool.
In the lexical aspect, opinions on the statistical significance for genetic connection vary from 150 cognates (G.Doerfer 1981) or every 70th word within a presumed basic 10,000-word dictionary, to a probability of 1:100,000 for “individual-identifying evidence” (J. Nichols 1996). That range of “opinions” on primary definition, from 70 to 1 individual, is ridiculous by any standards. For this examination, the G.Doerfer's suggestion, generally deemed to reflect a sound skeptical conservatism, is accepted as a vaguely defined threshold of credibility, as a lexical-statistical point which satisfies a minimal requirement for genetic connection. The lexical paradigm, nearly exclusively used in the comparative linguistics, is a low-hanging fruit. Other traits, like the paradigmatic transfer of the entire cooking lexicon, or the transfer of embedded morphology, are statistically immeasurably more weighty, each additional element exponentially reduces a possibility of falsification, quickly reaching a point of no return.
Under “normal” comparative procedure, geographic distribution rarely gets a cursory look, and when it does, it mechanically expands the depth of the Family Tree model to another level of a mature “pra-language” seed of the Nostratic theory. For this examination, the preconceived Family Tree model is dispensed with, and the term Nostratic is used for putative Eurasian Sprachbund elements connected with migratory flows prior to the domestication of animals as a means of transport. That invention cardinally changed the patterns of cultural exchange, replacing a slow-moving omnidirectional dispersion to a directional fast-pace dispersion.
The concept of genetic connection within linguistic family stipulates a base vocabulary shared by the members of the family. In essence, that is a standing non-codified definition of a linguistic family. Numerically, the base vocabulary is miniscule, numbering 10 to 20 dozen words selected for their stability across all candidate languages, it is a hard linguistic nucleus. In a conceptual 10,000-word dictionary, 200 words constitute 2% of the lexis. The remaining 98% of the lexis constitutes a shell enveloping the base vocabulary, it is malleable, it is not limited by any qualifications. The qualitative division onto the base and shell vocabularies was established by the “normal” comparative linguistics, it was a necessary theoretical accommodation of the fact that 98% of the Indo-European lexis is incompatible between the putative members of the Indo-European family. It also made “guests” an ordinary and predominating phenomenon, allowing a single “guest” to systematically infiltrate numerous languages from numerous linguistic families and their numerous branches. The conditional accommodation freed a 98% of any member's lexis from concordance with any linguistic laws, since the “guests” originated from any walks of life and joined via all kinds of paths.
The freedom from the laws allowed a freedom of typology, it brought, at least theoretically, under the “IE” umbrella such incompatible languages as Celtic, Armenian, Kartvellian, Ossete, and Kashmir. The conditional accommodation allowed to stipulate an attrition rate for the base vocabulary, at least for the tested European samples. Applying the formulated concept of genetic connection to the families other than “IE” flashed out an utter parochialism of the concept. In case of Türkic languages, and generally of typologically agglutinative languages, the core vocabulary numbered way in excess of 50% of the lexis, and the stability of the root as a key element was an order of magnitude higher than that for the “IE” languages. As a systemic diagnostic tool for genetic connection, the concept of the core vocabulary established for the European languages plus Sanskrit and Persian can't be extended across linguistic families other than the IE. For the non-IE substrate languages, the substrate concept must examine cases from the 98% shell, not stay shy from examining cases from the 2% base vocabulary, shrink down to individual words, their ultimate origin, their membership in the paradigmatic transfers, and to attempt to visualize historical paths between disparate linguistic families.
The method of the “normal” comparative procedure assembles a listing of the study's target words in allowed language (say, Lao) suspected to be cognates of the word list with known affiliation (say, Sino-Tibetan); the two listings are juxtaposed, compared, and analyzed in phonetic and vaguely defined semantic aspects, with episodic excurses into known political history as a dating tool. By definition, the method is not holistic, it leaves a bulk of the linguistic properties outside of the purview. At the same time the comparative procedure declines to give a credence to the analogous lexemes from unfavorable candidates. The two-faced-Janus approach proved to be beneficial for the sanity and racial purity of the “IE” comparative linguistics, imposing few limitations beyond the “normal” scope of purview, but at a price of introducing methodological flaw of circular logic, when the results filtered through the aperture of premises invariably validate these premises. With the circular logic, like in love, beauty is in the eyes of the beholder.
As a linguistic dating tool, the known political history may be a convenient, but profoundly unrealistic approach. The multi-ethnic composition of all Türkic confederations is not an exception, but rather a rule: during historical period, few political entities, even isolates, were monolingual, if only because the mammalian trait of sexual procreation extends way back beyond our historical period, and staunchly continues into our present. Way before the appearance of the human ethnicities, a drive for trophy husbands and wives was crossing any boundaries within the same species, the Neanderthalian admixture within the modern population saliently attests to that. Confusing political, ethnic, and linguistic categories is akin to a scholastic ghettoization of climate, you can do it, but dynamic events disagree with a static model. A fixated search for a ghettoized Urheimat instead of a linguistically fuzzy amalgamated and amalgamating Sprachbund in a time and space motion requires a holistic approach. That, in turn, would re-write definitions for the objective and the target.
The “IE” linguists routinely stipulate as a justification for the bifurcated methodology that the listings from uncouth suspects can't be taken seriously, asserting that unlike their sibling “IE” listings they are methodologically flawed, inconsistent with the given postulates, and prove absolutely nothing. The main tool of that approach is not to methodically refute alternate concepts, but to plant a doubt. At the same time, the miniscule qualifying requirements and the absence of concise definition allows essentially unlimited possibility to claim “IE” genetical connection for languages of entirely different origin, without any consideration for the relationship of the primary vs. the secondary, fluid, and possibly borrowed, properties. For this examination, the bifurcated methodology is dispensed with, the same criteria are applied without prejudice and any preconceptions. The body of cognates in the candidate language is viewed as a paradigm with its own structure, segmentation, and logics; the paradigm has to be consistent with advances accumulated by all disciplines including linguistics.
The “normal” comparative procedure does not trace evolution of the morphological elements, not in a small degree because no elements fit the entire “IE” Family Tree model, they belong to languages with incompatible typology and incompatible syntax, and offer commonalities only within certain Sprachbund areas. Within and without “IE” linguistics, the primacy of the language typology and syntax are established facts, phonetic modifications are effects and not causes of the linguistic changes. Consistent application of that cause and effect sequence creates insurmountable conflicts for the “IE” family concept; advancing phonetics into the cause position allows to save the concept by postulating, selectively for the “IE” family concept, malleable typology, syntax, and lexis. Morphology is not a building block of the “IE” Theory, it is its greatest Achilles' heel in need of secure disposition.
The proposed concept, in contrast, treats morphology as a most powerful diagnostic trait, it traces numerous European morphological elements to the Türkic agglutinative morphology, and demonstrates a genetic connection and adaptation to the typologically incompatible European languages. The treatment of morphology is not selectively fitted to any model, with understanding that every individual language formed from inherited, amalgamated, and innovated components, and a part of dialects of any linguistic grouping may carry traces of an archaic phenomenon shared with other dialectal groups, while any member of a dialectal group may replace archaisms with borrowings and innovations. In most cases, the English Turkisms allow to connect an English word with its real primeval root, still active, productive, and surrounded by a slew of morphologically derived offsprings, all ascending to the primeval notion of their living progenitor. The diagnostic tool of morphology is applicable across the entire language, without a need to target examination to particular grammatical classes.
The treatment of lexis within the proposed concept is based on the monumental work performed by “IE” linguists in the course of the past 200 years. The cognate listings cited in “IE” etymological compilations in most cases are used verbatim, extending beyond the “IE” horizon where applicable. One major difference is the accent on semantics instead of phonetics, the corollary of that difference is differentiation between homophones and allophones. Where the “IE” linguistics accentuates phonetics and treats semantics as a malleable property, a close attention to semantics allows to discard spurious and artificial parallels, cleansing analysis of notional biases aimed at a certain result. The other difference is an open horizon, a corollary of untargeted analysis, it expands linguistic geography to the places where the foot of the “IE” linguistics did not trod, and brings up systemic results outside of the “normal” purview. Another difference is the independence of the cognate candidates from the much berated “IE” linguistic laws. That is justified by the absence of linguistic laws that systematize malleability of Turkisms obtained in the processes of population replacement, amalgamation and cultural borrowing, and keeps in the parallels usually discarded by “normal” linguists who apply “IE” linguistic laws to stochastic phenomena in order to keep the stochastic process tamed and targeted. Another major difference is a healthy skepticism toward reconstructions fancied from applications of dubious laws to stochastic effects. Since the “IE” linguistic laws are no more than formulated observed tendencies, they carry a statically defined probability, and can be applied only in statistical context.
Conventional scripts that existed prior to codification, brought about by the introduction of printing, are conservative and traceable to their primeval forms. Scripts, however, are a separate branch of science neither endorsed nor used in comparative historical linguistics, to the detriment of the last. The independent life of graphemes is as much a historical evidence as are the spoken and written forms of phonetics. The proposed concept embraces the evidence, conveyed by the comparative historical orthography both in graphic and phonetic aspects, within the limits of immediate perception.
The statistical significance denotes a numerically expressed value of a set of data within a body of data, applied to measured parameters (statistics) and predicted statistical outcome (probability). The most informative statistical measurements in the proposed concept are the frequency of use, which is statistics on relative standing of a particular word in a language, and probability of chance coincidences. The frequency of use statistics allows to appraise numerically the place of the substrate language in the examined language, a most significant parameter of the examined language. The factor of probability of chance coincidences, on one hand, allows to validate or reject a test subject based on the valuation of probably vs. improbable, and on the other hand allows to validate or reject linguistic assertions made from the perceptions of personal intuition and ingrained biases.
Some statistical reality needs to be accounted for in assessing formulaic interpretations “fortuitous, echoic, onomatopoetic”, and similar dead-end etymologies. The limitations of the source base are not uniform, they vary greatly depending on subject, e.g. well documented religious lingo vs. poorly documented daily utilitarian lexis. That shortcoming is especially great in the paramount areas of the nomadic economy, animal husbandry and the metal and weaponry production. At times, barely 10% of the specialty lexicon recorded in the source base matches that documented by special studies, Cf. A. Shcherbak, 1961. The statistical chances of locating a relevant cognate for the niche semantics is really fortuitous, reflecting the ratio of the live lexis vs. the recorded compendium. Since the lexical distribution paths are totally unknown or at best tentative, an omission of a single pertinent cognate is critical in each individual case, denying an opportunity to locate a possible demographic path, and generally to establish possible genetic connection. Under such conditions, assertions on the fortuitous, echoic, etc. formulaic origins can be valid only when they are based on exhaustive study of a wide range of synonyms extended as far as the real and potential migratory trails.
The historicity of the comparative historical linguistics is an unsettled issue with diametrically opposing opinions, from purists arguing that comparative historical linguistics is unable to penetrate or reflect historical processes to practitioners associating linguistics with specific political events. A holistic assessment of the lexical material in the context of the proposed concept allows to link linguistics with history and the disciplines as diverse as biology, economy, ethnology, and technology, and to use the mutually corroborating evidence to affirm the proposed concept.
The trait of paradigmacity is a most powerful tool attesting to the genetic connection, it is one of the tenets of the “IE” comparative linguistics. The observed transfer of paradigms, traceable from the Türkic to Germanic and on to the English corroborate the proposed concept. Generally, members of paradigmatic transfer share common traits: their “IE etymology” bravely declares them to be “of unknown origin” or spottily suggests easily confuted mostly incredible etymology; in paradigmatic transfer cases cognates are endowed with their separate mutually unrelated “PIE proto-word” origins; the cases of paradigmatic transfer slip undetected and unaddressed; morphology-related paradigmatic transfer is ignored.
The trait of paradigmacity is a most powerful tool attesting to the genetic connection, it is one of the tenets of the “IE” comparative linguistics. The observed transfer of paradigms, traceable from the Türkic to Germanic and on to the English corroborate the proposed concept. Generally, members of paradigmatic transfer share common traits: their “IE etymology” bravely declares them to be “of unknown origin” or spottily suggests easily confuted mostly incredible etymology; in paradigmatic transfer cases cognates are endowed with their separate mutually unrelated “PIE proto-word” origins; the cases of paradigmatic transfer slip undetected and unaddressed; morphology-related paradigmatic transfer is ignored.
The reason for such inept treatment is that the bulk of the accumulated etymological studies is a century old, from the time of horse carriages and inchoative nation-states with high attention to creation their historical narratives. Nearly all studies were produced in Europe, by the European scholars, in accordance with the European norms of the day, and for the European consumption and mentality; exemplary pedantry was held in high esteem, it did not need an open mindset, abhorred scientific heresy, and had powerful tools to curb deviance. Lexical similarity and cognates were not only a base of the science, they were the science. Still, other than a general concept, the tool of the paradigmatic transfer is in its incipiency, a theoretical tenet in waiting for practical implementation. In support of the proposed concept, the method used is duly concerned with cases of paradigmatic transfer in their many configurations, and seeks to detect each case as the most credible evidence.
While the methodology used in support of the proposed concept in many respects conflicts with the tenets of the “normal” comparative historical linguistics, the method is productive in its approaches, in the spectrum of examined factual material, analysis, the width of corroborating evidence, and achievement of credulity for the proposed concept.
Given that English is a considerably modified version of Anglo-Saxon, the most expedient approach would be a direct comparison of Anglo-Saxon versus Türkic, a task beneficial for the present examination and fruitful for the “IE” linguistics. That such comparison, in spite of a plethora of documented indicators, has never been conducted, is a monumental methodological flaw. The expediency of the Anglo-Saxon – Türkic comparison would however miss English Turkisms absorbed via other languages that formed the English substrate, particularly Frisian, Celtic, and Gothic components. Numerically limited, such components are invaluable testimony to the richness and complexity of the English linguistic history; to deliberately abandon them would distort the evolution of a living language. The method used in support of the proposed concept, in contrast, attends to the substrate Turkisms irrespective of their source.
The English substrate words of Türkic origin are scattered in numerous works of mostly non-linguistic nature, where they are accidental to the topic of the work. A few of them are picked up from the linguistic work of G.Shuke 2010, who compares substrate lexicons of the Latvian and Russian vs. the Türkic, and unwittingly cites numerous English cognates in the Latvian and Russian Türkic-based substrates. Numerous Christian terms of the Türkic origin are analyzed in the work of Yu.N. Drozdov, 2011. The Old Türkic Dictionary (OTD, 1969), though extracted from the eastern Türkic languages, includes numerous words of the Türkic-English substrate lexicon, and hints at more words, of which only derivatives or some particular forms were recorded, leaving the stems to be produced by truncating their word-forming suffixes. G.Clauson Etymological Dictionary of pre-13th c. Turkish (EDT, 1972), though also extracted from the eastern Türkic languages, includes most of the cognates listed in this compendium, frequently indirectly and directly translated with their English cognates. A large number of Turkisms in Russian language covered in the work of E. Shipova Dictionary of Turkisms in Russian Language have matching English cognates identified in etymological dictionaries of English lexicon as “of unknown origin” or otherwise listed with partial or dubious etymology, frequently bent to Indo-European side. There is a tendency to use semantically unrelated Skt. examples as real cognates, just to make a point. In contrast with the flexive IE, the Türkic stems are not readily changeable. Generally, the romantic “IE” unattested *reconstructions of the English substrate lexicon are leaving a bad taste, confirming the old adage that Indo-European reconstruction inevitably has a character of a scientific fiction; not too numerous “IE” *stem conjectures are intentionally left out as confusing noise.
The listings of Turkisms in this compendium is intentionally limited to a number of 800, to prevent the task from being open-ended. A potential for increase is obvious even within a deliberately restricted scope, many words have semantically distinct derivative and allophonic versions, like the pair dip and deep, each with a trail of its own allophones and derivatives. Dozens of words are mentioned here as examples without elucidation, dozens more not mentioned here are obvious cognates. Increased inventory adds little to advance the concept. An expansion of the list has a trend of diminishing returns: although the words are innately English, the frequency of their use tends to decrease, with a net result that adding quantities does not materially increase the degree of the role Turkisms play in the modern English.
The whole body of the documented Türkic words in English can comfortably stand on its own without any non-attested stem forms. To illustrate this point, here is a list of words that are practically the same in the two languages, they only differ by divergent conventional Romanization.
These English words can be substituted in casual speech
with their properly suffixed Türkic counterparts, and nobody would hardly notice (like kel- >
kelter vs. kilter, qatïɣ > qatïɣir
vs. category, kast- > kastis vs chastise);
just the opposite, replace them with some colloquial English or European versions, and they would
stand out: compare with European (Fr. (de)calage, categorie, chatierai, Gmn. Gleich,
Kategorie, kasteien respectively), or with the barely recognizable 10th c. Old English forms
hlaford “lord”, brohte
“brought”, scolde “should”, licode “liked”, and the like. In many cases, Türkic
counterparts look like dialectal forms from the other side of the river, a type of the Cockney
version.
In many cases modern spelling obscures phonetic connection (like ög-, A.-Sax. ege, eage,
aga, modern eye); some regular alterations, like b/f, also obscure phonetic
connection (like bur “fire”, A.-Sax. fyr); such cases are not included in this
selection of easily recognizable samples.
The sample list of readily recognizable words (about 450) is pulled from the dictionaries
transcribing the Middle Age Türkic lexicon in Central Asia. It represents about 55% of the 800
lexemes cited in this compendium.
| English | Türkic | English | Türkic | English | Türkic | English | Türkic | English | Türkic | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | abode | oba | can | kanata | dumb (adj.) | dumur | king | kengu | sing (v.) | siŋ- (v.) |
| 2 | abundant (adj.) | abadan (adj.) | can (v.) | qan (v.) | dune | dun | lamb | -la:n | sink (v.) | siŋ- (v.) |
| 3 | abysm | abamu | candle | kandil | durable | dür- (v.) | loaf | lavāš | sip (v.) | syp (v.) |
| 4 | ache | аčï | cap | kap | duration | dür- (v.) | mallet | maltu | sling | salïŋu |
| 5 | acid (n., adj.) | аčï- (v.) | car | köl- (v.) | duress | dür- (v.) | mama | mamü | skull | kelle |
| 6 | act (v.) | aqtar- (v.) | caragana | qaraqan | dust | doz | mammal | meme | smile (v., n.) | semeye (v.) |
| 7 | Adam | adam | care | qorq | dye | dawa | man | men | soak (v.) | saɣ- (v.) |
| 8 | again | aga (adj.) | carnival | kerme | earl | yarlïqa- (v.) | many | munča (adv.) | sock (beating) | sok- (v.) |
| 9 | age | aga | case | kečä | Earth | Yer | mantra | maŋra- (v.) | sock (legging) | sok- (v.) |
| 10 | ago (adj., adv.) | aga (adj.) | case | qaza | eat (v.) | ye- (v.) | marasmus | maraz | socket | sok- (v.) |
| 11 | aggrieve | aɣrï | cash | kečä | eave | ev | mare | ma: | sodden (adj.)) | sod |
| 12 | alimentation | alım | cast (v.) | kus- (v.) | eke | eken (v.) | matt (adj.) | mat (adj.) | son | song |
| 13 | alimony | alım | cast (v., n.) | qïsdï (v.) | elbow | el | me (pron.) | min (pron.) | sorrel (adj.) | sary (adj.) |
| 14 | all (n., adj.) | alqu (n., adj.) | castigate (v.) | kast- (v.) | eligible (adj.) | elïg- (v., n.) | means | min | squeeze (v.) | qis- [qys-] |
| 15 | Alban | аlban (n., adj.) | category | qatïɣ | elite | elit- (v.) | mengir | meŋgü | stay (v.) | üstü- (v.) |
| 16 | alms | almak | cattle | katıl | elk | elik | mental (adj.) | meŋtä (adj.) | subliminal (adj.) | sumlîm (adj.) |
| 17 | amen (adj.) | ämin (adj.) | cause | köze:- | ell | el | menu | meŋ | suck (v.) | saɣ- (v.) |
| 18 | analogue | anlayu (adv.) | cavalry | keväl | elm | ilm | mickle | mig | sundry (adj.) | sandrı:- (v.) |
| 19 | apt | apt | cave | kovı: | en- | en- | mind | ming | sure (adj.) | sürek (adj.) |
| 20 | arch | arca | cavern | kovı: | endure | endür- (v.) | mint (v., n.) | manat | surrender (v.) | süründi- (v.) |
| 21 | argue (v.) | arqu- (v.) | cavity | kovı: | enigma | tanığma | mist | muz | swell | siwel |
| 22 | Arthur | artur- (v.) | Celt | kel- (v.) | -er | er (morph.) | monastery | manastar | tab | tap- (v.) |
| 23 | as (adv.) | aδïn (adv.) | chalant (adj.) | čalaŋt | Erik | erk | money | manat | tablet | tü:b |
| 24 | ashlar | aslïq- | chalk | chol | equal (adj.) | egil (adj.) | mother | mamü | taco | toqüč |
| 25 | ass | eš(äk) | chastise (v.) | kast- (v.) | ether | äsir | mount (v.) | mün- (v.) | tad | tat |
| 26 | assign (v.) | asïɣ | chat (v.) | čat- (v.) | evacuate (v.) | evük- (v.) | mouse | muš | tag | toqu |
| 27 | astute (adj.) | asurtɣuq (adj.) | chattel | čatïl | evict (v.) | evük- (v.) | much | munča (adv.) | tack (v., n.) | tak- (v.) |
| 28 | at (prep.) | at- (v.) | chatter (v., n.) | čatu:r (v.) | evil (adj., n.) | uvul- | murky (adj.) | mürki (adj.) | tale | tili- (v., n.) |
| 29 | Augean | aqür | cheap (adj.) | čıp (adj.) | evoke (v.) | evük- (v.) | nose | ñü:z | talk (v., n.) | tili- (v., n.) |
| 30 | aught | ot (adj.) | check | chek | ewe | eve | oat | ot | tall (adj.) | tal |
| 31 | aurora | yar- | cheek | čaak | fare (v., n.) | faqr(lïq) | oath | ötä- (v.) | tally (v., n.) | tili- (v., n.) |
| 32 | awe (v.) | ö- (v.) | cherub | čebär | feeling | bilin- | ocean | ӧkän | tambourine | tambur |
| 33 | awhile (adv.) | äwwäl (adv.) | chill (v., n.) | čil | gabble (v.) | gap- (v.) | ogle (v.) | ög- (v.) | tap (v., n.) | tap (v.) |
| 34 | baby | bebi | chip | čïp | gadding | qad | ok (interj.) | ok (interj.) | tap (v.) | tap (v.) |
| 35 | bad (adj.) | bäd (adj.) | chisel (v.) | čiz- (v.) | gaffe | ɣafillïq | old (adj.) | ol- (adj.) | tar (v.) | ter- (v.) |
| 36 | bag | bag | chitchat (v., n.) | čit čat (v.) | gain | gänč | omen | aman (adj.) | tariff | tarïɣ |
| 37 | baize | bez | chop (v., n.) | čop- (v.) | gamut (adv.) | qamit (adv.) | on (prep.) | on- (v.) | tart (adj.) | tarqa (n.) |
| 38 | bake (v.) | baka:č (n.) | circle | sürkülä (v.) | gaze (v.) | giz- (v.) | onus | önüs (adj.) | tell (v.) | tili (v., n.) |
| 39 | bald | bül (adj.) | clinch (v.) | qïlinč (v.) | gene | gen- (v.) | orate (v.) | orı: (n.) | terrain | ter- (v.) |
| 40 | bale (v., n.) | bele- (v.) | coach (v.) | köch (v.) | gift | kiv- (v.) | ore | öre: | theriacum | tiryak |
| 41 | barge (n.) | barq | coagulate (v.) | qoyul- (v.) | gird (v.) | qur- (v.) | ortho- | örti- | thick | sik |
| 42 | bark | barq | cock (latch) | kök | give | kiv- (v.) | other | ötürü (adj.) | thief | tef |
| 43 | baron | baryn | cock (fowl) | kök | God | kut | otter | ätär | think (v.) | saq- |
| 44 | bash (v.) | baš (v.) | cockney | köken | goose | qaz | ought | ötä | throne | tören |
| 45 | bath (v.) | bat (v.) | colon | kolon | gore (v.) | göres- (v.) | owe (v.) | oye- (v.) | tick (v., n.) | tiki |
| 46 | be (v.) | buol- (v.) | colossal | qolusuz | Gorgon | qörq- | ooze (v.) | ӧz (v.) | tick | tik- (v.) |
| 47 | bear (v.) | ber- (v.) | con- (pref.) | kon- | grey (adj.) | ğır (adj.) | pat | pata (v.) | till (v.) | til- (v.) |
| 48 | beetle | bit | coney, cony | kuyan | groom | görüm(čï) | penny | peneg | time | timin (adv.) |
| 49 | Belgi (adj.) | Belgü (adj.) | cook | kok- (v.) | guest | göster | pot | patır | tire | teyir |
| 50 | bellow (v.) | belä- (v.) | copious (adj.) | köp (adj.) | gut | kut | pour (v.) | pür | tit | tiši: |
| 51 | belt | bel | corset | qursa | habitat | oba | push (v.) | puš- (v.) | to (prep.) | tu- (v.) |
| 52 | berm | bürma | count | köni | hador (OE) | xatär | pussy (n., v.) | päsi (n.) | toe | toy |
| 53 | bet (v., n.) | büt- (v.) | courage | kür (adj.) | hard (adj.) | qart (adj.) | quality | qïlïɣ | toilet | tölet |
| 54 | big (adj., adv.) | big | court | qur- (v.) | hare | horan | queue | kü | toll | tol |
| 55 | bill (v., n.) | bil- (v.) | cousin | qazïn | haze | häzl | quit (v.) | ket- | tomb | tumlu |
| 56 | bill | bilä- (v.) | cove | kovı: | heap | kip | robe | rop | tooth | tiš |
| 57 | bode (v.) | bodi | cow | coy | Helen | ellen- (v.) | sag (v.) | sök- (v.) | top | töpü |
| 58 | bodega | butïq | coy (adj.) | köy- (v.) | herd | kert | saga | savag- (v.) | topple | topul |
| 59 | body | bod | crime | krmšuhn | hilarious (adj.) | güleryüz (adj.) | sagacity | sag | torah | tör |
| 60 | bog | bog | cue | kü | host | göster | sage | sag | toss (v.) | toš- (v.) |
| 61 | bogus (adj.) | bögüš (adj.) | cull (v.) | čul- (v.) | I (arch. ic) | ič (es) | sail (v.) | salla (v.) | tuber | tü:b |
| 62 | boil | bula- (v.) | culture | kültür- (v.) | ideal (adj.) | edil (adj.) | sale | sal- (v.) | truth | dürüst |
| 63 | bong | böŋ | cup | kap | idyl (adj.) | edil (adj.) | sane | san- (v.) | tuck (v.) | takın- (v.) |
| 64 | boot | bot | cure (fix, v.) | kur- (v.) | ilk | ilk | sanity | san- (v.) | turkey | turuhtan |
| 65 | booze (v.) | buz (v.) | cure (food) | kuri:- (v.) | in (prep.) | in (n.) | sapphire | sepahir | turf | ter- (v.) |
| 66 | bore (v.) | bur- (v.) | curd | ko:r | inch (n., v.) | ınča | sari | sarïl (v.) | turn (v.) | tön (v.) |
| 67 | Boris | böri | curt (adj.) | qïrt (adj.) | inn (n.) | i:n (n.) | sash | saču: | twat | tat |
| 68 | boss | boš (adj.) | curve | qarvï (adj.) | jack (v., adj.) | cak- (v.) | satisfy (v.) | satsa- (v.) | udder | ud |
| 69 | botch (v.) | bud- (v.) | curse | qur- (v.) | jag | čak(k) | satyr | satir | ululate (v.) | ulï- (v.) |
| 70 | boutique | butïq | curtain | qur- (v.) | jam | jem | savant | savčï (v.) | un- | an- (morph.) |
| 71 | box | boɣ | dad | dedä | jar | jart | savvy | savan (adj.) | under (adv.) | aŋıttır- (v.) |
| 72 | brother | birader | dam | da:m | jar (v.) | jar- (v.) | say (v.) | söy- (v.) | unite (v.) | una- (v.) |
| 73 | bulge (v., n.) | beleg (n.) | dash (v., n.) | taš- (v.) | jeer (v.) | jer- (v.) | sea | si | until | anta |
| 74 | bunch (v., n.) | bunča (adv.) | dash (n.) | taš- (n.) | jig (v.) | jïq (v.) | secede | ses- (v.) | us (pronoun) | ös (pronoun) |
| 75 | bundle (v., n.) | bandur- (v.) | dawn | tang (taŋ) | jig (n.) | jig | secret | soqru | usher (v.) | üšer (v.) |
| 76 | burl | burnï | deep | dip | jog (v.) | jag (v.) | sector | chektür | vacuum | evük- (v.) |
| 77 | bursary | bursaŋ | delve (v.) | del- (v.) | jolly (adj.) | yol | sell (v.) | sal- (v.) | vat | but |
| 79 | bust | basta | dementia | dumur | journey | jorï (v.) | sepia | sepi- (v.) | voucher | vučuŋ |
| 80 | butt | büt | derrick | terek | juice | jü | seize (v.) | sız- (v.) | while | äwwäl (adv.) |
| 81 | cab | qab/qap | descend (v.) | düšen (v.) | jut (v.) | jalt (adj.) | seizure | sïzğur- (v.) | whip | yip |
| 82 | cabbage | qabaq | diadem | didim | keen (adj., v., n.) | qïn- (v.) | sever (v.) | sevrä- (v.) | wig | yü:g |
| 83 | cackle (v.) | kakla- (v.) | dick | dık- (v.) | keep (v., n.) | kap- | sharp (adj.) | šarp (adj.) | will (v., n.) | bil- (v.) |
| 84 | cadre | kadaš | dike | dık- (v.) | Kent | keŋit- (v.) | she (pron.) | šu (shu) (pron.) | yacht | yaɣ- (v.) |
| 85 | caginess | qïjïm | dingdong | daŋ doŋ | kick (v., n.) | kik- (v.) | sheep | sıp | yell (v.) | yel (v.) |
| 86 | cairn | kayır | dip | dip | kill (v.) | öl- (v.) | shilling | sheleg | yet (adv.) | yet- (v.) |
| 87 | cake | kek | do | tu- | kilter | kel- (v.) | shit (v., n.) | šıč- | yield (n., v.) | yılkı: |
| 88 | call | qol | doll | döl | kin | kin/kun/kün | shock (v., n.) | šok- (v.) | you (pron.) | -üŋ (pron.) |
| 89 | calm (v., n., adj.) | kam- (v.) | don (v.) | ton- (v., n.) | kind (adj.) | keŋ (adj.) | short (adj.) | qïrt (adj.) | young | yangi: |
| 90 | callous (adj., v.) | qal (adj., v.) | sick (adj.) (ill) | sık- (v) | Yule | yol | ||||
| 91 | sin | cin (jin) | youth (n., adj.) | yaš (adj.) | ||||||
| sinew | siŋir | yuck (excl.) | yek (n., adj.) | |||||||
| yummy (adj.) | yemiš (adj.) |
Of the approximately 450-word sample list of readily recognizable words, about 320 words are identical semantically and strikingly close phonetically. The main differences are few morphological endings (like -age in courage vs. kür-), fluctuation of vowels (like amen vs. ämin), voiced/unvoiced d/t, b/p, g/k, and the like. Some of these words are amazingly old, they display attested endurance and conservatism over record-grade timespans. The title earl vs. yarlïqa- ascends to the 21st c. BC, 4200 years ago, it means “councilman”, and refers to the title of the Gutian ruler of Akkad. The Augean vs. aqür ascends to the Greek legends of the 1st millennium BC, 3000 years ago, it literally means “horse stables”. The Adam vs. adam and ewe vs. eve ascend to the Hebrew Bible, they literally mean generic “man” and “female”, the Bible story ascends to the 1st millennium BC, 3000 years ago. A real record-setter could be cairn vs. kayır, the first cairns belong to the 6th millennium BC, 8000 years ago, they belong to the dawn of the Kurgan Cultures, cairn literally means “heap of stones”. Their Gaelic and Scottish forms could only come with the Celtic circum-Mediterranean migration, arriving to Europe in the 28th c. BC, 4800 years ago. The selection of enduring words (about 320) represents about 40% of the 800 lexemes cited in this compendium, it demonstrates an amazing lexical conservatism traceable over millenniums.
| English | Türkic | English | Türkic | English | Türkic | English | Türkic | English | Türkic | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Adam | adam | caragana | qaraqan | eligible (adj.) | elïg- (v., n.) | mock (v.) | -mak | suck (v.) | saɣ- (v.) |
| 2 | amen (adj.) | ämin (adj.) | Charlemagne | Charla-mag | elite | elit- (v.) | monastery | manastar | sundry (adj.) | sandrı:- (v.) |
| 3 | -an (pl.) | -an (morph.) | chat (v.) | čat- (v.) | elk | elik | mouse | muš | sure (adj.) | sürek (adj.) |
| 4 | apt | apt | chattel | čatïl | ell | el | much | munča (adv.) | surrender (v.) | süründi- (v.) |
| 5 | arch | arca | chatter (v., n.) | čatu:r (v.) | elm | ilm | murky (adj.) | mürki (adj.) | swell | siwel |
| 6 | archaic (adj.) | arca | cheap (adj.) | čıp (adj.) | en- | en- | oat | ot | tab | tap- (v.) |
| 7 | are (v.) | -ar (v., n.) | check | chek | endure | endür- | OK (interj.) | ok (interj.) | tad | tat |
| 8 | argue (v.) | arqu- (v.) | cheek | čaak | enigma | tanığma | omen | aman (adj.) | tag | toqu |
| 9 | Arthur | artur- (v.) | chill (v., n.) | čil | -er | er | on (prep.) | on- (v.) | tack (v., n.) | tak- (v.) |
| 10 | ass | eš(äk) | chip | čïp | Erik | erk | onus | önüs (adj.) | tale | tili- (v., n.) |
| 11 | at (prep.) | at- (v.) | chitchat (v., n.) | čit čat (v.) | ewe | eve | orate (v.) | orı: (n.) | tall (adj.) | tal |
| 12 | Augean | aqür | chop (v., n.) | čop- (v.) | gader | qad | ore | öre: | tally (v., n.) | tili- (v., n.) |
| 13 | aught | ot (adj.) | circle | sürkülä (v.) | gamut (adv.) | qamit (adv.) | ortho- (adj. prefix) | örti- (v.) | tambourine | tambur |
| 14 | awe (v.) | ö- (v.) | clinch (v.) | qïlinč (v.) | gaze (v.) | giz- (v.) | otter | ätär | tap (v., n.) | tap (n.) |
| 15 | awhile (adv.) | äwwäl (adv.) | coach (v.) | köch (v.) | gene | gen- (v.) | ought | ötä | tap (v.) | tap- (v.) |
| 16 | baby | bebi | coal | kül/köl | goose | qaz | owe (v.) | oye- (v.) | tar (v.) | ter- (v.) |
| 17 | bad (adj.) | bäd (adj.) | cock (latch) | kök | gore (v.) | göres- (v.) | ox | öküz | tariff | tarïɣ |
| 18 | bag | bag | cock (fawl) | kök | Gorgon | qörq- | ooze (v.) | ӧz (v.) | tell (v.) | tili (v., n.) |
| 19 | baize | bez | cockney | köken | groom | görüm(čï) | pat | pata (v.) | terra | ter- (v.) |
| 20 | bake (v.) | baka:č (n.) | colon | kolon | guard | qur- (v.) | pot | patır | theriacum | tiryak |
| 21 | bale (v., n.) | bele- (v.) | con (v.) | qun- (v.) | guest | göster | pour (v.) | pür | thick | sik |
| 22 | barque (n.) | barq | con- (pref.) | kon- (n., adj.) | gut | kut | push (v.) | puš- (v.) | thief | tef |
| 23 | bark | barq | cook | kok- (v.) | haze | häzl | pussy (n., v.) | päsi (n.) | throne | tören |
| 24 | baron | baryn | copious (adj.) | köp (adj.) | heap | kip | queue | kü | tick (v., n.) | tiki |
| 25 | bash (v.) | baš (v.) | corset | qursa | Helen | ellen- (v.) | quit (v.) | ket- | tick | tik- (v.) |
| 26 | bastard | bas + tard | count | köni | herd | kert | quite (emph.) | ked (emph.) | till (v.) | til- (v.) |
| 27 | bath (v.) | bat (v.) | courage | kür (adj.) | hilarious (adj.) | güleryüz (adj.) | robe | rop | time | timin (adv.) |
| 28 | bear (v.) | ber- (v.) | cousin | qazïn | host | göster | -s (pl.) | -z (morph.) | tire (n.) | tire- (v.) |
| 29 | bear | böri | cove | kovı: | house | koš/quš/xüžə | -'s (poss.) | -si (morph.) | tit | tiši: |
| 30 | beetle | bit | cow | coy | ideal (adj.) | edil (adj.) | sag (v.) | sök- (v.) | to (prep.) | tu- (v.) |
| 31 | Belgi (adj.) | Belgü (adj.) | coy (adj.) | köy- (v.) | idyl (adj.) | edil (adj.) | sage | sag | toe | toy |
| 32 | belt | bel | cue | kü | ilk | ilk | sail (v.) | salla (v.) | toilet | tölet |
| 33 | berm | bürma | cull (v.) | čul- (v.) | in (prep.) | in (n.) | sale | sal- (v.) | toll | tol |
| 34 | bet (v., n.) | büt- (v.) | culture | kültür- (v.) | inch (n., v.) | ınča | sane | san- (v.) | tooth | tiš |
| 35 | big (adj., adv.) | big | cup | kap | inn (n.) | i:n (n.) | sapphire | sepahir | top | töpü |
| 36 | bill (v., n.) | bil- (v.) | curb (n., v.) | kır | jack (v., adj.) | cak- (v.) | sari | sarïl (v.) | tor | tärä |
| 37 | bill | bilä- (v.) | cure (fix, v.) | kur- (v.) | jag | čak(k) | sash | saču: | torah | tör |
| 38 | bode (v.) | bodi | cure (food, v.) | kuri:- (v.) | jam | jem | toss (v.) | toš- (v.) | ||
| 39 | bodega | butïq | curt (adj.) | qïrt (adj.) | jar | jart | satyr | satir | tuber | tü:b |
| 40 | body | bod | curve | qarvï (adj.) | jar (v.) | jar- (v.) | say (v.) | söy- (v.) | tuck (v.) | takın- (v.) |
| 41 | bog | bog | dad, daddy | dedä | jeer (v.) | jer- (v.) | sea | si | turn (v.) | tön (v.) |
| 42 | bogus (adj.) | bögüš (adj.) | dam | da:m | jig (v.) | jïq (v.) | secede | ses- (v.) | twat | tat |
| 43 | bong | böŋ | dawn | tang (taŋ) | jig (n.) | jig | sector | chektür | un- | an- (morph.) |
| 44 | boot | bot | deep | dip | jog (v.) | jag (v.) | sell (v.) | sal- (v.) | unite (v.) | una- (v.) |
| 45 | booze (v.) | buz (v.) | derrick | terek | jolly (adj.) | yol | sepia | sepi- (v.) | until (Prep., Conj.) | anta |
| 46 | bore (v.) | bur- (v.) | descend (v.) | düšen (v.) | journey | jorï (v.) | seize (v.) | sız- (v.) | us (pronoun) | ös (pronoun) |
| 47 | Boris | böri | diadem | didim | juice | jü | seizure | sïzğur- (v.) | usher (v.) | üšer (v.) |
| 48 | boss | boš (adj.) | dick | dık- (v.) | keen | qïn- | sever (v.) | sevrä- (v.) | voucher | vučuŋ |
| 49 | boutique | butïq | dike | dık- (v.) | keep (v., n.) | kap- | sharp (adj.) | šarp (adj.) | wake | vak |
| 50 | box | boɣ | dingdong | daŋ doŋ | Kent | keŋit- (v.) | she (pron.) | šu (shu) | was | var- (v.) |
| 51 | brother | birader | dip | dip | kick (v., n.) | kik- (v.) | sheep | sıp | while | äwwäl |
| 52 | bunch (v., n.) | bunča | do | tu- | kilter | kel- (v.) | shilling | sheleg | whip | yip |
| 53 | bursary | bursaŋ | doll | döl | kin | kin/kun/kün | shock (v., n.) | šok- (v.) | wig | yü:g |
| 54 | bust | basta | don (v.) | ton- (v., n.) | kind (adj.) | keŋ (adj.) | short (adj.) | qïrt (adj.) | yacht | yaɣ- (v.) |
| 55 | butt | büt | dune | dun | king | kengu | shove (v.) | sav- (v.) | yah (interj.) | yah (interj.) |
| 56 | cab | qab/qap | duress | dür- (v.) | loaf | lavāš | sick (ill) | sık- (v) | yeah | yah (interj.) |
| 57 | cabbage | qabaq | dust | doz | lamb | -la:n | sick (vomit) | sök- (v.) | yell (v.) | yel (v.) |
| 58 | cackle (v.) | kakla- (v.) | dye | dawa | make (v.) | -mak | sin | cin (jin) | yet (adv.) | yet- (v.) |
| 59 | caginess | qïjïm | earl | yarlïqa- (v.) | mama | mamü | sing (v.) | siŋ- (v.) | you (pron.) | -üŋ (pron.) |
| 60 | cairn | kayır | Earth | Yer | man | men | sink (v.) | siŋ- (v.) | young | yangi: |
| 61 | cake | kek | eat (v.) | ye- (v.) | matt (adj.) | mat (adj.) | sip (v.) | syp (v.) | Yule | yol |
| 62 | call | qol | eave | ev | mental (adj.) | meŋtä (adj.) | soak (v.) | saɣ- (v.) | youth (n., adj.) | yaš (adj.) |
| 63 | can (v.) | qan (v.) | eke | eken (v.) | menu | meŋ | sock (beat) | sok- (v.) | yuck (excl.) | yek (n., adj.) |
| 64 | candle | kandil | elbow | el | mint (v., n.) | manat | sock (cloth) | sok- (v.) | yummy (adj.) | yemiš (adj.) |
| 65 | cap | kap | son | song | ||||||
8
The role of the Türkic substrate in English speech can be evaluated with the help of the word frequency listings, as for example are given in http://en.wiktionary.org/wiki/Wiktionary:Frequency_lists/TV/2006/1-1000, Rev. date 5 September 2013. The ongoing minor tweaking of the Wiktionary lists is inconsequential. The frequency count of the words comes from a collection of TV and movie scripts/transcripts of the actual words said by the speakers. The total word count in the collection at the time was 26,376,342, far in excess of the needs for a present rough assessment. Slight modifications were required to combine entries listed separately, like I, I'll, I'm, I've etc., and varying transcriptions like yes, yeah, ya, etc. Accounting for these peculiarities of the Wiktionary lists makes results more accurate by upping the partial values of frequency and rating for few most frequently used words, but affect little the conceptual valuation.
The usage frequency should not be confused with the composition of the lexis, which refers to the fractions of the entire lexis. The test was conducted in two steps, first on a subset of the common vocabulary containing about half of the examined vocabulary, and then repeated for the other half. The standard experimental method of independent testing examines random subsets of data, in computational linguistics it is applied for statistical validation of reliability and results. The method produces repeatable and predictable outcomes independent of the researcher. The experimental method arrived with conclusively close numbers.
The method produces accurate results for major classes of simple words. However, it does not account for compound words of a type “notwithstanding” that agglutinates the words “not”, “with”, and “standing” that accounted for would boost a frequency result. Such a conservative method raises a confidence level of the exploratory assessment.
Initial trial of the frequency test, using a 2000-word frequency list and 450-word list, found a match for 129 more frequently used words, producing a combined number of 26.9% frequency. Results of the trial indicated that allowing a conservative 3.1% frequency for the remaining 300 unmatched words, about 30% of the English daily lexicon is retained or is based on the lexical base that originated with the Türkic linguistic family. So few words constitute such a huge portion of the language because we have to use them continuously to keep English the English. Considering the volume of the texts sampled for the frequency listings, in this case 26,376,342 words of text, the results were fairly accurate, and would fall into that ballpark number at any similarly structured frequency test, even if some correspondences are disqualified.
A consequent frequency test, using the same 2000-word frequency list and a 800-word list, found a match for 217 words, producing a frequency value of 36.39%. The last, 2000th, word on the list carried a frequency of 0.0036%; allowing on average for each additional word to add half of that, or 0.0018%, out of the total 800 words the 585 remaining unmatched words would be expected to add a product of 585 words times factor 0.0018% or 1.05%. The total for the 800-word list would be approximated as 37.4%. The result of the expanded calculation agrees within reason with the result of the initial trial, confirming that about 1/3 of the modern English daily lexis originated with the Türkic linguistic family. For the validation of the Türkic substrate hypothesis, precise accuracy is pointless, the impressive result of approximately 1/3 of the lexis amply proves the concept.
Assuming that the 800-word listing of Turkisms covers 2/3 of the entire body of Turkisms in English, and that each Turkism has a trail of 5 cognates and derivatives, a ballpark estimate for the entire body would amount to 7200 words, or 1.5% of the English vocabulary of 500,000 words. The lexis' 1.5% produce 1/3 of the daily vocabulary. It does not take a strenuous effort to appreciate, with no exaggeration, the extent of the Türkic component’s presence in the daily English speech. The top ten most used cognates, the you, I, and, that, this, my, do, time, tell, and make, according to an independent study of 26 mln words of text, comprise a disproportional 16.6% of the non-specialized English usage.
The body of the Turkisms in English constitutes a massive case of multi-faceted paradigmatic transfer, it provides incontrovertible attestation of the Türkic admixture in English. For comparison, the Russian lexis reportedly consists of 25% of the Türkic admixture, in reality much more, with the 25% portion so far documented academically. The numbers in English and Russian are quite compatible, difference lays only in the degree of the admixture. Some native clusters consist exclusively of Turkisms, take the unrefined sexual lexicon: Eng. sex, Rus. sik(at), Tr. sik- (v.) “sex, copulate”, sik (n.) “penis”, Eng. cock, dick, Rus. huy, Tr. kök, küy “penis”, dık- (v.) “erect, stand straight”, and so on, extending to compounds, Cf. Eng. childbearing, Rus. ber(emen), Tr. ber- (v.) “carry”, ko:l (n.) “comrade”.
Considering that the western Türkic languages are severely underrepresented, with only a few chance citations by the Classical authors, that they do not have dictionaries or texts compatible in scope with that of the EDT and OTD, and that numerous old languages are classified provisionally or for various reasons are misclassified, it is very safe to assert that a significant portion of the western Türkic lexicon is not available for comparisons, with a considerable portion of the Türkic substrate lexicon remaining unexplored, and their English counterparts remaining either “of unknown origin” or dubiously etymologized.
A notable device of the common etymological practice is to present the “onomatopoeic” or “echoic” origin as etymology. In most cases such diagnosis is a true non-statement, since different people draw completely different onomatopoeic imitations, and to be valid an assertion of onomatopoeia must be specific to either a linguistic branch or at least to a linguistic family. Comparison of onomatopoeic forms from different sources makes guests from local languages and from different linguistic families readily visible. Diligently applied, onomatopoeia is a valid diagnostic tool on the philological origin, be it a peculiarity, a Sprachbund or a substrate rudiment.
The Türkic–English onomatopoeic correspondences demonstrate closer connections than their many
counterparts supposedly grown from the same PIE root. The onomatopoeic roots of any lexicon ascend
to the first linguistic experiments, when they were a part of a mimic display needed to convey an
idea with inchoate vocabulary. Agglutinative languages allow to observe a gradual, step-by-step,
formalization and build-up of the primitive onomatopoeic stems into developed lexemes that stand on
their own after grammatical, phonetical, and metaphorical transformations.
9
Sorted by column Rank
Orthography is adjusted for phonetical clarity; the ɣ, ŋ, and x = kh are retained
The column “Rank” reflects relative sequential standing by frequency in English
Allophones are combined into a single summary value marked by symbol Σ
| No | English | Türkic | Rank | Frequency | No | English | Türkic | Rank | Frequency | No | English | Türkic | Rank | Frequency |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | you | -üŋ (pron.) | 1 | 4.63% | 73 | jack | cak- (v.) | 257 | 0.05% | 145 | count | köni | 896 | 0.01% |
| 2 | I | ič (es) | 2Σ | 5.04% | 74 | old | ol- (adj.) | 264 | 0.05% | 146 | bill | bil- (v.) | 902 | 0.01% |
| 3 | to | tu- (v.) | 3 | 3.12% | 75 | money | manat | 271 | 0.05% | 147 | bill | bilä- (v.) | 902 | 0.01% |
| 4 | and (conj.) | anta (conj.) | 6 | 1.92% | 76 | son | song | 276 | 0.05% | 148 | short | qïrt (adj.) | 943 | 0.01% |
| 5 | that | šu (pron.) | 7 | 1.57% | 77 | girl | kyr | 286 | 0.05% | 149 | gift | kiv- (v.) | 967 | 0.01% |
| 6 | me | min (pron.) | 10 | 1.18% | 78 | world | аbïl | 299 | 0.04% | 150 | owe | oye- (v.) | 972 | 0.01% |
| 7 | in | in (n.) | 13 | 1.01% | 79 | hurt | ur- (v.) | 310 | 0.05% | 151 | bitch | bi | 977 | 0.01% |
| 8 | this | šu (pron.) | 14 | 0.95% | 80 | boy | bo:y | 311 | 0.04% | 152 | Earth | Yer | 990 | 0.01% |
| 9 | yes | yah (OFris.) | 89 | 0.90 | 81 | while | äwwäl | 316 | 0.04% | 153 | box | boɣ | 993 | 0.01% |
| 10 | my | -m | 20 | 0.80% | 82 | kill | öl- (v.) | 323 | 0.04% | 154 | judge | ayg- (v.) | 996 | 0.01% |
| 11 | not | ne (part.) | 23 | 0.74% | 83 | hard | qart(adj.) | 324 | 0.04% | 155 | mama | mamü | 1013 | 0.01% |
| 12 | do | tu- | 24 | 0.74% | until | anta | 326 | 0.04% | 156 | Adam | adam | 1026 | 0.01% | |
| 13 | be | buol- (v.) | 25 | 0.73% | 84 | car | köl- (v.) | 327 | 0.04% | 157 | bag | bag | 1029 | 0.01% |
| 14 | on | on- (v.) | 26 | 0.73% | 85 | yet | yet- (v.) | 335 | 0.04% | 158 | deep | dip | 1041 | 0.01% |
| 15 | was | var- (v.) | 28 | 0.70% | 86 | once | ön (adv.) | 339 | 0.04% | 159 | key | kirit | 1054 | 0.01% |
| 16 | we | ös (pron.) | 29 | 0.69% | 87 | second | eki | 350 | 0.04% | 160 | crime | krmšuhn | 1057 | 0.01% |
| 17 | so | aša (adv.) | 32 | 0.64% | 88 | truth | dürüst | 353 | 0.04% | 161 | joke | elük | 1069 | 0.01% |
| 18 | all | alqu (n., adj.) | 34 | 0.60% | 89 | face | yü:z | 355 | 0.04% | 162 | push | puš- (v.) | 1089 | 0.01% |
| 19 | are | -ar (v., n.) | 36 | 0.58% | 90 | cause | köze:- | 360 | 0.04% | 163 | boss | boš (adj.) | 1094 | 0.01% |
| 20 | will | bil- (v., n.) | 76Σ | 0.58% | 91 | wife | ebi | 365 | 0.03% | 164 | seat | čıj- (v.) | 1120 | 0.01% |
| 21 | get | qay- (v.) | 42 | 0.48% | 92 | use | tusu | 367 | 0.03% | 165 | brain | beini | 1130 | 0.01% |
| 22 | yeah | yah (interj.) | 47 | – | 93 | heart | chäre | 377 | 0.03% | 166 | hide | qoy- (v.) | 1131 | 0.01% |
| 23 | she | šu (shu) | 50 | 0.42% | 94 | many | munča | 386 | 0.03% | 167 | hide | qujqa | 1131 | 0.01% |
| 24 | can | qan, kanata | 51 | 0.41% | 95 | case | kečä | 393 | 0.03% | 168 | age | aga | 1142 | 0.01% |
| 25 | think | saq- | 54 | 0.39% | 96 | case | qaza | 393 | 0.03% | 169 | sell | sal- (v.) | 1149 | 0.01% |
| 26 | go | git | 60 | 0.38% | 97 | turn | tön (v.) | 394 | 0.03% | 170 | quit | ket- | 1150 | 0.01% |
| 27 | at | at- (v.) | 62 | 0.35% | 98 | trust | dörs (t) | 398 | 0.03% | 171 | faith | vara | 1157 | 0.01% |
| 28 | how | qalï | 63 | 0.33% | 99 | check | chek | 399 | 0.03% | 172 | board | batɣa | 1195 | 0.01% |
| 29 | see | süz- (v.) | 66 | 0.40% | 100 | means | min | 413 | 0.03% | 173 | kick | kik- (v.) | 1209 | 0.01% |
| 30 | come | qam- (v.) | 67 | 0.29% | 101 | brother | birader | 414 | 0.03% | 174 | cat | četük | 1217 | 0.01% |
| 31 | good | kut | 68 | 0.29% | 102 | ago | aga (adj.) | 417 | 0.03% | 175 | yep | yah (interj.) | 1226 | 0.01% |
| 32 | see | süz- (v.) | 69 | 0.29% | 103 | sit | čıj- (v.) | 424 | 0.03% | 176 | bunch | bunča | 1231 | 0.01% |
| 33 | as | as- (v.) | 71 | 0.26% | 104 | watch | aɣtur- (v.) | 433 | 0.03% | 177 | peace | barısh | 1237 | 0.01% |
| 34 | will | bil- (v.) | 75 | 0.58% | 105 | question | kušku | 458 | 0.03% | 178 | cash | kečä | 1260 | 0.01% |
| 35 | time | timin (adv.) | 78 | 0.25% | 106 | far | ıra:- | 461 | 0.03% | 179 | nose | ñü:z | 1263 | 0.01% |
| 36 | mean | many (mahny) | 83 | 0.23% | 107 | hit | it- (v.) | 482 | 0.02% | 180 | king | kengu | 1291 | 0.01% |
| 37 | tell | tili (v., n.) | 84 | 0.23% | 108 | child | koldaš | 500 | 0.02% | 181 | laugh | gül- | 1337 | 0.01% |
| 38 | hey | ay (interj.) | 87 | 0.22% | 109 | young | yangi: | 510 | 0.02% | 182 | smile | semeye (v.) | 1339 | 0.01% |
| 39 | yes | yah (OFris.) | 92 | 0.21% | 110 | fire | bur- | 525 | 0.02% | 183 | cost | kı:z | 1355 | 0.01% |
| 40 | been | buol- (v.) | 94 | 0.21% | 111 | shit | šıč- | 530 | 0.02% | 184 | sing | siŋ- (v.) | 1378 | 0.01% |
| 41 | some | kim (morph.) | 99 | 0.20% | 112 | cut | kes- (v.) | 540 | 0.02% | 185 | foot | but | 1380 | 0.01% |
| 42 | say | söy- (v.) | 102 | 0.19% | 113 | quite | ked | 541 | 0.02% | 186 | tree | terek | 1392 | 0.01% |
| 43 | ok | ok (interj.) | 103 | 0.19% | 114 | sick | sık- (v) | 544 | 0.02% | 187 | butt | büt | 1418 | 0.01% |
| 44 | take | teg- | 104 | 0.19% | 115 | sick | sök- (v.) | 544 | 0.02% | 188 | cry | qïqïr- (v.) | 1421 | 0.01% |
| 45 | us | ös (pronoun) | 107 | 0.19% | 116 | eat | ye- (v.) | 548 | 0.02% | 189 | guard | qur- (v.) | 1432 | 0.01% |
| 46 | make | -mak | 109 | 0.17% | 117 | bet | büt- (v.) | 595 | 0.02% | 190 | cake | kek | 1435 | 0.01% |
| 47 | too | de (adv.) | 114 | 0.16% | 118 | lie | yalgan (v.) | 599 | 0.02% | 191 | cup | kap | 1452 | 0.01% |
| 48 | sure | sürek (adj.) | 115 | 0.15% | 119 | dear | terim | 602 | 0.02% | 192 | taste | tat- (v.) | 1455 | 0.01% |
| 49 | over | up- | 118 | 0.15% | 120 | body | bod | 621 | 0.02% | 193 | land | elen < el | 1461 | 0.01% |
| 50 | man | men | 128 | 0.15% | 121 | worse | uvy | 626 | 0.02% | 194 | breath | bu:r | 1502 | 0.01% |
| 51 | uh | yah (interj.) | 133 | 0.14% | 122 | ass | eš(äk) | 655 | 0.01% | 195 | band | ba- (v.) | 1527 | 0.00% |
| 52 | much | munča (adv.) | 140 | 0.13% | 123 | secret | soqru | 672 | 0.01% | 196 | ought | ötä | 1545 | 0.00% |
| 53 | any | ne: | 141 | 0.13% | 124 | luck | аlïč | 675 | 0.01% | 197 | hall | qalïq | 1550 | 0.00% |
| 54 | give | kiv- (v.) | 148 | 0.12% | 125 | touch | toqï (v.) | 681 | 0.01% | 198 | bastard | bas + tard | 1552 | 0.00% |
| 55 | talk | tili- (v., n.) | 153 | 0.11% | 126 | cold | xaltarä | 693 | 0.01% | 199 | guest | göster | 1564 | 0.00% |
| 56 | God | kut | 155 | 0.11% | 127 | food | apat | 699 | 0.01% | 200 | jerk | jul (v.) | 1592 | 0.00% |
| 57 | stay | üstü- (v.) | 235Σ | 0.11% | 128 | act | aqtar- (v.) | 738 | 0.01% | 201 | cousin | qazïn | 1604 | 0.00% |
| 58 | find | yind- (v.) | 159 | 0.10% | 129 | top | töpü | 742 | 0.01% | 202 | skin | saɣrï | 1613 | 0.00% |
| 59 | again | aga (adj.) | 161 | 0.10% | 130 | swear | vara- (n.) | 749 | 0.01% | 203 | dumb | dumur | 1662 | 0.00% |
| 60 | call | qol | 165 | 0.10% | 131 | black | belä- (v.) | 751 | 0.01% | 204 | hole | ol- (v.) | 1670 | 0.00% |
| 61 | feel | bil- | 174Σ | 0.13% | 132 | less | es- (adv.) | 762 | 0.01% | 205 | bear | ber- (v.) | 1684 | 0.00% |
| 62 | first | bir | 174 | 0.09% | 133 | dog | dayğa:n | 769 | 0.01% | 206 | bear | böri | 1684 | 0.00% |
| 63 | other | ötürü (adj.) | 173Σ | 0.09% | 134 | till | til- (v.) | 776 | 0.01% | 207 | scare | qor | 1704 | 0.00% |
| 64 | home | qom | 179 | 0.09% | 135 | till | teg (adv.) | 776 | 0.01% | 208 | gold | al(tun) | 1713 | 0.00% |
| 65 | put (v.) | put- (v.) | 186 | 0.09% | 136 | evil | uvul- | 782 | 0.01% | 209 | tie | taŋ- (v.) | 1724 | 0.00% |
| 66 | day | dün | 186 | 0.08% | 137 | eye | ög- (v.) | 787 | 0.01% | 210 | tad | tat | 1728 | 0.00% |
| 67 | keep | kap- | 187 | 0.08% | 138 | calm | kam- (v.) | 807 | 0.01% | 211 | sea | si | 1760 | 0.00% |
| 68 | stop | top | 191 | 0.08% | 139 | court | qur- (v.) | 818 | 0.01% | 212 | queen | yeŋä | 1791 | 0.00% |
| 69 | big | big | 204 | 0.07% | 140 | wake | vak | 833 | 0.01% | 213 | vampire | ubyr | 1799 | 0.00% |
| 70 | kind | keŋ (adj.) | 210 | 0.07% | 141 | message | muštu | 837 | 0.01% | 214 | coat | gömlek | 1802 | 0.00% |
| 71 | guess | us- (v., n.) | 217 | 0.07% | 142 | stick | tik- (v.) | 859 | 0.01% | 215 | color | kula | 1878 | 0.00% |
| 72 | care | qorq | 219 | 0.07% | 143 | write | 'rizan (v.) | 866 | 0.01% | 216 | master | bögü: | 1885 | 0.00% |
| bad | bäd (adj.) | 220 | 0.07% | 144 | early | ertä- | 868 | 0.01% | above | bava | 1914 | 0.00% | ||
| woman | ebi- + men | 263 | 0.07% | shock | šok- (v.) | 1951 | 0.00% | |||||||
| dad | dedä | 226 | 0.06% | |||||||||||
| mother | mamü | 228 | 0.06% | |||||||||||
| baby | bebi | 234 | 0.06% | |||||||||||
| father | ata | 236 | 0.06% | |||||||||||
| might | bögü: | 240 | 0.06% | |||||||||||
| mind | ming | 244 | 0.06% | |||||||||||
| hell | qalïq | 248 | 0.06% | |||||||||||
| own | oye- (v.) | 252 | 0.06% | |||||||||||
| house | quš | 253 | 0.05% | |||||||||||
To gauge linguistic kinship of two lexicons, is used a Swadesh list of “basic words”, it provides some uniformity on the level of a linguistic gage. It is a kind of a canonical list of the “IE” “basic words”, ascending to the kernel of the hypothesized PIE language, supposedly found in the majority of the 439 “IE” languages, and in the majority of its individual branches. Based on the faulty Family Tree model, and based on what was held as specifically “IE” “proto-language” or a grouping of kindred languages, Swadesh list is conceptually wrong, it is actually a random collection of lexemes tailored for a special pleading case. This is a list that substitutes for a missing definition of the “IE” paradigm, a surrogate of the definition agreed to by the “consensus” of the “IE” linguists. It is a core fundament of the “IE” linguistics. The list was assembled on a faulty presumption that all languages use the same basic toolbox of grammatical nouns, verbs, adjectives, etc., and compatible syntaxes that allow them to be compiled into phrases. That presumption fits well into the bulk of the “IE” languages, but can’t be generalized for all earthly languages. Even within the “IE” family are oddballs that defy that presumption and add uncertainty to other traits contradicting their “IE” classification. Comparisons of languages deviating from the basic presumption with those that are in full accordance with the presumption encounter obstacles that necessitate introduction of additional presumptions to synchronise comparisons, Cf. languages where nouns can serve as adjectives vs. languages where adjectives are formed morphologically. The Türkic linguistic group falls into noncompliant category, comparisons are augmented by vaguely interpreted presumptive caveats. With that qualification, Swadesh list generally remains a useful, but far from universal, tool. But it is its randomness that makes it a quasy-universal tool for linguistic studies across the Earth languages. Swadesh list is routinely used as an objective tool to get a rough statistical assessment on similarities and differences between sampled languages. In the course of the present study, Swadesh list is used to objectively assess the Türkic contribution to the English language, and as a side benefit the Türkic contribution to the “IE” languages.
According to the Swadesh 207 count, the basic vocabulary of English has 113 or 55% “IE” *reconstructed roots, another 31 words or 15% are of dubious “IE” *roots, 63 words or 30% are definitely non-IE, and the combined dubious and positively non-IE words constitute 94 words or 45% of the Wikipedia “Appendix: Proto-Indo-European Swadesh list”. The heavy doze of non-IE component supplies ready candidates for statistically credible admixture. To be validated, these “essential basic words”, and the rest of the candidates need to undergo a scrupulous testing procedure suggested by G.Doerfer 1981. It has been estimated that the English lexis consists of 70% Romance lexicon, and the balance of Germanic, Celtic, and unknown. However, within the basic vocabulary of, say, 2000 words, Romance holds a considerably more modest place, and still smaller place in a base lexicon of, say, 1000 words, and a miniscule place in the usage frequency of the daily vocabulary. The above frequency test shows that a mere 10.75% or 216 words of the 2000-word basic vocabulary pull disproportionate 36.35% of the usage frequency, significantly contributing to the daily lexicon at the expense of the Romance components, while leaving enough room for the prehistoric Germanic and Celtic languages of the Northern Europe.
Numerous “IE” *roots come as close allophones of the real Türkic forms. The PIE reconstructions for these words create some phantom lexicon that would be nicely dubbed a Proto-Türkic (PT) lexicon (like the PIE “reconstruction” *h3okw for eye, eidetic to the real attested Türkic root ög-). A dictionary of PIE reconstructions composed of such real Türkic words would replace phantom fictions with real attested Türkic forms. In essence, that dictionary would attest to the Türkic origin of the “IE” languages within the scope of the Türkic part. The portion of such PIE basic words in the Swadesh 207 English list, plus the portion of the non-IE words of Türkic origin in the Swadesh 207 English list would provide a numerical approximation on the Türkic contribution to the English language. A fairly large proportion of these words permeate the “IE” Romance, Germanic, and Slavic branches of Europe, and in the “IE” linguistics is taken exclusively as an absolute criterion of Indo-Europeanism. It was keenly noted that in respect to the core vocabulary, the eastern “IE” languages fall far behind European languages. Since there is no definition of the “IE” paradigm, an eastern version of the Swadesh list may as well demonstrate that the western “IE” languages fall far behind the eastern “IE” languages.
Sample list of PIE “reconstructions” versus the Türkic originals
Numbers correspond to the conventional numbers on the Swadesh list
Numbers correspond to the conventional numbers on the Swadesh list
| No | English | Türkic | Proto-Indo-European |
|---|---|---|---|
| 1 | I | ič (es) | *éǵh2 |
| 8 | that | šu (pron.) | *só |
| 16 | not | ne (part.) | *ne |
| 19 | some | kim (morph.) | *kaylo- |
| 42 | mother | mamü | *méh2tēr |
| 43 | father, dad | ata (father) dede (= daddy, dad) |
*átta, *ph2tḗr |
| 51 | tree | terek | *dóru |
| 74 | eye | ög- (v.) | *h3okw |
| 75 | nose | ñü:z | *nā́s |
| 80 | foot | but | *pṓds |
| 90 | heart | chäre | *ḱḗr |
| 93 | to eat | ye- (v.) | *h1ed- |
| 176 | black | belä- (v.) | *bhleg- |
| 178 | day | dün | *dei-n |
| 202 | in | in (n.) | *(h1?)en |
About 62 of the Swadesh list 207 words correspond to the respective entries in the 800-word listing of English Turkisms. Most of them do not have any hypothesized “*PIE proto-words”. That confirms the complex origin of English. The results are random coincidences between two independent listings, a complete examination would produce a higher number of matches. The number 62 is approximate because linguistic notions may be expressed by more than a single word, Cf. the notion “father”, with English forms father and dad (daddy) corresponding to the Türkic forms ata and dede, both matching the notion of the Swadesh list without a particular preference to the either word. In few cases PIE hypothesizes more than a single form, offering a choice to suit each of the different “IE” branches; at least some of the “PIE” forms ascend to the Türkic origin shown in the listing, Cf. ič – I – *éǵh2 and the like. The entries like this and that, differentiated by locative suffix and similar inflectional markers, may originate from a single form in languages like Türkic, where a series of locative suffixes form different locative aspects; such duplicative derivative entries can't be classed as “basic words”, making the valid words number less than 207.
The 62 Türkic–English correspondences in the Swadesh list constitute exactly 30% of 207 words, or higher accounting only for valid Swadesh entries. That number matches other lexical valuations of around 1/3 of the English daily lexis derived from the Türkic phylum.
Properties like phonetic and spatial dispersion, overlaid on the historical background extracted from written, archeological, and genetic dating, allow to narrow dating of the most components to not much earlier than the 1st millennium BC, the time of the reverse wave of the linguistically European refugees returning to the Central and Southern Europe, and the Sarmat influx into the Northern Europe. Such conceptual dating puts into question the much older hypothetical dating of the remaining PIE part of the list, the dating deduced nearly exclusively from the linguistic theoretical considerations. Similarly, some postulations concerning temporal changes within “IE” family are not applicable to the “reconstructions” of the non-IE admixtures, Cf. ič – I – *éǵh2 and the like. Applying to the case of English the attrition rate suggested as a valid rate for any language would increase the hypothetical fraction of English Turkisms at the turn of the eras to about 50%, a most questionable scenario. Interpolating observations for some cases to the entire class of words intuitively held as “IE” leads to erroneous “reconstructions” for all cases materially different from the cases underlying the temporal postulations. On the other hand, some unadulterated words, like the ata “father”, are also shared by some Amerindian languages, attesting to their existence prior to the 15th millennium BC Amerindian migration from Asia to the Americas. Such deep connections protrude far beyond the PIE temporal horizon.
The Swadesh list's Turkisms come in 3 flavors, either Proto-Indo-European “reconstructed” forms are some allophones of the attested Türkic form (20 cases, Cf. No. 1 ič ~ *éǵh22), or the English word does not belong to the PIE phylum (18 cases, Cf. No. 15 how), or the PIE “reconstruction” is unrelated to the English word (24 cases, Cf. No. 7 this ~ *kos), or even a combination of some two flavors. These etymological flavors extend far beyond the “basic words” vocabulary, with the edition of the dubious “echoic” origin, they are endemic for the rest of the 800 cited English Turkisms.
Numbers correspond to the conventional numbers on the Swadesh list
ashes, belly, bird, bite, black, blood, bone, breast, burn, claw, cloud, come, die, dog, drink, dry, ear, egg, eye, fat,
feather, fish, fly, foot, ful, good, green, hair, hand, head, hear, horn, knee, know, leaf, lie, liver, long, louse, meat,
moon, mouth, name, neck, new, night, one, person, rain, red, road, root, round, sand, seed, seed, sleep, small,
smoke, stand, star, stone, Sun, swim, tail, thou, tongue, two, walk go, warm, water, what, white, who, woman, yellow
| No | Dybo No/p. | English | Türkic | Proto-Indo-European | Notes |
|---|---|---|---|---|---|
| 1 | 42/335 | I | ič (es) | *éǵh2 | |
| 2 | you (singular) | -üŋ (pron.) | *túh2 | ||
| 4 | 95/520 | we | ös (= us) | *wéy | |
| 7 | 86.3/500 | this | šu (pron.) | *kos | PIE unrelated to English |
| 8 | 85/498 | that | tet (pron.) | *só | |
| 15 | how | qalï | English unrelated to PIE | ||
| 16 | 62/416 | not | ne (part.) | *ne, *ney | |
| 17 | 1/16 | all | alqu (n., adj.) | English unrelated to PIE | |
| 18 | 52/370 | many | munča (adv.) | English unrelated to PIE | |
| 19 | some | kim (morph.) | *kaylo- | English unrelated to PIE | |
| 21 | other | ötürü (adj.) | *h2el-yó- | PIE unrelated to English | |
| 27 | 5/116 | big | big | English unrelated to PIE | |
| 30 | thick | sik | *bhenǵh | PIE unrelated to English | |
| 33 | short | qïrt (adj.) | *mreǵhú- | PIE unrelated to English | |
| 36 | 99/527 | woman | ebi + men | English unrelated to PIE | |
| 37 | 51/367 | man (adult male) | men | *h2nḗr | PIE unrelated to English |
| 39 | child | koldaš | English unrelated to PIE | ||
| 40 | wife | ebi | English unrelated to PIE | ||
| 42 | mother | mamü | *méh2tēr | ||
| 43 | father | dede (= daddy, dad) | *átta, *ph2tḗr | ||
| 47 | dog | dayğa:n | *ḱwṓ | PIE unrelated to English | |
| 51 | 90/509 | tree | terek | *dóru | |
| 53 | stick | tik- (v.) | *ǵhasto- | PIE unrelated to English | |
| 58 | 3/87 | bark (of a tree) | ver | English unrelated to PIE | |
| 62 | 75/470 | skin | saɣrï | *pel- | PIE unrelated to English |
| 74 | eye | ög- (v.) | *h3okw- | ||
| 75 | 61/409 | nose | ñü:z | *nā́s | |
| 77 | 89/506 | tooth | tiš | *h3dónts | PIE unrelated to English |
| 80 | 31/270 | foot | but | *pṓds | |
| 90 | 40/330 | heart | chäre | *ḱḗr | |
| 93 | 23/232 | to eat | ye- (v.) | *h1ed- | |
| 95 | to suck | saɣ- (v.) | *dheh1(y)- | PIE unrelated to English | |
| 101 | 72/455 | to see | süz- (v.) | *derḱ- | PIE unrelated to English |
| 104 | to think | saq- | *tong- | PIE unrelated to English | |
| 110 | 43/337 | to kill | öl- (v.) | *gwhen- | PIE unrelated to English |
| 113 | to hit | it- (v.) | *pleh2k- | PIE unrelated to English | |
| 114 | to cut | kes- (v.) | English unrelated to PIE | ||
| 122 | to come | qam- (v.) | *gwem-, *gweh- | ||
| 124 | 74/468 | to sit | čıj- (v.) | *sed- | |
| 126 | to turn (intransitive) | tön (v.) | English unrelated to PIE | ||
| 128 | 33/278 | to give | kiv- (v.) | *deh3- | PIE unrelated to English |
| 130 | to squeeze | qis- [qys-] (v.) | English unrelated to PIE | ||
| 135 | to push | puš- (v.) | English unrelated to PIE | ||
| 137 | to tie | taŋ- (v.) | English unrelated to PIE | ||
| 138 | to sew | suk- (v.) | *syuh1- | ||
| 139 | to count | köni | English unrelated to PIE | ||
| 140 | 71/451 | to say | söy- (v.) | English unrelated to PIE | |
| 141 | to sing | siŋ- (v.) | *kan- | PIE unrelated to English | |
| 146 | to swell | siwel | English unrelated to PIE | ||
| 154 | sea | si | English unrelated to PIE | ||
| 158 | dust | doz | *pers- | PIE unrelated to English | |
| 159 | 22/224 | earth | yer | *dhéǵhōm | PIE unrelated to English |
| 160 | 14/195 | cloud | bulut | *nébhos | PIE unrelated to English |
| 167 | 28/260 | fire | bur- | *h1égnis | PIE unrelated to English |
| 171 | 55/378 | mountain | mün- (v.) | *gwerh3- | PIE unrelated to English |
| 176 | black | belä- (v.) | *bhleg- | ||
| 178 | day | dün | *dei-n- | ||
| 181 | 15/192 | cold | xaltarä | *gel- | |
| 184 | old | ol- (adj.) | *senh1ó- | PIE unrelated to English | |
| 186 | bad | bäd (adj.) | *h2wap- | PIE unrelated to English | |
| 191 | sharp (as a knife) | šarp (adj.) | *h1edh- | PIE unrelated to English | |
| 198 | far | ıra:- | *wi | ||
| 201 | at | at- (v.) | *h1ad | ||
| 202 | in | in (n.) | *(h1?)en |
Comparing lexicons and trying to get to the prehistoric level is fraught with lots of white noise. Enthusiastic linguists easily fall prey to their gusto, and the “IE” paradigm provides lofty examples of that, in loving hands the noise of homonyms and conflations is confused with cognates, mistaking a chance consonance for linguistically meaningful coincidence, and creating a path for phantom PIE concoctions. The process biased with contracted horizon is leaving untoward cognates unexplored. Etymology has two components, a descent from a root and a path that reaches the subject word. A focus on the root leaves out an implied or vaguely presumed path, but it is the path that determines diffusion and development of the word. Circular logics brings circular results, an incorrect premise leads to unsound conclusions, usually salient due to unrealistic semantic stretch. Combined with the simplistic Family Tree model, the wayward finale is inevitable. Circular results obscure the path, spread, and development, obscure distinct tell-tale transformations inflicted in propagation along contrasting Sprachbunds, and in the end lead to a result opposite from that intended. Instead of illuminating very specific linguistic aspects of the history, false etymology smothers them into historical mythology. Lacunas in the records, especially beyond the range of the literary purview, leave some candidates unprovable and undatable except for purely linguistic evidence, like the words bode, boss and vampire.
Linguistics has devised a system of checks and balances to filter the noise out. Computer
literacy brings acceptance of mathematical methods to linguistics, abhorred by the old linguistic
schools. For quantitative analysis of the established kinship in the lexicon is used Swadesh method,
equally applicable to the romantic Genetic Tree and the Wave models. It establishes statistical
correlation between different languages using a standardized linguistic test, shedding some light on
the linguistic development. Reasonable lexis-related criteria for establishing kinship were
formulated by G.Doerfer 1981
![]() , he gave a definition
to the perennial linguistic bewilderment of what exactly is necessary to firmly establish genetic
relations between two different languages. Evaluation of statistical chance resemblances is offered
by M. Rosenfelder 2002
, he gave a definition
to the perennial linguistic bewilderment of what exactly is necessary to firmly establish genetic
relations between two different languages. Evaluation of statistical chance resemblances is offered
by M. Rosenfelder 2002
![]() . These criteria rarely
apply to morphology and other key linguistic properties, but with consistent transparency in
application and similarity in function, it would be difficult, for example, to deny morphological
continuity between the Türkic aɣrïüt, English
aggravate,
and Lat. aggravare, or Türkic baiyar, Russian boyar, and
Indian Boyar caste. In all fairness, each etymologized word should be assigned a
credibility or confidence weight, equally applied to the proposed “IE” and non-IE etymologies. Such
weighting would allow comparison between alternate etymologies, and would enable to calculate a
Bayesian probability for the suggested etymologies for each set of the words.
. These criteria rarely
apply to morphology and other key linguistic properties, but with consistent transparency in
application and similarity in function, it would be difficult, for example, to deny morphological
continuity between the Türkic aɣrïüt, English
aggravate,
and Lat. aggravare, or Türkic baiyar, Russian boyar, and
Indian Boyar caste. In all fairness, each etymologized word should be assigned a
credibility or confidence weight, equally applied to the proposed “IE” and non-IE etymologies. Such
weighting would allow comparison between alternate etymologies, and would enable to calculate a
Bayesian probability for the suggested etymologies for each set of the words.
The concept of paradigmatic transfer defines borrowing of some entire complex of features. In the past few centuries, paradigmatic transfer became a universal tool of acquiring terminology with technology, at first medical and biological terminology based on Latin and Greek, then industrial terminology from industrialized nations, and lately the computer terminology from the American English. On a different level, the paradigmatic transfer may have been a driving force of human evolution since the earliest times. Any complex of linguistic traits borrowed entirely of partially is an example of paradigmatic transfer: typology, syntax, morphology, script, and lexicon; in extreme case nearly entire language is transferred, Cf. Latin American versions of Spanish. Statistically, a probability of chance independent invention of a paradigm is negligible, and any appeals to chance coincidence not supported by evaluation of numerical probability carries no weight, because any additional element, however minor, reduces the value of chance coincidence probability by orders of magnitude. Since civilizations developed not as much on inner innovations as on cultural borrowings, the examples of paradigmatic transfer are innumerable: Lat., Gk., and Türkic terminology was borrowed complete with morphological modifiers, morphological systems, entire alphabets and entire letters, partial alphabets, lexemes and their calques, idioms, folklore, practically any aspect of civilization. The phenomenon of paradigmatic transfer is a powerful diagnostic tool in cases when a mechanical transfer can be positively excluded (Cf. alphabet, economy, ideas); a transfer that necessitates a demographic component (Cf. morphology, alphabet elements, idioms) attests to a -strate model, such as substrate, adstrate, superstrate, etc. A paradigmatic transfer of entire phrases is one of indelible diagnostic parameters.
Numerous phrases in English, and by association in other European languages, are close allophones of the real Türkic forms. Practically, they are a word-for-word re-formulations of the Türkic phrases. The statistical significance of such allophonic phrases is enormous, since each additional phoneme reduces chances for accidental coincidence by orders of magnitude, making genetic connection obvious. The following is some sampling of allophonic phrases taken directly from EDT and similar works, with retained transcription and punctuation. In more than few cases, the literal and literary meanings are identical, a separate literary form is not needed, since the Türkic phrase is transparent without much elaboration:
| Phrase | Literally | Literarily |
|---|---|---|
| belin badı | belly his he banded | his belly he banded (girded) |
| er sö:züg kevdi: | H(err) saying kewed (k ~ ch) | Herr chewed (his) sayings (speech) |
| oldačı kiši | old geezer | |
| öčür kül | charcoal | quenched coals |
| ne yedi (ne yemadi, -ma- negation) | not eat | |
| ne tedi (ne temadi, -ma- negation) | not told (tell) | |
| tal bodı | tall (and slim) body | |
| tö:š ba:ğı: | teat bag | bra, breast binder |
| yuğrut koyuldi: | yogurt coagulated | |
| ğır aŋdï- | greyhound | grey ambusher |
| tıš ağrığ | tooth aching | |
| tiši erdi | teeth are | |
| kutluğ kıvlığ | God given | |
| ič sök- | I (am) sick | |
| yer kaba | earth cave | earthen cave |
| ačığ аčï | acidic ache | bitter ache |
| tarka аčï | tarty ache | bitter ache |
| topildi: yer | toppled (kicked) earth | earthquake |
| kurultai | be cured (family) ties | restore family ties |
| ınča: munča | inch (less) or more | more or less (idiom) |
| ınča: bunča | inch (less) or bunch | more or less (idiom) |
| ınča kutluğ kıvlığ | inch (less) by God given | deprived by God, not so fortunate |
| kır(mu) durur | girl durable | virgin daughter |
| bıšığ siŋir | boiled sinew | steamed sinew |
| meŋgü: ber- | mengir bear | bore (convey) a mengir (gravestone) (for somebody) |
| ne qayar (qorq) sen (or seni) | no care (in) thee [ni kara þuk (Goth.)] |
Thee (do) not care |
| meni: tonatti: | don on me (dress, hat) | |
| ämin qamuɣ | amеn (OK, assured) gamut | gamut (is) amеn (assured) |
| azı:ma:k | ooze make | make (to) ooze |
| küp azi:di: | cup oozing | cup (is) oozing |
| jolda ämin jorït | on the yule (on the road) amеn journey | on the yule (road) amеn (assured) journey |
| tilge: ye:r | till (furrow/strip) of earth | strip of earth |
Few examples of extended phrases would illustrate the concept. An arsenal of about 800 words in the present compendium, constituting statistical 35% of the English daily vocabulary, allows to compose many types of phrases where English text is closely mirrored in the Türkic text, recognizably resembling each other in spite of incompatible syntaxes and discrepant morphology. Illustrations are staple phrases, cited in English, Türkic, and German, Turkish, or Slavic (Russian) adjusted for the modern Türkic syntax.
| I + to be + verb | |||
| English | I am thinking | I am aging | I am argue(ing) |
| German | Ich (bin) denke | Ich (bin) Alterungs | Ich (bin) argumentiere |
| Türkic | Ich (bol) thakip tur [saqip ~ thakip] | Ich (buol) ag | Ich (bol) arqu- (tur) |
| Turkish | Ich (bol) düshün(üp) (tur) | Ben yašlanma am | Ben savunarak am |
And
| Eng. | to be or not to be – this is the question | I do argue, making others feel bad |
| Türk. | bul(mak) ya da bulma(mak) - ište alqu (gamu) kušku bu | Ötürü bäd hissettiren, ben arqu(mak) |
| Slavic. | быть или не быть - есть все сомнение вот | Других плохо чувствовать делая, я аргументы делаю |
| Sl. transl. | to be or not to be - is all (gamut) question be | Others bad feel making, I argue(make) |
Lining up word for word, the English-Türkic-Slavic match looks like this. Few words shown in bold do not have direct correspondence. Square brackets stand for words indicated by agglutinated morphology, round brackets enclose suffixes and suggest synonyms. Experimenting with other Gmc. languages would bring somewhat resembling results.
| to be or not to be – this is the question | |||||||
|---|---|---|---|---|---|---|---|
| With Türkic syntax | to be (be'd) | or | not to be | is | all (gamut) | question | be |
| Türkic transliterated | bul(mak) ya | da | bulma(mak) | ishte | alqu (gamu) | kushku | bu |
| Russian Cyrillic | быть | или | не быть | есть | все (гамма) | сомнение | вот |
| Russian Roman | byt | ili | ne byt | est | vse (gamma) | somnenie | vot |
| I do argue, making others feel bad | |||||||
| With Türkic syntax | others | bad | feel | making | I | argue | do |
| Türkic transliterated | ötürü | bäd | bil- | [mak] | [Ich] | arqu(mak) | tu(mam) |
| Russian Cyrillic | других | плохо | чувствовать | делать | Я | аргументы | делат |
| Russian Roman | drugih | ploxo | chuvstvivat | delat | ya | argumenty | delat |
Except for conjunctions, all other words are allophones of Türkic lexemes, with some shifts: Türkic gamu “gamut, all” in English is expressed with synonymous all, and in Russian with “IE” vse, while the Russian allophone of the Türkic gamu is spelled gamma and designates the whole, all octave; Russian somnenie is a derivative of Türkic ming (miŋ) “mind” and an allophone of English mind with stem mn and “IE” prefix s-/so- “with”.
A cross-comparison of Slavic, Baltic, and English Turkisms helps to detect less obvious Turkisms in English. Dating is problematic, it is vaguely anchored to the known historical events or archeologically detected known historical events, confirmed by isotope and genetic allele dating. Within the holistic body of the evidence, genetics attest that Germanic people of the European Sarmatia are the same people who originated from the Sarmatian area in the heart of the Eurasia, archeology and genetics assert that with various Kurgan waves they spread out to flood the same area of the Western Europe, they introduced to the Western Europe the identical peculiar runiform alphabet with common graphical symbols and some preserved common phonetics, they share hundreds of common words, and they retained legendary memories of their Asian origin. Under the weight of the evidence, any branch of science would find it scandalous to even question a common origin.
The Old English (OE) is a euphemism for the Anglo-Saxon language, used to create periodization without turning to the historical people who brought the English over to the isles. Whether called OE or Anglo-Saxon in the etymological references, it is still the same old Anglo-Saxon language, documented mostly between 700s and 1050s, after the encroaching of Christianization, and before the Norman conquest. At its dawn, the Anglo-Saxon English used runic script; a modern codified version, that probably does not include all real non-codified graphemes and all sounds peculiar to the languages of its creators, still contains a number of graphemes that display a genetic connection with the Horezmian (Turanian) and Orkhon versions of the Türkic alphabet, and also contains few Roman or Greek letters. The formal transition of Anglo-Saxon literature from the runic to the Latin alphabet took place in the first two centuries in the new lands. Before its migration to the British Isles, runic script was a means of written communication in Scandinavia and on the continent, its monuments are engraved on gravestones and stones, metal, and rare perishable relicts that survived the period of severely enlightening Christianization.
The term Anglo-Saxon in the England's context refers to the conglomerate of tribes that moved to England in force, over extended period, from their initial location at the junction of modern Moravia, Germany, and Poland. As their name implies, initially it was a union of two major components that likely absorbed numerous local fragments, of which Gothic left a detectable trace. The union was further enriched in their location along the southern banks of the Channel, of which Frisian left a detectable trace. The contributions of the local vernaculars are not always readily identifiable, and in dictionaries are cited under an indiscriminate Anglo-Saxon label. Probably, the motley composition of the migrants helped in some standardization of the island's runic alphabet before the illiterate monks denounced it as some type of supernatural satanic device. In view of the historical longevity in the correspondence between the shape of the graphemes and their morphemes which allows tracing of the alphabets to their most remote ancestors, the morphemic reshuffling of the runic alphabet from its original and traceable composition to the haphazard sequence of the Futhark happened in the darkest period of the early Dark Ages. The Germanic Futhark appears without a prehistory, compiled in a rigidly structured form, with its morphemes mechanically reshuffled without any visible taxonomy, as a work of some invisible intelligent design. Stalin and Mao were not the inventors of the methods to mass-convert literate people into illiterate. The oldest runic inscriptions, composed before the miraculous reshuffling, remain systemically undeciphered, and held as written in unknown languages. The later runic inscriptions, composed according to the Futhark sequence, are readily deciphered, and even freely read by scholars steeped in Futhark.
The discovery of the Germanic-looking runiform script in the far-away Siberia was an exciting
news in the 18th c. The discoverers were struck by the similarity of the Orkhon script with the
Germanic runes. Graphical similarity was so strong that the European zealots had to re-define the
very term “runes” as solely “Germanic runes”, leaving other runes to come up with their own terms.
The trademark patent did not expire in 17 years, various encyclopedias still define runes as
“Germanic runes”, a unique case of copyright protection extending more than 2 millennia backwards.
The oldest runic inscription was carbon-dated by the 5th c. BC, it is the Issyk inscription found in
1970 in the nomadic kurgan in the vicinity of the lake Issyk in Kazakhstan, the homeland of the Saka
Scythians according to the historical records. The Orkhon discovery hibernated for two centuries,
till the Finnish scholars started exploring a possibility of the Germanic runes written in an
unknown language with some connection with the Finnish past. Of the Scandinavian people, only Finns
came from Asia, they could have brought the runic script to the Northern Europe. Finnish scholars
attracted attention of all Scandinavian paleographers, they were the first who published a
compendium of the Siberian inscriptions. In 1893 the Dutch Vilhelm Thomsen (1842 - 1927) deciphered
the bilingual Türkic-Chinese inscription from Orkhon in Mongolia. After that, the interest to the
Türkic script for another half-century again went into hibernation. Any links between the Germanic
and Türkic runes were repudiated, any similarity was denounced as fortuitous, any genetic connection
as chimerical.
11
Graphical-morpheme similarity
(Ref. Mukhamadiev Azgar, Ancient Coins of Kazan, Kazan, Tatar Publishing house, 2005, ISBN 5-298-04057-8)
(Ref. Mukhamadiev Azgar, Ancient Coins of Kazan, Kazan, Tatar Publishing house, 2005, ISBN 5-298-04057-8)
| Lat. | Turanian letters | Türkic letters | Unicode Türkic |
Anglo-Saxon | Lat. | Turanian letters | Türkic letters | Unicode Türkic |
Anglo-Saxon |
|---|---|---|---|---|---|---|---|---|---|
| а, ä |
|
 |
о, и |
|

 |
||||
| č |
|
 |
p |
|
 |
||||
| i |
|
 |
s1 |
|
 |
||||
| j1 | - |
|
 |
t1 |
|
 |
|||
| l1 |
|
 |
th | - |
|
 |
|||
| m |
|
 |
x1 | - |
|
 |
|||
| n1 |
|
 |
Even more striking is the cross-comparison of the whole alphabet sets. Each grapheme of the Anglo-Saxon alphabet finds an exact counterpart in the Orkhon alphabet, with seemingly random shuffling of phonetics. The northern Europeans with high presence of Turkisms in their languages managed to independently invent, sometime at the turn of the eras, a whole set of symbols totally identical to another alphabet used in the Middle Asian coins of the turn of the eras and in the 8th c. Türkic Kaganate. Such a coincidence between two alphabets that reportedly have no connection whatsoever, and are localized at two different ends of the Eurasia, must be ascribed to no less than a miracle, it can't be sanely explained within the framework of the prevailing postulates. If it can be even more miraculous, the shape þ of the grapheme for the voiced interdental th (ð, the δ of the OTD), not found in other alphabets, is identical in the Middle Asian (Turanian) and the Germanic Futhark alphabets. Even today, the depictions of the Latinized Gothic, ONorse, and Anglo-Saxon words use the grapheme þ, first depicted on the Middle Asian coins with Türkic legends.
Statistically, a chance coincidence of the same form and sound from two unrelated alphabets, selected from a limited subset of the forms of all alphabets compiled by humanity during its whole history, is so small that it would require lots of paper to place all preceding zeroes. The long-denounced connection between the Türkic alphabets and the Futhark alphabet is undeniable, the question is only on the mechanism of that connection. Modern forensics asserts that perfect crimes do not exist, any criminals leave traces beyond their capability to wipe them clean. It is only a matter of the willingness and ability of the investigators to to find and analyze the traces.
(cited in: Halvorsen I.,2004, http://www.sunnyway.com/runes/origins.html)

Latin and Türkic Languages
Numerous English words are ascribed to the Latin and Latin via French, implying that either the
English did not have words for such concept at all, or that the Anglo-Saxon (OE) lexicon was fully
supplanted. Numerically, the Romance strata in English is estimated to be on the order of 70%.
However, an assessment of the set of 800 Türkic-English cognate words cited below finds that
– much of the corresponding Latin vocabulary is related to the same Türkic substrate that formed the
English lexis. Historically, such continuity is consistent with the thesis that most of the “Old
Europe” population was vanished by the 3rd mill. BC, and from the 3rd mill. BC to the 1st mill. BC
it was replaced by various Türkic populations and their varieties of the Türkic languages.
– a very significant portion of the “Latin” lexicon belongs to the Vulgates, Late and Middle Latin,
and is Latin only in name. Although Latin is cited as a dead, frozen language, the cited words
belong to a living language. The Turkisms used by post-Classical Latin include some significant
proportion that originated from the nomadic nations - Vandals, Burgunds, Alans, etc., and from the
Germanic nations, including Anglo-Saxons, Goths, Lombards, and others that influenced the local
Latin vernaculars. For centuries, the academical and ecclesiastical Latin co-existed along the
Vulgate Latin languages of various nations.
– a portion of the “Latin” lexicon originated in the Gallic space, it is usually denoted as OFr. fr.
Lat., where Lat. is an indiscriminate blend of the Classical and post-Classical Latin, and where
Burgund and Alan words were assimilated into post-Classical Latin.
An initial trial of the English-Latin-Türkic lexical correspondences, using a preliminary 400-word list of the English-Türkic correspondences, found a match for 127 words, producing a combined 32% of the sample. That number couldn't be applied to the whole body of the Romance in English, which is expected to be much diluted, and be smaller by an order of magnitude. Results of the initial trial indicated that arbitrarily allowing a conservative 10% for the remaining Latin lexis, about 40% of the Latin lexicon is retained or is based on the lexical base that originated with the Türkic linguistic family. The results were fairly reasonable, and should fall into that ballpark number at any similarly structured test, even if some correspondences are disqualified.
A consequent test cited below, using the 800-word list, found a match for 334 words, or 41% of the sample (Table 2a). The result of the expanded comparison agrees within reason with the result of the initial trial. The test covers apparent Turkisms in Latin; it is a statistical indicator of the Türkic-Latin lexis vs. the Türkic-English 800-word list. In respect to the Latin lexis, it is a random lexical selection: 334 words of a random 800-word list. This number can't be applied to the whole body of the Romance in English, which is expected to be much diluted by various admixtures, and be smaller by an order of magnitude. In the context of the Türkic-Latin-English commonality, the number 41% is significantly exaggerated by dubious Lat. cognates. It can be inferred that without Vulgates', Middle and Late Latin words, and dubious cognates, the proportion of the Turkisms of the Classical Latin origin would be reduced by half, to about 20% of a random sample. Allowing another 5-10% to cover the other Latin Turkisms from the remaining portion of a typical 10,000-word Latin vocabulary, a very rough prediction can be made that about 25-30% of the Classical Latin lexis hails from the Türkic phylum. The numbers in English and Latin are quite compatible, difference is but in the degree of admixture.
Visible indicators point to the Latin and English Turkisms originating from much different
versions of the Türkic vernaculars, likely separated by timespans measured in millennia, relayed by
different sources, planted on completely different substrates, and compared with the geographically
far remote OTD/EDT lexis recorded for a time period one millennium later in the English case, and a
few millenniums later in the Latin case. The Latin lexicon of the Türkic origin was superimposed,
supplanted, and conflated with the English innate lexicon of the Türkic origin, forming a local
version of something like a European Türkic-based Sprachbund layer.
12, 13, 14
In all cases, a borrowing from Latin and English into Türkic is positively impossible, especially so in the case of the Central Asian and Far Eastern Türkic languages. In case of Uigur, for example, Uigurs are continuously attested in the Central Asia-Far Eastern region from the 3rd c. BC, before the rise of the Roman Empire on the other end of the Eurasia. Numerous Türkic tribes are attested still further east of the Uigurs. Neither the Romans, nor the English possessed the mobility of the mounted Türkic tribes, used the steppe belt as a transportation corridor, or are known for their mass migrations across Eurasia to effect such borrowing.
| No | English | Latin | Türkic | English | Latin | Türkic | English | Latin | Türkic |
|---|---|---|---|---|---|---|---|---|---|
| 1 | abode | habitatio | oba | cure | cura | kur- (v.) | nascence | nasci | ña:š |
| 2 | abundant | abundantem | abadan (adj.) | curt | curtus | qïrt (adj.) | nose | nasus | ñü:z |
| 3 | abysm | abysm | abamu | curve | curv- | qarvï (adj.) | not | non | ne (part.) |
| 4 | access | accessus | ačsa:- | dad | tata, atta | dedä | obturate | obturare | tiy- (v.) |
| 5 | acid | acidus | аčï- (v.) | day | dies | dün | ocean | ocean(us) | ӧkän |
| 6 | act | actus | aqtar- (v.) | deliver | deliber | döle- (v.) | ogle | oculus | ög- (v.) |
| 7 | age | aetas | aga | dementia | dementare | dumur | old | altus | ol- (adj.) |
| 8 | aggrieve | aggravare | aɣrï | derma | derma | deri | omen | omen | aman (adj.) |
| 9 | agile | agilis | ačïl | descend | descendere | düšen (v.) | on | an- | on- (v.) |
| 10 | aid | adiuvare | jarï | divide | divide | dil- | onus | onus | önüs (adj.) |
| 11 | alimentation | alimonia | alım | durable | durabilis | dür- (v.) | orate | oratio | orı: (n.) |
| 12 | alimony | alimonia | alım | duration | durationis | dür- (v.) | ortho- | ortho- | örti- (v.) |
| 13 | all | omn- | alqu (n., adj.) | duress | duriciam | dür- (v.) | other | alter | ötürü (adj.) |
| 14 | alms | eleemosyne | almak | ea | aqua- | aq- (v.) | otter | lutra | ätär |
| 15 | amorous | Amor | amran- | eat | edi | ye- (v.) | owl | ulula | aba(qulaq) |
| 16 | anger | angustus | özak (adj.) | elbow | ulna | el | pan | patina | ban |
| 17 | anguish | angustus | özak (adj.) | eligible | eligibilis | elïg- (v., n.) | papa | papa | baba/babai |
| 18 | apian | apis | arï | elite | eligere | elga- (v.) | peace | pax | barısh |
| 19 | apt | aptus | apt | elk | alces | elik | period | periodus | ö:d |
| 20 | arch | arcus | arca | elm | ulmus | ilm | pot | potus | patır |
| 21 | ardent | ardere | arzu (n.) | en- | in- | en- (v., prepos.) | prior | prior | ür |
| 22 | argue | argutare | arqu- (v.) | endure | durare | endür- (v.) | purge | purgare | pür- (v.) |
| 23 | arrogant | arrogantia | orı: | enge | angustus | özak (adj.) | purl | burra | bu:r- (v.) |
| 24 | Arthur | Arturius | artur- (v.) | engine | ingenium | ïjïn- | purse | bursa | bursaŋ |
| 25 | asp | aspidem | äväs | enigma | aenigma | tanığma | push | pulsare | puš- (v.) |
| 26 | ass | asinus | eš(äk) | equal | aequalis | egil (adj.) | pyre | pyra | bur- (v.) |
| 27 | assign | assignare | asïɣ | ether | aether | äsir | quality | qualitas | qïlïɣ |
| 28 | astute | astutus | asurtɣuq (adj.) | Europe | Europa | ev + opa | quantity | quantitas | köni |
| 29 | at | ad | at- (v.) | evacuate | evacuare | evük- (v.) | quarrel | querella | qaršï |
| 30 | Augean | Augeas | aqür | evict | evictio | evük- (v.) | quilt | culcita | kübil |
| 31 | augur | augur | ay- (v.) | evoke | evocare | evük- (v.) | quit | quietus | ket- |
| 32 | aurora | aurora | yar- | Eve | ava | eve | ration | rata | ruzi- (v.) |
| 33 | axle | axis | i:k | ewe | ovis, ava | eve | regal | regalis | arïɣ (adj.) |
| 34 | barge | barga | bart (adv.) | exhaust | exhaurire | qoxša- (v.) | sack | saccus | sak |
| 35 | bark | barca | barq | eye | oculus | ög- (v.) | sagacity | sagax | sag |
| 36 | barley | far | arpa, urba | face | facies | yü:z | sage | sage | sag |
| 37 | be | fui | buol- (v.) | faith | fides | vara | salary | salarium | salɣa (v.) |
| 38 | bear | fero | ber- (v.) | false | falsus | al- (v.) | saliva | saliva | liš |
| 39 | bear | ferus | böri | far | per | ıra:- | sanitary | sanitas | esan (adj.) |
| 40 | belt | balteus | bel | fart | bombulum | burut- (v.) | sanity | sanitas | san- (v.) |
| 41 | board | bordus | batɣa | father | atta | ata | sapient | sapere | savan (adj.) |
| 42 | boil | bullire | bula- (v.) | feel | palpare | bil- | sapphire | sapphirus | sepahir |
| 43 | bore | forare | bur- (v.) | fire | pyra | bur- | satisfy | satisfacere | satsa- (v.) |
| 44 | box | buxis | boɣ | first | primus, prae | bir | satyr | satyr | satir |
| 45 | brother | frater | birader | fissure | fissura | öz | savant | sapere | savčï (v.) |
| 46 | bruise | brisare | bürt, bert | flask | flasconem | baklaga | say | (in)seque | söy- (v.) |
| 47 | brute | brutus | börü | food | pabulum | apat | sconce | sconce | quč- |
| 48 | bulge | bulga | beleg (n.) | foot | pes | but | seat | sedess | čıj- (v.) |
| 49 | bull | bovis | buqa | frog | varde | baga | secede | secedere | ses- (v.) |
| 50 | burl | burra | burnï | gene | genus | gen- (v.) | second | sequi | eki |
| 51 | bursary | bursar | bursaŋ | genu | genu | yinčür- (v.) | sector | sector | chektür |
| 52 | cabbage | caput | qabaq | George | Georgius | urï | seize | sacire | sız- (v.) |
| 53 | callous | callus | qal (adj., v.) | get | prehendere | qay- (v.) | sepia | sepia | sepi- (v.) |
| 54 | calm | cauma | kam- (v.) | glue | gluten | yelïm | sever | separare | sevrä- (v.) |
| 55 | calumny | calvi | čulvu | glut | gluttire | oglït- (v.) | sew | su(ere) | suk- (v.) |
| 56 | can | canna | kanata | gluten | gluten | yelïm | shade | čadïn | |
| 57 | candle | candela | kandil | goat | caper | käči | sharp | scalpellum | šarp (adj.) |
| 58 | cap | cappa | kap | gore | cruore | göres- (v.) | sin | sons | cin (jin) |
| 59 | capture | captura | hapset | grind | frendere | qïr- | sip | sipho, suppa | syp (v.) |
| 60 | capuche | kapuce | kapšon | guest | hostis | göster | sit | sedere | čıj- (v.) |
| 61 | car | carrus | köl- (v.) | hash | ascia | ash | so | suad | aša (adv.) |
| 62 | care | cura | qorq | heap | chupa | kip | sock | soccus | sok- (v.) |
| 63 | carpus | carpus | qarï | heart | cor | chäre | son | sunus | song |
| 64 | case | capsa | kečä | herb | herba | arpa: | stick | instigare | tik- (v.) |
| 65 | case | casus | qaza | hernia | hernia | urra | suave | suavis | šuvlaŋ |
| 66 | castigate | castigare | kast- (v.) | hey | eho | ay (interj.) | suck | sugere | saɣ- (v.) |
| 67 | castle | castrum | kishlak | hilarious | hilaris | güleryüz (adj.) | sure | securus | sürek (adj.) |
| 68 | casualty | casus | közün- | hoopoe | upupa | üpüp | susurrate | surdus | šar šar (v., n., adj.) |
| 69 | cat | catta | četük | I | ego | ič (es) | suture | sutura | sač |
| 70 | category | categoria | qatïɣ (adj.) | ideal | idea | edil (adj.) | swear | verus, fides | vara- (n.) |
| 71 | cause | causa | köze:- | idyl | idyllium | edil (adj.) | tab | tabula | tap- (v.) |
| 72 | cavalry | caballus | keväl | ignite | ign(ire) | yaq- (v.) | tablet | tabula | tü:b |
| 73 | cavern | cavus | kovı: | inch | uncia | ınča | take | tolle | tut- (v., n.) |
| 74 | cavity | cavus | kovı: | itinerate | iter | ïd- (v.) | tally | talliare | tili- (v., n.) |
| 75 | cemetery | coemeterium | semäklä- (v.) | jar | jaru- | jar- (v.) | tariff | tarifa | tarïɣ |
| 76 | chagrin | gravus | qadɣur | jelly | gelu | yelïm | taste | taxare | tat- (v.) |
| 77 | chalk | calx | chol | joke | iocus | elük | tavern | taberna | tavar |
| 78 | chastise | castigare | kast- (v.) | journey | diurnalis | jorï (v.) | tend | tueri | taya |
| 79 | cheap | caupo | čıp (adj.) | judge | iudex | ayg- (v.) | terrain | terra | ter- (v.) |
| 80 | check | scaccarium | chek | juice | ius | jü | testament | testis | tutsuğ |
| 81 | cherub | cherub | čebär | Kent | Cantia | keŋit- (v.) | testicles | testis | tasaq |
| 82 | chill | gelidus | čil | key | clavis | kirit | theriacum | theriacum | tiryak |
| 83 | chip | cippus | čïp | kin | gnasci | kin/kun/kün | throne | thronus | tören |
| 84 | chisel | caesus | čiz- (v.) | kitchen | coquina | qatna- | till | tegula | til- (v.) |
| 85 | circle | circulus | sürkülä (v.) | language | lingua | luɣat | toilet | tela | tölet |
| 86 | coagulate | coagule | qoyul- (v.) | leak | libarе | liš | tire (n.) | ? | teyir |
| 87 | cob | caballus | kev- | might | magus | bögü: | toll | tolonium | tol |
| 88 | coffin | cophinus | kovı: | mallet | malleus | maltu | tomb | tumba | tumlu |
| 89 | cold | gelu | xaltarä | mama | mater | mamü | too | etiam | de (adv.) |
| 90 | collect | colligere | kölar (v.) | mammall | mamma | meme | tor | torus | tärä |
| 91 | colon | colica | kolon | marasmus | marasmus | maraz | torah | Torah | tör |
| 92 | color | color | kula | master | magister | bögü: | touch | toccare | toqï (v.) |
| 93 | colossal | colossus | qolusuz | me | me | min (pron.) | tower | turre | türma |
| 94 | com- | com-, cum | kon- (n., adj.) | mental | mentalis | meŋtä (adj.) | tremble | tremere | četre (v.) |
| 95 | con | concipere | qun- (v.) | menu | mand(ucare) | meŋ | tuber | tubus | tü:b |
| 96 | con- | co-, con- | kon- (n., adj.) | message | missus | muštu | tumulus | tumulus | tumlu |
| 97 | confer | conferre | ber- (v.) | mickle | magnus | mig (n., adj., adv.) | turn | tornare | tön (v.) |
| 98 | cook | coquere | kok- (v.) | milk | mеlса | meme | udder | uber | ud |
| 99 | copious | copia | köp (adj.) | mind | mens | ming | ululate | ululatus | ulï- (v.) |
| 100 | cork | quercus | kairy | mint | moneta | manat | unite | unus | una- (v.) |
| 101 | cost | cost | kı:z | mock | modus | -mak | us | nos | ös (pronoun) |
| 102 | count | computare | köni | model | modus | -mak | use | usus, uti, oeti | tusu (v., n.) |
| 103 | courage | cor | kür (adj.) | moisture | mucidus | mayi | usher | ostiarius | üšer (v.) |
| 104 | cove | cavus | kovı: | monastery | monasterium | manastar | vacate | vacare | evük- (v.) |
| 105 | cowl | cuculla | kalpak | money | moneta | manat | vacuum | vacuum | evük- (v.) |
| 106 | coy | quietus | köy- (v.) | mother | mater | mamü | valerian | valerianus | pultäran |
| 107 | crime | crimen | krmšuhn (v.) | mount | mons | mün- (v.) | voe | vah, vае | uvy (interj.) |
| 108 | crow | corvus | karga | mountain | mons | mün- (v.) | vouch | vocitare | buč- (v.) |
| 109 | crust | crusta | kairy | mouse | mus | muš | voucher | vocitare | vučuŋ |
| 110 | cry | quiritare | qïqïr- (v.) | munch | manducare | meŋ | wake | vegere | vak |
| 111 | cull | colligere | čul- (v.) | muscle | musculus | muš | watch | vigil | aɣtur- (v.) |
| 112 | cup | ciphus | kap | worse | vah, vае | uvy (interj.) | |||
| yet | sed | yet- (v.) | |||||||
| young | juvenis | yangi: |
The quite substantial presence of Türkic–Latin–English lexical correspondences mocks the standing thesis that the Centum language group is devoid of the Türkic presence. The Centum group includes Italic, Germanic, Celtic, and Hellenic languages, and besides English and other Germanic languages, numerous cognates of the Türkic stems belonging to the Italic, Celtic, and Hellenic languages. Originally, the thesis may have reflected the true extent of the knowledge of its authors, but the continuous recitation of the old thesis must be an embarrassing display of orthodox beliefs. The conundrum is not amendable: albeit in the past two centuries numerous modern languages underwent ethnic cleansing, it is impossible to mechanically cleanse the ancient Greek or Latin, their Turkisms have been sown wide and deep, and grew deep roots, and they provide indelible evidence.
Sanskrit and Türkic Languages
The “IE” linguistics holds Sanskrit as an “IE” language; the traditional “IE” theory claims its age at about 1700 - 1500 BC; one of the pillar tenets at the foundation of the “IE” theory was, and that is still holding, the great antiquity of Sanskrit. Sanskrit was and continues to be held as closest to the PIE language. The opposition within and without “IE” linguistics disagrees with every tenet. Long lists of non-IE Vedic and Sanskrit words were compiled, similar to the Germanic and Russian non-IE listings, believed to be of non-Aryan origin. Were identified extensive lexical, phonological, structural, and morphological correlations between the old and modern Indo-Aryan languages and the non-IE languages of India, mainly Dravidian and Munda. Indian scholars challenge the Eurocentric classification of the Sanskrit as an “IE” language, asserting that it is a product of socio-politico-cultural circumstances. The observed lexical and structural similarities are hardly traceable or attributable to borrowing, convergence, etc. Some opposition supports a concept of “South Asia linguistic area” covering various Indian languages and language families.
Historical background attests to more than 2 millennia of the Türkic presence in the South-Central Asia, with a long list of ethnicities and polities, starting with Indo-Scythians and ending with the Moghuls, from whom Britain wrestled control of India. The linguistic traces of the Türkic presence are indelible in the Indian languages, Cf. the Indian hallmark sari, the Türkic “wrapped”. In that respect, Sanskrit is consistent with the other Indian languages.
In the linguistic aspect, historical background should also question the linguistic cohesiveness of the Indo-Aryan farmers. No mass migrations can happen in one humongous swoop. Any migratory process has a wave character, with reciprocal movements that involve gradually increasing flows from gradually increasing source territories. Accepting that the source population even within an ethnically single phylum was a continuous chain of mutually incomprehensible vernaculars every 200 km, it is reasonable to propose linguistically motley sources of the migrants, who in new location for a millennium were forming a new lingua franca that finally reached us as a Classical Sanskrit. The surviving “IE” linguistic elements of the Classical Sanskrit are a sampling of the vernaculars involved in unidirectional migration.
The 800-word assembly of Turkisms and Türkic substrate in English includes frequent instances when the “IE etymology” cites Sanskrit to establish the “IE” origin of the English lexis. The body of the references to Sanskrit and Avesta attests that both were familiar with and to a degree amalgamated with the Türkic languages, even down to morphological elements. The status of Sanskrit, a product of the 2nd mill. BC, as some preeminent version of the PIE language, a vision dated to the 18th c., had long lapsed, but still lingers on in many “IE” etymological discourses.
An initial trial of the English-Sanskrit-Türkic lexical correspondences, using a preliminary listing of the English-Türkic correspondences, found a match for about 10% of the sample. Results of the initial trial indicated that arbitrarily allowing a conservative 10% for the remaining Sanskrit lexis, about 20% of the Sanskrit lexicon is retained or is based on the lexical base that originated with the Türkic linguistic family. Results gave some rough idea on the Sanskrit admixture, they were consistent with the assertion that only a fraction of the presumed European “IE” vocabulary reached the Indian subcontinent.
A consequent test using the 800-word list, found a match for 100 words, or 12% of the sample (Table 2a). The result of the expanded comparison agrees within reason with the result of the initial trial. The test covers apparent Turkisms in Sanskrit; it is a statistical indicator of the Türkic-Sanskrit lexis vs. the Türkic-English 800-word list. In respect to the Sanskrit lexis, it is a random lexical selection, since the content of Turkisms in English is independent from the content of Turkisms in Sanskrit, or of the Sanskrit loanwords in Türkic: 100 words of a random 800-word list. This number can't be applied to the whole body of the Romance in English, which is expected to be much diluted by various admixtures, and be smaller by an order of magnitude. In the context of the Türkic-Sanskrit-English commonality, the number 12% is significantly exaggerated by dubious Skt. cognates. It can be inferred that without Türkic words absorbed in the last two and a half millenniums, and the dubious cognates, the proportion of the Turkisms of the Classical Sanskrit origin would be reduced by half, to about 5% of a random sample. Allowing another 5-10% to cover the other Sanskrit Turkisms from the remaining portion of a typical 10,000-word Sanskrit vocabulary, a very rough prediction can be made that about 10% of the Classical Sanskrit lexis hails from the Türkic phylum. The numbers in English and Sanskrit are quite compatible, difference is but in the degree of admixture..
However, the number 10% is a very rough approximation, being dependent on the number of factors that influenced etymological sources. First and foremost is the poor appearance of Sanskrit cognates in the “IE” etymological exercises: the citing is spotty, only to the degree needed to establish connection consistent with the premise of the effort; just that flaw may underrepresent reality by a factor of 2 or 3, potentially raising proportion to 20-30%. Then there is a loose treatment of semantics, when Sanskritisms are cited inappropriately (Cf. janiṣ is cited both for “queen” and “wife”, “milk” is derived from “wipes off”, “bewail” equated with “call”, “Earth” is equated with thira which is an allophone of “terrain” and hails from the Türkic for “pasture”, etc.); that factor is falsely inflating the proportion. The presence of Sanskrit terms of Buddhist lexicon that grew on the Indian soil also inflates the proportion, since although they entered English as Turkisms, etymologically they originated with Sanskrit and were brought to English as the Türkic substrate at about the turn of the eras. These cases are few, but with the small sample of 100 words they need to be considered. Then there is a case of erroneous attribution to Turkisms in the body of the 800-word list; the questionable cases also inflate the proportion by as much as 1/3. Adjusted for these factors, the proportion of Turkisms in Sanskrit may be reasonably assessed as to be in the range of 10 to 15%. The presence of the basic vocabulary that could not have been introduced by the demographicly inferior Indo-Saka, Indo-Scythians, Huns, Kushans, Ephthalites, and later migrants, attests to a time depth of these loanwords ascending to the middle of the 2nd mill. BC, the time of the initial migration of the Indo-Aryan farmers to the South-Central Asia.
| English | Sanskrit, Avesta (Av.) | Türkic | English | Sanskrit, Avesta (Av.) | Türkic | |
|---|---|---|---|---|---|---|
| 1 | act (v.) | ajati “drives”, ajirah “moving, active” | aqtar- (v.) | ignite (v.) | agnih “fire” | yaq- (v.) |
| 2 | agile | aja- “drive” | ačïl | itinerate (v.) | e'ti “(he) goes”, Av. ae'iti | ïd- (v.) |
| 3 | anger, anguish | aihus, aihas, Av. azah- “need” | özak (adj.) | juice | yus- “broth” | jü |
| 4 | at (prep.) | adhi “near” | at- (v.) | kin | janati “begets, bears”, janah “race”, jatah “born” | kin/kun/kün |
| 5 | aurora | usah “dawn” | yaruk | lull (v.) | lolati | ulï- (v.) |
| 6 | axle | aksah | i:k | mama | matar- | mamü |
| 7 | bake (v.) | pakvah “cooked” | bukač | mantra | mantra-s “sacred message or text, charm, spell, counsel” | maŋra- (v.) |
| 8 | band (v., n.) | bandhah | ba- (v.) | me (pron.) | Skt., Av. mam | min (pron.) |
| 9 | be (v.) | bhavah “becoming”, bhavati “becomes, happens” | buol- (v.) | mead | madhu “honey, honey drink, wine”, Av. maδu | mir |
| 10 | bear (carry) | bhárāmi | ber- (v.) | mental (adj.) | matih “thought, mind” | meŋtä (adj.) |
| 11 | bode (v.) | bodhi | bodi | mickle | mahat- “great”, mazah- “greatness”, Av. mazant- “great” | mig |
| 12 | bow | bhujati | boq- (v.) | milk | marjati “wipes off” | meme |
| 13 | bursary | buddha sangha, | bursaŋ | mind | matih “thought, mind” | ming |
| 14 | call | garhati “bewail, criticize” | qol | mist | mih, megha “cloud, mist” | muz |
| 15 | candle | cand- “to give light, shine”, candra- “shining, glowing, moon” | kandil | mouse | mus “mouse, rat” | muš |
| 16 | cap | kaput- “head” | kap | oat | avasám “food” | ot |
| 17 | case (box) | karsha | kečä | ogle (v.) | akshi “eye” | ög- (v.) |
| 18 | case (instance) | sad- “a falling” | qaza | other | antarah “other, foreign” | ötürü (adj.) |
| 19 | cave | kupah “hollow, pit, cave” | kovı: | otter | udrah, Av. udra | ätär |
| 20 | chill (v., n.) | hladate “refresh”, (pra)hladas “cooling down, enjoy” | čil | pot | patra “bowl” | patır |
| 21 | chintz | chitra-s “clear, bright” (Hindi chint) | čit | purge (v.) | pavate “purifies, cleanses”, putah “pure” | pür- (v.) |
| 22 | cook | (pa)kvah “cooked” | kok- (v.) | queen | janiṣ “wife, woman”, gna “goddess”, Av. jainish “wife”, gǝna-, ɣǝna, ɣna, ǰaini “woman, wife” | yeŋä |
| 23 | cow | gaus | coy | regal (adj.) | raj- “king, leader” | arïɣ (adj.) |
| 24 | crust | krud- “make hard, thicken” | kairy | sapphire | sanipriya “dark precious stone” | sepahir |
| 25 | curt (adj.) | krdhuh | qïrt (adj.) | sari | sati “garment, petticoat” | sarïl (v.) |
| 26 | daddy | tatah (Hindi dada) | dedä | sew (v.) | sivyati “to sew” | sač- |
| 27 | day | dah “to burn” | dün | shade | chattra “parasol” | čadïn |
| 28 | dementia | matih "thought," munih "sage, seer” | dumur | shake | khaj “agitate, churn, stir” | silk- (v.) |
| 29 | din | dhuni “roar” | tоŋ | shock (v., n.) | khaj “agitate, churn, stir” | šok- (v.) |
| 30 | ea (OE) | ap “water” | aq- (v.) | sinew | snavah, Av. snavar “sinew” | siŋir |
| 31 | Earth | thira | Yer | sip (v.) | sabar- “sap, milk, nectar” | syp (v.) |
| 32 | eat (v.) | atti | ye- (v.) | sit (v.) | sidati “(he) sits” | čıj- (v.) |
| 33 | enge (adj.) (OE) | aihus, aihas, Av. azah- “need” | özak (adj.) | smile (v., n.) | smayatē, smayati, smēras, smitas | semeye (v.) |
| 34 | ewe | avih | eve | son | sunus | song |
| 35 | eye | akshi | ög- (v.) | stair | stighnoti “mounts, rises, steps” | šatu |
| 36 | far | parah “farther, remote, ulterior” | ıra:- | susurrate (v.) | svara- “sound, resound” | šar šar (v., n., adj.) |
| 37 | fart | pard | burut- (v.) | suture | sutram “thread” | sač |
| 38 | father | pitar- | ata | terrain | Skt. thira | ter- (v.) |
| 39 | fire (v., n.) | pu | bur- | this, that | ta- | šu (pron.) |
| 40 | first | Skt. pura “at first, in the past”, Av. paro “in the past” | bir | tree | dru “tree, wood” | terek |
| 41 | fissure | bhinadmi | öz | turf | darbhah “bale of grass” | ter- (v.) |
| 42 | foot | pad-, Av. pad- | but | udder | udhar | ud |
| 43 | itinerate | Skt. e'ti “(he) goes”, Av. ae'iti | ïd- | ululate (v.) | lolati | ulï- (v.) |
| 44 | gene | janati “begets, bears”, janah “race”, janman- “birth, origin”, jatah “born”, janiṣ “wife, woman” | ken- | us (pronoun) | nas, Av. na | ös (pronoun) |
| 45 | genu | janu, Av. znum | yinčür- (v.) | wake | vajah (n.) “vigor”, vajayati (v.) | vak |
| 46 | go (v.) | gjihite “goes away” | git | was | vasati | var- (v.) |
| 47 | God | huta- “invoked” | kut | wife | janiṣ “wife, woman”, gna “goddess” | ebi |
| 48 | gold | hiranyam, Av. zaranya | al(tun) | wise | veda “knowledge” | vidya |
| 49 | herd | sardhah | kert | wolf | vrkah, wrkas, Av. wəhrko | börü |
| 50 | I (arch. ic) | ah(am) | ič (es) | young | yuva | yangi: |
| yuck | ye:k “demon” | yek |
The detectable presence of the Türkic substrate in Sanskrit points to the demographically mixed origin of the Indo-Aryan farmers, an idea that seems to have never crossed the minds of the “IE” linguists. At the dawn of the Bronze Age, and enduring into the 21st century, ethnicity and trades were connected very tightly. The leaders and rulers could have been of one ethno-linguistic group, the military base and its economy of another ethno-linguistic group, the Indo-Aryan Levites of a third group, farmers and their economy of a fourth group, and artisans still of another group. We know for whom the Hebrew Levites wrote their version of the history, but we may never know the native vernacular of the Indian Levites. The Sanskritic foundation may be a layered cake, misdated, misinterpreted, taken for a gospel, and exploited by patriots and politicians. The problems of the “IE” theory are rather systemic, precipitated and protracted by loyalty to the premises grown more on the notions of aged popular beliefs than on empiric experience. Started as a lump of raw dough, it was baked into a good-looking tangible and spongy loaf, tunneled through in all directions by incessant criticisms, and now stands as a fossilized crust, to be re-ground and re-baked with whatever flour it contains.
Germanic and Türkic Languages
There goes around a notion that Türkic-IE connection does not exist, that the “IE” could and was solely impacted only by the Ugro-Finnic group. In that scheme of geographical ethnography, the highly mobile Türkic people were confined to Altai, and Altai is too far from the European arena to possibly pass any borrowings into the “IE” languages. As a principle, alternate explanations are not considered, facts are viewed through a lens of preconception. This myth is solidly supported by a thorough disregard of linguistic reality. In contrast with the “IE” etymologies, most of the Türkic borrowings, or rather sharings, are so transparent, it takes a certified blind to pretend not seeing them with a naked eye. The etymology of the Türkic substrate in English practically does not exist, most of the Türkic words in English are left without any, even most flimsy, explanation. Etymological dictionaries and encyclopedias state with a straight face an “unknown origin”, or at best lead to OGk. or OLat., like if those were there on the first day of creation. Within the IE-centered enterprise, etymologies of “unknown origin” are routinely fossilized, for centuries recited between publications in defiance of scientific curiosity within the “IE” cocoon.
The reality is much simpler than it is popularly presented, and at the same time much more interesting.
Forrer (1894–1986) advocated that “IE” was composed of two unrelated languages (Forrer E., 1934,
Neue Probleme zum Ursprung der indogermanichen Sprachen.
“Mannus”, B. 26).
- Von den Velden, Friedrich, 1912, 1920 stipulated Uralo-Altaic origin of the Germanic substrate.
At the time, the Uralo-Altaic was a pre-1950's concept.
- Also, Feist, Sigmund (1865–1943), 1932, “The Origin of the Germanic Languages and the
Europeanization of North Europe”. Language (Linguistic Society of America) 8 (4): pages 245–254.
doi:10.2307/408831.
http://jstor.org/stable/408831
- Also, Uhlenbeck C.C., (1866–1951), 1957, suggested that “IE” was a mix of Ural-Altaic and
Caucaso-Semitic type languages, The indogermanic mother language and mother tribes complex //
American Anthropologist, Philadelphia, v. 39, no. 3, 385-393.
- Also, John A. Hawkins (1990), Germanic Languages, in The Major Languages of Western Europe,
Bernard Comrie, ed. (Routledge). ISBN 0-415-04738-2
- Also, Edgar C. Polomé (1990), Types of Linguistic Evidence for Early Contact: Indo-Europeans
and Non-Indo-Europeans. In: Markey-Greppin (eds.) When Worlds Collide 267-89.
The list is going on and on.
Notably, in reconstructive phonology, “The development of vowels in German languages shows a feature resembling the reconstructed development in Altaic: the reflexation of vowels (in particular the short ones) in stem-initial syllables strongly depends on the vowels of the following syllable(s)”, which allows reconstruction of Germanic phonology using Altaic parallels (A.V. Dybo, G.S. Starostin, 2008, In Defense of the Comparative Method, or The End of the Vovin Controversy//Aspects of Comparative Linguistics 3, p.139, Moscow, RSUH). One has to climb a Türkic ledge to reconstruct the Pra-Germanic phonology. Is not this an ultimate insult to the “IE” pedigree and philologists who were solemnly lodged on an island, unaware that they are perched on a fringe of the Eurasian peninsula. Like in the geocentric model, Eurasia rotates around Alps.
The Family Tree model keeps inflicting serious damage. With the Family Tree blinds on, any
aberration either creates a mental block that leaves it alone, or engages an overdrive not unlike
the universally supported science on the Aristotle's geocentric model with its ever growing
entangling of the embedded epicycles before the appearance of the heliocentric model in the course
of scientific revolution. The phonetics, for example, instead of surveying a list of possible
phonetical kins in search of corroborating evidence, keeps developing epicycles to fit into the
traditional creationist model the widely acknowledged phenomena of the Germanic and Türkic
phonetical parallels. It was not the door that was tightly closed, it was the model that spurns the
open doors. Opening the door would not only advance the English and Germanic linguistics, but would
also illuminate the non-IE contributors to the “IE” line. A good example of the fruitfulness of such
studies is the Bulgar lexicon extracted from Hungarian; it meshes up with other Türkic vernaculars,
enriching not only Hungarian and Türkic philology, but also going far beyond into the “IE” and
Oriental studies not confined to linguistics alone. Such single-dimensional self-impairment breeds
primitive concoctions compatible with miraculous stories that produced simplistic models parodying
intricacy and magnificence of the actual evolution.
15
Aside from the Old French impact, in English is visible a blending of three unrelated languages, and some attentive eye would detect that the historical development of English differs from the bulk of the Germanic languages, pointing to a separate, yet related, source. Sufficient indicators point to languages with their own version of lexicon and morphology. The main gap that separates English from German is filled with French borrowings that introduced Latin-derived lexis. The French borrowings, however, have a superficial nature, they did not impact too much the old Old English daily vocabulary. In contrast, unlike English and other Germanic languages German was not affected by the French borrowings.
The commonalities between English and Germanic languages are enduring, for example the difference between the front rounded morpheme u (muse, ü) and back morpheme u (cook, u) are consistently retained going all the way to the pra-pra-language. Graphically, they are frequently camouflaged by the attempts of various writers to present the front rounded u distinctly from the back u: you, iou, ui, ull vs. u, ou, oo, oue, ul; same with the front i vs back i: e, ea, ee, ei, “IE” vs. i, y. In the pra-pra-language the difference was semantic and critical, carried on as far as it was needed, but the creolized English mostly lost that semantic function, as well as the ancient suffixes, and the retention of the once critical differences is purely inertial. Still, the abundance of spellings for the phoneme i, for example, is quite telling, at the dawn of Romanization the differences were significant enough to warrant explicit coding e, ea, ee, ei, ie, in addition to the laconic i, with an emphasis on the semantically distinct special quality of the rendered phoneme. Other languages, encountering the same problem with the front i vs back i, similarly came up with local inventions, like the Cyrillic и vs. ы or ï. Prima facie distinct, these are paradigmatic solutions to a paradigmatic transfer problem. The imprint of the substrate phonemics still lives in the daughter languages.
An unintended consequence of the search for the origin of the English's substrate is a review of the state of the purported “IE etymology” for the English Turkisms, where there is one. Except for the candid “of unknown origin” and “no known cognates beyond Germanic (and at times Celtic)”, the rest is marked by systemic dishonesty, artificiality, or open flimsiness. Where the “IE etymology” of Turkisms appeared to be plausible, a doubt was interpreted in favor of the “IE” version, and such words were not credited as Turkisms. Some trends, like appealing to Lat. prefixes to chop down an original root, may even be formulated as some “IE” linguistic law: all original stems starting with e-, for example, can be wiped out with a single device of “assimilated ex-” - “out”, even in cases when a cognate family clearly attest that e- is a part of the root. The appeal to “onomatopoeic” or “echoic” origin is a routine antic, never supported by a survey of the “echoic” forms across linguistic families. Flimsiness or sleight of hand reigns in not citing inconvenient cognates not only from the eastern languages like Kor. or Mong., but even from within the “IE” languages like the Sl. In some cases, falsification borders on ridiculous, see mare for example. While cognates of mare predominate across Eurasia, the “IE etymology” boldly declares that there are “no known cognates beyond Germanic and Celtic”. Criticisms and disputes on the “IE” etymological methodology are as old as the “IE etymology” itself, and the present review of the substrate layer presents abundant illustrations of its shortcomings.
A majority of the Turkisms belongs exclusively to a class of the Germanic languages, with a sprinkle of random guests into selected neighboring languages. Etymological assessments glide over that exclusivity without specifically noting it and any systemic analysis. Result is a loss of the historical connections, the very objective of the etymological history. With the tool of the faux “reconstructions”, a word is doomed to be sunk into the netherworld of the PIE smoke pool. It is an image of a Tree of Life with apples and watermelons hanging off the same branch. It is an image of a special pleading PIE Babylon Tower and miraculous creation and scattering for a peculiar group of languages. Besides the class of the Germanic languages, there is a distinct class of the Germanic-Slavic strata. While the etymological historicity of the Norman-Anglosaxon blend is perfectly transparent, the Germanic-Slavic blend is blurred in the smoke pool as Germanic-to-Slavic loanwords, albeit a good slice if not a majority of it is rooted in the omitted shared Turkisms. Each side is cooking their own historical broth within proprietary confines of the etheric “proto-language”. Under a guise of loanwords, history is stripped off the historicity, turning its linguistic aspect into a mystic unlit forest.
Scandinavia has a distinct and uncluttered genetic footprint, with salient haplogroups I1, R1b, and R1a. The haplogroups I1 and R1a came from the continent, they probably were already amalgamated and shared a common “Old Europe” language. The haplogroup R1b came as a nomadic wave of Kurgans from the Eastern Europe, they belonged to the Kurgan Pit Grave archeological culture, liable to speak their own distinct Kurgan language. At about 3700 ybp (1700 BC), the newcomer Haplogroup I1 supplanted and joined the genetically related older 8000 ybp-old (6000 BC) Scandinavian haplogroups I2 and I. The haplogroup I1, previously widely scattered across Europe, found a refuge in Scandinavia. The other refuge area was the forested northern area of the Eastern Europe with the Corded Ware Sprachbunds. The Scandinavian blend of I1, I2, I, and R1a makes a good candidate for the Indo-European Scandinavian Sprachbund that later expanded back to the continent. The haplogroup R1b, nowadays spread in the Scandinavia almost equally with the leading haplogroup I1, appeared in the continental Europe 4800-4500 ybp (2800-2500 BC). That makes a cause for the European mix of I1 and R1a, with the newcomer R1b, to come to Scandinavia safe heaven as a compact, in a single movement that could last for centuries, akin to the directional movement of the Bulgar and Slav compact to the Danube Bulgaria. Demographically, the R1b nomadic Kurgans were a minority, the I1 and R1a farmers were a majority. The nomadic Kurgans were the military and ruling force, farmers were the manpower and economic base. These first Kurgans in Scandinavia should not be confused with the later Kurgans around the New Era. 1500 years later, by the Sarmat time, the Scandinavian blend of the I1, R1a, and R1b had probably amalgamated, with only traces of the former statutory stratification.
By the turn of the eras, they formed a distinct ethnicity named Germanic, we have a good idea of the early Germanic languages, and of the dialects within individual languages. At the base of the Germanic languages lay the surviving languages of the “Old Europe”, enriched by a heavy admixture of traceable Turkisms. From the Scandinavia of the 2600-2300 ybp (600-300 BC), Germanic people and languages rolled down to the Alps and Black Sea, to the Gaul in the west, and Vistula in the east, reconstituting the “Old Europe” languages in their newer “IE” hypostasis, and leaving Pomerania with its predominately R1a population an isolated island. The languages of the Scandinavian migrants to the continent constituted a single Germanic phylum, mutually incomprehensible neither with the continental “Old Europe” languages, nor with the European Türkic vernaculars.
With the arrival of the haplogroup R1b, connected with the Celtic Beaker culture spreading from the west, and the Pit Grave culture spreading from the east, nearly entire male farming population in the continental Europe marked by the haplogroups I1, I2, E1b, and R1a had waned, leaving there only the haplogroup R1b for an auspicious period of 4500-3500 ybp (2500-1500 BC). The old female European population endured and even increased. If languages are anchored by women, after 3500 ybp (1500 BC) the “Old European” fraction had to increase, at the expense of the prior Türkic fraction. Return of the Scandinavian-Germanic and Corded Ware refugees repopulating Europe after 3500 ybp (1500 BC) reseeded Europe with the male haplogroups I1, I2, E1b, and R1a, and with the relict reflexes of the “Old Europe” languages.
The Scandinavian languages and haplogroups provide a lab-quality experimental data on the correlation of binary genetic/linguistic components prior to the Scandinavian-Germanic expansion to the continent. Presently, Sweden has R1b 22%, with I1 37% and R1a 16%; Norway - R1b 32%, with I1 32% and R1a 26%; Denmark - R1b 33%, with I1 34% and R1a 15%. The kindreded haplogroup I2, fairly well correlated with the “IE” Slavic populations and ubiquitous in the Old Europe, is currently present only in trace numbers, Sweden 1.5%, Norway 0%, and Denmark 2%. The R1b/(I1+R1a) numbers serve as a ballpark predictors of the Türkic/IE linguistic admixture, about 20-30% of the Scandinavian lexis. The proportion of Turkisms, in agreement with the clinal distribution of R1b as a marker of originally Türkic phylum, has to reduce from the European North to the Mediterranean South, while allowing local spurts to extend at any distance in any direction. The older R1a, sedentary in Europe and nomadic in Asia, the “Old Europe” in the European west and Türkic in the Eurasian east, would play a secondary swing role, depending on the time and source of its presence.
There is no sane explanation on the origin of the “IE” component in the Scandinavian languages other than the people marked by the haplogroup subclades I1 and R1a, and in the Slavic languages other than the people marked by the haplogroup subclade I2. That leads to the Old Europe and its languages, a de-facto “IE” lexical majority in the Scandinavian languages, and de-facto property of the “IE” Slavic languages. The opposite assertion, advanced by the investigators of the Pit Grave kurgans' genetics, on the “IE” R1b and the Türkic I1 and R1a, leads to a nonsense, to the opposite, a Türkic component majority and “IE” component minority in the Scandinavian languages, and a pile of other corollary absurdity. The Scandinavian linguistic lab provides incontestable evidence in favor of the “IE” – I1 and R1a correlation.
This non-thought experiment in the Scandinavian lab identifies the Old Europe of the 8000-4500 ybp (6000-1500 BC) as a transitory station on the “IE” path, a time of creeping agriculture and a demise of the hunter-gatherer economies. The period of 4500-3500 ybp (2500-1500 BC) is a transformative period, connected with massive relocations, realignments, and amalgamations. For a thousand years, or for 40 generations, the fractioned “Old Europe” male fugitives procreated with the local females at dispersed refuges, grew up with their languages, and were forming amalgamated “IE” Sprachbunds. Their return and dispersion 40 generations later was no less eventful. The relatively late in the reverse flow migrations, the first historical records from the first literate sources relay the stories of the Dorian invasion, Achaean invasion, Hittite invasion, Aryan invasion, wars of conquest, etc., emanating from the N. Pontic area, with no less destructive consequences than the Kurgan invasion of Europe in the 4th-3rd mill. BC. In the 1st mill. BC episodes of relocations, realignments, and amalgamations lay the roots of the Anglo-Saxon origins, the origins of numerous Germanic tribes connected with the history of England and English language, and with the history of the “IE” layer in their languages.
It is highly unlikely that a scientific luck will ever encounter a situation duplicate of the massive Scandinavian case, where a historical prism would separate long past events into clearly readable distinct beams of reproducible genetic and linguistic pattern. It is especially fortunate that the Scandinavian lab is a test bed for the very “IE” family, the scholarship, historiography, enigma, and speculations of which easily exceed those of all other linguistic families combined. At the same time, the improved methods of genetic analysis, improvements in the accuracy of the genetic dating, and philological advances may allow analyses of much less clear-cut situations.
| Figure 4. Neighbor-joining tree of European, Turkic central Asian and Turkish
(Anatolian) populations constructed from HVS I sequences (Hatice Mergen et al., Mitochondrial DNA sequence variation in the Anatolian Peninsula (Turkey)//Journal of Genetics, v. 83, No. 1, April 2004) |
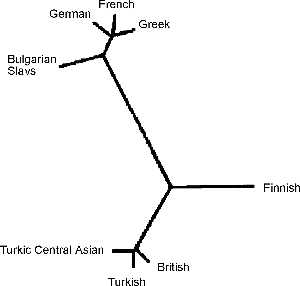 |
|---|
In 2004 came out the Hatice Mergen et al., Mitochondrial DNA sequence variation in the Anatolian Peninsula (Turkey) that surprised the world with the results of genetic connection between the British and Turkish mamas. The linguistics, which ordinarily is at a loss with the genetics, unwittingly got a shot in the arm: the genetically closest kins of the Turkish mamas turned out to be the gelding-riding nomadic Central Asian Türkic mamas (no surprise there) and the British mamas (what a surprise!). And where the mama goes, there goes the language [Hatice Mergen, Department of Molecular Biology, Science Faculty, Hacettepe University, 06532 Beytepe, Ankara, Turkey. E-mail: mergen@hacettepe.edu.tr].
The male Y-DNA R1a and R1b, ubiquitous among the Türkic papas, do not hurt either, they mark genetic protraction between the Türkic peoples and the populations of the European countries.
Latvian is held to be the most archaic language in the N. Europe, and accordingly it is cited as
closest to the pre-IE languages of the N. Europe. It also happens to be the only N. European
language that was examined for substrate languages, and viola, one of them turned out to be Türkic.
The substrate lexicon, morphology, syntax, phonetics of vowels and consonants, even the
agglutinative suffixes, all find their roots in Türkic, and they are yet quite compatible with the
modern Turkish, although the Turkish belongs to the Oguz branch, and the Latvian demonstrates
features and has historical links pointing to the Ogur branch. The difference must be on the range
of Hittite vs. modern Italian, and still the volume of evidence is more than overwhelming to
demonstrate intimate genetic connection. A close look at Latvian also allowed discerning that its
substrate Türkic lexis substantially differs from the Türkic substrate lexis of the Slavic
languages. Latvian and Slavic use numerous different synonyms in their languages, evidently coming
from different Türkic phyla. And if the Latvian is archaic, what about its substrate?
16
Close to the 3rd millennium BC, at about 3500 BC, Europe was invaded by the Kurgan wave 2, and soon after that, at about 3000 BC, came the Kurgan wave 3. These Neolithic waves, archeologically associated with the cultures dubbed Battle Ax and Corded Ware, first migrated to the right banks of the river Dnieper, and then farther on to the Central Europe. How numerous was the part of the ancient Türkic tribes and which Türkic tribes passed through the Dnieper area is a moot matter. Most of them amalgamated with the local aborigines, that is amply attested. A part of them moved to the Central Europe, roughly coinciding in time with the Celtic expansion to the Central Europe, wrecking there a havoc known as the Central European “killing fields”. Both invader flows were predominantly marked by R1b haplogroup, the survivals marked by an alphabetical soup of male haplogroups fled to the E. Europe. Of the invaders, only two Türkic tribes, that of the ancient Bulgars and Akathirs, retained their ethnic identity; the Celts were too far remote from their roots, they received a non-ethnic moniker Kelty (y as i in sit), meaning plural “newcomers”. The female-perpetuated creole languages, augmented by diverse admixtures, became the Celtic languages that reached the literate times. The Bulgar-descendent tribes of the Tatars, Chuvashes, and Balkars in their languages have preserved some idiosyncrasies that better resonate with the European Latin, Germanic, and English languages; of all the Türkic languages, some cognate lexemes are attested exclusively in the Chuvash. Many Latin Turkisms can be alternatively attributed to the Celtic or Türkic influence. The ancient Greek Turkisms differ from those of the Italics, they did not have the Celtic influence. The Greek and Latin Turkisms, at times also attested in India, are now classed as innate PIE vocabulary.
The analytical work performed in 2015 determined genetic composition of two archeological cultures, Kurgan Pit Grave and Corded Ware, the first called in Russian Yamnaya, from yama “pit”. The Kurgan folks were predominantly marked by Y-DNA haplogroup subclade R1b-M269 on the male side and mtDNA haplogroup subclades western Eurasian U2e, U5a, T and eastern Eurasian C and A10 on the female side; migrants moved by whole families. The Corded Ware folks were marked by Y-DNA R1a, E-V13, G2a, I2a, I2b, I1, N1c1 on the male side and mtDNA H, K, U5 on the female side. According to M.E. Allentoft et al., 2015, Pit Grave Kurganians were nearly exclusively R1b, Corded Ware were a mix of 3/4 Kurganians and 1/4 locals of the above Y-DNA haplogroups. The steppe migrants replaced ~3/4 of the central Europeans' ancestry. Before 3000 BC the native genomes resembled those of early farmers from the Middle East (G2a) and even earlier European hunter-gatherers (I2b, I1). By 2000 BC the native genomes were more like those of the Pit Grave people. The steppe ancestry persisted in all sampled central Europeans from about 4,500 to about 3,000 ybp. It can be safely submitted that on the average, the local Sprachbunds amalgamated in the same proportion, the Türkic phylum predominated. Migrations were followed by resurgences of the previous inhabitants between the Late Neolithic and present, the farmer and hunter-gatherer lineages rose again when the Bell Beaker and Unetice groups reduced the Pit Grave lineage to the comparable levels of the present-day Europeans. That had to raise accordingly the proportion of the non-Türkic linguistic component. These results elucidate the spread of kurgan burials in the central and western Europe, and provide support for the concept of the steppe origin of the Türkic substrate of the European Indo-European languages (M.E. Allentoft et al., 2015, W.Haak et al., 2015).
Perusal the body of the words of the “possibly pre-IE Mediterranean language”, of the “uncertain origin” words, and a mass of dubious “IE” and Germanic *asterisked conjectures, gives an impression that most of the “uncertain origin” “IE” *reconstructions are simply fancifully (or unskillfully, or primitively) slightly distorted Türkic stems and derivatives. On the other hand, excepting conjectures that are too imaginative or semantically too far afield, the “IE” conjectures do end up resembling their Türkic siblings: a round peg forced through a square hole comes out squarish. A statistical value of the *reconstructions is nil: they are not independently calibrated, are not corroborated with later discoveries, and their only utility is to remold the past. In most cases, a basic understanding of the morphology of the Türkic languages would greatly alleviate the scholarly puzzlement, too often linguists confuse suffixes with parts of the stem, and stem parts with prefixes. Filtering English vocabulary on the “of unknown origin” and the like readily supplies a listing of substrate candidates, and the base words of 2000 years-old life make it easy to locate the Türkic substrate originals with close phonetics and exact or nearly exact semantics.
The concept of Nostratic was formulated in the early 20th c. as an Ursprache pra-language Family Tree model that originated most of the Eurasian languages, from “IE” to Sino-Caucasian. In its most radical interpretation, the Nostratic concept is reduced to a mega-IE axis. The concept was formulated exclusively on studying the linguistic cognates found in very diverse languages, on the continental geographical scale, and with the implied Family Tree model. It was formulated before the development of the linguistic Wave model, knowledge of the Kurgan waves, understanding of the continental-scale migrations, and methods of genetic tracing and dating. In conceptual dating, and under the Family Tree model, the Nostratic concept envisioned for the Ursprache the times as remote as 30-20,000 ybp. Correcting for the later developments, the Nostratic idea contracts to the linguistic layer disseminated across Eurasia by the Kurgan waves during pre-Kurgan (R1a and R1b haplogroups) and Kurgan periods (R1b haplogroup) that started in the Neolithic and continued till and including the Middle Ages. Some pre-Kurgan Nostratic spread (R1a and R1b haplogroups) started around 10,000 BC, it intensified around 6,000 BC, greatly intensified around 4,000 BC, and reached India and China during 3,000-2,000 BC. The effect of refugees from the Kurgan waves constitutes an innate component of the Kurgan waves' phenomena, with its own linguistic and cultural propagation.
Links
http://s155239215.onlinehome.us/turkic/40_Language/OTDictionary/OTDictionaryAffixesEn.htm
http://s155239215.onlinehome.us/turkic/40_Language/ClausonEDT/Clauson_EDT_Suffixes.htm
“Türkic” languages is a vast family of languages distinct from non-Türkic families by a crisp definition of its properties. Its earliest documented phrase ascends to a 5th c. AD. Runic alphabet in inscriptions may be a millennium older; one day we may be able to date many of stone-type inscriptions. The term “Türkic”, as the language reached us, refers to a linguistic family with languages from mutually comprehensible to mutually incomprehensible, pretty much like many other families, Cf. Gmc. The global term “Türkic” can't be confused with a particular term “Turkish”. “Türkic” in practice is a language frozen in time prior to 13th c. AD and scattered across languages over most of the Eurasian latitude; “Turkish” is a particular branch with its own particular vocabulary and particular history. The difference is no less than between, say, Eng. and Gmc.
Typologically, Türkic languages are SOV-type agglutinative, genderless, they feature sound harmony, exclusively suffixing word formation, extensive use of pre- and post-positions, dependents precede their head, and they form numerous nonfinite verb constructions. A hallmark of Turkism is an inordinate number of derivatives: a single root producing endless generations of offsprings; in medieval India creation of new derivatives became a kind of sport. Nominal stems take on nominal suffixes, and verbal stems take on verbal suffixes. Most stems are polysemantic, with a trail of largely overlapping meanings related to the main notion, with figurative extensions tenuously connected to the main notion, like “break” with figurative “weak” and “melt”. A common development is the use of a single root to create contrasting (e.g. guest vs. host), complimentary (e.g. tick, tack, tuck), and metaphorical (e.g. give, open) notions, it allows great expansion with economical means. Languages form semantic expressions by adding suffixes to the root stem. Like in English, the adjectives are morphologically not clearly distinguished from nouns. The expressive verbal morphology is rich with markers of actionality, possibility, negation, voice, aspect, mood, tense, person, interrogation, attitude and more. Just the Turkish alone, accounting for the vowel harmony alternations, theoretically has over a thousand of grammatical morphemes. Unlike English, which has a canonized list of all English words with a defined total count, the Türkic words can't be counted because new forms are continuously created using a conventional set of suffixes and a conventional practice of their usage, learned with the language and intuitively applied. Theoretically, the Türkic lexis is finite, but nobody knows what is that theoretical number.
On the other hand, the quantity of the Türkic stems is not large, they comfortably fit into single volume linguistic dictionaries. Prefixes are structurally counter indicated, they impact the root and baffle the crisp mechanism of semantic content. Instead of prefixes are used prepositions, audibly identical to prefixes. The accent on the last syllable leaves the root portion undisturbed in any environment, while internalization in English moves the accent to the first syllable. These simple structural conventions secure the distinct endurance of the root system. Words are formed starting with a single morpheme (of which Eng. preserved just one, ö, the word awe), first by agglutinating distinguishing functional morphemes one at a time, then by agglutinating semantical morpheme units (like -lig- “like”), ending up with verbal conjugational morpheme units. Generally, the logical structure of the language allows to trace a word through a linked chain of derivatives to its source, that is a monumental difference between the Türkic and the “IE” languages with their haphazard mix of agglutinative and random (borrowings and amalgamation) word-forming practice that can't be called “procedure” with the absence of such. Unlike the “IE” word-forming practice, the Türkic practice is usually predictable in both directions, with the loanwords standing out; that makes the science of Turkologists incompatibly easier than the tortured science of the Indoeuropeistics.
A common feature of the base roots is their two-dimensional semantics, one immediate, and one implied; both sememes may develop derivatives, with the immediate derivative carrying over the implied meaning (like “do something” vs. “do something together”), and the implied derivatives directly continuing implicated sememe but indirectly implying the base meaning (like “together (do something)”). This bifurcated semantics may puzzle a student who sees only a direct meaning, and erroneously concludes that there is no connection between a base root and its derivative; or the connection may appear to be too far-fetched to be credible; while an understanding of the implied notion puts connection in proper perspective (like “stopover” also implies “bunching together”, and thus “tribe”, “crowd”, “companions”, and the like). Frequently, the subject of the implied semantics is not included in a phrase, and a translator of the phrase puts the crucial implied subject in parentheses for the phrase to make sense. The two-dimensional semantics first appears in the linguistic relicts, the single-syllable stems, and continues undiminished well into the era of technological revolutions marked by lexical expansion into construction, metallurgy, and producing pastoralism, when grammatical developments supplanted notional expressions with morphological means to form precise semantic variety by an assortment of grammatical modifications. The use of agglutinative method (Cf. -iš as cooperative mood marker) made unnecessary the use of implied semantics (Cf. “together” as a derivative of “bunch together”, an implied notion of the word “stopover”). At times, from the distance of ages, the base notion may retreat to a background blanketed by its derivatives; that may result in misguided etymology (Cf. šarp, Eng. “sharp”, with a base notion of “steep incline” essential in the mountainous pasturing, it can be used and interpreted as “rough”, “inaccessible”, “difficult”, “tapered”, even “acerbic (taste)”, etc., with the physical base notion on the plains' pasturing atrophied). In a single-dimension linguistic world, the two-dimensionality of the often metaphorical notional semantics may be an impediment. A tree appears as a bush, with stalk obscured by the crown.
A common phonetic feature of the Türkic languages is a somewhat wild, somewhat organized alternation mirrored, for example, by the strongly pronounced Germanic d/z alternation shared with the Türkic family. The most prominent of them are the m/b and z/d/y alternations. Phonetic alternations from the beginning were probably a consequence of amalgamations, and of consecutive amalgamations thereafter. The m/b bifurcation is most telling, the peculiar coexistence of the m/b alternation within the same communities endured for 7 millennia and has survived into the present times, occasionally within a single family the alternation is not registered by the speakers or listeners themselves. Traces of the m/b divide extend far beyond the Türkic milieu, extending across the eastern and western parts of the Eurasia and crossing barriers between linguistic families, with a heavy imprint within the entire “IE” family. The oldest traces of the m/b alternations are visible in Sumerian, they are also a trait in the Finno-Ugric family including Hungarian. Sumers are believed to have migrated to Mesopotamia between ca 5500 and 4000 BC from the area between Caspian Sea and Hindu Kush and Kopet Dag mountains, about the area of the modern Turkmenistan. They carried an R1b-M269 subclade haplogroup marker (Klyosov A., 2012, 87on). The genetical and archeological datings are largely consistent. Suggestions on a temporal priority of one phoneme over the other are unsupportable. The Sumer migrants were but an offshoot of the R1b migration flow, a sidestream of the much greater demographical situation marked by numerous other R1b subclades.
The English, via Anglo-Saxon, lost most of the Türkic suffixes, and added some to its morphology. The modern Turkish retained most of the suffixes, reactivated some that were out of use, and simplified orthography, collecting some phonetically close phonemes under a common symbol. The following listing of the Turkish suffixes allows to highlight modern English suffixes genetically connected with the modern Turkish suffixes; as a body, they constitute a stand-alone paradigm that inescapably attest to the common genesis, a paradigmatic transfer evidence in concert with all other systemic cases of paradigmatic transfer. One of the most significant Türkic suffixes is –t that forms deverbal nouns. The final –t in Anglo-Saxon and English nouns is a good pointer to locate the underlying verbal stems for the nominal derivatives, Cf. Türkic bert “tax, return” (ber- “to give”), ölüt “'killing” (ölür- “kill”), bütüt “completion” (bütür- “finish, complete”); English port “harbor” (bar- “depart”), unit “part of” (una- “agree”), gift “present” (kiv- “give”). Since the suffix –t in English lost its original function, it became an indelible part of the root: port, unit, gift.
The modern Turkish language is a product of amalgamation of numerous Türkic languages, which in varying degree contributed to the modern Turkish language. The Turkey's ethnic map discriminates 25 constituent ethnicities on top of the titular Oguz component, a number of those ethnicities, including within the Oguz fraction, before the amalgamation had distinct languages up to mutually incomprehensible. As a result, Turkish is but one of the Türkic languages with its own peculiar lexis, removed fairly far from many other sibling Türkic languages and likewise from the OT variegated collection, and it can't be used as a weighted instance of the Türkic phylum. According to some estimates, Turkish is a blend of about 86% Türkic lexis and 14% of admixture lexis; it is fairly far removed from the formalized OT sampling, and its daily lexis is variegated much above the 14%. A careful examination of the lexicons of 42+ Türkic languages (the vague number reflects the current state of affairs, not the actual number) would likely produce forms that are genetically nearer to the historical and current English forms. Comparison of the English and Türkic lexicons is largely limited to the root forms, with not infrequent cases of the Türkic suffixes embedded into the English word stem. English was already heavily creolized when the Anglo-Saxons brought it over to the Albion, but the traces of its substrate are still fossilized in the lexis and morphology, and the agglutinated suffixation is an ingrained and burgeoning part of its morphology.
In addition to exclusively suffixing word formation, Türkic languages widely use prepositions that are indistinguishable from prefixes neither phonetically nor functionally. Türkic languages also widely use postpositions that modify conjugated or declined forms. Written separately, phonetically they are indistinguishable from the prefixes and suffixes. The conditional status of the prepositions and postpositions adds caveats to the doctrinal assertion of the absolute absence of prefixes in the Türkic languages. Some of them made their way to English, retaining their semantic function in a new syntactic environment. These cases belong to the body of paradigmatic transfer evidence.
Grammatically genderless for inanimate objects, or where gender is irrelevant, or where gender is
clear from the context, Türkic languages may use suffixes -čïn, -kčïn and -lai to mark
female gender; otherwise gender, like the age and other traits, is indicated by determinants. In
that, Türkic and English are identical, the other Germanic languages are not too far off with their
haphazard treatment of gender. In all cases, gender markers are borrowings from neighboring
languages; the Türkic gender markers are borrowings from Mongolian and used by the neighboring
eastern Türkic languages.
17
The “IE etymology” tends to follow a path of deriving verbs from nouns. The Türkic linguistic tendency is the opposite, the prime stem is mostly verbal, the noun semantic is a derivative. The difference is of a cardinal nature for understanding the “IE” lexicon of the Türkic origin. Among the Indo-European languages the Türkic verbal-nominal homonymy, the system of roots in Türkic languages where the verbal root also serves as a noun, in a most developed form is represented in English, but albeit in an incomplete form is also known in some other European languages (Sevortyan, 1974, 39). The English and Türkic innately share this morphological feature. English has stand (v.) and stand (n., adj.), sit (v.) and seat (n.), sleep (v.) and sleep (n.), with uncounted others, and continues to productively use this inherited Türkic word-forming vehicle. In the Türkic languages, the productivity of the verbal-nominal homonymy faded by the Middle Ages, but in English this ancient Türkic linguistic backbone experienced its Renaissance before the 13th c., and still keeps developing, illustrating a spiral conversion trend in the linguistic processes.
The “IE” linguistic paradigm is built on attested lexicon, non-attested lexicon, and phonology to explain the linguistic past seen from the perch of the viewer, with little or none attention paid to morphology or syntax. The PIE dictionaries are widely available, they inventory the attested lexicons and suggest non-attested *reconstructed forms, ostensibly in their stripped state, without morphological modifiers, but in fact frequently confusing unperceived suffixes with parts of the stems. The modifiers are structured individually by “IE” linguistic branch, i.e. Proto-Germanic, Proto-Slavic, etc., but they did not come from the same tree, and even conceptually are not compatible across the “IE” family. Accordingly, there are no PIE morphological dictionaries, nor a PIE morphological inventory. Such a pathetic state, after generations of linguists spent gargantuan efforts on PIE, has a good reason, reflected in the competing models of the linguistic development: the absence of any trace of commonality.
In the usage frequency statistics, morphological elements are buried with the words, making it impossible to assess the extent and the role morphological elements of different provenance play in forming a language. A cursory qualitative assessment readily shows importance of some morphemes: the listing of words beginning with negation element un-, an allophone of the Türkic negation element aŋ/an, far exceeds the number of words with stems starting with un- (undue “not due” vs. unary “single”): of the approximately 320 words beginning with una-, only 5 stems start so; in this case the amplification factor of the single morphological element un- thus exceeds a factor of 60, it enormously enriches English vocabulary, empowers its expressiveness, and enables stinting communication, all without a hint of a due statistical credit.
The overwhelming majority of the Türkic vocabulary is produced internally, from the basic, mostly verbal, stems of the language. Signally, some Old Türkic words bear unmistaken indicators of being borrowings: they are stand-alone entries without extensive nest of derivatives and without a transparent base stem. This class has few words smacking of the European extraction; the path from the Old Europe to the Old Türkic, which is a collection of exclusively eastern lexicons with a shade of the western languages, is unclear. These borrowings are a class of the words separate from the class of the religious borrowings from the Buddhist (Skt., Prakit, Hindi) and Islamic (Arabic, Persian) lingo.
In Türkic linguistic family numbering 42+ languages, stem defines notion, and grammatical constructs are formed by agglutinating suffixes specific for parts of speech. With some exceptions, English lost many suffixes at some pra-English stage; thus the Türkic generic stems became English verbs and nouns without functional markers; in English, they are used at random as verbs, nouns, and verbal or noun adjectives, and then they develop various verbal and noun derivatives. Both in English and Türkic, the suffixation method is extremely productive, it allows to create the same notions with different nuances from a variety of unrelated stems, like cloudy, dimly, murky, shady in English and 20+ forms for greedy in Türkic, greatly enriching the language. In Türkic, the verbal form of the stem is predominant in forming nouns and other derivatives, which in turn may develop, in a spiral fashion, verbs from the derivative nouns and adjectives. With time, some Türkic suffixes waned from active use, remaining active relicts, while the replacement suffixes rose; parallel usage of relict and active suffixes is normal, with different forms at times acquiring differing semantics. In some cases, the English substrate and loanwords stick out because they carry imbedded vestiges of the long-gone Türkic suffixes.
In any language, lexis alone does not make a language. A collection of structural grouping of sound bits aligned into into morphemes and words that constitutes lexis is no different from a pile of components in a scrap pit, be it a ruined cathedral or electronic refuse stripped of precious metals, that is an unidimensional pile. A second dimension is a structure, it made the cathedral before its ruin and a computer before salvaging, it makes a language. The structure of a language makes it a systematic means of communication to convey meaning. At the sound level, closely related dialects may differ wildly one from each other while at the structure level the same wildly differing dialects would be nearly identical. In the accepted classification typology with linear order of precedence, the Türkic and Germanic languages are classed as SOV-type, while English lost its initial SOV structure, and replaced it with a rigid SVO-type, obliterating a significant former structural commonality between English and the domain of the Germanic group. Of the complexity of the Germanic group SOV languages, represented by Dutch, German, and Frisian languages, with their main clauses SVO and embedded clauses SOV, English retained the SVO order of the main clauses. English shares genderless typology with the West Frisian and Türkic, and shares indiscriminate treatment of female gender with the Scandinavian, Frisian, and Türkic. The absence of grammatical gender indicator is not the same as the absence of the gender, it is the absence of the load of the grammatical gender synchronization between parts of speech. The gender is conveyed by other means without any synchronization effort (Cf. Türkic prepositions er, kïz “man, girl” vs. Eng. she-), and only when it is relevant. As a group, Germanic languages have never digested completely the alien gender grammar. Of the Germanic languages, even though the links are present, German is distinguished by weak and erratic link between declension and gender, gender and sex. Agglutination within the Germanic group varies from minimal to heavy. The erratic typology within the Germanic group is consistent with the substrate/adstrate concept.
If a presence of systemic grammatical gender was used in the definition of the “IE” family, the size of the family would be greatly diminished.
It is generally believed, with a support of historical examples, that a phenomenon of a widespread multilingualism (bilingualism in a minimal case) is needed to affect a structural change of the language. Under that premise, a linguistic structural change is a manifestation of the multilingualism, it is an effect of amalgamation. History of English allows to discern interference patterns of recurring amalgamations, with Anglo-Saxon carrying a major doze of Türkic lexical and morphological inheritance, Turkisms from other sources (primarily Frisian) overlay the resultant blend with the Anglo-Saxon component, the Romance layer carried over another load of Turkisms, and each one either directly impacted the structure of the English, or created conditions for a needed change. In such dynamic situation no conclusions are obtainable with static methods of discrete universe for each conglutinate language, internal reconstruction, lexicostatistics, or glottochronology, or they are easily vitiated when drawn with such methods.
A syntactical feature shared by the English and Türkic is the wide use of paired words - idioms, frequently used as compound words: horsetail and horse tail, bluegrass and blue grass, etc. Some words have dozens of such pairs, in English blackback, blackball, Blackbeard, etc., in Türkic qara ačı, qara baš - qarabaš, qara boɣuq, etc. Phonetically, the compounds and paired words are indistinguishable, the spelling is purely conventional. And all languages have polysemantic words; English and Türkic lexicons contain thousands of them; and miraculously, frequently the specific polysemantic meanings survived from the substrate Türkic into the modern English: yer/earth are both land and dirt, tili/talk are both a communication process and a story, etc. This mechanical transfer of polysemantic word from a language to language complete with the word's polysemantic meanings is a main indicator of the genetic connection, in contrast with the loanwords, which are borrowed with a specific semantic meaning when a receiving language adopts a word with only a meaning it needs to fill in. Below are cited numerous examples of polysemantic meanings carried over to English.
An univocal syntactical feature shared by English and Türkic is the use of predicate nouns with marker of belonging instead of accusative case: in Türkic “my uncle” with agglutinated suffix, in English “my uncle” with a pronoun instead of an article; thus “father loves her”, but “she loves her father”, and not “she loves father” or “she loves the father” ~ “ella ama a su padre” (Romance), but “she loves father” ~ “она любит отца” (Slavic). In Türkic example Huar-Ases (Suar-Ases) > Chorasm > Horezm “(land) of River People”; there -m is the Türkic possessive marker, a forerunner of the English “my”.
Another notable univocal feature that until 19th c. was shared by the English and Türkic is the now forgotten English passival reflexive form, where progressive aspect of a verb (Eng. -ing, Tr. -inč) was used in active voice with passive semantics (“breakfast eating” ~ being eaten), equivalent to the reflexive forms apparently ascending to the European Sprachbund vernaculars that existed in the Central Europe before the crucial events of the 3rd mill. BC. Relicts of that form are preserved in Eng., Dan., Sp., It., Lith., Serb., Pol.: pre- or postposition self/sig/se/si/save/se/sie (ascending to the Tr. öz “self”) respectively, and suffix sya in Russ., all meaning “self" and forming reflexive semantics were the objet is the subject. This now lost English form was creolized very late, in the 19th c.; in the Shakespearean time it was still active, and Johnny could be bathing (i.e. bathing himself), house could be building (i.e. building itself ~ to be under construction), breakfast could be eating (i.e. eat itself ~ be consumed), and lovers could be kissing ( (i.e. kissing themselves ~ kissing each other). In Türkic, the passival form is formed with the suffixes -m/-ïm/-im/-um/-üm and nearly universal stem öz “self”, all denoting “me, mine, self”. The öz, grammatically pre- and postposition, is a forerunner of the English possessive -'s, and European variations of pre- and postpositions “self”.
Till the Middle Ages and the input of foreign writers into the Türkic literary languages mostly via religious translations, Türkic languages did not know relative pronouns. In Türkic, suffixation serve the relative function. That inheritance is still prominent in modern English; while the presence of relative pronouns is characteristic, in particular, of the written Standard English, the standard variety has influenced the dialectal English, but had not taken over. The verbal use of relative pronouns is still subdued, with the absence (zero case) of relative pronouns reaching 30%, and a single particle that taking another 40%; the combined 6 relative pronouns share less than 40%, and that in spite of the absence of the suffixation tool available in the Türkic languages.
Another distinct feature shared by Germanic and Türkic languages is rhotacism. Rhotacism is one of the main traits that separate Oguz (-s-) and Ogur (-r-) languages, to a degree that these groups are defined as an s-language versus r-language. This preeminent trait is continued to the Germanic languages, notable, among others, in the Dutch (Y-DNA R1b 70%, R1a 4%) -s plurals and (by rhotacism) Scandinavian (Swedes, Y-DNA R1b 17%, R1a 21%) -r plurals. The ratios of the Y-DNA components point that Y-DNA R1b marker is correlated with the -s- form, and Y-DNA R1a marker is correlated with the -r- form. The same separation appears among the Türkic ethnicities historically connected with the Oguz (Common Türkic) and Ogur (Karluk subgroup, Uigurs, Uzbeks) groups, and is supported by paleogenetic testing.
Both English and Türkic have a preference for closed syllables ending with a consonant morpheme. That proclivity may be reversed passing through a language with an opposite tendency for open syllables ending with a vowel morpheme. The most frequent adaptation of a closed syllable by the alien linguistic inertia is by adding a prosthetic consonant in front of the initial vowel (VC > CVC). The initial vowel may be dropped (Cf. Türkic apat vs. “IE” pat “leg”, Cf. podiatry, peddler, pedal). Because such changes are caused by structural and not phonetic adaptations, such adaptations are unexplainable phonetically, as also are unexplainable the cases of metathesis (e.g. ab > ba etc.). The mere observations are routinely stated as exhaustive explanations: “h is often wrongly prefixed to words, as in Cockney English” (Hall J.R.C., 1916, 142). In Slavic, and shared by some Germanic languages, a prosthetic s- is systemically appended in front of the root, or is appended a prefix s- marking the perfect tense, the two can be easily confused. The systemic nature of prosthetic consonants is suggested by the mass of cases in the present study, these cases as a paradigmatic body extend a conspicuous diagnostic and tracing opportunity for the direction of borrowing and the nature of the guest and host languages. Systemic inattention to the structural and morphological properties of the languages in favor of the lexical content is perilous for etymological screening.
At each stage on their historical path, communities encountered alien communities and formed their unique lingua franca. Linguistic changes reflected initial idiosyncrasies for each unique situation. Each situation predicated its unique results at the terminal point, which marked a belonging to the previous stage, and a beginning of the next stage. It is impossible to account for all the past stages, for all the past players, for the murky linguistic relations during each stage. With so many largely unknown variables, any generalizations have their uncertainty and defined limits, both of which are critical in significance but can’t be defined for the prehistorical and most of the historical periods. None of the phonetic changes are predictable either backward nor forward. Consequently, the most that can be accurately stated etymologically is the vague “usual phonetic changes” and “few vowel variations”. Without a statistical assessment of the entire body of evidence for each variable parameter encapsulated between two terminal points, any assertion is no more than a hypothesis lacking a factual foundation.
A correlation between centum (k) and satem (s) languages in Europe is similar to the situation with the r/s alternation. In most -k- lands (Celtic, Italic, and Germany), R1a is the significant population component. R1a comes close to a minority in most -s- lands, where it may be compatible with the R1b content (Slavic). Comparing France (cent, -s-, R1b 50%, R1a 10%, I 30%) and Germany (hundert, -k-, R1b 50%, R1a 25%, I 25%), the main difference is with the R1a extent, and it correlates with the switch, from R1b -s- and small R1a, to -k- with greater R1a. It appears that relatively greater R1a tends to shift -s- to -k-. That observation is consistent with the earlier dating of the R1a and the earlier origin of the velar fricative in parallel with k- and q-. The corollary of that process may be a conclusion that the vicinities of the Aral-Caspian area, extending to the north to the Urals and in the south to the Mesopotamia, where the k/s furcation is most pronounced, initially were predominantly peopled by the R1a -k- type populations. The modern predominance of the -s- type in that area was caused by later migrations.
The European s/k divide is shared by the Türkic family, with a mirrored symmetry predicated by the demographic events. Within the Türkic milieu, the divide is more like s/h in today’s Romanized form. The -s- form is now predominant across Eurasia, the -h- form is scattered around the fringes, largely coexisting with and being supplanted by the dominant -s- form, except for the Alats/Khalajes who live in the -h- area. The modern spread of literacy and the influence of the titular languages tend to isolate and dilute the relict -h- islands. Still, the divide is very tangible (the Swadesh 100 list’s examples are from Dybo 2013, total 11 examples): “all, entire” Tat. saw, Bashk. haw; “belly” CT ičiksi, Sary-Yig. hijigï; “cold” Tat. sumk, Bashk. himk; “die” Tat. ül-, Khalaj hil-/hel-; “egg” Chuv. smarda, Dolgan himït; “far” Khalaj hiraq, Yig. iraq; “fat” Tat. simez, Bashk. himeδ; “kill” Tat. üter-, Khalaj hilär-; “thou” Tat. sin, Bashk. hin; “warm” Kumyk isi, Khalaj hissi; “water” Tat. su, Uzb. suv, Bashk. hïw. The -h- examples are limited to the Bashk. (5), Khalaj (4), Sary-Yig. (1), and Dolgan (1) languages, a tiny surviving relict of once dominant linguistic subdivision now extending to the European languages. The divide affords diagnostic value for the European linguistic pedigree.
The spotty bits and pieces hint that R1a are Scythians, Huns, Ases/Alans/Massagets, Kangars, and their lesser kins Bulgars, Suvars, As-Tokhar Yuezhi, called Ogur tribes in the modern linguistic nomenclature. The spotty linguistic traces point in the same direction, corroborating genetic indicators. Indications for the R1b marker are still blurrier yet, hinting toward the northern Tele tribes and their descendants Oguzes, Kipchaks, Uigurs, and their lesser kins Tele, Teleuts, Telengits, called Oguz tribes in the modern nomenclature. Except for few isolated cases, all populations were genetically mixed, covering diverse constituents under umbrellas of a leading tribe or a common unifying designation, like the Huns “kins”, Saka “mountaineers”, Alans, Ases “flatlanders”, etc.
An interesting case is the suffix -an, which survived in Türkic languages as an abstract
noun suffix forming derivative nouns from concrete nouns. In English, -an
survived as abstract suffix forming denoun and deverbal adjectives (terranean, distant), and
a spectrum of deverbal nouns (appearance, servant, lubricant). Apparently, its initial
function was a universal generic abstract applicable to all word classes, and its functional
stratification developed at a geographical-dialectal level; it fossilized as an abstract suffix
forming verbal infinitives within the Gmc. group (Cf. A.-Sax., Gothic, etc.), while the Balto-Sl.
and Indo-Aryan languages adopted for verbal infinitives the Türkic 3 sing. suffix marker
-t/-ti/-d/-di. Depending on the scenario of the stratification, the ingrained division may be
timed by the Balto-Sl. and Indo-Aryan separation, by the 2nd mill BC that division already had a
systemic nature that has survived to the present. At first, English had inherited the suffix -an
as a marker of verbal infinitives, but eventually abandoned it in favor of the preposition marker
to, apparently genetically a reflex of the Balto-Sl. suffix marker -t/-ti/-d/-di. This
adaptation is consistent with the documented process of the development of English, and points to
the demographic pressure of the Balto-Sl.-type vernaculars in the development of English. The end
product of adaptation was a result of a play of competing tendencies between the sedentary majority
and waves of intruding minorities, the Normans, Anglo-Saxons, Romans, and so on into pre-historic
times.
18, 19, 20, 21, 22, 23
The following Table 3 provides a cross-reference between the Türkic and English suffixes; it demonstrates a morphological continuity between Türkic, Latin, and English suffixation, an indelible example of an extremely massive paradigmatic transfer. That transfer is not only consistent, it is predicated by the archeologically and genetically established nomadic waves flooding the European peninsula starting in the middle of 4th mill. BC. The table lists nearly all active and productive English suffixes, allowing to discern the relative extent of the heritage and innovations. The fields that do not have Türkic entries are loan forms and/or innovations. Quite a significant proportion of the English suffixes is shared between Türkic, Germanic, and English languages. Of the 76 English suffixes, 48 or 63% were inherited from the Türkic mother lode, either directly, or via a Lat./Fr. intermediary.
English has abandoned the complexity of agglutination recorded in the Anglo-Saxon speech. Mastering agglutination allows to express relationships and nuances that without agglutination require a descriptive form, but that is a long process, impossible when the lingua franca is created on the run. Among the lost Anglo-Saxon suffixes are -u and -an, -isc, -e, -re, -an (gen.), -a, -ra, -na, -as (pl.), -an, -ang (negation), -m (poss.); adding these 13 vanished suffixes to the list would make the respective numbers in the Old English 89 and 61, and rise the Türkic suffix component in the Old English to 69%. The comparison illustrates not only the morphological losses, but also the power of heritage and its conservatism.
| Suffix | English Sample | English Usage | English Etymology | Türkic |
|---|---|---|---|---|
| -a | loanwords: bandana |
perceived as a part of the stem | -a, forms nouns of verbal stems for result of action named by the stem: yar - yara (cleave - wound) | |
| -able | enjoyable; lovable; suitable | forms adjectives from verbs with sense of “capable or susceptible of being" | Lat. -abilis, -ibilis > Eng. -able, -ible, conflated with “able” (adj.) | -bilä (“ability”) after -a/i forms adjectives expressing 1. likeness, reciprocity, proximity 2. instrumental(ity) 3. temporalityy Ultimately from stem bil- “know” |
| -al (1) | national; historical | forms adjectives with sense “of the kind of, pertaining to, having the form or character of” | Fr. -alis, Lat. -alis | -al, ultimately fr.-alqu “all”: ulus - ulusal (nation - national); -al/-il “with” |
| -al (2) | refusal; denial; arrival | forms nouns of action from verbs | ME -aille, Fr. -aille, Lat. -alia | Ditto |
| -an | terranean, american | forms adjectives from nouns | Fr. -ain, -en, Lat. -anus | -an instr. case |
| -ance | appearance; clearance | forms nouns from verbs with sense “characterized by or serving in the capacity of” | Fr. -ance, -ence, Lat. -antia, -entia | Dittoo |
| -ant (1) | contestant; servant | forms nouns with a sense of being someone | OFr., Fr. -ant, Lat. -antem | Ditto |
| -ant (2) | lubricant; deodorant | forms nouns with a sense of being something | Ditto | Ditto |
| -ant (3) | distant; dormant; pleasant | with a sense of doing or being something | Ditto | Ditto |
| -ar (1) | burglar; scholar | forms various nouns including occupations | Lat. -arem, -aris | -ar/-er “man” |
| -ar (2) | circular; singular | forms adjectives with sense “of the kind of, pertaining to, having the form or character of" | Ditto | -ar active voice |
| -ate (1) | consulate (n); elaborate (adj) | forms nouns & adjectives with various meanings | OFr., MFr. -at, Lat. -atus, -atum | -t abstract noun |
| -ate (2) | populate (v.) | forms verbs with various meanings | Ditto | -t verb voice |
| -ce | once; twice; thrice | forms numeric terms indicating a multiplying effect | A.-Sax. -ce, adverbial genitive suffix. | -ča/-čä (-cha/-chə) adverbial genitive suffix |
| -cy | delicacy; piracy | forms abstract nouns from adjectives | Lat. -cia, -tia, Gk. -kia, -tia, from stem ending -c- or -t- + -ia abstract ending | -č (-ch) abstract noun suffix -y/i - v. > n. |
| -cy | Nancy, fancy | forms diminutive-endearment nouns, adj. | Ditto | -kïya/-gïyä/-qïia/-qïna distinguishing-diminutive suffix-particle |
| -ed (1) | counted; worked | forms past tense and past participle of verbs | A.-Sax. -ed, -ad, -od > ME -ed, ONorse -tha, Goth. -da, -ths, OHG -ta, Gmn. -t; Lat. -tus, Gk. -tos, Skt. -tah | -da/-δa/-ta(čï), dä/-δä/tä(či) (-də/-δə/-tə) participle suffix |
| -ed (2) | winged; bearded | forms adjectives from nouns indicating attributes | Ditto | -ad/-äd noun > adjectival participle -da/-δa/-ta(kï), dä/-δä/tä(ki) (-də/-δə/-tə) adjective suffix |
| -en (1) | wooden | forms adjectives from nouns indicating attributes | A.-Sax. -nian, ONorse -na, Lat. -ine, Sl.-an, Latv. -na, ne | -an/-än (-ən) noun instrumental suffix |
| -en (2) | broken; rotten, written | forms adjectives from verbs indicating attributes | A.-Sax. -nian, ONorse -na, Sl.-an, Latv. -na, ne | -an/-än (-ən) verbal adjectival suffix (passive voice) |
| -en (3) | children; oxen | forms plurals for some nouns | A.-Sax. -nian, ONorse -na | -an/-än (-ən) obs. pl. |
| -ence | abstinence; difference | a noun suffix equivalent to “-ance", corresponding to the suffix "-ent" in adjectives | Fr. -ance, -ence, Lat. -antia, -entia | -an/-än (-ən) instr. case |
| -ent (1) | different; absorbent | forms adjectives with a sense of doing or being something | Fr. -ent, Lat. -entem | -an/-än (-ən) obs. verbal adjectival suffix |
| -ent (2) | deterrent; adherent | forms nouns with a sense of being something | Ditto | -an/-än (-ən) noun instrumental suffix |
| -er (1) | teacher; fisher | forms adverbs & adjectives of comparison | Gmn. -er, Herr “man”, A.-Sax. -ere, ONorthumbr. -are “man who has to do with”, Sw. -are, Dan. -ere | -ar/-er “man” |
| -er (2) | older; faster, better, elder | forms adverbs & adjectives of comparison | A.-Sax. -ra (masc.), -re (fem., neuter), Goth. -iza, OSax., OHG -iro, ONorse -ri, -iro, Gmn. -er | -raq/-räk high (absolute) or higher (relative) degree of quality in adj. and adv. |
| -er (3) | soccer, primer | English innovation recycling -er (1), 1860s | ||
| -ery | fishery; perfumery; shrubbery | forms abstract nouns from other nouns | ME -erie, Lat. -arius | Türkic yer, yeri (Eng. earth) “place, location” ~ “fish place” -y/i - v. > n. |
| -ess | stewardess; actress; waitress | forms feminine nouns | A.-Sax. -icge, Fr. -esse, LLat. -issa, Gk. -issa | |
| -est | oldest; hottest; sexiest | forms superlatives | Goth. -sts, Du. -st | |
| -ful (1) | doubtful; peaceful; beautiful | forms adjectives with a sense of “characterized by" | A.-Sax. -full, -ful,“full” (adj.). | |
| -ful (2) | cupful; spoonful | forms nouns with a sense of “fullness" | Ditto | |
| -fy | beautify; simplify | forms verbs with a sense of “to make, to become, cause to be" | Fr. -fier, Lat. -ficare “make” | |
| -hood (1) | neighborhood; brotherhood; falsehood | forms nouns of things with sense of “character, nature, condition, etc." | A.-Sax. -had, Gmn. -heit, Du. -heid, from hade “condition, position, manner, quality” | -qut/-ɣut/-gut/-qüt/-ɣït/-güt plural, alp “shooter” ~ alpaɣut “retinue”, bai “rich person, sing.” ~ baiaɣut “rich (people, pl.)” |
| -hood (2) | priesthood; womanhood | forms nouns of persons of a class or character | Ditto | Ditto |
| -hood (3) | childhood; adulthood; boyhood | forms nouns indicating a time period in life | Ditto | Ditto |
| -ible | credible; horrible; contemptible | forms adjectives (equivalent to “-able" suffix) | Lat. -abilis, -ibilis > Eng. -able, -ible, conflated with “able” (adj.) | -bilä after -a/i adjectives expressing 1. likeness, reciprocity, proximity 2. instrumental(ity) 3. temporality |
| -ic | poetic; scientific; artistic | forms adjectives with sense of “aptitude, characteristic of, in the style of” | Fr. -ique, Lat. -icus, Gk. -ikos | -g/-ɣ/-ag/-aɣ/-ïg/-ïɣ/-ig/-iɣ/-ug/ -uɣ/-üg/-oɣ/-ög forms nouns, adj. |
| -ical | electrical; historical | forms adj similar to “-ic" suffix, with sense of “having ability or characteristic of ” or “in the style of” | Ditto + -al | |
| -ile | docile; volatile | forms adjectives with sense of capability or characteristic | Fr. -il, Lat. -ilis | -ile “with”: “with docility”, “with volatility” |
| -ing (1) | smiling; crying | forms present participle verbs that may be used as adjectives | A.-Sax. -ende, Gmn. -end, Goth. -and, Lat. -ans, Gk. -on, Skt. -ant | -an instr. case |
| -ing (2) | building; sewing | forms nouns from verbs expressing the action of the verb or its result, product, etc. | A.-Sax. -ing, -ung, ONorse -ing, Du. -ing, Gmn. -ung | -ïn (-in), -ïŋ (-iŋ) deverbal noun/adj. result |
| -ion | contrition; suspicion; creation | forms nouns denoting condition, process, action, etc. | Fr. -ion, Lat. –ionem (part -em does not have etymology, corresponds to Türkic –em/-im) | -ön/-öng “space, in front of” > -ion |
| -ish | yellowish; childish, British | forms adjectives with sense of “somewhat, rather so, characteristic of" | A.-Sax. -isc, ONorse -iskr, Gmn. -isch, Goth. -isks, Gk. -iskos (dimin.) | -g/-ɣ/-ag/-aɣ/-ïg/-ïɣ/-ig/-iɣ/-ug/ -uɣ/-üg/-oɣ/-ög forms nouns, adj; -čа/-čä (-cha/-che) |
| -ism | consumerism; alcoholism | forms nouns denoting action or practice, state or condition | Fr. -isme, Lat. -isma, -ismus, Greek -isma | |
| -ist | dentist; conformist; conservationist | forms nouns that denote a person that is concerned with something or holds certain principles | Fr. -iste, Lat. -ista, Gr -istes | |
| -ity | capability; diversity; disability | forms abstract nouns expressing ability, state or condition | OFr. -ite, Lat. -itatem | |
| -ive | active; corrective; restive | forms adjectives & nouns expressing tendency, disposition, function, condition, etc. | OFr. -if, Lat. -ivus | |
| -ize | customize; fantasize | forms verbs with a sense to make, convert into, subject to; give a special character or form | Fr. -iser, Lat. -izare, Gr -izein | |
| -let | booklet; droplet; eyelet | forms nouns with a sense of smallness or triviality | ? | |
| -ling | duckling; hatchling; underling | forms nouns with a sense of smallness or being diminutive | A.-Sax. -ol, -ul, -el; + -ing | |
| -ly (1) | casually; carefully; gladly; hourly | forms adverbs with sense of “how done or when done" | A.-Sax. -lic, OFris. -lik, ONorse -ligr, Du. -lijk, OHG -lih, Gmn. -lich | -lig/-lan “like” |
| -ly (2) | weekly; fully; locally | forms adverbs with sense of similarity | A.-Sax. -lice, OFris. -like, ONorse -liga, OSax. -liko, Goth. -leiko, Du. -lijk, OHG -licho, Gmn. -lich, cognate with “like” (adj.) | -lig/-lan “like” |
| -man | airman, yeoman | forms instrumental nouns | Eng. -man, Gmn. -mann | -man emphatic “very, main, most” |
| -ment | agreement; judgment; ailment | forms nouns denoting an action, condition, product, result, etc. | Fr. -ment, Lat. -mentum | |
| -ness | kindness; correctness | forms abstract nouns denoting quality, state or condition | A.-Sax. -nes(s), OSax. -nissi, Goth. -inassus, MDu. -nisse, Du -nis, OHG -nissa, Gmn. -nis | |
| -or (1) | actor; creditor; juror | forms nouns denoting a person who does something or who has some particular function | OFr. -our, Fr. -eur, Lat. -orem, -atorem | -ar/-er “man” |
| -or (2) | error; pallor; squalor | forms nouns denoting action, state or condition, quality or property | OFr. -our, Fr. -eur, Lat. -orem, -atorem | |
| -ous | dangerous; glorious | forms adjectives with a sense of having a certain quality | Fr. -ous, -eux, Lat. -osus | |
| -ry | bravery; jewelry | forms abstract nouns from other nouns & adjectives | ME -erie, Lat. -arius. | |
| -ship | friendship; censorship | forms nouns denoting condition, character, office, skill, etc. | A.-Sax. -sciepe, Ang. -scip “state, condition of being", OFris. -skip, ONorse -skapr, Dan. -skab, Du. -schap, Gmn. -schaft, “cognate with “shape”” (speculative etymology) | -sig/-siğ/-siɣ denominal and deverbal instr. case “resembling (something)” |
| -sion | decision; invasion | nouns denoting condition, process, action, etc. | Lat. -s + -io | -ta, -te (locatve “in” ) + ön/öng “space, in front of” > -taön, -taön, -taöng, -taöng ~ “in space, in place” > -sion |
| -sy | clumsy, folksy | forms denoun adjectives | -si/-sï denoun adj.: yarsı:- “revolted, disgusted”, simulative verbs (“rare”) | |
| -t | part, port, unit | (atavistic) forms deverbal nouns | Lat. forms deverbal noun (par - part) | -t deverbal noun |
| crept, slept, burnt | forms past participle of weak verbs | A.-Sax. -ed, -ad, -od > ME -ed, ONorse -tha, Goth. -da, -ths, OHG -ta, Gmn. -t; Lat. -tus, Gk. -tos, Skt. -tah; d/t alteration | -da/-δa/-ta(čï), dä/-δä/tä(či) (-də/-δə/-tə) participle suffix | |
| Lat. -t/-te | -ta, -te locatve “in” | |||
| -tain | chieftain, captain | forms | Lat. ten- “have, hold" > tain, ten, tent, tin | |
| -ter, -ther, -ster |
mister, father | obsolete notion of respect |
-ter/-der pl., suffix of respectful appellation |
|
| -th (1) | birth; death | forms nouns of action | A.-Sax. -ðu, -ð, ~ Skt. -tati-, Gk. -tet-, Lat. -tati- | -ta, -te locatve “in” |
| -th (2) | length; depth; width | forms abstract nouns denoting quality or condition | A.-Sax. -ðu, -ð, ~ Skt. -tati-, Gk. -tet-, Lat. -tati- | Ditto |
| -th (3) | fourth; sixth | forms ordinal numbers | A.-Sax. -ða, ~ Skt. -thah, Gk. -tos, Lat. -tus | Ditto |
| -tion | alteration; location | forms abstract nouns | Lat. -t/-te + -io | -ta, -te (locatve “in” ) + ön/öng “space, in front of” > -taön, -taön, -taöng, -taöng ~ “in space, in place” |
| -ty (1) | loyalty; purity | forms adjectives denoting quality, state, condition, etc. | ME -tie, -te, OFr. -te, Lat. -tatem ~ Gk. -tes, Skt. -tati- | -te, -ta (locatve) > Gk. -tes |
| -ty (2) | twenty; sixty | forms numerals denoting multiples of ten | Goth. tigjus, ONorse tigir “tens, decades”; A.-Sax. -tig, Du. -tig, OFris. -tich, ONorse -tigr, OHG -zug, Gmn. -zig | |
| -ure | departure; failure | forms abstract nouns denoting action, result, agent, instrument or apparatus | OFr. -ure, Lat. -ura | -r/ur/ür/ir/ïr verbal analytical intrans. base > depart + ur > departure |
| -y | cloudy; dreamy; juicy | forms adjectives with sense of “characterized by, inclination, condition" | A.-Sax. -ig, Gmn. -ig) ~ Lat. -icus, Gk. -ikos | -ig/-iɣ/-ik/-ïg/-ïɣ/-ïk - verbal adjectives -y/i - v. > n. |
| Plurals | ||||
| -an | A.-Sax. -as | -an (pl.) | ||
| -s | books | forming plural nouns | A.-Sax. -as, Du. -s plurals, Scand. -r plurals (rhotacism) | -s (obs.) |
| -es | ashes | forms plural nouns | ||
| -ies | armies | forms plural nouns | ||
| -ves | calves | forms plural nouns | ||
| 3rd Person Singular Verbs | ||||
| -s | makes; creates | forms 3rd person singular verbs | A.-Sax. -es, -as, Northumbr. -eð (-eth, voiced) | -sa/-sä (sə) predicate of subordinate clause |
| -es | touches; finishes | forms 3rd person singular verbs | Ditto | Ditto |
| -ies | defies; cries | forms 3rd person singular verbs | Ditto | Ditto |
English retained from the Türkic ancestry the relict paradigmatic suffixes that lost their active function: stay > stanch, staunch with -an (deverbal continuous action) + -ch (deverbal noun/adj.) “stop (water, process)”, “stay, remain (loyal)” respectively.
English also recycled the Türkic prepositions (phonetical and functional prefixes), postpositions, and suffixes into prefixes, retaining their original function either literally or notionally in a new syntactic typology.
| Prefix | English Sample | English Usage | English Etymology | Türkic |
|---|---|---|---|---|
| de- | debase, defibrillation, dismount, destiny, deserve | Locative, from | A.-Sax. te-, OSax. ti-, OHG ze-, Gmn. zer-, Lat. de- locative “down, down from, from, off; concerning” | -da-/-de-/-ta-/-te- locative “down, down from, from, off; concerning” |
| dis- | dismount, disengage, dishonest, disallow | forms nouns, adjectives from verbs with sense of “capable or susceptible of being" | A.-Sax. te-, OSax. ti-, OHG ze-, Gmn. zer-, Lat. dis- locative “apart, in a different direction, between, not, un-” | Ditto, crasis of the locative -da:/-de: |
The morphological and syntactical trail left by the Türkic languages in English and other Germanic languages is so deep and wide that it is embarrassing to think of the reasons why such obvious spoor was left unexplored for so long by the European linguistic community.
The scholarship of the Türkic languages' phonetics is fairly well established. To a limit. Beyond the limit lie unexplored seas and untouched unknown gulfs. Phonetic interdentality is both unknown and ignored. That provides misleadingly simplified scholarly transcriptions yer or yers in lieu of yerth for the “earth”. The English and other Germanic languages suffer from that unexplored gap, especially so because the probable origin of many Germanic substrate Turkisms is connected with the modern Turkmen language and location called Turkistan in the 19th c., and now called Turkmenistan, Uzbekistan, China, and Iran. Labiodentality, bilabiadentality, and labialization, palatalization, velar plosiveness, post-palatal velar plosiveness, and voicing of velar plosives, and some more traits are out of view. Beyond the limit lie the Türkic phonetics endowed with “no single phonemic system for modern Türkic languages” (EDTL v.1 51). Transcriptional violations are endemic in Turkology. A jumble of individual ad hoc alphabets was created by individual schools to fit their own phonetic interpretations palatable to their peculiar tongs and ears. The past efforts to Romanize, Sinicize, Arabicize, Cirilicize, Russify Türkic vernaculars adds to the distortion maze. A comprehensive phonemic system would uncover presently obscured phonetic features. Such a system would definitely affect masses of accumulated renditions, uncover substance presently obscured by the poorly fit machinery, and bring new study material to the field.
Three traits dominate Türkic phonetics: division into front (palatal) and back (velar) phonemes, practice of using syllables composed of either front or back phonemes, and practice of composing words of either front or back syllables. In the words, neutral phonemes may complement either front or back phonemes. The result of this simple arrangement, called vowel harmony, is efficient verbal communication with minimized articulation, and efficient written depiction with reduced to no need to indicate trailing vowels. The initial consonant or vowel sets a tenor for the whole word.
The written world that we have inherited approximates the wealth of the spoken language very economically. A written word reduces a spoken world to a some palette with a kit of phonemes that may range from a couple of dozens to few dozens. They usually allow to grasp a meaning of a word, but render specifics of a live speech as a rough sketch. A good example is given by the phoneme n, that in Türkic may be a dental n, palatal n, or a guttural n (ŋ), and can be strengthened to ŋg, ŋğ, ŋk, with further variations. Some phonetic foibles can be rendered by some alphabets and not the others. An element of phonetic ambiguity is always present, especially when rendered by alphabets that formalized a significantly different phonetic system. Any perceived phonetics of the recorded spelling implies a degree of latitude. For the vanished languages, the span of the latitude always rests in a speculative sphere. That makes comparisons of words coming from different times and different languages a sorely imprecise science.
Some peculiarities are connected with the conventions of transcription, with the Romanization of the alphabet, and similar-type peculiarities introduced by the Arabic, Cyrillic, Chinese, and other non-native renditions. Romanization, for example, replaced the interdental unvoiced and voiced fricatives with Roman plosives d and t, Cf. Türkic yer q.v., Gmn. erde, A.-Sax. eorð, Goth. airþa “earth”. The A.-Sax. and Goth. indicate the final consonant fricative, retained in Eng., while the conventional renditions of the Türkic yer do not. That may be accurate for simplified modern pronunciations, but does not reflect the relict and dialectal versions, Cf. simplified spellings for “below”: kodi: (EDT) and qodï, qoδï, qojï, qozï (OTD). Simplification and debasement seriously affect interpretations concerning the r/s/l alternation paradigm, where the arguments on the primacy find tangible support for every scenario. They end up as premises and lead to circular logic conclusions. A fairly clear example of the r/s/l assimilation is set by the sibilant vibrant rz/rs in Polish and Czech that corresponds to either r or s reflexes in contact languages with their own particular phonetic preferences. There, the r may be articulated as r or l, called rhotacism, and s may be articulated z, š, č, and ž, Cf. riz-/ris- in the Türkic rizan/resim and the OHG rizan, and Türkic čiz-, which originated as a stem for “chisel, carve” that later grew to mean “writing”. The r/s/l alternation is shared by numerous languages across linguistic families and across the length of the Eurasia. Numerous independent archeological, biological, and linguistic indicators allow to assess the timing for at least some of the linguistic contacts, providing the r/s/l transitions with timeframe boundaries. The Sl. rz/rs and the r/s split are not two independent puzzles, they are two separate segments of a single development that was probably connected with the pan-European Y-DNA haplogroup I community of the 5th mill. BC. That community initially accommodated the first Kurgan waves, and was reduced and scattered by the following Kurgan waves. In the hideout areas, it amalgamated with diverse locals, stratifying their phonetics into numerous prongs distinguished by peculiar r’s and s’es from the roaring r’s to the mute r’s, and from the whispering and whistling s’es to the thundering shch’s.
All attempts to classify Türkic languages note the Ogur/Oguz divide, with Ogur languages distinct by initial semi-consonant or consonant where Oguz languages start with vowel. The primacy of the Ogur or Oguz version has long been debated, and settled by G. Clauson (1972) with observation that some derivatives have forms with and without anlaut prosthetic phonemes while the stem shared by all languages goes without it. The conclusion is that Oguz languages were older, with a corollary that Oguz-type Tele languages were parental to the Ogur languages. On the other hand, scientific consensus sides with the conclusion of O. Pritsak that Ogur languages predominated in the European part of the Eurasia prior to the 10th c. AD. The tumultuous events of the first 1500 years of our era broke the clear division between Oguz and Ogur languages in the western Eurasia, mixing and amalgamating peoples and languages. That created monumental problems for the linguists, who largely did not see the Ogur component in the Oguz ocean, and ended up classifying the Ogur component as Oguz languages, on the way leaving the Ogur component out of the focus. The conspicuous Oguric properties of the Germanic languages, such as initial prosthetic consonant or truncated suffixes, were dutifully noted and then left without explanation.
Oguric languages are linked with the Aral basin and its western and eastern extensions, south of the forest-steppe belt with its Oguzic languages. Since the Aral basin area was repopulated by the Kurgan Timber Grave nomads from the west and from the east starting at about 1000 BC, the Aral basin's Sprachbund may have evolved by the middle of the 1st mill. BC. Prosthetic consonants present in the few Scythian words attest to their Oguric-type language (e.g. Scythian jilan vs. Oguzic ilan “Snake”), consistent with a tentative Scythian stop-over in the Aral basin on their way from the Altai to the N. Pontic. In the nomadic world, however, it is perilous to presume a static scenario for mobile dynamic populations with their mixes and matches.
The prosthetic initial consonant was noted as typical for the Germanic languages, and it takes a prominent place in English. Cockney is distinguished for adding prosthetic anlaut h- to the English words that exist nicely without it. That is also a noted feature of a group of the Türkic languages, with the prosthetic hard h- appearing in a range of qualities, Romanized as c-, k-, q, and extending to j, y, ch, and even dialectal sh-. An opposite propensity of the historical English phonetics is to drop the initial h-, like turning hlað- “laugh” into lað- “laugh”. These opposing trends are probably associated with the inherited Oguz-Ogur (adding h-) and the Ogur-Oguz (dropping h-) transitions. Taking the initial prosthetic consonant for a part of the root wrecks a havoc with the “IE” etymology, readily supplying homophonous roots with unrelated semantics then somehow imaginatively linked with the principal word and its semantics. Ignoring the dropped initial consonant of the root wrecks a similar havoc with the “IE” etymology. These tendencies are systemic, they are fairly easy diagnosed, and at times they serve to help to find a semantically sound alternate explanation. Frequently, the semantics of the suggested Skt. cognates is so far from the semantics of the principal word that just citing them undercuts, rather than confirms, the “IE” paradigm.
A major alternation that seems not to be connected with the Oguz/Ogur divide is the m-/b- alteration, illustrated by the English pair be and am of the verb “to be”. The m-/b- alteration has very long documented roots, it was very common in Sumerian, where, for example, bal and me are two forms of the verb “to be”. Much later, it is a common Chinese trait. In old and middle Chinese, labials m- and b- were often interchangeable, particularly in transcribing non-Chinese words and names (Chen S. 72). In Türkic daughter and affiliated languages b- may take a range of qualities Romanized as p-, v-, and w-, with further variations, like Pahlavi and Hungarian bh alternating to v-, and Russian b- to v-. According to G. Clauson (1972), b- was a prime Türkic consonant, and in respect to b-, the m- alteration was a later development. However, that judgment was drawn mostly form the eastern and quite late sources, and rested on particular historical presumptions. A phonetic review of the unappreciated linguistic relicts from the Sumerians, Scythians, Sarmatians, and Huns, including the still unexplored early Indian sources, may modify or alter that exploratory conclusion. Under the “IE” umbrella, in modern and medieval Greek the voiced plosive /b/ was written as digraph μπ, while the late Roman/Byzantine authors regularly used β and not μπ for /b/; the Byzantines articulated β and υ as a /b/, and in Classical Greek β stood for /b/. This most unlikely Greek transition, reportedly in late antiquity, from β to μπ (betacism) parallels the most unlikely process asserted for the Türkic languages as a stipulated observation.
One of the observations in the early days of Turkology was that Türkic languages avoid words with initial liquids in general and initial r- in particular. With time, that observation turned into an accepted dogma. By definition, all Türkic words with initial r- were loanwords. That is mostly true for the fairly recent borrowings. A closer inspection would find out that the words with initial r- are habitually articulated with a prosthetic initial vowel, most frequently with a like of a neutral e-/ə-, but also with a and o-/ö-. A more granular observation helps to discern the initial evolution, which in turn allows to visualize the murky origin of etymologically uncertain lexemes, like erpe:- “cut, cut off” vs. a modern “robe” with assigned most incredible speculated etymology. For obviously very old lexemes, where a pick between a borrowing and an original is a personal opinion, ability to discern a prosthetic morpheme is an indispensable methodical tool.
The immense geographical spread of the Türkic languages inevitably had to develop a series of Türkic Sprachbunds and lingua francas crossing linguistic barriers with uncounted neighbors spread across Eurasia. A single meridional pasturing route extending for a thousand kilometers could have crossed five alien Sprachbund zones, each requiring a doze of bilingualism to keep things smooth and safe. Compounded with periodic reciprocative longitudinal migrations, a doze of commonality and variation was inevitable. That created numerous phonetic versions of the same root, numerous phonetic versions of the same morphological elements, and numerous synonyms for a great number of words. In various degrees they were passed on to the Türkic-substrate and neighboring alien languages. Attempts to systematize the largely stochastic interrelationships between the Türkic languages were many, different schemes tried to use few selected parameters as systemic criteria, but a crisp and clear systematization still escapes all attempts of linguistic classification. During historical period, Scythians carried their language from the Altai to the Aral basin and on to the Near East and Balkans. They were but one group that fell into the limelight of their literate neighbors; other main groups are known from excavations, and many others are not detectable at all. In the next millennium, such examples infringe on the limits of scientific imagination, with Sarmats, Alans, Huns, Kangars, and many others covering awesome distances. In the last millennium, the map was again completely re-drawn. Each stage recombined local and migrant, creating a linguistic picture resembling impressionist paintings, comprehensible from a distance but totally chaotic at a close examination. Few regular correspondences may be asserted and listed, but a great number is doomed to remain unexplained, left “with no close semantic connection (within Türkic languages)”. At such points, etymology switches from a tracing mode to observation mode.
Various traces of the substrate Türkic phonetics still play a salient role in the daughter languages; the deviance of the Germanic languages within the “IE” family was noted and studied at the dawn of philology. It is especially prominent for the rounded vowels, being in a constant conflict with the Latin-derived alphabets which necessitated a slew of roundabout methods to depict them in writing. English inherited a bouquet of spelling renderings reaped from the neighboring donor languages, and developed a number of its own ways to cope, ending up with a maze of semi-rules and a snarl of related exceptions which supports the industry of spelling education and spelling bee competitions. The Slavic languages, with phonetics bearing heavy substrate traces of the inherited Türkic phonetics, overcame the conflict by creating a set of alphabet graphemes to depict rounded vowels, sibilants and other oddities. The maze of adaptations tends to mask lexical similarities, misleading uninitiated and providing ammunition for jaundiced protagonists.
Unlike the Norse peoples, England has not preserved its sagas, unlike the Slavic folklore she did not incorporate Türkic history and folklore in her literary inheritance, and the most outstanding relict of its linguistic substrate remains the name cockney, in Türkic spelled köken - “motherland, native place, ancestral land”. Sticking out through the fluff of the later fantasies, the earliest reference to the Cockney is a “mythical luxurious country, first recorded in 1305”, a clear reference to the “ancestral land”, which turned out to be not that luxurious, since its inhabitants ended up in the distant foggy Albion and speaking a creolized mixture of Türkic, Norse, and Romance.
The “IE etymology” is built on the Ursprache Family Tree model, oblivious to the complex historical processes that were cardinally changing the face of the European peninsula during the last 5 millennia, it is little suitable to describe the dynamic linguistic situation during Neolithic and Metal Ages. Numerous vestiges of the past events either do not find reflection in the “IE” etymology, or are etymologized with most unsuitable phonetical resemblances to force them into the faulty model. The first category leaves about a third of the Germanic lexis classed as “of unknown origin”, the second category artificially creates misleading evidence that contorts the past. Most “IE” etymologies are circular, departing and arriving at unknowns, with some phonetical manipulations in-between. In the practice of the Family Tree model, the asterisked conjectured words dissolve like the seeds of the trees, without a trace. In real experience, some words survive for millennia unchanged, passing from language to language like precious stones, with all facets intact. In numerous instances Türkic words survived practically in their original forms, and in some instances still retain their Türkic suffixes, allowing to expose delusory etymology and provide a credible authentic source. In many instances examination of cognates provides no additional leads, and serves purely a perfunctory function to justify the ends.
The Romance borrowings in English are attested historically, and they do not need to be specifically examined to determine direction of borrowing. The Germanic substrate in English is also attested historically, and does not require such examination. The remaining part of the English lexis needs such examination, and the results are not always obvious. A common criteria in such examination is the distribution of the cognates: a word is considered to belong to a linguistic family if most branches of the family have cognates of the examined word. If a word does not appear in the majority of the branches, it is held to be a loanword from another family. In case of far separated branches, like Germanic and Indo-Iranian, a word should be found in both legs, otherwise it is held to be a loanword from another family. The same criteria is applied for borrowings between branches, a word should appear in most languages of the branch to be considered to belong to that branch, and a branch that has it in a minority of its languages is held as a receiving branch. As a rule, distribution is not examined, numerous “IE” etymologies fail to meet the basic criteria, and the “IE” classification must be dismissed.
Traditional assumptions on the direction of borrowing at times fail such tests. In most cases, a comprehensive listing of cognates clearly defines the direction of the borrowing, and the density of the borrowings between languages, branches, and families is a good indicator of the cultural penetration or influence. The opposite is true oppositely, a selective choice of cognates forms a delusive indicator and leads to special pleading distortion. Other indicators are the semantic meanings. A generic meaning that turns into specific application (e.g. snake vs. cobra), and polysemantic word that retained only a partial meaning indicate that the specific meaning is a loanword. A nearly mechanical transfer of a polysemantic word complete with its multiple discrete meanings indicates assimilation of a paradigm, a genetic connection driven by demographic events with linguistic consequences.
Latin serves as a main protagonist of English, never failed to be cited. Although some words may
have existed in Latin long before it became an imperial language, in a temporal historical
development Latin is a late newcomer, contemporary with the spread of the Sarmatian languages into
the Western Europe, and long after the Scythian migrations into the Northern Europe. The Latin's
reach into the depths of the Eurasia had been minimal temporally and spatially. In contrast, the
influence of the Kurgan waves on Latin and other European local languages was massive both
temporally and spatially. That is attested by numerous Türkic - Latin cognates in lexis and
morphology. With such historical background, the direction of borrowing from Latin into Türkic
languages must be deemed impossible, while the direction of borrowing from Türkic languages into
Latin must be expected. Many Türkic lexemes reached English by two independent paths, one via
demographic path generally synchronous with the spread of Turkisms into other Mediterranean and
Northern European languages (the R1b path), and the other via late, started at the turn of the eras,
cultural influence of Latin on the Northern European languages. The last path is well documented, it
coincided with a rise of literacy and the switch to the Latin-based alphabets.
24, 25, 26, 27, 28
In the process of linguistic amalgamation, because any languages have numerous totally unrelated homophonic lexemes, the receptor languages gain homophones from the donor languages, adding semantic meanings to the existing indigenous words. Traces of such amalgamation are found in nearly all languages, and the Türkic languages, due to the nomadic economy that necessitated amalgamation across Eurasia, are especially endowed with polysemantic vocabulary, frequently passed along during following amalgamation cycles, and that includes the English. Numerous homophonic words in English have diverse origin, much of the natural dialectal variability persevered into the printing age, and dictionaries furnish both the allophones from the pre-printing era, and synonyms originated in various languages. Attempts to etymologize them within the ideology of the Family Tree model are overtly artificial and subject to criticism. Practically all following lexical examples have homonyms and innovations in English, they are of little relevance to the present scope.
Restricting semantic latitude filters out homonyms and incredible etymologies. Restrictions need not to be rigid, they should allow for natural transition from a figurative to fossilized semantics where such transition is obvious, at the same time inhibiting an optimistic overpermissiveness. The span and propensity for forming figurative expressions are not mechanically transferable from a language to language, each language or a group of languages finds its own methods of expression and innovation using its own set of grammatical and morphological tools. In contrast with the flexive-type languages, the specifics of the Türkic agglutinative morphology allows phonetically economical production of a wide range of literal and figurative derivatives of the same root extending to the opposite ends of the semantic spectrum. The morphology-enabled semantic jumps are routinely accomplished with minimal phonetical means, allowing liberal reuse of the same root (Cf. English raise vs. rase). The roots qab “vessel” or dür- “stand” are good examples of the width and limits of the semantic latitude.
Random examples of linguistic layers in English and sister languages deeper than the Middle Age cultural borrowings are compiled in the Table 4, with comments appended. A thorough examination of the English lexicon should locate many more; only semantically distinct verbal, noun, or adjective forms are listed, so an expanded listing with complementary forms and derivatives would be 3-5 times more extensive. The specifically Chuvash cognates are explicated following V.Stetsyuk, 2003. Chuvash is variously classed as Oguric and as independent branch.
The only words included in the OTD are those traced in an actual medieval Turkic text of the eastern provenance, in the earlier period they occur as cognate loan-words in foreign languages in forms indicative of early borrowing. The texts indexed in OTD are a fraction of those which once existed, and undoubtedly other words existed but did not happen to occur in the used surviving texts. Some words occur in medieval texts or in modern Turkic languages. A large number of early words are hapax legomena, they occur only once, and have not been found elsewhere; it is impossible to determine whether hapax legomena are correctly transcribed or interpreted. The perfect tense transcription of the verbs tends to be most accurate, but the OTD does not always explicitly delve into alternate transcriptions or interpretations.
The concept of paradigmatic transfer defines borrowing of some entire complex of features. Paradigmacity literally saturate English Turkisms. Lexical paradigmacity is the most visible trait, at times an entire complement of lexemes is transferred from the substrate language to the daughter language. Those are most powerful examples of the genetic connection, and typically they ascend to the most archaic linguistic layers, like cooking food. Cooking may be done by heating on fire, by smoking, by hot ashes or charcoals, and by boiling. Boiling appear as steaming and burling (churning, purling); thus the lexeme for steaming should be a derivative of steam (bu) or burling (qat-, qatïn-, qatna- “purl, purling”); accordingly, we have words like boil (lit. “steamed” fr. bu- “steam” with passive suffix -l- ), bouillon (lit. “steamed” fr. bu- “steam” with passive suffix -l- and abstract noun passive suffix -on) and kitchen (qatïn- “boil, purl, cook”). Analogous processes are cooking with hot ashes or charcoals, the lexeme for “cooking” should be a derivative of ash (kok-) “(cook food) over fire or smoke” (lit. “ash, ash-burn (it)”, “smoke (it)”). Such complex transfers of the entire paradigm vividly demonstrate multi-faceted genetic connection.
The paradigmatic transfer of the entire cooking lexicon corroborates the genetic findings that the Pit Grave Kurgan migrations were not a series of military raids, but a series of cohesive massive relocations of the tribal societies, with the women being instrumental in relocation of the cooking lexicon. The complex nature of relocation is also corroborated by the paradigmatic transfer of the animal-related lexicon, probably largely carried by the male population, especially so in respect to the wild animals. The replacement of the pre-Corded Ware farming population marked by lactose intolerance by the steppe Kurganians marked by lactose tolerance coincides with the period of the Central European “killing fields”. Since the appearance and dissemination of the biological lactose tolerance in a population is a slow process that requires millenniums to build up, the societies that brought over the trait of the lactose tolerance to the Central Europe must have had millenniums of cohesive development with the diary as a staple food necessary for subsistence of the steppe herders. The steppe lexis replanted to the Corded Ware soil attests to the cohesiveness and endurance of the steppe migrant population and their language. The Central Europe was not a sole destination of the Kurgan waves. Reflexes of the same lexicon recorded in the Sumer tablets point to Mesopotamia as another migratory spur, possibly connected with the southern, Maikop area (ca. 3700 BC—3000 BC) of the Kurgan cultures.
Some of the “unknown origin” words showed up as American English, they are dated to the 18th c. (i.e. the first records) or later. On arrival to America, those Brits and their companions used plenty of Türkic (Cf. boss, chunk, derrick, ok, toilet). Some of the American English lexicon points to the nomadic animal herders (Cf. tire). Before surfacing in the New World, the American Türkic had to be lurking in England for nearly two millenniums.
The Türkic orthography in Table 4, taken from different incompatible sources, is mostly adjusted for phonetical clarity: c = j in jet, č = ch in cheap, y (OTD ï, EDT Turkish ı) = i in sit, ü = u in mule, ä, ə (EDT Turkish e indistinguishable fr. e) = a in apple, ö = o in champignon, š = sh in she, ɣ = voiced guttural g (go), ŋ = ng in ping, δ (EDT Turkish d) = voiced interdental th, Germanic and Horezmian þ, usually rendered as t, d, s, or f depending on Roman or Cyrillic rendering.
Table 4. Türkic–English lexical correspondences
English |
Türkic |
English |
Türkic |
English |
Türkic |
English |
Türkic |
English |
Türkic |
|||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | abode | oba | case (instance) | qaza | essen (Gmn.) | ash | mallet | maltu | skin | saɣrï | ||
| 2 | above | up- | cash | kečä | ether | äsir | mama | mamü | sling | salïŋu | ||
| 3 | abundant (adj.) | abadan (adj.) | cast (hurl) (v.) | kus- (v.) | Europe | ev + opa | mammal | meme | skull | kelle | ||
| 4 | abysm | abamu | cast (form) (v.) | qïsdï (v.) | evacuate (v.) | evük- (v.) | man | men | smile (v., n.) | semeye (v.) | ||
| 5 | access (v., n.) | ačsa:- | castle | kishlak | Eve eve | eve | many | munča (adv.) | so (adv.) | aša (adv.) | ||
| 6 | ache | аčï | casualty | közün- | evict (v.) | evük- (v.) | mantra | maŋra- (v.) | soak (v.) | saɣ- (v.) | ||
| 7 | acid (n., adj.) | аčï- (v.) | cat | četük | evil (adj., n.) | uvul- | marasmus | maraz | soap | sabun | ||
| 8 | acorn | yaɣaq | category | qatïɣ (adj.) | evoke (v.) | evük- (v.) | mare | ma: | sock (beating, v.) | sok- (v.) | ||
| 9 | act (v.) | aqtar- (v.) | cattle | katıl | ewe | eve | massif | basɣuq | sock (stocking) | sok- (v.) | ||
| 10 | ad | öt | cause | köze:- | exhaust | qoxša- (v.) | master | bögü: | socket | sok- (v.) | ||
| 11 | Adam | adam | cavalry | keväl | eye | ög- (v.) | matt (adj.) | mat (adj.) | sodden (adj.)) | sod | ||
| 12 | again | aga (adj.) | cave | kovı: | face | yü:z | me (pron.) | min (pron.) | some | kim (morph.) | ||
| 13 | agaze | ög- (v.) | cavern | kovı: | faith | vara | mead | mir | son | song | ||
| 14 | age | aga | cavity | kovı: | false | al- (v.) | mean (v.) | many (mahny) | sooth | čïn | ||
| 15 | agile | ačïl | Celt | kel- (v.) | far (adv., adj., n.) | ıra:- | means | min | sorrel (adj.) | sary (adj.) | ||
| 16 | ago (adj., adv.) | aga (adj.) | cemetery | semäklä- (v.) | fare (v., n.) | faqr(lïq) | mengir | meŋgü | squat (v.) | čat- (v.) | ||
| 17 | aggrieve | aɣrï | chaff | čob | fart | burut- (v.) | mental (adj.) | meŋtä (adj.) | squeeze (v.) | qis- [qys-] (v.) | ||
| 18 | aid | jarï | chagrin | qadɣur | father | ata | menu | meŋ | stair | šatu | ||
| 19 | aim | amač | chalant (adj.) | čalaŋt (adj.) | feel (v., n.) | bil- | mere | mürän | stale (v.) | si:t- (v.) | ||
| 20 | akin (adj.) | yakin (adj.) | challenge (v.) | čalïš- (v.) | feeling | bilin- | message | muštu | stay (v., n.) | üstü- (v.) | ||
| 21 | alimentation | alım | chalk | chol | find (v.) | yind- (v.) | mickle (adj., n.) | mig (n., adj., adv.) | stick (v.) | tik- (v.) | ||
| 22 | alimony | alım | champ (v.) | čap- (v.) | fire (v., n.) | bur- | might | bögü | step (v., n.) | tep- (v.) | ||
| 23 | all (n., adj.) | alqu (n., adj.) | chapman | čıp + man | first | bir | milk | meme | stop | top | ||
| 24 | Alban | аlban (n., adj.) | char (v.) | öčür- (v.) | fissure | öz | mind | ming | suave | šuvlaŋ | ||
| 25 | alms | almak | Charlemagne | Charla-mag | flask | baklaga | mint (v., n.) | manat | subliminal (adj.) | sumlîm (adj.) | ||
| 26 | ambush (v., n.) | buš- (v.) | chastise (v.) | kast- (v.) | folk | bölük | mist | muz | suck (v.) | saɣ- (v.) | ||
| 27 | amen (adj.) | ämin (adj.) | chat (v.) | čat- (v.) | food | apat | mock (v.) | -mak | sundry (adj.) | sandrı:- (v.) | ||
| 28 | amorous | amran- | chattel | čatïl | foot | but | model | -mak | sure (adj.) | sürek (adj.) | ||
| 29 | -an (pl.) | -an (morph.) | chatter (v., n.) | čatu:r (v.) | frog | baga | Mohn (Gmn.) “poppy” | mäkän | surrender (v.) | süründi- (v.) | ||
| 30 | analogue | anlayu (adv.) | cheap (adj.) | čıp (adj.) | full (adj.) | yӧlä- | moisture | mayi | susurrate (v.) | šar šar (v., n., adj.) | ||
| 31 | and (conj.) | anta: | check | chek | gabble (v.) | gap- (v.) | monastery | manastar | suture | sač | ||
| 32 | anvil | andal | cheek | čaak | gadding | qad | money | manat | swear (v.) | vara- (n.) | ||
| 33 | anger (v.) | özak (adj.) | cherub | čebär | gaffe | ɣafillïq | moose | mus | sweep (v.) | süpür- (v.) | ||
| 34 | anguish | özak (adj.) | chew (v.) | kev- | gaggle (v.) | qaɣ quɣ- (v.) | mother | mamü | swell | siwel | ||
| 35 | antler | anten | child | koldaš | gain | gänč | mount (v.) | mün- (v.) | swill | ašbar | ||
| 36 | any (adj., adv., pron.) | ne: | chill (v., n.) | čil | gamut (adv.) | qamit (adv.) | mountain | mün- (v.) | tab | tap- (v.) | ||
| 37 | apian | arï | chintz | čit | garden | karta | mouse | muš | tablet | tü:b | ||
| 38 | apt | apt | chip | čïp | gaze (v.) | giz- (v.) | much | munča (adv.) | taco | toqüč | ||
| 39 | arch | arca | chirp (v., n.) | čïlra (v., n.) | gene | gen- (v.) | munch (v.) | meŋ | tack (v., n.) | tak- (v.) | ||
| 40 | archaic (adj.) | arca | chisel (v.) | čiz- (v.) | gentle (adj.) | yinč- (adj.) | muscle | muš | tad | tat | ||
| 41 | ard | or | chitchat (v., n.) | čit čat (v.) | genu | yinčür- (v.) | murky (adj.) | mürki (adj.) | tag | toqu | ||
| 42 | ardent | arzu (n.) | chop (v., n.) | čop- (v.) | get (v.) | qay- (v.) | my | -m | take (v., n.) | teg- | ||
| 43 | are (v.) | -ar (v., n.) | chunk | sïŋuq | gibber (v.) | gep- (v.) | nag (v., n.) | öyäz | tale | tili- (v., n.) | ||
| 44 | argue (v.) | arqu- (v.) | chute | čüm- (v.) | gift | kiv- (v.) | nascence | ña:š | talk (v., n.) | tili- (v., n.) | ||
| 45 | arrogant (adj.) | orı: | circle | sürkülä (v.) | gird (v.) | qur- (v.) | needle | ine | tall (adj.) | tal | ||
| 46 | Arthur | artur- (v.) | clan | oglan/ulan | girl | kyr | nose | ñü:z | tally (v., n.) | tili- (v., n.) | ||
| 47 | as (adv.) | aδïn (adv.) | clinch (v.) | qïlinč (v.) | gist | göz | not (interj.) | ne (part.) | tambourine | tambur | ||
| 48 | As | Yazï | cloud | bulut | give | kiv- (v.) | oat | ot | tap (v., n.) | tap- (n.) | ||
| 49 | ashlar | aslïq- | coach (v.) | köch (v.) | glue (v., n.) | yelïm | oath | ötä- (v.) | tap (v.) | tap- (v.) | ||
| 50 | asp | äväs | coagulate (v.) | qoyul- (v.) | gluten | yelïm | obturate (v.) | tiy- (v.) | tar (v.) | ter- (v.) | ||
| 51 | ass | eš(äk) | coal | kül/köl | glut | oglït- (v.) | ocean | ӧkän | tariff | tarïɣ | ||
| 52 | asquint | qïŋïr (n., adj.) | coat | gömlek | gnat | öyäz | ofett (OE) | apat | tart (adj.) | tarqa (n.) | ||
| 53 | assess | asiɣ | cob | kev- | gnaw | öyäz | ogle (v.) | ög- (v.) | tasse (Gmn.) | tas/taz | ||
| 54 | assign (v.) | asïɣ | cock (latch) | kök | go (v.) | git | ok (interj.) | ok (interj.) | taste (v., n.) | tat- (v.) | ||
| 55 | astute (adj.) | asurtɣuq (adj.) | cock (rooster) | kök | goat | käči | old (adj.) | ol- (adj.) | tasty | tati (adj.) | ||
| 56 | at (prep.) | at- (v.) | cockney | köken | God | kut | omen | aman (adj.) | tavern | tavar | ||
| 57 | attach (v.) | atkan- (v.) | coffin | kovı: | gold | al(tun) | omni- (pref.) | omqï | tell (v.) | tili (v., n.) | ||
| 58 | Augean | aqür | cold | xaltarä | good | kut | on (prep.) | on- (v.) | tend | taya | ||
| 59 | aught | ot (adj.) | collect (v.) | kölar (v.) | goose | qaz | once | ön (adv.) | terrain | ter- (v.) | ||
| 60 | augur (v.) | ay- (v.) | colon | kolon | gore (v.) | göres- (v.) | one | öŋ | testament | tutsuğ | ||
| 61 | aurora | yar- | color | kula | Gorgon | qörq- | onus | önüs (adj.) | testicles | tasaq | ||
| 62 | awe (v.) | ö- (v.) | colossal (adj.) | qolusuz | grave | kör | orate (v.) | orı: (n.) | that | šu (pron.) | ||
| 63 | awhile (adv.) | äwwäl (adv.) | comb (v., n.) | kem-(v.) | gravy | kurun | ore | öre: | theriacum | tiryak | ||
| 64 | axle | i:k | come | qam- (v.) | greave | kurun | ortho- (adj. prefix) | örti- (v.) | thick | sik | ||
| 65 | baby | bebi | con (v.) | qun- (v.) | grey (adj.) | ğır (adj.) | other | ötürü (adj.) | thief | tef | ||
| 66 | bad (adj.) | bäd (adj.) | con- (pref.) | kon- (n., adj.) | grind (v.) | qïr- | otter | ätär | think (v.) | saq- | ||
| 67 | bag | bag | confer (v.) | ber- (v.) | groom | görüm(čï) | ought | ötä | this | šu (pron.) | ||
| 68 | baize | bez | coney, cony | kuyan | guard | qur- (v.) | over | up- | thread | telu- (v., n.) | ||
| 69 | bake (v.) | baka:č (n.) | guess (v., n.) | us- (v., n.) | owe (v.) | oye- (v.) | thrive (v.) | tir- (v.) | ||||
| 70 | bald | bül (adj.) | cook | kok- (v.) | guest | göster | owl | aba(qulaq) | throne | tören | ||
| 71 | bale (v., n.) | bele- (v.) | copious (adj.) | köp (adj.) | gut | kut | own (v.) | oye- (v.) | tick (v., n.) | tiki | ||
| 72 | band (v., n.) | ba- (v.) | cork | kairy | habitat | oba | ox | öküz | tick | tik- (v.) | ||
| 73 | bane | < pata | corset | qursa | hack (v.) | kes- (v.) | ooze (v.) | ӧz (v.) | tie (v., n.) | taŋ- (v.) | ||
| 74 | barge (v.) | bart (adv.) | cost | kı:z | hador (OE) | xatär | pan (n., v.) | ban | till (v.) | til- (v.) | ||
| 75 | barge (n.) | barq | count | köni | hah | qatur (v.) | papa | baba/babai | till (adv.) | teg (adv.) | ||
| 76 | bark (v.) | ver | courage | kür (adj.) | hag | karga | pat | pata (v.) | time | timin (adv.) | ||
| 77 | bark | barq | court | qur- (v.) | hard (adj.) | qart (adj.) | peace | barısh | tire (v.) | tur- (v.) | ||
| 78 | barley ~ Türkic | arpa, urba | cousin | qazïn | hare | horan | penny | peneg | tire (n.) | teyir | ||
| 79 | barn | ambar | cove | kovı: | hash | ash | period | ö:d | tit | tiši: | ||
| 80 | baron | baryn | cow | coy | haze | häzl | phlegm | balgam | tit for tat (phr.) | tite tit (phr.) | ||
| 81 | bastard | bas + tard | cowl | kalpak | heap | kip | pole (n., v.) | bal- (v.) | to (prep.) | tu- (v.) | ||
| 82 | bash (v.) | baš (v.) | coy (adj.) | köy- (v.) | heart | chäre | port | bar- (v.) | toe | toy | ||
| 83 | bat (v.) | pata (v.) | crime | krmšuhn (v.) | hall | qalïq | pot | patır | toilet | tölet | ||
| 84 | bath (v.) | bat (v.) | crop | körpä: | Heimat (Gmn.) | xajmatläx | pour (v.) | pür | toll | tol | ||
| 85 | battle | pata- (v.) | crock | kurun | Helen | ellen- (v.) | prior (adj.) | ür | tomb | tumlu | ||
| 86 | bazaar | baz | crow | karga | hell | qalïq | puppy | papak | too | de (adv.) | ||
| 87 | be (v.) | buol- (v.) | crunch (v.) | qurt (v.) | herb | arpa: | purge (v.) | pür- (v.) | tool | tolɣa- (v.) | ||
| 88 | bear (v.) | ber- (v.) | crust | kairy | herd | kert | purl (v.) | bu:r- (v.) | tooth | tiš | ||
| 89 | bear | böri | cry | qïqïr- (v.) | hernia | urra | purse | bursaŋ | top | töpü | ||
| 90 | been (v.) | buol- (v.) | cuddle (v.) | koy- (v.) | hey (interj.) | ay (interj.) | push (v.) | puš- (v.) | topple | topul | ||
| 91 | beetle | bit | cue | kü | hide (v.) | qoy- (v.) | pussy (n., v.) | päsi (n.) | tor | tärä | ||
| 92 | Belgi (adj.) | Belgü (adj.) | cull (v.) | čul- (v.) | hide (n.) | qujqa | put (v.) | put- (v.) | torah | tör | ||
| 93 | bellow (v.) | belä- (v.) | culture | kültür- (v.) | hilarious (adj.) | güleryüz (adj.) | pyre | bur- (v.) | toss (v.) | toš- (v.) | ||
| 94 | belt | bel | cup | kap | hit (v., n.) | it- (v.) | quake | bez- (v.) | total | tutuš | ||
| 95 | berm | bürma | curb (n., v.) | kır | hole (n.) | ol- (v.) | quality | qïlïɣ | touch (v., n.) | toqï (v.) | ||
| 96 | bestow | bestle- | cure (fix, v.) | kur- (v.) | homeland | xajmatläx | quantity | köni | tower | türma | ||
| 97 | bet (v., n.) | büt- (v.) | cure (food, v.) | kuri:- (v.) | hooligan | qïčür- (v.) | quarrel | qaršï | trash (v., n.) | tarıš | ||
| 98 | big (adj., adv.) | big | curd | ko:r | hoopoe | üpüp | quaver | bez- (v.) | tree | terek | ||
| 99 | bill (v., n.) | bil- (v.) | curt (adj.) | qïrt (adj.) | horse | arɣun | queen | yeŋä | tremble (v.) | četre (v.) | ||
| 100 | bill | bilä- (v.) | curve | qarvï (adj.) | host | göster | question | kušku | trust | dörs (t) | ||
| 101 | bitch | bi | curse | qur- (v.) | house | quš | queue | kü | truth | dürüst | ||
| 102 | black | belä- (v.) | curtain | qur- (v.) | how | qalï | quilt | kübil | tsk | a click | ||
| 103 | blade | baldu | cut | kes- (v.) | howl (v.) | yel | quim | em | tuber | tü:b | ||
| 104 | blend | bulɣa- (v.) | cytren (OE) | xitren | hurl | ur- (v.) | quit (v.) | ket- | tuck (v.) | takın- (v.) | ||
| 105 | board | batɣa | dad | dedä | Goth. holon, skaþjan |
ur- (v.) | quite (emph.) | ked (emph.) | tumulus | tumlu | ||
| 106 | bode (v.) | bodi | dam | da:m | hut | quš | rate | ruzi- (v.) | turkey | turuhtan | ||
| 107 | bodega | butïq | damp (adj.) | dymly (adj.) | I (arch. ic) | ič (es) | ration (v.) | ruzi- (v.) | turf | ter- (v.) | ||
| 108 | body | bod | dash (v., n.) | taš- (v.) | ideal (adj.) | edil (adj.) | regal (adj.) | arïɣ (adj.) | turn (v.) | tön (v.) | ||
| 109 | bog | bog | dash (n.) | taš- (n.) | idle | ytla | robe | rop | twat | tat | ||
| 110 | bogus (adj.) | bögüš (adj.) | day | dün | idyl (adj.) | edil (adj.) | -s (pl.) | -z (morph.) | twist (v., n.) | tevir- | ||
| 111 | boil | bula- (v.) | dawn | tang (taŋ) | ignite (v.) | yaq- (v.) | -'s (poss.) | -si (morph.) | udder | ud | ||
| 112 | bold | palt | dear (adj.) | terim (adv.) | ilk | ilk | sack | sak | uh | yah (interj.) | ||
| 113 | bong | böŋ | deem (v.) | demek (v.) | in (prep.) | in (n.) | sag (v.) | sök- (v.) | ulan | oglan/ulan | ||
| 114 | boot | bot | deep | dip | inch (n., v.) | ınča (adj.) | saga | savag- (v.) | ululate (v.) | ulï- (v.) | ||
| 115 | booze (v.) | buz (v.) | deliver (v.) | döle- (v.) | inn (n.) | i:n (n.) | sagacity | sag | un- | an- (morph.) | ||
| 116 | bore (v.) | bur- (v.) | delve (v.) | del- (v.) | -ish | čа/čä | sage | sag | unite (v.) | una- (v.) | ||
| 117 | borrow (v.) | borğ | dementia | dumur | itch (v., n.) | кichi (v.) | sail (v.) | salla (v.) | under (adv.) | aŋıttır- (v.) | ||
| 118 | Boris | böri | derma | deri | itinerate (v.) | ïd- (v.) | salary | salɣa (v.) | undies | andarak | ||
| 119 | boss | boš (adj.) | derrick | terek | jabber (v.) | gap- (v.) | saldo | salɣa (v.) | until (Prep., Conj.) | anta | ||
| 120 | botch (v.) | bud- (v.) | descend (v.) | düšen (v.) | jack (v., adj.) | cak- (v.) | sale | sal- (v.) | us (pronoun) | ös (pronoun) | ||
| 121 | bother (v.) | busa:- | diadem | didim | jag | čak(k) | saliva | liš | use (v., n.) | tusu (v., n.) | ||
| 122 | bouillon | bula- (v.) | dick | dık- (v.) | jaggery | yaɣïz (adj.) | sallow (adj.) | sary (adj.) | usher (v.) | üšer (v.) | ||
| 123 | bound (adj.) | baglandi (adj.) | dike | dık- (v.) | jam | jem | sane | san- (v.) | vacate (v.) | evük- (v.) | ||
| 124 | boutique | butïq | din | tоŋ | jar | jart | sanity | san- (v.) | vacuum | evük- (v.) | ||
| 125 | bow | boq- (v.) | dingdong | daŋ doŋ | jar (v.) | jar- (v.) | sanitary (adj.) | esan (adj.) | valerian | pultäran | ||
| 126 | box | boɣ | dip | dip | jaw | jaŋaq | sapient (adj.) | savan (adj.) | vampire | ubyr | ||
| 127 | boy | bo:y | divide (v.) | dil- | jeer (v.) | jer- (v.) | sapphire | sepahir | vat | but | ||
| 128 | brain | beini | division | dil- | jelly | yelïm | sari | sarïl (v.) | Vesen (Gmn.) “bran” | pečen | ||
| 129 | breath | bu:r | divvy (v.) | dil- | jerk (v.) | jul (v.) | sash | saču: | voe | uvy (interj.) | ||
| 130 | brother | birader | do | tu- | jig (v.) | jïq (v.) | satisfy (v.) | satsa- (v.) | vouch (v.) | buč- (v.) | ||
| 131 | bruise (v., n.) | bürt, bert | dog | dayğa:n | jig (n.) | jig | satyr | satir | voucher | vučuŋ | ||
| 132 | brute | börü | doll | döl | jog (v.) | jag (v.) | savant | savčï (v.) | wake | vak | ||
| 133 | bucket | but | don (v.) | ton- (v., n.) | joke | elük | savory | saɣur (v.) | ware | tavar | ||
| 134 | bud | buqüq | drag (v.) | tar- (v.) | jolly (adj.) | yol | savvy | savan (adj.) | was | var- (v.) | ||
| 135 | bulge (v., n.) | beleg (n.) | dumb (adj.) | dumur | journey | jorï (v.) | say (v.) | söy- (v.) | watch (v.) | aɣtur- (v.) | ||
| 136 | bull (edict) | bel | dune | dun | judge | ayg- (v.) | scare | qor | wax | avus | ||
| 137 | bull (animal) | buqa | dung | tuŋ- (v.) | juice | jü | scatter (v.) | ta:r- (v.) | we (pron.) | ös (pron.) | ||
| 138 | bunch (v., n.) | bunča (adv.) | durable | dür- (v.) | junk | ček | schabracke (Gmn.) | cheprak | Wermut (Gmn.) | armuti | ||
| 139 | bundle (v., n.) | bandur- (v.) | duration | dür- (v.) | jut (v.) | jalt (adj.) | sconce | quč- | whelp | bala:p | ||
| 140 | burg | balïq | duress | dür- (v.) | keen (adj., v., n.) | qïn- (v.) | sea | si | while (n., v., conj.) | äwwäl (adv.) | ||
| 141 | burl | burnï | dust | doz | keep (v., n.) | kap- | seat | čıj- (v.) | whip | yip | ||
| 142 | bursary | bursaŋ | dye | dawa | Kent | keŋit- (v.) | secede | ses- (v.) | wife | ebi | ||
| 143 | bust | basta | ea (OE) | aq- (v.) | key | kirit | second | eki | wig | yü:g | ||
| 144 | butt | büt | earl | yarlïqa- (v.) | kick (v., n.) | kik- (v.) | secret | soqru | wiggle (v., n.) | ügril- (v.) | ||
| 145 | cab | qab/qap | early (adv.) | ertä- (adv.) | kill (v.) | öl- (v.) | sector | chektür | will (v., n.) | bil- (v.) | ||
| 146 | cabbage | qabaq | earn (v.) | ar- (v.) | kilter | kel- (v.) | see | süz- (v.) | wise | vidya | ||
| 147 | cackle (v.) | kakla- (v.) | Earth | Yer | kin | kin/kun/kün | select | seč- (v.) | wlita (face, obs.) | bet | ||
| 148 | cadre | kadaš | eat (v.) | ye- (v.) | kind (adj.) | keŋ (adj.) | sell (v.) | sal- (v.) | wolf | börü | ||
| 149 | caginess | qïjïm | eave | ev | king | kengu | sepia | sepi- (v.) | woo (v.) | bü | ||
| 150 | cairn | kayır | eke | eken (v.) | kitchen | qatna- | seize (v.) | sız- (v.) | world | аbïl | ||
| 151 | cake | kek | elbow | el | knack | qan- (v.) | seizure | sïzğur- (v.) | wormwood | armuti | ||
| 152 | call | qol | eligible (adj.) | elïg- (v., n.) | know (v.) | köni (v.) | sever (v.) | sevrä- (v.) | worse (adj.) | uvy (interj.) | ||
| 153 | calm (v., n., adj.) | kam- (v.) | elite | elga- (v.) | laber (OE) “thistle” | läbär | sew (v.) | suk- (v.) | would (v.) | 'yu | ||
| 154 | callous (adj., v.) | qal (adj., v.) | elite | elit- (v.) | lamb | -la:n | shade | čadïn | wrinkle (n., v.) | burki: | ||
| 155 | calumny | čulvu | elk | elik | lame (adj.) | ulam (adj.) | shake | silk- (v.) | write (v.) | 'rizan (v.) | ||
| 156 | can (jug) | kanata | ell | el | land | elen < el | sharp (adj.) | šarp (adj.) | 'd (would) | yu | ||
| 157 | can (v.) | qan (v.) | elm | ilm | language | luɣat | shatter (v.) | ta:r- (v.) | yacht | yaɣ- (v.) | ||
| 158 | candle | kandil | en- (prefix, prepos.) | en- (v., prepos.) | laugh | gül- (v.) | she (pron.) | šu (shu) (pron.) | yah (interj.) | yah (interj.) | ||
| 159 | cap | kap | endure | endür- (v.) | leader | elit- | sheep | sıp | yard | qur- (v.) | ||
| 160 | capture (v., n.) | hapset | enge (adj.) (OE) | özak (adj.) | leak | liš | shield | čyt (chyt) | yeah | yah (interj.) | ||
| 161 | car | köl- (v.) | engine | ïjïn- | leather | eldiri | shilling | sheleg | yell (v.) | yel (v.) | ||
| 162 | caragana | qaraqan | enigma | tanığma | less (adv.) | es- (adv.) | shit (v., n.) | šıč- | yep | yah (interj.) | ||
| 163 | care | qorq | -er | er (morph.) | lie (v.) | yalgan (v.) | shock (v., n.) | šok- (v.) | yes | yah (OFris.) | ||
| 164 | carnival | kerme | Erbse (Gmn.) | arpa | loaf | lavāš | short (adj.) | qïrt (adj.) | yet (adv.) | yet- (v.) | ||
| 165 | carpus | qarï | Erik | erk | luck | аlïč | shove (v.) | sav- (v.) | yield (n., v.) | yılkı: | ||
| 166 | carve (v.) | kert- (v.) | equal (adj.) | egil (adj.) | lull (v.) | ulï- (v.) | sick (adj.) (ill) | sık- (v) | you (pron.) | -üŋ (pron.) | ||
| 167 | case (box) | kečä | lullaby | balu baju | sick (v., n.) (vomit) | sök- (v.) | young | yangi: | ||||
| 168 | might | bögü: | sicker (v.) | sarq- (v.) | Yule | yol | ||||||
| 169 | make (v.) | -mak | sin | cin (jin) | youth (n., adj.) | yaš (adj.) | ||||||
| 170 | sinew | siŋir | yuck (excl.) | yek (n., adj.) | ||||||||
| 171 | sing (v.) | siŋ- (v.) | yummy (adj.) | yemiš (adj.) | ||||||||
| sink (v.) | siŋ- (v.) | |||||||||||
| sip (v.) | syp (v.) | |||||||||||
| sit (v.) | čıj- (v.) |
Etymological notes
Numerous Türkic roots are extremely productive, they engendered multiple series of derivatives. A selection of a keyword for productive stems is somewhat arbitrary, and likewise the selection of the contrasting derivatives is arbitrary, only to demonstrate contrasting semantics, Cf. cup, cap, cab, cabbage. Categorical breakdown is much conditional, since all words carry more than one meaning, applied in different contexts and frequently metaphorically, like the “daily bread” may not at all refer to either daily nor bread. It would be naïve to search for exact correspondence between any two figurative constructions. The abstract categories of Social, Religious, and Life tend to overlap in more than one dimension. Every category as a whole constitutes a paradigmatic transfer, an ensemble of thematic vocabulary transferred from the Türkic linguistic group to English; it is an indelible evidence of common genetic origin. Every effort has been made to make each entry of Etymological notes self-sufficient without a need to visit other entries, references are given only when the needed explanations are very extensive; that caused repetitive information scattered throughout the Etymological notes section, especially so when the entries are etymologically connected. When applicable, for reference, the Swadesh List number, Frequency rating and percentages are shown in parentheses: (Sw3, F37, 0.57%).
| Categories: | |||||
| 1. General, 28 | 2. Morphology, 35 | 3. Verbs, 37 | 4. Nouns | 5. Adjectives, 122 | 6. Other, 130 |
| 1.1 Pers. Pron.'s | 4.1 Body, 65 | ||||
| 4.2 Dress, 71 | |||||
| 4.3 Social, 74 | |||||
| 4.4 Religious, 89 | |||||
| 4.5 Commercial, 93 | |||||
| 4.6 Household, 94 | |||||
| 4.7 Cooking and food, 95 | |||||
| 4.8 Animals, 96 | |||||
| 4.9 Life, 97 | |||||
Tatsiz türk bolmaz bašsïz börk bolmaz
No Türks without aliens as no hats without head
Нет Тюрок без иноземцев, а шапки — без головы
(МК II 281)
Some common linguistic terms:
allophone - various acoustically different forms of the same words or phonemes in systemically
related languages irrespective of the source language, e.g. “no, not”, Türkic ne, ni, Lat.
non, A.-Sax.
na, no, Welsh nid, Hu.
nem, Gujarati na, nathi, Kor. ani, Jap. janai; allophone is a type
of correlator, linguistically a word in mutual, complementary, or reciprocal relation
anlaut - first sound of a word or syllable
auslaut - last sound of a word or syllable
cognate - same words in different languages, presumably directly or indirectly descending from the
same ancestor root
inlaut - middle sound of a word or syllable
lexicon - a set of words in the language
lexis - all meaningful word forms and grammatical functions of the language
morphology - practice of forming words
syntax - arrangement of words in sentences
synonym - different interchangeable words in the same language
translation - communication in another language of the meaning in a source language
Preliminary Note. In the context of this work, “cognate” is a word cited in the reference sources nearly exclusively limited to the “IE etymology” and thus exceedingly presumptive for the content of this work. The “cognate's” doctrinal precondition “descending from the same ancestor language” is a special pleading limitation. It burdens any study with an imposed doctrinal concept of a Family Tree model's single parental language. There is no evidence that a single “ancestor language” ever existed for any language. When they were first documented, all Germanic languages were amalgamated languages with a substrate and an adstrate, and treating them as single-sourced offshoots is methodologically faulty. Since the objective of this work is to establish ancestral connection, the term “cognate” is used provisionally subject to a critical review and examination. It may refer to any semantically and phonetically suitable candidate, and improperly to unsuitable candidates. The sibling words from different languages may stray quite far apart both semantically and phonetically. The term “allophone” describes the acoustically varied sibling forms equidistant from the same word of the long-gone vernaculars that used them in the prehistoric times, long before they were ever recorded. A typical Türkic word may have from as little as few to as many as as a dozen allophonic forms, some acoustically quite distant. A typical Etymological note lists “IE” cognates as a subset of allophones, complemented with a set of other allophones, e.g. for “big” the Gmc. cognates micel, bugge, and the non-Gmc. allophonic forms big/mig, bi:g/mi:g, ben, bog, min, mi:n, müg, pin.
For clarity, prefixes and suffixes may be parsed with brackets to show the stem.
1. General (few salient words supposedly present in any language) (32)
1.1
and (conj.) “plus, also, too” (Sw204, F6 1.82%) ~ Türkic anta: (locative-ablative pronoun,
adverb) “there, then”, “that, from there, from that”.
Semantically, the Türkic anta is a locative synonym of the verb bul-, bol- “be”, a
precursor of the Eng. be (Cf. Eng. heterogeneous be and is), and a notion
“also”, expressed with available lexis. Ultimately, a derivative of an emphatic an “there,
now, here” that serves as auxiliary adverb + directional suffix -da/-ta.
The form
anta: is one of the allophones of antaq, where the suffix
-taq/-teq/-tiq is a derivative of a most popular and very universal verb
teq- “touch, relate” expressing physical or analytical connection. The
anlaut vowel wobbles between a-, o- and u-, the second consonant wobbles between
-t- and -d-.
Distribution of the words an (ana) and anta: is truly Eurasian, from Fennic to
OPers. and Indo-European, and to Manchu/Tungus and Korean. The innovation of the
semantic extension is peculiar to the Gmc. branch. The A.-Sax. and, ant, ont, unt originally
meant “thereupon, next”, essentially versions of “there, then”, semantically extended to mean “and,
but”. The A.-Sax. form, in turn, is speculated to originate from a “PG” *unda, a transparent
allophonic form of the Türkic anta. With the same credibility the origin can be ascended to
the Proto-Fennic or Proto-Manchu. Cognates: A.-Sax. and, ant-, ont-, unt-
“thereupon, next, and”, OSax. endi, OFris.
anda, ONorse enn, OHG enti, Goth. anda “along”, MDu ende, Gmn.
und “and”; Ir. ann, Gaelic ann, Welsh yna, all “there”; OLith.
anta “on to”; Hett. anta “there, to that”, andan “to there, in this, in that”;
LAv., OPers. ana “this”, and “here”; Buryat ene “this”; other linguistic
families are noted in
EDTL v. 3 147, 149, 173, 456. Distribution covers entire Eurasian Steppe Belt with
widely dispersed fringes. There is no need for the faux “PG proto-word” *unda “?” or “PIE”
*en “in”. Under an PIE model, the ubiquitous Türkic suffix -ta/-da stands saliently
inscrutable. The ken of the semantics for Türkic and Gmc. words, translated by a generous complement
of semantic siblings, is essentially focused on the notion “next, following, also”. The antipode of
“here” vs. “there” and “this” vs. “that” created semantic extensions signifying “opposition,
against”, and “in front of, before, end” found in Gk. anta (αντα), anti (αντι) anten (αντεν);
Lat. ante (prep., adv.), in derivative compounds starting with ante- (Cf. antechamber)
and anti- (Cf. antibiotic); Skt. anta “end, border, boundary”; Hitt. hanti
“opposite”. The southern vernaculars display an emphasis on “there” and “that” side. Phonetic and
semantic similitude leaves no room to doubt a common and relatively recent genetic connection of the
Gmc. and Türkic twins, that is amplified by the preserved original Gmc. meaning of the word. The
Türkic version has an ablative shade conveyed by the suffix -ta, due to the expressed
presence of the ablative syntax and morphology in Türkic languages. The Gmc. languages metamorphosed
to shed the ablative morphology, and absorbed the remainder of the suffix into the root. Across
Eurasia, a majority of the cognates have retained the ablative suffix -ta, and some may have
retained its function. The “IE etymology” suffers a major bout of incoherence, ascending
and separately from an unattested “PIE root” *en “in”, and ante- separately
from an unattested “PIE root” *anti- “opposite, against”. The first “root” happened to
reflect the attested Türkic root an-, an oblique case of and heterogeneous with
bul-, bol- “be” with no relation to the etymology
and semantics of in (prep.) “toward the inside”, which happened to be the a retained Türkic
noun in “bottom, descent”, see in. The second is minimally adulterated Türkic anta
retained with intact and truncated ablative suffix
-ta. Truncation may be specifically attributed to the Sarmat vernaculars. The southern traces
attest to the presence of the formed word before the Indo-Aryan-type migrations of the 2nd mill. BC.
The absence of the formed word, and the consistent presence of the root an- in the Celtic
languages attest to the existence of the root word in the 5th mill BC prior to the Celtic
circum-Mediterranean migration. Taken together the quartet, the anta with the
prepositions/postpositions in and on, and the directional suffix -ta, presents
a salient case of paradigmatic transfer, attesting to a common origin from a Türkic linguistic
milieu. The unattested “PG” and “PIE” words, naturally, had never existed. Notably, the word and
is a major contributor to the English daily language, alone producing about 2% of the English
ordinary lexicon. See be, at, in, on 1, on 2, till, to.
1.2
big (adj., adv.) “large” (Sw27, F201, 0.08%) ~ Türkic biŋ (bïŋ, miŋ, minŋ, mïŋ) (n., adj.,
adv.) “big”,
“much, big number, huge amount, intensity”, büyü “enlarged”.
An “IE etymology” rates it a routine “of unknown origin”, “of obscure origin, possibly from a
Scandinavian source”. A literary example for the allophonic boŋ cites identical form in the
Norse: Khakass boŋ kiši: “big man”, Norse bugge “great (man)”,
the o/u in Türkic languages are interchangeable. A synonymous “great”, the A.-Sax.
great(ae), ascends to the Türkic gür “thick, dense, abundant, luxuriant” with about
identical semantics. A synonymous “large”, the Lat. largus, also “of unknown origin”, ascends
to a Türkic ular(-di, -g, -ɣ, etc.) “enlarge” fr. ula “join, unite, attach”. In
Türkic, “big” also means “thousand”, like the Sl. “dark” and “fog” (Sl. tma (тьма) and
tuman (туман) respectively) are semantic extensions of the Türkic tümän “ten thousand”.
The Türkic big has numerous allophonic forms, most important is m/b alternation,
biŋ/miŋ, the other forms are miŋ, mi:g, mi:ŋ, müŋ, beŋ, bi:ŋ, boŋ, pin, etc. The form
biŋ/bi:ŋ is recorded in Ottoman, Türkü (Türkic Kaganate, pre-Uigur period), Uigur and OKirgiz.
The form mig is recorded in Khakass, Horezmian, Chagatai, and Koman, encountered in English
Turkisms. Which particular tribe(s) left their trace in English is impossible to suggest: outside of
OKirgiz and Khakass, the three major entities were huge polities covering hundreds of ethnic tribes.
Cognates: A.-Sax. micel (mikel) “great”, Norse bugge “great (man)”; Rum.
bimbaše, bombašir “big (boss), major” (n > m); Bulg.
bimbašyja, bumbašir ditto, Serb. bimbaša ditto; Alb. bimbaš ditto; Osset.
min, ming “big”; Gk. bimpasis (μπιμπασης) “major (big boss), bimpas”; Mong.
mingaan, mingãan, mıngan “big”; Mongor.
minhän “big”; references to Caucasian languages: Balkar, Karachai, Kabardin, Shaps, Abaz.,
Ubykh; reference to Ch. language. Distribution traces the Türkic trails,
across Eurasia from Atlantic to Pacific. No “IE” etymology, but still funny suggestions of origins
from “dwell”, “PG” *bewwuz “crop, barley”. The A.-Sax. micel (mikel) consists of
mic-/mik- (~ mig/mi:g) + Türkic adj., adv. suffix -al/-el (-la/lä), “rare” in the eastern
languages. The form comes from a linguistically separate source, possibly related to Khakass or
Horezmian. Notably, both OKirgiz and Khakass refer to the same Enisean Kirgiz people at different
stages of their history. An m/b
alternation mic- > big bears some diagnostic trait. A triad “big”, “great”, “large” presents
a case of paradigmatic transfer, attesting to a genetic origin from Türkic sources. See bunch,
mickle, might.
1.3
black (adj., v., n.) “pitch-dark” (Sw176, F751, 0.01%) ~ Türkic belä-, bele-, bula-, bulɣа-
“smear, mar, soil, dirty”.
A polysemantic primary verbal root bul- forms 9 notions, a verb belä- “smear” is a
derivative of a secondary notion “mix”. The achromatic notion “smear” extends from extreme light to
extreme dark, which leads to the opposite ends of a grey spectrum, Cf. Tr.
bulut “cloud” (i.e. lit. “grey, smeared”), see cloud. A black shade is on one
extremity and a white shade (e.g. bald, blanch, blank, bleach, bleak, blear, blaze, pale,
etc.) is on the other end. The bifurcation was numerously noted within the “IE” philology but never
properly understood nor intelligently explained. A noun/adj. notion beläk “black” and its
dialectal siblings are formed with a deverbal noun suffix -k/-q. The root vowel takes form of
-u-, -e-, -ï-, -i-, and -o-, creating a two-dimensional semantic/phonetic spectrum of
randomly connected derivatives, Cf. bald, bleach, blitz, blur, etc. E. Sevortyan asserts a
predating antiquity of the base root bul (EDTL, 1978, 252-3). Cognates: A.-Sax.
blac, blaec “black, dark”, “ink”, “bright, shining, glittering, flashing”, and “pale, pallid,
wan”, blaecce “black matter”, blaecfexede “black-haired”,
blaechorn (e) “ink-horn”, OE blæc “dark”, ONorse blakkr “dark”, OHG blah
“black”, Sw. bläck “ink”, Du. blaken “to burn” (charred black?); Lat. flagrare
“to blaze, glow, burn” (?) (< fiamma “flame”, red tongues of fire); Rus. bulyndatsya
булындаться) “blemish, mar”, balmosh (балмош) “mixed up, tangle”, Serb. bulandisati
“maroon”, Pol.
bulany ditto; Osset. bulğaq “brush, jumble”; Kalm. bulngir, bulngr “dirty,
unclean, muddy, mud, sediment”; Tung. bula- “swamp, bog”. Distribution spans Eurasia
from Atlantic to Pacific, with a Gmc. isle in Europe. An “IE” notion of “burn” is etymologically
unrelated to the notion “black”, i.e. burned meat made black and the like. Suggested “PIE
proto-word” *bhleg- “burn, gleam, shine, flash”, *bhel- “blaze, bright” are beyond
contempt. The unattested fictitious PG and PIE *blakaz “burned” and *bhleg-
“burn” are no more than mechanical spoofs of the attested Türkic root belä- and its Gmc.
cognates without a hint on a morphological role of the suffixes -kaz and -eg. The
contrasting content of Sl. beliy (белый) “white” vs. Eng.
black, amplified by a host of conforming derivatives, is noted by OED: “In ME. it is often
doubtful whether... (it) means 'black' or 'pale'...”. A synonymous A.-Sax. sweart/swart/sweard
“swarthy, black, dark”, swearttan “become, make black”, and wan/wann “dark, dusky,
lurid”, wannian “become, turn dark-colored, black” attest to the amalgamated nature of the
A.-Sax. language, where the old European sweart and wan were supplanted by the Türkic belä-. The replacement attests to a local demographic predominance of the Türkic lexis. In
contrast, the old European A.-Sax. term hwit for the “white” had survived, attesting to a
demographic balance contrary the situation with sweart. The form belä- and the notion
“smear” carry a diagnostic weight, they are colloquial: belä- Tr., Uz., “smear” Kir., Kip.,
Kaz., Karakalpak, Tat., Uig., Tuv. “mix”. They point to an easterly origin extending in the west to
the Itil (Volga). Such a scenario definitely expands the amalgamation period into remote
pre-historical times. Notably, the word entered European languages not as a color or shade, but as a
notion of a “mar” or “smear” leading to them, as an innovation peculiar to the Gmc. phylum with some
random and distinctly different reflex found in the Italic Lat. That sets the date to prior to the
Italic exodus from the E. Europe ca. 1500 BC, and excludes the Celtic knowledge of the word at the
time of their circum-Mediterranean route from the E. Europe ca. 5th mill. BC. That is corroborated
by the Celtic forms dubh/du (Ir., Welsh, Gaelic) for the word “black”, a cognate of the
Türkic dawa:/dava “dye”, see dye. A phonetic and semantic
concordance, the peculiarity of the contrasting derivatives, the peculiarity of the exclusively Gmc.
European provenance, the absence of credible etymological alternatives, and indirect attestation of
the Celtic examples provide convincing and vaguely datable evidence of a Türkic origin. See bald,
bleach, blitz, blur, cloud, dye.
1.4
child (n.) “youth, minor” (Sw39, F497, 0.04%) ~ Türkic koldaš, qoldaš (n.) “comrade, friend,
fellow”.
The word koldaš is a noun describing persons associated with in some way, fr. ko:l
“arm, upper arm”, it means “comrade”, lit. “one with whom one links arms”, and applies to the court
pages and servants from noble families. The terms for front legs and their parts in Türkic and Eng.
are identical for animals and humans, unlike e.g. Rus. or Tung.-Manchu.
According to M. Kashgari I 461, “the word (koldaš) is used only between servants of notables”; i.e.
it is a word from a category of “upper class word”, like, for example a “bestow” give. Cf.
Rus. eidetic term deti boyarskie (дети боярские) “Boyar's children” vs. Sl. otrok (отрок)
and rebenok (ребенок) “youth, child”, see tad. The deti underwent identical
social shift in meaning and application, expanding from a specific to a generic noun. A devaluation
of the term and its adoption across a society is alike in both cases. Cognates: A.-Sax.
cild, childe, pl.
cildru (with k-) “youth of gentle birth”, Dan. kuld “children of the same
marriage”, OSw. kulder “litter”; Pers. qolčaq “bracer” (< Tr.); Mong. qolturi-,
qolturqai “handicapped arm”, qol- “armpit (< qoluŋ(gusu) “armpit stench”, < Tr.),
Khalk.
holtoroh “handicapped arm”; Tungus-Manchu xoldo “side (left, right)”; references to
Balkan Sl. languages. Distribution for the base “arm” spans the width of Eurasia, derivative
“child” spans Steppe Belt with an isle in the European NW. The “IE etymology” asserts that it does not
know any “certain cognates outside Germanic”. In a circular logic it then deduces child fr.
A.-Sax. cild, childe
“fetus, infant”, dropping crucial “gentle birth”. Then it appeals to unrelated Goth. kilþei
“womb”, inkilþo “pregnant”, while the A.-Sax. native “womb” is hama, fahame, cildhama,
fea-hama, feorh-hama related to haeman “intercourse, cohabit, marry”, vs. Goth. kilþei,
but Cf. Goth. derisive kalkjo “harlot”. The OE interpretation “fetus, infant” in the context
of the social function is an open manipulation. The “IE” etymology's reference to the girls is also
out of kilter. It conflicts with the known institute of the male pages and service boys: female
companions were next to invisible, and in contrast the page boys, dubbed as bodyguards, courtiers,
etc., were groomed to be army commanders and a ruling elite. An ascent to the root gen- is
tempting but conflicts with the attested historical sequence and is unattainable phonetically, see
gene. The social nature of the terms
koldaš and child, the repeated emphasis of independent sources separated by a
half-continent distance, on their noble origin and identical function, the accent on the noble
descent of its carriers makes incredible a thesis that the term is a derivative of the words like
“womb”: everyone comes from the womb, but very few are distinguished by nobility. The same with the
genesis nature of gen-. None of the cognates offer an “IE” origin, the word cild (with
k-) and its allophones are lucid loanwords within the “IE” family, their origin came from
elsewhere. The search for etymology of the word child is marked by parochialism, it
inevitably had to produce flimsy results palatable only to the believers. One language that
penetrated all corners of the Eurasia has not been explored, probably because of a subliminal
combination of self-supremacy vs. insignificance typical for confined mentality. A diligent search
would definitely have produced less tenuous results. This is not a question of expanding the search
filed, it is a question of following precepts of scientific research. The phonetic contraction of
-aš for an assimilated word, the fluidity of the vowel -i-/-o-/-u-, and the alternation
k-/ch- are routine. The actual semantic drift is well documented. The word child
illustrates a wider aspect, a tackling of etymology should expect not entirely predictable
ingenuity, it calls for a cast beyond mechanical manipulations in a search for nearest phonetic and
semantic siblings. At the ridges of blending cultures, interaction of the linguistic nature and
environmental nurture creates lexical innovations. See gene, give, tad.
1.5
dawn (n.) “sunrise” ~ Türkic daŋ, dang, taŋ, čaŋ (n.), taŋla:-, daŋla:- (v.) “dawn”.
Sunrise had a primary role in Türkic societies, it was a morning prayer and a new day. It carried a
daily flavor of awe. A.-Sax. had an extensively developed lexicon for “dawn”, attesting to an old
age of internalization. Cognates: A.-Sax. dagian (v.) “dawn”, dagung, daegred
“dawn, daybreak”, daegredwoma “dawn”, daegredleoma “light of dawn”, ONorse dagan
“dawning”, Dan., Sw. dagning (v.) “dawn”, Gmn. tagen (v.) “dawn”; Ch.
dan, dang (旦) “sunrise, morning”. Distribution extends from Atlantic to Pacific. Both
an “IE” family and a PG are innocent of originating the word. No references to Tungus-Mong. cognates.
Whether Türkic inherited the word from Ch., or Ch. inherited it from a Türkic Zhou is a mute
question. For a 3-phoneme word the coincidence may statistically be not overly impressive, but in
“IE” etymological context it is ominous. It moves any claim to “IE” or Gmc. origin to a category of lunacy,
and sends any and all related “reconstructions” to a dust bin of the “IE” theory. The only reasonable
link connecting Gmc. and Sino-Tibetan languages is an overreaching mobility of the Türkic languages.
Aside from a Forrer's unstated surmisal about Türkic being a substrate component of the Gmc. branch
of the “IE” family, that would need an unprejudiced stamina to absorb. Considering that SE Asia had
its own motley path of peopling totally isolated from that of a Middle Eastern path, that lexical
continuity should have inspired some inquisitive thinking. There was a total absence of biological
genetic connections between the Old Europe I Y-DNA, Chinese O2, and Türkic Kurgans' R1a/b. The
Türkic dün ~ Eng. day ascend to the same stem
tang/taŋ/toɣ “dawn”, the pair constitutes a case of paradigmatic transfer attesting to a well
established demographic convergence, linguistic amalgamation, and to an origin from or via a Türkic
phylum. See day.
1.6
day (n.) “daytime, 24-hour interval” (Sw178, F183, 0.11%) ~ Türkic taŋ, daŋ, toɣ- (n.) “dawn,
sunrise”, dün “yesterday”.
Two allophones, toɣ- and taŋ/daŋ “dawn”, molded the European Gmc., Balto-Sl., and
Romance forms. Day and dawn are two siblings of the same root, see dawn. The
European forms for the “day” ascend to the concrete noun “dawn” and its notion of coming or having
daylight. Cognates: A.-Sax. dæg “day”, OSw., MDu., Du. dag, OFris. dei,
OHG tag, Gmn. Tag, ONorse dagr, Goth. dags; Balt. (Latv.) diena >
Slavic den; Lat. dies; Ch. dan, dang (旦) “sunrise, morning”. Distribution
extends from Atlantic to Pacific. Like in a case with “dawn”, both an “IE” family and a PG are
innocent of originating the word. No references to northern Far Eastern cognates. Whether Türkic
inherited the word from Ch., or Ch. inherited it from a Türkic Zhou is a mute question, but numerous
prongs of the “Scythian” nomads moved to the Far East. For a 3-phoneme word the coincidence may
statistically be not overly impressive, but in “IE” etymological context it is ominous. It moves any
claim to “IE” or Gmc. origin to a category of lunacy, and sends any and all related “reconstructions”
to a dust bin of the “IE” theory. The only reasonable link connecting Gmc. and Sino-Tibetan languages
is an overreaching mobility of the Türkic languages. Aside from a Forrer's unstated surmisal about
Türkic being a substrate component of the Gmc. branch of the “IE” family, that would need an
unprejudiced stamina to absorb. Considering that SE Asia had its own motley path of peopling totally
isolated from that of a Middle Eastern path, that lexical continuity should have inspired some
inquisitive thinking. There was a total absence of biological genetic connections between Old Europe
I Y-DNA, Chinese O2, and Türkic Kurgans' R1a/b. Transition from Türkic toɣ- to Gmc. dæg,
dag, tag, etc. is transparent, likewise is a transition from Türkic taŋ/daŋ to Balto-Sl.
diena, den, etc. The Romance, Eng., OFris. forms follow either the -n-/-y-
or -g > -y > zero alternation, routine for the Türkic languages. A transition
of the Türkic labial vowels to diphthongs in the Baltic languages is systemic. The transition
ü => “IE” is one such systemic transition, with subsequent reduction of diphthongs in Slavic
languages, which is one of the diagnostic parameters for the direction of the linguistic substrate
process: Türkic > Baltic > Slavic. Dialectal transition of the Türkic consonants to semi-consonant
-y- is well documented, hence the Kipchak 13th c. form
tayn, and the -y ending instead of consonant in numerous languages,
including English, Cf. ig, iy “illness, disease”, dag, day. Another form for day
in Türkic is kün, a word for sun, which is still active. The semantics of sun is preserved in
Turkic “south”, “midday”; reflexes of the Türkic kün with dialectal k/d alternation
are preserved in Skt. dah “to burn”, Balt. (Lith.) dagas “hot season”, OPrus. dagis
“summer”. The presence of the Skt. cognate, and the presence of both still active forms in Türkic
indicates that the split into kün/dün versions happened before an eastward march of the Aryan
agriculturists crossing the N. Pontic steppe ca. 2000 BC. The closest to the NE European forms is
the form dün meaning “yesterday” in Az., Osm., and Tkm. (düyn) languages located in
the southern end of the Sarmat area, and in the Central Asian Tuvan language that may have
re-borrowed a Mong. form borrowed from the eastern Huns at the turn of the eras. The pair “dawn” -
“day” constitutes a case of paradigmatic transfer attesting to a well established demographic
convergence, linguistic amalgamation, and to an origin from or via a Türkic phylum. See dawn.
1.7
Earth (n.) “earth, Earth” (Sw N/A, F987, 0.01%) ~ Türkic er, yer (n.) “earth, place”, erdä,
yerdä “on earth, in place”.
The Türkic er “man” must be an archaic semantic relative of the er “earth”, or
vice-versa, like a “man” and his “place”. A spectrum of phonetic allophones is scattered among
Türkic languages: yer, yar, jer, djer, cher, chir, dier, sar, ser, tier, ker, they offer
plenty of choices for the daughter forms, Cf. Ir. cre, uir. A Sum. yer attests to an
origin predating 4th mill. BC. At one time, around 4,000 ybp, the word er “earth” spread
truly international, it is native to the Old Semitic, Sumerian, Germanic, Tungus, and all Türkic
languages, covering a space from Mediterranean to Korea. The later Semitic cuneiform records put it
in female gender with a suffix -at, pointing to a primeval notion of a “man” being a “woman”.
An anlaut consonant probably was not a later prosthesis, but represents an original archaic form of
the Ogur languages. With consonants g- and d-, and semi-consonants j- and
y-, ger/der/jer/yer, it was also recorded in the Scythian Oguric form Gerra
“the land of our ancestors”. The Oguz branch lost the anlaut consonant: Oguz and Gk. er.
Cognates: A.-Sax. ear, eard, eorð, eorðe, heorð “earth”, Gmn. erde, from the
Türkic root er (yer) which produced Gmn. noun ertho, and ultimately Gmn. erde,
Du. aarde, Dan. and Sw. jord, and English earth; Ir. cre, uir, Welsh
ddaear/daear “earth”, erw “field”; Lat. terra; Gk. er, era, eraze “on the
ground”; Skt. thira; Hu.
szer(е) (/sere/); Basque lurra; Arm. erkir (երկիր)
“earth”; Arab., Maltese
art, ard; Sum. yer “earth”, Akkad. yersat; Pers. yer, arz, arazi
(pl.) “earth, lands”; Kurdish yer; Kuchaean (“Tocharian B”) yare “gravel”; Tungus,
Manchu, Even yerka, jerke “earth, world, universe”; Cuv. sar; Telengut ser
“earth”.
Distribution on Eurasian scale, with spills to Europe and far East. A myopic “IE etymology” is
funny, it limits its scholarly horizon to “IE cognates” and offers a 3rd mill BC faux “proto-word”
for an attested 4th mill BC ancestor. The Common Gmc. form Erde is peculiar, supposedly
-de is a female gender marker under an incompatible typology, and the marker was preserved after
another creolizing metamorphose to an analytic typology, becoming a tautological die Erde
with a female form of an article and an archaic gender marker suffix and aka eorðe. Rather,
the -de is a Türkic locative suffix appropriate for a reference to a place, q.v.. The anlaut
consonant common to the European reflexes in Welsh, Basque, and Lat. probably reflects an early form
brought over to the European Iberia 4800 ybp by the circum-Mediterranean Celtic Kurgan migrants from
the Pontic steppes. By that time, Kurgan waves had ingrained in Europe their continental allophones.
The Skt. reflex comes later from the Pontic steppes to India ca. 3600 ybp. Another migration path
from the Pontic steppes was direct to the Balkans and C. Europe connected with the Kurgan
migrations. The forms with the anlaut t-/d- ascend to the Türkic ter “pasture land”.
The duo of er “earth” and er “man” constitutes a case of paradigmatic transfer,
indelibly attesting to a genetic origin from a Türkic linguistic milieu (A. Dybo 2013, 219). See
-er, ore, terrain, turf.
Numerals – Preliminary Note. The “IE” ordinals vs. cardinals for numerals one and two are suppletive. The duality does not have an accepted explanation. The origin of the ordinals for the pair is deliberately excluded from the “IE” base vocabulary, and any suggested etymologies are distinctly unrealistic. At the same time, the nearest cognates for one and two are geographically close neighbors of the Athens and Rome, they are the Türkic bir “one” and ikki “two”. It would be both prudent and wise to succumb to reality and explore linguistic situation as it comes rather than as it ought to be.
1.8
first (adj., n., adv.) “ordinal of one, initial, beginning, preceding” (Sw N/A, F171, 0.09%)
~ Türkic bir (n.) “one”; bir, birinč “first”.
Suffix -inč consists of a selective suffix -in, and -č corresponds to the Eng.
ordinal suffix
-th, Cf. tenth. An older Türkic suffix -inti ~ -inch uses suffix -in and
ordinal marker -ti that corresponds to the suffix -th, Cf. ekinti “second”. In
different languages -ti/-č is reflected with forms -th, -st, -t, -sht. A cardinal
“one” originated with a Türkic ӧŋ “first, smallest whole number, front, beginning”. Of 44
European languages, 32 (73%) use allophones of the bir, matching a level of the European
50.6% R1a/b demographic presence in Europe. The other 12 languages use their own 7 native words.
Cognates: A.-Sax. aerest, fyrst “first, in front of”, for “before”, OSax.
fuirst, OFris. ferist, ONorse
fyrstr, Dan. første, Du. vorst, OHG furist, all “first”, MDu vorste
“prince”, Gmn. fürst “prince”; Balto-Sl. (Lith.) pirmas, (Latv.) pìrmais, Sl.
pervyi (первый) “first”, also Cf. teper (теперь) “now”, Serb. birzeman “once”,
birden, birlija “unity”, Bolg. birebir “unilateral”; Lat. primus “first”,
prae
“before”, It., Sp. primo; Gk. protos (πρωτος) “first”, pro, paros “in the
past”; Pers. bir “one”; Skt. pura “at first, in the past”, Av. paro “in the
past”; Heb. (Yid.) ersht (ערשט), Heb. reshith “first”; Malay
pertama “first”; Hu. első and Afrikaans eerste (elided initial b-/p-/f-).
Distribution uniformly lines up as appendages to the length of the Eurasian Steppe Belt,
covering a space from the European Atlantic to the Kamchatka Peninsula on the Pacific. “IE”
languages have a spectrum of genetically unconnected stems for cardinal “one” (Cf. one and
ek), but the ordinal “first” is fairly universal. A motley origin of the cardinal “one” forced
“IE” theoreticians to exclude “one” from a small complement of the “PIE proto-words” that constitute a
PIE theoretical “base vocabulary”. European forms for the notion “first”, other than those derived
from the Türkic bir, tend to derive not from the native cardinal “one”, but from the native
words for outset, beginning, and the like, attesting that the native Sprachbunds did not have
a word for “first” (Cf. Basque bat “one”, lehen “first”). A paucity of synonyms for
the secondary notion “before” attests to a great lacuna in expressing that notion. In addition to
first and bir, both Türkic and Eng. have numerous synonyms to express “first”, in both
cases the main metaphor is head (Cf. headmaster). Both languages use the word
ilk for a prototype, with modest semantic difference. “IE etymology” ascends the “IE” cluster for
the ordinal “first” from a preposition per with a basic meanings of “forward, through”. That
is an artificial non-viable construct in inverted sequence that derives a base word from its
derivative. That negates the “IE” thicket of pretentiously ancestral fore, the “PG” *fur,
*fura, *furi “before”, *frestaz, *fristiz, *fresta “date, appointed time”, “PIE”
*per-, *pero-, *pres- “forward, beyond, around, forth, over”, *prae- “in front of,
before”, *pre-isto- ditto. A base cardinal “one” had to appear first, in that mental
enchilada it is sorely missing. A common attested Türkic bir with areal articulations as
for, fyr, pr-, etc. turns fantasy into reality. The ordinal “first” was used as pre- and
post-positions (Cf. A.-Sax. forwost “first, leader, head”) that have developed into prefixes
in languages with typology that allowed a contamination of the roots with prefixes, i.e. did not
rely on the primacy of the root in a derivative. The vowel-initial forms aer “ere”, Heb.
ersht (ערשט) and reshith (metathesized version) etc. elided an initial consonant. A
decent fr. the Semitic ahad, awwal must be excluded. Except for few metaphoric expressions,
practically all “IE” forms for the notion “before” ultimately ascend to the Türkic cardinal “one”.
European languages have developed numerous derivatives and applications using cognates of bir
“one”, attesting to a long history of internalization, further amplified by the innovations of the
prefixes pr-, pre-, pri-, and the like. As a result of Indo-Europeanization, first of the
European languages, and then of the internationalization of the European vocabularies, these words
occupy a prominent place in the dictionaries of many languages of the world. The degree of
internalization by the time of the initial written records attest to exceedingly deep roots. The
phonetic and semantic differences attest to numerous and independent paths. The shared words between
the European and Asian “IE” fractions attest to the presence of the source word prior to the ca. 2000
BC Indo-Aryan migration from the Eastern Europe to Asia. The absence of the cognates in the Celtic
languages dates the emergence or spread of the Türkic form by the time later than the Celtic
departure from the Eastern Europe to Iberia ca. 5th-4th mill. BC. These terminal dates point to
dissemination of the word during Kurgan migrations of the 4th-3rd mill. BC. That also allows a
provisional dating for the -ti/-č transition, becoming a dating indicator for the
Türkic/Germanic separation, since the Gmc. fraction retained the Türkic -ti form as -th
and -st, and the Gk. retained the form protos with the original suffix -t.
Dissemination realistically explains the suppletion of the “IE” ordinals vs. cardinals, solving the
insurmountable puzzle of the “IE” linguistics and connections between the Türkic and “IE” cardinals. The
paradigmatic transfer of the complex first, second, and ilk, and of the integral
morphological elements unimpeachably attests to their Türkic origin. See ilk, Numerals –
Preliminary Note, prior, second.
1.9
land (n.) “ground, grounds” (Sw N/A, F1458, 0.01%) ~ Türkic elen (n.) “certain land,
possession, its people”, ellä-, illä- (v.) “unite, confederate”.
Incoherence and incredulity of the “IE” etymology is barely masked by excessive chatter. An ultimate
origin comes from a base notion el/il “tribe, people” and its overlay “master, ours, rule
(v.)” from a base notion el “arm”. Form ıl- (with ı-) “descend” points to a
notion “descent from progenitors”. The forms el and il have diverged into phonetically
and semantically overlapping ethnic lines, attesting to primeval origins. Chains of the earliest
notions “tribe” > “confederation” > “people, land” > “country” > “state”, and “peace” >
“concordance” > “tranquility” defines “land” in a context of the notion “people” as an attribute of
“country” and “state”. The notions “country” and “people” are interchangeable. The root el/il
is generic and polysemantic, it forms an array of notions each equipped with its array of meanings
from “tribe” to “quiet”, etc. Subdividing overlapping el/il (n.) into separate lines el
and il mars the issue: articulations are local. Flavors of the base notions are carried by a
vast array of derivatives. The
elen is an inflexion of el/il (n.) “land, country, realm, people” to convey a
relation. A wealth of attested phrases reflect elen = “land”: elin arturu “conferred
land” (artur “give, confer”, see Arthur), bodunuŋ elin törüsin “ruled people of
the land” (törü “law”, see torah), elin etti, beklädi, tüzdi, törüsin
“prepared, strengthen country, people”, elin saqladï “saved country, people”, elin qoδtï
“left the land”, etc. (EDT 58, 109, 111, 169, 171, 172, 389, 487, 570, 602, 665). An attested
verbal form iləndi-/ilindi:/ilinti- “landed, entrenched, hooked, ruled (a beachhead, land)”
is a second, largely interchangeable form ilən = elen = “land”.
Of 44 European languages, 13 (30%) use their own 16 different terms, 11 (25%) use Balto-Sl. zem-
“low”, and 20 (46%) use off-Türkic terms tera “valley, lowland” and elen “land”
approximating a level of the European 50.6% R1a/b demographic presence in Europe, see terra.
An unaccented anlaut vowel e-/i- elided at early Gmc. internalizations, Cf. Gk. Ellada,
Ellas, Ellin. Cognates: A.-Sax. land, lond “earth, land, soil”, inland
“demesne”,
landwela “possessions” (+ 5 dozens more), WFris. lan “land”, ODu. lant, Du.,
Norse, Sw., Icl., Gmn., Goth. land “land, country”; OIr. lann “heath”, land,
Scots laund “land” (+ fearann), MWelsh llan “open space”, Welsh “enclosure”,
Breton lann “heath”; OCS ledo (лѧдо), ledina “heath”, Cz. lada “fallow land”;
Fr. lande “land”; Gk.
Hellada (Ελλαδα), Hellas “Greece”, ellinikos (ελληνικος) “Hellenic” (< Tr. el;
+Tr. elläš- (v.) “accordant, peaceful”), Hellene “Greek, ethnic or of Greece country”
(< el); Alb.
lëndinë “heath, grassland”; Mong. el “peace”, else- “peaceful”, elči
“envoy, peacemaker”, ulus “people”, elde- “handiwork” (< el), ili-, iləh,
ele-, ile- “canoodle, caress, stroke, rub (< handiwork)”, Kalm. el “peace, concordance,
tribesman, familiar”, Evenk ılel “people, public”; Tungus elgemnı “leader” (<
el), elke “quiet” (~ “peaceful”), elket “cautious”, Manchu elhe
“familiar” (~ “peaceful”), Nanai elžini “leader” (< el); Kor. elluda, eruda,
(v.) “lead”.
Distribution is ubiquitous from Atlantic to Pacific, a Gmc. isle is a European NW fringe. An
“IE etymology” for “land” does not exist. On one hand it rightly “suspects a substratum word in Gmc.”,
but on another hand drowns in uncouth origins. The letter are faux and unrelated PG *landja-
(“?”), PIE *lendh- (2) “hip, kidney”, attested A.-Sax. hland, hlond “urine, lant (aged
urine)” ~ PWG *hland < PG *hlanda “urine” < PIE *klan- “liquid, wet ground”,
and some more of the likewise pearls. The Eng. “land” has eidetic forms in all other Gmc. languages.
The Gmc. form “land” is eidetic to the Türkic form. The El/il in “Île-de-France” is
traditionally held as “Island-of-France”; but for a landlocked territory with a river in its center
splitting it into two half-pies the “island” does not make sense, a “France land” is more suitable.
The Gk. terms are “IE” rated as “words of unknown origin”, but they make perfect sense in Türkic, and
are supported by an ancient Türkic-Gk. symbiosis (Herodotus IV 108, 109, 120); this list of 800 Eng.
words numbers 500+ Gk. cognates. The form Ellas is a reflex of the verb elle:-
“peaceably incorporate into the el realm”, a
deverbal noun for the Greek settlers in the N. Pontic Scythian lands, Cf. Herodotus q.v.: “Gelons
were Greeks from long ago, they speak partly in Scythian, and partly in Hellenic”, they belonged to
the populace called Budini, see body. For the “land”, Greeks had their own term, they
did not have to borrow it. The elision of the anlaut vowel e- and the presence of the auslaut
suffix -d are morphologically explainable effects, Cf. bilge:d-, Kashgari II, 340. The
anlaut vowel e- may have been an early Oguz peculiarity in articulation of the initial
liquids, in contrast with the Ogur articulation that either did not add an initial e- or
covered it with a consonant. A targeted study of Ogur linguistics has not been yet initiated. See
Arthur, body, terra, torah.
1.10
man (n.) “person, human, male” (Sw37, F128, 0.15%) ~ Türkic man (n.) “man, men, mature
sheep”, man- (v.) “go, move”, manlai “forehead, scout, front line of army”, mãn(ã) (Chuv.) “adult” .
An “IE etymology” offers a “probably” inexplicable primordial “man”. Ultimately fr. a Türkic pronoun
root men/min “I, me” and a postpositive pers. marker in nominal and participle compound
predicates. Although the form man, maŋ has developed a vast semantic array, the ones
connected with aspects of a notion “man” - size, strength, maturity - are present in all
applications. Türkic has a quartet of terms for “man”, with different distribution levels and
semantic shades: adam (casual), er (muscular), man (stranger), and kiši
(neut.). As a “man”, a noun man is attested in the Caspian-Aral basin, Cf. Azeri bir man
“a man”, man gəldi “man (has) arrived” (~ kel- “come”, see Celt) vs.
bən gəldim “I arrived” vs. Turkish adam geldi (adam “man”, see Adam). That is
consistent with numerous other Horezmian (Turanian, Turkmenistan) Türkic-English parallels. As an
instrumental noun suffix, -man can form both animate and inanimate derivatives. Of 44
European languages, 15 (34%) use allophones of “man”, 2 (5%, Ir. and Hu.) use allophones of er,
thus 17 (39%) use off-Türkic roots, approaching a level of the European 50.6% R1a/b demographic
presence in Europe. 9 (20%) languages use allophones of Romance hom-, 7 (16%) use Sl.
chelo- “face”, 2 groups of 2 (9%) languages use their own different words, and 7 (16%) others
use their own 7 different words.
Cognates: A.-Sax. man “man”, meh, mec (pron.) “me (1 pers. sg.)”, min, mine
(pron.) “my, mine”, OSax. man “man”, Fris. man, ONorse maðr, OHG, Sw., Du.
man, Dan. mand, Goth. manna, Icl. maðr, maður, menn (pl.), Gmn.
mann, “man”; OCS myaj (мѫжь) “man, husband”, Sl. muž, muj (муж), mujik (мужик)
(dim.) ditto, moy “mine”, mï “us”; Lith. žmogus “man”, žmones (pl.)
“people”; Arm. mard (մարդ) “man”; Kurd. mer “man”; Pers. man “I, myself”, Taj.
mard “man”, Pahlavi ma:n “us”; Sogd. man “me, myself”; Fin. mies, Est.
mees “man”; Gujarati mena (પુરુષ)
“man”; Skt., Av. manus, manu- (मनु, मानस) “man, human”; Evenk.,
Negid., Ulch., Udegei bi “I, myself”, bu “us”; Ch. ben (本) “I, myself, personally” (m/b
alternation, ~ Türkic ben/men “I”), another one of the peculiar Eng.-Türkic-Ch. coincidences.
In addition to the above non-exhaustive listing, languages have developed derivative lines, some of
them most extensive, Cf. Eng. manful, manly, manhandle, manhole, one-upmanship, + many more.
Distribution extends from Atlantic to Pacific, way beyond a Gmc. reach. No etymological “IE
etymology”. In addition to “probably”, it runs in myopic circles with a faux “PG proto-word”
*mann- and “PIE proto-word” *man- or *mon- “man”. Either one is not too
enlightening etymologically. With a straight face it also cites an expert historian Tacitus with his
folk Мannus - a progenitor of the Germans and Manis (Μάνης) - a progenitor of the Phrygians.
In his time (ca. 100 AD) Tacitus have not known of a legendary progenitor of progenitors, a
synonymous
Adam “man”, and could not have enlighten his audience on the Genesis story. The entire case
of myopic etymology is due to be gracefully retracted. A.-Sax. had 13 ways to express “man”, of
which at least 4 were metaphorical extensions (healer, match, herdsman, producer), 4 were Türkic
cognates (beorn ~
ber- “bearer”, carl ~ kür “courageous, manly”, man ~ men “man”, weor, wer ~
er “man”), and 6 belonged to the European native languages (guma, gome Cf. Italic homo,
human,
leod Cf. Gmc. liut “people”, maecga “match, companion”, rinc “rink”,
secg “segge”, waep “male”). The breakdown illustrates an amalgamated nature of the
A.-Sax. language inherited by Eng. In Eng., like a postposition in Türkic, man also serves as
an suffix of a noun, as in workman, serviceman, with some peculiarities. For example in
Türkic agglutinative languages alternation man/men indicating plurality is impossible, it is
an Eng. innovation. The Sl. mujik was formed with a Türkic diminutive suffix -k
reflecting a subordinate status of the object. Since the notion “man” also dubbed as a “warrior”,
numerous dictionary words expressing “warrior” also dubbed as “man”. Compounds of the type object
+ man are standard in both Türkic and English, Cf. A.-Sax.
ancorman, chapman, hierdeman, and the Tr. ataman “leader”, lit “father-man”, dušman
“enemy”, hetman (getman) “title”, müsülman “Moslem”, etc. In all these instances, the
suffix -man is definitely not “I, me”. A standing “IE” objection is that the “man” and “I, me”
are semantically incongruent, but the actual practice of the “IE etymology” more than regularly allows
much wider and often incongruent semantic fields than this (e.g. see -like q.v., references
“body”, corpse”, etc.). Distribution of the Türkic part -man is clinal, the western
areas tend to form concrete agent derivatives, while the eastern areas tend to retain archaic
generic function. The split points to some tumultuous events of the late 3rd mill. BC that split the
Eastern European farming population, drove some of it southeastward, and some of it westward.
Nowadays those migrations are traceable by genetic dating. The synonymous trio adam, man, er
“man” constitute a case of paradigmatic transfer, indelibly attesting to an origin from a Türkic
phylum. See Adam, -er, Celt, -like.
1.11
no (nah, nay, neither, nope, nor, not, -n't) (negation part., interj., adv., adj.) “not”
(Sw16, F18 Σ3.37%) ~ Türkic ne, ni, no, nü, nor, aŋ “negative, negation
(emphasis)”, ne:ŋ “not any, at all”, ne:če: “nothing”, (part., adv., adj., n.).
A homophonic ne, genetically connected with the negation ne, dubs as a base for
interrogative lexemes. Taken as two semantic lines of a common ne, the negating ne is
direct “no” (ne jatmaz “not located”, ne uδïmaz “not sleeping”) and emphatic “not
this, not that” (~ “neither...nor”). The interrogative ne is “what, how”, negative “how
come”, and the like. The negative ne has developed a system based on combinations with
reliable indicators and as syntactic phrases, but is frozen at incipiency. It parallels numerous
other negation lexemes and morphemes (e.g.
-ma- etc.), some of them reflected in Eng.: del- “delete”, den- “deny”, Cf.
synonymous Lat. negare “deny” (< Tr. ne), Fr.: pa, pas- “not”, Cf. pas
comme, ne pas “not like, not” (pas < Tr. -ma-, b/m/p alternation). The
Türkic negation forms probably are developments of primeval indiscriminate front vowels a:, o:,
and u:. It was noted that rounded and back vowels are unsuitable for expressive negation
(Clauson EDT 3). The Türkic negation part. ne, ni, no gained a wide circulation in
Europe: of 44 European languages it was adopted by 35 (80%) languages. A runner up 2-language Fennic
group takes 5%, and the other 7 (16%) languages use their own terms. With their long roots ascending
to the first Kurgan waves of the pre-Corded Ware times, a share of the off-Türkic allophones more
than matches a 50.6% R1a/b demographic presence in Europe. Syntaxes and morphology of the European
languages freed the Türkic negation from a rigid syntax, allowing it to blossom with grammatical
functions and semantics. The English no is used as noun, adjective, adverb, and interjection.
Cognates: A.-Sax. na, no (adv.) “no, never, not at all”, nan “none, not any”,
na... na “neither...nor”, OSax. nigen “not any”, OFris. nan, nen “no, none, not
any”, Saterland Frisian naan, neen ditto, NFris. nian ditto, WFris. gjin ditto,
OFris., ONorse, OHG ne “no”, Goth. ni, Sw. annu (?), Gmn. nein, Icl.
nr; Ir.
uimh, no, Scots nae “no, not any, none”, Welsh nid, or dim (?); Latv,
Lith.
ne; Sl. net (нет) “no”, Rus. nechego, nichto (нечего, ничто) “nothing”;
Romance
no, Lat. non, nihil “no, not”; Gk. den (δεν) (Cf. Welsh dim) (?); Hu.
nem, meg; Pers. nah; Gujarati na, nathi; Kor. ani (아니)
“no”; Jap. janai “no”; a mark (?) denotes aberration. Distribution spans from Atlantic
to Pacific. A majority of the “IE” languages use a Türkic form, affirming a Corded Ware melting pot
as a cradle of the “IE” languages. Other than that, there is no common “IE” “no”. Attempts to
privatize in favor of some parochial interests an attested Türkic word are not sustainable. Or
attempts to portray it as a European loanword to an opposite end of the world. To save a face, such
fictions should be tactfully retracted: a faux “PG proto-word” *ne and “PIE proto-word”
*ne, “PG” *aiwi- and “PIE” *aiw- “vital force, life, long life, eternity”, PWG
*nain, “PG” *nainaz “not any”, “not one” supposedly leading to ne, no. It goes in
circular logics no < na < no +a “ever”, and uses unattested PGmc. and PIE “reconstructions”
to come up with natural allophonic variations. At the end, it is reverting to the old basic Türkic
stem ne. The “IE” etymological fantasies can't be called etymology. For “not”, the Eng., like
the Türkic, has numerous allophones and spellings. In the usage frequency rating, these allophones
occupy a very prominent place (Table 1a): no (F18, 0.81%), not (F23, 0.74%), neither (F948,
0.01%), nope (F1496, 0.01%), -n’t (1.8%) for a total of 3.37% usage frequency, or about every 30th
word of the daily Eng. language. Frequency listing table summarily shows them under a less frequent,
but more concise entry not. The Gk. and Welsh den, dim are false cognates
ascending to a Türkic tan-, ton-, tun-, den- “deny”. The Sw. annu is a false cognate,
it ascends to a Türkic aŋ (“no”, interjection), with a non-nasal
velar version an used in speech in some Türkic languages and found in records that don't
discriminate nasal and non-nasal -n- (e.g. A.-Sax. Latinized records). Türkic uses regular
aŋ and superlative aŋ aŋ for emphatic negation. The Türkic aŋ is a precursor for
the Eng. un-, A.-Sax. an- and un-, Gk. and Lat. ana- (e.g. anaerobic),
etc., see un-. One case sprouts a typical Gmc. prosthetic anlaut g-; expect occasional
cases of metathesis or phonetic shift. The Celtic forms attest to a presence of ne- in the N.
Pontic prior to the Celtic departure of 5th-4th mill. BC on their circum-Mediterranean voyage,
millenniums before the Corded Ware time. A widely distributed Far Eastern anlaut j- prompted
early scholars to suggest a common origin of the pan-Eurasian and Far Eastern “no”. Notably, a
consensus Swadesh List carries “no”, but excludes “yes”. Although both are originally Türkic, only
one is held as “IE”. The other is a foster child. A paradigmatic transfer of the no-yes couple
serves as an indelible attestation of a genetic origin from a Türkic linguistic milieu. See deny,
un-, yeah.
|
Supplementary Note. Direction of borrowing. An assertion of ne “no, nor” being a Pers. loanword can’t be taken seriously, for a slew of reasons. A first because the direction of the borrowing is scientifically presumptuous and groundless. Secondly because chronologically, the not numerous Indo-Aryan farmers (here, Pers.) were latecomers (ca 1500 BC) to the Near East populated by Semitic, Dravidian, and Türkic people (Guties, Kangars, Kumans among others, ca 4500 BC), and the direction of cultural borrowing would flow in the opposite direction. Thirdly because the Pers. form ne was just one of very numerous allophones with cognates spread across Eurasia: ne, ni, no, nor, not, nyet, nein, nah, nay, neither, nope, and so on. The selection of the Pers. “proto-form” appears to carry a certain biased pretense. Fourthly, because reliance on a tiny segment of linguistic evidence, based mostly on late foreign sources, can’t pretend to reflect the linguistic developments spread across 6 millennia, from ca. 5000 BC (Kurgan migrants did not migrate to the Near East without their own languages) to ca. 1000 AD. Fifthly, unlike a massive influx of the Türkic haplogroups R1a and R1b into the western Europe, a demographically massive influx of the Persian predominantly J2 haplogroup to the western Europe never happened. Each one of these reasons is sufficient to discard the Pers. loanword speculation. The unwarranted assertion on the direction of borrowing must be retrieved. A more acute perception would connect the Türkic fundamental root aŋ (“no”, interjection) both with the negation no in all its allophonic forms, with the negation clitic -ma-, and with the negation a- and un-. A transposition and transition to nasal and non-nasal velars are of routine linguistic evolution in both internal and loanword processes, greatly amplified with the development of writing and internationalization of scripts and communities. The Türkic aŋ as a precursor for the above negation forms appears in Eng. un-, Anglo-Sax. an- and un-, Gk. and Lat. ana- (e.g. anabiosis), etc. A peculiar -ŋ- was a Türkic phoneme that could not be reproduced in many other alphabets (e.g. the Anglo-Sax. Romanized records etc.). |
1.12
one (n., adj., pron.) “smallest whole number” (Sw 22, F63, Σ0.49%) ~ Türkic ӧŋ “one, first,
smallest whole number, front, beginning”.
Ultimately a derivative of a notion ӧn- “pierce out, grow (of a plant)” with 17 semantic
clusters. The root ӧŋ is very productive, with ca. 19 derivative semantic clusters. The
notion “one” is a derivative of a notion “first”, as in “first shoots”. A presence of two synonymic
forms, undifferentiated cardinal/ordinal ӧŋ and bir, points to an amalgamation period
ending with a winner bir (cardinal, ordinal), while the ӧŋ remained a polysemantic
relict, and an underlying ašnu remained as “initial, early”. European statistics for “one” is
similar to a percentile for the “first”, 89% vs. 73% of the European languages. In both cases, they
are international words spread across relevant languages and territories. Such uniformity comes only
with a “guest” word, a cultural borrowing from an external source. The origins, archetypes, and
etymologies for both came from a Türkic phylum, a node of cultural transmission. Only a few European
languages had and retained their native terms that managed to survive to the present. Fictitious
etymology notwithstanding, there is no Pan-European or a common “IE” term that arouse on an European
soil. A cognate listing is partial to a particular borrower contingent, random other cognates are
cited, and analysis is parochial.
Cognates: A.-Sax. an, aen, ana, on, anan, anne, aenne “one, each, every one, all,
single, alone, sole, only....”, OFris., NFris. an, Saterland Fris. aan, WFris. ien,
Dan. en, een, Du. een, Sw. en, ett, ONorse einn, Norw. Nynorsk ein,
Icl. einn, Goth.
ains, LGmn. een, Gmn. ein, eins; OIr. aon, Ir. ceann, Scots
ae, ane, wan, yin, Welsh un; Sl. ena, jedan, adzin (адзін), eden (еден), odin (один);
OLat.
oinos, Lat. unus “one”, (coni)ungere “unite”; Gk. enas (ενας); Udi
paenia (root -en-) “face, facade (side)”; Chuv. um “that in front”, umal (um-al
< öŋ-al); Mong. öŋge “front”, öngge “complexion”, ӧmïne, emüne “in front”,
ešin “beginning” (š ~ n?); Sum. aš (> ašnu?); Drav. ondu; all “one”
unless noted. The notions are seamless:
one stands in front, front is face, face is complexion, complexion is
color, etc.
Distribution: From Albion to Pacific. Phonetic and semantic differences attest to numerous
and independent paths. In a numerical line-up, a base cardinal “one” had to appear first, but it is
sorely missing there. “IE” languages have a spectrum of genetically unconnected stems for cardinal
“one” (Cf. one and ek). A European distribution points to an existence of the term in
the Corded Ware milieu, when diverse populations fled away from the Central European “killing
fields”, causing demic displacements, dispersions and amalgamations that boosted cultural exchange.
A conflict between the “IE” fractions of an-, on-, un- and the Asian ek-, ik- (Hindi,
Finnish, Estonian...) attest to an absence of the “IE” word in Asia at ca. 2000 BC Indo-Aryan
migration from the Eastern Europe to Asia. Thus the terminal dates point to dissemination of the
word during Kurgan westward migrations of the 4th-3rd mill. BC. Dissemination realistically explains
the suppletion of the “IE” ordinals vs. cardinals, solving an insurmountable puzzle of the “IE” linguistics and connections between the Türkic and
“IE” cardinals. A motley origin of the cardinal
“one” forced “IE” theoreticians to exclude “one” from a Swadesh complement of the “PIE proto-words”
that constitute a PIE theoretical “base vocabulary”. A paucity of synonyms for the notion “before,
in front” is a great lacuna in expressing that notion. The parochial Gmc. and Altaic lenses provide
a perverted primitive picture with bogus etymologies. Neither of above the two schemes bear
scrutiny. A bold ignorance of the scholars is of epic proportions. A Gmc. “IE” etymology is totally
bogus, built on unattested claims and a circular logics. It asserts a faux “PGmc. proto-form”
*ainaz and a faux “PWGmc. proto-form” *ain “one”, and a faux “PIE proto-root” *oi-no-
“one, unique” and a faux “PIE proto-word” *oynos “single, one”. None of the fabrications are
needed, a wealth of the attested material is not only overwhelming, it has a depth, it contains
ethnical, geographical, and historical backgrounds, and provides insight into primeval philological
development and dissemination. The Celtic lexis points to an existence of the word in the Eastern
Europe prior to a Celtic departure on their circum-Mediterranean migration. The A.-Sax. forms hint
to a marital compact between those two tribal groups, a traditional Türkic marital arrangement best
known from the As-Tokhar confederation that lasted for millenniums. The cardinal “one” was used as
pre- and post-positions (Cf. A.-Sax. ancor, ancora “hermit, one-loner”, se ana, he ana
“she, he one”). They have developed into prefixes in languages with typology that allowed compounds
and a contamination of the roots with prefixes, i.e. did not rely on a primacy of a root. Many “IE”
forms for the notion “before, in front” ultimately ascend to the Türkic forms for “one”. As a result
of Indo-Europeanization, at first of the European languages, and then of the internationalization of
the European vocabularies, these words occupy a prominent place in the dictionaries of many
languages of the world. The existence of the terms by the time of the earliest written records
attests to exceedingly deep roots; the Gmc. forms are a lacquer layer on the surface. A paradigmatic
transfer of the complex one, first, second, and ilk, and of the integral morphological
elements unimpeachably attests to their Türkic origin. See first, ilk, second, Numerals –
Preliminary Note, prior, second.
1.13
same (adj., pron., n.) “similar, comparable” (Sw N/A, F276, 0.05%) ~ Türkic siŋa:r, syŋar,
syğnar, sïyar (i = y = ï) “identical, [very] similar, like”.
A notion “similar” is ultimately a derivative of a notion
syŋar “one of a pair, one of two” that harbors 6+ semantic clusters. Relevant clusters refer
to kins of various relatedness and to various similarities, outward and generic. The base term
syŋar is a derivative of a sïn “appearance, form, figure” or a notion “side (of smth.)”.
Phonetic alternations m ↔ n, ŋ, ğn, y, etc., a ↔ i, ï, y, etc., and a loss of extra
final consonant are regular phonetic adaptations. Its Türkic cousin is ilk “a kind of person,
like”. Its A.-Sax. spelling ilca, ilcy, illca “just as” ascends to its Türkic origin, see
ilk. A corollary of siŋar is som, soma “appearance, form, image, outlines”,
semantically they partially overlap. Areal distribution of the form som is generally limited
to eastern languages (Alt., Khakass, Toba, etc.), suggesting its archaic origin and possibly a
precursor of siŋ-. A cousin some “(something) few, little, petty, unspecified,
unknown” possibly formed via linguistic evolution, as guessed by a rambling “IE” etymology. In that
case the meaning “some” ascend directly to the base “same”, but see some, so. There is no
common “IE” or European “same”. 44 European languages use 23 different words, a largest consumer
with 8 (18%) languages uses European versions of sam- of the Türkic syŋar “same”.
Cognates: A.-Sax. sama, same “as”, samhwylc “same (family)” (hiwna, hi(g)na
“members”), Fris. selde “same”, OSax., OHG, Goth. sama, ONorse same, sumr, samr
“same”, Norw. (Bokmal) samme “same”, (Nynorsk) same “same”, Dan.
samme “same”, Du. samen “same, together”, zamelen “collect” (?), Sw. samma,
Icl.
sama, Lux. selwecht, gläich “same, like”, OHG. samo, samant, Gmn. samt
“together, with”, zusammen “together”, selbe, selbig “self” (?), Goth. samana
“together”; OIr. som, Ir. caanna, Scots samin “same, like” + “together”; Rus.
samyj (самый) “most” (?), Bosn., Croat, Serb. isti “same” (ӧ → i, without suffix
-(a)m, with suffix -ti) (?), Maced. istite (истите) (?), Bolg. sysch (същ)
“same” (<
syn); OGk. homos (ομος) “same”; Maltese istess “same” (?); Fin., Est. sama;
Hu. azonos “same”; Skt. sam, sama (सम) “similar” (vs. “together”
(?)), Av. hama “similar, same”; Pers. ham (هم) “also, same”; Mari syn “look,
shape, image”; Mong. šinži “mark, feature”; Ch. xiang (相)
“mutual (~ pair)”; all “same” unless noted. Not all cited cognates are really applicable, a mark (?)
denotes aberration. Distribution: From Atlantic to Pacific. Distribution is furcated
into western sin- vs. eastern som-, though migrations made a divide amorphous. A
European distribution of the “same” and “some” follows close patterns: 32% vs. 36% languages use
their unique native terms, followed by groups from 5 - 6 to 2 languages, with largest spread of 10
(native, Sl., 22%) vs. 8 (< Tr., “guest”, 18%). An “IE etymology” is a parody, it suggests Gmc.
origins and “PG/IE proto-words”. Those are a faux “PGmc. proto-form” *samaz “same” and faux
“PIE proto-forms” *samos, *somHos “same”, and a faux “PIE proto-root” *sem- “one, as
one, together with”. The chimeric quasi-etymological constructs lack etymology, sources, historical
and geographical footing, time clock, and a source language. No “IE” connection whatsoever, the
proposed “PG” and “PIE” “restored proto-words” are reverse engineered mechanistic phantoms. In light
of the attested Türkic originals and traceable pedigrees no super-patriotic assertions are needed.
Forms of same and its twin sister some are spread far and wide, crossing linguistic
borders across Eurasia. By heritage, contact or osmosis, the primeval word kept spreading across
millennia. Its presence in the Celtic languages attests to its existence in the Türkic phylum of the
N. Pontic, prior to the Celtic Kurgans' departure from the Eastern Europe on a circum-Mediterranean
voyage to Iberia ca. 5th-4th mill. BC. Its presence in a minute fraction of the Gmc. languages
attests to a guest status in the few hosting languages, Cf. Tr. alkudın siŋar “(on) all
sides” (al “all”, siŋar “similar, like, side”, EDT 841). Until an Indo-Arian
migration is disproved or otherwise re-written, Skt. form sam may be a “guest” from a Corded
Ware period, or acquired roughly coevally with classical Sanskrit between 400 BC and 300 CE, or a
Türkic trace in the Himalayas area. Av. term developed during a 3rd or 4th century AD, or is an
acquisition associated with the lore that Buddhism originated from the Saka Scythians. By then the
language had been extinct for many centuries, and only remained in the Avesta canon. The claimed
false Sl. cognates point to an absence in the Eastern Europe at the time of the Sl. Old Europe (aka
coded WHG) language: all Sl. languages came up with their own expressions. Fin., Mari, and Mong.
coexisted with Türkic ethnoses; so did Ch. when ca. 16th c. BC they fell to the Zhou “Scythians” who
brought writing over to the future China. Demographically, the flow of farmers was eastward, to the
Kurgan's lands. Linguistically, the demic flow was from the Kurgans westward. A palpable supplanting
of a small speck of the native European lexicons with the “guest” terms provide vivid picture of
areal amalgamation and co-existence. The Türkic pronoun syŋar is an attested reality. A
paradigmatic transfer of the forms, semantic contents, derivatives, and idioms with the base lexemes
attests to their origins from a Türkic milieu. See all, ilk, so.
1.13
second (adj., n., adv.) “ordinal of two” (Sw N/A, F347, 0.04%) ~ Türkic eki, iki (n.) “two”;
eki, ekinti, ekkinč “second”, ikkiz “twins”.
Ultimately eki “two” is a derivative of a verb
qos-, qös- “add, join (two)”, noun qos, qös “pair”, Cf. kijin “after, later (of
“1”)”.
An A.-Sax. word for numeral “second” was
aefterlic, lit. “following (one)”. Such definition of “second” is traceable in most
languages. The ONorse forms positively bridge the Türkic eki/iki with a raster of the Gmc.
forms (ikki > ykkar, igqar > unhar (unchar) > unker > unk), and lead to understanding of the
Lat. and OFr.
-ek- versions. A single consonant k/q was probably a root of a primeval notion of
movement from one thing to another, Cf. Sl. k: k tebe (к тебе) “toward (you)” (to
= Tr. -ta). The older Türkic suffix -inti (-inch) consists of selective suffix -in
and ordinal marker
-ti, Cf. ekinti “second”. The last corresponds to the Eng. ordinal suffix -th,
Cf.
tenth; -ti probably originated articulation -č. Its other Türkic form is
-inč, the -č corresponds to the Eng. ordinal suffix -th. In different languages
-ti/-č is reflected with the forms -th, -st, -t, -sht. A.-Sax. cognates of eki
were used for a complementary notion “dual”. Transition from aefterlic “following” to the
second is connected with the Norman conquest and is unrelated to the form unc “two”.
Romance derivatives are formed with a prosthetic/prefix s- (se-) typical for the European
zone, Cf. secludo “off-claudo” (“shut off”). It probably denoted a perfect tense verbal form
as compared with infinitive, morphologically
se- + -k- (-kw under “IE reconstructions”), Cf. Sl. delat - sdelat (делать - сделать)
“make (of clay)- made (of clay)”, Lat. sequi, secundus, and corresponding Gmc. forms.
Besides derivatives of eki “two”, Türkic has 22 more words to express the notion “join,
unite”, attesting to the innate societal role of cooperation, in a stark contrast with a vile image
cultivated on the western end of the Eurasia. Ultimately, the form eki was reintroduced into
Eng. disguised as second. Among 44 European languages, the Sl.-Türkic drug- “other” (<
Tr. dürli “other”) is used by 9 (20%) languages, Romance-Türkic “second” is used by 8 (18%)
languages, forms of duo- (< Tr.
dürli) is used by 6 (14%) languages, Gmc.-Türkic anden (< Tr. andai “that,
other”, pointing to a distant object) is used by 5 (11%) languages, Gmc.-Türkic tweede, an
allophone of duo-, q.v., (< Tr. dürli) is used by 5 (11%) languages, Fennic toinen
“that” is used by 3 (7%) languages, Balto-Sl. vtor- “further” (< Tr. dürli) is used by
3 (7%) languages. The remaining 5 languages use 5 their own native words. The Türkic roots are
shared by 31 (70%) of the European languages, abundantly compatible with a 50.6% R1a/b demographic
presence in Europe. There is no common European or “IE” “second”. Cognates: A.-Sax. unc
(with k-), uncer, uncet (with k-) “two (of us)”, OSax. unc (with k-),
uncero (with k-) “two (of us)”, OHG unch (with h-), unchar (with
h-) “two (of us)”, ONorse okkr, ykkr, okkar, ykkar “two (of us)”, Goth. igqar “(of
you) two”; OFr. second, secont, Lat. sequi “follow”, secundus “following”; Hu.
kettö “two”, ikker “twins”,
köt- “tie”; Kuchean (aka Tokhar B, Tuhsi) ikam “two”, Agnean (aka Tokhar А, Tuhsi)
wiki “20”; Mong. ikire “twins”, ekis, ikes “placenta”, Kalm. ikr “twins”,
Evenk
igire “twins”; Kor. pegim “next, second, following”, Cf. čeim “first”.
Distribution: truly Eurasian, from sea to shining sea. “IE etymology” is non-existent, it
appeals to freshly cooked “PIE proto-root” *sekw- “follow” and “PIE participal
proto-compound” *sekw-ondo-. Of those are credible only the attested local suffix ondo-
and the notion “follow, further, that, other”. The form ikkiz, like its European calque
twins, contains an archaic Türkic dual plural marker -s/-z, applicable to objects that
come in pairs, like eyes (göz), horns (buynuz), twins (ikkiz). In English, the
archaic Türkic dual plural suffix became a generic plural suffix -s, see -s.
Besides Türkic, the dual plural suffix -s is used in Greek; it is absent in the European
languages. A contrast between Gmc. and Romance forms attests that the Gmc. forms lived in an
agglutinative Sprachbund, where words started with roots uncontaminated by prefixes. They
carried roots well into the turn of the eras period of Romanized Indo-Europeization, while the Lat.
and OFr. forms evolved and were internalized in a polysynthetic Sprachbund with vigorous
preference to prefixation. The Balto-Sl. vtor- and Gk. hateros (ατερος) “following,
different” attest to a presence of the word in the Corded Ware period. It is split-present both in
the NW Europe and in the Hindustan peninsula, carried there in the 2nd mill. BC by the Indo-Aryan
migrant farmers, Cf. Skt. vitaram, Av. vitara- “further” fr. Skt. vi “apart”.
The Celtic forms Ir. dara, Scots darna (~ tor-) may even carry the dating to
the 6th-5th mill. BC Eastern Europe before the Celtic departure on their circum-Mediterranean
anabasis. Archeological evidence, genetic dating, and lexical evidence of absence of some but
presence of other words in the Asian Indo-European languages signal nuanced linguistic
transformations. They allow tracing of demographic flows and timing of demographic splits. A
paradigmatic transfer of the complex first, second, and ilk, and of the integral
morphological elements, emphatically attest to their origin from a Türkic lexicon. See first,
Numerals – Preliminary Note, -s.
1.14
sex (n.) “copulation” (Sw N/A, F640, 0.02%) ~ Türkic sik (n.) “copulation, fuck” (of male
only, with a female), sikiš (n.) “sex, copulation” (mutual).
The term flagrantly carries a standard European etymological stipulation “of uncertain origin”, but
with a nod to a related homonym “gender”. Ultimately fr. a noun root sik “penis” and its
prime functions, a derivative of the verb sik-/siy- “urinate”, see sit. The verb
sik- is a variation on a theme “water, liquid” expressed with a most common noun syllable su
and its allophones su:, so, si, suv and the like. A prosthetic consonant -v- (suv)
with allophones -w-, -d-, -δ-, -g-, -γ-, -k- apparently emerged to link with vocalic suffixes
and fossilized as a part of the root, forming suv, su:v, suw, sug “water, liquid” and the
like. The suffix
-g-/-γ-/-k- corresponds to a result of action, in the case of sik “urinate, urine”,
“penis”, and on to “mating, copulation”, “sex”, and “gender” (“gender” as jins, jenes, cins,
cinsiyet, cinsellik, Scotts gne, etc.). Every European language has its native synonyms
for “copulate”. The A.-Sax. came with numerous synonyms, some of them were iape/yape, sard, fucke
(~ Ar. facara), swive. A singular European presence of the form “sex” attests to its
“of uncertain” non-IE origin. Cognates: A.-Sax. sard “fuck, copulate”; Lat. sexus
“gender”; Mong. sige- “urinate”; Manchu sike “urine”, site- “urinate”.
In-between Lat. and Mong. fit ca. 80 Türkic languages. Distribution: From Atlantic to
Pacific. The form sard echoes the Türkic forms sid and sidik “urine”
(Alat/Haladj, Tabgach/Tofalar, Saryg Yugur, Khakass). The Khakass connection is most prominent among
the Eng. Turkisms. The s/h alternation is well established for the Aral-Caspian basin.
Starting from a 1st mill. BC, the southeastern Kurganians repopulated an Aral-Caspian basin; the
s/h alternation there can be only dated to a post-Corded Ware period. The Far Eastern connection
is reliable, it retained the prime semantics of “urinate”. A synonymous A.-Sax. iape/yape,
with cognates Skt. yabhati, Sl. ebat (ебать) “copulate”, a derivative of the Türkic
noun eb/em/am “vulva, female” and a cognate of ewe, Eve, provides another attestation
of the Türkic – A.-Sax. connection. A connection between sik and fuck is tenuous,
predicated on s/h/f alternation: OE (15th c.) fukkit, Gmc.
fokken, fanden, faen, ficken, fiksje, and the like, “fuck, copulate”. A transition h/f
is dubious, even with all Gmc. weakness for an initial f-. The term “sex” flagrantly carries
the standard European etymological stipulation “of uncertain origin”. Any “IE” efforts to fabricate a
local connection for sex are pathetic, neither “division”, nor “to sever”, nor “cut up” fit
the bill to any sane degree. Whether sex was inherited or passed via Lat., an ubiquitous
sexual septet of sex, dick, cock, pussy, quim, ewe, and cynd/cunt provides ample
evidence for paradigmatic transfers from a Türkic milieu. See ewe, cock, dick, kin, pussy, quim,
sit.
1.15
some (adv., adj.) “unspecified, unknown” (Sw N/A, F93, 0.76%) ~ Türkic ӧsüm, ӧsǝm (relative
indefinite pron., conj.) “(something) few, little, petty, unspecified, unknown”.
Ultimately a deverbal noun derivative fr. a verb ӧš-/os-/aša- (emph. adv.) “(degree)
excessively, very” fr. a base notion “to grow”,
formed with a suffix -(a)m/-äm to denote a degree as an abstract noun, or result or object,
Cf. gleam “glitter, Helios” fr. Türkic yal- “shine”; seam “sew”
fr. Türkic sok-, suq- “sew”, also Cf. ošadïɣï, ošatïɣï “similar, corresponding”
related to “same”, see same. A semantic derivative of
ӧ5-/os- is a pron. ӧša- “that”, “that one (mentioned)”, “as, like, similar, resembling,
compatible”, “this way”, “so, thus, such”. The ӧš-/os- with suffixed demonstrative pronoun
-o formed a type of ӧša/osa with alternating -a, -o, -ï which in turn led to a
loss of the initial vowel, ӧša/osa > šo-, so-, and to a rendering
swa. That metamorphose had been described still in 1920 (Deny J., Grammaire de la langue
turque (dialecte osmanli), §311, §1041. Paris, 1920).
Corollaries: 1. In applications, the emphatic ӧš-/oš- tended to fuse with demonstrative
pronouns bu and ol: ošbu (is) “this”, ošol (passive -l) “that”.
The oš- and ošbu are protagonists for the A.-Sax. swa “so” with š and
b pronounced s and w respectively, peculiar to the E. European and Gmc.
articulations. The basic form ӧš-/os- > A.-Sax.
swa elided indigestible ӧ-/o carrying a rich throve of meanings from their Türkic
ancestors. The prosthetic g- (gleam) and h- (Helios) point
to Oguzic articulation with an initial consonant/semi-consonant. A prosthetic initial h- is
peculiar to Aral-Caspian area, now carried by Bashkir vernaculars. 2. A Türkic adverb
a:z/az “few, scanty, little, rare” is semantically and phonetically a reflex of ӧš-/os-,
and may have a shared ancestry.
It is held as an independent lexeme. Treated as two forms of an allophonic verb a:z/a:r- with
s/r split, its basic notion is “macerate, slimmer”, which produces derivational “few”, i.e. it
is synonymous with “some”. The form ar of a:z/a:r- also produced an Eng. conj. “or”,
see or. Either etymology is sufficiently substantiated via attested ӧsüm or attested
a:z as azam, semantically equivalent to “some” without appealing to any faux
“proto-roots”. 3. A personal pron. ӧz “self, own” that parallels ӧš- and a:z.
Its function as a personal pronoun “self” echoes the demonstrative pronouns of the ӧš-
“that”, “that one”, “same” and “some”. The lines ӧš- and az were found to be the most
ancient. Only their pale traces remain in Europe. 4. An interrogative relative pronoun kim
under k/s alternation would also fit the bill: sim (adv.) “what, degree”. In any case,
an “IE” stipulation that “some” is a form of “same” is not needed. Among 44 European languages, a
Türkic root ne-, neke- predominates with 16 (36%) languages, followed by Romance algu-
“some” 7 (16%) and Türkic ka-, ka:- “some, how, which? what?” 4 (9%), and then by Türkic
ӧš- “some” 3 (7%) and Balt. da- 3 (7%) languages. The remaining 12 languages use 10 their
own different native words. Originally Türkic roots are shared by 23 (52%) of the European
languages, matching a 50.6% R1a/b demographic presence in Europe.
Cognates: A.-Sax. sam, sum “some”, OSax., OFris., OHG sum, ONorse sumr,
Goth.
sums, Du. sommige, Sw. somliga, Icl. sumir. Distribution: Is
confined to a small fraction of the Gmc. languages, attesting to a guest status in the hosting
languages, all of which have their own native synonyms. Within Gmc. languages it may be dialectal,
or survived only in derivatives or compounds. No “IE” connection, the proposed “PG” and “PIE”
“restored proto-words” are doctrinal phantoms. In contrast, the Türkic pronoun ӧsüm is an
attested reality. The properties of exclusivity provide an exceptional ethnological diagnostic value
independent of biological genetic tracings. Within a framework of a relatively late Corded Ware
period, it was a late acquisition, probably no earlier than the second mill. BC. At the same time,
the phonetic and functional parallelism within the cluster os/ӧz/az/ar/kim is striking, it
suggests a primeval common origin. That would point to the word's belonging to a very early period
of linguistic evolution, and would help to explain the indiscriminative nature of the A.-Sax.
internalization. The swa was a latecomer to A.-Sax./English, it took eons for it to supplant
the native hwilc ubiquitous for the A.-Sax. See as, same, so.
1.16
terra, terrain (n.) “grounds, ground for training horses” ~ Türkic tera, terä (yeri)
“valley”, teriŋ, tirän (n.) “valley, lowland”, ter- (v.) “pasture”.
A prime notion is ultimately connected with terä “lowland valleys of mountainous terrain”, a
derivative of a verb ter- “graze”, from a noun-verb
ter/ter- “toil, collect, scoop”, “scoop” ~ “graze”. A paired idiom terä yeri, in Eng.
terra earth “valley land, place, land” reflects one of several flavors of the idiom, see
earth. With various suffixes of grammatical modifications (verbal, nominal, adj., possessive,
etc.) semantics shifts, hops, and expands. A homonym of tera, terä is deri, tere, ter
“leather, skin” that stands for “surface”, making them likely cognates, see derma, leather.
The largely synonymous terra and earth came to Europe via different channels, one
ended up on a path leading to Lat. or Romance languages, the other leading to the Gmc. languages.
Thus, of the paired terä yeri, the
terä was internalized by the Romance group, and yeri was internalized by the Gmc.
languages; the terra came to Eng. via Lat. The Old Europe languages retained versions of
their native term zem-. Of 44 European languages, 14 (32%) use allophones of Türkic ter-
and 8 (18%) use allophones of Türkic > Lat./Romance terra, for a combined 22 (50%) languages,
matching a level of 50.6% R1a/b demographic presence in Europe. 13 (30%) languages use allophones of
the Old Europe Sl.
zem-, and the remaining 10 (20%) languages use their native 9 different words. There is no
common “IE” term; instead stands a nearly Pan-European Türkic ter. Cognates: A.-Sax.
ðorp, ðrop “farm”, ðerscan “thresh”, OFris thorp, Fris. terp “farm”, ONorse
ðorp “farm”, MDu, Du. dorp “farm”, OHG, Gmn. dorf “village”, Goth. þaurp
“field”; OCS trezati (трѣзати) “pluck” (~ graze), Rus. trava (трава) “grass”,
trepat (трепать) “thresh”, Slov. trzati “graze, pluck”; Eng. place names ending in
-thorp, -thrup. No references to Distribution: Eurasian Steppe Belt plus 3 out of
10 Indo-European branches. No references to any cognates outside of Lat., Gmc. confines, no listed
Far Eastern connections, a perennial consequence of intentionally primitive myopic horizons.
Nowadays an international word found across the globe, Cf. Jap. tera, terein (テラ、テレイン),
Hu. terra, terep. An assertion of an “IE etymology” of an origin fr. a faux “PIE proto-word”
*ters- “dry” (but Pers. xofki “dry, dry land”, Sl. suh-, sush (сухой) “dry”) is
way beyond incredible, on a level of a wild goose chase like terry or terse. Compared
with semantics of “valley” or “lowland” pastures, an appellation “dry” is delirious. An appeal to a
faux “PIE root” *treb- “dwelling” is bogus, its supposed underlying “tavern” is a derivative
of a Türkic
tavar “goods”, see tavern, ware. All machinations are offensive to science. The
non-grammatized verb ter- must ascend to pre-domestication times, when hunter-gatherers'
prime concern was pasturing animals. It spread far and wide, becoming a focus of daily life in a
pastoral economy and a most productive stem. Interchangeability of back and middle vowels a-e-o-u
> tar-ter-tor-tur forms allophones and homophones. Semantic fields derived from “valley” ~
“pasture” developed into “land” (terra, territory, terrain), “dry land”, “flat land”, “land
tract”, “valley”, “soil-tilling”, “hard labor”, “stop-over”, “stay over”, “dwelling” (Cf. tower),
“tarry”, “earthwork”, and to “estate”, “village”, and so on. Many derivatives have reflexes in “IE”
languages. Taken as a group, these “IE” derivatives do not find a common etiological stem, they
wander like tipsy sailors on a way back to a ship. The word had reached three European branches by
three independent allochronic paths reflected in different developmental scenes. Some derivatives
came directly from the source language, usually rated as “of uncertain origin”. Others came via Lat.
or French, and thus dead-end at Lat. etymology. Some more are supplied with unattested “IE
reconstructions” of dubious relevance. The English cluster includes numerous words with the tVr
stem: tarry, terra, terrace, terracotta (earthenware), terrace. terrain, terrene, terrestrial,
territory, tower, turf (“surface of grassland”, hence Turfan “pastureland”). The Ir. and
Scots Celts left Eastern Europe before domestication of eutherians, invention of pastures, and of
the term ter. The Welsh apparently migrated after such domestication. The word terrain
carried over a non-adjectival suffix -an (Cf. adjectival Indian, riparian) of its ancestors
teriŋ, tirän and their ilk. The complex of phonetic, semantic, and morphological coherence
vividly attests to an origin from a Türkic milieu and of a certain epoch. See derma, earth,
leather, tavern, turf, ware.
1.17
time (n.), timely (adv.) (Sw N/A, F75, 0.27%) ~ Türkic timin, demin (adv.) “time,
moment, now, outright”.
Ultimately an instrumental case of an adv. tem/tim “just, recently” with few more meanings,
including homophonic “help” with its derivatives. The word belongs to an oldest
lexicon (EDTL 187). Türkic has numerous words to refer to an abstract continuous time, but
except qolu none of them have an element of time measurement: öd, öδ period, moment
(see period); öδla choose, appoint moment, period; öδläk time period, time
(generic); čer season, period; čerig, čerlik suitable moment; oɣur period <
timely; qačan, qaju when; qolu ten second period; rüzgar epoch;
tïδïn moment in time; turum аrа during (period, month, hour); tuš period, all
time; vaqt defined period; zamana epoch, fate. It appears that a notion of certain
time expressed by Türkic timin developed into an adverb timely, and then expanded to
the notions of time duration (hours) and moment (10 o'clock) time (n.), and of a time flow
time (n.). Cognates: A.-Sax. tima “limited space of time”, -tid in
compounds, Fris. tiid “time”, Dan. tid “time”, time “hour”, Dut. tijd
“time”, ONorse timi “time, proper time”, Norw. time “time, hour”, tid “time”,
Sw. timme “an hour”, tid “time”, Faroese tími “hour, time”, Icl. timi
“time, season”, Alemannic Gmn. zimen, zimmän “time, time of the year, opportune time”, Gmn.
zeit “time”, Yid. tsayt (צייַט) “time”; Scots tym, tyme “time”; Fr. temps,
Lat. tempus “time”; Pers. dǝm “moment” (< Tr. dǝm ditto); Mong. dem
“timely (help etc.)”. Distribution: staple in the Steppe Belt spilling to adjacent fringes.
The “IE” family does not have a common stem for “time”. That makes all allophones of the form time
guests from a non-IE family, with peculiar distribution among few Gmc. and Romance groups. There is
no need for “reconstructed” ersatzes. No concocted “PG proto-form” *timon- or *timo or
a faux “PIE proto-form” *dehimo or *dimon- or *dehy- “divide” is needed, the
claimed fictions are eidetic with an attested Türkic timin. The incoherent “IE
etymology” suggests unattested “IE root” *da- “cut up, divide”, an origin from a “tide”, a faux “PIE”
*tempos “stretch” > “time” or a faux “PIE” *temh- “to cut”. The IE-locked queries are
ludicrous, a wild goose chaise in search for a problem. Türkic is a good example on an antiquity of
the notion of time, it had developed 11 discrete references to time, and probably some others did
not enter a dictionary. A.-Sax. host had at least 3 phonetic forms (tima, tiema, tyma) plus a
contracted form -tid in compounds, and at least 8 derivative forms. The semantics and
phonetics of timely, time, and timin suggest down-to-earth etymology without any
long-haul fishing expeditions and phantom conjectures. The time has no relation to cutting or
tides leading to a word that existed in any human society from the days immemorial. A case of
paradigmatic transfer of two time-related words, the timin “time” and öd “period”,
attests inescapably to a genetic origin from a Türkic lexicon. See period.
1.18
woman (n.) “female” (Sw36, F263, 0.07%) ~ Türkic ebe, eve, eme, ebi, ama, ämä (n.)
“wife, mama”, ebi-, ebe-, eve- (v.) “engender, birth-giving”.
Standing European etymological rating is as “of uncertain origin”. A noun is recorded in a wide
range of fairly close forms. Ultimately it is derived from or has produced a stem eb/em
“female genitalia”
and its derivative emig “nipple, teat”, see
tit. A component wo-, wi- in the compound “woman” (A.-Sax. pl. wi-: wimmen)
relays a notion “female” and its siblings, see wife. Since woman is a neologistic
compound, except for the part wo- it does not belong to a category of “basic words”. It
endured a chain of correlated transformations, ebi- > wefi- > wif, where ebi- is one
of allophonic forms, wefi- has added a prosthetic anlaut consonant, and wif is a
fossilized A.-Sax. form for a “woman, female, wife, lady”. The part men > man > -man “adult
human” ascends to a notion “I, me”, see
man.
A Gmc. genderless man “person” fossilized with A.-Sax. extended semantics of “person (male or
fem.), mankind, brave man, hero, vassal, servant”. The word ebe belongs to an earliest period
of the humanity, preceding an appearance of family-based society/relations. It is shared by
genetically distinct lines, e.g. Mongolian (Y-DNA Hg. C ca. 40kya), European (I ca. 48kya, H ca.
48kya), Finno-Ugrian (N ca. 44kya), Manchu-Tungus (O1/2 ca. 40kya), Altaian (R1a/b ca. 24kya), i.e.
migrations ascending to the Out-of-Africa times. Semantically, the term evolved from an earliest
notion aba “senior, dominant” to gender undifferentiated aba “senior relatives” to
gender undifferentiated aba “grandparents, father, mother” to gender differentiated aba,
ebe “father, mother, uncle, aunt, etc.” The notions reflect the social structures of the times.
Only spotty attestations of the earliest semantics have survived to modernity in some linguistic
islets; intermediate traces are well attested; and the later appellations are well documented. The
term reached literate times in two gender-differentiated lines, a male aba and a female
ebe, each in a variety of allophones, 31+ and 15+ respectively. In the 2nd-1st mill. BC the
aba “senior, father, etc.” was supplanted by a newcomer ata “father” which gained wide
circulation across Eurasia (Cf. Lat. atta, Hunnic Attila, Turkish Ataturk)
without impacting ebi “senior female”. There also were Türkic transitions from matriarchate
to patriarchate (ca. 5th c. AD ±2 cc.), which impacted correlation of the terms. Continued
amalgamations of newly confederated ethnicities impacted areal terminology. A.-Sax. had a rich
native vocabulary for “woman”:
-estre “fem. suffix”, heo, bitch, cilfor, cwene/cwine/cwyne, maeg, gemaeg, -oge (<
ebe?), ðir, quean < Goth kwino “prostitute”, spinelhealf “female line
(of descent)”, plus the “travelling term” ebi-/wif. Of 44 European languages, 27 (61%) use
allophones of the Türkic ebe/eme and Eng. ewe, matching a level of the 50.6% R1a/b
demographic presence in Europe. The remaining 17 (39%) languages use their own 15 different native
words. There is no common “Pan-IE” root. Cognates: A.-Sax. eowu “female sheep”, eow
“sheep”, Eng. ewe “female sheep”, Eve “pra-mother” (< Tr. “mother, engender”; Biblical
“pra-mother”), WFris. ei “ewe, female sheep”, Du. ooi “ewe”, vrouwmens
“wife”, a neologistic compound lit. “free-woman person”, Gmn. aue “ewe, female sheep”; OIr.
oi “ewe”; Lat. ovis “ewe”; Balto-Sl. (Lith.)
avìs “ewe”, (Rus.) ovtsa (овца) “ewe”; Fin. еmä “mother (of animal)”, Est.
ema, Hu. eme “ewe, bitch (animal)”; Kuchean (aka Tokhar B, Tuhsi) auw “ewe”;
Nenets (Urak) newe, niemea “mother”, (Tavgi, Nganasan) name “mother”, (Selkup) аmу,
еu “mother”, ima, еmа “woman, old woman”, (Koibal) nemyka “old woman”; Lapp.
(Saami) ibme, ime “uncle's wife (mother's, father's side)”; Ostiak (Khanty) imi
“husband's mother, husband's older sister, mother's older sister, wife of father's older brother”;
Mong. eme, ǝm “woman, wife”,
emege, ǝmeg “old woman, granny”; Kor. emeži, eomma (엄마)
“mommy”. Distribution: Terminological parallels across linguistic borders and geographies
were numerously observed, noted, and attempted to be explained. Although semantics may be area
specific, the spread spans across an Eurasian width. For a phenomenon “of uncertain origin” any
claim of a “reconstructed proto-word” is a quasi-scholastic absurd. There was no need to invent faux
“PG” *awiz “ewe” nor a faux “PIE” *howis “ewe”. By the PG time, the word already
belonged to a very hoary antiquity, its origins and period are fairly clear. The W. Eurasian
turbulence of the 3rd-2nd mill. BC, the two-way migrations connected with the period of the Central
European “killing fields”, the demic displacements, dispersions and amalgamations drove intensive
cultural exchange known only in a fuzzy outline. A mass of social and technological traits was
disseminated extending from Iberia in the west to the Far East in the east. A Türkic-Scythian-Kurgan
tradition related to the notion woman was a single combat between a prospective bride and a
groom, with a bride as a jeŋ- “win” prize (i.e. a “trophy”), as opposed to a statutory (ebe-
“wife”) and a favorite (sevig “beloved”). The A.-Sax. cwen, Eng. quinn, Goth
qens, qeins, qineins, qino “wife, woman” ascend to that ancient tradition, eons before an
invention of the family names. In a chain of innovations, the A.-Sax. wifmann “woman, female
servant” (m., 8th c.) metamorphosed to wimman, wiman “woman-man” (fem.), i.e. exclusively a
“female (adult)”. A.-Sax. used 10 ways to express “woman, wife”, of which 5 were T ürkic cognates (bryd
“bride, wife, consort” < be:r- “bear/carry, give”; wif “wife, woman” ~ eve-
engender”; bert “given”; awe “married woman” < eve- “engender”, Cf.
ewe; cwen “woman, wife, consort; queen” ~ yeŋä/jenä “wife”; gemaeg
“wife, woman” i.e. “of major, close (relative)” ~ ögü:/mögü: (m/b alternation)
“might”); two belonged to the European vernaculars (famne “woman, maid, virgin, bride” Cf.
Lat. femina “female”, but ides “woman, wife”), and at least 3 were metaphorical
extensions (freo, frowe “free”, haemedwif “married woman”, meowle Goth.
mawilo, Cf. maw “mouth”). A complete epithet complex, starting with the primeval aba
and in a wealth of social reflexes has survived only in a body of the Türkic languages, attesting to
a dissemination via a Türkic philological node. See Eve, ewe, man, tit, wife.
1.19
yeah (ay, aye, huh, uh, uh-huh, yah, yea, yeah, yes, yep, yup) (interj.) “affirmative,
affirmative response” (Sw N/A, F47 Σ0.89%) ~ Türkic yah, ye, yeh, de (interj.) “affirmative,
affirmative response”.
There is no common “IE” “yes”, and no faux “PIE” ersatz. In Europe, Gmc. and Sl. are the groups that
follow a Türkic trail. Of 44 European languages, Gmc. (ja etc.) leads with 18 (41%), and Sl.
(da etc.) with 8 (18%) languages, for a combined total of 26 (59%), matching a level of the
50.6% R1a/b demographic presence in Europe. The other 18 languages march to their own tunes with 9
distinct native words. Like Türkic, English has numerous allophones and various spellings. In a
usage frequency rating, Eng. allophones occupy a very prominent place (Table 1a): yeah
(F47, 0.46%), yes (F89, 0.21%), uh (F130, 0.14%), huh (F199, 0.08%), yep
(F1223, 0.01%), for a total of 0.89% usage frequency, or about every 100th word in a daily language.
Table 1a summarily show them under a less frequent, but more formal entry yes. Cognates:
A.-Sax. ge, gea, gese, gise, gyse, ise “yes” (g- ~ ž-, y-) , Eng., Dan., Norse, Sw.,
Gmn., Slov., Welsh, Yid., Latv., Fin., Est., etc. ya “yes”, Serb., Croat, Russ., Ukr. da
“yes” (< Tr. de); Pers. ye “or”; Gujarati ya (જ) “yes”;
Ar. ya: “oh!”; Kalm. dzä, dzǝ “OK, good”. The listing is sorely incomplete since
“IE etymology” does not poke its head beyond the “IE” dome, albeit studies do note strong parallelism of
the “IE” and non-IE vocabularies. Other European forms: Fin. kyllä, Hu. igen, Basque
bai; Lat. imo, Fr. oui, Sp., It.
si, Port. sim; Slovak ano, Lith. taip, Gk. ινα, και, εaν, αλλa, δε
(ina, kai, ean, alla, de), etc.
Distribution: is Eurasian-wide across linguistic borders. “IE etymology” offers a preposterous
origin (for the Eng. “yes” only, not for the “IE” “yes”) from a compound of “so” + “to be” > gea,
ge + si > yea, a desperately bizarre and unrealistic dream. With a complex of attested Türkic
forms there is no need to invent new “PG proto-words”. For the Sl. allophone da and the Gk.
allophone δε (de) it offers an auslaut part of random Gr. words ending in -δη (-dι) <
Tr. 3rd pers. past. tense suff. There is a handful of other, not any less bizarre suggestions beyond
a point of absurdity. A consensus Swadesh List notably carries the “no”, but excludes the “yes”. The
A.-Sax. forms, the Sl. cognate da, and its Gk. version δε (de) with an anlaut
consonant betrays a Türkic Oguric origin. Ditto the forms with an anlaut semi-consonant y-, j-,
dz- (Cf. Hunnic Ogur titles in Chinese 2nd c. BC rendition Chjuki-Prince ~ Türkic jükü
(Hunnic Ogur)/ükü (Oguz) “wise”; Ükü Bek; Luli-Prince ~ Türkic luli
(Hunnic Ogur)/ulu/ulug/uluγ (Oguz) “great”, i.e. Ulu(g) Bek, etc.). The forms with an
anlaut vowel either elided their anlaut consonant or supplanted it with an Oguzic articulation. The
attested allophone ya is a form of the attested Türkic yah “yes” (OTD 252). Although
both are originally Türkic, only one is rated “IE”. The other is a neglected foster child; go guess.
For the English - Türkic pair yeah - yah, the semantic and phonetic equivalence are absolute,
for the other allophones a common Türkic origin is perfectly clear. See no, un-.
1.20
1.1 Personal and demonstrative pronouns (I, me, my, she, us, we,
you, dual plurals, and demonstratives)
Interrogative, Reflexive, Reciprocal, Indefinite, and Relative pronouns are outside of this section
the Germanic-Türkic cognates are highlighted in bold;
the Türkic ikki “two, dual” is seen in Goth., ONorse dual okkar/ugkara and the field of their allophones
the Türkic Oguz b is rendered v and w in Germanic languages;
the Türkic Oguz z, s is rendered þ, ð in Germanic languages;
the Türkic Oguz conjugations are for illustration only, to show nuances lost in conversion
the Türkic sen/sin apparently used to be polysemantic, applicable to the 2nd and 3rd person.
| lst Person | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| SINGULAR | |||||||||||
| Conjugation | English | OE | Türkic | Gothic | A.-Sax. | OSax. | OFris. | OHG | ONorse | Notes | |
| Nom. | I | ik (ic) | ič (ich), es | ik | ic (ik) | ic | it | ik (ihha) | ek | ||
| Gen. | me | min | miniŋ, minüŋ | meina | min | min | min | min | min | ||
| Dat. | me | me | miŋä | mis | me | mi | mi | mir | mer | ||
| Accus. | me | mek, me | mini, minig | mik | mec, me | mic, mi | mi | mih | mik | ||
| Accu. Init. | – | – | minigdin, miniŋtin | – | – | – | – | – | – | ||
| Accu. Loc. | – | – | miniŋdä | – | – | – | – | – | – | ||
| Loc. | – | – | mintä | – | – | – | – | – | – | ||
| Loc. Init. | – | – | mindin, mindän, miniŋdin, mintin | – | – | – | – | – | – | ||
| Instr. | – | – | minin, minniŋ | – | – | – | – | – | – | ||
| Poss. | – | – | minin | – | – | – | – | – | – | ||
| Neg. | – | – | minigsiz, minsiz, | – | – | – | – | – | – | ||
| DUAL | |||||||||||
| Nom. | – | wit | biz (ikki) | vit | wit | wit | – | *wiz | vit | ||
| Gen. | – | uncer | biziŋ (ikkiiŋ) | ugkara | uncer | uncero | – | unchar | okkar | ||
| Dat. | – | unc | bizkä (ikkikä) | ugkis | unc | unc | – | *unch | okkr | ||
| Accus. | – | unc | bizni (ikkini) | ugkis | uncit, unc | unc | – | *unch | okkr | ||
| PLURAL | |||||||||||
| Nom. | we | git | biz | veis (weis) | we | wi, we | wi | wir | ver | ||
| Gen. | us | incer | biziŋ | ös/öz | unsara | user (ure) | user | user | uncar | Var (vor) | |
| Dat. | us | inc | bizkä | ös/öz | unsis, uns | us | us | us | uns | oss | |
| Accus. | us | inc | bizni | ös/öz | unsis, uns | Usic, us | us | us | unsih | oss | |
| 2nd Person | |||||||||||
| SINGULAR | |||||||||||
| Nom. | thou | þu (thu) | sen | þu (thu) | þu (thu) | thu | thu | du | þu (thu ) | ||
| Gen. | thou | þin (thin) | seniŋ, seniŋdä, seniŋdin | Þeina | þin | thin | thin | din | þin | ||
| Dat. | thou | þe (the) | saŋa, saŋar, seŋär | þis | þe | thi | thi | dir | þer | ||
| Accus. | thou | þek (thek), þe (the) | seni, sini | þik | Þec, Þe | thic, thi | thi | dih | þik | ||
| Respectful | you | eow | -üŋ (-jung) | jus | eow | iu | iuwe | iu, iuwih | yor | ||
| DUAL | |||||||||||
| Nom. | – | – | ikki | ös/öz | *jut | git, gyt | git | – | *jiz, iz | it, þit | |
| Gen. | – | – | ikkiiŋ | ös/öz | igqara | incer | *incero | – | *inchar | ykkar | |
| Dat. | – | – | ikkikä | ös/öz | igqis | inc | inc | – | *inch | ykkr | |
| Accus. | – | – | ikkini | ös/öz | igqis | incit, inc | inc | – | *inch | ykkr | |
| PLURAL | |||||||||||
| Nom. | ye | biz | senlar | jus | ge | gi, ge | i, gi | ier, ir | er, þer | ||
| Gen. | ye | biziŋ | seniŋ + pl. aff. | izvara | eower | iwar | iuwer | iwar | yðar | ||
| Dat. | eow | bizkä | saŋa, saŋar, seŋär + pl. aff. | izvis | eow | iu | iu, io | iu | yðr | ||
| Accus. | eow | bizni | seni, sini + pl. aff. | izvis | eowic, eow | iu | iu, io | iwih | yðr | ||
| Plural | eow | eow | jus | eow | iu | iuwe | iu, iuwih | yor | |||
| 3rd Person | |||||||||||
| SINGULAR | |||||||||||
| Nom. | he, she | ol | is, sa | he m. heo f. hit n. | – | – | – | – | |||
| Gen. | him, her | anuŋ | seina | – | – | sin | sin | sin | sen/sin? | ||
| Dat. | him, her | aŋа | sis | him | (sig, sih, sic) | – | – | ser | sen/sin? | ||
| Accus. | him, her | anï, anïŋ | sik | – | (sig, sih, sic) | – | sih | sik | sen/sin? | ||
| DUAL -None- | |||||||||||
| PLURAL of he, heo, hit /// pron. 3 pers. | |||||||||||
| Nom. | they | olar | – | he m. heo f. hit n. | – | – | – | – | |||
| Gen. | them | anuŋlar | scina | – | – | – | – | sin | sen/sin? | ||
| Dat. | them | aŋаlar | sis | him, heom, eom, inc, | (sig, sih, sic) | – | – | ser | sen/sin? | ||
| Accus. | them | olarnï , olarda | sik | – | (sig, sih, sic) | – | sih | sik | sen/sin? | ||
|
Immediate impression shows a time and geography-dependent vanishing cline from basic to complicated. The most basic Türkic pronominals, learned in a childhood or early personal contacts, are internalized with minor changes. The rarer complicated forms are internalized with a loss of grammar and accuracy. The rarest most complicated forms are not mastered at all. Internalization is reduced with geographic distance. Internalizations among oldest ancestors, Goths, ONorse, and A.-Sax., had retained grammatical elements of the the dual form. In Türkic it originally was reserved only for the paired objects, like eyes and river banks; in English it grew to a plural -ss. Those folks also became famous for the most consequential adventures of the Goths, Alans, Vikings, and Northmen. Their aftermath pursues us into the present, including a devastating impact on the Eastern European Khazaria, and the discovery of Iceland, Greenland, and America. |
|||||||||||
1.21
he (pronoun) “male personal” (Sw3, F37, Σ1.41%) ~ Türkic hu, šu (shu) (pronoun) “this, that”.
The Eng. he is a result of sequential diversification and specialization of the universal
undifferentiated basic polysemantic šu
to the allophonic se, he, and on to he and she. The attested h-
allophones heo, hio of the seo are the Aral-Caspian area reflexes ho/hu of the
common Türkic
šo, so, šu. By the 13th c. the form se “he” faded, supplanted by he, while the
forms seo, sio “she” stabilized as she “she”. The transition from the A.-Sax. form
se to
he attests to а significant demographic presence of the Aral-Caspian element in the pre-13th
c. society. The genderless forms se and he continued to coexist till they were forced
into а dominant gender-sensitive grammar, which induced speciation. In a male-dominates society,
likely he tended to become gendered, while se remained genderless, akin to “it”, and
applied to chattel, females, and other property. There was no “shift” of he from the female
to male, in both instances the shift was from genderless to gendered. The Türkic šu is
genderless, it comes in flavors šo, so and šu, with a Sprachbund-originated allophonic
articulation ho and hu. Türkic has at least 6 basic ways to express the demonstrative,
as opposed to the conjunctional, “that”: o/ol, so/šo/šu/sol/šol/šul, leš, te/ti/tu/tet/tes,
an/ïn/un, and
gol; of that lineup, the šu is but one particular form (Dybo A., EDTL v. 9
497-8). Romance languages had inherited leš, an ethnically diagnostic trait recorded in
Chuv., arguably of archaic Bulgar. The A.-Sax. forms of the šu are masc. se, and fem.
seo, the se, seo incorporated into A.-Sax. with the entire semantic bouquet of its Türkic
sibling: personal, demonstrative, and relative pronoun, see so, this, that. The A.-Sax. neut.
personal pronoun ðat, ðaet “it, that” is a part of the A.-Sax. triplet se, seo, ðaet.
It originated fr. a Türkic form Romanized as tet, etymologically unrelated to the form šu.
It is a derivative of a verb te- “tell, state” used for the neut. pronoun “it”, as a
conjunction “that, so that, in order that, after that, then, thence”. It developed into an article
the (Sw N/A, F7, 2.92%). Cognates: A.-Sax. he, heom, hea, heora, hi, hie, hyra, se
“he” (nominal, dative, accusative, etc., forms), the nom. he and se are allophones,
OSax., OFris., MDu. he, hi, Du.
hy, OHG he. The ethnic diagnostic bifurcation points to an amalgamation of the
vernaculars closer to the CT (so/šo/šu) with the vernaculars closer to the Aral-Caspian area
(he, hea, hi, hie). Distribution: smeared across Eurasia, but the relevant form so,
šo, šu is used by a fraction of vernaculars, 7 out of 13 vernaculars listed (EDTL v.s.).
A European fraction is limited to languages enumerated above. Under an “IE” paradigm, ðaet
etymologically is erroneously confused with the origin of the unrelated personal pronouns se
and seo. The “IE etymology” offers a “PG proto-word” *hi- and a “PIE proto-word”
*ki-/*ko-
“this, here” supported by the attested Hitt. (16th c. BC) ki “this”, Gk. sou (σου)
“you”, ekeinos “that person”, Balto-Sl. (Lith.) šis, (OCS) si “this”. The
attested Hitt. ki and Gk. -kei- happened to be allophones of the attested Türkic
(Chuv.)
ko “this” and the OT nominal suffix -oq, with numerous cognates in the Far Eastern
languages (Dybo A., q.v., 493). The Balto-Sl. ši/si and the Gk. sou happened to be
allophones of the attested Türkic form sï “this”, an allophone of the same Türkic šu
(q.v.). Neither Hittites nor Greeks nor Balto-Slavics are suspected to have originated in the Far
East. There is no need to invent PG and PIE “proto-words”. The total overlap of the conjured “PG/PIE
proto-words” with the attested Türkic lexicon carry a ghostlike character, like a shade glued to the
Türkic soles. The carryover of the personal pronouns I, we, he, she is an authentic case of
paradigmatic transfer attesting to a common genetic connection in demographic and linguistic
aspects. The two derivatives of šu, he (0.57%), and she (0.42%), and 3 derivatives of
te-/tet/tes
the (2.92%), that (1.57%), and this (0.95%)” are a most popular group in English, contributing
combined 6.43% frequency usage, that brings a total frequency usage of Turkisms in English to reach
over 50% with some to spare. See she, so, this, that.
1.22
I (pronoun) “1st pers. sing.” (Sw1, F2, Σ5.34%) ~ Türkic ič, es (pronoun) “I, 1st pers.
sing.” (OTD 201, “3. auxiliary postposition I”), self, a semantic extension of the ič “inner,
viscera”. A base meaning of ič is “inside, inner, core” > “self (myself)” > “I”. Homophonic
with ič “drink” (< “drink in”). The pronoun ič is declined as any other noun:
ičinte: beg “I (was a bek)”, balık ičiŋe “I (entered town)”.
The Gmc. Ich, Ih “I”, English I “I” and the attested in Türkic runic script Khazar![]() (ik) Ik “I” are allophonic forms of the form ič “inner”. The same ligature
(ik) Ik “I” are allophonic forms of the form ič “inner”. The same ligature![]() depicts
a particle
ok/ök, a preceding word defines the vowel. In Türkic syntax, attached to personal and
demonstrative pronouns, the ok/ök is synonymous with the pronoun, e.g. (ben) ök “I,
me”. Used in an alien syntax as a separate word, it directly interprets and forms a
notion “I” as a most frequent word. Without vowel indicated, it is up to a reader to
articulate it as
i-, o-, or ö-. In practice, the three articulations conflate to a single accepted
Sprachbund version. The word had a pronounced areal distribution, never used in the
south-east, and long ago waned in the south-west, leaving it to circulate exclusively in the
north-west (EDT, 76). As an emphatic particle particle, it forms the word OK (o'kei), see
OK. The form ič is Common Türkic (Oguz), the phonetic renditions of the Khazar “I”
(likely Ogur) waver between -k and -x (kh): Ik/Ix/Ikh/Ih/Ich. The modern English form
(12th c.) is a contraction of the A.-Sax. ic, 1st pers. sing. nominative pronoun. There is a
semantic grey area between “I” and “me” that points to their interchangeability. The English form is
ultimately derived from the Türkic allophonic form ič via Gmc. ih without voicing and
aspiration. Cognates: A.-Sax. ik (spelled ic), OFris. ik, ONorse ek,
Norw. eg, Dan., Norw. jeg, OHG ih, Gmn. ich, Goth. ik, Icl.
eg; Ir. agam, me ag “I mine, me I”, Welsh wyf; Balt.-Sl. (Lith.) aš,
(Latv.) es, (Sl.) ja; Lat. ego, Fr. Je; Gk. ego (εγω), ekho (εχω)
“I, me”; Fin. itse “me, self” (initially “soul”; Archaic Bulg.
ičurgu, ičirgu “inner”; Mong. ečine “secretly”, Tungus ečesin “turn inside”,
Gold. ečen-, ečien- “ache inside”; Skt. ah(am) “I, me”; Hitt. uk “I, me”.
Except for a more remote Welsh form, all cognates are immediate allophones of the Türkic ič
(Gmc., Celtic, Gk., Skt., Hitt.) or es (Lith., Latv, Sl., Fin., Tungus). Distribution: across
Eurasia; spans Eurasia in a wide ark from Atlantic to Mongolia; more consistent across Europe than
across Eurasia. The “IE etymology” ascends the “IE” forms for “I” to an unattested faux “PIE proto-word”
*eg-, without addressing its source and etymology, and disregarding the crucial Türkic ič
and Türkic connection. That kind of etymology has no use. The Türkic word “me” (min, men, bin,
ben) is an objective form of “I”, it appears to have been in circulation before the appearance
of the word ič as “I”. The Irish compound form is peculiar, it literally combines the
semantics of “inner” with the semantics of “me”. A dictionary should list them separately and as a
compound. The Irish agglutinative agam is a compound of ag “I” synonymous or
homophonous with “inner” and possessive suffix -m standing for “mine”, forming a notion “I”
from the compound “mine inner” distinct from the “inner”. The Ir. analytic compound me ag
serves the same function, it combines the objective form
me of “I” with the discriminant “inner”, creating the notion of “I” from “me inner”. Irish
has preserved frozen archaic forms in agglutinative and analytic syntax versions from the time when,
without a definition “me”, “mine”, the ič still denoted “inner”. They attest to the existence
of the components me and ag in the 6th-5th mill. BC, prior to the Celtic
circum-Mediterranean migration. They allow a peek into the Kurgan culture's prehistoric vernaculars
in the N. Pontic area spoken by the Y-DNA R1b-marked people. The Skt. and Hitt. examples attest to a
presence of the word in a period of 2000 - 1500 BC in locations separated by a half of a continent.
Chances of their independent invention are as would be between Du. and Jap. for the allophones for
“tea”. Considering Indo-Arian migration, the Skt. form is predictable, it reflects a typical s/h
alternation in the Aral-Caspian basin. It could ascend to either ič or es, but it
can't reflect a later Pers. phonology since that is a parallel prong of the 2nd mill. BC Indo-Aryan
migration. Most of the European forms ascend to the form ič, but the archaic Lith. and Latv.
forms differ, pointing to an origin fr. the Türkic phonetic form es. In agglutinative
languages like Türkic and Sanskrit, the 1st, 2nd, or 3rd pers. is indicated by modifying roots with
corresponding suffixes, and the use of the 1st pers. sing. pronoun is minimal. In Türkic, the
objective form of the personal pronoun is morphologically an individual lexeme and a suffix marker,
used individually or in combination depending on the syntax of the sentence. With a switch to the
syntax of the flexive languages arises a need to separate the agglutinated pronoun suffixes into
individual lexemes. The Hitt., Gk., and CT forms are nearly identical. The I, me, and
a host of other roots, pronouns, and derivatives are members of a massive class of pronouns carried
to the A.-Sax. and on to English as a hefty case of paradigmatic transfer, attesting to their origin
in the Türkic phylum. See me, OK.
depicts
a particle
ok/ök, a preceding word defines the vowel. In Türkic syntax, attached to personal and
demonstrative pronouns, the ok/ök is synonymous with the pronoun, e.g. (ben) ök “I,
me”. Used in an alien syntax as a separate word, it directly interprets and forms a
notion “I” as a most frequent word. Without vowel indicated, it is up to a reader to
articulate it as
i-, o-, or ö-. In practice, the three articulations conflate to a single accepted
Sprachbund version. The word had a pronounced areal distribution, never used in the
south-east, and long ago waned in the south-west, leaving it to circulate exclusively in the
north-west (EDT, 76). As an emphatic particle particle, it forms the word OK (o'kei), see
OK. The form ič is Common Türkic (Oguz), the phonetic renditions of the Khazar “I”
(likely Ogur) waver between -k and -x (kh): Ik/Ix/Ikh/Ih/Ich. The modern English form
(12th c.) is a contraction of the A.-Sax. ic, 1st pers. sing. nominative pronoun. There is a
semantic grey area between “I” and “me” that points to their interchangeability. The English form is
ultimately derived from the Türkic allophonic form ič via Gmc. ih without voicing and
aspiration. Cognates: A.-Sax. ik (spelled ic), OFris. ik, ONorse ek,
Norw. eg, Dan., Norw. jeg, OHG ih, Gmn. ich, Goth. ik, Icl.
eg; Ir. agam, me ag “I mine, me I”, Welsh wyf; Balt.-Sl. (Lith.) aš,
(Latv.) es, (Sl.) ja; Lat. ego, Fr. Je; Gk. ego (εγω), ekho (εχω)
“I, me”; Fin. itse “me, self” (initially “soul”; Archaic Bulg.
ičurgu, ičirgu “inner”; Mong. ečine “secretly”, Tungus ečesin “turn inside”,
Gold. ečen-, ečien- “ache inside”; Skt. ah(am) “I, me”; Hitt. uk “I, me”.
Except for a more remote Welsh form, all cognates are immediate allophones of the Türkic ič
(Gmc., Celtic, Gk., Skt., Hitt.) or es (Lith., Latv, Sl., Fin., Tungus). Distribution: across
Eurasia; spans Eurasia in a wide ark from Atlantic to Mongolia; more consistent across Europe than
across Eurasia. The “IE etymology” ascends the “IE” forms for “I” to an unattested faux “PIE proto-word”
*eg-, without addressing its source and etymology, and disregarding the crucial Türkic ič
and Türkic connection. That kind of etymology has no use. The Türkic word “me” (min, men, bin,
ben) is an objective form of “I”, it appears to have been in circulation before the appearance
of the word ič as “I”. The Irish compound form is peculiar, it literally combines the
semantics of “inner” with the semantics of “me”. A dictionary should list them separately and as a
compound. The Irish agglutinative agam is a compound of ag “I” synonymous or
homophonous with “inner” and possessive suffix -m standing for “mine”, forming a notion “I”
from the compound “mine inner” distinct from the “inner”. The Ir. analytic compound me ag
serves the same function, it combines the objective form
me of “I” with the discriminant “inner”, creating the notion of “I” from “me inner”. Irish
has preserved frozen archaic forms in agglutinative and analytic syntax versions from the time when,
without a definition “me”, “mine”, the ič still denoted “inner”. They attest to the existence
of the components me and ag in the 6th-5th mill. BC, prior to the Celtic
circum-Mediterranean migration. They allow a peek into the Kurgan culture's prehistoric vernaculars
in the N. Pontic area spoken by the Y-DNA R1b-marked people. The Skt. and Hitt. examples attest to a
presence of the word in a period of 2000 - 1500 BC in locations separated by a half of a continent.
Chances of their independent invention are as would be between Du. and Jap. for the allophones for
“tea”. Considering Indo-Arian migration, the Skt. form is predictable, it reflects a typical s/h
alternation in the Aral-Caspian basin. It could ascend to either ič or es, but it
can't reflect a later Pers. phonology since that is a parallel prong of the 2nd mill. BC Indo-Aryan
migration. Most of the European forms ascend to the form ič, but the archaic Lith. and Latv.
forms differ, pointing to an origin fr. the Türkic phonetic form es. In agglutinative
languages like Türkic and Sanskrit, the 1st, 2nd, or 3rd pers. is indicated by modifying roots with
corresponding suffixes, and the use of the 1st pers. sing. pronoun is minimal. In Türkic, the
objective form of the personal pronoun is morphologically an individual lexeme and a suffix marker,
used individually or in combination depending on the syntax of the sentence. With a switch to the
syntax of the flexive languages arises a need to separate the agglutinated pronoun suffixes into
individual lexemes. The Hitt., Gk., and CT forms are nearly identical. The I, me, and
a host of other roots, pronouns, and derivatives are members of a massive class of pronouns carried
to the A.-Sax. and on to English as a hefty case of paradigmatic transfer, attesting to their origin
in the Türkic phylum. See me, OK.
1.23
me (pronoun) “1st pers. sing. accu.” (Sw N/A, F10, 1.18%) ~ Türkic min, ben, men, mən
(pronoun) “me”.
Ultimately fr. 1st pers. sing. pronoun bi- “I, me” with a possessive suffix -n.
Male/fem. gender may differ by a vowel. With the b-/m- alternation, me/be, min/bin,
and men/ben belong to the same cluster, and the Türkic and others'
men/ben is as good for “I” as it is for “me”. There is a semantic grey area between “I” and
“me” and their interchangeability in both languages. Türkic min “I, me” is regular, ik
“I” is a metaphoric extension. In English, both forms I and me have equal standing.
Dative agglutination is preserved in meseems, methinks. European languages are strikingly
uniform in their lexicons, of 44 European languages, 37 (84%) and 35 (80%) use allophones of Türkic
men/me “me” and ik/I “I” respectively. Accounting for transposed phonetics and semantics
(“me” for “I” and “I” for “me”) increases further the Türkic component to 95% and 86% respectively.
The remaining languages use their own native terms, 2 (5%) “me” and 4 (9%) “I” respectively. The
predominance of “me” is predicated by its universal spread in Türkic languages, unlike an areal
spread of ik “I”. The universal spread of “me” shows that: 1) European languages did not have
their own related lexical apparatus; 2) or that any of their native lexemes were supplanted by alien
“guests”; 3) all European languages are a product of amalgamation; 4) related amalgamation ascends
to a single domineering source. Out of 44 European languages only 2, Hungarian and Maltese, use
their own terms. They surely are recent (post-AD) additions to the European pool. It is natural that
they came with their own vocabularies. Cognates: A.-Sax. oblique cases of I me
(dative), me, mec, meh (acc.), OSax. mi “me”, OFris. mi/mir, Saterland Fris.
mie, MDu.
mi, Du. mij, ON, Goth. mik, Icl. mer “me”, OHG mih, Gmn. mi,
mich, mir “me”; OIr., Scots me, Welsh mi “me”; Latv. manis (gen.), man
(dat.),
mani (acc.) “me”; OCS mene, Sl. menya (acc.)
“me”; Lat. me, mihi “me”; Gk. eme, me (εμε, με) “me”; Skt. ma-, mama, man (मा),
Av. mam “I, me”; Pers. män, Taj. man “I, me”; Parth. man (sing.),
ma:n (pl) “I, me”; Sogd. mn, män “I, me”; Hitt. ammuk “me”; Mong. bi “I,
me”, mön (deictic demonstrative pron.), Bur. bi “I, me”; Manchu bi “I, me”,
Tung. (Evenk., Even., Oroch., etc.) bi “I, me” (bu pl. “us, we”); Sum. me,
(Emesal) ma(-e), me-a, me-e “I, me”, -me (1st pl. poss. suffix) “our”. Distribution
spans from Atlantic to Pacific. Distribution covers nearly entire Eurasia in all directions across
linguistic borders. The “IE etymology” ascends the “IE” forms for “me” to an unattested faux PG *miz,
*mes, *meke and a faux PIE *me-, *hme “me”, without addressing source, morphological
indicators, and etymology, and disregarding the crucial Türkic sources me/be, min/bin and
historically attested connection with Türkic Kurganians. The fallacious conjecture can't stand. It
is eidetic with the attested Türkic lexemes and solely parrots the widespread original. There is no
need to invent PG and PIE “proto-words”. The “IE” trial balloons do not hold any water and only
propagate disinformation. Neither Gmc. nor Gk. can claim credit for educating the rest of the
Eurasia with their vocabularies. The Balt. (Latv.) forms match the modern Turkmen (Oguz) forms of
the personal pronouns “I” men: “me” menin (gen.), mena (dat.) “me”, meni
(acc.). The Celtic forms attest a presence of the form me before the Celts departed on their
circum-Mediterranean voyage in the 6th-5th mill. BC. The Sum. me confirms a presence of the
form me in the 4th mill. BC Mesopotamia. I and me are two members of a massive
class of personal pronouns carried to the A.-Sax. and on to English as paradigmatic transfer case,
directly attesting their origin from a Türkic phylum. See I, my, un, us.
1.24
my (1st pers. sg. possessive pronoun) “possessive of me” (Sw N/A, F20, 0.87%) ~ Türkic suffix
-m, -im, -ïm, -um, üm (1st pers. sg. possessive pronoun) “of me, mine”.
Its phonetics comes in only 5 forms, while a 1st pers. pl. numbers 15+ forms. A 2nd pers. pronoun
uses -ŋ/-n for the -m, and a 3rd pers. pronoun uses -i/-in for the
-m. Suffix -m is likely a contracted form of the reflexive suffix -min “me”.
That, in turn, is a derivative of bi “me” (b/m alternation) with a marker -r (bir)
for single, an -n (bin/min) for dual, and -z/-s for plural (biz), see
first. The Türkic suffix -m moved up to become an Eng. prefix: аčïm (achym)
> my ache (my ayk). That process is ubiquitous in Europe, where 41 (93%) of 44
languages use versions of -m for my. Gmc. has preserved the best the original Türkic
forms. The Eng. form my is a contracted form of the Gmc. mine that has survived in the
Eng. form mine. Cognates: OFris., OSax., Sw., OHG min, MDu., Du. mijn,
Gmn. mein, ONorse minn, Goth.
meins “my, mine”; Ir., Gael. mo, Welsh 'm, fy (~ by?) “my, mine”; OPruss.
mais, maian, Rus., Sl. moy, muy “mine”, menya (меня) “me”; Lat. mea, meus
“my, mine”, Rum. mele “my, mine”; Gk. mou (μου) “my, mine”, Hu. -szom “mine”;
Kurd. min “mine”; Tatar minem “mine”; Mong. miniy “mine”; Ch. wo de (我的)
“mine” (m/b > w); Jap. wa (私の) “mine” (m/b > w). Welsh
and Hu. retained my as an agglutinated grammatical suffix; the form
mVn is shared by Gmc., Sl., Kurd., Tatar and Mong. Distribution spans from Atlantic to
Pacific, covering nearly entire Eurasia in all directions across linguistic borders. The spread
points to an inheritance from very early times, possibly ascending to an age of Y-DNA haplogroup C
(50,000 YBP) before its numerous downstream mutations. A targeted study may trace its timing and
carriers. An “IE etymology” ascends the “IE” forms for “my, mine” to an unattested faux PG *minaz
“my, mine” and a faux PIE *meynos, moyos
“my, mine” without addressing source, morphological indicators, etymology, and disregarding crucial
Türkic sources min/bin and historically attested connection with the Türkic Kurganians. The
fallacious conjecture is rather ridiculous and can't stand: the earliest recorded cognate is a Sum.
predecessor me “me” attested from the 4th mill. BC. An idea that some “IE's” independently
invented a Türkic word is beyond contempt. The Celtic Ir., Scots, and Welsh forms attest to a
presence of the form -m, mo before the Celts departed in the 6th-5th mill. BC on their
circum-Mediterranean voyage. The continuity of the complex me and my, mine complete
with morphological elements constitutes a case of paradigmatic transfer indelibly attesting to a
genetic origin from a Türkic phylum. See first, me, un, us.
1.25
she (pronoun) “3rd pers. sing. fem. personal” (Sw N/A, F50, 0.60%) ~ Türkic šu (shu)
(pronoun) “this/that”. The Türkic šu is
genderless. The A.-Sax. forms of the šu are masc. se, and fem. seo, the
se/seo incorporated into A.-Sax. with the entire semantic bouquet of its Türkic sibling:
personal, demonstrative, and relative pronoun, see he, this, that. The A.-Sax. ðat, ðaet
“that” originated fr. the Türkic form tet, a derivative of the verb te- “tell, state”,
it was used for neut. pronoun “it”, and as a conjunction “that, so that, in order that, after that,
then, thence”, see that. Functionally, it was included in the triplet se, seo, ðaet.
Etymologically, ðaet is erroneously confused with the unrelated personal pronouns se
and seo.
Cognates: A.-Sax. se, seo “he, she”, heo, hio “she” (semantics shifted
to “he” by 13th c., see he), seo, sio “she” (after 13th c., fem. form of “this/that”).
Shared across Gmc. group, she is cognate with all Gmc. cognates of the Türkic šu
“this/that”, including the Du. zij, Gmn. sie, see this, that. The Eng. she
is a result of diversification and specialization of the allophonic forms of the universal
undifferentiated basic polysemantic šu to the allophonic se, seo, and on to she.
The Balt. (Latv.) preserved supposedly archaic form šis (shis) of šu. The attested
h- allophones heo, hio of seo are the reflexes ho/hu of the common Türkic
šo/šu in the Aral-Caspian area. Instead of the original attested pronoun te-, the English
linguists erroneously link the A.-Sax. ðat “this/that”, which turned into the article the,
with the form of fem. seo. The derivatives of šu “he, she”, and te-/tet/tes
“the, that, this” are a most popular group in English, contributing, 0.90%, 3.21%, 2.16%, 1.04%, and
0.66% frequency usage respectively for a combined 7.98%, and bring the total frequency usage of
Turkisms in English to about 55+%. See he, the, that, this.
1.26
that, this (pronoun) “adjectival demonstrative” (Sw8, F7, 1.96%, Sw7, F14, 0.95%) ~ Türkic šu
(shu), uš, oš (demonstrative pronoun) “that, this”.
A glance at Futhark and Orkhon scripts above shows correspondence between Futhark þ
and Orkhon
so (No.3). The graphics is identical, articulation may somewhat differ; the þ is also
depicted as a handwritten capital D and with an angledbubble of þ. Türkic šu
and its A.-Sax.-Eng. version seo is a genderless, neuter demonstrative pronoun and adj.
“this, that” synonymous with a primeval A.-Sax. articulation se. Anlaut consonant
articulation took graphical forms s-, š, þ, ð, d, t, and more; anlaut vowel wobble i, o,
eo, u, ü, and more. A final -t in “that” is a reflex a Türkic nominal abstract suffix
-t, a final -is in “this” is a reflex of a Türkic “rare” (i.e. archaic) nominal suffix
-ïš, -iš, -š. Inherited semantic range was vague, from emphatic and demonstrative to personal,
frequently augmented by service words. Dictionaries are vague, incomplete, notoriously
interpretational, and limited, incidentally weighted by a trail of notes. Cognates: A.-Sax.
ðat (aka þæt), ðæt (pronounced “that”) neuter sing. of the demonstrative pronoun and adj.
suffix, second form of masc. se, fem. seo “this/that”, þis “this” (masc. þes,
fem. þeos), allophonic with Türkic šu, tet- “that, this, the, he, she”, OSax.
that, these, OFris. thet “that”, this “this”, WFris. dat, Saterland Fris.
dät “that”, dusse “this”, MDu., dat “that”, dese, deze “this”, Dan., Sw.
det “this”, related to Gmn. der, die, das “the”, ONorse þessi “that, this”,
Icl.
það, OGutnish þissi “this”, LGmn. dat “that”, OHG deser “this”, Gmn.
dass, das “that”, dieser, dies, dieses “this”, Goth. þata, þat-ei, þe-ei “that,
this, the”, sah (fem.) “that, this”, (+ jains “that, yon”); Ir. sin, seo, si
“that, this, she”, Scots sin, seo, i “that, this, she”, Welsh bod, hon, hi “that,
this, she”; Lat. talis “such”; Balto-Sl. (Lith., OCS) to; Gk. to “the”; Skt.
ta-; Mong. ter “that, she”; the listing may be somewhat addled and out of sync with time.
Distribution: Across Eurasian Steppe Belt, with a narrow wedge in Europe and a spec in the Far
East Mong. with possible uncited reflexes in Tung. and Manchu. The English “that” reportedly emerged
ca.1200 AD, a pure nonsense in light of the attested trail to the A.-Sax., OSax., OFris., Goth.,
Gutnish, and MDu. forms. An “IE etymology” asserts fictions like a “restored” faux “PGmc.
proto-word” *that, “PWGmc., PG proto-word” *þat (þ = th), a “probably” “North
Sea Gmc. proto-word” *tha-si- <
*þa- + “probably” -s = se “the”, a faux “North Sea Gmc. Proto-base” *þa- “that”
from a faux “PGmc. proto-word” *þat, etc., overlaid on top of a faux “PIE proto-word” *tod
from a faux “PIE demonstrative base proto-word” to- modified with “NW Gmc. Proto-suffix”
-s derived from a faux “PIE proto-word” *so “this, that”. All that deep-thought
equilibristics to reach from a “this, that” to a quasi-scholastic and “reconstructed” “this, that”.
Given the inherited traceable trail, none of that nonsense is attested, needed, or productive. A
diversification from the allophonic forms of the basic šu to the allophonic se, seo,
and to ðat is apparent, ditto for the transition šu > she. The Balt. (Latv.) preserved
supposedly archaic form šis (shis). The A.-Sax. ðat, ðaet was largely a universal
undifferentiated notion with polysemantic applications “that, so that, in order that, after that,
then, thence that, so that, in order that, after that, then, thence”. Semantic differentiation
formed with amalgamation of local vernaculars. A spelling with the initial s- is somewhat
misleading, precipitated by inability of the Roman scribes to convey a quality of the initial
consonant. That was also a reason for a continued survival of the Central Asian runic letter þ.
Derivatives of šu and tet- “he, the, that, this”,
and “she” make a popular group in Eng., contributing 1.41%, 2.92%, 2.89%, and 0.60%
frequency usage respectively, for a combined 7.82%, and bring the total frequency usage of Turkisms
in English to 55+%. See she.
1.27
us (pronoun, objective case, oblique) “plural of we” (Sw N/A, F104, 0.19%) ~ Türkic ös/öz,
üs/üz (pronoun) “self (we, us, selves)”.
Ultimately an expression of “be own”; a suffix -ge makes it “other”, see other. An “IE
etymology” bravely asserts that it knows where the word came from. A generic notion of ös/öz/üs/üz
“inner, core” is declined as any other noun, it is synonymous with a generic notion of ič
(Gmc. ik, ich) “self, inner” that stands for sing. “I”, see I. Use of synonyms
probably developed to avoid confusion, a hazy synonym went extinct. With appropriate suffixes, ös
forms notions “me/us, you”, and “he/she/they”, eidetic with the notion ič that forms the
notions “I, myself”. The preserved semantics of the derivatives suggests that at one time both
synonyms were used interchangeably in a universal line of personal pronouns, and that a speciation
occurred at amalgamation with alien languages. The Gmc. group settled on the semantics “us”. That is
corroborated by the pronoun “you, yours”, a derivative of the pronoun suffix -üŋ, -uŋ. Of 44
European languages, 23 (52%) do have objective case pronouns, the rest is using non-objective “I,
me” forms. Of the 23 “us” group, largest are nas- with 9 members, 8 Sl. + 1 Hu., followed by
os-/us-/ok- (k/s alternation)/on-/un with 8 members, and the remaining a motley group of
6 languages. A majority have Vs- model, a few an NVs- model with a prosthetic anlaut
n-, and a few more have obliques of their own native origins. The European form -os-/-us-
mirrors the Türkic ös/öz, üs/üz as a base root of the oblique us. That matches a 50.6%
R1a/b demographic presence in Europe. Cognates: A.-Sax. us “us”, user “our, I,
me”, OSax. “us” OFris. us, Du. ons, Dan. os, Sw., ONorse oss, Icl.
okkur “us” (k/s alternation), Gmn. uns “us”, Goth. unsar “our”; OIr.
ni, Welsh ni “we, us”; OCS ny “us”, nasu “our”, Bosn., Croat., Cz., Pol.,
Rus., Serb., Slov, Ukr. nas (нас) “us”; Lat. nos “we, us”; Gk. no “we two”;
Skt. nas, Av. na; Hitt. nash “us”; Mong.
örö, öre “gut”, örü “epigastric cavity” (s/r alternation), Kalm. ör, örö
“gut” (s/r alternation); Evenk, Lamut. ur “stomach” (s/r alternation); Sum.
ez “us”; all “us” unless noted otherwise. Distribution: across Eurasia, from Atlantic to
the Far East, deeply ingrained across a width of Europe. Distribution of the allophones of the
-s- and -n- in Europe, Asia and across Eurasia is consistent with N.Pontic serving as a
sanctuary for the motley European refugees from a carnage inflicted during a 3rd mill. BC on the old
European farming populations marked by Y-DNA haplogroups G2a, E1b-V13, I1, I2, and R1a. From a
N.Pontic started a forked migration of the peculiar -n- form to the south-central Asia (Skt.)
and comeback to Europe (Lat., Gk.). Attested timeframe extends fr. 4th mill. BC (Sum.) and 2nd mill
BC (Hitt.) to the present, and on into a future. The “IE etymology” conflates the -s- and
-n- forms into a dubious unattested phantom “proto-word” *ns. It asserts a faux
“Proto-Gmc. proto-word” *uns “us”, and a faux “PIE proto-word” *nes- “accusative and
dative plural of we”, and a faux “PIE proto-word” *ne-, *no-, *n-ge-, *nsme “us”. That's how
the legends are built, from a fireplace story to a print. No “IE” acknowledgement of a preceding
dated Sum. ez “us”. A systemic “IE myopia”. Practically entire European pronoun fund consists
of petals of Türkic flower, with relatively minor exceptions. A dating of amalgamation keeps
sliding, from Attila time down to Gimbutas Kurgan invasion time and on down to a closer to 10th-9th
mill. BC. Development is drifting from anthropology to archeology and on to genetics. A fate of
pronoun “us” also befell to the pronoun “we”, a reflex of the Türkic pronoun biz, bez,
internalized with anlauts b- > v- ~ w- alternations. And to the “me”, an another form of the
same pronoun, internalized from a suffixed auslaut -m, and with anlaut mi-, me-, ma-
(e.g. Tat., Turkmen miŋа bir lit. “bring (to) me”, Uz. menga bering ditto, Kaz.
mağan berşi, ditto, etc.). That degree of myopia can't be accidental or absent-minded, it has to
be concocted and nurtured. An -n- form was active in Gmc., Celtic, Lat., Gk., Sl., Skt., and
Hitt. languages. The OIr. and Welsh -n- forms point to its presence in the N.Pontic as early
as the start of the Celtic circum-Mediterranean migration in the 6th-5th mill. BC. The Sum. ez
attests the 4th mill. BC timing of -s- form. A Türkic origin of the word us, and an
entire pleiad of its kins is beyond any doubt. See I, me, my, other, un, you.
1.28
we (pronoun) “1st pers. pl.” (Sw4, F29, 0.71%) ~ Türkic biz, bez (pronoun) “1st pers. pl.,
we”.
The biz is a copula, the notion “we” is a functional extension forming dual plural (Cf.
biz (ikki) “dual, copula”, and Goth., ONorse vit, OHG wiz “dual we”), which
further expanded to inclusive plural. Ultimately, biz is a derivative of bi “1st pers.
sing.” + -z pl. suffix, with regular alternations b- ↔ m- and -z ↔ -s, Cf. Eng.
pl. suffix -s: sing. thing ~ pl. things. In Türkic daughter and affiliated languages, b-
may also take a range of qualities Romanized as p-, v-, and w-, with further
variations. Cognates: A.-Sax. we, OSax.
wi, OFris. wi, Dan. vi, Du. wij, ONorse ver, OHG wir,
Goth. veis (weis); OIr. mu-idd (-id plural), Welsh ni; Balto-Sl. (Lith.)
mes, ve(du) “we (two)”, (Latv.) mes, (OPruss.) mes, (OCS) my (мы) “we”,
ve “we (two)”; Skt.
va(yam); Av. va(em), OPers. vay(am); Hitt. wesh; Hu. mi, min-k;
Est.
me, Fin. me; Arm. mеk; Ch. wo; Jap. wa-; Mong. bid (бид);
Sum.
me. Distribution: across Eurasia, from Atlantic to Pacific, deeply ingrained across a
width of Europe. An “IE etymology” asserts feigned pedigrees: a faux “PGmc. proto-form” *wiz
“we”, a faux “PGmc. proto-form” *wejes (“?”), a faux “PWGmc. proto-form” *wir (“?”),
and a faux “PIE proto-form” *we- (“?”), a faux “PIE proto-word” *wey “we plural”. All
that nonsense is not needed: it has no address, no timeframe, can't be reverse-verifiable, has no
use, and needs to be gracefully retrieved. Attested evidence shows much deeper roots. Cognates
across Eurasia demonstrate that European and Asian “IE” forms, each with its own flavor, are related
as a subset of underlying forms split along m/b divide that crosses the entire “IE” family.
The m/b split and co-existence extends across both the eastern and western parts of the
Eurasia. A Romance group has its own independent form: Lat. nobis, Fr. nous, etc., Cf.
Sl. nash (наш) “ours”. An oldest on record is the Sum. form of 4th mill. BC, leading to a
proposition that the m- form was a prime form, which separated into m- and b-
lines, with the b- line diffusing into areal b-/v-/w- variations. That is corroborated
by the OIr. m- form. Both the Sum. and OIr. -m forms are datable, the Sum. form by an
appearance of writing, and the Celtic form by the time of the Celtic departure from the E. Europe,
by the 6th - 4th mill. BC. Earlier dates are hinted by R1a genetic traces. Other diagnostic traits
are the inclusivity vs. exclusivity of the word, a presence of the dual form, the interrelation
between the notion “we” and the notions “I/me” and “you”. The
n- forms may putatively ascend to the Old Europe vernaculars prior to the 4th mill. BC, prior
to the period of the “killing fields”. A major overlap between Gmc. and Türkic personal pronouns
shown in
Table 5 provides a vivid attestation of a paradigmatic transfer case, and an indisputable
evidence of a common origin from Türkic vernaculars. See are, I, he, she, us, you.
1.29
you (pronoun) “2nd pers. sing. and pl.” (Sw2, F1, 6.21%) ~ Türkic -üŋ, -uŋ (agglutinated
pronoun) “2nd pers. sing. and pl., +respectful”.
Ultimate origin appears to be fr. notions “front, face” üŋ, öŋ, e.g. “one fronting (you),
“one facing (you)”, Cf. “new face, numerous new faces” for a person or persons. Agglutination
apparently made the pronoun invisible for the experts, Cf. G. Clauson EDT xiv, at best
defined it as an “exact function obscure”. Accordingly, it does not figure in etymological
dictionaries. Reality, in the very same dictionaries, however reflects it, Cf. köŋüŋče
“you think”, kögsüŋ “you throw”, közüŋ “your eyes”,
köŋülüŋ “your mind”, köŋülüŋin “your own mind”, kilimüŋge
“your kilim (blanket)”, süŋüküg “your bones” (Clauson, q.v.). The Türkic syllable is
semantically exactly the same as a detached English pronoun. The initial -ü/-u is most
typical, but can be ï/i/a/ä and more in consonance with the phonetics of the base root. The
auslaut ŋ is typical, but can be g/ɣ/q and more depending on the application: verbal,
nominal, declination, and conjugation; many of them sport component -üŋ-. The wealth of the
different forms, packaged with and among other agglutinated suffixes, is nearly incomprehensible for
alien ears. A most prominent phoneme -ü-/-u- had been internalized and reshaped into the
native grammars and articulations, and then codified into native scripts. In English, by 1450s, a
2nd pers. sing. respectful became a general norm, and the form
thou gained connotation of disrespect or intimacy. In transition to an alien phonetics and
syntax, if not earlier as a Sprachbund norm, occurred a leap from a suffix to a separate
word, and a loss of a nasal consonant. The most basic personal pronouns I, you, he were
internalized in their entirety and verbatim. More complicated forms were internalized partially,
some became indiscriminant 3rd pers. generic (he + she + they), some have retained a native base,
and others have not survived in the host languages. Dual plural for a time was partially absorbed,
but expanded to a generic “both”, breaking the original pinpointed connection with pared objects
like a pair of ears. Cognates: A.-Sax. ge, git (dual), eow, OEng. ye, ge,
OSax. iu, ye, OFris. iuwe, ONorse yor, MDu. ghi, Du. u, gij, OHG
iu, iuwih, German euch; Lith. jus; Hu. ön; Lat. vos, Fr. vous,
Sp. usted, usteres; Gk. hymeis; Sl. vy (вы); Skt. yuyam, Av.
yuzem, Fin. sinua; Mong. ӧngge “front , countenance, complexion, appearance,
color”, öŋe “color, appearance”; all “you” unless noted. Distribution: across Eurasia,
from Atlantic to Far East, deeply ingrained across a width of Europe with SE Asia fringes. In
addition to the Eurasian Türkic languages, the distribution is limited to the European zone and its
fringes, crossing linguistic family boundaries. Saliently, most cited European cognates carried the
Türkic-type indiscrimination between 2nd pers. sing. and pl., a unique trait of paradigmatic
semantic transfer. Essentially, there are no citable “IE” cognates from other “IE” branches. The faux
“PIE” *yu is unwittingly an allophone of the attested Türkic -ü. An idea that the
Corded Ware Kurganians spoke an “IE” language is beyond absurd. And that European people of the Corded
Ware spoke some unknown non-European languages is beyond absurd too. The Lat. and Fr. sport a
prosthetic initial v-, also an earmark of the Sl. languages. Outside of the literary usage in
Eng., and in daily use elsewhere, the pronoun thou, a detached cognate of the Türkic past
tense 3rd pers. suffix ti, continued to be used till present, another case of paradigmatic
transfer. In light of the 2015 discoveries on the genetic composition of the Corded Ware, a
reasonable suggestion would be that the -üŋ > ü
transition happened at the Corded Ware stage, and the Corded Ware inaugurated the pidgin of a blend
of the Turkic and Old Europe vernaculars that lost agglutination and recycled a number of Turkic
suffixes as prepositions that grew to independent words. That was the first draft of the “IE”
family. The use of
ü for both 2nd pers. sing. and pl. also presents a paradigmatic transfer case shared by a
number of the European descendents of the Corded Ware period.
Idioms (Examples found in etymological materials)
Numerous catch phrases are inherited from the pre-literate world, they are idioms peculiar to native languages, often untranslatable literally. Some idioms can be traced to the millenniums-old first literary works, and they are still with us. Few of them even get into etymological works, where they are translated and cited as etymological examples, and viola, some translations look like phonetic distortions of the regular catch phrases. In cases when a word does not have a single synonym, a translation is literally forced to use a cognate word, defeating any biases. In the literate era, these idioms are internationalized by the spread of literature.
English tit for tat “equivalent pain given in return” ~ Türkic tite tit, lit. “pain for pain”, an authentic Türkic idiom. The “IE etymology” does not have a sensible answer for this English expression, or a comic “nippel for a touch”, it is rated as a mystery. See tooth for tooth.
English tooth for tooth “equivalent given in return” ~ Türkic tiše tiš (tishe tish, Turkish diše diš (dishe dish), lit. “tooth for tooth”, a Türkic idiom. See tit for tat.
English eye for an eye “equivalent given in return” ~ Türkic közasa közas, lit. “eye for an eye”.
English (see) eye to eye “to be in agreement” ~ Türkic göz göze, Turkish köz köze lit. “gaze to gaze” (Russian calque s glazu na glaz, lit. “from eye to eye”).
English flea market “street market” ~ calque of the Türkic bit bazary “flea market”. Gmn. der Lausemarkt, Fr. marché aux puces.
A.-Sax. eorðscrafu “earth cave” ~ easily recognizable Türkic compound yerkaba, lit. “earth cave”. A.-Sax. is full of such compounds, Cf. modorcynn “maternal + kin” ~ Türkic mamü + kün, orceard “garden, lit. dug up yard” ~ Türkic or-, ore “dig, dug (ground)” + yer “earth, land”, steopsunu “step-son” ~ Türkic tep- “step” + song “son”.
See also examples in the section Phrases, q.v.: charcoal, greyhound, tooth ache, God
given, I (am) sick, acidic ache, don on me, old geezer, tall (and slim) body. For any distinct
semantics, every additional phoneme added to a string reduces chances for random coincidence by few
orders of magnitude. Beyond 5- or 6-phoneme strings, a chance possibility becomes impossibility. A
chance coincidence of two or more strings is infinitesimally small.
35
2. Morphology (comparing a few of English and Türkic morphological elements)
2.1
-an (suff. pl.) ~ Türkic suffix -an (suff. pl.): erän “men”, oɣlan
“children”, örtän “flames”.
Both Türkic (rare, archaic) and English denote plurality of objects or subjects, defined in English
as “weak nouns” category because they used the -an
suffix. The A.-Sax. plural suffixes -u and -an are not active any more, victims of
continued creolization. They were replaced with a Türkic plural marker -s, which has been
extended to singulars in the old collective sense formerly rendered with the suffix -an:
babes, sweets. See
-s.
2.2
at (prep.) “reference to position, direction, location, or time” (Sw201, F59, 0.35%) ~ Türkic
at- (v.) basic notion “throw at, shoot at”, with a very wide range of extended and metaphoric
meanings including directional, and a wide variation in cases of direct and indirect object.
In some languages at- has almost became an auxiliary verb (EDT 35): A.-Sax. at daw,
Eng. at dawn, Türkic daŋ (dang) at, all “at dawn”,
lit. “poking dawn”. Cognates: A.-Sax. aet (ət), a, ONorse, Goth. at, OFris.
et, OHG
az, Sw. at, Du. te, Afrikaans teen; Lat. ad, Romance a;
Skt.
adhi “near” (?), Gujarati ante; Ir. ag, Est. -ga, Az. -ed, Tr.
-de, -da. The vague A.-Sax. aet grew to cover “near, by, in” plus ~15+ other meanings,
quite a blurred internalization. Eng. uses both -t and -d forms, many of them echo
Türkic-based phrases: adapt < ad + apt (see aptitude), adage < ad + age (see
age > “old saying, proverb”), adequate < ad + equate (see equate), and so on. The
Romance a may be a relict of Burgundian Sarmats' systemic truncation. Agglutinated Est.
-ga may or may not be a form of Türkic directional -de/-da. Another European word for the
directional “at” is i, used in spots by diverse languages, it may ascend to a Balkan
Sprachbund of the Old Europe (e.g. Arm., Icl., Lith.). The simultaneous presence of the form
at/ad in the “IE” languages of Europe and Asia attests to its presence in the N. Pontic as a
directional auxiliary verb prior to the Indo-Aryan 2000 BC migration to the Indian subcontinent. See
and, age, at, aptitude, be, equate, dawn, in, on 1, on 2, till (prep.), to.
2.3
com- (prefix) “with, together” ~ Türkic qon-, ko:n- (v.) denoting cooperative action “with,
together”.
Ultimately from a polysemantic stem qo-/ko:- “all, together”, “stopover”. A qon-, ko:n-
expresses generic “to stop”, “to stay” (from sleepover to dwell) and “bunch together (stopover)”
among other meanings. The semantic component of “bunch together” makes qon-/ko:n- a precursor
of the European com- “with, together”, its antecedent con- (contrary to a claim of a
derivative),
co- (coact, coaxial, etc.). That Türkic component is illustrated by allophones and
derivatives: active deverbal noun konat (konot, qonat, qonot) fr. ko:n- “cumulate,
bunch together, companions”, kontur- (v.) “settle, lodge (together)”, i.e. “cohabit”,
konum (n.) “people living together”, i.e. “cohabit”, kop/kob “all”, koš- “conjoin,
unite (two things), together”, etc. The element qo-/ko:- did not survive as a stand-alone
word, it is well attested in derivatives. The complementary Türkic forms with -n/-m
assimilation (ki:m/gi:m/kem/kemi/kemi) form a credible link to realistic etymology, offering
viable prototype notions. The Türkic etymology is necessary to demonstrate a phonetic and semantic
congruity in Eng., Lat., and Türkic languages. In Europe, the prefix com- and its versions
blossomed into a major word-forming component, occupying a large place in the European vocabularies,
a list of cognates across languages would take volumes. Prefix
con-, com- nowadays is an international component. Cognates: A.-Sax. (ge)com,
(ge)coman, (ge)cuman, comon “come together, arrive, assemble” (ge- “together”); Lat.
com- “together”; Mong. qono- “to stay (together)”, xonača “guest”, qonaq
“guest, overnight stay, lay off stop”, Bur. xonoso “overnight, bednight, sleeper”, Khalk.
xonoč “guest”, honots “overnight sleeper”; in this context “stop, stay, guest” refer to
collective action. In some instances direction of borrowing between Türkic and Mong. etc. is
disputable. Distribution: From Atlantic to Far East. Within European languages, the European
prefix com- is a loanword, that is attested by its limited and peculiar distribution covering
an insignificant number of the “IE” languages. That makes the claim of a “PIE proto-word” totally
incredulous. Unwittingly, the non-attested, imagined “reconstructed PIE proto-word” *kom- is
eidetic with the documented Türkic form. An “IE etymology” stops at Lat. as though Lat. lays at the
root of all languages, a totally indefensible presumption based on its very late (turn of the eras)
dominant status throughout the western Roman zone. The “IE etymology” is notable for its circular
manner, as a prehistory it offers wysiwyg “what you see is what you get” with some
digressions into customary usage. Many words have became international, like cooperation and
convulsion. A fair number combine the Türkic qon-, ko:n- with another Türkic word, like
combat (com- + bat/pat) and coapt (com- + apt). Neither A.-Sax. (but see ge-compounds)
nor Gothic (but see k/s alternation sam < qam) have recorded traces of Türkic qon-,
ko:n-, so a path via OFr. or Lat. may be expected. A separate word in the Türkic syntax turned
in the European languages into preposition (Cf. cum laude) and prefix (Cf. concubine,
lit. “with stranger”). A Türkic preposition would seamlessly transit to a prefix within the chopped
European grammars. The phonetic and semantic concordance expands the short-circuited “IE” etymology
into a world of real linguistic processes. See con-.
2.4
con- (prefix) “with, together” ~ Türkic qon-, ko:n- (v.) denoting cooperative action “with,
together”.
A sibling of com-, see com-. Ultimately from a polysemantic stem qo-/ko:- denoting
“all, together” and “stopover”, among other meanings, qon-, ko:n- expresses generic “to
stop”, “to stay” (from sleepover to dwell) and “bunch together (stopover)”. A derivative form
konat indicates a prior existence of a complementary noun, preposition, or clitic (proclitic)
con (kon, qon) conveying a notion “with, together”. Neither the A.-Sax. nor Gothic used that
element, English acquired it from Lat., possibly via Norman French, thus the prefix con- is
an adstrate rather than substrate, con- is assimilated form of Lat. com- . Its path
via Lat. has bypassed the Gmc. phylum, attesting to an independent route and pointing to dialectally
independent intrusion. See com-.
2.5
en- (prefix) “make, turn into, put into” ~ Türkic eŋ (preposition service word) “in the
beginning, first of all”.
An “IE etymology” does not have any sensible explanation to its origin, the en- just appeared
from nowhere, and etymologists only report the status, referring to homophones like Lat. in-
“in”, Gk. en- “in”. The Türkic eŋ with its allophones developed into the Lat. in-
“in, into” and Gk. en “in”, OFr., Fr. en- “in”. In Türkic and in English, em-
is used before a p (emplace, proclitic) or b (embrace, proclitic). In Türkic and in
English, en- is homophonous with in- and an-, at times they are confused, at
times conflated, at times misinterpreted, which adds a much wider semantic spectrum. It is a formant
for the aspect of initial time in A.-Sax. and then in English, with a notion “to engage”: A.-Sax.anaegilan
“to nail”, anaeðelian “to degrade”, anbidian “to expect”, Eng. enchant “engage
in chanting”, encharge “engage in charging”, enact “engage in action”, encamp, enrage,
enable, encage, entail, etc. The prefix en- should not be confused with a preposition en,
an allophone of the Türkic en- (v., prep.) “descend, come down, sloping down, inclined down”
used in idioms “en route”, “en rule”, “en suite”, “en vogue”, etc. Those came to Eng. via Fr.
Semantically, the roles of the Türkic eŋ, Eng. en-, and A.-Sax. an- and en-
are the same. In A.-Sax. en- and an- stand for “and”, “un-”, “in-”, and “on-”, with
most lexicon predating and independent of a Lat. influence. Similar disarray had occurred with other
European languages, pointing to dialectal phonetic and semantic variations of the adopted sources.
Cases of vague semantics are rather exceptions, like the insure and ensure.
Undoubtedly, the Gk. and Lat. were instrumental in spreading eŋ across the European
languages, but neither Gk. nor Lat. originated it nor borrowed it from A.-Sax. It is tempting to
ascribe it's origin to the Sarmats of the 2nd c. BC, but the roots extend much deeper. The eastern
“IE” languages do not share this prefix, in Hindi and Urdu the role of the European en- is
performed by particles da- and daa-, allophones of the Türkic directional suffix
-ta/da-. That makes it impossible to claim a common origin with the European languages. That
sets an upper limit on the earlier date as post-2000 BC, an Indo-Arian outmigration. What unites the
Türkic, Eng., Lat., and Gk. splits the “IE” paradigm. The Türkic etymology offers semantic explanation
for en/en-, on/on- and in/in-, with further extensions to derivative adverbs and
adjectives. The trio belongs to a massive case of paradigmatic transfer of morphological elements
from Türkic to Eng. See in, on.
2.6
-er (deverbal, conjugational suffix) ~ Türkic -ar/-er/-ır/-ir/-ur/-ür aorist suffix (past
tense) deverbal nouns; Türkic complimentary er/ir/ar/härä (n.) “-man, -warrior, -sire”.
A difference between suffix and postposition is purely conventional; a homophonic postposition er
“man” in many cases might as well be taken for a suffix in a compound: udčï-er “shepherd”,
kеjikei-er “hunter”, etc., identical to the Eng. doublet of suffixes -er/-or and -man
(e.g. teacher, craftsman) (OTD 175). Eng. semantics
extends to a general instrumental suffix: stapler, machinery. In the modern times, it grew to a
global spread, Cf. computer etc. As an agent noun suffix it is widespread in Europe, with
allophones -or/-ar/-ir etc., Cf. Lat. -or. In the original sense of power, might,
superiority, it lives in the prefix ar-: arch-, archi-, archon, architect, etc., fr. a Türkic
root arqa “spine, hillock, hill, ridge, slope, mountain”, see
arch. The Eng. suffix -man indicates an agent noun, a human,: teacher, butcher etc.,
from the Türkic root er/ir “man”. In the exonym German “manly” or rather “very manly”
fr. the Türkic erman “very manly”, the -man is an emphatic suffix. The noun “man”
comes with at least ten semantic clusters and an astonishing variety of allophones, from ar
to ey and from
härä to herr and wer, attesting to deep antiquity and a rainbow of receptor
languages from Atlantic to Pacific. Cognates: (re: “-man”): A.-Sax. wer “man”,
here “troop, army”, ONorthumbrian -are; Dan. -ere, Sw. -are, Gmn.
-er, herr; OGk. ‘ερως (eros) “hero”; Scythian (5th c. BC) eor “man”; Mong. ere
“man, male”, MMong. ere “army”, Dagur er “male adult, husband, true man”; Tungus
ur “man, male, sire”; Manchu erke “manly”, Jurchen ere “patriarch”; Ch. err
兒 “male child, boy” (N.Bichurin, “Collection”, Vol.1, 46, Note 3). Distribution of the word
is truly Eurasian, from Atlantic to Pacific. In Eng. the suffix is generally used with native Gmc.
words, in Sl. languages it became -el after verbal infinitive suffix -t-: vodit (водить)
“lead” > voditel (водитель) “leader”. At the Herodotus' time, Scythians called their man
“er”, cited in the word Eorpata (Οιορπατα) with a part eor “man” (Herodotus IV 110),
see bat. The Scythian form pata “strike” and its Sumerian precursor bir-, ber-
also survived in Eng. as the words bat, beat. The Sum. form bir-/ber- is attested fr.
the 3rd mill. BC. The Scythian phonetic form rendered as eor reflects the Ogur articulation
yer/yir/yar with a prosthetic y-/j- in the anlaut, rather than the Oguz form er/ir/ar.
The Herodotus' form
eor is probably a reasonable rendition of the form wer, and the name Sax, Saxon
is a reflex of the ethnonym S'k “Scyth, Sak”. See arch, bat.
2.7
-ish (adj. suffix) ~ Türkic -čа/-čä (-cha/-che) (adj. suffix). Both Türkic and English
suffixes form adverbs, adjectives.
Cf. Eng. small > smallish, Tr. kičig (kichig) > kichigčа, Eng. Turk > Turkish,
Türkic Türk > Türkčä. Cognates: A.-Sax. (OE) -isc, ONorse -iskr, Gmn.
-isch, Goth.
-isks; Gk. -iskos. This suffix is absent in other “IE” languages, except the
Slavic-Russian, which retained exactly both phonetic and morphologic function of the Türkic
-čа/-čä: e.g. logics - logical logica - logichno (adv.) logichnyi,-en
(adj.)
(логика > логично, логичный, -ен). The Gk. allophonic form and function
is just another Gk. adoption or retention of the Türkic linguistic elements. If not earlier, it
could be spread across Gk. vernaculars by the N. Pontic half-Greek, half-Scythian speakers
(Herodotus 4.108).
2.8
-like (suffix) “like” ~ Türkic -lig/-lïɣ/-laɣ (suffix) “like”.
An A.-Sax. suffix -lic is an exact twin of the Türkic suffix -lig. Like the English
-like (antlike, beelike, etc.) the Türkic -lig is agglutinated to the stem to express a
notion of abstract similarity or possession of some property or quality of the root object: eŋ
“cheek” ~ eŋlig “cheeky”; erk “power” ~ erklig “powerful”; teŋlig
“measured-like (manner)”, tepizlig “marsh-like”, etc. A Türkic allophonic suffix is
-laju/-läjü (phonetically -laü) “like”, e.g. adïɣlaju “bear-like”. Apparently, in
-laju the auslaut consonant was truncated, replaced with a semi-consonant or a -g,
typical for the western Ogur languages. The A.-Sax. reduced the wealth of the Türkic like-type
forms articulated with front and rear consonants and vowels and used according to the vowel harmony
rules and grammatical conventions (-liğ/-lığ/-luğ/-lüg, -lik/-lık/-luk/-lük, -leč/-la:č/-lıč)
to a single form -lic, simplifying grammar, semantics, and phonetics. That simplification is
typical for creoles. Eng. has about 750 compounds with a popular suffix -like. Cognates:
A.-Sax. -lic, gelic “like, similar”, -lic appears about 1100 times representing about
4% of the Clark-Hall 2011, Anglo-Saxon Dictionary (about 20,000 words); OSax. gilik,
OSw. gilik, Norse glikr, Du. gelijk, Gmn.
gleich, Goth. galeiks “equally, like”. Cognates are built on the Türkic model with
numerous synonymic expressions for the notion “like”: оsuɣluɣ “like”, ančulaju
“such, resembling”, jölästürgülüg “compared, resembling”, munčulaju
“such, resembling”, and more. They convey formed from disparate roots adjectival notion “like” by
agglutinating allophones of the suffix -lig. The A.-Sax. and its daughter languages (OE, ME,
Eng.) retained the functional suffix -lig/-like and extended its function to different
grammatical functions of noun, verb, adj, and adv. Both in Türkic and Eng., a compound form serves
as a noun- or verb-derived adjective. Distribution: Cognates are confined only to the Gmc.
branch, no “IE” cognates whatsoever. The phonetic, semantic, syntactic, and morphologic similarity is
persuasive, in contrast to artificial and superficial “IE” attempts to derive an Eng. -like
from a homophonic (lic, lich) but totally unrelated “body”, “corpse”. Such intractable
suppositions heighten doubts about credibility of entire “IE” paradigm. The prefix ge-/ga-,
initially “with, together”, forms past participles. It is irrelevant to the suffix -like and
its allophones. The ubiquitous presence of the allophonous prefix ge- in the Gmc. languages
attests that these languages at one time formed their own Sprachbund with shared distinct
morphological features. The element -like is a salient member of a substantial body of
morphological elements constituting a massive case of paradigmatic transfer that vigorously attests
to its Türkic origin. Not formally accounted against a frequency usage of the Eng. Turkisms, they
still add mightily to the proportion of the Türkic inheritance in English, Cf. a respectful 4% in
the A.-Sax. vocabulary, probably much less in Eng. usage frequency contribution.
2.9
omni- (prefix) “all, everywhere” ~ Türkic omqï, omqu, umax, yimaɣ (adj.) “all”, lit.
“collected, gathered”.
Under “IE etymology” the word is either rated “of unknown origin” or of a “perhaps” type. Ultimately
a derivative of
om-, yom-, um-, yum- “collect, gather” formally rated as long-dead “Proto-Türkic”, but richly
furnished with presently active derivatives. The out of circulation word omqï/umqï and its
allophones (yomqï/yumqï in Ogur articulation) is an archaic word recorded in the OT and early
Middle Türkic periods. The omni-/omqu and total/tutuš share their fate of both being
the Türkic relicts, both apparently came to Europe with the Latin migrants. During the Middle Ages,
on the British Isles, they rejoined their originally Türkic A.-Sax. synonyms. On top of the somewhat
murky Türkic archaic inheritance, the trace of the Lat. relict allows to gain a view of the
Proto-Classic processes. Eng. has about 100 compounds with omni-. Nowadays prefix omni-
is an international word. Cognates: A.-Sax. (ins)omnian “gather in”, (aets)amne
(adv.) “united, together, at once”, (tos)omne, (tos)amne (adv.) “together”; Goth.
(ga-)qiman “assemble, come together”; Lat. omni-, omnis “all, every, whole, every kind”,
rated “of unknown origin”, but with a pedigree of the modern international word disseminated by the
modern science; Gk. mazevo (μαζευω), mazi (μαζι) “gather, together”. A phonetic spread that
reached a documentation stage covers both western and eastern (i.e. Türkic) spreads in the Eurasia.
The A.-Sax. composite
ymbcyme, ymcyme “assembly, convention” with cyme “come” reflects the Türkic om-
“collect, gather”, lit. “come to gathering”. An “IE etymology” came up from an “unknown origin” to a
speculation of ascending to the notion “work, produce”, based exclusively on an alleged phonetic
consonance, quite a desperate proposition. In contrast, the Türkic-based etymology is supported by
direct phonetic and literal semantic correspondences. All in all, English is using five of the
Türkic 32 ways to say “all”. That is quite an impressive case of paradigmatic transfer. See all,
entire, gamut, total.
2.10
on 1 (prep., postp., adj., Norse adv.) “on top of” (Sw N/A, F26, 0.73%) ~ Türkic ö:n, öŋ (n.)
“top, front (frontal part)”.
Ultimately a semantic extension of the noun ö:n “front, forepart, frontal, beginning”. A top
of a well is its front, for one example. Besides “top, front”, the polysemantic öŋ carries
another eight semantic branches with their own derivatives, e.g. öŋ “before, previously”, see
once. A largely synonymous directional suffix -ta, -tä, -da, -dä, -δa, -δä is more
concise, Cf. üstte “on top”, yerde “on the ground” (yer “ground”). With a
signal economy of material, Türkic has a complementing contrasting cousin in/en (n.) “bottom,
descent”, see in. Admittedly, öŋ and in/en are coevals from the same archaic
period. Except for few Türkic languages, the notion “top” was largely supplanted by the words
jer, orü, üst, üzä, and forms with directional suffix -ta/-da, Cf. Türkic onda
“there, then”, tepede “on the top” (töpü “top”), Cf. Eng.
onto “to on, on top of”. The ö:n/öŋ lives on in derivatives, Cf. öndün “ahead,
in front, forward, advanced”. In Eng., the fuzzy and fuzzily differentiated A.-Sax. on “on,
at, in, to, for” was widely supplemented by a cousin “in”. Like with in/en, the Eng. on
is a universal preposition, postposition, adverb, and adjective, with a wide spectrum of semantic
meanings: about, along, during, in, upon, with, active, etc., something activated or coming along.
In some applications, a blurry semantics of both on and in overlaps, confusing a
grammarian and a homegrown expert. The process of speciation continued well into the 2nd mill. AD.
The A.-Sax. on carries on the semantics of the Türkic ö:n “top, front, beginning”.
Semantic and grammatic haziness are symptomatic for the entire Gmc. group. Out of 44 European
languages, an -n- form predominates in Vn, nV, and Vm- forms (n ↔ m)
with 21 (48%) languages, approaching a level of the European 50.6% R1a/b demographic presence in
Europe. The remaining 23 languages largely use their own forms. Cognates: A.-Sax. aen, an,
on (prep.) “on, upon, during, at, about, against, towards, according to”, (adv.) “forward,
onward, continuously”, (prefix) aen(laenan), on(laenan) “lend, grant”, onbaec
“backwards, back”, Du. aan, Gmn. an, Goth. ana “on, upon”; Lat.
an-; Gk. ana (ανα) “on, top”, ano (ανω “up, top”); Av. ana “on”;
OCS na “on, upon”, nai- (prefix) “top”; Mong. ӧnge “frontal part”, ӧmïne,
emüne “front (frontal part)”. Distribution: Allophones of the forms on and pa
(Sum. ba “in”) predominate across Eurasia. Spread of the ba- is peculiar: Dan., Sw.
pa, Fris. op, Fin. päälle, Hu. tovabb, Rum.
pe. The Türkic form ö:n “top” has survived in the Uigur and Uzbek languages of the
Karluk group. There is no sensible “IE” explanation for the origin of on. The ideas of the
faux mechanical constructs like “PIE proto-root” *hen- and/or “PG” *ana “on” are
dubious, not needed in light of the attested Türkic originals. These “IE” fabrications need to be
rescinded for a sake of scientific credibility. That leaves no “IE” etymology, grammarians and
curtailed-purview etymologists act as confused observers. A similar “IE” etymological cacophony
surrounds the origin of in (prep.). The directional on, in, and at are
notoriously confused in daily life, vernacularly adding to a semantic spectrum. A direct comparison
of cognates is etymologically muddled, similar phonetic forms are semantically conflated, and any
type of movement in any direction is thrown into a same phonetic pile with little attention to a key
message. The Türkic etymology offers semantic explanation for both on (prep.) and in
(prep.), with further extensions to adv.s and adj.s. These prepositions have clear and discrete
semantic meanings, aiming to a higher state vs. a lower/inside state. An absence of the Celtic
cognates and the Gmc. convergence of the European cognates attest to either an absence of the word
at the time of the Celtic departure from the N. Pontic ca 5000- 4000 BC, a dubious premise, or an
dialectal -r/-n alternation. A presence of the word in the Av. attests to its European
presence at the time of the Indo-Aryan departure ca 2000 BC. That points to the Corded Ware hub as a
source of the European and South-Central Asian internalization. A healthy half-dozen of the Eng.
directional prepositions irrefutably draw their origin from a Türkic milieu. The Türkic origin is
the only realistic outcome. See and, at, be, in, on 2, till (prep.), to.
2.11
-s/-es (pl. suffix) ~ Türkic -s, -z, Chuv. -sem (pl. suffix).
Ultimately an archaic dual marker that survived to generic plural. Shared by Mong., Tung., Eng., and
Türkic; other users are omitted. Both Türkic and Eng. suffixes denote plurality of objects or
subjects and mark possessive case, see “-'s possessive”. The archaic suffix is now is
present only in some Türkic words, like biz “we” vs. ič “I”, ulus “people”,
qos, qös “pair” and is most actively coupled with other suffixes or particles: -ŋïz/-ïŋïz,
-dïmïz/-tïmïz, -mas/-mäs/-maz (-ma “negation” + -s/-z pl.), etc., Cf.
örmaz lit. “grow not they”, i.e. “they do not grow”, Cf. Fr. pas “not, negation” ~
-mas/-maz. Other archaic Türkic plural markers are -t/-ty, and -an (-lan) denoting
collectivity: bajaɣut “affluents”, oglan “boys” Cf. cognate
clan. A marker -an, -en is a Türkic and European staple, defined in Eng. as “weak”
nouns (i.e. regularly inflected) category because they used the -an suffix. Cognates:
A.-Sax.
dæg “day" > dagas “days”, us “us”, maennes “community”,
asegendnes “offering”; Du. -s plurals, Scandinavian -r plurals (rhotacism): Sw.
dagar “days”, Gmc. us, OSax., OFris. us, ONorse, Sw. oss, Gmn. uns
“us”, Goth. harjos “armies”; Sl. nas “us”; Lat. aves “birds”, collatus
“gather together”, montes “mountains”, nos “we, us”, omnis “all, every”,
testes “testicles”; Skt. imas “we go”; Mong. bide “we” (bi- “1st pers.
sing.” + pl. suffix,
z/d alternation), ayas “sounds”, zalgas “false braid”; Tung. bu “we”,
Manchu
biz “we” (= Tr. biz “we”), Evenk., Even., Solon., Negid. etc. bu “we”; Kor.
uri (< buri) “us, our”; Sum. ez “us”, šeš “siblings” (pl. daughters?) ~
Etruscan sech “daughter” ~ Hu. süz “virgin” (= Tr. kïz “girl”).
Distribution: from Atlantic to Pacific, across linguistic borders. Under an “IE” paradigm, the
Gmc. –s/-r declension is a peculiarity traceable to a presumed PIE inflection system. That is
a pure nonsense given the Eurasiatic spread reaching from Atlantic to Pacific, vs. a sporadic nature
among the “IE” members. In Türkic, rhotacism is connected with the Ogur (Western) languages:
Scythian, Sarmatian, Hunnic, Bulgar, Tatar, Halaj/Alat, etc., albeit the nomadic east-west concepts
are very fluid. The A.-Sax. plural suffixes -u and -an are not active any more,
victims of continued creolization. The process is not over yet, the plural marker -s has been
extended to singulars in the old collective sense formerly modified with the suffix -an:
babes, sweets. Both Türkic and Eng. did not use plural markers if plurality was conveyed by other
means: 3 sheep, 6 o'clock, 2-pound note, 7-year period. The continued creolization tends to add
plural marker -s to these plurals: 3 sheeps, 6 o'clocks, 2-pounds note, 7-years period. See
-an, -'s “possessive”.
2.12
-'s “possessive case suffix” ~ Türkic -si, -sï “possessive case suffix”.
Türkic possessive suffixes tally 18 clusters containing about 72 forms; the -si is one of
that crowd, or 1/72th of the total possessive phonetic wealth in a single morphological category. Of
that wealth, Eng. internalized a miniscule 2 (two) markers, -s and -n (in “mine”).
Türkic examples are ma:masi, mamüsi, annesi “mother's”; atası,
dedäsı, babası “father's” vs. Eng. “mother's, pop's, his, hers, theirs” etc. The
poss. -s was adopted as a Pan-European trend across brunch and linguistic barriers. Of 44
European languages, it is used by 29 (69%) languages. The remaining 15 (31%) languages use versions
of their own 10 forms; some of them may use alternate Türkic poss. markers, poss. -s/-z in
their compounds, or a truncated form -i.
Cognates: A.-Sax. –es: fæder (sg.), fæderes (gen. sg.) “father’s”,
windel (sg.) ~ windles (gen. sg.) “basket’s”; nations of 29 European countries; Uig.
tašı, Salar. (China's Qinghai, Gansu) tası “its outer side (of a wall)” (~ Tr. taš
“wall”). Distribution: from Atlantic to Pacific, across linguistic borders. A codified suffix
-'s is a contraction of A.-Sax. -es < Tr. –si, the apostrophe “’” is a
conventional scribal for -e- unrelated to the verbal form. Other relevant A.-Sax. suffixes
-e, -re, -an (gen.), -a, -ra, -na (pl.) etc. have vanished. It is peculiar that the -'s/-es
/-si have survived while the others have vanished. A similarly notated possessive marker may
have been used by prior populations. See -s/-es (suffix pl.)
2.13
to (prep.) “verbal marker of infinitive case” (Sw N/A, F3, 3.12%) ~ Türkic te-, ti-, de-, di-
(v.) “say” (plus 9+ other forms).
The verb numbers 12 semantic clusters and ca. 40 meanings. The subject's ultimate verbal semantics
comes fr. clusters of intentions and desires, the clusters 4, 5, 6, 7, 8 and 12 (EDTL v. 3 221): a
verb expressing intention. The verb is a grammatical function verb and auxiliary verb of action,
functionally eidetic to the Eng. infinitive case pair to and
do. Peculiarly, the semantics of “tell” and “say”, unique to the Türkic languages, in English
is the same but inverted: a Türkic te- “tell” is Eng. “say”, and a Türkic söy- “say”
is Eng. “tell”, see tell, say. That inversion has a tracing potential: Eng. neighboring
populations have their own developmental traces. A sibling of te- is a verb tur-/dur-,
Chuv. tu- (v., truncated form), “do, act”.
Among other derivative notions, a polysemantic CT verb tur-, dur- conveys notions of “intent
or readiness to act, duration or permanence of actions”. It is also a grammatical function verb and
auxiliary verb of action, eidetic to the Eng. pair to (infinitive case) and do. Since
all relevant forms mirror each other phonetically and semantically, they likely share a common
primeval root or were conflated. An archaic grammar is peculiar in that a predicate, depending on
the meaning, takes a form of a desirable, imperative, or a conditional mood (EDTL v.s.). That
peculiarity waned in later Türkic and was not picked up in European creolizations. Cognates:to,
till “in direction, for purpose of, furthermore”, OSax., OFris to, NFris. to, tö, tu,
WFris.
ta, Saterland Fris. tou, Dan. at, Du. te, toe, Norse a, Sw.
att, OHG zuo, Gmn. zu “to”, Goth. till; OIr., Ir. do “to, for”, Scots
tae, Welsh i “to, for”, Breton da “to, for”; OCS do “as far as, to”, Sl.
do (до) “until”; Lat.
donec “as long as”; Gk. -de (suff.) “to, toward”; Lith. da- (demonstr.) (“?”);
Alb.
ndaj “towards”; presumably all “to” unless noted otherwise. Distribution: from
Atlantic up to Far East, across linguistic borders. Peculiar to a European NW patch. Etymological
citations are heavy on Uigur sources. They do not include any references to Mong. and the balance of
the Far Eastern languages. An “IE etymology” is hopelessly botched. It asserts that an attested
A.-Sax. inflection of the verb to, till was a complete nonsense without any meaning. There is
no clue on flexible predicate. It ignores knowledge of a former conjugation. It ignores the evidence
of a Goth. form till “now, hitherto” and A.-Sax. till. It invents a form and substance
of an “ancestral” faux “demonstrative *de-”, invents a faux “PG proto-word” *to, *ta
“to”, and invents a faux “PIE pronominal base” *do- “to, toward, upward” and a “PIE
pronominal base” *de, *do “to”. The “to” is not a claimed doublet of “too” ~ “also” either.
The analysis is a disaster. Such consistent botch of etymology is worthy of a record in the “IE” etymological annals. Essentially, to is an allophonic form of the verb do to express
intention. A compound form to do is tautologic, repeating the verb do twice, in
different phonetic forms. The stem tö-, tü- serves in numerous Türkic derivatives expressing
semantics of “make, made”: tükät “completeness, completion of action”, törü- “happen
to occur, emerge, be born, appear, give birth”, törüt “create”, törči “happen, occur,
undertake, initiate”. The törči also serves as auxiliary verb exactly like the English
do, with a similar complement of functions: “make, engage, carry out, carry on, get done,
proceed, cause to happen, engage in, comport, execute, finish, complete action” with idioms and
nuances.
In the compound to do the part do “do, act” originated within the western Türkic
Sprachbund vernaculars as an allophone of the verb tö-/tü-, ascending at least to the 1st
millennium BC, while the part to “do, act” was a later accommodation to the typology of the
“IE” languages, replacing agglutinated verbal suffixes that made clear the verbal use of the stem:
to act, to pack, and the like, versus nominal use of act, pack, and the like, lit. do
act, do pack. In its syntactic function, to parallels the function of the noun articles,
it is a determiner that indicates the functional specificity of reference. The “IE” etymology
conflated the directional particle
to “in, into, towards” with the verbal determinant to, assuming that in spite of
drastically different function a phonetic likeness constitutes a common origin. That speculation on
Eng. peculiar independent semantic shift conflicts with the presence of cognates in other Gmc.
languages. Instead of recycling a functionally misleading directional marker to to denote a
verbal function, English seamlessly adopted as a verbal marker a verb to meaning “do”. Chuv.
is held as a language of the Ogur Hunnic circle, that allows to time the introduction of the
alternate form tu- for the verb do to the 4th c. AD or Sarmat expansion in the 2nd c.
BC. The frequency value is somewhat exaggerated because the source listing does not discriminate
homophonic adj.s and ratios, but impacts of those contaminants are negligible. See and, at, be,
do, make, in, on 1, on 2, till (prep.).
2.14
un- (prefix) “negation” ~ Türkic -an (аŋ, ang) (suffix) “negation” (MK I 40).
With the ancient English language speakers switching to a creole morphology of the new language(s),
the old negation suffix moved to become a prefix, and the original negation suffix -an (аŋ, ang)
had vanished as a suffix. The set of negations an and ma (the Fr. negation pas /pa/
in ne... pas may be an emphatic tautological allophone of ma) appears to have a
“Nostratic” primordial pedigree. They appear as prefixes and suffixes depending on the typology of
the languages, and include uncounted allophones and transpositions. See me, my, no.
3. Verbs (226)
3.1
access (v., n.) “entry, opening” ~ Türkic ačsa:- (achsa:-, v., desiderative), ačıš- (achısh-,
v., co-operative) “open”.
Ultimately a derivative fr. a verb ač- (ach-) “open”. The notion “open” forms a first
semantic cluster out of a total 16 clusters. Its elucidation lists 39 meanings, from “open” to
“sharpen a pencil”. The other 15 collateral clusters are more modest, from 3-4 to a single meaning,
spread across dozens of Türkic languages. Among those are notion #5 “conquer, capture” and #10
“start (war, process, discussion)” reflected in a Fr. semantics (EDTL v.1 209). The convergence of
the Lat., Fr., and Eng. versions in distinct semantic and phonetic aspects points to a single Türkic
origin. Eng., like Türkic, has numerous semantic meanings, few literal and many metaphorical, at
times unexpected (e.g. open door and open season, open sky, gift “open the door with a
gift”, open mind “non-prejudiced”, open-ended “changeable”, etc.). A transition fr.
ač- to ac- (ak-) is regular, the -c- indiscriminately stands both for -k-
and -ch- (e.g. tacan (tachan) ~ teach).
Cognates: A.-Sax. none; OFr. acces “onslaught, attack; onset”, Lat. accessus
(early 14th century) “entrance, coming to, approach”; Finno-Ugrian az “opening, hole, pit”,
Vogul as “hole, pit”; Mong. asa “split”, Kalmuk ats “split point between
brunches”, Kaz. aza ditto; Manchu asa “join, converge”, asap “conjoining
(joining, conversion point of mountain ranges)”. Distribution is not limited to a spec of W.
Europe, it extends from Atlantic to Pacific, way beyond a myopic sight. It crosses linguistic
barriers, including those with the European Romance branch. On semantic side, “IE” cognates
demonstrate a disconnect that can be only explained via a source that carries both an “entry,
opening” and an “attack”, a scenario that ascends to the Türkic verbal stem ač- (ach-)
“open”. On phonetic side, the “IE etymology” fictionalized a Lat. compound ad- “to” +
cedere “go, move” with a transformation from ad- to ac- (ak-) and “open,
entrance” to “move”. It conflated that with the Fr. separate semantic “onslaught” distinct from the
Eng. concise “entry, opening”. That is a typical etymological technique of creating brand new “IE
proto-words” on a fly. Unwittingly, that machination leads directly to the Türkic ač- that
statically makes impossible an existence of an analogous word in any other earthly language. It has
to be either a loanword or an imposter. The “IE” claim of an open road to nowhere prevents a promising
ethnolinguistic research of the available material, like an association of certain semantic clusters
with certain languages. That, in turn, is a potent diagnostic tool to trace the origins of the
English language and contributing routs, a sole task of the etymology.
3.2
act (v., n.) “doing or done” (Sw N/A, F735, 0.03%) ~ Türkic aqtar- (v., causative) “raid,
dunk, plunge”, akıt- “raid”.
Ultimately fr. the verb aq-, ak- with a prime notion “(river) flow, stream, jet”, aqtar- <
aq- + -t- (deverbal noun) + -ar (conjugational suff.). An initial origin from “(water)
movement” and “cattle rolling over” appear to be sound interpretations: cattle rolling likened to
agitated water. Like the Eng. “flow”, the aq-/aq (Cf.
aqua, aquarium) comes grammatically in noun-verbal homomorphic pairs, attesting to its most
archaic pedigree. It has a fistful of secondary notions (“liquefy, pour, bleed”), a few
direct and a wealth of metaphoric derivatives. One of those is verbal “attack, assault, raid” (fr.
prime “carried, float” of the notion “move, stream”). Even for the same word,
Türkic has numerous phonetic and rendering variations, ağtar-, axtar-, aktar-, akdar-, agdar-,
agnar-, agar-, ağna:- etc. The generic verbal “act” is synonymous with “do this, do that”
expressed (or translated as) in vast array of conc. acts: “knock down, bring down, overturn,
overthrow, defeat, beat, smash, pound, drag, rip off, destroy, crush, nock to the ground, push over,
turn over, throw to the ground, bring down”, etc. On the surface, without minute analysis, numerous
derivatives of aq-/aq appear to be homophones unrelated to each other. It is as much a notion
as a verb. Some, incongruent semantically, are held as true homophones, e.g. “white”, “net”, “elder,
aged”, “rake (glance)”, aktarma “contraband”, etc. It has numerous concrete extended meanings
“examine”, “search”, “translate”, some quite loaded, like “sudden raid at night”, fairly in line
with the spectrum of Eng. 200+ applicable meanings. The inlaut alternation -ğ-/-k-/-q-/-x-
allows semantic shifts and breeds dialectal diversity. The loss of the final element -er
shows that the internalized root was perceived as aqt. In English, a derivative -act
grew into a powerful suffix: contract, impact, react, transact, etc., with a slew of their verbal
and object derivatives. In one or another form, the word gained universal acceptance in most
languages of the modern world. Cognates:
A.-Sax. agan, aegan, agangan “go, go by, pass”, ONorse aka “to drive”; OIr. aigid
“act”, MIr. ag “battle” (Türkic “raid, attack”); Lat. ago “put in motion”, OFr.
acte “document”, etc., certainly of derivational origin; Greek ago (αγω) “I lead”; Skt.
ajati “drives”, ajirah “moving, active”; no references to Far Eastern languages.
Distribution is like needles in a haystack: too many meanings, too many possible languages.
An “IE etymology” stops at Lat: Lat. actus “a doing, a driving, impulse”, pp. of agere.
Its circular logics and an unattested faux PIE stem *ag- are mechanically deduced from
various derivatives in a myopic range of Lat., Gk., and Skt. The Skt. examples mingle roots and
suffixes, Cf. -ti, Türkic 3rd pers. suffix; the root is aja/aji. The Lat. act-
likely appeared as a reflection of the semantics “move”or “raid”, an echo of the Ir. “battle”. The
Celtic R1b Y-DNA haplogroup circum-Mediterranean migration of the 6th-5th mill. BC. brought them to
Iberia in the 3rd mill. BC, ca. 1.5 mill. earlier than the anachronic Lat. migration to the
Apennines, and of the Skt. migration to the SC Asia.
3.3
aggrieve (v.) “feel bad”, aggravate (v.) “make worse” (v.) ~ Türkic aɣrï-, aɣïr-, aɣru- (v.)
“feel bad, be sick, make sick”, “grow heavy, become a burden”.
Ultimately a derivative of a verb a:ŋ- “lean to one side, outweigh (on one side), hang down”.
Grammatically
aɣrï-/aɣrï is a noun-verbal homomorphic pair, attesting to its primeval origin unrelated to
the consonant gür (n.) “grave”, see grave. The Türkic stem is most productive, applied
with anything unpleasant, and in that respect closely parallels the English “sick” and “grieve,
onerous” respectively. The Türkic linguistic nest has aɣï “poison”, aɣïmaqlïɣ
“painful” aɣrïɣ “pain, sickness”, aɣrïɣlïɣ “sick, painful, suffering from disease”,
aɣrïɣučï
“suffering person”, aɣrïmaqlïɣ “painful”, aɣrïn “suffer pain”,
aɣruq “load, weight”, “seriously ill”, and so on. In the A.-Sax., with an initial vowel, it
wielded a notion of beginning or transition form a lighter to a heavier state, interpreting an
anlaut
a- as an unemphatic verbal prefix marking a verb a single momentary event, Cf. A.-Sax.
abakan “bake”, aberan “bear”. With aphesis of the unaccented first vowel, the root
ɣrï-/ɣru- produced a bifurcated host of grievous derivatives in the European languages: grave
(adj.), grief (~aggrieve), grim, grimace, grime, gravity, gravitate, gravel, and all their
derivatives with semantic meaning of “(pain, trouble, heavy) burden”. Cognates: A.-Sax.
egile, egle “grievous, painful”, ONorse uggr “dread”, Goth. aggwifa “anguish,
distress”, aglus “hard, difficult”, Gmn.
verärgert lit. “real grief”; Lat. aggravatus, aggravare “make worse”; Sl. gore
(горе) “anguish”; Mong. aɣur “anger, wrath”, ula-, uyila- (< uɣila-) “cry”;
Manchu uktu “crying, 'sobbing, wailing, sorrow, mourning” (< Mong.). Distribution is
ubiquitous across NE Eurasia, spotty and vague in Europe. In Europe a bulk of cognates are Gmc.,
pointing to two independent etymological paths, one via Gk.-Lat., and one Gmc. The latest
derivatives, like a modern noun “gravity”, echo the proto-root of “pain, burden, weight”. The “IE
etymology” misrepresents a huge raster of the derivatives with a faux “PIE reconstruction”, a Lat.
“from ad “to” + gravare “weigh down” < gravis “heavy” < a faux “PIE proto-root”
“heavy” *gwere-”. The ersatz *gwere- is an overture on the Türkic attested aɣïr
“heavy, weighty”, a very close cousin of the word aɣrï- “grow heavy, become a burden”. The
scam has no place in a fair analysis. It can't cite any cognates outside of the “IE” claim. See
grave.
3.4
aim (v.) “direct, target”, (n.) “target” ~ Türkic amač (n.) “aim, target”.
An “IE etymology” does not have a clue, it suggests a range of late European pseudo-homophones for a
word that existed from at least the primordial days of spears, arrows, and blow tubes, for some 40
millenniums. The “IE etymology” prefers to boil in its own juice. The word amač is formed
with a noun am and a diminutive denoun noun suffix -ač/-äč/-uč/-üč, lit. “small
pussy”, not an unexpected title for the exercise. Eng. internalization of the ürkic word stripped it
of suffixes: amačla “to target, aim” > aim, amačliq “target range” > aim,
etc.). Türkic synonyms for “shooting target” are a:ra, baj, bajge (Cf. “badge”), belek,
belgı, da:ra-, qabaq (from pumpkin), qaravul, u:č, u:r- and probably more.
Cognates: Osset. mil “aim, target”; Pers. aim “purpose, resolution, undertaking”
(< Ar. < Tr.). None is IE. A native A.-Sax. word was targa, targe, a term for a small shield
used for practice. Not supplanted by aim, it survived to the present. The suggested “IE” cognates are phonetically dubious and semantically unrelated: “estimate”, “value, rate, count”,
“plow”, etc. “IE” suggestions reek of desperation. They conflict with simple and vitally important
training requirements of many millenniums. The absence of the “IE” cognates indicates direct
continuity between the Türkic and English. That is corroborated by the timing: 15th c. AD, the time
of apogee of Turkish expansion in Europe. That suggests that the OFr. word came fr. the military
lingo of the European Türkic tribes, while the Pers. word hadaf for “aim, target” came from
the Mesopotamian Semitic sources. The suggested Pers. word for “plow” as a loanword for the Eng.
“aim” does not make any sense: the nomadic pastoralists and hunters had to aim millenniums before
the Persian appearance on the scene. The winded wordy rationalization used to cross from the “plow”
to “aim” shows a futile linguistic exercise based on some homophony. The phonetics is direct, and
semantics is perfect. The Türkic source is likely a metaphoric use of the noun am “vulva,
pudenda muliebria”, quite appropriate for its time, for predominantly male participation, and for
non-offensive nature of the word in the world where sexual reproduction of the herds was a daily
affair guided and assisted by people.
3.5
ambush (v., n.) “ambush, hide, lurk” ~ Türkic bus, busuɣ, pus, pusuɣ (n.) “ambush”,
buš-/bus-/baš-/bas-, puš-/pus-/paš-/pas- (v.) “push, wound”. A base meaning of the verb bus-/pus- is “ambush”, of the verb buš-/puš- is “push, press”; a semantic and phonetic overlap suggests
either conflation or relation. It has innumerable derivatives, of which a “sudden attack” is one of
many. In Türkic warfare it was a cardinal term for a tactics that over millenniums overpowered
nearly all lands from Pacific to Atlantic. Invariably, it was attested for the armies from the
Scythians to the late Türks. The form rooted in bos- dominates in Europe: of 44 European
languages a motley group of 17 (39%) languages use that form; 14 (32%) languages use Sl. native Old
Europe forms with a prefix za- (за-) “beyond-”; 3 (7%) Gmc. languages use a prefix “hinder-”.
The remaining 10 (23%) languages use 9 of their own native forms. Cognates: A.-Sax.
basnian “await, expect”, Dan. baghold “ambush” (s/k alternation), Sw. bakhall
(s/k alternation), Norw.
bakhold “ambush” (s/k alternation), +14 others; Serb. busija “ambush”; Lith.
pasala, Latv. pasleptuve; OFr. embuscher “ambush, hide in ambush”; an unrelated
example is Sl. (Bolg.) zasada (засада) +13 others.The late Fr. word is apparently an
accommodation of a Burgund form with then a Fr. prefix em-; an original busher with a
directional suffix -er/-r conveys a notion of “into an attack”. The Eng. form conflated with
the Fr. form and replaced the A.-Sax. native noun basnian “wait (in ambush)” and its verb of
the same root. The Eng. and Fr. words came via separate paths fr. divergent vernaculars, attested by
an absence of a prefix in the A.-Sax. and phonetic differences of the same root, the bush-
vs. bas-. An “IE etymology” is misleading and plain silly, a bus “ambush” is not the
same as a bush “woody plant”. The “IE etymology's” VLat. boscus “wood”, Frankish
“Proto-word” *busk “bush”, “PG Proto-word” *buskaz “bush, heavy stick” are a
self-deprecating nonsense. It fails to connect the dots, ignores or pretends not to know a
millenniums older native basnian “in wait”, and suggests a juicy Fr. version of some act “in
the bushes”. A primitive interpretation excludes real scenarios: from a hill, in a mountain pass,
from behind, etc. See
push.
3.6
are (v.) present pl. indicative of be “to be” (Sw N/A, F36, 1.20%) ~ Türkic er- (v.)
“be, am, are, is, exist”.
According to a standing “IE” etymology, the are supposedly has no “IE” cognates whatsoever, but
cf. Sp. yo era, tú eres, eras, él/ella/Ud. era, nosotros éramos,
vosotros erais, ellos, ellas, Uds. eran. The Türkic verb is conjunctional, noted as
accompanied by a predicate; it cannot be used by itself to mean “to exist”, but is often used as an
auxiliary verb of other verbs (Clauson EDT 193), and as a deverbal and
denominal suffix -ar/-er (with phonetic variations) for “be, to be”,
forming nouns and adjectives of the type eye + be > “ocular, visible” (körünü:r, fr. kör
(n.) “eye”), see + be > “ocular, visible” (okunur, fr. oki:- (v.) “see”), see eye.
In Türkic, the suffix forms -ar-, -är-, -ur-, -ür-, -ir-, -ïr- produce derivatives of the
type X-be, still preserved in English as “that be” (e.g. “powers that be”), “we be”, “us be”,
“blessed be”, “boys be”, and the like, see be. That echoes the Türkic applications: tutar
“caught be/be caught” < fr. tut- “catch”, kelir “come be/bring/convey” ~ came < fr.
kel- “to come”, ketär “depart be/take away” ~ remove < fr.
ket- “leave, depart”, etc. For a word “with no “IE” cognates”, are/er- and its siblings
take an exceptionally prominent place in Europe. Of 44 European languages, 24 (55%) use forms
related to er- directly or via an r/s alternation, matching a level of a 50.6% hg.
R1a/b demographic presence in Europe. A runner-up descendent of the Türkic bol, buol “be” is
used by 8 (18%) European languages, see be. A degree of etymological disinformation is
splendid. The remaining 12 (27%) languages use their own native forms.
Cognates: A.-Sax. ear(un) (the form ear- (ər-) may reflect dialectal variation
of the vowel), ar(on), Mercian ear(un), Northumbrian ar(on), Norse, Norw., Dan.
er-, Sw. är, Icl. ertu, er(um) (but Lux. bass (< bol, buol); Welsh 1
ry(dym) (but Ir. bhfuil (< bol, buol), Scots bheil (< bol, buol), Welsh 2 wyt (<
bol, buol); Lith. ar; Tr. er(tim) (but Tatar sez); a separate significant
motley fraction underwent an r/s alternation: Lat. sumus, It. sei, Fr. es,
Sp., Cat., Galician estas, Port. esta, Rum. esti, Gk. eisai, Maced.,
Bosn., Serb., Slov., Sloven. si, Bolg. ci (si), Czech jsi, Croat. jesi,
Pol. jestes, Corsican si; Latv.
esi, Alb. je, Tatar sez (сез); all er-/es- “are” excepts as noted
otherwise. Some forms elide a phoneme or add prosthetic phonemes but all are consistent with the
forms of their neighbors.
Distribution: ubiquitous across Eurasia, from Atlantic to Pacific, across linguistic
barriers. Distribution of the verb are is peculiar, the Lat. form corroborates the pra-Celtic
influence on the pra-Italics, the northern European cognates and the Türkic cognates are consistent
with the spread of the Kurgan's R1a/b haplogroup. The spread of the bifurcated “be” leg is
incompatibly more directional and focused than the dispersed spread of the “man” leg, and all seeded
languages are adjacent to the Eurasian Steppe belt. There is a striking dissonance between a myopic
“IE” preachment and reality. Genetic connections between all examples are indisputable. The Türkic
concrete er- “be” and generic bol, buol “be” express a same basic notion “exist” in a
range of overlapping functions, hence an overlap in specific applications. The Celtic forms attest a
direct inheritance of both forms, further supported by a use of a Türkic 1st pers. marker -m
encountered in the Celtic word, see me. The Lat. suffixes also mimic a Türkic suffix -ar:
-eram (with suffix -m), -ero. European (and Türkic) languages have three main
stems for “be”, er-, es-, (b)ol-:, and be-: Balto-Sl. (Latv.) esam (with
suffix -m), (Lith.) esame (with suffix -m), (Sl.) est (есть); Est.
oleme (with suffix -m), Fin. olemme (with suffix -m). The Uralic forms
acquired versions visibly ascending to the Türkic er-; Gmn. bist, Fris. binne,
Az., Turk., Kaz. biz, Mong. bid, these forms ascend to the Türkic bol- (v.)
“be”, q.v. The origin of “are” is supposed to be a puzzle, a screaming enigma in the “IE” paradigm. It
does not fit any scholastic “IE” schemes. It is an irregular, demonstratively non-IE verb with all
verbose conjectures befitting a great scientific conundrum. The origin, however, lays on the
surface: a Türkic form of the verb “to be” or a matching agglutinative suffix that produced
derivatives expressing an existence (being, presence, fact) of a property, action, or a trait. In
flexive milieu it is used either as a stand-alone application or in a form of agglutinated suffix.
The origin reliably points to a substrate language with an incompatible grammatical structure.
Apparently, in A.-Sax. be and are were used interchangeably, depending on the
analytical semantics of general vs. singular. Both Türkic and English have salient identical
bifurcated semantics of the stem ar/är (ər)/er. In Türkic it stands for “be” and “man”, in
English it stands for “be” and “man” in the form of instrumental suffix (teacher, dealer, etc.). A
transfer of bifurcated semantics is a case of paradigmatic transfer indelibly attesting to a common
genetic origin. See be, -er, make, me.
3.7
argue (v.) “quarrel”, “proving or refuting” ~ Türkic arqu-, arqula-, arɣula- (v.) “discord,
disagreement, strife”.
Ultimately fr. a polysemantic verb ar- “separate, part” for a piece that bridges two parts,
a:ra (n.) “middle, center”, its deverbal noun
derivative arqu: “ravine (valley)”, and finally its denoun verbal derivative arqula-
“sow discord”, lit. “cause ravine” between two sides. A semantics of the root ar- is “in
between”, like an arch connecting two sides, with bifurcating “intermediary” for positive and
negative derivative notions; in this specific case a rather negative connection. A suffix -la
forms a denoun instrumental verb. The verb ar- has a version az-/as- of the r/s
rhotacism, attesting to a deep age of the stem. It also has forms with prosthetic anlaut consonant:
ha:r-, ha:y-, xa:r-, and anlaut vowel versions u-/ï-. Where the EDT sees mostly a
positive, like a “messenger”, the OTD notes a homophonic negative. By now “argue” is an
international word via a scholarly argument. Cognates: A.-Sax. arteflan
“separate, divide” < arqu-, OFr. arguer “maintain an opinion or view, harry, reproach,
accuse, blame”; Lat. argutare “blabber” (negative), arguere “make clear, make known,
prove, declare, demonstrate” (positive); Hu. ervel “argue”; Mong. aračila “plead for
somebody”, marga(dar) “argue”, arga “method, means, way out, trick, cunning,
intrigues”; Tungus-Manchu arga (< Mong.) “possibility”, (Evenk.)
arga “faith”, (Even.) arga “method, way”, (Sol.) agga (< arga-), (Oroch.)
arga(n-) “cunning, deception”, (Orok.) arɣa “cunning, deceit, trick, means, method,
plan, calculation”, (Manchu) “method, means”; Kor. phariha “emaciated, gaunt”; Hittite
arkuuae- “plead”; Finno-Ugrian languages also have correspondences with the stem ar-
(Nemeth, 1928).
Distribution: ubiquitous across Eurasia, from Atlantic to Pacific, across linguistic barriers, a
feat patently unreachable by the Lat. The word probably gained universal distribution via a trade
chain, likely along with a spread of metals as objects of trade. It pointedly did not reach a W.
Europe at that time, leaving the Old Europe Sl. and its environs blank till an arrival of the
enlightened Lat. migrants. A Central Asian origin of the word is most palpable; the word illustrate
a linguistic development where new concepts are developed from existing material: a physical
“ravine” grows into an intangible “discord”. No “IE” etymology, the suggested faux “PIE proto-words”
*argu-yo-, *arg- “shine; white” are semantically unrelated and unsustainable. Myopic
perspective and whimsical treatment of historical events reduce science to a level of ignorant
propaganda and scientists to politicians. The Mong. form marga(dar) has a prosthetic anlaut
m-. The significance of the Kor. form is that it is an alternate meaning of the same verbal stem
ar-
in Kor. articulation. Hittite is far older than the Lat. and is not related to it. The Türkic
etymology reaches down to the prime stem, it is semantically and phonetically perfect, and is
corroborated by correct morphological elements, suffixes
-qu and -la. See arch.
3.8
assign (v.) “allot, arrogate, ascribe, delegate, portion” ~ Türkic asïɣ (n.) “benefit,
interest (on a loan), gain, profit, advantage”.
Ultimately a deverbal noun derivative fr. a root as- “hang”, its semantic extension “stick,
stuck”, and its verbal form asït- “profit”.
The Türkic notion is a “benefit” in a form of interest, gain, profit, or not necessarily material
advantage (like advantage of knowledge). The European core notion is “assignment of benefit” in the
same forms (interest, gain, profit). Usually, but not necessarily, it is in a form of a legal
document, best exemplified by the term assignation “grant a right (for benefit)”, related to
a transfer of property or a paper obligation to receive principal and/or interest. A shift from a
nominal to verbal predicate could be a western innovation, the eastern records cite only a noun
form. Cognates: A.-Sax. asegendnes “offering”, est “bounty”, OFr.
assiginer (v.) “assign, appoint, allot”, Lat. assignare (v.) “assign, allot, award”;
Welsh
aseinio “assign”; Fin. ase “get stuck”; Mong. asa “stuck, adhere”; Manchu
hasi “hang” (~ weighing?), a precursor of “stuck” a precursor of “gain”. Distribution:
from Atlantic to Pacific, across linguistic barriers. A myopic “IE etymology” offers a phonetically
dubious Lat. compound of ad- + signare (signum “mark, sign” > adsignare > assign).
The “IE etymology” imply that Siberian tribes had adopted a Lat. compound invention unknown to nearly
all “IE” languages. The chances that precisely the same very specialized trade word would arise
independently in two sources are nil because the semantic field width is extremely narrow (“getting
a benefit”). A complimentary term “allot” also has a Türkic match: Tr. atamak, Azeri etmək.
The base forms assignation, assignatio and assignacion demonstrate a fully articulated
-g (-ɣ/-ğ in Türkic case). A.-Sax. internalized a fossilized third-generation derivative
in its trade semantics. Apparently Eng. received that Turkism via French independently of its
inherited A.-Sax. cognate. The Türkic etymology has an advantage of being direct, simple, and
eidetic phonetically without a need for phonetic transformations. Türkic semantics and phonetics are
perfect. See attach, assessment.
3.9
attach (v.) “bind” ~ Türkic atka:-, atqï-, atkan- (v.) “attach, stick, cling, jump”.
A deverbal noun derivative is
atka:ğ (n.) “barb, burr”. The verb bears 3 semantic clusters: gush,
rush (cling, bind), and rise up. An ultimate origin is fr. at “horse” in adjectival form with
a frequentive suffix -ka, lit. “(stuck) to horse” or “jumps like a horse”, etc. Any
agglutinative language naturally forms derivatives of “horse” (here, at) semantically related
to grass, burr, and the like (Cf. Sl. generic loshadinyi (лошадиный) “horse's” with a Türkic
suffix -in/-an “of the horse”). A connection is to burred grass seeds atka:ğ that
cling and hurt herds. Cognates: A.-Sax.
aetcilfian, aetcilfian “adhere”, aeteaca “appendix”, aetfele “adhesion”
(loyally ascending to at “horse”), OFr. atachier (11c.), It. attaccare;
etymological sources do not cite cognates outside a Türkic milieu. No “IE” connection whatsoever, no
trace in the “IE” branches. A suggested “PG proto-word”, a Frankish *stakon “post, stake”, is
beyond absurd; cited “IE doublets” “attack, stake, stack” belong to the same absurd bag. A.-Sax. had
an impressive trail of derivatives, attesting to a long history of internalization within the
A.-Sax. milieu. Some of these words are compounds of two Türkic words: aetfeolan “stick,
adhere, continue” < atka:- “attach” + bilin- “feel, like” > “sticky, gluey” (see
feel), aetfele, aetfeolan “adhesion, adhere” (with semantic extensions “continue,
practice”). Others are a blend of the Türkic atka:- and a European word: aetgaedre
“united, together”, aethabban “retain”, etc. A palatalization -k- > -ch- is a
Sprachbund trait of the languages in the western steppe zone. The form aetheaca attests
to a divergent pronunciation of the sound -t-. In compounds the second consonant -k-
is routinely elided. The It. vs. OFr. examples attest to normal dialectal variations and
co-existence of palatalized and post-palatal velar forms. The “late” appearance of the documented
word parallels a host of other English words that the grammarian strata did not have any attachment
to. Internalization, amalgamation, and divergence point to a millennium-long process, which
potentially brings the Anglo-Saxon union back to the middle of the 1st mill. BC, and initial
internalization to a Corded Ware period. See feel.
3.10
augur (v.) “predict” ~ Türkic ay- (v.) “tell, talk, say, explain, interpret”, ayi (n.)
“sound”, ayığ (n.) “word, speech, command”.
An “IE etymology” asserts a “perhaps” level of credibility plus some guesses of wild goose
chase-type. The word's base notion is “voice, vocalize”, it is used for emphatic expressions like
predictions, praise, and accusations. In a earliest period, ay- was close to a honorific
“declare”. A 3rd person Türkic form is ayur, aygur, ajar, aygu (ayguc) “advise,
explain”; with an instrumental sufix -či (-chi) it is ayguchi, (ajguchi) “teacher,
adviser, councilor”. Suffix -gur, -gür, -ɣur marks causative and/or active verb
voice. Its retention in Lat. as a part of a root, along with a root ai(i)о, augurs a most
tractable historical connection. For percipient philologists and historians it is a valuable
bestowal. Gmc. languages routinely articulate it with a prosthetic w- or its equivalents, and
with negative overtones.
Cognates: A.-Sax. weman (v.) “voice, announce, be heard”; Lat. ai(i)о “declare,
assert”,
augur (n.) “religious official” foretelling events, auguro “prediction”; Goth. waya
(waja) “voicing, expression (blaspheme, slander)”; LAv. ad- “tell, say”; Mong. аyа,
ayas “sound, sounds (especially of speech, pronunciation, accent, rhythm, tone”, ajilad-
“tell, say” (aji “sound”), ajila- “announce, say”, ajiburči “gossip”.
Distribution extends from Atlantic and Mediterranean to the Far East, crossing linguistic
barriers and lands which a Latin sole never trod. The Türkic aiguchi'es “adviser, councilor,
chancellor” accompanied all Türkic epical and real monarchs. Tonükuk of the Orkhon runic
inscriptions was an Aiguchi. A dumbfounded “IE etymology” stops at a single Lat. instance, citing as
cognates a few mechanically applied nonsensical phonetic examples (avis “bird”, garrire
“talk”, augos “increase”). Semantic and phonetic match is perfect. In a feat of paradigmatic
transfer, Eng. possesses five main action words related to communication: declare, say, tell,
call, and gabble, the direct siblings of ay-, söy-/söyle-, til-/tili-, qol-, and
gap-/gapir-. Although overlapping and interchangeable to some degree, each one conveys its own
spectrum of very basic communicative notions. The origin from the Türkic milieu is indelible. See
call, gabble, say, tale, talk, tally.
3.11
awe (v., n.) “to be inspired, deep fear, reverence” (Sw N/A, F1140, 0.01%) ~ Türkic ö, ö-,
a-, u- (v.) “think, reflect, delve, understand”.
The word a: (’a) carries a flavor of “astonish, amaze, astound”;
u- is an allophone of ö-/a-. A single-phoneme allophonic line produces overlapping
derivatives with diverging outcomes, e.g. adar- (-dïr-, -δïr-, -tïr- -ŋa, -ŋla-), оdɣur- (-δɣar-,
-δɣur-, -jɣur-), etc. A use of non-rounded vowel word further extends the allophonic
derivational field. An extent of modifications involves nearly entire store of consonants:
öb(kälä-) “angry”, öč “revenge, anger”, öδ(ik) “passion”, öf(kä) “anger”;
ög, ök “intellect, thought” with a standard Türkic deverbal noun suffix -g/-ɣ, and so on.
The words ay “oh, ouch, ow, ouh, aah, uh-oh, ugh”, añığ “excessive(ly)”, ayman
“fear, timid, faint”., etc., are derivatives of a:-, ö-, and u- expressing a negative
excitement of awe. Of those, the ayman, with a relict deverbal noun suffix -ma,
portends the awe of fear predominant in the Middle Age A.-Sax. lexicon. Both Eng. and Türkic have
preserved the noun derivative ög/ök “mind, thought, understand”. The ög, ök formed
with a standard Türkic deverbal noun suffix -g/-ɣ/-k became the A.-Sax. eg, ege and
other Gmc. allophones. The A.-Sax. blurry transcription eg-, aeg-, eag-, ieg- simultaneously
attests to an accuracy of the spelling awe to render the rounded ö-, to attempts to
render a rounded ö- with the tools of the Roman alphabet, and to a wide spread of the word.
The final victory of the form awe (= ö-) over the A.-Sax. phonetic variety attests to the
demographic significance of the original Türkic component, probably numerously reinforced and
reinvigorated by continental refugees fleeing Middle Age religious persecutions like that of the
Tengrian Cathars. In Europe, the form ö-, are-, awe predominates with 13 (30%) languages; the
other 31 (70%) European languages use their own 22 words. There is no common “Pan-IE” root.
Cognates: A.-Sax. aege, ege, oga “awe, fear, terror, dread”, aghe, ege “fear”,
egesa “awe, fear, horror, peril”, ONorse agi “fright”, Dan., Norw. ære(frygt),
ære(frykt), OHG agiso “fright, terror”, Goth. agis “fear, anguish”; Ir.
ua(mhnach) “awesome”, iontas “astonishment”, Gael. obha “awe”,
iong(nadh) “astonishment”, Welsh ofn “fear”, anhy(goel) “astonishment”; Latv.
aizplust “astonishment”; Sl. ah, ahnut (ах, ахнуть) “astonishment, fear”; Lat. ave
“greetings”, afflictum “impressed”; Gk. akh(os) αχ(ος) “pain, grief”; Fin. joku
“some event”, Est. aukartus “awe, reverence”; Mong. aidas “awe”; Manchu
gelembi, golombi “angst”. An “IE” scholarship is limited by severe myopic horizons and
ingrained prejudice. Distribution is consistent with migrations from the Eurasian Steppe Belt
with Corded Ware expanses, with emanating westward prongs and a radiant spread. The A.-Sax. cognates
attest to an existence of the word for about 2 millenniums prior to the “IE” claimed ca. 1200 AD. A
standing “IE etymology” ignores inspiration and zeroes on the utility of fear. It connects awe
with Gk. akhos αχος “pain, grief, ally”, which semantics and phonetics make it an allophone
of the Türkic ö- (v.) and ög (n.), but does not make any sense in respect to kittens
and other awesome curiosities. It debases semantics with an assertion of a faux “PG Proto-root”
*agaz “terror, dread” (vs. the real “think, reflect, percieve”) from a faux “PIE Proto-word”
*agh-es- from a faux “PIE Proto-root” *agh- “depressed, afraid” or a faux “PIE
Proto-root” *hegh- “upset, afraid”. That kind of primitive speculations in the presence of
attested originals is not needed; the myopic horizons only breed confusion and spread
disinformation.The early literary examples apparently are heavy on religious admiration and fright,
while the “awe” is a more generic awareness than a particular cause like a fear. The simple modern
“awesome” has nothing to do with fear, the “awesome” are kittens, shoes, and manners, anything
worthy of admiration and inspiration. The English spelling quite clearly attempts to render the
labial ö in the ö- and ög with available means (the w is a labial
voiceless phoneme), and the spellings with auslaut -g and Gk. -kh-/-χ- faithfully
render the Türkic noun ög, i.e. ö-/ög “to think/a thought”. The A.-Sax.
egesa faithfully renders the Türkic ögsa, a desiderative form expressing intensity,
formed with the Türkic basic suffix -sa. The “IE” languages do not have single phoneme nouns
and verbs. Linguists in search for etymology should avail themselves of that reality. Numerous
single vowel words, like “think” and “eat”, probably ascend to a very beginning of the human
abstract thought. English has inherited and preserved many such words. The word ö-, awe,
preserved in its pristine phonetic form, in its verbal, substantive, and adjectival roles, with its
abstract and concrete semantics, with preserved Türkic suffixes, with millenniums long history,
constitutes a fierce case of paradigmatic transfer of absolutely indisputable common genetic origin.
On the banks of the Thames or Itil (Volga) it is still the same single phoneme word . The Celtic
forms still echo the modern Eng. and CT forms, in spite of a parallel 12,000 years of independent
existence. It lived through many alien influences after a Celtic circum-Mediterranean departure from
the Eastern Europe sometime in the 5th-4th mill. BC. That attests to a Celtic-Türkic common
linguistic phylum ascending to the 6th mill. BC, and an existence there of a single-phoneme
vocabulary. The autochthony of the word in the A.-Sax. is attested by a field of more than 30
derivational words and forms, an impressive impact for a tiny abstract notion of “astonishment”.
That number excludes the sibling words like the A.-Sax. aegleaw “law-knowing” from the ög
“knowledge”, and efen “awe, fear, horror, peril” from the ö- “think, reflect, delve,
understand” that belong to the same base mental function. And, English has inherited derivatives
like awesome, awful, awing, awe-inspiring, etc. We should appreciate an ingenuity of the A.-Sax.
scribes who invented a four-morpheme spelling aege for a single-morpheme rune ö to
relay a true articulation at a time when an only known alphabet was a chiseled runic script. To rob
Eng. of that precious inheritance in favor of a parochial jingoism is more than a petty crime.
3.12
bale (v., n.) “bound bundle” ~ Türkic bele- (v.) “bind, wrap, lace”.
The term is strikingly popular in Europe: of 44 European languages, 30 (68%) use versions of “bale”;
the remaining 14 (32%) languages use their own 8 words. The Türkic word is preeminent there; it is a
non-IE “Pan-European” term. Cognates: A.-Sax. belegde “covered”, belə(can)
“surround completely”, belecgan “to cover, surround”; OHG
balla “ball”, Dan. baal, Du. bale, Norse balle, vikle; Sw. bal;
Gmn.
Ballen; OFr. bale “rolled-up bundle”; Welsh bels, byrnu; Sl. pelenat,
pelenka (пеленать, пеленка) “wrap”; Hu. bala; Kor. beil (베일);
Heb. byyl (בייל); Chuv. piel, piele (< be:l) “swaddle”,
beshik “cradle”, Shor. (in Altai) nӧlä- “swaddle, wrap” (< be:l); Mong.
orooh “swaddle, wrap” (~ “wrap”); all “bale” unless noted otherwise. Distribution of
the allophones runs along Eurasian steppes from Atlantic to the Far East, across linguistic
barriers. Cognates demonstrate amazing uniformity across linguistic families, attesting to
widespread borrowing and high mobility across Eurasia long before an active trade exchange. The main
spreaders of the word probably were women, with mamas swaddling babies millenniums ahead of bales of
goods. The first swaddles were probably of leaves and pelts, Cf. Romance pelo “hair”, Eng.
pelt. An “IE” fantasy on a faux “PIE Proto-root” *bhel- “blow, swell” is beyond ridicule,
on a level of self-denigration. Numerous A.-Sax. derivatives and semantic extensions attest to an
antiquity of the word in the incipient A.-Sax. language. The phonetic and semantic match, and
gigantic geographic spread make a Türkic dissemination inescapable. See band, bazaar, belt,
bucket, bunch, bundle.
3.13
band (v., n.) “bind, tie, ring” (Sw N/A, F1524, 0.005%) ~ Türkic ba- (v.) “bind, tie, bound”.
A reflexive-passive form of the verb ba- is ban-/ba:n- (v.) “bind, tied on itself,
bound” and its m- allophone man- (v.). The intransitive form ba- of the verb
have not survived in the European languages, but the transitive form of the verb ban- not
only survived together with its agglutinated Türkic suffix -n, but blossomed into uncounted
derivatives in numerous languages, probably due to amalgamation in addition to a trading lingo.
Cognates: A.-Sax. bend “band, ribbon”,
bindan, ONorse band “tie strip”, OHG binda, Goth. bandi, bandwa; MIr.
bainna “bracelet”, Welsh band; OFr. bande, ONFr. bende, Fr. bander,
Sp.
bandana; Rus. bint (бинт) “bandage”; Skt. bandhah; Taj. moftan; Mong.
bind; Mongor. bo-; Kor. mukkda (묶다); Jap. baindo (バインド);
all “band” excepts as noted. Distribution:
From Atlantic to Pacific, across linguistic barriers. An unstoppable “IE etymology” came up with
faux “PGmc. proto-forms” *bindan “?” and *banda, *bandiz “band, fetter”, and faux “PIE
proto-root” *bhendh- “bind” and “tie, bind”. These useless fantasies have no home address, no
origin trace, illuminate nothing, and have no reason to exist. An absence of Lat. cognate indicates
particular north-west and south-east paths; the Skt. form dates the word to the migratory split time
before 1500 BC. The OFr. form allows to suggest Burgund-Provence source, the ONFr. form points to
Alans (Amorican Alans) of the 5th c. AD. The MIr. distinct semantics suggests 2800 BC
circum-Mediterranean route if not a later acquisition. The semantic and phonetic derivatives of the
Türkic intransitive verbal stem ba- “bind, tie, bound” in English are extremely numerous,
from band, bind, bound to military and social bands to the commodities like Band-Aid. The
substantial Türkic-based English lexical cluster related to tying and packaging (bale, band, bind,
etc.) and related derivatives (Cf. bandage, bonding, etc.) inextricably attest to their Türkic
origin. See bag, bale, bundle.
3.14
barge (v.) “break into, crash heavily into” ~ Türkic bar- (v.) “come, arrive”, bart, burt
“suddenly, bump”
The root comes in versions ba-, baj-/bay-, var-, par-, pïr-, and probably more. The verb
comes in a semantic plethora: 12 semantic clusters totaling 59+ meanings. In Eng., an anlaut may be
bar-, ber-, bir-, bur-, br-, etc. A suffix -ɣ (-g) adds an aspect of a danger warning
and a 2nd pers. (“you barged”), internalized as a part of the root with an air of calamity. The verb
is neutral to transitivity. Its syncretism attests to a primordial origin. The notion burst
“burst” is a complimentary allophone ascending to the same root bar-. Cognates:
A.-Sax. berst, bærst “bursting, eruption”, berstan “break, burst”, burst (16th
c.), OSax.
brestan, OFris. bersta, WFris. boarste, MDu. berstan, Du. barsten,
ONorse brestan, brast, brosten, LGmn. barsten, OHG brestan, Gmn. bersten
“burst”, Goth. *bristan (~ ONorse bresta); Ir. bris “break”; Mong. bara
“end it”, barag “in a main, as a whole” (~ “at the end”); Sakha barä “eliminate,
decimate”; all “barge, burst” except as noted. Distribution: From Atlantic to the Far East,
across linguistic borders. An “IE etymology” on purely phonetical homophony confuses the verb
barge “come” with a semantically incompatible noun barge “flatbottom boat” and its verbal
derivative barge “transport by barge”, of a Türkic root barq- “build, construct”, see
barge (n.).
Or it offers an alternative: a variant of Fr. barje, barjot, a Fr. argot of jobard
“gullible, crazy”. Neither one is palatable or any credible. That speculations are indefensible,
they jeopardize an entire method of an “IE etymology”. The “sudden intervention” and “crash into”
convey a true emphatic semantics. There is no chance for the notion bar-, barge, berst, burst
(v.) (ca. 1st mill. BC) to be related with the semantics “barge” (n.) “boat” (16th c. AD); an
anachronic Fr. argot is also beyond contempt. See barge (n.).
3.15
bark (of dogs) (v., n.) ~ Türkic ür, üyr, ürü, hür, Chuv. ver- (v.) “bark (of dogs)”.
An “IE etymology” asserts a generic “of echoic origin”, a typical useless fudging. The verb ür
and its cousin ör relate to voice, voicing, a generic notion, Cf. orate (v.), oration (n.)
“talk”, Türkic orla:- (v.), orı: (n.) “shout, yell”, see orate. Not to see a
connection requires a combination of aloofness and ignorance. The word is certainly one of the first
words of humanity. A prosthetic initial consonant is typical for numerous vernaculars stumbling on
initial vowels, Cf. Chuv. ver-. A Tr. form barak “dog (type)” attests that
prosthetization occurred within a Türkic milieu, it marks an eastward cultural exchange. The Chuv.
form with a prosthetic anlaut v- (corresponding to English b-) is an allophone of the
Türkic forms eerer, hur, örü, üjrek, üjürge, ür, üre, ürü, ürüü “bark”. They represent a
relict that went westward to Atlantic. Other forms extend all the way to Pacific. In Europe, out of
44 European languages, a motley Sl.-Romance group featuring a la- (Cf. Old Europe Sl. lai
“bark”) predominates with 10 (23%) languages out of 44, followed by a Türko-Gmc. group featuring
-Vr- with 6 (14%) languages. The remaining 28 (63%) languages use their own versions of 16
European native words. There is no common “Pan-IE” root; the European mixture is notably motley.
Cognates:
A.-Sax. beorc (n.), beorcan (v.) “bark”, ONorse, Norw. berkja, bjeffing “bark”,
Icl.
berkja, gelta “bark, bluster”, Lux. barken; Tr. barak “dog (type)”; Mong.
ülije, hülege (v.) “trumpet” (r/l alternation); Manchu fulqije (v.) “trumpet” (r/l);
Kor. pul (v.) “trumpet” (r/l); all “bark” except as noted; compare Sl. synonymous
lai (лай) “bark”, laika (лайка) “barking (dog)”. Distribution: From Atlantic to
Pacific, across linguistic barriers. No “IE” etymology, “of echoic origin” is as far from etymology
as it gets, a typical for “we don't have a clue”. Chuvash is thought to belong to the Ogur branch
(R1a Y-DNA Hg.), which dominated the Eastern and Central Europe for millenniums, from before a turn
of the eras to beyond 10th c. AD. The Eng. dog's bark with prosthetic anlaut consonant is
consistent with other Oguric traces in Gmc. and Eng. languages, along the lines of ür- > ver- >
bar-. The form barak is formed with deverbal suffixes for noun/adjectives and abstract
nouns, a common suffix -k (bark) and “rare” (in the eastern sources) suffix -ak (~ barak).
The Türkic verb ür- may very well predate domestication of the wolfs. Eventually, using
available grammatical tools, it developed derivatives for the notions of “bark” and “dog”. The
recorded A.-Sax. forms bearca, bearcae, beorc point to difficulties in rendering a quality of
the vowel using Roman alphabet.
3.16
bash (v.) “hit hard”, (n.) “heavy blow” ~ Türkic ba:s, ba:š (ba:sh), ba:θ (n.), ba:sa, ba:ša-
(ba:sha-) ba:θa (v.) “bash, whack, attack, assail, assault, wound”.
An “IE etymology” advances a “perhaps”-level or an echoic origin. That amounts to “no clue”.
Ultimately fr. a root ba-, Cf. ba-liɣ “wounded”, ba-lik “be wounded”. The
polysemantic verb's ba:š prime notion is “push, press from above”, along with nine other
semantic clusters. The word is peculiarly connected with a Türkic
baš “head”, pointing to an origin from a notion “strike from above, strike on a head”, and
thus ascending to a most primordial hunting time. “Ba:š” denotes a notion “tramp, thresh,
pound”. If “bash” was not a loanword from Türkic, it could be advertized as a native “IE” word:
among 44 European languages, it is a leading word with 28 (64%) languages. Most of them are
relatively recent loanwords, i.e. it is a classical “wanderwort”. The remaining 16 (36%) European
languages use 11 of their own native terms lead by a unner-up Old Europe Sl. group. Like numerous
other Turkisms, bash was probably lurking under a radar of contemporary grammarians.
Cognates: A.-Sax. pote, potian “butt, push”, ONorse basca (basha-), beysta
“strike”, Sw. basa “baste, whip, flog, lash”, Dan. baske “beat, strike, cudgel”; Ir.
bruth, putaidh “push”, Gael. bruth, buille “blow, push”; Catalan festa “strike”;
Galician bater “strike”; Rus. bastryk “yoke, weight, oppression”; Mong. basu-
“oppress”; Manchu basala “kick”; Kor. matta “break, crush”; Sum. badd “beat,
strike”; Az. vurmaq “bash, shoot” (b/v, s/r alternations). Distribution: From
Atlantic to Pacific, across linguistic barriers. A phonetic consonance between synonymous “bash” and
bat allows to suggest that “bash” is an allophone of the bat, both ascending to a
primeval root ba- (EDTL v.2 89), see band. Then the attestation of this word runs to
the Sumerian language of the 4th mill. BC (Sum.
badd, q.v.). A time of internalization of the Türkic with Eng. ascends to the time of the
A.-Sax. Türkic-Gmc. amalgamation. The ONorse and Sw. had preserved the Türkic morphology in forming
denoun verbs by suffixing -a. The perfect phonetic and semantic match, the authentic suffix,
a global spread, and the status of a non-IE origin leave no doubts of the Türkic origin. The word
belongs to the host of Turkisms that survived in English and Türkic without any substantive change.
The entire body of intact survivors constitutes an insurmountable evidence of a massive paradigmatic
transfer. See ambush, bat.
3.17
bat (v.) “beat”, (n.) “bat, club” ~ Türkic bad(ar) (v., n.) “beat, strike”.
A Scythian pata “to strike, to kill” was explained by Herodotus IV.110 as a Scythian for
“kill” in a compound eorpata - those who are killing their husbands, with Türk. er
“man, husband”, Cf. A.-Sax. wer “man, husband”, Gmn. Herr ditto, etc. In Türkic a
Scythian
eorpata is erbadar; if A.-Sax. had a “man-killer”, it would have been
werbatt/werbeot. A noun bad “(tree) limb” produces implements “bat, club”, it survived in
a form “boutique” = “branch”, see boutique. A causative form batïr of “bat” relays
“thrust, plunge, strike, stab, stick, jab” formed with suff. -ïr, -qïr, -tïr. Cognates:
A.-Sax. batt “bat, cudgel, club”, beot and (rarely) beoft “beat, strike,
thrust, dash, hurt, injure, tramp, tread”, fystgebeat “blow, beat with fist”; OBreton bath
“cudgel, club”, Breton bazh “swagger stick”, Ir., Gael. bat, bata “cudgel, staff”;
OFr. batte “pestle”, Lat. battuere, LLat. battre “strike”; Sum. badd
“beat, strike”. It is incompatible in Av., where pada is “heritage, offspring”. A Sumerian
badd is an oldest record for bat (v., n.) ascending to a 4th mill. BC, it is construed as
“to thresh (beat hard) with sledge (hammer)”. The Sum. word aligns with the Türkic Bulgars' folklore
story of their descent from Sumerians. That links Türkic with Sumerian and Scythian, and on to Gmc.
> Eng. The Breton word points to a Celtic inheritance from the Eastern Europe. A 5th century AD
Isfahan Codex in Yerevan with Hunnic grammar and wordlist lists a Hunnic batten as “push”, a
minor semantic twist produced by ancient or modern Armenian translators. That's in a ballpark.
Attested traces across Eurasia sequentially cover the Celtic circum-Mediterranean migrants from the
E. Europe ca. 5th mill. BC, then the agglutinative “isolate” Sum. ca. 4th mill. BC, then the
Scythian Kurganians from the Siberia ca. 3rd mill. BC, then the entire Eurasian agglutinative family
of the Türkic Kurganians, and reach to our days. An appeal of the unstoppable “IE etymology” to an
illusionary clone, a faux “PIE Proto-word” *bhat- “strike”, or its gilded faux clone a “PIE
Proto-word” *bʰedʰh- “strike, beat, pierce” are not not needed. In a “probably of Celtic
origin” a “probably” is not needed. A real attested material is a plenty of real evidence. Rather,
traces reflect an amazingly wide distribution long before the Corded Ware period and footprint.
Traces reflect a tight correlation with the attested spread of the (later Sarmatian) R1b and the
(later Hunnic) R1a Y-DNA haplogroups. A three-phoneme word must have numerous homophones in nearly
every language on the mother Earth, like the vat and butt in Eng., a huge playground
for lively imagination and storytelling. Of a relevance to the etymology of the word are only the
ones that directly convey the notions related to “beat, strike, branch, bat, club”. A Türkic -
Celtic - A.-Sax. - Eng. heritage is beyond any doubts. See battle, boutique, pat.
3.18
bath (v., n.) “immerse in water” (Sw N/A, F1370, 0.01%) ~ Türkic bat (v.) “immerse in water”.
Ultimately a derivative of a verb ba- “bind, tie, bound”, see band. A unifying
generalized meaning of the verb bat- is “enter into”. Depending on special conditions of its
manifestation, it is modified, becomes specific, and then determines portable meanings of the verb
by origin or use. The Türkic verb bat- comes in a range of forms and meanings. The stem forms
are also put-, but-, pat-, bad-, and ban-, randomly scattered among different
languages, a form bat- dominates. Acoustically different allophones
bat- and ban-, are verbal names for the same effect in related communities, Cf.
bath and banya, q.v. A range of meanings is astonishing, from “bath/bathe” to “bankrupt”
(i.e. “(river) bank, tub wall + rupture” > “go under”), “poke, pierce, stab” (i.e. “reach under”),
“dare” (i.e. “dive under”), altogether more than 50 meanings. In each individual language a number
is severely narrower, i.e. 5 “bath/bathe” in modern English. The causative-transitive suffix -t-
and causative-reflexive suffix
-n- are nearly synonymous, the -n- adding an aspect of benefitting the speaker. A
preservation or an absence thereof of a root verb ba- in daughter languages is irrelevant, a
range of its derivatives from various paths can peacefully co-exist in any language, Cf. band
and bath. A homophonic verb büt-/püt- “come to an end, be finished” (Cf. bud, butt)
may have further confused internalization, semantically conflating a process of moving “put, place”
with an end of the process “have put, have placed”. Semantic difference between the two is on the
level of a mere shade. Cognates: A.-Sax. bað, bæð, baeð, baðu, bathu “bath, bathing”,
also “water, etc., for bathing”, baezere “baptiser, baptist”, bedipan (v.) “dip,
immerse”, pitt, pytt “well, hole, pit”, piða “inner, pith”, and so on; ONorse
bað, botte “pail”, MDu. bat, Gmn. bad; Welsh baddon, maddon; Lat.
batus, puteus “pustule, blister”, Sp. bañera with -n-, Fr. bain with -n-;
Russ.
banya (баня) (with -n-), “bath”; Balt. (Latv.) vanna with -n-, (Lith.)
vonia with -n-, Arm. baghnik (բաղնիք); Georg.
abano (აბანო) with -n-; Mong. bann with -n-; Kor. baseu (바스);
Jap. basu (バス); Heb. bath (בַּת) “archaic unit of volume”. See put for more
cognates. Distribution reliably excludes both “PIE” and “PG” origin. Lexical and spatial
distribution shows that of the 50+ semantic meanings only a small stream was carried to the
northwestern Europe: a core meaning bath, plus derivatives put, well, poke. That lexical stream
reached Europe very selectively: a smatter of northwestern communities, plus spotty Lat. and Sl.
cognates. But eastward, cognates extend down to the Pacific. No suitable “IE” parallels, the “IE” etymological implication of the Lat. linguistic influence on the A.-Sax., Sakha (Yakuts), Uigurs,
Koreans, etc. is a patented nonsense. Suggested faux “IE” ersatzes, the faux “PWGmc. proto-form”
*baþ “bath?”, faux “PG proto-form” *baþą “bath”, faux “PG proto-form” *badan
“warm?, faux “PIE proto-root” *bhe- (v.) “warm”, faux “PIE proto-form” *bʰeh (v.)
“warm” are not needed. Those motions are a waste of ink: internalized loanwords carry etymology of
their predecessors, which needs to be established first. The faux absurdities are waiting to be
rescinded. Bathing was associated with hot water, especially with hot springs. A Somerset city in
England, the A.-Sax. (aka OE) Baðun, called so for its hot springs, exhibits ancient
Türkic-Celtic continuity. Another toponymic form is the Gmn. Baden. A major advance in
analyzing the word bat-/bat was done by E.V. Sevortyan, 1978, who brought together specks of
unheeded knowledge scattered in numerous patchy works but not covered in etymological compendiums.
We may feel bad for the throngs of “IE” etymologists who toiled to compile a rational story. A
paradigmatic transfer of the vernacular, phonetic, and semantic complexity indelibly attests to the
origins from a Türkic milieu. True victims are the misled masses who trusted misleading assertions.
See band, butt, put.
3.19
battle (v., n.) “open clash” ~ Türkic bat (v.) “beat”, bat (n.) “bat, club”, bad(ar) (v., n.)
“beat, strike”, butarla, butyrla “tear apart”, budun/yodun “obliterated, destroyed”; Scythian
pata “strike, kill”, Hunnic batten “push”.
Apparently, a lexeme battle “battle” had never arose in Türkic languages, or it was
supplanted by other lexemes: čalïš, süŋiš, süŋüš, süŋüšmäk, toqïš, toqus, tutulunč. An “IE
etymology” shyly suggests a credibility level of “probably”, “perhaps”, and a face-saving “probably
imitative” origins, but covers its rears with a few juke “reconstructions”, q.v. The form battle
is a cognate and allophonic derivative of a Sum., Scythian, and Türkic pata, bat (v.) “beat”,
see bat, formed with a rare (i.e. archaic) passive voice marker -l > “beaten,
vanquished”. In Türkic grammar, suffix -l forms deverbal and denoun adj. batl with
semantics “brave, daring, decisive”, etc. The notion's origin ascends to a noun but “branch
(tree)”, “leg”, ultimately from a notion “divergence, branching”, see boutique. The notion
furcated into bat and but, the bat line associated with violence (attack), and
but associated with trimming (trees). A surviving adj./noun is a Türkic form batyr widely
known across linguistic barriers as a heroic title from the Hunnic times to the present. A
verbal-nominal homonymy and furcated metaphorical semantics (branch ↔ leg) attest to a
primordial origin of the root. The root was explicated by Herodotus IV 110 in a compound eorpata
as a Scythian word for “kill” – those who are killing their husbands (Türk. er “man,
husband”, Cf. A.-Sax.
wer “man, husband”, Gmn. Herr ditto, etc.). The word ascends to the earliest symbolic
scribble; of 44 European languages, forms of “battle” are used by 22 (50%) languages, far ahead of
the second group (Gmc.) with sla- of 5 (11%) languages. The form bat- is largely a
Romance phenomenon. The remaining 17 European languages use their native 17 words. Cognates
battle: A.-Sax. plaett, plaettan “slap, smack” (b↔p, prosthetic -l-),
beado- (prefix to denote battle, war, slaughter, cruelty): beadogrim “grim battle”,
beat (n.) “scourging”, baetan “beat, strike”, beaterc “beater”; Scotts putt
“push, shove”; OFr. bataille; LLat. battualia, battuere; Rus. batog (батог)
“stick, length of wood, tree branch”, bitiyo (битьё) “beating”, bitva (битва), boy (бой)
“battle”, boynya (бойня) “slaughter” (t/y alternation), voina (война) “war” (b↔v);
Sum. bad “kill, die” (b↔w); Hunnic batten “push”, Chuv. patak “stick” (~
Tr. budyq, budaq ditto); all derivatives of bat-.
Cognates batyr: Ar. batal, battal “hero”; Pers. bahadur; LSkt.
bahadurah, Av. baxtar; Osset. batyra, batra, paxar; Batraz (name); Alan Badur
(name); Mong.
ba’atur, bagatur, Sagay (Khakass) matır (b- > m-); Hu. bator, Bator (name);
Sl., Rus. bogatyr (богатырь); all designate “warrior, hero, brave, strongman”.
Distribution:
Cognate distribution from Atlantic to Far East, across linguistic barriers. The word is incompatible
in Av., where pada is “heritage, offspring”. In addition to a “probably”-level assertions,
“IE etymology” came up with some faux “PGmc. proto-form” *plat- “strike, beat” and yet
better, a faux “PIE proto-form” *blod-, *bled- “strike, beat”. None of that treacly stuff is
useful, credible or non-disinformative; it is blind to or is soundly ignoring the attested lexicon
of ca. 6,000 years old on. That quality of myopia is impressive. The Türkic deverbal suffix
-ur/-r and their allophones denote personal possession. The inlaut -g-/-ğ-/-h-/-x- are
typical for Mong. suffixed articulation. The word is ultimately known from Sumerian, see bat.
The Isfahan Codex in Yerevan with Hunnic grammar and wordlist from the 5th century AD gives a Hunnic
batten “push” (with instrumental suffix -en), apparently with a minor semantic twist
produced by ancient or modern Armenian translators, but still in the ballpark. The settled Sumerians
were surrounded by nomadizing neighboring pastoral Türkic tribes of Subars (aka Suvars), Kumans,
Quties (aka Oguzes), Turuks, and who knows who else. Pastoralists appearance could be seasonal, for
trade and forage. Whether a word originated in a Sum. or a Türkic milieu we wouldn't know. Who
borrowed from whom between them, nobody knows. With a heft of paradigmatically transmitted mass of
clones and derivatives, a widespread origin via a Türkic phylum is incontestable. See bat,
boutique, pat.
| Be, bear – Preliminary Note. One of the most striking aspects of the “IE” family is a claim on sweeping correlations spanning entire conjugational paradigms observed across some, but utterly far from all, “IE” languages. The textbooks on “IE” linguistic theology uniformly cite tables illustrating the verb “to bear, to carry” which shows amazing lexical and morphological correspondences across Sanskrit, Greek, Latin, Gothic, Old Irish, etc., in most conjugational forms of the present tense, and in the lexical forms (Cf. Sanskrit bharami “I bear” (vs. Türkic bermi), Latin fero, Greek fero (φερω), Gothic baira, Old Irish beru “I bear” (vs. Türkic berü), etc.). The “IE” theory was founded on an underlying assumption that these patterns cannot be acquired and must be inherited. For example, Nichols (1996) says that these patterns are “individual-identifying evidence”, the evidence “obvious to the naked eye of a trained scholar” that the languages are genetically related. Alternatively, dissidents assert that because of the language change occurring during millennia, these patterns are too good to be the result of inheritance. One element the textbook tables are missing are the corresponding Türkic forms. The puzzle could be resolved on the spot: be, bear, dur- (Cf. endure), etc. were conveyed by the earliest Kurgan waves, and also acquired by various extracts from the central and western Europe during their millennium-long stay in the Eastern Europe. They were adapted and internalized by various people speaking various vernaculars. Some were internalized complete with suffixes, Cf. Sl. brat, beru (брать, беру) “to take, I take”, and Skt. bharami. The sweeping correlations spanning entire conjugational paradigms, spottily observed across some “IE” languages, form a theoretical base for justifying, under a Family Tree model, a genetic origin of the whole “IE” family. The spotty paradigm is then used as an example of borrowability of the entire conjugational pattern between languages, Cf. the Greek-derived tense markers in Romani characterized by a wholesale import of the entire paradigm. Thus the elements of the archaic Türkic conjugational system become a proof of a viability of a wholesale import, and a pillar in the theoretical base for the entire “IE” paradigm. |
3.20
be (v.) “exist” (Sw N/A, F25, 0.73%) ~ Türkic bol-/mol-, buol-, ol-, o- (v.) “be”.
The word is extremely universal, numbering 17 listed semantic clusters at its base, plus 13 service
functions. In addition to the b/m split, the form evolved b- > v- > 0 (bol,
vol, ol, o), leading to a present dominating spread of ol along with numerous relict and
dialectal forms (14+). A diphthong -uo- is a dialectal form of a long
vowel -o-: buol = bol. An “IE etymology” is completely lost between various internalizations
where a same form leads to different concrete expressions, i.e. pl. vs. sing., 1st pers. vs. 2nd
pers., etc. A habitual b→w, b→f articulation also throws a monkey wrench into semantic and
phonetic articulation. Sorting confusion with warped assumptions baffles even more. A range of
source articulations from different ethnic groups brings another element of confusion: the Türkic
14+ anlauts carry alternations bo-, bu-,- po-, pu-, vо-, wo-, and truncated forms o-, ol-,
etc. A spine of the Türkic articulations is apparent, it clearly elucidates the spine of the related
European “IE” forms. A European footprint of the Türkic origin leads with a combined motley group of
18 (41%) languages (17 b- + 1 a < o-, ol-), approaching a level of 50.6% R1a/b
demographic presence in Europe. It is followed by a largely Romance group es- with 7 (18%)
languages, a Gmc. group var- with 6 (14%) languages, and a motley group ser- with 4
(9%) languages. The remaining 9 (20%) languages march to their own tunes with 7 distinct native
words. There is no common “Pan-IE” root; the European mixture is notably motley. Cognates:
A.-Sax. beon, beom, bion “be, exist, come to be, become, happen”, OHG bim “I am” (<
Tr. bolVm, -m denotes I), bist “thou art”, Gmn. bin, bist; OIr.
bheith “be”, bi'u “I am”, Ir.
a “be” (~ o), Gael. bhith “be”, bha “was”, Welsh menjadi,
berada; Lat. fui “I was”; Gk. phu- “become”; OCS. byti (быти) “be”; Balt.
(Lith.) bu'ti “to be”, Rus. byt “to be”, etc.; Av. bu-; Pers. bu-, bulhös;
Skt. bhavah
“becoming”, bhavati “becomes, happens”; Fin. ole-, on “be”, Hu. vol-, van-
“be”; Mong. forms and semantics are largely identical with Türkic forms: MMong. bol-, Khal.
bol-, Bur. bolo-, Dag. bol-; Mogol bolu; Evenk bola-; Nenets bol-;
Chinese bei 被 “be”. In Türkic: OT, Kirghiz bol-, Chuv. pol-, Tat. bul-,
Yak.
buol-, Khak. pol-, Yugur pol-, Turkish bul-, dial. mol- “be,
become”, Uz. mul-; all “be” except as noted. The origin of the A.-Sax. forms is clear, they
are versions of
bol- + -än from a phonetic series -an/-än past tense participle suffix, i.e.
bolan > A.-Sax. beon, see been. In this construction the specific form bul-,
bol- is strictly conceptual, it could have been anything from the attested series bi-, by-,
bu-, be-, bo-, with consonant variations b-/p-/w-/f-. Historically, all non-Türkic (“IE”,
Chinese, Mongolic and Tungus/Manchu) examples are contiguous with the Great Steppe, and either
contain, or used to have contained sizable Türkic component. Distribution of the cognates is
nearly ubiquitous. In linguistic terms, the word points to what used to be called a Nostratic
origin. A peculiar m/b
alternation, present on the opposite ends of the Eurasian Türkic areal attests to its indigenous
origin and deep roots. In English, some paired compounds with be seem to preserve intact, Cf.
English “be abundant” ~ Türkic abadan bol “be (become) crowded, populous” > A.-Sax. beon,
beom, bion abadan > hide > be abundant. Another Türkic verbal stem for “being (v.)”
var-/bar-/par- was preserved in Goth. and daughter languages (Fris., Dan., Du., Sw., Norw.,
Icl.), incl. Eng., as var and was, see was. Another Türkic verbal stem for
“being” (v.), with a notion of permanency, is dur-/tur- “be, do, stay, remain, stationary,
halt, copula”, it overlaps with bol-/be to express “exist continuously”. It very successfully
survived in the Eng. do expressing abstract permanent action (e.g. “Do you like?”, “Do him
in, do it now”, etc.). Welsh forms echo the very old Türkic forms. The presence of the cognates in
Celtic languages attests to its existence prior to the Celtic departure from the N. Pontic in the
5th-4th mill. BC at the latest, Cf. Celtic buralo “wolf”. Gmc. phonetic forms are closer to
the Türkic forms than their older Celtic siblings. An Indo-Aryan presence attests that it existed in
the N. Pontic area before their anabasis ca. 2nd mill. BC. The Chinese presence ascends to the
arrival of the nomadic pastoralists toward the end of the 3rd mill. BC (the legendary Xia dynasty)
reemphasized ca.1750 BC with an arrival of the “Zhou Scythians” to the isle of the Shang China. The
“IE etymology” is lost in utter confusion, calls the “be” a “fragment collection, conglomeration”.
Still, it comes up with an unattested faux “PIE Proto-root” *bheue- with true semantics of
“be, exist”, and a slue of other ersatz speculations and “reconstructions”: “PGmc. Proto-forms”
*biju- “I am, I will be”, *beuna “be, exist, come to be, become”, *wesana (“?” ), “PWGmc.
Proto-form”*wesan (“?” ), and faux “PIE proto-words” *bheue- “be, exist, grow”, *bhuht
“grow, become, come into being, appear”, *hwes- “reside” *hesti, *hes (“?” ), even a
Lat. fui “I was” from an ersatz *bʰuH (“?” ). A most provocative is a chronologically
misplaced suggestion of a word borrowed from Rus. bɛ (бэ): Rus. did not yet exist
concurrently with A.-Sax., it started forming ca. 600 AD when Shambat (ca. 630 AD), a Samo of the
western sources, a younger brother of the the Bulgarian Khan Kurbat, retreated from the C. Europe
causing a first Sl. migration to the E. Europe. That event is not related to an acquisition of the
Türkic lexeme “be” by the Sl. tribes: the Türkic carriers of the Y-DNA Hg. R1 haplogroup reached the
Sl. carriers of the Y-DNA Hg. I in W. Europe by ca. 9th mill. BC. Whatever were the articulations of
the bol-, buol- ca. 9th mill. BC, there were enough opportunities to spread them in the
following 6,000 years period, engraining them in one or another form across most of the W. and C.
Europe. The bol-, buol- and its versions were long-ingrained guests, amplified by numerous
migratory waves of the R1a/b groups. At the time, majority of the W. European population belonged to
Hg. I, a Sl. haplogroup then disseminated across W. and C. Europe. The trio bol-, var-, and
dur- constitute an authentic case of paradigmatic transfer attesting to traceable and veritable
genetic connection from the Türkic Kurganic milieu. See Be, bear – Preliminary Note, been, do,
durable, duration, duress, was.
3.21
bear (v.) “carry, give” (Sw N/A, F1114, 0.01%) ~ Türkic, Türkic runic be:r- (v.) “carry,
give”.
The Türkic be:r- (v.) is extremely polysemantic: “give, hand over, grant, bring, bring upon”;
it carries 24 meanings in Türkic vs. 14 in Eng. With its semantic wealth, it lived on as a paradigm
onto Eng. and other European languages, with literal and figurative meanings, like “pay”, “marry
off”. With some modifications in semantic accents, it is preserved in Eng. as a paradigm with a
meaning “give”, it is a part of a paradigmatic allophonic triplet “give, bestow” and “bear”. A
homophonous bear (animal) fr. Türkic bori makes it a foursome transfer paradigm, see
bear (animal). It is Türkic most used auxiliary verb with participle, expressing direction for a
sec. pers. and expressing perfect tense actions: “carried out conquest”, “carried out ordering”,
“carry out sermonizing”, “carried out breaking something”, “bear praise”, “bear reward”, “bear
title”, “bore a baby”. Eng. carries both the literal meaning (“bear fruit” ~“give fruit”) and
popular auxiliary functions (“bear expenses” ~ “pay expenses”). Forms of the Türkic be:r-
lead in Europe with a motley group of 19 (43%) languages, approaching a level of 50.6% R1a/b
demographic presence in Europe. It is followed by a hefty Sl. Old Europe group nes- with 2
neighbors, with 14 (32%) languages, The remaining 11 (25%) languages march to their own tunes with 8
distinct native words. There is no common “Pan-IE” root; the European mixture is notably motley.
There is a certain parallel between the “IE” and religion paradigms: weeding out all non-compliant
paradigms leaves out a single universe of a paradigm “us, we, ours!”. Cognates: A.-Sax.
ber(an), bær, bor(en) “bear, bring, bring forth, produce, endure, sustain, wear”, OSax. beran,
OFris. bera, ONorse, Norw. Nynorsk bera, Norw. Bokmal bære, Goth. bairan,
OHG beran, Gmn. (ge)bär(en) “carry, bear, give (birth)”; Bulg. (Tr.) berü
“give”; Sl. bremya (бремя), ber(emen)- бер(емен)-) “load, carry (child, burden, bring)”,
Bolg. (Sl.) bir- “give”, Rus. beru, brat (беру, брать) “am taking, take” (vs. nesu
(несу) “bear”); Pers. bordan (بردن) “bear, carry” (-dan Tr. suffix. of
initiation); Skt. balü (bhaaloo) “bear”; Koman, Čag. bär, Kazakh, Kirgiz, Azeri ber,
Kazan bir, Oirot, Teleut, Lebedin, Shor är, Sagai, Koibal, Kachin per, Crimean
wär, Sakha
biär, Chuv. par; all “bring, give” unless noted otherwise. No Mong., Tungus-Manchu or
any Far Eastern correspondences. Distribution of cognates is limited to a ca. 80 Türkic
languages Steppe Belt and its periphery: Gmc. (9), Romance (6), Irish, Tatar, Greek (3), Bask (1),
and probably few more. Not only the phonetics and semantics of the stem are identical to the Türkic
word, but the morphological function of the participle is accomplished with the retained Türkic
suffix -an, -än that forms a past tense participle: Tr. beran “born”. The verb
“carry, bear” shows amazing correspondences across Tr., Skt., Gk., Lat., Goth., OIr., etc., in base
forms and in most forms of present tense declension (Cf. “I carry”: Tr. berim (-m = me, I),
Skt. bharami, Gk.
fero (φερω), Lat. fero, Goth. baira, OIr. beru, etc. The Skt.
agglutinated form is a clone of the Türkic agglutinated form. According to Kashgari, truncation is
typical for the western Bulgar language. Herodotus (4.117) wrote about Sarmatians in the same area
who spoke Scythian incorrectly. Variations in spelling and slight phonetic modifications can't
obscure the fact that the word survived from an archaic Türkic substrate into modernity with all its
polysemantic cache and with Türkic morphology. No need for unattested “PIE reconstructions” and
unrealistic reverse engineering of a particular application: a faux “PG proto-form” *beranan
and “PWG proto-form” *beran and “PG proto-form” *berana, and a faux “PIE proto-root”
*bher-, *bherti “carry, bring, born”. These poor man's patches are supposed to create a distinct
“Pan-Gmc.” etymology, but demonstrate an opposite by myopically including the Türkic suffixes -an,
and -ti in their “Pan-Gmc.” fiction. There is no escape from reality. Those inventions just
parrot the attested basic Türkic forms. A “birthing” triplet ber-, döl-, ken- stands as a
paradigmatic evidence attesting to its Türkic roots, in a way it is a trade terminology passed from
generation of “birthing” practitioners to their “birthing” daughters and granddaughters with the
other “secrets of the trade”. The triplet serves as unequaled linguistic marker bestowed from
generation to generation immune to all societal turmoils. A homophony with a noun
bear “large mammal” is predicated by the homophony of the Türkic stems of unrelated origin:
ber- and böri. See Be, bear – Preliminary Note, bear (animal), bestow,
confer, deliver, give, gene.
3.22
been (v.) “past participle of be (exist)” (Sw N/A, F91, 0.21%) ~ Türkic ben
“past of be (exist)” in predicate verb, see be for the root word.
Cf. (ičinte:) beg ben “(I've) been a bek (prince)”, bašı: ben “(I) was a
boss”. Ultimately a derivative fr. bol- (v.) “be, exist”.
The development of been is clear, bol-, buol- (v.) “be” > ben (predicate) >
A.-Sax. beon (v.) > Eng. been (v.); a suff. -n effects a base verb. The form
bul-/bol- is strictly conceptual, it could have been anything from the attested series
bi-/by-/bu-/be-/bo-, with consonant variations b-/p-/w-/f-. The original linguistic
efficiency is demonstrated by the opposition ol- (bol- ) “to be, to exist” vs. ӧl-
(bӧl- ) “not to be, not to exist”, i.e. die, death. Allophones of ӧl- (bӧl-)
are widely used in Gmc. daily and ritual languages, Cf. Walhalla “death-hall” with wal
< ӧl- “death”. A history of later lexical transformations past a beon stage (13th c.)
is well established; it is quite twisted, convoluted, unpredictable, and unsupportable by any
“phonetic laws” of the 19th and 20th centuries. Quite the opposite, the rule is “there are no
rules”, as is proper due to a stochastic process of amalgamation, internalization, and adjustment.
To overcome a conundrum, the “IE” theoreticians came up with a 1.) concept of a “b-root” with a
flexibility of a jell, which can accommodate all known forms for the generic notion “be, exist”, and
2.) invented fictitious PIE and PG proto-forms *bheue- and *biju- respectively. The
Türkic real bul-/bol-/ol- also fits nicely in a rubber scenario. A rubber scenario is OK in
observations but hapless in credibly explaining them. Forms of the Türkic predicate ben- < bol-
lead in Europe with a motley group of 23 (52%) languages (12 Sl., 3 Celtic, 2 Fennic, 2 Balt., 1
each Eng., Tatar, Hu., Lat.), approaching a level of 50.6% R1a/b demographic presence in Europe. It
is followed by a hefty Gmc. group wes-, ver- +2 neighbors, with 10 (23%) languages, followed
by a Romance group with 7 (16%) languages. The remaining 4 (9%%) languages use their own 2 native
words. Aside from the Türkic-derived, there is no common “Pan-IE” root; the European mixture is
notably motley and assembled from discrepant ingredients. Cognates: A.-Sax. buon, byan,
buwan, buian, buan “been”, Sl. bil, bio, bol, byl, buv, byc, byi, beshe “been”, Ir.
bhi, Scots
bhith, Welsh bod; Fin. ollut, Est. olnud; Latv. bijis, Lith.
buvo; Du (ge)weest; Fris. west, Dan. været, Sw. varit, Norw. vært,
Icl.
verið, Gmn. (ge)wesen, Yid. geven (געווען); Hu. volt “been”, voi-,
van “be, become”; Lat. fuit; Mong. bol-, bolah “be”; Tung. o “be, become”;
Evenk bola “maybe, probably”; Tatar ben; all “been” except as noted; references to
Finno-Ugrian, Nenets, Kalm. cognates. Distribution of cognates spans across Eurasia from
Atlantic to Pacific, across linguistic barriers. The presence of the oldest Celtic form bi'u
attests to the existence of that form in the N. Pontic at 6th-5th mill. BC, predating by far the
word's 2nd mill BC migration with the Aryan farmers to the south-central Asia. A presence of the
Türkic, Celtic, Chinese, Mong., Av., Pers., Skt. etc. forms flatly defies the “IE” Family Tree model
and irrational PIE and PG/PWG figments. An “IE etymology” displays both a severe myopia and a
parochial approach. It starts with attested A.-Sax. buon and projects it to a faux “PWGmc.
proto-form” *beun “be” and a faux “PGmc. proto-form”*beuna “be” “related to buan
“to dwell”, and then to faux “PIE proto-forms”
*bʰew-, *bʰuH- (“?” ). Since the “been” denotes a past tense, it appeals to faux “PGmc.
proto-forms” *wesana, *wesan and a faux “PIE proto-form” *hwes- (“?” ). A simple “IE”
miracle imparts a PGmc. stopgap *wesan into the A.-Sax. attested forms of “been” (conflation
). Viola!, done, and there are other similar ideas to spare! Then, a connection between homophones
buon “been” and
buon “dwell” just wanes peacefully. Remarkably, the Türkic grammatic function of the past
tense participle expressed with the suffix -an/-än has survived into the Gmc. bin,
A.-Sax.
beon, and modern Eng. been alongside the Türkic OT, Kirghiz bolan/olan,
Turkish, Tatar bulan, Khakass polan, and Uigur polan. Seeing screaming
commonalities, a linguist would not have problems locating cognates and coming to direct
non-prejudiced conclusions. See be; Be, bear – Preliminary Note; Walhalla; was.
3.23
beg (v.) “plead for something” (Sw N/A, F1837, 0.004%) ~ Türkic bag, baɣ, baq (v.) “look
pleading, plead”.
“IE etymology” rated “of uncertain origin”, but q.v. Ultimately fr. a polysemantic notion “see,
look” with 13 semantic clusters; a metaphorical extension baq “plead” belongs to a cluster 1
(EDTL v.2 38). Eng. allophones form with -g/-d alternation, with numerous derivatives:
beggar, begging, beggary, beg (pardon, mercy), “beg a question”. Cognates: A.-Sax.
bedecian (v.) “beg”, began, bugan “bow, bow down, bend, stoop”, Fris. biddel, Du.
bedelen, Norw. Bokmal be “beg, ask”, Icl. beg, Luxemb. bettel, Goth.
bidagwa “beggar”; Gmn. betteln, Yid. betn (בעטן); OFr. begart (beggar);
Bolg. bakadzik (< bakačak) “outlook”, bak, baka (v.) “look”; Serb. bakas
(bakač ?) “call”; reference to Pol. cognates; Tung. baka- “find, clarify”;
Tatar baq; all related to “beg, begging” unless noted otherwise. Distribution: spans
across Eurasia from Atlantic to Pacific, across linguistic barriers. No sound etymology, no viable
Gmc. connections, no “IE” parallels, but a wild faux of “PG proto-form” *beth- (“?”), a faux
“PG proto-form” *bedago “petitioner, requestor, beggar”, and few other “perhaps” wild
guesses. A source could be an Alanian source of the Amorican Alans who moved into Brittany in the
5th c. AD, or of the Brits of Brittany with Sarmatian, or Scythian, or even Cimmerian via Frisian
connections. In Eng., lexeme beg is recorded from ca.1200, but the substance of the base
notion “see, look” and a massive chain of semantic extensions points to a primordial origin, and the
attested Goth. form ascends to a 1st mill. BC. In the Middle Age society, pleading with a lord must
have been a daily affair, keeping the word rolling.
3.24
bellow (v.) “sound of an animal” ~ Türkic belä- [belə-], bele:-, be:le:-, mele-, mǝlǝ- (v.)
“bleat, sound of a sheep”.
Such notions are largely onomatopoeic, while specific to individual languages. English has
variations bawl “cry loudly”, yowl “utter shrieks”, holla (b- ↔ h-)
“sound of an animal”. Cognates: A.-Sax. bylgan, bylgean, bylgian, bellan “to
bellow”, hlowan, hlowung “lowing, bleating, bellowing” (b- ↔ h), Du. blaten;
Welsh beuo; Balt. (Lith.) bliuti, baubti; Sl. bleyat (блеять); Gk. velazo
(βελάζω); Fin. mylviä (< myl/byl); European versions with b/m alternation:
Lat. mugire, Port. mugir; Latv. baurot/maut; with b/h alternation: Fr.
beugler, hurler; with l/h alternation: Basque behean; with b/br
alternation: Da. brøle, Norw. brøle, Sw. vrala, Gmn. brüllen; Gael.
berrar; It. barrito; Balt. (Latv.) baurot/maut. Cognates point to ubiquity of
distribution, and various paths of acquisition. “IE etymology” abstains from parallels, apparently
suggesting echoic origin from numerous sources, but still comes up with a faux “IE” nonsense of faux
“IE proto-words” *bhel-, *bʰel- “sound, roar”. Unwittingly, the unattested “IE proto-word” is
a replica of the attested Türkic belä- “to bellow”. The echoic origin is apparently true and
beyond our horizons. The extant phonetic forms allow to diagnose much more specific sources.
Notably, morphology of the A.-Sax. bylgan has preserved Türkic suffix -gan/-ɣan/-an (-än,
-ın; -gän; -qan, -kän) that forms deverbal nouns: belä- (v.) > belägän (n.) >
A.-Sax. bylgan (n.) “bellow”, with a temporally close transition from the Türkic to the
A.-Sax. Gmc. languages have not retained that suffix. The homophonic bellows (n.) is probably
related via a woodwind flute. A Türkic origin is impeccable.
3.25
bestow (v.) “grant, give” ~ Türkic bestle-, besle- (v.) “feed, nurture”, besmek (v.)
“educate, feed, nourish”, besli, bestle (n.) “fattened, well-fed, fat”.
Etymology of the word is far away from that asserted by the “IE etymology”, q.v. Ultimately fr. a
root bes-, bäs- (v.) “pasture (cattle)”, reflected in the Eng. word “pasture”. The verb
“bestow” is a reincarnation of the form
bestle. The root is polysemantic with 4 semantic clusters expressing a combined 20+ meanings.
The form bestle- is an agglutinated compound of the root bes- + deverbal abstract noun
suff. -t- + verbal suffix -le, i.e. feed (v.) → feed (n.) → feed (de-n. v.) →
bestle (v.) “feed, grant, give”. A generic Türkic word extended a meaning of the bes-, bäs-
to reflect a reality of the day, a posse (comitatus) system of the times. Children of nobility were
enrolled into a personal guard service of the leader. They were bestowed nurture and tending in
exchange for a service. A substantial difference between Türkic and feudal systems was that Türkic
comitatus was of necessity voluntary: nomadic volunteers could mount their horse at any time,
disappear into a blue horizon, and never be seen again. The term outlived the archaic and feudal
times, and became a post-feudal exalted synonym of “give”, see give. The word is unique in
Europe, where a Sl. Old Europe dar- dominates with 10 Sl. and 5 non-Sl. words in 15 (35%)
languages. A second group is Gmc. schen- with 5 (11%); a third are 3 groups with 3 (7%)
languages each (Celtic, Gmc., Romance). Eng. belongs to a 4th grouping of 4 groups with 2 (5%)
languages each (Romance, Sl., Balt., Eng.), where Eng. group contains Eng. and Tatar languages.
There is no common “Pan-IE” root in Europe. But some 14 linguistic entities in Europe, incl. Tatars,
use versions of the root bes- for “feed, nourish”: 1. Azeri 2. Bashkir 3. Chuvash 4. Crimean
5. Gagauz 6. Karachay 7. Karaim 8. Kazakh 9. Kumyk 10. Nogai 11. Tatar 12. Turkish 13. Turkmen 14.
Urum. They complement the Eng. oddball “bestow”. Cognates: A.-Sax. beteon “bestow” (+agiefan,
aegift, agift, ametan, daelan, don, gaf, etc. “give”); Ir. beatha “feed”, Scots
biadhadh “feed”, Welsh ymborth “feed”; Gk. beslemes, peslegeve (μπεσλεμες, πεσλεγεβε)
“feed, eat”; Serb. besleisati “feed, eat”; Pers. baxš “gift” (< Tr. bakšiš,
Eng. bakhshish). All cognates either came fr. a Türkic milieu (A.-Sax., Serb., Celts), or
have a historical connection (Gk., Pers.). The last two are idiosyncratic, with a Türkic loanword
not present in other “IE” branches. Distribution: An Eurasian arc of the Türkic languages;
isolated presence in Eng. and Pers. The “IE” etymology suggests to parse the A.-Sax. beteon
“bestow” in a form bestow as a be- + stow, lit. “emplace”, and a faux “PIt.
proto-word” *pasko, a faux “PIE proto-word” *peh- “protect, shepherd” for a cognate
“pasture” (v., n.). Outwardly, the “IE, native” bestow looks quite suitable and phonetically
precise. But the construct be- + stow creates a semantically divergent paradigm that does not
convey the notion of “grant, give”. The stow “emplace” is not exactly a “give” or a “feed”.
The artificial compound
be- + stow unwittingly combines an Eng. allophone of the Türkic be- (see be)
with the Türkic üstü- (v.) “stay”, lit. “on feet, standing”, see stay. And the
non-Eng. cognates are absolutely unexplainable, Cf. Gk. beslemes. The “IE” assertion is a
shameless nonsense. A root best, for example, can be played on to produce many more “IE
etymologies” of a compatible quality. A Türkic trifecta of terms for “give” comprises a hierarchy of
qïv- (“bless, confer”), bestle- (“bestow, grant”), ber- (“give, bring, bear”),
with qïv- a most dignified and ber- a most mundane. English has preserved allophones
of all three words, give, bestow, and bear, with some change in semantic accents (Cf.
dignified Eng. bestow and a mundane give, the bear is more “carry” and less
“give”). This is a case of an entire paradigm borrowing, a clear attestation of the genetic
inheritance, and an impeccable evidence on the linguistic scales. In the English highly stratified
class society, such an important term as bestow could not fail to appear in historical
records way before the 15th c. That points to a winding path for the word, and its survival in the
folk lingo under a radar of the literary English. See be, bear, give, stay.
3.26
bet (v., n.) “wager” (Sw N/A, F592 Σ0.02%) ~ Türkic büt-, bit-, püt- (v.) “be determined,
confirmed, believe, trust” bütrüš- (v.) “wager, bet (between two sides)”.
An “IE etymology”: no cognates, “argot of petty criminals, of unknown origin”, with some fudge of
“perhapses”. The “IE” assertion essentially admits “we have no clue”. The polysemantic word büt-,
bit- carries 3 key semantic notions: (EDTL v.2) 1. end, finish, resolved (p. 152), 2.
believe, trust (p. 279), 3. all, completed (p. 302). Each one applies to a bet: semantics is not
specific. Cf. just a single notion “end” with 15 nominal and a verbal clusters. The verb
büt-, püt- was formed by a primeval monosyllabic model of noun/verb (EDTL v.2 280).
Derivatives of the verbal stem neatly fall into the notion of contest for something to be confirmed,
the truth to be determined: bütrüš- “contest, seek truth”, bütür- “confirm, find out,
attest”, bütünlä- “seek truth, search for truth”. Türkic has 11+ words to express “wager”,
vs. the Eng. two. That points to gaming as a national Türkic pastime, including children. Of 44
European languages, the form büt- dominates (Gmc. bet-, vet-, wed-, etc.) with 11
(25%) languages, followed by Old Europe Sl. with 7 (16%) languages, followed by a Romance group with
5 (11%) languages. That Y-DNA and geographic hierarchy ranks the specific weight of the origination
sources in time and spread: earlier > seeded more. The remaining 21 (48%) languages use their own 15
native terms. Constructs like a bet- require attentive parsing: with a root starting with
-t-, anlaut be regularly serves as a prefix be “to be”. Cognates: A.-Sax.
bet “better, one who bets”, betynung “conclusion, end”, buttuc “end”; Dan.
vædde, Norse edde, Sw. sla (vad), Gmn. vette, Icl. veðja; Fr.
pari, Sp. apuesta, Basque
apustu, Port., Catalan, Galician aposta; Lat. pateretur, pignus, Rum. pariu;
Serb. opklada (опклада); Alb. bast; Fin. veto, Est. panus, Hu. tet;
Kaz., Uz.
bet, Turk. bahis; Mong. bootsoo (бооцоо) “bet”. An assertion, q.v., of total
absence of cognates is a gross distortion. Distribution: An Eurasian arc of the Türkic
languages; partial spread in Europe. The “IE etymology” suggests a PG origin, i.e. either “IE” or by
default a non-IE, from nominally homophonic bait, A.-Sax. bat “food”, ONorse beita
“food”, beit “pasture”. A semantic incongruity puts that insanity beyond contempt: jumping
from a “wager,bet” to a “food”. In Türkic languages the alternation b-/v-/p- is regular; some
receptor languages also regularly palatalize initial b-. A prefix a- (apuesta
etc.) is also regular. Random variations at internalization should be expected. Some inferred
cognates may not belong to the lineup at all. A Türkic etymology is semantically proper,
phonetically reasonably close. It does not need to appeal to an argot of the criminals, especially
so considering that betting is an ubiquitous Eng. tradition of all classes from the earliest times.
The idiom I bet you illustrates the notion of bet “wager” in a sense of “I am sure (of
this truth), I would wager (that this is truth)”. An A.-Sax. betrendan “to roll” may be a
metaphorical derivative of bet- “roll a dice”. The homophonic better “betting person”
and the native better comparative of “good” are not related. A Türkic origin stands on its
own, supported by the lucid lineup of the cognates, known historical development, and unequivocal
genetic tracings.
3.27
bill (v.) “advertise, publicize” (Sw N/A, F899, 0.01%) ~ Türkic bil (v.) “find out, learn”.
The polysemantic word numbers 10 semantic clusters and some 60+ meanings. The “IE etymology” traces
an origin to Gaulish passed on to Lat. That sends the word to 6th-5th mill. BC, prior to the time of
the Celtic departure from the N. Pontic in the 5th-4th mill. BC at the latest. That, in turn, dates
the Türkic bil “know, understand” by ca. 6th-5th mill. BC, in conflict with some “IE
etymology”. The last asserts that a MLat. bulla “decree, seal, sealed document” comes fr. a
“bubble”, aka “boss, stud, neck amulet” and hence a “seal” and hence a “Papal bulla”. That kind of
etymological equilibristics from a Gaulish source to bubble is too uncouth. A Türkic, with its
refined morphological mechanism for producing grammatical forms, tends to use an active voice; Eng.
has a preference for passive voice verbs: “he is billed as an expert” means “he is said to be an
expert”. Türkic
billüg is “found out, known”, with extension to “famous”; a “publicize, advertise” is formed
with causative tense suffix -dur > bildur “notify, inform”. A derivative of bill (v.)
is
bill (n.) made quite famous with the Bill of Rights, followed up with thousands bills
approved regularly by Congress. Each enterprise has a billing system, we get daily, weekly, monthly,
and annual bills, we used to billet militia and army, we carry bills of different denomination in
our wallets, we trace billables, are overbilled and underbilled. The “learned” in the form Bilge,
usually translated as “wise”, was a popular title of the Türkic Kagans, including a famous hero of
the Bilge-Kagan inscription. The root bil- with the semantics “able” found employment as a
suffix -able in Eng. innovations like suitable and doable, the last is a
compound of two reflexes, the tü “do” and bil- “able”. Similar internalizations took
place in other amalgamated languages like Lat, Cf.
bil- “able” > Lat. -abilis, -ibilis ~ Eng. -able, -ible. Another prominent
derivative is the English verb feel “feeling”, a 15th c. contraction of the Türkic derivative
bilig, bilin-, see feel. Three words, bill (0.01%, rating 899), feel
(0.13%, rating 174), and will (0.58%, rating 75) contribute combined 0.72% frequency usage in
Eng., without accounting for forms like billable, feelingly, willful, and palpation.
That brings the total frequency usage of the Türkic bil-'s descendents to about one of every
hundred daily words, or a 5 words per page. With all the learning-related subjects at hand, the “IE
etymology” did not get even a hint of any “IE” cognates nor a clue on the origins of the so dear to us
existential and linguistic components of our accumulated cultural wealth. See -able, eligible,
durable, feel, will.
3.28
bode (v.) “augur” ~ Türkic bodi “insight, achievement of perfect wisdom”.
Ultimately fr. a Türkic root büt-, büt, püt-, püt (v., n.) conveying mystical notions
“believe, deity”, “pray, prayer”, “revere, idol, icon, cross”, “refer, truth, fact, verity”. The
Türkic word belongs to a class of grammatically most archaic, distinguished by homonymic noun-verb
pair and neutrality to transitivity. It was a primer of a word, not a tongue yet, in Skt. bodhi
“enlightenment, awakening”. Time has erased in Eng. linguistic traces of the past religions
supplanted by the later doctrines, leaving behind only monuments of the old cultures. The term
bodi is a Buddhist religious term of Türkic extraction, with vast spectrum of Indian
derivatives: Buddha, bodimant “throne of enlightenment”, bodisatva (bodhisattva)
“enlightened (bodhi) being (sattva)”, etc. Few of them rolled into a Türkic syncretic
lexicon. The first Buddha brought a Buddhist enlightenment to India. He was a Türkic Saka extract, a
Scythian “prince” Shakyamuni (6th c. BC), of the Saka (Saxon) Kurgan tradition. The Türkic bodi
underlies the entire Buddhist lexicon. Cognates: A.-Sax. Buddhistic bodi- derivatives:
bod “command(ment), message, precept, preaching”, boda “messenger, herald, prophet,
apostle, angel”, bodere “teacher”, bodian “foretell, announce, proclaim, tell,
preach”, bodiend “proclaimer, teacher, preacher”, bodlic “command(ment), decree,
ordinance”, bodscipe “message, command”, bodong “message, recital, preaching,
interpretation”, bodungdaeg “Annunciation Day”; secondary internalizations: OSax. (gi)bod,
ONorse boð, Gmn. (ge)bot; Balto-Sl. (Lith.) budeti “awake”, (OCS)
bludet “be alert, follow”; Skt. bodhati “awake, watchful, observe”, buddhah
“awakened, enlightened”, bud “Buddha” (and “planet Mercury”), Av. bütaj “name of one
of the demons”; Pers. but- “idol, fetish” (also “beloved, sweetheart”), pwt- “Buddha”;
Kor. mitta, mide, midin (믿다) “believe, trust”. Distribution:
An Eurasian arc of dashed lines of diverse Türkic languages centered as local communities;
polylingual nodes starting in India with branches scattered across Eurasia; ca. 1st mill. BC partial
spread in W. Europe; ca. 370 - 470 AD last Hunnic wave in Europe. Reportedly, the Far Eastern China
and Japan received their terminology via Sogdian intermediaries. Reportedly, the same with Türkic,
Mongol and Tungus-Manchu via Sogdian, attested by a form put-. That probably refers to
proselytizing of the following two millenniums, the secondary splashes of activities. A parochial
PIE- and PG-suggested etymology belongs to a genre of scientific fiction: local origins and unreal
etymological cures, the faux “PGmc. proto-forms” *budon- “message”, *buda “message,
offer”, the faux “PIE proto-root” *bheudh- “aware”, the faux “PIE proto-form”
*bʰewdʰ- “awake, perceive”. The inventions have nothing to do with the subject
bode (v.) “augur”, and need to be gently retracted. They flout the Buddhist period of the
rich, philologically documented multi-faceted A.-Sax.-Eng. history. The “IE ingenuity” suffers
myopia and blindness of politics. Digging for an “IE prime root”, it completely ignores the Buddhist
terminological nest. The “IE etymology” also suggested an origin linked to OIr. buide
“contentment, thanks” barely related to the notions of “enlightenment, augur”. The OIr. buide
may be a reuse of a Celtic Kurgans' semantics of the 5th mill. BC before their departure on a
circum-Mediterranean anabasis of the 4th mill. BC, separated from its siblings by a combined 8,000
years timespan. The semantics of bod- “augur, insight, enlightenment” first came to, and then
post-6th c. BC grew on the Indian soil. A few centuries were needed for the Buddhist terminology to
take root and develop in India. That points to a timing for the matured Buddhist formulaic
terminology penetration into the steppe belt. Instead of being exalted or accidental, migration of
the Buddhist enlightenment to the foggy Albion and its environs jibes with the historical canvas on
the known migrations of the Celtic Kurgans, Sarmat Kurgans, with the Buddhism's syncretism with
Tengriism, and the Gmc./Scandinavian innate religion of Thor of the 1st mill. BC. There also is a
linguistic connection between the Khakas of the Aral basin and the A.-Sax.-Eng. The Sogd of the Aral
basin was an intermediary between the Indian, Pers. and Türkic phylums; it was formed by migrants
from a present Baluchistan at the beginning of a 2nd mill. BC, 1500 years before Shakyamuni's
arrival to India and his idea of Buddhism. The expanded extent of the A.-Sax. lexicon attests to a
long syncretic period and deeply ingrained use of the Buddhist terminology. It was carried by the
Sarmat migrants of the Sarmat expansion period not earlier than the 3rd c. BC and not later than the
first references to the nomadic Vandals Wendeln “Wonderers” at the turn of the eras. Buddhism
was syncretically embraced by Tengriism, and spread from India to the western Asia and the eastern
Europe. The Gmc. cognates attest to a deep penetration of the Sarmat Tengriism into the life and
etiology of the Central European (A.-Sax., OSax.) and Northern European (Gmn., ONorse) populations.
The Lith. and OCS lexemes attest to the semantics and phonetics extant in the Eastern Europe in the
2nd c. BC. The penetration had to be directional, touching certain tribes and not reaching the
others. For temporal and spatial reasons, more westerly archaic Scythians, Cimmerians, the
Mesopotamia Kurgan nomads, the northern Tele tribes, and and the archaic Zhou in the east could not
have been affected by Buddhism. Those tribes would have preserved the archaic etiology of Tengriism
and the archaic religious terminology, missing on the Buddhist formulaic bodi and its
numerous derivatives including buddha. That lopsided penetration is reflected in the
dictionaries. An OTD succinctly lists a series of Buddhist lexemes, and an EDT ignores them
altogether. An influence of the Roman world in disseminating Buddhist terminology to the N. Europe
needs to be ruled out for two reasons. One is a spread of Mazdaism in conflict with Buddhism across
the Roman world precluded a spread of the Buddhist lingo there. The other was a lack of a Roman
religious influence on the outside world. The Romans neither mastered Buddhist terminology nor were
in a position to spread it. That again leaves only the Sarmatian part of the Scythian world to carry
Buddhist terminology to Europe. A return of a mutated Indian term to the Eastern Europe has not
caught on because Balto-Sl. languages have already developed their own synonymous lexicon based on
an Old Europe Sl. stem ved- “to know” (Cf. Sl. vedat, veschiy (ведать, вещий) (adj.)
“know, prophetic, enlightened”, etc.). It also did not infiltrate the Fennic population of the area.
The A.-Sax. term bod- affords a unique opportunity to trace physical and cultural migrations
across Eurasia that link the Indian subcontinent with the Atlantic seaboard, a yet unaddressed
unique and credible marker that propagated along the Eurasian steppe belt in the course of the
sequential Türkic migrations. See bursary, purse.
3.29
bore (v.) “drill a hole” (Sw N/A, F1969, 0.003%) ~ Türkic bur-, bür- (v.) “twist, wind round,
screw”, a subset of a generic meaning “twist, twirl, spin” applicable in non-bore related sense,
like twisted vines, etc.
Ultimately fr. a verb bur-, bür-, buz- that starts with “ruffle, pleat” and is consonant with
an antecedent bu- “steam”, probably referring to eddying twisting steam. The meanings of
those three stems are both overlapping and divergent. Various allophonic forms include ebir-,
egir-, evir-, evür- with a front prosthetic vowel and initial p- (b > p), Cf. “puff”. The
r/z alternation is equivalent to r/s alternation, it attests to a most archaic origin. Of
44 European languages, a large motley group of 21 (48%) languages uses forms of the Türkic bur-,
matching a level of a 50.6% Hg. R1a/b demographic presence in Europe. A remote second toch-
is used by 3 (7%) Old Europe Sl. languages. A very motley mass of remaining 19 (43%) languages use
16 of their own 16 native terms. There is no common “Pan-IE” root in Europe, where the Türkic
bur- dominates. Cognates: A.-Sax. bor “borer, gimlet”, borian “to
perforate”, (wede)berge “(helle)bore”, MDu.
boren, Dan. bore, ONorse bora, Sw. borra, Norw. Bokmal bore, OHG
boron, Gmn. bohren “drill”; Lat. foro, forare “drill”; Sl. allophones of
br-, vr-; Russ. bur (бур) “auger”, buravit (буравить) “drill”, vertet (вертеть)
“spin”; Bosn.
buše-, Serb. bush- (буш-) “to drill”; Alb. brime, birë “hole”; Fin.
porata, Est. puurida, Hu. furni “drill”, forog “rotate”; Mong. burgi
“eddy (smoke, steam, dust”), burzigina-, burziginah “puff up”, buran “tornado”; Even
mori “pucker, wrinkle, fold” (m/b alternation); Manchu foro “revolve”, forgon
“rotate”; Nanai poro “revolve”. Distribution: Eurasian including and adjacent with the
Eurasian Steppe Belt; W. European cognates are scattered in a geographically confined area,
consistent with the Eurasian distribution of other words of a Türkic origin. An “IE etymology” came
up with utterly myopic fantasies of the faux “PGmc. proto-forms” *buron, *burona “? hole” and
a faux “PIE proto-root” *bhorh “hole”. Given the Eurasian spread of the word, from Atlantic
to Pacific, such parochial pretentions on antecedence are beyond the pale. See wrinkle.
3.30
borrow (v.) “receive temporarily” ~ Türkic burč, borč, borğ, borığ, murıč (n.) “debt,
indebtedness, obligation, loan, borrowing”.
Ultimately a deverbal noun derivative fr. a verb be:r- “bear, give”, see bear (v.). An
anlaut consonant wobbles between b-/p-/m-, the vowel wobbles between e-/i-/o-/u-. A
deverbal noun suffix -č is one of the most productive suffixes, same with -ɣ/-ïɣ (ğ/ığ).
A form bert (-č > -t) conveys the same in a passive form, “something given”. The
European cognates are limited exclusively to a Gmc. group, attesting to a non-IE origin. A primacy
of Türkic or Sogdian origin is disputed. But Sogdians, the farmer migrants from Baluchistan, came to
the Aral area after the end of the 2nd. mill. BC, after an end of a desertification during entire
2nd millennium BC. That points to a Türkic origin of a very archaic term, further reinforced by
consistently Türkic morphological elements. The other suggestions of origin, the Syrian, Kalm.,
Mong., Manichaean lingo, etc. are likely adopted trade loanwords. Cognates: A.-Sax.
borg/borh “debt, pledge, security, obligation, debtor” (-ğ ↔ -h), borgian
“lend, be surety for”, boren pp. of beran, bringan “bring”, etc., with a significant
set of derivatives and extensions, OFris. borgia “borrow, take up money”, MDu. borghen
“protect, guarantee”, ONorse borga “bail, guarantee”, Goth. brahta “brought” (i.e.
“brought to” with a Türkic directional suffix -ta), OHG brahta ditto, Gmn. borgen
“borrow, lend”; South-Sl., Rumanian, Alb., NGreek bordž, bordžlu “borrow, lend” (< Tr.);
Sogd.
pwčr “debt”; Syrian porč “debt” (b/p alternation); Mong. buru
“responsibility, guilt”, Kalm. buršm “debt”; Karagas-Koibal (Tuvin.) bro “debt”; Kor.
bij (빚) “debt”. Among the Türkic family the form borğ, borg, borığ
(with -ğ/-g) is shared by Azeri, Chagatai, Crimean Tatar, Ottoman, Turkish, and Uigur.
Distribution: Geographical distribution extends from Atlantic to the Far East, across linguistic
barriers. Distribution pointedly avoids numerous linguistic groups, accentuating a local attachment
to the word. The focus of the Türkic -ğ/-g form centers on the Aral-Caspian area, consistent
with numerous other Türkic-Gmc. lexemes. The word has a rich range of phonetic forms, attesting to a
long history of circulation and plenty of amalgamation. With the weight of the complex and
overlapping diagnostic evidence, the simplistic phonetic knockoff of the faux “PGmc. proto-form”
*burg- “pledge”, “PIE root” *bhergh- “hide, protect” is perfectly ridiculous. The
combined evidence of carryover of the prime stem ber- “bear” and its derivative borg
lit. “something carried over, given” constitutes a paradigmatic transfer case that definitively
attests to their origin from the Türkic milieu. That evidence is corroborated by a sister case of
paradigmatic transfer, the “birthing” triplet terminology
ber-, döl-, and ken-, passed from Türkic moms to their daughters and granddaughters,
unambiguously attesting to the innate Türkic roots. See bear – Preliminary Note, bear (v.).
3.31
botch (v.) “destroy, ruin”, botcher (n.) ~ Türkic budun, buzun, yodun “obliterated,
estroyed”.
The word is “IE etymology” rated “of uncertain origin”, that is supported by late and alive Eng.
linguists. Ultimately, derivatives of yo:d- (bud-, buz-, pos-) “destroy, obliterate, wipe
out”; -č is a marker of deverbal noun (budč, buzč, yodč “destruction, ruination”);
inlaut -t- reflects -d-. -z-, -s-. The word numbers 11 semantic clusters; concrete
meanings are situation-formed, Cf. bad weather vs. weather worsening, etc. The Türkic semantics
includes both a lit. and a contrasting metaph. and sarcastic meanings, to ruin something for good
and to do something badly (spoiled work). There is no common “Pan-IE” root in Europe, where the
Türkic bud- dominates. A motley group of 19 (43%) European languages uniformly uses forms of
“botch” (Türkic, Celtic, Gmc., Sl., Bask, Cors. Maltese); the remaining 25 (57%) European languages
use their own 22 native words. Such breakdown attests powerfully to a “guest” status of the word in
Europe. No A.-Sax. cognates. An Eng. word bocchen with unrelated literal semantics “to
repair” is documented from late 14 c. A cure for the upside down semantics comes with a suggestion
that later, a semantic shift turned it to “spoil by unskillful work” (1520s), a noun from ca.1600.
Interpretation that a “black” turned into a “white” is ludicrous. Etymology is extremely succinct,
no “IE” cognates whatsoever, no restored “IE” “proto-word” to go around. A coincident presence of the
Türkic and Celtic sibling forms profoundly attests to an origin of the word from a far-away Siberia,
a motherland of the Y-DNA R haplogroup.
3.32
bother (v., n.) “trouble” (Sw N/A, F1073, 0.01%) ~ Türkic buša-, busa:-, bušan- bosa:-,
busan-, (v., n.) “alarm, irritation, grieve, sorrow”.
In an “IE etymology” book: one or two layered “origin unknown”, with some “probably”, “perhaps” to
boot. Ultimately fr. a polysemantic root bus/bus- “fog” that wields 15 nominal semantic
clusters form “fog” to “rubber” and 5 verbal semantic clusters from “smoke” to “hush”. Türkic word
belongs to a most archaic class, with a noun-verb pair and neutrality to transitivity. There is no
common “Pan-IE” root in Europe. Most loose interpretations come up with not less than 29 forms among
44 European languages. A closer inspection may raise that to about 38; practically every European
language has its unique form. Cognates: A.-Sax. bot “help, relief, advantage, remedy”,
bottan/betan “fix, amend, cure (trouble)”, botettan “improve, repair”, botleas
“unfixable”, “Anglo-Irish” pother; Gmn. busse “concern, worry”, beschwerde
“trouble”, Dan. besvær “trouble”, Du. bezorgdheid “concern”, beroeren
“trouble”; Ir. bodhraigh “bother”, Scots bodraigeadh “bother”, pother “stir,
commotion, bustle”, Welsh boeni, poeni “bother, worry”; Fin.
vaivautua, vaiva “bother, trouble”, Hu. baj, banat “trouble”; Rus. buza, buzit
(буза, бузить) “trouble, nonsense”, bus, busenets (бус, бусенец) “drizzle”, izmoros
(изморось) “mizzle” (m/b alternation); Kalm. bug “demon of fog”. Distribution:
From Atlantic to the eastern end of the Türkic Steppe Belt, across linguistic barriers. “IE
etymology” is non-existent, no “IE” cognates whatsoever, no “restored “IE” proto-words”. A suggestion of Ir.
physical “deafen” applied to the emotional “trouble” is unsuitable both semantically and
phonetically; less so with Ir. bodhaire “noise”. A citation of the agglutinated Ir. -im
in unrelated bodhairim
“I deafen” ascends to the Türkic standard “I, me”, corroborating a Türkic origin of a Celtic
lexicon. The Ir., Scots, and Welsh cognates carry the echoes of the forms ascending to the Celtic
Kurgans of the 6th-5th mill. BC, before their departure on a circum-Mediterranean anabasis of the
4th mill. BC. They must belong to the oldest known traces of the Türkic linguistic monuments. The
word must have lurked somewhere in the Eng. folk language until it surfaced to the grammarians
sometime in the 18th c. The A.-Sax. bot with its derivatives is connected semantically with a
process of recovery. With the frequency rating of 1073, the word has a decent status in Eng., ahead
of such prominent words as “island”, “broken”, “advice”, and “paid”. It was lurking right under the
surface. As a Celtic contribution to Eng., it parted with the E. Europe ca. 5th-4th mill. BC,
creating a 5-millenia phonetic/semantic gap with its less adventurous Asian siblings. Cognate
distribution across linguistic families, and the ingrained presence within the daughter Celtic
languages attest to a deep antiquity of the underlying emotional notion “trouble, grief” predating
by far the ancient Celtic migration.
3.33
bruise (v., n.) “light injury” ~ Türkic bart, bert, birt, bört, baš-, pert, mert (n.)
“injury, hurt, bruise, sprain, break, cut, hack, incise, wound”, bürt (n.) “contort, convulse,
sprain”.
The Eng. form with an elided vowel leaves the vowel obscure; a ber with -e- is likely.
A transition from -t to -z, -s may be a result of interdental -t- (-th-) not
rendered in the reference sources and receptor languages because of a peculiarity of the phoneme.
The two akin forms connected with inflicting injuries (war, wrestling) and the resultant injuries
(hurt, bruise, sprain, break, wound) point to a common origin with a wide spectrum of forms and
semantics. That leads to a conclusion on antiquity of the lexeme (EDTL v.2 71). A Tr.
bert- ~ Sl.
modr- “light injury” slightly dominates European lexicons with 7 (16%) languages, followed by
a motley group of sin- (blue) with 6 (14%) languages (Sl., Est., Yid.-Gmc.), followed by a
motley groups of
bla- with 4 (9%) (Dan., Du., Fr., Alb.) and bruis- with 4 (9%) languages (Eng., Ir.,
Scots, Basque). The remaining 23 languages use their own 20 native words. There is no “Pan-IE”
common “bruise” (v., n.) in Europe. There is a very common synonymic bert-, mert-, mort-
“heavy injury, death”, it is overwhelming in Europe: of 44 European languages, 31 (70%) use the
Türkic bort-, mert-. It is followed with a sprinkling of Gmc. ster- with 5 (11%)
languages, Gmc. död- with 3 (7%) languages, and 5 native terms in 5 remaining languages. The
mass of 7 (16%) + 31 (70%) of Türkic-based terms weights heavily on the soul of its etymology. The
root bVr- ~ mVr- was brought over to the Albion by Türkic migrants - Celts aka Kelts
(3rd mill. BC), see Celt/Kelt. It was carried by the older Hg. R1a/b Siberian Türkic migrants
of the 9th mill. BC to the initially a Hg. I Old Europe Sl. population (Cf. Sl. mort “dead”),
later on carried by their descendents Ir., Scots, Welsh, etc. By the times of the Central European
“killing fields”, newcomers of undifferentiated Hg. R1a/b successfully clubbed the Old Europe
populations of undifferentiated Hg. R1a/b + I + others. They were unaware that among the killed they
are killing descendents of their own forefathers. Cognates: A.-Sax. brysan, brysian
(v.) “bruise, crush, pound”, brysednes (n.) “bruise, crush”, Goth. brakja “strife”,
brikan “break, quarrel”, Anglo-Fr. bruiser “break, smash”, OFr. bruisier “break,
shatter”; OIr. bronnaim “I wrong, I hurt” complete with the Türkic suffix -im denoting
“me”, Breton brezel “war”, complete with the Türkic passive suffix -l; Lat. mortem,
mors, mortalis “death”, VLat. brisare “break”; Sl. bron (брон) “war”, oborona
(оборона) “defence”, (s)mert ((с)мерть) “death”, borba (борьба) “wrestling”, etc.;
Mong.
berte- “dislocate (bone)”, bertege- “damage (body part, organ)”, beye-, berteh
“bruised, wounded, maimed”, Kalm. bertǝhǝ “internal wound, injury”. Distribution: From
Atlantic via Türkic Steppe Belt to the Far Eastern Mongolia, across linguistic barriers. A parochial
“IE etymology” myopically resorts to dubious unattested lexemes starting with br- “smash, cut,
break”, with unverifiable variations derived from belated phonetics with a paltry sampling range.
Blind searches deliver unsubstantiable results: “perhaps” Gaulish *brus- (“?”) and a faux
“PCeltic proto-form” *bruseti “break”, faux “PGmc. proto-forms” *brusjan “smash, cut,
break up” and *brausijana, *brusijana “break, crumble, crack”, a faux “PIE root” *bhreu-
“smash, cut, break”, a faux “PIE proto-word” *bʰrews- “break”, and a faux “PIE proto-word”
*mertis, mer- “death, die”. Without ever glancing at the contiguous linguistic wealth of the
continent, a parochial exercises breed nonsense. The primitive drills are not worth a paper that
carries them: ignorance is a soil for disinformation. The OIr. bronnaim somes with a Türkic
suffix -im “me”, Breton brezel - complete with a Türkic passive suffix -l, Sl.
(с)мерть - with a Türkic 3rd pers. suffix -ti. These morphological markers serve as
lexical milestones tracing a road. The semantics is perfect, phonetics of the continental-wide word
falls into quite reasonable margins, Since Lat. did not have a br- root, the presence of late
VLat. and OFr. cognates may point to a Burgundian path. The path of a Siberian lingo to the Iberia
and on to the Albion is beyond any doubts.
3.34
bulge (v., n.) “protrude, bump” ~ Türkic baldïr, baldïrï “protrusion, bump”, baldaq “ephesus
(of sword)”. Ultimately fr. a notion “calf, shank” of people and animals; metaphorically “wrapping
(gift, etc.), pouch”.
A root bal- forms 50+ semantic notions, most with undetectable semantic connections, some of
immense importance. The Eng. notions “wrapping (gift, etc.), sac, pouch, nappy, diaper” are most
popular. There is no prehistory for the origin of the word baldïr, but compare its cousins,
the Türkic bal, balavuz “fastened, tightened”, beleg (n.) “wrapped, wrapping (gift,
etc.), pouch”, (v.) “swaddle a baby”, bele:- “bale, swaddle, wrap”, bala, balaqïnaq
“baby, infant”, baldïrï “ledge mountain)”,
balkan “high forest mountain range, Balkan mountains”, bal (aka käl, mal, kälä)
“cattle”. The Eng. verb bulge is a semantic extension of the noun bulge “pouch”;
bilge “bulge (ship)”, bulk (v.) “bulge, swell”, belch “swelling burst”,
pouch “sac”. Cognates: A.-Sax. bulge (n.) “bag, wallet”, belg (n.) “bag,
purse, leathern bottle, bellows”, balic- “encompass” (lit. “bind-like”, bealuelomm
“bond (oppressive)”, baalurip “fetter (oppressive)”, pocca, pohha, poh(ch)a “bag,
pocket”, and quite a few more; Goth. balgs “bag, wallet”; OIr. bolg “bag”, Breton
bolc'h “pouch (pod, of flax)”; Bolg. balder “calf, shank” (< Tr.); OFr. bouge, boulge
“pouch, leather bag, wallet”; Lat. bulga “leather sack”, Lat. valere “strong” (< Tr.
baldïr, baldyryan,
Cf. “bald”); Mong. baltaji “bulbous, bent out below”, balqagar “thick and fat,
paunchy”,
balei “plentiful”; Kalm. balxun “high banks, dry valleys”; Sakha baltaj “large
body, bulge”, baltarxaj “large” (Cf. Eng. “bulky”, Sl. bolshoy (большой) “big”).
Distribution: Across linguistic barriers from Atlantic and Türkic Steppe Belt to the Far Eastern
Mongolia. The “IE etymology” is utterly misguided in its claims that ascend the Eng. form to Lat.; its
references to “budget”, “bellows”, “belly”, “budge” etc. as “cognates” are pure nonsense. The faux
“PIE proto-forms” *bhelgh-, *bhel- “swell, blow” are merely propaganda soundbites. All that
nonsense must be honestly disclaimed. The references to asterisked Gaulish-Celtic bulga, bulgos,
bolgos reflect a true etymology, they are eidetic with the real world Türkic beleg
“wrapped, pouch, swaddle” q.v., brought over by by the Türkic Celts via Eastern Europe to the 3rd
mill. BC Iberia. Phonetic leveling took eons to transit from a pre-literal dialectal variety to a
grammatically unified written word. A technical progress forced extension to newer applications like
the maritime bilge, bulk, belch, etc., q.v. The semantic extension from
“protrusion” to Eng. “bulge” appears to be a local innovation. The derivative bulge
“protrude” and underlying bulge “pouch” are consistent with the Sarmatian Kurgans' spread to
the C. Europe simultaneously with the emergence of Rome as a colonial power in the Apennines in the
1st mill. BC. The OIr. and Breton forms point to a distinct possibility that the word was carried to
the European soil by the Celtic circum-Mediterranean migration in the 3rd mill. BC, and by the 1st
mill. BC it was deeply internalized on the European scene. See bag, bale, band, belt, bundle,
burg, pouch.
3.35
bunch (v., n.) “gather into cluster” (v.), “large number” (n.) (Sw N/A, F1228, 0.01%) ~
Türkic bunča (buncha) (adv.) “so many, so much”; “so, such (emph.)” Cf. so early, so kind.
Per “IE etymology” – “of uncertain origin”, with many dotty antics, q.v. A base notion is a semantic
derivative of an image of a hand and its skeleton – a gathering segment, precursor of a sheaf,
bundle, cluster. Ultimately from a Türkic stem bun-/mun- “sheaf, bundle” + equitive adverbial
suffix --ča. The archaic suffix
-n- or a synonymous -ɣ- (i.e. bu-n-, bu-ɣ-) mark a reflective aspect of an
archaic root bu- “tied together, tightened, strangled” fossilized as a root bun-, buɣ-
(EDTL v.2 13, 79). A normative noun form of the stem is bunaz, munaz with suffix
-az, from a parental root baɣ-, boɣ-, see bag. The root boɣun/boɣum (>
bun, mun, pun, buïn, etc.) numbers 16+ forms in 10 semantic clusters; the notion “sheaf, bundle”
forms a cluster I.5 (EDTL v.2 170). With a dialectal m/b alternation, bunča has
twins munča (muncha, adv.) and mïnča (myncha, adv.), with closely
related meanings of “such a number of, so many, so much”. They have found their way into the
A.-Sax., early Eng. and on to Eng., in A.-Sax. and Eng. complete with the Türkic suffix -ča.
Türkic languages have accumulated 38+ terms largely synonymous with “bunch” (as “so, such”). Such a
wealth comes only by internalization from diverse populations and languages. Only a miniscule
portion of that wealth is passed along for internalizations, in this case the bunča, and only
a portion of that gets internalized. In Europe, a shard Türkic bun- dominates with 7 (16%) of
44 European languages. A large group of 20 (46%) European languages uses 20 of their own diverse
native terms; each of the other 10 groups uses from 4 to 2 native terms each. There is no “Pan-IE”
common “bunch” in Europe. Cognates: A.-Sax. bund “bundle”, Eng. many, much,
Gmn. bündel, Yid. bintl (בינטל); Ir., Scots bun (but Welsh criw); Sp.
mucho; Alb. bandë; Mong. bogug, bоgаg, Kalm. boɣ “shoulder bone” (ɣ ↔ n,
< hand skeleton); all bunch except as noted. Besides dotty antics, not a trace of any “IE
etymology”. Distribution: Across linguistic barriers from the Atlantic and Türkic Steppe Belt
to the Far Eastern Mongolia. An “IE etymology” displays a severe myopia, a partisan approach, and a
rabid imagination. On top “of uncertain origin” and “perhapses”, it comes up with a pile of “PG” and
“PIE proto-words” *bunko, *bungo, *bʰengʰ-, *bʰengus,*bʰengʰus “heap, crowd, thick, dense,
fat” and cognates “bone, lump, bump, tuber, volume, fatness, knob, thick, diminutive of bump”, etc.
None in that pile approaches a notion “cluster, sheaf, bundle”. An only case rated as a “possible”
by the “IE etymology” a Flemish oddball boud “bundle” is a transparent cognate of a Türkic
bandur- and its Eng. form bundle. The references to a Sogd. βwn “base, basis,
basic”, Pers. mun ditto are unrelated homophones of bun-, a loanword in Türkic. A now
rare coincidence of the Ir. and Scots bun attests to the arrival of their predecessors to
Iberia in the 3rd mill. BC as a linguistically compact demographic group. Their anabasis from the
Eastern Europe is traced by an R1b Hg; they are an oldest attestation of the notion bunch.
The concordance is perfect, except for expected phonetical shifts: in Türkic grammatical definition
is done by agglutinating suffixes, so any part of speech can be formed from a single stem; in
internalized English, suffixes are dropped, and grammatical function is primarily defined by a word
order structure and traditional usage. See
see bag, bundle, much.
3.36
bundle (v., n.) “cluster” ~ Türkic ban-, ba:n- (v.) “bind, tie”.
Ultimately a reflexive and passive of ba:- (v.) “bind, tie”, bandur- (mandur-) (v.)
“bind, tie” causative of ba:-; the final -l (-le) reflects a passive aspect or marks a
denoun verb with a suffix -la, for morphological aspects markers see bunch. The Eng.
form bundle is a predictable deverbal noun innovation from some version of bandur-. A
Türkic shard bun- dominates in Europe with 11 (25%) of 44 European languages, followed by a
large Sl.-Romance group pak- of 9 (20%) languages and a 3 minor Sl.-Romance groups fas-,
bal, scru- with combined 7 (17%) languages. A 17 (39% ) majority of European languages uses its
own 17 terms. There is no “Pan-IE” common “bunch” in Europe. Cognates: A.-Sax. bund
“bundle”, bindan “tie, bind, fetter, fasten, restrain”, etc., MDu. bond, bondel, binden
“bind”, Gmn. bündel ditto; Sl. (Rus.) bant, bantik (dim.) (бант, бантик), becheva,
bichovka (бечева, бичёвка) “cord, string”, (Serb.) baglja “bunch (hay, straw)”,
bağlama “door hinge” (< “joint, tie”); Rum.
balama “door hinge” (< “joint, tie”), Alb. rez-baglama “door hinge” (< “joint, tie”);
Mong. baɣla- “tie knots, form groups”, Kalm. ba:g “bundle, group, node”; all “bind,
tie” except as noted; for systemic suffixing -ɣ- ↔ -n- ↔ -t- etc. see bunch.
Distribution: Across linguistic barriers from the Atlantic and Türkic Steppe Belt to the Far
Eastern Mongolia. A limited and peculiar distribution covers a dominating but insignificant number
of the European languages. Claims of a “PG proto-word” and “PIE proto-word” are totally incredulous,
it is an overt propaganda. The suggested “IE etymology” of some aspirated form of “PIE” *bend-
“bend” is candidly irrational, unwittingly it is a clone of the Türkic verbal form bantı
“bind, tie” a derivative of ba:-. The Gmc. forms carry versions of the Türkic stem complete
with the Türkic suffixes -t, -l and -en, a noun, passive and reflexive markers
respectively. A Türkic origin of the siblings “bundle”, “bunch” and “much” as a semantic and
phonetic transfer paradigm is impeccable. See bunch, much.
3.37
bust (v., n., adj.) “ruin completely, break into pieces, apart”~ Türkic bast (n., adj.)
“ruin”, bastur- (v.) “destroy, crush”.
An “IE etymology” offers an inexplicable “probably” origins, i.e. “have no clue”. Ultimately a
deverbal noun of a verb bas-/ba:s- “destroy, crush” with an abstract noun suffix
-t, see push, port; the verbal suffix -tur forms a causative of bas-)
The panoptic verb bas-/ba:s-/bas numbers some 175+ root meanings semantically divided into 10
clusters from “push, press” to “poke, cut”, basically or oddly related to applying downward pressure
(EDTL v.2 74-78). Most prominent nominal or verbal modifiers are -m, -qï, -(ï)q -qïn,
-qïč, -maq, -ma, -a, -qaq, each one starts a separate semantic line. Cognates: A.-Sax.
basnian “ambush”, Dan. børste
“beat up”, Sw. basa “beat (with rod), flog”, bösta “thump”; Ir. faisc, Welsh
bwyso “press”; OFr. embuscher “ambush” (en-/am- prefix), baston “stick”,
bastonnade “beat with stick”; Rus., Ukr., Rum., Serb., Bulg. basma “print, press” with
allophones, Serb. basamak, Bulg. basamaci “step-”, Pol. basaiyk “whip (prod)”;
Arab., Rus. baskak “official, tax collector”; Mong. basu- “press, throw”; Tung.-Manchu
basala, basalla “kick”; Nenets (Kamasin) baspa
“trap”; Kor. matta, mağa, mağin “beat (war), defeat” (Ref.s EDTL v.2 p. 77).
Distribution: Eurasian-wide across linguistic borders, Eng. is a rare speck in a linguistic sea.
The “IE” etymological speculations are pitiful: variant of “burst” with loss of -r-; a variant
of bursten, bresten “to burst”; semantics “frolic, spree”; “probably” from earlier expression
“bust (one's) boiler”. An interesting offer is a dubious Lat. bustum as a backformation fr.
Lat. urere, ustum “burn”. In the context of the bust “ruin” it makes a quite logical
“busted, broken statue”, and links homonyms bust “female chest”, bust “partial
statue”, and bust
“ruin”, all without any need for any urere, ustum. A survival of the Celtic Ir. and Welsh
forms attests to an existence of the word in the N. Pontic in 6th-5th mill. BC, prior to a start of
the Celtic anabasis to Iberia and their arrival there in the 3rd mill. BC. That predates by far the
word's 2nd mill BC migration with the Aryan farmers to the south-central Asia. A paradigmatic
transfer of the terms “bust”, “bastard”, “push”, “ambush”, etc. indelibly attests to an origin from
a Türkic phylum. See ambush, bastard, bust, push, port.
3.38
butt (v., n.) “thick end” (Sw N/A, F1415, 0.01%) ~ Türkic büt-, bit- (v.) “come to an end,
end, end up, befall”.
An “IE etymology” blunders between realities, “probables”, and outright fantasies. In Europe, out of
44 European languages, the Türkic büt- predominates with a miniscule 7 (16%) languages,
followed by a Sl. Old Europe zad- with 4 (9%) languages. The remaining 33 (75%) languages use
their own versions of 18 European native words. There is no common “Pan-IE” root; the European
mixture is hyper-motley. A status of a Türkic loanword is obvious. Cognates: A.-Sax.
buttuc “end, small piece of land (probably a tip of a lot)”, MDu., Du. bot, ONorse
bauta, ONorse butr “short (end), log of wood”, LGmn. butt “blunt, dull”; Ir.,
Gael. butt; Welsh fytiwyd; Fr. bout, OFr. bot “extremity, end”; Sl.
(Rus.) bodatsya (бодаться) “butt, gore”; Bulg. bitisam, bittisam, bitisuvam,
bitermedze “end”, biter “finished, ended”, bitermedze “end”; Serb. bitisati
“pass, die”; Mong. bütǝхǝ “complete”, bütxǝ “finished”; all “end” unless noted
otherwise. Distribution: ubiquitous across Eurasia from Mongolia to Atlantic, with
incidentally spotty appearances in Europe. The word's evading the Asian “IE” areas makes
etymological association with the Kurgan Sarmatians unavoidable. The Celtic
fytiwyd is inescapably an echo of the original büt- from the Eastern Europe of the
pre-migration period ca. 5th-6th mill. BC to Iberia of 3rd mill. BC. An “IE etymology” is badly
lost, stewed in its own juice, it is myopic, vague, with incidental conflations (button - bud)
and unrelated (button - Fr. boter “thrust”) words. Or it connects “butt” with
“digging”. The “IE etymologies” are unsustainable. The Türkic system of suffixing allows creation of
vast volume of derivations, e.g. bütün whole, entire; bütmäk ending, termination,
fulfillment, etc. So is its use in English: butt in, butt out, button, buttress, butt-weld, button,
buttock, and so on. The age of the lexemes is indicated by a proliferation of the Türkic suffixes,
pointing to the formation of the words like button still in the Türkic linguistic milieu:
suffixes -on, -ta, -uch, etc. The original semantic association with the human butt is
attested by the Türkic derivative form bütgü “baby excrement” (sounds much like the modern
“butt goo”). A Türkic origin is indisputable.
3.39
cackle (v., n.) “hens shrill squawk” ~ Türkic kak-, kakı:la:- (v.), kakı: (n.) “cackle”.
Ultimately fr. a verb qаqı- “blab, bleat, scream” with a denoun suffix -la; k ↔ q
etc. The verb conveys a range of flavors, from joy to complain. In Europe, the word spread like a
fire, becoming a literally Pan-European loanword: of 44 European languages, 37 (84%) languages use
versions of Türkic qаq-; the remaining 7 languages (Lat., It., Corsican, Gk, Pol., Hu.,
Scots) use their own 7 native words. An imitative origin of a bird call is quite convincing, but it
is known that in different languages imitations of the same are most different, any imitation
requires an address.
Cognates: A.-Sax. cahhetan, ceahhettan “cackle, laugh loudly”, cehhettung,
ceahhetung
“laughter, jesting”, ceahhe “thieving bird, jackdaw”; 11 Sl., 10 Gmc., 8 Romance, 2 Celtic, 2
Baltic, 2 Fennic, and 3 oddbal (Alb., Basque, Tatar) words constitute the 37-language majority; Hu.,
Scots, Lat., It., Corsican, Pol., Gk. words of non-qаq- variety; Pers. akaqib “lies,
falsehoods” (< Arab. ?); Mong. khashgirakh “cackle”; Ref. to Doerfer I 1400. Distribution:
ubiquitous across Eurasia from Mongolia to Atlantic, peculiarly ubiquitous across Europe and across
linguistic borders within Europe. For a linguistically patchy territory with ca. 50+ languages that
is an outstanding phenomenon. Not a scent of “IE etymology”. A suggested “imitative” is probably
true, but is useless in respect to the familial origin of imitation: nowhere else a chicken squawk
is imitated by a cackle-type form. The Türkic denoun verbal suffix –la had internalized into
an Eng. auslaut –le for both verbal and noun forms. The Hu. vihog and Scots uchd
appear to echo each other. The phonetic and semantic match is perfect. A chance of a pre-historical
borrowing fr. English into a bulk of the Türkic languages is absolute zero. This word belongs to a
cluster of Turkisms inherited by English independently fr. other Gmc. languages. It may be a useful
marker for linguistic and demographic tracings.
3.40
cagy (v.), cagey (adj.) “evasive, reticent” ~ Türkic qač- (qach-) (v.) “avoid, shun, escape,
disappear”.
An “IE etymology” rated as “of unknown origin”. Ultimately fr. a Türkic base qo/qon
“coach, migrate”, the form qač is related to an allophonic basic notion köč-, göč-
(v.) “ride a coach”, “migration, travel”, köč/göč (n.) “coach, carriage, wagon, house”,
fr. a Türkic base qo/qon “coach, migrate”, see coach, come, go.
Türkic qač has numerous derivatives. Due to a character of the surviving records a best
recorded is “avoid, slip away, escape” from an enemy. Cognates: Eng. coachman, Dan.
kusk, Du.
koetsier, Gmn. Kutscher, Norse, Sw. kusk “coachman”; Sl. (Bosn., Croat)
kočijaš, (Bulg.) kochiyash (кочияш), (Czech) kočí, (Ru., Serb., Slov., Slovt.,
Ukr.) kucher (кучер), (Rus.) qočqa (кочка) “escapee” (dial.); Romance (Cat.)
cotxer, (Fr.) cocher, (Galician, Port.) cocheiro, (It.) cocchiere, (Sp.)
cochero; Balt. (Latv., Lith.) kučieris “coachman”; Fennic (Est.) kutsar, (Fin.)
kuski “coachman”; Basque kotxezainak; Ch. ganche (赶车); references to Ugrian
correspondences;
all qač- “coach-” except as noted.
Distribution: ubiquitous across Eurasia from Atlantic to Pacific. No “IE” pretentions on the
origin of the word, but a hanging tail of “unknown origin”, “1896 U.S. colloquial”, “a “sportive” in
Eng. dialect”. That nonsense need to be cleared. No “IE” parallels, no surviving Gmc. parallels. Akin
to the Türkic nomads with their mobile homes, Serb. has a term koch (коч) for their
stationary homes. The Türkic origin is semantically pinpointed and phonetically precise. See
coach, come, go.
3.41
call (v.) “verbal touch” (Sw N/A, F162, 0.16%) ~ qol- Türkic (v.) “call on, for, ask, beg,
pray”.
An “IE etymology” silently suggests that it is a loanword. An origin of the Türkic verbal stem
qol- may be a reflex of a noun qulaq “ear” or its archaic predecessor, corroborated by a
Hu. cognate hal “hear”. Or a reflex of a noun
qol “arm, limb” as syncretic with a gesture of “ask, beg”, Cf. qolči “petitioner,
beggar”. Over the ages, the verb has developed a respectable derivative tree. Eng. too has an
assembly of 25 semantic meanings for the verb. Gmc. forms with auslaut -g are allophones of
the Türkic deverbal noun qolɣ formed with a deverbal noun/adj. suffix -g-/-ig-/-yg-.
In Europe, out of 44 European languages, the Türkic kol- predominates with a miniscule 6
(14%) languages, followed by a Romance group with 4 (9%) languages. The remaining 34 (77%) languages
use their own versions of 24 native European words. There is no common “Pan-IE” root; the European
mixture is hyper-motley.
Cognates: A.-Sax. ceallian, clipian “call, shout, loud utter”, glesan “gloss”,
MEng. “clepe, yclept”, Dan. kalde “call, name”, MDu. kallen “speak, say, tell”, Du.
“talk, chat, chatter”, Sw. kalla “call, refer to, beckon”, ONorse kalla “cry loudly,
loudly summon, name, call by name”, Norw. kalle “call, name”, Icl. kalla “call, shout,
name”, OHG kallon, kallen “call, speak loudly”, kalzen, kelzen “talk, brag”, Gmn.
kallen “call”,
klage “complaint, grievance, lament, accusation”; OIr. kalla “calling, singing”, Scots
call, caw, ca “call, cry, shout”, Welsh galw “call, demand”; Cimr. galw
“calling”; OCS glasit (гласить) “say”, glagolit (глаголить) “speak”, klikat
(кликать) “call”, Pol. głos “voice”, Rus. golos (голос) “voice”; Lith. gal̃sas
“echo”; MLat.
glossare, LLat. glossa, OFr. gloser “speak nicely”, lit. “say it, explain
voicing”; Gk. klisi (κλήση) “call”; Alb. gjuhë “language, tongue”; Hu. koldus
“beggar”; Skt. garhati “bewail, criticize”; Mong. ɣujl-, ɣuli- “call”; all “call”
unless noted otherwise. Distribution: From Atlantic to the Far East, across linguistic
barriers. The word is non-IE. The “IE etymology” recognized qol- for Cimr. galw and OCS
glasit, but not for the MLat. glossare etymologically confused with a notion “thorn”.
Most “IE” languages do not have parallels, and those few that have historically or biologically
documented Türkic links. In O. Maenchen-Helfen's favorite expression, the “IE etymology” is pure
galimatia, piling up all allophones in one uncouth heap. Among faux speculations reside the faux
“PGmc. proto-forms” *kall- and *kalzona “call,
shout”, and faux “PIE proto-forms” *gal- “call, shout” and *gal(o)s-, *glos-, *golh-so-
“voice, cry”. These pretentious inventions add nothing to the etymology of the word, and should be
replaced with attested material. The word has been around for quite a while: the Cimmerians of the
10th c. BC are youngsters against Skt. of the 16th c. BC and the Celtics of the 28th c. BC. Against
their dated counterparts, the Gmc. are late arrivals. What unites these diverse people is that they
are all living on the outskirts of the great steppe, bordering, occasionally amalgamated, and at
times being the original Türkic tribes. In a feat of paradigmatic transfer, Eng. possesses four main
action words related to communication: say, tell, calll, and gabble, the direct
siblings of the Türkic söy-/söyle-, til-/tili-, qol-, and gap-/gapir-. Although
overlapping and interchangeable to some degree, each one conveys its own distinct spectrum of very
basic communicative notions. These are in addition to the cognate terms for animal utterances and
other sounds. They form an indelible case of paradigmatic transfer, a testament to a common origin.
A Türkic origin of the word is irrefutable. See gabble, say, tale, tally, tell.
3.42
calm (v., n., adj.) “quiet” (Sw N/A, F804, 0.01%) ~ Türkic kam-, ka:m- (v.) “weaken, lower”.
An “IE etymology” rated “of uncertain origin”. Semantics depicts a change in intensity (i.e. wind
died, heat or cold diminished, sea calmed, etc.). Of the word's five semantic clusters, the “weaken”
cluster is an oldest, the other four are derivative. The phoneme -l- in the Eng. stem
probably simulated a long -a- also rendered as -aa-. Out of 44 European languages, in
Europe the Türkic kam- predominates with 14 (32%) languages, followed by a mix Gmc. ra-
group with 6 (14%) languages, followed by a mix Sl. mir- group with 6 (14%) languages and a
Sl. spo- group with 5 (11%) languages. The remaining 12 (27%) languages use their own
versions of 11 native European words. Other than the Türkic kam-, there is no common “Pan-IE”
root; the European mixture is fairly motley. Cognates: A.-Sax. col, coll “calm”,
cama “muzzle”, Norse calm; OFr. calme, carme, OIt. calma “tranquility,
quiet”, Sp. (and other Romance languages) calma; Malt. ikkalma, Sl. (Ukr.)
(v)gam(uvati) ((в)гам(увати)), (Russ.) (u)gom(onitsya) ((у)гом(онится)); Est.
külm(avereline); Mong. (nam)gum ((нам)гум); Uzb. jim, Az. həlim; all “calm”
unless noted otherwise. Distribution: From Atlantic to the Far East, across linguistic
barriers, peculiar and suggestive. The word does not belong to the “IE” family, is peculiar only to a
specific European audience, and an oddity among a mass of the “IE” languages. A “PIE etymology” is
unimaginable. A Romance group probably received the word via Burgund nomads, in the second part of
the 1st mill. AD. Cited pearls for the notion “calm” are unrelated to the subject: the LLat.
cauma “heat time (siesta)”, Gk. kauma “heat”,
kaiein “to burn”; spelling influenced by Lat. calere “hot”. To a detriment of its own
objectivity, the circular “IE” “etymology” omitted calm-type cognates scattered across Eurasia.
In above LLat./Gk. example of fabricated “IE etymology”, the only savvy element is its ingenuity. An
idea of the Romans carrying their “hot siesta” to the fringes of the Mongolian desert to express
“quiet” extends beyond absurd. A.-Sax. had plenty (24) of native words for “calm” with a rich
complement of derivatives, attesting that “calm” was a demographic oddball: acelan, astilllan,
bliðe, fedlice, and more. Many of them are still active in English with their prime semantics.
For a notion “calm sea” A.-Sax. already carried native dumb, cool, still, tame, blithe, fade,
mellow, row, soft, plus now lost swig “silence”. Apparently, the forms for the notions
“calm” and “cold” were mixed up, resulting in ambiguous col/coll “cold, calm”. True cognates
are scattered across Eurasia, across linguistic groups, with European scene a minor remote appendix.
In a sane world, a notion of “sea on siesta” for the “calm sea”, and the like dotty leaps of
imagination would not make sense. The Greeks did not need to derive “quiet” from “burn”.
Phonetically, the Azeri form is a first-line candidate for dissemination, it is connected with
As-eri Scythians (Ishguza/Ashguza Scythians in Sakasena, modern Azerbaijan), Ashkenazim Scythians (אשכוז’
škuz
and
אשכנז’ šknz, Hebrew, Biblical records) and with a Scandinavian folklore of the latter days.
Phonetically, most European cognates introduced an inlaut -l-, while the Sl., Mong., and Uzb.
forms, and the modern English with a silent -l-, do not use it. The absence of cognates in
the Celtic languages allows to suggest that the form kalm-/kam- evolved after 5th mill. BC,
after the Celtic departure from the Eastern Europe to Iberia.
3.43
calumniate (v.) calumny (n.) “malicious charge, trickery, subterfuge, misrepresentation” ~
Türkic čоlvu, čуlvu (v.) “defame, disparage, libel” (+ yala-, jala, etc.).
Ultimately fr. a verb čоl- “weaken”, and its derivatives related to “damage”, Cf. čolmaq
“vice, defect, disable”. The anlauts č-, y-, or j- reflect scribal articulative
versions. In the Christian Manichaean lingo, and then with an advent of Islam, it came to
designate blasphemy and became a popular daily mantra. Out of 44 European languages, the Türkic
čоl-, kal- predominates in Europe with 18 (41%) languages, followed by an Old Europe Sl./Türkic
kl-, -kl- with 9 (20%) languages, altogether 27 (61%) use Türkic word. The remaining 15 (39%)
languages use their own versions of 13 native European words. Other than the Türkic, there is no
common “Pan-IE” root; the European mixture is fairly motley.
Cognates: A.-Sax. hol (n.) “slander”, holian “betray”, Goth. holon, holian
(v.) “deceive, injure”, ONorse hol “praise, flattery”, OHG huolen, huolian “deceive”;
Ir.
calumnach, Scots calum “slander” (but Welsh drygair); Sl. (OCS, Serb., Croat,
Bulg., Czech, Slovak) xula, xoula, kleveta, etc. “slander, deceive”; Lat. calvi, calvor
(v.), calumnia (n.) “false statement”; Gk. kelein “bewitch, seduce, beguile”; MFr.
calomnie “slander, deceive”; Mong. jala “fine, atonement”; all “charge, accusation”
unless noted otherwise. Distribution: From Atlantic to the Far East, across linguistic
barriers. There is no need for unattested faux “PIE roots” *kel- “conceal”, or *kelh,
or *khl-, or a “PIE cognate” Gk. kelein “bewitch, cast a spell”, or for a “perhaps” in
a ”from the same root as call (v.)” (see call). The Türkic čоlvu is still active, its
numerous allophones attest to its geographical, temporal, and dialectal diversity. A learned Lat.
was instrumental in spreading the word in Europe. The Lat. calvi “trick, deceive” matches
exactly the Türkic čоlvu in phonetics and semantics, leaving no doubt on the origin of the
word. The ONorse hol “praise, flattery” saliently falls out from the semantic uniformity
across numerous languages and timespans, but Cf. Sl. xula < čоl-. The transition Türkic
čоlvu > Lat. calvi > Lat. calumnia > MFr.; the A.-Sax. holian (v.),
calomnie > English
calumny clearly demonstrate the paths and directions of the phonetic shifts within narrow
semantic field. The ubiquity of the word in time and space attests to the ubiquity and importance of
the calumny in the life of numerous societies from at least the 1st mill. AD to the days of
enlightenment. A fairly rich research trail leaves no doubts of a Türkic origin. See call.
3.44
can (v.) “able to” (Sw N/A, F51, 0.41%) ~ Türkic qan-, ka:n- (v.) “happen, occur, meet a
desire”.
For uninitiated etymologists, situation is confusing and confused. The verb has at least 23+
meanings in 5+ clusters. A main cluster denotes a notion “can (execute, achieve a desire)”. A
secondary cluster denotes a derivative notion “know”. That created a bifurcated semantic split of
“can” and “know”, see know. What appear to be homophones are two offshoots of a single
parental root. The Gmc. cognates are semantically split, and are innocently treated as homophones.
Out of 44 European languages, an Old Europe Türkic-Sl. mog- predominates with 11 (25%)
languages (see
might), followed by a Türkic original qan-, ka:n- with 10 (23%) languages, followed by
a Romance pot- with 7 (16%) languages. The remaining 16 (36%) languages use their own
versions of 13 European native words. Altogether, the Türkic share of the European languages is 21
(48%), nearing a 50.6% R1a/b demographic presence in Europe. There is no common “Pan-IE” root; the
European mixture is fairly motley. Cognates: A.-Sax. can, con “can, able”, and “learn,
know”, ONorse kenna “know, known”, OFris. kanna “recognize, admit”, Gmn. kennen
“know”, Goth. kannjan “to make known”; Mong. qan-, qanu- “meet a desire”. More
cognates are provided by derivatives in a range of languages, Cf. Türkic qantar, Manchu
qantara “impatiently wait (desire)”, Türkic qantar “caprice, whim”, “tilt, twist”.
Distribution of the can “able” and “know”, peculiar to the Germanic and Türkic languages,
proves its linguistic affiliation. An “IE etymology”, myopically or maliciously but surely
pretentiously, invented an entire saga-type tale. There are ghosts of faux “PGmc. proto-forms”
*kunnjanan “mentally able, have learned”, and *kunnana (“?”), a faux “PWGmc. proto-form”
*kunnan (“?”), and a faux “PIE proto-root” *gno- “know”, and a faux “PIE proto-form” *gneh
(“?”). This potato soup of egg whites is also supposed to etymologically explain terms of con
“swindle”, couth, uncouth “refined, unrefined”, could “able”,
canny “cagy”, cunning “guile”, etc. All gifts are pulled from a same bag. The myopic
experts do not bother to see beyond their parochial horizons. The nonsense leads from nowhere to
nowhere, traces nothing, it is a classical game of blind shooting. For couth, uncouth see
quite, for
con see con. Versions of the form and semantics cantnt “tilt, twist”, rated as
“a word of uncertain origin”, are found in many languages: Teutonic, Slavonic, Romanic, Celtic,
Latin cantus (OED). In the east, the older notion “can” retained its primacy frozen in time.
In the west, A.-Sax. carried the conventional bifurcated semantics eidetic with the Türkic original.
Gmc. languages internalized bifurcation “can, able” and “know” in a process of a paradigmatic
transfer. A common trend starting with the Goth. was a Gmc. shift to the semantic prong “know”,
while the older native words
haban “have, possess, hold” and d magan, mahteigs, mahtig “might” filled a function of
“can, able”. The near-perfect phonetic and perfect semantic congruence attests to a Türkic origin of
the Eng. word can “able”. Like the can “able” and can “know” separately, and
the A.-Sax. pair “able + know”, the magan “might” came from the Türkic linguistic phylum,
constituting an authentic case of paradigmatic transfer to the Gmc. languages. See -able, con, I,
do, know, might, quite, this.
3.45
capture (v., n.) “take” ~ Türkic kaptur, kapdur (v.) “seize, embezzle”.
An mentally blind “IE etymology” deadlocks at Lat. captura and calls it “etymology”. A notion
“capture” ascends to traditional Türkic methods of encircling hunt. Ultimately a verbal form of
kap “bag, pouch”, later “vessel, cup”. A Türkic suffix -tur forms a causative form of the
verbal base
kap-, qap- (v.) “seize, grab”, qapsa- (v.) is a desiderative form of kap-, qap-
“surround, encompass all sides”; also form hapset-/hapis “capture” (v., n.). The anlaut
reflexes
h-, с-(k-), сh-, х- indicate transmission of Turkic initial glottal h- (q-) with
dialectal variations, and the Gmc. -ft may reflect the original Turkic form hapset-/hapis
presently spelled -pset in Romanized transcription. In addition to a direct “take” with
different angles, the verb produced passive and metaphorical extensions: “trapped”, “catch (an
infection, an idea)”, “bite”, etc., selectively used by receptor vernaculars. Out of 44 European
languages, a Türkic original root qap-, kap- predominates with 15 (34%) languages, followed
by an Old Europe Sl. hvat- with 9 (20%) languages, and Gmc. group fan- with 5 (11%)
languages. The remaining 17 (39%) languages use their own versions of 11 native European words.
Except Türkic, there is no common “Pan-IE” root; the European mixture is fairly motley. Ironically,
the Lat., a key of the “IE etymology”, is using an exact clone captura of the Türkic
kaptur. Cognates: A.-Sax. hæft “take”, hæftling (n.) “taken” (+beridan <
ber- “bear”, see bear (v.)); OIr.
gaib “grasping”, gabaim “I take, grasp”, Scots cum “hold, taken” Welsh
cymryd ditto; Lat. captura, capere “take”; Sp. capish “capture (the meaning)”, fr.
Türkic
kapıš- “capture, understand”, a reciprocal and co-operative form of kap-, qap-; Sl.
hapat- (хапать) “grab” with dialectal variations, kapkan “trap, snare” ; Hu. kap-,
kapni “grasp”; Fin. kaappaa- “capture”; Arab. qabada; Mong. qabla “seize,
arrest”, Kalm. xawl- “catch (ball), bite”, Khalh. havshih “bite (of fish)”; all
“capture” unless noted otherwise. The Eng. capture and Lat. captura and captus
“taking” attest to immediate inheritance from the Türkic complete with the Türkic causative, active
suffix -tur.
Distribution: From Atlantic to the Far East across linguistic families, with a major presence
in the “IE” languages. A taxonomic group without a certain definition, the “IE” languages are
presently conventionally held as a positively non-Türkic linguistic family. Geographic spread finds
ancient Türkic lexicon in the areas of the Italic (R1b 19%, R1a 3%, I 11%, E 14%, J 18%, G 12%),
Gmc. (R1b 18%, R1a 12%, I 20%, E 5%, J 6%, G 5%), and in the Slavic branch of the Baltic family (R1b
8%, R1a 30%, I 38%, E 15%, J 8%, G 3%). Naively presuming that genetically and linguistically the
otherwise indiscernible Southern Siberian R1a (24 ky BP) and R1b (19 ky BP) constituted a range of
kindred biotic communities before and after their long-range migrations and various amalgamations.
Only their linguistic and genetic traces in various degrees survived to our times. Phonetic
consonance is striking, and semantic match is perfect. An “IE etymology” is non-existent, a faux “PIE
proto-root” *kap- “grasp” solely parrots the attested Türkic kap-, qap- (v.) “seize,
grab”. To parrot some eastern articulations, a hardline M. Vasmer in desperation suggested an
unattested faux “IE proto-word” *-khar. Those claims are groundless and pretentious. Türkic
has numerous terms and derivatives with wide geographical spread of the terminology related to
encircling hunts ascending to the ancient hunter-gatherer society. The OIr.
gabaim came complete with an agglutinated Türkic suffix -im “me”. The OSl. form
hapyashte preserved the Türkic deverbal noun suffix -č. A Türkic hunting word
qapsa “encircle, surround on all sides” is paradigmatically connected with the English “circle”.
See bear (v.), circle.
3.46
care (v., n.) “attend, be concerned, safeguard” (Sw N/A, F216, 0.09%) ~ Türkic kör-, gör-,
qara- (v.) “look after, care for” .
It would be honest to declare a routine “of unknown origin”, with no “IE” connections, but q.v..
Ultimately fr. a kVr-, kVs-type prime verbal cluster variously articulated with anlaut
k-/g- and vowels ö/ü/a, connected with aspects of vision. A branch of verbal allophones
kör-/gör-/qara- relays a prime semantics “look (attentively)” (Cf. stare, gaze, see), and
semantics “care for” among various extensions. The Eng. idiom “look after” is a calque of the Türkic
expression. The form qara- of the cluster is validated by a derivative word qaraɣu
“watch, patrol”. A complimentary word of the same semantic branch is sorrow, scare of the
Gmc. linguistic trunk, see scare, gaze. The Türkic form kör- gör- qara- predominates
in Europe, out of 44 European languages, it is used by 13 (30%) languages, vs. 3 largest secondary
groups with 3 (7%) languages each. The remaining 22 (50%) languages are a constellation with their
own 19 European native words. Other than the Türkic, there is no common “Pan-IE” root; the entire
European mixture is perfectly motley. Cognates: A.-Sax. carian, cearian “care for”,
carseld
“home of care”, OSax. karon “to care, to sorrow”, OE. cearu, Goth. kara, OHG.
chara “care, anxiety”; Ir., Scots curam “care” (but Welsh gofal); Lat.
cura, curae “care, concern, trouble, treatment”, It.
cura “care, cure, treatment”; Alb. Albanian kujdes; Mong. qara- “see”; Manchu
qara- “look, scan, observe”; Evenk, Even qaray “care, save, preserve”, Evenk
qaray “guard, watch, ward”; all “care” unless noted otherwise.
Distribution: From Atlantic to the Far East, across linguistic borders, a popular loanword in
Europe. OED erroneously emphasizes that albeit Lat.
cura is a suitable match semantically and phonetically, it is in “no way related to the
“care, concern, trouble”. OED should instead emphasize that it is in no way related to a notion of
“scream”, and any other subject semantically unrelated to care. There is no need to conflate
phonetic resemblances, like the unattested faux “PGmc. proto-form” *karo- “lament, grief,
care” or *karo- “care, sorrow, cry”, or the faux “PIE proto-word” *gehr- “shout, call”
and a faux “PIE proto-root” *gar- “cry out, call, scream” fr. Ir. gairm “shout, cry,
call” (see cry). Or an Eng. garrulous “chatty, talkative”, Du. karig “scanty,
frugal”, OHG chara, charon “to lament, wail”, Gmn. karg “stingy, scanty”, and the
like. They deserve and have their own cognates. That kind of antics is not needed, it leads from
nowhere to nowhere, and only pretends to cloud an issue. The attested material is profound. Türkic
has two phonetically close distinct siblings with close, but different semantics, a qorq “be
concerned, safeguard, be afraid for” and gӧrg “scare”, apparently conflated in the phonetic
structures of sibling vernaculars. The A.-Sax. carig “sorrowful, anxious, grievous” is a NW
European form of the Türkic qorq “scare, fear, panic, horror, phobia”, and Gorgon
“monster” is a Greek Mediterranean form. See caginess, cry, gaze, Gorgon, scare.
3.47
carve (v.) “cut by chipping away at a surface, engrave” ~ Türkic kert-, kert (v., n..)
“incise, carve a mark, engrave”.
Ultimately fr. a verb ker-, ger- “strech” formed with a causative suff. -r fr. a root
ke-, ge- with the same prime notion “stretch”. The suff. -t is a reflex of a directional
suff. -ta, -da forming a notion ca. “stretch out”. The prime notion “stretch” numbers 6
semantic clusters. Of the 44 European languages a motley group with Türkic ker-, car- with 5
(11%) languages trails an Old Europe Sl. group ris-, rez- with 9 (20%) languages, a Romance
scul- group with 6 (14%) languages, and a Gmc. schni- group with 5 (14%) languages. The
remaining 19 (43%) languages use their own 15 European native words. There is no common “Pan-IE”
root in Europe; the entire European “carve” mixture is utterly motley. Cognates: A.-Sax.
ceorfan, cearf, corfen “carve, cut, cut down, slay, cut out, engrave”, OFris. kerva,
WFris. kerve, Du. kerven, Gmn. kerben, LGmn. karven “cut, notch”; Gk.
graphein (γραφειν) “scratch” (> “write”, It. graffire “make graffiti”); Mong. kerči
“cut, hew, notch” (~ Sakha kärči, käčči (v.) “notch”), kherchim “piece, chunk”,
kherchi “slice, cut”, Kalm. krchm “cut, piece”; all “carve” unless noted otherwise.
Distribution: From Atlantic to the Far East, across linguistic borders; scanty loanwords in
Europe. A foxy “IE etymology” comes up with a pile of faux origins: the faux “WGmc. proto-forms”
*kerbanan and *kerban (“carve” ?) and the faux “PGmc. proto-form” *kerbana
(“scratch” ?), and the faux “PIE proto-root” *gerbh- and *gerbʰ- “scratch”. For an
ornament come unrelated but real OPruss. gırbin “number” and OCS жрѣбии
(žrěbij) “lot, tallymark”. All that myopic drivel leads to nowhere etymologically, serves no
need, and asks to be kindly excused. The auslaut consonant adopts to the local articulative
conditions with -t/-f/-v/-b/-ph. The A.-Sax. cweorn “millstone”, i.e. “scratch pad”,
cweornbill “chiesel”, quern, and their European cognates probably are remote derivative
siblings of the
kert. The various forms are consistent with the Türkic kert phonetically and
semantically. See cut, curt, short.
3.48
cast (form by pouring) (v., n.) “form in mold” ~ Türkic qïsdï (qysdy) (v.) “squeeze, form in
mold”..
An “IE etymology” rated “of unknown origin”. Ultimately fr. of a verb qïs- “squeeze, press,
compress, clinch, force, coerce, restrain, crush, suppress”, see squeeze; -dï is
predicate and analytical formant. The “cast (in mold)” has numerous homophones unified by a common
spelling only; a most popular homophone is “throw”. Cognates: A.-Sax. (ge)cwysan
“squeeze”, Du.
giet-, Sw. gjut-, Gmn. guss; Ir. caitheadh, Scots (til)geadh (but
Welsh bwrw); It. ghisa; Gk. chytos- (χυτοσ-); Balt. (Lith.)
ketus; Basque “cast”; Yid. kast (קאַסט); Mong. kisa “furnace”, Bur. xyaha
“furnace”, Kalh. xyas “crucible”; Manchu xuža “furnace”; Tatar qïsdï; all
“cast, form in mold” except as noted. Distribution: From Atlantic to the Far East, across
linguistic borders; scanty loanwords in Europe. The Celts (Cf. Ir., Scots) but not the Sumerians
have used the term. The “IE etymology” escaped an embarrassment by not citing any faux proto-words
with a truthful excuse “of unknown origin”. Since the Türks carried technique of a bronze metallurgy
from the Urals and Carpathians to around much of the Eurasia, they are an only candidate to bring
the term to the Far East (Cf. attested Zhou metallurgy carried to China) and to the Far West. The
future Germans of the Corded Ware were on the far fringes of the main trade routs connected with the
spread of metal casting. They probably learnt their terminology from some intermediaries, probably
of numerous sources. English has retained a trace of the suffix -dï in the form -t;
the others contracted -st to -t, or retained the stem qïs- (Gmn., It.).
Various European spellings of the anlaut consonant reflect attempts to depict an uvular consonant.
The It. form differs from the Lat.-Romance model, it is likely of Gmc. provenance. The “IE
etymology” confuses homophones
cast “form in mold” and cast “throw”, and even then it can't yield to a rational
origin. The duo of cast (v.) “send forth” and cast (v., n.) “form in mold” (< “squeeze”)
demonstrates a remarkable case of paradigmatic transfer and creolization, where a semantic group (qus-,
qïsdï) is transferred in its entirety while phonetic simplification created homophones out of
distinct originals. The oldest known Türkic castings and the casting lingo were carried by the “Zhou
Scythians” from Mesopotamia to the Altai and on to China, bringing ca.1750 BC the casting technique,
including the monetary knifes, to the Shang China. The word probably ascends to a Kargaly time in
the Urals, where metallurgy started in the 5th mill. BC and was famous till the 2nd mill. BC, or
originated in the 4th mill. BC not too far from the Carpathians, a center of the European
metallurgy. It was spread far and wide by the horsed nomads who brought it first to Altai and then
to the Far East. It was carried to the Central and eventually to the Western Europe by different
horse nomadic groups. The Mesopotamian horse nomadic Guties in the 3rd mill. BC already mastered a
perfected casting of socketed joints; a bronze cast monetary knifes were brought from the Altai to
the China's Shang Dynasty by the Zhou “Scythians” ca. 17th c. BC. The “IE”-cited AD dates of the
term are ridiculous. See squeeze.
3.49
cause (v., n.) “origin of something, producing an effect, motive” (Sw N/A, F357, 0.04%) ~
Türkic köze:- (v.) lit. “stir up burning embers”, “get charred” (see char), used mostly
metaphorically, Cf. Eng. “inflame (feelings, etc.)”.
An “IE etymology” rated “of unknown origin”. The köze:- is a denoun verbal derivative of
kö:z, kör, köre “flare up, ignite, catch fire”, a derivative of a verbal root kö- “burn”,
Cf. Eng. coal. It phonetically echoes derivatives
kön-, köy- “burn” and kol “coal” (see coal). The essence of the notion is
“conflagrate, stir up, inflame, foment, instigate”. Out of 44 European languages, a Türkic original
root kö:z- predominates with 14 (32%) languages, followed by an Old Europe Sl.-Gmc. urs-,
ars- with 12 (27%) languages and a Sl. group príč- with 7 (16%) languages. The remaining
10 (23%) languages use their own versions of 9 native European words. Except for a Türkic, there is
no common “Pan-IE” root; the European mixture is moderately motley. Cognates: Ir. cuis,
chuis, Welsh achos “cause”; OFr. causer “cause”, MLat. causa (n.) “cause”,
incaendefacio “torch”; Bulg. kauza (кауза) “cause”; Latv. celonis; Maltese
kawza; Gujarati kojha (કોઝ) “cause”; Mong.
shaltgaan (шалтгаан) “reason”; Tatar köze:- “cause”. The Latv., Gujarati, and Mong.
appear to be derivatives directly from the word kol for “coal”, in line with semantic
connection and skipping the “embers” stage. The “IE etymology” states a routine “of unknown origin”.
Distribution of the word indicates both colloquial and global character, with uncounted
allophones across Eurasia due to importance of the chore “ignite”. The EDT cites only 3 groups that
use this verb: Turkmen (i.e. Aral basin, consistent with other geographical associations), Khakass
(i.e. Enisei Kirgiz, another link consistent with other associations), and Koibal, a small
off-Khakass branch of recent provenance; EDTL cites 13 forms of a Türkic belt. Historically and
philologically, such “rare” words may be very helpful in diagnosing genetic origins not only of the
English people, but also of the Ephthalite Huns (Gujaraties), Latvians, etc. The Ir. form with /sh/
could originate from few closely related words: kol “coal”, köz “embers”, and the like,
attesting to their use prior to a Celtic departure fr. the E. Europe ca. 5 c. BC. A displacement of
a native A.-Sax. intinga shows a demographic predominance of the Türkic-derived lingo in the
Albion. Paradigmatic transfer of etymologically related triplet, a metaphorical
cause and substantive char and coal indelibly attests to a common genetic
origin from the Türkic milieu. See char, coal.
3.50
challenge (v., n.) “confront” ~ Türkic čalïš (chalish) (v.) “call to fight”, a challenge to a
hand to hand match.
An “IE etymology” offers pure nonsense, q.v. The “call to fight” challenge supposedly is
recorded in Eng. from 1520s, but A.-Sax. cognates testify to a time preceding by far the advertized
references. Ultimately from a stem čal-, talq- “strike, shove, thrust down” with cooperative
and reciprocity suffix -ïš, lit. “fight each other”. In a modern lingo it corresponds to a
bar-room “let's step outside”. The čal- also denotes a peaceful “strike a percussion
instrument” and an explosive “flare up, ignite”. In Türkic traditions, wrestling and single combat
were a crucial part of any festivity. In most European languages, “challenge” is rendered as a form
of “call”, Cf. Sl. vyzov < zov “call”. In Europe, the čalïš ~ challenge is
practically invisible: out of 44 European languages they carry 2 (5%) (Eng., Türkic), reliably
attesting to a non-IE origin. Two groups predominate, an Old Europe Sl. -zov- “call” and a
motley -fi- “fencing” with 9 (20%) languages each. The remaining 26 (59%) languages use their
own 17 native terms. There is no common “Pan-IE” root; the European mixture is predominantly motley.
Like most of the European languages, a dominant Sl. native base is amalgamated to a variable degree
with Türkic languages. Cognates: A.-Sax. clepe, beclepe, clipian, yclept “challenge,
lawsuit”, lit. “call”; OFr. chalonge “challenge, call to fight”; Mong. dejil-, dejile-
“defeat, beat, overcome” (j ↔ č, ~ Sakha dneliy). A paucity of the non-Türkic cognates
contrasts with semantic and phonetic bounty of the Türkic vocabulary. The paucity provides an ultra
slender path for diagnostic tracing matching a slender European distribution. Distribution:
Across the Eurasian Türkic Belt, with a minimal extension to the W. Europe. A suggested “IE”
etymology of the word is strikingly frivolous. Etymology is ascribed to an unrelated Lat.
calumnia “trickery” via VLat. calumniare “to accuse falsely” (see calumniate) with
a reckless jump to OFr.
chalonge “challenge” or an unrelated faux “PIE proto-word” *kel- “invocation,
beguile, feign, charm, cajole, deceive”, and the like. Besides phonetically challenged, a semantic
connection to an invitation for a clash on a carpet or in court is missing there. With an absence of
a sane “IE” etymology, the Fr. chalonge directly ascends to the Türkic čal-/čalïš and
some local Gaulic articulation. A parallel Ir. dushlan echoes the Türkic dushman
“opponent”, a Gael. dubhlan is very similar, and the Welsh term (herian) is akin to
“manliness”, Cf.
German “manly, brave, strong”. The preserved auslaut suffix -ïš, reflected in the Fr.
-onge, Eng. -enge, in the original substrate language could have had an allophonic form
-ïch, -ïj, -ïg, -ïk, -ïkh etc., it is a suffix of reciprocity, transmitting the sense of “us,
them” (go, fight, eat, etc.). A related allophone čalaŋ (chalang) “babbler, chatterbox” with
a negation suffix -aŋ (see –un) is opposite of
challenge for a nonchalant “unruffled, oblivious, dismissive”. Its suggested “IE etymology”
fr. Lat. calere “hot” and Fr. chaloir “care” is most dubious. See calumniate,
chalant, –un.
3.51
champ, chomp (v.) “chew noisily” ~ Türkic čap- (chap-) (v.) “noisy action”, including “chomp,
chew noisily”.
The origin of the Türkic čap-, with attested forms
čар-, čat-, čïb-, čub- and probably more, comes not from chewing, but from a whipping, “whip,
lash, click”. In an auditory sense that means “chat, click”. The verb champ corresponds to
the original Türkic semantics of chatting and clicking associated with a whipping sound to control
herds. By now, it is rather an international word among a sea of colloquialisms. Cognates:
Balto-Slavic chav- (chavkat, чавкать) “chew noisily” (b/p/v ~ m
alternation). Distribution: Across the Eurasian Türkic Belt, with accidental extensions to
the rest of the Eurasia in many allophonic versions. An “IE etymology” is “probably echoic”; that is
likely true, from a some very particular source. An absence of a champing echo in the “IE” languages
points to a specifically Türkic echo vs. Romance mordendo, ronge, picar, Gmc. kauen,
etc. The kauen is a form of the Türkic kev-, kevsa- “chew” (v.) preserved with
somewhat derisive meaning, nowadays supplanted by a regular beißen. The Balto-Slavic forms,
active in the Sl. languages, descended from the Türkic verb likely brought over to the British Isles
with the A.-Sax. speech. No connection to champagne, jam (v.), champed, champing, Fr.
“field”, etc.
3.52
char (v.) “burned, turned to charcoal”, (n.) “charred” ~ Türkic öčür- (v.) “quell, extinguish
(fire)”.
An “IE etymology” asserts “probably a back-formation from charcoal”, Cf. “red” is a back-formation
from “red herring”. Ultimately a causative form of öč- “quell (a fire)”, semantically
connected with o:t (o:d) “fire, anger (metaph.)”. The öč- is neutral to transitivity,
attesting to its primordial origin. The Eng. compound charcoal is an allophone of a Türkic
compound öčür kül “quenched coals” with anlaut ö- elided about a time of
internalization. The importance of the charcoal for the incipient metallurgy can't be overestimated,
entire forest tribes were engaged in supply and production of the charcoal for the metal industry.
Out of 44 European languages, a Türkic original öčür- (> char-) predominates with 21
(48%) languages, followed by a Türkic-Romance group car- (< öčür-) with 5 (11%)
languages for a combined 26 (59% ) languages, matching a level of a 50.6% Hg. R1a/b demographic
presence in Europe. The remaining 18 (41%) languages use their own versions of 16 native European
words. Except for a Türkic, there is no common “Pan-IE” root; the European mixture is grossly
motley, attesting that its lingoes fossilized long before the öčür- came to the European
scene. Cognates: A.-Sax. cer (/č-/), cerr (/č-/), ceorr (/č-/), cierr (/č-/) “churn,
turn, change”,
charren “turn (to coal)”; Ir. charraig “char”, Scots char “char”, Welsh
(torg)och “char”; Serb. chhar (цхар) “char”, Blr. char (чар), Maced. shar (шар);
OFr. charbon “charcoal”; Lat. carbo “charcoal”; Mong. ečüd, ečül “douse,
quench, end, quell”, еčüs “end”, ečül “quench, cease, go out, fade”; Tatar öčür-
“char”. Distribution: Across the Eurasian Türkic Belt, with a massive extensions to the W.
Europe, the Far East, and who knows where else since before the last glaciation. No senile “IE” etymology. No
“IE” cognates, attesting to a non-IE origin. In a perverted sequence, the “IE etymology” ascends char to charcoal, failing to come up with a rational etymology. It also
ascends char to an unattested faux “PIE proto-word” *ker- “heat, fire”, and “perhaps”
to a strikingly unrelated MLGmn. schar “flounder, stagger, dab” (= “awkward walk, behavior”,
“fish (type)” (n.), “wet (v.)” from the faux “PGmc. proto-forms” *skardaz “shard, potshard
(n.)” and *skerana “cut (v.)”. The myopic nonsense demonstrates complete misunderstanding of
the linguistic phylogeny and false preconceptions driven by a circular logics. In the process, it
unwittingly “reconstructs” an allophone *ker- “heat, fire” of the original attested form of
the Türkic öčür-. The run amuck runs from nowhere to nowhere. The A.-Sax. word was a stack of
two homophones from two independent sources, one a Türkic “churn, turn, change”, the other a native
“affair, business” unrelated to the notion “char”. The A.-Sax. c-- was articulated as either
/č-/ or /k/; Eng. has preserved the quality /č-/ of the initial consonant. Very
peculiar etymology allows to trace the word to its early ethnic origins. Char is a member of
a four-word fire-related paradigm transferred from Türkic languages: öčür- “char”, öč
“ash”, kül “coal”, “ashes, cinders”, kandil “candle”. A conservative probability
estimate for the case of these four words (15 phonemes) accidentally appearing in two independent
languages is infinitesimally small, one chance out of 1025, one trillionth of 10
trillionth, for details see ash. Char is a member of a huge cluster of the European words
starting with char-/kar- and dealing with burning: carbon, cremation, etc. The
importance of the word carbon for the Eurasian languages can't be overestimated. Notably, in
addition to an amalgamated or adopted form of the word carbon, nearly every Eurasian language
has retained in continued use its own synonym. The adopted word is used as a wad of concrete nouns
and verbs in the cultural borrowing portion of the lexicons. The words carbon and
cremation are now truly international words. See ash, candle, coal.
3.53
chat, chatter (v., n.) “small talk, gossip, babble, gabble” ~ Türkic čatla-, čatu:la:-,
čatı:la:-, satu:la:-, šatu:la:- (v.) “chatter, talk non-stop, chirp, gossip”.
An “IE etymology” is mum on etymology, asserting “of imitative origin”, q.v. Ultimately fr. čat-
(v.) “make thud (sound), noise, spread rumors”. The term may refer to any nature of a sound of
chatter, chirk, chirp, chirrup, twitter, etc., of nature, beast, or human. The Türkic notion of
“buzz, small talk” and the like can be expressed singly, reduplicated, or in combination of elements
čatt, čet, čıt, čit, see chitchat. In Türkic vernaculars an alternation s/š (sh), č
(ch), y is a regular dialectal event. A prominent expression of čat is coined in the term
četük for “cat” that formed European, Asian, and African term cat with its many
allophones, see cat. The root čit is likely unrelated to the word chit
“improper girl” or to the word chattel “private movable property”, a derivative fr. a
homophonic root čat- “gather, assemble” (see chattel), but formed the notion
cheat “practice trickery or fraud”, that is “talk somebody into doing something for their own
disadvantage”, and chatter “din, twitter, gossip”. The word is a wonder of a miracle, an
unadvertised appearance in Europe, and explosive spread. Like a sudden fashions of funny costumes
and wigs, of 44 European languages 12 (27%) adopted forms of chat - Gmc.'s, Romance, Sl. The
other 32 (73%) languages retained 27 terms of their own native vocabularies. Cognates:
A.-Sax. no references; WFris. tsjotterje
“chatter”, koeteren “jabber”, Dan. kvidre “twitter, chirp”, Du. schateren,
schetteren
“chatter, blare”, koeteren “jabber”, Gmn., Luxemb. chat, Gmn. kaudern “gobble
(turkey)”, Sw. chatt, Norw. chatte; Gal., Malt. chat, Sp. charla, It.
chiacchierare, Cors. chjachjara; Serb. chaskanje (ћаскање); all “chat” unless
noted otherwise. Distribution: In a range of articulations ubiquitous across Eurasian Türkic
Steppe Belt, plus some extensions to some W. European areas. It is fairly clear that once the word
landed in the NW Europe, in the neighborhood it spread like a fire, attesting to a large demographic
mass and its linguistic uniformity. No “IE” etymology, a peculiar isle nearly exclusively in the NW
family, thus clearly a loanword of a non-IE origin. The “IE etymology” thesis “of imitative origin”
is useless without ethnologic specificity, a twitting in one language is cvrlikaní in
another and a
kukatene in a third. A connection with the chirping of the birds and cats miaul have endured,
supporting an initial echoic origin of the čat. Cognates point to an original anlaut
consonant that could develop into affricate or plosive. The č-/k- alternation parallels that
of the form četük/cat. The words “chat” and “chitchat” entered Eng. as undifferentiated
verb/noun. They are paradigmatic transfer cases along with “say”, “tell”, “tale”, “saga”, “message”,
and other words related to verbal communications. Further derivatives arose as innovations in the
course of Eng. evolution. Each word separately, and the systemic nature of the paradigmatic transfer
indisputably attest to a Türkic linguistic phylum. See cat, chattel, chitchat.
3.54
check (v., n.) “examine, ascertain, mark” (Sw N/A, F396, 0.04%) ~ Türkic ček- (chek-) (v.)
“separate, draw, identify, mark with markers (dots, ticks, checks, etc.)”, čik- “an alchik
“dice” concave side”.
An “IE etymology” asserts a ridiculous proposition, an origin fr. a chess game, q.v. A semantics of
ček- is fuzzy, it denotes some 30 meanings, a “pull” (v.), “mark” (v.) and few other meanings
are cited (G. Clauson, EDT 413). An OTD offers only key semantics, with “pull (v.)” and “mark
(v.)”. The notion is eidetic with idioms “show me”, “check the box”, and “dot the i's”. The verb
carries a bifurcated notion of taking toll with actions of picking and notching. It likely
originated from counting on fingers, and then for marking similar objects. Literal and metaphoric
derivatives, at times very remote, fit into bifurcated semantics. Concrete applications reflect
realities of the times: “mark (with diacritics)”, “inspection (military)”, “pick (separate)”, “draw
(gambling)”, etc. Eng. derivatives are semantically connected with “secure, verify” rather than
“count”: bank check, checking account, hotel check in, checkup, rain check, double-check, spell
check, checkout, checklist, checkpoint, paycheck, unchecked, checker, hat check, etc. Cognates:
A.-Sax. ciegan, cegan, cegian “call, call out, summon”, ðywan “check” ? (č ↔
ð); Fr. eschekier, exchequer “treasury, fiscal department”; Cat. xecs
“check”; Tr. ček “mark”, čıkıš “come out, profit”, čikšerü “pull (locative)”.
Distribution: Ubiquitous across Türkic Eurasian Belt; just foursome among 44 European languages
(Türkic + OFr. + Cat. + Eng.), indelibly attesting with an irrefutable return address to a “guest”
status among the European languages. The EDT used the essential Türkic verbal root ček-
100+ times. The “IE” paradigm confuses the word ček- “draw, mark” with gaming semantics
“threat, attack, block” of the homophonic check, checkmate related to OFr.
eschequier “chessboard”, MLat. scaccarium “place for (chess piece) shah, king”. The
Eng. terms of the “IE etymology” are inconsistent with the chess' meanings “threat, attack”, nor
with the chess terminology (“checkmate” means “shah-mate”, shah is a “king”), nor with
related name for the
checkers game. The semantics of the Türkic ček- is a world away from notions specific
to the chess lingo “check” and “checkmate”. In contrast, the Eng. terms are consistent with the Fr.
eschekier, Eng. exchequer “fiscal department”, i.e. “money, treasury, lot”. For the
ček- connotation “secure, verify” neither an Arabic nor Pers. shah (aka check mate
“king is killed” make any sense. The check “chess” is grossly anachronic (ca. 1300) against
the indispensible in trade and commerce since most ancient times the Türkic ček-. Thus, no
“IE” parallels whatsoever. The misleading etymology profanes the great place this rich and productive
word occupies in the Eng. language.
3.55
chew, chaw (v.) “manducate, masticate, ruminate” ~ Türkic kev-, gev- “chew, chaw,
ruminate”.
Ultimately a denoun verbal derivative fr. a homophonic kaw “dry grass”, i.e. out-of-season
horse food, “dry”, “dead wood, tree”.
The word came to us from a dawn of productive enterprising. It left an unmatched-long trail of
derivatives and allophones like ku-, kug-, quɣ-, коу-, etc. The term was of a prime
importance for people and their sustenance source. Managed herds of pre-domesticated wild horses
survived on grass from under a cover of snow. The practice of grazing horses from under snow
extended to the domestication time and well into the present. For a better survival of the herds
they were driven to winter quarters in the warmer and greener lowlands by river deltas and lakes.
For pastoralists, that was a practical solution: preservation of their herds without toil to fodder
the animals. From the shades of the notion chew it appears that the word eat was
primary and included the notion chew, and a notion chew was a later development
connected with ruminants and rumination, complementing the initial notion. That conjecture is
supported by the exceeding wealth of the nouns and verbs chaw, cud, quid that point to
rumination rather than to human chewing. The conjecture is also supported by the Balto-Sl. and Pers.
examples with forms for chaw connected with a related jaw. The word kev-/gev-
has survived into the Eng. cow and Gmn. kaff. Via various paths, the Türkic notion of
“chew” came to Eng. as a part of a wide food consumption paradigm: eat, cheek, chew, jaw,
manducate. The k-/ch- transition is peculiar to Eng. and probably originated still in the
Türkic milieu. Another Gmc. alternation is g-. Of 44 European languages a prevalent is an Old
Europe Sl.
ž- with 12 (27%) languages, followed by a motley Gmc.-Celtic-Türkic k-group with 11 (25%)
languages, followed by a largely Romance motley ma- group with 10 (23%) languages and a
largely Gmc. t- group with 5 (11%) languages. The other 6 (14%) languages use 6 of their own
native terms. None of the groups can be rated as Pan-European, each one can profess an “IE
etymology”. Cognates: A.-Sax. ceow(an) (with ch-) “bite, gnaw, chew” (unlike
the A.-Sax. ligature cs- unambiguously denoting phoneme sh, the A.-Sax. anlaut c-
depicts the phoneme ch without marking a modifier), cow (with ch-) “chaw,
food”, cu, cu(e), cy, cus, cue, cu(n)a, cyna; cum “cow”; cubyre, cucealf, cueage, cuhorn,
cuhyrde, cumeoluc, metecu “cow-shed, cow calf, cow eye, cow horn cowherd, cow milk, met cow”
respectively, WFris. kogje; MDu., Du. kaf, kauw(en) (but Dan., Sw., Norw. tygg-),
OHG hewi “hay”, kiuw(an), MLG
keuw(en), LGmn. käww(en), Gmn. kau(en), kaff “chew”; Goth. hawi “hay”;
(OCS) živo “chew”, Rus. kovyl (ковыль) “grass (type)”, kavaleriya (кавалерия)
“cavalry”, Pol. zuc “chew”; Lith. žiau(nos) “jaws”; Lat. gingiva “gums”; Pers.
jav(idan) “chew”; Pashto; žovạl “bite, gnaw”; Kuchean (“Tocharian B”)
suwaṃ “eat”; Mong. qag “dry”, qawdan “dry grass”; Khalkha hagd “dry
grass”; all “chew” unless noted otherwise. The cavalry is lit. a derivative of “(riding) a
ruminate, chewer” with its rich trail of cognates. The “IE
etymology” came up with few invented “proto-words” like *gyeu-, mimicking Gmc. roots and
unwittingly inventing non-existing acoustically different allophones of the real Türkic roots. Among
other fantasies are the faux “PWGmc. proto-forms” *keuwwan, *keuwan “bite, gnaw, chew”, a
faux “PGmc. proto-form” *kewwana , all crowned with the faux “perhaps” “PIE proto-forms”
*gyeu-, *gyewh “chew”. All that nonsense adds nothing to the real etymological knowledge. All
those oddballs are demonstratively unrelated to the bulk of the “IE” vernaculars or the “IE family”:
these “reconstructions” are suspended in nowhere and are quite flagrant. A “restored Proto-Gmc.”
form *kaf- “chew” is identical to the attested Türkic
kev-/gev- “chew”; a parochial ideology can't swallow that. A truncated form qu- is
used in A.-Sax., Gmn., and in Kipchak and Altaian, a version hu- in Khakass (EDTL v.5
169). The A.-Sax. forms attest to multiple articulations of the anlaut c-, lining them up
with the Gmc. forms as opposed to the Balto-Sl./Pers. forms. The form champ with b-/w-/m-
alternation attests to a connection with m- vernaculars. In Balto-Sl. and Pers. case the
line-up of “IE” cognates appears to confuse “chew” with the word for jaw- (with allophones),
in Türkic čügtä, čügde, čökdä “jaw” with the allophones of the Türkic kev-/gev- “chew,
ruminate”. That creates a false correspondence and consequently a
spurious assertion for k-/ž-/j- alternation. The forms for the word eat (Türkic
ye) are shared by the Türkic and a number of “IE” languages, none of them include the notion
chew, while the notion chew in the above languages was derived from two distinct
concepts, one “ruminate”, and the other “jaw”, attesting to parallel and independent processes. The
segregation between chew/chaw/chow and cud/quid appears to be artificial
because their semantics is identical, and the forms are eidetic, given the fluidity of the second
consonant or semi-consonant like
-y. The -y is frequently a second form for a number of weakly articulated consonants.
The allophonic cognates for the form cud are A.-Sax. cudu and cwudu, where
ligature
cw- stands for q- or dg-: ONorse kvaða “resin”, OHG quiti “glue”,
Gmn. kitt “putty”. Besides Gmc. confines, these semantic derivatives of the original kev-,
gev- find a parallel in the Sl. žvachka (жвачка) “cud, chewed mass”, a derivative of a
Balto-Sl. žiau/živo. See eat, cavalry, champ, cheek, jaw, menu.
|
Supplementary Note. Chance paradigm
Some statistics for an 1-word paradigm, a chance coincidence of a PG *kaf- “chew” and a Türkic kev-/gev- “chew”, and for a 5-word paradigm for food consumption: eat, cheek, chew, jaw, manducate. Semantics: In a 10,000-word basic dictionary, the terms connected with the physical process of food consumption would not exceed 100. Actually, that number would be closer to 20; a number 100 is extremely conservative. Next, in the food consumption semantic field of 100, the subset for physical oral grinding “chew” would not exceed 20. Actually, that number would be closer to 5, thus the number 20 is extremely conservative. Phonetics: A 50-phoneme language can be broken into 10 phonemic categories, with average 5 phonemes in a category. In actuality, most categories would be closer to 2 phonemes, thus the number 5 is quite conservative. In case of *kaf-, the forms gaf, haf, kaf, qaf; gef, hef, kef, qef, etc., would all be deemed eidetic to a *kaf-. The accidental semantic match for 1-word paradigm “chew”in any language is Psem = 20/10,000 = 0.002. The accidental phonetic match for a 3-phoneme *kaf- in any language is Pph = 1/103 = 0.001. Thus a 10,000-word basic dictionary would produce 10 statistical matches, ensuring that any 10,000-word language would have at least one match. The simultaneous accidental semantic and phonetic match for “chew” and *kaf- in any language is P1 = Psem X Pph = 0.002 X 0.001 = 0.000002. In other words, it would take fifty (50) 10,000-word dictionaries to produce a single statistical match. Our human world's 6000 languages would produce 6000/50 = 120 languages satisfying the requirement. Not a small chance. In actuality, that number would be closer to 12, correcting for excessive conservatism of the premises. Still, statistically there is a chance of an accidental match. For a 5-word paradigm for 3-phoneme word roots of the words eat, cheek, chew, jaw, manducate, accidental match probability P5 = (P1)5 = 0.0000025 = 0.000,000,000,000,000,000,000,000,000,032. It is an absolute impossibility, an enormously conservative impossibility. Be it 10,000 times smaller, it would add no substance: beyond a threshold of possibility, 10,000 impossibilities equal the same 1 impossibility. The verdict must be: The English eat, cheek, chew, jaw, manducate, and the Türkic ye-, čaak, kev-, čügtä, meŋ constitute a case of paradigmatic transfer. They are genetically connected and must have had originated from a common linguistic phylum. |
3.56
chill (v., n., adj.) “coldness, cold” ~ Türkic čı:la:-, čile-, čısdı: “drizzle”, čil (chil),
syil, yel, ye:l (v., n., adj.) “wind, windy”, čilə (chile) “cool”, Bashkir halqïn “cold”.
An “IE etymology” is thoroughly confused on the issue of chill and cold, q.v.
The forms čil “wind” and xaltarä
(v.) “freeze” are cited for Chuv. language, they are a sample of an anlaut cornucopia
č-/s-/š-/y-/j-/dj-/z-/ž-/d-/Ø. A spread of akin forms and undifferentiated grammatical use
attest to a most primeval origin of the word. Abundance of forms and semantic affinities numbering
in dozens form a dynamic cluster in time and demographies. A CT is a y-type, a č-type
is second in popularity (including Khakass), an s-type shows up in the Far East. In CT čil
is vocalized ye:l with a semi-consonant, aka (EDT) “with usual phonetic changes” and
few vowel variations. Individual languages have their own semantic extensions. The Türkic chill,
cold, drizzle and
wind are allophones, with alternation of the initial k-/ch-/h-/x-/g-, and probably
more. The form xaltarä in some Türkic languages echoes a form katur-
“freeze”, fr. the verb ka:d- “freeze” and noun ka:d “snow-storm, blizzard”; it is a
sibling of cold . An underlying notion of the stem ka:d- is “harden”, hence the
metaphoric “freeze”.
Alternatively, xaltarä may be a derivative of ka:r “snow” (like in Kar Sea
“Snowy Sea”) with -r-/-l- alternation typical for the Chuv. language.
All the roots, the “wind/blow”, “drizzle”, “freeze”, and “snow” are phonetically and semantically
connected with
chill and cold (+ numerous other roots). In warmer climes, the notion čil/ye:l
“wind/blow” was associated with “coolness”, and in northern climates čil/ka:d-
“freeze” and “snow” were associated with “cold” and “chill”. The wind also stands for “scream” of
the čil/ye:l. In Eng., the common form ye:l has produced words “yell” and “howl”,
paradigmatically transferring the meaning of the wind's distinct “howl”, see howl, yell. The
mechanism of metaphoric semantic extension, especially in the northern area with continental climate
like that of the Chuvashes and their neighbors, fr. “wind” to “howl” and to “chill, cold” is
identical. The notion of the cold has been preserved in the A.-Sax. and OE semantics for chill
“feel cold, grow cold”. Cognates: A.-Sax. ceald (with ch-, cheald) (n.)
“coldness, cold”, (adj.) “cold, cool”, (adv.)
cealde (with ch-, chealde) “coldness, cold”, ofcalan (with ch-, ofchalan)
“chill down”, Goth. kalds (adj.) “cold”, OHG. (adj.) kalt “cold”, Du. hаl
“frozen ground”; OCS (adj.) hladn- “cold”, prohlada
“cool (place, air, etc.)”, hlad, hlod (n.) “coldness”, (v.) ohladit- “cool down”; Lat.
(adj.)
gelidus; Hu. szel (sel) “wind”; Pers. caidan (< ka:d-) “chill”, catarrh (<
ka:d-) “cold”; Skt.
hladate “refresh”, prahladas “cooling down, enjoy”;
Dravidian cali “cold”; Mong.
höldöh “cold”, salki (ch- > s) “wind”, shivree “drizzle” (sh ~ š ↔ č).
Sl. languages relay minor variations. The Skt. forms are barely distinct fr. the Sl. and Mong. forms
both in phonetics and semantics. Distribution of the cognates is manifest, from its start as
a Siberian NOP Y-DNA Hg., its incipience as R1a Hg., its offspring as R1b Hg., its spread in all
four directions reaching Atlantic ca. 9th mill. BC and China in the 2nd mill. BC. It amalgamated
with all encounters on the way. From a 5th mill. BC it made from a wayfarer to a horseman, and on to
a carriage. Its ancient traces are marked by all kinds of kurgan burials. Distribution reflects a
Corded Ware-type vernacular(s) that split and migrated westward, eastward, and southeastward, with a
finger extending to the Apennines. The direction and timing of the split have been reliably traced,
the Indo-Aryan migration ca. 2000 BC, the Apennine migration ca. 1500 BC, the Sarmat migration ca.
200 BC. Languages that carried diagnostic markers were not necessarily those named out in the titles
of the periods. They could have been those of the displaced, displacers could superimpose over the
displaced. Flashes of primary and secondary events are reflected in biology (genetics), archeology,
and later in historical records. “IE etymologists” are thoroughly confused on the issue of chill
and cold, offering conflicting asterisked “PIE proto-words” to jam reality into ordained
ideological chimera. The “IE” assertions are faux “PGmc. proto-forms” *kal- and *kaliz
“cold”, and a faux “PWGmc. proto-form” *kali “cold”, and a faux “PIE proto-root” *gel-
“cold, freeze”. The “IE” confusion is precipitated by a second European line of non-cognate
“cognates” derived from the Türkic stem for “frost, hoar” and, of all the words in the world,
“pendant”. A primary word for “pendant” (EDT 826, silk- “shake, shiver”,
salkım “pendant (adj.), cold, hoar-frost”) is a cognate of Eng. “sag”, something that is
hanging, drooping, and swinging. It produced the name for icicles, precipitation, and for
“shivering” and “freezing”. Etymological conflation of two terms with their own etymological
histories does a disservice by using a postulate as a proof of that premise. Hence the confusing
cognates: Lith. (adj.) šaltas “cold”, Hu. szel (sel), Osset. (n.)
sald “cold”, Av. (adj.) sarǝta “cold”, i.e. the reflexes of the Türkic salkım,
šarkım
“cold, hoar, frost, pendant (adj.)”, Yakut šel “wind”, siel “hair, mane”, CT yelpi
“wave, flatter, swing”, yelke “nape” (hair on the nape side, like horse mane), etc. An oldest
attested word is a Middle Eastern-native Dravidian, held to precede by far the Semitic and Aryan
migrations. The sil- line is synonymous with a parallel ye:l line. The Skt. vs. Av.
languages are demographic components of the same migratory events. Naturally, a bulk of the
population remained behind, they furnish markers of who, when, and where, in addition to the older
clues datable by common genetic alleles. The NW European forms of the yel line bear their
allophonic nature and a volatile nature of the anlaut consonant ch-/k-/h- grown in the
linguistic ambience of consonantal anlaut dominance. They are eidetic with the analogous phenomenon
typical for the Oguric languages, Cf. the same process for the homophonic “hair, mane”: CT (Turkmen,
Gagauz, Turk., Az., etc.) ye:l, Chuv. čil, čilxe, Tuv. čel, Khak. čil(in),
Yak. šel, šiel. The notion “hair, mane” reflects a visual aspect of the wind action
(Cf. Romance pelo “hair”, Eng. pelt, i.e. something flattering under wind). The
Ogur-type forms, and especially the Khakass (Enisei Kirgiz) form are diagnostic. The Ogur-type forms
corroborate a thesis that the Hun and Scythian languages were of the Ogur-type. The Khak. form is
consistent with the other forms of the Eng. Turkisms. The Chuv. form čilxe “mane” corresponds
to the A.-Sax. form feaxe “hair, mane”, differing in the quality of the anlaut consonant and
elided -l-. The Chuv. forms point to their coming from Asia to the Eastern Europe in the
7th-6th mill. BC with their dominant R1a Y-DNA allele and an archaic Türkic language. In the middle
course of the river Itil (Volga) 8-6 thousand years ago they initiated the Middle Volga, Samara and
Khvalynsk Pit Grave (aka “Kurgan”) archaeological cultures. That contravenes a presumptive
association of Chuvash with a Far Eastern origin, where Mongols, Tunguses, and Manchu, and their
relatives Koreans and Japanese, are marked by the Y-DNA group C. DNA links Chuvashes with the R1a
Y-DNA Huns. That links Chuvash with a R1a Y-DNA modern Russians, who carry more native Chuvash blood
than anything else. The Chuvash-Mongol linguistic similarities ascend to 93 AD, when 100,000 Hunnic
families numbering 500,000+ people submitted to the ruling minority of Syanbi (pin. Xianbei 鮮卑)
Mongols, essentially making the Hunnic language a language of the Syanbi. From the Eastern Europe,
the R1a people expanded to the Balkans and to the heart of Europe, amalgamating with the local
farming populations. Upon the arrival of their violent mounted cousins marked by R1b Y-DNA
haplogroup, and after a period of the “killing fields”, a chunk of the western settlers retreated
back to the Eastern Europe. See cold, howl, yell.
3.57
chirp (v., n.) “high-pitched sounds” ~ Türkic čïlra, (v., n.) “jingle, clink, ping, ring”,
čiriɣ “sound (metal)”.
Derivatives lead to a root čï-, či- “(specific) sound”. Presently there is no etymology other
than a superficial “echoic”. An “IE etymology” asserts “of echoic origin”. That verdict is
inadequate, same “chirps” produce different terms, 15+ different “chirps” in the European peninsula.
A maze of echoic origins should have the same trail of origins as any other etymologically
scrutinized lexeme to be credible. Out of 30 European languages, 16 use ch- type terms of a
half-dozen varieties; 14 use non-ch- terms. Cognates: A.-Sax. cearcian (with
ch-, chear-) “to creak, gnash”, ME chirken “chirp”; Sl. chirikat (чирикать),
Sloven. cvrkljanje, Croat., Serb. cvrkut, Cz. cvrlikaní, Maced.
čir, Pol. cwierkanie; Lith. čirškimas, Latv. čīkstet; Sp. chirrido,
Port. chilro, Rum. ciripit; Est. siristama; Hu. csipog; Mong. jirgee
(č ↔ j); Ch. zha (č ↔ j); Jap.
tsuitta (č ↔ ts); but Gmc. Dan. pippe, Du. piepen, Sw.
kvittra, Norse kvitre, Gmn. zwitschern; other European languages have for the
word 12+ different roots. Distribution: From Atlantic to the Pacific; individual echoes
should have a same scrutiny as any other etymologically scrutinized lexeme. The Eng. “chirp”
distribution is very telling: “chirp” is very mobile and easily crosses linguistic barriers, it
appears spottily in different European branches, has a spotty appearance in the NW Europe, spotty in
the Slavic branch, and extends eastward along the Steppe Belt to the Far East. The harmonious
correspondence between čïlra and
chirp point to the Türkic milieu as a source for a common origin.
3.58
chisel (v., n.) “carve” ~ Türkic čiz- (chiz-), čizdür-, čiztür-, čarmala- čermele- (v.)
“chisel, scratch, draw (depict), write”.
Ultimately fr. čiz-, čïz-, -sız-, čar-, čer- and yaz-/jaz-, one of he two phonetically
diverging basic forms in two geographical zones. A third form is particular: ir-/i:r- “notch,
scratch”.
Instrumental suffix -l is of European provenance, Cf. A.-Sax. cisel “gravel”, cecel
“cake”. An Old Europe Sl. dol-, expanded by a motley retinue, is prevalent among 44 European
languages with 13 (30%) languages, followed by a Türkic čiz- motley group with 11 (25%)
languages, followed by a Gmc. group with 5 (11%) languages. The other 15 (34%) languages use 11 of
their own native terms. None can be rated as a Pan-European, each one can profess an “IE origin”
albeit the čiz- group is using Türkic root. Cognates: A.-Sax. none recorded, OFr.
cisel “chisel, scissors, shears”; Croat chr- (crtanje), Serb. tsr- (цртање) “draw,
draw lines”, Rus. cher- (чертить, чертеж, черта) “draw, drawing, line”, Slov. kre-
(kresli); Hu. ir- “write” (s/r alternation); Mong. tsüüts “chisel” (ts ~
č); Ch. chokokuto (彫刻刀) “chisel”. There is practically no presence
in the “IE” family, the word comes of a non-IE origin, any “IE etymology” can only be figmentary.
Distribution: From Atlantic to Pacific, across linguistic barriers. A major presence in the Sl.
and few other languages points to the Sl. as an eldest spreader with a notion “batter, beat”.
Together, the Sl. dol- and the Türkic čiz- define a majority of the European contents.
The standing “IE etymology” stops at a vanishing Lat., under a dubious assertion of an origin fr. a
“PIE proto-verb” *kae-id- (v.) “strike”, which in reality is Lat. < Gk. cide <
skotono (σκοτώνω) “cut, killing”, not exactly “carve, scratch”, nor a chis-, čiz-. Since
a *kae-id- is not a member of 12-word Lat. dictionary for “strike”, the “IE reconstruction”
of a Lat. word belongs to an unrelated alternate macrocosm, it is a fiction. The word “cut” is a
reflection of a Türkic kıd-, kı:d- “cut” that reached Gk. and then was adopted by Lat. (Gk.
was there first), see “cut”. The notion “carve” predates Lat. and Eng. by a long shot, the word came
to Eng., and by the same token to Sl. (but not Balt.-Sl.) via independent paths. The OFr. likely
gained the word fr. a Türkic milieu, either Alanic or Burgund. As indicated by the consistent
initial ch-, the word came as a legacy. Like other survivors in Eng., it was a trade term
below a radar of the grammarians. The stem čiz- “draw” has European siblings ris-/riz-
and Skt. rikh- “carve, scratch, draw” (derivative rizan, Turkish resim, see
write) that left a lasting trace in Gmc. and Sl. languages for the notions “draw” and “write”.
The Skt. inlaut -kh- (-h-) is consistent with the s/h alternation typical for the Aral
basin vernaculars, Cf. Lat. ignis vs. Skt. agnih “ignite”, Cf. Türkic yaq-, yak-
“ignite”. A perfect phonetic and semantic match between the Türkic čiz- and Eng. chisel,
an absence of “IE” European presence, and identical semantic developments to “draw (depict)” and
then to “write” leave no room to doubt of a common genetic origin from a Türkic phylum. See cut,
ignite, write.
3.59
chitchat (aka chit-chat, chit chat) (v., n.) “gab, schmooze, buzz, hum” ~ Türkic čit čat (v.)
“make thud (sound), noise”.
An “IE etymology” is etymologically perplexed and mum, but carries a reflexive hint in a chit
“young of an animal, small child”, “blab”. The “chitchat” is a paired idiom typical for Türkic
languages, Cf. balu baju “Hushaby!”, аč qïz “hunger and want”, and ca. 1460 others (OTD).
The Türkic notion of “buzz, small talk” and the like can be expressed singly, reduplicated, or in
combination of the elements čat, čet, čıt, čit, the form čit čat ~ chitchat is but one
of them, synonymous with chat “talk idly, babble”, see chat, chatter. Another
prominent expression of čat is contained in the term for “cat” četük that formed the
European, Asian, and African term cat with its many allophones, see cat. The root
čit/chit is likely unrelated to the word chit “improper girl”, or to the word chattel
“private movable property”, a derivative fr. the root čat- “gather, assemble” (see chattel).
It formed a notion cheat “practice trickery or fraud”, that is “talk somebody into doing
something (for their own disadvantage)”, and a chatter “din, twitter, gossip”. No “IE” etymology, practically no presence in the
“IE” family, thus obviously of non-IE origin. Cognates:
A.-Sax. used c (~č) for both /ch/ and /k, q/; except for cicen “chicken”-like
cases, articulation is unclear; Du. koeteren “jabber”, Dan. kvidre “twitter, chirp”;
Mong. chatlah (чатлах) “chat”. The č-/k- alternation parallels that of the form
četük/cat. A primeval connection with the chirping of the birds and cat miaul have endured for
the birds, attesting to an initial echoic origin. The words “chat” and “chitchat” entered Eng. as a
verb and a noun, without any phonetic or semantic changes; further derivatives arose in the course
of Eng. evolution. They are members of the paradigmatic transfer series along with “say”, “tell”,
“tale”, “saga”, “message”, and other words related to verbal communications. The compound
chitchat is also a paradigm in its own right. Each word separately, and the systemic nature of
the paradigmatic transfer indisputably attest to a Türkic linguistic substrate. A chance coincidence
calculation similar to that for “chew” q.v. for the whole paradigm would produce a number thousands
times smaller than the probability value P assessed for the “chew” paradigm, a positive
impossibility. See cat, chat, chatter, chattel.
3.60
“” “” “” “” “”
chop (v.) “cut into pieces”, (n.) “(lamb) chop” ~ Türkic čap- (v.) “chop, strike (behead,
with sword, whip)”, čöp (n.) “debris, scraps, piece of”.
A myopic “IE etymology” offers “of uncertain origin” with some impossible “possibles” just for
laughs, one of them a lustrous “possibly an onomatopoeia”. Ultimately fr. a root čö- “small,
diminishing, lower” seen in numerous derivatives, Cf. Eng. “short, curt”, Sl. korotkiy (короткий)
“short”, and ca. 30 of their European siblings (kurz, gearr, etc.). The English chap,
chapp “crack, split, burst open” appears to be an allophone of the Türkic verbal stem čop-.
The prime notions “chop, chippings” lists only 4 semantic clusters, but a loose semantic range is
exceedingly wide: soften (in water); squeeze, wet, sediment, leftovers, residue, sludge, cracklings,
scum, etc. A range of articulations is loose likewise: anlaut č-, ž-, j-, c, vowels -ö-,
-o-, -a-, -i-, -ı-, etc. A Türkic noun-verb primacy is transposed in Eng. to a verb-noun. For a
verbal stem, the OTD and EDT list čop as čap-, but G. Clauson observes that a
surviving causative denoun verb čobart- “strip” is a product of the verbal stem čöb-/čöp-
(EDT 398). The same with a passive verbal form čobul- “split, part”. Whether a primary
form was a noun čöp “piece” or a verb čop- “chop, strip, part apart” is untenable. The
surviving OTD and EDT attestations of the area and period corroborate sufficiently a G. Clauson's
presumption of the verb's usage outside of a purview of the sources: čö:b (čö:p) “residue”,
čöbik (šöbik), čöpür “debris”, čopra: “rubbish”, čobulmak “apple piece”,
čaput/čapğut “quilted”, čaptur- “strike, ruffle”, čapıl- “stricken”, etc. In a G.
Clauson's opinion, -b- was a primary, and -p- was a secondary articulation. That
opinion too is untenable; the -p- form may help with diagnostic evidence. The Türkic čöp
is a prominent internalized loanword in Europe. Of 44 European languages, a Türkic group čöp-
with 7 (16%) languages and a motley group ha(ch, k)- with 7 (16%) languages dominate,
followed by a Sl. group sek- with 6 (14%) languages, and a Sl. group kot- with 4 (9%)
languages. The remaining 20 (45%) languages use their own versions of 14 native words. There is no
common “Pan-IE” root; the European lexical mixture is fairly motley. Cognates: A.-Sax.
scafan, sceafan “shave”; MDu. kappen “chop, cut”, Dan.
kappe, Sw. kappa “chop, cut”, Gmn. schabracke “leather piece”; ONFr. choper,
OFr. coper, Fr. couper “to cut, cut off”; Gk. tsipouro (τσιπουρο) “grape
pomace”; Hu. sepro “sediment”; Ukr., Rus. chapra (чапра) “grape pomace”, Pol.
сzарrаk “leather piece”; Osset. сürv, cirwae, ciwrae “sediment, grounds (beer)”; Mong.
ceb, tsev “sediment, cracknel”; Bur. сüb, süb ditto; Kuman čöpre, čöp
“sediment, bagasse”, čepure “bagasse”, cıbır, cibindirik “cracknel”, yibi
“sodden”, Tatar. čüрrä “sediment”.
Distribution: From Atlantic to the Far East, across linguistic barriers, with a decent
imprint in Europe. There, the word is associated with the area populated by R1b Y-DNA-marked
haplogroup. In the Eurasia this word is associated with the Türkic people marked with varied
mixtures of the R1a and R1b Y-DNA haplogroups. No “IE etymology” whatsoever. There, etymology does not
even reach a Lat. The three somewhat different phonetic forms indicate three different paths to
Eng., Gmc., and Romance groups respectively. The čöp as “leftover pieces, leftovers, rubbish,
sediment” also produced the Eng. chaff, probably via a separate path of a dialectal form
čouml;:b. The English slightly denigratory chap “boy or man” is a reflex of the Türkic
idiom čöb (kiši:le:r) “(human) rubbish”. The English chop (“chopstick”, lamb chop,
etc.) is a reflex of the Türkic form čobul- “split”, Cf. čobulmak “slice (of apple )”.
See
chaff.
3.61
circle (v., n.) “ring, encircle” ~ Türkic sür- (v.) “surround, cordon off, besiege,
pursuit, lead, drive”, sürkülä-, sürkïla-, sürgü:le:- (v.) “pursuit”.
Under “IE etymology” a “circle” ascends to a Lat. circulus stopping short of its origin, q.v.
The phonetic and semantic allophony is striking. The terms “drive, pursuit” are traditional Türkic
methods of encircling hunt, they provide both phonetic and semantic unity. Türkic has numerous terms
and derivatives related to encircling hunts, attesting to an ancient origin (hunter-gatherer
society) and geographical spread of the terminology: abla-, avla-, er-, ir-, qačrus, qapsa, qov-,
saɣïr, sür-, sürkïla-, sürkülä, sürus, and probably a few more. Of 44 European languages, two
Türkic-derived sister groups cVr- and kVr- dominate with 22 (50%) and 16 (36%)
languages respectively, or combined 38 (86%) languages. The remaining 7 languages use their own 6
native terms. If there is a Pan-European common term, it is overbearingly Türkic. The first European
hunter-gatherers, and all later migrants undoubtedly carried over their own terms, but most of them
were supplanted by amalgamated versions of the lingua francas. Cognates:
A.-Sax circul, Dan., Du., Sw., Norw. cirkel, Icl. hringur, Gmn. kreis,
kranz, zirkel, Yid. kurts (קרייַז); Basque zirkulu; Ir., Scots ciorcal,
cearcall, Welsh cylch; Lat. circulus “circle, ring”, Fr. cercle, It.
cerchio; Sl. krug, круг, Pol. okrąg, Slovak kružnice; Gk.
kirkos “ring”; Hu. kör (< sür-), Mong. ergekh (эргэх) (<
sür-). Distribution: Spans the width of the Eurasia, emphatically attesting to a
non-IE origin. An “IE etymology” is non-existent. A speculated “IE” derivation of “circle” from
“circus” is ridiculous. A hunting word qapsa “encircle, surround, surround on all sides” is
etymologically connected with the Eng. “capture”. See capture.
3.62
clinch, clench (v.) “grasp, clutch” ~ Türkic qïlïnč (v.) “tie, link, brace, bracket, girdle”,
from a stem qïlïn- “to come about, arise, make, appear”: be made, formed, appear, arise.
Ultimately fr. qïl- “do, make, act, copulate”, qïl- “sharp”,
qïl “barb, awn”, a derivative of a qï- “do, make” attested in derivatives.
Judging from etymological explanations, the term qïlïnč is a tool, to grab and stabilize
something in a device. Examples of the mentioned devices may relate to a weaving loom or a shaman's
drum. A qïlïnč grabs and stabilizes a warp fabric or a drum; it acts as a stationary or a
movable brace; it clinches, clenches, or clings. Like other technical terms, it was carried with,
passed along, and internalized like any other internalized terms, cf. boss, chunk, derrick, ok,
toilet. Seemingly appearing fr. nowhere, in Europe the term spread like a wildfire, apparently
accelerated with an advent of technology and literacy. A single Türkic-A.-Sax. word metastasized
into a series of daughter terms. In all cases, the Turkic form leads, of 44 European languages
qïlïnč in “clinch” with 27 (61%) languages, in “clench” with 11 (25%) languages, in “cling” with
13 (30%) languages. The remaining languages use their own native 17, 33, and 31 native terms
respectively. A common portion of the “Pan-European” lexicon is exclusively Türkic. Cognates:
A.-Sax. (be)clencan, (be)clingan, clingan, clang “hold, cling, bind, stick together”, Dan.
klynge, klinke (v.) “cluster”, knuge “clench”, klamre “cling”, Du. klinken
(v.) “clench”, kleven “cling”, ONorse klengjask “press onward”, Norw. klamre
“cling”, Fris., clinch, clench, Icl. lench, Luxemb. clenchen, OHG klinga
“narrow gorge”, Gmn. klinke “latch”, clinch “clinch”, Yid. klintsh (קלינטש);
Ir., Scots, Welsh, q.v.; Fr., Malt., Port., Sp. clinch “clinch”, Malt.
clench; Bosn., Croat. klinč “clinch”, Sloven. klinču; Latv. klinčs
“clinch”, etc.; Mong. kilagu, Khal. hialu “sharp (tool); ”all “clinch”, or clench”, or
“cling” except as noted; the list is tiresome, with 51 European members. Distribution: From
Atlantic to the Far East, across linguistic borders. Since at the time of the Celtic departure from
the E. Europe in the 5th - 4th mill. BC the looms (2nd mill. BC) were not yet known. The Celtic
migrants could not carry a concept of the loom from the Egipt. The pedestrian migrants' Ir., Scots,
Welsh terms (clinch, clench, cling), like most of the cognate list, must be neologisms
borrowed from later arrivals. An “IE” assertion of the word's origin from a “Proto-Germanic
*klingg-” is etymologically useless, leading from nowhere to nowhere; such uncouth pretentions
only hurt the thesis of a PIE paradigm. The Eng. word fell from a blue sky in 1560s, with no “IE” or
any other origins. An intellectual influence of the late Ottomans or Tatars can be sensibly
excluded. The word most likely survived in its pristine form in the context of wrestling matches, an
eternal Türkic tradition along with the game of polo. A convergence of numerous indicators make an
origin from a Türkic milieu unavoidable, and may hint that the Egyptian looms had a cultural
predecessor elsewhere.
3.63
coach (v.) “drive, ride a coach”, coach (n.) “carriage” (Sw N/A, F1934, 0.00%) ~ Türkic köč-
(köch-) (v.) “ride (a coach)”, Eng. coach (n.) “carriage, wagon”.
A myopic “IE etymology” asserts an origin fr. a Hu. town Kocs, q.v. Ultimately “coach, migrate” (v.)
fr. a base Türkic root qo-/qon-/ko:n- with notion “descend, stop, settle”, the -n- is
a reflexive suff.; see come, go.
The word is neutral to transitivity and noun/verb function, attesting to its utter archaism. It is a
member of a cluster gi:r-/ki:r- “enter”, git-/kit- “leave”,
göč-/köč- “move”, qo:n-/kön- “descend, stop, settle”, gö:q-, qoq- “go down,
decrease, subside, fall off ” conveying different motion aspects relayed with means of phonetic
synharmonism. The cluster points to a single consonantal phoneme root g-/ɣ-/k-/q- “go”,
suffixed with a single consonantal phoneme č-/n-/q-/r-/t- to form grammatical aspects of the
notion “move”. The single consonant word receded by far an appearance of a productive pastoralism.
Initially it had to be a word of a time span from a roaming to a hunter-gathering economy. It is an
ancestor of the Eng. come, go, etc. Such evolutionary scenario calls for batches of cognate
lexemes diffused across Eurasian linguistic families. In the nomadic society, a derivative coach
must have been a most popular word that defined a daily life, with a wide spectrum of semantic forms
and extensions. Its traces are found in most languages with a Türkic nomadic component or directly
affected by their steppe neighbors. For millennia, coach was a pinnacle of progress, a
transportation, a home, a homely hearth, a focus of life, and a way of life. Sedentary people do not
have nor need a trade lexicon related to professional nomadism. They have to borrow it from the
nomads, thus the abundance of the Türkic terminology across Eurasia. Cognates: Eng.
coachman, Dan. kusk, Du. koetsier, Gmn. Kutscher, Norse, Sw. kusk
koucher; MFr. (16th c.) coche, Gmn. kotsche; Latv., Lith. kučieris; Serb.
koch (коч) “home”, Bosn., Croat kočijaš, Pol. kосz “cart”, kосzу “wagon”,
Bulg. gjoč “family”, kochiyash (кочияш), Cz. kočí, Ru., Serb., Slov., Slovt.,
Ukr. kucher (кучер); Cat. cotxer, Fr. cocher, Galician, Port. cocheiro,
It. cocchiere, Sp. cochero; Pers. kuč “migration, striking camp, marching”;
Hindi kochavaan; Est. kutsar, Fin. kuski, Hu. kocsi (~ Türkic köčür
“transfer, move”); Basque
kotxezainak; Brahmi köjür “to coach, move”; Mong. köčke “caravan”, köške
“travel luggage”; Ch. ganche (赶车); all “driver, coachman” except as
noted. Distribution: Allophones of the köch are known from Atlantic to Mesopotamia to
lake Balkhash and to the Pacific. The depth of the attestations related to the carriage industry in
the Eurasia, the distribution of cognates and a variety of phonetic forms attest to the antiquity
and diversity of internalizing paths. An abundance of unacknowledged cognates in all diverse
Eurasian linguistic families attests to grubbiness and manipulations within the “IE linguistic”
cohort. The “IE etymology” “from a name of a Hu. village” is beyond laughable, it is a disgrace for
the entire “IE” etymological industry. For a word that still occupies a major place in the European
and Eurasian vocabularies, from transportation to home furnishings to tending to a home itself, that
IE-centered “etymology” is most uncouth, brazen, and dishonest. Pretentions to have myopic horizons
only uncovers a professional penury of the “IE etymology”. Serb. uses koch (коч) for their
stationary homes, a calque from the Türkic mobile homes. The Ch. form ganche ascends to the
earliest known form
kang “cart, wagon” recorded in Sum., Cf. Kangly as a tribe and a coach. The Ch. kangchi
“coachman” was internalized in Ch. complete with the Türkic instrumental suffix -chi. The Ch.
name Gaoche 高車 for the northern nomads is a Türkic compound köch +
-chi “coachman”. See Celt, come, gamut, go, hide, home, house.
3.64
coagulate (v.) “turn from liquid to thickened or solid state” ~ Türkic qoyul-, kogul- (v.)
“thicken, inspissate (liquid), curdle, coagulate (of milk)” (passive), from a verb qоyï-
“condense, coagulate, thicken”, from a koy- “sediment, clot”.
An “IE etymology” boldly asserts an anachronic Lat. origin, q.v. The ultimate origin comes from a
notion “squeeze, press, dry”, and is associated with preparation of curded milk products, from
yogurt
(curdled milk) to qurut (dried curd). A form kogul is an Ogur version of the Oguz
qoyul, the -l is a passive suffix in Türkic and Lat.. An incomplete listing of forms
numbers 17 root versions: goyu, hojïɣ, hoyuɣ, хoyu:, хoyuɣ, kojïɣ, кoyu, кuyu, qoyï, qoyu, qоyuɣ,
qоyuq, quyï, quyu:, quyuɣ, quyuq, yava. The yava represents a poorly documented series of
Chuv. forms. One of those forms reached Lat., initiating a European mini-enlightenment, its path is
unknown. The Eng. curd/curdle < qurut is a relict. A confusion with ko:d “put,
put down, abandon, give up” is an error (Clauson EDT 595). “Coagulate” became an
international word in nearly every European language, while many languages retained their own terms
for “thicken, curdle”, pointing to a pre-historical usage of milk (Celtic, Fennic, Gk., Alb., etc).
The Turkic forms lead, of 44 European languages versions of qoyul- lead with 28 (64%)
languages, an Old Europe Sl. gus- (гус(теть) “thicken” follows with 6 (14%) languages. The
remaining 10 (22%) languages use their own native 10 terms. A common portion of the “Pan-European”
lexicon is exclusively Türkic. Cognates: Icl. hlaupi, Gmn. gerinnen; Gael.
gruth; MFr. coaguler, Lat. cogere “curdle, collect”, coagule, coagulare
“cause to curdle”; Taj. qoyu- “thicken”; Mansi qoyu- “thicken”; Evenk qoyu-
“thicken”; Azeri čürü- (chürü-); all
“coagulate, thicken” except as noted. Distribution: From Atlantic to Manchuria, across
Eurasia and across linguistic barriers. The “IE etymology” suggests an origin fr. an anachronous
Lat. cogo “bring together, gather, collect”, from co- “together” + ago “do,
make, drive”, a rare case of appealing to a real, non-asterisked “proto-word”. Firstly, yogurt,
qurut belong to the Türkic, and not Lat. phylum, see curd , see Khak. idiom yuğrut
koyuldi: “yogurt coagulated”. Secondly, yogurt and qurut are innate to the
Türkic nomadic kitchen that ascends to a well dated time of horse domestication ca. 4th mill. BC,
about 3 mill. before Lat. comes to the Apennine Peninsula and to the pages of history. That does not
completely exclude Lat. from the picture: the Lat. predecessors could have come fr. a Türkic phylum,
their pre-Apennine history is not known. A Lat. predecessors' origin from a Botai-type culture can't
be excluded. An “IE” assertion of a
coagulate “Doublet of quail (bird)” is sorely uncouth; the entire “IE” assertion is
slippery. Türkic has allophonic forms that correspond to Lat. and Gmc. versions, qoyul- and
čürü-. The lexical-semantic coincidence is perfect, the phonetic correlation with liquid
-r-/-l- alternation is expected. The paths from qoyul-/qogul- to Lat. cogere,
and from the Eng.-Gael.-Gmn. čürü- to curd/curdle/gruth/gerinnen are separate in space
and time. Like the Lat. form, the Icl. form hlaupi is connected with the Türkic
qoyul-, historical reasons point to a separate path: sheep herding was a main Norman means of
subsistence, the opportunities for a lexical borrowing did not exist, and they did not need a Lat.
loanword to be borrowed. See curd, cuddle.
3.65
comb (v.) “groom (hair), ransack (area)”, (n.) “toothed tool” ~ Türkic kem-, kemdï-, kemür- (v.) “gnaw, bite”. Ultimate semantics is “to bite something, ruminate”, forming allophonic forms gev-, kev-, kep-, kip-, keg-, and a good half a dozen more within a Türkic milieu. The -m- form may be a reflex of the -v-/-p- forms with m/b alternation. A root vowel is notoriously fluid. Since comb may stand for a tool and a crest on top of a human or fowl head or a helmet, the term is furcated. A semantic chain of bite > tooth, teeth > toothed > tool, scallop runs without an end, Cf. gear teeth, toothed wheel, etc. Of 44 European languages, a mostly Türkic-Gmc. motley form cam- predominates with 12 (27%) languages, followed by a strong Romance-Sl. group pe- with 9 (20%) languages, and a largely Sl. group ches- with 7 (16%) languages. The remaining 13 (30%) languages use their own 8 native words. There is no common “Pan-IE” or just an “IE” root. Cognates: A.-Sax. (ge)cemban, comb, camb, cambo, cumb, combol “comb, crest”, kemb, honeycomb, cumbol “sign, standard, banner”, cumb, coomb “valley”,
flaeðecomb, fleðecamb “weaver’s comb”, horscamb “horse-comb, curry-comb”, etc., total 11 words; Eng. unkempt, Fris. kaam, Anglian comb, OSax. camb, MDu. cam, Du. kam, ONorse kambr, OHG camb, Gmn. kamm “comb”; Welsh cwm; Sl.
kusat (кусать) (v.) “bite” (< Tr. kuyshe-), kushat (кушать) (v.) “eat” (< Tr. kushe-); Agnean kam “tooth”, Kuchaean keme- “tooth”; Dagur kem- “chew”, Baoan kamel- “bite”; Mong. kemi, Ordos keme “marrow”, Khal. χim, χəm, Kalm. kem “fatty marrow”, kemlx “gnaw (bone), draw marrow” (Cf. Eng. ham); Manchu kemin “bloody marrow”; all “comb” unless noted otherwise. Distribution: across entire width of the Eurasia from Atlantic to Pacific across linguistic families, and in Europe exclusively within the Gmc. and Sl. groups. That excludes any uncouth “IE” speculations of the type like a faux “PGmc. proto-form” *kambaz “comb” and faux “PIE proto-word” *gombhos and its faux “PIE proto-root” *gembh- “tooth, nail”. That kind of Munchausen tales is useless. Instead of unwittedly ornamented model, the
“IE etymology” should have cited the direct, attested, and documented Türkic form gem- (v.) “gnaw, bite”. The Celtic Ir. cior, Gael. cìr, and Welsh crib/grib “comb” (all r ↔ s) echo the Sl. forms with r/s alternation typical for the Ogur/Oguz distinction. The uniformity of the Celtic forms bespeaks of the common origin from a point in the 6th-5th mill. BC E. Europe prior to the Celtic anabasis. The relicts kempt, cam, and the modern camshaft and their siblings are the modern versions of the cognates. The silent auslaut -b apparently is a handy discriminator from an acoustically different version of the final -m-. The peculiarity of the -m- form vs. a slew of other versions bears a certain diagnostic value.
3.66
come (v.) “arrive, reach destination, happen” (Sw N/A, F67, 0.38%) ~ Türkic qon-, ko:n-
(v.) “come, reach destination, stop”, An “IE etymology” boldly asserts a Gmc. origin fr. an
“IE” original, q.v. Ultimately fr. a
polysemantic verbal root qo-, qon- (refl. suff. -n) “come to a destination”, “leave
(something), put, put down, abandon, give up”, “all, together”, expressed in a wide range of concrete and metaphoric applications with a rich, exclusively Türkic-Gmc., trail in the European languages. No Sl., Romance trail in the European languages. The basic notions refer to separate aspects of reaching a destination: coming to a stop, staging a stop, reuniting at a stop. The basic form qon- has an allophone qam- “put down, knock down, lower” with the meanings of the sister form qod- “put down”, i.e. “settle for now”. It has survived and blossomed into numerous derivatives, ending with the Eng. gamut, gamma and come, cum, common, commons, commodity etc., see gamut. The split points to a relatively late differentiation of the form qam- into a specialized areal “come” and “put down”. The semantic raster extends further out, Cf. Kelt/Celt “newcomer”, camp “stopover”
company, campaign “gathering”. The stem qon-/qam- is a deverbal verbal derivative, it
carries a long trail of verbal and nominal derivatives rooted in the specific notion of reaching a
stopping point destination. The word and its first derivatives must have arisen during an agelong
hunter-gatherer period, long before the coming of a pastoral period. The form qon- must have
formed before the other derivative verbs, the qop- “all, together” and qod-/qam- “put
down”, which are the attributes of the base notion “come to a stopover” and its deverbal noun
derivative “camp, stopover”. Of 44 European languages, a Türkic-Gmc. form can- predominates
with 12 (27%) languages, followed by a strong Romance group ven- with 9 (20%) languages, and
a Sl. group pri-, do- with 10 (23%) languages. The remaining 13 (20%) languages use their own
9 native words. There is no common “Pan-IE” or just an “IE” root. Cognates: A.-Sax. coman, cuman “come, approach, land”, OSax. cuman, OFris. kuma, Eng. cum “orgasm”, MDu. comen, Du. komen, ONorse koma, Goth. qiman, OHG queman, Gmn.
kommen, Icl. kom; Lith. gemu “born”; Sl. konets, konec (конец) “end point” in a number of Sl. languages and allophones across Central and Eastern Europe; Bulg., Serb., Croat. qonaq “day of travel”; Mong. kono- ~ OTürkic kona- (Doerfer III 1539), konak “guest”, honača “overnight guest, visitor”; Chuv., Mari hana “guest”; Bur., Khalka
honog “day and night” < Tr. конок, honuk ditto; Bur. honoso “overnight stay, lodging”; Ch. guolai (过来); Jap. kite (来て); all “come” except as noted. Distribution: From Atlantic to the Pacific, across linguistic barriers. A borrowing of konak “guest”, etc. in different languages see Doerfer q.v. No attested “IE” common word, no European common word, q.v. In the European lexical spectrum, a Lat.
veni is but one of many etymologically unconnected words. The uncouth “IE” speculations of the type like the faux “PGmc. proto-form” *kwem-, the faux “PGmc. proto-form” *kwemana, the faux “PWGmc. proto-form” *kweman (v.) “come”, and the faux “PIE proto-root” *gwa- “go, come”, the
faux “PIE proto-form” *gʷemt, *gʷem- (v.) “step” are not needed. The fictions explain
nothing, lead from nowhere to nowhere, they pretend to look informed, but only display a myopic depth and parochial vision. A hypothetical PIE fantasy in lieu of the continent-wide attested qon-/qam- is not needed. The two Gmc. forms co- and cu- attest to an amalgamation of -o- and -u- dialects, still present among Türkic languages. The Goth. qiman and Lith.
gemu illustrate a general fluidity of the vowels. The -m-/-n- alternation is a regular effect of amalgamation with local articulations, whether of Türkic or Gmc. variety. Persistence of the specific -m- form among the Gmc. languages points to its initial linguistic uniformity and thus a compact spread. Aside from the come, European languages retained a sister form qod- “put down” that developed into the now international words code, codex, and their -i- versions
codify, codicil, coding, codicology, etc. The massive presence of the of the Türkic derivatives in Eng. and other Gmc. languages attests to numerous parallel cases of paradigmatic transfers of the semantic allotropes ascending to the verb qo-. Of those, a paradigmatic transfer of the derivative qon-/qam- is a particular case. They incontestably demonstrate a genetic origin from a Türkic milieu. See Celt, gamut, go.
3.67
con (v.) “steal by deceit, swindle”, conman (n.) “swindler” ~ Türkic kun-, qun-, xun- (v.)
“snatch, steal, rob, carry off”, with literal and metaphoric applications. An “IE etymology” boldly asserts of a later days and derivative origin, q.v. Semantically and phonetically con is allophonic to Eng. cunning “shrewd deceptiveness” of a root cun- and a suffix -ing. No recorded A.-Sax. or
“IE” trail, but a re-appearance of the word in the American English slang on the other side of the pond points that for ages it lurked under a radar of grammarians, Cf. bogus junk, use, vouch, etc. Distribution is peculiar: only 5 (11%) words of the 44 European languages are related to phonetic con-, conning (Türkic, Eng., Ir., Welsh,
Yid.). An Old Europe Sl. group dominates with luk- and xitr- forms with 9 (20%) languages, and a Romance group trails with 4 (9%) languages. The remaining 25 languages use their own native versions of 22 words. There is no common “Pan-IE” or just an “IE” root. European languages are as motley as they come, every piper sings its own song. Cognates: A.-Sax. none, Gmc. none, “IE” none; Türkic
kun-; Eng. con; Ir. cuasach, Welsh cyfrwys, Yid. kumen (כיטרע); vague references to Nenets group “and other languages”.
Distribution: Türkic Eurasian Steppe Belt extending to the Siberian tundra, Celtic Albion and
Ireland islets; traces to N. America. With quite ingenuous artistry, on purely phonological differences, the “IE etymology” ascends the siblings con and cunning “skillful in deception” to different roots. Those pseudo originals carry incompatible semantics and a temporal distance (“lateral time”) in millennia: “confidence” vs “to know”. In the first case it is exploiting a stripped prefix con-
“with” (intensifier), i.e. “with (fidelity)”, OFr. conceveir, Lat. con(cipere), con(ceptus)
“take, hold”. These conjectures are laughable, they portray a Türkic qon-“swindle” as an
“IE”
com-/con-/co-“with”, and a Türkic kap-/qap- “hold, capture” as an “IE” faux *kap-
“grasp”, see com-, keep. In the second case it portrays Türkic köni- “verity, truth” as an “IE” fictitious *gno- “know”, see know. Every “IE” suggestion is an unwitting flop. The phonological difference between -u- and -o- should not be overrated, in Türkic -o-/-u- interchanges are routine, they could signify two different paths. Phonetic and semantic match is as close as they come. The accent shift from a generic to a stealth mode is a minor modification since the semantics of “snatch” carries an implied shade of “deceit”. A derivative konurčuk for a “doll”, lit. “pretender (toy)”, illustrates an application bridging the notions of “deceive” and “purloin (by deceit)”. The absence of recorded attestations for con and cunning in the Gmc. languages is consistent with numerous other lexemes that came to linguistic attention on another continent, no more tamed by a “correct” English, Cf. boss, OK. A possible storage closet for these words was cockney, the Türkic
köken “ancestral, motherland, native place” that referred to a motherland's language, or what was left of it. A.-Sax. had 9 words expressing a notion “deceit” (bepaecung, beswic, dwild, fleard, folcwoh, forleornung, leasbrednes, listwrenc, lotwrenc), of which just one had survived to English (swindle, A.-Sax. swice). The word con is an another survival, via Celtic and possibly, but not necessarily, via A.-Sax. path. See boss, cockney, com-, cunning, keep, OK.
3.68
confer (v.) “bestow” ~ Türkic ber- (v.) “carry”. See bear (v.) for polysemantic meanings and cognates of
ber- . Cognates: MFr. (con)ferer “give”, with extensions “converse, compare”, Lat. (con)ferre “bring together”, with extensions “compare; consult, deliberate, talk over”, fr. Lat. prefix com- “together” + ferre, an allophone of Türkic ber- “bear, carry, give”. The Lat. prefix com- of Türkic origin (see com-) came to Eng. with Lat. loanwords (confer, conference, conferee, etc.) unrelated to English substrate, while indelibly illustrating the Turkisms' via Lat. path to English. Related conference. See bear (v.), bestow, com-, give.
3.69
crunch (v., n.) “crackle” ~ Türkic qurt-, kürt- (v.) “produce crunching sound, crunch”, karč, qarč, qurč, qars, qars (n., v.) “crunch, crackle”. Etymology: no “IE” original source claimed, “probably of imitative origin”, hence supposedly no cognates, but... Ultimately fr. a verb quru-, küry- “dry” formed with a deverbal noun suff. -t, adj.
kurut “dried”. European spread of the notion “crunch” is peculiar. Of 44 European languages, a Türkic form qur- dominates with 26 (59%) languages, it is shared by a motley mass of Celtic, Sl., Romance, Gmc., Baltic, and few other languages. The other 17 (41%) European languages use their own 12 native words. Other than Türkic, there is no common “Pan-IE” or just an “IE” root. Cognates:
Fris. crunch, Yid. khromtshen (כראָמטשען), Du. kraken, Gmn. knirschen, krachen “crunch”, knistern, knacken “crackle”; Ir. gearchor, Scots crog; Balt. (Latv.) skraustet “squeak, rattle”, (Lith.)
skrudeti “crack, flake”, Sl., OCS hrst, hrust (хръст, хруст) “crunch”, “scrunch” (< Tr.), “crackling bug”, Rus. krut (крут) “dry cheese” (< Tr.); Ukr. khruskit (хрускіт) “crunch”, Pol. chrustač́ “crunch” (< Tr.); Fr. croquer, Sp. crujido, Cat.
cruixit, Port. crise; Gr. vrouchos (βροῦχος) “crackling (bug)” (< Tr.); Mong. khuurai, üirmeg “dry, crunch”; Jap. kuranchi (クランチ); borrowing of kurut into Pers., Mong., Mari (Doerfer III, 1472); all “crunch” unless noted otherwise. Distribution: Eurasian-wide, from Atlantic to Pacific, and ubiquitous in Europe compatibly with the Türkic Steppe Belt. The “echoic” Türkic qurt (ɣurt with glottal ɣ-) and similar forms suggests a Türkic source of imitation, further supported by numerous Balto-Sl. reflexes. The claim “of imitative origin” is quite offbeat in that this echoic crunch is mostly confined only to the northern Europe north of Italy and the Eurasian steppe belt. The -č/-nč/-ch/-nch is a Türkic denoun suffix forming synonymous nouns, it has survived intact in Eng. crunch turning into an integral part of the Eng. root, and with various allophonic morphemes is visible in Balto-Sl. forms. The appearance of prosthetic anlaut s- in some forms is consistent with a process of adaptation of other loanwords into a Baltic family. Of the European forms, the Sl.-Pol. form chrasc (xrasch) is closest to the English
crunch, it may had been an A.-Sax. form before it became a Pol. form. Semantic extension to anything that is conspicuous by a scrunching sound is an ordinary process congenital to all languages in endless variety of forms; in Sl. such extension formed a word hryashch for “cartilage”; the Eng. came up with crush, crackle, etc. The late record (17th c.) attests that like many other Turkisms, it was a “folk speech” lurking beneath a literary language.
3.70
cry (v., n.) “shout, howl, sudden loud utterance” (Sw N/A, F1438 0.01%) ~ Türkic gürle-,
kürle-, kürlen-, čarla:- (v.) “cry, roar”, kür (n.) “cry, shout”. Alternatively orla-, orlaš-, urla- etc., “cry”. A myopic “IE etymology” offers a routine “of uncertain origin” and “possible” with few impossible “possibles”. Ultimately fr. an adjectival generic root kür “strong” applicable to numerous subjects and names, Cf. “thick” etc. Türkic verbs are formed with versions of a denoun suffix -la, Eng. verb/noun forms are undifferentiated (anthimeria). A primordial origin, for example, may ascend to a crow caw “qarr”. Usually etymologically attributed to different origins, all related forms are consistent, suggesting a long prehistory and plenty of mutual influence that ruffles any notion of a separate etymological source for each one. Out of 44 European languages, predominates a version of
gürle- with 31 (70%) languages, exceeding by far a level of a 50.6% Hg. R1a/b demographic presence in Europe. The remaining 13 (30%) languages use their own versions of 9 native European words. Except for the Türkic, there is no common “Pan-IE” root; a native European mixture is motley, attesting that its lingoes fossilized before the versions of gürle- came to the European scene
and supplanted most of the native words. Cognates: A.-Sax. ceir, cier, cerm, cearm, ceorm, cierm, cirman, cirm (with possible /c-/ ↔ k-, q-, or /ch-/) “cry, shout, outcry”, Fris. kriete, OSax. hragrа, Dan. græde, Du. krijten, krijsen “shriek”, Sw.
grata, Norw. grate, OIcl. skrikiа, Goth. kreitan “cry, scream, call out”,
hrukjan (v.) “crow”, LGmn. krieten “cry, call out, shriek”, Gmn. kreißen “cry, wail, groan”; Gael. gairm “cry”, one of candidates for Eng. “cry”, MIr. grith “cry”, Welsh gryd (n.) “scream”; Cimr. сrусh (~ Tr. kürč); Sl. krik (крик), kukareku (кукареку) “cock-a-doodle-doo, rooster's cry”; OFr. crier “shout, scream, proclaim, publicly announce”, Lat. quirritare “squeal (pig)”, queror “complain” (≈ croak, scold), VLat. quiritare “wail, shriek”, MLat. crido “shout, cry out, proclaim”, It. gridare, OSp. cridar, Sp., Port. gritar; Balt. (Latv.) krikа (Lith.) kryksti,; Gr. krike (κρικε), kravgí (κραυγη); Ar.
qara’a “aloud” (Cf. Quran), Heb. gaar “shout”, kara “cry”; Ugarit. qr' “call, invoke”; Akkad. karu “call, invite”; Pers. gerye “cry”; Skt. krandana “cry, lamentation”; Nenets karga “scold”; Mong. khertsgii (v.) “crow”, karija “scold, berate”, all “cry” unless noted otherwise. The OSax., Goth., OIcl., Cimr., Lith., Latv., Sl., Gr., Nenets, Mong. forms ≡ qarqï. Distribution covers Eurasia from Atlantic to Pacific and to Arctic Sea. It traces a spread of the Celtic Kurgan people from the E. Europe to Iberia, their incursion to the Apennines, and an independent overland path from the Steppe Belt to the Baltic and on toward Albion, a distinct path of the Türkic Kurganians. On top of the positively “of uncertain origin”, the “IE etymology” offers quite a few scenarios, like an anachronic faux Frankish “Proto-word” *kritan “cry, cry out, publish” with a faux “PGmc. proto-form” *kritana “cry out, shout” and a faux “PIE proto-word” *greyd- “to shout”, or a Lat. queror “complain” or quirritare “squeal (pig)” fr. a faux (Lat.?) onomatopoeic “Proto-word” *quis “squeal (pig)”, or a “help of the Quirites”. In all that nonsense one moment is probably right: an ultimate origin is likely onomatopoetic; instead of a late Gmc. swine's squeaking, oinking and “khru” grunts, probably it came, while still on the African soil, fr. a birdie's caw “qarr”. An Eng. battle cry in A.-Sax. sounds
beadu ceir and in Türkic something like batten qarqï, with second -q-, if any, assimilated to palatal or elided. That idiom highlights a Türkic Saka component in A.-Sax. and in Celtic, Gaulic languages. It excludes the faux “PIE” *qer-/*qor-/*qr- as a viable vehicle for Eurasian distribution. A sense of weeping is a much later innovation, probably recycled on religious grounds. The root qar- is specific to a certain group of Türkic languages - specifically mentioned are “Tatar”, Chuv., Tuvan. The term “Tatar” was a Russian moniker for a multi-lingual political entity, like “American” or “Canadian” “languages”, it is largely Kipchak and Bulgar. The OSax., A.-Sax., and similar forms are distinct reflexes of the Türkic kür- with its dialectal allophones. By the time Gmc. languages coagulated, the word was already internalized across much of the Eurasia. A Türkic origin is inescapable. See call, gabble, say, tale, tell.
3.71
cuddle (v.) “nuzzle, embrace for comfort, hug (a baby)”, (n.) “cuddle” ~ Türkic kod-, koy- (qod-, qoy-) (v.) “cuddle, lay in embrace”. Ultimately fr. kod/koy (qod/qoy) (v.) “put, put down”. An “IE etymology” offers a routine “of uncertain origin” and bravely suggests a few “possibles” and “probably”'s. Türkic has dialectal allophones of kod (n.) in the forms qon, qoyïn, qoyun (EDT 2 *ko:ñ “bosom, quiet, coy”) and in the allophones godak, godal, godik, godek “infant, suckler, adolescent”. With a passive suffix -l the kodul-/koyul- matches Eng. form “placed, nuzzled”, with quite a few more meanings, one of which is a kind of “pacify”. Turkish has two forms, apparently coming from two dialectal groups, koynuna and kucak (kujak), originating from the same root kod, with a meaning “breast, bosom, embrace, hug”. Overall, Türkic has a near endless line of allophonic terms related to “cuddle” from multilingual (ca. 80 languages) synonymous forms and their literal and metaphoric semantics. Out of 44 European languages, a version kod- predominates with 7 (16%) languages, followed by a Gmc. group ku-, knu- with 4 (9%) languages. The remaining 33 (75%) languages use their own versions of 23 native European words. Except for the Türkic kod-, there is no common “Pan-IE” root; a native European mixture is super motley, attesting that its lingoes fossilized before the versions of kod- came to the European scene supplanting few native words. Cognates: A.-Sax. cull, coll (v.) “embrace” (recorded with elided -d- or -y-), MDu. kudden, Yid. kadal (קאַדאַל); Ir. cuaille, Welsh cwtsh; Latv. cwtsh; Cors. coccola (cc = k). Distribution: With all the paucity of the European forms, Eurasian spread extends across Türkic Belt with few “guests” in remote spots. The Ir. and Welsh cognate “guests” point to a Celtic anabasis running fr. E. Europe via Africa, Iberia, and eventually to the NW end of Europe, a call fr. a 5th mill. BC. No “IE etymology”. The best, not too enlightening nor insightful attempt suggests “at first a nursery word” without a clue on where, when, and whom was the nursery located. The myopic guesses call for re-examination of the entire paradigm. The English pra-mothers had Türkic bosoms and gave Türkic hugs to their nestlings. A Türkic origin is indelible, it can't be shaded by any trickery.
3.72
cull (v.) “pluck, pick” ~ Türkic čul- /chul/, yul- (v.) “pick, pull out, pluck”. An “IE etymology” bears no inkling to an
“IE” origin. Among allophonic forms yul-, yol-, čul-, etc. (ca. 8 forms), stands out a Khakass (aka Enisei Kirgiz) čul- paralleling other Eng. Turkisms of Khakass origin, q.v., and ǯulq- “jerk, pluck, yank, snatch”.
Cognates: OFr. cuiler “pluck, select, collect”, Lat. colligere “select, choose”, probably also related to Lat. coleus “strainer bag”; Basque hilketa; Yid. flikn, kaling (קאַלינג, פליקן); Mong.
julga, ǯulga “cull, pluck, evulsion”; Evenk nul- “skive, scour, scrape” (~ Sakha
sul- ditto, ~ sului, sül); all “cull, culling” unless noted otherwise.
Distribution: From Atlantic to the Far East, with incidental solitary “guests” in Europe (Türkic Tatar, Eng., Basque, Yiddish). Distribution positively attests to a status of a Türkic “guest”, apparently first documented in the west quite late, and in Lat. By that time, all European languages had their own livestock practice and fossilized terminology related to culling. Instead of any hints on any “IE connection” are suggested wild speculations based on some phonetic consonance. The
“IE” speculations exploit various late derivatives with vague semantics. Notably, A.-Sax. has an overabundance of 12 stems to express “pluck (v.)” (alucan-, aplue-, gad-, luc-, nim-, pluc-, plyc-, pull-, traeg-, twic-, upateon-, utabre-), of words from numerous dissimilar languages, but it does not have the Eng. stem for cull-, attesting that the cull- lived beneath and independent from a strata of written records. Like many other Eng. Turkisms, the cull- belongs to the lexicon that largely escaped literary language and appeared suddenly and fairly late in the body of the Eng. vocabulary. The perfect phonetics and semantics attest to a heritage nature of the Türkic vs. Eng. forms. Eng. colloquial terms used in some trade lingos are “reject, discard, cast away”.
3.73
curdle (v.), curd (n.) “coagulate, coagulated liquid, milk” ~ Türkic kurt, qurt (n.) “curd”, “in some north-central, north-western languages” (EDT 648). An “IE etymology” via a “perhaps” suggests an “ancestor of Gaelic gruth (“press”)” or a q.v. Türkic languages also have a prevailing allophonic form kurut, both are derivatives of a verb kuri:- “dry”, and ultimately fr. a verb
kur- “fix, set in order” used in physical and metaphorical contexts. Alternatively, curd may be a verbal form of a noun ko:r “curd” with verbal suffix -t/-d that reverted to a noun use. The -l- in curdle is a verbal suffix of passive voice, “curdled”. A cured NY steak is dried, not healed, fr. kuri:- “dry”. European distribution is peculiar, some motley linguistic masses cross linguistic barriers, others' mass is a pile of single forms. Out of 44 European languages, versions cur- and cog- (~ coag-) dominate with 12 (27%) and 11 (25%) languages respectively, followed by an Old Europe Sl. group zgr- with 6 (14%) languages. The remaining mass of 15 (34%) languages use their own 14 native words. The first two groups obviously use loanwords fr. external sources; the mass of natives is larger than individual masses of copycat loans; only the small Sl. group can pretend to represent the European lingo. Curdle is a “guest” in Europe. Cognates: A.-Sax. crud, Fris., Sw., Norw., Luxemb., Icl. curdle; Ir., Scots curdle, Gael. gruth; Gmn. gerinnen, Yid. kurdle (קורדלע); Malt. curdle; Rus. kurt, krut (< kurut); Mong. χuru “curdle, curd”, Bur. hurkhan ditto; Kalm. hursï ditto; Manchu χuru (< Mong.); all “curdle, curt” except as noted;
references to loanwords in Pers., Mari, Rus., Afghan (Doerfer III 1472, p. 458). Only Gael. and Gmc. have preserved a version of a native Celtic word carried fr. the E. Europe to the west. Distribution: Fr. Atlantic to Pacific, across linguistic borders; minor presence in NW Europe. Distribution attests that the word is non-IE, and any assertions of a “reconstructed PIE word”, “from a PIE Proto-word” *greut- “press, coagulate” are a bold and shameful overt sham. The
“IE etymology” also suggested an origin fr. “urge, coerce”, which is an unsuitable metaphoric and not physical expression, and uncouthly suggested a connection of the milky crud with “crowd”. An imaginative trip to a fantasyland substitutes for a sober analysis to cover for myopic horizons. A metathesis of A.-Sax. crud “press, drive” ascends to the verb kuri:-, q.v. The presence of the Celtic form attests to the existence of the word in the 6th-5th mill. BC N. Pontic area, thus horses were milked millenniums before their postulated domestication. The Türkic-Eng. precise semantics and perfect phonetics attest to a common origin, and the Gaelic form attests to the origin in Neolithic times, prior to the Celtic migration ca. 5th mill. BC.
3.74
cure (v., n.) “fix, mend, heal” ~ Türkic qur-, kür- (v.) “fix, set in order”. Both Eng. and Türkic verbs have a wide range of meanings, without knowing a subject an exact meaning cannot be determined. The term “cure, curing (food processing)” also ultimately ascends to the Türkic verb kur-, but originates from
a derivative kuri:- (v.) “dry (i.e. fix by drying)”. It refers to a process of hardening or solidification by cooling or drying, which covers not only a traditional conservation of food by drying, salting, smoking, or heating, but also cures concrete and plastics. In some metaphorical sense a medicinal usage may be part of it, an extension of “take care”, but a Türkic concept “heal” is much younger than qur-, and is expressed with a root em-. The “cure” by far outpaces any of its synonyms in the European languages. Across linguistic borders, out of 44 languages, it is used by a motley group of 11 (25%) languages. The other 33 (75%) languages use 20 of their own native terms. That distribution attests to its “guest” status in Europe. To pin down a timing of its origin, it was suggested that “possibly” a notion “fix” originated in rising yurts, incompatible with Mong. tatah “rise yurt”. However, it is equally applicable to rising the preceding pit-house-type “long
houses” that were a staple of the Türkic abodes from the
Hunnic Neolithic times and beyond, ascending to a cave time. Cognates: A.-Sax crudan “press, hasten, drive” (< aka “fix”); OFr. curer, OSp. guarir, Fr. guérir, It.
guarir, Lat. curare, cura; Mong. quri-, qura- “gather” as “organize” (troops, march, battle, resistance, camp” etc.); all “fix, care, concern, trouble” unless noted otherwise. Some semantic extensions are astounding: secure (Lat. se + cure), curable, incurable (Lat.
curabilis), sinecure (Lat. sine + cure), procure (pro + cure), scour (Lat.
ex + cure), manicure (mani + cure), curator, curate (cleric), cure (cleric), curia, and
more. Distribution: from Atlantic to the Far East, across linguistic borders. An “IE etymology” is erroneous in confusing two independent homophones. While the first has numerous noun derivatives, the second has only one English noun, curing “solidify”, see curdle. The linguistically scattered European distribution attests to a patently non-European origin, a loanword status. A spectrum of semantic extensions in Eng. attests to a path separate from that of the Romance languages, and separate from the A.-Sax. lexicon, where “cure” supplanted a native “heal” and an Old Europe lacnian (lek-). A Romance path may be via Alan/Gothic (Visigoths) and Burgund, 1st mill AD. A late Scythian/Cimmerian path via Jute and Frisian could be a possibility. A phonetic and semantic match leaves no room to doubt a Türkic origin. See curdle, cure (food), yummy.
3.75
cure (food processing) (v.) “harden or solidify” ~ Türkic kuri:- (v.) “to dry (i.e. fix
by drying, usually by smoking or heating)”. The Türkic word originated in food processing, ultimately ascending to the Türkic verb kur- (v.) “fix, set in order”, widely used in physical and metaphorical senses. It is a member of an extensive lexical conglomerate that denotes a range of cultural memes: belt, time, dry, grouse, build, insect, and ca. 26+ more; nearly each one denotes clusters of sememes, and every one comes in a range of dialectal spellings. Cognates: Balto-Sl. (Lith.) kuriu “to heat”, karštas “hot”, (OCS) kurjo “to smoke, cure”. Both Balto-Sl. forms are semantically identical and practically exact reflexes of the Türkic word. The English term refers to a process of hardening or solidification by cooling or drying, which covers not only the traditional conservation of food by drying, salting, smoking, or heating, but also extends the meaning to cure concrete and plastics. The “IE etymology” is erroneous in confusing two independent homophones, cure (food processing) and cure “fix, mend, heal”. For example,
kurgan is a derivative of kur- (same verb base, here meaning “fix, organize, arrange”), the same with kurultai “arrange (family) ties”. They are not related to kuri:- “dried, hardened”. While the first has numerous noun derivatives, the second exclusively denotes only one Eng. noun,
curing, and a handful of peculiarly distributed cognates in Tr. and Balto-Sl. languages. Inability to understand homophonic nature of the words is a result of circular logic unable to recognize reality
in conflict with dogmatic scenarios. See cure (fix).
3.76
count, counting (v., n.) (Sw N/A, F893, 0.01%) ~ Türkic köni, qoni (v., n.) “measure,
veracity (size)”, könilig (adj.) “fair, true”. An “IE etymology” is absent, q.v. Ultimately fr. a verb kön- “straiten, correct, rectify, right way, move straight, directly”, etc. It apparently ascends to a beginning of a trade exchange, to a Çatalhöyük time. In the European lexicon, the form kön- occupies respectable grounds, 12 (27%) of the European vernaculars, followed by a Gmc. tell- group with 6 (14%) languages, and a Sl. group with 4 (9%) languages. The remaining 22 (50%) languages use 16 of their own native terms. Since the kön- and tell- are Türkic, the Türkic fraction stands at 18 (41%), approaching a level of a 50.6% Hg. R1a/b demographic presence in Europe. Irrelevant for the overall picture, some of the remaining 22 (50%) languages may also reflect a Türkic synonym of
köni. Except for the Türkic kön- and tell- , there is no common
“Pan-IE” root. The European mixture is very motley, attesting that its lingoes fossilized before the versions kön- and tell- came to the European scene supplanting the native words.
Cognates: A.-Sax. reccan, reckon, recche “count, account”, Sw. räkna
(~ recon); Ir. comhaireamh, Scots cunnt, Welsh cyfrif; Sp. contar, It. contare, Cat. comptar, Port. contagem, Gal. contar, Cors. cunta, OFr. conter, conte “count, calculations, reckoning, add up”, Fr. compter, Lat. computare < kön “count” (n ↔ m) + putare “clean”, i.e. “accurate, true measure” “count, sum up, reckon together”; Basque zenbatu; Mong. kemjüür, kemjih “measure, fair, true”; all “count” except as noted. Distribution: Ubiquitous along a Türkic Steppe Belt extending to the Far East, with a substantial isle in the W. Europe consistent with a Celtic spread. The myopic “IE etymology” blunders with a Lat. computare < kön “count” (n ↔ m) + putare
“clean”, i.e. “clean, accurate, true measure”. It is reinterpreting it as a com “with, together” + putare “reckon” fr. “prune”, equating that with the “count, sum up, reckon together”. A prefix produces a substantive, a semantic miracle repeated over and over by the “IE etymology”. The term evolved independently from a different root (vs. Lat. numer-, duc-, calc-, etc.). An “IE” assertion of an origin from a faux “PIE Proto-root” *pau- “cut, strike, stamp” for a motion “count” is absurd. The hoax is a substitution/reinterpretation jugglery. Given 13 other very normal ways Romans could say “count”, where the word “count” is not one of them, a phonetic transition from computare to count is inconceivable. Apparently, Lat. received the word fr. Celtic speakers, and adjusted it to the Lat. users. None of the “IE” pseudo-etymology is credible or is needed to lead to a Romance verb “count”. The other Eng. word tally for “count” ascends to a primordial Türkic stem tili/tele/dili “tell”. The attested köni, qoni “measure” works without any tricks. The trio count, tally
and quantity constitute an indelible case of paradigmatic transfer testifying to a common origin from a Türkic phylum. See quantity, tally, tell.
3.77
cut (v., n., adj.) “separate” (Sw N/A, F537, 0.02%) ~ Türkic kıd-/kı:d-, kıy-, qïj-, kes-, keš-, geč- (v.) “cut”. An “IE etymology” rates it “of uncertain origin” with a pile of giddy “perhapses”, q.v. Ultimately fr. a ket, get (n.) “breach” which points to a primordial single-syllable homonymic noun-verb root ke-, ge- with a noun suffix -t. The word developed a few of nominal and a range of verbal extensions ultimately leading to a notion “cut”: (n.) gap, hole, notch; (v.) break off, split, cut, cut off, gouge, etc.
Some of them may have evolved at a primordial stage. Eventually that developed into grammatized lexicons above
(geč-, kıd-/kı:d-, etc.), adorned with suffixes (d- intrans., -š noun, -s causation, etc.), modifications, and spread among distinct Türkic languages
increasing a variety of forms. A spectrum of vowels in various languages suggests that the original vowel was of front quality: ka-/ke-/kı- (kï-)/ku-, probably weakly or vaguely articulated. Hence the raster of forms found in base forms and derivatives: kad-, kaf-, ked-, ker-, kes-, kıd-, kıf-, kıy-, kut-. Some other viable variations escaped records: e.g. we do not know a quality of the vowel that stands behind keor- (A.-Sax. spelling ceor- “cut, separate”). Variation in the second consonant points to alternations: -s/-r typical for Oguz/Ogur vernaculars, Cf. Heb. chereb (xereb) “knife”. Sound change d ↔ z is typical for numerous Türkic languages (and Gmc. in Europe), -f may be a rendering of -ð/-þ; and -d is regularly changed to -y (Cf. badram/bayram/mayram “feast”). All these forms are acoustically allophonic. Phonetic variation is well pronounced in the derivatives: kadıš “strap” (lit. “a cut”), kıftu: “scissors” (lit. “cutters”), kaftan “coat, robe”, (lit. “scissored”), kedir-, kedriš- “cut a strip”, kert- “cut a notch”, kıd-/ kıy- “cut, separate”. The form kut- is an allophone of the kad-/ked-/kıd-. European footprint of surviving forms for cut is modest, 5 (11%) of 44 European languages (Türkic, Eng., Ir., Scots, Norw.),
it follows a Sl. group with 6 (14%) languages. The other 33 (75%) languages use their own 18 native terms.
There is no shared “Pan-IE” term; a modest Sl. group is the largest. Cognates: A.-Sax. ceor-, (be)ceorian, corfen, ceorfan, curfon, cyrffi, (s)cieran, (s)ciran, (s)coren, (s)cearon, (s)cearp, (s)ceoran “cut, separate”, ceorfaex “axe”, ceorfsaex “scalpel” (+ non-cognate forms: snaedan, sniðan, ðwitan, toceorfan); MSw. kotta “cut, carve”, Sw. kuta, kytti “cut, knife”, kata “cut, chip”, ONorse kytja, kutta “cut”, kuti “small knife”, Norse
kytja, kutta, kutte “cut”, kuti “knife”, Icl. kuta “cut”; MIr. gearr, gerr, Scots kut, kit, gearradh (s/r ) (but Welsh torri, dorri); OFr. couteau “knife”; Akkadian kes-, kas- “cut, chop, break, shorten, abbreviate”, käs- “separate into small pieces” (an earliest record of 28-24 cc. BC); Ar. (< Akkadian) re: “cut”: kasap, kısım, kasım, kısmet, etc.; Heb. gedud “cut”, geduda “incision”; WMong. kidu- “cut”, Mong. khutga “cutter, knife”; all “cut” unless noted otherwise. Cognates include innumerable derivatives of “cut”: A.-Sax. ceorfaex “axe”, ceorfsaex “scalpel”, Eng. carve (v.) “cut a mark”, cutter, cutlery, ONorse kuti “knife”; OFr. couteau “knife”; Rum. kutsit “knife”; Türkic kert (v.), OT kingirak (> Gk.
akinak) “knife”, kezlik (dimin.) “small knife”; WMong. kituga “knife”, Dongxiang
quduyo “knife”. Distribution extends from Atlantic to the Far East; an “IE” portion is but a tiny dot isle on the map. Cognates cut across linguistic families to a degree that the word was claimed to be a Nostratic ancestor. The notion “cut” probably precedes by far a Neolithic economy associated with fine stone cutting tools, it had plenty of time to disperse its phonetics long before the Celtic anabasis to Iberia. In an upside-down airing, the Scots kut, kit is claimed to come fr. a N. Gmc. origin, albeit the Celtic migration fr. the E.Europe is well-traced and dated, while the Gmc. anabasis origin, route, and timing is yet a speculative matter. The Celtic terms are consistent with the Türkic terms, they attest to an origin prior to the 4800 ybp (2800 BC) arrival of the Neolithic Celtic carriers of the R1b Hg to Iberia via Near East and N. Africa. In all languages the verb “cut” is a prime, all other grammatical forms are derivatives. A “PIE” origin is delusory. On top of a “presumed” faux “A.-Sax. Proto-word” *cyttan “cut” are suggested a faux “NGmc. proto-word” *kut- “cut”, and a faux “perhaps”, “related to” “PG Proto-word” *kwetwa “meat, flesh”. Or a brazen hoax “of uncertain origin” and “perhaps” a faux “PG Proto-word” *kutjana, *kuttana “cut” which has nothing to do with another faux “PG Proto-word” *kwetwa “meat, flesh” nor with an unrelated ONorse kvett “meat”. That pile of absurdities has to be gently rescinded. The Eng. semantic raster mirrors that of the Türkic (e.g. cut me a deal, cut them off, cut corners, cut it out, etc., for withdraw, change, abandon, etc.). It is a member of a paradigmatic transfer complex, attesting to its Türkic heritage. See carve, curt, short.
3.78
dash 1 (v., n.) “move quickly” ~ Türkic daš- (dash-), taš- (tash-) (v.) “erupt, burst over an edge (like boiling milk)”, with prime connotation “sudden spill, burst”. The word is “IE etymology”-rated “of obscure origin” and “somehow imitative”, q.v. It comes in a series of vaguely related homophones: 1) “overflow, run”, 2) “outer, outside, appearance, far”, 3) “beat, hit”, 4) “drag, hyphen”, etc., in practice discriminated by agglutinated suffixes. A three-phoneme verb is highly polysemantic, the dash 1 packs two semantic rubrics, of 11 and 4 clusters, and averages about 2 meanings per cluster, thus about 30+ total meanings per a first homophone (e.g. 1. overflow, cross bounds, (water) rise, run away (about milk, water), 2. spill, pour out, (water) rise, gush, 3. arrive, add, 5. boil, boil away, etc.), see daš 2 “appearance, look”, daš 3 “beat, hit”, daš 4 “drag, hyphen”. That leaves out a Türkic daš, taš “stone” and a dart (v., n.) “draw, draft, dart”. Not Türkic but Eng., has a dash (v.) “break into pieces”, apparently a neologistic extension of the notion “burst, boil over”. A Dan. daske, dash “beat, strike”, Sw. daska ditto also relate to the notion “break into pieces”. An Eng. dashboard “splashboard” is a neologistic relict of a faded base. Of 44 European languages, a miniscule group da-, de- of 6 (14%) languages leads with 3 Türkic entries (Türkic, Ir., Scots) and 3 “guest” entries (Eng., Fris., Yid.), followed by a Sl. group lih- with 4 (9%) languages. The remaining 34 (77%) languages use 31 of their own native terms. A “guest” status of the daš in Europe is certain. Cognates: A.-Sax. dollic, dolwillen “dash, rush”, Fris. dash ditto, Yid. dash (דאַשינג) ditto; Ir. deifir, Scots deoir, (but Welsh rhwyg); all “dash, rush” unless noted otherwise. Various extensions with semantics of “sudden, eruptive move” are later innovations: race run “dash”, brilliant act “dash”, etc. Distribution: extends from Atlantic to the end of a Türkic Steppe Belt. Unlike other meanings of daš-, the notion “erupt, burst” does not bear any references to loanwords in other eastern languages. The “IE etymology” is not even attempting to claim the word or invent a suitable descent, a bravest claim is a ridiculous “somehow imitative”. A passage “probably from a Scandinavian source” does not carry any water: the Celts came to the NW Europe before a Scandinavian's migration ca. 1750 BC with a Battle Axe culture of the Pontic–Caspian R1a - R1b Hg. steppe herders. Perpetuation of particular polysemantic word with its particular semantic meanings is a positive attestation of a genetic heritage. The word presents a uniquely huge case of paradigmatic transfer: without any changes, Eng. inherited a mass of the Türkic daš semantics; a proportion of later innovations and extensions is fairly modest. In such massive case of paradigmatic transfer, chances for odd coincidence are nil. See dash 2 (n.) “outer, far”, dash 3 (v.) “beat, hit”, dash 4 (v., n.) “drag, hyphen”.
3.79
dash 3 (v., n.) “beat, hit” ~ Türkic daš- (dash-), taš- (tash-) “beat, hit”. The word is “IE etymology”-rated “of obscure origin” and “somehow imitative”, a pure nonsense. Ultimately one of the pleiad of homophones of dash, dash-, a denoun verbal derivative fr. a base notion “carry, drag” loaded with 10 semantic notions. A notion daš (n.) “dash, hyphen, hyphenate, hyphenation” is an extension of the base notion “carry, drag”; it is a late development predicated on an existence of bound books, see dash 4 (v., n.) “drag, hyphen”. Cognates:
see dash 1 (v., n.) “move quickly”. Distribution: extends from Atlantic to the end of a
Türkic Steppe Belt. An Rus. ion of the “IE etymology” of a “probably from a Scandinavian source” is
a dubious non-statement, at best it points to an undifferentiated in time Türkic-Scandinavian lexical continuum seen in a shared R1a/b Hg. A systemic paradigmatic transfer of daš lexical complex indelibly attests to an origin from a Türkic milieu. See dash 4 (v., n.) “drag, hyphen”.
3.80
dash 4 (v., n.) “drag, hyphen” ~ Türkic dašu- (dashu-), tašu- (tashu-) “drag,
hyphen, punctuation mark”. For the “IE etymology”, the word is non-existent. Ultimately a semantic derivative of the notion “drag” expressing “continue, go to the continuation”, a late development predicated on an existence of bound books. It belongs to a corpus of the root daš words, the final -u, -a do not have a defined grammatical function. In the sense of “hyphen” the word is notable for its
universal spread typical for a neologistic lexicographic dispersion. The corpus of the root daš
was adopted in Eng. nearly in its entirety, albeit in somewhat truncated scope and with few novel semantic extensions. Such literate case of paradigmatic transfer of an entire verbal and semantic corpus is a rare event in Türkic substrate in Eng. See dash 1, 2, 3, 4.
| Supplementary Note. Two identical words. The chances that two words in one language would accidentally coincide in semantics and phonetics with two words in another completely independent language are slim to none. They can be assessed statistically. For simplicity allowing 20 consonants and 5 vowels in each language (for Türkic, EDT lists 27 consonants, in reality about 10 more, plus 8 vowels), and a some overlap like -t- vs. -d- that somewhat reduces that number, 10 consonants and 5 vowels in each language would be a conservative phonetic approximation. A 10,000-word vocabulary broken down into 1000 semantic fields (10 synonyms per field on an average) would be a quite conservative semantic approximation, since within a basic dictionary words blessed with synonyms are a small minority. A completely independent language must belong to a separate linguistic family, and the subject word must be innate to that linguistic family. A 3-phoneme word of 2 consonants and 1 vowel, like cat, would have 1/10 X 1/10 X 1/5 = 1/500 = 0.002 phonetic probability times 10,000 tries. About 20 words would statistically meet the phonetic criteria. Chances of these 20 words to meet the semantic coincidence is determined by a semantic probability. The semantic probability would be 1/1000 = 0.001. For a word cat, that semantics would cover 10 statistical small animals: cats, squirrels, rats, and the like. The probability of both phonetic and semantic match would be 20 X 0.001 = 0.02. It would take 50 of 10,000-word vocabularies from different languages to bring that low probability to a level of certainty, to find a single chance match in unrelated language for a single 3-phoneme word, say cat, also meaning cat or a similar small creature. All of the 6,000 world languages would have 120 statistical words meeting the desired criteria. In reality, a much smaller number of independent languages would produce a much smaller number of the random coincidences. The probability of encountering the same word with certain different semantics, say cat meaning a “cat” and a “gossip”, would be, 0.02 X 0.02 = 0.0004. In a case of such duplet, it would take 2500 independent lexicons of 10,000-word dictionaries, way more of what our small world can supply, for that to have a meaningful chance to happen. Such a coincidence would be a sound proof of a paradigmatic transfer case between languages. Thus, excessively conservative estimate for the word dash with only two meanings, “move quickly” and “beat, hit”, to have a simultaneous chance match in some other unrelated language, would statistically take an order of magnitude of some 2500 unrelated languages. Ditto with the two meanings “move quickly” and “outer, external”. For three concurrent meanings, “move quickly”, “beat, hit”, and “outer, external”, would be needed an astronomical 6,250,000 languages. Then, the chances that the English and Türkic words dash are genetically connected are much-much better than 6,250,000 to 1. But in the 800-word study list, dash is not the only such case. A second case brings the chance probability to 6,250,000 squared, or 1 in 39,062,500,000,000. That is languages, not the words. An only objection to the magnitude of this fact may be that a doubter is not keen on statistics. That, no doubt, would be very true. |
3.80
deem (v.) “think, recon” ~ Türkic demek (v.) “think, mean, believe, suppose”. An “IE etymology” suggested how to replicate a Türkic root te:-/de: with a copycat mock “PIE root”, q.v. Ultimately a semantic derivative of a base te:-/de:/-diy-/tejän “tell, say”, the same base that developed an Eng. tell “tell”, relaying a kernel notion of “speech” and “thought”. The deverbal verbal form shows in the verbal suffix -mek “make” for the root te:-/de:, lit. “tell-make/act”. The verb is held as one of the oldest Türkic words. Unlike the tell “tell”, demek “deem” is not used in direct speech, but in conjunction with an impersonal form of the verb, e.g. “I deem that ~ in my opinion... (John came, it will be raining, etc.)”. For transposition of Eng. say and tell see say. Semantic spread extends to two dozen (!) immediate derivatives and numerous grammatical functions. Apparently, the form similar to demek (inf.) was internalized on the Gmc. and Sl. scene as a root dem- with morphological adoption for local use. The Gmc. extended usage focused on the notion “mean”, as in “I mean that”, the Sl. usage centered on the notion “think, thought”. Of 44 European languages, a decent group dem-, dum- of 12 (27%) languages leads, followed by a Romance group
consi- with 4 (9%) languages. The remaining 28 (64%) languages use 20 of their own native terms. A “guest” status of the deem in Europe is certain, other than Türkic-Eng. demek ~ deem, there is no shared “Pan-IE” term. Cognates: A.-Sax. deman “tell, deem, think, consider, judge”, dem, demend, demere “judge, ruler”, OFris. dema (v.) “judge”, OSax. domian, Icl. telja “deem”, MDu. doemen, ONorse dma, OHG tuomen, Goth. domjan, doms (v.) “deem”, (n.) “opinion”; Ir. deir, Gael. duil “deem”; Balto-Sl. (Latv.)
duoma, duomat “thought, think, believe”, Sl. duma, dumat (дума, думать) “thought, think”, Rus. de-, deskat (де-, дескать) “as though, as deem(ed)”, Bulg./Bolg. demek “think”; Gk. θῡμός “thought, spirit”, Skt. dhumas “thought”; Gujarati
dharavum (ધારવું) “suppose”; Mong. üzeh, üdeh “see, deem”, duu “song”; all “deem” unless noted otherwise.
Distribution extends across a width of the Eurasia, covering only a smattering of the “IE” languages, and reliably excludes both “PIE” and “PG” origins. No suitable “IE” parallels, the
“IE” etymological divination on PIE “set”, “put”, “doom” are totally inapplicable, a mock “PIE root *dhe-” unwittingly mimics the attested Türkic te:-/de:. Geographic distribution and phonetic dispersion attest to a long history ascending to a 2nd mill. BC (Aryan migration), Corded Ware period (3rd mill. BC), and a Celtic anabasis fr. E. Europe to Iberia via Africa ca. 5th-4th mill. BC. The entire trio of the Eng. “say, tell, deem” speech-related lexicon constitutes an indelible case of a paradigmatic transfer, inextricably attesting to a common origin from a demographic milieu of the Y-DNA R1a/b Türkic Kurganians. See
tell, say.
3.81
delve (v.) “cut into” ~ Türkic del-/tel-, deš-/teš- (v.) “pierce, punch, break through”. An unstoppable “IE” etymology came up with “perhaps” a faux “PIE root”, q.v. The -l- and -š- forms are about equally spread, frequently in the same languages, and even formed a paired jingle a la delik-dešik “Swiss cheese”. Its many reflexes in “IE” languages were dutifully noted and cheerfully explained away. On a European scene the Türkic del- is first with a modest 7 (15%) languages, followed by a Sl. Old Europe kop- with 6 (14%) languages. The remaining 31 (71%) languages use their own 23 native words. The Türkic del- is a humble best to represent a Pan-European “IE” line, attesting to its “guest” status in Europe. Apparently, by the coming of the “guest” del-, the native Europeans had their own terms fossilized and resistant to a newcomers' supplanting. Cognates: A.-Sax.
delfan (v.) “dig, dig out, burrow, bury”, delf, gedelf “digging”, dælf “ditch”, OSax. delban, WFris. dolle “dig, delve”, Du. delven, MHG telben “dig”, LGmn. dölven “dig, delve”; Balt. (Lith.) delba “crowbar”; Sl. (Pol.) dłubać, dłuto “chisel”, (Cz.) dlabati “gouge”, dlato “chisel”, (Russ.) dolbit (долбить) “gouge, crack, peck, pound”, doloto (долото) “chisel”; Tr. telik/tešük “puncture, hole, aperture”; all versions of “dig” unless noted otherwise. Distribution: extends across a width of the Eurasia, covering a smattering of the “IE” languages, and reliably excludes both “PIE” and “PG” origins. All European cognates are Gmc./Balt./Sl., solely N. European, that should have
been a salient message to the “IE” philologists. No “IE” cognates, the “PIE reconstructions” are unattested quasi-scientific fantasies and speculations: “perhaps from a (faux) PIE root *dhelbh- doloto, chisel”, or a faux “PGmc. proto-form” *delbana (v.) “dig” fr. a faux “PIE proto-word” *dʰelbʰ- (v.) “dig”. With the continent-wide attested Türkic archaic form del-, a later attested development deš-, and the historically attested westward migrations of the Hg-s. R1a/b from Siberia, no parochial speculations are needed or justified. The “perhaps” Rus. ions should be quietly retrieved. The word belongs to a host of sibling lexemes shared exclusively by the Gmc., Balto-Sl., and Türkic families. Notably, the sibligs tel- and teš- are noted in the same body of literature, attesting that the archaic sound change l ~ š lingered in the Oguz languages. The form -l- was attested in the Ogur Karluk language of the Huns, and the form -š- is present, for example, in the Chuv. The suffix -fan/-ban/-ben and its truncated (Sarmatian) forms
-ba/-bi/-v, specific to the Gmc./Balt./Sl. groups, is a palatalized reflex of the Türkic suffix -pan that forms participles: digging, piercing. The consistent use of the combination of
the Türkic root and suffix is a binding case of paradigmatic transfer, vividly attesting to a common origin from a Türkic scene.
3.82
descend (v.) “move lower, plunge, fall, go down” ~ Türkic düš- (v.) “lower, fall, pour”. An “IE etymology” myopically suggested a Lat. origin replicating a root te:-, de:- with a copycat mock “PIE root”, q.v. Ultimately fr. a düš- “fall”; the Türkic düš-/tüš- “fall” in its various renderings defines the action. A model for a compound “descend” universally consist of two elements, “down + move”, in a direct or reverse sequence. The “move” portion is specific for each language; in Türkic, a stand-alone dü-, tü- has not survived, its derivatives point to a generic sense of action mirrored in the Eng.
do, dash. A prime notion “fall” forms 4 extended semantic clusters, another 10 clusters are secondary, and a massive 15th cluster provides numerous grammatized services: complex verbs, auxiliary, etc. With a suffix -an/-en the stem düš- fills numerous applications: voice,
participle, reflexive, noun, plus grammatical forms with a nasal suffix -aŋ/-eŋ rendered -an/-en in Gmc. languages. A Türkic original form düšen covered most of the practical needs. The Türkic düš- served as a base for the Lat. prefix de- “diminish” which propagated to the local languages within the sphere of Lat. cultural influence (Cf. Lat. pre- fr. Tr. bir “one” etc.). Among 44 European languages the Türkic-based motley form düš-, des- leads with 8 (18%) languages, followed by a Gmc. ned- with 4 (9%) languages. The remaining 32 languages use their own 24 native words. Other than a Türkic-based, there is no “Pan-European IE” line, attesting to its “guest” status in Europe. Cognates: Fris.
delkomme “descend”, Luxemb. (d)erofkommen; OFr. descendre (10th c.) “go down, fall into, originate in, dismount”, douche (v., n.) “shower, spray”, Sp. descender, Port.
descer, Lat. descendere “come down, sink”; Rum. dušis “stumbling”; Mong.
tülge, tölge “fate”, dülüre “come off, break” (of a glued), (š ↔ l), Bur. tülgü- “arrive, enter, show up” (š ↔ l); Kor. tilda, tida “enter, cost (of money), taken ill, come (time)” (š ↔ l); all “descend” unless noted otherwise. Distribution: widespread distribution across the Eurasian Steppe Belt from Atlantic to Pacific. In a bulk of the European “IE” languages the word is absent. The de- “down” is an allophone of the Türkic adverb düš- “down”. The
“IE etymology” interprets the Lat. form descandere as a composite of de- “down” + scandere “climb, jump”. Using a Lat. “climb” for “descend” is a nonsensical idea. The Lat. element -scandere functions only as an auxiliary verb to augment a main, the Lat. adv. de- “down”. A Lat. origin does not hold any water, it must be tossed out. Lat. was only instrumental in popularizing a Türkic word for a very limited audience. The “climb” is a derivative of “spring, leap, ascent” with cognates like “hasten, leap, jump”. That is a totally uncouth logic for notions of falling and going down. A Lat. etymology unwittingly leads to another Türkic stem, sön- (v.) “die down, disappear”. Two Türkic siblings,
sön- and siŋ- (sin-) “sink” have overlapping meanings of original allophones that gained individual semantic overtones. The sön- does not mandate disappearance from the view, and the siŋ- implies that it is stronger on disappearance, that's how we have sinks and not songs in our houses. Unwittingly, descandere leads to another series of cognates:
A.-Sax. senc(an) “sink, plunge”, saeg(an) “sink, settle”; OFr. (des)cen(sion) “descent” ~ Lat. (des)cen(dere) “descend”; Sl. sig(at), sgin(ut) (сигать, сгинуть) “plunge, disappear”. An evidence suggests that Lat., and Sl. are using a Türkic word obtained independently of each other via different paths. In all cases the grammar, phonetics, and semantics are pinpointed and exact. Since it is not shared by other Gmc. languages, the Eng. word came a separate path The Lat. form, if it is a Classical Lat. and not LLat., also demonstrates a separate path, it could not originate neither fr. Fr. nor Eng. The notion of descendant “originate in” has already been recorded in the OFr. form, positively excluding an Eng. innovation. The A.-Sax. form eventually conflated with its OFr. allophone. See toss.
3.83
dip (v., n), deep (n., adj., adv.) (Sw N/A, F1038, 0.01%) ~ Türkic tüb, tüp, düb, dip, düyp (n.) “bottom”. An “IE etymology” bravely invented an “IE” origin, q.v. Ultimately fr. a notion “root” (n.), hence homophonic cognates denoting roots and tubular structures, and foundation, substrate: tuber, tube, tablet, table, (bath)tub, type (impression), type (precursor), typing, etc. The polysemantic word carries 10 semantic clusters, from “bottom” to “pile” (63+ meanings) and a line of grammatical postpositions. A slew of Türkic derivatives include a notion “submerge”, “go under water”. Eng. internalized the word without changes. European assemblage is peculiar: of 44 European languages, a Türkic dip- dominates with 13 (30%) languages, followed by Sl. off-Türkic divergent variations dub-, glob-, hlob- with 12 (27%) languages. Combined, two groups cover 25 (57%) languages, matching a level of a 50.6% Hg. R1a/b demographic presence in Europe. A Romance group follows with 8 (18%) languages. The remaining 11 (25%) European languages use their own 8 native words. If there is a common “Pan-European” word, it originated fr. a Türkic archaic lexicon, it is a nomadic “guest” to a “IE” European family. Cognates: A.-Sax. diepan “immerse, dip”, deop “deep”, OSax.
diop, OFris. diap, Dan. dyb, Du. diep, ONorse djupr, Goth. diups, OHG tiufi, Gmn. tief, teufe “deep”; Ir. domhain (b/m alternation), Welsh (Cimr.) dwfn “deep”; Balto-Sl. (Lith.) dugnas (< dubnas) “bottom”, dubus “deep”, dubti “immerse, dip”, dauba “ravine”, (Latv.) dubens, dibens, dibins “bottom”,
dubt “immerse, dip”, dauba “ravine”, (OPruss.) padaubis “valley”, (OCS) duno (< dbno) “bottom, foundation”; Brahmi tüp “bottom”; Mong. (Kalm.) töb “foundation”; Akkadian dibdibbu “water clock, clepsydra”, reduplicated, an earliest record of 28-24 cc. BC; all “deep” unless noted otherwise. Distribution: The word was internalized by an amazing scattering of diverse populations across entire Eurasia, across linguistic barriers, and by all Gmc. and Sl. languages. Some demographic events are datable, traceable by genetic markings of migratory flows. There is a rare conversion among Celtic languages with the Welsh in concert with the Ir. and Scots forms. Given their peculiar individual migrations, such uniformity points to the very deep common roots ascending to a
Celtic departure fr. the E. Europe ca. 5th - 4th mill. BC. The “IE etymology” is not palatable. It suggests a faux “PWGmc. proto-form” *deup “deep”, a faux “PGmc. proto-forms” *deupaz “deep”, and *dupjana “deep”, and *daupijana “dip”. All that poetic circus only parrots the Türkic attested dip widely spread across Eurasia, and is preceded by the Celtic, Akkadian, Brahmi, Mong., and Goth. predecessors which in their own distinct ways tacitly internalized the Türkic dip.
The circus unwittingly recycled a slightly distorted clone of the Türkic tüb, düb, dip. The “proto-words” must be a neologism (Leiden, 2013): during the scientific apotheosis of the Aryan-race cleansing the Proto-Judaic Akkadian word could not have survived as a “PG proto-word”. Since “deep” is an extension of the notion tube (< “root”), all cognates of the tü:b “tube” belong to the host of cognates. An Eng. assemblage of the derivatives of the Türkic prime notion “root” magnificently attests to their common origin from a Türkic linguistic milieu. See table, tablet, tuber.
3.84
divide (v.) “split, separate, fraction”, divvy “apportion, deal, share” ~ Türkic til-, dil- “divide, cut to pieces”. An “IE etymology” bravely suggests an “IE” origin, q.v. Ultimately fr. a lost primeval root ti-, di-, probably a generic action word like the Eng. “do”, with a passive and medial verbal suff. -l: til-, dil- “divide”. The archaicness of the root is attested by a homonymic noun-verb pair and a neutrality to
transitivity. As a “guest” to Europe, the til-, dil- is a champion: of 44 European languages the siblings dil- and div- carry a motley pack of 33 (77%) languages, of them with form
dil- 23/44 cases, and with div- (l ↔ v) 9/44 cases. The remaining 11 languages use their own 11 native words. The Türkic-based root is an only candidate for a common “Pan-European” term. There is no “IE” terms in Europe. Cognates: A.-Sax. daelan, (to)dælan, Goth.
dailjan, Sw. dela, Da., Norw. dele, Du. (ver)delen, OHG teilen, Icl.
deila, Norse divide, Du. delen, Yiddish tyyln; Ir. deighilt, Welsh
darni (r ↔ l); Lat. divide, Rum. diviza; Gk. diaírei (διαίρει); Balto-Sl. (Latv.) dalit, (Lith.) dalyti, (Sl.) delit (делить), (Pol.) dzielić, (Lusatian) zelis (jelis), (Serb.) dilum “part”; Mong. čilügen “split” (< tilü), Kalm. dil “win”(< “cut, split”); numerous roots are preceded by a native prefix; all “divide” unless noted otherwise. The l > v transition juxtapose Gmc. vs. Romance forms; in Pol. and Lusatian an initial d-/t- form is dz-, j-, a Gk. transition is l ↔ r. Distribution: widespread across the Eurasian Steppe Belt from Atlantic to the Far East. The European loans apparently came from the Sarmatian tribes; the Gk. and Ir. point to independent paths. Lat. is possibly an allophone of Ir. with gh > v transition, probably via a local intermediary. The Eng., in addition to divide and divvy, has derivatives
deal, division, till (booty for division). An “IE etymology” guestimated a faux “PIE proto-form” *(d)uid- “separate, distinguish” and a “PIE word” *dwoh “divide?”. That enterprising is not needed, it contributes nothing, leading from nowhere to nowhere. The antiquity of the substrate and cultural borrowing is attested by various derivatives developed in the individual languages. Türkic has synonyms for “divide”, a bӧl- (e.g. parse) and kes-, they found their way into the languages of diverse linguistic groups from the Europe to the Far East. Paradigmatic transfer of a series of lexemes, including a homophone til- “tell” attests to a common origin from the Türkic phylum. See deal, division, do, tell, till.
3.85
do (v.) “make, act, perform, cause, put, place” (Sw N/A, F24, 1.89%) ~ Türkic tur-, dur-; Chuv., Uig. – a truncated form tu- (v.) “do, act”. An “IE etymology” asserts a Gmc. and “IE” origin, q.v. The CT polysemantic verb tur-, dur- conveys among other derivative notions “intent or readiness to act, duration or permanence of actions”. The t-/d- alternation is usage-specific: the anlaut t- forms a rising/going aspect vs. the d- a down/stopping aspect. It is a general grammatical function verb and an auxiliary verb of action, eidetic to the Eng. pair to do (infinitive case). “Among Turkic verbs with grammatized functions, tur-/dur- occupies a special place in terms of richness, universality, and diversity of its grammatical application” (EDTL v.3 299). The word carries 14 semantic clusters, from “stay” to “intend” (116+ meanings), +6 clusters of grammatized meanings with open end functions, +a cluster of distinct meanings with named specific suffixes. Apparently, each Turkic vernacular scooped words from a common well for its particular needs. Likewise, the Eng. closely reflects the universality of the lexeme while not carrying over a full wealth of concrete applications, nor reflecting a wealth of its conjugations. Türkic has a complimentary stem tö-, tü- “make, made” (vs. do), Cf. törü- “happen to occur, emerge, be born, appear, give birth”, törüt “create”, törči “happen, occur, undertake, initiate”; törči also serves as auxiliary verb exactly like the Eng. do, with a similar complement of functions: “make, engage, carry out, carry on, get done, proceed, cause to happen, engage in, comport, execute, finish, complete action” with idioms and nuances. In a lineup of the European languages the word “do” takes a leading place: a potpourri group of 11 (25%) languages (Türkic, Eng., Fris., Du., Sw., Yid., Irish, Scots, Rus., Czech., Latv.). That attests to a status of a Wanderwort, a wondering loanword. It is followed by Romance and Sl. groups, with 8 (18%) and 6 (14%) languages respectively. The remaining 19 (43%) languages use 13 of their own native words. If there is a “Pan-European” common word in Europe, it is a non-“IE” Türkic “guest” to Europe. Cognates: A.-Sax. don (-n reciprocity suff.), dide, didon, dyde, dydon “do”, doere “doer”, OSax. duan (suff. -n), OFris. dua, Du. doen (suff. -n), OHG tuon (suff. -n), Gmn. tun (suff. -n); Gk. ντουρμα “enduring”; Sl. (Rus.) torg (торг) “market (livestock)”, (Bolg.) durdisvam (дурдисвам) “be, stay”, (Serb.) dur, dura “stop, stay”,
durbak “stop and look”, durmadan “incessantly, constantly”, durun orda “stay there”; Alb. dur, dura “stop, stay”; Balkar turku “corral”; all “do” unless noted otherwise. Türkic cognates include a form tu. Distribution: is typical and peculiar: the width of the Eurasian Steppe Belt plus a smattering in some European corners. A dreamed up “IE root” *dhe- “set, put, place” is a flight of fantasy derived solely from the Gmc. roots mimicking the Türkic original. A suggested semantics of the “IE root” trails an aspect of the Türkic tur-, dur- “stand (physically or to stop)”. That specificity trivializes and utterly distorts a majestic role the service word “do” holds in Eng. and Türkic languages. The “stand” is only one of 116+ conc. meanings, while as an auxiliary verb, the “do” is universal. The “IE” pretentions of ownership are ludicrous, built on faux material: a verbal faux “PWGmc. proto-form” *don, faux “PGmc. proto-form” *dona, faux “PIE proto-word” *dʰeh “put, place, do, make”, faux “PIE “reduplicated” proto-word” *dʰedʰehti < *dʰeh- “put, place, do, make”. That just parrots an attested Türkic tur-, dur-, tu- ignoring its auxiliary service function of an action verb. The reality can't be hidden, overridden, or erased. Any misleading claims should be gently retrieved. As for a supplementary claim of a proposed Brittonic pedigree, the Brittonic is a Celtic language which in the 3rd mill. BC came to Europe via an African path after leaving the E. Europe millenniums earlier. The Celts brought along their versions of the Old Türkic vernaculars, still detectable millenniums later in non-supplanted Celtic lexicons. The Celtic languages ultimately ascend to a S. Siberian nest of the R1a/b Hgs. provisionally dated by a 22,000 to 25,000 ybp (R1a) and 18,000-14,000 ybp (R1b). The series of act, do, make, and a host of other action lexemes form a case of paradigmatic transfer, inescapably attesting to a common origin from a Türkic phylum. See act, make, kin, to (prep.).
3.86
don (v.) “put clothes on” ~ Türkic don-, ton- (v., n.) “put clothes on” (v.), “clothes” (n.). An “IE etymology” suggests some loony versions for an “IE” origin, q.v. Ultimately it has to be fr. an inchoate root do-, since -n is a reciprocity suff.: “do yourself” > don (v.) “dress (yourself)”. Nearly forgotten, the word is pretty much active in idiomatic expressions: “it donned on me”, “don an evening dress”, etc. A European spread attests to a certain loanword status: the word dispersed across linguistic borders, a positive attestation of a loanword status. Of 44 European languages, a motley group do-, don- of of 11 (25%) languages dominates (Eng., Turk., Yid., Du., Fris., Luxemb., Lat., Lith., Rus., Sloven., Ukr.). The remaining scattering of 33 (75%) languages use 21 of their own native terms. Other than the Türkic-Eng. don, there is no shared “Pan-IE” term. Cognates: A.-Sax. (onscry)dan “to clothe”, (scry)dan “vestry”; taken from the church lingo, scrydan is “sacral vestments”, tunece, tonice “garment”; Ir. guna “clothes”, Welsh (ao)dach “clothes”; Rus. oden (одень) “don” (imperative); Bolg. donove “attire”; Lat. induo “don”, tunica
“tunic”, toga “drape”; Gk. chitоna (χιτωνα) “tunic”; Pers.
pufidan “wear, clothe”; Khotanese thauna- “clothe”; Kannada (u)ḍuge (ಉಡುಗೆ) “don”; Brahmi tom; Mong. daashinz (даашинз) “clothes”, tonug “horse harness”; Kor. deuleseu (드레스 /tirisi/) “clothes”, Jap doresu (/donese/) “clothes”; Tat. tyŋ- (v., n) ditto; all “don” unless noted otherwise. Distribution: across Eurasia and linguistic families, and a positive oddball within the
“IE” family, attesting to a loanword status in the “IE” languages. No credible “IE” etymology. A first offered folk-type “IE” etymology, a neologistic “contraction of do on” is
spurious and laughable. It implies that an honor of being a proto-word belongs not even to, say, a Brahmi
but to a newbie Eng. Thus, after millenniums of being donned, a name for dressing has been invented.
A second, a reference to doff, dup, dout does not lead anywhere. It is unconscionable that an abundance of the cognates on the European peninsula and across Eurasia went unnoticed. The etymology from an unattested “PIE root” *(s)teg- “cover, roof, roofing material” semantically echoes the notion “cover, clothes”, and at best is likely a 3rd c. BC allophone of the don, ton. The first consonant is fairly consistent across Eurasia, the second consonant is more fluid, attesting that the original
-n- might have had a peculiar articulation, Cf. ñ, ñ, ŋ. The Tat. form corroborates that conjecture. The t- (OTD)/d- (Eng.) shift is a strictly dialectal variation, both forms coexisted from early times. G. Clauson (EDT 512 on) notes record the form
don- (vs. ton-) specifically to Azeri, Turkmen, and Ottoman Turkish, i.e. roughly the Aral-Caspian interfluvial. That is consistent with other pointers to the Aral area origin of the Gmc. forms. Curiously, like the Türkic generic agach “tree” became the Gk. acacia for a specific type of trees, so the Türkic generic ton/toŋ “dress, clothing” became Lat. for specific types of dress. The word falls into a pattern of paradigmatic transfer as a member of a baker's half-dozen dress terms, directly attesting to a Türkic origin. See belt, cowl, robe, sari, sash.
3.87
drag (v.) “pull”, (n.) “hindrance, impediment” ~ Türkic tar-, tart-/dart-, tarït- (v.) “pull, drag, draw”. An “IE etymology” asserts a Gmc. and “IE” origin, q.v. The form tarït- and its contracted form tart-/dart- form intensive aspect of the base tar-. The verb is neutral to transitivity, attesting to its origin prior to a rise of a grammatical transitivity. The verb is very polysemantic, numbering 10 main semantic fields, plus 15 semantic offshoots, plus a scattering of 17+ single senses in separate sources, plus uncounted subsenses. A listing of distinct semantic meanings numbers 128 entries before conjugations. It is likely a Türkic, and possibly one of a world's semantic champions. The mind-boggling semantic spread points to its amalgamative origin from once independent languages. The base meaning of the root
tar- is “pull, drag, draw”, shared by most of the Türkic languages, it alone has 30+ distinct semantic flavors. The other main senses of the main semantic fields are “drag on/trail”, “continue/last”, “jerk/yank”, “weigh”, “ponder”, etc. Numerous words form idioms. In the processes of an immediate inheritance, and direct and secondary loanword acquisition, such prodigious polysemantic word had to leave a stupendous trail in daughter languages and a series of culturally impacted languages. The Gmc. languages were immediate beneficiaries of the inheritance, Cf. Eng. drag, draw, dredge, dregs, drive, tardy, trace, track, tract, tractile, traction, tractor, tradition, traffic, trail, train, tram, trammel, trap, travel, traverse, trawl, tray, tread, truck, retard, and more. The whole shmear probably started with a pair of logs dragged by draft animals with rollers and wheels added millenniums later. In snowy and swampy areas where wheeled transport does not work, the original Stone Age technology lasts well into the 21st c., now mostly in sledging and logging. Time has expanded semantic range with an explosion of derivative innovations related to pulling, like the northern runners and the southern rollers, and then the wheels. They ascend to the Stone Age technologies. The published cognates are but a small and selective sampling. An attempt to trace all cognates of the 128 meanings would be a gargantuan task. Of 44 European languages, dominates a motley group tar-, dra- of 15 (34%) languages, followed by a mostly Romance group
arras- with 5 (11%) languages, a motley group sle- with 4 (9%) languages, and a motley group vil- with 4 (9%) languages. The remaining 16 (36%) languages use 11 of their own native terms. Other than the Türkic-Eng. tar-, dar- there is no shared “Pan-IE” term. The lexeme's motley ethnical lineup attests to a Türkic non-“IE”, “guest” or a Wanderwort in Europe. Cognates: A.-Sax. dragan, draege, drogon, droh, drohnian, drohtnian, trog, troh, ðroh, trugon “drag, draw, protract”, daerst, daerste “dregs, refuse”, droht “condition of life”, drohtað “mode of living, conduct, environment, society, condition, employment, vocation”, drohtnian, drohtian “behave, associate, live, continue”, trod, trodu “track, trace”, OSax. dragan “carry”, OFris. drega, draga, ONorse draga “draw, drag, pull”, dorg- “fishing tackle”, OIcl. draga “drag, pull”, dorg “fishing tackle”, Goth. dragan “carry, drag”,
draibjan, dreiban “drive”, OHG tragan “carry, bring, lead”, Gmn. tragen “carry, bear”, darge “fishing tackle”, MDu. draghen “carry, bring, throw”, dorg- “fishing tackle”, Sw. drag “to tense, draw”, drag “long narrow depression in soil (trace, trail)”,
dörj, dorj “fishing tackle”; OIr. tarla “pull”; Lat. trahere “draw”; Gk.
travixte (τραβηξτε) “pull”; Rus. doroga (дорога) “trail, road, way”, doroga, dorojka (дорога, дорожка) “fishing tackle”, droga (дрога) “beam (between wagon axles”, drogi (дроги), drovni (дровни), aka rozvalni (розвальни), volokusha (волокуша), volochuga (волочуга) “sledge, stone-boat”, drojka, drojki (дрожка, дрожки) “light carriage”, tarabit, tarabanit (тарабить, тарабанить) “drag, pull”, tarabarka (тарабарка) “traverse, crossbeam” (Türk. compound with ber- “bear, carry” and diminutive suffix -k), tarak (тарак) “pole, rod (for drying nets)” (Tat. tartyq, with instr. suffix -yq/-ïq), tarantas (тарантас) (Tat. taryntas) “long-base wagon”; Pol. dorozka “light carriage”, darka “fishing tackle”, taratatka, taradajka, taradejka “wagon”, таранкат “trail, lag, linger”,
tarambuchit “cling, annoy” (Fr. tarabuster “cling, annoy”); Skt. dhrajati “pull, slide in”; Fin. tarttu- “seize, catch”, tork(k)o “fishing tackle”, Mordvin targa- “pull”;
ODravidian tor, dor, tallu “push”; Nenets tartaɣaš “pull”; Kalmyk, Mong., Manchu tatxa “drag, pull, pull over” (tata- < tarta-); Kor. talda, tada (달다) “weigh, weighing” (< tara-, < tan-); Chuv. turt- “pull”; Alb. tartis “weigh, weighing”. The first consonant tends to wobble between d- and t-, like in Türkic languages, the first vowel wobbles between -a-/-o-/-ö- and zero. Numerous words carry traces of the Türkic suffixes with -g/-ɣ/-k/-q for forming conjugations, declensions, and derivatives. Distribution: From Atlantic to Pacific, across linguistic borders. Any claims to an “IE origin” and “PIE proto-words” are doomed by the spread of the word across linguistic families and continent-wide vast geography, impossible without mobile Türkic nomadic pastoralists spreading the word across Eurasia from Atlantic to Pacific. Forsaking its creed concept of the “proto-wording”, the
“IE etymology” invented a slew of different “proto-words” pleading a special case for each special instance descended from a primeval notion of dragging a sledge or a fish out of water. The ethereal cornucopia includes the faux “PIE roots” *dhregh- “draw, drag on the ground”, *der-, *dreb- “run”, *do- “give”, *drou-, *deru- “firm, solid”, *pag-, *pakslo- “fasten”, *drogon “wheel”; the “PG roots” *draganan “draw, pull”, *tred- “tread, step”, *trep- “snare, trap”, *traujam “flat wooden board with a low rim”, “OE roots” *dreaht, *dræht, and the “VLat. roots” *tragulare “to drag”, *tragere *traginare “to pull”,*tardivus “slow, sluggish”, *transfricare “rub across”, *tripaliare “to torture”, *tripalium “instrument of torture”, and many more. Notably, the VLat. inventions are demonstrably anachronic, since they refer to the post-Latin words of the New Era and can add nothing to etymological tracings. Instead of ascending to a base root connected with various aspects of the notion “pull, drag, draw”, this industry manufactures individual “proto-words” rammed to fit into a narrow
linguistic window. The distribution of the word in the Northeastern Europe points to the amalgamation within the Corded Ware (3rd mill. BC) archeological culture. The Celtic form is significant in that the Celtic Kurgans arrived to Europe in ca 2800 BC, 800 years before the time of the Aryan southeastern migration. The consonance of the Far Eastern forms with the Türkic tar- corroborates that the Zhou-type “Scythians” at the turn of the 2nd millennium BC reached the Pacific belt and amalgamated with the local populations. Without demography of the physical carriers conveying cultural influence, there is no place for the faux “PIE” root *dhregh- to penetrate innumerous far-flung alien languages. There is no other alternative for the Stone Age-technology society to spread the word across Eurasia from Atlantic to Pacific except for the mobile Türkic nomadic pastoralists. Of the recorded Türkic 128 meanings based on the root tar-, quite a few words from the other 9 main semantic fields had to be disseminated across the languages of the Eurasia and leave their traces in the local languages, like the notions of the weighing and measurement cited for the Alb. and Kor. languages. A realistic etymology has wide-open fascinating perspectives.
3.88
earn (v.) “deserve by efforts or actions” ~ Türkic ar-, er-, jer- (v.) “tire, weary”, “get tired, get weary”, i.e. “after hard labors”.
An “IE etymology” asserts a Gmc. and “IE” origin, q.v. Ultimately fr. a notion “overwork, overstrain” of a base notion ar-, a:r- “tire, fatigue” with a sibling form da:r- “narrow” > “difficult, with difficulty”. A reflexive form
arïn with Ogur prosthetic initial consonant g- and a reflexive suffix -(i)n produced synonymous Eng. forms earn ~ garner “earn”. In antiquity and middle ages, the literary examples of the notion “earn” regularly dealt with politics and military affairs, never referring to any granaries, harvests or autumns. In Europe, the roots of the line (X)ar- “earn” dominate in a range of vernaculars with 20 (45%) languages, followed bay a Romance group gan- with 7 (16%) languages. The remaining 15 (34%) languages use 13 of their own native terms. Other than a Türkic-Eng. (X)ar- there is no shared “Pan-IE” term. A dominance with a motley ethnical lineup attests to a Türkic “guest” status of the non-“IE” lexeme in Europe. Cognates: A.-Sax. earnian “deserve, earn, get a reward for labor”, OFris. fer(tsjinje) “earn”, esna “reward, pay” (r ↔ s), Du. ver(-dienen) “earn”, Gmn. ver(-dienen), Luxemb. ver(-dengen), Yid. far(-dinen) (פאַרדינען); Pol. (z)ar(abiać) (rab- “work” < rabota (typ.)), Bosn. (z)ar(aditi), Croat. (z)ar(aditi), Maced. (z)ar(abiti) (зарабити), Serb. (z)ar(aditi) (зарадити), Slvt. (z)ar(obiť), Ukr. (z)ar(oblyati) (заробляти), Rus. (z)ar(abatyvat) (зарабатывать), Blr. (z)ar(ablyats) (зарабляць); Lith. (uz)dir(bti); Basq. ir(abazi); Gk. (k)er(dízo) (κερδίζω); Hu. erni “worthy, deserving”; Sum. ir ditto; all “earn” unless noted otherwise; non-grammatical prosthetics are included with a root; brackets are intended to highlight a root.
Distribution: Across Türkic Steppe Belt with quite a few “guests” in widely scattered Eurasian spots. Attempts to cook an “IE” origin lead astray to unrelated phonetic ringers and creative fictions. The “IE” etymology for earn, garner is sorely fictitious, first connecting it with an unattested “PIE” fictitious root for “grain”, and then evoking an A.-Sax. rinnen, iernan, irnan “run”, or “or a back-formation from (archaic regional) earning”. The last closes a loop: earn < earning. The whole enchilada is laughable; the verb with the semantics “earn, garner” was etymologically confused with the noun “harvest” and its verbal version “harvest” conflated with “autumn”. There are a faux “PGmc. proto-form” *aznon “harvest work, serve” (based on r ↔ s evidence), a faux “PWGmc. proto-form” *aʀanon (“?”), a faux “PGmc. proto-form” *azanona (“?”, r ↔ s), a faux “PGmc. proto-form” *rinnana (“?”), and complimentary faux “PIE proto-root” *es-en- “harvest, fall”
(r ↔ s), and a faux “PIE proto-word” *her- “move, stir, rise, spring”, and *azno “labor”. A pile of indigestible galimatia has no connection with the notion “earn, garner, deserve, reward”, or its attested Sum. antecedent ir “worthy, deserving”. The Sum. ir and Hu. erni, like the Türkic “having labored hard”, provide a direct semantic correspondence and phonetic match, and take the word earn from a peasant labor to a larger world of contracts, mercenaries, and obligations that reflect the substance of the word: “earned salary”, “earned living”, “earned trust”, “profited from laborious activity”. The forms earn and garner attest to two separate demographic paths, one Oguz and the other Ogur, which brought to English two forms of the same word. They grew to two distinct shades of the same notion. The documented pair of Türkic ar- and Sum. ir “earn” provide sufficient evidence for an origin fr. a Türkic milieu.
3.89
eat (v.) “to eat, devour, consume” (Sw N/A, F545, 0.03%) ~ Türkic ašа- (ashа-), ye- “eat” (v.), a suggested variation dye-; aš “food” (n.). An “IE etymology” falsely asserts a Gmc. and “IE” origin, q.v. Ultimately, all forms probably ascend to a single-vowel word, a what is now ı: “vegetation”, as a generic appellation for any plant and then food. The tail of the ı: (or e-, a-, etc.) is formed by suffixes, mostly borrowed and non-active; at the times of of internalization they were incorporated as a part of a root. A Türkic suffix -ta/-tan/-ten/-zen/-sen is a marker related to grammatical person and tense. The synonymous ye- and ašа- have nuanced semantics,
ye- is a mundane, and ašа- is a dignified act of eating, Cf. Sl. otkushat, potchevat (откушать, потчевать) “dine” vs. kushat (кушать) “eat”. The anlaut y- (j-) in ye- is prosthetic; various prosthetic consonants and palatals show up in numerous cognates. Türkic has a form
yedi/ye:di: with conjugational suffix -di, that suffix is widely used as an indefinite form marker by the “IE” languages with the roots in the Eastern Europe of the 3rd mill. BC, Cf. Gmc. it/et, Gk. edo (ἔδω), Lat. edi, Skt. atti, “eat”, Sl. yesti (jести), eda “food”, see edacity. The ašа- has a tint of nobility; thus the Eng. eat and Gmn. essen constitute a bifurcated paradigmatic transfer of the same notion, semantically akin to an English usage of thou vs. sg. you. A second member of the Türkic idiom aša- ič- “eat and drink” > ðič has been preserved in the A.-Sax. ðicgan and ge-ðicgan (with
-ch-) “drink” and “eat”, another case of paradigmatic transfer. The immense variety of forms and the Eurasian spread attest to a supremely long history of amalgamations, Cf. modern Türkic forms aš-, ye-, ij-, či-, i-, e-, ije-,'im-, em-, em-, če-, cie-, či-; European aš-, ät-, eat, ed-, es, et-, ies-, it-, ith-, ja-, jes-, jie-, jis, sö, yes-, yis, ya. Of 44 European languages, a heavy collection of ašа- clones dominates with 28 (64%) languages, followed by a modest Romance group man- with 5 (11%) languages. The remaining 11 (25%) languages use 8 of their own native terms. A motley lineup of the clones of the Türkic ašа- evinces to a non-“IE”, a Türkic origin of “guest” word: Türkic (Tatar, Bashkir, Gagauz, Bosniak, etc.) ašа-, Sw. äta, Eng. eat, Lat. edo, Yid. esn (עסן), Gmn. essen, Latv. est, Hu. eszik, Du. eten, Luxemb. iessen, Fris. ite, Ir., Scots
ithe, Basque jan, Pol. jesc, Slov. jest, Bosn. jesti, Croat. jesti, Sloven. jesti, Malt. jieklu, Czech jist, Est. sö, Rus. yest (есть), Blr. ёsts (ёсць), Ukr. yisty (їсти), Maced. jadat (јадат), Serb. jesti (јести), Bolg. yajte (яжте). Other than the versions of Türkic ašа-, there is no shared “Pan-IE” term. Cognates: A.-Sax. et (v.) “eat”, OFris. ita, OSw. etan, MDu., Du.
eten, OHG ezzan, Gmn. essen, ONorse eta, Goth. itan; Baltic est, ist, emi, edu; Slavic forms isti/ests/jести/jėsti/jisti/jesc; Skt. atti “eat”,
ye:k “devourer demon”; Arm. utem (Türkic 1st pers. sing), Gk. edo (εδω), esthio (εσθίω), estho (εσθω); Lat. edi; Chinese
chi (吃); Mong. ide- (syn. asara, another Turkism, Cf. Gmn. essen); all “eat” unless noted othervise. Distribution: Ubiquitous across a Türkic Steppe Belt with quite a few “guests” in widely scattered Eurasian spots fr. Atlantic to Pacific. The distribution of the forms across families points to an unequaled reach across Eurasia. A pretentious “IE etymology” builds an air castle using its deliberate myopia as a tool for constructing a deceptive “IE” paradigm. In a course of a sloppy falsification it created a series of faux predecessors inventing precursors on a fly. Those are a faux “PGmc. proto-form” *etana “to eat”, a faux “PWGmc. proto-forms” *etan and *at, and a faux “PGmc. proto-form” *eta “food, thing to eat”, and a faux “PIE proto-root” *ed- “eat”, and a faux “PIE proto-word” *hedti “eat”, and a faux “PIE proto-word” *hed- “eat”. All that scholastic
nonsense is useless, it does not add a single poppy seed to etymology, it is merely provocative, and needs to be gracefully retracted. The spread of the word is impressive, with terminal points in Western, Northern, and Mediterranean Europe in the west, India in the south, China and Manchuria in the east, and the Eurasian Steppe belt in between. The spread of the forms it- (at-, et-, ut-)/id- (ad-, ed-, ud-) may point to an original form it-/id-. The modern Türkic form ye- is a contraction; that links Eng./Gmc. forms with Mong. form via some intermediaries like the Scythians (Cf. Gk./Lat./Sl. form), Khakass or the Eastern Huns. The Gmn. form essen (v.) may alternatively be a desiderative form ye:se:- of
ye- “want to eat, hungry”, or ascend to the Türkic noun aš (ash) “food”, verb aša:- “eat”. The Skt. ye:k is peculiar and diagnostic, it is a component of a duo of Skt. Buddhist terms of Türkic origin, a Türkic
ye:k “demon” lit. “devourer”, and yakša “demon” lit. “gluttonous, desirous to englut”. They complement the Skt. Buddhist bhüta “ghost”, in Türkic ičgek (ičkak) “drinker, vampire”. The significance of the duo is that these Skt. Buddhist terms use terminology carrying transparent Türkic etymology, complete with the desiderative suffix -ša, with minor phonetic adaptations, and semantic field expanded from concrete nouns to generic concept. These Skt. Buddhist terms set an upper dating limit of 6th c. BC, they provide attestation to the form of the Türkic lexemes (ye:) at the time of their adaptation. The terms may be much older than Buddhism, which likely used an inherited Skt. lexicon to express a new concept. The Chinese word is likely a reflex of the Scythian Zhou component in the Chinese language. The Türkic prosthetic consonant
ch-/j- in ye, i.e. či, če, cie, či, Slavic jести, jėsti, jisti/jesc “eat”, eda “food”, and Chinese form shi (去), with
Türkic transposed prosthetic -j-/-y- in ij, ije, point to the Ogur form i/e >
ye/chi/che, vs. Gmc., Balt., Slavic, Skt., and Arm. unadulterated i/e forms. The multi-faceted aspects of paradigmatic transfers impress with their attestations of traceable and vivid Türkic genetic connection. See chew, edacity, vampire.
3.90
eke (eke out) (v.) “live from day to day, with difficulties, hardship, precarious” ~ Türkic ek- (v.) metaphorical “eke out”, “with efforts and strain”. An “IE etymology” falsely asserts a Gmc. and “IE” origin, q.v. Ultimately fr. a polysemantic verb ek- “till (farming work)”, and Cf. iki “two, secondary”. The verb is Common Türkic, but the specific notion “till, hard work” are known only in some languages, which allows a demographic tracing. The verb numbers 5 semantic clusters and a fairly compact semantic spectrum, from “sow, till” to “get rid”. Türkic derivatives include verbs eklä- (erkla-) “apply efforts, strain”, eksï- (eksü-) “diminish, reduce, lack”, eksük “shortage, loss, inadequate, defective”, eken “indefinity, being, while”, erki: “perhaps, uncertain, doubt”, etc. They carry a notion of precarious transitivity. Semantics includes “supplementary, supplemental, additional, extra, further, addendum, extension”, etc., Cf. an A.-Sax. eaca “increase”. Parallel derivatives carry a notion of sourness, applied in metaphorical and physical context; that conflates sourness and hardship: ekši:- (v.) “sour, acid, tart”, ekšig (adj.) ditto. An ekin is a deverbal noun with notions of insufficiency and sourness, acridity (> Eng. “augment, increase”); the suffix -in is retained in the Gmc. languages as a part of a root. The ek- words echo a stem erk- denoting “force, power”, reflected in the unit of energy/work erg and in the Gk. ergon (εργων) “work/task”. Other than some conflation and phonetic homophony, the stem erk- is not related to the stem ek- and its Eng. sibling eke, albeit in some languages it is articulated with a prosthetic -r-.
Cognates: A.-Sax. echen, ecan, eacan, eacian, ieċan /ietsan/, at-, be-, ofer- weaxan (v.) “increase”, eaca (n.) “increase” (vs. native waestme, waestmas (n.) “increase”), OFris.
aka, OSax. okian, Dan. öge, Sw. öka, ONorse auka, auki, Norw. Bokmål øke, Norw. Nynorsk auka, Icl. auka, OHG ouhhon, wahsan, Goth. aukan, wahsjan “increase”, auk “also”, Gmn. wachsen; Lat. augeo, Kor. ekta-
(v.) “harrow” (< ek “till”), all “augment” unless noted otherwise. Distribution: Atypically, out of the entire Eurasian spread the acknowledged cognates are confined to the flecks of Gmc. and Kor. languages. Distribution attests to a non-“IE” origin of the word. The myopic “IE etymology” claims a Gmc. and “IE” origin, and supports that with a line of “probably” surmises. Those are a faux “PWGmc. proto-form” *auk, a faux “PGmc. proto-form” *auk (presumably “to grow, increase”?), a faux “PGmc. proto-form” *aukan “increase”, a faux “PGmc. proto-form” *aukana “grow, increase”, or a faux “Pre-Gmc. proto-form” *hew “away from, off, again” + *g(ʰ)e (“?”), and faux “PIE proto-forms” *aug- “increase”, *hewg- “enlarge, increase”. Given the attested material, that kind of rogue ingenuity is useless, there is no need to reinvent a past when that past is documented, nor does it explain the attested Kor. cognate. An original singularity of the notion ek/eke across Eurasia probably comes fr. a Türkic specifically nomadic aversion to hard labor generally, and a tillage
particularly. A toil was escapable by a trade and a force; annual trades and raids were a nomadic norm for
millenniums. The few Türkic ethnicities that practiced tilling, like the Cuv. (aka “till”), tended to extend the meaning: pour, plant tree (v.), graft, engraft, beget, etc, and in the west ― “eke out, augment”, etc. On the European scene, the aversion semantics is replaced with a positive desire: “augment, increase”. It is fairly profound that the Kor. farmers used a Türkic farming word. The affinity is supported by a farming semantics of the form *aug-. The allophonic *aug- “grow, increase” is rated as an allophone of ek-; instead of a hardship, in Eng. it bears a sense of deficiency. The semantic and phonetic analogy would add Lith. augu, augti, aukštas, Lat. augmentum, augere, Gk. auxo (αυξω), auxein (αυξειν), Skt. ojas-, vaksayati, all expressing “grow, increase, supplement” to the above cognate line-up. The uniqueness of the semantics, near-perfect phonetics, a farming connotation, and a peculiar spotty distribution makes the Türkic origin indisputable. Given the uniqueness of the word, a chance coincidence is a blunt impossibility.
3.91
fart (v., n.) “expel intestinal gases through anus, flatus ventris” ~ Türkic burt-,
burut- (v.) “expel intestinal gases through anus, smell badly”. An “IE etymology” asserts an “of imitative origin” and a Gmc. and “IE” origin, q.v. Ultimately a verbal denoun derivative fr. a noun/verb base bu/buru/pu “vapor, steam”, see steam, cloud, mist. Clones of bur- are ubiquitous in Europe, of 44 European languages, clones of Türkic bur- dominate with 35 (80%) European languages in an endless parade of articulations from a range of incompatible languages. That attests to the loanwords' “guest” status on a level of today sharing of a term “computer”. The remaining 9 (20%) languages use 8 of their own unsupplanted native terms. Cognates: A.-Sax. feortan “fart”, OHG ferzan, ONorse freta, Dan.
prut; Rum. bășina; Lith. perdzu; Russ. perdet (пердеть) “fart”, bus, busenets (бус, бусенец) “drizzle, mizzle, fog”; Serb. bug, bugi, bugija “vapor, steam”; Gk.
perdein; Skt. pard; Fin. pieru, Est. pieru; Punjabi pharata; Mong.
bug “vapor, steam”, Kalm. bug “vapor, steam” + “a demon of steppe, of fog”; Ch. pi
(屁); all “fart” unless noted otherwise. The Lat. bombulum also belongs to this lexical cluster derived from some mill. BC pre-migration forms of bu, bur, and burut-. Distribution: Ubiquitous across Eurasia, from Atlantic to Pacific, including places where a Gmc. boot never stepped in. Phonetic modifications correspond to the linguistic families of the recipient. The myopic “IE” etymology gives an empty claim of a “of imitative origin”, which does not work across a span of Eurasia. The Türkic
bu, bur is vapor, gas, hence the Sl. par (пар) “vapor, stream, gas”; the verb burt- is a derivative of the stem bu, bur, no need for any “imitative origin”. The myopic “IE etymology” claims a Gmc. and “IE” origin, and proclaims a faux “PGmc. proto-form” *fertana (“fart?”) and a faux “PIE proto-form” *perd- (“fart?”). These pseudo-scientific claims fail to see the Mong. and Ch. cognates; they are not needed for the attested term that covers many times over the teeny Gmc. blob on the Eurasian linguistic spread. The Kurgans took it to Central and Western Europe with the first (5th mill. BC) and the following waves, in the 2nd mill. BC the Gk. and Skt. have spread the word southwest and southeast. Together, the A.-Sax. feortan and aeðm, the Türkic burt- and osur-, and the English fart constitute a “farting” transfer paradigm, categorically attesting to the genetic connection of the three languages. The Türkic bu, bur is a spectacularly productive stem playing on a number of steam properties: boiling, bursting,
whirling, burning, purging, and the like, it was especially productive for the terminology of the ordinary cooking. Ultimately, derivative cognates of bu, bur are principals like bake, boil, breath, bullion, fart, fire, fog, mist, murky, purge, pyre, (see highlighted entries) and trivia like burp, puke, and possibly turbulence (see turn and boil).
3.92
feel (v., n.) “physical or emotional sensation” (Swadesh N/A, F174, 0.13%) ~ Türkic bil- (v.) “know, understand, perceive”, and “learn, discern, detect, probe, scout” . An “IE etymology” asserts a Gmc. and “IE” origin, q.v. In both subject languages the underlying prime notion is “to know, perceive”. Of 44 European languages, a Sl. group chuv- is a notch ahead with 10 (23%) languages, followed by a Gmc. feel and a Romance sen- with 9 (20%) languages each. The remaining 16 languages use 11 of their own terms. There is no shared “Pan-IE” term, Europe is a linguistic conglomerate of 4 linguistic segments. One of the segments, the feel, is a “guest” in Europe, it came fr. a distant Siberia. Only Ir. and Scots came with their native vernaculars, the other members of the last segment use internalized loanwords. Cognates: A.-Sax. felan “feeling, perceive, touch” with a notion of “perceive through senses of not any special organ”, OSax. (gi)folian, OFris. fela, ONorse falma “grope”, Du. voelen, Dan., Norse føle, Sw.
känna (calque), OHG vuolen, Gmn. fühlen, Icl. finnst, Yid. filn “to feel”; Ir. airigh, Scots faireachd; Lat. palpare “feel, touch”; Mong. bilig “knowledge”; Ch. ganjue (感觉) (calque). Distribution: Ubiquitous across Eurasia, from Atlantic to Pacific, including a Gmc. enclave in Europe and the rest where a Gmc. boot had never stepped in. Still, a myopic “IE etymology” came up with a line of delusions, a faux “PGmc. proto-form” *foljanan “feel”, a faux “PWGmc. proto-form” *folijan “feel?”, and “possibly” the faux “PIE
proto-forms” *pal- “touch, feel, shake, strike softly” or *pel- “thrust, strike, drive”. That reverse ingenuity is not needed, the link between notions “know” and “feel” of the same Türkic root bil- is attested and documented. The A.-Sax. synonymous fredan (frod “wise, old”) and the Sw., Ch. “feel, perceive” are formed out of the same notion “know”. That link documents an ancestral
linguistic connection between the Türkic and Gmc. phylums ascending to a Stone Age, to the time of a Battle Axe and Corded Ware cultures. A transition from a plosive labial to a fricative labial b > f is endemic to the Gmc. group. In Türkic languages, the notion feel fr. the notion know is expressed by four roots, bil-, sez-, tartil-, tuj-. The tartil- is an extension of tart-
“pull, guide”. The Türkic developmental model is shared by the Gmc. and Sl. languages, the Sl.
chuvstvovat (чувствовать) “feel” is a derivative of chu- (чу-) “to get wind of, smell, hear”, i.e. “know”. While the Lat. palpare ascends to the Türkic bil-, the Lat. sensum “feel” is an offspring of the synonymous Türkic root sez- “come to know, to learn, to feel”. The
“perhapses” of the “IE etymology” essentially resign to a no meaningful etymology. The English verb
feel “feeling (v.)”, a progeny of the A.-Sax. lexis, is a 15th c. articulation of the Türkic
bil-. The Gmc. forms, consistent in transitions b-/v-/f- vs. the Italic b-/p- transition, point to independent paths and timing. Italic b-/p- transition follows a trail of Türkic vernaculars, it has a special diagnostic value. Another utilization of the root bil- with the semantics “able” serve as a suffix -able in Eng. innovations like suitable and doable, the last a compound of two reflexes, the tü “do” and bil- “able”. The Eng. forms conflated with the Lat. Turkisms of the same word bil- “able”, the Lat. -abilis, -ibilis, the Eng. -able,
-ible. A case of paradigmatic transfer of the discrete meanings of the same root attest to a common genetic origin from a Türkic milieu. See feeling.
3.93
find (v.) “discover” (Sw N/A, F156, 0.11%) ~ Türkic ind-, yind- (v.) “find”. An “IE etymology” asserts a Gmc., Sl., and “IE” origin, q.v. Ultimately fr. in, i:n “voice” with a list of 11 semantic clusters, from “call, summon” to “turn attention to”, totaling 30+ meanings. A derivative form inde denotes relevant notions “worry”, “question”, “search”, “search for”, “demand”, etc. A common Gmc. prosthetic anlaut f- is a common trait of articulation, a routine trait of internalization. A Türkic counterpart yind- of the form ind- bears a prosthetic anlaut glide semivowel y-, consistent with the Oguz (ind-)/Ogur (yind-) divide. The Ogur form is associated with a western Türkic phylum, particularly with the Sarmat area of the northern European antiquity. In all Gmc. forms the Türkic anlaut glide y- is replaced with voiced or unvoiced labial fricative v-/f-.
A similar process is typically observed in the Sl. Turkisms. Of 44 European languages, a Türkic-based -ind- dominates with a motley contingent of 12 (27%) languages, followed by a Sl. group nait- with 9 (20%) languages and Romance group tro- with 4 (9%) languages. The remaining 19 languages use their native 16 words. Other than the Türkic-Eng. there is no shared “Pan-IE” term. A motley ethnical lineup attests to the ind-/find- status as a “guest” in Europe. Cognates: A.-Sax., OSax.
find(an), OFris. finda, ONorse finna, MDu. vinden, OHG findan, Gmn.
finden, Yid. gefinen (געפינען), Goth.
finþan; Welsh ffeindi; Lat. inveniet; all “find”, all consistent with the modern English form find. Distribution: Ubiquitous across Eurasian Türkic Steppe Belt; Lat. and Gmc., islet prongs in Europe. Consistency of the internalized forms of ind- > find points to a single focus of internalization that spread to close-knit demographic communities (Eng., Fris., Dan., Du., Norw., Icl., Luxemb., Gmn.; +Yid., Welsh, Lat.). The Welsh form attracts attention: an oddball among Gmc. languages, it was suggested to be connected with with a Balkan Türkic tribal name Vlah aka Vlach, Wallach, of disputed origins. A convoluted “IE etymology” offers a slue of faux “PGmc. proto-forms” and corresponding faux “PIE proto-forms”: a faux “PGmc. proto-form” *findan “come upon, discover”, a faux “PGmc. proto-form” *finþana “?”, a faux “PWGmc. proto-form” *finþan “?”, a faux “PIE proto-root” *pent- “tread, go”, a faux “secondary verb” of the same “PIE proto-form” *pent- “go, pass”, *pontohs “path bridge”, and a reference to a “Grimm's Law” change of -th- to -d-. All that myopic artillery only distracts from a transition of ind- to find- along the paths typical for Gmc. internalizations, Cf. face < yü:z, ñü:z; father < ata; faith < but, büt; foot < but; folk < bölük; etc. There is no need for the useless faux substitutes and a gibberish semantics of they type “tread, go, pass, bridge” unrelated to the notion “find, discover, search, seek”. There is no need for the useless “PIE root” *pent- “tread, go”. To make things even sillier, the “IE etymology” does not cite a single word meaning “find” outside of the Gmc. group, Cf. Lat. inveniet, Welsh ffeindi, demonstrating that the word does not belong to the
“IE” family at all. The phonetics, consistent with the Ogur/Oguz alternation, is quite perfect; semantics is unambiguously precise. That leaves no room for doubts about the origin of a Gmc. word from a Türkic linguistic milieu.
3.94
gab, gabble, gibber, jabber (v.) “speak chattering, blabbering” ~ Türkic gev-, kev- “chew”, gap-, gep-, gapir- (v.) “speak, conversation” (Gadjieva N.Z, Koklyanova A.A., 1961, 365). An “IE etymology” asserts an Old Norse origin, q.v. Ultimately fr. a metaphorical base notion kev- “chew” in two aspects, “speak clearly, think”, and “gabble, garble, misarticulate”. A base notion comes in a range of similar monosyllabic forms,
keb > kev, keg, gey, köb, kö:b, ke:b, kob, kög, keg, kеm, käb, käp > kösä. It is neutral to a noun/verb function and to a transitivity, attesting to an archaic origin that extends to a current Eng. trait. The traits point to pre-grammatical times, possibly originated still in Africa. Verbs are formed with a verb-forming archaic suff. -(V)r; more recently – with verbal suff. -le and frequentive suff. -(V)š. One of the three listed metaphoric meanings, a pertinent gǝ:w(üše)- “keep repeating the same” with a frequentive suff. -(V)š corresponds to “chattering, blabbering”. A complementing gev- “speak clearly, think over”, and gev- “misarticulated (speech)” must have been discriminated somehow, but there are no pointers to that. In a negative aspect, the terms have a facile (loose) articulation. They carry a shade of quality or derision.
In Eng. “my child has learned to say (Tr. söy/söyle)” is an improper form of “my child learned to talk (Tr. til/tili)”, so in Türkic instead of improper söy/söyle “say” or til/tili “tell” a proper use is gap-/gapir- “my child learned to gabble”. Cognates 1: Dan. gebabbel “chatter, babble”, Du. gabbelen “chatter, babble”; Pers. gep- “boastful speech”; Ar. qavl- “word, expression”; Mong. kebi- “chew”, kewχǝ “chaw”, kebil- “craunch”; Osm. geviš (< kebiš) “ruminate, chew cud”; Chuv. kavle “chew”;Kyrg. babıroo, ebiröö “bug me, annoy”. A second series of cognates is of local provenance and of much later times. It mimics the “chatter” as a mock. Each rendition conveys its own spectrum of very basic notions, intersecting at Dan. and Du. Cognates 2: A.-Sax. gabban “scoff, mock, delude, jest”, Saterland Fris. gabbelje “mock”, NFris. gabben “jest, sport”, ONorse
gabba “mock, make fun of”, Dan. gebabbel “chatter, babble”, Du. gabbelen, gebabbel “chatter, babble”, MDu. gabben “mock”, LGmn. gabbeln “mock”, MLGmn. gabben “jest, have fun”; Scots gab “mock, prate”; OFr. gaber “mock, jest, brag, boast”, Fr. bagou “sales pitch, throat”?. Bifurcation brought about two linguistic prongs, each with its own reality and distribution. Distribution: Cognates 1 – From the Baltic via Türkic Steppe Belt to the Far East, across linguistic borders; Cognates 2 – NW Europe isle, predominantly Gmc., with a Lat. prong, possibly spread via a Battle Axe culture. To its detriment, a myopic “IE etymology” stops at isolated Gmc. neighborhood, reaching its horizons at a vague “Scandinavian source”. It ignores the Dan. and Du. evidence. It forgets that a destination is “chattering, blabbering” and “keep repeating the same”. It invents fictitious “PIE proto-words” and dubiously speculates with a faux “PGmc. proto-form” *gabbona “to mock, jest” and a faux “PIE proto-form” *ghabh- “split, forked, gape”. That ingenuity is not needed, it misleads, it can't replace the trail of attested material. The A.-Sax. had 4 native words for silly, foolish, empty talk. The Türkic “gab” etc. supplanted those 4 words. That attests to a change in a demographic composition, to an influx of a considerable proportions, i.e. a “guest” with its own lexicon. The spread, morphology, and
phonetic and semantic variations within the Türkic linguistic family attest to an innate Türkic
origin. That is affirming that the Ar. qavl- “word, expression” and the Pers. gep- “boastful speech” are probably late loanwords, albeit the Hg. J Arabic Y-DNA genes were a first to cross fr. Africa to Eurasia. The deverbal noun form gibberish, syntactically spelled in a reciprocal-cooperative Türkic aspect form giperiš (giperish) “chat, chitchat”, is indistinguishable from an Eng. form. The attested phonetic variation of the allophones gibber/jabber is consistent with the common Oguz/Ogur phonetic variation of the anlaut consonant, and with an imperative inflection of the verbal stem
gib- > gibber. In a feat of paradigmatic transfer, Eng. has five communication words related to call, cry, gabble, say, and tell. They are clones of the Türkic qol-, qar-/čar-, gap-/gapir-, söy-/söyle-, and til-/tili- respectively. The lexical group constitutes a prominent case of paradigmatic transfer, indelibly attesting to its origin from a Türkic phylum. See
call, cry, tale, tally, tell, say.
3.95
gaggle, cackle (v., n.) “goose talk” ~ Türkic qaɣ quɣ (v., n.) “goose talk”,
metaphorically “cry loudly”. An “IE etymology” asserts “possibly” an Old Norse origin, q.v. Ultimately fr. a goose call rendered qaɣ quɣ which formed a noun derivative kaz “goose” that included gander, swan, and duck; a final -s/-z is probably a relict of an archaic verbal suff. -sï. The Türkic qaɣ quɣ dominates in Europe and across Eurasia, taking 31 (70%) of the European languages, and leaving the remaining 14 (30%) languages to use their own native 12 terms. Other than the versions of the Türkic qaɣ quɣ, there is no shared “Pan-IE” term. Cognates: A.-Sax. gos, ges “goose”, goshafoc “goshawk (falconry)”, MEng. gaggle, gagelen, Fris., Norw.
kakkel, ONorse gagl, Du. gagelen, Dan. kagle, Sw. kackla, OIcl. agl, MHG gagen, Gmn. gackern, Yid. kakl; (Balt.) Ltv. gagat, kikinat, Lith. gageti, gagu, kakti; (Romance) Fr. caqueter, Sp. cacareo, Port. cacarejar, Rum. cotcodăci; (Sl.) Rus. gogotat (гоготать), kazy, kazy “lure call for geese”; Cz. kejhat, Slv. chichotat, Croat. kikotati, Maced. klukaam (клукаат); Fin. käkättää, Est. kakerdama; Gk. kakophonia, kakophonos “harsh sounding”; Alb. kakarisin; Osset., Yass (Hu. Alanic) qäz “goose”; Kurd. qaz, qäz “goose”; Afgh. käz “wild goose”; Urdu qäz “goose”; Yagnob. (Neo-Sogd.) qoz “goose”; Mong. gogotat, Mong. qaz, galayun “goose”; Kor. geowitte (거위떼); Jap. kari “wild goose”; except as noted, all referring to a geese call and by extension to a female talk. Distribution: From Atlantic to Pacific, across linguistic borders, spread across N. Europe to Mong., Kor., and Jap. The standing “IE etymology” offers inconceivable “one of the many artificial terms invented in the 15th c.”, a patented nonsense given that the cognates are spread across N. Europe to Jap. They congregate in area demarcated by particular historical distinctions, and except for the Far Eastern languages are marked by a substantial presence of the Kurganians' R1a/b haplogroups. The notation of “possibly of imitative origin” for gaggle is not any better, the question is not the dimly enlightened news of the echoic origin, but where this echoic origin came from, and where it spread to. In the post-4th mill. BC there was only a single known entity, of the Türkic Hg. R1a/b, dynamic enough to spread a single term across Eurasia between uncounted isolated linguistic groups.
3.96
gaze (v., n.) “stare” ~ Türkic gör-, kör- (v.) “see, gaze” (+qara-, baq-), göz, köz (n.) “eye”, Cf. közin körüp “gaze with eyes”. A third member of the homonymic verbal triplet is giz-, gez-, kez- (v.) “walk, wander, roam, travel, i.e. onlooking, observe”.. A fourth member is göster “host, guide” showing around, see guest. An “IE etymology” asserts “possibly” of Scandinavian origin, q.v. Ultimately fr. göz “eye”, fr. a root gö-, kö- modified by archaic suffixes -r, -z/-s. In its 13 semantic clusters, the polysemantic noun göz renders 60+ (!) entries, from an “eye” to a “pound (weight)”, all related to a conceptual notion “hole”. An s/r divide settled the -z form as a noun vs. the -r as a verb, with some mystery of detail. An affinity of the forms öz, kör- “eye, see” is apparent. The adjectival version “agaze” splices the Türkic
göz/köz with an A.-Sax./Gmc. prefix a- to mark the verb as momentary, a single event, Cf. abide, arise, awake, ashamed. A Sl. prefix za- serves the same function, Cf. zaglyanut (заглянуть) “glance in”. Only 2 European languages know the word gaze, göz (Eng. + Türkic), an atypical case, since a majority of the Türkisms are prominent in a European lexical lineup. Such oddity points to a “guest” status of that particular loanword. Of 44 European languages, the Sl. (po)gleg and Gmc. blik- lead with 4 (9%) languages each, followed by a Gmc. stir- and Sl. zur- with 3 (7%) languages each. The remaining 33 (75%) languages, incl. Eng. and Türkic, use 28 of their own native and borrowed terms. There is no shared “Pan-IE” term, the nomenclature is as atomized as they come. Cognates: A.-Sax. gor(ian), goret(tan), goret(tung) (with -r) “gaze, stare”, caes, ceas, ces, cys, ceos(an) (with -s, < göz, köz “eye”) “seek, choose”, Goth. (au)gö “eye”, geisnan “scared, aghast” (us-geisnan ditto), Norse, Sw.
gasa “stare, gape”, Fris., Gmn. kieze “choose”, Du. kiezen “seek”; Ir. cas “see” (with k), Welsh ceis(iwch) “seek”; Sl. glаzet (глазеть) (< глаз “eye” <
köz “eye”), Serb. göre “looking”, coz “eye”, Bolg. guzen “attentive”;
Turkish gözünü (with -s) “eye (look)”; Hu. keresni “choose”; Osset.
cozbaw “flattery, fawn, fawning”; all “gaze, stare” unless noted otherwise. An absence of the Far Eastern Mong., Tungus, Manchu, Ch., etc. cognates attests that their base lexicons fossilized before an appearance of the Türkic tribes in the Far East, i.e. before the late 3rd, early 2nd mill. BC.
Distribution: Türkic Steppe Belt, a minimal presence in Europe except for a Balkan area with Türkic and Bosnyak (< Khakas: Pečenek) loanwords. The meanderings of the Oguz and Ogur tribes are well known, the extensive pre-historical migrations have been reliably detected and genetically traced. A myopic “IE etymology” comes on a level of “probable's” and “perhapses”, a level that does not scratch a surface; it means “we don't have a clue”, bringing the subject to the investigators' level in more than one aspect. As far as the etymology goes, there is no there there. The semantics “to gaze” of the Türkic gezer/gizer/kezer is quite natural, especially so since the prime meaning of the verb
gez-/giz-/kez- is “travel, wander”, nowadays called sightseeing and tourism. The semantic extension from “see” to “seek” and “choose” was predicated by the ingrained semantics of the native word for “see” in the receptor languages, Cf. 20+ semantic extensions for the “see” in English. The prime notion of the word
giz shifted to “wonderer”, its kinship with the göz/gör- “seer/gaze” is retained as a metaphorical expression. Ligatures -ae-, -ea-, -eo- and the like reflect a millenniums-long struggle that attempts to express rounded vowel with means of the Roman alphabet, which makes the English spelling a curious wonder. The modern coexistence of dichtonomy köz and kör among Türkic languages attests to a stability of the phenomenon across millenniums. Particularly, it passed the melting pot of the Corded Ware culture of the 3rd mill. BC exemplified by dichtonomy across the Gmc. languages. The Celtic examples suggest a primacy of the -s- form, at least in the E. Europe at times prior to a Celtic circum-Mediterranean migration. The Eurasian spread, largely limited to the Türkic and Gmc. families, attests that host populations along migratory paths had well-established terms for “eye” and “see”. The carryover of the duplex köz/kör- constitutes a case of paradigmatic transfer, indelibly attesting to a common origin from a Türkic phylum. The Türkic origin is preeminent, there are no other contenders. See gist, guest.
3.97
get (v.) “obtain, receive”, getter (n.) “who gets, gains, obtains, acquires, begets, procreates” (Sw N/A, F42, 1.03%) ~ Türkic get-, göt-, ket-, köt- (v.) “bring, carry, deliver”. An “IE etymology” bravely asserts a “PGmc.” and “PIE” origins, q.v.
Ultimately fr. a primeval verbal root ge- “come, happen” with a line of derivatives formed with once active suffixes -l, -m, -r, -t, -v, -z, and a few more, Cf. gel-/kel- “come” in Kelt, Celt (n.) “newcomer, comer, arriver” formed with verbal suff. -l and abstract noun suffix -t, see
port; Cf. ge(l)tir- > getir-, keltir-, kelür- “bring”. The causative form geltir assimilated to getir ~ ötir, modern Turkish infinitive form götmek “bring, carry”, lit. “bring, get make”. That etymological observation has already been made in early Turkology, laid out or contributed by J. Zenker (1866), L. Budagov (1871), H. Vambery (1878), W. Radloff (1910), M. Räsänen (1969), (cited by EDTL v. 3, 31). Whether original or by assimilation, firmly established is the existence of the root get-/göt- “bring, carry, deliver”. A counterpart to a positive form
göt- is a negative git- (Clauson EDT ke:ter- 705) “leave, disappear”. Git- is confusable with kel- “come”, (q.v., and Clauson EDT ketür- 706, keltür-, kel- 716, etc.). Overlapping with Eng. in prime meanings, get- has rich and fuzzy semantics from “fetch” to “translate”. It lacks an universality of the Eng. word, an auxiliary plus about 36 meanings. In Eng., the semantics of the word expanded from a generic “receive, obtain, bring” to include a narrow “get (understand) an idea”, a local assimilation. There is no shared Pan-European or “IE” term, the European nomenclature is as atomized as they come. Indeed, the Eng.-Türkic term is a “guest” in Eng., carried from the depth of the E. Siberia over some centuries by a horsed relay. For a notion “get”, of the 44 European languages, a Celtic-Gmc. group fa- leads with 8 (18%) languages, followed by a Romance group with 6 (14%) languages.
To the remaining 30 (68%) languages that use 19 of their own and borrowed terms belongs a petite Eng.-Türkic group get with 2 (5%) languages. Cognates: A.-Sax. giet-, gotten, gat, gitsian “attain”, beget, (be)gietan, (be)geotan “get, find, acquire, attain, receive, take, seize, happen”, gitsian “attain”, (for)gietan, (for)git- “forget”, almost exclusively in compounds (vs. Scandinavian fa- < Celtic Ir. fhail, Scots faigh, Welsh gael); ONorse geta, gatum, very broad meaning, OSw. gissa “guess (metaphoric)?”, Goth. gatilon “attain, obtain”, gatiuhan “bring, take, draw, lead”, Dan. gæt, Gmn. geitzen; Hu. gondolom “I get it”; Serb. djuture “wholesale, drove, in droves”; Rum. gjoture ditto; Alb. kuturu ditto, Rus. gurt, gurtom (гурт, гуртом) ditto (Cf. Turkish götürü); Kor. gat-ayo (같아요) “I get it”; all “get” unless noted otherwise. The word has survived in the Balkans as a trading term on a wholesale supply of delivered goods. Sited as cognates the variations of ges- “guess” are inapplicable, they exploit a colloquial semantic extension of the get to shift from a direct “obtain, receive” to a metaphoric “don on, cached, get it (idea, news, etc.)”. Distribution: From Atlantic to Pacific, with a nominal presence in Europe except for a Balkan area with Türkic and Bosnyak (< Khakas: Pečenek) forms. Distribution screams of a non-IE origin. A stipulated faux “PIE proto-root” *ghend- and a faux “PGmc. proto-word” *getan are flimsy fictions, calques of the attested Gmc. forms and the clones of the attested Türkic forms. The newly reinvented “PIE” and “PGmc.” suffix -an (~ -en) is not a chance coincidence either, it is a relict from the Türkic morphology (-an, -än) for the effect of base intrans. verb (EDT xivi, OTD 658). Both the Türkic root and the suff. components were internalized into the Gmc. languages. Clauson noted a phonetic aspect of a -d-/-t- to -y- transition within a certain group of pre-13th c. Türkic languages, with -y- presumably a later form. That process pertains to the Gmc. languages, demonstrating zonal furcation into a more western get- and a more eastern gei-,
gey-. See Celt, give, God, Kelt.
3.98
gird, girt, girdle (v.) “put a waistband on or around”, girdle (n.) “sash, waistcloth” ~ Türkic qurša- (v.) “gird, begird, encircle”, qur (n.) “sash, belt”. An “IE etymology” bravely asserts a “PGmc.” and “PIE” origins, q.v. The stem forms 16+ semantic clusters extending from girdle to garden and far beyond, it includes celebrities Kurgan, Kur/Gur/Chur (royal title), and a trail of mundane vocabulary on anything encircling or encircled. A complimentary qür-/gür- extends vocabulary and emphasizes some words. A synonymous Türkic term is
bel- “belt”, see belt, and kušak “gird” () The Türkic loanword qur- predominates in Europe with 13 (30%) languages; grouped with bel-'s 3 (7%) languages, they account for 16 (37%) of the European languages. Sl. group pas- is a close second with 11 (25%) languages, trailed by a Romance group cin-
with 7 (16%) languages. The remaining 13 languages use versions of their own 5 terms. If there is a
“Pan-European” common word in Europe, it is a non-“IE” Türkic “guest”. Cognates:
A.-Sax. gyrdan “put a waistband, belt on or around; encircle, surround”, begyrdan
“gird, clothe”,
geard “hedge, enclosure”, forgyrdan “enclose, encircle”, gyrdel “girdle, belt”,
gegyrdan, gyrde “gird (sword)”, ongyrdan, ungyrdan “unbuckle, unfasten”, ymbgyrdan
“gird about, encircle, surround”, OSax. gurdian, OFris. gerda, gerdel, WFris. gurdzje, girdzje, Du.
gorden, gordel, ONorse gyrða, gyrðill, Sw. gjorda, gördel, Goth. gards, garths, OIcl. gerði,
Icl. gyrða, OHG gurtan, gurtil, Gmn. gürten. gürtel “belt”;
Welsh gwregysa; Gmc. and Sl. cognates of garden, court, yard, and
curtain; Sl. grad (град), gorod (город), gorodit (городить) (v.) “enclose, surround,
enclosed, surrounded”; Chuv. karta “fence”; Alb. garth “gird”, ngërthej
“bind, tie”; Balt. (Lith.), OSax.
“enclosure”; Gk.
korthílai (κορθίλαι); OHindi grhas “house”, ghira “encircle”, Av.
gǝrǝδo “cave”, Arsi oasis (aka Tokhar B)
kerciye “palace”; Phryg. gord; Mong., Kalm. bus “hoop, ring” is a semantic
mirror of Türk. parts of yurt; Türk. derivatives and
allophones yarïndaq, qur, qursaɣ “sash, belt”, kurgan “built kurgan tumulus”,
qurla- (Cf. garland),
qurša- (v.) “girdle”, qursaɣïl “be surrounded, enclosed”, etc.; all related to “gird,
encircle, enclosure” unless noted otherwise. Distribution: From Atlantic eastward along
Turkic Steppe Belt and spread out environs. A nominal presence in Europe except for a Balkan area with Türkic and Bosnyak (< Khakas: Pečenek) forms. Distribution also screams of a non-“IE” origin.
An “IE etymology” suggests a few grotesque ancestors: a faux “PGmc. proto-forms” *gurdjan
and *gurdijana (v.) “gird” and their ancestors faux “PIE proto-forms” *ghr-dh-, *gher-
(v.) “grasp, enclose” and *gʰerdʰ-, and a faux “PIE proto-root” *gher- “grasp,
enclose”. Mimicking the attested and traceable Türkic originals, they confuse “grasp” with “gird,
encircle”. A myopic take failed to note a salient case of paradigmatic transfer of the roots qur
“sash, belt” and bel “belt”. The pretentious ersatzes lead from nowhere to nowhere; they are
a disgrace.
The A.-Sax.
begyrdan “gird, clothe” is lit. a compound of 3 Türkic lexemes: be (bol) + gird (qur) +
dan (don) ~ “be donning a gird”. A paradigmatic transfer of 3 Türkic words in one 3-syllable
compound should have woke up any unconscious etymologist. The widely shared and still active agglutinated Türkic suffix
-t/-d forms abstract nouns. The distribution of the allophones and derivatives points to an
origin of the verb qur- to at least 5th mill BC (Celtic departure
from N.Pontic at or before 5th mill BC, Celtic in Europe 2800 BC, migration to India 1500 BC, Phrygian migration 1200 BC). Accordingly, that dates the Türkic abstract noun suffix -t to at least 5th mill BC, i.e. to the early stages of the nomadic massive expansions to Europe. The gird and belt are parallel constructions from their respective stems qur-/gur and bel “belt, waist”
respectively. Together, they present a paradigm transfer case attesting to an inheritance from a Türkic phylum. The bel happened to be just one of 12 synonyms for “belt”. See belt, court, curtain, garden, guard, yard.
3.99
give (v.) “gift, grant, bestow, confer, lend, impart, present, hand over, pass” (Sw N/A, F145, 0.16%) ~ Türkic qïv-, qïw-, guv-, kïv- “give, bestow, bless”. An “IE etymology” inaptly asserts a Gmc., and “IE” origin, q.v. A notion “give” is a part of a Türkic canonic idiomatic prayer qut qiv “(God, almighty) give happiness, blessing” where qut denotes “soul, life” and positive “happiness, blessing, grace, well-being, luck, success, happy lot”. A transition of qut to gut and Gott is a Gmc. internalization. An archaic qut started as a basic “food, survive”. The qïv “give” part is a request, prayer, appeal for a beneficial assistance in earthly needs; the other needs were covered by reincarnation. The qïv is synonymous with bağıš- (/baish/ with silent -ğ-) “bestow, confer, present” and ber- “give, hand over, grant”. In a Lat. calque
annuit the notion “give (blessing)”, “nod assent, anoint, favor, bless” is imprinted on the USA currency. The literal notion “give” had to coagulate long before a fuzzy sacral notion “bless, give blessing”. It can be timed at least to the first signs of Tengriism attested by the first cairn kurgans about 6th mill. BC. Some Türkic Sprachbunds sacramentalized the word qïv- “give”, replacing it with lay metaphoric meanings of other words (Cf. ber- “bear”). Other Sprachbunds (Cf. Gmc. gib mir “give me”) continued its use in its lit. sense. The Türkic trifecta of terms is a hierarchy of qïv- “bless, confer”, ber- “give, bring, bear”, bağıš- “bestow, grant”, with qïv- a most dignified and ber- a most mundane. In religious contexts
qïv-, kïv- is used as “bestow (a fortune)”, a relationship akin to the Eng. sg. you vs. thou. With little change in semantic accents, Eng. has internalized all three words, give, bestow, and bear, (Cf. dignified bestow and mundane give; the bear is more “carry” and less “give”). Of 44 European languages, a motley group da- dominates with 24 (55%) languages (Sl., Romance, Balt.), followed by a “guest” group giv- (Türkic, Gmc.) with 10 (23%) languages. The remaining 10 (23%) languages use 4 of their own native and borrowed terms. This is a rare instance when a European language has a “Pan-European” spread. It points to an early period of first African
Y-DNA Hg. I adventurers crossing to the Eurasia and spreading their lexis to the later newcomer migrants to the Eurasia. The word da- may be a first known word of the Eurasia. The later newcomers and migrants helped to spread the word from Atlantic to Pacific. A Bible tells that for the next 40,000 years that was an only language till in order to make peoples powerless, the Babylon Tower event formed innumerable demographic entities to re-educate folks to speak their own languages. Cognates: A.-Sax. geaf, giefan “give, bestow”, WSax. gief, OE giefan, OFris. jeva, ONorse gefa, ODan givæ, OHG geban, Goth. giban, MDu. gheven, ME yiven, Du. geven, Gmn.
geben; Mong. qubi (n.) “lot, destiny, fate” (< Tr. gobï “luck; empty, hollow, useless, unsuccessful”), qubiɣa- “divide, allocate” (but “give” - a Sl. nadad), Bur. xübi “lot, fate, fortune”, Khal. huw “fate, lot”, Kalm. xüve “portion of smth.”; all “give, bestow” unless noted otherwise. Distribution: From Atlantic to Pacific, with spot presence in Gmc. Distribution screams of a non-IE origin. The myopic “IE etymology” cites cognates only for a Gmc. group. That is profoundly misleading (otherwise called falsification or machination), Cf. expressions: Eng. give me, Gmn. gib mir, Tk. kiver min, Turk. kiv bana (m/b alternation), Az. mənə kivmək. A fictitious “PIE” surrogate *ghabh- “give or receive”, and a faux “PGmc. proto-form” *geban and its clone a faux “PGmc. proto-form” *gebana “to give” are mechanically derived from the Gmc. forms. Contrary to all contraindications they are brazenly assigned to a whole “IE family”. Etymologically, all that kitchen is unsustainable and needs to be gently rescinded. For the etymology of kiv-, G. Clauson waded through a series of cognates and analogues, in both sacral and secular fields, only incidentally referring to the embarrassing word
qïv- “give”. The OTD cites qïv- as a noun “fortune, fate”, but immediately cites expression qïvčaq (v.) qovï (n.), lit. “given (bad) fate”. The form qïvčaq positively attests that qïv- is a verb formed with exclusively deverbal adjectival suffix -čaq. Qovï is a grammatical noun with possessive 3rd pers. sing. and pl. suffix -ï: “given, bestowed (deverbal adj.) (bad) fated” (denoun adj.). The expression lit. means “unfortunate” ( adj.), i.e. “(his, their) bestowed (bad) fate”. The same is attested by the expression
qutadmaq qïvadmaq “be, become fortunate”, where qutadmaq (n.) is “fortune” and
qïvadmaq (v.) is “given”. Or expression qutluɣ qïvlïɣ “lucky, fortunate” where adjectival suffixes -luɣ, -lïɣ indicate possession of property: “lucky” + “given”. The word qïv “give” probably existed long before the primitive etiological figments crystallized into a harmonious system of Tengriism, which gave it a sacral connotation of “bless, send fate, give fortune”. That premise correlates with the first Tengrian cairns and kurgans of the Middle Volga, Samara, and Khvalynsk archaeological cultures dated by 8-6 thousand years ago. An A.-Sax. deverbal noun giefu, giefe (n.) “gift”, giefe, giefes (v.) “grace, favor” carried a sacral underpinning of the verb
qïv-, kïv- “give, bestow (grace, blessing, supreme favor)” documented in the sources (i.e. formulaic kïv kut “give grace, fortune”, see God). That is a case of paradigmatic transfer (See gift). In the eastern languages, the verb kiv- historically had a notion of expressly gracious form “bestow” vs. a mundane “give”. It can be asserted that the initial semantics of the
qïv-, kïv- was a mundane “give”; similarly to a use of archaic oration in other religions, starting with Sum., in the milieu of the eastern languages it shifted to sacred connotations. Traces of the gracious notion are clearly seen in the archaic Gmc.: “give, bestow; allot, grant; commit, devote, entrust”. In the internalized Gmc. languages “give” did not carry over a sacral connotation, attesting to its Gmc. origin from the western Türkic sphere, outside of the eastern Türkic languages. Suffixes -an/-en, documented in the Gmc. forms, are reflexes of the Türkic verbal suffix -an, -än (-n, -ïn, -in; -un, -ün) marking an active verbal voice. In the past, the origin of the word give remained conjectural at best, defying all attempts to find it. The word
give is a member of paradigmatic transfer of a large group of Türkic sacral terminology that attests to its common origin from the Türkic linguistic community. A very presence of these words in English is a clear attestation of a genetic inheritance, a significant evidence on the linguistic scales. See bear, bestow, gift, God.
3.100
go (v.) “move” (Sw N/A, F57, 1.08%) ~ Türkic git-, kit-, ket-, ked, keδ-, kej- (v.) “go”,
with notions “leave, depart, pass, disappear, die, refrain”, and as auxiliary verb of action. An “IE etymology” brazenly asserts a Gmc. and “IE” origin, albeit noting defective verb and cognate list, q.v. Ultimately fr. a primeval verbal root gi-, ki- “go” with a line of derivatives formed with once active suffixes -d/δ, -l, -r, -t, -v, -z, and a few more, Cf.
gel-/kel- “come”, Kelt “(new)comer”. It is nearly synonymous with it-, yit- “go, go in front, lead”, see itinerary. Both words were falsely appropriated into an “IE” arsenal. In modern English, past tenses of go (went < Türkic maŋ-, maŋla-/baŋ-, baŋla- (v.) “stepp(ing), stride” (m/b alternation) and be (< Türkic var- (v.) “be”) come from entirely different verbs, probably results of amalgamation. Of 44 European languages, a largely Sl. group iti- leads with 13 (30%) languages, followed by a mostly Gmc. (+Türkic) “guest” group go- with 11 (25%) languages. The remaining 20 (45%) languages use 16 of their own native and borrowed terms. The Sl. Y-DNA Hg. I was a first to cross fr. Africa to Europe, and had a priority in spreading its 40,000+ years old lexicon to the later migrants to the Eurasia. If there is a “Pan-European” common term in Europe, it is a Sl. term, by ca. 30,000 years ahead of the now dominating Europe Y-DNA Hg. R1 Türkic “guest” from a heart of Siberia. Cognates: A.-Sax. gan “go, advance, depart, happen, conquer” (but witan “go” (> went)), gaed (past tense), OFris., OSw. gan, MDu.
gaen, Du. gaan, OHG gan, Gmn. gehen; Fin. kiita “hurry”; Tokhar B
käl-, kel- “bring, lead”; Mong. kür- “arrive, approach”, Kalm. ketrxǝ “go by”, ketüre-, ketere- “leave” (< Tr. kät- “leave”); all “go” unless noted otherwise. In a large fraction of the Türkic vernaculars went on a transition of initial and inlaut k > č (//ch/). The form it-, yit- has produced OIr. synonymous eth-, ethaim “go, I go”, Ir. (bo)(i)thar “(cow) road”, Gaul. eimu “we go”; Goth. iddja; Balt. (Lith., Latv.) eiti, eimi, iet, eimu, iemu, eit, eisei; Sl. idya, ida, iti, idu, isi, issti; Lat. iter “way”, Skt., OHindi eti “goes”, Skt. jihite “leave”, Av. eiti; OPers. aitiy, Gk. adeia (αδεια). Distribution: covers the width of the Eurasia, crossing linguistic barriers, incl. most areas an “IE” foot did not trod. That positively refutes any claim to an “IE” origin. The forms' homogeneity across families (Celtic, Türkic, Skt., Gk., Fin., Tokhar, Mong.) points to a pre-2000 BC origin from a single linguistic node. A faux “PWGmc. proto-form” *gaian “advance, walk, depart, leave, happen, take place, conquer, observe, practice, exercise”, and a faux “PIE proto-form” *ghe- “release, let go” are a folk-type hyper-hypothetical speculations mimicking the attested Türkic forms. Other than a parade of intentional myopia, that nonsense contributes nil to the etymology of “go” and need to be gently rescinded. The Goth. forms are eidetic with Sl. and Balt. forms. They may reflect a panic confusion of the “killing fields” time that left enduring footprints. A Türkic prosthetic anlaut consonant g-/k- points to the Ogur form it > git, from which developed the Gmn., Skt. and Chinese 去 (shi) forms. The Türkic deverbal suffix -t is is a marker of deverbal nouns, see port. The Goth., Skt., OInd., Av., OPers., and Gk. forms point to an alternation
i-/e-. The form baŋ- is idiosyncratic because its many CT homophones are confusing and unsustainable; that makes it a potential diagnostic trait. Both Eng. and Tr. have preserved a semantics of intention. i.e. “I am going to do something”. The Celtic forms follow a Türkic grammar and attest to an existence of the word prior to the Celtic circum-Mediterranean anabasis of the 5th-4th mill. BC culminating in “killing fields” and long-range conquests. The Chinese word is likely a reflex of the ca. 1700 BC Scythian Zhou component. A peculiar uniformity across Eurasia rules out an origin from any of the “PIE-type” hypothetical kernel locations, leaving the Türkic nomads as agents of dissemination. A paradigmatic transfer of the synonymic words for go and be across languages vividly attests to a common source from a Türkic linguistic milieu. See itinerary, port, was.
3.101
gore (v.) “wound by piercing” ~ Türkic göreš-, kӧreš- (v.) “penetrate, fight, kill”, güreš-, kӧreš- (v.) “kill” (Robbeets M., 2004, #62), göreš, kӧreš (n.) “battle, war, fight, quarrel”. An “IE etymology” myopically asserts a Gmc. and “IE” origin, q.v. Ultimately fr. an adj. kür, gür “brave, mature, superior, eminent”, etc., popular across numerous languages from illiterate times. The Türkic derivatives göreš-, kӧreš- etc. have a wide spectrum of fairly close articulations, ca. 21 for a verb and ca. 20 for a noun; that reflects a degree of demographic dispersion. A paucity of the Türkic pinpointed semantics compensate for the heap of articulations: “fight, battle, quarrel” are the only meanings. In contrast, the A.-Sax. gar “spear, dart”, gore “piercing”, gara “corner, point of land, cape” are only a few of the many semantic extensions. The basic forms göreš-, güreš- and küräš- are connected by invisible ties (Cf. A.-Sax. garraes “battle”) with the kür, gür “courageous”, and the title “Kur, Gur, Chur”. They all came from a same ultimate origin, and settled in a raster of languages. Of 44 European languages, a motley group with Türkic gor- dominates with 24 (55%) languages, matching a level of a 50.6% Hg. R1a/b demographic presence in Europe. The remaining 20 (45%) languages use 14 of their own native terms. Other than a Türkic-based, there is no shared “Pan-IE” term. Cognates: A.-Sax. gar “spear, dart”, garcwealm “death by spear” (wealm < Tr. öl “death”), gara “corner, tip (of cloth, land)”, garbeam “spear-shaft”,
garberend “warrior”, garcene “bold in fight”, OFris. gare “cloth wedge, gore”, Du.
geronnen, Sw. göra, Norse gørr, Gmn. gehren; Heb. ngoah (לִנְגוֹחַ); Ir. goire “gore”, Scots gorren “pierce, stab”, Welsh gornio; Ru, Ukr. kol- “pierce”, Bolg. gjureš “gore”; Lith.
kraujas; Lat. cruore, Sp., Fr., It., encornar “gored”, Sp.guerra “war”; Gr.
gkor (γκορ); Finn. hurme, Hu. har-; Azeri koy; Arm.
aryun (արյուն); Georg. gori (გორი); Guj. gora (ગોર); Ch. geer (戈爾); Jap. goa (ゴア) “gored”, korosu “kill, murder”; Kor. go-eo (고어); all “gore” unless noted otherwise. Distribution: Ubiquitous across Eurasia, from Atlantic to Pacific, including a Gmc. enclave in Europe. This most ancient word is one of the early infiltrators into European languages. The amazing Eurasian distribution covers numerous linguistic families indicating widespread borrowing and a true mobile source not replicated till the Information Age. Cognates are found in nearly every Eurasian language save for relatively few. The uniformity of the forms points to a raster of loanwords spread from a linguistic node. A self-serving Gmc. and “IE” etymology with a line of delusions claims a patent on an origin. Those are the faux “PGmc. proto-forms” *gaizon- “?” and *gaizaz “?”, and the faux “PIE proto-forms” *ghaiso-“stick, spear” and *gʰoysos “?”, and a claim that “triangularity” is a “connecting sense” of all that soup. I.e. the war, the fight, the bravery, the battle, the titles, all supposedly descend from a sharp tip of a spear or a sharp end of a land plot. An audacity of that nonsense is striking. A spatial distribution of the allophones and derivatives points to an origin of the verb göreš- “fight” fr. at least 5th mill BC, Cf. Celtic departure from N.Pontic before the 4th mill. BC, Celtic in Europe 2800 BC. Its presence in the Celtic group attests to its presence in the Eastern Europe at 6th-5th mill. BC, way before 2-3 mill. later the first Kurgan waves ventured to the Central Europe. The göreš- must be one of the most ancient known Türkic lexemes introduced into European languages by people marked by a Kurgan R1b Y-DNA marker. The
distribution traces the spread of the Celtic people from Iberia, their incursion to the Apennines, and an independent overland path from the steppe belt to the Baltic and on toward Albion, a distinct path of the Kurgan people. The phonetic homophony is striking, and semantic match is perfect. In nearly every language has developed a nest of derivatives connected with wound, blood, piercing, kill, and many more. The Türkic lexeme could have been introduced to the Far East by the Xia nomads reported in the Chinese annals ca 2300, and by the Zhou “Scythians” Kurgans migration of 20th – 16th cc. BC. That attest to the Türkic cultural influence in forming the Chinese nation and language, and to blending with people that later came to be Koreans and Japanese. Its appearance in the Heb. may belong to the 7th c. BC time when in the Scythians dominated Palestine. It is one of the few Türkic terms in Hebrew. Its appearance in the Gujarati corroborates Gujarati claim to an origin from the Ephthalite Huns. The singular -r/-l alternation of liquids, characteristic to Chuv. but not to the Sl. group, and absent in the Lith. form, points to a separate Sarmatian path datable to the 2nd c. BC or to the Western Hunnic time. The distribution of the word, from Pacific to Atlantic, makes the etymological association with the Kurgan people and the Scytho-Sarmatians unavoidable. A connection of the gore- and quarrel
is equivocal: there is a different Türkic word (qaršï “1. palace, 2. quarrel”). See courage, quarrel.
3.102
grind (v.) “fragment, abrade, scour, scrape” ~ Türkic qïr- (v.) “scratch, scrape, scrub”, reflexive form qïrïn- (v.), passive deverbal noun (Turkm.) ğırındı, Khak. kırındı: “crumbs, small fragments”. An “IE etymology” myopically asserts a Gmc. and “IE” origin, q.v. Ultimately fr. an archaic root-notion qï- “bad, negative” that grew into more specialized notions: qïp-, qïr-, qïs-, etc. Besides “scratch”, it also denotes “uproot (plant)”; altogether, the verb carries 11 semantic clusters, from “scratch” to “bend”. Elision of two vowels shows that the Eng. word was internalized in a furnace of a heavily consonantal language with aversion to “extra” vowels. A modifier -ındı comes from suff.'s -ın and -di. A group g(V)r- has a minor presence among 44 European languages with 3 (7%) languages (Türkic, Eng., Friz.), far behind a motley dominating group mal- with 20 (45%) languages, and a mixed sl- group with 6 (14%) languages. The remaining 15 (34%) languages use 11 of their own native terms. The mal- group (Cf. Sl. molotit (молотить) “thrash”) is a best approximation of a shared “Pan-IE” term. The
notion “grind” is distinctly a “guest” in Europe: in Europe, the word is an oddball, an overt loanword.
Cognates: A.-Sax. grindan “grate, scrape”, cearclan (with k-) “gnash”,
cearcetung (with k-) “gnashing, grinding”, forgrindan “grind down”, etc., Saterland Fris. griende, griene “grind, mill”, grind “gravel, shingle”, Du. grenden “grate, scrape”,
grinden “grind”; Lat. frendere “gnash (teeth)”; Gk. khondros “corn, grain ?”; Sl.
koryabat (корябать) “scrape”; Lith. grendu, gresti “scrape, scratch”, Alb. grind “brawl, fight”; Mong. khusakh “scrape” (s ↔ r); all “scratch, scrape” unless noted otherwise.
Distribution: Türkic Steppe Belt plus excursions to Albion and Mong. An “IE etymology” asserts the unworkable “PG” and “PIE” origins: faux “PGmc. proto-forms” *grindanan, and *grindana, and a faux “PWGmc. proto-form” *grindan, and a faux “PIE proto-form” *ghrendh-, all supposedly “grind”. Since all that pile conflicts with the attested but not acknowledged Türkic material, that entrepreneurship is not needed. Attempts to invent some made to order “proto-word” are misleading and misguided. The myopic inventions need to be gently discarded. The Lat. version is so distinct fr. the Gmc., Sl., and Türkic forms that apparently Lat. carried its word via a separate route, even if “scratch” and “gnash” are seen as homonyms. A most interesting are the intermingling Celtic and Sl. forms: bleith and meileann (b ↔ m) vs. mleti, melene, etc. A phonetic and semantic continuity between the Türkic and Eng. allophones stands beyond any doubts. A paradigmatic transfer of a related cluster grind, curt, short attests to a common genetic origin from the Türkic milieu. See curt, short.
3.103
guess (v., n.) “suppose” (Sw N/A, F214, 0.07%) ~ Türkic us- (v.) “think, suppose”, us (n.) “mind, wits, thought, supposition” . An “IE etymology” blazingly asserts a Gmc. and “IE” origin, q.v. Ultimately, once us- was a single-vowel word u/ö, Cf. awe < ö, see awe. The word us-/guess is a member of an intellectual complex transferred to English as a paradigm: ö-, san-, saq-, us-
which respectively made the Eng. awe, sanity, sagacity, guess, see awe, sagacity, sanity. An Ogur prosthetic anlaut consonant g- did not always survive, it was supplanted by an Oguz
non-prosthetized form beginning with vowel, Cf. A.-Sax. geong “young” vs. Eng. young and Tr.
yangi:, see young. The form us is one of the series us, hus, hos, is, üs, ug, uq, ög, ök with related and at times overlapping semantics “wit, mind, think, smart, suppose, percept”, etc. The Türkic forms developed in closely related vernaculars, in allophonic forms attaining synonymous modifiers -s, -g, -q, -k. Each form blossomed in Sprachbund environment into derivative clusters of initial root form and a bouquet of fraternal lines. They underwent a sequence of
Sprachbunds' amalgamations. Descendent Sprachbunds retained bouquets of articulations and semantics. To a certain degree English is a linguistic island preserve filled with joyful zombies.
Guess is an allophone of us- “think, suppose” with a prosthetic anlaut g-/ɣ-, attested by a Romanized pronunciation hus-/hos- and spelled e.g. gus- and hus-. Of 44 European languages, a group of Türkic us, gis- dominates with 9 (20%) languages, followed by a Sl. group -gad- with 6 (14%) languages and a rad- group with 4 (9%) languages. The remaining 25 (57%) languages use 16 of their own native terms. There is no shared “Pan-IE” term, a leading European term is Türkic-based. Cognates: A.-Sax. none, guess supplanted native terms araedan, eaðraede, eðraede, aleo “guess, prophesy”; MEng. gessen “guess”, Saterland Fris.
gisje, ODan. getse, gitse, getsa “guess”, MDan. gitse, getze “guess”, Dan. gisse
“guess”, MDu. gessen, Du. gissen, ONorse geta, Norw. gissa, gjette, Sw.
gissa, Icl. giska, MLGmn., LGmn. gissen, Gmn. vermuten (< ur + muten “divine”); Ir. tuar, thuig, Scots tuigsinn, guidh, Welsh gesio; Latv.uzminet; Rus. gadat, ugadat (гадaть, угадaть) “conjecture, guess, divine” (< ug;
угадaть < ug + дaть, lit. guess + give), Ukr. (v)hadaty ((в)гадати) (< ug), Sloven. verjetno, Bosn. valjda; Rum. ghici; Hu. esz “perception; awareness”; Alb.
gjëzë “riddle”, gjej “find, recover, obtain”; Mong. oi ~ оуun, оуin “mind, sense”, oi ~ оуun “wisdom”, Kalm. es “perception; awareness”; Tung. (Solon, Evenk.) oimar “insane, crazed”, oibangu “lost mind, grown old, forgetful”; Manchu ojbo ditto; Chag. us, is, es “mind, sense”; all “guess” unless noted otherwise. An Arab. form ğuš, ğušiya “not to understand, to be at a loss” closely parallels the Tr. compound idiom (g)usi az- “guess”, in
both cases lit. “understand little”.Tracing a two-phoneme word in a sea of articulations and morphologies is a somewhat goofy task of balancing fluid articulations with concrete semantics in an imprecise science under an umbrella of a distinct notion “mind”. Distribution is peculiar, largely across a width of Eurasia with confined outlier islets in the far west and the far east. Among a mass of the European languages it is an oddity. The “IE” etymological attempt to equate “guess” and “get”, and then use “get” to invent etymology for “guess” is ludicrous. The “get” is not a salvation: a Türkic action get-, göt-, ket-, köt- (v.) “bring, carry, deliver” is unrelated to a purely mental “guess”. The wild guesses “perhaps” and “probably” stipulate a vague Scandinavian or NGmc. origin and offer a slue of faux specifics: the faux “PGmc. proto-forms” *getan “get”, *gitisona “guess”, *getana “get”, *gitiskona “?”, and an apogean faux “PIE proto-form” *gʰed- “take, seize”. All that galimatia has no use and no standing. It leads fr. nowhere to nowhere, and given a wealth of attested but neglected documentation, only exposes a degree of institutional ignorance. A MDan. prosthetic inlaut ligature -ts-/-tz- does not form a notion “get”. The Eng. ligature -ue- apparently attempted to transmit a -u- sound conventionally spelled in English with -oo- (Cf. cook). The guess is peculiar only to a handful of specific languages originated in a non-“IE” phylum. Only a European Scotts word may claim its primeval origin from the time of the Celtic departure from the E. Europe sometime before the ca. 4th mill. BC. However, except for the Türkic original, all other European “guesses” are much later acquisitions, not earlier than the Corded ware period. A modern phonetics /ges/ is reconciliation between a customary pronunciation and the written form. The Arab form with the prosthetic anlaut g- attest to an Oguric source for both Türkic and Ar. languages; its timing is no earlier than a first Ar. encounter with the Türkic nomads. That is also a vivid testimony against a “PIE” origin. An assertion that the word us is peculiar to the Türkic “purely Western word” (Clauson EDT 240) is clarified by a statement that “the form us is typical in south-western areas, the form es is typical in north-western languages and Uzbek and Uigur (Karluk group), and both forms are used in Kipchak (CT)” (EDTL v.1 606-607). The Huns collected tribute from the Far Eastern China in the 2nd c. BC and then from the Mediterranean Rome in the 5th c. AD, they profoundly defy the Eastern/Western areal presumption. An allophone distribution rather resembles a pie chart, with sectors shaded by geography and colored by modern ethnic assemblies. The presence of the fossil R1a Y-DNA marker both in the Western Europe and in the Far East tells that the Hunnic western incursion of the 4th c. AD probably was neither a first nor the only one. A transfer of the entire intellectual paradigm, q.v, the phonetic and semantic match indelibly attest to the genetic connection with Türkic linguistic field. See awe, cook, sagacity, sanity, young.
3.104
hack (v.) “chop, cut away” ~ Türkic kıyık, köčük/köyük, kyjyk,
qyjyk, kıj-, kıd- “hack, chop diagonally, mince”. An “IE etymology” dazzlingly asserts a Gmc. and “IE” origin, q.v. Ultimately fr. a verb kıj-/qıj- “hack, chop diagonally”, a derivative of a primeval word
kı-/qı-, probably connected with reducing experiences: a verbal suffix -ki, -qï denotes decrease, Cf. Tr. yakı “humble, vile”, Eng. yucky “disgusting”. An inlaut is spelled with -y-/-j-, -d-, -k-, -g-, and an unvoiced -č-, all probably dancing around /ʤ/. A derivative qıyaq “sedge” refers to its spikelets that cut into hands. An indiscriminate noun/verb root attests to its antiquity, an yearly stage of the language. Türkic has numerous allophones and derivatives, and wide semantic range, attesting to deep antiquity and geographic spread. The differing morphologies of the siblings indicates that the branches did not mingle too much. In Europe, cognates of
kıyık “hack, chop” are popular: of 44 European languages a motley group of 15 (34%) languages uses versions of hack (Türkic, Gmc., Fin., Ir., Fr., Malt., Yid.), followed by a Sl. sek- group with 6 (14%) languages and a haphazard group pir- with 4 (9%) languages. The remaining 19 (43%) languages use their own 12 different terms. There is no shared “Pan-European” term in Europe, a leading European term is a Türkic-based. Cognates: A.-Sax. haccian “hack” tohaccian “hack to pieces”, hacod “haked, pike”, ahaccian “pick out”, OFris. hackia “chop, hack”, Saterland Fris. häkje “hack”, WFris. hakje “hack”, Dan. hakke, hugge “chop”, Du. hakken “chop up, hack”, Sw. hacka, hugga “hack, chop”, ONorse, Icl. höggva, hoggva “chop”, OHG
hacchon, Gmn. hacken, hecht “chop, hack, hoe”; OFr. hache “axe, pickaxe”, hachete “hatchet”, Fr. hacher “chop”; Hu. hasit “split”; a Sl. kuü, kovat (кую, ковать) likely transferred pre-metal terminology to metallurgical times; Mong. kidu- “exterminate, kill, annihilate”, Bur. hüdaha ditto, hüdasha “cutter (occupation)”, Kalm. kudh “exterminate”, Kalka hyadah “kill, annihilate”; Osm. kyj- “break into small pieces”, Tuvan
xïdï- ditto, Soyot xydy- “exterminate, annihilate”, Sakha qïdïy-
ditto; all “hack” unless noted otherwise. Distribution: Eurasian spread fr. Atlantic to Pacific, across linguistic borders. A myopic “IE” etymology missed ca. 90% of the related Eurasian territory and its vocabulary. An “IE etymology” asserts fictitious “PG” and “PIE” origins: a faux *hakkon (“?”) and a faux “PWGmc. proto-form” *hakkona “chop, hew, hoe”, and a faux “PIE proto-forms” *keg-, *keng- “sharp, peg, hook, handle”, *kau- “hew, strike”, and a faux “PIE proto-root” *keg- “hook, tooth”. Accidental references to a later Eng. “hew” and the ONorse, Icl. höggva are the only accurate assertions, a granule of truth in a pile. That pile conflicts with the attested but omitted Türkic material. The go-getting is not needed. Made to order “proto-words” inventions are misguided and misleading. The myopic inventions need to be gently discarded. A compact European distribution points to a demographic migration of a Battle Ax culture fr. the NE. Europe to Scandinavia and on westward and southward. The dispersion did not touch the Romance and Indo-Iranian branches with their native terminology. The conundrum is clear, either Northern European, or Southern European (Lat. trucido), or Indo-Iranian version (Pers. nofuz) can be held as “IE”, but not all three. The OFr. form with -ch vs.
-s/-sh and vs. -k forms probably reflects a Middle Age Alan or Burgund source. These were the western Türkic branches, collectively called Sarmats, they carried the form hach/hack to the Northern Europe and to the Ugrian languages. The transition k/h is regular between the OT (Oguz) forms and Gmc./Eng. forms, e.g. gird ~ hilt. A Türkic origin is impeccable. See curt, cut, short.
3.105
harm (v., n.) “damage, injury” ~ Türkic ur-, wur- (v.) “beat, strike”, “swelling (body)”. An “IE etymology” myopically asserts a Gmc. and “IE” origin, q.v. The ur-, wur- is a root base of undifferentiated verb/noun function neutral to transitivity, attesting to its utter archaism. It bears 11 semantic clusters, plus 15 “loose” meanings, plus numerous paired idioms. The form
wur- is a most rare case of a prosthetic anlaut. A word's penetration into eastern languages has long been established. The Eng. and Gmc. allophones of ur- have acquired a prosthetic anlaut h-
(w- ↔ h-) typical for the Gmc. and Sl., A.-Sax., and Cockney, attesting to a probable path distinct from that for the word wound (< yon, prosthetic v- ↔ w-), see wound. That hypothesis is supported by a presence of the ONFr. hurter “strike, collide”, in contrast to a compact distribution of the harm and wound cognates. The synonymy and consonance suggest that harm is an allophone of hurt that reached A.-Sax. together with wound but separately from hurt, see hurt, wound. The A.-Sax. hearm ends with with the auslaut
-m, a relict of the Türkic/Celtic suff. -im “me”, Cf. Tr. ursïqïm “(beaten, stricken I am)”. The same process with a Türkic 3rd pers. suffix -ti:/-di: produces the forms hurt (v.) and hurt (n.) with with a deverbal abstract noun suffix -t, see
port. Cognates: A.-Sax. awyr(dnes) “hurt, harm, destruction” (< ur-),
hearm “harm, damage, hurt, pain, injury”, etc., hearmian “hurt, injure”, iernan “ride, gallop, pursue” (< ur-), ierre “angry, fierce”, ierrenga “angrily, fiercely”,
ierscipe, iersung “anger” (< ur-), OSax. harm, OFris. herm “insult; pain”, OE hurt (1200) “injure, wound”, Eng. hooray, hurray, hurrah, huzzah, hoorah “battle call to violently baste” (< Tr. ura! “strike, beat”), Dan. hurra ditto, Du. harm “harm”
hoera “strike”, ONorse harmr “grief, sorrow”, Sw. harm “anger, indignation, harm”,
hurra “strike”, Norw. hurra “strike”, Icl. harmur “sorrow, grief”, OHG, Gmn. harm “harm, grief, sorrow”, hurra “strike”; Fin. pure “bite, chew, sick, afflict, ail, burn, fever”; Mong. uruldu- “competition, contest, races”, Kalm. urida ditto (< ur- “beat, strike”, OT “battle”); Manchu fori “beat, strike, signal dawn, knock (on gates), drive (nail, stud)”; Kor.
pure “into pieces, smithereens”; all “harm, injury” unless noted otherwise. Distribution: Eurasian-wide fr. Atlantic to Pacific, across linguistic borders. The form ur- overwhelmingly dominates; a minority of forms vur-, wur, var-, and uj-/uy- is scattered. The Türkic call urа! “beat (them)!” in its numerous reiterations became an international war cry; that fact remains sorely unknown to the “IE etymology” experts. The “IE etymology” boldly reinvents a fresh tale for a hoary past: a faux “PGmc. proto-form” *harmaz “pain”, a faux “PGmc. proto-form” *harmaz “harm; shame, pain”, a faux “PWGmc. proto-form” *harm, a faux “PIE proto-word” *kormo- “pain”. It is touching that in the “IE” kitchen not only a form and a meaning, but even location (WGmn.) could have been asserted. At the same time, a more prominent siblings hurrayand hurt are left with “etymology unknown”. Cognates are absent in the Romance and the Asian “IE” groups. An oddball loanword in ONFr. probably ascends to an Alanic source. While Goth. does not appear to have a cognate for harm, it has numerous synonyms shared with A.-Sax., pointing to an older common Goth. - A.-Sax. linguistic base. With a discrete and unique paths for each member of the linguistic community, they amalgamated with Türkic languages. The word's ubiquity in the Gmc. group attests to, first, distinct northern and southern Sprachbunds, and second, to the later internalization by the northern Gmc. group, after ca. 1500 BC the Romance farmers bounced back to the south-central Europe, and the Indo-Aryan farmers departed ca. 2000 BC on their S. Asian trek. The possible time for the internalization appears to be the long period from the Corded Ware bloom to the Sarmatization of the North-Central Europe. The Türkic idiomatic compound ur- yon- combines two nearly synonymous words into an emphatic pair, of ur- “beat, strike” and yon- “wound, hew, cut”, translated as “beat, torment”, see allophonic forms of ur- hurt, hurl. A paradigmatic transfer of the cluster harm and hurt, hurl ascending to a common root ur-, and the
ur- “injure” and yon- “wound” separately, and ur- yon- paired in an attested Türkic emphatic idiom, provide irrefutable evidence of the Türkic origin for these words. See hurt, hurl, wound.
3.106
have (v.) “possess”, (n.) “possessor” (Sw N/A, F19, Σ1.25%) ~ Türkic qab-, qap-, kap-
(v.) “keep, hold, seize, grab”. An “IE etymology” myopically asserts a Gmc. and “IE” origin, q.v. Ultimately fr. a verbal root qab, qap, kap (v.) “grab, enclose” (lit. interpretation), or a a container (metaph. interpretation), see cap, cup. The verb has 7+ semantic clusters containing at least 30+ meanings, with a prime meaning “grab”. That points to an origin from a trapping hunt, i.e. a deep antiquity. The have is an allophone of keep, is partially interchangeable with it, see keep. The notion “have” is of atypically “European” nature: 44 European languages use only 11 roots, a salient uniformity pointing that the notion “have” formed differently from a usual, which mostly vary doubly or more of that. The causes of that uniformity lay in consistency of Sl. and Türkic-Gmc. lexicons, the first of -ma- with 13 (30%) languages, the second with ka- with 12 (27%) languages. The remaining 20 European languages follow a customary distribution with 9 roots used by 20 (43%) languages. The Sl. and Gmn.-Türkic form a diplex of “Pan-European” terms in Europe. Without a Türkic-based lexicon, Sl. is a “Pan-European” term of Europe. Cognates: A.-Sax. habban, hafian “keep, have, guard” (also with prefixes at-/aeth-, be-, n-, etc.), nabban “not have”, aethabban “retain”, ofhabban “held back”, OSax. hebbjan, OFris. habba, WFris. hawwe, Saterland Fris. hääbe, Dan. have, Du. hebben, ONorse
hafa, Norw. Nynorsk ha, Sw. hava, Icl. hafa, LGmn. hebben, hewwen, Goth. haban “keep, have, possess, hold”, Gmn. haben; Lat. capere “grasp, seize”, capio “take”, It. capisci, Sp. capiche “seize (an idea, a thought)”; Rus. xapat (хапать) “seize”; Alb kap “grab, catch”; Fin. kaapata “capture”; Hu. kap “receive, get”; Mong. havshix “bite (fish)”, Kalm. xawl- “catch (ball), bite (fish)”; all “have” except as noted. A cognate line can keep going for a good while more, only the Eng. has 11 formalized forms for “have”. Generations of linguists massaged the word for more than a century, and there is still more to grasp.
Distribution: is typical for Türkic loanwords: Eurasian steppe width with some far western and far eastern appendages, across linguistic barriers. The quasi-etymologies reek of myopia and quasi-scientific charlatanry. They dead-end at neologic “reconstructions” with a faux “PGmc. proto-form” *habejanan “have” and a faux “PGmc. proto-form” *habjana “have” and a faux “PWGmc. proto-form” *habbjan “?” and a faux “PIE proto-root” *kap- “grasp” and the faux “PIE proto-forms” *khpyeti, *kehp- “take, seize, catch”, and a have “related to heave” with heave meaning “utter, throw, rise, move, lift, breathe, bend, retch”. That nonsense innocuously claims the Türkic qab- “grab”, abstract suffix -an, and a verbal suffix -ti as Gmc. inventions. Somehow, a cognate keep was assigned another faux “PIE proto-word” *gab- “to look after”. There is no sane “IE” etymology. In a blink of sanity comes a sober grand finale: “PIE probably lacked the have structure”, i.e. “have” was expressed with non-“have” devices. In Türkic languages possession is formed by a choice of suffixes, most frequently -lig/-lïɣ, so a need for a separate verb “have” is minimal and it is usually formed by a denoun verbal expression “be” or “be owner”. A European notion “have” is mostly formed fr. a notion “get, grab, hold”. A re-purposing of the notion to a “have”, and its use as an auxiliary verb with heavy syntactical load are uniquely European. It is typical to particular European areas and to the European vernaculars. Although different groups of vernaculars adopted different Türkic verbs, they are calques of the Gmc. “have”: Türkic taŋ /tang/ “tie” > Romance tengo, tener “have”, Türkic menin “mine, my” > Sl. moi, imet, Fin. minun. The internalized phonetic and semantic match was soundly established within the “IE”-centered etymology. The Romance cognate capisci, capiche, capere was assigned a faux Romance “proto-word” *kapio. The omnipresent importance of the “have” in Gmc. languages is supreme, it fills 1.25% of the English daily lexicon, or every 80s word in a random English text. It is too hard to bungle. A listing of paradigmatically transferredqab, qap, kap- in English number in dozens, an inextricable evidence of a common genetic origin from a Türkic phylum. See cap, capture, cup, keep.
3.107
hide (v.) “conceal” (Sw N/A, F1128 Σ0.01%) ~ Türkic qod-, qud- (v.) “put aside, deposit,
lodge”, (n.) “inside, bosom, hollow”; the “hide” (v.) and “hide” (n.) are concrete semantic extensions. An “IE etymology” myopically asserts a Gmc. and “IE” origin, q.v. Ultimately a derivative fr. a root qo “lay, drop off, complete, completeness, done, leave behind”, e.g. something finished and over. The Türkic term means “placed inside, into the bosom”. With a noun-producing suffix -qa, -ɣa, -gä, -kä it forms quyaɣ “armor, cuirass, shell” (lit. “over a bosom”) and qudqa (n.) “hide, pelt, skin”. At a high end of the Türkic variability are acoustic modifications. The transitions g, k, q to h, and of a semi-consonant y to th/t/d are consistent with observed linguistic modifications; they may be a result of assimilation into an alien linguistic system, or a local development within a Turkic family under an influence of an alien linguistic system. A primeval second consonant wobbles between -d, -δ,-n, -y. Observed alternations suggest an initial form kon, kod, and hint on a dialectal split, bifurcated into western and eastern forms for Celtic (-l/-n/-r forms) and Gmc. (-d form). Of 44 European languages, a Sl. (& 1 Celtic) group kri- dominates with 10 (23%) languages, followed by Türkic - Celtic - Gmc. - Lat. group
qod- (> hide) with 7 (16%) languages and a mostly Romance esk- group with 4 (9%) languages. The remaining 23 (52%) European languages use versions of 16 their own native words. There is nothing like a common “Pan-European” or “IE” term in Europe. The European lexis is a quilt with a Sl. largest patch. Naturally, there is nothing “Indo-” in the European languages. A motley Türkic-European lexicon indelibly attests to a loanword status of the Eng. hide. Cognates: A.-Sax. hydan, hedan, MDu., MLG huden “hide”; Ir. cheilt, chur, chun “hide”, Scots seiche (< Sl.), Welsh
guddio, kuddio, chuddio; Gk. keuthein “hide, conceal”; Mong. ebür “bosom”, övör “southern slope, bosom, breast”, qodi- “late”, Mong., Bur. hojguur, hojno “behind, northward”, hoksho “back, northward”, hojmor “northern side” ~ “back side” (initially – “pectoral indentation”, then – “bottom of inside clothing”); Bur. übər “southern, i.e. frontal slope, frontal or solar side, bosom”; Kalm. övr “bosom, garment board”, “southern, i.e. frontal slope”; all “hide” unless noted otherwise.Distribution: is typical for Türkic lexicon, ubiquitous across the length of Eurasia, and spotty along the fringes. The “IE etymology” is feeble. It uses a severely myopic series of “reconstructed” ersatzes to establish a self-serving paradigm. Those are a faux “PWGmc. proto-form” *hudjan “cover, conceal?” and a faux “PWGmc. proto-form” *hudijan “conceal” and a faux “PGmc. proto-form” *hudijana “conceal” and a faux “PGmc. proto-form” *hudiz “conceal” and a faux “PGmc. proto-form” *hudi “conceal”, followed by a faux “PIE proto-form” *keudh- “cover, conceal” and an attested Gk. keuthein “hide, conceal” (< Tr. qud-), and a faux “PIE proto-root” *(s)keu- “cover, conceal” and a faux “PIE proto-word” *(s)kewdʰ- “cover, wrap, encase” and a faux “PIE proto-word” *(s)kewH- “cover” and a faux “PIE proto-word” *kew(H)tis “skin, hide” (skin (n.) ≠ hide (v.)). All those bogus “Gmc.” speculations follow “PIE” speculations that follow the attested Gk. word that is a loanword fr. the Türkic attested original qod-, qud- and its well-documented etymology. The myopic speculations miss a use in the “Gmc.” ersatzes of a Türkic verbal suffix -an and in a Gk. a calque, thus missing substantial inherited morphological elements. The whole enchilada of speculations addresses only selected samples forged for predestination, and loosely resorts to random, unsuitable, and far-fetched cognates, at first attempt like “eyebrows” and “clouds”, “hut” and “sky” and “guts”, later – “wrap, encase”, “skin (n.)”, unwittingly echoing the Türkic semantics of “inside, bosom”. The Celtic cognates carry a mark of a local Sprachbund, the Ir. chun (~ hun) reflects a form cited by G. Clauson (EDT 631). The Celtic forms suggest two separate paths, one overland, and the other a Celtic circum-Mediterranean path. The Mong. semantics ascends to a base semantics of a root qo-. A Gmc. origin is laughable, the Türkic origin is impeccable. See gut, hide (n).
3.108
hit (v., n.) “afflict suddenly” (Sw N/A, F479, 0.02%) ~ Türkic at-, ït-, it-, jit- (yit-)
(v.) “push, thrust, shoot”. An “IE etymology” myopically asserts a Gmc. and “IE” origin, q.v. Ultimately fr. a verbal root at- “throw, cast”. The word has at least 10 semantic clusters; a prime notion of the verb is “throw”, cited in all semantic listings of the verb, along with secondary meanings like a “hit”. A voiceless affricate jit- has voiced semantic and phonetic siblings chit- (Cf. cheat) and shit- (Cf. allophones shot, shoot). A likely blank for the A.-Sax. form shot was a form at- more common in circulation. The internalization shot and shoot is distinct and by a different rout from the form hit. Of 44 European languages, a Sl. group (u)dar- dominates with 10 (23%) languages. It is followed by a modest Gmc. group sla- with 4 (9%) languages. The remaining 30 (68%) European languages wield versions of 17 their own native words, including Türkic-Eng. at and a hit with a prosthetic anlaut h- typical for Gmc. languages. If there is a common “Pan-European” or “IE” term in Europe, now it is a Sl. word. But before it became a Sl. European word, it was a Türkic word dara- “attack, pounce”. So, a real compounded Türkic contribution to the European “hit” stands at least at 12 (27%) languages. A meager presence of the word in the W. Europe attests to its “guest” status there. Cognates: A.-Sax. cnossian “strike, hit upon”, sceotan (with sh-) “hit, hurl, strike”, foresceotan “anticipate, forestall, fore-hit”, ofsceotan “shoot down, hit”, sceat, sceotan, sceoton, scuton, scoten, scyt “shoot, hurl, cast missiles, strike, hit”, hydan, hyttan, hittan, hittan(y) “‘hit’ upon”, OE hyttan, hittan “hit”, Dan., Norw. hitte “hit, find”, Sw., ONorse hitta “hit, strike, meet, find”, Norse, Dan. hit, hitte, Icl. högg, Gmn. hauen; Fr. heurter; Balt. (Lith.) atsitrenkti; Gk. epitychia, ktypi̱ma, chtypo, ktypo (επιτυχία, κτύπημα, χτυπω, κτυπω); Alb. qit “hit”; Kor. ath “throw away”; all “hit” unless noted otherwise. Distribution: Ubiquitous across much of Eurasia, fr. Bulgar to Uigur and the fringes. The “IE etymology” is myopic and wussy. It uses a blend of “reconstructed” ersatzes, source fr. “of uncertain origin”, a vague reference to a “Scandinavian source such as”, “shifted meanings”, and the like. The myopic “IE etymology” misses reality and resorts to fictitious creations. Those are a “PGmc. proto-form” *hittijana “come upon, find” (for a notion “hit”?), a faux “PGmc. proto-form” *hitjan “?”, and a faux “PIE proto-word” *kheyd- “fall, fall upon, hit, cut, hew”. Those constructs are etymologically useless, and as a self-serving paradigm need to be discarded. In contrast, the attested material is concise and pinpointed. Other than a faux “reconstruction” hit = it “this one” that unwittingly hits on the prosthetic initial h-/k- stipulated above the word has no “IE etymology”. For the hit, in spite of the extensive Gk. forms, not even “of unknown origin”. The prosthetic h-/k-/ch- allows to suggest an Oguric origin, like Sarmat, Hunnic, and Bulgar for the northwestern European zone, and Gk. forms and Oguz for the Lith. form. A prosthetic anlaut consonant at the northwestern European cognates of the Türkic lexemes is typical for the other cognate forms. Indeed, a perfect phonetic and semantic match makes a random phonetic coincidence between the numerous European languages and even more numerous Türkic languages impossible. An origin from a Türkic linguistic milieu is impeccable.
3.109
howl (v.) aka wail, yawl, yell, yowl, holler “shout, loud cry” ~ Türkic ulï- (v.)
“howl”, yel (n.) “howl, wind”. An “IE etymology” myopically asserts a “probably” “of imitative origin” and/or Gmc. and “IE” origin, q.v. Ultimately fr. a single vowel root u-, e, ye- with other variations plus archaic suffixes l- and ŋ-. A semantically related yaŋ (n.), yaŋra- (v.) “echo, loud reverberation” suggests that the initial root was ye-/ya- “loud sound, boom, roar, thunder”, and the l- and ŋ- once were morphological discriminators. For a raster of verbal notions, cognates, and development of the notion “howl/wail/yell” as a verbal derivative of the yel “wind”, see yell. Türkic forms come in an abundance of variations and a raster of semantic shades: jel, uwla-, uwlä-, u:la-, y:la-, uγulda-, uvulda-, uwïlda-, and much more. The Türkic verb
ulï- “wail, moan, bellow” is an allophonic derivative of the noun and verb yel. Phonetic range is wider than usual, just for yel dictionary lists yel, yǝl, yil, yi:l, jiil; yïl,
jel, djel, žel, žil, zel, del, chil, šel, sil, kül(ək), plus Pers., Mong., Tungus, Manchu versions. Distinct forms afford valuable diagnostic opportunities. For the noun “wind”,
A.-Sax. had adopted a peculiar “IE” form, an allophone ve- of A.-Sax. hallmark prosthetic anlaut
v-/-w and -l/n- variation, consistent with numerous “IE” allophones, Cf. Lat. ventus,
ululo “wind” “howl” and Gk. anemos, ourliazo. Dictionaries tend to disperse allophones in
alphabetical order, separating allophones far and wide. The European forms including Eng. are transparent allophones of the Türkic prototypes yel, yaŋ, etc. A basic word turned to be a nice loupe into the “IE” origins. Of 44 European languages, a Türkic-Eng. ulï-, yel, howl
predominates with 20 (45%) languages, approaching a level of 50.6% Hg. R1a/b demographic presence in
Europe. It is followed by predominantly Sl. groups url- and voy- with 5 (11%) languages each, but url- is most likely a version of the Türkic ulï-. The remaining 14 (32%) European languages wield versions of 8 their own native words. If there is a common “Pan-European” term in Europe, it is a Türkic word. Cognates: A.-Sax. gyllan, OE giellan, Mercian gellan “yell”, allophonic cognates “gale”, “nightingale” from gaile “wind, song” fr. howl, claimed as “origin uncertain”; ONorse gjalla “reverberate”, gol “breeze”, galinn “bewitched”, OHG gellan, MDu. ghellen, Du. gillen, Gmn. gellen “yell”; Welsh weiddi, gweiddi “yell”; Balto-Sl. (Latv.) kliegt, (Lith.) kliegti “yell”; possibly Gk. kikhle (κίχλη) “songbird”; Hu. szel (sel) “wind”; Mong. salki (n.) “wind”; Even. nələ “wind”; all “howl, yell” unless noted otherwise. Distribution: Is typical for Eurasian Turkisms, from the Eurasian Steppe belt to the Eurasian fringes, across linguistic barriers. The “IE etymology” did not recognize that the “ululate, lull” and “howl, wail, yell, yawl, yowl” are bona fide allophones. Myopically, on purely phonetic grounds, it tried to seek “PIE” precursors for this series with close phonetics and semantics. Thus, to begin with, we have “imitative origin” and “compare owl”. Those are non-definitions: possibly reasonable, imitations come in thousands of renderings, and rather unrelated sources. Nothing can be asserted beyond realization that howl, owl, and ulï-, yel are probably related. Then, we have imagined reality: a faux “PWGmc. proto-form” *huwilon “?”, a faux “PGmc. proto-forms” *huwilona, *hiuwilona “howl”, and a faux “PIE proto-form” *ku-, *kew- “howl, scream”. That ingenuity connecting nothing with nothing is useless. It can't substitute for a mass of well-documented Türkic material. A claimed association with the Sl. golos (голос) “voice”, a cognate of Eng. call and Türkic qol, is erroneous. A paradigmatic transfer of both meanings, the “wind” and “howl”, from a Türkic milieu is incontestable. See yell, ululate, lull.
3.110
hurl (v., n.) “throw” ~ Türkic ur- (v.) “beat, strike, throw” (+wur-, vur-, var, uj-). An “IE etymology” of OED myopically suggests an “imitative” of Gmc. origin, q.v. For semantic spectrum of ur- see
harm. The term is best known for an Eng. call Hurray! (+hoorah, hooray, hurrah, hurroo), an untranslated and unacknowledged OED calque of the Türkic Ura! “Beat!, Strike!”. On ur-, wur- details on semantic clusters and transitivity, archaism see harm. Morphologically,
hurl is formed with a Gmc. habitual prosthetic h- and a poly-functional Türkic-Eng. suffix -l, here a passive voice verbal suffix and adjectival, adverbial suffix -l, Cf. “usual”. Much like the Türkic/Eng. universal verb tu-/do- “do, act”, the verb ur- is universal and polysemantic, it carries a notion of sharp or short movement (i.e. throw an arrow, throw a glance, step on) or a directional action (i.e. extend a hand, give/bestow name, title, law), to name just two of many uses. For English hurl, the best example is a fully conjugational paired expression oq ur “to shoot an arrow”, where oq is “arrow”, and ur denotes the action of “throw, shoot”. The notion is an one-time event, like a strike, or it could be a series of one-time events. Of 44 European languages, a Romance lan- predominates with a meager 5 (11%) languages, followed by Türkic-Eng. ur- ~ hur- and Sl. met- with 3 (7%) languages each. The remaining 33 (75%) European languages use 29 their own native words. There is no common “Pan-European” term in Europe; European lingo is a random pile of random components. Cognates: Since “hurl” and “harm” ascend to a same root ur-, see
entry Harm. Distribution: parallels that of Harm. A horizon-poor “IE” mentality invented a faux “PGmc. proto-form” *hurr “rapid motion, hurry”, calls the word “imitative”,
“onomatopoeic”, and “confused”. None of that nonsense apply, it needs to be gently excused. The affinity of the notions “harm”, “hurl, “hurt” and the root ur- is attested by a perfect semantic and close phonetic similarity, by a systematic prosthetic anlaut h-, and by the attested Türkic idioms with the verb ur-. The concrete meanings are inherited by the A.-Sax. and OE lingoes and by a complementary A.-Sax. wound. These are emphatic idioms oq ur q.v. and ur- yon-. The Türkic idiomatic compound ur- yon- combines two nearly synonymous expressions into an emphatic pair, ur- “beat, strike” and yon- “hew, cut”, translated as “beat, torture”, see allophones of ur- harm, hurl, hurt. The cluster harm, hurl, and hurt is formed by internalizing into the roots of the Türkic suffixes -m, -l, and -t respectively. A paradigmatic transfer of two roots, ur- and yon- separately, their attested compound in the Türkic emphatic idiom ur- yon-, and the line-up of the Türkic suffixes provide irrefutable evidence of the Türkic origin for the entire cluster inclusive of wound. See harm, hernia, hurt, ore, usual, wound.
3.111
hurt (v., n.) “ache, harm” (Sw N/A, F310, 0.05%) ~ Türkic ur- (v.) “beat, strike”.
An “IE etymology” calls it “a word of uncertain origin”, q.v. For details on ur-, wur- semantic clusters and transitivity, archaism see harm. The Eng. and Gmc. allophones of ur- have acquired a prosthetic anlaut h- typical for the Gmc. languages, A.-Sax., and Cockney, attesting to a probable distinct path for the wound, see wound. The final -t is probably a relict of the 3rd pers. verbal suffix di:, or the pl. suffix -ter/-der contracted to -d, -t, Cf. ONFr. form hurter “strike, collide”, or a deverbal noun suffix -t, see port. It also parallels the bifurcated articulation of the synonymous Türkic dialectal (Ottoman) yon-, yont- for the allophone wound, which otherwise etymologically comes as non-explainable observation. The semantic raster of the Türkic cognates is far wider then that of the Gmc. cognates, attesting to a much wider dissemination of the word among the Türkic ethnic communities, and accordingly far deeper roots. Cognates: A.-Sax. hearm “harm, injury”, OE hurt (1200) “injure, wound”, ONFr. hurter “strike, collide”, MHG hurten “run at, collide”, ONorse hrutr “ram”, MDu. horten “knock, dash against”, Ir.
dochar “hurt”, Scots goirteachadh “hurt”, Welsh brifo (ur- > w/b-ur- > br-) “hurt”. The A.-Sax. hearm is a natural allophone of the hurt, with the auslaut -m a relict of the Türkic -im “me”, i.e. “(I am) beaten, stricken”, see harm. The ONorse moniker is a semantic derivative. A complete absence of the cognates in the Romance and Asian “IE” groups, an obvious oddball loanword in ONFr., probably from an Alanic or Burgund source. No “IE” cognates whatsoever. The “IE etymology” stipulates “a word of uncertain origin”. In support of a PIE dogma, the “IE etymology” had
invented some ethereal PG and PIE “proto-words” for the wound, and separate PG and PIE “proto-words” for the harm, while mysteriously allowing hurt to come from an “uncertain origin”. The ubiquity in the Gmc. group attests to, first, a distinct areal northern and southern Sprachbunds, and second, to the later internalization by the northern Gmc. group, after the Romance farmers bounced back to the south-central Europe ca. 1500 BC, and the Indo-Aryan farmers departed on their South Asian trek ca. 2000 BC. The possible time for the internalization appears to be the a long period from the Corded Ware bloom to the Sarmatization of the North-Central Europe. The Türkic idiomatic compound ur- yon- combines two nearly synonymous expressions into an emphatic pair, of ur- “beat, strike” and yon- “hew, cut”, translated as “beat, torment”, see allophones of ur- harm, hurl. The Eng. and Gmc. allophones of ur- with prosthetic anlaut h- are attesting to a probable distinct path from that for the wound. That hypothesis is supported by a presence of the ONFr. hurter “strike, collide”, in contrast to a concentrated distribution of the cognates for the wound. The paradigmatic transfer of both words, ur- and yon- separately, and their attested compound in the Türkic emphatic idiom, provide irrefutable evidence of the Türkic origin for both words. See harm, hernia, hurl, wound.
3.112
ignite (v.) “conflagrate, enkindle” ~ Türkic yak-, yaq- (v.) “ignite, burn”.
An “IE etymology” peremptorily attributes it to Italic and “IE” origins, q.v. Ultimately a reflexive form of a verbal root ya:- “ignite, shine, flame”; variations are ya:-, ae-, i-, o-, a-. Parallel second forms are yan- (v.) “ignited, shine, flame”, yal- “blazed, burned, shined”; a causative suff. -q, and if needed a noun result suff. -n “fire”. The form yal- is typically intransitive, yak-, yaq- is typically transitive and can form a passive yakıl- “ignited”. The Eng. (+ Türkic & Lat.) group yaq-, ig- occupies a minor place in Europe, with 3 (7%) of the European 44 languages, behind a motley group encen- with 7 (16%) languages and Sl. group -pal- with 5 (11%) languages. The remaining 23 (52%) European languages use 19 of their own native words. There is no common “Pan-European” term in Europe; European lingo is a random pile of terms. Of 3 European yaq-, ig- one (Lat.) is long dead, one (Eng.) is a unique “guest” in Europe, and a third is a native Türkic (there are more, like a Gagauz or Crimean, not addressed in the “IE” listings). A best that we know of the Lat. Y-DNA is its Hg. R1b in few subclades. The R1b is a daughter of an elder R1a and both are associated with the Central Siberia, Türkic kins, and Türkic migrations. The Lat. ign(is) “fire” < Türkic yaq- should not be a shocking revelation. The Lat.
ign- had marched for ca. 30,000 years fr. the C. Siberia to the Latium. Ditto for the Eng.
ign-. Cognates: A.-Sax. ael(an) “ignite, kindle, light, set on fire, burn”, (on)ael(an) “set fire to, ignite, inflame, burn”, (on)ael(end) “incensor”, onaelet “lightning” (typ. < ya:- + -l); OPruss. ugnis; Lat. ign(is) “fire”, ign(ire) “set on fire”; OCS ogni “fire”; Lith. ugn(is); Skt. agnih “fire”; Hitt. akniš (ca. 1,600 BC.); Ch. huo (火) “fire”; all “ignite” unless noted otherwise. Scholarship is confined to neighborhood and a peremptory level, q.v. Distribution: Typical for Eurasian Turkisms, from the Eurasian Steppe belt to its fringes, across linguistic barriers. A likeliest conduit to Eng. was a Saka (aka Saxon) part of the A.-Sax. union. All Türkic confederations were always based on a system of marital unions between non-blood related and largely alien members that led to linguistic amalgamations. For a Türkic yak-, yaq- the myopic “IE etymology” deals a Lat. origin fr. a faux “PIt. proto-form” *əngʷnis “ignis, fire” (n.) and a faux “PIE proto-form” *hngʷnis “fire”. It stops at unetymologized speck ign-. That nonsense is blind to the sibling Hitt. form by a full millennium ahead of the oldest Lat. inscription. That leaves, in addition to a Gmc. native “kindle”, the ign- a “guest” status in a Saka prong to Albion. Both Lat. and Hitt. forms transparently ascend to the Türkic yaq-. A word for “fire” came to Eurasia with the first African migrants bearing Y-DNA Hg.'s I and J. In another 20,000 years it reached a level of Hg.'s NOP > R and diverged into siblings. A Lat. prong migrated fr. Siberia to the E. Europe and crossed to the Apennines fr. the north. The Hitt. prong veered southward to the Anatolia. The base stem ya:- is nearly a single-morpheme word, an oddity to the “IE” family. The auslaut consonant morphological elements -l, -n, -g attest to a deep timeframe. A collection of 7 active synonyms (ču:k-, ya:-, yak-, yal-, yan, yaru:-, kün-/gün-)
points to a large time depth. A synonymous Türkic root ot, öt (öd) “fire, flame” eventually grew into
a Gk. adis (αδης) and ad (αδ, ад) for a scorching “hell” and
an A.-Sax. ad, adwylm “whirlpool of fire”.
The word for “fire” and its derivatives persevered through most of the Eurasia and diffused way beyond their original Eurasian homeland.
A Türkic origin of the “ignition” lexicon stands beyond any doubt.
|
Supplementary Note. Linguistic Model. The Lat. word ign(is), ign(ire) and its Skt. form agnih, and other allophones in the “IE” languages, are held and cited as the fundamental proof of the “IE” linguistic paradigm. It is cited as uncontestable proof, and then etymologized as ascending to a bogus asterisked “IE proto-word”. A less myopic review disbands the incontestability of the argument, and thus seriously undermines the “IE” linguistic concept. If the “IE” linguistic theory had a definition of what constitutes the “IE” family, and that definition included the word ignite and its cognates, the definition would have to be re-defined. An absence of clear definition saves the the day for the Family Tree theory. A switch to a concept of a series of areal Sprachbunds created by amalgamation of diverse local and migrant languages would resolve the uncounted controversies and theoretical chaff, and free scholars for explorations unburdened by patriotic prejudices. |
3.113
itch (v., n.) “dermal irritation, pruritus” ~ Türkic kiči:-, gici:- /kichi-, giji-/
(v., n.) “itch” and “scratch, tickle; lichens, scabies”. An “IE etymology” offers an “unknown” or a Gmc. origin, q.v. Ultimately fr. a root ki-, gi- retained in derivatives; the č-, či:- is a fairly multifunctional suff. that can be used in few ways. Of 44 European languages, a Türkic (k)ič-, local
jVk- (č ↔ k) predominates with a meager 6 (14%) languages, followed by Sl.
sve- with 5 (11%) languages and Gmc. kl- with 4 (9%) languages. The remaining 29 (66%) European languages use 22 of their own native words. There is no common “Pan-European” term in Europe; European lingo is a pile of random components. Cognates: A.-Sax. giccan, gyccan, gicce, gicenes, gicða, (v., n.) “itch”, Scots yeuk “itch, itchiness” (but Ir. word was supplanted by Eng. one), WFris.
jukje “itch”, MDu. jöken, Du. jeuken, jeuk “itch”, OHG jucchen, LGmn.
jocken “itch”, Gmn. jucken “itch”; Mong. qol- “rub”, qus “rubbed spot”, qalti- “scrape off, clean unevenness, smooth, clean hair from skin or leather” (with suffixes -l, -ti); all “itch” unless noted otherwise. The verbal “itch” and “scratch” are used as overlapping synonyms, i.e. jucken “itch, rub off, scratch, groom”, etc. Distribution: Points to a long-range spread westward and eastward fr. a Siberian nest leading
to a Sarmatian Europe: Vandals, Burgunds, Thurings, Alans, and the like “wanderers”, with fingers extending west and east. The “IE etymology” stipulates an “unknown” and a Gmc. origin fr. a faux “PWGmc. proto-form” *jukkjan “itch” and a faux “PGmc. proto-form” *jukjo (n.) “itch”, both “of unknown origin”. Other than noting a Gmc. channel, those advertisements carry a zilch of etymological value. The documented OT sibling forms kashı, qashï match the oldest recorded western forms and substance; the anlaut alternations q ↔ γ ↔ j are routine; the Scots yeuk (č ↔ k), Mong. qus (č ↔ s) and A.-Sax. gicce (č ↔ k) bridge the ends. There is no room for any “IE” penetration. Four Türkic bases (emri-, кiči-, qašï-, qurtan-) form agglutinated active and passive verbs and nouns. Probably, the Ogur form gi- was a first source, and the Oguz form i- supplanted it. A phonetic similarity between the root gici:-/gicce- and the root element -ich (bitch, glitch, pitch, witch, etc.) corresponds to the Tr. suffix -ich/-ish that forms abstract nouns. In A.-Sax. the double
-cc- (giccan, gicce) apparently stands for -ch-/-č-, though at the beginning of the word the -ch- is systematically depicted with a single c-. A phoneme depicted with a triplet -tch reflects the fricative -ch, probably with a hint of dialectal initial dental plosive
-t- peculiar to A.-Sax. vernacular. The initial g- in the western forms (gi-, jö-, ju-) is consistent with the phonetic peculiarity of the Ogur languages. The survival of both forms
(gicc etc. and itch) in the historical records indicates that they were brought over and used by at least two lexically distinct groups. Eng. has lost the agglutination capacity, and turned to an alien Lat. pruritus. A phonetic match with regular correspondences is perfect, the semantics is perfectly identical, and both are within a range of phonetic and semantic dispersion within the Türkic linguistic family.
3.114
itinerate (v.) “go, travel” ~ Türkic it-, ïd- (ïδ-, ïs-, ïz-, ïǯ-, ıy-, ı-) (v.) “send (to go)”. An “IE etymology” states a Lat. origin, q.v. The Eng. “send” synonymically stands for “cause to go”. The Türkic verb ïd- is polysemous with 7 semantic clusters, a base connotation “go” and second connotation “intent”, retained in the Eng. idioms like “(I am) going (to go, to sleep, etc.)”, “(I was) going (to go
to..., but...), etc.)”. Unlike Eng., the Türkic expressions largely imply but omit “go”, and include
an intended action, like “send (him to go)”. Translations omit “go” and translate an action, thus translation “I send a letter to (recipient)” interprets the notion “send” as a meaning of the stem ïd-. Actually, it means “(I) send (a letter) to go (to the recipient)”. The initial -t-, -d- was suggested to be a suff. of a root ï-, making it a super-polysemantic oddity not for a generic use, but Cf. Sl. kladu, edu (кладу, еду) “lay, ride” with -d fr. kla-, e-. Of 44 European languages, the Sl., Gmc., and Romance lead with 10 (23%), 8 (18%), and 8 (18%) languages respectively. The remaining 18 (41%) European languages use 11 versions of their own native words. There is no dominating “Pan-European” term in Europe; European lingo is a loose collection of areal vernaculars. Cognates: A.-Sax.
at- (atgin conj. v. gin), adrran (intr.) “go”, Goth. iddja “went”; OIr. ethaim “(I) go” (Cf. Tr. idim, ıdayın ditto); Gaul. eimu “(we) go” (d-, y- transition); Lith. eiti, eimi, eidinti, eidine “go”, eidy “leave!” , Latv. iet, eimu, iemu “go”; OPruss. eit, eisei “go”; OCS iti, idu, idj (идѫ) “go”, Ukr. idu, iтu, Bulg. itsi, istsi, idu (iцi, iсцi, iду) “go”, ida “(I) go”, Cz. jdu, jiti “go”, Pol. ide, isc, wiesc, wiode “go”, Rus. idti “go”; Lat. iter “travel”, ire, it, еo “go”, Serb., Croat idem, iti (идем, ити), Sloven., Slvt. idem, iti, ist “go” ; Gk. eimi, εἶσι, iμεν, iασι “go”; Skt. eti “(he) goes”, imas “go (we)”; Av. aeiti, OPers. aitiy “(he) goes”; Kuchean, Agnean (aka Tokhar) i- “go”; Mong. od- “go”, odumui “goes”, Kor. gada (가다) “go”, (but with Ch. qu (去) “go”, Jap. iku (行く) “go”). Strikingly, identical conjugational agglutination, Cf. “(he) goes”: Tr.
idti, Skt. e'ti, Av. ae'iti, OPers aitiy; “(I) go”: Tr. idim, OIr.
ethaim, Gk. eimi; all “go” unless noted otherwise. Distribution: Versions of it-, ïd- cover Eurasia across linguistic borders, fr. the Albion to the Far East. A myopic “IE etymology” dives as deep as a Lat., a late newcomer to Europe. That is a misleading nonsense. The brief listing of cognates corroborates both the broad historical picture of demographic movements in the western Eurasia, and the specialized disciplines of archeology and biology in respect to migratory flows, including those of the Kurgan Waves, and the Celtic, Indo-Aryan, and Sarmatian migrations in and out of Europe and beyond. By dozens of millenniums Lat. trails in time the old-timers like a Sl. with its out-of-Africa Y-DNA Hg.'s I, J. The Lat. ascend to the times of the distant Siberia's Y-DNA Hg.'s R1a/b, i.e. 30 - 20 ky later. The roots of Lat. are probably connected to some cultures of the Kurgan burial and horse domestication, ca. 5 - 6 mill. BC. Some R1a/b's reached Europe and grew to become a major component there while others populated different Eurasian territories. In those millenniums were disseminated ideas of a matriarchate, of marital unions, of Tengriism and its babies Buddhism and Yule, of kurgan burials, of a nomadic mobile home, and plenty of other cultural and technological traditions. A degree of detail allows to trace grammatical metamorphoses of a Tr. 3rd pers. perf. tense to Balto-Sl. infinitive form (suffix di/ti), or Tr. causative ide:r to Lat. iter “going”, and other transitions. The initial notion “go” was literal. That is attested by the derivatives retained in the sister languages (Sl. idti, hodit (идти, ходить, inf.). It is an allophone of the Türkic idti (ıdtı) “send to go”, “made to go” (3rd pers. perf. tense, lit. “made (him, it) gone”). The Goth. cognate iddja “gone” (perf. tense) conveys the Türkic idti (ıdtı) semantically and grammatically. As a preposition (Goth. id-weitjan (v.), id-weit (n) “reproach”, lit. “going to approach”, OE ed-wit ditto, OHG. ita-wıč, ditto) it is a calque equivalent of the modern Eng. “going to”, where “go” expresses not a physical movement, but lit. or metaphorical “intent”. The Goth. word precedes the LLat. word by better than half a millennia. That shows a direction of borrowings, and disbands the “IE” etymologies that ascribe the origin to the Lat. Statistics: With a 2-phoneme single syllable word, chances of a random coincidence are fairly high, about 1/5 = 0.2 (phonetic coincidence 1/50, semantic coincidence 1/1000, 10,000 tries). A set of 5 10,000-word vocabularies from different languages would bring that probability to a near certainty. Bringing suffixes into a calculus would lower the chances of accidental coincidence to infinitesimally small number, requiring thousands of 10,000-word vocabularies to bring probability to a certainty. With a ruled out chance of random coincidence, a scenario of common origin is inevitable, and the Eastern Europe of the 3rd mill. BC becomes inescapable as a source from which, at different times and by different routs, the word could have traveled to the Mediterranean, Northwestern Europe, and South-Central Asia. The Celtic trail extends the existence of this word in the Eastern Europe, complete with its morphological modifiers, to a 5th mill. BC. Morphological evidence suggests an areal language or group of languages with largely shared morphological system consistent with the morphology of the Türkic languages down to a series of minute details.
Similarity is closer than that between the adjacent European languages of a same linguistic group, like a French and Italian, Spanish and French, or Polish and Russian. That is in spite of a great temporal differences between, say, Türkic and Avestan or Türkic and Old Irish. A complex of converging evidence unequivocally points to the Türkic phylum as an origin of the word. The phenomena of retention opens a large window for further investigations. See period, time.
3.115
jar, jarring (v.) “conflicting, abrupt, fragmenting” ~ Türkic jar-, yar-, ya:r- (v.) “split, cleave, crack, rive”. An “IE etymology” suggests a series of “said to be echoic or imitative origin”, “of uncertain origin”, and a “WGmc. origin”, q.v. Ultimately fr. a base ja-, ya- detectable in derivatives with old suffixes fused into the roots: Cf. just the negatives “precipice, split, wound, poor, half”, etc. yar-; “lightning, harm”, etc. yas-; alien, sick, etc. yat-, etc., etc. The Türkic stem jar- (v., n.) is extremely productive, with multifaceted semantics in 8 clusters carrying 80+ meanings, fr. “split” to “open (wound)”. The anlaut semi-consonant j-/g- is a trait of the Ogur languages, while the Oguz languages start with the vowel, ya-, hence the forms
jar- vs. yar-. Of 44 European languages, the Sl. -del-, Romance div-, a Sl.-Celtic. skol-, and a Gmc. spl- lead with 8 (18%), 6 (14%), 5 (15%), and 4 (9%) languages respectively. The remaining 21 (48%) European languages, incl. Eng. and Türkic, use 16 versions of their own native words. There is no common or dominating “Pan-European” term in Europe; the European lingo is a loose collection of areal vernaculars. Cognates: A.-Sax. (be)ceorian’ “cut, cut off, separate”, ceorian “murmur, gripe, complain”; Sl. yarost (ярость) “rage, fury, wrath”, yariy (ярый) “ardent”; unspecific references to Mong. parallels (G. Ramstedt). No “IE” cognates. Apparently no etymological scholarship was defiled by tracing cognates across Eurasia. Distribution: Spans across Eurasia, W. - E. fr. Bosnia to Sakha (aka Yakutia) and N. - S. fr. Arctic Ocean to the Strait of Hormuz, across linguistic borders, in contiguous and islet demographies. No detectable or proclaimed “IE” cognates.The sources of origin advanced by the “IE etymology” stand for ignorance or illiterateness, as far from a sanity as they go. The “echoic, imitative, uncertain” sources are laughable, a faux “PWGmc. proto-form” *karen “complain” is an utter nonsense unless attested otherwise. So is a faux “Proto-Slavic proto-word” *jarъ “furious”. These fictions need to be delicately rescinded. A quasi-scientific machine needs a wash and a turn to reality. With a list of documented 80+ meanings and a spread across continent, it takes a major effort to pretend to be linguistically blind and lingually nescient. In Lat., a homophonic and allophonic jaru- (v.) “illumine” turned into an allophone aurora, now an international word, see aurora. It is unlikely that the original Türkic jar- “crack, cleave” have originated from a splitting sound, but some of the “IE” speculation on echoic or imitative origin may not be totally baseless. The speculations on a relation to a homonymic Türkic words jar (n.) “vessel” and
earl “title” is baseless. The chances that two homonyms jar- “fragmenting” and jar “vessel” may accidentally evolve in two language families are nil. They constitute a salient case of paradigmatic transfer attesting to a common origin from a Türkic phylum. See aurora, earl, jar (n.).
3.116
jeer (v.) “ridicule, contempt, derision” ~ Türkic jer- (v.) “deride, dismiss, reject, repel, slander, disparage”. An “IE etymology” rates it “of uncertain origin”, “beyond existing evidence”, and a few more pearls, q.v. It partially overlaps with a stem hool- in a Celtic word hooligan. There is no common or dominating “Pan-European” term in Europe; the European lingo is a loose
collection of areal vernaculars. Among 44 European languages, the leading are a Sl. -sme- with 5 (11%), Romance bur- with 4 (9%), and a bitty Türkic-Eng.-Fris. jer- with 3 (7%) languages respectively. A majority of the other 32 (73%) European languages use 26 versions of their own native words. A miniscule distribution is consistent with the Türkic-Eng.-Fris. jer- being a walking “guest”
loanword in Europe. Cognates: A.-Sax. gyr “deride, mock”, MDu. scheeren “vex”, Gmn.
scheren “vex”; Ir., Scots geansaí (? ~ jenč, the -n- marks reciprocity, -č marks noun). A paucity of linguistic data contrasts with an ubiquity of the phenomenon: mocking is an eternal joy and entertainment in all human societies. Distribution: Spans across a bulk of the Eurasia, with a teeny speck in the NW Europe. Not a trace of any “IE” etymology, “uncertain origin” is its best contribution. An anlaut (semi)consonant points to an Ogur (Hg. R1a) subfamily; the Oguz (Hg. R1b) peers typically do not use an anlaut consonant: > er. But who could tell them apart before ca. 2000 AD? The Oguric would produce der-, jer-, ger-, ɣer-, her-, and the like. See hooligan.
3.117
jerk (v.) “jolt, abrupt movement” (Sw N/A, F1589 0.005%) ~ Türkic julq, yulq, yolq “jerk” (emphatic intensity form), jul- (v.) “jolt, jerk, pull (out, away), extract, extricate”. An “IE etymology” calls it “of uncertain origin”, “perhaps echoic”, with quite a few
pearls more, q.v. Ultimately fr. a root (j, y)ul- “strip, rifle”. The prosthetic anlaut phoneme takes forms listed as j-, y-, dj-, ts-, č-. An -l → -r alternation is an areal adaptation, possibly via a Türkic Saka (> Saxon) or a like dialect not friendly with -l-'s,
Cf. jolt. The prosthetic anlaut consonant wobbles between Ø-, j-, y-, g-, dj-, š-, ǯ-, ts-, f-, d-, n-, ...; the vowels are -u-, -ü-, -o-, -e-, -ea-. Eng. uses “jerk” with a connotation of a slang, a vernacular claimed as first recorded in 1570s as a “sudden sharp pull”. In some ethnically compact populations, it apparently was lurking for centuries under a radar of grammarians. The Türkic verbal form, like its Eng. variety, has derivatives associated with abrupt move, unsteady affect, clinching action. A most sited applications are “snach, seize, redeem, rescue, save”; some derivatives are on an exotic side: yuluɣ “ransom, redeeming, save”, from yul- “ransom, redeem, liberate”, ul- “shave”. The word comes in 4 distinct forms and correspondingly in 4 semantic clusters with 27, 13+, 3, and 6 meanings respectively, fr. “jerk” and “tear out” to “redeem” and “shave”. The original range of notions exceeds by far the miniscule fraction that settled, survived, and evolved in Eng. That is a fate of the “guest” borrowings that typically echo the original. Of 44 European languages, the Türkic, Eng., and Fris. 3-language group julq-, and a Gmc. 3-language group ruk- are most substantial with 3 (7%) languages each. The remaining 38 (86%) European languages use 35 versions of their own native words. The jerk or julq is a “guest” in Europe. There is no dominating or common “IE” term in Europe; the European lingo is a loose collection of areal vernaculars. Cognates: A.-Sax. gearcian (v.) “procure, furnish, supply”, gearc (adj.) “active, quick”, ferclan “convey, bring” (j ↔ f), gearobrygd “quick movement”, MEng. yerkid “tightly pulled”,
ferken “move hastily, drive (sth.) forward” (j ↔ f); yare, ȝare “agile” (? < gearu, gearo); Fin. nylke- “flake the skin”; Mong. šulga-, ǯulga- “tear out”, ül-gü, jil-gü “scrape” > Soj. čülgü “swipe”, doli “pay, ransom, buy out”; Evenk nul- “scrape (remains of wool from soaked pelt)” (ul- > nul-), (~ Sakha sül- “rip off, peel (pelt)”, sul- “naked, with scraped bark”; references to Tung.-Manchu correspondences. Distribution: From the NW Europe through Fennic and Eurasian Steppe Belt to the Far East and Pacific, across linguistic barriers. The word's geography tended to fraction semantically, with different clusters in different languages, and some with only one, unique meaning. On top of “uncertain origin” and “perhaps echoic” the myopic “IE etymology” suggests the faux “PWGmc. proto-form” *garu and faux “PGmc. proto-form” *garwaz “ready”. That's on top of real attested A.-Sax. forms. It relates that with etymologically later form yare, ȝare, and unrelated Du. gaar “done, well-cooked”, Gmn. gar “done, well-cooked, wholly, at all”, Isl. görr, gerr “perfect”. All that animated circus is not needed, is absolutely unrelated to a well-documented Türkic ancient julq, yulq “jerk, pull (out, away), extract, extricate” or a massive family of its derivatives. A semantic parity is perfect, a phonetic correlation with liquid -r-,-l- is regular and credible, the final -k/-g points to a regular Türkic deverbal noun suffix -k, -g, -ɣ, -q, Cf. buzuq “fragment” (buz- “break”), jaruq “ray, light” (jaru- “radiate”). The geographic spread of the allophonic forms suggests an early scatter, pointing to the Kurgan or Sarmatian waves from the east. The initial consonant j-/z-/d- points to the Ogur-type languages of the Huns, Sarmatians, and Alans.
3.118
jig (v.) “jerk, yank (dance)”, MEng. ghyg “spinning top” ~ Türkic jïq-, yık- (v.) “bring down, plunge, cast down, fell, crush (by blow)”, jiglä, jiklä- “tramp”, (n.) “spindle”, with usual phonetic changes jeg, jïk, yıx. An “IE etymology”-rated “of unknown origin”. Ultimately fr. dancing notions jïq-, yık- (v.) of dance squatting, spinning, tramping, and jumping. Eng. spelling comes in two flavors,
jig and gig, reflecting the Ogur anlaut consonant. In Oguz version the word starts with semi-consonant or vowel yig-, ig-. Cognates: Dan. gig “spinning top”, ONorse geiga “turn sideways”; OFr., Fr. gigue “dance (type)”, Sp. giga, It. giga; all “dance (type)”, not a generic “dance”; a Türkic bödi:-, Cf. body. The Türkic verbal notion largely implies movements down, Eng. movement is not specifically down. No “IE” or any other etymology whatsoever. There is no need for an OFr. “proto-word” gigue “fiddle” and its Romance cognates; the truth is much closer to home. The form jiggle (v.) may be frequentative or diminutive, as claimed by the European philologists, or it might as well be a Türkic regular denoun verb jiglä formed with a suff. -lä that smoothly diffused into Eng. to be eventually re-interpreted. See
body.
3.119
jog (v., n.) “run, walk, ride” ~ Türkic jüg-/yüg-, jüɣ-/yüɣ- (v.) “go, run, fast”, jügür (indef. tense) “run”, a parallel form to jor- “walk, march, go”. An “IE etymology” rating is “of uncertain origin”, “perhaps”, “PWGmc.”, plus some other
ideas, q.v. Ultimately fr. a primeval root of a type ja-, jo-, jü- “leg” > generic “run, move, action”. Suff. -ür forms indef. tense; suff. -n denotes reciprocation “I, we run”, suff. t- causative: yügür, yügün, yügürt respectively. A spectrum of documented Türkic forms numbers 31+, an astonishing variety for a 3-phoneme word, Cf. a cognate journey. That attests to a deep antiquity of the word. The word developed into an Oguz tribal name Yoruks, Jürüкs “beduin, nomad” of Turkmen ethnicity expanding to Persia and Byzantine (11th c. AD). Of 44 European languages, a predominantly Romance group cor- leads with 9 (20%) languages, followed by a jog- group (Türkic, Eng. Du., Norw.) with 4 (9%) languages. The
remaining 31 (71%) European languages use 24 versions of their own native words. Considering the importance and antiquity of the notion “run”,
the dating of 15th c. AD is incredible; it rather states an earliest documenting in Eng. which could be off by millenniums. Lately, as a suppletive modern athletic term, the “jog” gained popularity in numerous languages without supplanting the native “run”. Cognates: A.-Sax. iernan, urnen, urnon “run, ride, gallop”, (ge)iernan, aernan “run, ride, gallop”, iernan, rinnan, ornon “run, ride, gallop”, uron, urum, ure “run, move rapidly, hasten”, (a)iernan, aetiernan, ayrnan “run away”, beiernan, beyrnan, bearn, born, barn “run up to”, foriernan, forerun “run before, outrun”, forwiernan, forwyrnan “hinder, prohibit, prevent, repel, refuse”, (gen)iernan “run against”, oniernan, onarn “give way, open (door)”, toiernan, toirnan “run to, run together, flow away”, ðurhiernan “run through”, undierne “open, manifest”, Du. joggen “jog”, Norw. joggetur “jog”; Serb. Ioruk (Иорук) (name), Croat. Yoruk (name), Bolg. Ĭoruk (name), Maced. Joruk (name);
Mong. zugt (зугт) “run” (v.) (< zug, -t causative), güikh (гүйх) (n.) “run”,
Yuryuk (Юрюк) (name); references to borrowing of Türkic words in Balkan languages; references to name Yoruks (pl.) in various publications; references to Gagauz form of name Yoruks as Jürüк, Ürüк and
to possible contaminations of the term. Distribution: Eurasian width with western and eastern
appendages. The depth and scope of the related A.-Sax. vocabulary expose a continental-size
distribution fr. Albion to Mongolia. The myopic “IE etymology” for a basic concept “run, jog”
is shameful. Besides somewhat realistic “a word of uncertain origin” and some wild “perhapses”, the
rest is beguiling. Among the pearls are the notions “touch, push”,
“stir”, shog “jolt”, “shake”, MEng. joggen “pierce, prod”, and an apotheosic faux “PWG
proto-word” *skokkan “move, shake, tremble”. All that nonsense is to re-engineer the attested
Türkic jüg-, yüg- “run” without hurting foul prejudices. The crispiness of the
Türkic semantics is predicated by the mounted existence of the Türkic
Kurganians vs. sedentary environments. The Türkic-Mongol linguistic similarities ascend to 93 AD,
when 100,000 Hunnic families numbering 500,000+ people submitted to the ruling minority of the
Syanbi (pin. Xianbei 鮮卑) Mongols (Western Tunguses marked by Y-DNA haplogroup C vs. Türkic R1),
essentially making Hunnic language a language of the Syanbi, and continual amalgamation in the
following centuries. The Eurasian-wide spread of the jüg-, yüg- + jog “run” makes a
Türkic origin of the term inescapable. See jag, yacht.
3.120
journey (v., n.) “travel” ~ Türkic jor-, jorï-, yor-, yör-, yorï-, jur-, yürï-, jürü-, yuɣur- (v.) “go, walk, march, run”. An “IE etymology” suggests an “IE” origin and a “day” for “journey”, q.v. Ultimately fr. an archaic root jo-, yo- known fr. its primeval suffixed derivatives like jor, jӧr-, jol, jog, joj, ja:rïš, jorɣa, jügür, dai, etc.; the -n- is a reflexive suffix “I, we go; ride”, etc. Unlike a verb bar- “go” (directional, one-time event), the yör- “go” is omnidirectional recurring, Cf. bar- “go”, ber- “bear (~ give)”. Primeval status is attested by diverse forms and semantic excursions. To name a few: forms ascend to an oldest
yorï-, from roots jor- to su:r and the like. The forms have eight zonal variations, each with its overlapping semantic clusters. Endemic to real lexicons, they are stochastic trails with parallel forms in same texts. Additionally, the word is an auxiliary verb and a component in compounds in diverse Türkic languages. Forms switch from a smooth evolution to an observational ledger. Of 44 European languages, a Gmc. group res- leads with 8 (18%) languages, followed by a Romance via- group with 7 (16%) languages and the Sl. groups dor- and -tov- with 5 (11%) and 4 (9%) languages respectively. The remaining 20 (45%) European languages use 14 versions of their own native words, including Türkic-Eng. jor- with a petty 2 (5%) participation. As a secondary entry, a Romance group of OFr., Sp., and It. use it as an internalized loanword journee “travel” vs. a Romance “voyage”. A significance of the notion “go, journey” can't be taken lightly: it belongs to the first words carried fr. Africa to Asia 40 kybp. It travelled fr. the Red Sea to Iberia (Y-DNA Hg. I) and to a heart of Siberia (Y-DNA Hg. NOP > R) 20 kybp. A first version, an it-, id-, had survived to the present in Sl. languages, Cf. Sl. id-ti, id-em. The second version took 20 kybp to develop a form jo-, yo-, it spread fr. Siberia all the way back to the Mediterranean and Atlantic. It settled there as a
Wanderwort “guest” with weak local roots. There is no common or dominating “Pan-European” term in Europe; the European lingo is a loose collection of areal vernaculars. Cognates: Scott cuairt “travel” (j ↔ c); OFr. journee “travel”, Sp. jornada ditto, It. giornata ditto, Port. jornada ditto; Rus. ajda (айда) “go”; Osset. erysjeris “competition, contest”; Georg. (y)eriši “battle, onslaught”; reference to Kabardin: “ens” ?; Beng. jatra “travel”; Nepal yatra “travel”; Skt. yatra “travel”; Kuchean (aka Toch.B) yalneall “travel”; Mong. ajalal “travel” (< Tr.), žо1 “happy travel, success, happiness”, žajidaŋ “saddleless”; Tung.-Manchu. žо1 “success” (< Mong.); Kor. jeongdo (정도) “journey”; Tr. (d)jolo “hit the road”, jalda- “hold on to mane”; jan- “return”, ja:jla “stopover”, jajuw “afoot, on foot”, jeɣer “saddle”, jele “mane”, jelt “lead up, guide”, ja:rish “run, race”; all related to “travel” unless noted otherwise. Distribution: Eurasian width with western and eastern appendages, across linguistic borders. The “IE etymology” suggests a faux “Vulgar Lat. Proto-form” *diurnum “day” fr. (attested) VLat. adj. diurnus “of one day” fr. (attested) Lat. dies “day”, fr. a faux “PIE Proto-root” *dyeu- “shine”. That philological vinaigrette does not make any sense: a Lat. dies “day” (n.) in no way is related to a “journey” (v., n.). It ascends to a Türkic taŋ, daŋ, toɣ- (n.) “dawn, sunrise”, Cf. day. In Türkic societies the daŋ “dawn” was a sacral event, a moment of worship and obeisance. With OED methodology applied to a ca. 6,000 earthly languages, besides the jo- “day” the OED could anoint a semantics of jo- to a huge host of meanings probably numbering in thousands. Chances that any two identical three-phoneme words can exist in two independent languages are quite high, but chances that those same two words would happen to share a same
semantics, in this case “journey”, are infinitesimally small. That nonsense is demining to OED and needs to be prudently retrieved. The OFr. journee “day's, daily” and the Eng. “journey” are accidental homophones. They do sound about the same, but can't be and should not be confused. A first one is a cognate of Lat. diurnalis “daily” fr. a root dies “day”, q.v. A second is a cognate of the Türkic jor-/jur- “travel”; Ir. turas “travel, journey”; Mong. ǯori- (/djori-/) “head to, intend”; Tung. düre- “walk”; Yürük, Yörük ~ Türkic tribe, lit. “nomad, rover”. The verb reportedly came to light in 12th c., linked to OFr. journee (v., n.). If that is so, it became a European word fr. the Alanian, Burgund, or Vandal versions of the Türkic lexicon. Typical for lexemes coming from different sources, journey is synonymous with voyage from LLat. viaticum “journey”, a traverse comes from a Lat. transversare “journey, pass across”, a
travel is its contracted derivative “journey”. The noun journal “daily ledger” is derived from the noun “journey” or from a LLat. diurnalis “daily (ledger)” etymologically conflated with “journey”. The Türkic etymology is direct and straightforward, the “IE etymology” is artificial and tenuous. See amen, bar-, ber-, day, you.
3.121
jut (v.) “protrude”, jut (n., metaph.) “precipice, brink, cliff, bluff” ~ Türkic jalt (adj.) “precipitous, brink (adj.)”, jut, djut (n.) “rinderpest; murrain”. There is no coherent “IE” etymology; an “IE etymology” suggests a shallow story for a precipitous case, q.v. A std. transition is yut > yüt > *d'üt (djüt) > *jüt > *čüt (G. Doerfer,
Türkische elemente im neupersischen, BD 4, p. 209, no. 1911). Articulation of the initial
j- is harder in the Ogur languages and lighter y- in the Oguz languages (jalt vs.
yalt). The “hunger” and “food” were a matter of survival; hence originally, primordial terms are more than likely. In a cattlemen lingo, epizooty is a fatal cattle disaster leading to a mass human starvation as opposed to a seasonal starvation. An “IE” suggestion of cognates jet (v.) “stream” or “throw” (v.) are semantically unrelated, they do not jibe with protrusions, brinks, and a dread of murrain. An elision of inlaut liquid -l- should be expected; the -l- is likely a passive suff., the -t is likely a causative suff. Cognates: A.-Sax cealer, calwer, ceoldre, celdre, celras, ceallras “jetty of curds”, Eng. jetty “seawall”; Mong yut, jud “cattle calamity”; Nenets čüt “jut, hunger”; Kamasin čüt “sickness, sick”; S.Siberian hüt, yüt “bad weather”; Chuv. sut “greedy, glutton”; Tuvinian čut; Chakavian (Serbo-Croat ?) čut; Avar, Rus.‘džut (dжут) “winter hunger, murrain, starvation”; Osset. žut “glazed frost”; Balkar zut (жуть) “dread”; possibly Jutes “exile, outcast, castaway”, q.v.
Distribution: nearly complete Eurasian width with the term smeared across linguistic borders. Nowadays, “jut, jetty” as a marine vertical barrier is a widely used semantic neologism fr. once a precipitous word. The jut “fiber”, and adjutant “helper” are semantically unrelated accidental homophones. A protruding jut is a majestic protruding mountain cliff, a symbol of a disastrous crush, euphemistically associated with a disastrous cattle plaque. Sibling versions of a term for a drastic crush spread with nomadic movements disseminating it as a term for a worst disaster in a cattle-breeding society. An “IE etymology” is utterly lost. In a way, its shallow surmises are adorable: “protrude” = “to jet” < “to throw” = Lat.
iacere “lie, rest”, fr. a faux “PIE proto-root” *ye- “to throw, impel”. Or an “echoic” (sic!) “strike, hit, shove, push”. Or a “cognate of jetty”: a marine “jetty” formed a mountain “cliff”. A base notion “stick out” is rated “obsolete”, as though etymology “history of a word” is an opposite of “history”. All that galimatia is supposed to form a crisp notion “precipice, brink, cliff” recycled as a “pestilent precipice”. At OED, a notion “etymology” needs to be resurrected. The name of the Jute people may be related to a jüt “calamity, pariah, cast-off”. A “Scythian” tribe, Jutes preceded Scythians to the Mesopotamia, lost a catastrophic defensive war, and were driven across W. Europe to a most unreachable territory named Jutland, protected by a band of endless swamp marshes. Later, Jutes had distinguished themselves as expert cavalry and a strong fighting force. The word's phonetics is near perfect, and semantics is precise; a Türkic origin is well-documented.
3.122
know (v.) “cognize, recognize, perceive, aware” (Sw N/A, F15, Σ1.02%) ~ Türkic ka:n-, q:an-, qanï-, köni, göni (v., n.) “know, verity, truth”. An “IE etymology” brassily claims an “IE” and “PGmc.” origins, q.v. Ultimately a derivative of a verb kön-, gön- “right (something), make things right”, qan-, qanï- “understand” with a rich trove of derivatives. They number at least 7+ semantic clusters carrying 31+ meanings believed to be based on a notion “straight” (adj.), and 2 semantic clusters carrying 7 meanings based on a notion “quench thirst” respectively. The words come in 17+ articulations (köni, göni, kӧnü, konu, xӧnü, hӧne, kӧ:nӧ, etc.), and 7+ articulations (qan-, kan, qaŋ-, etc.) respectively. The forms köni, göni etc. are members of a large family. A proximity of the words related to knowledge and mind points to an once common origin: köŋül, göŋül, köngül, göwün, kölün (n.) “consciousness, thought, mindset, memory, meditation, conviction”, q:an-, qanï-, ka:n- (v.) “cognize, understand, consider, convinced, reckon”, etc. The notions “straight, right” (adj., adv., n.) and “quench thirst” (v.) are uniformly held as most basic notions which produced all derivatives, including the “know, (ac)know(ledge)” (v.), etc., Cf. oğrı: köndi: “thief (ac)know(ledged), admitted” his theft, cited by G. Clauson (EDT 726), etc. The notion “know” has more than 20 Türkic synonyms with 10 distinct stems, each with its own pleiad of grammatical derivatives. That makes chances of catching a particular form say ca. 1/20 or ca. 5%. That shows a drift: secondary senses develop in semantic proximity or metaphorically, e.g. “straight” and “truth”, “heart” and “truth”, etc. Few tribes, like Gmc. or Romance, were lucky to inherit a word with a promising future. An internalization with an anlaut kn- etc. is routine: the oddball -ö- is not a European household phoneme. A line-up of the European “knows” is illuminating: 44 European languages use only 13 lexical roots. The early Europeans had fossilized lexical communities, later overlaid with migratory waves. 3 groups dominate: a motley but basically a Sl. group ved- with 11 (25%) languages, a Türkic-Gmc.-Romance group kön-, kn- with 10 (23%) languages, and a second motley Sl. group zna- with 9 (20%) languages. In European languages the trio constitutes a 68% majority. The remaining minority of 14 (32%) languages use a strew of 10 their own native words. The Sl. forms of the earliest stumblers to the Eurasia (40 kybp) dominated the land with altogether 20 (45%) languages, disseminating their lingoes across ethnic borders to Gmc. and Ugric folks. The Sl. preeminence lasted to a Killing Fields time of the 3rd mill. BC that reduced or almost completely annihilated W. European populations marked by the Y-DNA haplogroups E, F, G, J, I, and K. A male European
Y-DNA genetic soup was completely redone. Waves of Hg. R1 became a dominant European reality, reinforced over and over again by a “first night” wonts of the following times. The notion “know” is but one of the facets there. Besides “know”, Gmc. languages propagated numerous carryover meanings connected with the Türkic base kön. A notion “know” (v.) of a verb q:an- is one of at least 23+ meanings in 5+ clusters, extending to a notion “can (execute, achieve a desire, able)”, see can. The notion “know” is one of the secondary clusters, a bifurcated semantic split of “can” and “know”. What appear to be homophones are two offshoots in a pack of siblings from a single parental verb. For uninitiated etymologists, situation is confusing and confused. Gmc. cognates are semantically split, and viscerally are treated as homophonic lines. Once common in Gmc., the verb fully survived only in the A.-Sax. Eng. The notion “know” (v.) fr. a verb köni is one of them. Cognates: A.-Sax. can, con “learn, know” and “can, be able to”, cnawan (also with prefix a-, be-, to-) “know, perceive”, cnawlaec “knowledge”,
cnawe “conscious”, etc., all opposed to “believe”, OFris. kanna “recognize, admit”, ONorse
kenna “know, make known”, Goth. kannjan “to make known”, kann “know”, OHG chnaan (also with bi-, ir-) “know”, Gmn. kennen, erkennen, können “know”; Ir. gnath “known, famous”, Welsh gwy- “know” (but Scots fios); OCS znati; Lith. žinoti,
žinau, Latv. zinu, zinat “know”; Fr. connaitre “perceive, understand, recognize”; Lat. gnoscere “know, recognize”, agnoscis “recognize”, cognoscere “get to know, recognize”; Gk. gnos (γνωσ), gnosko (γνωσκω) “knowledge”,
gnosiz (γνωις) “cognition”; Alb. njoh; Skt. janati;; Kuchean
(aka “Tokhar B”) knan “know”; Mong. qan-, qanu- “meet desired”, all “know” unless noted otherwise. Distribution: From the W. Europe via Eurasian Steppe Belt to the easternmost Far East Tele tribes (aka Teleut, Tiele, Tuoba Wei, Wei), across linguistic barriers. Geographic and phonetic spread attest to an archaism of the word and its wide circulation. In the east, the later Türkic forms köni, q:an- “know” did not gain popularity. That corroborates a thesis that the Türkic-Gmc. amalgamation took place within the confines of the Corded Ware period and space; Gmc. has also retained a synonymous
wissen “know”. In the west, A.-Sax. carried the conventional bifurcated semantics eidetic with the Türkic original. The “IE etymology” falsely claims an “IE” and a “PGmc.” origins. Among the claims are a faux “PGmc. proto-form” *knew- “know”, a faux “PWGmc. proto-form” *knaan “know”, a faux “PWGmc. proto-form” *kneana “know”, and a faux “PIE proto-root *gno- “know” and a faux “PIE proto-word” *gneh- “know”. All that OED's and freelance galimatia is not needed. The documented Türkic
originals provide a fairly complete rendering of the semantic and phonetic genesis of the notion “know” and its Gmc. adoptions. The Gmc. records document amalgamation of the elder Gmc. and the historically Türkic terminology: Gmc. already had a set of its own fossilized terms. Those are: Goth., OHG., OE. finþan, frafjan findan “know”, Goth. ga-sweran “make known”, Goth. wait, lais, OHG. weiz, OE. wat “I know”, etc. Besides the “know”, a presence of a Türkic amalgamated lexicon in Gmc. is well attested: the Goth. ga-teihan “tell, make known”, OE. tion, teon “tell, make known” fr. a Türkic til, tili, tele, dili (n.) “tell”, see tell. A mass of other ancient Turkisms in Eng. and Gmn. numbers in thousands. A native A.-Sax.-Gmc. term for “know” was wit, witt (n.) “intellect, understanding, sense, consciousness”, witan (v.) “know, understand, aware, conscious, observe, perceive”. The line-up of the cognates is remarkable, Cf. the Gmn. können and the Türkic könen-, a verbal derivative of the verbal root kön-, gön- denoting a meaning “know” and “enjoy, rejoice, achieve prosperity”. The two are identical. The Gmn. können is universally recognized as a cognate of all the cognates listed above. That is indelible attestation of a common origin. The genetic connection does not conflict with the “IE etymology” deep thought on the diphthong cluster kn- as a result of peculiarly European process of regular phonetic shifts. In reality, it was
a particular propensity to consonantal clusters, a predictable vowel elision in a process of internalization. That converted a syllable kön-, gön-, q:an- into a consonantal diphthong cluster kn-, in some instances with succeeding elision of k-. Like the can “know”, the can “able”, the magan “might”, the cant “tilt”, and the nearly synonymous pair deem and know present an authentic case of paradigmatic transfer from a Türkic linguistic phylum to the related neighboring Gmc. languages. That is an indelible testimony of a common genetic origin from a Türkic milieu. See can, deem, do, I, might, this.
3.123
keep (v., n.) “hold” (Sw N/A, F184, Σ0.11%) ~ Türkic kap-, qab-, qap-, qarp-, (v.) “keep,
seize, grab, hold”. An “IE etymology” rating is both “of uncertain origin” and a “PGmc.”, q.v. Ultimately: from kap, qab, qap (v.) “cover, enclose, confine”, (n.) “container, vessel, box” (lit. interpretation) or a shape of the container
contents taking a shape of the container (metaph. interpretation), like frozen water caught in a container,
see cup. A hunch of an onomastic origin of the root is not needed, the kap- “cover, capture” leads to “seize, grab, hold”. The verb has 7+ semantic clusters containing at least 30+ meanings, a prime
meaning is “grab”. Related to Eng. capture, cab, cap, cup, cabbage, cable, have, and far beyond, reflecting 39 derivatives listed in a small Turkish dictionary plus independent European innovations. The dialectal variation qarp- with a prosthetic -r- is a clone of qap- with an accent on “grab”, Cf. carp (fish), lit. “grabbing, grabber” ~ Cf. qïp- and qïrp- “blink, wink”, Cf. qarp- ~ qarpï- ~ qarpïš- “grab much, by large chunks”. Of 44 European languages, a motley Gmc. group hal- leads with 10 (23%) languages, followed by a Romance group mant- and a Sl. groups der- with 6 (14%) languages each. The remaining 22 (50%) European languages use 18 versions of their own native words, including a scanty 1 Eng. and 1 Türkic “keep”. There is no common European “keep”. Cognates: A.-Sax. cepan (kepan) “keep, guard” (also with prefix a-, be-, etc.), ONorse hafa, OSax. hebbjan, OFris. habba, Gmn haben, Goth. haban “keep, have, possess, hold”; It. capisci, Sp. capiche, Lat. capere “grasp, seize”; OCS habit (хабить) “grasp”, Ukr. hapati (хапати) “grasp, seize”, hapkij (хапкий) (adj.) “grasping, thieving”; Hu. kap “get, receive”; Fin. kaapata “capture”, pitää “keep”; Pamirian qapdad- “grasp”; Mong. qabci- “press together”, havshix “bite (fish)”, Kalm. xawl- “catch (ball), bite (fish)”; all “keep” unless noted otherwise. Distribution: is typical for Türkic loanwords, Eurasian steppe width with some far western and far eastern appendages, crossing linguistic barriers. Clauson gives kıp as an allophone of kap (EDT: 580). No sane “IE” or any other etymology whatsoever, just some childish artifices. Among those are modest “perhapses” and “of uncertain origin”, followed by a faux “PGmc. proto-form” *kopjan (“look?”, “?”) “which is of uncertain origin” and a faux “PGmc. proto-form” *kap- which is not “keep, grasp” but is a “keep an eye”, and a faux “PGmc. proto-form” *kopijana “look”, and a faux “PIE proto-word” *gab- “look after”. A faux “PIE proto-word” *kap- is mechanically derived from A.-Sax. cepan with two independent meanings and a Türkic verbal instrumental suffix -an. The Gmc. “IE etymology” is thoroughly confused, unwittingly mixing up two independent Türkic words, one a kap- for “capture, keep”, and the other a kö:z/gö:z- for “gaze, look”. It asserts “no certain connection to other languages”, i.e. other than Gmc. a funny claim. It also suggested a faux Romance “proto-word” *kapio and faux “PIE proto-word” *khpyeti fr. a faux root *kehp- “grab, seize”, a very special pleading for an “IE” Romance case. All that potpourri is unrelated to the notion “keep”, it needs to be rectified. Incredibly, while the expert gurus kept discovering a series of fictitious proto-words, they have completely missed the ubiquitous Gmc. “have”, a cognate of the “keep, hold”. An omnipresent importance of the “have” in Gmc. languages is supreme, it fills 1.25% of the English daily lexicon, or every 80s word in a random English text. Supposedly too hard to miss, but with luck, they somehow managed. The “keep” indelibly belongs to a host of Turkisms paradigmatically transferred from a Türkic phylum to the Eng. See
cap, capture, cup, have.
3.124
kick (v., n.) “strike” (Sw N/A, F1206 0.01%) ~ Türkic kik-, kak-, qaq- (v.) “parry, punch,
strike”, batter two objects, like honing knifes by whetting one knife against another (Kashgari II 293); the waves parry; the arguing people parry. An “IE etymology” rating is on a level “of uncertain origin”, “perhaps”, “probably”, “guessed”, and
pretentions “PGmc.”, “PIE” , q.v. The word belongs to an allophonic cluster with extended range of forms:
kik-, kak-, qaq-, qoy-, goğ-, goɣ-, and their dialectal variations. Secondary meanings are connected with anger and conflict, Cf. qačis (~ qaqis) “discord, strife”. Of 44 European languages a motley international group kik- leads with 10 (23%) languages (Türkic, Eng., Welsh, Ir., It., Lat., Cors., Luxemb., Malt., Serb.), followed by the Sl. groups udar- and kop- and a Gmc. group spar- with 5 (11%), 4 (9%), 4 (9%) languages respectively. The remaining 21 (48%) European languages use 15 versions of their own native words. There is no common European “kick”. Save for the Türkic, the spectrum of the European “kicks” came of the borrowed “guest” lexicons. Cognates: Celtic Ir. ciceail “kick”, Welsh cic, chic “kick”; ONorse kikna “sink at the knees”,
keikja “bend backwards”, Luxemb. kick “kick”; Lat. calce “kick”, It. calcio, Cors. calci, Maltese kick “kick”; Serbian kitsk (кицк) “kick”; Mong. (Kalm.) kekixǝ “angered, enraged, flighty”; all “kick” unless noted otherwise. Distribution: is typical for Türkic loanwords: Eurasian steppe width with some far western and far eastern appendages, crossing linguistic barriers; sibling forms are areal. An atypical scarcity of Türkic derivatives points to a relatively recent spread. The same is also attested by the limited geographic distribution and the atypical absence of a cluster of dialectal allophones. The “IE etymology” is loony. It is unable to look over a fence into a real world. At first it suggests a series of sane disclaimers: “of uncertain origin”, “perhaps”, “probably”, “guessed”. Then it jumps into a neverland paradise: a faux “PGmc. proto-form” *kaikaz “bent backwards” ~ “of uncertain origin”, a faux “PGmc. proto-form” *ki-, *kij- “split, dodge, swerve sidewards” and an apotheotic faux “PIE proto-form” *geyh- “sprout, shoot” from a faux OSax. *kikan “look”. The “look” is apotheotic too, its kick “strike” turning into a “look” is no less than miraculous. The whole enchilada is indigestible in an earthly world. This philological farce needs to be graciously retracted. A Türkic noun kik “wild animal” points to a notion “attacking, rushing (animal)”, Cf. “discord, strife”. In a Khakass (Enisei Kirgiz) lexicon the word related to whetting as a primary meaning. Reference to whetting by banging knifes points to an Iron Age. Centuries before and after the turn of the eras the word was used in Türkic Buddhist lingo before an advent of the Manichaeism and Nestorian Christianity. A metaphorical religious term was a secondary semantics. The dignified Buddhist word
used in the translation of the Bible, in Eng. turned into prosaic parliamentary idioms: “kick the can down the road”, “kickbacks”, and “get a kick out of”. The Türkic twin physical and figurative semantics presents a case of a paradigmatic transfer with perfect phonetics and peculiar semantics: eidetic kick “parry, fence” and kick “quibble, argue, retort, recoil” (Cf. Tr. kikinč “retort”, kikšür- “argue” and a derivative kikne:- “flurry, derange”). A paradigmatic transfer of the terms
resolves all fictitious riddles of the “IE etymology” and provides indelible attestation of a genetic origin from a Türkic phylum.
| Kill – Preliminary Note. One of the first words documented by humanity is “kill”, a Sumerian gil of a 4th mill. BC. All kinds of “kill” forms are spread across many languages. It is presumed that all of them have retained an -l- in whatever host language morphology: with a retained vowel (al, öl, el, etc., Øl, tl, vl, etc.) or without. Such words number about 60 (“kill”, Wikipedia's listing, non-validated). A verified count probably would be about half of that. Languages that articulate -l- with alternate consonants are not accounted for. Who borrowed what and how it was internalized does not matter, the Sumerian gil came from somewhere else anyway. It may pop up in a Mayan or an Amerindian script, and then a 4th mill. BC would be a later milestone. But for us now it is a certain milepost that allows to comprehend later developments and later claims of origins. |
3.125
kill (v., n.) “cause to die” (Sw N/A, F320, 0.08%) ~ Türkic kıl-/qıl- “do, make, act”, kılıčla:- “kill with sword”, ӧl- “die, death”, Chuv. vil-, wil- “kill”. An “IE etymology” is super-inapplicable, flimsy, myopic, and pretentious, q.v. Ultimately fr. a verb kıl- “do”, kılıčla:- “kill with sword”, with persuasive derivatives:
qïlïč ‘sword’, qïla, qïlaɣï “острый” ~ Skt. kuliča “ax, axe”. The Türkic kıl- kïl- comes in a range of articulations, kıl-, qıl-, gıl-, hıl-, heleh, etc. Complimentary to kıl- “do” is
ӧl- “die, death” that comes in a range of 11+ articulations, ӧl-, ül-, jӧl-, jül-, jul-, u1-, etc. The twin roots kıl- and ӧl- likely ascend to a same common source, in time endowed with prefix, prosthetic anlaut, and suffix modifications, Cf. A.-Sax. a-cwel-an, be-cwel-an, etc. A Sum. gil “kill” and the Eng. “kill”, a temporal polar opposites, are linked with the Türkic intermediates qıl- “do” and öl- “death, kill”. The Sum. term may have internalized from the lingo of the still illiterate Türkic nomadic tribes surrounding Sumer from the east and northwest. Of 44 European languages a Sl. group bi- leads with 12 (27%) languages, followed by a Romance group mat- with 4 (9%) languages. The remaining 28 (64%) European languages use 17 versions of their own native words, incl. Eng. (1), Basque (1), and Türkic (1) cognates of ӧl-, kıl-, qıl-. Except for Sl. forms, there is no widespread European term for “kill”. The Eng. “kill” is explicitly a Türkic “guest”. Eng. has inherited those two synonymous Türkic service words, kıl-/qıl- “kill” and tu-, tur-, dur- “do” that refer to, but not specify, a concrete action or result, see do.
Cognates: A.-Sax. wael “slaughter, carnage” (< ӧl-), Waelheall “death-hall” (see hall), acwelan, acwylan (v.) “die, perish”, acwellan, aquell “kill, destroy”,
acwellednes (n.) “slaughter”, asweltan (v.) “die”, becwelan “die”, cwelan “die”, diegan “die”, foraweltan “die”, leoran “die” (< öleoran),
oðcwelan “die”, (ge)sweltan “die”, OSax. cuellian “kill, torture”, Goth.
waltjan “beat upon”, Walhalla (Valhalla) “death-hall” (Hall of dead), ONorse kvelja “torment”, MDu quelen “vex, tease, torment”, OHG kuellan “suffer pain”, Gmn.
quälen “to torment, torture”; Hu. gyil, öl “kill”; Arm. kelem “I torture”;
Pers. koflan “kill”, Sum. gil “kill”, gilal “butcher”; Mong. kilagu, Khalka χialu “edge, spike”; all “kill, death” unless noted otherwise. All articulations in their own ways mimic the underlying Türkic phonetics. A ligature wae- in Wae(l) etc. mimics -ö(l)-; Walhalla (Valhalla) “death-hall” (Hall of dead) is an allophone of the Türkic ölqalïq “death-hall” (öl-qalïq) and A.-Sax. Waelheall “death-hall”; Arm. kelem is formed with a Türkic 1st pers. sing. suffix -em; Hu.
gyil, öl “kill” has preserved both Oguric and Oguzic forms, the Ogur form gyil matches the Sum. gil and Eng. kill; Sum. gil, gilal “kill, butcher” ~ öl- with Ogur prosthetic initial g-, k-. Distribution: the extent of Eurasian steppe with far western and far eastern appendages, across linguistic barriers, with a variety of sibling forms. A myopic “IE etymology” starts with a self-deprecation, piling on hypotheticals as a philological foundation. The pearls are the “obscure”, “perhapses”, “possibly”, “unrecorded”, followed by chains of speculations. Those are a faux “PGmc. proto-form” *kwaljanan “throw, reach” extended with extended sense extension “pierce”, a faux “PGmc. proto-form” *kwuljana “throw, hit, hurt by throwing”, a faux “PWGmc. proto-form” *kwulljan ditto, and a faux “PIE proto-root” *gwele- “throw, reach, with”, and a faux “PIE proto-form” *gʷelH- “throw, hit, hurt by throwing”. Semantics “throw, reach, pierce, hit” is unrelated to a “kill, slaughter”. As a way out of unscholarly abyss, the “IE etymology” offers “a variant of” cwellan, which is just one of a dozen A.-Sax. forms with -wel- ~ öl-, q.v.
An another wild goose chase is too embarrassing: kill (v., n.) < unrelated Du. kil, kille
“cold” and < MDu. kille “riverbed, channel”: that Du. kille is a common Türkic qïlï “confluence of an oxbow bend and a main channel”. A situation is beyond folly: either a picket is
too high for a short scholar's eyes, or an eyesight is too low without heels. An “IE etymology” case extends way beyond myopia.
To blunder unintentionally so severely is impossible. An intentional deceit is screaming for a justice. The A.-Sax. root cwell < öl- ~
cwellan formed the Eng. kill (ca. 1200). A transition from the form öl- to
cwell is two-step, one with a prosthetic w- (wöl-, Cf. Chuv. form), and then with a perfect tense prefix k- (c-) to form cwell “kill”. The form wöl- “death” is attested with ligatures e-, wae-, wea-, we-. The wael is a phonetic equivalent of the form öl “to die”, it is reflected in the Chuv. vil-, il-. The word waelm (~ ölm) is a phonetic equivalent of the Türkic ölüm “death”. In both cases, the part -üm/-m is a Türkic-A.-Sax. deverbal noun suffix. Transition to a Roman alphabet caused inconsistency of spellings, Cf. el, wael, wel, weal, wiel. The Clark-Hall Anglo-Saxon Dictionary lists a trove of 104 words derived from the word
wael “death”, including those with prefixes a-, be-, c- (cwelan “to die”), etc. The compound c- + wael forms the words cwalu (n.) “klling, murder, violent death, destruction”, cwellan (v.) “to kill, murder, execute”, cwellend “killer, slayer”, and a derivative trail with their allophones. A form with a prefix c- (k-) turned out most productive, it corresponds to the “IE” prefix s- that forms perfect tense (s-/k- alternation, aka satem-kentum split), and thus is archaic. The form öl- could be a contraction of a base form with an initial consonant or semiconsonant, Cf. attested versions jӧl-, jül-, jul-, wil-. The qıl- “do” is mirrored by the Eng. mysterious idiom do in “kill” and idioms like “be done” alluding to an irreversible deed. From an auxiliary “do (something)” Eng. retained a “do” and a most drastic and frequent semantics of a concrete verb “kill”, “make dead”, see do, q.v. That unambiguously attests to a genetic connection. Directional confinement of the verbs do and kill to a Gmc. group attests to their “guest” status within the “IE family”. A.-Sax. and Eng. have various ways to express the notion “kill”; some of them may ascend to a yet unexplored “Old Europe” Sprachbunds of the pre-“IE”,
pre-Celtic, pre-Gmc. families. For example, Herodotus IV. 110, in the compound eorpata - those who are striking their husbands (Türk. er “man, husband”, Cf. Gmc. Herr) noted a Scythian pata- (v.) “strike, kill”. A Sum. badd is an oldest record for an Eng. bat (v., n.) ascending to a 4th mill. BC, see bat, pat. A “gore” is a truly Eurasian word, extending from Scotland to Japan, see gore.
With
the Sum. gil “kill”, the precise semantics makes a random coincidence unlikely, whilst its
origin ascends to a Türkic stem qïl- “make, do”. That
echoes the Eng. inexplicable idiom “do (him) in” for the verb “kill”, using the qïl- “do” for
“do” would make the idiom to ring “qïl (him) in”, a striking incidence. The Sum. form ascends
to the 4th mill. BC, Sum. is unrelated to the “IE” family, that brings the origin of the term kill
via allophones gil and öl- way beyond the width and depth of the extant “IE” etymology.
See bat, battle, do, gore, hall, Herr, mist, pat.
3.126
laugh (v., n.) “guffaw” (Sw N/A, F1337 0.01%) ~ Türkic gül-, kül-, kӧlü-, wül- (v., n.) “laugh, laugh at, smile”. An “IE etymology” has fair reasons to it blunder, q.v. Ultimately fr. two complementing forms, gül- and küle-, both “laugh”, but gül- a gentle “smile, grin”, and küle- a loud “cachinnate”, apparently fr. a same root. Gül- conveys a cache of ca. 14 meanings in 5 semantic clusters, küle- – a cache of ca. 9 meanings in 2 semantic clusters. Internalization's mechanics is fairly transparent. Versions internalized by Gmc. relay anlaut consonant g-, k- as h or Ø, elide anlaut -ü-, retain
-l- as a root, and may append an areal morphological modifier or an echo of a guffaw, Cf. hla-, le, la-, lau-. An Old Europe Sl. group predominates in Europe. Of 44 European languages a Sl. group sme- leads with 12 (27%) languages, followed by a Gmc.-Türkic group kel-, l- and a Romance group ri- with 9 (20%) languages each. The remaining 14 European languages use 12 versions of their own native words. There is no common or overlapping European “laugh”; each main grouping stands proudly discrete. The “laugh”, shared in Europe exclusively by Gmc. and Türkic languages, is traceably an inheritance of an old Türkic “guest”.Cognates: A.-Sax. gliwung “laughter” (< gül-), ahliehhan, hilehhan, hlagol, hliehhan, ceahhetan “laugh” (< kül-, gül-), hlæhh, leah, cahhetan, ceahhetan “laugh”, hleahter, hleahtor, hleahtorsmið, cineung “laughter” (< gül-), hleahterlic, hleahtor, leahtorbere “laughable” (< gül-), hleahtrian, behlyhhan, bilaugh “deride” (<
gül-), OSax. hlahhian, OFris. hlakkia, Fris. laitsje, Faroese
latur, Dan. le, MDu., Du., OHG hlahhan, Afrikaans lag, Gmn. lachen, Luxemb. laachen, ONorse hlæja, Norw. latter, Goth. hlahjan, Icl.
hlatur, Yid. gelekhter (געלעכטער), lakhn (לאַכן); Ir., Scots gaire (l ↔ r), Scots (> lauch); OGk. gelos (γελως); Lith. klageti “cackle”; Arm. cicał (ծիծաղ); Georgian sicili (სიცილი); Javanese guyu; Malay gelakall; all “laugh” unless noted otherwise. Nearly all cognates retained -l- as an anchor. Erroneously suggested as cognates the Eng. cackle, OHG kachazzen, Lat. cachinnare, Skt. kakhati, OCS
chochotati (хохотати), Gk. kakhazein, Arm. karkach (կարկաչ). They are allophones of an attested Türkic kakı:la:-, kakı: “cackle, cachinnate”, which is stronger than laugh, see cackle. Distribution: is consistent with other English Turkisms, across Eurasian Steppe Belt plus NW European fringes, and unexpected Javanese and Malay cognates. The last two may represent stray migrant waves split fr. the bulk of the Y-DNA Hg. NOP migrant waves that are believed to move across Asia on their way toward Siberia and a downstream Y-DNA Hg. R. No “IE” cognates, positively no connection to the “IE” family. The “PG proto-word reconstruction” *hlahjana is a mechanically assembled nonsensical faux “proto-word” divorced from etymology, history, and demography. The same with “of imitative origin” a faux “PGmc. proto-form” *klakhjan, a faux “PWGmc. proto-form” *hlahhjan, a faux “PGmc. proto-form” *hlahjana, and a faux “PIE proto-word” *kleg-, presumably all “laugh”. A poverty of perception and intellectual myopia are of abusive proportions. That nonsense has to be gently disposed of. The Eng. laugh is a shift of the allophonic hlæ- of the ancestral ül-, kül- toward A.-Sax. hlæ(hhan), hlie(hhan), hli(hhan). The root is combined with a Türkic infinite suffix -an, or with native modifiers -hlyhh-, hlag-, hlað-, lað-, leahtor- (hleahtor-) or/and with elided anlaut h- (Tr. g-/gü-), softened inlaut -hh-/-g-, also transcribed -h-, and shed
conjugational suffixes. The vowel transcription -æ-, -ie-, -y- corresponds but not
necessarily reflects the CT rounded -ü- or an -e- of the Caspian basin languages.
Both the h- and l- forms are recorded for the A.-Sax. That attests to elision commenced on the continent, either during or before an amalgamation of the Anglian and Saxon, within the Saxon, Sekler, Scythian vernaculars, or at the conflation of the future Scythian, Sarmatian, and the Corded Ware vernaculars. Of the five Türkic terms related to laugh, four were paradigmatically transferred to Eng.: gül- as hlæ- > laugh and hilarious; kakı:la:- as cackle, cachinnation, gag; and the jer- as jeer, the elük as
joke. These four Türkic words complemented and supplanted the corresponding native European lexicon that came as a part of the A.-Sax. language but faded with time. The paradigmatic transfer of the Türkic quartet testifies to the common genetic origin from a Türkic phylum. See cackle, hilarious, jeer, joke.
3.127
lie (v.) “deceit”, liar (n.) “deceiver” (Sw N/A, F596 0.04%) ~ Türkic yalan, yalgan (yalɣan, yalğan) (adj., n.) “deceitful, false, deception, lie/lies”. An “IE etymology” rates it as “a word of uncertain etymology”, with some added spice, q.v. Ultimately fr. a verb
yala:- “suspicion, incriminate” fr. a stem yal “ignite, heat up, flair up”, a derivative of a verb ya:- “ignite shine, flame” which produced the “IE” ignate (see
ignite ) and its passive form yal- “blazed, burned, shined”. Gmc. incl. Eng. have retained an elided stem lag- with a deverbal adj. suffix -ɣ-/-g- “lying”; in the Gmc. internalizations the frontal
ya- was elided, Cf. gül-, kül- > hl-, Øl- in “laugh”, q.v. A breakdown of the European lexicons shows that for a long initial period European peoples were honest: they did not have a word for “lie”, and learned it quite late from an invader “guest”. Of 44 European languages a group lg- (~ lie, Türkic, Gmc., Sl.) leads with 20 (45%) languages, followed by a Romance group mVn- with 8 (18%) languages. The remaining 16 European languages use 11 versions of their own native words. There is no common native European “lie”; each group stands proudly discrete. The breakdown clearly demonstrates a “guest” status of the word. Cognates: A.-Sax. leogere “liar, false witness”, OFris. liaga, OSax. luggi “lie”, OSax., OHG liogan, lugi, lugin “lie”, Gmn. lüge “lie”, ONorse ljuga, Dan. lyve, løgn, Goth. liugan, Gmn. lugi, lüge, liogan, lügen; Ir. log-, logaissi “mendacious”, fol-lugaim “I hide, conceal” (Tr. suff. -im “me”); Sl. yala (яла) “punish”, lgat (лгать) “lie”, OCS
lugati “lie”, Rus. lgat, lož, laža (лгать, ложь, лажа) “lie”, Bolg. laža (лъжа) “lie”; Lith. luginaite “traitorous”; Mong. žali “deceit”, zalga:, zalgas “false (braid)”; all “lie” unless noted otherwise; the word yalɣan was directly borrowed into Mari, Lezgin, and Balkan languages (EDTL v.4 91). Distribution: spans Eurasia from Atlantic to the Far East, crossing linguistic borders adjacent to the Eurasian Steppe Belt. An “IE etymology” first defines the “lie” as “a word of uncertain etymology”, i.e. a myopic but reasonable “we do not have a clue”. Then, it commences unreasonable: a faux “PGmc. proto-forms” *leuganan, and *lugiz “lie, falsehood”, and an apotheosic faux “PIE proto-form” *lewgʰ- “tell lies, swear, complain”, a steep jump fr. a “no clue” to assertive faux “PIE proto-word”. That kind of nonsense needs a gentle excision. The Eng. nominal liar is an echo of a simple yalan, yalgan “lying” or of an adjectival paired compound yalɣan ar “lying man”. The Gmc. forms are fairly uniform, attesting to a stable Sprachbund of the Corded Ware period societies. No “IE” parallels, the “IE” did not touch the word. Rating the word with a routine “a word of uncertain etymology”, etymological speculations did not strain too much besides few wild fantasies. The Turkological studies pursuing Altaistic models made good inroads on amalgamations. In the archaic Türkic culture, lying was among the greatest human vices, so the word had grave connotations. Vestiges of that attitude still survive in the British culture, to a much lesser degree in the American culture, and fairly well in the modern Türkic cultures. That trait stands in sharp contrast with the Near Eastern – Mediterranean cultural heritage and its syblings. See ignite, laugh.
3.128
lull (v., n.) “hush to sleep, hum a lullaby” ~ Türkic ulï- (v.) with some variations
(-a-/-u-) “wail, moan, bellow, sing drawly”. An “IE etymology” rates it as “probably imitative” and “from la-la-la”, and abstains fr. any “IE” claims, q.v. Ultimately fr. a root u:-, uw- + denoun verbal suff. -la > ul-, u:lï-, ulï-, ula-, uluj-. Elision of an initial vowel is an areal routine. The lull is connected with lullaby and is a cognate of ululate, a derivative form of ulï-. Of 44 European languages, 10 (23%) use Sl. -tiš-, 7 (16%) use Romance calm-, and a motley group lul- numbers 6 (14%) languages. The other 20 languages use their own 17 native words. An Old Europe Sl. predominates; there is no common “Pan-European” term in Europe. The motley “lull” is a “guest” in Europe. Cognates: Friz. lulk “lull”, MDu. lollen “mutter” (but lullen “cheat”), Dan. lulle “lull, sing to sleep”, Sw. lulla “lull, hum a lullaby”, OE, Gmn. lullen, lollen “hush to sleep, rock”, Gmn. lullen “lull”, Icl. lulla “lull”; Ir. lull (native canadh, caoineadh), Scots lul, lule, loll “lull, put to sleep, howl” (native taladh); Sl. lulukat, lyalyat, lyalya (люлюкать, лялять, ляля) “lull”; Lat. ululare “howl”, ulula “owl”; Fin. laulaa “sing, chant”, Est.
häll “lull”; Skt. lolati “rock”; Mong. uli-, ulih- “howl (dog, wolf)”; Hiligaynon (Philippines) lala “lullaby”; all “lull” except noted otherwise. Distribution: spans Eurasia from Atlantic to the Far East across linguistic borders adjacent to the Eurasian Steppe Belt, with a surprise finger at Philippines. Atypically, the “IE etymology” modestly does not claim an “IE” origin, suggesting instead a “probably imitative” reverse engineering fr. a “lu-lu sound used to lull a child to sleep”, with a cart ahead of the horse. Such approach is unproductive, an intentionally myopic horizon is
self-deprecating. A difference between ulï-, ula-, uluj- and la-la-la is that one is attested and functional, and the other is a scholastic chimera. A “quiet period” is a late Eng. semantic innovation. See ululate, howl.
3.129
make (v., n.) “produce, create, form” (Sw N/A, F106, Σ0.32%) ~ Türkic -mak (-mek, -mək, -maq, -mäk) “make” (v.), deverbal noun suffix (or postposition; a difference is purely conventional) that makes a transition verb→ noun. An “IE etymology” claimed quite a few solutions on a level fr. “perhaps” to daring and funny, q.v. In Türkic, any stem with a suffix -mak becomes a deverbal noun: verb-mak → noun-make, like abmak “hunt-make”, akmak “white-make” (~ “stream”). A deverbal noun modifier “do, make” follows a regular morphology of the language(s). It was also used to form archaic denominal nouns. To reinforce the concurrence, a form -madï, a match for the Eng. form made, is a version of the same suffix -mak. It forms non-finite negative participles of following tense, functionally it was retained in Eng., Cf. “made-up excuses” < “excuses-made”. In Eng., the suffix/postposition turned into a stand-alone action verb “make”. The Eng. mock “make an imitation, imitate” belongs to the same cluster. Of 44 European languages, 9 (20%) languages use Romance fa-, a Türkic-Gmc. group
mak- uses 7 (16%) languages, and the other 28 languages use their own 18 native words. There is no common “Pan-European” term in Europe. The Türkic-Gmc. group is using an amalgamated Türkic “guest” word “mak”. An importance of the word in Eng. is beyond emphasis; ditto in Türkic: Clauson
EDT cites me:k, ma:k 2,413 times. Cognates: A.-Sax. macian “make, form, construct, do, ...”, macung “making, doing”, macian up “put up”, OSax. makon “make”, OFris. makia “make, build”, Saterland Fris. moakje “make”, WFris. meitsje “make”, Dan. mage “make, arrange (in a certain way)”, MDu., Du. Low Saxon, Du. maken “make”, OHG
mahhon “construct, make”, Gmn., LGmn. machen “make, do”; Goth. ana-mahtjan “make, do” (violence, injure, damage, revile) (but ga-skapjan “create, make”); Kor. -mida, functionally, morphologically, and as a postposition syntactically used analogous to the Türkic -mak “do, make”. Distribution: A Türkic historical spread across Eurasian Steppe Belt. A splinter of Gmc. languages furcated lexically its historical body by internalizing a Türkic suffix -mak “make” into a stand-alone word “make” (i.e. splinter “make” vs. Sw. göra, Norw. gjøre, Icl. gera). Myopically, the Gmc. etymology failed to properly appreciate that peculiar split. A Türkic derivative “make” can't have any “IE” cognates under any sauce: no cognates can exist on the native Gmc. side. An “IE etymology” optimistically raises “perhapses” to a level of certainty, claiming miracles upon miracles: a faux “PWGmc. proto-form” *makon “make, build, work”, and a faux “PIE proto-root” *mag- “knead, fashion, fit”, and a faux “PIE proto-form” *mehg- “knead, mix, make”. All that Gmc. uber-scholastics is pure nonsense, due to be gently rescinded together with other crackpot nonsense. Those are sited as a Lat. macero “apprentice”, macer “lean, skinny”, OGk. masso (μασσω) “mince”, OEng. gemaca “mate, equal, companion, peer” > MEng. make, imake, ȝemace “equal, companion, peer”, or a suggested agricultural tool name. A Scots mak “make” as a recent loanword fr. an Eng. lexicon is quite reasonable. There is a remote possibility of its origin ascending to a Celtic vernacular of 4th-5th mill. BC, prior to the Celtic
circum-Mediterranean anabasis fr. the E. Europe to Iberia, albeit that conflicts with the attested Ir.
dean, Scots deanamh “make”. A legacy of the forms “make”, “made”, “mock”, “do” etc. is an
unambiguous case of a systemic paradigmatic transfer between the Türkic and Eng. and other Gmc.
languages. The Eng. word probably ascends to Sarmatian, and the Korean word may be of Zhou origin,
but probably of more local sources incl. Türkic. Thus the linguistic traces of the Türkic-speaking “Scythians” may come from the opposite ends of the Eurasian Steppe Belt. See do, mock, model.
3.130
mean (v., n., adj.) “intend, have in mind, denote” (~ “think”) (Sw N/A, F80 0.26%) ~ Türkic manï, maŋïz (n.) “meaning, sense, essence, idea, thought”. An “IE etymology” flooded the subject with “perhaps” things and spicy claims, q.v. The word is connected with a notion “brain”, Türkic meŋ “mind, brain”, Cf. ex, xe “brain” (native, European), braegen “brain” (< Türkic beñi:, beyin; beyini, beyni), see brain. The word comes in “a puzzling variety of forms” (Clauson EDT 348), four b- words and nine m- words are cited
(beñi:, beyin, meŋ, miŋi, etc.). Attesting to a great historical time depth, dispersion of forms exceeds most of recorded, for example, for the A.-Sax. The word very well may have come to the Europe fr. Africa with the first out-of-Africa to Asia migrants 40 kybp. It went from the Red Sea to Iberia (Y-DNA Hg. I) and to a heart of Siberia (Y-DNA Hg. NOP > R) 20 kybp. The m- form is equivalent to a b- form (m/b alternation), it carries ethnologically diagnostic insights. Of 44 European languages, 10 (23%) languages use Türkic-Gmc. mani-, a Sl group zna- with 6 (14%) languages; the other 28 languages use forms of their own 19 native words. There is no common
“Pan-European” term in Europe, a Türkic-based term predominates there. An abstract meaning of the word allows development of numerous derivatives in English and Türkic, each with a trail of its own derivatives, some present in both languages (e.g. mind ~ maŋ /ming/).
Cognates: A.-Sax. mænan “intend”, OFris. mena “signify”, WFris. miene “deem, think”, OSax. menian “intend”, MDu., Du., Gmn. menen, meinen “think, suppose, mean, intend, opinion”, Goth. mаn, munan “think, suppose, recall”; OPruss. minisnan “memory”; OIr. mian “wish, desire”, Welsh mwyn “enjoyment”; OCS meniti “think, suppose, opinion”, Bolg. mlya, mnya (мля, мня) “think, suppose, opinion”, Sloven. mneti, mnim “think”, Cz. mneti “mean”, Pol. pomniec “remember”; Lith. mineti, menu, miniu “recall, mention”, Latv. minet, minetu “mention”; Lat. memini “recall”, mens, mentis “mind, thought”; Gk. μῆνιγξ (meninx) “brain membrane”, μέμονα “remember”; Pers. maɣž “brain; marrow”, “mind, wits”; Skt.
manyate, manute “thinks, remembers”, Av. mainyete “thinks, believes”, memini “recall”;
Mong. oüun, uhaan, gəsən “mind, say”; all “mean” unless noted otherwise.
Distribution: Eurasia-wide; nowadays its siblings are international words due to shared medical and trade terminology. The myopic “IE etymology” indulges into geographically and historically-curtailed
inventions devoid of etymology: a faux “PWGmc. proto-form” *menjojanan “mean?” and a faux “PWGmc. proto-form” *mainijan “mean?” and a faux “PGmc. proto-form” *mainijana “mean, think, complain”, derived fr. a faux “PIE proto-form” *meino- “opinion, intent” and a faux “PIE proto-form” *meyn- “think”, or “perhaps” fr. a faux “PIE proto-form” *meyno-, *meino-
“opinion, intent”, an “extended form” of a faux “PIE proto-form” *mey- “mean?”. In addition, some “authoritative” studies, especially older Rus. and Gmc., turn things upside down, against all evidence ascribing origination to Pers. (Cf. Doerfer BD 4, 35, 1751 majna). All that kindergarten nonsense needs to be gently retired. Both related notions, the “mind” and the “brain”, have no credible “IE” nor Eng. etymology. Besides a dozen of m-/b-/h- forms ascending to the Türkic m-/b- (incl. Celtic), Europeans have 3 a- forms (Uralic), 8 cereb-, 1 kef- (Gk.), 1 tr-. A homophonic mean “average, middle” is unrelated to the mean “idea”, it is a derivative of a notion “community”, Cf. A.-Sax. maennes “community”. See brain, mind.
3.131
mock (v.) “imitate, jeer” ~ Türkic maq, -mäk (adv.) “together”.
An “IE etymology” asserts “a word of unknown origin” and then paints its own desires, q.v. Ultimately fr. a Türkic suff. -maq “together”, with various elements of similarity: namesake, cooperation, connection, reciprocity, joining, etc. The Eng. “mock” addresses just one faucet of the Türkic-Eng. “mock” complex, an uncouth mirror image of an original subject. The explicitly attested Türkic applications of maq are: adašmaq, atašmaq, and oyna-š-maq: ada-š-maq, ata-š-maq < ad, at “name” + -š- suff. “cooperative, reciprocity” +-maq (adv.) “together” > “reciprocal namesakes altogether”; “play- cooperative, reciprocity- together” > “joint cooperative play”. In the A.-Sax. vernacular, the word had already simplified from an amalgamated morphology to a stand-alone part of a speech denoting similarity or connection. The Eng. “mock” opposes two sides of a subject, while the Türkic -maq highlights different aspects of similarity. Of 44 European languages, the Türkic-Eng. group mag- leads with 6 (14%) languages; a remaining spread of 38 languages use forms of their own 27 native words. There is no common “Pan-European” term, the Türkic-based oddball term hulks in Europe. Cognates: A.-Sax. maec “companionable, similar, equal”, maca, (ge)maecca “one of a pair, comrade, companion”, macian “make, form, construct, do” (presumably fr. a same root, see make); Ir., Scots
magadh “similar, equal”; Luxemb. mock “derisive imitation”; OFr. mocquer, moquier, “deride, jeer”; Maltese mock ditto; all “mock, deride, jeer” unless noted otherwise. Distribution: Eurasia-wide as a suff.; NW Europe areal verb. The word fell a victim of an
“IE” ingenuity in a series of “probably” guesses and direct falsification. There is a faux “PWGmc.
proto-form” *mokkijan, *mukkijan “bellow, low, mumble”, a faux “PGmc. proto-form” *mukkijana, *muhana “bellow, low, shout”, and a faux “PIE proto-word” *mug-, *muk- “mumble, low”.What all these bellowing sounds have to do with humans mocking each other is a scholary etymologist's undisclosed secret. The “ultimately imitative origin”, “probably's”, bellowings, “mope”, “murmur”, “kiss”, VLat. *muccare “blow nose”, Lat. “mucus”, “mumble” and any other parochial nonsense needs to be delicately and completely rescinded. Against a backdrop of the European “IE” gross nonsense, the nature and
detail of the Türkic etymology raises like a light of a dawn, dissipating the darkness and
illuminating the whole neighborhood as a sentence and as a word. A Türkic origin is irrefutable. See do, jeer, make, model.
3.132
model (v., n., adj.) “imitation, representation, likeness made to scale” ~ Türkic met, bet, bit, meŋiz (m ↔ b) “face, look, form”. An “IE etymology” asserts an origin fr. a Lat. modulus, with a dubious turn, q.v. Ultimately fr. an archaic bit, bet “face”, Cf. facade. The notion “face” heads 4 literal and 5 metaphorical semantic clusters, from “face” to “surface” and from “cheek” to “layer”, a total of 25+ sememes. After an oldest “face”, all meanings are derivative extensions. Selective internalizations are to satisfy immediate needs, starting usually fr. a header notion, in this case with met. A Türkic-based term hulks in Europe, the word is quite popular: of 44 European languages, versions of “model” are used by 39 (89%) languages, leaving only 5 (11%) languages to their own devices. The number even exceeds a 23 (52%) European languages popularity for such a recent and hot word as a “computer”. That demonstrates that some innovations were so badly needed that they internalized on arrival, at least by the artisan crafts. In the Europe, the newbie spread like a wildfire. The Türkic word is a de-facto “Pan-European” term; as a trade term denoting “a model” it could go as far as a trade spreads. Cognates: VLat. modulus, modus “small measure, standard, manner, measure”, modus “manner, measure”, Fr. modelle (16c.), modele
“model”, It. modello “model, mold”; Gmn., Sw. modell, Du., Dan. model, Icl.
(fyrir)mynd “model”; Nenets, Ostyak mitte, mitt “similar, identical”; Mong. (Kalm.)
bütü, bötö, betǝ, metǝ, mötö “as, like (smth.), alike,
similar” (~ Tr. metü, betü “similar”, bet “face, exterior, appearance”), Bur.
metü (~ Tr. bet, q.v.); Tung., Gold. matu “as, like, alike, similar”; Uzb.
bet-kəy > küngey, küngӧy “face turned towards Sun”; all “model” unless noted otherwise. Distribution: Initially Eurasian Türkic Steppe Belt; nowadays scattered around the globe, Cf. Ch. moudakji, motelu, mato, moter, botekji, botekli, etc., etc. An “IE etymology” asserts an origin fr. a VLat., i.e. 3rd - 6th cc. AD timeframe. That is millenniums younger than the notion met, bet “look, form” at the root of the word. A nescient turn to a faux “PIE proto-root” *med- “take appropriate measures” is absurd. That unattested *med is not a model, i.e. “representation on a small scale”, nor a model is an “appropriate measures”. A model is a copy, a working imitation at some scale of a target object. The working copies were frequently etched on a floor of an object to guide the generations who would continue the work of the previous generations, be it a certain
design, a mosaic mural, or a structure in progress. The unattested “proto-root” does not hold water. The evolution is the same as for the word “derrick”, a log hoist frame named after tree logs, see
derrick. The pair “face, look, form” and “derrick” present a case of paradigmatic transfer from
a Türkic milieu. See derrick, do, make, mock.
3.133
mount (v., n.) “climb atop, mounted horse-riding” ~ Türkic men-, min-, mün- “ascend, climb on, mount, ride (a horse)”. An “IE etymology” asserts an origin fr. a Latin mons “mountain”, an inverted idea, with a bogus “IE” meddling, q.v. Ultimately fr. a version of a root men- etc. “ascend, climb”. The verbal root carries 7 semantic clusters expressing 13 concepts, fr. a “mount, mount a horse” to a metaph. “take one or another action”. All derivative meanings ascend to a core meaning “ride (a horse)”. Evolution went toward greater semantic abstraction: riding animal was replaced by a vehicle in general; the ascent (v.) and its object (n.) were routinized, Cf. “mountain” (EDTL v. 7, 66 ). An idiom tutu:pan minmi:š “caught and mounted (horse)” reflects a pre-domestication time ca. 6th mill. BC when riding was a prize of a hunt (Clauson EDT 348). An idiomatic mingǝš > miŋǝš, ~ biŋǝš packs an entire sentence: “mount in tandem astride a horse”, with a newer “ride in a vehicle (bicycle, etc.) together” (-g- suff. noun, adj., -ǝš - suff. denoting cooperation, reciprocity). The verb min-, bin- joined other synonyms for a “rise”. A Türkic term dominates Europe: of 44 European languages, versions of “mount” are used by 31 (70%) languages; only 12 words in 13 (30%) languages are left to their own devices. Domination even exceeds a 23 (52%) popularity of such a hot and recent word as a “computer”. The Eng. and Fr. form moun- probably attempts to convey the rounded -ü- in mün-; that would allow to trace the form to particular tribes and dialects. Clauson EDT cites the form mün- “mount, ride a horse” in Uigur, Kirgiz, and Khakass languages. The causative/passive (trans.)/active (intrans.) suffix -t is also carried to Eng.; from transitive verbal base mün- it forms the word münt that serves as causative and passive verb “mount” and a noun “mount” (Cf. port). In some “IE” languages (Cf. Sl., Av.) -t is used as a marker of infinitive. Cognates: A.-Sax. mont, munt “mountain”, muntaelfen “mountain–nymph”, muntelyse “mountain prison”, muntland “hill-country”, neahmunt “neighbouring mountain”; OFr. monter “ascend, mount”, Lat. mons “mountain”, Rum. biniš, binišel “races, mantle”, binmek “riding”, biniği “rider”;
binigiü “stable hand”; NGk. bintxis (μπιντξης)
“rider”; Bulg., Bolg. bineg “horse, racer”, binija “races”, bined ija “best horseman, rider”, biniš “cape, mantle”; Serb. binjek, binjak “charger”, binjed ija
“horseman, rider”, binjektas, binjek kamen “(stepping) stone”, binija “doorjamb”; Alb.
biniš “wide clothing, cape”; Fin. mennä- “go”; Mong. moriton “rider”;
Sino-Kor. > Kor. meida, mеda “carry on a shoulder” (Doerfer BD IV, 1750, p. 35); all “mount” except as noted. Distribution: Eurasian-wide, fr. Atlantic to Pacific; predominant in Europe. A common “IE” stem for “mountain” is hor-/gor- with no connection to the notions of
climbing, climbing on, mounting, or riding (a horse). Thus it plainly is a non-“IE” “guest” word. A brief of later historical attestations, i.e. the “IE etymology's” listing of the early Lat. and V.Lat. forms, does not lead to a source. A bogus “PIE proto-root” *men- (v.) “project” suggested as a tenable source is unsustainable. It merely parrots a base semantics of the attested men-, min- “ascend, climb” that heads the notions “mount, ride (a horse)” and on to the “mount, mountain”, see
mountain, port. The Türkic, the Gmc. Eng., and the Romance Fr. and Lat. carry these notions, plus peculiar innovations of “mountain” and “montage”, derivatives of mounting, climbing and
climbing on. The perfect phonetic and semantic match, attested cognates, and a status of a non-“IE” origin leave no doubts of a Türkic origin. Curiously, although the mounted nomads were settling in Europe since a 5th mill. BC, and throughout the historical period amalgamated with numerous W. European people, the term mount for mounted riding is supposedly recorded only in the 12th century. That OED dating is incredible: an earliest direct evidence for a horseback riding in central Europe is dated by 3,000 BC. See montage, mountain, port.
3.134
munch (v.) “eat, bite, chew” ~ Türkic meŋ “food, fare (food and drink)”. An “IE etymology” suggests “imitative”, “perhaps”, and “probably imitative” levels for origins,
q.v. Ultimately, the word meŋ (b- counterpart beŋ) ascends to a word aŋ, eŋ denoting wild game and food. Dialectal adaptations have slightly different phonetics and meanings. Its hunting semantics and a variety of -aŋ-/-eŋ- words attest to its primeval origins. A paired tautologic compound of two synonyms eŋ meŋ (idiom) “food food” is of a typical Türkic style. Related to food and consonant with meŋ, the European terms are connected genetically and can't be Lat. loan-words. The Eng. food- and drink-related lexicon is nearly entirely native non-IE, with separate vocabularies connected with supplies (meat etc.) and with consumption. Consumption is centered around words of child rearing, like “suckle, bite, chew”. That points to local females in the households of migrant males speaking versions of Türkic vernaculars. In European lingoes the Türkic meŋ dominates: of 44 European languages, versions of meŋ are used by 23 (52%) languages, followed by Sl. žev- with 7 (16%) languages. The remaining 14 languages use 12 of their native words. A Türkic “guest” is a
“Pan-European” term in Europe. Cognates: A.-Sax. mocchen “munch”, Eng. munch “chew”, Gmn. mampfen, mummeln “munch”, Goth. ga-matjan “eat, feed”; Ir. manduch “munch”, Scots manducaich ditto, Welsh manduciaeth ditto; Lat. mand(ucare), It. mang(iare), OFr. mangier “eat, bite”, Fr. manger, machez, Rum. manca; Fr. phrase menu de repas “menu”, lit. “food to serve”; Arm. muyk (uույք) “eat”; Mong. (Kalm.) meŋ “bait, lure”; all “munch” except as noted. Distribution: a skimpy record provides two opposing points, Turkic and Sakha, i.e. fr. the eastern and central Europe to the far-flung eastern Sakha, with local extensions fr. Mediterranean to Albion and on to nearby environs; a predominant term in Europe. A myopic “IE etymology” on its horizon reaches as deep as a Lat. Via layered “perhaps” and “probably” it suggests a murky “imitative” origin, but to its credit does not assert any unattestable “reconstructions”. Inconceivably, the “IE etymology” links a menu with a Lat. “diminish”. Given the attested Türkic lexemes and sentence idioms, plus a continental-scale distribution, a Türkic origin is impeccable. It is also corroborated by a simultaneous presence of the meŋ “food” in the Romance Lat. and the Gmc. A.-Sax.: the A.-Sax. blend, and the Romance languages do not share their vocabularies and locations; their common lexemes come from a shared “guest” sources. A systemic absence of some basic Turkisms in the A.-Sax. Eng. on the background of their systemic presence in the Romance languages and later Eng., attests to independent influences at different time periods. See menu.
3.135
ogle (v.) “look at, peer, stare”, ogler (n.) “looker”, agaze (adj.) “staring” ~ Türkic uk-, ög- (v.) “eye, penetrate, perceive”. An “IE etymology” is myopically unable to connect a Türkic ög- “eye” and Du. oog “eye”, q.v. Ultimately fr. a Türkic verb ö:- “think, reflect, delve, understand” ~ Eng. awe: same phonetics, exaggerated perception, insight, visualization. First nominal derivatives of ö- are formed with deverbal suffixes -g, -k, -z, -ge or dialectal -n, -ŋ for a name, instrument, or means of action. The ög, uk is a deverbal noun derivative “thought, mind, memory, meditation, reflection, intelligence, expectation”, Cf. ögä “wise (adj.), wise man”, metaphorically a visionary with perception, visualization, insight, Cf. Aga Sophia “Wise Sophia”. Perception comes in two aspects, a visual perception through the senses, and a mental perception. A notion “desire to see (each other)” is a desiderative verbal derivative ögse formed with suffix se-/sa-. The term is purely abstract. Ultimately, the Türkic-Gmc. verbal ög- and the “IE” ok- is the same stem, distributed nearly equally to form grammatical forms for perceptive vision. Of 44 European languages, the Türkic-Eng. group ög-, uk- leads with 32 (73%) languages; a remaining spread of 12 languages use forms of their own 12 native words. The Türkic-based term looms in Europe, otherwise there is no common “Pan-European” term there. The Türkic-based term assimilated into 3/4 of the European languages. Cognates: A.-Sax.
ege (Mercian), eage (WSax.), OSax. aga, OFris. age, ONorse auga, Goth. augo, Sw. öga, Dan. øie, MDu. oghe, Du. oog, ogen “eye, look at”, OHG ouga, LGmn. oege, oegen “eye, look at”, Gmn. auge, all “eye”; Ir.
feach, Welsh lygad, Gael. suil; Balto-Sl. (OCS) oko, oglyad-, oglyan- (око, огляд-, оглян-), (Lith.) akis, (Latv.) сs, OPrus. ackis; Lat. oculus; Gk.
okkos “eye”, opsis “sight”; Skt. akshi, Hindi aankh; Agnean ak, Kuchean ek; Arm. akn, all “eye” except as noted. The Eng. ogle, Dan. øgle, Norw. øgle use the Türkic derivative ögl formed with an adjectival suffix
-l “agaze, staring (glance, man)”. Ditto Sw. ögon(flirta), Du. ogen, LGmn.
oegen with frequentative (oeg)len. Distribution: cited fr. Turkish to Sakha; a major spread in Europe at 3/4 of a full variety of the European languages; direct borrowing to the Eng. awe < A.-Sax. aege, oga, oht, ege. There can't be a better evidence than the Eng. awe.
Distribution tends to point to a western, versus an eastern, provenance of the word. Areal semantic shades and articulations are spread across entire Eurasia. A blend of many dozens Türkic languages with other linguistic groups created a rainbow of applications. The myopic “IE etymology” parrots the Türkic terms. and on a level of “probably” invents some clones: a bogus “PGmc. proto-form” *augon- “see” and a faux “PIE proto-root” *okw- “see” “from oge “eye”” adding nil to the etymology of the word. The cheerful enterprising is not needed, it falsifies and masks a real historical development. Pretentions of the homegrown patriots lack a standing. They needs to be brought back to reality. The Eng. eye closely follows the Dan. øie: øie > øye > eye, a form of øğe; (ğ may be articulated silently). Nearly all Gmc. forms retained a tint of a rounded ö in the Türkic ög-, attesting to direct genetic connection. A morphological -l points to the same. In a Nostratic romance the ög- would be a classical Nostratic stem. The forms were inherited via numerous independent paths, creating a spectrum of diverse allophones. Gmc. allophones are notably closer to the Türkic version than to the Slavic-Balt.-Skt.-Gr.-Arm.-Hindi (Hindi, Agni, Kucha) forms. A paradigmatic transfer of an allophonic quad ogle, awe, eye, gaze of the Türkic ögl-, ö, ög-, göz respectively profoundly attests to a genetic origin from the Türkic Kurganians' milieu. See awe, eye, gaze.
3.136
ooze (v., n.) “leak, trickle” ~ Türkic azı:-, ӧz-, üzi:- (v., n.) “flow, ooze, leak, seep”; ӧzüg lit. “oozing”, “any place that produces springs from the earth”, ӧzük “irrigation channels”; ӧzek “small creeks”, Khazar ימג (yüz.g) “river”; Ottoman Özi, Özü name for river “Dnieper”. A base notion of the verb is “flow”, fr. a noun “river, channel”. An “IE etymology” is incomprehensible, q.v. Ultimately fr. a Türkic ӧz- “ooze”. Of 44 European languages, the Türkic-Eng. group ӧz-, ooze- leads with 10 (23%) languages; a remaining pack of 34 languages uses forms of their own 24 native words. The Türkic-based term modestly leads. Other than Türkic, there is no common “Pan-European” term in Europe. Cognates: A.-Sax. wosan (wos-an, wes-an) (v.) “leak”, wos (n.) “juice, sap”, wesc, waesc “ablution, washing”, wesan “soak, macerate”, Fris. ooze “ooze”, Dan. oser “ooze”, ӧs “lake”, OSw. os, oos “ooze”, Norw. oser “ooze”, Icl.
eysa “ooze”, OHG wazzar “water”, wasal “rain”, MLG wose (n.) scum”, Gmn.
wasser “water”, OPruss. аssаrаn “lake”, Yid. uziz (וזיז) “ooze”; Ir. uisce “ooze”, Scots uisg “ooze” (but Welsh diferu), Gael. uisge “water”; OCS. ozero (озеро) “lake”, Rus., Bolg., Ukr. ditto, Slvt. jazero, Bosn., Croat., Cz., Sloven., Serb. jezero, Pol. jezioro, Blr. vozera (возера), Maced. езеро “lake”; Lith. ežeras, Latv. ezers; Fin. järvi, Est. järv; Skt. vasa (वसा) “fat”; Hu. özön “stream”; Mong. goojikh (гоожих) “ooze”; all “ooze” or “lake” unless noted otherwise. Distribution: extends along the Steppe Belt across Eurasia incl. Far East; spread across linguistic barriers; heavy in Europe due to Gmc., Celtic, Sl. A prosthetic initial w-/f- is typical for Gmc. and Eng. Turkisms, Cf.
wael vs. ӧl “death”, see kill. The “IE etymology” in a disjointed circular logics suggests nothing better than unattested faux “PIE proto-words” *weis- “flow” or *woseh2 “sap”, with no cognates outside of Gmc., and thus a non-PIE by definition. What unites the Türkic and Gmc. splits the “IE” paradigm. That kind of enterprising besmirches the objective. The ligature wae-, wea-, we-, and corresponding Khazar yü-, are probably attempts to render -ö- with means of the Roman or Hebrew alphabets. That makes a root wes- a phonetic equivalent of the form öz. A Khakass phrase küp azi:di: is identical to its Eng. form cup oozing; similar infinitive azı:ma:k “ooze” is reflected in Eng. as lit. make (to) ooze. The Eng. tends to regularly echo Khakass peculiarities. The phonetics and the range of notions are matching. The verb ӧz- has produced derivatives like ӧzük “small lake”,
a precursor of Sl. ozero/езеро (озеро) “lake”, a distant cognate of ooze, and the Gmc., OPrus., Lith., OCS, Gael., Gk., Hitt., Skt., etc. terms for “water”, with and without a prosthetic consonant. The form azı:- with its allophones clearly shows the origin of the terms for the moisture, water, and other derivatives. It traces the datable splits branching off the Celtic circum-Mediterranean route with a departure around 5th mill. BC, with the Anatolian Hittite and the Indo-Aryan branching off around 2nd mill. BC, and later Mediterranean, Northern European, and Balto-Slavic splits. Other terms connected with water also have Türkic stems: Lat. aqua, Pers. apa are derivatives of the Türkic verbal stem aq- “flow”; the Sl. tok (ток) “current” and
potok (поток) “stream” are reflexes of the Türkic tök- “pour”. These semantic siblings with particular distribution patterns attest to a common genetic origin from a Türkic lexical millieu. See kill, water.
3.137
orate (v.), oration (n.) “talk” ~ Türkic orla:- (v.), orı: (n.) “shout, yell”. An “IE etymology” is curt,
while it holds Lat. form as “a name of uncertain origin”, “we know it fr. Lat., hence the Lat. is a beginning and an end”, q.v. Ultimately fr. a Türkic or- “scream, roar, moo”. Orı: is a deverbal noun derivative of the verb ö:r- “rise, sprout”, thus orı: “shout, yell” is a metaphoric noun derivative with a lit. meaning of “rise, stand out”. Among numerous other meanings, the base lexeme ö:r- is best known as a derivative ortho- (orthodox, orthodontic, orthogonal, etc.). A bifurcated semantics reflects both notions, “stand out” and “be loud”, with numerous derivatives and semantic extensions. Derivatives attests to an archaic origin with a range of forms: orɣu-, orɣul-, ogur-, oqla-, etc., with a widest articulations. A switch from rounded -ö- to unrounded -o- is consistent with a practice of producing converse or complimentary notions with phonetically close morphemes. A suff. -g/-ɣ forms deverbal nouns, a suff. -la forms denoun verbs. Of 44 European languages, the Türkic root ö:r- overwhelms with 32 (73%) languages. The remaining 12 languages use 8 forms of their own native words. The Türkic forms are a de-facto common “Pan-European” lexis in Europe. Cognates: A.-Sax. orgnian (v.) “sing”, organa, organe “musical instrument”, orgyte “well known, manifest”, orgel “pride”, orgel(word) “arrogant speech”, etc; Ir. oraidi “orator”, Welsh areithiwr ditto; OFr. oraisun “musing”; Lat. oro, orare “speak”, oratio “speech; Sl. orat (орать) “shout, cry” (typ. for Sl.); a series with elided anlaut o-: Fris., Du. redenaar “orator”, Icl. ræðumaður, ditto, Gmn. redner, ditto, Yid. redner (רעדנער), ditto; Gk. ritoras (ρήτορας), ditto; Mong. yarih (ярих) “speak”; Tk. or- “shout, yell”.
Distribution: is typical for Turkisms, a Eurasian Steppe Belt plus fringe appendages crossing linguistic barriers. Distribution is typical for the “guest” lexemes: a needful expression is spread as a forest fire across linguistic barriers. A myopic “IE etymology” crows a Lat. oro and is shamelessly blind to a Türkic orla:-, orı: that precedes Lat. by millenniums. This compendium cites ca. 1300+ of the Lat. cognates of a Türkic origin. Another 300+ known cognates are left out. In other words, about 1700 Lat. lexemes are shared between the two languages. That mass is substantial enough to propose the Lat. as one of a hundred branches of the Türkic linguistic family. A philological aspect is supported by a genetic testing of some Roman remains run into Y-DNA of R1a Hg. That attest that the remains ascend to a Siberian zone where the R1 split fr. the Hg. NOP ancestor. Initially insignificant tribe ca. 2nd c. BC managed to create in Europe a most powerful empire of those times; likewise ca. 3rd c. BC a most powerful empire of those times in the future China, and likewise ca. 210 BC a most powerful of those times the Hunnic empire in the Central Asia. The insignificant Roman tribe had managed to drug along in time and across Eurasia an eternal Türkic creational myth of a wolf and its sucklings. In time, the Roman echoes helped to build a myth of an “IE” linguistic unity and its majestic spread. The
A.-Sax. inherited a full complement associated with the prime source or-, the Lat. and Sl. retained partial meanings. The Türkic derivatives tend to retain their affiliation with the verb, the European derivatives, aside from retention of the initial verb (orate, oro, orare, orat), lean to the nominal applications. The words arrogance (unduly stand out) and organ (musical instrument)
are also derivatives of the A.-Sax. stem org-, with a noun/adj.-forming suffix -an. Both Lat. and Sl. forms employ the Türkic 3rd sg. verbal suffix -ti/-di, Cf. Tk. prototype orı:tı, Sl orati “shout, yell”. The role of the Türkic ö:r- for the western civilization can't be overvalued, it forms base concepts in philosophy and math, with religions proudly applying it to define their claimed true nature. See arrogant, ortho-.
3.138
ought (v.) “should, owe” (Sw N/A, F1542, 0.005%) ~ Türkic öde:-, ötä-, öte:- (v.) “perform, fulfill, settle, carry out an obligation, debt”, odlaмak (v.) “pay, pay up”. An “IE etymology” provides no etymology, only functional and grammatical details culminating in “probably” and “a misdivision of a nought”, q.v. Ultimately fr. öt- “pay” (articulated as “ought”). Semantics of both allophonic forms, the ought and öt-, is “what one has to do”; odlaмak with two denoun verbal suffixes -la and -mak shows a development stepped in time. Recorded Türkic forms are weighted towards religious obligations of the Islamic period. The A.-Sax. forms must be millenniums older and certainly more secular; both forms include a notion owe of paying debts and other obligations. Of 44 European languages, a Romance deb- leads with 7 (16%) languages, followed by a mostly Sl. treb- with 6 (14%) languages. The remaining 31 (70%) languages use 22 of their own native words. Of the two dominating languages, the Romance version comes as to have elided an anlaut o-: odeb- > deb- = debt. Then, the Romance forms also ascend to the Türkic öde:-, and the Türkic share is 7 + 2 = 9 (20%) of the European languages, i.e. it is a de-facto dominant entry. Cognates: A.-Sax.
aught “ought”, nahte “ought not” (with ne), aehte, ahte, agan (< Tr.
eden, öyen-) “owe”, ahte “at all, good, value”, ahtes “any account or value”,
aht, eaht, awiht, aught “anything, something”, etc.; Goth. dulgs “debt” (but skula “owing, indebted, debtor, +guilty”), dails “portion, share”, daug “good for, profits”,
dis-dailjan “share, divide”; Ir. dligim “owe, claim”, dligid “debt”; OCS dlg (длъгъ) “debt”, Sl. dluh, dlh, dɫug “debt”; OFr. dete “debt”; Lat. debitum “debt”; no references for Far Eastern languages; Skt. isvara (ईश्वर) “capable of, liable” phonetically does not fit öde:-, ought etc.; see owe. Distribution: Türkic Eurasian Steppe Belt, with considerable extensions across linguistic borders to Europe. The myopic “IE etymology” chews on the linguistic recriminations of the
A.-Sax. forms as a best source. It is blind to the widespread öde:- but trumps up the unrelated isvara. The selective blindness is disgraceful. It does not appreciate that the A.-Sax. is an amalgamation of Gmc. (Anglo-) and Türkic (Saka, Saxon) languages. The analysis needs to be properly differentiated. Amalgamation probably ascends to a Corded Ware area and times, i.e. an extended period leading to the formation of the A.-Sax. entity. The paucity of the cognates points to a geographically local internalization. Of the Türkic öde:- these receptor vernaculars have retained a root -d-/-t- and -dl- with an adjectival suffix -l “owed”, probably a reflex of a demand request. Other suggested ideas, like a faux Lat. compound of de- “from” + habeo “I have” (*dehibeo “I have from”) are phonetically and semantically inconceivable for the notions “pay” and “debt”. Or a none at all for ought, not even a standard refrain “of unknown origin”, leaving it an etymological mystery. A Türkic areal form oye- was a proto-form for the Eng. cognate owe and derivative own complete with a reflexive suffix -n/in for “self”. Convincing phonetics and perfect semantics of the two forms owe and own attest to their allophonic origin. The A.-Sax. form aught transmits the initial rounded sound ö even better than the current spelling ought, it was conflated with the Türkic allophonic ot “useless (vegetation), weeds”, the A.-Sax. awiht, Eng. aught “little, nothing, something”. See aught, oath, owe.
3.139
pat (v., n.) “hit lightly” ~ Türkic bad(ar) “beat, strike” (v., n.). An “IE etymology” ignores A.-Sax. harbingers and fancies Gmc. and “IE” origins, q.v. Ultimately fr. a Türkic root bad “beat, strike”. A
pata- (v.) “strike, kill” was explained by Herodotus IV. 110 as a Scythian word for “kill” in a compound eorpata - those who are striking their husbands (with Türk. er “man, husband”, Cf. Gmc. Herr.). The Türkic badar relays a sound of patting (light strike) too, Cf. Eng. patter. Hence both a verbal and a noun use, Cf. Clauson EDT, 308, entry čalk, the badar- (padar-) is translated with a verb “thumped”, “thumping”. Of 44 European languages, versions of the form pat- dominate with 26 (59%) languages across a range of linguistic borders, followed by a largely Gmc. motley group with 8 (18%) languages. The remaining 10 (23%) languages use 4 of their own native words. The Sum.-Türkic-Scythian-Kurgan lingo dominates in Europe with a function of a common “Pan-European” term. Cognates: A.-Sax. beot, baetan and (rarely) beoft “beat, strike”;
Scyth. -pata “kill”; Khak. badar “footsteps (footstep beat)”, badar qïl “beat,
punch” (Sum. qïl “kill”); Fris., Du., Luxemb. pat “hit lightly” (but Dan., Sw., Norw., Icl., Gmn. “klopfen”, Cf. Sl. hlopat (хлопать) “clap”); Alb. pat ditto; except as noted otherwise all “beat, strike”; there is no systemic correlation between the European languages and the notion “pat”; its appearance in any particular language is a chance matter. Distribution: Typical for Türkic languages, across the Steppe Belt with few extensions to Europe. Most of the European spread appear to be a modern bandwagon: languages have their distinct native synonyms. For such a basic word as a “pat”, “IE etymology” offers no credible cognates, and feebly concludes with uninspiring “perhaps originally imitative of the sound of patting”. An “IE etymology” fantasizes a faux “PGmc. proto-form” *plat- “strike, beat” and a faux “PIE proto-word” *blod-, *bled- ditto. That ignores the Herodotus' attestation, and uses “perhapses” for the attested facts. The notion of “thumped”, “thumping” is complimentary to the notion “beat, strike”. An intentionally myopic approach and the flights of fantasy are not rightful substitutes for attested material. The “Gmc.” plats with inlaut -l- appear to be reflexes of the old Sl. synonymous hlopat. Their acoustics and semantics are pretty close. That makes the invention of a faux “PIE word” *blod- etc. superfluous. A proximity of the thump and beat, strike is obvious without any “imitative”. A claimed Av. pada “heritage, offspring” is incompatible; so is the plaett, plaettan of a faux *plat-, *b(e)lad-, *b(e)led- “put, place, plant”. In reality, bat, beatt, and pat are allophones, cognates are more than abundant, see cognates for a synonymous bat (v.). The “strike” was first recorded a millennia earlier in the agglutinative Sum. eons before the English records of ca. 1400. A 5th century AD Isfahan Codex in Erevan with Hunnic grammar and a wordlist gives the Hunnic batten “push”, with a semantic shift by the Arm. translators. It is still in the ballpark, close to the semantics of the pat (v.). The words bat, pat, patter, beot constitute a paradigmatic transfer case from the Türkic to English. See bat, battle.
3.140
pour (v.) “spill, spurt, gush, spray (liquid)” ~ Türkic börk-, bürk-, pürk- (v.) “spurt, gush, pour down”, pür “pour, full, fill, fully”. An “IE etymology” rates the word as “of unknown origin”, q.v. The verb has 16+ recorded forms, attesting to its wide distribution and long history. A
line-up of 16+ forms includes oddball forms büvkür-, büvkü-, and purka- that contain an unusual -r-/-v- alternation and an euphonic -a-, they may be traced as markers to shed more light on the historical paths. A prime form conveys a causative mood. An initial form
bürkür- with a causative suff. -ür dropped the suff. (e.g. bürkür-, bürkü-, bürk-; pürkür-, pürkü-, pürk-);
the suff. -k/-q forms deverbal nouns and adj. The elision is typical for western languages, it was noted by M. Kashgari for the languages of a Bulgar circle. Bulgars, in turn, are tentatively identified with the Sarmat circle that included the tribes of the Wendeln “Wonderers”, the Vandals, Goths, Burgunds, and other horse nomadic tribes of the Classical European period. The palatalization (b-/p-) is also typical for the Eastern European languages. These are mutually corroborating traits, consistent with the historical flow, linguistic records, and geography. Cognates: A.-Sax. byrelian “pour, serve with drink” (> MEng. birlen ditto, wapelian, wapolian “emit, pour forth”; Fris.
pourr; Du. pouren “pour”; Welsh bwrw “rain, cast”; OFlander purer “pour out (liquid), sift (grain)”; OFr. (~Flanders) purer “pour out (water), sift (grain)”; Lat.
pürk- “pour, spurt”, porrum “leek (~onion)”; Cors. pour; Luxemb. pour; some “pour” are likely recent acquisitions; no cognates in the Balto-Sl. (< Sl. ielej), and Sl. (liti) languages. Distribution: confined mostly to Türkic languages, with a limited spread in Europe. The “IE etymology” stipulation “of unknown origin” notwithstanding, the OTD-recorded Türkic form pür is adjectival, related to a result of action. It can only be a derivative of a verb. Like many other Türkic “guests” in Eng., the word pour is “IE etymology”-ascribed to the 1300s; the sense of “flow, pour” is ascribed to 1530s. It is held as popped out from nowhere. The word is semantically unrelated to a homophonic Lat. purare “to cleanse”, a cognate of Eng. pure. In reality, it came to Albion at least with the A.-Sax. arrival, as a member of Sax. lingo (< Saka, Sakha 塞 tribes), see references to Saka, Sakha Scythians herein. The word is also “IE etymology”-suspected to be of a Celtic origin, thus possibly of a Celtic circum-Mediterranean anabasis fr. the Eastern Europe direction (6th-5th mill. BC). A genetic relationship between the Celtic and the other Scythian tribes is yet to be addressed; archeological indicators point in that direction. The word's semantics is perfect, phonetics is transparent, consistent, and near perfect.
3.141
purge (v.) “blow off, eject, empty of (something)” ~ Türkic pür-, bür- (v.) “twist,
spin, rub, wind round, screw, divert, wind up, wrap up, bore”.
A myopic “IE etymology” starts with PIE and Lat., q.v. Ultimately fr. bu:, pu: “steam, fog”, and related to bula- (v.) “boil” swirl, see boil. Apparently a boiling, twisting movement of vapor was a metaphoric model for a derivative of bu: denoting a generic “twisting movement” with denominal suffix -r that forms intransitive verbs. The stem pür-, bür- is rich not only in the width of its direct, metaphoric, and derivative semantics, but also in form, “there is great inconsistency in modern languages, several having forms both with front and with back vowels, usually with slightly different meanings” (EDT, 354), and regular alternation p-, b- propagates slightly different phonetics and meanings among sister languages. The core semantics of the pür-, bür- is “rotate, twist”, which extends its meaning to “twister”, and then to “swipe” with twisting motions. That brings about a most prominent routine usage for “cleaning”, “sweeping”, “purifying”, and “twisting flow (air, clouds, water, snow)”. Accordingly, the semantics splits to different effects, from “pure” to “storm”, to “purge”, and “bore”. Of 44 European languages, versions of pür-, bür- dominate with 14 (32%) languages across ~6 linguistic borders, followed by a Sl. group -čis- with 10 (23%) languages. The remaining 20 (45%) languages use 16 of their own native words. If there is a common “Pan-European” term in Europe, it is a Türkic “guest” word, internalized and locally dispersed. A native counterpart term is a Sl. Old Europe čis- “cleanse”. Cognates:
A.-Sax. byre “strong wind, storm”, faru “storm” (in hagolfaru “hailstorm”); OFr.
purgier “wash, clean, refine, purify”; OLat. purigare, a compound of “pure” and “act”, Lat. purgare “cleanse, make clean; purify”; Rum. burgij, burgias “borer, bur, drill”; Rus.
burya, buran, purga (буря, буран, пурга) “storm, blizzard, snowstorm”, burlak, burgalak “(one) twisting rope, cord”, Bolg., Serb. burma “ring, signet”, burgija (n.) “drill”; Fin. puhdistaa “purge”, Est. puhastamine “purge”; Mong. burgi-, burgih “swirl (smoke, dust, water)”, “rise in clouds” “get irritated, enraged”, buruɣu “opposite (direction)”, boraɣan “rain”, boro'an “blizzard” (> Sl. buran), murui- “curve (v.), bend”, etc. (Cf. Sakha bur-bur “curl (of smoke)”; Tung. (Evenk) mori- “assemble, make folds (sewing)”, (Orok., Mosira-) mori- “wrinkle (v.)”; Manchu foro- “turn, turn over”,
forgon “rotation, turn over, revolution”, Gold. (Nan.) poro- “turn, turn over”, etc.
Distribution: widely used fr. the Far East and the Eurasian Turkic Belt, with some echoes reaching C. and W. Europe incl. Lat. For a time, the “classical” Lat., Gk., and Skt. were held as scholarly etalons, the alpha and omega of philology. The pretentious others were disdained. A time debased their sanctity to a level of reality, incl. philology. The spread makes ridiculous an assertion of a Lat. origin of the word or of a “PIE contribution” root *ag- “drive, draw out or forth, move”. Instead of a common stem, an “IE” etymological appeal to a Skt. pavate “purifies, cleanses”, putah “pure” leads astray without reaching the origin of the “pure”. The A.-Sax. byre and faru both refer to a “storm” as a “twister”, reference to strong wind property of the storm ascending to the verb pür-, bür-. That is attested by the cognates in the Sl. languages, all traced etymologically to the Türkic origin, and all ascending to the same verbal stem pür-, bür- that millenniums later produced the Lat. and Eng. cognates. See boil, breath.
3.142
purl (v.) “whirling flow”, purl (n.) “twisting stitch” ~ Türkic (v.) bu:r- “turn, twirl”, bü:r- “twist, fold, evaporate”, bu:, bu:r (n.) “steam”. An “IE etymology” rates the word as “of unknown origin”, q.v. Ultimately bu:r- is a denoun verbal derivative of bu: “steam”, anything swirling; purl is a passive form of bu:r-
(pu:r-) “steamed”, here with a sense of “whirled” or “back-and-forth” ~ “twisting stitch” etc. The bu:r- and bü:r- relate to each other semantically. To convey a chaotic movement, the Türkic notion “steaming” is Eng. “boiling”. The Eng. purl and burl are two allophones of the same word that went through different paths to Eng. The purl is a palatalized version of
burl (Cf. Sl. par (пар) “steam”). The terms survived as versions of concrete nouns of a same root and notion. Cognates: A.-Sax. burreaf “woven, hand-woven (fabric, tapestry)”,
burston, berstan “burst, break, break away, escape”; Eng. purl “swirled flow”, burl “burlish, twisted (bulge on a tree)”; OFr. bourle “tuft of wool”, LLat. burra “wool”, It.
pirolare “twirl, twist, spin”, Venetian pirlo “woven threads decoration”; Rus. buran (буран) “blizzard”, burlit (бурлить) “stirred, agitated”; Bolg., Serb. burgija (n.) “drill”; Alb. burgij “drill”; Oset. byraw, buraew “drill”; Uig. bora “matting”; for more cognates see purge. Distribution: widely used fr. the Far East and the Eurasian Turkic Belt. Nominal presence in Europe. A myopic “IE etymology” rates it “of unknown origin”, ignores the A.-Sax. attestation, and does not suspect a routine b ↔ p alternation. Fortunately skipping a “PIE reconstruction” stage, it leads fr. nowhere to nowhere. The A.-Sax. cognates provide an element of timing: ca. 1,000 BC or earlier, a formation of Anglo- (Gmc.?) + Saxon (Saka) union. The OFr. and LLat. cognates are concrete derivatives of the above bu:r- (something burled, purled, whirled, swirled, twirled).
They are reflexes of a notion “boil (n.)” or its siblings; Cf. Sl. burlit (бурлить). “stir, be agitated” with ending -it/-ить, a reflex of a Türkic verbal suffix -ti/-di, and likewise a Sl. burya (буря) “blizzard, twister”. Besides Türkic, the word is peculiar to a handful of European languages with
a peculiar semantic and phonetic distribution. A Türkic origin is beyond any doubts. See boil, burl, whirl.
3.143
push (v.) “press, drive, impel” (Sw N/A, F1086, Σ0.01%) ~ Türkic family of allophones (v.) baš-, baša-, bas-, ba's-, ba:θ-, bäs- and pa:s-, pas, pus-, was- > puš- (push-) (v.) conveying a notion “pushed, pressed”. An “IE etymology”
suggests most chimeric ideas, q.v. The word with 10 semantic clusters carries dozens of meanings in its clusters. Tracing them is a task in itself. Expressing an essence of the stem puš- a deverbal noun busuɣ “ambush” with b-/p-, -u-/-ü-, -s-/-š-, -ɣ/-q alternations is formed with a nominal suff. and an adjectival suff. -uɣ, lit. “a push, pressure, thrust”. A prime meaning “push, press” is overgrown with numerous forms and innumerable derivatives, from physical to emotional, of which the busuɣ and consequently “conquer, attack, subdue” is historically most significant. A metaph. “irritated, annoyed” and a “print (book, cloth, etc.)” are effects of “be pushed”. Print and imprint is its significant part. Of 44 European languages, versions of the Türkic baš-, pus- are most prominent with 7 (16%) languages, followed by a Romance group empu- and a motley group sku- with 4 (9%) languages each. The remaining 29 (66%) European languages use 17 of their own native words. If there is a common “Pan-European” term in Europe, it is a Türkic “guest” word, internalized millenniums ago and locally dispersed. Cognates: A.-Sax. basnian “ambush”, OFr. embuscher “ambush” with prefix en-/am-; Rus., Ukr., Rum., Serb., Bulg. basma “print, press” with allophones, Serb. basamak, Bulg. basamaci “step-”, Pol. basaiyk “whip (prod)”; Arab., Rus. baskak “official, tax collector”; Mong. basu- “press, throw”; Tung.-Manchu basala, basalla “kick”; Nenets (Kamasin) baspa “trap”; Kor. matta, mağa, mağin “beat (war), defeat” (Ref.s EDTL v. 2 77). Tracing cognates across publications and dictionaries for meanings and spellings is quite a task in itself. Distribution: Eurasian-wide across linguistic borders; the Eng. form is a speck in a sea. An OED's “IE etymology” is incredible. On a questionable phonetic resemblance it suggests a dubious Lat. pulsare “knock” (+? beat, strike)” neither semantically nor phonetically related to the “push”. Or an unrelated faux “PIE proto-root” *pel- “thrust, strike, drive”. Or a “probably” Fr. poche which is a “pouch”, i.e. a bag. Or a faux “PIE proto-word” *pewk- “covered with hair, bushy”, “maybe related” to a Skt. पुच्छ (puccha) “tail”??. Or an unrelated “Rus. Proto-Sl. proto-word”*puxъ (пух), i.e. a feathery “down, soft feathers”. Like many other Eng. words, the eminently prominent word “push”, with about 22 direct synonyms and 35 nuanced synonyms, is held in a mass of “probably” “IE words” of some mysterious provenances. A pile of that nonsense is a result of a dreadful myopia that afflicts not only the eyes. Propagating that bunk to an innocent audience is fallacious. An Eng. palatalization came with a source word, it provides an idiosyncratic indication on the source vernacular (Alt., Sal., Süg., Chuv.). An oddball word among the European languages, the “push” bears diagnostic properties, it is mentioned with p- in the Kaz. and Ott., and with a -š (-sh) in the Kipchak languages (EDT 371). Those are the closest known phonetic kins. The A.-Sax. used to have a store of native synonyms. In some impercipient lexical revolution, except for a “shove” they were
supplanted by a Türkic “push”. A toponym Bessarabia (Basarabia) may be a cognate derived from a Türkic basar- “reign, dominate”, lit. “press, oppress”. The “push” breaks the carefully milled linguistic dogmas. A case of a paradigmatic transfer of the siblings “push” and “ambush”, a derivation of the “ambush” from the “push”, a perfect semantic and phonetic match of the stems constitute a case of paradigmatic transfer from a particular strata of the Türkic languages. See ambush.
3.144
put (v., n.) “place, arrange, give” (Sw N/A, F186, 0.09%) ~ Türkic bat-, put-, but-, ban-, bütür- (v., a ↔ u) “put, lay, place, locate, deposit, install”. A stupefied “IE etymology” suggests “probably from a Germanic stem”, q.v. Ultimately a derivative of a verb ba- “immerse” or ba- “bind, tie, bound”, see band, bath. The root denotes a generic “go, enter into (smth.)” modified to a figurative meaning of the verb. A unifying meaning of the verb is “into”. It comes in a range of forms and meanings. By origin or use modified to specific conditions, it determines a portable meaning of the verb bat-, put-, ban-, pun-. The stem takes forms randomly scattered among different sibling languages: bat-, but-, pat-, bad-, and ban- (see bath). A form bat- predominates. Archaic suffixes
-t and -n form synonyms, i.e. bat-, ban-. The put- and bat- are acoustic allophones, Cf. bath and banya, q.v. The causative-transitive suffix -t- and causative-reflexive suffix -n- are nearly synonymous, the -n- adds an aspect of benefitting a speaker. An obscure form put- from one of the dialectal brunches, with its minor semantics of “placing”, lived on to become an essential lexical member of the world's lingua franca. Like the with the lexis, the productivity, function, and popularity of the suffixes were never frozen in time and space, some of them are echoes of the times long gone by. A preservation or an absence thereof of the initial verb
ba- in the daughter languages is irrelevant, its derivatives from various paths can peacefully
co-exist in any language, Cf. band and bath. Astonishingly wide range of more than 50 meanings is from “bath/bathe/dip/deep” to “bankrupt” (i.e. “go under”), “poke, pierce, stab” (i.e. “reach under”), “dare” (i.e. “dive under”), etc. In each individual language the range is much narrower, closer to the “place, locate” count of 9 in modern Eng. Of 44 European languages, versions of the Gmc. set- are most prominent with 10 (23%) languages, followed by a Türkic-Eng. group put- with 8 (18%) languages and a Sl. group stav- with 5 (11%) languages. The remaining 20 (48%) European languages use 14 of their own native words. There is no shared “Pan-European” term in Europe; a Türkic “guest” but-, put- takes a respectable second place presence in Europe. Cognates: A.-Sax.
putian “push, put out”, putung “pushing, impulse, instigation, urging”, potian
“push, thrust, strike, butt, goad”, pytan (v.) “put (out eyes)”, Cf. Rus. pytka “torture”, bað, baeð, baðu, bathu “bath, bathing”, bedipan (v.) “dip, immerse”, pitt, pytt “well, hole, pit”, piða “inner, pith”, etc.; Dan. putte “put”, MDu. pote “scion, plant”, Du. poten (v.) “set, plant”, Sw. putta, pötta, potta “strike, knock, push gently, shove, put away”, ONorse pota “poke” (vs. botte “pail”), Norw. putte “set, put”, Icl. pota “poke”; Welsh pwt (perhaps, possibly?); Lat. puteus “pustule, blister”; Rum. batakčı “deceiver, 'fraudster”; Rus. batqaq (баткак) “swamp, mud”, pytka (пытка) “torture”; Serb. batisati “disappear” (~ dive, sink); Pers. batau “east, sunny spot”, batlaq, bodaq “swamp, marsh” (< Tr. batdag, putlah “swamp”); Mong.
bagta- “contain, hold”; Tung. he “unable”, Evenk bat-, bati- “bat-”, q.v., Solon. bakta-, batta “fit in”; Gold. pa-, pago- “fall, finished”; Manchu fa- “finished, ready”; Kor. ppažida “fall, plunge”; all “put” unless noted otherwise.
Distribution: Eurasian-wide across the Türkic Steppe belt and linguistic borders. Dispersal of areal distribution points to a “guest” status among European languages (Türkic, Eng., +Catalan, Galician, Est., Malt., Sp., Slov, Rum.). An “IE etymology” is totally lost. After starting with attested forms of the Dan., Du., Sw. and ONorse, it switched to wild guesses of “probably” and “of uncertain origin”, and the uncouth refabrications of conflicting semantics. Those are a faux semantically unrelated “PGmc. proto-form” *putona “stick, stab” “of uncertain origin”, an unrelated OFr. pute “prostitute”, an unrelated Skt. बुन्द (bunda) “arrow” to be a cognate of unrelated a faux “PIE proto-word” *bud- “shoot, sprout”, and an attested “potential” Welsh pwt short-circuited to an Eng. provenance as a butt with unrelated semantics “stub, thicker end”. That comedy of errors starts and ends with no connection to the subject notion “place, arrange, give”. A myopic attitude leads from nowhere to nowhere and needs to be discarded together with the wild speculations. The Eng. “guest” is a speck among attested forms. The lexical stream reached Europe very selectively: a smatter of northwestern communities, plus tentative Lat. and Sl. The lexical and spatial distribution shows that of 50+ semantic meanings only a small stream was carried to the northwestern Europe: a core “bath”, plus derivatives “put, well, poke”. A closest sibling to the outright Türkic put “put” is a verb budu-/bodu:-, a metaphoric “attach (something)” accusative to something dative, and its passive form budul-, bodu:l-, as in “I am attached to”, i.e. “I have entered into attachment to”. A morphological etymology of the budu-, bodu:-, budul-, bodu:l- is held as unclear, but -l is a passive marker. Of the “IE languages”, Eng. is alone in Europe to have an ingrained endowment of both core meanings and its numerous derivatives. That attests to deep demographic roots, long amalgamation period, a very specific path, and particular ethnic composition. The specificity of sources has a diagnostic value, it allows assessment of a timeframe. A.-Sax. has retained direct and derivational correspondences. A major advance in analyzing the word bat-, bat was done by E.V. Sevortyan, EDTL v.2 78 on, who brought together specs of unheeded knowledge scattered in numerous patchy works but not yet covered in etymological compendiums. A wild nature of the “IE” etymological fabrication “research” is indelible. A case of paradigmatic transfer of such vernacular, phonetic, and semantic complexity indelibly attests to the origins fr. the Türkic milieu. See band, bath.
3.145
quit (v.) “finish, end, conclude, close” (Sw N/A, F538, Σ0.03%) ~ Türkic
ket- (v.) “leave, depart, disappear”, ket (n.) “finish, end, behind, posterior”. An “IE etymology” runs a circular logics: quit ~ quite ~ quit, etc., q.v. Ultimately fr. a *ket, *kit (VEWT 258b) > git-, ket-, käd-, ked-, etc., in 12+ forms. A base semantics is ket- “leave, disappear, go” > “quit”. The notion ket- “finish, end, behind” echoes a notion köt/göt “buttocks, backside, tail end”, and points to its origin. In the notions “backside, rump” and “leave, depart”, and a vast range of preserved forms ascending to a prehistorical era is seen an archaic origin. A “guest” status in the “European” Europe is undeniable. The sited dates of 2nd c. AD are millenniums younger than the age of the originals. In a blind zone of a “European” horizon a single “guest” ket- stands in a neglected line of the European Azeri, Balkar, Bashkir, Crimean, Gagauz, Karaim, Kuman, Tatar, Turkish, and many more “non-European” European Türkic languages. Of 44 “European” European languages, the Türkic, Eng., and Lat. form a single group
ket- with 3 (7%) languages, followed by a constellation of 6 distinct motley groups with 2 (5%) languages each. The remaining majority of 29 (66%) “European” languages use 29 of their own unique native words. Excluding European Türkic languages, there is no space for a shared “Pan-European” term in Europe; including them the Türkic ket- dominates. The derivatives of ket- (v.), a desiderative ketar “remove, erase, clear (of something)” and ketgü (n.) “departure, disappearance” trace a transition from a horse tail to a tail end, to ending something, and then to a finish and a pay off. Cognates: A.-Sax. giefan, ofgiefan “quit” (but Friz. oerjaan), cutaegl “tail of a cow, back”, Dan. kvitte “quit”, Du. kwijten, Sw. qvitta, kvitta “quit, leave, set off”, Icl. kvitta, LGmn. quitten, Gmn. quitten, quittieren “quit”; OFr. quite, quitte “clear, discharged (debts)”, quitance “discharge (obligation)”, aquiter “settle (claim)”, Lat. quietus “free (debts)” (i.e. “end (all debts”)), MLat. quietus est “he is quit”; Mong. gädä “back”, keder “evil, grim, angry”; Sojot (Nanaj) kädä “back side”; all “quit” unless noted otherwise. The Sw. semantics exactly duplicates the Türkic semantics. Unrelated to the consonant “quiet”, emphatic “quite” (fr. emphatic ked, see quite) erroneously cited as cognates.
Distribution: Eurasian-wide across the Türkic Steppe Belt and linguistic borders, with a nominal presence in the “European” Europe (Türkic, Eng., Lat.). With the attested precursor, there is no need to invent faux “proto-words” or push unrelated semantics and words. A non-myopic eyesight makes content clearly visible. A speculation of “probably of imitative origin” is wildly uncouth. An unrelated fictional “PIE proto-root” *kweie- (v.) “rest, be quiet” is wildly off target. A homonymous emphatic quite ”free, clear, entire, at liberty, discharged, unmarried” (actually only an emphatic particle that must be associated with another word or phrase to impart meaning, it does not have its own lexical definition, i.e. “free, clear, etc.” is nonsense) is not related to the subject quit. Mingling unrelated homonyms into a single pile is wasteful, good only for flummoxing the subject. The phonetic, grammatic, and semantic match is consistent and apparent. The consonance between queue, quit, and quite is predicated by the consonance between the underlying stems kü, ket-, and
ked respectively. As a set, they constitute a case of paradigmatic transfer, bearing witness to a common origin from a Türkic milieu. See queue, quite.
3.146
sail (v.) “travel on water” ~ Türkic sal-, salla (v.) “sail on a raft, cross on a raft”,
säl (n.) ship . An “IE etymology” rolls in a daydreams pretending to have a grain of knowledge, q.v. Ultimately fr. sal/sa:l (n.) “raft, pontoon, float, vessel, bark, boat, ship”. A verb salla- is formed with a Türkic typical denoun verbal suffix -la. A salïɣ, salɣ with a suffix -ïɣ, -ɣ is a deverbal noun fr. salla- (v.) “sailing, seafaring”, Cf. Gmc. saɣl with a metathesis lɣ/ɣl. In some Gmc. spellings an alternation
-i-/-ɣ-/-ğ- is salient. Of 44 “European” European languages, a Türkic sal- dominates with 11 (25%) languages, followed by a Romance group nav- with 7 (16%) languages. A remaining majority of 26 (59%) “European” languages use 14 forms of their own unique native words. Of the non-“European” Türkic languages 13 live in Europe; with them a total of “qualified” European languages numbers 57, and the European group sal- grows to 24. If there is a shared “Pan-European” term in Europe, it is definitely a Türkic sal-. Excluding the European Türkic languages, there would be no shared “Pan-European” term in Europe at all. Cognates: A.-Sax. segl (v.)
segilan (n.) “sail”, ofersegl “top–sail”, ofersegllan “sail across”, seglan, seglian, segliani “sail, equip with a sail”, ymbliðan “sail round”, oferseglian “sail across, oversail”, OFris. sailje, seil “sail”, WFris. seil, sile “sail”, ONorse sigla, segle (v.), segl (n.) “sail”, Icl. sigla “to sail”, Dan. sejle, sejl, MDu.
seghelen, Du. zeil, zeilen, Sw. segla, segel, OHG segal, LGmn. segel, seilen, MLG segelen, Gmn. segeln, segel “sail”; Ir. seol, Welsh hwyl “sail”; Arm. sal (սալ) “raft”; Mari shlo “raft”; Mong., Kalmyk, Qalqa
sal “raft”; Chuv. sula “raft”. More cognates are referred to in Finno-Ugrian, Hu., Khanty, Iranian, and Nenets languages, with respective references (EDTL v. 7, 187); all “sail” unless noted otherwise. An “IE etymology” rolls in its daydreams, disgracefully pretending to have a grain of knowledge, q.v. Ultimately fr. sal, sa:l, säl (n.) “raft, pontoon, float, vessel, bark, boat, ship, generally large boat, nautical vessel”. An original meaning of the word was a “raft”, Cf. Chuv. sula (n.) “raft” (su “water” > “watering” > “raft”, Mong. us “water”). The affinity of Türkic and Mong. forms makes the origin of the terms inconclusive. With a magic of suffixing, the “raft” was recycled for a “sail” (v., n.), Cf. salla (v.) with a Türkic denoun verbal suff. -la. The suff. survived in the A.-Sax. segilan, Sw. segla, Icl., ONorse sigla. A salïɣ, salɣ with a suffix -ïɣ, -ɣ is a deverbal noun fr. salla- (v.) “sailing, seafaring”, Cf. Gmc. saɣl with a metathesis lɣ ↔ ɣl. Notable alternations of systemic nature are ɣ ↔ g; j, i ↔ g, in some Gmc. spellings -i-/-ɣ-/-ğ-. Of 44 “European” European languages, a Türkic sal- dominates with 11 (25%) languages, followed by a Romance group nav- with 7 (16%) languages. A remaining majority of 26 (59%) “European” (located in Europe) languages use 14 forms of their own unique native words. 13 “non-European” Türkic languages are located in Europe; with them a total of “qualified” European languages numbers 57, and the European group sal- grows to 24. If there is a shared “Pan-European” term in Europe, it is definitely a Türkic sal-. Excluding the European Türkic languages would exclude a shared “Pan-European” term in Europe. Cognates: A.-Sax. segl (v.) segilan (n.) “sail”, ofersegl “top–sail”, ofersegllan “sail across”, seglan, seglian, segliani “sail, equip with a sail”,
oferseglian “sail across, oversail”, ymbliðan “sail round”, OFris. sailje, seil “sail”, WFris. seil, sile “sail”, ONorse sigla, segle (v.), segl (n.) “sail”, Icl.
sigla (v.) “sail”, Dan. sejle, sejl, MDu. seghelen, Du. zeil, zeilen, Sw.
segla, segel, OHG segal, LGmn. segel, seilen, MLG segelen, Gmn.
segeln, segel “sail”; Ir. seol, Welsh hwyl “sail” (seol ↔ h(w)yl); Fr. sal “raft, boat, ferry, vessel”; Bulg., Bolg. sal “primitive sailing gear between two river shores”, Rus. saly “reed raft for getting luggage across river (Don)” (but native plyt (плыть)); Arm. sal (սալ) “raft”; Mari shlo “raft”; Mong., Kalmyk, Qalqa sal “raft”; Chuv. sula “raft”. More cognates are referred to in the Finno-Ugrian, Hu., Khanty, Iranian, and Nenets languages, with respective references (EDTL v. 7, 187); all “sail” unless noted otherwise. Distribution:
closely follows Kurgan culture fr. Mong. to Albion. Cognates of “sail” are stretched along the Eurasian Steppe Belt and its NW and Far Eastern fringes, crossing linguistic barriers. The “IE etymology” of the word started with a routine “of obscure origin with no known cognates outside Gmc.”, a glaringly invalid assertion. Then it switched to “reconstructive” illusions: a faux “PWGmc. proto-form” *segl, a faux “PWGmc. proto-form” *siglijan and *siglijana, a faux “PGmc. proto-form” *segla. No better are the suggestions of a semantically unsustainable “IE” faux root *sek- “cut” or a mechanically constructed “PG proto-word” *seglona, *siglijana (v.) “sail” that ignores non g-carrying members, the cited zeil, seol, hwyl, sal, shlo. The myopic “IE” etymology is either ignorant of or scornful of the facts in the real Eurasian world: a Türkic sal-, salla, a Mong.
sal, etc. with a wealth of the Türkic and alien forms across Eurasia. The “IE philology” fails to address the suff. -la in the Fris., Norw., Icl., Sw., Dan. verbs, i.e. “sail (fabric)” (n.) ~ “to sail” (v.). It is an atavism in the Gmc. languages, an atavism that can't be philologically neglected. That critical element is meaningless within the Gmc. grammars. Archeology knows that a Türkic–Mong. Far Eastern contact ascends to a beginning of the 2nd. mill. BC, preceding a Shang period. From Mesopotamia, the Zhou “Scythians” brought to China a Sum. concept of writing (Oracle bone script, aka Oracle turtle script), and some other unique markers. An alternation s → h is peculiar to the languages of the Aral-Caspian basin and Bashkir, it forms the notion “sail” with an anlaut -h. That group may relate to the Welsh dialects (Vlach, Wlach ~ Hu. Olah ~ Türkic Cuman).
The Celtic forms point to an independent parallel development, consistent with trifurcate migrations of the once Kurganic word: a 4000 - 1000 BC overland route, a completed by 2800 BC circum-Mediterranean route (Celtic), and the 100 BC overland route, all from the Eurasian steppe belt extending from the Manchuria to Pannonia and Iberia. The difference between the Celtic form and the OT form is a result of the word's bifurcated parallel development for about 3,800 years, for a combined linguistic time distance of 7,200 years. That is a calibrated gift to a glottochronological timing. A change between the Eng. and Celtic forms adds another millennium to a third leg of the fork, some 8.200 years of independent parallel development. All three prongs of the fork passed through vast territories with innumerable unknown different people speaking numerous unknown languages, diffused through alien lands via divergent paths. The picture of migrations and internalizations deviates so much from a glottochronological model of internal development that a priory it should reject any convoluted unidimensional construct. The converging evidences unimpeachably attests to an origin of the word from a Türkic milieu.
3.147
satisfy (v.) “meet requirements or expectations” ~ Türkic satsa- (v.) “satisfy, be suitable”, from a stem sat- “sell” (v.), “sale” (n.), satɣa (satga) “satisfy payments, payoff”. An “IE etymology” shallowly suggests a Lat. origin, q.v. Ultimately a derivative fr. the verb
sa:-, sa:y “count, say, respect, think” (plus ~15 other meanings). The anlaut sa- and the final suffix -sa are not only acoustically consonant, but also synonymous, showing that a desiderative suffix -sa developed from the same verbal root sa “count, consider”. The suffix forms a notion of a desire (to obtain, trade, and the like). Of 44 “European” European languages, a Türkic-Eng. group satsa- dominates with 11 (25%) languages, followed by a Sl. group -dav- with 9 (20%) languages. A remaining majority of 24 (55%) “European” (Europe-located) languages use 19 forms of their own unique native words. The groups satsa- and -dav- form two dominant European groups. Cognates: A.-Sax. sedan, asedan “satisfy”, saednes “satiety”,
saed “satiated, sated”; Lat. satis(facere) “discharge fully, comply with, make amends”, lit. “do enough”, from satis “enough”; Mong. sana- “think”; Tungus sa- “know”.
Distribution spans from Atlantic to Pacific along the Eurasian Steppe Belt and its fringes. The “IE etymology” is compliant, it adopted the Türkic sa:- (sa, seh-) as its own, a kind of an afflatus from the heavens, except for the attestation of the Türkic root sa-, sat- and the suffix -sa. The fantasies of a faux “PIE proto-root” *sa- “satisfy”, a faux “PIE proto-root” *dhe- “set, put” are not needed. The Türkic satsa-, English satisfy, and Lat.
satis- denote satisfaction of a desire, visibly inherited from the same primordial Türkic substrate satsa-, satisa:-. See sagacity, sage, salary, sale, sundry, sapient, say, sell, sever, tell, think.
3.148
say (v., n.) “utter, state” (Sw N/A, F99, Σ0.40%) ~ Türkic söy-, söyle-, suy-, söle-, süle-, sülä- (v.) “say”. An “IE etymology” has developed 5 (!) nonsense versions of origin, q.v. Ultimately fr. sa:- “count, think” and dozens more of close notions. Türkic and Eng. have parallel verbal and nominal derivatives, Cf.
söyle-, sözlä- “speak, tell”, sayra:- “twitter, sing (of a bird)”. A verbal stem söy- has a noun form sa:v “say, speech”, a denoun verb savla:- “talk”, a verb
sez- “think, perceive, feel, discern”, and deverbal derivatives or reflexes fr. sa:-, say- “think, reckon, count”. The form söy- vs. the form söz- (or sög-, süy-, etc.) is distinct for the NW Türkic languages. Except for few languages where its semantics had narrowed or diverged, the stem söy- and its numerous allophones carry a generic meaning, it belongs to a basic lexical groupings related to speech and communications across the Türkic linguistic family. Its basic notion is an act of stating reflected in lexical derivatives. Similar to the Gmc. group, the Türkic verb is shared by all Türkic languages, from Gagauz and Chuvash to Khakass and Uigur, exclusive of the Asian Indian/Iranian languages,
which split away at about 2000 BC. The Eng. say belongs as much to the Türkic family as to the alien “IE” family. The difference between söylä- and savla:- is qualitative:
söylä- is a shorter utterance than savla:-. A derivative notion sa:yikla:- “blabber, tattle” for mouthing the words was calqued in Eng. The Eng. duplex tell “narrate”, say “utter, state” constitutes a (transposed) transfer paradigm of the Türkic duplex til “utter, state”, -söy “narrate”, an irrefutable evidence of a genetic connection. In addition to the basic phonetics and semantics, the transfer paradigm preserved a semantic subtlety between the tell “story, account, record, news” and say “speak, utter, express”, apparent in the idioms “tell apart” “tell off” vs. impossibly awkward “say apart” “say off”, Cf. Türkic savaš- “say (words)”, i.e. “argue” vs. Eng. inexplicable idiom “words were said”, i.e. “argue”. In Europe, the Eng. say leads a lonely existence, unaware of the neighboring non-“European” surroundings. I.e. the European Azeri, Balkar, Bashkir, Crimean, Gagauz, Karaim, Kuman, Tatar, Turkish. All of them use versions of say in their daily life. To add insult to injury, they all also use tell, both in a reverse semantic syntax, see tell.
Cognates: A.-Sax. secgan (with -k-) “utter, say”, OSax. seggian, OFris.
sedsa, WFris. sizze, OSw. seggian, Sw. säga, ONorse segja, Bokmal
si, Nynorsk seia, Dan. sige, MDu. segghen, Du. zeggen, OHG, Gmn.
sagen “say”, Yid zogn (זאָגן) “say, tell”; OIr. insce (inche) “speech”; Balt. (Lith.) sakyti “say”; Sl. (OCS) sociti (with -k-) “vindicate, show”, (Sl.) skaz; OLat. (in)seque “to tell, say”; Hu. sol “say, speak”, saval “recite”, so “word”; Kurd. (kor-zäzä) söz “word, promise”; Chinese shua (说) “say, tell, talk”; Hitt. shakiya- “declare”; all “say” unless noted otherwise.
Distribution runs from Atlantic to the Far East along the Eurasian Steppe Belt and its fringes. No acknowledged cognates fr. Mong. eastwards. No credible “IE” etymology, suggestions are rather a joke. A slue of suggestions start with a sane “No certain PIE etymology”, and then explodes into fireworks of faux “reconstructions” and wild chases. Those are a faux “PGmc. proto-form” *sagjanan “say”, a faux “PWGmc. proto-form” *saggjan and a faux “PGmc. proto-form” *sagjana “say”, and a faux “PIE proto-root” *sekw- “follow”, and a faux “PIE proto-form” *sokw-h-ye- and a faux “PIE proto-form” *sekw- “tell, talk”, and a Lat. saga “military cloak”, and a poor man's “aphetic” assay, and a Scotland say “strainer for milk”. And a proposed unattested faux “PIE” *sokei- or a more ornamented *sokʷ-h-ye- revert directly back to the forms of the Türkic verb söy, suy “speak, sprechen”, Cf. above sög-. All that “IE” and “PG” nonsense has a zero etymological weight. It is sorely embarrassing and degrading to a clownade. It stops short from arriving at the real ultimate source sa:-, say- “think”. The Ir. form attests to an existence of the word prior to the Celtic Kurgans' departure on their circum-Mediterranean anabasis (6th-5th mill. BC), millenniums before a budding of the “IE” Corded Ware cradle. The Chinese word is likely a reflex of the Scythian Zhou component in Chinese, ca 2000 - 1600 BC, one of the borrowed innovations of the times. The Gmc. and Lat. forms point to Ogur Türkic source with y ↔ g alternation (Cf. Tuv. sögle-). In a feat of paradigmatic transfer, Eng. internalized the four main action words related to communication: say, tell, call and gabble, direct siblings of the precursory söy-/söyle-, til-/tili-, qol-, and gap-, gapir-. Although overlapping and to some degree interchangeable, each one conveys its own spectrum of very basic notions. An origin fr. a Türkic linguistic milieu is inextricable. See call, gabble, tale, tally, tell.
3.149
scare (v., n.) “fear” (Sw N/A, F1701, 0.004%) ~ Türkic qorq- (v.), qorq (n.) “fear, phobia, horror, panic” (v., n.). An “IE etymology” audaciously asserts a Gmc. origin, q.v. Ultimately a
denoun verbal derivative fr. qor (n.) “evil, damage, loss” + a denoun verbal suffix -q “fear”, variously articulated with vowels ö/ü/a/o and related to aspects of vision. Numerous allophonic forms attest to a very archaic origin: gorg-, gӧrg- ɣorɣ-, qorqu-, qoruq-, quj-, etc. To those should be added the Celtic forms. A prefix s- is specific to a northern European morphology as a marker of one-time event and an emphasizer. Slavic has retained a Türkic suffix
-s as a prefix s- in both verbal and nominal use, complete with its semantics of incoming or future perfect event. Of 44 “European” (W. Europe-located) European languages, a dominates a Türkic-Eng. group qorq-, cra- with 9 (20%) languages. A remaining mass of 35 (80%) “European” languages uses 24 versions of their own unique native words. Europe also features 13 more “non-IE” Türkic languages. Accounting for them would more than double a fraction of qorq- languages in Europe to 22, i.e. to about
1/2 of all Europe-located languages (based on the initial kernel of 44 European languages). That is close to a 50.6% Hg. R1a/b demographic presence in Europe. Cognates: A.-Sax. ascyhhan “scare away, reject”, fer-, far-, fear-, feor-, fier-, for- “fear” (q > h > f, typ.), eargian, fyrht, fyrhto, fyrhtu “fear, tremble” (but (n.) ondrædan > dread), faeran “frighten”, forhtlan “afraid, fear, dread”, forhtlic “fearful, afraid”, forhtnes “fear, terror”, forhtung “fear”, fyrhtan “fright”, fyrht “afraid, timid”, fryhtnes “fear”, etc., OSax. farr “ambush”, faron “lie in wait”, MEng. skerren “frighten”, sker, skere “terror, fright”, MDu. vaeren, Du. gevaar “fear”, ONorse skirra “frighten” (+ 4 more), skjarr “afraid, timid, shy”, far “harm, distress, deception”,
faera “taunt”, OHG faren “plot against”, Gmn. gefahr “danger”; Scots skar, skair, skar, skeer, skear “wild, timid, shy”, Welsh (dy)chryn “scare”; Gk. gorgos “terrible”,
Gorgon (n.) “evil monster”; Mong. qour, qourа “harm; poison”, Kalm. horn “harm, evil, poison”, Bur. khoro, khoro(n) “harm, evil, malice, anger, poison”, Khalk. khora “harm” (~ Tuvan ditto); all “scare, fear, harm” unless noted otherwise; some Mong. and Türkic forms overlap phonetically and semantically. Distribution: is spotty outside of the Steppe Belt, Far Eastern, and Gmc. languages. A myopic “IE” etymology is unaware of the archaic Türkic and Far Eastern siblings of the Gmc. allophones. Etymology is supposedly “of unknown origin”, i.e. at a dead end. To correct for the “unknown origin”, the “IE etymology” invented a line of “proper”, i.e. Gmc. cognates. Such as a bogus “PGmc. proto-form” originated “from a root of fear (n.)”. The Eng. scare and fear are both a verb and a noun. Like the 472 other Eng. verb-noun words, they can't come fr. each other in a circular fashion. Then a faux “PGmc. proto-form” *feraz “danger”, and an unrelated to “scare” a faux “PIE proto-form” *per- “try, risk”.
All that nonsense needs to be dispensed with. A time of a Gmc. internalization may be reasonably suggested to date to a Corded Ware-Battle Axe period. Numerous tribal masses were fleeing in all directions from a 3rd mill. BC C. European “killing fields”. The period was conductive for a Türkic Battle Axe-Corded Ware symbiosis. Contemporaries millenniums later described that symbiosis as a “European Sarmatia”. In the Sarmat vernaculars an unaccented second -q in the syllable qörq had a tendency to contract. The Türkic qörq- dubs as a “care”, reflected in identical semantics in English: “have fear” ~ “be afraid” ~“be careful”. For few specific forms, a question of Türkic vs. Mongolic primacy is inconclusive, but Gmc. does not even enter that debate. Apparently, the word entered the NW Europe via independent Norse, Celtic, and A.-Sax. channels. A case of paradigmatic transfer of both fear and care indelibly attests to an origin from a Türkic phylum. See gaze, Gorgon, caginess, care.
3.150
scatter (v., n.) “disperse” ~ Türkic ta:r-, darɣa- (v.) “disperse, divide”. An “IE etymology” rates origins “possibly”, q.v. Ultimately fr. a Türkic root tar- “disperse, scatter”, originated fr. a notion tar- “comb, separate (hair)”. A prefix
sca-, sco- “begin, initiate”, peculiar to a Gmc. and a few other's forms, once served a semantic function. Eventually it was confused with a root phoneme or taken as a non-semantic prosthesis. The prefix is functionally identical to its Sl. clone, a most active prefix s- “begin, initiate”. The Sl. prefix may ascend to an “Out of Africa” period, a Sl. Hg. I age of ca. 40,000 ybp. Of 44 European languages, the word ta:r- shows twice, in a Türkic and in an Eng. That demonstrates its “guest” status in Europe, and its connection with a Türkic milieu on one hand, and with the early Europeans on the other hand. Within a Türkic world semantic furcates, one fork knows only a semantics “hair”, and the other fork knows both a “hair” and its metaph. meaning “disperse, divide”. That points to the “hair” as a prime semantics.
Cognates: A.-Sax. sceadan “scatter” (Cf. scaffot (sca-ffot) “splay-footed, outward, open, apart”); Welsh darfu “scatter, disperse”; ODu. schetteren, Du.
strooien, LGmn. schateren, Gmn. streuen; Balt.-Sl. (Lith.) drai(kyti); Mong.
tar(haltyn) (тархалтын) “distribution”, Mong., Kalm. tar “hair, types of hair (different lengths, colors, hair in fur products)”; Kor. tharak-cul “human hair rope”; all “scatter, disperse, divide (comb)” unless noted otherwise. Distribution: The root tar- “disperse” is spread across most of the Eurasia and across linguistic families reaching to a single European outpost in Eng. and a cluster of outposts in the Far East. An “IE etymology” can't cross its myopic confines. It does not perceive a substance of a prefix sca-, sco-, scea- (A.-Sax., Lat., Sp.), and gets lost on tentatives. Among the conditional clauses are “possibly”, “probably”, “influence”, and “apparently”. They can't substitute for parsing and competent morphological analysis. A good part is understanding the ONorse as one of the feeder channels. A bad part is unrelated to “scatter”, the Gk. skedannumi (σκεδaννυμι) as “scatter, disperse” (Gk. σκορπίζω, διασκορπίζω), and the Toch. B kät- “scatter, sow seeds”: unrelated to the “sca-tter” kät. A non-myopic objective analysis is overdue. A non-“IE” origin of the root is evident, it is a fringe “guest” in a body of the “IE” languages. The scattering pattern excludes a direct cross-borrowing between a Far East and a Far West, pointing unambiguously to a Türkic intermediary between two extremities. The Welsh's presence is notable, it is inconsistent with a borrowing from the Scandinavian languages. The contact routs are the Celtic Kurgans' circum-Mediterranean cruise of a ca. 5000-2800 BC, the post-“killing fields” contact period with the Kurganians of 2500-2000 BC, and a Welsh - Valah (Cuman, Hu. Olah</>) suspected connection. An allophonic form of the scatter is shatter, with accent closer to the notion of “divide” rather than to “disperse”. See
shatter.
3.151
secede (v.) “splinter, break away, separate, detach” ~ Türkic ses-, seš-, säs-, säz- (v.) “separate, segregate, detach, release, untie”, sesin-, sešin, sesken- (v.) “separate, split” . An “IE etymology” attributes origin to a Lat. and “IE”, q.v. One of the basic semantics of the ses- is “unravel, untie, untangle” > “go away, part”. Articulation is most diverse, including a root anlaut s-/š-/č-, inlaut -a-/-e-/-ǝ-, auslaut -s-/-š-/-č-, and some more, attesting to a deep antiquity and a wide dispersion with numerous ses-looking, acoustically overlapping homophones. Ignored by the “IE” etymologists, A.-Sax. had in excess of 80 forms for “separation”, with a tiny sprinkle of sid-derived Turkisms. Distribution is heavily slanted in favor of ses- forms, in line with their “guest” status. Of 44 European languages, versions of the ses- are the only prominent, with 8 (18%) languages. The remaining 36 (82%) European languages use 26 of their own native words, a most of 3 per language, or on average 1.4 words per language. Aside of the Türkic ses- there is no shared “Pan-European” term in Europe; a Türkic “guest” ses- is a best approximation for a
“Pan-European” term in Europe. Cognates: A.-Sax. allophone sceadan “separate, scatter, divide, shed” (also with prefixes a-, be-, ge-, etc.); Lat. secedere /si'seed-/ “secede” (+Türkic, Eng., It., Sp., Fr., Catalan); Skt.? sedhati (सेधत) “dispel”, Av.?
siazdat “dispel”; Mong. saču-, čaču- “disperse”, seli, selbe-ji, selbü-ji “dissolve”; Bur. heli “dissolve”; all “secede” unless noted otherwise. Distribution: a
Türkic Kurgan Eurasian spread + 1 Türkic “guest” to Lat.; a subsequent dissemination of the Lat. word to the W. Europe; Far Eastern spread of sibling ses- forms. No “IE” cognates at the western and the eastern Eurasian extremes. From the early human societies all languages needed a word “separate”; an absence of the “IE” roots and cognates is striking. A suggested “IE etymology” from a Lat. compound se “apart” +
cedere (v.) “yield” implies that it blundered into a virgin Türkic phylum and then exploded into the huge Türkic semantic clusters. That scenario is unconceivable. Albeit domestic and political squabbles and their terminology were around for millenniums,there is no attestation of the Lat. compound ever existing in nature. The claimed Skt. and Av. forms are false cognates. They are unrecognized “guests” from the Kurgan
vernaculars. They are allophones of an unrelated Türkic verb sid-, sıd-, set- “strip, peel, scrape”. The Lat. word is a stand-alone within the “IE” family, a positive attestation of a “guests” status. A presence of the Lat. attested counterparts separ and sevoco vs. the faux se-cedere, a semantic clash between the Türkic “untangle, splinter” and the Lat. “to yield” (actually “to go”, i.e. “walk away, depart”, se-cedere lit. “away walk away”), and the nature of Lat. cedere (v.) from its basic verb stem (supposedly from another unattested “PIE root” *ked- “go, yield, way”) makes the IE/Lat. multilayered concoction untenable. The “IE” etymological alternative of the origin from the notions “here” and “to sit” is too as much flawed. The terms secession, secessionism, secessionist are common European innovations, completely absent in the Asian “IE” languages that evolved in the last 3500 years, and likewise are absent in the Türkic languages.
The Türkic languages derived these terms from different stems. With the Lat. to Türkic borrowing impossible, an only remaining option is a case of random coincidence of Lat. and Türkic lexemes. That is a long shot with negligible probability. An inevitable conclusion is that whether the Eng. path was via Lat./Fr. or directly from Lat., ultimately both Eng. and Lat. forms ascend to the primordial Türkic verb ses-,
seš-.
3.152
see (v.) “observe, perceive by sight” (Sw N/A, F66, Σ0.39%) ~ Türkic sez-, se:z-, siz-, söz-, süz-, hüz- (v.) “see, look, perceive”, lit. “clarify, make clear”, “stare, blunt look”;
see sezmoq, sezmamoq “see, look, perceive”, etc. An “IE etymology” claims a “PGmc.” and “PIE” origins, q.v.
Ultimately fr. a metaph. notion of süz- (v.) “sift, filter, catch (a substance)” > “perceive” ~ “look around, look closely, glance, squint”. Phonetic alternations carry diagnostic clues, leading to specific locations and languages. The süz- “to look”, metaph. “see, think”, and sez- “perceive, discern, understand” likely descended fr. a same primordial root. A.-Sax. vocabulary had four terms for “see”, of them one, locian, was a native European; a two, seon and witan, were of a Türkic origin, and one, sceawian, is so far unclear. Of 44 European languages, versions of the Sl. ved- dominate with 18 (41%) languages, followed with Türkic-Gmc. se- with 8 (18%) languages. The remaining 18 (41%) languages use their own native 15 terms. The Old. Europe root serves as a “Pan-European” term in Europe, followed by the Gmc. root. Cognates: A.-Sax. seon “look, behold” , , OSax. sehen “see”, OFris. sia “see”, WFris. sjen, ONorse, Nynorsk sja, Bokmal se, Dan., Sw., Bokmal se, MDu. sien, Du. zien “see”, OHG sehan “see”, LGmn. sehn, MHG, Gmn. sehen, Goth. saihwan “see”; Alb. shih, shoh “look, see”; Hu. szem (sem); Mong.
šigü-, sügü- “catch (a substance)”; Medo-Scythian (Behistun 2nd inscription) se “see”; Lat. ? signum “sign, token”; all “see” except as noted; semantically distinct derivatives of the same root are cited for Hu., Mong., Halha, Buryat (EDTL, v. 7, 340). The citation of the Lat. ? signum “sign, token” is dubious, semantically inapt and not a verb. Ditto with a Lat. and OFr. noun “see/seat”, as in “an episcopal see”. Distribution: spans from Atlantic to the Far East, crossing linguistic barriers. The “IE etymology” starts with reserved “no certain PIE etymology”, “opinions differ”, and “not easy to accept with confidence”, but then dives into cheerful fictions. Those are a faux “PGmc. proto-form”
*sehwanan “see?”, a faux “PGmc. proto-form” *sehwan “see?”, and a faux “PGmc. proto-form” *sehwana “see”, and a faux “PIE proto-root” *sekw- “see”, and a faux “PGmc. proto-form”
*sekʷ- “to see, notice” “probably identical with *sekw- “follow”. The brave “IE” experts do not hesitate to use in their proto-reconstructions a Türkic suffix -an denoting result, Cf.
seen. The later days alchemy leads fr. nowhere to nowhere, substituting its myopia for a linguistic ken; Cf. sezmoq q.v. in common listings. The A.-Sax. semantics “observe, perceive, understand, experience, visit, inspect” accurately matches the Türkic semantics “clarify, make clear”. The form seen “perceive by sight” is visible in A.-Sax., OSax., MDu., OHG, MHG, and Gmn. infinitive forms. Of all the “IE” languages, cognates are cited almost exclusively only for the Gmc. group. That positively attest to a non-“IE” provenance. That is also corroborated by the cognates in Hu., in the non-“IE”, non-Persian 2nd Behistun inscription, and in the Tung.-Mong. vernaculars. The -p forms deverbal analytic nouns, that helps to
discern the Herodotus' Scythian appellation Arimaspi for the eastern squinted-eye people as a compound
arïmsepï of an arïm “half” + sep “see”, lit. “half-seer” rather than the
reading “half-eyed” for the Herodotus' “one-eyed”. Notably, the Türkic “see” süz-/siz- and
the “sea” si sound distinctly different, while in Eng. they are acoustically conflated to sound exactly the same. An origin fr. a Türkic milieu is beyond any doubts. See sea.
3.153
seize (v.) “capture, grab, clutch”, seizure (n.) “arrogation, spasm” ~ Türkic sı-, sı:- (v.) “break”, sızı-, sızla- (v.) “sharp pain”, sal- “hit, grab”, salgïn “raid, invasion”, serme-, sirt-, sïdïr-, sïfgar-, sïrga- “surround, rob, grab”. An “IE etymology” states “exact source is uncertain”, and briskly suggests origin of OFr., LLat., Gmc., “perhaps” Frankish, and even a “PIE”, q.v. Ultimately fr. a root sı-, sı:- (v.) “break” with a host of derivative forms and applications pointing to most primeval times of non-generic, specific uses, Cf. “grab with teeth”. A few specific cases bear structural parallels: Cf. kap-, karp-, qap- “seize, grab” and sep-, serp- “seize, grab” with alternation
k-/s-, see cap (n.) and cup (n.). A presence of “seize” in the W. European languages is minimal, 3 languages at best (Türkic, Eng., Fr.), not accounting for a 13 W. European Türkic languages. That attests to
a “guest” status in the W. Europe. A.-Sax. had its own 44 native ways to express “seize, grab, grasp”, from
aetfon to ymbfon, it did not need to add one more synonym, see seizure. Of 44 European languages, versions of a Gmc. grip- dominate with 8 (18%) languages, followed by a Romance group
apro- with 5 (11%) languages. The remaining 31 (70%) languages, incl. the above-named 3 languages, use 24 of their own native terms. There is no shared “Pan-European” term in Europe.
Cognates: Brit. seise “seize”, OFr. (13th c.) seisir, Fr. saisir “take by force”; Mong. huraah (хураах) “seize” (s/h alternation), shüürəh (шүүрэх) “grab” (s/sh alternation), barikh (барих) “capture” (s/b alternation), sirkire-, sirkira-, sarkira- “acute pain (seizure)” (z/r alternation); all “seize” unless noted otherwise. The LLat. (8c.) sacire “sacrifice” is a false cognate, q.v. Distribution: spans across Eurasia from Atlantic to the Far East, trolling the Türkic Steppe Belt and its neighbors. An “IE etymology” suggests a line of inapplicable “cognates”: sacire (8c.) (i.e. “sacrifice”), Goth. sokjan “seek”, A.-Sax.
secan “seek”, faux “PGmc. proto-forms” *satjan “place (v.)” and *sakjana, *sakona “strive, brawl”, a faux “Frankish proto-form” *sakjan “lay claim to”, an OHG sahhan “bicker, quarrel, rebuke”, and some more along the same lines. The claimed LLat. word is a false cognate with an inlaut /k/, it is an allophone of a root sik-, exemplified by the Gmc. lineup A.-Sax., OSax. sakan “struggle, dispute, accuse”, OHG sahhan “to bicker, quarrel, rebuke”, Goth. sokjan “seek”, Frankish
sakjan “sue, litigate”, or Lat. sacire/sagio “perceive”, etc. Hence the “IE” apologetic qualification “or maybe or of uncertain origin”. The inapplicable and unattestable nonsense needs to be gently
and firmly resiled. A mass of these incongruent notions only serve to confound a phonetically opaque lexical web.
The form sız- has a sibling sır- (s/r alternation) with about the same complement of derivatives and suffixation. The notion seize (v.) “clutched (by spasm, seizure)” is linked to a metaph. extension seize (v.) “seize, grab, grasp”. It came to Eng. via a Middle Age OFr. legalism
seisir “take possession by force”. A late timing of the Lat. word and a paucity of the cited cognates attest to the non-IE origin of the word, its guest status among the “IE” languages, a trait that could not have escaped scrupulous etymologists. The word belongs to the cluster of Turkisms related to human wellbeing, the sextet of ache, aggravate, feel, ill, sick, seize/seizure, the direct siblings of аčï-, aɣrï-, bil-, il-/iyl-, sık-, sïz-, a spectacular gild of a paradigmatic transfer case inalienably attesting to their common origin from the Türkic linguistic community. See ache, aggravate, feel, ill, sick, seizure.
3.154
sever (v.) “cut off, separate” ~ Türkic sevrä- (sevrǝ-), savra- (v.) “decrease, diminish, get rid of”. A myopic “IE etymology” suggests a Lat. composite, q.v. Ultimately a derivative of a verb sav- “repulse, divert, stand aside, disperse, get out of the way, let loose”. The root sav-, sev- “get out of the way” is homophonous with the root sav-, sab-, say- “say”, a derivative of the root sa:-/say- “reckon, count” that produced the Eng. verb say, see say. A polysemantic stem lends vagueness to the readings and etymological tracings. Eng. has numerous homophonic words: severe, sewer, swear, and more, none connected with removing a part of a whole. A Lat. has a similar separare (v.), it produced an Eng. separate (v.). In the “IE” family both Lat. and Eng. words are “guest” aliens.
Cognates: besides an OFr. late borrowing sevrer (12 c.) there are no “IE” cognates; Mong.
sejire “become small”; Nanai sər “scanty, sparse ”; Manchu səri ditto; Mansi and Manchu-Tung. cognates are reflects of the Türkic forms (EDTL 290). Distribution: spans across Eurasia from Atlantic to the Far East incl. Just a single A.-Sax. language had 32 synonyms to express; it was not starving for another synonym. Lat. had about 8 synonyms for “cut off”. Phonetically, sever (v.) can't be derived from separare (v.) or separate (v.). The internalized Eng. twin semantically and phonetically ascends directly to the Türkic sevrä (v.) and its dialectal allophones. The suggested Lat. twin is either a perfect chance coincidence with the Türkic and Eng. words, or an accidental neologism. A random coincidence of the Lat. separ with the Türkic sevrä with perfect semantic congruence is a very far shot with negligible probability. It can't be credibly advocated. A Lat. composite neologism se + para could not have propagated across Eurasia to the entire Türkic family of ca. 80 native languages, it would be confined to the W. Europe. That chance can't be credibly advocated. An only credible conclusion can be that the Lat. cognate belongs to a massive body of the Turkisms in Lat. The Lat. separ- is an allophone of the Türkic sevrä- and the Eng. sever (“cut off”), a semantic contraction of “decrease, diminish”). A Türkic or Mong. origin is inescapable; “a question about a Turkic vs. Mong. connection for now remains open” (EDTL 286). See say.
3.155
sew (v.) /sō, sou/ < /souk, souq/ “stitch” ~ Türkic suk-, sok- (suq-, soq-) (v.) “sew”, plus “weave (fabric)”, “knit”, and the like. An “IE etymology” cheerfully suggests a “PGmc” and “PIE” origins, q.v. Ultimately fr. suk-, sok- in -k, -g of a primeval stem su, so, tı, čı “sting, strike, jab”. The prime verb has ~62 meanings in 16 semantic clusters, from “thrust” to “expose”, with downstream layers, and those produce clusters of ensuant layers. An intra- and inter-cluster correlation has a high degree of pliability. At least two synonyms are concordant with suk-, suq-: the tık-, tıg- “insert, sting”, “sew” (Cf. tıkıt- “sting, pin”, tığı, čigil), and čık-, čıg- “sting”. They are extensions “insert, sting” fr. the prime notion suk-, sok- (v.) “beat, strike”, a downstream extension of the “sting, bite” of the prime notion, see sock. An etymological hierarchy of the notions is fairly arbitrary. The homonymic forms suk- and sok- “beat, crush” show traces of undifferentiated use, with areal predominances and overlapping semantics. “Kashgari treats both verbs in the same paragraph; ...it is simply a matter of judgment which verb is involved” (Clauson EDT 805). The stem suk-/suq- forms derivatives connected with subduction, anything that goes into inside, from “socket” to “sugar” (of inner juice). The form suk- “insert” predominates in the western area, in the east “insert” is sok- along with other meanings. The link between “insert” and “stitch” is illustrated by archeological study of the oldest pants, a nomadic riding pants from the Tarim basin ca 1300 BC, weaved on a loom as a single piece. Required for continuous riding thigh inserts were stitched in, reflecting archaic means of
“patching”, “stitching together” prefabricated sections. Of 44 European languages, a Türkic > Sl. > Gmc. etc. (s/š)i(t-) (~ sV-) dominates with its 12 (Sl.) + 6 motley siblings with 19 (43%) languages, approaching a level of 50.6% Hg. R1a/b demographic presence in Europe. It is followed by a Romance group cos- with 8 (18%) languages. The remaining 19 languages use a spectrum of their own 12 terms. A first to Europe migrants (ca. 40,000 ybp) of the Sl. Y-DNA Hg. I, a de-facto European educational leader, in the following millenniums disseminated the Türkic “sew” terminology. Cognates: A.-Sax. seowan, seowian, siwian, siowian “sew, stitch, mend, patch, knit together”, OFris. sia “sew”, NFriz. saie, sei, Saterland Fris. säie “sew” (but Ir. fuaigh, Scots fuaigheal, Welsh
gwnio); Dan. sy, sye “sew”, Sw. sy, ONorse syja, OHG siuwan, Goth.
siujan “sew”; OCS šijo, šivu “seam”, Rus. shit (шить), Pol. szyc “sew”; Latv. siuviu, siuti “sew; Lat. suo, suere “sew””; NPers. sökülmä “sword” (< Tr. soqul- “stub, stuck”); Skt. sivyati “sew”; all “sew” unless noted otherwise. The Eng.
sew lacks a suitable “IE” etymology; it is indeed one of the many “guests” in Europe. Distribution:
covers the Steppe Belt and its extensions; no references to the Far Eastern languages. The “IE etymology” is lacking an initial word that developed into a concept of sewing. There is no need for a faux “PGmc. proto-form” *siwjanan “?” or a faux “PGmc. proto-form” *siwjana “sew”, nor for a faux “PIE proto-root” *syu- “bind, sew” and a faux “PIE proto-word” *syewh- “sew”. The “IE etymology” dubiously attempts to link the notions of “yarn” and “sewing”, which are unlikely to be related. Yarn appeared far ahead of sewed garments, and the first sewing was done with natural materials like plant fiber and animal sinew. The yarn-connected notions of spinning are not related to sewing. All these speculations need to be gently retracted as misleading up to a point of attested terms. In Türkic languages, phonetic transition from post-palatal velar plosive consonants -g-/-k-/-q-/-h- to weak or silent -ğ- and a semi-consonant -y- or a null consonant are regular. The areal forms suy- and su- are a fairly suitable rendering for the western Türkic vernaculars, attested in the Lat. su(ere) “sew”, and in the Gmc. renderings
sy- and siu-. The A.-Sax., Gmc., and Goth. versions preserved a Türkic instr. case suff.
-an: sewan “to thread” and a 3rd pers. past suff. -ti: siuti “sewn” adopted by Sl. languages to the present. A derivative sut- in the Eng. sutura “fibrous joint”, Lat. sutura “a seam, a sewing together”, sutus “sewn”, Skt. sutram “thread” are formed with the Türkic causative verbal suffix -t- “something made using a verb base”. The antiquated Türkic notion of “inserting” was eventually replaced with other verbs denoting “stitching”. By that time, the European forms for “sew” were internalized and fossilized. See dick, socket, stick, tick.
3.156
shake (v., n.) “rock, jolt” ~ Türkic silk- (v.) “shake, swing”, sok-, čok-, šok- (shok), soq- “strike, beat”,. Extended semantics “brandish, tremble, glide, hasten, flee, depart”. Allophonic forms sık-, sığ-, sig (v., n.) “press, strike”. An “IE etymology” offers a “PGmc” and “PIE” origins, q.v. Türkic has 26 semantic clusters with about a hundred meanings, plus a few clusters of homophones with dozens of their specific meanings. Individual languages have their own overlapping semantic line-ups. Eng. has retained original phonetics without a significant change. Of 44 European languages, a motley group shak- of 14 (32%) languages dominates, followed by a Sl. group tres- with 7 (16%) languages. A remaining 23 (52%) languages use 12 of their own native terms. Accounting for the 13 Türkic W. European languages would significantly shift the balance of the users of “shake”. A motley contingent of “shake” users in Europe attests to its “guest” status there. If there is a shared “Pan-European” term in Europe, it is a reflection of the Türkic silk-, sok-. Cognates: A.-Sax. sceacan (sh-, infin.), scoc (sh-, past tense 3 pers. sg.) “shake”, Dan. skage “shift, turn, veer”, MDu. schokken (sh-) “push, jolt”, ONorse, Sw. skaka, OHG scoc (sh-) “jolt, swing”, Gmn. schlagen “strike, beat”; OFr. choquer “strike”, MFr. choc “attack”; Skt. khaj “agitate, churn, stir”; NPers. so:qu:m “slaughter (fattened cattle)”; Mong. segsrekh “shake” (~ Tr. silk-, Gmn. schlagen), Mong., Kalm. tsoh, tsokh “strike, beat”; all “shake” unless noted otherwise. Distribution: Spans from one end of Eurasia to another. No credible “Gmc./IE proto-word”. Blurry indicators use vague assertions: “reconstructed”, “imitative”, “probably”, “origin unknown”, “from Frankish”, further diminished by unrealistic semantic suggestions. They are solely parroty, not adding any etymological value to the attested Türkic and European “guest” words. Those are: a faux “PWGmc. proto-word” *skakanan “shake, swing” with that “swing” unrelated to neither “shake” nor a boggling “escape”; a faux “PIE proto-root” *(s)keg- “jump, move”, or faux *skakana, *(s)keg-, *(s)kek-,
or Sl. skak “gallop, jump, leap”, etc. An assertion of “no certain cognates outside Germanic” is equally false: the attested roots čok- (chok), šok- (shok), silk- etc., and the lexicons of 13 Türkic W. European languages produce a solid attested evidence. They are true precursors for the Gmc., Sl., Romance, etc. internalizations. A reference to a Frankish involvement may reflect a reality: the Frankish was a western descendent conglomerate of the Attila state's posterity, Cf. the Arthur's kurgan grave in Briton, see
Arthur. There is no need for a faux “Proto-Germanic imitative base” nor for the other fictions; they should be gently rescinded. The Türkic examples lean toward warfare, matching the Fr. examples, with plenty of semantic extensions matching and overlapping other European semantics. The Türkic phonetics with
initial s-, ch-, sh- matches that of the A.-Sax., Gmc., and Fr. forms. The Skt. form matches the
Türkic s-/h- alternation typical for the Aral-basin vernaculars. The Skt. auslaut -j matches
the Türkic final -k/-ğ/-y alternation, allowing to trace the Skt. form to particular
Türkic locations and dialects. The suggested “IE” cognates are phonetic mirrors possibly derived from a second semantic meaning of the verb silk- recorded for its Türkic synonym tebrä- “twitch, move, motion”, OCS “leap”, Welsh “move”. The phonetic and semantic match is clear, their concordance leaves no doubts about a Türkic origin. The triplet sock, shock/shake, tremble constitutes a hard case of paradigmatic transfer from a Türkic lexical phylum. See Arthur, shock, sock, tremble.
3.157
“” “” “” “” “” “” § & * = ≠ ~ ≈ ≡ ± °– → ↔ џ(dž)aæδεχƔɣčšäïüӧəǯØΣ
13 W. European
English shatter (v.) “fracture into many bits” ~ Türkic sïtür- (v.) “crush, fracture”.
Ultimately a causative derivative of sï- (v.) “break”. Eng. has preserved the original
phonetics with minimal change. Cognates: ODu. schetteren, LGmn. schateren, Du.
strooien, Gmn. streuen; Balt.-Sl. (Lith.)
sutrai(kyti); Mong. sinal- “broken (heart)”; Even. siŋnǝ- “break”; Nanai, Orok.
siŋgǝrǝ “break”, common for the “scatter” and “shatter”. The
sïtür- “break” is scattered across Eurasia and across linguistic families. A non-IE origin of
the word is evident, it is a guest on the opposite fringes of the Eurasian languages. A scatter
pattern excludes cross-borrowing between the Far East and the Far West, unambiguously pointing to
the Türkic intermediary source. Gmc. forms start with sibilant t s-, š- and their variations.
The fluidity of the initial sibilant is illustrated by a varied articulation of the word schedule.
A European allophonic form of the shatter is scatter, with accent closer to “disperse,
scatter” rather than to “break, divide”. See scatter.
3.158
“” “” “” “” “” “” § & * = ≠ ~ ≈ ≡ ± °– → ↔ џ(dž)aæδεχƔɣčšäïüӧəǯØΣ
English shit (v., n.) “defecate, poop” (Sw N/A, F527, 0.02%) ~ Türkic šıč- (shich-), šıčıt-
(shichit, inf.), sıčtur- (sichtur, caus.) “defecate, poop”. Türkic
phonetics is fluid, with wide phonetic changes (s-/š-/č-, -s/-sh/-ch). The verbal form
šıč-/šıš- is homophonic with nominal šıč/šıš/sı:š meaning 1. like in shish-kebab
“piece, bit (roasted meat)”; 2. “swelling, boil”. That refers to an elongated shape of the poop,
probably in a primeval lexical experience. Unless it was the other way around, shish-kebab
reflecting a shape of the poop. The word was internalized with ad hoc spelling variations, with
dento-palatial -ch-/-t- alternation. Eng. shit reportedly comes from Fris. and Du.,
that origin is apparently predicated on the absence of the word in the literary sources.
Cognates: A.-Sax. scytel (shytel) “shit, excrement”, scitan (shitan, inf.)
“shit, defecate”, ME shitel, Fris., NFris.
skitj, Du. schijt, schijten, Gmn. scheissen. European distribution is limited
to the Gmc. languages, that clearly attests to a non-IE origin, and to a status of a loanword.
Otherwise, distribution extends from the Atlantic to Pacific along the Steppe Belt and its fringes.
The fanciful “IE etymology” ascends to phonetically similar, but semantically odd notions of “cut,
split, divide, separate, shed”, and as example cites the A.-Sax. scearn (shearn) “dung,
muck”, allophonic to the same Türkic šıč- (shıch) “poop”. There is no need for scholastic
equilibristics that makes shit a cousin to science and conscience. A.-Sax.
directly reflects the Türkic šıčıt- (inf.), recorded complete with the Türkic adjectival
suffix -l, instrumental suffix -an, and 3rd pers. verbal suffix -tï/-ti
internalized as abstract infinitive verbal suffix in some “IE” languages.
3.159
“” “” “” “” “” “” § & * = ≠ ~ ≈ ≡ ± °– → ↔ џ(dž)aæδεχƔɣčšäïüӧəǯØΣ/
English shock (v., n.) “rock, jolt” (Sw N/A, F1948 0.003%) ~ Türkic sok-, čok-, šok-, soq- (v.)
“strike, beat”, soku: (n.) “blow, beat”.
“Shake” is a second allophonic form of the same origin, Türkic forms sık-, sığ-, sig
(v., n.) “press, strike”, silk- (v.) “shake, swing”, with
extended semantics “shake, swing, brandish, tremble, glide, hasten, flee, depart”.
Cognates: A.-Sax. sceacan (sh-, inf..), scoc (sh-, past tense 3 pers. sg.)
“shake”, MDu. schokken (sh-) “push, jolt”, OHG scoc (sh-) “jolt, swing”, ONorse, Sw.
skaka
(sh-), Dan. skage (sh-) “shift, turn, veer”; OFr. choquer
“strike”, MFr. choc “attack”; Welsh ysgogi “move”; OCS skoku “leap”; Skt.
khaj
“agitate, churn, stir”. The Türkic examples lean toward warfare, matching the Fr. examples, with
plenty of semantic extensions matching and overlapping the other European semantics: “beat, strike,
crush, dig, pierce, peck, bite, card (wool)”. The Türkic phonetics with initial s-, ch-, sh-
matches that of the A.-Sax., Gmc., and Fr. forms; the Sl. form matches that of the Scandinavian
forms. The Skt. form matches the s-/h- alternation typical for Aral basin vernaculars, the
Skt. auslaut -j matches Türkic final -k/-ğ/-y
alternation; that allows to trace the Skt. form to particular locations and dialects. The “IE
etymology” has no claimed cognates outside Gmc., and even does not extend a dubious PGmc.
“proto-form” to the cousin shake. A phonetic and semantic match is perfect and near-perfect,
concordance leaves no doubts of the Türkic origin. The triplet sock, shock/shake, tremble
constitutes a hard case of paradigmatic transfer from the Türkic phylum. See
sock, shake, tremble.
English shove (v.) “push, press, drive, impel” ~ Türkic sav-, saw- (v.) “drive away, repulse”.
The base notions are “push away” and “disperse”, metaphorical notions are “escape” and “disappear”.
The Türkic verb sav- is an exceptionally generic abstract concept not connected with any
specific act, and perfectly suitable for polysemantic development. On the Gmc. soil it continued
innovations that produced derivatives scuff, scuffle, shuffle, shovel, etc. Cognates:
A.-Sax.
scufan (shuf(an)) “push away, thrust, push with violence”, ONorse skufa, skyfa, OFris.
skuva, Du. schuiv(en), OHG scioban, “push, thrust”, Goth. skiub(an),
also suggested Balto-Sl. (Lith.) skubti “haste”,
skubinti “hasten”. No “IE” links whatsoever, the “IE etymology” does not even reach the Lat. The
“IE” etymology, in its efforts to create a single original PIE “proto-word” for the cognates, comes up
with a tailor-made scenario for each phonetic form of the allophonic cluster, inventing different
asterisked models for obvious cognates, like *skeubh- and
*skublo-, with remarkable resemblance to the Türkic original. The Lith. examples are
unrelated to the word shove, they are confused with the allophones of the Tr. verb
čap-/cap-/šap- connected with hurrying and driving chattel by making noise,
a very peculiar retention. The queer A.-Sax. Romanized alphabet coded -sh- as -sc-,
masking the anlaut consonant that survived in the original palatalized form -sh- of -s-,
and in written metamorphosed form -sc- (-sk-). The European Türkic languages tend to
pronounce the -s- of the eastern languages as -sh- of the western languages.
Migrations of populations disseminate both forms in opposite directions. The auslaut -l is a
Tr. passive voice suffix. Confused with the root in the above example, it makes derivatives formed
on the model of shoved (“shovel”, deverbal noun) and scuffled (“scuffle”, deverbal
noun). See scuff, scuffle, shuffle, shovel.
58
English sick (v.) “vomit, disgorge”, (n.) “dejection, excreta” (Sw N/A, F541 0.02%) ~ Türkic sök- (v.) “have diarrhea”, “destruction of some kind” (OTD 510). The root sök- is more suitable for the specific semantics then the root sık because cognates of sick “ill”, limited to the Gmc. group, do not universally support the notion “vomit”, making it concordant with the Türkic sök-. In English to sick “to destroy (them), set upon (them)” parallels Tr. semantics. A derivative of sök- (v.) is sökäl (n.) “sick person”, formed with poly-functional suffix -al, still active in Türkic and English. In this case sökäl is “to turn ill, sick”, equivalent to English “is sick, turned ill”. Türkic sök- also has a verb sökmak, lit. “make sök” - equivalent to “(be) diarrheic (v.)”. Cognates: A.-Sax. siht “flux, diarrhea”. The notions of sick/ill and vomit probably already conflated within the Türkic milieu. That is attested by a presence of semantics vomit in the allophones of sık- in other Gmc. languages. A simplification of phonetics to sick was a result of Gmc. internalization. The “IE etymology” goes standard “of uncertain origin”, a euphemism for “we poor linguists do not have a clue”. English has plenty of related semantic innovations, while Turkish uses the stem sök-, and not sık- to form an innovation “patient”.
English sicker (v.) “ooze, percolate, trickle” ~ Türkic sarq- (v.) “ooze, seep, leak”. The form sayik-, sayeg- “shallow, dry riverbed”, a derivative of sa:y (šay) “shallow, dry riverbed” also means “trickle”, phonetically it is close enough. That also apply to saɣ- which produced Eng. “soak” and “suck”. These acoustic twins describe overlapping notions, the sicker, sok, and sarq-/sayik-/sayeg-/saɣ- are allophonically equidistant from each other. In English, sicker “ooze” is rated as a provincial talk, with no etymology. It does not even merit to be included in standard dictionaries, has no date of first record, and is an example of a real folk language. Agewise, it may be older than a Corded Ware itself, with a knack to survive, at least as a trade term. Cognates: A.-Sax. sic “small stream, runnel”, sicerian “trickle, penetrate, ooze”; Sl. sochitsya, sok, sochnyi (сочиться, сок, сочный) “to ooz, juice, juicy”, also acoustic twins in both languages with no established etymology and apparently no Balto-Sl. cognates. The Slavic lost -r- in comparison with Middle Asian Türkic, and English transposed -rq-, pointing that the Western Türkic source probably was not exactly of the Middle Asian form. A likeliest source for both the English and Slavic forms is Sarmatian, since Sarmats covered both the C. European Anglo-Saxon and Slavic areas. See soak, suck.
English sing (v.) “vocalize” (Sw N/A, F1375 0.01%) ~ Türkic siŋ (sing) (v.) “ring, buzz”. Apparently, the semantic shift or extension from “buzzing” sound to “singing” sound was specific to the western Türkic languages of the Scythian-Sarmatian circle. The eastern (largely Oguz) group of Türkic languages is using a synonymous verb yarla-, which found place in Heb. (yarla- “sing”), in the Sl. (gorlanit, горланить, “loud utter”) the word comes with Ogur-type prosthetic initial -g. The Türkic stem siŋ has two meanings, “sing” and “sink”. Both have survived into the modern English, a salient case of paradigmatic transfer. An A.-Sax. galan- “sing” is a reflex of yarla-/garla- and a cognate of the Eng. call, A.-Sax. ceal-, fr. Türkic kol-. Cognates: A.-Sax. sing-, OSax. sing-, OFris. siong-, ONorse syng-, Goth. sigg-, OHG sing-, MDu. singh-, Du. zing-, Gmn. sing-, Sw. sjung-, “sing”. Demonstratively no cognates outside of Gmc. and Türkic languages, no common “IE” “proto-word”. A faux “Gmc. proto-word” *seng is plainly identical with the real Türkic siŋ (sing). Dazed by its own brilliance, the purblind “IE etymology” shamelessly dupes “no related forms in other languages”. Ironically, the “IE etymology” legitimized “sink” with an invention of a faux “PIE root” *sengw-, a feeble distortion of the homophonic real Türkic siŋ-, while the unlucky companion “sing” was left out in the cold. With the A.-Sax. homophones sink and sing, and galan- and ceal-, the paradigmatic transfer case includes a quartet of similar words. Such chance event by a random coincidence is absolutely impossible. This is a clear case of paradigmatic transfer, unambiguously attesting to the common origin from the Türkic milieu. See sink, call.
English sink (v.) “go under” ~ Türkic siŋ- (v.) “dissipate into the ground, be absorbed (water), be sucked up”. For such primeval notion, a spread of phonetic forms is uniquely narrow and predictable: only sin-, sig-, syŋ-, xiŋ-, iŋ-. A Türkic bifurcation “sink”, “digest” was paradigmatically transferred to A.-Sax, a salient case of a common origin. With a spread of kitchen sinks, the word gained a status of a true international word. Cognates: A.-Sax. sincan “sink, become submerged”, “digest easily”; OSax. sinkan, MDu. sinken, Du. zinken, OHG sinkan, Gmn. sinken, Goth. sigqan “sink”; Mong. siŋge- “sink”, Kalm. šiŋg-, Bur. šǝŋgǝ- “sink”. Some of those and other eastern languages also retained the meaning “digest”. Distribution is across Eurasia and linguistic barriers. All European cognates are Gmc., no “IE” cognates, a positive attestation of a non-IE origin. That makes any “IE” pretensions ludicrous. A suggested unattested PIE *sengw- is just a poor man's distortion of the real attested Türkic siŋ-. A claimed ONorse pseudo-cognate sökkva is an allophone of an unrelated Türkic stem saɣ- “soak”. An agglutinated Türkic suffix -an/-en in the Gmc. forms marks passive voice and participle. All Gmc. words are close allophones of the Türkic word. The Türkic stem siŋ has two meanings, “sing” and “sink”, both have survived into the modern English, a salient case of paradigmatic transfer. With the A.-Sax. galan- and ceal-, the paradigmatic transfer forms a lexical quartet of sing, sink,. Such chance event by a random coincidence is absolutely impossible, this is a clear case of paradigmatic transfer, definitively attesting to the common origin. See sing, soak.
English sip, sup (v.) “drink small mouthfuls at a time”, sip (n.) “small mouthful of drink” ~ Türkic syp-, sеp- (v.) “by drops”, syp (n.) “drop (of liquid)”. It is a phonetically modest (8 allophonic forms), semantically capacious lexeme (4 semantic clusters, ~40+ meanings). Of those, Eng. retained 2 meanings (sip, seep). Cognates: A.-Sax. saep “sap, juice”, seaw “sap, juice, moisture”, supan (WSax.), suppan, supian (Northumbr.), sype “wetting, act of soaking”, sypian, sipian “absorb, drink in”, soppian “soak”, ONorse supa, MLG supen, Du. zuipen, OHG sufan, Gmn. saufen “to sip”; Hu. chepp “drop”; Sum. sheks (n.) “drop”; Hu. szepla “freckle”; Mari šuvaš “pour, shower”; Mong. seb “scale (fish)”, sebke “hives, freckle”; Kalm. sevg “freckle”. The notion “freckle” and the like are connected with meanings “drip” and the like. Like Türkic, Hu. and Sum. agglutinate suffixes to the stem to produce derivative verbs and nouns. Distribution spans across Eurasia and linguistic barriers. The “IE etymology” is funny, it circles and blunders, asserting “from a Gmc. source”, thus completing a full circle from enigmatic Gmn. into the bushes and back to enigmatic Gmn. It turns to notions from “press out juice” to “juice”, “rain”, “to suck”, “flowing sap”, A.-Sax. seaw “sap”, “eat the evening meal”, and finally OFr. super and soupe “broth, soup”. Some of these accidentally are derivatives of syp-, sеp-and thus are true cognates of the Türkic original precursor. The Gmc. sup and Eng. sip are allophones with identical semantics. Ultimately, the notion of a sup ~ sip “drop” is connected with water, in Türkic su/suv/sub, and must be its early derivative. The Türkic su/suv/sub must have sired the enigmatic Gmn. sup and its Fr. version soupe “broth, soup”, MDu. sop, Lat. suppa. The Eng. sap also belongs to the same circle of derivatives, with cognates A.-Sax. sæpm, MLG, MDu, Du. sap, OHG saf (sav), Gmn. Saft “juice”, Ir. sug “sap”, Balt. (Lith.) sakas “tree-gum”, Sl. sok “sap”, Skt. sabar- “sap, milk, nectar”. Ditto the Lat. sipho and the Gk. siphon “siphon”, both “draw liquid by sucking” (v.), “device to draw liquid by sucking” (n.), Hu. szop (sop) “draw liquid by sucking”. Starting with the Sumerian cognate dating to the 4th mill. BC, numerous derivative semantics and a collection of allophones all point to the Eurasian continental-wide distribution of the root su/suv/sub, and a slew of derivatives long preceding the Indo-Aryan migration to India ca 1500 BC and the birth of the Latin and Greek.
English sit (v.) “squat, hunker, rest on butt, lounge” (Sw N/A, F421, 0.12%) ~ Türkic si:t-, si:d-, sıt-, sıd-, siδ- (v.) “squat”. Türkic men urinated sitting (squatting), that was and still is one of national ethnological idiosyncrasies not mentioned in the linguistic dictionaries. The stem si:t-, sıt- means “urinate squatting” or “squat to urinate” (Cf. er sitti: “man squatted to urinate”); which part is primary is obscure and etymologically irrelevant. Thus, the Türkic verb si:t-, sıt- is “to squat” (Eng. sit, seat, and stool (chair), and “to urinate” (Eng. stale, stool (excrement)), the last extending to “to defecate” and in Tr. to “defile”. The CT form of the stem si:t-, sıt- is siy-, Cf. Az. siymək, Kor. swiya. A complimentary form čıj-/čij- (čıž-/čiž-) (chij with -j- as -j- in jest, -g- in gel) (v.) is translated as “lay down” (of the horses) and “sag, droop” (of the horses). Those forms are close phonetically and semantically to suspect a common origin with a notion “get down”. Judging by the spread of the term sit “sit”, squatting and excreting was a salient occupation of the Eurasians ever since they could name their fave. The notion “sit” must have preceded an adoption of the fire, and belongs to the most ancient elements of the human speech. Its commonality across later language families is natural. Some semantic derivatives are: yearly - seat (n), late - sedentary (adj.), etc.; the verbal form seat is practically synonymous with the form sit. The modern Türkic word olur- “sit” with a sense of “settle temporarily, occupy” initially applied specially to rulers (Clauson EDT 150), it is the form that survived to the present. It is a dignified form of the archaic inelegant verbs si:t-, sıt-, čıj-. Both forms left enduring traces specific for the notion “sit”: čıjdı: (2nd pers. sg.) is homophonic with the Sl. sidi (сиди) - imperative “sit”, and sidet (сидеть) - infinitive “sit” (Skt. sidati “(he) sits”, is homophonic with both Tr. čı- and 3rd pers. suffix -ti), čıj- is phonetically homophonic with siju (сижу) - 1st pers. sg. “(I am) sitting”; so do the Ir. shuío(chán)“seat”, Fr. siege (sij), Taj. čoj (ҷой) “place”, Ch. zuo(wei) 座位 “seat”, Jap. shito “seat”. A Sl. y-/j-/d- alternation is consistent with that of the Turkic languages. A dental plosive -d-/-t- is routinely interchangeable with the semiconsonant -y- and the dentipalatal affricate -j-. A ch-/sh-/s-/z- alternation is routine. Thus, the forms sit, sidi, and čıj-/čıjdı: and siju are allophones expressing a notion “sit”. That is an overwhelming line of evidence: there is no doubt that sit and sidet are cognates, that sidet and siju are cognates, that sidi and čıjdı: are cognates, and siju and čıj- are cognates. The other variations of the čı- words point to a notion of flexing: čıp “slender twig”, čıbık “flexible rod”, “trilby cap”, či:če:k “flower”, čıča:lak “little finger”, či:t “silk”, čı:ğ “reed”, čı:ğlan- “measuring flexible cloth”, čığa:n “poor, destitute” (flimsy, slender living), čik “bent (concave) side of a knucklebone”, and so on. That is consistent with the CT form si:- “break” in a sense of “flex” and the forms si:t-, sıt-. Taken along with translations, čıj- lit. expresses a type of flexing at the hips, below the back and above the knee, and thus it is an appropriate stem for the verb “sit” and the noun “seat” (Cf. genuflex “bending of the knee” fr. yinčür- (v.) “bow, bend”, bow (n.) “bending in the spine” fr. buq-/bük- (v.) “bend, bow”). In the eastern Türkic languages the uncouth stem sit- and the fuzzy stem čıj- were supplanted by a more couth stem olur- “sit” with a sense of “settle temporarily, occupy”, while the western languages have retained the primeval stems sit- (sit-, sid-, zit-) and čıj- (sež-, sizz-). Cognates: A.-Sax., OSax. sittian, ONorse sitja, Dan. sidde, OFris. sitta, MDu. sitten, Du. zitten, OHG sizzan (Cf. čıž-/čiž-), Gmn. sitzen, Goth. sitan; OIr. suide “seat, sitting (remaining in one place)”, Welsh sedd “seat”, eistedd “sitting”; Lat. sedere; Gk. ezesthai with a prosthetic anlaut e-; Balto-Sl. (Lith.) sedmi, (OCS) sežda, sedeti, (Sl.) sidet (сидеть); Skt. sidati “(he) sits”; Mong. sige- “urinate”; Manchu site- “urinate”. A preponderance of evidence identifying relict forms sit- and čıj- with the versions scattered across Eurasia from Ganges to Atlantic (verb) and from Pacific to Atlantic (noun) excludes a fortuity chance for their uniform appearance, connecting genetically various descendent forms. In many instances the root -sit- contracted to -st-: stable, static, etc. The peculiar Fr. form probably was introduced by Burgunds, independently from the source of the peculiar Sl. form. The Celtic examples indicate the existence and the form of the lexeme prior to the Celtic departure from the Eastern Europe in the 5th - 4th mill. BC. Eastern languages carried on the original sense of “peeing”. The word, in a form echoing čıj- and sit-/sid-, probably was brought to Europe between 4500 and 2800 BC, probably via numerous paths separated in time and space. The morphological wrapping of the common to the Türkic - Sl. - Skt. verbal conjugational elements (e.g. -ti/-di, -t) can be dated by the 3rd mill. BC, i.e. the latest time when Skt. and Sl. shared a common Eastern European territory. The lexical, semantic, and morphological elements of the batch sit “squat” and stale “urinate”, sit “squat”, pee “urinate”, mark “tag, track”, connected by dual semantics of sitting (squatting) and excreting constitutes a paradigmatic transfer loaded with nuances and idiosyncrasies. They supply ample evidence for genetic connection to a common source propagate by restless nomadic Kurganians. See bow, genu, seat, stale.
English smile (v, n.) “sweet facial expression” (Sw N/A, F1336 0.01%) ~ Türkic (gülüm)seme (n.), (gülüm)semeye (v.) “smile”. The Türkic gül is “laugh”, a suffix seme has a connotation of “sprouting, seed, beginning, genesis”, Cf. Sl. semya (семя) “seed”, the part seme/semeye of the jingle expresses “joyful, happy, cheerful”, so the compound gülümseme accentuates a notion “smile” as opposed to a full laugh. In the west, correlated with the populace marked by the Pit Grave Y-DNA groups R1b-CTS7822 and R1b-Y14512 (European branch), descendent from the Y-DNA group R1b-Z2108 subclades CTS1843 and Z2109, the part seme split and continued its own happy independent life. Cognates: A.-Sax. smerian “to laugh at”, smearcian (modern smirk), Dan. smile, Sw. smila, OHG smieron “smile”; Balt. (Latv.) smiet, smeju, smeju, smaidit, smidinat, sminet; Sl. derivatives trail the Balt. (Latv.) smekh (смех); Skt. smayate, smayati, smeras, smitas. Distribution of the word points to a procession Türkic > Gmc. > Sl., with Skt. forms budding off after an initial European development. A telling absence of parallels in the Romance and other branches of the “IE” family attests to a non-IE origin. An unattested fictive “IE proto-word” *smoisos was mechanically derived from the Türkic reflexes in the Gmc./Sl. languages. The Latv. smaidit “to smile” – smaidigs “smiling” has preserved a reflex -īg of the Türkic suffix -gen used to form qualitative adjectives from verbal stems. The Skt. forms with Türkic verbal suffix -te/-ti point to a E. European connection prior to ca. 1500 BC and probably ascending to 2000 BC.
English soak (v.) “imbue with liquid” ~ Türkic saɣ(ur)-, suğ(ur)- (v.) “soak, absorb”. The form saɣur is a derivative of the verb saɣ- “to milk (an animal)”, a root that has a long trail of allophones and a spectrum of semantic meanings, where a particular semantics of “extract milk” (v.) produced derivatives “suck”, “suckle”, “soak”, “absorb”, “get”, and the like, and then some more. Saɣur consists of the root saɣ- + suffix -ur (active voice marker) ~ “soak, absorb”. An alternate form saɣen is a deverbal noun derivative formed with a suffix -en/-an. Cognates: A.-Sax. sucan, WFris. suge, OSw., OHG sugan, ONorse suga, MDu. sughen, Du. zuigen, WFlem. soken, Gmn. saugen “suck”; OIr. sugim, Scots souke, Welsh sugno “suck”; Lat. sugere “suck”, succus “juice, sap”; Sl. sosasat, sosu, soska, sosok, sosunok (сосать, сосу, соска, сосок, сосунок) “suck”, “suckle”, “nippel” etc; Mong. saga “suck”; Fin. saada “get”. Distribution - across Eurasia from end to end. No sane “IE” etymology. The “IE etymology” offers two different, both unattested, separate origins for the siblings “soak” and “suck”, a PG *sukon “absorb” modeled on attested and real WFlem. soken, and an “IE” root *seue-“absorb”. The origin of *seue- in a circular illogic mode is brazenly derived from a notion “soup”. Or a Lat. neologism absorb from ab- “from” + sorbeo “suck”, even without connecting the word “soak” with some “reconstructed” PIE word. But at least moving in a right direction by inventing a clone sobriquet for the Türkic real and attested saɣ-, suğ “suck”. The WFlem. example comes with the Türkic suffix, the Sl. cognates are marked by s/k alternation. The pair “soak” and “suck” constitutes a clear case of paradigmatic transfer, unambiguously attesting to a common origin from the Türkic linguistic store. See suck.
English sock (v., n.) “beating” ~ Türkic sok-, suk- (v.) “beat”. The sok- and suk- have overlapping topologies and semantics (the other semantic is an unrelated “insert, socket”), and “it is simply a matter of judgment which verb is involved”. Cognates: A.-Sax. aetsacan, oðsacan “beat off (deny)”, onsacan “beat off (contest, attack)”, sac, sacan, sacu “beat off (conflict, battle)”, sacful “beat off (contentious)”, Goth. sakan “beat off (rebuke, dispute, strive)”, sakjö “beat off (strife)”; Mong. tsoh, Kalm. tsokh “strike, beat”; Sum. sig- “beat”. The Eng. word is direct and unchanged Türkic word, it comes to English as a part of a massive paradigmatic transfer case, complete with morphological elements and its semantic cluster, and along with synonymous bat, beat, also ascending to Sum. via Türkic. Distribution spans a width of the Eurasia. A bedazzled “IE etymology” is non-existent, no cognates offered. So comes a routine refrain “of uncertain origin”. It can be positively stipulated that the 3rd mill. BC did not carry a massive demographic movement of the Sumerians to England to bring over that paradigmatic transfer. In both cases the only viable alternative are the Türkic Kurgan horse nomadic tribes. See bat (beat), sock (stocking), socket.
English squeeze (v.) “press firmly” ~ Türkic qïs- (qys-), sïq- (syg-) (v.) “squeeze, press”. A base notion of the word qïs- is “tight, narrow” with 7+ semantic clusters. The word has a constellation of semantic and grammatical derivatives, all developed from a semantic cluster “squeeze, press”. Both verb forms qiïs- and sïq- could produce the Gmc. and English forms. Cognates: A.-Sax. qwysan “squeeze”, Gmn. quets[chen] “squeeze”, predictably defined “of unknown origin”, with no “IE” cognates whatsoever. The Gmc. form points to either the English anlaut s- being a prosthetic innovation for a particular stem, or to an areal and probably temporal dialectic preference for one or the other form. Most of the English derivatives likely came together with the base verb, squeeze “coerce, intimidate, fit, force, grip”, squeeze by “barely manage” (v.), squash (v.) and obsolete squiss (v.) “squeeze or crush”, “grip”, “tight situation (money etc.)”, “impassable situation (money etc.)”, “pressed situation (social etc.)”, squeegee (n.) “wooden scraping instrument with a rubber blade”, squeezers (n.) “pinchers”. Türkic has a number of synonymous allophones that open gate for all kinds of semantic and phonetic innovations: qarish, qavir, qavur, qurul, and phonetically more remote cognate synonyms.
English stale (v.) “urinate (horses, cattle)” ~ Türkic si:t-, sıt-, si:d-, sıd-, siδ- “urinate (humans)”. Türkic men urinated sitting (squatting), that was and still is one of national ethnological idiosyncrasies not mentioned in the linguistic dictionaries. The stem si:t-, sıt- means “urinate squatting” or “squat to urinate” (Cf. er sitti: “man squatted to urinate”); which part is primary is obscure and etymologically irrelevant. Accordingly, the Türkic verb si:t-, sıt- is “to urinate” (Eng. stale, stool (excrement)), extending to “to defecate” and in Tr. to “defile”, and “to squat” (Eng. sit, seat, and stool (chair). The CT form of the stem si:t-, sıt- is siy-, Cf. Az. siymək, Kor. swiya. Possibly, the stem si:t-, sıt- is a derivative extension of the verb si:-, attested by the Tkm. form si:- “urinate” phonetically identical with the CT si:- “break” that could signify a squatting position. Other Türkic cognates are sidük, siki “urine”, sik “penis”, sik- (v.) “sex, copulate”, sikiš “sex, copulation”, as a complex these last cognates imply some kind of a past genital notion for the primeval si:-. Eng., like Türkic, has separate words for human and animal urination with transposed semantics (Cf. Eng. stale (v.) “urinate (horses, cattle)” and pee (v.) “urinate (people, animals)” vs. Tr. kığla- “defecate, urinate (horses, cattle)” fr. kığ “dung” and si:t-, sıt- “urinate (people)” ). In this idiosyncratic example, in Eng. the Tr. stem si:t-, sıt- is a calque of the Tr. stem kığla- in Türkic. Another salient parallel is the notion of relief associated with physiological excretions (Cf. Eng. “relieve oneself” vs. Türkic qašan (kašaŋ) (n.) “relieve, relax” and reflexive form qašan- (kašaŋ-) (v.) “relieve (urinate)” especially of horses, derivatives of qaša- (kaša:-) “relieve (by scratching), scratch”). In this idiosyncratic example the Tr. noun qašan is replaced by synonymous idiomatic calque “relieve oneself”. By now, in respect to sitting, the CT word olur- “sit” with a sense of “settle temporarily, occupy” completely supplanted the word si:t-, sıt-. G. Clauson's misinterpretation of the verbal stem si:t-, sıt- as a term solely for “urinate” propagates into his admitted confusion with its derivatives, caused by truncated interpretation of one component of the semantic complex. The duality of the notions sit and urinate expressed by the same verb permeates the Eng. q.v. lexicon but does not earn any explanation. According to the “IE” etymology, the verb sit is an allophone of the PIE verb *sta- “to stand”, and the stale “urinate” is an allophone of the Frankish *stal- “position” fr. stall (in a stable), the same PIE *sta- “to stand”, unrelated to either “sit, squat” nor to “urinate”. The verb sit “squat, sit”, according to the “IE” etymology, ascends to another PIE verb *sed- “sit” connected with “sedentary” but in reality probably older by eons. The “IE” etymological speculations are completely irrational, whimsical, apparently mechanically driven, unsustainable, and disconnected from cognates. Cognates: the MDu. stel (adj.) “stale” (of old urine) is puzzling, what's the MDu. name for new urine, for regular urine? Probably the citation is on stratified (settled) urine as a construction or medicinal fluid, and then stel is not a cognate of “urine”, but of “distilled”. Sl. sat (сать) “urinate” is singularly and in compound pisat (писать), pisyat (писять) “urinate” fr. the common Eurasian pi-/bi-/be-/mi-/vi- “urinate” + sat (сать) “urinate”. Sl. has a rich endowment of sat (сать) derivatives: sykun, sykach (сыкун, сыкач) “pisser”, sykuha (сыкуха) “pisser (fem.)”, saki (саки) “urine”, etc. Discounting the irrational MDu. “cognate”, “IE etymology” knows no European cognates at all. The closest cognates are all Türkic. The A.-Sax. stale is very polysemantic, but “urine” or “urinate” for it is not listed among the “IE” languages ( “urine” is Gk. non-IE ouron (ουρον) “urine”). Thus the verb stale “urinate” appears to be a hapax legomenon in Europe and within the “IE” languages, unequivocally attesting to its Türkic origin. The stem pi-/bi-/mi- “urinate” is a singular common Eurasian term scattered from Atlantic (Cf. Basque pixa, Icl. pissa, míga, Lat. mio) to Pacific (Cf. Ch. 排 pai, Kor. baenyo), while the stem sit- shows up episodically (Cf. Ch. 撒 sa, Kor. swiya, Turk. sidik, etc.). The stem pi-/bi-/mi- is connected with the attested Türkic excretion lexicon: mayaqa:- (bañaqa:-) “defecate” (stem may-/bañ), also “leave traces, markers”, mayaq (bañaq) “dung”; semantic bifurcation points to a metaphorical derivative origin of the notion “defecate” from the notion “mark”, and would point to the origin of the Gmc. “mark”. The duo stale “urinate” and sit “squat” constitutes a paradigmatic transfer case, complete with nuances and idiosyncrasies. The paradigm also includes the stem pee and the notion mark, supplying ample evidence for the Türkic genetic connection. An outstanding trait of the pee/mark bifurcation is a b/m alternation widespread across Eurasia. It could not have emerged spontaneously among drastically diverse Eurasian human lines, it is a universally spread effect of a single cause. The semantic transposition and semantic shifts and losses, and intensive lexical supplanting attest to deep antiquity of the Gmc.-Tr. separation, much deeper than the Sarmatic period. That antiquity is masked by the endurance of the Türkic stem phonetics, later amalgamations with kindred vernaculars, and peculiar demographic movements. The origin of the Western European forms can confidently be asserted as coming from the Eastern Europe at a point later than the Baltic-Slavic divergence. See sit.
English stay (v., n.) “stand, be upright, stop” (Sw N/A, F235, 0.11%) ~ Türkic üstü- (v.) “stay”, lit. “on feet, standing”. The üstü- is a form of the verb üst- “get up”, “standing on feet”, lit. “atop, aloft, upward”, formed with a verbal locative suffix -t/-d “up, upward movement” modifying the base üs, Cf. Eng. stay, stand (v.) “to stay” and stay, stand (n.) “layover”, “pedestal”, etc. The base üs, in turn, denotes a notion “top, above, over (something)”. In the native language, it does not denote a notion “stop”, which is a form of the word top “closer, block” with a prosthetic anlaut s-, see stop. In the process of dispersion and internalization, the initial vowel in üstü- was elided, although in some instances the word had preserved the initial vowel or added a prosthetic vowel, Cf. the initial e- in the Eng. establish, Sp. estacion “station”, Sl. ustanovka (установка) “installation, establishment”, lit. “standing”. In some particular internalization processes, phonetic resemblance of the particular forms for “stand” and “stop” had conflated two different words into a semantically extended single word, leading to confused etymological explanations for some particular languages. Depending on the language, the etymological semantic field is also extended to etymologically unrelated metaphorical additions, like “be, exist”. Cognates: A.-Sax. standan “stand, stand still, stop”, stow “spot, site, station, locality, position, place”, stowian “retain”, OHG stantan, stan, sten “stand”, OLG stouwen, stauen “retain, block, dam”, Goth. standan “stand, stand firm”, stojan “steer”; OFr. estare “stay, stand”; Lat. sto “I stand”, restaurare “restore”, Lat., It. stare “stand, stand still”; Gk. stoa (στοα), Eolian stoia (στωiα) “pillar, porch”, istimi (ιστημι) “stand”, Homeric sti (στη) “stand”; Balto-Sl. (Lith.) stoveti, stoviu “stand”, stoti, stoju “start, become”, (Latv.) stavet “stand”, stat “become”, (OPruss.) роstat “become”, (Sl.) staviti, stavya (ставити, ставя) “to stand”; Pers. istadan “stand”; Skt. astht “rose, became (aorist form)”, tisthati “stands”, Av. hištaiti “stands”. The “IE etymology” offers a cluster of explanations for a jumble of similarly-sounding st- words without discerning between the root and a prosthetic s-, without differentiating between the verbal and noun roots, and without differentiating the deverbal and denominal morphology. Apparently a thought of an elementary morphological analysis never donned on the “IE” linguistic school. A thought of the Eng. verbal -ed, Skt. -t/ti, Av. -t/ti, Sl. -t/ti, Türkic -di/-ti being allophonic morphological elements originated from a common source has never struck the “IE” etymologists. Pers., Skt. and Av. retained the stem üstü- almost intact. Among the “proto-words” are a jumble of an unattested “PIE *sta-” (v.) “stand”, an unattested “PIE *stak-” “stand, place”, an unattested “PIE *steh2-” “stand”, an unattested “PIE *steh2tis” “standing”, an unattested “PIE *(s)teg-” “rod, pole, stick”, an unattested “PG *stagaz” “stick, stake”, an unattested “PG *stadiz” “standing, place”, an unattested “PG *stako” “stake, bar, stick, pole”, an unattested Frankish *staka “support”, an unattested ODu. *stad “site, place, location, standing”. That cheerful cornucopia is further adorned by the last finishing strokes of the OFr. estaye, estaie “be, stand, continue, remain”, an allophone of the Eng. is “be” in all its semantic glory, and completely unrelated to the notion “stand up, be upright, stop”. The presence of the word in the Skt. and Av. sets a lower limit on the time of internalization as before the 2nd. mill. BC. The absence of the direct cognates in the Celtic languages points to its absence before the onset of the Celtic migration, ca. 5th mill. BC. None of the “PIE etymologies” are sustainable. In contrast, the Türkic etymology lays a direct path form an attested verbal root to the raster of the Eurasian languages, each with its own internalization specifics. It is a member of a large family of internalized verbs ingrained into the “IE” languages, such as act, are, awe, bash, bath, be, bear, step, stop, etc., cumulatively constituting a case of paradigmatic transfer from the ancient Türkic milieu. See step, stop.
English stick (v., n.) “implant, put, fix, force” ~ Türkic tik-/dik- (v.) “stick, insert, implant, erect”. Cognates: A.-Sax. stician (v.) “stick, prick, stab”, sticca (n.) “stick”, OSax. stekan, OFris. steka, ONorse stik (n.), OHG stehhan (v.), stehho (n.), MDu. stecke, stec (n.), Du. stecken, Gmn. stechen “stab, prick”, Lat. instigare “goad”, instinguere “incite, impel”; Balto-Sl. (Latv.) tukat “poke, insert”, (Sl.) tknyt, tyk (ткнуть (v.), тык (n.)), shtyk (штык) “bayonet”; Mong. čig “direction”, čike “vertical, straight”; Manchu čiŋ, či- “vertical, straight”; Kor. čik “straight”; Sino-Kor. čik “directly”. Eng. derivatives dyke, dike “standing barrier”, ditch “channel”, Sp. dique “levee, upright wall”. Distribution centers on NW Europe and Eurasian steppe belt extending to Pacific. The “IE etymology” confuses prefixes and euphonic modifications with roots, and semantically close, but different phenomena of sharp sticks (nail, thorn-like) with blunt sticks (club-like). The “IE etymology” does not even reach Lat. A “PG reconstruction” is a bland clone of the Gmc. forms with the Gmc.-specific prosthetic s-, with no “IE” links whatsoever. Both Gmc. and Sl. forms are regular attested phonetic modifications, and the semantic match is perfect. Gmc. version starts with etymological s-, Sl. versions start with etymological v- (votknut, vtyk (воткнуть, втык)) indicating direction of action. A Gk. stizein “prick, puncture”, stigma “mark with a pointed instrument” belongs to a second semantic class represented by Tr. sibling verbal form tik- (v.) “sting, pin”, tikän (n.) “thorn, spine”. There also belong the OPers. tigra- “sharp, pointed” and Av. tighri- “arrow”. An utter confusion is demeaning, and not due to an absence of prior scholarship. See tack, tick, tuck.
English step (v., n.) “pace, stride, tread” (Sw N/A, F751, 0.01%) ~ Türkic tep- (v.) “stamp,
kick”, tap(a)- (v.) “stomp, stomping, stamping, stumping, tromping”, tap (n.) “trace, mark, scar”.
Apparently, ultimately fr. noun tab/tap “trace, mark, scar”, with particular derivatives
“sole of foot”, “foot (measure of length)”, “foot (of leg)”, “stomp, flatten (the ground)”, “run
over”, and many more. Usual phonetic variations include d-/t-, -a-/-e-/-ö-/-ə, and
-b/-p/-v/-w/-m, Cf. tab-, tam-, tav- (Mong.), taw- “foot, sole, paw”,
tüp(lïk) “shoe sole”. The Gmc. versions are fairly uniform, attesting to either a recent
internalization or extensive amalgamation. They are also not numerous compared with the host of the
A.-Sax. synonymous feðelast, fotmaelum, fotstapol, fotswaeð, fotswatðu, grad, gride, last,
middelfot, siðstapel, stride, swathu, tredan, treddan, treddian, tredel, and their derivatives.
Abundance of synonyms indicates extensive spatial and temporal amalgamation. At the same time,
modifiers and compounding demonstrate deep internalization. Cognates: A.-Sax. taeppelbred,
taeppilbred “footstool”, staepe “step, pace”, “step, stair”, steppan “to step”,
steop/-dohtor, -faeder, -modor, -sunu “step/-daughter, -father, -mother, -son”, steppescoh
“slipper”, WSax. stæppan “take a step”, OFris. stapa, OHG stapfon, MDu., Du.
stappen “step”; Balto-Sl. (Latv.) tарat “stomp, to step”, tара, tарu, “stomp”,
tарat “walk, stomp”, (Lith.)
tарuоti “stomp, to step”, tарšt “tap”, tapštereti “to tap”, (OCS)
stopa “step, pace, foot”, stepeni “step, degree”, (Sloven.) tǝptati, (Cz.)
deptati, (Slvt.) dерtаt, (Pol.) dерtаc “to stomp”, (Rus.) tоpot, toptat
(топот, топтать) “stomping, to stomp”, stupnya “foot”; Gk. typto (τυπτω) “kick,
strike”,
typos (τυπος) “mark, press”, tympanon (τυμπανον) “tambourine, drum”,
stypos (στυπος) “stick, handle”; Skt. topati, tupati, tumpati, tumpati, pra-stumpati
“nudge, push”; Fin. tap “stomp, push”; Nenets tap- ditto; Mong. tab- “foot,
paw, sole”; Ch.
ta- 踏 “to stomp”; Kor. dangye 단계
“step”; Jap. teppu テップ “step”. Distribution spans across
Eurasia and linguistic barriers. Without demography of the physical carriers conveying cultural
influence, there is no place for the faux “PIE” root *stebh- to penetrate innumerous
far-flung alien languages. While the Balto-Sl. languages have the initial t-/d- and
st-/sd- evenly, and the Skt. and Gk. have both initials, the Gmc. group nearly exclusively has
st-/sd-. That distinction points to the morphological, and not prosthetic function of the
initial s-. It is a universal Eastern European areal prefix to mark a perfect tense, Cf. Eng.
tab/stab, lather/slather, mud/smudge, Rus.
delat/sdelat (делать/сделать) “to do, make/was done, made”. That points to the Corded Ware
(3rd mill. BC) archeological culture, with a Gmc. internalization after the modified prefixed form
gained a wide areal acceptance. Internalization of the forms with the alien prefix s- had
likely occurred without understanding its grammatical significance. The consonance of the Far
Eastern forms with the Türkic tab/tap corroborates that the Zhou-type “Scythians” reached the
Pacific zone and amalgamated with the local populations at the turn of the 2nd millennium BC. There
is no alternative in the 3rd - 2nd millennium BC for the Stone Age-technology society to spread the
word across Eurasia from Atlantic to Pacific except for the mobile Türkic nomadic pastoralists. See
stop.
59
English stop (v., n.) “halt”~ Türkic to:-, tu:- “to close, block”. Ultimately fr. an adj./adv. to “much”, and its utilitarian verbal form toδ-/tod- “satiated” with passive suffix δ-/d-. A suffix -p forms deverbal analytic nouns, to:- > top “closer, block”. Semantically identical, the Gmc. forms differ by a morphological anlaut s-. The anlaut s- regularly shows up in the N. European or Gmc. and Sl. forms of the words (see crunch “crackle” Lith. skrudeti “crack, flake”, Latv. skraustet “creak, rattle”; sconce “fortification”, Du. schans “earthwork”, OHG schanze “bundle of sticks”, Sl. kucha (куча) “pile” fr. Türkic qučaq “bundle, armful, pile”). A version stop evolved and then emanated from the Gmc. phylum, and now is an international word. Cognates: A.-Sax. -stoppian (for-stoppian “stop”, Eng. stopper “plug”, OSax. stuppon, WFris stopje, OHG stopfon “plug up, stop up”, OLFrankish (be)stuppon “to stop (the ears)”; It. stoppare, Fr. etouper “stop by plugging”; Skt. stambh (caus. stabhayati स्तभायति), stha (caus. sthapayati स्थापयति) “stop”. An “IE etymology” is confused and divided. With no “IE” “proto-word” across a predominant majority of “IE” languages, the word is a loanword within the “IE” family. The It. form, without a Lat. precedent, points to a loanword status. The Fr. word, without the initial -s, may have passed from Burgund, and gained a Mediterranean prosthetic anlaut e- on the way. The Skt. forms attest to the presence of the word in the 2nd mill. BC among the demographically mixed Indo-Aryan farmer migrants from the Eastern Europe. The utilitarian use as a “stopper” likely propagated the word along Eurasia before it reached international spread in the modern times. Türkic offers a morphologically, phonetically, and semantically sound etymology where the “IE” has none. See step.
English suck (v.) “draw, absorb (by vacuum)” ~ Türkic saɣ-, suğ- (v.) “suck”. Across 42+ Türkic languages and uncounted dialects can be found numerous slightly different forms: sak/sag/saq, and the like. Suck and soak are semantic siblings of the same root. The OTD gives 40 derivative forms found in Middle Age literature, probably at least as many did not get on the paper. Dictionaries do not list meanings like fellation, but they can be suspected to be there and survive through millennia and upheavals. In nomadic ranching society, the origin of the word and its main meaning are natural, “to milk, extract”, and likewise natural are the numerous derivatives that correspond to English “suction”, “sucking”, “sucker”, “suckling”, and so on. Cognates: A.-Sax. sucan, OSw., OHG sugan, ONorse suga, MDu. sughen, Du. zuigen, Gmn. saugen “to suck”; OIr. sugim, Welsh sugno “to suck”; Lat. sugere “to suck”, succus “juice, sap”; Sl. sosasat, sosu, soska, sosok, sosunok (сосать, сосу, соска, сосок, сосунок); Mong. saga “suck”; Fin. saada “get”. Distribution - across Eurasia from end to end. A suggested unattested “IE” *sug-/*suk- with primitive “of imitative origin” was derived from the Türkic reflexes in western European languages, without pondering on the Slavic cognates, which obviously descended from the same Türkic root with s/k alternation or with Eastern European endemic palatalization. One of the Türkic derivatives is saɣur “soak, absorb”, mirrored in English soak with unreal “IE” unattested etymology of P.Gmc. *sukon modeled on attested and real WFlem. soken, reputably “from (unattested) “IE” root *seue- “to take liquid”, but in reality ascending to the same Türkic root saɣ-. Phonetics and semantics show perfect match. English has preserved some derivatives together with their Türkic suffixes: sucan = sak + -an (verbal suffix to produce noun), suckling = sak + lïg (lyg, noun suffix to produce abstract, collective, or specific semantics). The confluence of Gmc. and Celtic forms points to deja vu of circum-Mediterranean and overland sources separated by 2 to 3 millennia. Lat. words join numerous others that testify to common Türkic roots of Lat. and English forms. The pair “soak” and “suck” constitutes a clear case of paradigmatic transfer, unambiguously attesting to a common origin from the Türkic linguistic milieu. See soak.
English surrender (v.) “give up” ~ Türkic süren- (v.) “to be dragged off”, süründi (adj., n.) “dragged off”. The stem of the Türkic word is a polysemantic universal verb sür- “lead, chase, drive, strip off, pull off”, with numerous semantic derivatives. A notion “surrender” is a reflex of the notion “driven, submitted”. The part -ündi/-undï/-ündi is deverbal suffix forming adj. and nouns for type or result of action: “led away, chased away, driven away, displaced, expelled, stripped off, pulled away” (n.), or “be led away” (n.) etc., or “(one that is) led away, taken, seized, scattered, mushed” (adj.) etc. The Türkic also has a very specific derivative noun süründi (n.) describing a disenfranchised and expelled potential successor (heir) to the throne, fief, and the like. The Slavic calque izgoi conveys the Türkic semantics with the Slavic vocabulary: an offspring ineligible for succession, since the early Slavs followed the Lateral Succession Order of the Türkic tradition. Cognates: OFr. surrendre “to give up”. The “IE etymology” is unsuitable. It presents the word as recent neologism without “IE” cognates at all, and forges a circuitous construction: stem der (dare) “give” > rendre = ren + dre “give back” > surrendre = sur + ren + dre “over, above, beyond, in addition” + “back, again” + “give”. That suits the modern legal semantics of “turning something back over”, like surrendering a property, but is in conflict with the underlying meaning of “going to captivity”, “stop resisting, fighting”, present in the Eng. original and in the Türkic semantics. On the European scene the neologism is unrelated neither to the “IE” languages nor to the Gmc. phylum. In contrast, just a single A.-Sax. language has 5 synonyms of “surrender” other than surrender. Among dozens of etymologically perfectly transparent European synonyms, “surrender” sticks out as a sore thumb. The “IE etymology” does nothing for the etymology of the word but illustrates the length of casuistry employed in furthering the “IE” paradigm and obfuscating European history.
English susurrate (v.) “chirr, murmur” ~ Türkic šar šar (v., n., adj.) “chirr, murmur”, šaršara “waterfall”, specifically using a sound of running water churring in a creek to convey a general idea. Cognates: A.-Sax. ceorran “to creak”, ceorung “churring” (both probably with anlaut -ch, Cf. Gmc., Rus. forms), Gmn. schwirren “to buzz”; Fr. sourd “deaf”; Lat. surdus “dull, mute, unheard, silent” (supposedly, sound); Gk. syrinx “lute”; OCS svira- “to whistle”, Rus. shurshat, shurshit (шуршать, шуршить) “chirr”; Skt. svara- “sound, resound”. With a near-perfect phonetic and semantic concordance, with the attested Türkic šar and šar šar spread across Europe and carting to India, no farfetched “PIE imitative base *swer-” is needed. To support an “IE” case, the “IE etymology” also offers some loose unrelated homophones as supposed cognates: swarm, pipe. An etymological suggestion of echoic origin of the word šar/chir is quite reasonable, but leads to nowhere etymologically. A suggestion should lead to a source. In Türkic languages, šar is used separately and in reduplication, as reflected in the Rus. allophone shurshat. Reduplication is a colloquial feature with a diagnostic value. In a flush of quite a glorious carrier for a quiet creek murmur, by a chain of metaphoric analogies, in 14th-15th centuries the primeval šar has produced most outstanding scientific words surd and absurd, the first to define irrationality (number) via the notion “dull, mute, unheard, silent” of the Lat. surdus, and the second as a Lat. compound absurditas “out of tune”, figuratively “incongruous, silly, senseless”, fr. ab- “intensive prefix” + surdus. The origin of Skt. form ascends to the 2000 BC departure date of the Indo-Aryan farmers from the Eastern Europe, and the Gmc. forms came to Europe with the prehistoric and historic Kurgan waves.
English swear (v.) “take an oath” ~ Türkic vara (n.) “piety, reverence (fear) of God”.
The stem of the word is the verb
be:r-/ber-/ver- “bear, give, convey”, the “IE Tocharian” Agnean and Kuchean pär-,
see bear (v.). That allows to suggest that the notion of reverence formed as a consequence of
sacrificial offering. The word is indelibly connected with the cognates
“faith”, “faithful”, and “veracity”. The origin of the word ascends to the pre-historic times,
because it is found in all three branches of the European “IE” languages, and in the Asian languages.
The initial has become v- in the southwest, particularly in Azeri and Ottoman vernaculars.
That is consistent with other indicators that the English substrate language was carried from around
the Aral-Caspian basin.
Cognates: A.-Sax. (OE) swerian “take an oath”, OFris. swera, OSw. swerian,
ONorse sverja, OHG swerien, OGmn. wara “truth, faithfulness, grace”, war
“truthful, loyal”, Goth. swaren “to swear”, tuzwerjan “to doubt”, unwerjan
“discontented”, MDu. swaren, Dan. sverge, Gmn. schwören; OIr. var “vow,
solemn promise”, fir “true, veracious”; Lat. verus “veracious, true”, veritas
“truth”; Bulg. bir- “give”, berü-; Av. var- “believe”, varǝna- “faith”;
Brahmi ber-; Hu. ber-, bir-; Evenk bərin-. Distribution: Across Eurasia
and across linguistic barriers. In this listing, all entries are straightforward, clear, and
consistent, e.g. “Under fear of God's penalty, I swear...”, except that in few cases a more accurate
translation could be selected, and Av. and Goth. need clarification. Av., like Türkic, is an
agglutinative language with master stem and suffix modifiers, thus all grammatical forms of verbs
and nouns can be obtained from a single non-flexive stem; “I faithfully swear” ~ “I take an oath” is
one-word construct. With the Türkic
vara, there is no need for scholarly manufactured unattested “IE” *bheidh- to come up
with English, Gmn., and Slavic forms for swear and faith. Gmc. languages sport both s- and
v-/w-
initial, with s- systemically appended in front of the root, attesting that it is a
morphological prefix (marking a perfect tense?) rather than a prosthetics: each form with s-
at one time had a companion without s-. The Goth. tuzwerjan is transparent rendition
of the inverted Türkic veransiz: ver + an (noun suffix, rendered yan) + siz (negation
suffix, rendered tuz) “faith (n.) without”, i.e. “infidelity” => Goth. tuz + wer + jan.
Both the inversion and the translation are suspect, but inversion is theoretically possible.
However, neither “doubt”, nor “infidelity”, as an august “IE” pundit M.Vasmer would want us to
believe, are synonymous with “oath, take an oath”. In fact they convey the opposite. The Goth.
unwerjan “discontented, not allegiant” is a similar case, the inverted Türkic veranаŋ:
ver +an (noun suffix, rendered yan) +аŋ (negation suffix, rendered un) “faith (n.)
none”, i. e. “infidelity” => Goth. un + wer + jan (See un-). Both the inversion and
the translation are suspect, but inversion is a frequent linguistic assertion and must rest on some
positive attestation. Only the “infidelity” translated as “discontented” is out of line and
unrelated to taking an oath under fear of God's punishment. M.Vasmer lists these two Goth. words
under the entry of Sl. vera “faith”, a Türkic word in Sl. lexicon. The Lat. fides is a
rendition of the same Türkic vara (n.) “faith”, with all its Lat., English, and international
derivatives: fidelity, Lat. fidelitatem, fidelitas, fidelis, fides
“faithfulness, adherence, faithful, true, faith”; faith, Lat. fides “faith”, and so
on. The OIr. forms attest that the word was carried in Celtic circum-Mediterranean migration of the
3rd mill. BC. Millenniums later it shows up in the Indo-Aryan records. The Eng. duplex swear
and
oath constitutes a transfer paradigm of two basic Türkic words, an irrefutable evidence of a
genetic connection. See bear (v.), faith, oath, ought, un-.
60
English sweep (v.) “brush” ~ Türkic süpür-, sipir-, süple- (v.) “sweep” with various phonetic changes across Türkic languages (-i-/-ü-, -p-/-b-). Ultimately fr. an undifferentiated noun/verbal root süp “scrap, trash”; denoun verbs are also formed with verbal suffixes ür-/-ir/-le. The old undifferentiated form attests to a deep antiquity of the word. The verbal form denotes a notion “clean (v.)” with 14 semantic clusters, from “sweep” to “exaggerate”, 8 of them directly relate to “clean (v.)”, including “sweep”. A semantic extension “rub clean” opens an etymological path to the “soap” (Cf. Norse sopa) and swipes aside unneeded “IE” etymological fantasies. Cognates: A.-Sax. swapan, WFris. swiepe, ME swope, Eng. swoop “sweeping movement”, NE Eng. soop “sweep”, ONorse, Icl., Norse sopa, Gmn. Schwung; Ir. scuab, scuabadh, Gael. sguab, Welsh ysgubo; Balto-Sl. (Latv.) sužerti, (Sl.) smatat (сметать); Hu. söpres; Mong. ši'ür-; Ch. saopin 扫频; Kor. seuwib 스윕, seuwipeu 스위프; “sweep”. Distribution truly Eurasian. Etymology: “of uncertain origin”, or a faux PG *swaipana. That should equally apply to the swipe and soap, negating a flimsy “IE etymology” for soap. No sane IE-centered etymology for sweep and soap. No “IE” or European cognates outside the N. European and Türkic phylums, but otherwise plenty across Eurasia. The m/b(p) alternation is systemic, Cf. Ch., Sl. and N. European forms. Celtic forms show amazing retention, a presence of cognates in Celtic languages attests to the word's existence prior to the Celtic departure from the N. Pontic before the 4th mill. BC. The phonetic forms are consistent, the semantics is pinpointed and perfect, leaving no room to doubt a Türkic origin. Only Kurganians could have seeded the word from Atlantic to Pacific. See soap.
English tack (v.) “attach, fasten”, (n.) “attachment, fastener (pin, short nail)” ~ Türkic tak-, taq-, dak-, daq- (v.) “tack, fix, pin, put up”. Ultimately fr. da/ta (conj.) “and”, an allophone and sibling of Gmc. “and”. A powerful notion of “attach, fasten” could not fail to develop a constellation of derivatives in a wide range of spheres and grammatical forms. A listing of prime meanings numbers 11 semantic clusters. It is echoed in a sibling verbal form tik- (v.) “sting, fix, pin, put up”, tikän (n.) “thorn, spine” (lit. and metaphoric). Either of these synonymous forms could have originated a common Gmc. form tak; that is illustrated by the Eng. synonyms for “sew”, tick, tack, tuck, and attach, attack. Like their Tr. cognates, the first three synonyms also convey a notion “fix, attach, fasten”, attesting that the interchangeable forms survived with their dual and complementary semantics. A semantics “sew” is a particular use of the notion “fix, fasten” alluding to the underpinning verbal application of “thorn, spine” for needlework. A semantics tick- “tap, light touch” is another particular verbal derivative of the notion “prick” of the “thorn, spine”. An archetype of tik- is seen as tiŋ-, which adds a related form tin- with few articulations of -n and further semantic developments. The sense “thorn” points to the technology predating a use of bone and stone needles. Some derivative forms carry into the modern Eng. a Tr. passive voice suffix -l (Cf. tığıl-/tagil- “blunted (tip)”): tickle, tackle. Others preserved both passive voice and deverbal abstract noun suffix -ish: ticklish. It is a stochastic whim that we do not have treats like attacklish to tease etymological ingenuity into a clone of *hwadeklic. Cognates: A.-Sax. ticla “tick (insect)”, Fris. tak “tine, prong, twig, branch”, LGmn. takk “tine, pointed (something)”, MDu. tacke “twig, spike”, Du. tik “tap, jab”, Gmn. Zacken “sharp point, tooth, prong”, MHG zic “tap, jab”; ONFr. taque “nail, pin, peg”, OFr. tache “nail, spike, tack, pin”; Mong. taqul “infection”; Tungus takul, takus “fastened, stuck”; Kor. takta, takka “stick to”. The whole bouquet of forms and semantics has no “IE” links whatsoever, the “IE etymology” does not even reach the Lat., the best cogitation is a not impressively deep “probably from a Gmc. source” and (for tickk) “perhaps ultimately echoic”. The last elucidation, supremely popular with “IE” etymologists to explain indigestible issues, is definitely invalid, since the tick both phonetically and semantically is a clone of somehow “explainable” tack and tuck. See sew, tackle, tick, tickle, ticklish, tuck.
English take (v., n.) “grab, acquire, convey” (Sw N/A, F101, Σ0.25%) ~ Türkic teg-, tek-, deg- (v.) “take, reach, convey”. An ultimate origin is fr. a directional root de with allophones, Cf. Eng. abide, hide, side, slide, stride, trade, etc., all with a flavor of direction. It is undoubtedly one of the most popular and conservative verbs in any language. It is extremely versatile in both English and Türkic, English numbers 42 distinct meanings, and Türkic also has an inordinate number of meanings and derivatives in 13 clusters, “take” one of the prime meanings of the first cluster “touch, reach”, Cf. Goth. tiuhan and tekan, see touch. Like most languages of the world, European languages have a dozen unique native words, they reflect native languages of the Old Europe before their amalgamation with Türkic and Lat. vernaculars. The Türkic base notions are touch, take, and an element of reciprocity. The notion of reciprocity leads to acts of mutuality like exchange, meeting, etc. In addition to “take”, words rooted in teg- are translated to Eng. with a cornucopia of concrete synonyms: attain, absorb, bring, convey, deliver, dues, perception, sensation, and so on; Türkic extensions are facilitated by a wealth of suffixes and relict use of a stem as a verb, noun, adjective, adverb, paired compound, and so on. In many cases a semantic connection of an overly extended or metaphorical meaning with teg- is obscure. The phonetic and semantic connection of the words take and touch probably led to some etymological confusion, Cf. Lat. example. European cognates are limited to the Gmc. group. Cognates: A.-Sax. tacan (takan?), MDu. taken, Sw. ta, ONorse taka “take, grasp, lay hold”, OIcl. taka (pret. tök) “take”, MLG tacken, Goth. tiuhan “take”, but tekan “to touch”; Lat tolle is a stand-out; Spanish tomar “take”; Fin. ottaa “take”; Mong. täda, teda “touch, reach”; Kor. tei “touch”. Distribution spans from Atlantic to Pacific, and across linguistic barriers. Etymologically, take is rated “of uncertain origin”, “probably of Gmc. origin”, it does not fit the “IE” paradigm. A suggestion for that paradigm, floated theretofore on purely phonetical homophony, that the notion “take” is a derivative of the notion “tough”, is unsustainable. As a rule these unconnected notions are systemically distinct and unrelated. The Türkic teg- has at least two documented allophones, tey- (Kuman. Kipchak) and tek-, and since “take” is semantically equivalent to “seize, grasp”, it is possible that the form tut- (v. & n.) “seize, capture” appeared as a dialectal allophone of the form teg-/tek-/tey- or their ancestors.. In the process of segmentation and re-amalgamation, allophones gain their own independent life, typically of close semantics with distinct cognitive shades; both forms are attested. The form tut- “seize, catch” appeared in the only surviving Hunnic phrase of the 4th c.: Süčy tiligan, Pugu'yu tutan “Army commander would order (to march, go), Pugu would (be) taken”. Tentatively accepting the allophonic nature of the two forms, the Hunnic phrase said at the capture of Luoyang in 328 in the future China contains three English cognates: tili- “tell, order”; teg-/tut- “take, capture”; and 'yu “would, 'd”. Gmc. languages had native synonyms for take in local European languages. They bear a diagnostic value and depict a pre-amalgamation linguistic situation, Cf. Eng. grasp, Du. nemen, Goth. niman, fahan, greipan, haban. Gmc. languages bear the legacy of both parents. Phonetic and semantic parallelism between take and tek- are striking, and that includes parallels within the polysemantic spectra. Semantic clusters in polysemantic spectra alone attest powerfully to a case of paradigmatic transfer, providing indelible evidence of a common genetic origin from the Türkic phylum. Most likely, the word take originated form the Sarmatian/European forms of the Ogur-type Türkic languages, via amalgamated vernaculars of the Burgundians, Vandals, Goths, and their ancestors. See talk, tell, touch.
English talk (v. and n.) ~ Türkic til-/tel-/dil- (n.) “language, tongue, speech”. The notion “talk”, “tell” is a denoun derivative of the word til/dil (n.) for “tongue” and “language”. Related to Eng. tell, tale, and told. Cognates: A.-Sax. talken, ME tale “story”, East Frisian talken “to talk, chatter, whisper”, OScand. tulkr “translator”, Goth. talzjan “teach”, OHG tolk, Du. taal “speech, language”, Dan. tale “speech, talk, discourse”; OIr. þulr “poet, sage, weave”, Ir. ad-tluch “thank”, totluch “ask”, Balt.-Sl. (Lith.) tulkas “translator”, (Latv.) tul̃ks “translator”, (OCS) tlk- (тлък-) “discourse, explain”, tolmach (толмач) “translator” (Türkic tolmač, ditto). Notably, a wide swath of Europe is using derivatives of the Türkic tolmač “translator”, lit. “talker”, for “interpreter”; that attests to close relations and an imparted need for translations into a variety of the local vernaculars. The etymology of the Rus. tolmach from the the Türkic tolmač is well established and documented, negating attempts to re-fashion the stem as an “IE” “proto-word”. Ironically, the proposed “IE etymology” with unattested PIE root *del- “to recount, count”, the absence of Indian/Iranian cognates notwithstanding, reverts back to the Türkic verb tili-/tele-/dili-. Apparently, the Türkic concept tili “speech” is a later development compared with söy “say”, which is mirrored in the Chinese 说 (shua) “say, tell, talk” as a reflex of the Scythian Zhou component in the Chinese language. The authentic Ir. semantic derivatives attest to the presence of the word in the N. Pontic before the Celtic departure way back in the 5th mill. BC, if they are not relicts of the later NW European Sprachbunds. See say, tale, tally, tell.
English tally (v., n.) “total (score, count)” ~ Türkic töla-, töle:- (v.) “pay, pay off”, tölač
(n.) “compensation, fee”.
An ultimate underlying notion is connected with final delivery: birthing, cropping, delivery of
newborn, Cf. töl “newborn, moment of birthing”, see doll, toll. The meaning “pay, pay
off” is a metaphorical derivative, popularized in the Middle Ages by ubiquitous tolls for roads,
crossing bridges, and ferries. Cognates: A.-Sax. talian “reckon, account, count,
calculate, esteem, value”, tellan “to reckon, account, calculate, consider”, OSw. tellian,
ONorse telja, OFris. tella “count”, Du. tellen “count, reckon”, OSw. talon
“count, reckon”, OHG zalon, Gmn. zählen “count, reckon”,
erzählen “recount, narrate”; MLat. talliare (v.) “tax”; Mong. tölö-
“pay (debt), repay (loan)”. There is a degree of conflation with a near-homophonous
tele-/tili-/dili- (v.) “tell”, in a right context it is close enough semantically and
phonetically to produce “tally”, see tell. A Chinese reflex shua (说) “say,
tell, talk” is likely a reflex of the Scythian Zhou component söy “say” in the Chinese
language. A related semantic synonym known as Fr. conter “to count”, raconter “to
recount”, It. contare, Sp.
contar “to count, recount, narrate” ascend to another Türkic word köni “count,
quantity, measure”, see count. The A.-Sax. talian attests to a link töle:-
“pay” > talian “count” > tally “count”. Distribution runs across Eurasia from
Atlantic to Far East, crossing linguistic barriers. Ironically, a proposed “IE etymology” with faux
unattested PIE root *del- “count, recount”, is a mirror image of the Türkic attested
töle:- and
tele-. No Indian/Iranian cognates exist. An “IE” *del- had no chance to ever establish a
Mongolian cognate in Mongolia, it had to come from a Türkic milieu. An “IE” etymological excurse into
chiseled marks on wood to produce “IE” *del- “account”, with the same argumentation could have
produced “IE” “tell”, “IE” “tally” or what you have. A paradigmatic transfer of the Türkic quartet
töle:-, töle:-, döl/tö:l, tele- “tally”, “toll”, “doll”, “tell” respectively vividly attests to
the origin of the “tally” from a Türkic linguistic milieu. See count, say, tale, talk, tell.
61
English tangle (v.), better known as entangle (v.) “jumbled mass” ~ Türkic taŋ (tang)/daŋ (dang) (v.) “tie, fasten, bandage”. Cognates: A.-Sax. teag “tie”, tagilen “entangle, involve (in difficult situation)”, ONorse taug “tie” tygill “string”, Sw. taggla “disorder (entangle)”, ONorse thongull “seaweed”; Mong. tanu-, tamu- “tie”; Evenk. daŋama “tight, tightly”; Kor. tan “bundle, sheaf”. Distribution covers entire width of the Eurasia across linguistic barriers. A suggested unattested PIE root *deuk- “to pull, to lead” is semantically unsuitable faux construct. A vowel rendition -ea-, -au-, -y- points to attempts to depict an original laryngeal -a- with alien tools. Close phonetics and exact semantics validate the Türkic origin. In a nomadic world, strings and tying were a major utility. Thus an abundance of derivatives, one of which has fossilized into a European “enigma”, fr. taŋığma: (homophonous with tanığma:) “riddle”, of taŋ + ığ + ma: (root + deverbal noun suffix + negation), lit. “untangleable”. A Türkic origin is unchallengeable. See tie, enigma.
English tap (v.) “attain”, “attain by drawing from”, (n.) “faucet in pipe or cask” ~ Türkic tab-, tap- (v.) “receive, attain”. Ultimately fr. a root tap- “stomp, hurry” and its semantic extension “rush, dart, jump to action”. Of those come four distinct basic notions, “attain”, “scratch”, “serve”, “find”. The sense “attain” is an extension of a notion “find”. Due to minuscule length of the word, every Eurasian language has its own homophones. That drives, along with the tap/tab and loans internalized into the Türkic, an ever increasing semantic expansion, Cf. A.-Sax. toppa “thread” vs. A.-Sax. top/Türkic töpü (highest part), see top (n.). In every case, only some of a choice of the Türkic notions were internalized by the inheritor languages and have survived. Cognates: A.-Sax. tappa, tæppa “tap, spigot”, MDu. tappe, Du. tap, OHG zapfo, Gmn. Zapfe, ditto. No “IE” cognates; off the cuff an ingenious revelation “ultimately imitative of a sound of tapping”. All cognates are limited to Gmc. group, a positive indication of the loanword status within “IE” family and thus confidently of a Türkic origin. On top of that, the “IE etymology” erroneously conflates unrelated homonyms tap “draw from”, i.e. “attain from”, and tap “light strike” that ultimately comes from the same Türkic root but is a different notion. The Türkic tap- matches the English tap “attain”, phonetically and semantically. A group tap “attain”, get “obtain”, tap “touch”, and tab “account” constitute a case of paradigmatic transfer to English, attesting to a common origin from the Türkic phylum. See get, tab, tap “strike”, top (n.).
English tap (v., n.) “strike (gentle)” ~ Türkic tab-, tap- (v.) “strike (lightly)”. Ultimately fr. a noun/verb notion “trace, footprint, mark, stomp” of the root tap/tap-. The polysemantic word has a rich direct progeny and indirectly “worship” (e.g. tabernacle < taber, with causative suffix -er), see tab. The word belongs to a small class of the most basic, single syllable three-phoneme lexemes with innumerous allophones and derivatives across Eurasia and linguistic families. Due to its minuscule length, every Eurasian language has its own homophones, presenting along with the Türkic tap/tab an ever increasing semantic expansion, Cf. A.-Sax. toppa “thread” vs. A.-Sax. top/Türkic töpü (highest part), see top (n.). In every case, in the inheritor languages only some of a range of the Türkic notions were internalized and have survived. A duality of the auslaut b/p probably recombined the initial dialect-specific articulation, it was carried over to the host languages, e.g. tap/tab “knock, spigot, bill”, Cf. bifurcation guest/host etc., see guest, host. Cognates: A.-Sax. tapereax “small (tapping) axe”, taporberend “acolyte” (compound of two Türkic roots, tap “poke, scratch” + ber- “carry” with tapor refering to the wick hole pocked in an oil lamp, tappian “to tap (a vessel)”, taeppa “tap, spigot”, taeppere “tapster, tavern-keeper”, ONorse taparox “ax”, MDu. tappe, Du. tap, OHG zapfo, Gmn. Zapfe “tap, spigot”; OFr. taper “tap, strike”; OIr. tараrа- “ax”; Latv. tapat “stomp”, tapa tapu (interj.) “top, top”, Lith. tарšt (interj) “slap, bang”, tapštereti “slam”, tapuoti “stomp”, OCS tepya (тепѫ) “beat, strike”, topor (топоръ) “ax”, (topat) топать “stomp”; MPers. tabrak, NPers. teber, Kurd tefer, Balochi tараr, all “ax”; Arm. tараr “ax”; Fin. tарраrа, Mari tabar, Fin.-Ugrian. tap “ax”, Hu. tipor “stomp”, Nenets tap- “beat, shove”, Türkic täbär “ax”, tap tap “stomping sound” (see tap “attain”), Türkic (Kipchak, Tatar, Kazakh) tapta- “stomp”. The “IE etymology” suggests independent origins for most of the allophones and derivatives, a bouquet of custom-devised “PIE proto-words”, and a range of semantic roots: “uncertain origin”, an ingenuous Slavic origin, sound/noise, stopper, tent, hut, cabin, dwelling, beam, timber, and so on. The only phonetic law that is never broken is a systemic myopia and incoherency. None of the phonetic recreations are able to address an extent of the Eurasian spread, a remarkable spread across far-flung linguistic families, an absence of the historical lexical amalgamation between disparate languages like the Nenets and Persian, etc. At the same time, all the mentioned populations had experienced a documented Türkic demographic, political, and/or cultural influence during some periods of their history, and have retained archeological, biological, and etiological evidence of their past. The Near Eastern/Southwest Asian forms for “ax” can be attributed to the Indo-Aryan migration of the 2nd mill. BC from the fringes of the Corded Ware populations. The Ir. form attests to its presence two millenniums earlier in the same Eastern European vicinity before the Celtic circum-Mediterranean departure. Today that form covers northern Eurasian space from Atlantic to Pacific. So also do the allophonic forms for its ascendant word tap/tab “strike”. The common origin is also attested by the paradigmatic transfer of unrelated notions expressed by the same word, the Eng. “strike” and “receive/attain”. A bundle of evidence is intertwined so tightly that any attempt to rig a partial storyline is due to fail because it brings more unknown than explains the known. The common genetic origin from a Türkic milieu is way beyond any doubts. See guest, host, tab, tap “attain”, top.
English tar (tarred, tarring) (v.) “toil” ~ Türkic ter/der (n.) “sweat, work, earned wage”, terit-/derit-, terle:-/derle:- (v.) “sweat, work, earn wage”. The Türkic noun is used literally and metaphorically “earn by sweat”, the verb lit. means “to sweat” with figurative meaning “work hard” and the same with extensions, e.g. terči: “laborer, toiler”. A Türkic idiom “to sweat” meaning “work hard” is calqued in the English “to sweat” meaning “work hard”. Reference to sailors is an example of an agent noun. Also, a Türkic idiom tis teri “tooth tarring (lit. sweating)” in Eng. tuned into a calque “sweat through the teeth” with outwardly nonsensical identical semantics. Cognates: A.-Sax. taru “rent”, etymologically confused with unrelated teran (v.) “rip, tear” and tar (n., v.) “pitch”; Rum. terlik, sterlik “slippers” ; Bulg. tajakter “reward for walking”; Serb. terluci “fem. galoshes”; Alb. tirk, terlik “gaiters”. The unrelated teran q.v. is a derivative of a Türkic homophonic root ter-/der- “gather (harvest)”, tarı:- “cultivate”, and the like. The documented A.-Sax. semantics is modern interpretation, the “rent” in feudal economy was paid in kind with a share of the harvest by a corvée, i.e. hard labor. The trade terms “tar the roof” and “tar the boat” are generally out of circulation, the semantics “coat (with tar)” and “mar” is unrelated, the word tear “rip” gained its own form, the word tear “eye secretion” for some reasons has not even been appealed to by the “IE” etymologists, and the verb tar survived with its original Türkic metaphorical meaning “work hard”: tarring it up, tarring away, tarring over, etc., frequently conflated with the semantics “marred”. The Balkan languages' cognates came from a Turkish inheritance, a Turkish idiom ayak teri “foot sweat” lit. “reward for walking (to deliver something, for foot effort)” was first adopted by the Türkic Bulgars, then by Sl. Bulgars, and then metamorphosed into a Balkanic concrete term for footwear. No cognates outside of Türkic languages. Notably, the semantics “work hard” has never separated from “sweat”, it still has connotations of “sweat it out”. The Türkic deri “skin” and der- “to sweat” are genetically connected, they have developed into specialized allophones. The word is a salient case of paradigmatic transfer, it was transferred complete with lit. and metaphorical semantics, and complete with peculiar idiomatic expressions. See derma.
English taste (v., n.) “savor”, tasty (adj.) “savory” (Sw N/A, F1452, 0.01%) ~ Türkic tat-, tatïɣ- (v.) “taste, savor”. Common derivatives extend to “try”, “savory”, “sweet”, “pleasure”, “eat”, “drink”, “flavor”, “accustom”, “get used to”, which exceed by far the extent of the OFr./Fris./Eng. semantics. None of the Türkic originals use a prosthetic inlaut -s-, it must be a product of dialectal internalization, Cf. Fr. tater vs. taster. Native words for “taste” existed on the European scene long before the arrival there of the horsed nomads with their peculiar lexicons, e.g. A.-Sax. had already 6 prior roots for “taste” before the Fr. form tast, tat was adopted. Cognates: OFr. tast, taster “taste”, Fr. tat; Mong. dad-, das- “accustom, get used to”; Manchu tačı- “accustom”; Evenk. tatiga “accustom”; Ch. dan (味) “taste”, Hui (~Uigur) ta (味道) “taste, suppose”; Kor. that “accustomed”. Distribution spans from Atlantic to Pacific. The Ch. dan and Hui ta directly reflect the Türkic phonetics and semantics of taste and food, linking Atlantic and Pacific oceans via a Türkic linguistic bridge. No credible “IE” etymology. Apparently, English, Frisians, and French are oddballs among the Europeans and “IE” Asians in using this Türkic word. Conventional “IE” etymology ascends to a nonexistent VLat. taxtare, a frequentative form of nonexistent Lat. taxare “evaluate, handle”. A real Lat. had instead “gustum” and “sapor” and no dreamed-up taxare from tangere “to touch”. The real Lat. words are reflected in real Eng. “gusto” and “savor”. The “IE etymology” ascends “taste” to the notions of “tax” and “touch”, dubious phonetically, weird semantically, and in a stark conflict with the available linguistic evidence. The Ch. ta, dan “taste” have native synonymous forms 啖, 尝 chang “taste”, mirroring a guest status of the word in a real European lexicon. The Fr. form tat is an unadulterated Turkism unaffected by local idiosyncrasies.
English tell (v.) “narrate, inform” (Sw N/A, F81 Σ0.57%) ~ Türkic te-, ti- (v.) “say, state”, til/tili/tele/dili (n.) “language, tongue, speech”. Ultimately a derivative of te:-/de:- “say” as opposed to söy- “tell”. Related to tale, talk, tattle, and told (ta-, te-, to-). Interestingly, the semantics of “tell” and “say”, unique to the Türkic languages, is the same but inverted in English, Türkic “tell” is Eng. “say”, and vice versa. That trait alone signals a genetic connection. Türkic has numerous forms of denoun verbal derivative “tell, say”, vacillating around tell and told: te-, teyän, teyin, tep, tiyin, tildä-, tilde-, tïlda-, tïlta-; tildä “eloquent”, to cite the few listed in OTD 1969. Cognates: A.-Sax. tellan (v.) “account, reckon, calculate, consider”, OFris. tella “tell, count”, tälle “say, tell”, telle “count”, fertelle “tell, narrate”; allophonic EFris. MDu, MLG, tateren “chatter, babble”, MFlem. tatelen “stutter”; OCS deet (дeеть), deskat (дескать) “says” (fr. de- “say”); Hu. tolmacs is a loanword of Türkic derivative talmač, “interpreter, translator” in both languages, lit. “speaker, talker”; Mong. khelekh, khelev “tell, said”; Kor. tel 텔 “tell”; Sum. dal, danol “sing, song”. Distribution spans from Atlantic to Pacific, crossing linguistic barriers. European distribution is focused and limited to the Gmc. group, excluding the rest of the “IE” family, a sure indication of the non-IE origin and a “guest” in Europe. The “IE etymology” throws in the same pot phonetically distinct OHG zalon, Gmn. zählen “to count, reckon”, Gmn. zählen “to count”, erzählen “tell, narrate, recount”, all semantically and phonetically allophones and derivatives of the Türkic sa:- “count, reckon, think”, see say, talk. The “IE etymology” cites unrelated Fr. conter “to count”, raconter “to recount”, It. contare, Sp. contar “to count, recount, narrate” in an effort to genetically link disparate lexemes, see talk. A Hunnic phrase said at the capture of Luoyang in 328 AD in the future China contains three English cognates: tili “tell, order”; tut “take, capture”; and 'yu “would, 'd”, like in “Would he tell/order” ~ “He'd tell/order”. The absence of Indian/Iranian and other “IE” branches' cognates notwithstanding, an “IE etymology” suggests for tell a faux “PG proto-root” *talą, “number, counting” and an unattested faux “PIE root” *del- “recount, count”, reverberating back to the Türkic base til/tili/tele/dili. The Eng. duplex tell - say constitutes a transposed transfer paradigm of the Türkic duplex til - söy, an irrefutable evidence of the genetic connection. Notably, the transfer paradigm transplanted not only the basic phonetics and semantics, but also preserved the semantic subtlety between tell and say, apparent in the idioms “tell apart” “tell off” vs. impossible “say apart” “say off”. In a feat of paradigmatic transfer, Eng. possesses four main action words related to communication: say, tell, call, and gabble, the direct siblings of söy-/söyle-, til-/tili-, qol-, and gap-/gapir-. Although overlapping and interchangeable to some degree, each one conveys its own spectrum of very basic communication notions. See call, gabble, say, tale, talk, tally.
English think (v.) “reason”, (n.) “thinking” (Sw N/A, F54 Σ0.45%) ~ Türkic saq-, sa:k-, sa:ğ-; saqan-, sağın-, saqın-, sa:qın-; san-, sana-, sanğar-; sez-, se:z- (v.) “think, consider, take for something”. an emphatic derivative of sa:- “think, reckon, count, desire, worry”. Ultimately derivatives fr. sa:-/se:- “think” + “reckon, count, desire, worry”. In turn, it possibly ascends to a primeval form ö:-, Eng. awe, with a fundamental notion “think”, see awe. The stem sa:- has sired a multitude of progeny. Along their historical paths, derivatives stratified, amalgamated, adjusted phonetics to local type, and developed their own flavors and semantic extensions which could shift or supplant a primeval semantics. In addition, a Türkic toolbox has three more stems, bïš-, tüš-, and us- for “think”, the us- may also ascend to a primeval ö:-. Alternation of anlaut s-/th-/t-/d- is probably connected with a consonantal specifics of the early Gmc. recipients, ditto with the alternation of the inlaut -q-/-k-/-ğ-/-n-/-m-, where -m- is specific to some Sl. languages. Some languages do not handle interdental sibilants and that may be a case with the saq- to thaq- transition. Cognates: OE þencan, A.-Sax. þencan, þohte, (ge)þoht “conceive in the mind, think, consider, intend”, OFris. thinka, teenk, taanke, tanke, toanke, tinke, OSax. thenkian, ONorse thekkja, huginn (“thought” in Edda), Dan. tænke, Du. enken, Sw. tänka, Icl. þekkja, hugsa, OHG denchen, Gmn. denken, Goth. doms “thought”, thagkjan, all “think”; Latv. duoma “thought”; Sl. dumat (думать) “think” (n > m); Ch. sikao 思考 “think”; Kor. saeng-gag 생각 “think”, saeng 생 “student”. Distribution spans from Atlantic to Pacific along the Steppe Belt and its fringes. An “IE etymology” supposedly comes from a “proto-IE” unattested faux root *tong- “to think, feel”, a mechanically concocted surreal proposition practically indistinguishable from the attested Gmc. and Tr. forms. Forms thekk- and thagk- signal a path distinct from þen- and then. The A.-Sax. þencan is misinterpreted to be a causative form of a distinct OE verb thyncan, thuhte (ge)thuht “to seem or appear”, a proto-form for “seem”, a Gmn. dünken, däuchte. Its Türkic allophone is sakı:- “see faintly, seem, reciprocal of watch”, with the deverbal noun sakığ “vision, mirage”, ascending to the common verbal base sa:- above. A Romanized phonetics is blurred with a cornucopia of phonetic conventions reflecting a clearly non-Roman phoneme: Türkic ṣ-/ṭ-/s- (ṣağ-/ṭalğ-/sak-), compare OE þenc-, OFris. think-, OSax. thenk, ONorse thekk-, hug-, OHG dench-, Gmn. denk-, meinen “think”, Goth. þagk-. The OTD spelling saq- (МК I 85) is also a phonetic approximation, since the Rus. Cyrillic rendition does not distinguish interdental phonemes. The OTD is using only a voiced form δ, and no unvoiced symbol. A Mahmud Kashgari's form may be thaq, much closer to the English phonetics, while the ONorse huginn points to an s ~ th ~ h/x variation typical for the Aral basin vernaculars. The h form of the s/h alternation is associated with the Aral Sea - Horezm area, a homebase of Ases, Alans, Tokhars (i.e. the real Aral Tokhars, not the misnamed Kucheans and Agneans of the Tarim basin), Masguts, and their neighbors, quite consistent with the contents of the Edda. On top of the obvious phonetic parallelism, the Eng. and Türkic semantic parallelism is not less striking, demonstrating nearly perfect paradigmatic transfer: OE “think, imagine, conceive in the mind; consider, meditate, remember, intend, wish, desire” vs. Türkic “think/reckon/ponder/deem/count, imagine, conceive/plan, consider/ponder/meditate, remember, intend, desire/wish”, plus metaphorical “worry, alert, wary, protect, keep distance”. The Türkic semantics correlates perfectly. Notably so with the additional semantics of “to seem or appear”. The pair think and seem constitutes a complimentary paradigmatic transfer case, in addition to the stand-alone phono-semantic paradigmatic transfer for think. In English, think, sane and sanity, and mind form a cluster that ascend to the eidetic Türkic cluster of san- “think” and ming “brain”. The multifarious parallel lexical clusters constitute cases of paradigmatic transfer, a positive attestation of the genetic origin from a Türkic vocabulary. See mind, sane, sanitary, sanity, seem.
English thrive (v.) “flourish” ~ Türkic tir-/dir- (v.) “live, alive”. The notion “live” can also be expressed with the verb bol- “to be”, its cognates are also spread among Eurasian languages (Cf. A.-Sax. bide, bidan, buan “live, remain”). The tir-/dir- has a secondary notion (flavor) of inchoative dynamics, of “coming alive”, which distinguishes it from the stationary “to be” and makes its application more descriptive. The notion “live” has also meanings of “nimble, agile”, “energetic”, “authentic”, “active”, etc. A dynamic notion “live” can be positive and negative, flourish vs. endure, and physical vs. metaphorical. The same A.-Sax. expressions on the positive side used native, non-Tr. words. Such peculiarity points to a social stratification based on ethnic affiliation. A.-Sax. had numerous neutral and negative metaphorical derivatives ascending to tir-/dir- and expressing the burdens of life, in two basic forms, dreogan and dragan. Cognates: A.-Sax. droht “condition of life”, also “pull, draught”, drohtað “mode of living”, drohtnung “condition, way of life”, drohtian, drohtnian “lead a life, live”, dragan “drag, draw”, with conjugational forms trog, drog, troh, ðroh, trugon ascending both to the stem tir- and dir-; ONorse þrifask, Norse trives, Sw. trifvas, trivas, Dan. trives, Du. tieren, Icl. þrífast, OHG. tragan “drag”, Goth. driugan “to soldier”, dragan “drag”; Lith. tarpti, all “thrive, flourish” except as noted. Distribution covers most of the Eurasian width, apparently falling short of the Far Eastern part. No “IE” cognates. “IE etymology” ignored depth and spectrum of the A.-Sax. lexis, confining to mechanical inclusion of phonetic clones. Accordingly, the “IE” etymological verdict is an unwarranted routine “of unknown origin”. Or alternatively from faux unattested “PG proto-word” *þrībaną “to seize, prosper” and faux unattested “PIE proto-word” *trep-, *terp- “to satisfy, enjoy”. There is a substantial morphological difference between the Türkic forms (Cf. tirig “living, alive; life”, tirgür- “revive, bring to live”, tiril- “revived, brought to live”) and the Gmc. forms (with elision of the vowel -i-, peculiar to Gmc. and Sl. languages). Celtic languages do not have cognates. Both factors attest to internalization of the stem prior to the Sarmat expansion to the Western Europe, to before our era but after the Celtic departure. See be, draw, draft.
English tick (v., n.) “clicking or ticking sound” ~ Türkic tiki (v., n.) “sound, noise, murmur”, tikir “make light cracking, crunching, ticking sounds”. Cognates: Du. tik, Gmn. zic; Ir. tic (n.), ticeáil (v.), Welsh tic/dic/thic with derivatives; Balto-Sl. (Latv.) tikškešana (n.), tikšķet (v.), (Sl.) tikat (тикать) “tick”. No “IE” cognates. The word's distribution extending to the Balto-Sl. milieu points to a common, and likely echoic, Türkic origin of the source expanding in the NE Europe. Phonetic forms are consistent, semantics is pinpointed and perfect, leaving no room to question an origin. This peculiar Türkic form of “echoic origin” had to travel mightily to spread to the Denmark and England from the Chinese borders. Two Türkic words tiki and tik-/dik-, likely related, constitute a case of paradigmatic transfer to the Eng. tick “sound” and tick “insect”, an irrefutable evidence of a genetic connection. See tick (insect).
English tie (v., n.) “fixate (by cord)” (Sw N/A, F1721, 0.01%) ~ Türkic taŋ- (tang), tay-, tüg-
(v.) “tie, fasten, bandage, wrap”.
Türkic has five stems (ba-, saru-, tаŋ-/tay-, tüg-, urun-) expressing a notion “tie, bandage”
with different and shifting semantics, of which three (ba-, tаŋ-/tay-, tüg-) are found in the
historical NW European languages, Cf. band, tie, tangle, and one more (saru-) in the
recent past came as a visitor via India, Cf. sari. A variety of the forms reflects the
antiquity of the term, probably ascending to the pre-horse husbandry times of foot hunters and
backpacks, 6th mill. BC. Cognates: A.-Sax. teag, Ang.-Sax. teag, tiegan “tie,
bind”, tan (in becnyttan “to knit, tie, bind”), ONorse taug “tie”,
tygill “string”; Sl. tük “bundle”, (za)tyan(ut) (затянуть) “tighten (bundle)”,
tugoi (тугой) “tightened up” and corresponding reflexes in other Sl. languages; Gk. tai
(-ται); Tr. derivatives tüglun- “wrap into bundle” and
tüglüš- “tied with knots” preserved the original stem tüg- and the narrow semantic of
tying/tightening a bundle; Mong. tanu-, tamu- “tie, bind”, Kalm. tanха “tie, bind”;
Evenk. danama “tight”; Kor. tan “bundle”. A spatial distribution of the word, in
Europe limited to the Gmc., Sl., Gk., and than the length of the Eurasian steppe belt allows to
narrow the source to the steppes from Pontic to Altai. No “IE” cognates, the proposed unattested PIE
root *deuk- “to pull, to lead” is semantically and phonetically unsustainable. An absence of
cognates in Baltic languages indicates a later borrowing into Sl. The OE and ONorse forms point to
an effort to render the phonetics of the rounded -ü- with the limitations of the novel Roman
alphabet, the vowel rendition -ea-, -au-, -y- point to attempts to render the original
rounded -ü-, also present in the Sl. forms, or the laryngeal -a-. A phonetic
contraction of ŋ > g probably reflects the local Türkic languages or dialects, the forms
tüg- and taŋ- are dialectal allophones that separated and formed distinct semantic shades
deep within the Türkic milieu. A Türkic cognate taia-, identical
to the English form tie- (v.), means “to support, to brace”, like in “tied with braces”, a
perfect semantic and phonetic match; that form and the tay- propagated into the modern
English. A Türkic compound kurultai, made famous by Chingiz Khan, uses the word tie/tai
in a sense “family ties”, kurultai lit. means “be cured (family) ties”, “cure (the family)
ties”. In the same sense the word tai (sai) is used in the names of the Scythian eponymic
ancestors Targitai, Koloksai, Lipoksai, there tai (sai) refers to the clan ties. The
Gk. suffix -ται is a specific marker of family, clan, and tribal ties: in addition to
Targitai, Koloksai, Lipoksai of the 5th c. BC, we have 10th c. AD Bechens
Patzinakitai (Πατζινακΐται), Bechen's prince Kourkoutai (Κουρκοΰται), Sarmats
Σαρμάται, Kherosenesans Χερσωνϊται, Stenon's sailors Στενίται, Islamic Fatemites
Φατεμΐται, and hundreds more. The borrowing of a generic term with specific semantics indicates
the direction of the borrowing from Türkic to Greek. The use of the marker in Herodotus' time allows
to date the word by no later than 5th c. BC. A close phonetics and exact semantics validate a Türkic
origin. A presence of three recognizable forms,
tüg-, taŋ- and ba- (i.e. teag-, tieg-, tan, bundle), in the NW European
languages demonstrates a profound case of paradigmatic transfer from a Türkic phylum. See band,
tangle.
62
English till (v.) “harrowing, plowing” ~ Türkic til- (v.) “slit into narrow strips, furrow”. The word till/til- is intrinsically connected with the Türkic allophone or- “cut, break, reap” of the Eng. ard “scratch plough”, and refers to breaking the earth before planting. It may ultimately be a semantic derivative of til (n.) “tongue”, as the narrow strips are called tongues, Cf. idiom “tongues of flame”, and thus be a cognate of tell, talk, tale, etc., and of dole “share, part”. Cognates: A.-Sax. tilia, tillgea, tilian, OFris. tilia, OSax. tilian, MDu., Du. telen, OHG zilon, Gmn. zielen, all connected with cultivation; Serb. dilum “piece, chunk of bread”; Türk. tilgä “strip of land”. OE used tile for “bricks”, semantically also connected with striping. Etymologists conflated that with the origin of till “harrowing, plowing”, although the stems and the paths of these two words are obviously separate, with English tile and Fr. tuile “tile” related to A.-Sax. tigel, tigele, Du. tegel, ONorse tigl, Lat. tegula “tile” fr. Lat. tegere “roof”, which quite uncertainly may ultimately ascend to the Türkic til- “slit into narrow strips” applied for roofing. The distribution of the trio till, ard and dole is focused in Gmc. group, with a Lat. outlier, pointing to separate paths, one of which was probably via the overland Türkic-Sarmatic migration preceding the rise of the Western Huns in the 4th c. The trio presents a case of paradigmatic transfer, profoundly attesting to a genetic origin from a Türkic vocabulary. See ard, tale, talk, tell.
English till (prep.) “up to, before the time, until” ~ Türkic tiy-, teg, tegi:, degi: (postp.) “up to, before the time, until”, ultimately a derivative of tiy-, teg- “reach, achieve”. Cognates: OE (Northumbrian), ONorse, Dan., OFris.; possibly related to Gmn. Ziel (n.) “limit, end, goal” and Sl. do (до) “until”; Skt. tevat; the attested distribution is focused on the Gmc.-Sl. family. Other Türkic forms include semantically identical tegi, tegïn, teginč, tegü, all obvious variations of teg; in Türkic languages the auslaut hard g tends to be dialectally articulated with semi-consonants y/j, which in Gmc. case apparently reverted to dialectal liquid l and in Skt. to v. The “IE etymology” for the time notion “untill” appeals to the phonetic allophones of “convenient” (Goth.), “scope”, “death”, “end of life” (Icl.), the case of last two is obvious the Icl. derivative form aldrtili of the Türkic noun öl “death”, with the part tili being either a reflex of the Türkic verb til- “to scratch” (See till (v.)), or the till “until”, which makes the Icl. noun compound aldrtili either a “stroke of death” or a phrase “until death” with the til “to, until”. In addition, the “IE etymology” attempts to confuse the time notion “until” with the notion “to plow” of the homophonic verb till “to plow”, which is an allophone of the Türkic verb til- “to scratch”, all these incoherent scholastic speculations are semantically implausible. See and, at, be, in, on 1, on 2, to.
English tire “weary” (v.) ~ Türkic tu:r-, tal- (v.) “loose strength, consciousness, be exhausted, faint, dull”. The verb is very polysemantic; out of seven semantic clusters, main meanings are “tire”, “weaken, dystrophy”, “submerge”, “namb, murky, sick” illustrated in the following cognates. The forms tu:r- and tal- may have originated from different verbs with much overlapping semantics. In that case. they practically conflated into one with largely synonymous semantics but two ways of articulation. In dictionaries the stems are listed separately, with episodic cross-reference. Cognates: A.-Sax. teorian “to fail, cease; become weary; make weary, exhaust”, аdeorclan “dull, murky”, adl, adle “disease, infirmity, sickness”, adlian “diseased, ill, languish”, adlig “sick, diseased”, Eng. dull “blunt, numb”; Dan. uitlaat, Norse trett, Sw. trött; Ir. tuir- “tire”; Sl. ustal (устал) “weary”; Georgian daghl-; Arm. tsel-, all “tire, weary”; Rum. daldisi “dive”; Serb. daldisati “dive”. Distribution: spotty in NW Eurasia plus Steppe Belt. “IE etymology” is peculiar: No cognates, no “IE” connections, no “IE” etymology, no English etymology; declared “of uncertain origin, not found outside English”. That is pitiful. On closer inspection, it is surely found outside English, in Khakass, Uigur, Chagatai (Karluk), Horezmian, Kirgiz, Turkmen, and other Türkic languages. Even in England, q.v. Türkic wide spectrum of semantic extensions and metaphoric meanings, and the wide distribution indicate an ancient origin. Some more tar-/tal- semantic extensions can be expected in the Eurasian areas adjacent to the steppe belt. See murky.
English topple (v.) “tumble down”, “to tumble or roll about” ~ Türkic topul-, tepul- (v.) “rip, rupture, breach, punch”. The English top/topple corresponds to the Türkic töpü/topul, in both cases the stem is modified by the Türkic transitive suffix -l. The semantic, the grammatical, derivational, and phonetic parallels are absolute, topple is pronounced tó-pul. A Türkic transitive verbal suffix -l is a now nonproductive and obsolete (inactive): tusu “use, usage” > tusul “to use”, see use. The Eng. suffix -le in topple is explained as a frequentative suffix -l, but in case of denoun verbal derivative that would be a grammatically unsuitable suffix. And in case of deverbal verbal derivative that would be a semantically unsuitable suffix: from top “exceed” to toppl “(often) exceeding” does not make a semantics of “tumble down”, “tumble or roll about”. This is one of the cases when a Türkic derivative is adopted with its archaic suffix. On top of that, the root top has no “IE” connections outside the Gmc. branch and Roman words, and those few are clear borrowings. The Türkic-English succession is traceable down to phrases, Cf. tepildi: yi:r lit. “toppled earth” (earthquake). Even pronunciation did not change thru eons and migrations, /tó-pul/ “topple” is still topul-. See earth, top, use.
English toss (v.) “lightly throw” ~ Türkic tüš-/düš- (v.) “spread, pour, fill”. The notion of the root tüš- is a general down direction: fall, precipitate, alight, land, reef, descend, dismount, diminish, collapse, halt, stop, fail, happen, occur, depose, and so on. A wide semantic spectrum creates limitless variety of applications in the host languages, Cf. cognates douche (v., n.) “spray” and toss (v., n.) “fling, spurt”. A semantic notion “falling event” is identical with Eng. notions, Cf. idioms “it donned on me”, “it fell on me”, see don. Cognates: A.-Sax. toscea(cerian) (with -sh-, toshə-) “scatter”, tosawan (with -s-) “strew, scatter, spread”, tosaelan (with -s-) “unsuccessful, fail, lack, want”, toscaenan (with -sh-, toshene) “break, break down into pieces”, toscead (with -sh-, toshə-) “distinguishing, distinction, difference”, tosceadan (with -sh-, toshed) “part, separate, scatter, divide, discern, discriminate, distinguish, decide, differ”, and more, Norse tossa “strew, spread”, the ss corresponds to the Türkic š; Hu. döl-, ditto; Pers. toš, ditto; Rus. tushevatsya (тушеваться) “diminish, melt away”, the Rus. word is distinct from the Sl. synonymous lexicon, an obvious loanword. The unique word spreads from Atlantic to Pacific and is shared by Gmc. and Türkic families, is a loanword in Pers. and Rus. A grammatical and semantic abundance demonstrates a long history of internalization. Like many other Turkisms in English, the word was lurking in the “folk speech”, and popped up late. The A.-Sax. forms alternate between -s- and -sh-, they inherited a full spectrum of the Türkic semantics, and developed some more. That lexical treasure was nearly entirely lost in English. The initial t-/d- alternation has a diagnostic value: the d-forms tend to center in the Caspian-Aral area, i.e. Azeri, Ottoman, Turkmen. The “IE” linguistics is utterly dumbfounded: “of uncertain origin” for toss and an irrelevant Lat. ducere, dux “to lead” for the douche. The demeaning assertions should be gracefully retracted. In English, douche is a recent (1766) addition, it is a deja vu of the long separated siblings.
English touch (v., n.) “tap” (Sw N/A, F678, 0.01%) ~ Türkic teg-, deg-, teɣ-, deɣ-, tei-/tey- (v.) “touch”, toqï-, toki:-, doki:- (v.) “beat, knock, pound”. A polysemantic word of 13 semantic clusters with 113+ concrete meanings is matched by its English descendent with 15 meanings. One of the clusters carries a meaning “dig” paralleling that of the Eng. tap “dig, mine”. The verb semantically overlaps with numerous meanings of the Türkic verb toqï “pound, pestle” and may descend from a primeval common root. Some semantic expansions in English to a “stirred emotionally”, “affecting emotions”, “concern”, “refer, relate” and the like are later developments, and expansion is still continuing. Cognates: A.-Sax. ðaccian “touch” (toqï ?), OFr. touchier “touch, hit, knock”, touche (n.) “touching”, Sp. tocar (with -k-), It. toccare (with -k-), Lat. tangere (n.) “touch”; Mong. täda, teda “reach, touch”, tege- “hook”; Kor. tei- “reach, touch”. Distribution extends across linguistic barriers from Atlantic to Pacific. Positively no “IE” parallels, the word is alien within the “IE” family. A standing “IE etymology” is an uncouth routine: “perhaps of imitative origin”. In contrast with teg-, “IE etymology” furnished toqï with with its own devised roots closely mimicing the attested Türkic original. The European phonetic shift -k-/-g-/-ch- is consistent with with the areal tendency for palatalization, Cf. clatter vs. chatter. The word reached Gmc. and Lat. areas by different paths and times. See tack, tuck.
English trash (v., n.) “scrap” ~ Türkic tarıš (n.) “trash, scrap”, tarıšla:- (v.) “break up”. Ultimately fr. the verb ta:r- “scatter, disperse, divvy up, separate, cause dissension, distress” that with the initial sc-/sh- formed the base for the Eng. “scatter, shatter”, see scatter, shatter. Other semantic prongs of the verb ta:r- are the notions “sow” lit. “scatter (seeds)”, and “break up” tarıšla:-. The last is denoun verb formed with a verbal suffix -la fr. an apparently extinct noun tarıš “debris, scrap” that had survived in Eng., Scandinavian, and Sl. vernaculars. Of the two notions “sow/scatter” gained a wide circulation, and “break up”, predominantly used by the northwesterly communities, is spotty in the east. Cognates: ONorse tros “rubbish, debris”, Norw. trask “trash”, Sw. trasa “rags, tatters”; Ir. bris(-eadh, -teadh) “break” also echoes the root ta:r-; Sl. tara (тара) “waste”, dermo (дерьмо) “trash”, der (дерь) “rag, rags”, drat (драть) “break”; Mong. tarka- “scatter, disperse”. Distribution extends across linguistic barriers from Atlantic to Far East. А standing etymology of a routine “of unknown origin”, a euphemism for no “IE” connection, a guest from a another linguistic family. The eidetic semantics and phonetics, focused distribution, and non-IE origin testify in favor of its Türkic origin. Phonetic modifications parallel those of other similar cases: loss of vowel after adoption of consonant-dominated language, -s-/-sh- alternation, transformation of the Türkic deverbal noun suffix -iš into “IE” forms -ash/-os/-as, and an initial marker s-/h-/sc-/sh- in case of cognates scatter, shatter. The -s-/-h- alternation is an articulation of the -s-/-k- alternation anchored in the Aral-Caspian basin of the Central Asia. See scatter, shatter.
English tremble (v.) “twitch (of body parts)”, “shake, shiver, jerk involuntarily”, tremor (n.)
“trembling, shaking”, trembler (n.) “quaker” ~ Türkic tebrä-, teprä-, depre-, ditre-, titre:-,
ditre:-, četre (Chuv.) (v.) “to tremble”, “twitch (of body parts)”.
A prime notion of the word is “move”, the notions “shake” and “vibrate, swing” are secondary, with a
total of 8 semantic clusters. A trait of neutrality to transitivity attests to deep antiquity. Not
too far from a rich English assortment, Türkic has 9 roots and 11 basic forms to express “shaking” (aj-,
bez-, birgä-, četre- (Chuv.), ïj-, ïrɣa-, yay-, sapï-, silk-, tebrä-, teprä-), three of
which, “tremble”, bez- “quake”, and silk- “shake”, were carried to English in a case
of a paradigmatic transfer. A notion “quiver, dread, trepidation” is a European innovation.
Cognates: OSax. thrimman “jump, hop”, Gmn.
zittern “to tremble”; OIr. tarrach “tremble”; Balt.-Sl. (Lith.) trimti, trimu “shake”,
tremti, tremiu “tumble”; (OCS) treso “shake”, (Rus.) trepet, trepetat (трепет,
трепетать) “tremble, to tremble”, droj, drojat (дрожь, дрожать) ditto, tryaska,
tryasti (тряска, трясти) ditto; Lat. tremulus, tremere “to tremble, shiver, quake”, Vlat.
tremulo, It. tremolare, Sp. temblar, OFr. trembler; Gk. tremo, treo
(τρεμω, τρεω) “shiver, shake”, tromos (τρομος), tremein “trembling”, atrestos
(ατρεστος) “fearless”; Alb., Tosc.
trëmp “shake (in scare)”; Gheg trem “scare”; OAgnean (euph. Tokharian A) träm-
“tremble”, OKuchaean (euph. Tokharian B) tremem “tremble”; Skt., OHindi trasati
(त्रसत) “tremble”, Av. trsaiti “tremble”; Mong. derbe-, Kalm. derw’хǝ
“rush about, scratch (cattle), flutter”. Distribution is truly Eurasian, from Atlantic to
Indian and to Pacific. A Chuv. čětre “to tremble” has produced the Gmn. zittern (with
suffix
-n/-an/-en) “to tremble” (tebrä- is eastern Oguz form, čětre- is western Ogur
form). A skewed distribution, shared by Türkic, Romance and Balto-Slavic groups, points to an
Eastern European origin of the Romance loanword, apparently brought to the Romance group with their
reverse migration back to the Central Europe in the 2nd-1st mill. BC. Geographical spread points to
movements of the Türkic mounted nomadic tribes across Europe, the two different forms point to the
eastern Hunnic (tebrä-) and western Sarmatian (čětre-) heritage. The transposition
-br-/-rb-
points to a direction of borrowing, it is near impossible to reach tebrä- from
trem-/treb-, but the opposite is normal and should be expected after landing on the Gmc.
soil. The amateurish “IE etymology” is purely phonetical, the “reconstructed IE” *trem- “to
tremble” is a clear mimicry. Mong. forms are later, coinciding with the later Türkic form terbe,
a source for Mong. forms where appeared an initial d-. A “reconstructed PIE” root *ter-
simply mimics an attested Mong. derbe- and its Türkic predecessor terbe. The
alternation
b/m (p/m) is regular in a number of Türkic languages, the form tremor (without -b-)
vs. tremble (with -b-) echo the elided -b-. Mongolic tribes, marked by Y-DNA
haplogroup C, could acquire the word when they joined the Eastern Huns, marked by Y-DNA haplogroup
R1a, in the 3rd c. BC, or later, when 500,000-srtong population of the Hunnic nomads submitted in 93
AD to a ruling minority of Syanbi (pin. Xianbei 鮮卑), essentially making the Hunnic language a
language of the Syanbi. A close phonetic and perfect semantic congruency, and the obvious case of
paradigmatic transfer do not allow doubts on the Türkic origin of the words. See quaver, quake,
shake.
63
English tuck (v.) “fit snugly, gather in folds” ~ Türkic taq-, tak-, dak-, dağ-, daq- (v.) “tack, fix, attach, fasten”. The word numbers 11 semantic clusters with a prime notion “hook up, hitch”. Probably, Türkic mamas kept this word alive, tucking in their kids from generation to generation and from homeland to homeland. Cognates: A.-Sax. togian “draw, drag, tow”, tucian “disturb, ill-treat, torment, punish, bedeck (decorate) [tuck]”, MDu., MLG tucken “tug, pull up (stop), draw up (stop)”; Sl. (podo)tk(nut) (подоткнуть) “tuck in, tuck up, tuck under”; Mong. taqu- “infectious (disease)”; Tungus taku- “join, reinforce”; Kor. takta “replenish, follow (something)”. Distribution is peculiar, NW Europe isle, Eurasian Steppe Belt, and Far Eastern fringes. An “IE etymology” is fascinating: 3 uncouth versions and one reverting to an unannounced correct Türkic verb. The last unwittingly cites A.-Sax. togian, a derivative of the same Türkic root daq- (v.) “hitch, tie, fasten” with a quirk of misinterpreting it as “pull” which it is not, but may be one of consequent actions. It also cites unrelated A.-Sax. tucian that also may only be one of consequent results. The other three ideas come up with faux PG *teuh-, *teug- “to draw, pull” and faux PIE *dewk- “to pull” that substitute for the attested taq-/daq- q.v., or suggest OFr. estoc “rapier”, It. stocco “truncheon”, or suggest irrelevant OFr., OOccitan tocar “strike, touch”. Those three are beyond criticism. “Reconstructions” imitate attested Türkic verb. Phonetic and semantic concordance is perfect, down to the Türkic reflexive verbal suffix -in in an idiom tuck in.
English turn (v.) “change orientation or direction” (Sw N/A, F391, Σ0.06%) ~ Türkic tön-, tö:n-, tün-, dön-, dün- (v.) “turn, return”. The word numbers 4 semantic clusters with a prime notion “turn around” and one of secondary notions “return (sickness)” echoed in Even. Semantic application is completely identical, the Türkic tön- as a verb includes connotation of return found in the later English. Semantic clusters of the word in both languages include figurative abstract extensions like convince “turn somebody around”, refuse “turn down”, influence, bend, tilt somebody “turn”, repulse “turn off”, turnaround, turnabout, turn upside down, turn over, and the like, with each language using its own morphological tools. Cognates: A.-Sax. tyrn(an) “turn, move round, revolve”, turnian “rotate, revolve”, OFr. torner “turn”; Fr. tourner, Lat. tornare “turn (lathe)”, tornus “lathe”; Gk. tornos (τόρνος) “lathe, compass”; Even. tönŋer- “dizziness, reeling”. Distribution is typical for European Turkisms, Steppe Belt plus spotty fringes. A stipulated “IE etymology” from an unattested “IE” root *tere- (Sl. teret (тереть) “rub” fr. Türkic ter-/der- “move, touch, wriggle” ) “to rub, rub by turning, turn, twist” is sorely laughable. There is no need to invent fictitious roots, while an attested root is very real. The inlaut -r- (tön- > turn) serves as a prosthesis used to transmit the phonetics of the labial -ö/ü-, later fossilized and articulated. The difference between the Türkic labial ö and English u most likely came about by reflecting that in Türkic ö and ü are not clearly differentiated. Many words have forms with either vowel not differentiated in the Runiform script, like kök and kük standing for “blue”, at times in the same text. The English turn (v.) is articulated identically to the Türkic tün- (v.) “turn, return” with the same unmistakable semantics.
English twist (v., n.) “turn, curve, bend, braid, writhe” ~ Türkic tevir- “twist, turn”, a derivative of the verb tev- (tüv-) “string, pin, pierce, impale”. The Türkic allophones reported by Clauson (1972, 443) to be late versions (13th c.) are evir- and čevir-. That means that A.-Sax. inherited an earlier version. For the archaic form tevir-, Clauson cites Khakass (Enisei Kirgiz), Koman, and Kashgar (Tarim Basin) example of M. Kashgari, giving some indication on the provenance of the Eng. twist. A reflexive form teviš- (tevish-), lit. “gyrate, revolve (+ -ing?)”, is phonetically closest to the A.-Sax. form twist. A deeper analysis leads a root tev- to an ancestor form teg-, its predecessor ten-, and its predecessor teŋ-, pushing its origin millenniums back (EDTL vol. 3 172) from the form tevir-/devir-. A.-Sax. has a rich throve of documented cognates, connected with ropes. In English, of the 26 synonyms of twist, the most conspicuous are “braid” and “twine”, connected with daily use of ropes, with twine producing its own nest of derivatives. That throve of synonyms is a fairly good mirror of the Türkic derivatives emanating from tevir- and its allophones evir- “turn, overturn, skirt, alternate, plait” and čevir- “twist, rotate, turn, translate”, tevrat-/devrat- “twist, spin”, Kumandu tabrat- “turn (something) on a spit” with semantics connecting this word with tevir-. The Eng. twine with its derivatives “double up, fork, double object, divided object” mirrors the Türkic semantics “plait, braid” with doubling thread back upon itself, reflected in the Gmc. cognates of the form tevir-. Cognates: A.-Sax. mæsttwist “mast rope”, candeltwist “candle rope, wick”, twin “double thread, twist, twine”, twistrenge “two-stringed”, ONorse tvistra “divide, separate” (unwind?), Du. twist, Goth. twis- “in two, asunder”, Gmn. zwist “quarrel, discord” apparently remote derivatives; Serb. deverein “scythe blade”; Mong. tögüri-, tögüre- “encircle, circle”, dӧgürgei “round”; Kalm. tögrxa “round”. Distribution of the form devir-/tewir- is peculiar, Oguz and Uigur languages but without Turkish. That is a potent diagnostic marker. Other forms, especially degir-, are widespread in the Türkic milieu across Eurasia with its fringes and across linguistic barriers. The unsustainable “IE etymology” zeroes on the meaning “double”, leaving the remaining broad semantic spectrum undisturbed, and suggest a later development of such attested basic notion as “rope”. The “IE” logical jump fr. “two” to “rope” is way beyond credible, while evolution fr. “turn” to “twist, rope” and “double” is reasonable and traceable.
English ululate (v.) “long loud crying, howling”, ululation (n.) “long loud emotional utterance”
~ Türkic ulï- (v.) “howl, wail, moan, bellow”. The -l-
is an archaic verbal marker. Ultimately fr. a polysemantic verb yel-, yek- “shout”, a
homophone of “wind, blow”. Those, in turn, share a primordial root ye- “wind, wind howl”. As
a rule, words with
yek- denote negative aspect, see yuck. Cognates: A.-Sax. gylian, gyllan
“yell, shout”, Norse. hyle, ule, Dan. hyle, Sw. howl, yla, Du. huilen,
huilt, gehuil; Welsh wail, hwyl; Lat. ululatus, ululare; Sl. (Russ.) ululukat
(улюлюкать) (v.),
ululukanie (улюлюканье) (n.); Skt. lolati; Hu. üvölteni “howl”, szel
“wind”; Pers. Sum. i-lu, e-lu, u-lu (v.); Heb. urla-; Mong. salki “wind”;
Tungus (Evenk.) nəldi, nəldə “blow”, nələ- “wind”. For more cognates see howl.
These all are dialectal variations of the Türkic “wind” and “howl” carried by different paths to
different areas of Eurasia. Distribution is Eurasian-wide from Atlantic to Pacific across
linguistic barriers. The “IE etymology” did not perceive that “howl, wail, yell, yawl, yowl” and
“ululate, lull” are allophones, and on purely phonetic grounds tried to seek and invent diverse
individual “PIE precursors” for this series with close semantics. Those patriotic assertions need to
be retracted. Gmc. languages have prosthetic anlaut
h-/g-/j-, probably a relict of the Türkic Ogur dialects. Slavic languages have forms with
prosthetic anlaut v-. Thus, Gmc. languages have form gyl- and howl, while
Slavic languages have form voi (вои) (n.) and vyt (выть) (v.). Türkic languages had
forms with consonants -d-, -b- instead of -l-, which produced essentially the same
forms that differ only in the second consonant. Some post-Lat. languages added prosthetic -r-
in the inlaut, e.g. It. urlo, urla, unless they are, together with the Heb. urla-,
allophones of the Türkic
yırla:-/ırla:- “sing, recite”. The Sum. cognate attests to the
existence of the word in the 5th mill. BC. The Skt. word attests to the presence of this word in the
N.Pontic lexicon prior to the 2nd mill. BC, unless it was carried to the Indian subcontinent
directly in the course of pre-Arian Kurgan migrations. A universally near perfect phonetic and
perfect semantic concordance does not leave any room for doubts of the Türkic origin of all these
dialectal forms, including the form
howl. See howl, lull.
64
English unite (v.) “join” ~ Türkic una- (v.) “have unanimity, consensus, understand”, um- (v.) “hope, expect”. Ultimately, they ascend to a primordial root on-/oŋ- > un- “succeed, right, good, fair”. They express strictly abstract, non-material notions of mental process and products. Phonetics and semantics of three linguistic instances overlap and diverge, with time gaining new applications. The verb una- expresses secondary notions of “understand, recon”, “want”, “yield, listen (agree)”, “adjust”, “suit”, “like, prefer”, “trust”. The verb um- has secondary notions of “want”, “believe”. The Türkic etymology ascends to the root cause for uniting - “to agree”. Both English and Türkic have uncounted number of derivatives with semantics “agree on”: union, unanimity, united; uniting, disunited, unionize, reunite/reunion, communion, etc. The word smacks with a European cardinal “one” that lays at the foundations of its “IE etymology” and “IE” cardinals, see first. With the attested Lat. unus a derivative of the attested Türkic una-, its “IE etymology” becomes a small branch on a genealogical tree of the primordial Türkic root on-/oŋ-. A primacy of the Lat. word disappears, it enters a community of Eurasian nations like its any other member. Cognates: A.-Sax. an, ONorse einn, Dan. een, OFris. an, Du. een, Gmn. ein, Goth. ains; OIr. oin, Breton un; Balt.-Sl. (Lith.) vienas, umas “sense”, aumuo “mind”, aumenis “memory”, omenis, оmеnа “senses”, оmе “habits”, (Latv.) viens, uoma “wits”, omen “omen”, (OCS) inu-, ino-, (Pol.) um “wits” ; Lat. unus; Gk. ενας (enas); OPers. aivam; Mong. onu- “guess correctly, foresee, find answer, penetrate (mentally), solve, understand”; Kalm. onox, nox ditto; all related to unity unless otherwise noted. Distribution merits the semantic breadth, semantic shards are ubiquitous across Eurasia and across linguistic borders. An “IE etymology” deduces unite fr. Lat. unus “one”, LLat. unionem, unio “oneness, unity, uniting”, with semantics “to become one”, qualitatively a substantial difference with the primeval nature of the Türkic-based etymology. In favor of Türkic etymology attests the presence of stem una- in nearly all 42+ Türkic languages, many of them geographically quite distant from the Apennine peninsula: Enisei Kirgiz, Khakass, Uygur, Uzbek, Altaic, Kazakh, Tatar, Kumyk, Cuvash (a few Türkic languages use a Mongolic word). In the “IE” family the word un for “one” has a distinct northern European flavor. A presence of the word in Celtic languages attests to its existence prior to the Celtic departure from the N. Pontic in the 4th mill. BC at the latest. The “IE” families may have inherited the Eastern European areal “Sprachbund” word of the 3000 BC, which at 2000 BC migrated toward Mediterranean, India and Middle East, and at 1000 BC migrated to the Northern Europe. The “IE” languages carried the notion of numeral “one”, while the Türkic languages carried the notion of “agreement, unity” across the Kurgan steppe area, and into the Mediterranean and Northern European fringes. See first.
English use /yooz/ (v., n.) “use, employ, practice, make use of” (Sw N/A, F364, 0.09%) ~ Türkic tusu-, tušu- (v., n.) “make use of, suitable, occasion”. Ultimate meaning is “run into, meet, encounter” with a notion “moving toward, opposite, facing”. The notion “useful, suitable” is a secondary semantic extension. Homophonic with düš- “fall, down”, and probably originated from a common predecessor, see descend, toss. A CT form is tušu- fr. tuš-, the form tuz- /t-yooz/ that matches Eng. articulation /yooz/ is cited specifically for Saryg-Yugur (Yellow Yugurs). A.-Sax. had well-ingrained 4 native words for “use”. Their complete replacement suggests that some allophone of a form use was used in A.-Sax. under a radar of grammarians. Cognates: OFr. user (v.), uss (n.) “use, custom, skill, habit”; OLat. oeti (n.), Lat. uti (v.) “use”, usus “use”; Mong. tus “opposite, facing”; Mongor tus “face to face”, and more. Distribution is typical for the European Turkisms, from Atlantic to the Far East. “IE etymology” holds “of unknown origin”, positively pointing to a non-IE origin. The unvoiced anlaut t- elided still on the Romance soil, Cf. uti > usus, the Tr. form likely had a weakly articulated t-. The coincidence of form and semantics, the spread of the word across most of the Eurasia, and a non-IE provenance attest to the Türkic origin. A derivative usual is formed with poly-functional Türkic/English suffix -l, here a verbal suffix of passive voice and adjectival/adverbial suffix. See descend, toss.
English usher (v.) “host” ~ Türkic üšer (üsher) (v.) “to gather, to meet”, üšsera (üshsera) (v.) “visit, call in”, a derivative of a stem üš- (v.) “assemble, gather, inflow”. With an aorist (past tense) participial suffix -er it forms (rare) nouns and noun/adjectives “greeter, host” and the like. Suffix -er also forms inchoative mood of the verb, üšer “(to come) to gather, (to come) to meet”, expressing a shade of “show up”, “coming”. The üšsera- is a specifically Kipchak synonymous form. A sibling form of üš- (v.) is tuš- (du:š-) “meet, encounter” with a shade of “drop down”, a verbal form of an adjective tuš (du:š) “equal, equivalent, opposite to, facing”, which points to a common origin of both stems. Cognates: OFr. (12c.) ussier, uissier “porter, doorman”. Distribution: Türkic much of the Eurasia and one stray wonderer. An “IE etymology” builds a sand castle from faux “PIE” *os- “mouth” to “door, entrance” to Lat. stiarius “door-keeper” to a faux VLat. *ustiarius “door-keeper” to attested OFr., of which only the OFr. allophone is credible. The “IE etymology” does not offer any attested cognates within the massive “IE” family. That positively attests the non-IE origin of the word and renders baseless the “IE reconstructions” as a zealous exercise. The spelling of the initial ui points to an attempt to render a rounded vowel like -u- in mule. An origin of the OFr. form is likely Burgund of the Provence-Savoy time. Phonetic and semantic continuity is perfect, leaving no room to doubt a direct genetic connection of the two words. The consonance of the tentatively Burgund and attested Kipchak forms is consistent with the assertions that Burgunds are a Kutrigur Bulgar tribe, and that at least some Bulgars spoke a Kipchak-type language. The A.-Sax. and OHG form lesan “collect, gather” and Goth. form lisan “gather together, meet together, assemble” may render the Türkic üš- “assemble, gather, inflow” with an atypical anlaut prosthetic l-, their hapax nature leaves their provenance unprovable.
English vouch (v.) “summon (order) into court” ~ Türkic buč- (buch-), buy- (v.) “(to) order”. The original verb did not survive, and by the time of the earliest records even derivatives were already obsolete. Two conjugated forms are documented, bučur- and buyur- “order, command”, with further cognates, e.g. buyruq “commanding (officer title), executive, executor, officer, official, order, command”. In British army, it was an “orderly sergeant”. The derivative bučur is formed with verbal suffix -ur forming 1st pers. verbal active voice, absolute participle, and predicate. An allophone vučur would be a dialectal form. Cognates: A.-Sax. weman (peman ?) (v.) “sound, heard, announce, persuade, convince, lead astray”, wemman “defile, besmirch, calumniate, profane, injure, ill-treat, abuse”, wemend (pemend ?) “herald, declarer”, wemere “procurer”; OPruss wackis “cry”; Gmn. er-wähnen “mention”; no other cognates sited for Gmc. branch, A.-Sax. is a stand-alone; Non-Gmc.: OFr. vocher “call, summon, invoke, claim”; Lat. vocitare “call to, summon insistently”, voco, vocare “call, name, invoke”; Gk. epos (επος) “word”; Skt. vakti “speak, say”, vacas- “word”; Av. vac- “speak, say”; Chinese buchun, po-čhuŋ (憑證), pyn. pingzheng “make up, compensate”. Distribution: the archaic title buyruk/buyuruk and his orders are mentioned for 9 prominent groups, including Oguz and Uigur on the opposite ends of the Steppe Belt. Of those, Tuhsi/Tohars, Chagatai, and Naymans are often erroneously held as non-Türkic. An “IE etymology” builds a case for an “IE” origin via a notion “voice/vocality” fr. hypothesized “PIE proto-root” *wekw- “speak” where in few instances “invoke” is interpreted or translated as “summon”. That concept is unsustainable. The path from the theoretical *wekw- “speak” to the A.-Sax. weman (peman ?)“sound” is also unsustainable. A path from the attested weman - unattested peman to vouch is unsustainable either. The entire linguistic chain is built of wanton speculations and logical holes. The archaic word is most remarkable: once ubiquitous across vast distances, it practically vanished from a Türkic lexicon, but became a fixture in a remote fringe. From early days, the buč- “order” was a word of state administration, a word of authority. In a Middle Age Khakass, it was “title of a man who puts notables in their order of precedence in a presence of a king” (Clauson EDT 387). Türkic, probably still of Zhou nomads' milieu, has derivative cognates in English and French, and none in alleged Gallo-Romance, Lat., and Gmc. The forms indicate a western (like Ogur Sarmatian or Hunnic) and eastern (like Zhou, Tokhars/Uezhi, early Huns) types of phonetics. The source of the borrowing could be one of the overland Kurgan waves of the 3rd - 2nd - 1st mill. BC. The words vouch and voucher lurked somewhere in the European Sarmatia and reached Fr. with a torrent of nomadic Goths, Burgunds, or Alans. The archaic word lurked in English until it popped out sometime in the 17th c. A meaning “guarantee” is a late local innovation. See voucher.
English was (v.) “past tense sg. of to be” (Sw N/A, F28, Σ0.76%) ~ Türkic var-, bar- (v.) “to be” (i.e. in Eng. “was”, in Türk. “is”). An r/s alternation var-/was- is connected with the Ogur/Oguz distinction, q.v. Partial demographic ratio determined predispositions. The trait bears a certain diagnostic value. Grammatically, var-/was- initially was an undifferentiated nominal for anything existent or present, that distinction is preserved in the modern languages. Main meanings of the nominal stem are “existing, present”, “existence”, “all”, “everybody, everything”, thus concrete “property, belongings”. In the modern languages, its predicate applications grew to a dominance, leaving a verbal function in a position of archaism. But what is archaism in Türkic languages was vivified in the Gmc. languages. That is likely a result of the archaic nature of the Oguric Sarmatian languages of the 3rd mill. BC. A.-Sax. took a full advantage of the var-/was- bifurcation, actively using both forms, Cf. wæs, wær-. In A.-Sax., wesan “to be, happen” was a distinct verb that became used for the past tense of the 1st pers. form am of the verb to be, a process shared with Goth. and ONorse. A phonetic parallelism between Gmc. and Türkic forms of “be” is as striking as it is for the pronouns. Cognates: A.-Sax. wesan, wæs, wæron (1st, 3rd pers. sing.) “to be, happen”, OSax. wesan, ONorse vesa, OFris. wesa, MDu. wesen, Du. wezen, OHG wesen, Dan. var, Icl. var, Norse var, Sw. var; Skt. vasati; Hu. van; Mong. baraɣa “property, belongings” and others. Distribution is along the Eurasian Steppe Belt with digressions to the NW Europe, South-Central Asia, and Far East. Historically, all non-Türkic (“IE”, Fennic, Tungus) examples are contiguous with the Great Steppe, and either contain, or used to contain sizable Türkic R1a/b component. The “IE” etymology, apparently on a premise that Skt. is a a mother of all “IE” languages, ingeniously “restored” the Türkic real var-/bar-/par- as an unattested faux PIE root *wes-, soundly ignoring the doctrinally inconvenient Dan., Icl., Norse, and Sw. forms. Among its 42+ modern languages, Türkic has numerous variations of the base form: bar- (Karachai, Kazakh, Kumyk, Tatar, Turkmen, Sakha), pur- (Chuv.), var- (Azeri, Gagauz), boluu- (Kirgiz), bolur- (Tuv.), wor- (S.Altai), bor- (Karluk gr.), par- (Khakass). The Dan., Icl., Norse, Sw. form var has preserved the original phonetics, matching exactly the Türkic form var-. The path of the –r forms generally differs from the path of the complementary –s forms. That enables linguists to examine their historical development, in particularly the path to A.-Sax. and Skt. The trio bol-, var-, and dur- constitute an authentic case of paradigmatic transfer attesting to traceable and verifiable genetic connection. See be.
English watch (v.) “observe”, (n.) “guard duty and period, patrol” (Sw N/A, F430, Σ0.04%) ~ Türkic aɣtur-, aqtur-, axtur- (v.) “rouse, wake up”, a causative form of the verb a:ğ- “rise, climb, ascend” (Cf. high). The antiquity of the verb shows in its relict distribution, supplanted by four other synonyms, its neutrality to transitivity typical for pre-literal times, its ubiquitous presence in the oldest records. European forms preserved a semantic element of a causative voice of the duty, some forms have preserved Türkic suffixes for causative (-ur, -ung, -a), passive (-l), and abstract notion (-an, -en), demonstrating diverse paradigmatic transfers from a same source to numerous destinations. Cognates: A.-Sax. wacen, wæcce “wakefulness, watching, vigil, division of the night”, wacian “to be awake, keep awake, watch”, with developed derivatives, A.-Sax. wacol “awake, vigilant, watchful, attentive”, OSax. wakon, OFris. waka, WFris. weitsje “wake, watch”, ONorse vaka, Dan. vaage, Du. waken “(be) awake”, OHG. wahhen “watch”, wahta “service period (duty or patrol)”, Gmn. achtung “attention”, and its cognates, wachen “(be) awake”, Goth. wahtwo (n.), wakan (v.) “watch”; Lat. vigil, vigilia “watchful, awake”; Sl. vaxta (вахта) “watch”, with developed derivatives; Mong. aɣsa- “rise”. Once, distribution was ubiquitous across Eurasia with its western and eastern fringes, since the semantics “on guard, watch” was of a vital importance both for sedentary and pastoral societies. No “IE” cognates, the word is an alien guest. The “IE etymology” is mum on the etymology, the best it offers is “perhaps a Northumbrian form”, an etymological non-statement. It is tough to etymologize Türkic substrate without turning to a Türkic lexicon. A faux “PG proto-word” *wakona, *wakjana is a jazz ouverture on an old tune, unconnected with what is held as etymology. All cited accidental phonetic resemblances have no connection with a night patrol duty or a duty turn period. Most of the European forms have prosthetic anlaut v-/w-, typical for Gmc. and Sl. forms (Cf. Tr. ulï- “howl”, Sl. vyli (выли), Eng. yawl, yowl). They probably originated still in the western Türkic milieu: unlikely that the Gk., Lat., Sl., and Gmc. forms came via a single demographic, spatial, and temporal path. It is embarrassing for linguistic professionals not to be aware of the prosthetics in their areas of study, especially so in their native languages. Vigil is LLat. (12th c.), pointing to a Burgund Provence-Savoy source. Bacchus and bacchanalia, connected with traditions of night orgy, are likely ritually canonized reflexes of the same root and of the same night patrol notion. The Türkic etymology not only fills vacuum produced by the “IE” etymology, it offers regular phonetic transitions, perfect semantic match, and a path for innovations like watch “timepiece”, vigilance/vigilante, and a wealth of metaphorical extensions. See high, wake.
English wiggle (v., n.) “rock, sway” ~ Türkic ügril-, öğrel- (v.) “rock, sway”. The ügril- and öğrel- are passive forms of the allophonic stems ügri:- and öğre- “wiggle, rock, sway” with numerous derivatives. Part of them has survived into English as a paradigm: “rock (cradle, boat)”, “sway (talk into)”, “trick”, “fidget”, “wiggle out”. In Türkic the leading and probably the initial semantics is “to rock a cradle”, also predominant in the Gmc. languages. Cognates: A.-Sax. wagian “move, shake, swing, totter”, wagung “moving, shaking”, waeg “wave, billow”, OFris. widze “cradle”, MDu., MFlem. wiegen, wigelen (v.) “rock”, wiege (n.) “cradle”, OHG wiga, Gmn. wiege “cradle”. Distribution typical for the Gmc. Turkisms. No cognates outside of Gmc. and Türkic languages, no connection with the rest of the “IE” family. No connection to the semantics of “weigh” or wein “waggon”, ingeniously suggested on purely phonetic resemblance. A prosthetic anlaut w- is typical for Gmc. (and Sl.) forms of the stems starting with vowel. It may be a graphical result of adjusting to Romanized script to convey a rounded vowel. The -r-/-l- liquid alternation could have originated from the stem ügri:-, öğre-, or as likely be a contraction of the passive form ügril- and öğrel- as a morphological paradigm. The semantics of the whole paradigm is perfect, the phonetics is close and consistent with the Türkic forms.
English will (v., n.) “choice, decision, intention” (Sw N/A, F76, Σ0.58%) ~ Türkic bil- (v.), an auxiliary (modal) verb denoting “ability or skill to act”. The Türkic verb has a wide semantic spectrum of 11 semantic clusters from a noble “know” to humble “visit”, but in popularity the “will” beats them all. The verbal root has its nominal correlate bil, Cf. billüg (bil-lüg) “known, famous”. The Türkic verb is ubiquitous, its noun is known only in derivatives. A transition from an anlaut b- to w- is routine in Gmc. internalizations. There are some uncanny correlations with the bi- notions “sharp, tip, blade” and “to be” (buol, be) that may connect the origin of the word with a long-lost ancestral notion bi-. From two separate semantic clusters, the Türkic bil- has engendered three English daughter words, “will (aux. v.)”, “will (n.)”, and “feel (v.)”, see feel. An internalized Eng. form further developed its own grammatic words: verb, noun, and auxiliary, with further semantic extensions. The Eng. verb has two senses: 1. intention, 2. volition, both of the substrate bil-. An origin of a vowel in wolde lacks explanation; it may be a recycled vestige of divergent articulations like the attested bul-, bül-, pyl-, and the like. An internalized Sl. developed its own extensive lexical trail. Cognates: A.-Sax. will, willa wyll, wylla, “mind, will, determination, purpose, desire, wish”, gewill “will, wish, desire”, verb wilian, wile, wille, wieile, wolde (pret.) “to will, willing, wish, desire”, nyllan, nolde “refuse, prevent, unwilling” out of ne willan with elision and compression; OSax. willian, OFris. willa, ONorse vilja, OIcl. val, OHG wellan, Goth. wiljan “to will, wish, desire”, waljan “to choose”, Du. willen, Gmn. wollen; Ir. beidh, Welsh ewyllys, ewyllysio; Lat. volo, velle “to wish, will, desire”; Skt. varas “desire”, vrnoti “chooses, prefers”, varanam “choosing”; Av. vara- “will”, verenav- “to wish, will, choose”; Balto-Sl. (Lith.) valià “will”, velyti “to wish, favor”, pa-velmi “I will”, viliuos “I hope”, (Latv.) vala “power”, (OCS) voljo, voliti “to will”, (Sl.) volya (воля) “will”; Fin. varmaan; Mong. bilig “knowledge”, bolno “will”. Balto-Sl. extended semantics from “wish” to “order” etc., pointing to the social status of the word. The South-Central Asian inlaut liquid -r- for -l- calls for a closer assessment. Distribution: far exceeds the areal of the Gmc. languages, reaching across Eurasia from Atlantic to Mongolia and across linguistic barriers. An idea that there was a self-contained PG language that engendered Gmc. languages is as asinine as an idea that there was a self-contained PEng. language that engendered English. Ditto with the PIE language. The faux PG *willjan and *wiljon-, and PIE *wel- “to wish, will” have never existed, they are jazzy improvisations on the theme of the attested bil- with its many phonetic and semantic shades adopted by a host of the host vernaculars. The conjectural nature of the “restorations” is an acknowledged reality. Conjectures are tested by reality and dropped in the face of the fact, they should be dutifully and timely rescinded. Any idea of Lat., or Gmc. borrowing into Mong. is patently absurd waiting to be rescinded. The ubiquitous distribution and deep internalization of the bil-/will attests to millennia of infiltration and amalgamation. The ubiquitous continent-wide lexical spread could only be accomplished by supremely mobile nomadic populations and their dominating political role with cultural consequences. In contrast, dozens of native forms for “will” used by various Eurasian sedentary populations are not internationalized, remaining confined to their native linguistic areal. A likeliest timing for a linguistic amalgamation is the Corded Ware period. That is corroborated by the European distribution pattern focused in the Gmc. branch, and by the assessed ratio of the nomadic and sedentary populace in the Corded Ware area by disciplines of archeology and genetics. The perfect phonetic correspondence and the paradigmatic transfer of the semantic versatility and specificity vividly attest to a Türkic origin. See feel.
English write (v.) “mark with letters” (Sw N/A, F863 Σ0.03%) ~ Türkic čiz-, čïz- (chiz-, chyz-) (v.) “draw, draw lines”, with a base meaning “scratch, chisel”, a cognate of Eng. chisel, see chisel. Ultimately, allophones čiz-, sız-, yaz- “scratch, chisel, draw (line), write” are forms of diz- “string (beads), row (series)” and its diverged siblings tiz- “compose”, düz- “compose, invent, create, construct”, der- “compose” and unrelated doqa- “compose, invent, create”. In all those cases, the above cited semantics is secondary, a derivative of a respective prime semantics. In most cases, a presumed precedence of prime semantics is tentative to some degree as a matter of individual judgment. A root riz- “draw, draw lines” is an allophone of the root čiz- “draw, draw lines”, with a base meaning “scratch, chisel” for both forms, a cognate of Eng. chisel. The surviving forms riz- and čiz- “scratch, chisel” are allophones produced by the phenomenon titled r/s split, with the initial č- being a form of š- which is a form of s- ultimately ascending to d- in the form of the attested diz-. The phenomenon is likely an assimilation to articulation specific to different groups, i.e. Sl. fricative trill -rz-, or Udmurt ʤ- vs. Komi r-. see section Phonetics. The origins of the western form riz- as a source of the western ancestral notion “scratch, chisel” and the north-western “write”, and correspondingly of the western Türkic rizan, resim “draw (picture), drawing, image, likeness” are well established separately for each one. The two attested siblings of etymological chain are conjoined by a link of r/s articulation. Cognates on the r- side: A.-Sax. writan “to score, outline, draw the figure of”, later “to set down in writing”; OFris. writa “write”, OSw. writan “scratch, write, tear”, ONorse rita “write, scratch, outline”, OHG rizan “to write, scratch, tear”, LGmn. wrieten, rieten, Gmn. reißen “sketch, draw, design, tear, pull, tug”, Sl. risovat, risowač (рисовать) “draw, paint”, risunok, rysunek (рисунок) “drawing”, all congruent with the Türkic rizan. Distribution: at the turn of the eras the r- version was confined to the north-central isle of the W. Europe, surrounded on three sides and intermixed with various generations of the č- version Türkic Kurganians that extended across Eurasia to Mongolia. This is one of primary examples on impropriety of family tree model applied to real languages. A paucity of cognates attest to confinement in close quarters and a loanword from outside. Both groups used customary non-codified overlapping versions of a runic script for their writing and parallel identical etymology for the word “write”. No credible “PIE etymology”, no similar word exists in any other “IE” branch, clear attestation of a guest status within the “IE” family. A -z-/-d-/-t- alternation is endemic for the Gmc. languages. Slavonic preserved the original Türkic semantics “to draw” fr. “chisel, scratch”: Pol. rysowac from riʒen/riʒʒan ~ Ukr. risuvati (рисувати) ~ Russ. risovat, risunok (n), riska (n) (рисовать, рисунок, риска), with numerous cognates and derivatives in every Gmc., Slavic, and Türkic language. In the compound writer both stems, rit and ar are Türkic: “draw” + “man”. “Write” is a cultural word, it is intrinsically connected with the appearance of the runic writing in the NW Europe. The earliest European runic writing coincided with the Sarmatian migration to the NW Europe. Temporally it coincided with the references to the As ancestors and the almighty Thor in the Younger Edda. On the parallelism between the Türkic and Gmc. runes, see section Runes. The appearance of European Sarmatia temporally coincided with the disappearance of the Early Sarmat males from the Southern Urals, and their replacement by the horse nomadic males attributed to a Jezkasgan archeological culture of the Middle Asian interfluvial. Temporally, the Gmc. runes concord with the Issyk runiform inscription (5th c. BC), the Chinese records that Huns write on wooden planks (3rd c. BC), and the runic notations left in the Hunnic royal kurgan cemetery (1st c.) in Egyin Gol. On a short side, the suggested etymology is no worse than the de-facto absent “IE” etymology. On a long side, the suggested etymology offers a viable path with traceable phonetic correspondence and semantics identical with the Skt, Gk., and Lat. examples. See chisel, Phonetics, Runes.
English woo (v.) “woo, court, charm” ~ Türkic bü-/bö (v.) “sorcery, witchcraft”, a base for the derivatives bögü:/bögö: (n.) “magic, sage, wizard, sorcery” which combines notions of wisdom and magic, bölcs “wise”, bögä “hero, strongman, bagatir”, bögtag/böktag “blessing, mystical help”, and uncounted plenty more across Eurasia and linguistic families. The A.-Sax. had preserved in a pristine form one of the oldest religious terms on the planet. Since the Stone age, the woo (n.) was not used to attract consorts, there were more tangible allures. A semantic shift was predicated by the forced introductions of new religions and condemnation of the old beliefs, the old was driven underground to have blossomed and survived to the present to meet the utilitarian needs of the populace. The new religions offered plenty of prayers and good wishes, while the old one took care of the medicine, love affairs, revenge, and the like. Syncretization was unstoppable. Wooing spirits was a daily affair in all human societies, and globalizations of the Middle Ages and modernity only complements its staying power with a global dispersion. On the paper, wooing was frequently reduced to sexual affairs. In reality, all forms have survived, and many carry the woo name of Vudu, Voodu, Voodoo, Woodoo, and the like, on all populated continents across the globe. An A.-Sax. words for a magical spell were a native hagorun and an allophonic derivative galdor/galder of the Türkic stem kol- “ask for”, see call. A mini-sampling of cognates: Cognates: A.-Sax. wogian “to woo, court, marry”, wogere “wooer, suitor, sweetheart”, wogerlic “amorous”, wogung “wooing”; Gael. buid(seach) “witch”, Welsh wrach “witch”, Sl. bog (бог) “God”, ved(ma) (ведьма) “witch”; Lat. (py)thonissam (b/p alternation) “witch”; Gk. py(thonistis) (πυθονιστης) (b/p alternation) “diviner”, mag(issa) (m/b alternation) “witch”, fagein (φαγειν) “edacious god”; Skt. bhagas “giver (deity), possession, fortune”, bhaja- “provide, endow”; Av. baɣa “god”, baɣa-, baga- “dole, fate”, baχšai- “godsend, fortune”; OPers. baga- “god”; Mord. (Fennic) pavas, paz “god”, Mong. bükü, bügü, buɣu “diviner, divination”; OCh., wu 巫 “witch, magical women”, Kor. ma(nyeo) 마 (녀) (m/b alternation) “witch”, Jap. ma(jo) 魔 (女) (m/b alternation) “witch”. Distribution: the spread of the word woo covers entire Eurasia except small isles in Europe (god, deos), see God, Near East (al, allah), and some extreme fringes. The “IE” asserted etymology is “of uncertain origin and with no known cognates” a profoundly deprecating claim. Side suggestions of an origin from a notion “bend, lean, crooked, twist, corner” of the A.-Sax. and ONorse origin in reality revert back to the Türkic homophonic verb buq-/bük- “bend” unrelated to the mystic nature of the Eng. woo. The ancient Chinese sources assert that not only the Chinese word wu, but the whole healing process is derived from the steppe peoples (Maspero 1978, 166). Hints of the woo/bü-/bö in the Celtic languages allow to date the word to prior to the Celtic southwestern migration of the 5th-4th mill. BC. They positively predate the Aryan southeastern migration of the 2nd mill. BC, and also connect it with the Kurgan southeastward migration of the 2nd mill. BC to China, Manchuria and beyond. With the b-/m-/p- alternation, an innocent Stone Age magic of mystical healing turned into a most powerful vocabulary of magic, might, and even the very deity Bog (Sl. God) scattered from the Elbe to the Ganges and the Sea of Okhotsk. The near-synonymous duo woo and galdor is a salient case of a paradigmatic transfer, attesting to the common origin from the Türkic linguistic milieu. See call, God.
English wound (v., n.) “cut” ~ Türkic yon-, yo:n-, yont- (v.) “wound, hew, cut, carve”. Ultimately a semantic extension of a notion “hew”. The form yont- corresponds closer to the Gmc. forms, it is recorded only in Ottoman, along with the CT yon- (Clauson EDT 221). That attests that an oddball form was peculiar only to some Türkic vernaculars, it may serve diagnostic purposes. European forms nearly uniformly start with a prosthetic v-/w-, typical for Eastern European, and particularly Gmc. allophones, v-/w- + yont-. The semantic raster of the Türkic cognates is far wider then that of the Gmc. cognates, attesting to a much wider dissemination of the word among the Türkic ethnic communities, and accordingly far deeper roots ascending to common notions “hew” and “hack”. In contrast, the Gmc. cognates are limited to the ONorse homophone without a prosthetic anlaut consonant, followed by a cluster of verbal and concrete noun derivatives starting with the prosthetic anlaut consonant. Cognates: A.-Sax. wundlan (v.), wund (n., adj.) “wound”, OSax. wunda (n.), OFris. wundia (v.) wunde (n.), ONorse und (n.), Goth. gawundon (v.), OHG wunton (v.), wunta (n.), Gmn. verwunden (v.), wunde (n.), MDu., Du. wonden (v.). Distribution is spotty both in the European arena, and on the Türkic Eurasian side. Phonetic and semantic correlation is perfect. No “IE” cognates whatsoever. A complete absence of the cognates in the Romance and Asian “IE” groups, and their ubiquity in the Gmc. group attests, first, to the areal northern and southern Sprachbunds, and second, to the later internalization by the northern Gmc. group, after the Romance farmers bounced back to the south-central Europe ca. 1500 BC, and the Indo-Aryan farmers departed on their South Asian trek ca. 2000 BC. The possible time for the internalization appears to be the long period from the Corded Ware bloom to the Sarmatization of the North-Central Europe. In support of the PIE dogma, the “IE etymology” had invented some alchemic PG and PIE “proto-words” for the wound, and separate PG and PIE “proto-words” for the harm, while allowing hurt to come from an “uncertain origin” standing for “we don't have a clue”. These drills, however, utterly fail to explain the etymology of the words, not only contributing nothing enlightening to the disciplines of history or linguistics, but rather beclouding them with unsubstantiated assumptions and idle conclusions. In historical aspect, in spite of being repeatedly jolted by the modern genetic tracing of the Kurgan peoples to the European populations, linguistics tramples backward. Hurtful as it is, the wounded discipline should finally return to our mother Earth. All cited verbal roots could be used with a prefix ga-/ge/ver- independent of the accuracy of the cited examples. A Türkic idiomatic compound ur- yon- combines two nearly synonymous expressions into an emphatic pair, ur- “beat, strike” and yon- “hew, cut” translated as “beat, torture”, see allophones of ur- harm, hurt, hurl. The Eng. and Gmc. allophones of ur- have acquired a prosthetic anlaut h- typical for the Gmc. languages, A.-Sax., and Cockney, attesting to a probable distinct path from that for the wound. That is supported by a presence of the OFr. hurter “strike, collide”, in contrast to the concentrated distribution of the cognates for the wound. The paradigmatic transfer of both words, yon- and ur- separately, and their attested compound in the Türkic emphatic idiom, provide irrefutable evidence of the Türkic origin for both words. If not for a record on the Türkic idiomatic couple, there would be little chance to validate indisputably its Türkic origin. See harm, hurt, hurl.
English yell (v.) “shout, holler”, (n.) “loud cry, yowl” ~ Türkic yel- (v.) “blow (wind)”,
“gallop, race”, “conjure” (yelwillä-), “blow (excite), “fan, fend, wave, wag, flutter”, shake
(excite)”, yel (n.) “wind, demonic (howl)”, “flit, flitter”, “cold (illness)”.
Examples of derivative verbs demonstrate semantic spectrum of the stem yel, paralleled in the
lineup of nouns and adjectives. A logical jump from “wind” to “demonic” puzzled etymologists who
could not figure out a quite obvious connection. A howl of the wind was terrifying both in the
steppes and in the foothills, wind was a yel tengri “wind spirit”. Etymological sources of
Old Türkic imply that howl was its supernatural and terrifying manifestation. Western sources
corroborate the implication. Notions of “wind, demonic (howl)” and “howl” separated along the
east/west divide early in pre-historic times, but endured a parallel existence for at least a
millennia. That is attested by all three semantic notions of the ONorse, a descendent of the Gothic.
Cognates: A.-Sax. gyllan,
giellan, Mercian gellan “yell”; allophonic cognate of the part -gale in
“nightingale”, from gaile “wind”, with etymological pedigree of “origin uncertain”, howl,
Saterland Fris.
gälje “to yell”, ONorse gjalla “reverberate”, gol “breeze”, galinn
“bewitched”, OHG gellan, MDu. ghellen, Du. gillen, Gmn. gellen “yell”;
Welsh
weiddi, gweiddi “yell”, Cf. Sl. veter (ветер) “wind”, vyt (выть) “howl”;
Balto-Sl. (Latv.) kliegt, (Lith.) kliegti “yell”, Sl. golos (голос) “voice”;
possibly Gk.
kikhle (κίχλη) “songbird”; Hu. szel “wind”; Heb. hyul/hiyul/hayol (היול)
“yell”; Mong. salki “wind”; Oirot. jül- (yül-) “blow it (go crazy)”; Evenk. nəldi
“blow, winnow, rock, sway”; Even nələ “wind”, nəldə “blow” . Distribution is
truly Eurasian, from the Atlantic to the Far East and across linguistic borders. All European
cognates are limited to the N. European Gmc./Celtic/Balto-Sl. groups, with no “IE” cognates. Any
references to any “PG proto-word” are bogus and misleading. The source of the -gale (“song,
sound, tweet”),
gail “wind”, and galinn “bewitched” reflects not “the origin uncertain” but the attested
semantic faucets of the Türkic yel. Türkic allophonic remnants of
yel- “blow” and “howl” are jeldir-, jeltir-, jeldirmaz, jeldirdi, etc. “blow”, and the
form
yarla- “sing”, likely a later dialectal form. The anlaut g- and h- (howl)
demonstrate a typical property of the Ogur languages, consistent with other substrate roots with
initial vowel or semi-vowel. The survived Türkic form yel with initial semi-consonant attests
to commingling of the Ogur and Oguz forms. A trio chill, gale, and howl constitute an
authentic case of paradigmatic transfer attesting to traceable and verifiable genetic origin form
the Türkic milieu. See chill, gale, howl.
65
English ache (n.) “physical pain” ~ Türkic аčï (achy) (n.) “physical pain”. Etymological origin of the Türkic idiomatic аčï comes from the аčï meaning “bitter”, then extending to “sour”, like in “sour-tasting, sour mood, sour attitude”; the аčï “sour” has extended to more meanings, first to “pain” and then to “compassion”. Cognates: A.-Sax. ece, OE æce, Icl. ache, Gk. akhos “pain, distress”. The phonetic and semantic congruence of the English ache and Türkic аčï (achy) is perfect, the use of the phoneme “k” for “ch” is a recent development ca. 1700, that is still reflected in the conservative spelling. The complete absence of cognates in all branches of “IE” languages is a good indicator of a “borrowed” lexeme, in this case a survived vestige of the substrate language in English, and a borrowing into Greek at another time, place, and from another Türkic group. The Gk. borrowing opens a gate for further tracing, since the migrations and datings of the Greek prehistory are fairly well studied, and other Gk. borrowings from “the Scythian language” are recorded in the Classical sources. Unlike the аčï lit. meaning “sour” that nearly universally penetrated all European languages, the idiomatic аčï “unhappy” survived only in the descendent languages of the Vikings/Goths, and in the Türkic languages. See acid, acidify.
English asquint, askance, askant “slanted, oblique, cross-eyed” (adj.) ~ Türkic qïŋïr (n., adj.) “slanting”, from the Türkic root qïŋ/kıŋ “mean, hateful (of a gaze)”. Some cognates are in other Gmc. languages and in Fr.: Du. schuinte, Fr. equinter, (e)squintar, It. scancio. Both in English and Türkic, the semantic meaning is a triplet, 1. glance of disapproval directed to one side; 2. slanted; 3. cross-eyed. The English inherited all three meanings, and developed new words, like askew. The Türkic root qïŋ points to the origin of the word: mean > mean glance > asquint glance > askance. The Türkic has numerous allophones with related or close meaning: kyi “slanted cut”, qïyïq “slanted (adj.)” , qïŋu “glance unfriendly, slanted, mean”, and various derivatives. Quite likely, the close phonetics and semantics conflated some forms and developed a tree of variations, one of which was retained in English. No “IE” etymology, the etymology is rated “of obscure and contested etymology”, but the phonetic and semantic congruence and continuity unambiguously connect the Türkic and English words. The inheritance of all three meanings attests to a case of paradigmatic transfer, an irrefutable evidence of the genetic connection.
English bald (adj.) “lacking hair” ~ Türkic bül, bol (adj.) “bald”. The Türkic term bül/bol is denoted specifically in respect to horses and a bald patch on the head of a horse (blaze). Significantly, Celtic bal means the same, “white patch, blaze, especially on the head of a horse or other animal”, attesting that if not earlier, the word existed at the time of the Celtic Kurgans' departure from the Eastern Europe in the 4th mill. BC. The “IE” etymology offers a range of unsuitable phonetic conjectures, essentially corroborating the non-IE origin, the word is a guest within the “IE” family. Notably, the semantically distant homophonic English bald and bold originated from close, but certainly phonetically distinct Türkic stems, bül and palt/bald. The presence in English of the duplet bald and bold constitutes an authentic case of paradigmatic transfer, unambiguously attesting to the genetic connection. See bold.
English body “entire structure of an organism” ~ Türkic bod, bo:y “body”.
Contrary to G. Clauson (1972), the modality of the semantic spectrum attests that the meaning “body,
carcass” was primary, the meanings “tribe, clan, mass of people, mob” were secondary, and the
meanings “size, stature, height (body), physical form, branch”, etc., the “earthly, worldly, mortal,
soul”, etc., and the “lineage” are grades of metaphoric extensions. English had preserved the base
meaning and a few idiomatic calques, Cf. “body of people”, “body of evidence”, “bodily”, etc. The
modern allophones bud and buddy designate “equal, comrade, companion”. The modern
allophone boy designates “youthful male”, “subordinate, subservient”. Cognates: A.-Sax.
bodig, OHG botah, Turkish beden, Arab. bädän “body”, Kor. badi 바디;
these four forms belong to 4 linguistic families. Another Eurasia-wide word is the Türkic ten/tan
“body”,
with reflexes in A.-Sax. tin, tinn “beam, trunk”, Lat. tegus “inner, body”, Sl.
telo (тело), Pers. tanu, Hu. test, Sum. teshti, Ch. di/ti
体 for “body”, this one belongs to a different group of 4 Eurasian linguistic families. Phonetic
consilience attests that the Pers. form ascends to Türkic rather than Sum. via Akkadian. English has
preserved the unadulterated Türkic form bod, used for a human body, informal for a person,
and for a faceless mass of people. From the Türkic bod
came the Türkic budun “a mass of bodies”, generic for “people”, which in the Herodotus time
had already obtained an invidious semantics of “human material”, “chattel”, i.e. Herodotus' “Budini”
(aka Bodini) describes the human chattel under the Scythians; ditto the budun of the Orkhon
inscriptions. Except for the Türkic, the reflexes of the terms
bod and ten/tan are consistently anomalous in their host linguistic families and
branches, definitely pointing to a loanword status in each of the host languages. The “IE etymology” for the English “body” is a standard “of unknown origin”, attesting that the spirited
“IE” linguists
are weak not only in history and Türkic languages, but in Semitic and other Eurasian languages too.
The secondary form bo:y is most significant, it parallels the semantics of bod, it is
a faceless “servant, commoner, knave, boy”, with likewise etymology declared as “of unknown origin”.
Phonetics of the form boy, as opposed to bod, is due to the peculiarities of the
Türkic articulation, where a group of languages tends to use -y- for
-d-. Applied generically, the word boy is a derisive term, widely used long before the
colonization of America with its slavery and a derisive boy for male slaves of any age.
Besides the principal modern meaning “young male”, the word retained its original notion of
“chattel”, used for a wide variety of dependents, Cf. bell-boy, cabin-boy, cow-boy, errand-boy,
ball-boy, and a slew of other disrespectful monikers. The legacy of three forms, body, bod,
and boy constitute a tangible case of paradigmatic transfer coming from different parts of a
single phylum, an irrefutable evidence of the genetic connection. See boy.
66
English brain (n.) “flesh inside cranium”~ Türkic beñi:/meñi:, beini/meini (n.) “brain”. The Türkic “brain” comes in two main flavors, with m/b and m/n alteration that created a line of b-words (brain, brainwash) and m-words (mental, meningitis), in a variety of forms ultimately ascending to beñi:/meñi:. That m/b bifurcation is continued in the Europe. Cognates: A.-Sax. brægen (bregen), MLG bregen, OFris., Du. brein; Gk. brekhmos, no IE-wide cognates, no common “PIE” “proto-word”. Of the 13 most prominent Türkic languages, phonetically closest forms to the European cognates are beini (Turkmen) and beyin (Turkish); the Kazakh and Kirgiz form could be restored to similar beyit, the Chuvash form mime could be restored to bine (articulation with m/b alternation and m/n alteration). The variety of other Türkic forms attests to widespread dialectal differences where the Eng. brain is but one of many: b-form beyin, beyni, beyini; m-form may, me:, meŋ, meŋi:, meyi, meyini, mi, mime, miŋ, miŋe, miŋi, miy, miya. The Türkic allophonic bouquet contains forms practically indistinguishable from the European forms, Cf. mental < meŋtä “mental” ~ beŋtä < beini, see mental. The suffix -tä in meŋtä/beŋtä is locative “to the brain”, the final -l in mental may be a verbal passive voice marker. With a complete absence of the “IE” cognates, the forms beini/beyin/bine/beyit are the best phonetic match for the English brain, the common origin is uniquely corroborated by parallel m/b bifurcation on both sides of the Türkic-European divide. The Frisian word may point to the Cimmerians, then the modern Türkic form is separated from the Middle Age Frisian word by combined 6,000 years distance from the common ancestor, 2,000 years on the Frisian side, and 4,000 years on the Turkmen side. See mental.
English breath (breth) (n.), breathe (breeth) “inhaling-ехhaling, aspiration” ~ Türkic bu:s/pu:s/bu:r/bug “breath, mist, fog, steam”, ultimately fr. bu: “steam, fog”, and related to the verb bula- “boil”, see boil. The bu: and most of its derivatives also carry, directly or indirectly, a notion of “smell, scent, fragrance”. Cognates: A.-Sax. braeð (breth) “vapor, exhalation, odor, scent, stink”, Dan. vejrt(rækning), Norse puste, pust “breath”, OHG bradam, Gmn. Brodem “breath, steam”; Sl. par, para “steam, steaming breath”. Türkic used various properties of the notion “steam” to create numerous derivatives of bu: “steam, fog” for smell, whirly nature of steam, human gaseous exhaust, etc., and many downstream derivatives ascend to the Tr. forms for “steam” and expand the reach of various European vocabularies, Cf. purge and purgatory, Sl. cognate forms. Explicitly no “IE” connection, the purported “PG proto-form” is a weirdly twisted overture on the Gmn. theme with no etymology other than circular reasoning. The variety of the extant forms attests to a great time depth of the word, its distribution runs along the Eurasian steppe belt to the Atlantic. Notably, the older Baltic languages have their own words for “breath” and “steam”, while younger Sl. shares Gmc. and Tr. lexicon. See boil, booze, bouillon, fart.
English cheek (n.) “side below eyes” ~ Türkic ča:k, jak, ja:k, yak, yaak, caŋak (n.) “cheek”.
Ultimately fr. eŋ/ya:n (n.) that was originally an anatomical term for “hip”, it grew to mean
“side”, and semantically expanded as eŋek/yaŋa:k to “cheek, cheekbone”.
The juxtaposition of yaŋ- and eŋ- forms demonstrates a textbook example of Ogur CV-
anlaut vs. Oguz V- anlaut; the English
cheek is of the Ogur origin. Each of the two forms developed a trail of its own allophones, with
the form eŋek and its forms and derivatives taking on their own life. The form yaŋa:k
with the initial semi-consonant, typical for the Ogur branch, turned into Eng. “cheek”. The
phonetically closest form ča:k
hails fr. the Tuvinian language, originally the Tabgach tribe, which ruled the Chinese Tabgach
(modern Ch. 拓拔 Tuoba, Early Middle Chinese Tak-bat ca. 600 AD) empires Northern Wei
(386–535) and Northern Zhou (557 to 581), and the Tuyuhun state (284–670). These dates postdate the
hatching of the Anglo-Saxon language. The other forms jak, ja:k, yak, yaak, and caŋak
(with initial ch-) also could tentatively produce the Eng. “cheek”. Respectively, they hail
from Kirgiz, Kazakh/Karakalpak/Nogai, Koman, and Horezm/Oguz languages. The form čaak of
caŋak
(with initial ch- and elided -ŋ-) of Horezm/Oguz provenance would perfectly fit the
bill. Unlike the Far Eastern Tabgach, the second group of languages, especially so the Horezmian and
Oguz, belong to the Aral basin areal. Pinpointed location of the distinct form affords a research
diagnostic value. The Tuva form čaak
appears to be the preserved in Mongolian as a Türkic Hunnic form of the Syanbi period, ca. 150 AD,
when a small supposedly Mongolic grouping Syanbi (Ch. pin. Xianbei 鮮卑) took over control of 500,000
Huns. The Horezm/Oguz provenance is consistent with other linguistic pointers. The semantic of the
word in Türkic languages somewhat alternates, the “cheek” in the majority of languages denotes a
“chin” or “jaw” in few others. That furcation is carried into the European languages, Cf. Gk
genus “jaw, cheek”, geneion “chin”. The “IE etymology” is non-existent, it blends
cheek, jaw, and chin into a single undifferentiated entity, and then expands on jaw
and chin to come up with cheek. However, the presence of undifferentiated Türkic words
for cheek, jaw, or chin may also be a trait used for diagnosis. The closest
semantically valid cognate for the English cheek comes not from the Gmc. languages, but from
the Sl. shcheka (щека, ščeka) “cheek” and the Mong.: jaŋaq > jaaq > chaak “cheek” with
elided -ŋ-, probably of the Eastern Hunnic descent. There is no common Sl. designation for
the “cheek”, pointing that the Eastern Slavic forms constitute a borrowing, apparently from the same
underlying language as the English cheek, That also positively points to the Türkic origin,
since the early Slavic and especially early Eastern Slavic languages are more than saturated with
Turkisms. The Eng., Sl., and Mong. “cheek” stand in opposition to the Gmc. forms centered around the
form chin (Goth. kinnus, OHG. chinni, “cheek”, in contrast with the A.-Sax.
form cinn “chin”). That points to the path fr. “hip” and “side”, and separate independent
developments for the terms chew and jaw and cheek. That also debunks the
etymological comparisons with undifferentiated Gmc. forms. Notably, the A.-Sax. native word hleor
“cheek, face” also carries a notion that may be interpreted as “sidewise, sidestep”: hleor
“leer, sidewise gaze”, hleoran (v.) “to go, depart, pass, vanish, die”. That appears to be a
local semantic calque of the underlying notion “side” ascending to the term for “hip”. Another
alternate, the A.-Sax. word ceace/ceacei/ceaceo (with initial
ch-) “cheek, jaw, jawbone” is an allophone of the Türkic čügtä, čökdä (chugtə, chokdə)
“jaw”, in a Romanized transcription with a loss of distinctive articulated rounded vowels, it
superficially appears homophonic to the form for “cheek”, causing a confused mistranslation (See
jaw). The conventional etymology is driven to confuse jaw and chin with cheek,
hence a jumble of guesses and little in terms of etymology; the best morsel offered is that
conflated forms for jaw/chin/cheek
are not found outside the West Gmc. milieu. See jaw.
67
English carpus (n.) “anatomical assembly connecting wrist to forearm” ~ Türkic qarï (n.) “lower part of arm, forearm”. Qarï is a derivative of qar “arm” with 3rd pers. sing. and pl. poss. suffix, lit. “arm's, of arm”. Emblematic for Türkic lexical development, among numerous other things, the consonantal forms qol and qöl also mean “arm”. Cognates: Lat. carpus fr. Gk. karpos (καρπὁς) “wrist”. The Ancient Gk. karpos stands for “fruit, harvest”, semantically unconnected to “wrist”, the “wrist” is an oddball in the “IE” family, an obvious loanword, and obviously fr. the Türkic. The A.-Sax. “wrist” was wyrst, wrist, hence this Turkism passed by Ancient Gk. and Lat. With such pinpointed semantics and accurate phonetics, the Türkic origin is beyond doubts. With the attested Türkic original for “arm, forearm”, no “PIE” and “PG” inventions *kʷerp-, *hwerbaną “to turn” are needed.
(Skip) English colon “large
intestine toward anus” ~ Türkic kolon, Gk. kolon, “the part of intestine that ends with
anus”, from Türkic kilak “stomach ache”. Cognates: Fr. qolique, Lat. colica,
Gk.
kolike, also from the same Türkic root kilak.
68
(Skip) English dementia (n.) “mental deterioration” ~ Türkic dumur (n.) “weakening, atrophy, degeneration”. Numerous Türkic words ascend to the notion of cold as a symbol of bad, they cover notions from headache to tranquility and far beyond. The allophones of “cold” are tum/dum, tom/dom, ton/don, toŋ, and more; the basic dictionaries alone name 24 base stems for “cold”. The semantically closest Türkic word is duma:ğu:/tuma:ğu:/tumaɣu “headache, cold (illness), rhinitis”, which is a a deverbal noun from the duma-/tuma- “(fell with) headache, cold (illness), rhinitis”, hence the Türkic dumur “weakening” and A.-Sax. dem/demm “injury, damage, loss, misfortune”. Cognates: A.-Sax. dem/demm “injury, damage, loss, misfortune”, dumb “dumb, silent”, adumbian “become dumb, keep silence”, dumbness “dumbness”, OSax. dumb, Goth. dumbs, ONorse dumbr “dumb, silent”, Lat. damnum “loss, hurt, damage”, all related to an impairment condition, and largely confined to the Gmc. languages. In view of the A.-Sax. dem/demm based on the root dem, this etymology negates the possibility of the alternate (IE) etymology based on the root mens “mind” with a prefix de-. The alternate (IE) etymology is also little suitable semantically, it is an active form “irritate” of the passive notion “be irritated, be driven crazy, be driven insane” rather than a decease of mental deterioration. Ironically and unwittingly, the alternate (IE) etymology ultimately ascends to the Türkic noun ming “brain”, see mind, and the Türkic locative suffix ta/tä/da/dä/δa/δä “of, from”. Accordingly, the cognates of the root mens “mind” must be rejected: A.-Sax. mynd “memory, thinking, intention”, Goth. muns “thought," munan “to think”, ONorse minni “mind”, Gmn. minne “memory, loving memory”; M.Fr. démenter, LLat. dementare “to drive out of one's mind”; Lat. mens “mind, understanding, reason”, memini “I remember”, mentio “remembrance”; Balt. (Lith.) mintis “thought, idea”, OCS mineti “to believe, think”, Rus. pamiat “memory”; Gk. memona “I yearn”, mania “madness”, mantis “diviner”; Skt. matih "thought," munih "sage, seer”. All these cognates fairly relate to the Türkic min(g) “mind”, but are in conflict with the attestation of the A.-Sax. dem/demm. The timing of the suggested Romance cognates is also in conflict with the native A.-Sax. word, the M.Fr. and LLat. words belong to the later Middle Age period of immense barbaric linguistic influence, but are not attested within the Classical Latin. For the etymology of the cognate dumb, the “IE etymology” invented two roots, *dheu- and *dheubh-, with meanings of the first “dust, mist, vapor, smoke”, it is a phantom allophone of the Türkic doz/toz- (n., v.) “dust” and A.-Sax. dust “dust”, dustig “dusty” , and with meanings of the second invention “confusion, stupefaction, dizziness”, both inexplicably unrelated to either “dust” nor “dementia”. The Türkic dumur, like the English dumb, can't be derived from the Lat. de mente, but both dementia and dumb, and other Gmn. dem-/dum- cognates are derivatives of the Türkic dum-/tum- with noun/adjective suffix -ğu:/-ɣu and -ur/-ür. See mind, dust.
English derma, dermat-, dermato- (n.) “pertaining to skin” ~ Türkic deri/teri (n.) “skin”. Ultimately, deri/teri ascends to the verb tar-/ta:r-/tara- “disperse”, where the Eng. allophone tear “rip” is a concrete application of the verbal notion “disperse, i.e. tear, separate into different outcomes”. Cognates for the Türkic tar-: A.-Sax. ter- (v.) “tear, lacerate”, ter (n.) “tearing, laceration”, Goth. tair- “tear, destroy”, OHG zeran “destroy”, Gmn. zehren; Gk. derein “flay”; Arm. terem “I flay”, identical with the Türkic 1st pers. sing. form terim; Sl. drat (драть) “rip”. The origin of the English word derma is ultimately ascribed to Gk. derma “skin”, dermato- and dermo- in compounds, via Modern Lat. derma. Hence, originally Latins did not know this word, while the Greeks used for “skin” a Türkic word deri “skin”. The “IE etymology” guessed correctly the origin of the notion “skin” from the notion “tear, separate into different outcomes”, but contrary to the feverish “IE etymology” there was no “PIE root” *der- “split, peel, flay” to form derma, and the “IE” connection to the consonant Eng. verb tear “rip” comes via a separate path from the Türkic to A.-Sax. and on to Eng. There is no need to invent a phantom “PIE root” *der-, where the “split, peel, flay” are concrete applications of the notion “disperse, tear apart, separate into different outcomes”. The presence of a duplex of the Türkic words “tear” and “skin” in the A.-Sax. and then in Eng. attests to a case of paradigmatic transfer. See skin.
English dick (n.) “penis” (folksy) ~ Türkic dık- (v.) “erect, stand straight”. The derivative slang senses are very old and naturally were not recorded in the surviving records. Meaning “penis” was first attested in the British army's slang, the slang for “fellow” is synonymous with “fellow, lad, man”. No parallels in Indo-Iranian languages, PIE, or even in the *PIE, but probably a daily term among Sarmatians, Goths, and other Wendeln tribes. As an uprightly erected structure, erected posture, standing and protruding, the Türkic dık- is found in Du. (dyke, dike “standing barrier”), Spanish (dique - “levee, upright wall, vertical rock stem protruding to the surface”), and popular appellations that refer to exaggerated masculinity. No “IE etymology” whatsoever. The pair dick - cock is a case of the transfer paradigm, the transfer of synonymous set of terms for a particular object, that evidence attests for certain of the linguistic genetic connection. See cock (rooster).
English elbow (n.) “joint between forearm and upper arm” ~ Türkic el (n.) “arm, forearm”. The Türkic element el starts the English elbow, A.-Sax. elnboga, from ell “length of the forearm” + boga “bow, arch”; OIr. uilen, Cymmer. elin, Goth. аlеinа; Du. elleboog, MDu. ellenboghe, Gmn. Ellenbogen, OHG elinbogo, ONorse ölnbogi, Norse albue, Balt. (Latv.) elkonis, Balt. (Lith.) alkune, Sl. lokot (локоть, with contracted el), all expressing compound arm + bend, with bend coming in two flavors: the Gaulic kon in Basque ukondoa (probably contracted lukondoa), Gujarati koni, Hindi kohani, Hu. könyök, Balt. (Latv.) elkonis, Balt. (Lith.) alkune, Sl. lokot; and the Gmc. bog < Tr. bük in A.-Sax. elnboga, Du. ellenboghe, Sw. armbage, G. elinbogo, Norse ölnbogi. Of Gmc. languages, only Sw. changed the Türkic el to Gmc. arm: armbage. In time, the Türkic el shows up in Cimmerian in the 10th c. BC, Indo-Iranian (Avesta, Skt.) after 6th c. BC, and in the European sequence is roughly Celtic > Gaul/Irish > Goth. > Gmc. > Balt. > Sl. The Gk. (Hestius) reflects the Cimmerian Türkic form: elin > olene ὠλένη > Lat. ulna “elbow”. The part bog in various allophones is the Türkic bük- “bend, twist, curl, wrench, contortion, wring”, which produced English bow < boga < bük. All Gmc. languages uniformly inherited the Türkic bük, boq- (v.) (in modern Turkish bük(mek) (v.) “bend, twist, curl, curl up, flex, fold”, bükül(mek) (v.) “twist, bend, curve, fold, spring, wind”, bükme (n.) “bend, twist, curl, wrench, contortion, wring”; the Türkic part mek is the English make, infinitive verbal suffix agglutinated to the stem). The little elbow allows to trace two Türkic words from 6000 ybp in the Pontic steppes to the Mesopotamian Guties ~ Guzes 4300 ybp, to Mesopotamian Cimmerians 3000 ybp, via Balkans to Jutland Danes 2000 ybp, and into the literate period; and on circum-Mediterranean route from the same Mesopotamian Guties ~ Guzes to Iberia 4800 ybp (Beaker Culture), and Celtic spread up to the Western Europe, British isles and Ireland, and into the literate period. Two forms for “bend”, the Gaulic kon and the Gmn. bog attest to two independent routs, circum-Mediterranean and overland via Balkans. The Gk. and Lat. forms attest to a third path to Europe, potentially connected with the population replacement of 6500 ybp, or with the Hellenic immigration 4000 ybp. See bow, make.
English eye (n.) “organ of sight” ~ Türkic ög- (v.) “to eye, perceive”. The verb ög- comes in two allophones, ög- and uk-/uq-, both used to refer to perception expressed in Eng. idioms “I've got it”, “I see it”, “I understand (it)”; the notion of “see” in these idioms is not literal and physical, it is metaphorical as in literal “perceive”. The verb's noun forms are ukuğ and ukuš, both “seeing, understanding”, and ögli: “seeing, thinking”, with metaphorical “see”. The ög- has a dialectal form öy- in SW languages like Azeri, that form neatly matches the Eng. eye and Dan. øie. However, the Türkic allophones carry a fundamental notion “perceive, insight” forming a notion related to “seer, wisdom” instead of an instrumental derivative for “organ of physical perceiving” which is the eye. That difference attests to the time depth of the stratification, since none of the extant Türkic languages has preserved neither direct correspondence nor a derivative directly drawn from the notion “eye”. Moreover, the Celtic Welsh form appears to be an allophone of ög-/ok- with a prosthetic -l. That may be a relict carried from the E. Europe from the time of the Celtic departure ca. 5th-4th mill. BC, attesting to the existence at that time of the form ög-/ok- with distinctly singular derivative semantics “eye”. Ultimately, the Türkic-Gmc. ög- and the “IE” ok- is the same stem, distributed nearly equally to form grammatical forms for vision: A.-Sax. ege (Mercian), eage (WSax.), OSax. aga, OFris. age, ONorse auga, Goth. augo, Sw. öga, Dan. øie, MDu. oghe, Du. oog, OHG ouga, Gmn. Auge, all “eye”; Welsh lygad; Lat. oculus; Gk. okkos but opsis “sight”; Balto-Sl. (Lith.) akis, (Latv.) acs (ach), (OCS) oko; Skt. akshi; Gujarati ankha, Agnean ak, Kuchean ek; Arm. akn; Ar. 'ayn, all “eye”. The English eye closely follows the Dan. øie:, øie > øye > eye via form øğe; -ğ- may be articulated silently, or denote the phoneme -y-. That particular form points to the areal origin in the Black Sea/Caspian basin. Nearly all Gmc. forms have preserved an indicator or a tint of the rounded ö- in the Türkic ög-, and point to the direct genetic connection that, given the Welsh form and due to the Welsh exact semantics, may also ascend to the 5th-4th mill. BC. The non-Gmc. forms show separate paths; the eastern “IE” forms ascend to the 3rd mill. BC, prior to the Indo-Aryan departure ca the turn of the 2nd mill. BC. Obviously, all these forms were inherited via numerous independent paths, creating a spectrum of allophones and split semantics; the Gmc. allophones are notably closer to the Türkic version than to the Balt.-Sl.-Skt.-Gk.-Arm.-Indian (Agnean/Kuchean)-Ar. forms. Notably, the Ar. 'ayn “eye” has preserved the Türkic double semantics of “eye” and “spring”. The Eng. triplet of eye, gaze, and see constitutes an authentic case of paradigmatic transfer from a common source, albeit probably at different times and of ethnically different populations. See eye, gaze, ogle, see.
English face (n.) “nose and vicinities” ~ Türkic yü:z (ñü:z) (n.) “face”, generically “surface”, with as many semantic and idiomatic extensions as are endowed to English. The word “face” came to Eng. as a paradigmatic transfer, with a prototype ñü:z for “nose” and old A.-Sax. wlita/wlite, Goth wlits “face”, a cognate of the Tr. bit/bet “face”. Sometime during the Middle Ages, the A.-Sax. wlita/wlits lost a popularity contest to its synonym face, but it rightfully belongs to the substrate category. The transferred paradigm also transmitted peculiar idiomatic expressions, i.e. – confront: “something facing us” is “something confronts us”, “face the reality” is “confront the reality”; – orientation, across, opposite: “cafe facing the road”, “facing north”, “facing page”, “turn to face”, – surface: “Earth's face”, etc. The Eng. form starts with a version of the prosthetic anlaut v-/w-/f-, a regular correspondence between the modern Türkic and the Gmc. and Sl. languages, which sounded something like vü:z/wü:z/fü:z “face” and produced the OFr. (12th c.) face “face, countenance, look, appearance” and VLat. facies “appearance, form, figure, visage, countenance”. The appearance of OFr. and VLat. forms is obviously a late borrowing, probably from the Burgund of Provence/Savoy. The “IE” phonetic and semantic spectrums probably developed gradually in time. Other cognates: Chuv. ner, Mong. ni'ur, niğur “face”; these siblings to the Eng. face are most significant: first, they attest to the initial anlaut n-, justifying the form ñü:z for “face”; secondly, they attest that the Chuv. (and Mong. loanword) forms descended from the Ogur branch (r- branch) while the Eng. form descended from the later Oguz branch (z- branch); thirdly, they corroborate the relative sequence from Ogur to Oguz in the evolution of the Türkic languages. Since “IE” languages have a large collection of different nominals, the origin of the word “face” is clearly non-IE, obviously comes from a variety of non-IE sources, and the deficient “IE etymology” rightfully flops on it face. The close phonetics, exact semantics, and the transfer of the tri-partite paradigm and its semantic corollaries validate the Türkic origin beyond any doubts. See nose, wlita.
English foot (n.) “lower leg” ~ Türkic but (bot), bu:t, bu:d (n.) “leg, thigh”. Cognates: OSax. fot, ONorse fotr, Du. voet, OHG fuoz, Gmn. Fuß, Goth. fot “foot"; Fr. pied, It. piede, Sp. pata, Lat. pes; Gk. pos; Skt. pad-, Av. pad-, all “foot”, Balt. (Lith.) padas “sole”, peda “footstep”. It is obvious that “foot” belongs to an areal “Sprachbund” language, which at 3000 BC centered in the Eastern Europe, at 2000 BC migrated toward Mediterranean, India and Middle East, at 1000 BC migrated to the Northern Europe, and in the second half of the 2nd mill. AD dispersed across the globe. Apparently, the voiced bilabial stop b turned into voiceless p in the southern fringes, and into voiceless labiodental fricative f in the northern fringes. The foot belongs to the collection of the “Sprachbund” words common with the Türkic languages and geographically adjacent to the steppe Kurgan area. The spelling with long -u:- matches exactly the phonetics of the Eng. -oo-. The Eng. pair of foot and elbow constitutes an authentic case of paradigmatic transfer from a common source, pointing to the direct genetic connection. Notably, while under the “IE etymology” the foot is endowed with an extensive etymology and an imposter “PIE root” *ped-, its obvious sibling and allophone boot is left a total orphan, classed by the “IE etymology” as “of unknown origin”.
English genu (n.) “knee” ~ Türkic yinčür- (v.) “bow, bend”. Ultimately fr. yi:n “body, flesh, limbs, body part, skin”, with diminutive denoun suffix -č to produce yinč- (v.) “bend, bow, slight, delicate, thin, slim”; yinčür- is a causative form of the verb yinč-. Numerous derivatives of the stem yi:n convey connotation of material weakness, as opposed to the stiffness of hard materials, thus the prevailing notion is metaphorical “flesh” as a material, with adjunct secondary notions of “bow, bend” with further semantic and morphologic extensions. The semantics of “flexibility” propagates into notions of “joint”, “flexible”, and the like; the semantic of “knee” is a derivative of yinčür- with idiomatic meaning “(bow with) bent knees” as a gesture of submission. The word genu does not refer to the physical knee, as in “knee hurts”, it refers to the knee action as a hinge joint, expressed in LLat. (14th c.) Latinized neologistic calque with noun of action genuflexio “bending of the knee” and the verb genuflectere “genuflect”. Cognates: A.-Sax. cneo, cneow, OSax. kneo, OFris. kni, ONorse kne, Goth. kniu, OHG kniu, Gmn. Knie , MDu. cnie, Du. knie; Lat. genu; Gk. gony “knee”, gonia “corner, angle”; Skt. janu, Av. znum; Hitt. genu, all “knee”. The Ogur form of the Oguz yinč- is jinč-, ginč-, and other dialectal versions (like kinč-, closer to Gmc. forms) with anlaut consonant from the Ogur prosthetic consonantal lineup h-/k-/g-/d- specific to Oguric branch (see Skt., Av., Hitt., Gk., Lat. forms), the morpheme y- may be Oguric with expressed articulation or Oguzic with nearly undetectable articulation. The late adoption of the Türkic secular-religious term “genuflect” into the Church Lat. is probably connected with some Cathars escaping religious genocide by joining the Church ranks, its history may be illuminating. It may be suggested that the Gmc. anlaut kn- ment to render some version of g-/j-, that would bring vocalization closer to the Turkic Ogur jin-, gin- and its south-western allophones.
English heart (n.) “muscular pump organ” ~ Türkic (Chuv.) chäre (chere), (OT) yürek, yüräk (n.) “heart” (n.). The Türkic notion of “heart” is connected with the notion of “bravery”, that linkage was transmitted as a paradigmatic transfer into the European and Far Eastern languages. Cognates: A.-Sax. heorte “heart, courage”, Yak. süreq, Tuv. chürek, Khak. chüräk, OT yürek; jüräk, ǯüräk; OSw. herta, OFris. herte, ONorse hjarta, Du. hart, OHG herza, Gmn. Herz, Goth. hairto; OIr. cride, Welsh craidd; Lat. cor; Gk. kardia (καρδιά); Balt. (Lith.) širdis, Rus. serdce (сердце); Skt. hrid-; Av. zared-; Hitt. kir; Mong. kirüge, kürüge, kürüke, kiruke “heart”. The eastern (largely Oguz) group of Türkic languages starts with anlaut vowel or semi-vowel, the western non- Türkic languages start with Ogur-type prosthetic initial of anlaut prosthetic consonantal lineup h-/k-/g-/d- specific to the Oguric branch. The initial s- forms süreq, chürek, ǯüräk, širdis, serdce juxtaposed against initial k- forms point to the k-/s- divide of the Eurasian speech and the kentum (centum)/satem origin as a consequence of the front/rear harmony, and point to the primacy of the k- forms. The Gmc. h- forms uniformly attest to the Aral basin origin featuring s-/h- alternation. The Mong. forms, close to Eng. and Chuv., are Hunnic forms acquired by Syanbi (Xianbei 鮮卑) Mongols with ethnic Hunnic majority, they are positively identified as Türkic loanwords adopted during the Second Period.. The English form is closer to the Chuv. form. The common origin of all forms is obvious. Essentially, all forms show an international European/Great Steppe word that probably was seeded in Europe by overland and circum-Mediterranean horse-mounted Kurganians. Any idea of Gk., Lat., or Hitt. borrowing into Mong. is patently absurd waiting to be rescinded. The Celtic k- form ascends to 6th-5th mill. BC N. Pontic area starting from before the Pit Grave period. The distribution points to the Türkic languages bridging Lat., Gk., and Gmc. on one end and Mong. on the other end. The A.-Sax. and English spelling of the first vowel -ea-/-eo-, and the Goth. -ai- point to attempts to render the quality of that vowel depicted as -ä-/-ü- in Türkic transcriptions, and approximated as -e- in Gmc. versions: the -ə-. The A.-Sax. heorte “heart, courage”, figurative “breast, soul, spirit, will, desire; mind, intellect” closely follows the extensive Türkic semantic of the notions “heart” and “courage”. See courage.
English hernia (n.) “outside bulge of internal organs” ~ Türkic urra (n.) “hernia”. Ultimately, fr. the Türkic verb ur- “punch out”, the deverbal derivative ura widely disseminated in Europe long before it was formalized in the medical jargon. Hernia, with a prosthetic initial h-, is an obvious allophone, perfect semantically and phonetically. The “IE etymology” suggests that hernia, a Latinized neologism documented fr. late 14th c., relatively recently etymologized fr. a putative PIE asterisked invention for “gut, entrail”, is derived from the allophones of yarn, a somewhat circuitous and incredulous path. The yarn phonetically sounds like a distorted homophone of the real Türkic urra for “hernia”, but semantically it is as far from “hernia” as they come. That version does not answer two aspects, first, how M. Kashgari in his remote Kashgar of the 11th c. could have known that the European medics in the 14th c. would come up with the name hernia, and secondly the mechanism of that European colloquial neologism spreading across Eurasia into the Türkic languages. The possibility of Lat. borrowing into the body of the Tr. languages is unreal, and a chance coincidence can be positively ruled out as statistically unviable. The direct assimilation of the Türkic term centuries before 14th c. appears more coherent, simple, and realistic. Now, as a medical term, hernia is an international word, with local equivalents practically in every European and “IE” language.
English jaw (n.) “structural part of mouth” ~ Türkic čügtä, čügde:, čökdä (chugte, chugde, chokde ) (n.) “jaw”. The Türkic term čügtä, čökdä includes the vertical joint of the jaw: čökdä uluxsa “acclivitous bones of lower jaw” (МК 21016//OTD p. 155, 157) The English jaw came from jowl, after ME chawl (late 14c.), chavel (early 14c.), A.-Sax. (OE) ceafl, with the dates attesting not the usage in time, but records in time. English also preserved jowl, ME cholle for “fold of flesh hanging from the jaw”; MHG kiver, Gmn. kiefer, ONorse kjoptr “jaw”, Dan. kæft, Flem. kavel, Du. kevel “gum”; OIr. gop, Ir. gob “beak, mouth”; they are phonetically as close to jaw/ceafl as the čügtä, čökdä, considering the vast geographical and time differences between these forms: the anlaut semi-consonants/consonants j-/dj-/ch- and the labial ö and ü are fluid between different dialects, and may be legitimately rendered -ow-/-aw- to show labial vowel, the final -tä/-dä may be reflected in the Dan. -t of the kæft. The closest cognates to English jaw comes not from the Gmc. languages, but from the Slavic: jevat (жевать) “to chew”. Slavic also has completely separate “jaw” chelust, and “cheek” shcheka (щека), pointing to separate independent developments for chew and jaw and cheek, and enlightening us to be mindful of our own confusion before we address that of the others. Among many allophones and polysemantic meanings, one that ties together jaw and čügtä, čökdä is the stem čöq- with semantics “bent, curved, knee-like”, used to produce derivatives like čügtä, čökdä and čögän, čoɣan “polo mallet”, pointing that initially the curved jaws of animals were used as tools and in games, forming nouns of the stem čöq- (with allophones čök-, čög-, čöɣ-) with deverbal noun suffixes -tä/-dä/-än/-an to make nouns meaning “hokey-stick shaped”. Note that English jaw and chin are synonymic, chin has distinct Gmc. roots, while jaw has cognates outside of the Gmc. field. In light of the forms clustering around čöq- “bent”, a temptation to connect the forms jaw and jevat with the verb ye “eat” is not sustainable. See eat.
English lame (adj.) “crippled (in legs)” ~ Türkic ulam (adj.) “continuous, lasting, permanent”,
with both positive and negative connotations, also used as adverbial noun, ultimately fr. ula:-
“repair, join, writhe together, union, tie”, formed with deverbal abstract noun suffix -m to
name an object, express result or degree.
In the context of a human, ulam means “crippled permanently”, as illustrated by its Sl.
calque uvechenyi (adj.), uvechie (n.) (увеченый, увечье), lit. “forever, for
ages” from the “IE” stem vek- (vech-, viej-) “old, age, ancient”. In the example, uvechie
(увечье) (n.) is a noun derivative from adjectival noun/adverb, morphologically “permanency” but
semantically “(permanent) injury” (Cf. Sl. direct derivative lomat (ломать) “break”). The
stem ulam is multi-layered, its semantics besides “debility” conveys notions of
“break/repair” and “support”, both physical and metaphorical, e.g. ulamsiz “unattached”,
ulamsuz
“unsupported”, making the notion “permanent” totally transparent in its
content, a la “permanently debilitated by broken support”. The spread to Balto-Sl. languages points
to bilingualism that allowed adoption of the multifaceted loanword into the “IE” syntaxes. The elision
of the anlaut vowel u- was an adaptation to the host vocalizations, in the Eurasian southwest
the word took a form leng-, like in Timurleng “crippled (or humped) Timur”. In Türkic,
the anlaut u- is purportedly a prosthetic vowel typical for loanwords, but the uninterrupted
etymology ascending back to the base root ula:- attests otherwise (Clauson EDT, 146).
Cognates: A.-Sax. lama “crippled, lame, paralytic, weak”, unrelated to homophonous lam,
loma (tool), lim (foam, day, earth), or limb, usually cited in the “IE” phonetical
exercises; ONorse
lami, OFris. lam, Du. lam, Gmn. lahm; Lith. luomas, all “lame”; the OCS
cognates lomiti, Sl. lomat (ломать) “break” are Sl. derivatives of the Balto-Sl..
luomas
“lame”. No “IE” connection whatsoever, the ulam/lame “crippled” is an oddball in the “IE” family,
with a peculiar steppe belt-adjacent distribution typical to other European Turkisms. The
near-perfect and consistent phonetics and perfect semantics, peculiar distribution, and the status
of the guest word within the “IE” family attest to its Türkic origin.
69
English milk (n.) “secretion of female mammary glands” ~ Türkic meme (n.) “(female) breast”. The underlying form for milk is the form memeleki, a derivative formed of meme “brest” + suffix –le “with” + suffix –ki “that”, i.e. “that of the breast”, which for millennia could accumulate all incidents of dialectal modifications and allophones. The putative form, morphology, and semantics of memeleki, with its characteristic -lk of the agglutinated suffixes, is just right for the form “milk”. In the Türkic languages, the “breast”, “breastfeeding”, and “milk” süg were separate notions. Cognates: A.-Sax. melc, meolc, meoloc, meoluc, mylo, W.Sax. meoluc, Anglian milc, ONorse mjolk, Du. melk, Ger. Milch, Goth. miluks; OIr. melg; Lat. mеlса “sour milk”; Gk. amelgo, armego (αμελγω, αρμεγω); all Sl. languages have versions of moloko (молоко, млеко, etc.). The derivative verb is ONorse mjolka, Du., Ger. melken, Gk. amelgein, Lat. mulgere, OCS mlesti, Lith. melzu “to milk”, etc. In these attested forms the original memeleki is clearly visible. Geographically, the word is shared by Türkic, Gmc., Celtic, and Sl. branches, plus accidentals. The accidental is Lat., whereas the Lat. milk is lacte with allophones in all Romance languages; the accidental Gk. whereas Gk. milk is gala (γάλα); the accidental Baltic whereas Baltic milk is pien. That clearly indicates a status of loanwords for the Lat. mеlса, Gk. amelgo, Baltic (Lith.) melžti. The Lat. mеlса names specifically a sour milk, an exclusive hallmark of the Türkic nomadic diet noted by a pleiad of chroniclers across millenniums and across Eurasia. A constellation of Eurocentric-Slavophile-Iranophile presumptive linguists have dug in to come up with an “IE” etymology: Brueckner, Berneker, Endzelin, Ernu, Frenkel, Hirt, Janko, Lëve, Lyapunov, Meillet, Meyer, Obnorsky, Pereveden, Schrader-Nehring, Selishchev, Semerene, Sobolewski, Trubachev, Uhlenbeck, Vasmer, Walde-Hofmann, Yagitch, to list just a few. The suggested “IE etymology” is a preposterous phonetic speculation, deduced fr. Skt. verb marjati “wipes off”, which ostensibly produced “IE” verbs “to milk” and then on to produce a noun “milk”. That is neither lucid nor philologically, nor evolutionary sustainable, since the breast milking came long before domestication of cows and sheep. Applying the concept of Skt. “wiping, stroking” in reference to the hand motion in milking an animal to the human breastfeeding is absurd waiting to be rescinded. In the Asian “IE” languages, milk is versions of duh, dudh (see udder), and again, any reflexes of the form milk are accidental loanwords. The “Aryans” of the Eastern Europe, although genetically associated with the Eastern European farmers of the 2000 BC, attained a different ethnicity upon reaching the Iranian highlands and Indian subcontinent, because the Persian milk is shir “milk”, and “to milk” is dushidan, quite different from the Illyrian, Scandinavian, Baltic, and Germanic versions. The “Aryans” did not bring the European milk lexicon or culture to India either, since lactose intolerance is innate for India and the “IE” Persia, and the Skt. milk lexicon is a cognate of the Persian, not of the European word. The memeleki milk must be one of the most ancient Türkic lexemes introduced into European languages ca 4800 BC via circum-Mediterranean Kurgan route of the people with R1b Y-DNA marker, and ca 3,000-2,500 BC Turkification of the Europe and South-Eastern Europe via overland routes by the same Kurgan R1b people. A mechanism of introducing the word is blurry. Its presence in the Celtic group attests to its presence in the Eastern Europe at 6th-5th mill. BC, way before the first Kurgan waves ventured to Europe 2-3 mill. later. Its absence in the Baltic group and its presence in the Slavic group attests to its late northwestward movement, after the breakup of the Baltic group into Baltic and Slavic languages, tentatively dated by the 1st mill. BC. The same is corroborated by its absence in the Fennic languages and in the Asian “Aryan” languages: it smoldered from 6th to 1st mill. BC, and bloomed northwestward in the 1st mill. BC. The absence of a common “IE” word positively points to the Türkic origin of milk in the Gmc., Celtic, and Sl. languages. See udder.
English mind (n.) “faculty of reason” ~ Türkic ming (n.) “brain” with a constellation of dialectal forms for brain: meji/meŋä/meŋi and men/min/ben/bin/beñi: (m/b alternation). EDT and OTD combined list 17 allophones, G.Clauson notes: “This word occurs in a puzzling variety of forms” (Clauson EDT 348). The Türkic forms come with interspersed m/b alteration, the b- forms center around Black Sea - Caspian zone, the m- forms span across Eurasia. It is apparent that generally, the faculty notion “mind” is a derivative of the word “brain” with m/b alternation, Cf. Sl. mysl (мысль) “thought” and mozg (мозг) “brain”. Cognates: A.-Sax. mynd “memory, remembrance”, ONorse minni “mind”, Goth. muns “thought”, munan “think”, maud “remember”, ufarmaudei “oblivion”, Gmn. minne, originally “memory, loving memory”; Balto-Sl. (Latv.) smadzenes, (Lith.) smegenys “brain”, (Sl.) mozg (мозг) “brain”; Lat. mens “mind”; Skt. matih “thought, mind”. The abundance of phonetic variations points to a lengthy history of the word, the reduced g in ng may be an archaic reflex of the suffix -k/-q/-g signifying derivative nouns and adjectives. A presence of the Skt. word indicates either a time earlier than 2000 BC, or a later borrowing, the latter is likelier, since the notion of brain is not necessarily connected with thought, take for example chickens and fish that have one but not the other. The dictionaries do not necessarily include all the extant, deviant, or archaic forms. The ancient forms with prefix ge-/ga must be Gmn. innovations; the auslaut -d likely reflects the original Türkic dialectal form of the elative locative suffix ta/tä/da/dä/δa/δä, lit. “of brain”. In English, the mind, brain, mental, and sane and sanity form a cluster that ascends to the identical Türkic cluster of ming/ben “brain” and san- “think”. The cluster constitutes a case of a transfer paradigm, a positive attestation of the genetic connection. See brain, mental, mentality, sane, sanitary, sanity, think.
English muscle (n.) “organism's contractile organ” ~ Türkic muš, müš (mush, müsh) (n.) “mouse”. Cognates: A.-Sax. mus, muse, mys “mouse, muscle”, muscelle, muscule “mussel”; MFr. (14th c.) muscle “muscle, sinew”, Lat. musculus “muscle”, all lit. “little mouse”, diminutive of mus “mouse”. The semantic bifurcation “mouse, muscle” is a paradigm attested among the Türkic languages: sıčğanak “muscle” is a diminutive form of sıčga:n, lit. “little mouse”; this paradigm was transferred to Lat. (musculus), Gk, and A.-Sax. The modern science made the Gk. allophone of the Türkic muš an international word, e.g. myalgia, myotrophy, myocardium, myotome, myasthenia, and many more. Aside from the same old Türkic metaphor “little mouse” neither the Türkic, nor the European “IE” languages have a standard word for “muscle” (Clauson EDT 796). See mouse, cat.
English nose (n.) “facial central prominence” ~ Türkic ñü:z (yü:z) (n.) “face”, generically “surface”, with as many semantic extensions as are endowed to the English nose and face. Cognates: ONorse nös, OFris. nose, Du. neus, OHG nasa, Gmn. Nase; Balto-Sl. (Lith.) nosis, (OCS) nasu; Lat. nasus; OPers. naham (with s/h alternation); Chuv. ner “face”. How the Türkic ñü:z “face” became a European “nose” will likely be never known, but the fact that nose is a most prominent part of the face, and the phonetic equivalency are undeniable. The form ñü:z is a form of the “regular” yü:z, Clauson asserts that “words which began with y- in 8th century had earlier begun with d- or n-”, and specifically cites the form ñü:z as the older form of yü:z; he also asserts that “There is, however, seldom any difficulty in determining the original forms of such words (Clauson EDT 869).” Absent a contemporary record of the older form ñü:z, the phonemic study is the best initial terminus that leads to the common European word matching the archaic form and more than relevant semantics. The transfer of the Oguz form vs. the Ogur form ner is a diagnostic peculiarity, since the oldest Kurgan vernaculars of the Celtic and overland waves, and the later Hunnic-circle vernaculars, tend to attest their Oguric affiliation. The word “nose”came to Eng. as a paradigm, together with two forms for “face”, yü:z with prosthetic anlaut f-, and old A.-Sax. wlita/wlite, Goth. wlits for “face”, which are cognates of the Tr. bet “face”, and via Goth./A.-Sax. intermediary produced the Sl. litso (лицо) “face” with an elided w-. Although during the Middle Age the A.-Sax. wlita/wlits lost a popularity contest to its synonym face, it rightfully belongs to the substrate layer status and to the “nose” paradigm. The OPers. form is consistent with s/h transition typical for the languages of the Aral area. If the European forms were acquired via or from the Aral area, they would have carried -h-, its absence attests that the OPers. form originated fr. the northeastern Europe sometime prior to the Indo-Aryan migration in the 2nd mill. BC. The origin of the paradigmatic “nose” and “face” is clearly non-IE, since “IE” languages have a large collection of different nominals for the “face”, obviously taken from a variety of non-IE sources, and there, the deficient “IE etymology” rightfully flops on it face, undermining the Family Tree model. The exact phonetics, close semantics, and the transfer of the tri-partite paradigm validate the Türkic origin beyond any doubts. See face, wlita.
(Skip) English phlegm “lung discharges” ~ Türkic balgam (balɣam) “lung discharges”. The Gk., Arab. phlegma is etymologized as related to Gk. phlox “flame, blaze”, but there is a long way from the Classical Greece to the S.Siberian steppes for a Gk. loanword to penetrate into Oguz languages. A Gk. borrowing from the Western Scythians, who brought the word from the north-eastern fringes of the Middle Asia, would appear to be a better scenario, but an absence of a suitable base stem, of which balgam would have been a derivative, makes the direction of borrowing a mute matter. The Gk. dissemination at a time of the Gk. domination of the South-Central Asia is a viable path.
English quim “cunt, vulva, vagina” ~ Türkic kin “vulva, vagina”; am, em ditto.
The Türkic two forms, kin and am, em, and the eb with an -m-/-b-
alternation, are likely second forms of a single primary root ken-/gen- for the
notions of childbearing and generations. Or the vice versa, there is no way to tell which form of
the three allophones appeared first. The forms are so close that they can hail and ossify from two
ends of the same Sprachbund. The anlaut q- (k-) could be an articulation of the root
kin-/ken-, or an Ogur prosthetic consonant with am, em. This is one of those eternal
words that are transmitted before puberty, and never go away. In pastoral societies engaged daily in
reproduction of animals, butchering, and anatomical evisceration, there was nothing obscene in the
nature of sexual procreation, reproductive organs, or its terminology: sik- (v.) “sex,
copulate”, sikiš
(n.) “sex, copulation”,
dick/dık- “penis”/“erect, stand straight”, kin “vulva, vagina”, and probably other trade
terms now scattered among Eurasian languages (Cf. Sl. khui (хуй) “penis” from Türkic
kü:g/küy “horny (sex), sexy”). Cognates: Anglo-Sax. cynd(lim) (with -k-, -n-)
“womb, genitalia (pl.)”, cwene (with -k-, -n-) “woman, wife”, MEng. cunt
(1230), cunte, cwen, queen “woman, wife”, OFris., MDu. cunte, ONorse kunta,
Norse kvinnе “woman”, MLG kunte, OHG. quena, “woman, wife”, Goth.
qina-kunds, qineins “female”, qino, qens (qeins) “woman, wife”, ga-qiujan
“give life to”, Icl. kven(sköp); Lat. cunnus, Gk. κόλπος
(< am/em/eb
with prosthetic k-, -l-), Alb. qepurat (< am/em/eb); Est. häbe (<
am/em/eb), Fin. häpy, emätin (< am/em/eb); Kaz.
qın(apşıq), Uz. qin. All cognates relate to female genitalia, female sex, and feminine
production of offsprings. The auslaut alternation -n/-m is historically documented, Cf.
attested continuity of cunt and quim “vagina”. The more westerly form eb is due
to the m-/b- dialectal alteration. It is a cognate of innumerous derivatives, one of which is
the Biblical Eve and Sl. ebat/ibat
(v., n., derivatives) “to copulate”. European examples are notable for the same bifurcation
“vagina”/“female” as that notable in Türkic: küŋ “slave maiden” (Cf. Goth.
qina-kunds lit. “familiar vagina”), küni: “concubine”,
etc. A huge trail of semantic extensions with minor phonetic variations grew from the primary root
ken-/gen- and its immediate derivatives, some with reflexes in the Gmc. group, e.g. ke:nč
“baby (fauna and human), child, new” (Cf. Gmc. kinder), ka:n- “satisfied, satiated”
(Cf. cum “experience sexual orgasm”), kın-
“desire, love, arouse” (Cf. keen “strong, impatient wish”), etc. A separate group of the
apparent derivatives is the terms of kinship: kün “kin, kindred, relative, blood relative”
(Cf.
kin “kin”), kün (Cf. Hun “Hun”), kingü (![]() kng,
vowels not marked) “king” (Cf. king “king”), kaŋ “father” (Cf. ka:n/xa:n
“khan, ruler”, kaɣan/kağan “Kagan, ruler (kaan with silent -ğ-)”; the
khan and kagan are extensions of the kaŋ “father”, qunčuy/xunčuy/koŋčy
“princess, female of royal blood, female noble” (Cf. Ch. 公主 koŋčy, pyn. gongzhu,
ditto). Etymologically, the word is supposedly rated “of unknown origin” for both allophones,
quim and cunt, in a perfunctory non-scientific assertion parochially limited to the “IE” paradigm given the weight of cognates across Eurasia. See cum, dick, Eve, ewe, gain, gene, keen,
kin, king, sex, wife, woman.
kng,
vowels not marked) “king” (Cf. king “king”), kaŋ “father” (Cf. ka:n/xa:n
“khan, ruler”, kaɣan/kağan “Kagan, ruler (kaan with silent -ğ-)”; the
khan and kagan are extensions of the kaŋ “father”, qunčuy/xunčuy/koŋčy
“princess, female of royal blood, female noble” (Cf. Ch. 公主 koŋčy, pyn. gongzhu,
ditto). Etymologically, the word is supposedly rated “of unknown origin” for both allophones,
quim and cunt, in a perfunctory non-scientific assertion parochially limited to the “IE” paradigm given the weight of cognates across Eurasia. See cum, dick, Eve, ewe, gain, gene, keen,
kin, king, sex, wife, woman.
(Skip) English saliva
“liquid in mouth” ~ Türkic liš (lish) “saliva, spit, mucus, phlegm”. The Türkic word comes in
numerous forms, attesting to the time depth and dialectal spread: lešp/lisip/lisp/liš/salya
(leshp/lisip/lisp/lish/salya), and more. Cognates: MFr. salive, Lat. saliva, Ir.
seile, Balt. (Latv.) seiles, Est. sülge “spittle”, Sl. sluna “spittle”,
sliz “mucus, phlegm”, etymology “of unknown origin”. The Gmn. word is spit (spittle), and
apparently saliva and spit survived in English due to parallel usage. The recurrent
element sl in numerous European languages points to a common s- form of the word that
entered the Europe from the west, the Celtic Kurgan circum-Mediterranean migration, and from the
east with the Kurgan overland waves that started in the 4th mill. BC.
70
English seizure (n.) “bout, sudden attack of illness” ~ Türkic sïzğur- (v.) “get sick”, a derivative of sız (n.), sızla- (v.) “acute pain, languish, pine, ache, slenderize, stunting”. Sïzğur- is either a verbal denoun derivative fr. sız (n.) “pain, ache” or a deverbal derivative fr. polysemantic verb sız- (v.) “atrophy, shrivel, wither”. Both English and Türkic terms refer to medical condition. The velar plosive -ğ- is silent or elided in many languages, resulting in a vocalized form sïzur /si-zhur/ perfectly homophonic with Eng. seizure /see-zhu(r). The noun sız and the verb sızla- are deverbal polysemantic derivatives fr. the verb sı:- “break, destroy” with both literal and metaphorical semantics. Sı:- has produced a notion of “weakness, flaw”, conveyed by the derivative verbs sı:z- “melt, melt down, ooze”, and sızla- “languish, slenderize, stunting” loaded with the causative notion of “acute pain, pine”. The verb sız- “to melt, ooze” is a cousin of thaw, with the semantic extension of metaphorical “melt, shrivel, wither” in respect to health and body; the sïzɣur- (sïzğur-) is formed with the “rare” in the eastern vernaculars inchoative suffix -ɣur (-ğur-) that makes causative “bring about exhaustion, shrinkage, weakness, enfeeblement”. The notion “seizure” is derived from the notion “acute pain, bout”. The derivative verbs sızla:- and sïzğur- conflated all above notions, the suddenness, the sharpness, the attack, the debilitation, and the pain. In turn, the notion “seizure (medical)” has produced the notion “seize” meaning “grab, grasp”, which offered further semantic branching like the verb seize “capture, take by force” that echoes the underlying notion of “break, destroy” with semantics of “vanquish and capture”, presumed “fr. a Gmc. source”, with its own etymological history, etymologically rated “of uncertain origin”. It is semantically incongruent with the notions of “death, disease”, etc., see seize. The form sız- has an allophone sıs- (NE Türkic form, Altaic, Teleut) found in the Fr. cognate. That specifically links the European forms with the particular areal Türkic forms (i.e. sıs- for sı:z-, sı:sla:- for sı:zla:-). The “IE etymology” proposed an arbitrary derivation of the parental nominal form seizure (n.) from the daughter verbal form seize (v.), with further ascend to an unrelated cluster of the allophones for seek (with the second consonant -k-). Cognates: Brit. seise, OFr. (13th c.) seisir “take by force”, LLat. sacire (/sasire/) ditto, “of uncertain origin”. The late timing of the Lat. word and a paucity of cognates attest to the non-IE origin. The Brit. form accentuates the second consonant -s- (versus -k-). The derivative noun seizure “capture, take by force” is homophonous with the parental noun seizure “sudden convulsion, illness, pain attack”. Both seize and seizure “capture” probably came to OFr. and LLat. from the Early Middle Age Burgund (Provence, Savoy) nomads. The “IE etymology” commits double whammy, on phonetical similarity it confuses seize, seizure “capture”, a legal term in reference to property holdings or offices, with seek (Goth. sokjan “seek”, A.-Sax. secan “seek”), an obviously doomed proposition that links the incongruent “capture” and “seek”, and fails to link the seize, seizure “capture” with medical seizure “sudden convulsion, illness, pain attack”. Undoubtedly, phonetic similarity and semantic parallelism (Cf. “seized with emotions”) caused routine semantic conflation where the emphasized abruptness of the notion of “sickness” became complimentary to the alternate notion of “seize”. Notably, Sl. has a calque of the verb seize “capture” based on the Sl. root hvat- “grab” in both medical and property senses (Sl. shvatka (схватка) “seizure (med.)”, also “contest (struggle)”, zahvat (захват) “capture”, identical with English case, but unlike the Türkic languages, which did not produce synonyms for “capture” from the root sız. That particularity attests to that the notion “capture” from the root sız evolved in the NW European Sprachbunds as an amalgamation of the Türkic lexus with the areal semantics. The drastic semantic difference between “capture” and “pain, sickness” points to two independent paths, one by a southern route to OFr. and LLat. as a loanword and then to Eng. as as legal term, the other term joined English demographicly as a household lexicon. The morphological mechanisms forming these two distinct notions had to be also distinct. Over the ages, the derivative homophones conflated, confusing etymological experts. But the words' status of non-IE origin “of uncertain provenance” and the perfect phonetic and semantic match leave no doubts of the Türkic origin and ultimately from the same stem for both homophones seizure “pain, sickness” and “capture”. See seize.
English sinew (n.) “sinew, tendon” ~ Türkic siŋir (n.) “sinew, tendon, nerve, blood vessel”, fr. siŋ- “infuse” + -ir verbal suffix. Cognates: A.-Sax. sionu, seono “sinew”; OSw. sinewa, ONorse sina, OFris. sine, MDu. senuwe, OHG senawa, Gmn. Sehne “sinew”; Welsh gewyn “sinew”; Skt. snavah, Av. snavar “sinew”; Balt. (Lith.) sausgysles, sausgysliu; Arm. neard, Gk. neuron “sinew, tendon”; modern Turkish sinir. Via Gk., the Türkic siŋir entered European languages for the “nerve”. The credit of using the Gk. alternative neuron for nerve may belong to Galen. The westward and eastward spread of the word siŋir can serve as a marker of migrations: northwestern into Gmn., southwestern into Balkans and Romance, and southeastward to Skt. and Av. migration across Eurasian steppes between 4000 and 3600 ybp. The Balt. (Lith.) and the Welsh forms may point to the path around Mediterranean via Iberia to the Baltic zone starting at 4800 ybp. The “IE etymology” is notable for its choppiness, shallowness and creative inventions, and the abundance of forms in the European languages points to multiple independent sources introducing the word “sinew” into the daily life.
English skin (n.) “animal hide, epidermis” ~ Türkic saɣrï (n.) “animal hide”, particularly the pelt from the back or hindquarters. The word comes in allophones “with large phonetic changes”, attesting to pastoralism of a hoary antiquity; the Gmc. phonetic spectrum is wider still. The Türkic stem saɣ has connotations of an animal, and particularly of the sheep, this stem produces words for milking, hunt, sheep, and the like. The word saɣrï, however, is more specific, it generally refers to the horses, pointing to the steppe hunting and wild horse herding eventually developing into horse husbandry. That narrows the timeframe to between 7th mill. BC (the first Eastern European kurgans) and 4th mill. BC (Botai domestication). Cognates: A.-Sax. scinn, ONorse skinn, OHG scinten; Gmn. schind, schinden, Flem. schinde, Breton scant, Dan., Norse skjule; Welsh cuddio; Sl. shkura (шкура), Pol. skorа; Gk. skutos (σκῦτος), all referring to animal hide, fur, skin or outer cover (bark, fish scale). Eng. also has a later loan-word allophone of skin/saɣrï, the shagreen leather, which unbeknown to its users is a tautologic composite. Sl. cognates retained the Türkic r, the northern European switched r to n, among other variations. The distribution of the word, from Mongolia to Atlantic, and its absence in the Asian “IE” areas, makes etymological association with the Kurgan people and Scytho-Sarmatians unavoidable. The “IE etymology” somehow connects skin with cut, which is semantically and phonetically unsustainable and, considering uniformity of allophones and their particular distribution, unnecessary. The quartet of kindred terms, derma, leather, skin, and suave, complemented by the late acquisition of shagreen, powerfully demonstrates an authentic case of paradigmatic transfer from a common source, attesting to the direct demographic connection. See derma, leather, suave.
(Skip) English skull (n.) ~ Türkic kelle “head”, a cognate of the ancient word form which produced English skull < general Scandinavian skulle/skult “head”; Slavic glava and golova: Türk. kelle > Balt. (Latv.) galva > Sl. glava, golova, hlava, glowa, hlowa; Aramaic gulgulta, lit. “(place of the) skull”, cognate with Heb. gulgoleth “skull”, the famous name for Golgotha where Jesus was executed; Armenian gluχ “head”. The predominance of anlaut g and presence of Slavic anlaut forms hl point to original glottal stop phoneme /q/, transmitted with local phonetical tools, with the Oguz Turkish kelle being only one of the dialectal forms. The spread of the word from northwestern Europe to Levant and Mesopotamia doubtlessly singles out the horsed Kurgan riders as the source of the borrowings, and allows to assign terminal dates of the borrowing by following the traces of the migrants' genetic mutations and literary traces. Another notably shared feature is the use of the same root in numerous languages for the generic “kill”, exemplified in English, where the word “behead” stripped the word “kill” from its origin, while in other languages the semantic “behead” from the kelle has survived, like the Russ. obezglavit (обезглавить) “behead”.
English swell (n.) “abnormal protuberance or localized enlargement” ~ Türkic siwel (n.) “swelling
(on skin, body)”, like wart, nipple, and piles. G. Clauson
observes “chaotic vocalization” and lists a complement of allophones, with the form siwel
noted in 15th c. Chagatai records, not too far from the Aral basin and Horezm, which are consistent
with the address of many other English substrate words of Türkic origin and specific location of the
denoted Türkic forms. A CT form is sigil/sügül/sükül, the -w- in
siwel connotes a silent -ğ-, making articulation peculiar enough to narrow
pronunciation to very few candidates, and allowing to further pinpoint the candidates within the
Chagatai domains. Cognates: A.-Sax. swellan “grow or make bigger”, OSax. swellan,
ONorse svella, OFris. swella, MDu. swellen, Du. zwellen, OHG swellan,
Gmn. schwellen; the uniformly and exclusively Gmc. lexicon is not even attempted to be
etymologized as an “IE” word, a mechanically produced “PG proto-word” is offered as an explanation,
with a routine “of unknown origin”. The very specific phonetic form, on the background of large
spectrum of “chaotic vocalizations” points to relatively focused origin in time and space, to the
nomadic people called Wendeln “Wonderers” Vandals, that is the Goths, Burgunds, Turings, and other
folks known under a general term Sarmats, who in the 2nd c. BC rolled into the Western Europe, which
at the time became known as European Sarmatia. Notably, before the arrival of the Sarmats, that part
of Europe did not have any particular name, it was largely a terra incognita. Although only a
nominal form has been recorded, it is likely that the word migrated with both verbal and nominal
functions, and some form of the modern Eng. verbal derivatives, like “puffed up”, have already been
around.
71
English testicles (n.) “scrotum purse (external pouch that contains testes), male penis with scrotum” ~ Türkic tašaq (tashaq) (n.) “scrotum, male penis with scrotum”, ultimately fr. the Türkic tašaq lit. “little stone”, fr. taš “stone”; that Tr. metaphor became an international word spread around the globe by the modern medicine. No sane “IE” cognates, the Lat. testis “testicle” ascends to the same Türkic word tašaq. Dictionaries do not offer dialectal variations, but it is doubtless that among 42+ extant Türkic languages, variations ascending to the pre-historical periods do exist, Cf. the eidetic Sw. testiklar, complete with the Türkic pl. ending -lar, and the modern Turkish tašaklar. The ancient Greeks with their presence in Central Asia and their parastates for “testicles” could not be the originators of the Far Eastern Türkic words, any borrowing would have preserved the prefix para as a stem, and modified the part states as an appropriate Türkic string of suffixes. The only plausible far-reaching candidates for transmission and dissemination remain the fluid Türkic mounted nomads.
English tit, teat (n.) “nipple, breast” ~ Türkic töš/tö:š (n.) “breast”, tiši:/dıšı: (n.) “female”. All Türkic terms for “female”, “wife” were extensions of the notion “clan, reproduction” or, in parallel, allusion to female physical particulars. The first line is evči: “housewife” (ev “house” ), displaced by urğačı/ura:ğu:t “housekeeper” (ur- “establish, organize”) that alludes to clan, reproduction, and nascence, displaced by ka:tu:n “Queen, lady”. The second line, not always entered into dictionaries in their lit. sense, is eb/em/am “vulva, pudenda” (Cf. emig “nipple, teat”) and töš/tö:š/döš/dö:š “breast”, which produced a series of Eurasian allophones including the Eng. tit, teat. The form eb rings in the name of the pra-mother Eve “progenitor, engender” and the Türkic aba “mother”. The word mama “mother” is a derivative of word mamu: “nipple, female breast”. The connection between the Türkic forms for “breast” and “female” and the English tit/teat is obvious. It parallels the other appellations which eventually became wife, ultimately a derivative of ebi- or ebe- of the stem eb/em “female genitalia”, emig “nipple, teat”. Transition from an adjectival form to noun is documented in the idiom tiši kiši (tishi kishi) “a female”, lit. “teats' person”, and in such semantics it is also applied to mammals, like “tits camel”, “tits goat”. Another example is tö:š ba:ğı:, lit. “breast binder”, a specifically female application. Cognates: A.-Sax. titt, Du. tiet, Sw. tutt, Gmn. Titt, Welsh titw; OFr. tete; Hu. cicik, Fin. tissit, Est. tisse; Sl. (Rus.) siska (сиська), tsitska (цицка); Hebr. tyz, etc. In contrast, Lat. had a distinct form mammis “breast”, an allophone of the Türkic mamu:. Notably, Balt. and Sl. forms have different roots, and so do the “IE” languages at large in and outside of the Europe; the Sl. form agrees with Gmc., Fennic, and Türkic forms. The Eng. and Gmc. form tit came via different path from the form teat, a potentially valuable diagnostic trait for the English philology. The words tit and teat belong to a glut of the words related to femininity and female physical attributes that abundantly attests to the common origin of the Türkic and English vocabulary. See Eve, mama, wife.
English toe (n.) “front part of hoof” ~ Türkic toy(nak), tuy(aɣ) (n.) “hoof”, -nak, aɣ is a diminutive suffix. Türkic has an abundance of allophones modeled after toy + allophones of diminutive suffix -nak. Contrary to Clauson, the base root appears to be to- “stop, end”, not ton-: the -n- systemically belongs to the diminutive suffix. Cognates: A.-Sax. ta (plural tan), Mercian tahæ, ONorse ta, OFris. tane, MDu te, OHG zecha, all “toe”. The A.-Sax., OFris., and Du have retained on record the Türkic archaic pl. suffix -an “hoofs, toes”. The semantic derivative “digits of the foot” probably developed in the Türkic milieu, it is limited to the Gmc. languages, the other European languages use various terms for “finger” and not “hoof”. Gmc. languages have retained relicts of the original semantics connected with the front part of the hoof, e.g. toe crack (of the hoof), toenail, tiptoe. The distribution, limited to the Gmc. languages, clearly attests to the non-IE origin. The “IE etymology” is zanily laughable: PG *taihwo “toe”, PIE *deik- “to show”. The triplex of toe, hoof, frog, all connected with hoofs, constitutes an authentic case of paradigmatic transfer, indelibly attesting to the common genetic connection. See hoof, frog, stop.
English tooth, teeth (n., adj.) ~ Türkic tiš (tı:š, dı:š) (n., adj.) “tooth”, the oldest Gmc. form is Goth. tunthus (tunþus). This must be among the oldest known words of vocabulary shared with Türkic. Cognates: A.-Sax. toð, OSax., Dan., Sw., Du. tand, OFris. toth, ONorse tönn, OHG zand, Gmn. Zahn, Goth. tunþus; OIr. det, Welsh dent, Lat. dens; Gk. odontos; Balto-Sl. (Lith.) dantis, Sl. zub (зуб); Skt. danta; Sum. zu. All cognates are fairly transparent, with initial t-/d-/z- alternation consistent with typical Gmc.-Gmn. phonetic transformations that in this case also cover Sl., and a prosthetic -n- as a second consonant. With the direct correspondence of the attested teeth/toð/toth/det - tiš, there is no need neither for conjectural PIE *dent-, nor for PIE origin, nor for conjectural i-mutation (tooth - teeth) as both the A.-Sax. toð and the Türkic tiš were already around and ready for adoption. Alternately, the first consonant -z- and the second consonant -n- may be an Afro-Asiatic inheritance, Cf. Arab. sinn “tooth” and Sum. zu; in that case Gmc. forms have dual predecessors. The absence of cognates in the other “IE” languages attests the origin of the term as a loanword from a non-IE language. Rather, the object of the inquiry should be, what was the European “Old European” word for “tooth”, which of the European languages carried it to the present, and what Y-DNA haplogroup is connected with that language. Answers to those three questions would be a step toward elucidation of the fate of the “Old Europe” languages and the origin of the “IE” variety.
English wlita (obs. n.) “face, countenance” ~ Türkic bet, bit (n.) “face”, generically “surface”, The form bet, bit does not have an obvious etymology, which leaves room for possible origin from the local languages, in that case the Corded Ware culture (3200-2300 BC), which bordered on and interspersed with the Pit Grave culture, could be a viable source. Then the direction of the initial borrowing and the sequence of phonetic adaptations would be reversed. Cognates: A.-Sax. wlita/wlite, Goth wlits “face”; Sl. litso (лицо) “face, cheek” with elided w-. Tracing the Sl. form leads to the OIr. lессо, Ir. lеаса, OPruss. lауgnаn, all “cheek”. That points to the period when Celtic and Sl. people occupied the same area in the Central Europe, the period extending to the historical times, and validates the relative preeminence of the Gmc. form. The word “face” came to Eng. as a paradigm, two forms for “face”, the bet transcribed wlit- and the version of yü:z with prosthetic anlaut v-/w-/f- that formed something like vü:z/wü:z/fü:z for “face”, and a ñü:z for “nose”. The A.-Sax. wlita/wlite lost a popularity contest to its synonym face sometime during the Middle Ages, but it rightfully belongs to the faded layer of the substrate category. The origin of the two forms for “face” is clearly non-IE, since “IE” languages have a large collection of different nominals, obviously taken from a variety of non-IE sources, and the deficient “IE etymology” rightfully flops on its face to legitimize them. Whatever the original source for the bet, bit, the close phonetics, exact semantics, and the transfer of the tri-partite paradigm validate the Türkic origin beyond any doubts. See face, nose.
English baize (n.) “woolen fabric resembling felt” ~ Türkic bez (n.) “baize (coarse woolen cloth)”, generic for “cloth, fabric”. At first a semi-baize (with cotton) and then the hemp and cotton versions were the most widespread inexpensive type of fabric before and after the industrial revolution. During Middle Ages bez was a Central Asian trademark product. The logical origin of bez is the verb bezä-/beze:- “adorn, ornament”, a verb that also formed the Eng. bezel “edge, frame”, lit. “adorned”, see bezel. A questionable alternative, for cotton version in the context of a Rus. etymology, is suggested to originate fr. the Turkish beyaz “white, bleached”. Cognates: ME bayse, Fr. baies; Sl. byaz (бязь); Gk. bussos (βυσσος); Arab. bazz/bezz, Heb. buss; Mong. bös, bes; Tungus/Manchu bashu/boso/bosu/busu “cloth, fabric”; Ch. 布 pu/bu; Chuv. pir. The Chuv. form with r/s alteration attests to the archaic origin, a borrowing would have retained the CT -s. The Türkic word is recorded at least 500 years before its appearance in the French records. Any “IE” etymological speculations to extract this word from “IE lexicon” are pure fantasies, for 8,000 years the Türkic pastoralists relied on products of animal husbandry, and developed numerous terms connected with felt and its production; there is no need to derive Eng./Fr./Sl./Gk./Arab. term from semantically unrelated phonetic resemblances like a reddish-brown bay color of the Fr. baies that ignore the Arab. and Sl. allophones. The majority of the Türkic forms is böz, the peculiar form bez/biz, closest to the European forms, is recorded specifically for the Türkic Southwestern languages (Turkmen, Ottoman, etc.), consistent with other English Turkisms, and that origin is corroborated by the Arab form bezz (In the New Era, the Arab expansion first encountered Türkic populations during the 100-year war with the Caucasus Huns that started in 642 AD). Etymological interpretation of baize as linen reflects the natural use of available materials by different economies to produce a desired effect in different markets. The Gk. “linen” is linon (λίνον), hence the spread of the European allophones for “linen”, unrelated to the woolen baize neither phonetically nor materially, there is no need to appeal to the Gk. allophone. A manufacture of the baize-type fabric from flax could theoretically have been done by the Scythians, since Herodotus attested that the Scythians had enough hemp to make their weekly baths for each Scythian, a fact probably irrelevant for etymology. Since no names for fabrics were recorded for A.-Sax. or its sister languages, the form bayse probably reflects the nomadic legacy of the Türkic bez.
English belt (n.) “waistband” ~ Türkic bel (n.) “belt, girdle, waist”.
The form belt is a deverbal noun from the verb belä-/bele:-/be:le:- “to lace, wrap”,
grammatically “belting, lacing”, formed with the suffix -t, like the words part, port,
unit, etc.; the notions of “waist”, cradle lacing, “small of the back”, “col (narrowing of a
mountain pass)”, “satisfy (somebody's belt with food)”, and “kidney” are semantic extensions. The
bel happened to be just one of 12 synonyms for “belt”, that points to a long period of
development and acquisition. The oldest belts are depicted on the “Scythian” memorial stone
balbals, spread from Pacific to Atlantic; the latest balbals belong to the Kipchaks of
the Middle Ages. Belt was a key component of the nomadic kaftan coat, it was a service belt
for carrying essentials starting with Neolithic stone axe and grindstone. The traditional and the
only Türkic attire, for men and women, was a left-lapelled caftan with a belt, described by all
kinds of literati from early writings to the 19th c. and in places beyond that, and graphically
immortalized on the carvings of the mengir funeral steles. The form of another Türkic
expression for belt, belbaɣ, points to the mechanism of forming derivatives (Tale of
Oguz-khan, 13th c.). The same morphological mechanism is used in forming the Sp. bolsa,
“something hanging at the waist”. The absence of a final -t- may point to Ogur languages,
Herodotus on Sarmats noted distortion, and M.Kashgari on Bulgars noted that they truncate suffixes.
Cognates: OHG balz, ONorse balti, Sw. bälte; Lat. balteus
“girdle, sword belt”, said by Varro to be an Etruscan word; Sl. (Rus.) pelenat (пеленать)
“wrap, swaddle”; Hu. (be)polyaz ditto. The Etruscan-Türkic correspondences is a separate
subject, it was analyzed in detail by the former ambassador to Italy Adile Ayda,
Etrüskler (Tursakalar) Türk idiler, Ankara, 1992, In Turkish, Les Etrusques étaient des
Turcs preuves, Ankara, 1985, In French, and numerous other scholars. Notably, the eminent
sitting etymologists assert an implication that the secretive Latins passed the word only to the
Gmc. brunch, bypassing their own Romance family, a grand circus trick on the grand European scene.
To keep the secret, from generation to generation, in front of their toddlers they as one must have
used a codeword for belt, like a cinturon, and disclosed the true word only at
maturity for the secret to be passed to their grandkids. The Latins did not limit their secrecy to
the word belt, a number of other words of the Table 2 are also shared only by Latins
and Germanics, presenting some heavily trotted mystical trail of conspiratorial evidence. See
bull (edict).
72
English boot (n.) “tall footwear” ~ Türkic bot, but (n.) “leg, foot, thigh”. Like the English foot, the Türkic bot/but is a very productive stem, it can form anything connected with or resembling legs: butïq/butaq “branch (tree)” (see boutique), “sprout”, “shoot”; but “leg of trousers” (Cf. leggings), butla “kick a leg”, butluɣ “with legs (chair)”, etc. The “IE etymology” is non-existent, the word supposedly is of “unknown origin”, “perhaps from a Gmc. source”. Cognates: ODorsetshire (scilty-)boots “(shield-)boots”; OFr. bote /bot/ “boot”, with corresponding words in Provencal (France) and Spanish, originally for riding boots only. The part scilty-/skilty “shield” is synonymous with the Türkic verb sap- “sheathe, envelop”, thus scilty-boots is synonymous with leggings-boots. This word has a glorious Eurasiatic circulation: Besenyo and Kipchak sapag/sapug “(boot with) upper”, Est. sааbаs, Fin. sаараs, Fr. sаbоt “foresten boot”, Karel shоарроа/sаарраgа, Latv. zabags/zàbaks, Balt. (Lith.) sopagas/zopagas, Manchurian sabu, Mong. sаb, Sl. sapog and chobot, Sp. zapata. The Türkic origin of the words sapog, zapata, boots was a point of perennial contention and ridicule between Turkologists and advocates of the European primacy or exclusivity, for different reasons equally uncomfortable to both sides, and mostly caused by the timing of the term predating the Mongol expansion. See boutique, bodega, bud.
English cap (n.) and cup (n.) ~ Türkic kap (qab/qap) (n.) 1. “container, vessel, box”, 2.
“cover”; and all the derivatives of the “sack”, “vessel” and “cover”.
The verbal form is homophonous with the noun form, kap- (qab-/qap-) “capture, grab, grasp,
seize”, it is likely a denoun derivative of the
kap (n.), lit. “contain”, Cf. Eng. idioms “bag it”, “box it up”.
The “IE” speculation is “likely via Etruscan and Lat. (Lat. cappa
“cape, hooded cloak”, ciphus “goblet”)”, which brings etymology to two other speculative
unknowns. The “IE etymology” also claims the unattested*kap-
as its own PIE root meaning “to grasp”; that is probably based on a myopic interpretation on the
pervasion of the root within the IE-centered studies. The reality attests to the opposite, almost
all “IE” languages use instead their own native forms for the most ubiquitous verbal form kap-,
translated by G. Clauson with a pharmacopeia of literary terms: “capture, take, seize, catch, grasp,
snatch, take hold, steal”. Instead, the form is used by far-flung languages from incompatible
linguistic families: Fin. kaapata, Gujarati kabaje, Punjabi
kaipacara, Jap. kyapucha. The base lexeme is shared across different linguistic
families. Languages that can't make the consonant cluster -pt-
contract it to -t-/-d-: It. catturare, Kor. gajda, jabda, jabgi. The most
salient are the Celtic forms: Ir., Gaelic ghab-, Welsh gaf-; they attest to the
presence of the word kap/kap-
in the N. Pontic prior to the Celtic circum-Mediterranean outmigration of the 6th-5th mill BC.
Notably, in the European languages two Türkic nominal and a verbal semantic meanings are
correspondingly replicated in distinct semantic fields, “vessel”, “sack” and “upper cover”, and a
verbal “capture”. A.-Sax. cognates: caeppe “cap, cope, hood” (Lat. cappa), caepse
“box”, cop,
copp “cup”, cypa, cype, kipe “vessel, basket”; the terms like cab “carriage,
compartment” also belong to this throng. The fecundity of Türkic kap produces 39 derivatives
listed in a small Turkish dictionary, it is mirrored in the European languages, from cap to
cup and far beyond. “IE etymology” credits it with forming all or part of the modern Eng. lexis:
accept; anticipate, anticipation, behave, behoove, cable, cacciatore (dish), caitiff (cowardly),
capable, capacious, capacity, capias (arrest warrant), capiche (captured it?), capstan, caption,
captious, captivate, captive, captor, capture, catch, catchpoll (sheriff), cater, conceive, cop (v.)
“sieze, catch”, copper (n.) “policeman”, deceive, emancipate, except, forceps, haft, have, hawk
(n.), heave, heavy, heft, incapacity, inception, incipient, intercept, intussusception (pocketing),
manciple (quartermaster), municipal, occupy, participation, perceive, precept, purchase, receive,
recipe, recover, recuperate, sashay (dodge), susceptible. On top of that, the “IE etymology” piles
dubious cognates based on superficial phonetic resemblance. The list amply demonstrates how a
pretentious “IE” clone of the real Türkic root blossoms into a European tree with branches
underpinning a huge layer of the European vernaculars. Related cognates are the Lat. capere
“grasp, catch, capacious, comprehend”, capax “capacious”, capistrum “halter”; Gk.
kaptein “gulp”; Rus. kobec “falcon”, lit. “grabber”, Cf. hawk, kabak “pumpkin”,
kavun “water melon”, kabak “tavern”, kaban “pile, haystack”, and quite a few more,
most are recent Rus. acquisitions fr. the ambient Türkic languages; Latv. kampiu
“seize”; Skt. kapati “handfuls”. The verb cap- “capture” lives both in the Eng.
capture and numerous “IE” allophones. Gmn. Kapf, and Lat. caput for the “head”
belong to the same cluster. Ditto the Eng. cabbage and Türkic qabaq “cabbage”, with
the Türkic extension bal qabaq “pumpkin” illustrating the process: “pumpkin” = “honey
cabbage” < “honey head”, reportedly of Fr.-Burgundian provenance. Moreover, derivatives like
hood/bonnet cap, a trademark of the Scythian, Sarmatian, and Türkic dress across millennia called
kapšon (kapshon) in Türkic, retained both its Türkic stem and its Türkic suffix in the
loanwords: Eng.
capuche, capote, Gmn. Kapuze, Spanish capucha, Fr. capuchon, Lat.
kapuce, Russ. kapushon (капюшон), Arm. kapot (կապոտ), It. Church capuccino
(Order of St. Francis), and so on. A good dosage of derivatives are direct inheritance of the
nomadic days: cab “folding hood”, cabriolet, taxicab, cabinet, cabana, cabin, capsule, cabaret (fr.
“shelter”, “tent”), caboose, cabasset (helmet), cable (“encapsulated rope, wire”), and their many
allophones and derivatives. The unequivocally identical semantics and eidetic phonetics, the
authentic multidimensional cases of paradigmatic transfer unambiguously attest to the genetic
connection. Adding all English derivatives would instantaneously balloon the count of Turkisms in
English beyond any reasonable objective, without a significant impact on the estimated usage
frequency. See cab, cabbage, capture.
(Skip) English chintz “cotton fabric” ~ Türkic čit (chit) “cotton fabric”. The English term was borrowed from Hindi chint, a reflex of the Türkic čit/chit (Cf. Türkic sari in Hindi). Chintz became an international word, due to the British learning in the India colony, “Hindu cotton fabric with bright prints and glaze”, used for sari. The original word likely referred to hemp fabric, and switched to mean a special type of cotton fabric after the advent of Türkic into Hindustan peninsula in the mid of the 1st mill. BC, permeating into Prakrit and Skt (Hindi chint, Skt. chitra-s “clear, bright”). Already in the Prakrit and Skt. time, the Hindu ladies wrapped themselves in a Türkic-derived sari made of chint. The word became international with the British industrial production and commercial spread in the 18th c. See sari.
English coat (n.) “outer garment” ~ Türkic
ked-/keδ-/kej-/ket- (v.) “to don, put on (clothing)”, with the dialectal form ki- found
in the Middle Asia and in the European lexicon. Cognates: OSax. kot,
OHG
chozza, Gmn. Kotze, Kittel; OFr. cote, Sp., Port. cota, It. cotta;
Sl. kitel (китель)
fr. Gmn., all forms for outer, coarse, woolen garment. The English “IE etymology” proclaims the
routine “of unknown origin”, but the Gmc. etymology connects
Kittel and its Sl. version kitel with with the Türkic form kedüt, kedgü, kedgülük,
ketgülük “apparel, clothing” (with deverbal noun suffixes).
The Scottish/Celtic kilt, and likely the Japanese kimono belong to the same series.
Albeit apparently arriving by different paths, the duplex coat and don presents a case
of paradigmatic transfer, attesting to the genetic connection. See don.
73
English corset (n.) “close-fitting undergarment” ~ Türkic qorsa-, qursa- (v.) “to gird, to put sash”, from the stem qur “belt, sash”; the form qur, qursaɣ is synonymous with bel “belt”, see belt. The -sa in qursa- is a rare in the eastern languages denoun verbal suffix, apparently a contraction of the easterly common suffix -saɣ. The suffix -t in corset is another rare in the eastern languages deverbal abstract noun suffix, converting the stem qursa- into noun corset “something akin to belt, sash”. The ascribed “IE etymology” from cors “body” to corps makes no sense neither phonetically nor semantically, nor morphologically, nor in the context of the transitions of the Lat. corpus “body”, which is neither “IE” nor related to corset. The Eng. for corset was bodice (bodik), an allophone of the A.-Sax. bodig/bodeg “body, frame” and of the Türkic bod “body”, Cf. Türkic bodluɣ “bodied, endowed with body”; a second meaning of bod is “size”. The A.-Sax. form comes complete with the rare in the eastern languages Türkic denoun noun suffix -ig/-ik (Cf. -aɣ in qursaɣ) for noun derivatives and diminutives. Notably, morphologically corset and corsage are synonyms, they only differ by the suffixes, denoun vs. deverbal (Cf. bodig and corsage, both with -ig/-ik). A borrowing from the OFr. (13c.) corsett “bodice” is probable, but not necessary, these two forms likely coexisted interchangeably, likely with some semantic, dialectal, or ethnic difference. The sibling corsage, besides being functionally nearly identical with the siblings corset and bodice, also carries a notion “size”. The trio is not a neologism, archeological remains extend beyond the 2nd c. BC, suggesting that their names were already around. The paradigmatic transfer of four synonyms complete with their morphological markers, recorded in a confined territory of the W. Europe, and indelibly linked with the Türkic milieu, inescapably attests to the common genetic origin. See belt, body.
English cowl (n.) “hood, bonnet hat” ~ Türkic ko:l (n.) “hill”, kalpac (n.) “hood, bonnet hat”. Türkic has at least 16 words expressing a notion “hill”, the abundance makes it clear that it is a collection from numerous languages, with a rich trove of cognates in the European part of the Eurasia: Eng. hill, Sl./Gmc. holm, Gk. kolonos, Lat. collis, and many more; the Lat. coll- is identical with the Türkic qol “hill”. Other meanings of the stem kol are “arm, upper arm, forearm, hand, arm-pit, wrist, wing (army), hill, hillock, ridge, notching, valley branch, direction, thigh (meat)” plus a mass of metaphoric derivatives, quite a fecund stem. Its sibling cal is no less productive, with substantially complementary semantics like qalnu- “grow up”, qalva “arrow shaft”, etc. Ultimately a derivative from the stem kol (n.) “cone” ending in -pak, a metaphorical extension of “hill, hillock, ridge” in reference to the shape of a cone, lit. “hill (hat)”. Cognates: A.-Sax. cule, cug(e)le, cufel, cüfel, cufle, cuffle, cyfl, cuhle, scyfel, scyfele, Norse cowlen; Sl. kalpak (kalpak), klobuk (klobuk); Lat. cucullus, cuculla, Rum. gluga; Welsh cwfl, gwfl; Hu. csuklya (chushiya), kalpag; Yid. kovl; Jap. カウル kauru, Kor. 고깔 gokkal “cone”; Tatar kalfak, a form resembling the Gmc. forms; all “hood, cowl, bonnet hat”. The suffix -pak or any of its allophones is not used to modify the root in any of the Gmc. forms. The Tr. -pak and Sl. -buk are thought to be allophones of the Türkic diminutive suffix -q/-k/-ïq/-ïk/-uq/-ük.Kalpak is a traditional hat of the Scythians, Kazakhs, Bashkirs, Cossacks, etc., including a uniform winter hat of the 19th c. Turkish army, Red Army bashlyks, and Soviet generals; it was adopted or duplicated as a distinct military trait by many armies. At different times, it was also used as a status symbol (European religions), a symbol of wisdom and supernatural powers (Cf. Merlin), and as a derogatory allegory in societal connotations and in religious persecutions. Statutorily, it is an equivalent of the British tall hat. The “IE etymology” is a habitual dead end “of uncertain origin”. The recorded spectrum of the A.-Sax. forms illustrates that in the 5th-11th cc. all dialectal forms co-existed and were mutually understandable. The inlaut consonant -g-/-f-/-c- (-k-)/-h- appear to be a reflection of a native articulation, Cf. Lat. cuculla and Kor. gokkal. Such precise semantics and eidetic phonetics is a bad candidate for a random coincidence. Distribution across Eurasia and linguistic families attests to the high mobility of the carriers of the word along the Eurasian steppe belt. Sl. has preserved a secondary semantics of “cover”, attesting to a paradigmatic transfer and genetic connection between the entire spectrum of the Eurasian variety of the forms.
English (n.) diadem “headdress of sovereignty” ~ Türkic didim (n.) “diadem, wreath of bride”. Ultimately fr. tit (töš/tö:š) “tit, teat”, it alludes to generic female, and has survived as titir “female camel”, tiši kiši (tishi kishi) “a female”, lit. “teats' person”, and use of tiši as a determinant for female animals, Cf. she-goat, see tit, teat. In respect to the marriage rituals, the old records have preserved the words didim “diadem”, initially a name for a bridal wreath, and di:dek/didäk “(bridal) veil” (Kor. deop 덮, Gujarati dado (/dido/) ડદો, Turkish duvak), which reflect a distinct cultural tradition. Cognates: OFr. diademe, Lat. diadema; Gk. diadema (διαδημα); Sogd. didm (δyδm), Mong. udim, Khal. titem “crown”. From Korea and Khalkha to Greece: who else could seed this word across the Eurasia? The Hunnic diadems, like their caldrons, were archeologically traced across Eurasia, from Manchuria to Europe. Etymological conflation of an artifact and its name does not make any sense: although the artifact was known at least from 2nd mill. BC, the Egyptian, Mycenae, etc. diadems likely had their native names not connected etymologically with the Türkic, Greek, Mongolian, Khalka, and English words. The horse road from the Far East to Greece was an order of magnitude shorter than the infantry road from the Greece to the Far East. Prima facie, the Gk. etymology appears credible and viable, a compound of prefix dia- “across” and dein “bind”, but only if the myopic etymology zeroes on the “IE” objective. A wider review demonstrates its historical insolvency even within the “IE” frame, since the “IE” languages use a wide spectrum of individual terms, and the Gk. spread does not reach far and wide enough. The diadem belongs to the mass of the Türkic cultural words connected with royalty that distinguish the Gmc. and E. European vernaculars from the rest of the Europe, see baron, earl, king, queen, throne, tit, teat.
English robe (n.) “loose garment” ~ Türkic erpe:- (v.) “cut, cut off”. Türkic languages tend to pronounce the initial r- with preceding e-, like the Germanic languages' addition of the initial consonant (h- was the most popular, among others). That general observation ignores the tendency of the Oguric Türkic languages to add a preceding consonant to the words with initial vowel. The deverbal formation fr. erpe:- is consistent with akin deverbal formations in Eng., e.g.. bathers, jumper, shorts, wraparound: robe is a sleeveless mantle, cloak, gown. Not attested historically, the Türkic rob “robe, female gown without sleeves” was probably reborrowed fr. the modern European languages after it settled in Europe, fr. Gmc. via OFr. The Gmc. forms are A.-Sax. rift, rifte, rifty, reaf, reafe “cloak, veil, curtain”, homophonous with the forms for “booty”, which allowed some etymologists to conflate the two; OHG rouba “vestments”, Sl. (Rus.) rubashka (рубашка) “shirt”, a diminutive of rub-, and roba (роба) generic for “drape, working clothes”; OFr. (12c.) robe “long, loose outer garment”. It is fairly obvious that the A.-Sax., OHG, and Sl. forms came from a common Central European Sprachbund, and the late OFr. came via a different path, probably from the Burgund/Alan vernaculars; due to the shortness of the root, the word gained associations with resemblances rob “steal”, “booty”, rab “slave”, rabota “work”. The notion of “booty” that included the most valuable commodity of the combat armor, in a reverse etymological process was confused with its generic appellatives of “garment”, “vestment”: a concrete noun for combat armor can't grow into some incompatible generic appellation for a loose flowing gown. In the end, the references to a Germanic source lead nowhere close to the ultimate source. The spotty distribution, limited to the speck of the NW Europe, points to a compact group of migrants little connected to the local vernaculars on their track through the Central Europe. Notably, A.-Sax. had numerous Gmc. synonyms for the robe, attesting to a melting pot conglomeration from diverse sources. Instead of a state-of-the-art suit of armor, the Türkic origin suggests a simple cut of fabric or remains of a vestment with extraneous parts removed, a concept suitable for both sexes. See belt, chintz, cowl, don, sari, sash.
(Skip) English sari (n.) “Hindu female garment of a length of light material draped around body” ~ Türkic passive form sarïl (v.) “coiled, wrapped”, saraɣuč (n.) “female covering”, a derivative of the verbal root sar-, saru- “wrap, enwrap, encircle”. A.-Sax. has a nest spelled sarw-, searw-, serew-, serw-, sierw- with a number of disconnected meanings, some of them appear to be reflexes of the notion “wind, encircle”: “trick, snare, ambuscade, plot, treachery, cunning, device, armor, war-gear, trappings”, while the other come from some other, apparently European but not “IE” homonyms: “art, skill, cleverness, work of art, device, engine (of war)”. A paucity of examples does not allow to assert their origin. Cognates: Prakrit sadi “garment, petticoat”, Skt. sati ditto; Akkadian a-saru/e-seru “to surround, besiege”, the earliest record from 28-24 cc. BC. Due to the British learning in the India colony, sari became an international word. The word in English is recent, ultimately derived from the Türkic verb saru- (v.) “coil, wrap”; already in the Prakrit and Skt. time, the Hindu ladies wrapped themselves in a Türkic-derived sari. See chintz.
English sash (n.) “waistcloth, cincture” ~ Türkic saču: (n.) “fringe, hem” (of a garment, towel and the like). The word saču: is a deverbal noun derivative fr. a fairly universal verb sač- “scatter, sprinkle, drip, drop, throw away, sow” that among others also produced the word shower “sprinkle”. English usage: “waistcloth”, “strip of cloth worn over the shoulder”, “frame (window, door)”. The trade term for a frame attests to the existence of the word in the substrate language, the term could not be derived from the Ar. shash “cloth”, nor fr. the northern European countries that have their own lexicon for sashes using a derivative of the Türkic sak “sack”, Cf. OFr. escarpe “neck sack” and its numerous allophones, the Gmn. Schärpe (Gewichtsschnur), Dan. skærf, Du. sjerp, Sw. skärp (fönsterbagen, fönsterbage), Rus. sharf (шарф), MLat. scirpa; Rus. is using another Türkic derivative of the sak “sack”, kushak “sash”, borrowed directly fr. Türkic during the Late Middle Ages. Origin fr. the OFr. (13c.) chassiz “frame” is phonetically incredible, a semantic jump from “frame” to “waistcloth” is equally implausible. Even less credible is ascending the chassiz to Lat. capsa “box, case”, which is an allophone of the Türkic kap (qab/qap) “container, vessel, box”. That is a long shot from the form sash. Chances of reverse borrowing from English to the Old Türkic languages are also less than none. See cap, cup, sack, shower.
English shield (n.) “armor carried on the arm” ~ Türkic čyt (chyt) (n.) “fence, wall, guard”, with numerous semantic extensions of the notion “guard, hinder”: “hedge, stockade, boundary, edge, seam, enclosure, hut”, etc. The meaning “wattle fence” is most likely a prototype word for the early wattle shields attested at the ancient nomadic armies. Türkic has at least other six names for the “shield”, the word čyt belongs to that collection. Another term from that collection is tura:, a cognate of the Eng. tower, see tower. Cognates: A.-Sax. scield, scild, related to sciell (shell), ONorse skjöldr, OSax. skild, MDu. scilt, Du. schild, Gmn. Schild, Goth. skildus; Sl. shchit (щит) “shield”, zashchita (защита) “defense, guard”. The Slavic form nearly exactly duplicates the original Türkic form, it bridges the Gmc. and Türkic forms, and excludes the reckless “IE” etymologies from the unattested “IE” stems for “cut” or “shell”. The inlaut -l- may be a dialectal euphony, or be a denoun verbal marker of a passive case. In the latter case a metathesis would be needed to explain a transposition -tl to -lt. The abundance of the anlaut sc- (sh-) in the A.-Sax. is akin to the Türkic ts-ing dialect, where the first consonants ch-/j-/y-/dj- were pronounced ts-, like in scène vs. scene (stsène vs. seene). In the literate English, the ts- consonant phoneme is replaced with phonemes s- (seene) or sk- (spelled sc-, scatter), sometimes with sh- (sciara ~ sharuu). In Roman times, the ts- consonant was active and interchangeable with k- (Caesar ~ Tsezar vs. Caesar ~ Kesar). Admitting a ts- dialect for Anglo-Saxons would make many of their words closer to the Türkic forms: shield ~ scield. The couple shield and tower constitutes an authentic case of paradigmatic transfer, incontestably attesting to a common genetic origin. See shell. scene, tower.
English sock (n.) “ short stocking” ~ Türkic sok-, suk- (v.) “insert, thrust, fill up, stuff, hide”; the sok- and suk- have overlapping topologies and semantics (the other semantic is unrelated “beat, crush”), and “it is simply a matter of judgment which verb is involved”. The notion of the “sock” ultimately ascends to the stem suk- (sok-) that stands for index finger (n.), thrust (with an index finger) (v.), and in a passive form “thrusted, indented” (n., adj.). Unlike the fuzzy distribution, the meaning of the sok-, suk- “insert, stick in” (and in Eng. also “slip in” to form “slippers”) is very definitive, related to the notion of “socket, receptacle”, see socket. Cognates: A.-Sax. socc, socn “sock, light shoe, dipper”, OHG soc, Gmn. Socke, MDu. socke, Du. sok, all “sock”; Lat. soccus “slipper, loafer”; Sl. nosok (носок) “sock”; Gk. sykchos “shoe type”. The Sl. version, together with the name for “stocking” chulok (чулок) fr. Tr. uyuq, uğuk, comes as a paradigm, irrefutably attesting to the Türkic origin of both words, and thus directly attesting to the origin of the Gmc., Lat., and Gk. source. The Lat. word, if not via Gk. or Etruscan, and if it is not a late borrowing fr. Burgund, may be of Sarmatian origin, borrowed together with military tactics and paraphernalia. The form stoking with prosthetic -t- is probably a local innovation from the came root. The “IE etymology” does not exist, it meekly suggests “perhaps from Phrygian or another Asiatic language”, i.e. patently non-IE source. With its sibling socket, a derivative from the same stem with the Tr. suffix -ut, and the sock “beat”, an allophone of the same stem, the converging compounded evidence of massive paradigmatic transfer makes the Türkic origin of the whole cluster inescapable. The idea that Gmc. has borrowed the word fr. Lat. is grotesquely laughable, in the nomadic horse-riding world, from Mesopotamia to Mongolia, socks were around long before the Latins came to the forefront. See sock (beat), socket.
English suave (adj.) “smooth” ~ Türkic suvlaŋ (suvlañ) (adj.) “smooth” (i.e. as water, suv).
A version of suave is suede “suede leather with napped surface”, a type of soft
leather, made an international word by the modern commerce. Cognates: Middle Fr. suave, Lat.
suavis. The name “from Sweden” appears to be a folk etymology grown out of phonetic homophony
(French Suede “Sweden”), but a “suede jacket” in Sweden is “suede jacket”, not a “Svenska
jacket”. Also badly problematic is to connect suave/suede with the Lat.
persuasionem, persuasio, persuadere fr. per- “strongly” + suadere “to urge”, which
produced OFr. and English persuasion. These funny “IE” etymological ideas lead to nowhere,
stopping far short of the smooth nature and smooth leather.
74
English tag (n.) “badge” ~ Türkic taɣ, tag, ta:ğ, da:ğ (n.) “mark, brand, badge”. A Türkic homophone taɣ, tag “herd, flock” points to the association of the notion “branding” with the notion “herding”, either one could be a primary notion. Tagging must have been one of the most ancient words, contemporary with the first spread of the domesticated fowl and goats. The tag is uniquely English word, apparently with no known European cognates. The erroneously suggested as cognates the Gmc. close homophones Norse, Sw. tagg “point, prong, prickle, thorn”, MLG tagge “spike” denoting a nail-type sharp object are instead allophones of the Eng. tack “nail” and of the Türkic noun form of the verb tak-, taq- (v.) “tack, pin, fix”, and its sibling verbal form tik- (v.) “sting, pin”. A derivative toɣu, toqu, toğa:, toku: “buckle, clasp” illustrates the semantics of “badge”, belts were a part of Türkic traditional triad attire caftan-belt-boots for men and women, and buckles had numerous utilities beyond keeping kaftan fastened, one of them was a badge to indicate official position, thus the toqu “belt buckle” is equivalent to the tag “badge”. The word belongs to the numerous English orphans “of uncertain origin” with no “IE” connection, but with phonetic and semantic cognates in Türkic, toka/toğa loanword in Persian, and other languages, and probably with cognates in Afganistan, Pakistan, Indian, European Türkic and Eastern Siberian Türkic languages. The duplex of tag, tack constitutes an authentic case of paradigmatic transfer, indelibly attesting to the common genetic connection. See tack.
English undies (n.) “underwear, lingerie” ~ Türkic antarï, anteri, antery (n.) “short dress worn under caftan” (Dahl V. Encyclopedic dictionary of live Great Russian language [Толковый словарь живого великорусского языка], Мoscow, GIIINS, 1955), v. 1, 78, in E.N. Shipova Turkisms in Russian [Cлoвapь Тюpкизмoв в Pуccкoм языкe], Alma-Ata, “Science”, 1976, 33). Cognates: Gmn. Unterrock; Rus. andarak/andrak/antar “underwear skirt”, from Türkic; Pol. inderak ditto. This type of disgraceful words is usually not included in the old dictionaries. A consonance with the Eng., A.-Sax. under, OFris. under, ONorse undir, OHG untar, Goth. undar, Du. onder, Gmn. unter “under” appears to positively connect the Gmc. and Türkic origins, while clashing with the more remote Skt. adhah, Av. athara-, and separately with the Lat. infernus, infra. A suitable progenitor for the “IE” European and Eurasian forms for “under” is aŋıttır- “bow, bend”, a peculiar formation fr. the verb eŋ- “bend” with two stacked causative suffixes, lit. “force to coerce to bend”, translated as “subordinate, subjugate”. It is a functional equivalent of “under, go under”. The documented articulation aŋıttır- is a peculiar version of the causative eŋittir- “force to coerce to ...”, a causative of eŋit- “coerce to ...”, a derivative of the eŋ- “bend”. With the nasal -ŋ- assimilated to -n- (Tr. antarï, Gmc. under, Lat. infra) or elided (Av. athara-), and modified locally (Skt. adhah), the semantics “go under (something)” and its phonetics are suitable for the both words “under” and “undies” without a need to invent an unattested and unexplainable (i.e. what is the function of the -er, and what the root ndh- stands for?) “PIE” *ndher- “under”. See under.
English wig (n.) “false hair, hairpiece” ~ Türkic yü:g (yug), yün/yuŋ (yung) (n.) “feather, wool”. Cognates: A.-Sax. perwyke “feather wig”, OFr. perruque “natural head of hair”, It. perrucca “head of hair, wig”. The “IE etymology” for this compound is “of uncertain origin”, but maybe fr. Lat. pilus “hair”, pluma “feather” with “considerable phonetic difficulties”; the “IE etymology” for the part wig of the compound is more than funny, suggesting a contraction of periwig to a noun and verb wig, with the verbal semantics “hysterical”, “fight or rumble”, “scold”, and finally “wigging” (scolding) and “wigged” (wearing a wig). Semantically connected with assimilated OHG fedara “feather”, which would bridge the OFr. perruque as an allophone of fedara + yü:g “feather wig”, etymologically a tautological compound of “feather” + “feather”, a standard assimilation of alien terminology. The word per- for “feather” is a part of the standing European-type lexicon: OHG fern “fern”, Balto-Sl. (Latv.) sparns, (Lith.) sраrnаs, (Sl.) pero (перо), also parit (парить) “to fly”; Skt. parnam, Av. раrǝnа-, all “feather, wing”, or both. The second “feather” is clearly visible in the OFr. perruque with -uque representing -yü:g. The Middle Age appearance of the alien customs of feathers and wigs in C.Europe is probably connected with introduction of nomadic customs of the Burgund Kingdom (Savoy and Provence), accompanied by introduction of relevant lexicon. The semantic connection and perfect phonetics attest to the equivalence of the wig and yü:g.
English ace (n., v.) “dazzlingly skilful in some activity” ~ Türkic us, usïč, üz (n., adj.) “ace, skilful, experienced”. This Türkic word can't be a random coincidence, because of precision of its meaning and perfect phonetics. It could not be a late reverse borrowing from the European languages because of universal spread and universally developed derivatives. The phonetic dispersion also points to deep roots. Among notable prototypes are us- “think”, as- “to transcend, overcome”, and esi “older male sibling, elder brother”, they point to the notions of completing a task and looking up to, the first of them still active, like in a “flower fully opened”. Among very numerous derivatives of as are asig, asil, ash, and ashil, “benefit”, “substance”, “increase”, and “growth” respectively, all with connotations toward superlative. A confusion and semantic conflation with the numeral 1 on a dice apparently is based on purely phonetic homophony. That is the best that the “IE etymology” is able to suggest. It is obvious that the dice terminology trails that needed in daily life, like the notion of a skill, and if there is a metaphoric connection, its direction is outright the opposite, from the skill to an ability to control the dice. The same applies to the card game, the name for the card is an extension of a theretofore existent terminology. The suggested transition fr. the widespread in the European languages Lat. “unit, unity, one” and Gk. enas (ενας) “one” to the notion of a superior artistry appears incredulous in concept and unsustainable in detail. Apparently, the word was lurking around as a trade term in the Northern European languages till popularized by the Fr. sporting publications for especially skilful sportsmen, and later pilots.
English aid (n., v.) “help” ~ Türkic yüv- (v.) “furnish, secure, provide”, yӧlä-, yülä- (v.) “prop, support, aid”. Albeit yüv- and yӧlä- describe separate notions, they overlap on the notion “aid”. Ultimately, they ascend to the verb u:-/ü- “able, capable”. The transformation of the word yüv- to aid is a song in its own right, by far outclassing etymological darings of the fearless etymological captains. The connection between the two drastically distinct forms of aid and yüv- rests in the Lat. verb iuvare “to help, give strength, support, sustain”, a semantic and phonetic clone of the Türkic verb yüv-. Although the chances of any two languages to have a root resembling üv are near or even above certainty, as in a case of more than a single homophone, the chances of encountering identical semantics are microscopic, fostering a high degree of confidence. With the locative prefix ad- “to, toward”, an allophone of the Türkic locative suffix -ta/-da, the compound became adiuvare "to give help to”, a metamorphosed form of the Türkic agglutinated yüvtä. A Lat. derivative deverbal noun is adiuta, which had nothing to do with the Lat. root iunior, iuvenis “younger, youngster” suggested by the brave “IE etymology”. In turn, iunior is an allophone of the Türkic yangi: (adj.) “new”, see young. The Lat. noun, truncated down to its prefix, assimilated into a cluster of the local Romance languages, producing the OFr. aiuda and then aide, which through a circuitous route became the Eng. aid, the Catalan, Portuguese ajuda, Fr. aide, Galician axuda, It. aiuto, Rum. ajutor, Sp. ayuda. In the Far East, the Türkic yüv- had reached China: Ch. ju 助 “aid”. The Fr.-Eng. form aid supplanted the old A.-Sax. fylst, fulaest, fultum “aid”, an allophone of the Türkic yӧlä- formed with a prosthetic f-. The major difference between the A.-Sax. and Lat. forms attests to the source vernaculars with a choice between the synonymic yüv- and yӧlä-. Notably, the A.-Sax. used nine roots to form synonymous “help”, of which at least two (bot-, ful-), and likely three or four, ascend to the Türkic languages. Of the nine synonyms, Eng. has retained three (bother, full, help), and additionally acquired one (aid), of them three (bother, full, aid) ascend to the Türkic languages. The predominance of the Türkic cognates attests to the deep penetration and wide spread of the Türkic languages across the Europe. The presence of the three “aid” synonyms in English points to three source paths, the Turkic-Romance aid, the Turkic-A.-Sax. fylst, and the Old Europe or a local European help. See full, bother, young.
(Skip) English Alban (people) (n.) ~ Türkic alban, alpan (n., adj.) “tribute, duty, dependent, tributary”. Ultimately a derivative of a polysemantic al (v., n. adj.) with few meanings conductive to form a notion of subjugation: “bottom, lower part”, “status, position”, “collect, take, receive”, “get, acquire”, “barter”, “catch”, “confiscate”, “conquer”, and more. The Romance female name probably referred to blonds, but elsewhere was likely a term for a trophy concubine or a wife. Two peoples are known under the name Alban, one in the S. Caucasus at the turn of the eras, and the other in the Balkans from the Middle Ages. In the case of the Balkans, it is positively known as an exonym, since no ethnic group there called themselves “Albanians”. The same applies to the Caucasus Albania, in the sources the term is used exclusively as a politonym. The ruling tribe in the Caucasus Albania was a Türkic tribe Kayi, the present Kaitags (Mountain Kayi) who may have called the indigenous tributaries “аlbans”, hence the Armenian and Gk. reflex “Albania”. Both places at some time were dependent members and tributaries of the Türkic states. The presence of the Mong. form alba(n) “tributary” points to a Hunnic source of the Syanbi times, when in 93 AD a 100,000 Hunnic families numbering 500,000+ people submitted to the ruling minority of Syanbi (pin. Xianbei 鮮卑) Mongols, essentially making the Hunnic language a language of the Syanbi.
English alimony (n.) “payment” ~ Türkic alım “debt, payment, tax”, alım is a noun describing a single action fr. the verb al- “take, receive, capture”. No “IE” connections, the etymology is described as an oddball among “IE” languages fr. the Lat. alimonia “food, support, nourishment, sustenance” fr. alere “nourish” + -monia “action suffix”. Chances of a Lat. oddball invention spreading across Eurasia to beyond China like a wildfire are precisely nil. Chances that it is oddball and not an internalized Türkic word are also suspiciously close to nil: in the context of a levy, the “payment, tax” and “taxes in kind”, i.e. produce levy, are one and the same. Meanwhile, A.-Sax. had in its active vocabulary a nest of derivatives fr. the verb al- “take, receive, capture”, all clearly unrelated to the “IE” milieu: alaeccan “take, catch”, alaedan “lead away, carry off”, alaenan “to lend, grant, lease”, which clearly demonstrate that not only the A.-Sax. used the Türkic verbal root al-, but also that it had inherited agglutinative suffixes to produce derivatives and even a reverse action (take vs. give, lend). Cognates: A.-Sax. al- q.v., with derivatives; OIr. alim “I sustenate (by taxes, nourishment, etc.)”, Cf. OT alayım “I will take”, aldım “I have taken/received)” with the same OT suffix -ım “I, me”, alımın (“debt”) aldı: (“took”) “he took (collected) debt (levy)”. The Lat. semantics of “food, sustenance” is a concrete derivative for the receipts in kind, widely used prior to a switch to a monetary tax. It reflects a system of dependents and allotments that was inherited by the Roman and other societies (Cf. Sl. “allot to a table” (поставить на стол) meaning to give a right to collect taxes in kind, a princely prerogative). The Lat. version may be attributed to the Celtic origin within the Italo-Celtic contact model, separate from the A.-Sax. path, but ultimately ascending to the common Türkic source as a derivative of the verb al-. The word has survived from the A.-Sax. into English, and may have re-conflated with its Lat. sibling. Under a hypothesis of the Saxons being another form for the Saka Scythians, their lexical forms may be reflexes of the original Scythian speech. See alimentation.
English Arthur “legendary king of Britons” ~ Türkic artur (v.) “donate, present, gift”, “increase, grow, expand, excessive (i.e. exceed))” (v.). Etymology of the King Arthur's name has a long and wide trail with numerous offers that did not bother to suggest a Türkic etymology. The stubborn historical canvas also did not need to figure in. The Türkic has two forms that ascend to the stem art- (v.) “increase, add, amplify” with semantics “to grow”, derivatives artur “confer, present, gift, donate; entice, seduce” (v.) and arttur causative of art- “increase, add, amplify”. Semantically, both forms can be used for a title-name; in Türkic tradition the old baby name is abandoned at some point in life, and a new name is given or taken, a custom still retained in the Chinese ethnology. Outside of China, that custom disappeared with the switch to the novel religions, where the name had to be “Christian”, “Islamic”, “Buddhist”, and the like, given for life to display conversion. The traces of name change still linger in eastern Christian Orthodoxy, where baptized people have 2 birthdays with 2 names, one a home name, and the other the appropriate Saint's name, whose day is celebrated as a birthday (imeniny (именины) in Rus., i.e. “name-day”, from imya (имя) “name”). In Türkic uncluttered by allusions and surmises, the name King Arthur is а direct rendition of Kengu Artur “King Conferred (by Almighty)”, “King Bestowed (by Almighty)”, etc. In undisturbed Türkic, the title should be at the end: Artur-Kengu, but English successfully parted with most of the Türkic syntax, and Kengu Artur is a viable form for the 6th c. A couple of ethnological traits corroborate the Türkic etymology: a Türkic King was a position elected for life to preside over a counsel of nobles, and King Arthur is depicted as a presiding King of the Round Table. King Arthur is held as buried under a kurgan (e.g. Bossiney mound, Wormelow Tump burial kurgan of King Arthur's son Amr, and more); his son Amr carries a Türkic name amra- “love” (v.), Amran, Amraq Amïraq “loved” (adj.) (Cf. Amor “Cupid, god of love”, see Amor); his stallion Sigral is allophonic with Sïpqa “2-year old stud”. The “IE” and Lat.-centered etymology ascending to Lat. Artorius/Arturius, “of obscure and contested etymology”, in a way may be right, since it also ascends to the Türkic artur “gift”. The o and u in Türkic are interchangeable, both versions are fully consistent with the Türkic artur. In English, amor for love has a flavor of borrowing from the Romance languages, and probably it was resuscitated via Romance. But it is very unlikely that Sakha/Yakut amra has anything to do with the Romance languages. One day we could learn the Amr's Y-DNA, and correlate the male line with possible origins. The exactitude of the phonetic rendition with the Türkic lexeme tends to indicate a Hunnic origin rather than a Celtic Briton's, and the Y-DNA may supply a helpful clue. See king, Amor, Boris.
English As (tribe) (n.) ~ Türkic Yazï (tribe) fr. yazï (n.) “steppe, plain, flatland”. The names of the oldest Türkic tribes are nearly universally toponymic, alluding to mountains, steppe, rivers, etc., that tradition is as monotonous as the kurgan funeral tradition. The As people are known, in particular, from the Scandinavian sagas as conquerors and a ruling elite of the Scandinavians, the dynasts of the Scandinavian people. The legendary tradition is well-ingrained and richly embellished; Ases are extracts from somewhere in Asia, supposedly named after them. Besides the 1st mill. AD Scandinavian sagas, Ases are known from the 3rd mill. BC Assyrian texts as Askuza (also read as Ishkusa), from the 1st mill. BC Hebrew Bible as Ashkenaz (pl. Ashkenazim), from the Classical writers as conquerors of Bactria in 140 BC, as the 3rd c. BC Yuezhi of the Chinese annals, and from many other sources, events, and geographical locations. The part -kusa or -guza means “people”, but no source gives an etymology of the name As, and scholarly suggestions, in addition to the yazï, offer other phonetically justified and semantically possible etymologies: as, aš- (ash-) “cross over, pass, climb over”, “increase, grow”, az- “go astray, err, get lost”, “not numerous, small, few”, “greedy”. In addition, from general considerations, the as is suggested and held as standing for generic “tribe”. Because the names As and Alan were used interchangeably, and because the words yazï and alan are synonyms, with the alan also meaning “plain, flatland”, and because the form Yazï is recorded in many toponyms and chronicles, the As standing for “steppe people, plain people” is most convincing. Plenty of nomadic Türkic people lived in the steppes, besides the generic appellation Ases each separate group also had to have their individual appellation, thus the Huns, Bulgars, Uigurs, but not the mountaineer Tokhars or Saka, etc., belonged to the generic appellation Ases. The idea that the Ossetians were Ases or Alans does not hold the water, the historical sources identified Ases (Yases) with the Türkic Bulgars (that's natural, because Bulgars were steppe people). The very same Ossetians, and also their Abkhaz neighbors, identify Ases with their neighbors Balkars and Karachais, traditional nomadic horse husbandry tribes like the historical Ases, while the Ossetians are traditional sedentary farmers. The studies of the Y-DNA attest to the same, Ossetes are predominantly of a Y-DNA farming haplogroup G2 and J2 of Near Eastern variety, while the Ases should carry the steppe-type Y-DNA nomadic haplogroup R1a and R1b. The name Ossete, however, could be connected with the ethnonym As, just like the name of the Gaulic France was derived from the Gmc. Frank, and the name of the Slavic Russia was derived from the Gmc. Rus Vikings.
English assess(ment) (n.) “appraisal of worth” ~ Türkic asïɣ (n.) “interest, percent, benefit,
profit”.
The Türkic verbal stem as-, of which the noun asïɣ is a derivative, has a meaning
“desire, greed”. In the “IE” languages the prime meaning is also verbal, with noun derivatives. The
“IE” etymologies wind out to Lat. compound ad- + sedere (lit. “at sitting”), an exceedingly long
and thoroughly dubious shot both semantically and phonetically, while the Türkic etymology is direct
and pinpointed. The “IE” etymologies also stop at Roman time and geography, with no attempts to
recover a fictitious PIE stem. The need for the word goes much deeper than the rise of the Rome,
since trade, taxation, debts, and tributes are attested in the first written records, three
millennia before the Roman times, and by the time the Romans organized their state, the word must
have long been in circulation among most of the Europeans' and Asians' daily life. The “IE” derivatives assign, assignation also point to the underlying Türkic form asiɣ, the
disjointed Lat. etymologies notwithstanding. Apparently, English has received this Turkism via
French. See assign.
75, 76
English baby (n.) “infant, child before walking or talking” ~ Türkic bebe, beba, bäbä (n.) “baby, child”, bäbek, papak, pebek (Chuv.) “kids, children”. Ultimately fr. the verb ba-/be- “bind” (see band) and its verbal form bele- (v.) “wrap, bind, lace” (see bale) lit. meaning “bale, to bale, swathe, to swaddle”. Accordingly, this word is a cognate with the vast multitude of all Eng. derivatives of the verb ba-/be- “bind” in the classical definition of the word cognate “coming from the same ancestral language”. The verb bale is an undistorted pristine form of the original root ba- with the verbal suffix -le. Odiously, the EDT and OTD are silent on the word “baby”, in a stark contrast with the EDTL (Sevortyan pp. 95-97) which used three pages to address, with dozens of references, the Türkic “baby”. In Eng., this word is one of the quadruplet, with four unrelated parallel clusters, all of the Türkic provenance, the baby, child, puppy, and the obsolete bairn, a derivative of the verb bear (v.) “carry”, see bear (v.). The word has a potential of belonging to the oldest lexical layer, connected with the oldest textile (35,000 BC) and first swaddling of the newborns. Under the “IE” microscope, a cognate list is really short: OE (13c.) baban, notably with a Türkic diminutive suffix -an. With an unbridled perspective, a cognate list is macroscopic, extending from Atlantic to Pacific, and with an endless listing of the Türkic and related allophones: bebi, bäbi, bäbiš, bibi (Cf. loanword in modern Heb. Bibi ditto), böbü, bönö, böbüce, these Türkic forms can be used as concrete nouns, as plurals, as abstracts, metaphorically, and for baby animals and flora. Derivative forms and cognates: bäbek, babäk, bebek, babik ببك, dibik ديبك, dabak دبك, dibak ديباك (Cf. loanword in modern Hindi, Deepak ditto), dasak دسك, diaaltha دياالثا, bebäy, bäbäy, etc. In Türkic these forms have more of a connotation of plural and abstract. Other cognates: Ir. babaí, Welsh babi, baban “baby”, It. bambino, Sp. bebe; ditto, Hu. baba, babat “baby”; Hindi dibak ديباك ; Evenk, Even bebe “baby, cradle, rock (cradle), lullaby, nap, suckle”; Mong. buubaj, büübei, bübei “cradle, doll”; Ch. baobao 宝宝 “baby”; Jap. bebī ベビー ditto. Variously in various languages, the word covers much more than an “infant”: “suckling”, “doll”, “chick”, “lambkin, kid (goat), gosling, duckling” and such, “little brother”, “pupil (eye)”, “embryo”, “bud”, “offshoot”, “pinky”, “adult male” (in contrast with Eng. babe), “Бабек” (proper name, Cf. Bibi and Deepak). Puppy is a palatalized allophonic form of baby, it also found uncounted allophones across languages and across Eurasia, applied for babies, dolls, and baby animals, most of them much older than the 13th c. OE. The bulk of the meanings is metaphorical, not connected directly with the notions of “swaddle” and “infant”. With the pinpointed semantics of “infant” and perfect phonetic match, a long-distance borrowing from the OE into Türkic languages must be positively excluded. The apparent semantic development indicates that the notion “infant” is tertiary, after the secondary notion “swathe, to swaddle, cradle, to cradle”, and the original notion of “bind”. The term baby is essentially a bundle from a cradle. That allows to visualize conceptually a time and direction of the spread. Since the nomadic Zhou Scythians or their ilk reached the Far Eastern peoples before and during the Xia period (21st – 17th cc. BC), it can be reasonably suggested that the Mong. and Tungus (Evenk, Even) forms may far predate the Hunnic times, 2nd c . BC. The retention of the Celtic forms attests that their forms were already around at the time of the Celtic departure from the Eastern Europe to Iberia ca. 5th-4th mill. BC. Notably, the Ir. form babaí is an exact match of the babaí of the modern Bashkir, Nogai, and Tatar languages just north of the Caspian-Aral basin. The Indian form with the second consonant -s-/-š- appear to be the Türkic form bešik for “cradle”, conflated with the related notion of “infant”. The Sl. form kolybel (колыбель) “cradle” appears to be a calque of the Türkic form for “cradle” meaning “to rock (a cradle)”. Kolybel does not have any “IE” cognates, including the Sl., pointing to a loanword or a Sl./alien compound that incorporates the element be- for “rocking”. The quintet baby, puppy, child, bairn, and doll presents a salient case of paradigmatic transfer, attesting to the common origin from the Türkic linguistic milieu. The contrasting etymological suggestion within the “IE” paradigm, linking baby and babble may have a grain of truth in it, but has nothing to do with the etymology of the word baby. See bale, band, bear, child, doll, puppy.
English baron (n.) “nobleman title, peer of the lowest rank” ~ Türkic baryn دارين (n.)“high title”. Ultimately a derivative fr. the polysemantic verb bar- “is, existing, present” (see was), but in this case denoting “be rich, be wealthy, be affluent”, with the reflexive suffix -ïn/-ïm. The meaning“ rich” was not found in the OT records, leading to a speculation that it is a later development, which may be true in respect to the verb bar-, bit is unsustainable in view of the earliest historical attestations of the name and title baryn. Baryn's semantics is also а “chief executive” lit. “(possessor of) all, entire”, i.e. “supreme”. Cognates: A.-Sax., Fr. baron title, Rus. barin (барин) “owner of estate and its bondsmen”, also a nobleman title in various European countries. Baryn was a most prominent tribe of Suvars (aka Suei, the Swede ethnonym, the part Su/Sue/Sw stands for “water”, like in the ethnonym Suvar, see habitat), with no record on female or male dynastic side. Other than Suvars, in some Türkic courts Baryn was a title of a member of the state counsel with a right to sit on a bag of wool in the khan's presence or even next to the khan; that implied that Baryn was a title for the head of the maternal dynastic clan and a statutory Prime Minister and Superior Judge. Baryn was one of the Danube Bulgaria's boyar clans. The words peace, port, and their derivatives are later acquired derivative versions of the verb bar- from the raster of its particular meanings. The duo baron and was constitutes an authentic case of paradigmatic transfer attesting to the Türkic origin of the substrate language. See habitat, peace, port, was.
(Skip) English bastard (n.) “illegitimate child” ~ Türkic bas (n.) + tard (v.); bas “head” + tard = “turn your head away”; In English reportedly via Fr., OFr. bastard, Modern Fr. batard. Reference to OFr. likely points to the Burgund source via Provence path. The Türkic etymology closely follows the Türkic social tradition of gender equality: unmarried people, especially young, are not demonized about sexual encounters prior to marriage, but after marriage fidelity is absolute and no deviations are accepted. Marriages were monogamous. In spite of the millenniums of religious condemnations, in the northern Europe this liberal social tradition has largely survived to the present. In a tribal society, within the framework of the tradition, out of wedlock flings and children are events extraordinaire, with severe social consequences, hence the euphemistic term for not recognizing the offence. The Türkic elite practiced polygamy, and all offsprings of such marriages were equal, except that only the children of the First Wife (Queen, Hatun) were eligible for succession to the throne, and no one was held as a bastard. The fanciful “IE” etymologies formalistically concentrate on details of the encounter, like bast as fill of a straw mattress or barn with the same connotations, without appreciation of the social environment and social context. The suggested etymology is as much a guesswork as the “IE” etymology, it relies equally on phonetic consonance, but in addition it also relies on real ethnological aspect, making it relatively more credible, or notably less fanciful.
bastard (n., adj.) “ruin completely, break into pieces, apart”~ Türkic bastur- (v., n., adv.)
“crushed, subdued, suppressed”.
A myopic “IE etymology” utterly failed its etymological function with 600+ words-long dissertation
devoted mostly to divinations and imaginative re-interpretations. Ultimately a causative form of a
verbal stem
bas-/ba:s- “press, suppress, overcome, seize (rape)” with a causative form bastur-, Rus.
emphatic bastruk (< Tr.), see push. The panoptic verb bas-/ba:s- numbers some
30+ meanings related to applying downward pressure. With a suffix tur- a general connotation
of bas- is a definitive (factitive) “final, end” of action, “suppress (finish off)”. An
“undecipherable” substance of the “bust” is clearly explained in A.-Sax. 1. a notion “penis” does
not exist, its proxy is “horn, horu” ~ “horn”, Cf. “horny bastard, man” ; 2. hor “adultery”,
hore, horowene “whore, prostitute, adulteress”, ciefes, cifes “concubine, harlot” (Gmn.
kebsc) ~ “sex”; 3. (ge)horgian “defile, desecrate, maculate, violate”, horeht, horwiht
“defiled, filthy” ~ “abuse, sex, rape, raped”; 4. honruungsunu
“bastard” ~ “son from adultery”, cifesboren (adj.) “bastard, concubine's born”, docincel,
doc “bastard son”. Thus a bastard (m.) is an illegitimate son from an adulteress,
prostitute, or a rape, the last expressed etymologically from a Lat. rapere “seize, carry off
by force, abduct” and a Türkic bast < bas- + deverbal noun abstract suffix -t
or an elided bastur- > bust. A bastard's accession to a throne was possible only by a palace
coup, Cf. William the Conqueror referred to in state documents as “William the Bastard”, or a Rus'
Vladimir the Baptist. Cognates: A.-Sax. bestingan, beðryn, beðryccan “push, press”,
basnian “ambush”, Dan. børste “beat up”, Sw. basa “beat (with rod, flog)”,
bösta “thump”, ONorse beysta “beat”; Fr. bastonnade “beat (with stick)”, It., Sp.,
Port., basta “end, finish” (but not Lat.); Gk. bastazo (βαστάζω); Sl. (Rus.)
baystryuk (байстрюк) “bastard, boy, lad” (-ruq Türkic emph. suffix), bastryk
“subjugation”, busturgan, bastyrɣan “bogey”, baskak “tax collector”, basma
“stamp seal”, (Rus., Pol.) basta “end”, (Pol.) basalyk “lead-ended whip”, (Bolg.,
Serb.) basamak, basamaci “ledge, steppingstone”, (Bolg., Serb., Ukr.) basma “heeltap”;
Arab. bas “push”, basma “printed fabric”, “stamp, brand, imprint”, baskak “tax
collector”; Mong. basu- “press down, pin, throw, quit”, “offend, scold, humiliate”; Kor.
matta, mağa “break, crush”; Tungus, Manchu basala-, basalla- “kick”. Distribution:
The root bas- “press” in various articulations is ubiquitous across Eurasia, from Atlantic to
Pacific, across linguistic barriers. A peculiar areal distribution in Europe.
The form basting “strike violently” semantically and phonetically closely parallels the
Türkic bastïq “to be defeated, broken, suppressed”. Possible cognates may be Bastarnae,
a tribe at the end of the domain, neighbor (Ptolemy), bastion “tip, at the end” with its
derivatives, via Fr. No “IE” cognates; the suggested derivative distortion of burst (barsten,
bærst, bersta, berstan, borsten, brestan, bersten) “erupt, rupture” is too far fetched, does not
fit neither phonetically nor semantically. The suggested derivative of beat is not any
better. The word known in England in 1530s popped up in 1750s in the US, and became a popular
economic and action term. See ambush, bat, pat, push.
“” “” “” “” “”
43
English boy (n.) “youthful male”, “subordinate, subservient” ~ Türkic bod, bo:y (n.) “body”. The form boy/bo:y, as opposed to bod, is due to the articulary peculiarity in a certain group of languages that tend to to use -y- for -d-. It is one form from the allophonic lineup of bod/bud/boy/bo:yi:/bot/badan/pot/pos/poy, see body. One of the secondary meanings of the word bod/boy is “a body, someone”, for example “servant, commoner, knave, boy” with and without derisive connotations. The form bo:y is most significant for the NW European etymology as a noun signifying a faceless human mass (sailors, servants, etc.) or a concrete noun signifying an extract of that mass. Applied generically, the word boy is a derisive term, widely used long before the colonization of America with its slavery and the emergence of the derisive boy for male slaves of any age. It stands in opposition to cniht/knave/knape/cnafa/cnapa also meaning “male youth”, which produced an elevated knight. Besides the principal modern meaning “young male”, the word retained its original notion of “chattel”, used for a wide variety of “others”, Cf. bell-boy, cabin-boy, cow-boy, errand-boy, ball-boy, and a slew of other disrespectful monikers. The legacy of three forms, body, bod, and boy constitute a tangible case of paradigmatic transfer from different parts of a single phylum, an irrefutable evidence of a genetic connection. The form bod , which underlies the Eng. bod and body, predominates in the northeastern Türkic languages. The form boy predominates in the west: Oguz, Ottoman, Horezmian, and Chagatai. That attests that the form and the early known Eng. senses are connected with the Aral basin, like other words with similarly peculiar, geographically-identifiable forms. The Aral area was a homebase of the Ases (As-Tokhar confederation), the Yuezhi of the Chinese chronicles. Ases are prominent in the Scandinavian sagas as the noble ancestors. The literally sources corroborate linguistic indicators. Cognates: ME boi “churl, servant”, EFris. boi “young gentleman”, MDu. boeve, Du. boef “boy”, MLG buobe; Balto-Sl. (Latv.) puika, (Lit.) vaikinas; Hu. fiu, Fin. poika. These cognates are tied to the form and notion “boy” and its EFris. and MDu. predecessors; to the list must be added cognates associated with the word “body”: A.-Sax. bodig, OHG botah, Turkish beden, Arab. bädän “body”, Kor. badi 바디, and probably quite a few more in the areas close to the Eurasian steppe belt. Türkic languages have preserved a notion of a person's belonging to the category of a “mass of bodies”; the NW European languages have retained that as concrete nouns “servant, commoner, dependent”, and innovated to a “minor (person)” and then to “boy”, while retaining all past meanings and mostly negative overtones. A transition from a more generic to a more concrete meaning is typical for host languages, Cf. Türkic agač (agach) (tree) and Gk. acacia (ακακiα). An identical retention-innovation process had occurred with the form bod, used for a human body, informal for a person, and for a faceless mass of people. In the form budun (with allophones) that word is known from the Herodotus times and from the Orkhon inscriptions. Words for “boy” double with local calques as a notion “servant, attendant” across the Indo-European map, and a patchwork of the Türkic allophones from bod/boy to pos/poy extends that notion from one end to another across the entire Eurasia. For “boy”, the “IE etymology” came up with one lunatic suggestion, ascending to “shackle, fetter”, apparently because of the presumed slavery component, and consonance-based alternate conjectures of “babe”, “evil spirit”, and “brother”. For its allophone “body”, the “IE etymology” has advanced a more sober but equally incompetent “of unknown origin”. In all “IE” conjectures the phonetic consonance, however senseless, was a leading guide for philological speculations. See body.
English brother (n.) “son of the same mother” ~ Türkic birader (n.) “son of the same mother”, ultimately fr. bir (bi:r) “one, a man”; the notion “man” is inferred, akin to “this one (man)”, Cf. someone “a man”. The Türkic word literally formulates “son of the same mother”: bir “one”, as an article a, an “one” in English + ad/at “name, appellative, family unit” + er = male, man (n.) > “male of the same name”. Alternatively, birader consists of bir “sole”, like in “sole heir” + a euphonic filler + -der plural collective suffix used as a sign of respect, i.e. pl. of “one”, lit. “ones, solenesses, onenesses”, the word is modeled consistently with “father” and “mother” (Golden P., 2014, 19), see father, first, mother. Nothing even close to this etymology can be found in the “IE” etymology, which mechanically lists cognates to demonstrate that many “IE” languages share this word. Cognates: A.-Sax. brothor, ONorse broðir, Dan. broder, OFris. brother, Du. broeder, Gmn. Bruder, Goth. brothar; Lat. frater, It. fratello, Gk. phrater; Balt. (Lith.) broterelis, OPruss. brati, OCS bratru, Cz. bratr; Skt. bhratar-, OPers. brata; the OIr. brathir, and Welsh brawd came with the Kurgan migrants; all “brother”. The archaic plural suffix -der is associated with Bulgars (Cf. Onogundur Bulgars), attesting to its Sarmatian provenance, it is present in the OIr. form, providing an oldest datable attestation in the 5th mill. BC N. Pontic, 3 mill. before the departure of the Indo-Aryans from the same general area. The myopic horizon of the IE-school linguists does not dip deeper than the migrations of the 2nd mill. BC. The loanword nature of the “IE” versions is attested by the preserved original synonyms, Gk. adelphos, Lat. germanus, Sp. hermano, and their counterparts in other European languages. Notably, Eng. and other Gmc. languages have not preserved the spectrum of the Türkic basic terms for “brother”: abï, ačïq(ïm), aɣa/aqa, birader, eči, emikdaš, ini, ögdaš, qadaš/qaδaš/qaŋdaš, qarïndaš/qarundaš, with more regular phonetic variations; Eng. does not have a single synonym. That attests to the amalgamation process, where in the end survives only a most basic word. The idea that birader is a Kurdish/Persian loanword does not withstand a sanity check: the “IE” languages do not have a single common “proto-word”; distribution of the cognates aligns with the periphery of the Steppe Belt, its neighborhood, and the known migration paths; birader can't be etymologized from the “IE” “proto-language”, whether a spoken or theoretical model; the antiquity of the word allows plenty of time to spread it with numerous Kurgan waves and amalgamations. There are other indicators, like paradigmatic transfer cases, Cf. Lat. suppletive ordinal primus, a form of bir “one”, and frater, a form of birader, a derivative of bir, with the numerical duality not having an acceptable explanation. Semantic expansion from “son of the same mother” to generic “son of the same parent(s)” apparently developed within polygamous societies, is not connected with the offsprings of the second marriages, and every language was finding its own way to define half-brothers and half-sisters. See father, first, mother.
English Boris (n.) ~ Türkic böri (n.) “wolf”, barıs (n.) “leopard” (also stands for “lion”). Depending on the ethnic source, either meaning was the original one. Böri for wolf, bars/leopard, and bear (in different Türkic languages) was a popular name across Eurasia, before being replaced in the east by more orthodoxy-sounding Mohammeds and Abdullahs. Before that, Türkic names and titles based on animal names were a commonplace. In the West, the name kept its popularity, retaining an aura of upper aristocracy during the Middle Ages. A synonymous word for “bear/wolf” is böri:, and for “wolf” is kurt. In some Türkic languages the allophonic form barıs, a version of bars, designates leopard and extends to lion and tiger. The areal distribution of the terms böri: and kurt, and of the names Boris and Kurt (Curt, Curtis, ets.) points to the direction and timing of migrations. See Amor, Arthur, brute, king, wolf.
English bull (n.) “sealed document” ~ Türkic bel (n.) “belt, band”, bele:-/be:le:-, belä- (v.) “to bale, swaddle, wrap”, bal-/ba:l- “fastened”. Technically, bull is a wrap, a swaddle, which is how it is literally called in Türkic. In Türkic bel is a belt (lace) used to lace something, like a baby in a cradle or to make a bundle package, bale. Ultimately fr. the verb ba:- “bind, fasten”. English has two words related to “cord”, bull (bullae) and the A.-Sax. bul, bula, the first a document sealed with cord and signet, the second is a cord worn around a neck as a decoration. Both ascend to the Türkic bel “belt, band, swaddle, wrap”. The “IE etymology” suggests semantically most unsuitable fantasies connecting the word with the signet seal: “cheek”, “swelling”, “buttocks”, “bag”, “knob”, united by loosely construed phonetic consonance and an unattested reverse engineered “PIE stem”. An interpretation also connects OFr. bulle, It. bulla “sealed document” with a Lat. bulla “round swelling, knob”, which is obviously an allophone of the bubble “gaseous fluid sack” that according to the very same “IE etymology” has exclusively Gmc. origin: MDu. bobbel ditto, MLG bubbeln “to bubble”; LLat. bulla “bubble”. The “IE” etymology's attribution of the Lat. bulla “swelling” to a Gaulish origin also conflicts with its own assertion on the Gmc. origin of the “bubble”. It lends itself that the A.-Sax. bul, bula “decoration” precedes by far the time of the papal Middle Age bulls. The Türkic etymology of a wrapped document as opposed to a document with a bubble seal offers a straightforward explanation without resorting to the circular PIE reconstructions. See belt.
English cadre (n.) “core group (of people)” ~ Türkic kadaš, qadaš (n.) “family and kinsmen”. Ultimately, kadaš lit. “family member” is a derivative fr. ka- “family, tribe” with a noun-forming associative suffix -daš, applied to non-blood related relatives of the speaker; the truncation of the final suffix is typical for the Sarmat languages (Cf. end truncation in French). The extended meanings of kadaš include a wide range of rather non-blood related pals: friends, companions, associates, brother, fraternal brother, etc. Cognates: A.-Sax. (notion “individual”) hada, had “person, individuality”, hada, gehada “brother (monk)”, hadelice (adv.) “personal, individual”, hadswaepa “bridesman”, hadswape “bridesmaid”, hadesmann “member of a particular order, class”; (notion “fellowship”) hadgrið “privilege (of or within fellowship)”. To the last notion belong the Fr. and Eng. cadre “core people” and Fr. cadre “a single member (single movie frame, single entry on a personal roaster, etc.” that in a spiral semantical development derive a “member” from a “group” (Cf. archeologist fr. archeology, cleric “clergyman ” fr. clergy, etc.). A third A.-Sax. notion is “office”, an innovation connected with the encroachment of Christianity as a societal thought police: haddbot “fine for insult or injury of a priest”, hadbreca, had-bryce “violator of clerical order”, hadlan, gehadlan, hadung “ordain, consecrate”, hadnotu “clerical office”, hadungdaeg “ordination day”, etc. The Ch. chia “family” has been asserted to belong to the cognates of the ka- “family, tribe”, its origin may ascend to the Zhou nomads of the 16th c. BC. The “IE etymology” lists as cognates Fr. cadre “frame of a picture”, Lat. and It. quadrum, quadro “square”, and stops at that quite satisfied, ultimately implying that a word for a “human community” is a derivative of the number “four”. That is obviously a folk-type etymology based purely on consonance. The clue to the etymology comes fr the A.-Sax. hada, had “person, individuality”, which grew into a constellation of derivatives, branching to a notion “fellowship” and fellowship-related terms. Notably, the A.-Sax. composites with “man” and “day” completely correspond to the Türkic expressions; the A.-Sax. morphological modifications (-lice, -lan, -ung) are allophones of the Türkic forms. As a stand-alone morpheme, the suffix -da/ta is a locative marker, i.e. “familiar, of family”, the associative suffix -š (lit. “somebody related to family, tribe”) is “rare” in the eastern records, pointing to its western or archaic origin. The spectrum of the European derivatives far exceeds the myopic “IE” etymological pursuit: cadaster, cadaver, caddie, caddish, caddy, cadet, cadge, cadger may be traced to the notion of “person” and “pal” with different shades, and ultimately to the notion of “family, tribe”; the cadet and its derivatives is unequivocal “younger son or brother”, with an appropriate synonym “plebe”. The last explains the derisive content of other derivatives, like the cadge, cadger, caddish, and likely cadaver. The “IE” etymologies for these entries read like Baron Münchhausen preposterous tales, with different story for each venture.
English cavalry (n.) ~ Türkic keväl, kevel “galloper, well-bred fast horse”, a deverbal adjectival derivative fr. kev-/gev- “chew, chaw, cud, quid” formed with adjectival nominal suffix -l that usually forms intransitive or passive derivatives (Cf. tığıl-/tagil- “blunted (tip)”): tickle, tackle, see tick, tuck, cloud), lit. “a ruminant, chewer”. The semantic transition fr. “ruminant” to “horse” and “galloper” is peculiar, it parallels other unexpected semantic extensions endemic for the word-forming process in Türkic languages. The connection between the meanings “galloper, fast horse” and “cavalry” is obvious, and likewise obvious is that the Lat. caball is an allophone of the Türkic forms keväl, kevel, kewäl, kevil. The verbal stem kev-/gev- has a sibling kav-/gav- with complementary semantics: qavčï- (v.) “rush, assault, attack, catch”, kavid-, kavdın- “protect”, kavza:- “surround”, all complementary to the theme of the cavalry warfare, pointing to a common origin of these root forms, separate and distinct from the homophonic kav- “gather, collect, assemble”. A second sibling is the verbal stem kop-/kob- “rise” (Cf. A.-Sax. cop, copp “top, summit”) applied to the mounted riding (risen, mounted, climbed, etc.), a precursor of the Türkic kobyla lit. passive “climed” > Lat. caballus “cavalry horse”, used to also designate adult female horse in different aspects (sex, riding horse, draft horse, etc.), the form kob- with -b- is attested by derivatives kobar-, kobor-, kobsa- “lifted, elevated”. The origin of the term for “mare” is obvious, the opposition of “rise” and “risen (upon)” reflects a visual aspect of the mating horses, that term likely ascends to the earliest encounters of the hunters with their horse prey. During millenniums of their lifetime, the kev- and its siblings kav- and kob- were probably numerously conflated. Notably, the Türkic morphological formant elements -čï, -id, -dın, and -za are rated as “rare”, pointing to their status of “guests” within the eastern Türkic languages and thus the “guests” from the western Türkic languages. Semantic extensions of the word keväl, kevel are the Sl. utilitarian notion kobyla “mare, draft horse, docile horse” and Hu. gebe “mare”, “nag (female horse)”, “old skinny workhorse”. This semantic transformation carries a societal load: while the nomadic economy saw keväl as a battle horse, the peasantry saw it as a workhorse, probably a battle horse dumped into second life after retirement. The cavalry < cavalleria became international word that during Late Antique times supplanted the Lat. equites, with a parallel borrowing of the Türkic kobyla > Lat. caballus, in Türkic a name for 4+ years mares that were a preferred staple for the cavalry horses, and a generic allophone in Lat., it in turn may resonate as a reflex of the verb qavčï/kabčï (kabchy) (v.) > kabï + -lа/-lä > kabïlа “assaulter, rusher, attacker”. The accepted alternate etymology for Lat. generic for “horse”, based on the Gk. translations of the Scythian words, where the Türkic kobyla and Lat. caballus, the forms of the Türkic yabu and the Scythian ippa “horse”, which possibly was also applied specifically to mare, as attested by the Scythian derivative ippaka (hippaka) “cheese of mare's milk”. In the alternate yabu, the Ogur form must have had a prosthetic consonant reflected in the Lat. caballus. The non-IE origin of the word is beyond any doubts, the form keväl, with its robust sources, positively attests to its origin. It is also observable that the whole horse-related diverse and fractured lexicon of the “IE” languages ascends to the Türkic vocabulary. See cloud, cob, mare, tick, tuck.
English carny, carnival “festival” ~ Türkic kerme, kirme, kemre “carnival, festivities, fair”, fr. qïrï “merriment, amusement”. There is a conspicuously homophonic verb qïqïr- “shout, cry, scream” that in A.-Sax. sounded cirm(e)/cirman; the qïrï may be a deverbal derivative of qïqïr-, or at least a result of conflated semantics, associating merriment with loudness (see cry). There is a parallel formation bazar fr. baz- “shout, cry, scream”, see bazaar. Cognates: Du. kermis, Dan., kermisattracties, Flemish kermis “fair”, Icl., Sw., Norse, Gmn. karneval; Fr. carnaval, It. carnevale. Other claimed cognates: OPisan carnelevare “raising meat” interpreted as “remove meat”, and MLat. carne vale interpreted as “flesh, farewell!”; these “cognates” obviously do not make any etymological sense. The Türkic kerme fair is traditionally adjunct to a bazar market (see bazaar), but they are not the same, even if there is plenty of market activity at each kerme, like at any fair, carnival, or mass festivities. An annual autumn fair was a backbone of the state, it was an occasion to conduct state business with a head of the state or principality, there were collected annual taxes, held court, and it culminated in folk festivities on the account of the visiting ruler. Attractions traditionally included “competitions of wrestlers and poets, with jugglers and jesters, with horseraces and masquerade”. In the form carnivall, known from the late Middle Age, kerme became a European international term, and in the 20th c. it became an international term across the globe. The folk etymology promulgated by the professional “IE” linguists cites an origin from Lat. carne “meat, flesh” + levare “raise”, with a wretchedly wrenched semantics “'flesh, farewell!”. The claimed connection with the Lent is also unsustainable, since kerme and kermis in the Northern European predate Christianity, they were traditionally conducted annually a few times each year, plus a grand autumn fair. The part -val is apparently a variation of transparent modifications like -terrain, -grounds, -attracties, -jörn, -valen, valer, later -borough and -ville, etc. To the present, in its original Türkic form, the term apparently survived only in the Northern European Dutch, Danish, and Flemish. The Eng. form carny, denoting a fair and not a person, probably survived independently of the later form carnival, which eventually supplanted it. Besides the retention of the olden days celebratory traditions, many drawn through a prism of the specifically European Christian adaptations, the ritualistic couple kerme/kermis and Yule constitutes an indelible case of paradigmatic transfer, attesting to a common linguistic and cultural origin. See bazaar, cry, Yule.
(Skip) English Charlemagne (king) ~ Türkic Charla-mag “call for glory”, from čağrı (ğ is silent) “call”, -la adj., adv. suffix + maɣ “glory, fame”; čağrı+la + maɣ “(one) calling (for) glory” > Charla-mag (Charlemagne). In Sl. languages the proper name Charla turned into eponymic korol, krol (король, кроль) “king”.
English clan “people related by blood or marriage” and ulan “young man, usually with military connotations” ~ Türkic oglan, uhlan, ulan, oğla:n (ğ = silent g) “offspring, son, boy”. The root ög- (ö:g) is “mother”, og (ok) is “clan, inheritance” lit. “arrow” and metaphorically “family, tribe, familial branch, stock” with semantic extensions, la:n is an ancient Türkic suffix forming names of living creatures, Cf. arslan “lion”, bakla:n “lamb”, bula:n “elk”, čoğla:n “title”, jila:n “snake”, kaplan “tiger”, kula:n “kulan, onager”, yala:n “liar”, yamla:n “hamster”, etc. The oglan “of mother” is irrespective of sex, in Türkic it came to mean “boy” and such, while the Celtic retained a genderless meaning “offspring”. The form ulan is an obvious recent (Middle Age) borrowing from the Türkic military lingo probably ascending to the Hunnic times on. The form clan with elided or omitted o- (standard Etruscan spellings with vowel harmony implying dropped vowels except one) fr. the same word hails from the Early Classical Time, but speculated “likely via Etruscan”. The reference to the Etruscan, from before the concept of the Kurgan waves was recognized, is based on the 20th c. reading of the Etruscan inscriptions, where clan means “son”. The last 3,000 years had developed a slew of forms and meanings for oglan/ulan: “son” and its derivatives “offspring, youth, young man, hero, strongman, warrior, noble, rider, cavalryman, militiaman, descendant, clan of descendants, clan, family, stock”, and possibly hundreds more semantic derivatives across numerous different linguistic families. Cognates: OIr. cland “offspring, tribe”, Gaelic clann “family, stock, offspring”; Etruscan clan “son”, clan(l)ar “sons” with elided or unarticulated -l-. Notably, one of the Türkic pl. forms, oğlanım, carries carries a Heb. pl. suffix -im. That form may hail from the 3rd mill. BC Near Eastern Semitic influence. The Celtic form may be the oldest on the record, coming from the time of the Celtic departure from the Eastern Europe to Iberia ca. 5th-4th mill. BC. Notably, Celtic had preserved the original basic notion “of mother”. Immensely important, Celtic had also carried a synonymic tuath “clan”, a derivative of the Türkic verb töle:-/döle:- “parturition, birthing, farrow”, lit. “of motherhood”. The paradigmatic transfer of the two Türkic synonyms conclusively attests to the common origin of the Celtic and Türkic. As one of the most intimate terms of kinship, the underlying word “son” is most stable within its original milieu, it is not borrowed by the host languages to replace the native word for “son”, but is extensively borrowed as a concrete noun with non-intimate semantics: “boy, youngster, brave, warrior (usually light duty), servant, helper, prince, commander”, etc., with an emphasis on a military and princely status. Due to specific dialectal forms and distribution patterns, the word is uniquely positioned for historical and geographical tracing. The suggested “IE etymology” fr. Lat. planta “offshoot, sprout”, fr. unattested plantare “to plant”, a cognate of “place, drive in”, with a substitution of k- for p-, does not hold the water. Against the attested evidence no covetous speculation is needed, the attested Celtic and Etruscan evidence is way older than the Lat. language, the suggested lexical metamorphoses are implausible, the suggested “PIE proto-word” “to spread, flat” is delusory in fact and in application. The universal absence of the word oglan/clan in the Germanic languages attests to the demographic predominance of the natives versus the Türkic demographic minority. This single word is uniquely illuminating for the individual lexemes and for classes of lexemes an established pattern of the historical layers.
English courage (n.), courageous (adj.) “bravery, brave” ~ Türkic kür/gür (adj.) “courageous, brave, daring, stout-hearted”. The Türkic notion “bravery” is connected with the notion of “heart”, that linkage was transmitted as a paradigmatic transfer into the European languages, e.g. A.-Sax. heorte, Lat. cor; Gk. kardia (καρδια) “heart”, vs. Chuv. chäre (chere), OT yürek; Mong. kirüge “heart” (see the Eurasian forms for heart). Cognates: A.-Sax. craeft (cræft, cräft) “strength, might, courage”, heorte “heart, courage”; OFr corage (12c.) “innermost feelings; temper, wrath, pride, confidence, lustiness, or any sort of inclination”, a vague mush quite remote from bravery, but in reality just simple “courage”, Lat. cor “heart”, It. coraggio, Sp. coraje. The suggested OE cognate ignores the A.-Sax. cräft “courage” and instead suggests semantically incongruent A.-Sax. ellen “zeal, strength”, another Türkic word ellen- “rule”, see Hellen. From the “IE” listing of English synonyms, one would think that none of the English ethnic ancestors had any courage: they managed to live without a native word for it, a delusory proposition. Extracting the English (and others') bravery from the Lat. cor “heart” is dubious, the term has its own independent etymology ascending to the attested Türkic word for heart, rightfully expressed in the English idiom “to have heart to do something”. The Türkic kür shows up both in A.-Sax. cräft and Fr. corage. The close phonetic and precise semantic match attests to the common genetic origin, the proximity of the forms kür/gür “courage” and her/kor/kir “heart” make the primacy fuzzy and support direct and metaphorical origin. That is illustrated by the A.-Sax. heorte, both “heart” and “courage”. The distribution points to the Türkic languages bridging Lat., Gk., and Gmc. on one end and Mong. on the other end; the Mong. forms are positively identified as Türkic loanwords adopted during the Second Period. On the Eurasian scene, the kür/gür as a title Kur “brave” occupied a salient place for over 3 millennia. The title Kur is first attested in Mesopotamia in ca 2400 BC Akkadian cuneiform inscriptions as a title or name of the horse nomadic Gutian king’s Kurum, with the Akkadian ending -(i)um, long before the arrival of the “IE” vernaculars to the Near East. Later, in few allophonic forms (Kir, Chur, Chor, Gur), it figures as a popular name (Persian, Cf. Cyrus), it was ubiquitous in the Türkic names and titles (Cf. Kurbat, Gurkhan), it was recorded in the Germanic milieu as “courage”, and adopted in the Romance vernaculars meaning “brave”. See heart, Hellen.
English cousin “relative, nephew, cousin”, originally “mother's sister's son” ~ Türkic qazïn
(OTD also offers forms qadïn, qaδïn, qajïn) “relatives by marriage on female side” from the
Türkic stem qïz- “girl” (see girl), with possessive suffix of
3rd pers. -ïn
“female's (relative)”; also applies to qaδïn male relatives by marriage.
Cognates: It. cugino; Dan., Norse kusine; Sw. kusin, Alb. kushëri, Pol.
kuzyn; all directly from the same Türkic qazïn. Naturally, Türkic has a counterpart word
for the relatives on the male side bösük, bisük, expressed as Buzuk (likely, Büzük)
in the Oguz tribal structure. The notion that French could educate English on the word cousin
is laughable, the word was around much earlier than the French were; the French could pick it up
from the Sarmatian Burgunds, Burgundian Cathars, or the Franks. The IE's deriving cousin from
the Lat. calque consobrinus
“cousin”, originally “mother's sister's son” (not daughter) is a phonetically and semantically
unsustainable shot in the dark. Unlike the Türkic family, the “IE” family has no common word for
“cousin”, attesting for a need to invent numerous native words, and a need to have this word in the
native lexicons. That points to individual histories far beyond the Italo-Celtic origin somewhere
between the 3rd and well into the 1st mill. BC. The loss of semantic specificity (male vs. female)
is normal in adoption of the word into alien native languages. In English, -i- is not
articulated, the same as -ï- in Türkic. G. Clauson specifically cites Kashgari I 403 in
respect to the form kazın: in Kipchak with -z-, i.e.
kazın - Yağma:, Tuxsi:, Kıpchak, Yaba:ku:, Tatar, Ka:y, Čumul, Oğuz. Given the accurate
phonetic and semantic match between Türkic and English cognates, and the mass of the other common
terms of kinship, the common genetic connection is inescapable. See baby, brother, dad, father,
kin, mama, mother, papa, son, youth.
78
(Skip) English crime (n.) “evil act” ~ Türkic krmšuhn (krmshuhn) (v.) “mercy, ask for mercy”. This is a most interesting case: OTürkic does not have a word for “crime”, instead it has names for specific transgressions: kill, steal, lie, betray, etc. The “IE” does not have a sensible etymology, Lat. crimen “charge, indictment, accusation; crime, fault, offense” from cernere “to decide, to sift” is clearly not defensible; an unattested “IE” *cri-men for “cry of distress” is no better. In English, the word “crime” showed up only in 13th c. as “sinfulness”, which semantically harkens back to “forgiveness”, thus matching the Türkic word both phonetically and semantically. The Lat. crimen “fault, offense” also belongs to the semantic cluster “sinfulness, forgiveness, mercy, ask for mercy”. In Türkic, from the stem krm- can be produced practically any derivative connected with requirement for clemency. The loss of the part - šuhn (shuhn) or any suffixes is reasonable, considering the distance between Eastern Europe and Western Europe, and probably way more than that with a millennium of propagation. The semantic expansions are consistent with other lexical transformations from the Türkic.
English culture (n.) “art, manners, knowledge, and values favored by a society” ~ Türkic kültür-, költür- (v.) “bind, fetter” (EDT 717, OTD 326 “to harness”). Ultimately fr. the verb köl-/göl- “harness, rein in, subdue, tame”. An opposing notion is expressed with the noun/adjective kal/qal “wild”, Cf. derivative keyik/geyik “wild animal” formed with concrete noun suffix -k, and concrete name for wild animal, qоlan/kulan/qulan “wild ass”. Typical for Türkic languages, contrasting notions are formed from phonetically near-identical lexemes, and the opposition of the front and back vowels serve as a prime phonetic mechanism. The pair köl-/göl- and kal/qal provides a strong support in favor of the Türkic etymology. Today, culture is a universal international word with unlimited semantic field that depicts phenomena from a strain of microbes to art and human behavior. Astonishingly, this most significant cultural word does not have a credible PIE or “IE” etymology. The “IE” philology is ascending the origin of the word culture to colony (n.) “settled land, farm, landed estate; husbandman, tenant farmer, settler in new land; to inhabit, cultivate, frequent, practice, tend, guard, respect” ~ pp. of colere “to till” > cult (n.) “worship, particular form of worship; care, labor; cultivation, culture; worship, reverence; tended, cultivated” > culture (n.) “tilling of land; cultivating, agriculture; care, an honoring”, with no attested “IE” or PIE cognates outside of the European area. That line of argumentation is clearly a reverse projection based on phonetic resemblance of unrelated notions. The “IE etymology” discipline must be given a full credit for an extensive record of concocting most incredible linguistic scenarios. The Türkic verb kültür-, in contrast, directly alludes to a shaped “art, manners, knowledge, and values” that as concrete objects may apply to the land cultivation, bound piece of land, and the prized social aspects of life like “art, manners, knowledge, and values”. To suggest that cultural refinement waited from deep antiquity to the 1500 AD to be named is abomination: in Türkic societies youngsters were traditionally turned over to the mother's father to be properly shaped (e.g. constrained, bridled) in the art of life. The difference between kültür- and költür- is strictly dialectal (or even preferential, like tomāto and tomato), the -ö- and -ü- are readily interchangeable (kösä-, küsä-, “to wish”, kösät-, küzat-, “to guard”, etc.), transcription largely depends on the origin and availability of the sources, and notably, the runiform alphabet did not distinguish between -ö- and -ü-, denoting them with the same letter. The Türkic köl- “harness” positively can be applied to cultivated field, like the Lat colere, with no bearing on arts and manners.
English dad, daddy (n.) “father” (Sw N/A, F223, 0.09%) ~ Türkic dede:, dedä (n.) “father”. Like other Türkic terms of relationship, dede: is a notional term, with a general notion “ancestor, elder”, and in different contexts may mean and stick as father, grandfather, uncle, grandmother, and, like its European counterparts, the word may denote terms of relationship or respect (like papa of Christian clergy) or affection (toward an elder); lit. and formal translations are not always accurate: Dede Korkut (EDT Korkud) means “Elder, Ancient, Ancestor, Progenitor Korkut”, not a “Father or Grandfather Korkut”. The “IE etymology” easily came up with an idea “probably derived from baby talk”, and the like little educated pearls, implying that it is so obvious for the babies to identify their fathers with daddies that babies of widely diverse human trunks spontaneously invented the same word. Türkic has seven roots to refer to ancestral relatives: aba (Lat. ava), ace (allophones ece, eče:, ečü, ede (Norse edda, Sp. edad “age”), eke:), ata, baba, dedä, kök, tüp; of these, ata (allophones father, eðel), dedä (allophone dad), baba (allophone papa) endured into the modern Eng., some (dad, papa) are rated as colloquial, apparently in reference to the other Gmc. languages presumed as standard. Daddy appears as a paradigmatic transfer, with synonymous eðel and father, both are allophones of atta “father”, and papa allophone of baba, babai “father”, originally each one with its semantical nuance. To miss this screaming paradigm would take either a ton of ignorance or a strenuous effort by a partisan aficionado. The allophones of dedä are sown across Eurasia, mostly as concrete nouns. Cognates, west to east: Ir. daid, Welsh tad, thaid, Lat., Gk., Cz. tata, Lith. tete, Sl. ded (with allophones) “granddad, old man”; Bosn. deda “granddad”, Bulg dyado (дядо) “uncle”; Skt. tatah, Hindi dada (दाद); Ch. yeyey (爷爷) “father”. The anlaut transitions d-/ð- (th-)/y- are regular within Türkic languages, but could also be carryovers into the daughter languages. These few examples cover the extent of the Eurasia, following the Türkic general notion “ancestor, elder” applied to the male line of ancestors and nearest elder male relatives, and transcend linguistic families. At the same time, while extending across Eurasia, the term has a sporadic presence in the “IE” family, attesting to its non-IE origin. The other widespread term for “father” is aba and its allophones, it covers part of the Romance and Semitic groups, the most oft cited are Lat. avus and Heb. abba; also Goth. aba “man, husband”, OIcl. afe, Catalan avi “grandfather”, etc. In addition to the local designation, aba in the sense of “ancestor” was a Türkic alternate name for a “bear”. This other series of examples also cover the extent of the Eurasia, also follow the Türkic general notion “male ancestor, elder”, and transcend linguistic families; in the conventional definition of the linguistic families, they are guests, attesting to their alien origin. The third popular term for “father” is ata, it could be an early phonetic version of apa. Examples are Goth. atta “father, forefather”, OHG. atto, Ir. seanathair “grandfather”, Lat. atta, Gr. atta (αττα), Sl. otets (отец) “father”. Popular derivatives of ata are eðel and Attila, the last engraved on the Scythian coin as Atails (Gk. Ateus (Ατεας, Atheas), turn of 4th-5th cc. BC), a compound of ata “father” and il “land, possession”, an obvious throne name identical semantically and functionally to Attila and Atatürk, among many others; in the Gmc. milieu, the eðel became synonymous with nobility and a popular throne name for Attila's successors. The fourth term for “father” is baba, with allophones standing for the Catholic and other Popes, generic for the Eastern Orthodox priests, and among others the Arm. papik (պապիկ) “grandfather”, Eng. papa, pop, pappy, etc., Fr. papa “father”, Sl. baba “grandma, old woman”. In some instances all the above terms revert to their prime notion of the “ancestor, elder”, and apply to females as a concrete noun (Cf. Sl. baba). The point of the examples is the unfettered Eurasian distribution of the Türkic terms for “father”, unfettered variations of allophones, time depth ascending to the first historical compilations, and paradigmatic transfer of different subsets of the basic complex of seven designations into different languages and linguistic families. Such uniquely developed and multi-faceted paradigmaticity constitutes unfalsifiable evidence attesting to its Türkic roots (Eng. dad, father, and papa; Goth. aba and atta, Sl. ded and otets, Lat. avus and atta). It attests to demographic amalgamations effecting paradigmatic transfers of linguistic complexes from the donor ethnicities to the recipient ethnicities. A close study of the geographic and ethnic prevalence of the various terms may help to discern tendencies and connect the dots in demographic flows. See age, ethel, father, papa, uncle.
English doll (n.) “toy replica of a person” ~ Türkic döl/tö:l “newborn, baby, fetus, (and offspring, progeny, descendants, children, lambing, calf, moment of parturition)”. Cognates: Dan., Norse, Icl. dukk-, Sw. docka; Geor. t’ojina (თოჯინა), all “doll”; Ir. seoil, Gk. toketou (τοκετού); Hu. szülés; Az. doğuš, Mong. törölt (төрөлт), Somali dhal(mada), all “childbirth”; Balto-Sl. (Latv.) telu, (Sl.) tel(ya), tel(enok) (телиться, теля, теленок), Mong. tugal (тугал), Ch. tui 腿, all “calf”. The pattern indicates the prime source as the expression for a baby, taken into a range of languages as a baby animal, and into another group of languages as a childbirth deliver act, and still into another group of languages as a toy baby. Notable is the form common for Ir. and Hu., apparently a Celtic relict in Pannonia, and also a visitor from the Türkic languages into Afro-Asiatic Somali language, either an Ottoman relict, or possibly a trace of the Celtic circum-Mediterranean voyage. The perfect phonetical and semantic match indicate a direct insertion of the term into the local lingua franca, likely via commerce. The speculated “IE etymology” is parochil in light of the Eurasian-wide cognates. In modern Türkic languages, and a number of once neighboring languages, doll is called with allophones of the baby, including palatalized allophonic forms for puppy, another Türkic term for a baby. See baby, puppy.
English earl (n.) “British peer” ~ Türkic yarlïqa-, yarlïɣɣa-, yarlïɣqa- (v.) “to rule”. Ultimately fr. yarğu: “splitter, tribunal”, a deverbal noun derivative fr. yar- “split, cleave”. Cognates: A.-Sax. eorl “leader, chief”, Dan., ONorse jarl “under-king”, viceroys under the Dan. dynasty in England; Gutian Yarğan “Judge, Tribune” (in Akkadian cuneiform records on Gutian rulers, ca. 22nd c. BC); Russ. yarlyk (ярлык) “written certificate”. The title is richly attested in Türkic, G. Clauson (Clauson EDT 963) cites the name-titles Inanču Apa Yarğan Tarxan (8th c. AD) and Boyla Kutluğ Yarğan Suci (9th c. AD) in Türkü and Uigur records, and the Greek records have a regent Organa for Bu-Yurgan (7th c. AD). That position and title were perpetuated in the Bible's Book of Judges, in the Roman Republic, and in the legend of the Round Table of the King Arthur with its Earl tribunes. When the title Yarğa:n came to the attention of the Akkadian scribes it already was not new, then it lasted during the Gutian rule of the Akkkad and Sumer, and it outlived the Akkkadian Empire by more than 3000 years. The title Yarğan names the post of “judge, tribune” rather than “commander”, that is attested by the component Yarğan Suci meaning “Judge - Army Commander”, and the title Earl (a form of Yarğan) at the Round Table. The etymology of the position Yarğan ascends to the word yarğu: “splitter, tribunal, lawsuit, legal decision” denoting a legal tribunal at the head of the tribal administration, “i.e. an instrument for splitting facts and discovering the truth” from the verb yar- “to split, cleave”. The deverbal derivative yarlığ fr. yarlïqa- is a “command (from superior to inferior), edict”, it has civil and military applications, and yarğu:n is a “destroyer, ruiner”, a derivative of the same verb yar- meaning “destroy, ruin” with clear war-time application. (Clauson EDT, ibid) The Türkic verb yarlïqa- (yarlïɣga-) is a derivative of the same verb yar- meaning “to order, to command” (Balkan K., 2000, Relations between the Language of the Gutians and Old Turkish//Journal of Erdemir, c. VI). In the Gmc. languages the title is not a generic “ruler”, but a specific title “ruler”, still carrying the notion of the “Judge, Tribune”, member of the tribunal. The suffix -l- is an adjectival suffix. The Türkic adjectival derivative yarlïg is known from the Mongol times as an inscribed order, given on paper, copper, bronze, silver, or gold, hence the Russ. yarlyk, a written certificate; yarlyks were given to the Rus' Dukes for a right to reign. The “IE etymology” declares affiliation “of uncertain origin”. The Türkic preserved this word as a title, and its usage in Türkic is connected with ruling prerogatives (tаgri yarlïqaduqïn üčün... qagan olurtum “as Heaven behested, I sat a Kagan” (Tonyukuk inscription). The phonetic and semantic consistency demonstrates a peculiar linguistic longevity across a period of four millennia, and the immense geographical spread from China to the British Isles. The title is used in Anglo-Saxon poetry, and in ONorse sagas with allusion to the As rulers. Title's distribution is peculiar and diagnostic, since only a certain part of the Türkic peoples in Europe used that title; neither Alans, nor Burgunds have spread that title in the southwestern Europe. Carryover of the Türkic titles King, Earl, Baron is not only an authentic case of paradigmatic transfer attesting to a common genetic connection in demographic and linguistic aspects, but also attests to the ethnic traditions of the ruling elite. Of the above three titles, France only used the late borrowing of Baron. See As, Baron, king.
English elite (n., adj.) “of superior status, the best selected” ~ Türkic elit- (v.) “lead, take
away”, a derivative of Türkic verb elga- “distinguish and separate out, sift”.
Today, elite, synonymous with lead (n., Cf. “lead engineer”, “leader of a country”,
“lead culprit”, “loss leader”) as a status title is an international word, repeated around the globe
with minor allophonic variations. Ditto with lead, leader, which addresses the action aspect,
i.e. leading the followers, guiding a group. Status aspect cognates: Gmc. elite with various
allophones; Welsh elitaidd; OFr.
eslite (n., 12c.), elire, elisre (v.) “pick out, choose”, Fr. élite “selection,
choice”, Lat. eligere “choose”; Hu. elgarda, all related to status. The Hu. preserved
the form of the original root elga- “to separate”, probably a loanword directly from one of
its Türkic components. Action aspect cognates: A.-Sax. lædan “cause to go or act; lead a
group, guide, show the way, carry on, sprout forth, bring forth”, NFris. lud, luad, WFris.
lead, Du.
lood, Sw. lod, Gmn. Lot; Ir. luaidhe, Welsh elitaidd, all “lead”.
An aspect of physical movement is a metaphorical extension related to going, travel, and such,
semantically unrelated to the elite status or action leadership; some trade terms also use the
metaphoric term “lead” in fishing, for plumb line, sounding line, etc, exclusively within Gmc.
languages including some English. Notably, for “lead, leader” and metaphoric extensions Romance
languages use incompatible vocabulary, but they extensively use allophones of the Türkic elga-
“separate” for the notions of selection and separation. The presence of the Celtic Ir and Welsh
forms points to the presence of the verb elga- in the N. Pontic prior to the Celtic
circum-Mediterranean outmigration of the 6th-5th mill BC. The literal carryover of the original
semantic aspects of “lead” and “chosen” present an authentic case of paradigmatic transfer attesting
to a common genetic connection in demographic and linguistic aspects. The “IE etymology” is confused
and confusing, it piles up primary, secondary, and metaphoric meanings and invents unattested
tertiary constructs like the PG *laidjan, and PIE *leit- “go”, all the way down to an
incredible plumbum (“lead”), as related quasi-real primary sources. See
eligible lead, leader.
79
English Erik (n.) “popular name” ~ Türkic erk (n.) “strength, will, might, power”. Cognates: ONorse Eirikr, Gmn. Erich. Erik used to be a very popular name among the Germanic people and in their neighborhoods; in Türkic languages the term refers to power, authority, and independence: erklig “ruler, possessing power, authority, independence”, erklen- (v.) “powerful, authoritative”, etc.; in reference to Almighty it is “mighty, omnipotent”, it is used as a title-name. In self-imposed impotence, the “IE etymology” borders on lunacy, with the initial e- standing for “PG” *aiza- “honor”: aizarex “honorable king”. An etymological irony is that the Lat. rex in that unreal “Germanic” compound is an allophone of the Türkic arïɣ “clean, untainted”, a popular element in title-names of the rulers, paralleling that of the “saint”. See Arthur.
English equal (adj.) “equivalent” ~ Türkic eŋil, egil, (adj.) “common, ordinary, commoner”, also “poor”. Ultimately a deverbal noun/adj. derivative of the verb eŋil-, egil- “bent, bowed, bend, stoop, crawl”, a derivative of the verb eŋ-, eg- “bend, bow, fold, twist”. Forms with anlaut eŋ- are thought to be older, they are found in less than 10% of the Türkic languages: Turkmen, Turkish, Uzbek, and Saha (Yakut); that identification helps to asses timing and the area of the origin. The notion of physical equality must have existed as far back as exchanges and trade, it is immeasurably older than the 14th c. astrological notion of equality expressed by the European “equal”, with each language having its own means to express it. For example, along with other native expressions, A.-Sax. used a geminated Türkic suffix -lig “like” as a compound (ge)liclic for comparative equality. Cognates: the European philology classed the word as “of unknown origin”, there's no surprise there; A.-Sax. gel(lef)-, gel(if)- (in ungellef-, ungelif- “(extra, non-)ordinary”); Welsh gyf-; OFr. egal, Lat. aequalis “uniform, identical, equal”, aequus “even”; Mong. egel (егел), engiyn (энгийн) “ordinary”.. The Celtic forms do not belong to the cognate list, the Welsh full form gyfartal ascends to the number 1 (one), Cf. Sl. odinakovyi (одинаковый) “uniform” fr. odin (один) “1”, like the Ir. coimheid and Gaelic co-ionnan; all three Celtic examples are post-migration innovations. A.-Sax. used gellef-, gelif for “common, ordinary, commoner”, and the pan-Gmc. “even” for “equal” (A.-Sax. efen, Goth. ibna, OHG. eban), implying that gellef-, gelif specifically referred to a lower class, poor folks. That is consistent with the Türkic word being adopted as a diminishing moniker before it grew to a slogan for justice, “liberty, equality, fraternity”. The French Revolution made this word international, its reflexes are at least known throughout the world. Morphologically and phonetically, aequalis, egal, and egel came to Lat., Fr., and Mong. via separate paths, the Fr. probably directly from the Burgund Sarmats, with the Türkic semantics related to the status of people; the A.-Sax. had its own gel- “ordinary” independently fr. Lat. and Fr.; Mong. directly from Hunnic or Türkic. The Mongolian word is likely a Hunnic heritage from the days in 93 AD when 100,000 Hunnic families numbering 500,000+ people submitted to the ruling minority of the Syanbi (pin. Xianbei 鮮卑) Mongols, essentially making the Hunnic language a language of the Syanbi. The four independent reflexes with identical and overlapping semantic attest to a common source that endowed four major languages with the allophones of the Türkic egil carrying the notion of ordinariness, equality, evenness, and commonality. The grammatical functions, phonetics and semantics are congruent and near perfect. The Fr. and A.-Sax. forms are intermediary between the Türkic egil and the modern Eng. equal, the forms egal and equal were used in parallel for four centuries. On new soil and in new times, the original social equality added aspects of mathematical equality, chemical equivalence, financial equity, and many other facets as time required. In this case the “IE etymology” came out good by not trying to concoct something like ex + cue with loony PIE roots and tortured semantics.
English evil (adj., n.) “harmful” ~ Türkic uvul-, opul-, öpel-, öpül-, uyul- (v.) “collapse, squeeze, subside, suck in, swallow”, where the ul-/el-/ül- is a passive marker “sucked in, etc”. The verbal stem uv- “crush, grind, rub, wring” has a very physical origin, probably associated with food and material processing, but its derivatives also carry metaphorical notions, the form uvul- conveys an abstract notion of “demise, demised”, perpetuated to posterity by Tr. and Gmc. languages. Cognates: A.-Sax. yfel “bad, evil, wicked, wretched, worse”, OSax. ubil, OFris., MDu. evel, Du. euvel, Goth. ubils, OHG. ubil “evil”, Gmn. übel; Hitt. huwapp- “evil”. The minor phonetic dispersion attests to fairly late migratory scattering, probably by the 2nd c. BC Sarmat refugees escaping assault of invaders from the Central Asian interfluvial (Yablonsky L. et al, 2010) that created the European Sarmatia and Germania; the uniform distribution among the diverse Gmc. languages makes the late origin from the Western Hunnic phylum unlikely. The Hitt. form attests to much earlier presence of the word, predating 2000 BC, adding doubts to the “IE” classification of the Hittite language based on its other distinctions consistent with the traits of the Türkic linguistic family (agglutination, absence of grammatical gender, etc.). The word has no distribution across the “IE” family, the faux “PIE reconstruction” preposterously expands a distribution confined to the Gmc. and Tr. languages to the entire “IE” family (Cf. “IE” Lat. mal “evil”, and its widespread derivatives). The Türkic origin is attested by functional and semantic continuity, and perfect phonetic correspondence. The words evil and bad entered Eng. as a paradigm, shared by Tr. and Gmc. groups, with a similar peculiar distribution, the paradigmatic transfer renders the Türkic origin incontestable. See bad, voe, worse.
Start 8/30/2018 Stop
English father (n.) “male parent” (Sw43, F240, 0.07%) ~ Türkic ata “father”. It can be reasonably conjectured that the forms aba, ace, ata, baba, dedä, plus a stray aga, are archaic allophones of a single root expressing a notion “old, senior”. Türkic root ata is predominately “father” with an underlying notion “ancestor”, at times “paternal uncle”, and metaphorically “prince”, “tutor”, (Moslem) clergy, and such. Notable is the idiom ata adam “ancestral man”, “primogenitor”, with dependent ata “father, ancestor” preceding the head adam “man, Adam”. That idiom was a natural precursor for the Biblical name Adam (see Adam), predating the age of the spoken Bible. Türkic has seven roots to refer to ancestral relatives: aba (Lat. ava), ace (allophones ece, eče:, ečü, eke: “age”, ata, baba, dedä, kök, tüp, ede with Norse edda, Sp. edad “age”; of these, ata (allophones father, eðel), dedä (allophone dad), baba (allophone papa) endured into the modern Eng., some (dad, papa) are rated as colloquial, apparently in reference to the other Gmc. languages rated as standard or to some literary language. In some instances all the above terms revert to their prime notion of the “ancestor, elder”, and apply to females as a concrete noun (Gmc. languages exclusively to males and paternal line). Like other Türkic terms of relationship, ata is a notional term, with a general notion “ancestor, elder”, and in different contexts may mean, and be so fossilized, as father, grandfather, uncle, grandmother, and, like its European counterparts, the word may denote terms of relationship or respect (like “Father Christmas” for Santa Claus, “father” for Christian clergy) or affection (toward an elder). Gmc. practice is a calque of the Türkic practice, “father” with concrete (Cf. A.-Sax. feder, Gmn. vetter “paternal uncle”) and metaphorical (“ancestor, founder, predecessor”) extensions. Gmc. group has a pronounced prosthetic anlaut v- (f-), typical for words starting with vowel (vetter, feder), Mediterranean and Asian branches have the p- version of v- (pater, patria, etc); the t-/d-/th- alteration runs across linguistic branches (Cf. pater/padre, Goth. atta “father, forefather”, Gmc. ethel, etcel); the suffix -er/-ar is an agent suffix, its presence in numerous European and Asian languages emanating from the 3rd-2nd mill. BC E. Europe attest that the meaning of ata there and at that time was “ancestor”, and atar/ater was a denoun agent derivative. The Türkic plural collective suffix -dVr (-der/-ter/-ther, -dar/-tar/-thar, etc.) was once very productive and may ascend as far back as the Neolithic times, contemporaneous with other cognates from the most archaic lexicon. It is used as a sign of respect, i.e. pl. you vs. sing. thou, a form habitually used by self-aggrandizing personalities and in the E. Europe as a traditional pl. appellation for mother and father not infected by Russ. sing. appellation, Cf. čavındır, čavuldur, čavundur, čavdır “(You) famed” (čav “fame”), Bayındır/Bayındur – ruling dynasty of Ak Koyunlu confederation, Onogundur (Bulgars), etc. The Gmc. transition from pl. to sing. semantics attests that the appellation was picked up by languages that adopted form and substance but missed the semantic nuance. For the verbal stems, the suffix forms an energetic notion (causative, energetic mood), still active in Türkic languages. The connection with the E. Europe is established and dated genetically as a source of the southeastern migrations of the originally European folks. Cognates: A.-Sax. fæder “father, male ancestor”, OSax. fadar, OFris. feder, Du. vader, ONorse faðir, OHG fater, Gmn. vater; OIr. athir “father”; Sl. otets (отец); Skt. pitar-; OPers pita; Basque aita “father”. The OIr. form with agent suffix, and its Basque counterpart may attest that the agent suffix -er/-ar ascends to the 2800 BC Celtic coming to Europe via Africa, and earlier to the Celtic departure from the N. Pontic area in the previous millennia, i.e. to the period around 5,000 BC., before the appearance of the prosthetic v-/f-/p with the European refugees later in the 4th mill. BC. The Sl. form is a direct adaptation of ata, in parallel and independent of the prosthetised forms, in the E. Europe ata and otets interspersed and co-existed. The OPers pita vs. Skt. pitar- attest that at the point of departure in the 3rd mill. BC both forms co-existed. The “IE etymology” intimates that father ascends to the “PIE” *átta, and *ph2tḗr, which are obvious reflexes of the Türkic root ata, with some ingenious phonetical exercises and complete immunity to reality. In fact, the “IE etymology” unwittingly asserts that the “PIE” origin equates to the Türkic origin, a fatal anathema in the “IE” linguistics. An alternative would be to expand the non-existent definition of the PIE concept to include Türkic family as a daughter branch of the PIE trunk. That would give the PIE theory some breathing room, but with terrible consequences. In Eng., father appears as a paradigmatic transfer case, with synonymous dad, eðel and papa; father and eðel are allophones of ata “father”, and dad is an allophone of dedä “father”, originally each one conveying its semantic nuance. To miss this screaming paradigm would take either a ton of ignorance or a strenuous effort by a partisan aficionado. The examples demonstrate unfettered Eurasian distribution of the Türkic terms for “father”, unfettered variations of allophones, time depth ascending way beyond the first historical compilations, and paradigmatic transfer of different subsets of the basic complex of seven designations into different languages and linguistic families. Such uniquely developed and multi-faceted paradigmaticity constitutes unfalsifiable evidence attesting to its Türkic roots (Eng. dad, father, and papa; Goth. aba and atta, Sl. ded and otets, Lat. avus and atta, Swahili/Bantu baba, Kor. abeoji, Mong aav). It attests to demographic amalgamations effecting paradigmatic transfers of linguistic complexes from the donor ethnicities to the recipient ethnicities. A close study of the geographic and ethnic prevalence of the various terms may help to discern tendencies and connect the dots in demographic flows. See age, ethel, dad, papa, uncle.
English folk (n.) “people” ~ Türkic bölük, bölök (n., adj.) “subdivision, group, part, fraction”. Ultimately a derivative fr. the verb bӧl- “divide, separate” with a deverbal adjectival suffix -ük, -ök “separated, detached”, bölük covers an immense semantic spectrum: “section, part, share, separate, different, district, group, band, flock, villages, province, distinguish”. It is mostly reflected in its most visible administrative-military-political aspects, as for an autonomous province, district, for a unit of army, division, regiment, squadron, for province, district; the other meanings and shades belong to a casual speech, like a flock of animals. As a title-name in the Western Hunnic annalistic context, it is mentioned as Βαλαχ, Βαλας lit. “separated, autonomous”, i.e. an autonomous Hunnic ruler, for phonetical resemblance the European-driven onomastic studies suggested its etymology as a calf or buffalo. The Eng. and Gmc. usage is consistent with the Türkic semantics and collective appellation, save for the flock of animals and the like. The ubiquity of the word in the A.-Sax. lexicon is demonstrated by more than 70 forms and derivatives, a number of them are compounds of two Türkic words. Cognates: A.-Sax. folc “folk, people, nation, tribe, collection or class of persons, troop, army”, folcagende “ruling”, folcstede “battlefield, dwelling-place”, OSax. folc, OFris. folk, ONorse folk “army, detachment, people”, OHG folc, MDu. volc, Du. volk, Gmn. Volk “people”; Balto-Sl (Lith.) pulkas “crowd”, (OCS) pluku “regiment, division of an army”, Rus. polk “regiment”. Of the phonetically more remote suggested cognates are the Gk. plethos “people, crowd”, Lat. plebes “populace, commoners”. The transformation b- to p-/f-/v- is a regular affair in the Türkic - Gmc./Balto-Sl./Sl./Gk./Lat. phonetic adaptations, Cf. bürek/bürök “pirogi, pirog (пирог)”, Badjanaq/Beçenek “Patsinak, Pecheneg (Печенег)”, etc. The degree of internalization in the A.-Sax., and in other Gmc. languages points to a period millennia before the coming of the Huns to the Western Europe; the Hunnic form of word, if the pronunciation was significantly different from the Gmc., could only overlay on the existing lexicon. The Lat. and Gk. forms point to separate paths, possibly connected with the return of the European farmers from the Eastern European refuge back to the Western Europe ca. 2nd mill. BC. That dating roughly coincides with the southeastern Aryan outmigration from the Eastern European refuge, apparently without a bölük/folk in their daily vocabulary. That is consistent with the observation that only a small portion of the European vocabulary reached the South-Central Asia. The absence of cognates in the Celtic languages attests that the word formed after the Celtic circum-Mediterranean departure from the Eastern Europe of the 6th-5th mill. BC. Spectacularly, the Celtic (Ir.) cognates balis, balisau, palis, palisau, phalis, phalisau “divide, separate” of the root bӧl- “divide, separate” have survived for 8-6 millennia, attesting to the existence of that root among the Y-DNA R1b ancestors in the pastoral and hunter-gatherer Mesolithic Eastern Europe.
English gadding (n.) “kinsman, fellow, companion”, gad (v.) “rove about” ~ Türkic qad/qat “near, about, at, with others”, qadaš, kadaš (ka:daš, cadash) “kin, relative, relatives, brother, confederate” formed with denominal suffix of association -daš. Ultimately a derivative of qa, ka “family”, homophonous with qa, ka “vessel” (Cf. Eng. cap, cup) and obviously genetically connected with it. Socially, in the daily life, the semantics “friend, confederate” is most popular, it survived into modern English in general, and in sailing lingo as a noun gadabout “friend, confederate” and verb gad “rove about”. Cognates: A.-Sax. gada, cuða “comrade, companion, relative”, gædeling, ME gadeling “kinsman, fellow, companion in arms”, Gmn. gatte “spouse” (synonymous with Gemahl “to do together”), “mate”, “partner” synonymous with Sozius “with union”, “husband” (synonymous with Gemahl “to do together”); Ir. ceath-, Welsh cyd-; Hu. kat-, Fin. kav-. Notably, the word is shared by Celtic, A.-Sax. and Türkic, but is nearly absent in Gmc. and absent in “IE” languages, accentuating the ancient origin of the word ascending to the 6th-5th mill. BC in case of Celtic, and to the end of 1st mill. BC in case of A.-Sax. , and a different paths of A.-Sax. and Gmc. Türkic strata. The “IE etymology” is non-existent, not even “of unknown origin”. The significance of the cited synonym Sozius is in its Türkic origin from the root uz “union, partnership”, known fr. Sl. Souz (like in CCCP/USSR) and Kazakh and Usun Juzes (Unions), in this case we have three Gmn. synonyms derived from three Türkic synonyms (qad/uz/mak- vs. gatte/-zius/mahl), a salient case of paradigmatic transfer and genetic connection.
English gaffe (n.) “awkward act” ~ Türkic ɣaflät, ɣafillïq (n.) “inattention, carelessness”. Cognates: Eng. goof “awkward, stupid”; Fr. gaffe “clumsy remark”, linked to OProvenčal gaf, which in turn leads to the Burgundians, a Sarmatian horse nomadic tribe of Vandals, “Wanderers”, in the Classical sources (Theophylact Simocatta ) identified with the Türkic Bulgars; Pers. ɣavɣa “turmoil, tumult”; Arabic ɣaflät, ɣafillïq “inattention, carelessness, indifference”. The “IE etymology” piles up numerous unrelated homophones, semantically all wacky. All three surviving Türkic forms (ɣafillïq, ɣaflät, ɣaflet) have Türkic suffixes, attesting that the Arabic ɣafillïq with the Türkic (and English) suffix -lïq is a loanword from the Türkic.
English George (n.) “patron of England, royal name” ~ Türkic urï (n.) “son”. Cognates: LLat. Georgius; Gk. Georgos; Sl. Georgy, Üry (Георгий, Юрий). The Sl. form Üry clearly points to the original etymology, the anlaut g- in the western forms reflects the Ogur version of the name with a prosthetic consonant. The suggested Gk. etymology “husbandman, farmer”, fr. ge “earth” + ergon “work” is more than dubious, and would not come about without unwitting use of the Gk. allophones of the Türkic generic yer “earth, land” (Cf. the Scythian Gerra “land of our ancestors” with prosthetic anlaut g-) and ergü “strength, power, force”. Ironically, St. George, a Türkic “son”, after half a millennium of trepidations experienced by the western European lands at the hands of the Asiatic nomadic conquistadors starting with Alans still in the pre-Christian world and continuing with the dismemberment of the Roman empire by the Huns and their successors, turned into a supernatural protector from the very same Türkic nomads, who allegorically and single-handedly smote the snake of the nomadic menace.
English gift (n.) “present” ~ Türkic kıv- (v.) “give”, kıv (n.) “gift”. The A.-Sax. deverbal noun is giefu, giefe “gift”, to giefe, giefes “grace, favor”, it carried the sacral underpinning of the verb qïv-, kïv- “give, bestow (grace, blessing, supreme favor)” documented in the sources (formulaic kïv kut “bestow grace, fortune”); it is a noun component of a tri-verbal paradigmatic transfer (qïv- “bless, confer”, bağıš- “bestow, grant”, ber- “give, bring, bear”, see give). Cognates: A.-Sax. giefu/giefe/giefeo/giefi/giefy (to giefe, giefes) “gift”, ONorse gift, giþt “gift; good luck”, OSax. gift, OFris. jefte (yefte), MDu. ghifte “gift”, Gmn. Mitgift “dowry”. The ONorse has preserved the original notion of “good luck”: “heaven-given fortune”, a lit. content of the formulaic idiom kïv kut (see God). The “IE etymology” blunder blind, inventing an incredible “PIE” cognate *ghabh- “give or receive” from habit “behavioral pattern”, and citing in support the unrelated Sw. homophone gift “poison” as a cognate. Conversely, the forms qiv, kiv are attested, supported by converging phonetic and semantic molds, and even carry the archaic primary notion of being blessed with heavenly grace. The etymology is clear and obvious, without a need for unbelievable ingenuity. See bear, bestow, give, God.
English girl (n.) “maiden” ~ Türkic kyr (qyr, kyz, qyz, khyz, spelled kïr, kïz, qïr, qïz, χïz) (n.) “girl”. The complimentary forms kïr and kïz reflect the Ogur and Oguz pronunciation respectively. Cognates: OE (14th c.) gyrle “child” (of either sex), predictably “of unknown origin”; Low Gmn. gære “boy, girl”, Norw. dial. gorre, Sw. dial. gurre “small child”; the attestation of use for male child is obscure and quite unlikely, historically the difference between male and female children was paramount; Sum. gal, gašan (gashan) “girl” is attested fr. the 3rd mill. BC. The form qyr with auslaut -r is recorded in the derivatives qïrnaq “slave-girl, young slave-girl, concubine”, qïrqïn “slave-girl, concubine”; the form with auslaut -d is recorded in derivatives quduz, quδuz “previously married woman”, quδurčüq “doll”; the form with auslaut -z is recorded in kïz, qïz “girl”, and in Ch. 妻子 qïzi “wife”; the form with anlaut χ- is recorded in χïz “girl, daughter”; the form with auslaut -z is common in languages of Oguz-Kipchak branch. In English, -i- is not articulated, the same as -ï- in Türkic; the auslaut -l in girl is a Türkic adj. suffix. On the status of the girls in Viking society we have testimony of Ibn Fadlan, the local girls were maids and concubines of travelling princely traders; that status grossly contrasts with the status of native girls in the pre-Islamic Türkic society, where females enjoyed full equality, girls had sexual freedom, and in the property matters females had a status higher than that of the males. The stories on Amazons, Scythians and the native mythology provide a glance into female warriors. The Viking girls of Ibn Fadlan are likely of local Fennic extraction held as slave-maidens. In English and Gmc. languages, the term girl comes with a constellation of other Türkic terms for relatives, in English: cousin, father, kin, papa, son, youth; notable of that line-up, the term for “mother”, the Türkic ana/ani, is profoundly missing. That points that Türkic males supplanted the local males, but mothers were local, and local terms of Türkic extraction were used for “mother”, i.e. “mama” and its derivative “mother”, see mama, mother. Such nearly complete displacement of local males has been detected by archeological studies, discriminating, for example, between the Early and Late Sarmatians. At the same time around 150 BC as the Early Sarmatian Uraloid males disappeared from the Urals area, new Sarmatian tribes of Vandal “Wanderers” popped up in the Baltics and Poland river valleys, and pressed on the Scythians in Ukraine and Rumania, changing again the demographic and cultural picture in the Central Europe. The Sum. form attests to the temporal path Sum. > Türkic > English. The Chinese form attests to the cultural influence of the Zhou “Scythians” in forming the Chinese nation and language, the qïzi “wife” still has connotations separate from a regular wife, furen “wife, mrs., madam”. See cousin, father, kin, mama, mother, papa, son.
English groom (n., v.) “stable hand” ~ Türkic görüm(čï) “groom, stable hand”. The compound ascends to the base root gör-/ kör- “look, look after” + abstract noun suffix –üm + instrumental suffix –čï, lit. “looker, watcher”. Türkic languages have used dozens of native appellations for the notion “groom”. Probably, that was a result of two factors: grooms were not needed within the nomadic society, where every family tended to their own horses, and the appearance of stables and stud farms outside of the nomadic societies that employed nomadic expertise to breed their own horses. Thus, the appellation görümčï, like its numerous synonyms, were of insular, not universal nature, and appeared fairly late, toward the end of the Antique period. Cognates: “No known cognates in other Gmc. languages”; no known “IE” cognates either. The Türkic source is beyond doubts, c.f. Bulg.-Sl. calque (kone)glyadach (конегледач) “looker after (horses)”, Rum. grajdar “groom”, calque mire “look (after)”.
English guard (n.) “defender, protector, guardian” ~ Türkic, körüg, görüg, qaraɣü (n.) “lookout, guard”, garavul-, karaul- (v.) “watch, guard, sentry”, fr. kör- (v.) “see”. Semantically, guard is a surrounding protection, akin a to defensive wall, that is echoed in the nearly homophonic qur (n.) “sash, belt”, qur- (v.) “arrange, build, line up, gather, stretch”, Cf. Goth. gards, garths “enclosure”, Russ. karaul (караул) “guard”, see gird. Either one could have produced a derivative “guard”, phonetics supports both alternatives, but the Baraba karaul- “distant look” and “gun sight” weighs on the side of the kör- (v.) “see”. See gaze, gird, grave.
English guest (n.) “visitor”, host “owner, receiver” ~ Türkic göster, köster, közter- (n., v.,
adj., adv.), stem of göster(mek) “to show, guide”.
Derived fr. körtgür-/görtgür- “show”, ultimately a causative form of kör- “see, look,
obey, experience” with inserted euphonic -t-. “There is obviously a very old etymological
connection with kör-” (Clauson EDT 756), i.e. what started as kör- (v.) had
developed into
köz/köz “gaze, eye, sight, spring, aperture” and shifted to gös- (v.) and gös-
(n.), Cf. gaze. The labyrinth of changes is mind-boggling, but clearly traceable. With
agglutinated suffixes, the Türkic stem produces both active and passive verbs, which in turn produce
derivative nouns: göstermek “to show”, gösterdi
“to be shown”, hence the bifurcated semantics of the noun guest and host retained in
the Gmc. and Sl. languages, in Lat., and in Greek. The Türkic word is endowed with a remarkable
variety of forms, some languages have two or three, varying mostly in the selection of synonymous
morphological modifiers. That attests to a wide range of receptor languages and deep timeframe. The
notion host may have arisen from a pastoral tradition of a local leader showing to newcomers
the local sacred sites, places to settle, and the allotted pastures. Cognates: A.-Sax. gæst,
giest (Ang. gest) “guest, enemy, stranger”, OFris. jest, Du., Gmn. gast,
Goth. gasts “guest”; OCS gosti (гости)
“guest, trader, friend”, hozyain (хозяин) “host” (with aspirated anlaut ɣ- following
the Türkic articulation, thus forms with оспод- and Cz. hospodín with h-);
Lat. hospes “host”, hostis “enemy”; Gk.
xenos “guest, host, stranger”; Skt. jaspatiṣ “head of family”. Slavonic extended
semantics to traders and billeting (postoi, постой), hence the gospodi (господи)
“lord, master”, with connotation of strangers, and hozayin (хозяин), gospodin (господин)
“host, ruler”. The euphonic inlaut -p- (hospes) appears in Lat., Sl., and Skt. forms,
replacing the Türkic euphonic -t- (göster). The Sprachbund status of the term can be
dated by before the 2000 BC Indo-Arian migration. That may also be an indicator on when an
incidental trading turned into a trading profession along the Eurasian steppes. The “IE etymology” manages to come up with separate surmises for guest and host, inventing
non-etymologized unattested PG and PIE “proto-words” of the type *gastiz, *ghos-ti- is
“guest”, in a circular fashion leading from a supposedly unknown to a nowhere.English guest (n.)
“visitor”, host “owner, receiver” ~ Türkic göster, köster, közter- (n., v., adj., adv.), stem of
göster(mek) “to show, guide”.
Derived fr. körtgür-/görtgür- “show”, ultimately a causative form of kör- “see, look,
obey, experience” with inserted euphonic -t-. “There is obviously a very old etymological
connection with kör-” (Clauson EDT 756), i.e. what started as kör- (v.) had
developed into
köz/köz “gaze, eye, sight, spring, aperture” and shifted to gös- (v.) and gös-
(n.), Cf. gaze. The labyrinth of changes is mind-boggling, but clearly traceable. With
agglutinated suffixes, the Türkic stem produces both active and passive verbs, which in turn produce
derivative nouns: göstermek “to show”, gösterdi
“to be shown”, hence the bifurcated semantics of the noun guest and host retained in
the Gmc. and Sl. languages, in Lat., and in Greek. The Türkic word is endowed with a remarkable
variety of forms, some languages have two or three, varying mostly in the selection of synonymous
morphological modifiers. That attests to a wide range of receptor languages and deep timeframe. The
notion host may have arisen from a pastoral tradition of a local leader showing to newcomers
the local sacred sites, places to settle, and the allotted pastures. Cognates: A.-Sax. gæst,
giest (Ang. gest) “guest, enemy, stranger”, OFris. jest, Du., Gmn. gast,
Goth. gasts “guest”; OCS gosti (гости)
“guest, trader, friend”, hozyain (хозяин) “host” (with aspirated anlaut ɣ- following
the Türkic articulation, thus forms with оспод- and Cz. hospodín with h-);
Lat. hospes “host”, hostis “enemy”; Gk.
xenos “guest, host, stranger”; Skt. jaspatiṣ “head of family”. Slavonic extended
semantics to traders and billeting (postoi, постой), hence the gospodi (господи)
“lord, master”, with connotation of strangers, and hozayin (хозяин), gospodin (господин)
“host, ruler”. The euphonic inlaut -p- (hospes) appears in Lat., Sl., and Skt. forms,
replacing the Türkic euphonic -t- (göster). The Sprachbund status of the term can be
dated by before the 2000 BC Indo-Arian migration. That may also be an indicator on when an
incidental trading turned into a trading profession along the Eurasian steppes. The “IE etymology” manages to come up with separate surmises for guest and host, inventing
non-etymologized unattested PG and PIE “proto-words” of the type *gastiz, *ghos-ti- is
“guest”, in a circular fashion leading from a supposedly unknown to a nowhere.
80
English hag (n.) “ugly evil-looking old woman” ~ Türkic ğug, kharga, qarga, qarɣa etc., from Tr. ɣug, ğug, karga “raven”, with allusive meaning “old”, “old woman” (Shipova, Radloff, Zelenin, Berneker, Vasmer). The notion “old” comes from a pun qarï, kargan, karygan “old”. The Eng. hag is an ugly evil-looking old woman; the Türkic ɣug is the same (still living in the Rus. Staraya karga “Old karga”, i.e. old parched-looking woman). Eng. has preserved a synonymous calque of the original idiom, the “old crow”, aka the “sea hag”. Under “IE” paradigm, the Eng. Hag was surmised to come from a PG. *hagatusjon-, where -tusjon” ~ -tesse was a (fem.) suffix. In reality, the Eng. and Gmc. versions are descendants of the same root and concept. No “IE” connection, Gmc. group only, not in the Romance group, etymology is predictably “of unknown origin”. The perfect parallelism is obvious, this is a genuine case of paradigmatic transfer with perfect phonetics, semantics, untransferable idiomatic pun and its perfectly translated calque, incontestably attesting to a common genetic origin.
English hooligan (n.) “troublemaker” ~ Türkic čolvu (cholvu) (n.) “slander, condemn, defame, disparage, scold, vilify, repudiate; vilify, bear malice, slander”. Türkic has an assembly of allophones and synonyms: čantur-, časur-, časut, čïndutur-, čolvu, čulbu, čulvu, jer-, of which čolvu/čulbu/čulvu (n.) with apparent auxiliary particle -vu/-bu appear to be closest phonetical sibling; slander was a most powerful tool in the ancient Türkic political milieu, and the abundance of the word forms demonstrate its spread and importance. In English, the literary reference comes from Irish name Houlihan with connotations “troublemaker”, and from the English court records. The synonymous hoodlum appears to be a further contortion of the same old-age derisive hol-. Cognates: A.-Sax. hol “slander, calumny”, OE holian ditto, Goth. holon “deceive, injure”, OHG huolian “deceit, vilify”, Sl. hula “slander, malice, vilify”. Both Gmc. and Sl. etymologies lead to absolutely nowhere, with Gmc. etymology reduced to reciting latest anecdotes, and the Sl. etymology aimlessly wondering across the whole Sl. phonetic field. In dialects, the phonetic č/q > h/ɣ transition is observed as systemic. The Irish brought to us a derivative houlihan complete with the Türkic suffix of instrumental noun outcome -ɣan/-gän/-qan/-kän, a diagnostic suffix peculiar to Türkic. Not a whiff of the “IE” etymology, the primal A.-Sax. form is thoroughly omitted in favor of much later Ir. clone to imply an Ir. origin in Eng. The synonym jer- “slander, ridicule” has also survived in English, with about the same semantics. The pair hol/hooligan and jeer constitute a case of paradigmatic transfer between Türkic and Eng., indelibly attesting to the common genetic origin. See jeer.
English ilk (n., adj.) “kind of person” ~ Türkic ilk (n.. adj.) “antecedent, outset”, also
“beginning” (n.). The Türkic semantics is turned toward the root, Cf.
ilki “first, initial”, ilkin “from the beginning”, ilkisiz “without beginning,
very old”. The English semantics is turned toward the branches. Both refer to some specific kind of
origin, be it descent, race, or attitudes. Cognates: A.-Sax. had a form ilca with the same
connotation “same” (n., pron., adj.). The change in spelling ilca > ilk is somewhat puzzling,
since Eng. generally trod to the Roman alphabet substituting -c- for -k-. The
suggested as a Gmn. cognate eilen “sole of the foot, callosity, corn” is perfectly
inapplicable. The “IE etymology” cites that Gmn. “cognate” and builds some impossible pedigree using
creative unattested *reconstructions and perverted history from “family” to “kind”, while the word
from the outset was “kind, antecedent, from the beginning”. The Türkic etymology uses the same word
for the same purpose (OTD 208). Distribution of the word is consistent with that of all other
Turkisms, the Türkic belt across Eurasia, and the NW Europe. No “IE” connection, no cognates outside
of the Türkic milieu. The duo ilk and kin constitutes an authentic case of
paradigmatic transfer, incontestably attesting to a common genetic origin. See kin.
81
English judge (n.) “judicial person, arbitrator” ~ Türkic ayɣu- (v.) “advice, direct, prescribe” preserved in the Oguz designation ayɣučï “advisor, judge”, fr. ay- “speak, say, declare, prescribe” (Cf. unattested and probably arbitrary “PIE root” *au- “perceive”, Lat. audire “hear”, Eng. audio “sound”, Türkic aydï (3rd pers.) “said”, ayur (imp., “say”)), ayğ “word, speech, command”, the aygu “advice, directive, prescription” with nomen instrumentes suffix -gu, ayɣučï with nomen agentes suffix -čı:/-či:, lit. “commander, one who speaks (orders), or issues commands” (e.g. Tonyukuk, 7th c.). Cognates: OFr jugier /yuger/ “to judge, pronounce judgment; pass an opinion on”, Lat. iudex “judge, leader vested with temporary power”; Alb. gjyqtar “judge”; Sl. zakon (закон) “law”, with derivatives. The Eng., Alb., and Sl. forms point to the Ogur origin with prosthetic anlaut consonant (i.e. yayɣučï), the Lat. form is an allophone of the Oguz form without a prosthetic anlaut consonant. The “IE etymology” offers a compound of Lat. ius “right, law” + dicere “to say”, a circuitous, convoluted, and unnecessary concoction without cognates in other European and Asian “IE” languages. The Lat. ius is apparently a derivative of an allophonic form corresponding to the Türkic ay- in the attested ayɣučï and iudex “judge”. The Türkic form is semantically exact and phonetically agnatic. The difference between the Lat. and Fr. phonetics points to two independent paths, with the Fr. form likely ascending to the Sarmatian Alans (Amorican Alans) or Burgunds (Provence). The ethic origin of the Lat. form apparently can't be pinpointed, the likely timing coincides with the westward reverse relocations from the Eastern Europe of the “Old Europe” tribes at the end of the 2nd mill. BC. The titles Ayɣučï and Gutian Yarğan (“Judge, Tribune” in Akkadian cuneiform records on the Gutian rulers, ca. 22nd c. BC), i.e. the Eng. Earl, have an uncanny similarity in semantics and morphology. Both mean “judge”, and both are formed by exchangeable suffixes, a professional category suffix -čı: versus a denominal and deverbal category suffix -ğa:n/-ge:n (position, animals, etc.). The root part is also at least consonant. The title Yarğan is traced across 4 millenniums in the western Eurasia, see earl, the title Ayɣučï became prominent in the eastern Eurasia in the records of the 7th c. AD. Based on archeological evidence (socketed bronze axes, writing, bronze casting technology) and written evidence (militant nomadic pastoralists), “Zhou Scythians” carried cultural traits from Mesopotamia to the Altai and on to China, bringing them to the Shang China ca.1750 BC. That was the occasion when the title Yarğan could evolve or cue the birth of the title Ayɣučï that on the western Eurasian fringes became a word “judge”. See earl.
English Kent (n.) “county, kingdom” ~ Türkic keŋit-, keŋüt-, kiŋit- (v.) “expand, propagate, broaden, widen, enlarge, extend”, a causative form of the denoun verb ke:ŋü:- “broaden, widen, enlarge, extend”, fr. noun ke:ŋ “broad, wide”. The word ke:ŋ, in turn, is likely an allophonic form of the notion of the very productive word ge:nč, ke:nč (n., adj.) “young (fauna), new, child, baby”, a derivative of the adverb gen, ken “behind, after”, at times declinable as a noun, see gene. Cognates: A.-Sax. cennan “bring forth, create, produce”, cent-land “Kent”, OE Kent, Lat. Calnticum, Cantia, Gk. (51 BC) Kantion (Καντιον) (51 BC). The connection with the Celtic “coastal district” is left as an unexplained puzzle, likely an echo of folk etymology. The stray assertion of a form of “corner” is a false backformation, since the Gk. “angle or corner” is ογλος, modern γωνία, and the Lat. word was a loanword fr. the Gk. According to historical records, Anglo-Saxons inherited the name from the Roman times as the first land captured by the Romans; alternatively it is a Celtic name explained as “coastal district”. Either way, the meaning is clear, semantically it is a “New Acquisition” identical with the Ch. Xinjiang (Sinkiang) “New Territory”, the name for the captured Uiguristan and the unfortunate East Turkestan, or Rus. new acquisition Novorossia (Новороссия) “New Russia”. The Gk. reference positively points to the Scythian-Sarmatian origin. See gene.
English kin (n.) “blood-related” ~ Türkic kin, kün/kun (n., adj.) “kin”. The form kin/kün/kun, with its h- allophones hin/hün/hun, is but one of the seven (7) clearly demarcated semantic extensions of the root gen-/ken-. The stems kün/kin and gen-/ken- “young (fauna), new, child, baby” appear to be allophones, semantically the kün/kin carries a deep flavor of a common origin, echoing the notions of the gen-/ken- with phonologically unpredictable alternation, see gene. The stems kün/kin and qan “blood” also appear to be allophones, semantically the kün/kin carries a deep flavor of a blood relation, echoing the meaning of the qan with phonologically unpredictable alternation. The term of relationship kün is also linked with the female beginning, it is related to the base word kin for females meaning “female genitalia, pudenda, vagina, Eng. quim”, see quim. These ties are too vague to credibly pinpoint an ultimate origin for the word. For etymological understanding, the presumed unattested “proto-word” noun *ke “behind, after” (G. Clauson, ETD, 1972, 724) is irrelevant, the attested adverb gen, ken “behind, after” is sufficient to trace the linguistic development in morphological, semantic, and phonetic aspects. Cognates: Eng. akin, Hun, kin, kindred, kinship, A.-Sax. cyn “family, race, kind, nature”, OFris. kenn, OSax. kunni, ONorse kyn “kin”, kundr “son”, OHG chunni “kin”, Goth. kuni “family, race”, Balt. (Lith.) gentis “kinsmen”, janah “race”; Rus. kunak “relative, friend, acquaintance”; Urdu huuni in idiom “huuni rishtey daar, with Dari counterpart tariin rishtey daar “next of kin”. In the Romance group, common roots for the Gmc. “kin” are the incompatible famil- and parent- from obvious original notions of family and parentage; in the Sl. group a common equivalent root for the Gmc. “kin” is an incompatible rod- from obvious original notion of procreation, Cf. rodit (родить) (v.) “parturition, birthing”. Notably, the Scots Gaelic cairdeas “kin” is an obvious allophone of the synonymous with the kin Türkic qadash “kin, relative, friend”, attesting that both kin and cairdeas originated within the Türkic phylum. The notion kün “relative”, with a line of semantic applications, first of all denotes related tribes; that generic word became an ethnic name Hun that at one time (3rd c. BC - 6th c. AD) was a common appellation for a large group of nomadic tribes (Cf. Türks, Kirkuns, Agach-eri, On-ok, Tabgach, Comans, Yomuts, Tuhses, Kuyan, Sybuk, Lan, Kut, Goklan, Orpan, Ushin and other ancient Türkic tribes carried the name “Huns”; in each separate case the term “Hun” was equivalent to endonym of a tribe, and at the same time it was a wider concept, reflecting a certain commonality of the ethnic origin [Zuev Yu. A., 1960, 12]. The raster of the Gmc. forms attests that the word had a wide distribution long before the Hunnic expansion of the 4th c. AD, which overlaid the previous generations of the Kurgan pastoralists with their own spectrum of pronunciation. The cohesion of the Gmc. forms attests that the word was ubiquitous across a wide territorial span, pointing to either a Sarmatian massive migration of the 2nd c. BC, a massive Scythian/Cimmerian demographic movement of the 4th c. BC, or even to a much older Corded Ware populace. The peculiarity of the Gaelic form attests of the existence of the word in the N. Pontic steppes prior to the circum-Mediterranean Celtic outmigration of the 6th-5th mill. BC, indirectly corroborating the early timing of the Corded Ware possibility. The “IE etymology” connects Gmc. forms with an unattested “PIE root *gene- “engender, beget”, unwittingly revering to the Türkic origin from the stem gen-/ken- q.v. See gene, quim.
English king “monarch” (n.) ~ Türkic kengu ![]() (n.) “king”.
Ultimately, the Türkic root is kün “sun”, not the homophonous
Türkic
kun/kün, the English kin “blood-related”, as was suggested by “IE” philologists.
The kün with the Türkic suffix -gü makes
küngü
“of sun, solar, sun-like”, or the phonetic variation kengu. Cognates: A.-Sax. cyning,
Du. koning, OHG, N. konungr, Dan. konge, Gmn. könig; Balto-Slavic
(Lith.) kunigas “clergyman”, (OCS) kunegu “prince”, (Rus.) knyaz, (Boh.)
knez; Fin. kuningas; Ch. kung 宫 (pin. gong, Giles 6,580) “palace”. Note
that the OCS, Gmn., and Du. forms have perfectly Türkic form kengu/küngü ~
kunegu, könig, and koning, and since the Gmc. and Hunnic tribes largely divorced at
about 453, this shared Türkic/Gmc./Balto-Slavic word must have been shared quite before that.
Apparently the people who made the appellation “illustrious” knew the later lost meaning of the
kengu king, and that also shows that the kin/kun/kün “relative” is a false etymology.
Notably, the form küngü echoes the form Shanüy/Chanüy/Chanyu, Ch. 單于 “immense
appearance”, the “supreme ruler” of the Chinese annals, and a consonant form keŋ/ke:ŋ “broad,
all-inclusive, vast” also carries a semantics suitable for a superior
title, Cf. ke:ŋü:- (ke:ngü:) “enlarge, extend”. The
Ch. cognate points to the Zhou time internalization, the terms ordu “center” and
küngü/kung “palace” are functionally synonymous, both referring to the supreme leader, his
headquarters, and his troops. A thought that the resident of the Buckingham palace carries an
originally Chinese title is more unfeasible than the historically attested Türkic title. A parallel
title is Herceg (like in Hercegovina), formed eidetically, with parallel Türkic/Gmn. meaning
Er + eg, Herr +ceg “man + of” = “(Head, Leader) of men”. The Balto-Slavic
vernaculars borrowed both titles, King and Herceg, and the Gmc. does not have
herceg because it came as a later Bajanak (Besenyo) title. Historically, the appearance of the
form kengu/küngü coincides with the fragmentation of the Eastern Hunnic Empire that started
in 56 BC, leading to a prolonged hiatus, the rise of numerous independent polities, and dispersion
of the Hunnic population to all directions of the Eurasia. The form Kengu shows up on the
Late Antique Central Asian coins in a version of the Türkic runiform script, like on the Athrikh
(Afrosiab, 305-? AD) coin:
(n.) “king”.
Ultimately, the Türkic root is kün “sun”, not the homophonous
Türkic
kun/kün, the English kin “blood-related”, as was suggested by “IE” philologists.
The kün with the Türkic suffix -gü makes
küngü
“of sun, solar, sun-like”, or the phonetic variation kengu. Cognates: A.-Sax. cyning,
Du. koning, OHG, N. konungr, Dan. konge, Gmn. könig; Balto-Slavic
(Lith.) kunigas “clergyman”, (OCS) kunegu “prince”, (Rus.) knyaz, (Boh.)
knez; Fin. kuningas; Ch. kung 宫 (pin. gong, Giles 6,580) “palace”. Note
that the OCS, Gmn., and Du. forms have perfectly Türkic form kengu/küngü ~
kunegu, könig, and koning, and since the Gmc. and Hunnic tribes largely divorced at
about 453, this shared Türkic/Gmc./Balto-Slavic word must have been shared quite before that.
Apparently the people who made the appellation “illustrious” knew the later lost meaning of the
kengu king, and that also shows that the kin/kun/kün “relative” is a false etymology.
Notably, the form küngü echoes the form Shanüy/Chanüy/Chanyu, Ch. 單于 “immense
appearance”, the “supreme ruler” of the Chinese annals, and a consonant form keŋ/ke:ŋ “broad,
all-inclusive, vast” also carries a semantics suitable for a superior
title, Cf. ke:ŋü:- (ke:ngü:) “enlarge, extend”. The
Ch. cognate points to the Zhou time internalization, the terms ordu “center” and
küngü/kung “palace” are functionally synonymous, both referring to the supreme leader, his
headquarters, and his troops. A thought that the resident of the Buckingham palace carries an
originally Chinese title is more unfeasible than the historically attested Türkic title. A parallel
title is Herceg (like in Hercegovina), formed eidetically, with parallel Türkic/Gmn. meaning
Er + eg, Herr +ceg “man + of” = “(Head, Leader) of men”. The Balto-Slavic
vernaculars borrowed both titles, King and Herceg, and the Gmc. does not have
herceg because it came as a later Bajanak (Besenyo) title. Historically, the appearance of the
form kengu/küngü coincides with the fragmentation of the Eastern Hunnic Empire that started
in 56 BC, leading to a prolonged hiatus, the rise of numerous independent polities, and dispersion
of the Hunnic population to all directions of the Eurasia. The form Kengu shows up on the
Late Antique Central Asian coins in a version of the Türkic runiform script, like on the Athrikh
(Afrosiab, 305-? AD) coin:
![]() kηü trgi äthrx “King of state (Turan) Athrikh” (Mukhamadiev A., 1995, 51 text;
Vainberg B.I., 1977, Table XIX, G I coin) , and
kηü trgi äthrx “King of state (Turan) Athrikh” (Mukhamadiev A., 1995, 51 text;
Vainberg B.I., 1977, Table XIX, G I coin) , and
![]() kηü trgi bugra “King of state (Turan) Bugra” (Mukhamadiev A., 1995, 54 text; Vainberg
B.I., 1977, Table XIX, G III coin), in Biruni's list Bugra is listed right after Athrikh), and
kηü trgi bugra “King of state (Turan) Bugra” (Mukhamadiev A., 1995, 54 text; Vainberg
B.I., 1977, Table XIX, G III coin), in Biruni's list Bugra is listed right after Athrikh), and
![]() kηü trgi zkssk
“King of state (Turan) Zakassak” (Mukhamadiev A., 1995, 55 text; Vainberg B.I., 1977, Table
XIX, G II coin), and
kηü trgi zkssk
“King of state (Turan) Zakassak” (Mukhamadiev A., 1995, 55 text; Vainberg B.I., 1977, Table
XIX, G II coin), and
![]() kηü trgi humkr
“King of state (Turan) Humkar” (Mukhamadiev A., 1995, 56 text; Vainberg B.I., 1977, XIX, G12
coin).
kηü trgi humkr
“King of state (Turan) Humkar” (Mukhamadiev A., 1995, 56 text; Vainberg B.I., 1977, XIX, G12
coin).
In the legends, the root tr stands for “territory, terrain, lowland, land”, lit. “pasture”,
see
terrain; it may be interpreted as “state”, “land”, “domain”; the adjectival denoun suffix
-gi (qï, ki, ɣï) forms “of place, time”, it corresponds to the Eng. diminutive suffix -k,
Cf. hillock, buttock; the buğra “camel bull” was used around the Central Asia as a title of a
position.
The word kengu is later traced to the European Huns, to the Attila's son Digizikh who in 453
succeed hum as a Hunnic ruler:
![]()
![]() kiŋkeg
dikkiz... i.e. Kinkeg Dikkiz...
“(of) King Dikkiz”. The first grapheme
kiŋkeg
dikkiz... i.e. Kinkeg Dikkiz...
“(of) King Dikkiz”. The first grapheme
![]() (right-to-left) is a tribe, clan or state tamga (Mukhamadiev A., 1995, 74 text; Smirnov Ya.I., 1909,
dish 53; Orbeli I.A., Trever K.V., 1935, dish 53). Priscus of Panium, who met Dikkiz, reported his
name as Deggizix (Δεγγιζίχ).
(right-to-left) is a tribe, clan or state tamga (Mukhamadiev A., 1995, 74 text; Smirnov Ya.I., 1909,
dish 53; Orbeli I.A., Trever K.V., 1935, dish 53). Priscus of Panium, who met Dikkiz, reported his
name as Deggizix (Δεγγιζίχ).
A chain of toreutic inscriptions written in consistent Central Asian Türkic alphabet, read in Türkic
languages, supported by the historical sources, marked by identified and identifying tamgas, and
traceable over centuries, leave no doubts of the Türkic origin of the word. See earl, As.
English leader (n.) “chieftain” ~ Türkic elit-, elet-, elät- (v.) “lead, lead away”, with the agent suffix -ar/-er/-ir/-ur-/-är/-ïr/-ür , e.g. elit- + -er > lider. An alternate form yola- (v.) “travel, depart” of elit- ascends to the noun yol “road, travel”, with obvious etymology. The allophonic pair yola-/elit- points to the Ogur/Oguz stratification, the first with an Ogur prosthetic anlaut semi-consonant y-. A denoun verbal form jolda- demonstrates metamorphose of the common verbal suffix -la into a form -da with -d-. The European forms uniformly elide the unaccented anlaut vowel, such uniform process must have originated still in the Türkic milieu. Tracing the form jolda- would pinpoint the origin of the elided form ld-/lt-/læd- and their clones. Türkic has one more stem with close phonetics and semantically compatible with the notion “lead”. With the paucity of intermediate examples, the second option may be argued to be possible but unlikely. The second prospect is uludur (adj.) fr. ulu (uluɣ) “great” with a loss of the unaccented anlaut vowel and with active voice suffix -dur/-tur. Cognates: A.-Sax. lædere “leader”, lædan (v.) “lead, guide, conduct, carry”, OSax. lithan “travel”, ONorse liða “travel”, Norse, Dan. leder “leader”, Goth ga-leiþan “travel”, OHG ga-lidan “travel”, leitari “leader”, Du. leider “leader”, Icl. leiðtogi “leader”. The European forms alternate -d-/-t-/-ð-/-þ-/-th-. Distribution of the cognates is limited exclusively to the Gmc. group, making any claims to a pan-IE spread unsustainable. The “IE” etymological theory about an unattested “PIE *leit-” of the verb “go” (i.e. “travel”) unwittingly reverts back to the original attested Türkic word yol and applicable cases of its derivatives. Since Türkic does not start words with liquids, in a transition to the alien morphologies, a loss of the anlaut vowel in front of the liquid, and the t/d-series transitions are regular adaptations. The fairly good phonetic concordance and the semantic match, with no systemic “IE” cognates, and the cognates limited to the Gmc. group, constitute a positive attestation of the ultimate Türkic origin. See elite.
English lullaby “quiet song to lull child to sleep” ~ Türkic layla, lyuba “quiet song to lull child to sleep”. Ultimately from the notion “babble” of the stem lay- attested in the Azeri derivative layla- (v.) “prattle”, and CT derivative laylaq (n.) “blather, fluster, meaningless speech”. The word lay- echoes the word ulï- “cry, howl”, with its derivative appellation ulïčïm “my baby”, pointing to an ultimate origin from the sound of wind yel- “howl”, see howl. Within linguistic families and between families, the notion of lullaby is notable for an extraordinary spectrum of its forms and origins, attesting to a diverse ethnic origin of the motherly traditions. On the background of the extreme variety, the uniformity of the NW European grouping stands conspicuous. Cognates: ME lollai, lullay, Fris. lulk, Sw. lulla “hum a lullaby”, MDu. lollen “mutter child to sleep”, Gmn. lullen “sway (a crib)”; Lith. liūlia; Sl. lepet (лепет) “babble”, lulka (люлька) “sway (a crib)”; Skt. lolati “sway (a crib); Est. unelaulu “lullaby”; Az. layla- (v.), Kaz. lyuba (люба) “lullaby”. Of the listed ethnicities, only Kazakhs have a fairly clear composition of the Dulats, the former Usuns, ascending to the 2nd c. BC. The “IE etymology” suggests a primitive “probably imitative” without specifying what is imitated and who is imitating. Тhat suggestion starkly contrasts with the extraordinary variety of the forms obviously of the innumerably diverse origins. The distribution attests to the opposite, it is confined to the NW corner of Europe and crosses linguistic families. The uniformity of the form and semantics, and the spread to disparate languages and language families indicates a common origin and dispersion into numerous colloquial forms, carried over by mamas and fossilized over ages within familial lines. The Eng. verb lull and its derivativs are derivations of the primary lullaby and its allophones layla/lyuba. See howl.
English mama (mammy, mom, mommy, mother) “informal for mother” (Swadesh 42, F218, 0.16%) ~ Türkic mama, ma:ma, mamü “mother”, mamlä “motherly, friendly, peacefully”, mamläkät “motherland”. Ultimately an allophonic derivative fr. a suggested baby babble's onomatopoetic meme (me:me, mə:mə) “female breast, nipple, teat”, a reduplication of the same syllable. That closely parallels with the words baba, ba:ba, papa for “father” (see father, dad) and bebe for “baby” (see baby), corroborating a related onomatopoetic origin. Both cases reduplicate the base syllable, ma- and ba-. The related pair mama-meme “mama-breast/milk” has produced two overlapping semantic derivative clusters, Cf. milk, meal, etc., see mammal, milk, meal. The word mama comes in two flavors, mama and mother/mater, the second with the suffix -tur/-tür/-dur/-dür to form an energetic notion (causative, energetic mood), still active in Türkic languages. Etymological analysis must address individual daughter lines as a closely interconnected and overlapping single complex, without losing a trace of the intricate phonetic and semantic linkages. There also is a historical component, since mobile economy caused various migrations, amalgamations, and divergences, which all affected lexicons, Cf. a large tribe Alat that ended in Persia as Khaladj (Khalaj, Haladj, Halaj, Halač), with the Pers. added semantic extension of mama (ماما) to “midwife”. Not exactly the same, but obviously linked semantically. The phonetic spread of mama is extensive but readily recognizable. In Türkic languages, the word may also stand for “maternal grandmother”, “paternal grand-grandmother”, “old woman”, “aunt on father's side”, “mother-in-law”, “a woman”, “midwife”, “old mare”, “female name” (Mamik), “mother's, female breast”, “food, nutrition” (meal), “wet nurse”, “milking” (A.-Sax. mealc, Eng. milk), “woman accompanying bride on her first wedding night”, and some more exotic applications. It also serves as a designation of gender, motherly function, and native country. Ma:ma is synonymous with Türkic miši (mishi) “female creature”, a derivative of the same base root me- with an agent noun suffix -či/-ši, eve “engender, birth-giving (woman, mammal, etc.)”, and ani “mother”. Cognates: A.-Sax. moddor, moder, modor “mother”, medren, modorlic “maternal”, the Gmc. formal variety is composed of mama with an energetic suffix: OSax. modar, OFris. moder, mem, ONorse moðir, Dan. moder, Du. moeder, OHG muoter, Gmn. Mutter, Icl. móðir, etc.; of the Celtic Kurgan migrants OIr. mathir, Gael. mathair, Welsh mam,; N. European Balt. (Latv.) mamma, (Lith.) mote; OCS mati; Fin. emo, Est ema; Mediterranean Lat. mater, Port. mae; Gk. metera (μητερα); Basque ama; Geor. deda; Pers,. Taj. modar; Hindustan Skt. matar-, Hindi maan (मां), Punjabi mam (ਮਾਂ); Gujarati mata (માતા); Nepali ana; Ch. mu 母. At the dawn of the “IE” paradigm (1813), the mama became one of the few key words of the Indoeuropeism, a criteria that automatically drew into the “IE” family any stray language that had as a signal a proper allophone of the mama, even without a regard for its typology and grammar. It still is, in spite of the testimony to the contrary stated a century ago. The A.-Sax., along with form meder and its siblings, also used five other appellations: acennicge, lit. “parent (fem.)”, bearncennicge, lit. “bearing mother”, byrðere, lit. “bearer”, cennestre lit. “parent (fem.)”, sunucennicge lit. “descendant's ancestress”, and probably other undocumented “folk-type” appellations. The A.-Sax. cen- (ken-) at the root of acennicge etc. forms words with notions of “production, conception, procreation, birth, genitals, parent”, see gene. The Tr./A.-Sax. suffix -ge is a denoun directional suffix, a la “from birth, from procreation”, etc. In Kaz., Kara-Kalpak, Turkmen, Uz., and Uig. languages, the CT miši (mishi) has a form mädi (with interdental ð, mäthi) “female creature”, which corresponds to the “IE” moth(er), mat(er), they are morphologically modified allophones of the primeval form ma:, me:, ba:, be:, bi (with m-/b- alterations) that expresses femininity, see mare. The colloquial form mädi, and the form miši (with allophones) are used as a determinative in noun phrases (Cf. Türkic Saha mïsï bïsasar “female moose” (bïsasar “moose”), Pers. mädä-säɣ “female dog”, mädä-gav “female cow”. For the “IE” languages, the dispersion of the form mädi can be dated by the demographic dispersion of the farmer communities in the 2nd mill. BC. In the Türkic languages the form mädi is an innate variation on the primeval form ma: “of female gender”. Both Eng. and Türkic languages use mother/mama as an address for an elderly woman. In English, it is also used metaphorically for key element (e.g. “mother lode”, “mother superior”, “mother-of-pearl”, “mother of all wars”, etc.), Cf. Türkic mama for a leading ox in the center of working oxen. The traces of traditional Türkic formal appellation to the parents still linger in Eng., Gmc., and south Sl. languages; in the Ukrainian society parents are called with a formal “you” in plural, in contrast with the neighboring Slavic and Slavicized traditions of familiar singular. The semantic difference between the familiar mama and formal mother still exists in most European languages: a mother in the society is mama (mammy) at home, or mother in the 3rd person is mama (mammy) in the 2nd person. Now mama is an international word, with a predominant form mammy in the English-speaking world. Türkic has numerous words and word forms for “mother”, aba, ana, ani, ара, hana, ög, uma, and the mamü is just one specific form that belongs to the same semantic field. It was likely spread to Europe with the Kurgan waves, starting in the 4th mill. BC. The “IE etymology” starts at about 2000-1000 BC, when the Eastern European farmers, with already internalized Türkic form, have fanned out toward Mediterranean, India and the Middle East. That process should have retained various native appellations for mother, some of which may be the true “IE” “proto-words”. See brother, father, dad, gene, mammal, mare, meal, milk.
English mantra (n.) “commonly repeated word or phrase, slogan” ~ Türkic maŋra- (v.) “bay, bleat,
holler, yell”. Cognates: suggested semantically unsuitable and
historically unfeasible Skt.
mantra-s “sacred message or text, charm, spell, counsel”, none of which is either commonly
repeated nor a slogan, nor convey a notion of annoyance. The Türkic form maŋrat is
semantically more suitable (“cause to bleat”), carries the notions of repetition and annoyance, and
is suitable for an origin of the Skt. form. The suggested PIE etymology, derived from a “thinks” of
an unattested root, in turn derived from an unattested form for mind (n.) is no better,
considering the Türkic substrate origin of the term mind. The universal popularity of the
word mantra
(eg. Finnish, Indonesian, Serbo-Croatian, etc.) with negative connotations is inconsistent with the
suggested origin from the pre-Buddhist, pre-Hinduism sacral practices in India, and suggests
etymological conflation of little-related meanings based purely on phonetical homophony. See
mind.
82
English master (n.) “man in control or authority”, mister “unaccented variant of master”, mistress “female teacher, governess” ~ Türkic bögü:/bögö:/bok (n.) “magic, sage, wizard, sorcery, witchcraft, occult”, see magic, might. The form with an anlaut m- comes from systemic m/b alteration: bok ~ mok ~ mag. The Türkic word connotes both wisdom and mysterious spiritual power, that trifurcated semantic was carried on in many borrowings across Eurasia. The oldest evidence of a semantic extension from magic and might to nomen agentes “magician, one mighty” is recorded in the Greco-Roman world, Cf. Lat. magister. There, like in father and mother, the part -ster/-ther is a Türkic suffix of respectful appellation expressing notion of respect, under “IE” morphology usually relayed with substitute plural markers. Cognates: late A.-Sax. maegester/maegister/maegeter “one having control or authority”; Eng. master “man in control or authority”, mister “unaccented variant of master”, mistress “female teacher, governess”, Du. meester, Gmn. Meister, form influenced in MEng. by OFr. cognate maistre; OFr. maistre, Fr. maître, Sp., It. maestro, Port. mestre; Lat. magister (n.) “chief, head, director, teacher”, magis (adv.) “more”. The list of the direct equivalents should be appended by all cognates expressing the notions of might and magic, including the Türkic title boyar, and the Gk. magos (μαɣοσ) “great”. The vanishing of the consonant -k-/-g- probably started still in the Türkic milieu, and probably started as a transition from the hard -k-/-g- to the muted or silent -ğ-, as is attested by the ubiquitous form boyar (boğar). The English mister and mistress are derivatives, mistress corresponds to the OFr. maistresse “mistress (lover); housekeeper; governess, female teacher”, fem. of maistre “master”. The invented PIE *mag-yos- is a theoretical backward projection of the documented realities, a conjecture upon a conjecture. A striking implication of assertion about the Eng, master being an allophone of the Lat. magister rules out a direct path fr. the tentative Türkic bašer (basher)/mašer (masher) to the Gmc. meester/Meister from an m- form maš of baš (bash) “head” and a respectful form of address suffix -ter/-der or nomen agentes suffix -ar/-er (Türkic er “man”) masher, master, meester, Meister, lit. “head man”. That path is equally viable both semantically and phonetically, and via the attested OFr. maistre it cuts directly from a Burgund or Alanic source. One more path comes from the attested A.-Sax. maest “most, superior”, a superlative form of A.-Sax. micel “great, intense, much”, formed with the above suffixes -ter/-der or -ar-er. That path is also viable both semantically and phonetically. The compound form “master” exactly follows such Türkic compounds as Az-eri “Azeri, As Man”, Mih-ar “Mishar, Forest Man”, or Og-ur “Ogur, Tribes Men”, etc. That path leads much deeper in time compared both with the Lat. and the Burgund or Alanic sources. See magic, might.
English message (n.) “communication” (Swadesh N/A, F834, 0.02%) ~ Türkic emit- (v.) “send, sent”. Apparently it is ultimately connected with a primeval causative or active conjugation (depending on being perceived as a transitive or intransitive type) of the sexy verb em-/eb- either “suck” or “make love” (fr. the noun em/eb “vulva”. Its other meaning “lean, tilt, incline” tends to point in the same direction. The Türkic semantics was rather peaceful and casual, the sources that reached our days provide only comely semantic references without sexual or military shades. The initial unaccented e- was elided, the second -i- variously alternated with -e-, the regular -t-/-s- alternation is well established, Cf. emission and emitter, emissio and emittere, transmit and transmission. The progeny of the emit- is enormous, from emitter to missile to mission and message and to transmission. Cognates: OFr. message (14th c.), MLat. missaticum, Lat. missus. “IE” etymology: message fr. MLat. missaticum fr. Lat. missus “sending, throwing, hurling” pp. of mittere “to send”. So, the Lat. had initially internalized the Türkic word, and then during Middle Age reinvigorated it in OFr., possibly under new input of the Burgund influence. A late Lat. borrowing from the Ottomans should probably be positively ruled out. The phonetic and semantic concordance does not leave room to question the Türkic origin.
English means “considerable capital in wealth or income” ~ Türkic mün (min) “means, monetary wealth, capital”. Ultimately, possibly fr. m- form of bu: “this”, compare equative bunča:/munča “many, bunch” and bun “basis, foundation”, see bunch, much. Cognates: A.-Sax. mannes “movable possessions, means of subsistence”. The “IE” etymology, solely on phonetic consonancy, is confusing means with unrelated polysemantic adjective mean “statistical norm, malice, superlativity, poverty, stinginess, miserable” via OFr. noun meien “middle, statistical mean, intermediary”, a dubious proposition which candidly conflicts with the presence of the A.-Sax. mannes “wealth” long before the arrival of the OFr. meien “middle”, an allophone of Lat. medianus “in the middle”. Equally ridiculous is the claim that the related Türkic manat “money” is an allophone of the Rus. moneta, given that the Rus. monetary system and the bulk of its terminology originated and formed in the Türkic milieu, including the very term dengi (деньги) “money”. Ditto with the claimed credit that the Türkic term manat came from the cognomen of the Roman deity Juno, via non-existent Roman influence in the Central Asia. The stem mün has produced derivatives manat, money, moneta, mint, all connected with monetary exchange. See mint, money, penny, shilling.
English might (n.) “power, strength”, magic (n.) “supernatural feat” (Sw N/A, F240, 0.06%) ~ Türkic bögü:/bögö:/bok (n.) “magic, sage, wizard, sorcery, witchcraft, occult”, see magus. The form with an anlaut m- comes from systemic m/b alteration: bok ~ mok ~ mag. The Türkic word connotes both wisdom and mysterious spiritual power, that trifurcated semantic was carried on in many borrowings across Eurasia. Cognates: A.-Sax. maeg “might (strength)”, gigantmaeg “giant might (aeon)”, helicmaegen lit. “force(s) of hell”, hordmaegen lit. “mighty hoard”, innoðmaegen lit. “inner might”, maegsterdom “masterdom”, fifmaegen lit. “five magic (powers)”, gaestmaegen “travelling magicians”, etc., Eng. bogus “not real, artificial, fake”, Fris., MDu., Gmn. macht “might, ability”, Sw., Norse makt “might”, Icl. máttur “might”, Goth. mahts “might, force”, OHG maht ditto, OFr. magique, Lat. magnus “mighty”, magus “magician, learned magician”; Gk. megas (μέγας) “grand ”, megalos (μεγάλος) “great”, magos (μάγος) “magician”; Alb. math, madhi “great”; Balto-Sl. (Latv) burvis, (Lith.) burtininkas “magician”, (Rus.) mogu (могу), moch (мочь), moguschestvo (могущество), mosch (мощь) “might”; Skt. mаhánt- “great”; OPers. magush “magician”; Arm. mag (մագ); Az. məcu(si), Tr. büyü(cü) “magician”; Est. maagi, Fin. maagikko, Hu. buves (buvesz) “magician”; Mong. bö’e “magician”; Jap. mahōtsukai 魔法使い “magician”; Kor. masul 마술, masulsaga 마술사가 “magician”; Ch. moshu shī 魔術師 “magician”. The word bogus for wizardry and magic lurked in the Eng. folk speech before showing up in the far away America. The A.-Sax. word carried the bifurcated semantics of the power and occult noted by G. Clauson for the Türkic original (G. Clauson, ETD, 1972, 324). A link to the Türkic bögü: for the Sl./Rus. mogu had already been established (Vasmer M., 1986, v. 2, 636) as an argument against a Gmc. origin of the Rus. form. The transition of the allophonic m- form mögü: to the Sl. mogu illustrates clearly the origin of the Gmc. forms for “might” that likely evolved in parallel, likely recursive, numerous, and asynchronous paths. That assertion overlaps numerous inconsistent speculations on the origin of various derivatives of the Türkic original bögü:, predominantly advanced within the cloistered “IE” and “PIE” paradigms. The Türkic title boyar for the members of the State Council, of the Bulgarian/Hunnic origin, may also be a derivative of the word bögü with the suffix -ar “man”, boyars were powerful high dignitaries endowed with prophetic powers of the wizards, Cf. the legendary Merlin depicted with Scythian conical hat. The fairly localized distribution of the notion “might” with its numerous extensions relatively to the notion “magic, occult” points to a much later spread, probably dated by the 2nd mill. BC in both the westerly and southeasterly directions. Notably, other than the unattested asterisked “PIE” conjunctures *móghtis, *megh-, the reverse phonetic surrogacies naively mimicking some colloquial forms, there is no credibly attested cognate other than the bögü:/mögü: to serve as a prototype for the wide variety of the Eurasian forms and their semantic extensions. The complex evidence of the carryover of bifurcated semantics of the power and occult, and the systemic m/b alternation are components of a paradigmatic transfer case definitively attesting to their origin from the Türkic milieu. Cf. bogus, boss, OK.
English mint (v., n.) “coin production” ~ Türkic mün “monetary wealth, capital”, manat “money”. Cognates: A.-Sax. minte, mynetslege, mynetsmiððe “mint”, mynet (8th c.) “coin, coinage, money”, OSax. munita, OFris. menote, MDu. munte, OHG munizza, Gmn. münze, “coin, coinage, money”; Lat. moneta “mint”, numisma “coin”, OFr. monoie “coin, money”; Balto-Sl. (Latv., Lith.) moneta, (Slvk., Cz.) mince, (Pol., Rus. moneta) “coin”; Finn. myntti, minttu, Est. münt “coin”, Hu. menta “mint”; (Ru.) monetnyi (dvor) (монетный двор) “mint yard”. While the common Türkic term for coin is widely used in the area of the NW Europe across linguistic divides, the native terms for “mint” derived from roots other than the root for “coin” proliferate, with no clear common PIE “proto-word”, and few clear Türkic loanwords (Lat., Finn., Est., Hu., Ru.). The late Lat. word for “mint” apparently supplanted the native phrase term similar to the Rus. compound. Ultimately, the cognates of mint and money ascend to the Türkic base mün or some of its archaic allophones. The amalgamation and adoption paths were obviously different for different languages, and in some cases the paths were different within a single language (sf. A.-Sax. forms, see money). The semantic and phonetic match ascends to the Türkic primary base mün, that does not leave any chances for random coincidences, especially so considering the Anglo-Türkic triad of money - penny - shilling ~ manat - peneg -sheleg. See means, money, penny, shilling.
Englihsh mother “formal for mama” ~ Türkic ma:ma, mamü “grandmother; mother”, “midwife”, “woman accompanying bride on her first wedding night”, ultimately from Türkic meme “breast”, a word related to “milk” and “mammal” (nourished with breast milk), A.-Sax. mamme “teat, breast”, see milk. The word mother is a variation of mama (see mama) with the suffix -tur/-tür/-dur/-dür. The Türkic plural collective suffix -dVr (-der/-ter/-ther, -dar/-tar/-thar, etc.) was once very productive and may ascend as far back as the Neolithic times, contemporaneous with other cognates from the most archaic lexicon. It is used as a sign of respect, i.e. pl. you vs. sing. thou, a form habitually used by self-aggrandizing personalities and in the E. Europe as a traditional pl. appellation for mother and father not infected by Russ. sing. appellation, Cf. čavındır, čavuldur, čavundur, čavdır “(You) famed” (čav “fame”), Bayındır/Bayındur – ruling dynasty of Ak Koyunlu confederation, Onogundur (Bulgars), etc. The Gmc. transition from pl. to sing. semantics attests that the appellation was picked up by differing languages that adopted form and substance but missed the semantic nuance. For the verbal stems, the suffix forms an energetic notion (causative, energetic mood), still active in Türkic languages. Both languages use mother/mama as an address for an elderly woman. In English, it is also used metaphorically for key element (e.g. “mother lode”, “mother superior”, “mother-of-pearl”, “mother of all wars”, etc.). Both languages also lit. or metaphorically use mama for a team leader, in Türkic it is recorded for the lead ox in the center of working oxen. The traces of traditional Türkic formal appellation to the parents still linger in Eng., Gmc., and south Sl. languages; in the Ukrainian society parents are called with a formal “you” in plural, in contrast with the other Slavic and Slavicized traditions of familiar singular. The semantic difference between the familiar mama and formal mother still exists in most European languages: a mother in the society is mama (mammy) at home, or mother in the 3rd person is mama (mammy) in the 2nd person. Now mama is an international word, with a predominant form mammy in the English-speaking world. Türkic has numerous words and word forms for “mother”, aba, ana, ani, ара, hana, ög, uma, and the mamü is just one specific form that belongs to the same semantic field. It was likely spread in Europe with the Kurgan waves, starting in the 4th mill. BC. The “IE etymology” starts at about 2000-1000 BC, when the “IE” farmers, with already internalized Türkic form, have fanned out toward Mediterranean, India and Middle East. That process should have retained the native appellations for mother, some of which may be the “IE” “proto-words”. The A.-Sax., along with form meder and its siblings, also used five other appellations: acennicge, lit. “parent (fem.)”, bearncennicge, lit. “bearing mother”, byrðere, lit. “bearer”, cennestre lit. “parent (fem.)”, sunucennicge lit. “descendant's ancestress”, and probably other undocumented “folk-type” appellations. The A.-Sax. cen- (ken-) at the root of acennicge etc. forms notions of “production, conception, procreation, birth, genitals, parent”, see gene. The Tr./A.-Sax. suffix -ge is a denoun directional suffix, a la “from birth, from procreation”, etc. The true cognates of mother are the appellations that include the energetic suffix: A.-Sax. modor (with alternate spellings), OSax. modar, OFris. moder, ONorse moðir, Dan. moder, Du. moeder, OHG muoter, Gmn. Mutter, etc.; Mediterranean Lat. mater; Gk. meter; Hindustan Skt. matar-; N. European Balt. (Lith.) mote; OCS mati; and OIr. mathir of the Kurgan migrants. The Goth. aiþei, OHG eidi, MHG eide “mother” corresponds to the Türkic appellation of respect apa “senior female”, the Türkic ata “father”, and Gmc. edda “senior”. The complementary Goth. awo and Lat. ava “grandmother” correspond to the Türkic appellation of respect aba, aby for “senior male”, they demonstrate a parallel line of the paradigmatic transfer, see father. The “IE etymology” is laughable “probably derived from baby talk”; these babies ascend to the 4th mill. BC, and race far and wide across Eurasia. The “baby talk” comprises a faux *ma- and a faux “kinship term” suffix *-ter-. Since the ma-/ba- (ma:, me:, ba:, be:, bi) “mare” is a root for fem. animals (Cf. mare and bitch), the “IE” etymological pearl unwittingly ascends “mother” to “mare” (see mare, bitch), for which the same “IE etymology” cheerfully asserts the absurd “no known cognates beyond Germanic and Celtic”. It also invents a senseless “kinship term” faux clone of the real energetic suffix. In contrast, the complimentary “father” the same “IE etymology” is forced to recognize as ascending to the attested atta, in a “PIE” format a faux *atta, an obvious but unacknowledged reflex of the real Türkic ata “father”. Strangely, the fake “kinship term” suffix does not participate in forming the “PIE” atta fatherhood. This type of repugnance and mental rambling is symptomatic for the doctrine-driven immunity to reality innate to the “IE” school of thought. What, albeit unwittingly, leads to the Türkic origin of the “father”, does not come up in case of the “mother”, as though they are guests from different planets. In reality, “mother” belongs to the line-up of the Türkic terms of kinship widespread in the “IE” languages and in other linguistic families across Eurasia, mamü along with aba, ata, baba, and dedä (see father), the term meme “breast” inevitably also belongs to this paradigm. The energetic mood suffix -ter of the Gmc. branch, juxtaposed against the OIr. forms mathir “mother” and athir “father” of the Celtic branch, indicates that it had already existed by the time of the Celtic departure from the N. Pontic territory in the 4th mill. BC. Such uniquely developed and multi-faceted paradigmaticity constitutes authentic evidence attesting to the Türkic roots, a fatal anathema in the “IE” linguistics. It attests to demographic amalgamations effecting paradigmatic transfers of linguistic complexes from the donor ethnicities to the recipient ethnicities. Within a framework of a real science, a close study of the geographic and ethnic prevalence of the various terms may help to discern tendencies and connect the dots in demographic flows. See bitch, father, gene, mama, mare, milk, papa.
English nascence (n.) “birth, birthing” ~ Türkic ña:š (ñash) (n.) “fresh, year, life, small, young, child, young child, son, childhood”, fr. a polysemantic noun with prime notion “fresh, moist”, via a notion “fresh every year” and “a year of one’s life”, hence the “new beginning” and the “birth”, with further embodiments in concrete nouns “small” “young” “child” “son” “childhood”. The form ña:š is a form of ya:š, Clauson asserts that “words which began with y- in viii (century) had earlier begun with d- or n-”, and specifically cites the form ña:š as the older form of ya:š, “There is, however, seldom any difficulty in determining the original forms of such words.” Absent a contemporary record of the older form ña:š, the phonemic study is the best initial terminus that leads to the modern form ya:š from the ancient form and base semantics. The “IE etymology” ascends nascence to Lat. verb nasci “to be born”, unaware that the Lat. nasci is an allophonic form of the Türkic ña:š, and then it incorrectly jumps to the OLat. gnasci and genus, which are derivatives of an independent Türkic stem gen-, see gene. The ña:š comes from the name for the “spring”, the spring rebirth of the life, while gen- comes from the name for the female reproductive organ as a derivative for the notion of reproduction. The “IE” cognates are practically absent, nascence and its derivative nativity (Lat. nativus “born, native”) are unparalleled in the “IE” family, while the ña:š/ya:š is ubiquitous in the Türkic linguistic family. The etymological value of the word is its ascendance to the primeval notion, a trait missing in the “IE” constructs. The close phonetics and exact semantics validate the Türkic origin. See gene.
English needle (n.) “conifer leaf, spur, stylus” ~ Türkic ine (igne:, yignä, yiŋna) “needle”. In the daily life, needle is “tool for sewing”. Clauson (1972, 110) uses Türkic forms to demonstrate that prosthetic initial semi-consonant is secondary, as is also the -ŋ- for -g-; among good many variant forms are ine, ine:, yi:ne, igine, igne:, yigne, yigne:. From the line-up, it is clear that the form ine/ine:/yi:ne, preserved in the Kıpchak and Koman languages and the Qawanlmi l-kulliya dictionary contained a prototype for the Gmc. languages. Cognates: A.-Sax. nædl, OSax. nathla, ONorse nal, OFris. nedle, OHG nadala, Goth. neþla, Gmn. Nadel “needle”; OIr. snathat “needle”, Welsh nodwydd “needle”, nyddu “to sew”; OCS niti (нити) “thread”. In the Gmc. version, nee is an elided version of ine-, with allophones of adjectival/adverbial suffix -la/-lä: (i)nela > neþla (nethla) > nædl/næthl > needle. The Celtic forms snathat and nod(wydd) ascend to the N. Pontic forms of the 6th-5th mill. BC at the time of Celtic circum-Mediterranean departure, and indicate that the Türkic forms were probably elisions of the most ancient original nad/nath > ine. The Türkic etymology, though curvy and mushy after a timespan of 6000 years, appears preferable to the “IE” etymology, which invents phantom words and suffixes, and uses unrelated semantics of “wrap up” and “spin”. Notably, the pra-pra-Celtic Kurgans left from the N. Pontic 2000 years before the arrival there from the Central Europe of the much future Aryan farmers, and 3000 years before the Aryan departure to India and Iranian Plateau. That makes the connection between the Celtic forms for “needle” and Skt. form for “wrap up” very much phantom. The pra-pra-Celts also departed 4000 years before the arrival to the Aral Basin of the Kurgans that formed the Ogur languages after de-aridization and re-population of the Central Asia at about 1000 BC. That excludes any influence of the Ogur languages on the Celtic forms. The extent of our knowledge is Celtic > Late Türkic > Germanic > English. In contrast to the “IE” etymology, the Türkic etymology is feasible historically and phonetically, and pinpointed semantically.
English oath (n.) “solemn promise” ~ Türkic ötä-, (öte:-, öde:-) (v.) “perform, execute
(obligation)”. The modern Russ. does not discriminate between t
and th, the dictionary entry may in reality mean th instead of t, making the
proto-form even closer. The connection between the forms ötä- and ant/anta
probably ascends to a form of öŋdi: “customs, Common Law”. Cognates: A.-Sax. eaðan
“make oath, swear”, að “oath”,
cyningaeðe “oath to a king”, frithað “oath of peace”, etc., ONorse eiðr, Sw. ed,
OFris. eth, Du. eed, Gmn. eid, Goth. aiths “oath”; OIr. oeth
“oath”; the Irish might be a borrowing, but is argued to be a source; Mong., Tungus-Manchu anta
“oath”, Türkic ant, and “oath”. The time depth of the form að is attested by numerous
A.-Sax. compounds with að “oath”. All Gmc. cognates are phonetically close to the Türkic form
ötä and its derivative ötäg “obligation, debt”, with perfectly identical semantics. All
Gmc. cognates are phonetically close to the Celtic cognates phonetically and semantically, which
points to, but can't be validated, that it is among the earliest Celticisms in the Gmc. family
(Smirnitsky, 1998). It may ascend
to the Globular Amphora period, the time when it split the Corded Ware populace into two unequal
parts. The variety of anlaut spellings points to the vestiges of attempts to render the labial ö-:
ei-, ee-, ai-, oa-, oe-; the induced articulation ow- of the Eng. spelling oa-
still forces to produce a rounded vowel ö-. The use of the Türkic ötä
is connected with the verb ič-/ach-/ish- “drink”, since the numerously recorded and depicted
for the Scythians, Huns, and Türks act of pledging an oath was accomplished by joint drinking a mix
of blood and dilutant of water or wine from a sacred dish, if possible made of a skull of a
decimated enemy; in modern Türkic languages “to give oath” is still expressed as drinking: Kazakh
ant ishu, Azeri ant ichmek “drink oath”. Among the “IE” 439 languages, except for Gmc., no
cognates whatsoever; only Gmc. branch has cognates; both IE's Gmc. “proto-words” *aithaz and
“IE” *oi-to- are figments of aroused imagination, imposters mirroring the real attested Türkic
ötä-.
83
English papa (n.) “father” ~ Türkic baba/babai/papa/papai “father”. Türkic root baba/babai is “father, grandfather” with a notion “ancestor”, Cf. Scythian Papai “primogenitor, ancestor” (Herodotus, 4.59), Altaic, Chuvash, Khakas, etc. papai “father”. Papai is a full form, papa is a cognomen. Türkic has seven roots to refer to ancestral relatives: aba (Lat. ava), ace (allophones ece, eče:, ečü, ede (Norse edda, Sp. edad “age”), eke:), ata, baba, dedä, kök, tüp; of these, ata (allophones father, eðel), dedä (allophone dad), baba (allophone papa) endured into the modern Eng., some (dad, papa) are rated as colloquial, apparently in reference to the other Gmc. languages rated as standard. In some instances all the above terms revert to their prime notion of the “ancestor, elder”, and apply to females as a concrete noun (Cf. Sl. baba). Like other Türkic terms of relationship, papa is a notional term, with a general notion “ancestor, elder”, and in different contexts may mean, and be fossilized, as ancestor, father, grandfather, uncle, grandmother, and, like its European counterparts, the word may denote terms of relationship or respect (like the papa “pope” of the Christian clergy) or affection (toward an elder). Lit. and formal translations are not always accurate: “Pope Francis” is a throne name, with the original semantics “Father Francis” long abandoned, hence a lit. translation “Father Francis” or “Progenitor Francis” would be inaccurate. Papa appears as a paradigm, with synonymous dad, eðel and father, the last two are allophones of atta “father”, and dad is an allophone of dedä “father”, originally each one conveying its semantic nuance. To miss this screaming paradigm would take either a ton of ignorance or a strenuous effort by a partisan aficionado. The term baba for “father” has allophones standing for the Catholic and other Popes, generic for the Eastern Orthodox priests, and among others the Arm. papik (պապիկ) “grandfather”, Eng. papa, pop, pappy, etc., Fr. papa “father”, Sl. baba “grandma, old woman”. The allophones of papa are sown across Eurasia, mostly as concrete nouns. Cited cognates: Eng. papa, pappa, pa, pappy, pop, poppa, A.-Sax. fæder “father, male ancestor”, OSax. fadar, OFris. feder, Du. vader, ONorse faðir, OHG fater, Gmn. vater; OIr. athir “father”; Fr. papa, Lat. papa, pater; Gk. pappa, pater; pappas “father”, pappos “grandfather”; Sl. papa, otets, (папа; отец ~ Tr. ata); Skt. pitar-; OPers pita; Basque aita; Sem. aba, abu, Arab. ab (باء); Hu. apa; Sum. ab, aba; Kor. abeoji; Mong aav; Swahili (Bantu) baba. Most of these “cognates” are not cognates at all, they ascend to the alternate roots aba (aba, abu; apa, etc), ata ( father, eðel, etc), and baba (Swahili/Bantu baba) of the same paradigm. The “IE etymology” is laughable “probably derived from baby talk”; these babies must be older than the first dolmens, and ventured wide across Eurasia. The examples demonstrate unfettered Eurasian distribution of the Türkic terms for “father”, unfettered variations of allophones, time depth ascending to the first historical compilations, and paradigmatic transfer of different subsets of the basic complex of seven designations into different languages and linguistic families. Such uniquely developed and multi-faceted paradigmaticity constitutes unfalsifiable evidence attesting to its Türkic roots (Eng. dad, father, and papa; Goth. aba and atta, Sl. ded and otets, Lat. avus and atta). It attests to demographic amalgamations effecting paradigmatic transfers of linguistic complexes from the donor ethnicities to the recipient ethnicities. A close study of the geographic and ethnic prevalence of the various terms may help to discern tendencies and connect the dots in demographic flows. Notably, the Swahili/Bantu baba is consistent with the genetic finding that a part of the Celtic circum-Mediterranean Y-DNA R1b migrants in the 4th mill. BC ventured into the sub-Saharan Africa and amalgamated with the locals. See age, ethel, dad, father, uncle.
English peace “absence of war” ~ Türkic baz, barısh “peace”,
ultimately fr. verb ba- “wrap, band, bundle” via baz
“pacify”, and bar-
“going (visitation, social intercourse”). The forms baz and bar- (mar-
with m/b alteration) are largely parallel, lending to a common origin with eventual s/r
split and reciprocal spread. The form
baz is closer to the majority of the European forms. Türkic has a synonymous form amulluk
“peace, tranquility” in the eastern languages (Uigur); apparently baz, barısh and amulluk
were overlapping western and eastern terms respectively, amulluk has not reached Europe, but
its allophone mir- did. Cognates: A.-Sax. frið (frith), Goth. wairfi, wairbeigs
“peace” “at peace”, Gmn. Friede, Norse, Sw. fred, Icl. frið; Anglo-Fr. pes,
OFr. pais (11c.), Fr.
paix, Lat. pax, Provenčal patz, Sp. paz, It. pace, Cat. pau;
Hu.
béke; Latv. miers, Sl. mir (мир), Slvt. mier, Mong. amar (амар);
Hunnic bejke, Sum. pag, Ch. 和平 hepíng. The “IE” exercises notwithstanding, it is
quite obvious that all these allophonic forms derived from the same source, related to the 4th mill.
BC record of the Sumerian cognate, and split between m/b alternation versions, with the b-
version further splitting into b-, f- (v-), and p- versions: bir-, fir- (vir-),
and pir-; the quality of the phoneme rendered as -z- in the transcriptions of the
Türkic word corresponds to the transcriptions -s, -th, -tz, -z/-d, -c (-ch), and -x in
other European languages. Other modifications include the well-documented prosthetic anlaut h-
in and m/n (ng)
alteration in Chinese, contraction fir- > fr- in Germanic languages, and ending variations
-g, -sh, etc.; the Goth. rendition wairfi (~ bairthi) is a closest rendition of
barısh. The Balto-Slavic, Sl., and Mong. forms belong to the m- version: mir, mier,
amar. The Türkic, Hunnic (Isfahan Codex), and Hu. retained the b- formant. The systemic
changes allow to trace the separate paths, including those of the Burgund/Bulgar/Provence/Fr. p-
form, a separate and older Lat. p- form, NW European f- (v-) form, separate paths for
the Central European and Far Eastern m- form, and Eurasian steppe zone b- form.
Tracing also carries time stamps: 4th mill. BC Sum. fr. 6th-5th mill. BC Kurgan migration to
Mesopotamia, Chinese fr. Zhou Scythian Kurgans migration of 20th – 16th cc. BC, Burgund Vandal
Kurgan migration of 2nd c. BC – 5th c. AD. It is clear that the Sum. version is a vernacular
offshoot of the pre- 4th mill. BC western steppe belt Sprachbund that reflects, but not defines, the
variety of the allophonic forms of the time. The peculiar coexistence of the m/b alternation
within the same communities endured for 7 millennia and has survived into the present times. The
Eng. transition fr. Gmc./A.-Sax. wairfi/frið to largely Romance pax/peace
attests to linguistic turmoil at the beginning of the 2nd mill. AD. See band, frog, mare.
84
English quarrel (n.) “altercation” ~ Türkic qaršï, keriš (n.) “enmity, discord, quarrel”, ascending to qaršu “opposite, against, facing you”, a derivative of a polysemantic verb qar-/ker- “overflow, break out”. The Eng. unexplainable idiom “to throw out one’s chest” is a calque of the Türkic metaphorical “bark, quarrel”. Another form of qaršu, in the Hunno-Bulgarian language, was kötur “behind, facing your behind”, which gave its name to the Hunnic Western Wing ~ Kutrigurs in Gk. rendering. The path to English is described as going via OFr. querele, Lat. querella “complaint”, queri “to complain, lament”, which transparently ascend to the Türkic qaršï. No “IE” cognates whatsoever.
English queen (n.) “female sovereign ruler” ~ Türkic yeŋä/jenä “wife”. The word queen belongs to the cluster of Türkic terms connected with feminism that are found in English, Gmc., and many “IE” languages: Eve, queen, wife. The term ascends to the Turkic stem yen-/jeŋ- “win”, reflecting the ancient Turkic tradition of pre-marriage competitions, where wife is a prize for the pretender's winning a wrestling match with his chosen maiden, hence the idiom “prize wife”, a calque of the Türkic jenä. Cognates: A.-Sax. cwen “queen, female ruler of a state, woman, wife”, OSax. quan, ONorse kvaen, Goth. quens “wife, spouse”, qino “woman, wife”, qens “queen”; Gaelic bean, Ir. ben “woman”; Gk. gyne, gune (ɣυνή) “woman, wife”; Balt.-Sl. (Lith.) jmona, , (OPruss.) genna, (Pruss.) genno “woman”; Sl. (OCS) zena, (Ukr.) jona, jinka, (Blr., Bulg., Croat) jena,jena, (Sloven., Czech., Slvt.) žena “woman, wife”, (Pol.) żona, (Luz.) žona; Arm. kin “wife, spouse”; Skt. janiṣ “wife, woman”, gna “goddess”, Av. jainish “wife”, gǝna-, ɣǝna, ɣna, ǰaini “woman, wife”; Kashgar, Kucha sän, sana “woman”; Ch. 后, 後 (hou) “queen”, 妻 (qi) “wife”, 妻子 (qizi) “wife, family”, 的妻子 (de qizi) “wife, wives”. The term proliferates in the Türkic, Gmc, Celtic, Balt.-Sl., Indo-Aryan, and reaches Far East, covering most of the Eurasia and far exceeding the “IE” areal. In that, the term's distribution parallels that of the whole cluster. An attention attracts the Celtic group, which had to carry this word from the N. Pontic to the Bell Beaker Iberia on the circum-Mediterranean Kurgan route, which would attest that the conjugational wrestling tradition dates to prior the 5th mill. BC. The South-Central Asian areal distribution attests to the presence of this term in the N. Pontic area prior the 2nd mill. BC. The Chinese cognates reflect the Scythian Zhou component in the Chinese language, ca 2300-1700 BC. Proliferation of the term in the Balt.-Sl. languages attests to its adoption prior to the split of the Balt.-Sl. tribes, their palatalized form is shared between the Balt.-Sl. and Indo-Aryan vernaculars, accurately reproducing the OT form yeŋä/jenä. The Lettish sieva belongs to the same cluster, it is a form of the Turkic sevig “love, beloved, loving, darling”, from “sev-/seb- to love”. The path of the queen/yeŋä/jenä to English likely was the same as for the word girl/kyr, via a distinct Gmc.-Sarmatian path, the initial q- attests to the Ogur source. See Adam, Eve, girl, king, quim, wife.
English regal (adj.) “related to supreme ruler” ~ Türkic arïɣ (adj.) “noble, honorable, flawless, faultless, clean, unpolluted, pure”. The initial base notion is “pure, clean”. All European allophones elide the unaccented anlaut vowel and carry a distinct semantics of the “nobility”, “rule”, and “ruler”. Cognates: A.-Sax. -ric “king”, rice “rich, powerful”, A.-Sax. rice “kingdom”, Goth. reiks “leader”; OIr. ri “king”, Gael. righ, Gaul. -rix, Welsh brenhinol/frenhinol/mrenhinol “regal, royal”; Lat., rex “king”, regere “to rule”, regalis “royal”, OFr. roi “king”, regal “royal”; Skt. raj- “king, leader”. The attested Gaul. and A.-Sax. forms are agglutinated to the name according to the Türkic syntax (e.g. Chingis-khan, Boarix, Bilge-Kagan, Gunderic, etc.). Eng. cluster includes “royal”, “rex”, “regalia”, “regime”, “regent”, etc., all related to Fr. and Lat. sources supposedly derived from the Lat. stem rex “king”, an allophone and semantic extension of the Türkic designation arïɣ “noble, honorable”. It is unrelated to the “IE” directional notions of “right” and “straight”. Distribution indicates that the title was carried overland to the Northern Europe by the pastoral tribes of the Scythian, Sarmatian, and Hunnic circles, to the South-Central Europe by the circum-Mediterranean Celtic migrants who left the N.Pontic in the 6th-5th mill. BC, and to the South-Central Asia by the Aryan migrants between 2000 and 1500 BC. In the “IE” etymology, based on some phonetic resemblance, the dubiously compatible notions of “right”, “straight”, and “king” are conflated, and individual words are extracted from the eclectic pile based on the opinions formulated by reverse projections. The distribution of the words with the directional semantics “right” and “straight” attests a much later existence in the geographical area of the Eastern Europe of a parallel directional lexicon that did not affect the earlier circum-Mediterranean Celtic migrants. The directional cluster includes cognates that can be dated to the period much after 6th-5th mill. BC and before 2000 BC: A.-Sax. riht, Goth. raihts, OHG recht, OSw. reht, ONorse rettr “right, correct”; Lat. rectus “right, correct”; Av. raze- “to direct”, Pers. rahst “right, correct”. The terms for “king” (Skt. raj-) and “direction” (Av. raze-, Pers. rahst) migrated from the Eastern Europe to the South-Central Asia after 2000 BC. The “IE” linguistic etymology is in conflict with the dating provided by archeological and genetics disciplines. The Türkic etymology is semantically precise, phonetically near perfect, its distribution is consistent with other extracts from the Türkic phylum in the European and Eurasian languages. Combined with numerous other title-related Turkisms in English (baron, earl, king, queen), that presents a case of systemic paradigmatic transfer to English, an inescapable evidence of the common origin. See baron, earl, king, queen.
English saga (n.) “historical narration” ~ Türkic savga- (v.) “tell the history, narrate”.
The deverbal verb is formed from the verb
söy-/sav-/söjle/suj/söle/süle/sülä “say” with a rare in the eastern Türkic languages
imperative suffix -ga-, a variation of the “rare” in the eastern languages instrumental
deverbal noun suffix -gu, and thus the suffix is either a guest from the western Türkic
languages, or archaic, and likely both. Ultimately, the stem
sav/sab (and verbal sav-/sab-)
is a derivative of the stem sa- “count, reckon”, see sane,
sanity, say. The verb form with -g- (sög-) is cited specifically for the modern Tuvinian
(annalistic Tabgach) languages. The -g/-y
alternation is a case of very early sound change -g (-k) > -y > zero. Cognates:
A.-Sax. sagu “a saying”, ONorse saga “saga, tale, story”, MLG, MDu. sage, zage,
Gmn. Sage “legend, fable, saga, myth, tradition”; Ch. shua 说 “saga”. The “IE” etymological attempts conjectured an ultimate “PIE proto-word” *sekw- “say, utter”,
mechanically extracted from the Gmc. allophones, and unwittingly replicated the Türkic
söy- “say, utter” with its allophones, but without recognizing the origin from the base sa-.
The base sa- in turn, in addition to the secondary semantics “tell, narrate” also conveyed by
the form
sav-, can be also articulated sä-/sə- and the like, Cf.
articulation of the element in the forms sayla-/saila-/saylə-/seyle-/seiyle-/suyla-/šayla-
“discuss”.
These moments are consistent with the Gmc. articulations. The semantic and phonetic match is
perfect, independently confirmed by the “IE” etymological exercise. The form savga- serves only
as a marker on a road, the variety of the daughter forms and their Eurasian spread suggest more than
a single possible path, but the ultimate origin from the stem sa- is indisputable. The word
saga (n.) appears as a paradigmatic transfer case, with synonymous “tale” (n.), thus the same
stories are variously called saga or tale (tal), or even both, Cf. Saga “Ynglinga
tal”, lit. “Saga Ynglinga tale”, complete with the noun locative conjugational suffix
-ga, “Tale on Yngling” or “Story on Yngling”. Snorri did “Ynglings Saga” and Thjodolf did
“Ynglinga tal”. In a Ch. rendition the “Ynglings Saga” would be called “Ynglinga Shua (说)”, and the
“Ynglings Tale” would be called “Ynglinga Tan (谈)”, another Ch.-Türkic-Eng. paradigmatic transfer
link. Neither Eng. nor Ch. can ever be accused of historical cross-contamination. It is nearly
impossible for a professional to ignore the conspicuous paradigm. See tale, sane, sanity,
say.
85
English sagacity (n.) “insightful, wise” ~ Türkic sag, sağ (ğ may be articulated silently), saq “wise, talented, foresighted”, from the stem sag- “mind, intelligence, acumen”, deverbal noun fr. sa:- “count”. Cognates: MFr. sagacité, Lat. sagacitatem, sagax “sagacity”, also “of quick perception, prophetic”. The Romance and the English forms carry a trace of the Türkic agglutinated suffix -g/-ɣ/-ag/-aɣ/-ïg/-ïɣ/-ig/-iɣ/-ug/ -uɣ/-üg/-oɣ/-ög that forms nouns and adjectives, and produced a number of allophonic suffixes in Lat. The Romance form also retained the semantic derivatives of the Türkic sag, sağ. The confused “IE etymology” incredulously derives the English sage “wise (n.)” from the Lat. sapere “to taste”, entirely ignoring the Lat. word sagax “sagacity”, and then for some unspecified reasons uses sage < sapere “to taste” to etymologize sagacity. Go figure. See saga, sage, say.
English salary (n.) “compensation, payment” ~ Türkic salɣa- (v.) “to pay off compensation, to zero off payment account”, in both cases referring to periodical or final payment for regular or specific service. Ultimately a derivative fr. the verbal stem sal- “move, dispense” that conveys a notion of outward motion in numerous ways, of which “give” and “dispense” is but an one facet, represented by translations “expel”, “draw (something) aside”, “bring (carry, bear) to”, “send”, “spend”, “release”, “move”, “hurl”, and more, see sale. Cognates: OFr. salarie, Lat. salarium “salary, stipend” for “soldier's pay”. Türkic mercenaries served in all armies from Mediterranean to Yellow Sea for as long as we have written history, everybody had to learn to pay salɣa, including Romans, Greeks, Persians, and Chinese, among many others. The Alexander sarcophagus depicts Persian soldiers exclusively as Scythians in Scythian hats shooting Parthian shoot with composite bows, in the battle scene the Persians are nowhere to be found. Accordingly, the word salɣa had to enter lexicon of all those farming states that employed Türkic mounted mercenaries. We have OFr. salarie, Lat. salarium “salary, stipend” for “soldier's pay”; The “IE” folk etymology for “salary” of “pertaining to salt” is totally incongruent: if the Türkic word for payment would have resembled avis, this same kooky etymology would have had it “pertaining to birds”. The Türkic cognate of salɣa is salïɣ “taxes, dues, imposts” with the same notion of “you owe me, you pay me”. The original semantics, associated with payment for hired guns, and the phonetic similarity attest to the real origin. See sale, satisfy.
(Skip) English saldo (n.) “outstanding balance” ~ Türkic salɣa (v.) “to pay off compensation, to zero off payment account”. Ultimately a derivative fr. the verbal stem sal- “move, dispense” that conveys a notion of outward motion in numerous ways, of which “give” and “dispense” is but an one facet, represented by translations “expel”, “draw (something) aside”, “bring (carry, bear) to”, “send”, “spend”, “release”, “move”, “hurl”, and more, see sale. See salary, sale, satisfy.
English savant (n.) “scholar, pundit” ~ Türkic savan/saban “prophetic, wise” (adj.) with an instrumental noun suffix -an/-än (-ən), OTD form savčï/sabčï “prophet, messenger”, a derivative of sav/sab (v.) “word, speech” with an agent noun suffix -čï/-či (-chy/-chi) “speaker, teller, talker, informant” that grew into “foreteller” and then to “prophet, messenger”. The instrumental suffix -аn/-än (-am/-en) produced object noun savan/saban with semantic “speaking, speech, telling, tale, informing, information” that grew into “foretelling, divination” and then to “prophetic, wise”. Cognates: A.-Sax. sefa “mind, understanding, insight”; OSw. sebban “perceive, note”, OHG seffen; Fr. savant “learned man”, Sp. se, sabe “to know”, Lat. sapere “wise”, sapientem “wise” from palatalized form sab > sap. Notably, English, Gmc. and Lat. have all preserved the Türkic substrate form with the Türkic non-animated adjectival suffix аn/än, attesting to the origin of the word; the ending -t, -s, etc. are individual modifications. English and other Gmc. forms did not fall into the Lat. palatalized form sap, showing parallel independent processes of modification and innovation. All Türkic courts at all levels employed a staff of counselors whose duty was to know the future (Cf. the Merlin). Since the “recall” of the ruler was swift and lethal, counselors' importance at the courts was immense, and their accountability for predictions and advice was existentially crucial; their longevity was short, and their turnover was relatively high. At the Bulgar/Avar courts they were called Boyars/Bolyars/Boils, Cf. Tonyukuk's title Boila Baɣa Tarqan, Boila stood for “seer” and is usually translated “wise”. The Türkic root forms sav/sab/sag/sai have a flavor of suffixed derivatives of once one-syllable primal form se/sa that may be older than the haplogroups R or R1. The suggested “IE etymology” of sap “liquid in a plant” is as far from being relevant as it can get; no “IE” cognates whatsoever lay outside of the Gmc.-Lat. circle. See say, sage, sapient.
English secret “hidden” ~ Türkic soqru “secret, hidden, covert”, probably a derivative of
soq-/sïɣ-/suk- “hide, insert”. Cognates: Latv. slepens,
Lith.
slaptas; Sloven., Serb. skriv-, Slvt. skry-, Bosn., Croat skri-, skro-;
Lat. celatum and secretum; Fin. salaisuus, Est. saladus; Az. sirli;
Akkadian secru “concealed/closed up”, secretu/secratu “concealed woman” and an
Akkadian appellation for the goddess, the earliest record of the 28-24 cc. BC. The Akkadian word
does not ascend neither to the Sum. nor Semitic origin, and it is patently non-IE. The Az. form
allows development into both the sVl- and sVr-/sVkr- forms, covering the whole
spectrum of the European s- forms with quite peculiar distribution in Balt.-Sl., Sl., Fennic,
and Lat. Since the slp- forms of the Latv., Lith., Fin., Est., and of the Lat. celatum
form are incongruent with the skr- form of secret, as reasonable cognates they should
be rejected. That leaves the skr- forms of the Akkadian, Lat., and Sl. forms as reasonable
allophone cognates of the Türkic soqru. The perfect semantic and near-perfect phonetic match
practically exclude a random coincidence. The randomly accidental presence of the word within the
“IE” family attests to its status as a loanword and thus excludes an “IE” provenance of the word and the
absurd of the pseudo-scientific “PIE proto-word” *krey-/*krehi(y)- fantasies.
86
English son “male offspring” ~ Türkic soŋ (song) “offspring“,
soŋsuz (songsuz)
“childless” (-suz is a negation suffix), ultimately fr. soŋ (song) “end,
after, then, trailing” (M. Kashgari). Cognates: allophones of son in all Gmc. languages, all
archaic Gmc. allophones also denote “offspring, descendant”, with peculiar semantic dichotomy shared
with Tr.; A.-Sax., OSax., OFris. sunu, ONorse sonr, Goth. sunus, OHG
sunu, the Icl. sonur is a lit. compound allophone of the Tr. soŋ er
“male offspring”; Balto-Sl. (Lith.) sunus, (Slavonic) syn; Lat. sunus; Gk.
huios; Av. hunush; Skt. sunus; in Ch., sun 孙 and sunz 孙子 is
“grandson”, another peculiar English/Türkic/Chinese concurrence, with a spill into Romance (Lat.)
and Slavic. Lat. is an oddball in using an allophone of son, all other Romance (and Uralic)
languages use variations of fil. Besides archaic Skt., the eastern “IE” languages do not know
neither fill nor son, attesting to an absence of a pan-IE “proto-word”, and a guest
status of all stems but one. The A.-Sax. has numerous appellations for “son” (byre, doc, eafora,
hyse nap. hyacas, maeg, etc.), but only sunu
participates in forming relationship terms like “grandson”, attesting to its lexical primacy and
hence to the Türkic substrate origin. The “IE etymology” strenuously ignores linguistic situation
within the “IE” family, and suggests a partial solution exclusively for son, from a notion
“give birth” based on Skt. and OIr. distant homophones (sauti and suth
respectively). That partial suggestion is not sustainable, first because OIr. “son” is not an
allophone of son, secondly because it does not explain the path for the Türkic and Chinese
Eurasian languages that do use the allophones of son, thirdly, it can't explain the
Türkic-Gmc. dichotomy, and fourthly it does not explain the oddity of the Skt. and OIr. sharing the
same word for “parturition” in spite of these two migrant groups drastically different paths in time
and space (2nd mill. BC eastward vs. 5th mill. BC westward). Instead, the Kurgan migrations provide
corroborating scenario of spreading the term soŋ to the Northwestern Europe, Skt. and China,
and for the Türkic-Gmc. dichotomy. It also explains the absence of allophones for son
in Celtic languages, the Celtic Neolithic circum-Mediterranean departure from the Eastern Europe is
dated to 6th-5th mill. BC, before the soŋ became a term for “son” in the Eastern Europe, and
the Gk. and Aryan migrations from the Eastern Europe took place in the 2nd mill. BC after the soŋ
became a term for “son”. The anlaut -h- in Gk. and Av. is consistent with the s-/h-
transition observed for the Caspian-Aral basin. See
87
English sooth (n.) “truth, reality” ~ Türkic čïn [chyn] (n.) “truth”, (adj.) “true”. Ultimately an allophonic derivative of the verb sa- “count, reckon”, explicitly corroborated by the Sl. synonyms, Cf. sane. According to the “IE” explorations, soð is a contraction of an unattested sonð “true” from some imaginary unattested faraway neverland. The sonð, in turn, is a transparent allophone of the Türkic čïn, which closes the loop and gets rid of the imaginary neverland. Cognates: A.-Sax., OSax. (contracted) soð (soth) (n.) “truth, justice, righteousness, rectitude”, ONorse sannr (adj.) “true”, OHG sind, sand “true”, Goth. sind, sunja “truth”, OIsl. sannr, saðr “truth, veracity, dictum”; Sl. sut (суть), sa (са), su (су), jsou/ysou “substance, meaning, kernel”; Lat. sunt; Skt. santi; Ch. chin 真 “true, really”. No sensible “IE” etymology, it is roaming phonetically across the entire linguistic field, the mechanical constructs of the type *h1sónts, *es-ont-, *h1es-, *es- lead from nowhere to nowhere. Equally uncouth is a suggestion to mechanically link the word for truth with the word sin “transgression”, an unwitting allophone of the Türkic verb sın- “break, trespass”, see sin. In the Gmc. languages, the form sun-/san-/so- was supplanted by the synonymous forms of “true” (Cf. Goth. triggws), the allophonic forms of the Türkic dürüst, see true. Both, the Türkic forms for “truth”, and the word for “sin”, found their way into Gmc. languages. The separate paths crossing linguistic families to the European and Ch. groups are obvious. The Eng. form, a stand-out within the Gmc. languages, tentatively links its distinction with the anabasis of the Saxon-Sekler-Scythian-Saka people vs. the westward path of the Corded Ware Gmc. people and the eastward path of the Skt. The unequalled abundance of the A.-Sax. derivatives of soð points to a long cultural timeframe. The Chinese chin 真 “truth” is likely a reflex of the Scythian Zhou component in the Chinese language. Ultimately from the same source, the paradigmatic transfer of the duo's čïn and dürüst synonyms and allophonic forms forthrightly attests to the very specific common Türkic genetic origin. See sane, sin, true.
(Skip) English tend (v.) “look after”, tutor (n.) “guardian” ~ Türkic taya “nurse, nursing”. The notion of “save, preserve, guard” is expressed in Türkic with a verbal stem tut-, which is an obvious candidate for all the English, Lat., and Türkic derivatives and cognates. English has an abundance of derivatives: attend, tender, tutor, and many others; Türkic has a matching variety of derivatives, all congruent semantically across languages. The Türkic cognates include: taya- (v.) support (a child); tayjši (taishi) mentor; taytür fine, refined; tiun steward; among the cognates is Ch. tayshi 導師, complete with the Türkic suffix -shi/-chi of profession, trade, or involvement, apparently ascending to the Zhou tradition of mentoring the youngsters. In Türkic tradition, the honor and obligation of mentoring boys belongs to the grandfather on the female line, but with the Qin/Han takeover, the Türkic family tradition of tutoring was abolished, and tutors were appointed by officials or seniors. Likely, the Türkic notion of gentle support, a nurse, was a primary semantics that developed into notions of gentleness and tutoring, and ended up, among others, with English tending offers. The Lat. tutor (n.) “guardian, watcher” and tutela “guarding, watching” from the verb tueri “watch over” are direct reflexes of the Türkic taya “nurse, nursing”, complete with the Türkic suffixes -or for “man” and -la to form adjectives and adverbs. The Hu. dajka “nurse” apparently is also a reflex of the Türkic taya “nurse”, possibly taken from the Ogur branch. Genetic composition of the Hungarians suggests that Magyars were a union with predominance of Türkic Sarmatian males and Fennic Uralian females, and the females carried their language into posterity. This belief is corroborated by the archeological observations in the South Urals in the Late Sarmatian period. The “IE etymology” is absent, in the IE-centered compilations any etymology is missing, the attribution is a standard “of unknown origin”. Curiously, while the tend does not have an “IE” etymology, the attend does, from a Lat. tendere “stretch”. If one can stretch stretch into nursing and tutoring, stretching dinosaur into mama is a child's play.
English thief (n.) “stealer”, derivatives and variations thieve, theft (n.) ~ Türkic tef, tev (n.) “guile, deception”. Cognates: A.-Sax. theof, theofian, OFris. thiaf, OSw. thiof, MDu. dief, Gmn. diob, Gmn. dieb, ONorse thiofr, Goth. thiufs; Balt. (Lith.) tupeti “to crouch”. For theft: OE theofð, WSax. thiefð, OFris. thiufthe, ONorse thyfð, with suffix -itha, which is the Türkic abstract noun suffix -č/-čï/-ču/-čü cognate with the same function Lat. -ita, Balt. -ži, Slavic -ch/-ishch (-ч/-ищ). Thus, the Türkic tefč or thefč (tefch or thefch) corresponds to A.-Sax. theofð (theofth) etc. Theft is one of the cases where the modern English word, in addition to the stem, preserved the word with agglutinated Türkic suffix in its recognizable form.
English throne (n.) “monarch chair” ~ Türkic tör, törä “throne, honorific seat, imminence,
importance”, törä “throne, law, custom”, tören (n.) “celebration, ceremony”.
The analogy with the European (throne) and Hebrew (law, torah) is undeniable. Cognates: Lat.
thronus, Gk.
thronos “elevated seat, chair, throne”. The word throne became an international word
with the same meaning in all European languages, and numerous idiomatic extensions in every
language, mostly international calques. The Türkic traditional ceremony of physically raising to the
throne on a felt carpet retained its echo in the idiom “raise to the throne”, and in the British bag
of wool on the seat of the throne. The reunion of the base word, tör, törä, with the two
precise semantic meanings, throne and law, between the three unconnected languages
with the two distinct leading paths probabilistically is near absolutely impossible. The earliest
the word törä “law” could reach the Near East from the Middle East is with the Abraham
migration ca. 12-15th cc. BC, and on to English in the 5th c. AD. The earliest the word tör
“throne” could reach the A.-Sax./English is 5th c. AD, coming from the European Huns. These two
independent paths attest to a complicated case of paradigmatic transfer leading to the final reunion
in English, and indelibly attest to the ultimate Türkic common source that started in a nomadic
yurt. It is impossible for any etymologist to see the törä “law” and not to question the
reason for such a remarkable consonance with the torah /tora/ “law”, if only to dismiss away
the coincidence as purely fortuitous or by some other palatable explanation. It is equally
impossible to drop an explanation for the consonance between the second meaning of törä
“throne” and the word “throne”. The ethics and credulity of such research begs for skepticism. See
torah.
88
(Skip) English trust (n.) “certainty” ~ Türkic döres(t) (Tatar), tröst (Turk.) (n.) . Cognates: A.-Sax. treowian “to believe, trust”, treowe “faithful, trusty”, ONorse traust “confidence”, “to trust”, OFris. trast, OHG trost “trust, fidelity”, Goth. trausti “agreement, alliance”, Du. troost. Notably, “IE” cognates are nowhere in sight. Apparently, the only possible source is the Sarmatian migration from the Ural-Itil area, the “Wendeln/Veneds” circle, which brought over the Oguz-Kipchak form to the central and western Europe. The eastern Türkic forms, from the verb tayа- “rely, lean, rely on, depend upon” are phonetically much different from the western forms. The vowels -au- in the ONorse and -eo- in OE apparently tried to convey the Türkic round-labial ö well-preserved in the French phonology.
(Skip) Gmn. Ulan “cavalryman” ~ Türkic “ulan/oglan" - “young man”, “scion of a noble family”. Same word in Pol., Russ.. See clan.
(Skip) English Urheimat, German Heimat “fatherland, motherland, homeland” in Urheimat ~ Türkic xajmatläx (Chuv.) “kindred”. The same word in common Türkic would sound as hünmäklïg. The Chuv. composite consists of components xaj + mat + läx, or kin (Hun) + abstract noun suffix -mat (forms -ma/-mä/-maq/-mäk/-mïr-/-mur) + abstract noun suffix -lig (forms -lig/-liɣ/-lik/-lan) “like”, i.e. lit. “of the kinship”; the suffix -lic is still productive in English, it is a part of the nouns “public”, “alcholic”, “bucolic”, etc.; the form xaj, as a colloquial form of the kin/Hun, is known from the Armenian endonym Hai, as a Caucasian designation of the Hailandurk Huns, and form the modern ethnonym Haitak/Haitag for the descendants of the Caucasian Huns. Notably, the OHG pra-form heimoudil (hei-moud-il) of the modern Gmn. Heimat contains the Türkic root -il-, which stands for the “country, land, nation” i.e. lit. “of the kinship country”. In English, the Gmn. Heimat became popular in the compound Urheimat, widely used in linguistics in relation to the soil where the romantic tree of the Indo-European linguistics was gestated. It turned out, it was gestated in a wagon, on the road from the Balkans via N.Pontic to the Baltic. See kin.
English ware “manufactured goods, goods for sale” ~ Türkic tavar “goods, property for sale”. Ultimately fr. the verb tav- “(in respect to property) deal, dealing, turnover of working capital” recorded in the form tavïš- “to trade (mutually, cooperatively)”, initially for domesticated animal property, and later specifically for “merchandise, trade goods” property, i.e. manufactured goods. A synonymous Türkic satïš- “to trade (mutually, cooperatively)” found a wide distribution in India, even becoming a tribal/clan name, while an echo of the form tav-/tavïš- was recorded with an instrumental noun suffix -gach as an annalistic tribal name Tabgach (Tavgach, Tuba, Tuva, Tuvinian, Ch. Tuoba) for the rulers of the Chinese Empire Wei (Tuoba Wei 拓跋魏, 386–535). The uniformity of the Gmc. forms attests that the peculiar trade term was internalized at a very early stage with elided unaccented anlaut ta-, probably confused with the article die/de, Cf. Scand. die Waare/de Waare. Cognates: A.-Sax. waru, Eng. ware “manufactured goods, goods for sale”, OFris. were, MDu. were, MHG, Gmn. ware, Sw. vara, Dan. vare, Du. waar, Scand. die Waare/de Waare, all meaning “goods”. The Türkic and Gmc. forms are allophonically eidetic and semantically identical. With the Türkic word used from Pacific to Atlantic, there is no need to fantasize an artificial semantically incongruent” mechanical concoction of a “PIE root” *wer- “perceive, watch out for” to designate goods and trade. See tavern.
English Yule (n.) “winter holiday” ~ Türkic yol (n.) “road, way”, as a winter holiday “road, way (of fate)”; the original full name of the holiday was “Yule Tengri” ~ “Fate (from) Tengri” ~ “Fate (from) God”, it is celebrated on the winter solstice, with spruce, music, dances, and gift exchanges. Cognates: A.-Sax. geol, geola, Ang. giuli, ONorse jol, Gmn. Yule; OFr. jolif; Modern Fr joli “festive”, semantically extended to “pretty, nice”; Modern English jolly “festive”; Sum. yol “road, way”. In the religious and “IE” etymological fields, the term is dumbfoundingly rated “of unknown origin”, although it is still active in the Türkic-populated areas, and is sufficiently well described in the ethnological literature. An 8th c. Tibetan inscription from a Thousand Buddhas cave mentioned Yol-Tangri “God's Path” revered in the fortress Shu-balyk in Dunhuan. After advent of Christianity in the 4th c., the winter solstice period was reassigned to mean “the 12-day feast of Nativity”, with the advent of Christianity it was transported to Northern Europe, and in the 11th c. it was reassigned to Christmas, becoming a “Christmas Yule”, or “Christmas holiday”. The term is still active in the Northern Europe, with all its traditional trimmings. The Sum. yol attests 4th mill. BC, a long way to the Norse Christianity and Papal edicts. See jolly.
English youth (n., adj.) “young person” ~ Türkic yaš (yash, adj.) “youth, young, green”,
also “year” (in terms of age).
Cognates: A.-Sax. geoguð “youth”, related to geong
“young”; OSw. juguth, OFris. jogethe, OHG jugund, MDu. joghet, Du.
jeugd, Gmn. Jugend, Goth. junda “youth”. In ME, the medial -g- became a
yogh (geoyoghuð ), which then disappeared. The Türkic prosthetic y- is a dialectal
version of
yok-/jok- dialects that distinguish Ogur languages innate for the Huns and Bulgars, their
ancestors, and their descendants. It is expressed as anlaut y-/j-/g- and their close
allophones; Oguz languages do not use prosthetic consonants in front of the initial vowel. A
bifurcated version of yas is qar, with s-/r- alteration, also typical for
Ogur/Oguz split. The terms like young are derivatives of yaš “green, youth” with
suffix -n/-ng/-ŋ of adv. of quality from adj. Notably, English retained the connection
between youth and green, which in Türkic is a single polysemantic stem yaš. See baby,
brother, child, cousin, doll, puppy.
89
English abyss, abysm (n.) “bottomless (gulf), greatest depths” ~ Türkic abamu (n., adj.) “endless”; unrelated to homophonic abam/apam “if”. The abysm falls into the group of the terms inherited from the Buddhist nomenclature. Cognates: OFr. abisme, Fr. abime, Sp., Port. abismo, VLat. abysm, LLat. abyssus. No “IE” cognates outside confined examples, the VLat. and LLat. examples are late borrowings. For such a peculiar abstract notion, the phonetic and semantic coincidence is striking. The “IE” etymology is not applicable because the word lays outside of nearly all of the “IE” family's languages. A suggested etymology is Gk. a- negation + byssos (βασσοσ) “bottom” fr. bathos (βαθοσ) “depth”, which ultimately ascends to the Türkic verb bat (v.) “immerse in water”, see bath. A parallel emergence of the cognates abamu and abysm for “endless” is impossible, that casts doubt on the Gk.-origin etymology. The Türkic-language Buddhist nomenclature has a Buddha Abamu associated with eternal nirvana, another attestation against a Gk. origin, that also could have suggested a Hindi origin that penetrated Gk. and Türkic languages, but a parallel derivation of a concrete noun (Gk.) and adjective (Tr.) from a proper name of a deity is also too far fetched to be possible, and although Hindi does not have the word abamu for “bottomless”, “depths”, “endless”, “eternal”, and the like, the source may be Prakrit or some other Indian vernacular. That largely leaves Türkic as the most probable source that applied abamu to a concrete Buddha, came to Romance languages via Burgund nomads as attested by Fr. and LLat. connection, and was independently acquired by Gk. See bath, bode, bursary, mantra, monastery, sin, testament.
English Adam (via Bible) “first man, progenitor” ~ Türkic adam, adami “(generic) man, human”. Ultimately fr. ata/ada “father” with a possessive suffix -m “my father”, i.e. not a some abstract “father”. The Semitic aba/abi “father” is unrelated to the Türkic ata “father”, the possessive suffix -m can't be explained in the framework of the Semitic languages, and the Semitic aba could not have produced the form adam. Now Adam is international word, its origin is ascribed to the Heb., but except for the 42+ Türkic languages, no other language on our globe has adam for the generic “man”. Only the Türkic languages use adam in non-religious context: the English “I met an old man in the grocery store” in Heb. reads “פגשתי איש זקן במכולת” with איש “man” = hoish, not adam, while in the modern Turkish it is “Ben bakkal yašlı bir adamla karšılaštım”, with adam “man” + accusative case suffix -la. In Heb. Adam אָדָם is a proper name “Adam”, not a איש “man”; the האנושות is “mankind”, not “adamkind”; and adamah is “ground, earth's surface”, not a “man”. The Heb. etymology, albeit popular, does not hold the water, and even though during the last 3000 years the religious proper household name Adam had enough opportunities to dub as a common noun, it still did not go there. Only the Türkic phrase “God created man” uses adam for “man”: “Tanrı adam olušturulan”. With the advent of the Christianization in the 5th-7th cc., the Biblical Adam at times probably was used eponymously for “generic man” or “human, humans at large” as part of religious or literary rhetorical trade vocabulary. The Biblical presence of the eponymic Adam and Eve, both from the Türkic linguistic field, attests that the Genesis mythic story originated in the Türkic folklore. That guidance allows to suggest that the hero name of the Sumerian mythic story, conventionally read as Akkadian Gilgamesh, should be read as Sumerian Bilgemiš, from the Türkic Bilge “Wise” and an old denoun adjectival/adverbial suffix -miš, i.e. “Omniscient”, quite suitable for the epical superlative title-name. See Eve.
English alms “donation, offering” ~ Türkic alım “offering”, lit. “give takings” from a cluster consistent with religious semantics: аlmak/algı “taking, payment”, acıma “pity”. Ultimately a noun derivative of al- “take, capture, accept” (Cf. A.-Sax. alaeccan “catch, take”, alaenan “lend, grant”, the language of generous giving is extremely well developed in A.-Sax.). Cognates: A.-Sax., Gmn. ælmesse, A.-Sax. aelmes, almysse, OSw. alamosna, OHG alamuosan, ONorse ölmusa, Ecclesiastical Gk. “charity, alms”, eleemon “compassionate”; Lat. eleemosyne, eleemosyna; Romance languages: OSp. almosna, OFr. almosne, It. limosina. In Gmc. languages, allophones of the Turkism alms and their derivatives are practically the only way to express pious offering. Etymology: supposedly “of unknown origin”. The Türkic аlmak lit. stands for “make alms”, transposed in English to make alms “make alms” (inf.). Alms belongs to the transfer paradigm of the mortuary tradition terminology, along with the lexemes cairn, coffin, curse, God, grave, hall (e.g. Walhalla), hell, mengir, mound, pyre, tomb, tumulus. See cairn, coffin, curse, make, yield, etc.
English amen “so be it” (adj., adv.) ~ Türkic ämin (emïn, e:mi:n, imin) (adj., adv.) “safety,
security, protection”, the act of protection and reassurance.
Ultimately a derivative fr. the noun am “pudenda, quim, vagina, vulva”, Cf. amra:- “to
love”, see Amor, and an allophonic verb um- “desire”. The prime notion
developed into a cluster of flavors connected with female beginning, femininity, and motherhood.
Among illustrating derivatives are the notion “love”, Cf. amra:- “to love”, umdu:
“desire, covet”; the notion “safety”, Cf. ämin
“safety”, amrul- “calm down”,
amšu “offering”, amul “quiet, quietly, gently, peaceable”, amulluq
“tranquility”, amurt- “pacify”, amüč
“gift”; the notion “hope”, Cf.
umdur- “to hope, beg”, umid “hope”, umun- “to desire, request, pray”. Secular
applications of the form ämin/emïn/imin are expressed in the cited examples (for the purposes
of illustration, with maximum use of the English Turkisms):
ämin (“safe, assured, protected”) qamuɣ (all, entire, gamut), i.e. “all (is) safe”
lit. “gamut amen/safe/protected/assured” (OTD 75),
yolda (“yule, road”) ämin (“safe, assured, protected”) jorït
(journey), i.e. “yule/road (is) safe (for) journey”) (EDT 161, OTD 75).
In the religious context, the Ämin/Emïn/Imin literally means “Assure/Protect Us”, “(Give/Bless) us
(with your) assurance/protection”. The notion “us” is expressed with the suffix
-in, which forms reflexive verbs from the verbal roots “self, me, selves, us”, or noun result
(i.e. “protected, safeguarded”), or dominant nouns/adjectives “greater safety, security, protection”
(Cf. -en in Gmc. languages and its relicts in Eng.: children, oaten, oven). The suffix
-in also forms instrumental denoun nouns (i.e. “Protector, Guardian”), or noun/adjectives and
semantically not applicable to the religious context concrete nouns. The extreme polysemy of the
suffix -in and its use in forming numerous downstream suffixes attest to its high archaicity.
The same can be stated about the lexical cluster derived from the Vm-
type root, with its interlinked and synonymic derivatives. Considering that most of the religious
lingo is formulaic and extremely conservative (“amen” is used identically by all three contiguous
religions, starting from the Judaism, i.e. from the second half of the 2nd mill. BC), its use may
project beyond the Sumerian times. The interpretations “so be it”, “faithfulness, loyalty”, and a
host of other interpretations in numerous languages are conditioned on tradition and diverse
linguistic apparatuses. They are rather literary translations with means of specific vernacular
apparatus, practically useless for etymological exploration. Usually, semantics of those
translations is in stark conflict with the spirit of a prayer, they contravene the humility of
supplication. No prayer can end with a demand or an assertion that the demand must be satisfied.
Semantically, a prayer must conclude with an exclamation of the type “Please, we beg you to do
that”, where “that” is the content of the prayer, its expressed desire, its expressed expectation,
and its expression of a submittal to the will of the Almighty. Neither the edgy “so be it” nor the
senseless “faithfulness, loyalty” fits the plea. The Türkic ämin, with its allophones, does
not carry that conflict. It asks for protection, for safety, it asks for benevolence. The deverbal
noun ämin is a derivative of the verb äm-/em-/um- “ask, hope, desire, expect”, with
the suffix -in it produces a noun result expressing trust “reliable, reliably, dependable,
dependably, correct, correctly”, reassurance “safety, security, protection”. The religious and “IE” etymologies end up at Heb. amen אמן “faithfulness, loyalty”, but the idea that non-Judaic and
non-Christian Türkic tribes across Eurasia learned the word from Heb., or that this is a chance
phonetical and semantic coincidence is preposterous. The Arabic influence is ruled out for the same
reason, the non-Islamic Türkic tribes across Eurasia could not get it from the Arabs. In addition,
in parallel with the other religious terms like the
adam and eve, the Türkic word ämin is used for most casual speech: “safe roads”
(lit. “reliable roads”), “dependable caravan”, “do not trust (friends)” (lit. “do not rely on”),
“hope on somebody” (lit. “hope, sureness”). It is used with appropriate derivatives and numerous
allophones, a sure indicator of the indigenous lexeme with religious application being only a minor
semantic offshoot. None of the languages that utilize the formulaic religious “amen” use it as an
active word-forming root outside of the religious context. Adoption of the exclamation amen
from a Tengrian ritual into the pre-Heb. and then to Heb. ritual was a forerunner of its adoption
into the Christian and Islamic rituals, and a harbinger of its global spread. See Adam, Amor, Eve.
English Amor (God of love, Roman pantheon), amorous, amorist, etc. ~ Türkic amra/amran- “to
love”, amïraq/amraq “beloved, dear, friend”. The word Amor has found
broad international distribution as the Roman God of love, also known as Lat. Cupido (desire), Eng.
Cupid, and as a French noun les amours. The Roman
Amor was identified with the Gk. Eros. As Eros, Amor was a fourth primordial god to
come into existence, after Chaos, Gaia, and Tartar, mentioned in one of the most ancient Gk. sources
(Hesiod ca. 700 BC). The Türkic name of Tartar is tat, tatar “alien, foreigner”, its sacral
function was the alien underworld. So, three out of four Gk. primordial gods have corresponding
Türkic etymology. One of the two has largely synonymous Türkic predecessors, the amra
“to love” for Amor in the Roman pantheon, and a corresponding er
(with derivatives denoting masculinity, maleness, male potency) “to make love” for Eros in the Gk.
pantheon. Notably, the Amor/Cupido marks his victims specifically with arrows, the innate Türkic
weapon and tool, in contrast with lances, spears, javelins, darts, slings, etc. And from the first
depictions, Amor/Cupid used the unequaled composite bow, the distinct weapon of the Scythians,
Parthians, Huns, Türks, and Mongols. Herodotus attested a Greek – Türkic Scythian symbiosis in the
N. Pontic, hence the use of the Türkic terms in the Greek mythology should be expected, Cf. Herkul
(Hercules) “mighty man”, lit. “man (as big as) a lake”. A thousand years later, the verbal form
amïr- “to love, be friendly” and its derivatives amïrtɣur-/amïrtqur- “pacify, calm,
suppress” became the Sl. word mir (мир) for “peace”, “(peaceful) people”, and eventually for
“world”. See -er.
90
English bursary (n.) “treasury of religious order, student grant” ~ Türkic bursaŋ (bursoŋ, bursuŋ) (n.) “monk community”. The stem of the term is burs, and -aŋ/-oŋ/-uŋ is a 2nd pers. possessive suffix. Cognates: A.-Sax. purs “purse”, ONorse posi “bag”, LLat. bursar, bursarius, bursa “purse”, Romance bursa “purse”; Ukr., Sl. Bulg. bursa “religious school”; Ch. fosen, bvyr-sag “Buddhist monk community”. Ultimately a contracted form of the Skt. buddha sangha, the form bursa became an international term for a seminary and seminary student stipends, its spread and history are intimately connected with the Türkic languages. The spread started with the Middle Asian Manichean religious schools of the 4th c. AD, there was established the Türkic Manichean terminology. The word probably predates the advent of the Manichaeism, first appearing still in the Buddhist Türkic community prior to the 4th c., and rolled over to the Manichean terminology with the growth of the Manichaeism's popularity. In the Central Asia, popularizers of the terms were probably the travelling Sogdian and Türkic adherents, and in Europe the waves of the Türkic nomads possibly starting with Sarmats (carrying syncretic Buddhistic Tengriism), then Alans (adherents of the same) and Huns (adherents of the same), then the European Türkic converts to Christianity, before the advent of the Middle Age Kipchak Khanate (Tataria). The unexpected semantic transition to the notion purse went from the original “Buddhist congregation” to “seminary” (Sl, Ukr., Bulg. bursa “seminary”), to “stipend” for the seminary students, to a “seminary treasury” (Eng. bursary, bursar “treasury, treasurer of a college”), and on to the purse as a “money bag” (OFr.). The peculiar IE-centered philology plays a somersault acrobatics, turning etymology on its head: it starts with purse and bourse that date to the 12th and 16th cc. respectively, proceeds to the 17th c. bursary, and drifts to the 16th c. Scottish “stipend”. The Manichean religious schools of the 4th c., the antecedent Skt. Buddhist seminary, and the early turn of the eras Ch. Buddhist monks fall by the wayside. In the geocentric-like linguistic model, the Medieval Latin becomes a parochial center of a new etymological reality. The Burgunds, who likely endowed the OFr. and LLat. with their concept of the purse for religious education's public money, the A.-Saxon's purs, and the 1.5 millennium-long line of the scholarly predecessors are all dumped into a neverland.The duo of the bursary and purse constitutes a live case of paradigmatic transfer,via the Eurasian Türkic nomadic milieu, from the times older than the Roman Republic and the Roman Empire. See purse.
English cairn (n.) “mound of pebbles, stones” ~ Türkic kayır “small pebble”. Cognates: Gaelic carn, Scottish carne “heap of stones”; Kipchak kayır “small pebble”, OT qaya “cliff, rock (stone)” with derivatives, qayır “sand (rocky sand)” similar but different from kum “sand”. The practice of cairns is a manifestation of a belief that everything has a soul, small pebbles deposited at a certain place are symbolic donations to the soul (of the location, forest, gourge, etc.), called Saints and patrons in Catholicism, as a sign of respect and acknowledgement, and a prayer for a safe passage. The patrons are held as both kind and vengeful, able to be helpful or tricky depending on the degree of respect paid by the passer-by. A cairn over a grave serves the same purpose, to mollify the soul of the deceased to be kind to the passer-by. To transit an area devoid of the pebbles, they have to be carried as travel supplies, sometimes for a great distance, a kind of a ticket obtained in advance. Neither the tradition, nor the ritual are dogmatized, details vary from place to place; Christianity syncretized the ritual but moved it into the churches and associated with pictures, while Islam and Manichaeism are largely oblivious to the folk superstitions as long their tenets are observed. Cairns appeared at the very beginning of the Kurgan Culture in the areas near Asian - European divide. The presence of the tradition among Celtic people corroborate their Eastern European departure point timed to the 5th-4th mill. BC and somewhat contemporaneous with the first Kurgan waves into the Central Europe. The Celtic circum-Mediterranean migration path is traceable by markers of R1b Y-DNA haplogroup. The word is obvious “guest” in the European languages, and has no “IE” precedent. The forms qayır (/kayir/) and cairn (/keyrn/) are separated by temporal distance of 11 millennia (“lateral time”, 6 for cairn + 5 for qayır), and geographic spread across Eurasia. Cairn belongs to the transfer paradigm of the mortuary tradition, along with lexemes cairn, coffin, curse, God, grave, hall (e.g. Walhalla), hell, mengir, mound, pyre, tomb, tumulus. See cave, grave, tomb, tumulus.
English cherub “baby angel” ~ Türkic čebär (cheber) (n., adj.) “beauty, beautiful”. Cognates: A.-Sax. cerubin, LLat. cherub, Gk. cheroub, Hebr. kerubh “angel”. Possible link is based on consonance and suitable semantics.
English coffin (n.) “box (for a corpse)” ~ Türkic kovı: (n.) “cave, underground hollow”, with a second notion of kovı: “surrounded”, i.e. a passive form of the notion “box”, whereas “box” is active “surrounding, enclosing” something, and “cave” is contents passive “surrounded, enclosed”. The second notion allows derivatives of the “enclosed” type, like “container”, “bag” and “box”, best expressed semantically by the noun hamper “confining restraint”. The word “coffin” is a derivative of A.-Sax. cofa “cave”, burials in essence are artificial caves, cavities delineated by protective structure (Cf. synonymous A.-Sax. grafan “to dig, dig up”, Goth., OHG graban “to dig”, and A.-Sax. graef “cave, grave”; Cf. tomb, tumulus fr. Tr. “to dig”, grave fr. Tr. gür “ditch, cave”); coffins evolved fr. initial boulder, slab, or plank cage to self-supporting wooden box and stone monolith or slab sarcophagus. In the historical period, in the salient tradition of funeral rites, the deceased Türkic rulers before burial were carried by wagon for last respects around their country in a coffin casket filled with honey as a preservative (called arï yaɣï “bee butter” in the sources); in a country the size of Europe that trip could last for many months; burials were performed twice a year, after the ground thawed and before the ground had frozen; preservation of corpses for long periods was essential for successful funeral ritual, to ensure reincarnation of the dear deceased. The English kurgans attest that the traditional funeral ritual was observed on the English soil, and elements of its terminology must have been carried over to the later customs and periods. In Türkic languages, possessive form of the kovı: is kovı:n, lit. “his cave”, with the A.-Sax. base form cofa the same would be cofin; the form cofin (coffin) attests that the word has formed within the Türkic linguistic milieu, while the aliens took suffix -ı:n for a part of the root. The related recorded Tr. words are kovuk “hollow, empty”, kavuk “bladder”, kovğa: “pail, bucket”, ka:b “cover, sack, leather bag, water-skin, vessel, container”, kowuč “persecution”, kavıd- “protect”, etc. Allophones and derivatives of the Türkic kovı: occupy a substantial place in the Romance and Gmc. “IE” vocabularies in Europe, attesting to a long period of internalization, Cf. concave, cove, coffin, and cave in; the “IE” Asian vocabularies also have cognates. Cognates: OFr. (12th c.) cofin “sarcophagus”, with extension “basket, coffer”, Fr. coffin, Lat. cophinus “basket, hamper”, Gk. kophinos “basket”; under the “IE etymology” the source is rated as “of uncertain origin”. The case of OFr. “sarcophagus” firmly connects cofin with funeral ritual, the reference to “basket” attests to routine wattle construction, much more practical than a plank assembly till the spread of iron tools in Europe toward and beyond the new era; and the reference to “coffer” implies a hidden-away strong box-type container, a precursor of a modern safe; the peculiar Eng. (late 14th c.) semantics of “pie crust” attests that cofin was understood as a “shell”, irrespective of its mode of construction; the implied notion of the original “cave” has endured in the shades of semantic application across languages and time. The Gk. form came fr. the Scythians/Sarmatians they interspersed with in the N.Pontic and Balkans. The sacral terminology connected with funerals tends to retain its thematic connotations, profanation is avoided by using accepted synonyms; that ensures its survival along with its synonyms even in an alien element; it can be thus expected that the notion of “basket” for cofin (Cf. It. cafano, Sp. cuebano) carried its connotation of non-casual character of “ossuary” well into the present. The recorded A.-Sax. terms for “coffin” are all native European, non-nomadic terms: cist “chest, casket” (cistern), licbeorg “coffin, sarcophagus” (body-bearing), ðruh “trough, chest, tomb, coffin”, licðruh “coffin” (body trough), cystian (v.) “to put in a coffin”; the nomadic terminology escaped the literati, like the uncouth Cockney went unrecorded, and the “coffin” belonged to the under-radar lexicon of the Anglo-Saxon pastoralist class till it surfaced under the influence of the Norman lexicon. Although unattested by Romanized contemporaries, cofin belongs to the transfer paradigm of the mortuary tradition, along with lexemes cairn, coffin, curse, God, grave, hall (e.g. Walhalla), hell, mengir, mound, pyre, tomb, tumulus. See cave, cavity, grave, tomb, tumulus.
English curse “invoke evil upon” ~ Türkic qur- (v.): qarɣiš “curse, invoke evil upon”, qarɣa “to curse, to invoke evil upon”, qar-/cur- “choke, gag”. The stem qur with allophones is extremely productive, with wide and diverse semantics. No similar word exists in Gmn., Romance, or Celtic, but A.-Sax. cursian “to curse”, cursung “cursing, damnation, place of torment”, cursumbor “incense”; OFr. curuz “anger”; Sl. chur “hoodoo”; Hu. kar “damage”; Sum. kur, kar “damage”. The pinpointed distribution points to the Scythian-Sarmatian conveyance to the northwestern Europe, Burgundian conveyance to Fr., and Bulgarian conveyance to Sl. and Hu. The “IE etymology” has a standard “of uncertain origin”, but some attempts to ignore Türkic origin are inventive and imaginative. The distribution of cognates repeats the pattern of other words with “of uncertain origin” and “of unknown origin”, and with historical presence of the Sarmats/Saxons/Burgunds/Bulgars in the area where Gmn., Romance, Celtic, or Balto-Slavic languages have formed.
English Eden (Bible) “paradise garden, garden of Eden” ~ Türkic ed “property, riches, thing, article, object”. Now Eden is international word, its origin is ascribed to Heb. edhen “pleasure, delight”, and it may be so, who can tell? But Hebrews were much consistent in using untranslated foreign words in their Genesis story: Tr. Adam, Tr. Eve, Av. pairidaeza “enclosure, park”, from Akkadian pardēsu “enclosed garden”, earliest record 1000-700 BC, earlier than the earliest possible date of Avesta (4th or 6th c. AD), and a loanword within “IE” family ~ Heb. פרדס, pardes (later introduction not used in the Hebrew Bible), so why expect that Eden is different? The Türkic edin means “with riches”, -in is instrumental case noun suffix, and the explanation where the four rivers watering the Eden start is quite consistent with the Türkic naming convention: Four Rivers is as much a calque of Törtsu as Seven Rivers is a calque of Jetisu. See Adam, amen, cherub, Eve, ewe, loaf, torah.
English elf (n.) “mischievous small humanlike fairy” ~ Türkic elvir-/elwir- “unleash, charge, accuse”, a compound of elük “joke, jeer”+ ir “man, person”, fr. elü:- “mock, ridicule”; the path fr. elü:- to elük and elvir- may be parallel and not sequential, the elvir- has elided of -ir, but the intact elvir- has survived in the popular Gmc. and Sp. name Elvira. The other active forms are elves (pl.), which retained the original reflex elv- fr. elü:- and produced the Eng. derivative elf (sing.), elfin (adj.), elfish (adj.) and Tr. eliklä- “to joke, jeer”. Cognates: A.-Sax. elf (Mercian, Kentish), ælf (Northumbrian), ylfe (pl., WSaxon), -elfen (fem.), OSax. alf, ONorse alfr. The alleged Gmc. alp belongs to a completely different species, in Tengriism it is a super-being, conceptually giant, assistant of the Almighty, the angel and archangel of the Jewish, Christian, and Islamic genesis stories, and the eponymic name for the Alps mountains. The alp has nothing to do with albino “white” other than echoic articulation. The “IE etymology” of the “origin unknown” but possibly albino “white” to be used “figuratively” for a “mischievous small humanlike fairy” is bordering on mischievous lunacy, and would not fall under any of the hundreds of the phonological laws employed to disqualify on technicalities any unwelcome candidates. Besides Elvira, old and modern names survived as names Alfred/Ælfræd, Alvin/Ælfwine, Eldridge/Ælfric, etc. The name elf belongs to the host of the widely known religious and lore terms of the Türkic origin, see Adam, alms, amen, Amor, cherub, Eden, Eve, and so on.
English Eve (via Bible) “first man, progenitor” ~ Türkic eve, generic for “engender, birth-giving
woman”, ewči/evči “wife, woman”, ewinlig/evinlig “pregnant”,
Cf. Tuv. ava “mama”; the word is an allophone of the forms aba and baba, with a
slew of other allophonic forms that include the Lat. ava and Norse edda expressing
concrete notions of “ancestor, forerunner, predecessor” and generically a notion of “elder
relative”. The term Eve can't be separated from the primal forms for papa and
father, it is the same word with distinguishing semantical and grammatical shades of female
gender. Now Eve is international word, its origin is ascribed to Heb., but the Heb. popular
etymology does not hold the water: Heb. חַוָּה Hawwah, “living being” from base hawa
“he lived”, is phonetically and semantically far from being our “foremother”. The Türkic Eve is as
generic “foremother” as the Türkic Adam is generic “man”, and it also does not need subtle casuistic
reasoning to come up with incredible etymology. Statistically, the chances that these two generic
words would precisely coincide, both phonetically and semantically, in two unrelated languages is as
close to zilch as it comes, which means that if the Heb. etymology is correct, the Türkic Eve
“foremother”, save for a supernatural miracle, can't even exist. The term “Eve” predates Bible on
the European peninsula, it was deeply instilled in A.-Sax. related to notions “mother, womanhood,
progenitor”. Cognates: A.-Sax. awe “married woman”, aewbryce
“adultery”, lit. “beaking a woman”, aewenbroðor “brother by the same marriage (same woman)”,
aewielm “source, fount, spring, beginning”, aewnian “to marry”, aewumboren
“lawfully born”. These terms obviously predate the first translation of the Bible into the Greek. A
suggestion that A.-Sax. or Lat. had to borrow a Heb. word to denote primal notions of “mother,
foremother” is preposterous. The ewe “female, mama” unites the terms ewe, Eve, and
Adam into a separate complete paradigm that came to English via two separate and independent
paths, one native and innate, the other with the Christianization. See ewe, quim, tit, wife.
91
English faith (n.) “religious beliefs, system of religious beliefs” ~ Türkic vara (n.) “piety, reverence (fear) of God”. Forms and cognates: A.-Sax. faith “duty of fulfilling one's trust”, swerian “take an oath”, OFr. feid, foi “faith, belief, trust, confidence, pledge”, OSw. swerian, ONorse sverja, Dan. sverge, OFris. swera, MDu. swaren, OHG swerien, OGmn. wara “truth, faithfulness, grace”, war “truthful, loyal”, Gmn. schwören, Goth. swaren “to swear”; OIr. var “vow, solemn promise”, fir “true, veracious”, Lat. fides “trust, faith, confidence, reliance, credence, belief”, fidere “to trust”, verus “veracious, true”; Gk. pistis πιστησ “faith”; Sl. vera “faith”; Av. var- “believe”, varǝna- “faith”. Goth. tuzwerjan “to doubt”, unwerjan “discontented”;. M.Vasmer lists these two Gothic words under the entry of Sl. vera “faith”, a Türkic loanword in Sl. lexicon. Goth. tuzwerjan is transparent rendition of the inverted Türkic veransiz: ver + an (noun suffix, rendered yan) + siz (negation suffix, rendered tuz) = “faith (n.) without” = “infidelity” => Goth. tuz + wer + jan; both the inversion and the translation are suspect, but inversion is theoretically possible; however, neither “doubt”, nor “infidelity” are synonymous with “faith”, as the august “IE” maniac M.Vasmer would want us to believe, in fact it means the opposite; the Goth. unwerjan “discontented” is a similar case, the inverted Türkic veranаŋ: ver +an (noun suffix, rendered yan) +аŋ (negation suffix, rendered un) = “faith (n.) none” = “infidelity” => Goth. un + wer + jan (See un-); here also both the inversion and the translation are suspect, with inversion theoretically possible; but “infidelity” translated as “discontented” does not make sense, and the mother of all “IE” etymologists should not have produced the mother of all “IE” etymological blunders. With Türkic vara, there is no need for manufactured “IE” unattested *bheidh- to come up with English, Gmn., and Slavic forms for faith. (See swear). It appears that before the advent of the organized religions, the “(mandated, approved, or enforced) system of religious beliefs” did not exist, vara was strictly personal devotion for the Supreme Being (inclusive of demi-god or angelic auxiliaries), and there was no fact of life corresponding to the notion of faith that required the word “faith”. Upon the advent of the organized religions, the old word vara “piety, reverence”, in all its polysemantic and dialectal expressions, was recycled to reflect the new phenomenon. Assigning origination dates for such words is pointless, all kindred people had it from time immemorial (say, 15 kya), otherwise they would be arbitrarily stigmatized as irreverent without any trace of evidence. See swear
English God (n.) “supernatural being” ~ Türkic kut (ɣut, qud, qut, xut (hut)) (n.) “soul, deity,
divinity, spiritual being, spirit, host”. The word kut
must have evolved long before 5th mill. BC, when appeared first Tengrian kurgans marked by Tengrian
ritual of sending the deceased off to Tengri for reincarnation; the Kurgan migrants to Sumer brought
along the name for Tengri that we know in Sumer phonetics as Dingir and in Sumer cuneiform
writing of the 4th mill. BC. With the appearance of the monotheistic Tengriism, the previous kut
deities retained their functions as syncretic local patrons and protectors, subordinated to or
created by the Creator Tengri. From the available information, we can only guess that it were the
Kurgan waves that brought with them Tengri (later Thor) and kuts to the Central Europe and
Scandinavia. In the Tengrian hierarchy, the kut immortal deities occupied place a grade below
Tengri and a grade above immortal heroes Alps, but their roles overlapped. Among the Türkic people
Tengri retained the name as generic for God, but in Europe, Thor was a personal name of a Supreme
Deity, and could not be used as a genetic term for the newly introduced Christian God, while kut
retained the semantics of a Deity. Cognates: Eng., Du.
God, Dan., Norw., Sw., Gud; Gmn. Gott; Pers. kuda; Hindi Buddha;
Türkic
khudai (reportedly reverse re-borrowed fr. Pers.). The Hindi form Buddha appears to be a
structural transition from a closed syllabic morphology to an open syllabic morphology with
prosthetic initial consonant (B)u- + da: kut > khuda > uda >(B)u-ddha.
The appearance of the term Buddha (ca. 563-483 BC) is connected with the extracts from the
Scythian Saka tribes, Skt. Shakiya, reigning in N. India; the title-name Gautama
consists of the same stem kut “give (blessing, fortune, luck” + Türkic deverbal noun suffix
-ma voiced in an open syllabic morphology Gauta-ma; the notion “enlightened” is a
derivative of the Buddhist teaching. Not only the “IE etymology” is absent, but even any etymology is
missing in the IE-centered compilations. The phonetic and semantic match leave no doubts on the
Türkic origin of the Gmc. term. Notably, the formulaic “My God” ~ “mein Gott” carries the Türkic
suffix -m as prefix in the “IE” syntax, like the other suffixes reincarnated as prefixes in the
flexive morphology, the Türkic -m is my ~ mein in Gmc. languages (Deus meus in
Lat.). The term kut is extremely polysemantic, in addition covering “happiness, blessing,
grace, wealth, luck, success, happy lot, dignity, majesty, true state of being, bliss”, and probably
another lot not found in the dictionaries. See give, good, gut, my.
92
English Gorgon (n.) “evil monster” ~ Türkic qörq- (v.) “fear” (v.). Via Gk. (pl. Gorgones), gorgos “terrible”, so scary that a glance at monster turned a looker to stone. The conventional wisdom is that the scarecrow term “of unknown origin” came via enlightenment from the Gk., and could not have been home grown, which may be too presumptuous, given the exact functional, semantic and phonetic correspondence. In Türkic, the suffix -gün (-ɣïn, -gin; -ɣun, -gün; -qïn, -kin; -qun, -kün) forms a deverbal noun agent, thus Gorgon is just The Terrifying (OTD, pp. 195, 196, 653, 654), pointing to the origin of the Gk. myth without singularly defining the source of the English word. Notably, Skt. also uses suffix -gun to form deverbal agent nouns, Cf. Skt. dhutaguna “holy (person)”, demonstrating that syntactically, the original agglutinative Skt. was not aversive to internalizing Türkic morphological elements.
English grave (n.) “burial place” ~ Türkic gür (n.) “grave”. The Türkic allophonic forms are gör/gür/kör/xöor “grave, ditch, cave”, a fairly compact phonetic variety. Cognates: A.-Sax. græf (Middle Ages to 17c.) “grave, ditch, cave”, Dan. grav, Du. graf, Gmn. Grab, Icl. gröf, Norw., Sw. grav, OSax. graf, OFris. gref, OHG grab “grave, tomb”, ONorse gröf “cave”, Goth. graba “ditch”; Welsh garnedd, carnedd “burial kurgan”; Lith. grob “grave”; OCS grobu, grobnica “grave, casket”. The European distribution restricted to the northern Gmc., Celtic, Balt., and Sl. branches indicates transmission via Sl.-type languages that prefer anlaut consonant strings: gör > gr-. The distribution parallels that of the synonymic term tomb, but with a narrow northern path. The basic notion of the term grave/gür is “ditch, cave”, of the same source with the grave (engrave, scratch); the notion “tomb” is a derivative, and notwithstanding etymologies to the opposite, is unrelated to the adjective grave “make heavy, burden down” with the origin in Türkic aɣrï- (v.) “be sick, make sick”. The terms tomb and grave belong to the most conservative class of the words. Grave belongs to the transfer paradigm of the mortuary tradition, along with lexemes cairn, coffin, curse, God, grave, hall (e.g. Walhalla), hell, mengir, mound, pyre, tomb, tumulus. See aggravate, tomb, tumulus.
English gut (n.) “innards” ~ Türkic kut (qut) (n.) “soul, vital force, spirit”. Cognates: A.-Sax. guttas “bowels, entrails”, ME gote “channel, stream”, MDu. gote, Du. goot, Gmn. Gosse “gutter, drain”. The meaning of “abdomen, belly” in English is from ca 1400. In English, this word pops up from nowhere in the 19th c., with connotations “spirit, courage”. In Türkic, kut is the most valuable gift that a human can have, it is the soul in Christianity, and the soul in Tengriism, with the small difference that in Christianity, the soul is not a personal endowment, it is not connected with a personal act of Almighty, and in Tengriism the Almighty personally endows every human being with a personal kut soul. The Tengrian kut is indestructible, it can leave a body and come back, and upon a death it reverts to Tengri to be given a new body. Thus, no living human should be afraid of death, he or she is about to come back to our precious world in an act of reincarnation. Not for 40 days, as testified disciples during the Roman times, but for a whole new life. Upon departure, the kut enters into the inventory of the Almighty, and He himself gives it another body to live in on this Earth. Enter the Christianity, and the kut becomes innards, the soul becomes “spirit and courage” of the human being, and then his guts. The Türkic kut is polysemantic, its other meanings are “supernatural spirit (a la angel, but autonomous, not subservient); luck, blessing, grace, prosperity, good fortune, success, happy lot; dignity, majesty; praying”, one of the most important derivatives is qutadɣu “happiness, fortune”. The everlasting soul in one etiology becomes intestines in another etiology. No “IE” etymology, no speculative attempts to establish “IE” etymology. Nowadays, the guts have two non-intersecting meanings, it is an immaterial spirit burning in someone who has guts, and it is the intestines and other inedible organic matter in the bellies of mammals and fish. Thus, both Tengrian and Christian concepts peacefully coexist in our confused lexicon. The perfect phonetical and semantic coincidence is transparent with little understanding of religious dynamics.
| Side note on English god (n.) “supernatural being, deity”: The etymology of the English god might as well ascend to the Türkic kut (qut) of the secondary semantics of “supernatural spirit”. The phonetics and semantics are utterly consistent between the two words, but speculation on transition from kut to god would be precisely that, a speculation not supported by known historical sources. Notably, the “IE” speculation is a bad example to follow, it derives god from most bizarre semantic and impossible phonetical analogies: a bunch of unattested “IE” *conjectures, and OCS zovo “call”, Skt. huta- “invoked” = an epithet of Indra (note that huta sounds much like kut, and “invoke” is no different from “pray”, consistent with many other Türkic-Skt. parallels), and Gk. khein “to pour” with the phrase khute gaia “poured earth” referring to a burial kurgan. These amok etymologies make the ancient Gmc. tribesmen complete idiots without their own culture and history. The problem with Türkic kut lays in the name for the Creator, the Almighty God Tengri. The word Tengri, as a generic name for the Creator God, has survived in all Türkic languages under the banners of all religions and their factions: Buddhism, Christianity Catholic, Christianity Orthodox, Christianity Nestorian, Manichaeism, Islam, Lamaism, etc. It was supplanted in a number of instances, but was completely replaced with foreign word in very few instances. The notion of the people with duplex etiology Tengrii + kut to drop the main character of Tengri and replace Him with a substitute kut = “supernatural spirit” does not seem to be feasible. An alternate solution may be that kut is older than Tengri, and people who brought the term to the Western Europe did not have it at the time of their departure. In that scenario, the Scythians and Sarmatians must be excluded, because their funeral ritual, and their balbals, clearly indicate the Tengrian religion with its material appurtenances. Notably, the Herodotus' Papai as the Supreme God of Scythians ca 5th c. BC does not conflict with Tengri as the Scythian Supreme God, mush as the present appellation Heavenly Father (Papai is Father or Pra-Father in Türkic) does not conflict with the notion of Jesus or Jehovah being the personal appellation for the Heavenly Father. But excluding Scythians and Sarmatians leaves only their much older predecessors, the Gimbutas' three waves of Kurganians on the overland route, and circum-Mediterranean Kurganians associated with the Beaker culture, both being very long shots anchored in the realm of speculation. At any rate, the kut (qut) as “supernatural spirit” and god “supernatural being, deity” objectively offer the best phonetic and semantic proximity. The Türkic term Kut occupies a decent place in Turkological philological studies, it was addressed by A. von Gabain, Alttürk. Gram., 360a qut, Glück, Segen, Würde, Majestät, Geist, who expounded on the its semantical use as “spirit”, “soul”, “good luck”, “blessing”, “grace”, “dignity”, it figures prominently in the Assyrological and cuneiform studies. It was numerously encountered in the Assyrian materials related to the period of the Assyrian decline, when the nomadic Guties took over the Assyrian empire (124 years, ca. 2135 – 2050 BC provisional dating in short chronology). In the Assyrian tablets, the common form is Kutium (Gutium) with the Assyrian pl. ending -ium (Cf. Biblical Elohium “Gods” in Hebrew), an Assyrian appellation for the Guties (lit. Guts). The use of the appellation as ethnonym is traceable from the Guties to Goths and tentatively to Oguzes, adding another spark to the etymology of the name Oguz. |
English hall (n.) “expansive room” ~ Türkic qalïq “upper chambers, upper floors, hall, room”, “sky, heaven, air space, air”, a noun derivative fr. the verb qalï- “rise, airborne”. The notion of qalïq, besides the “upper chambers” and “sky, heaven, air space, air”, connotes specifics of “airy space”, “openness to heaven” and “gathering place”, making it an ideal word for religious imagery, epitomized in the Goth. expression Walhalla (Valhalla) “dead-hall” (Hall of dead), an allophone of the Türkic ölqalïq “death-hall” (öl “death”), and its A.-Sax. allophone Waelheall “death-hall”. The ligature wae- is probably an attempt to render -ö- with means of the Roman alphabet. The Buddhist roots of the heavenly concept Waelheall are illustrated in the idiom qalïqlïɣ nirvan, lit. “heavenly nirvana”, the qalïqlïɣ alone already conveys a sacred “heavenly”. Cognates: A.-Sax. heall “spacious roofed residence, house, temple, law-court”, OSax., ONorse höll, OHG halla, ONorse höll, Goth. heall Du. hal, Gmn. halle, “hall”; OE hell, Goth. halja “hell”. The conversion of the Buddhist “heavenly nirvana” to “hell” apparently is due to the inventiveness of the Christianization process; otherwise the etymological linkage of “hell” and “hall” is not quite apparent. The Gmc. semantics is a transparent continuation of the Tengriist and Buddhist religious tenets, the “death-hall” is a kind of a waiting room after death and before reincarnation; its conversion to a Christian purgatory is a much later invention, a concept introduced into Christianity as a reflection of the Gmc. religious model. Albeit the term hall is exclusively Gmc. inheritance, the “IE etymology” appropriates it as an “IE” word like if it was present in the majority of the “IE” languages, ascends hall to a navel-gazed PIE root *kel- with invented meanings “hide, cover, conceal”, and connects it with cell (with s-), testing the limits of credulity. On the way, it replaces the sacral meaning of heall with mundane semantic extensions, abandons its own asserted sacral connection with the notion of hell, and thus dispenses with the entire sacral concept conveyed by the Gmc. word Walhalla. A major documented Gmc. historical and ethnological layer is obfuscated on the altar of the “IE” linguistic theory. In reality, the word hall belongs simultaneously to the terrestrial and heavenly worlds, it is an earthly dwelling and a heavenly abode. English did preserve the semantics of a heavenly abode, for example the Hall of Fame far transcends the dimensions of an earthly dwelling, it is as secular as a purgatory or a death-hall.
English Helen, Hellen, proper name fr. Greek mythology” ~ Türkic ellen- (v.) “rule, govern, reign, subjugate”. Cognates: A.-Sax. ellen “strength, courage, zeal”, ellenlic “brave”, on ellen “boldly”, ellen(craeft) “might, power”, ellen(dead) “heroic deed”, ellen(gaest) “powerful demon”, ellenheard “mighty, brave, bold”, etc.; in Gk. mythology, daughter of Zeus and Leda, and a cause for Trojan War; as Hellene denotes Greeks; nowadays an international name. As an ethnonym, Hellene “brave” parallels the exonym German, Tr. erman “strong”, lit. “manly”; the Hellene also appears as a Tr.-based exonym. The notions of “mighty, brave, bold” and “rule, govern, reign, subjugate” are systematically synonymous, numerous ruling titles are reflexes of the notions “strong, mighty, large, wealthy” and the like. The Eng. word courage “bravery”, a derivative of the Tr. kür/gür (adj.) “courageous, stout-hearted”, replaced the A.-Sax. ellen, Tr. ellen- “rule”. Notably, the A.-Sax. compounds on ellen, ellen(gaest), ellenheard closely reflect the Tr. compounds en- + ellen-, ellen- + göster-, ellen- + chäre. See courage, guest, heart.
English hell (n.) “infernal place for sinners” is a convoluted case, with ingenuity and ideology
supplanting reality. The “IE etymology” conjectures that hell is either an allophone of hall,
or a native Gmc. word akin to hole. In the first, little credible scenario, etymology is
transparent, hell ~ Türkic qalïq “upper chambers, upper floors, hall, room”, “sky,
heaven, air space, air”,
a noun derivative fr. the verb qalï- “rise, airborne”. The notion
of qalïq, besides the “upper chambers” and “sky, heaven, air space, air”, connotes specifics
of “airy space”, “openness to heaven” and “gathering place”, making it an ideal word for religious
imagery, epitomized in the Goth. expression Walhalla (Valhalla)
“dead-hall” (Hall of dead), an allophone of the Türkic ölqalïq “death-hall” (öl
“death” qalïq “hall”), and its A.-Sax. allophone Waelheall “death-hall”. The concept
of Waelheall
is connected with the spread and syncretization of Buddhism, epitomized in the idiom qalïqlïɣ
nirvan, lit. “heavenly nirvana”, the qalïqlïɣ alone already conveys a sacred “heavenly”.
The secular sense of the word qalïq grew into the Eng. word “hall”, the A.-Sax. allophone
heall “hall”. According to the first conjecture, the sacral sense of that word hall
grew into the Eng. word hel, hell “hell”, a novel Christian concept that together with the
concept of sin did not exist in Tengriism. That is plausible, albeit improbable and unprovable. If
it is true, the sacral notion of “hell” is a debased notion of “death-hall”, with added unmerciful
judgment and eager physically sadistic torture for despicable ghostly souls. In support of the first
conjecture is cited its Lat. equivalent Limbus Patrum “Patriarchal Limbo”, a kind of a
business class purgatory lounge. The point of the argument is that both hall and hell
stand for “purgatory”, the first or second class sitting is irrelevant. If it is true, the term
hell is a derivative of hall that is an allophone of qalïq in its sacral function.
A little problem with that assertion is that cultural borrowings come with their own terminology,
and the terminology was abound, accessible, and drilled into innocent minds together with the novel
concept: ad, Hades, Gehenna, etc, that on top of the native euphemisms denoting the sacral
infernal place for sinners: grornhof lit. “sad home”, grund lit. “ground, bottom,
abyss”, manhus
lit. “home of wickedness”, weargtreafu lit. “home of the damned”, wyrmsele “hall of
serpents”. Such oversupply of the native “hell” terminology plus the proselytizing lingo prompts a
doubt on the first “IE” conjecture. An alternative, a calque of the notion grund “ground”, i.e.
Türkic el
with a prosthetic h-, would be consistent with the A.-Sax. huge scale of the hell
derivatives atypical for the cultural borrowings, the semantics of the calque, and with practice of
adoption native terminology for the new needs.
The second “IE” conjecture is more credible than the first, it connects Gmc. forms with A.-Sax. hol
“hole, cave, den”, helan
“conceal, cover, hide”, ONorse hellir “cave, cavern”, and with ONorse mythological female
ruler Hel of the Niflheim, the lowest of all worlds (A.-Sax.
nifol “dark, gloomy”). The ONorse mythology echoes in Gmc. rendering the Gk. mythology of the
underworld. It also brings hell to the Türkic phylum. In Türkic (Tuv.) khoolay (holai)
is “hole (vent opening in yurt)” fr. the verb oy- “peck, make hollow”.
The ONorse hellir is then a passive deverbal derivative of the verb oy- “hollowed,
hole”, modified with the typical Gmc. anlaut consonant h-, synonymous with the noun kaba
“cave, underground hollow”, see cave, hole. The second conjecture is more credible not
because it divorces the “IE” conjectures in favor of the Tr. conjectures, but because it rests on the
attested records of the ONorse mythology, ONorse and A.-Sax. lexical material, is consistent with
the abundance of Gmc. derivatives, and does not rely on post-Christianization Gmc. notions OFris.
helle, OSax. hellia, Du. hel, ONorse hel, Gmn. Hölle, Goth. halja
(halya) “hell”. It does not need to appeal to a questionable notion expressed by unwieldy “PG”
“someone who covers up or hides something”. A hole is a hole, it is sufficient without hiding. See
ad, cave, hall, hole.
English magic (n.) “supernatural feat”, magus (n.) “magician, sorcerer”, might “power” (Sw N/A, F1068, 0.01%) ~ Türkic bögü:/bögö:/bok (n.) “magic, sage, wizard, sorcery, witchcraft, occult”. The form with an anlaut m- comes from systemic m/b alteration: bok ~ mok ~ mag. The Türkic word connotes both wisdom and mysterious spiritual power, that trifurcated semantic was carried on in many borrowings across Eurasia, see might. Cognates: A.-Sax. maeg “might (strength)”, fifmaegen lit. “five magic (powers)”, gaestmaegen “travelling magicians”, gigantmaeg “giant might (aeon)”, helicmaegen lit. “force(s) of hell”, hordmaegen lit. “mighty hoard”, innoðmaegen lit. “inner might”, maegsterdom “masterdom”, etc., Eng. bogus “not real, artificial, fake”; OFr. magique, Lat. magus “magician, learned magician”; Gk. magos (μάγος); Balto-Sl. (Latv) burvis, (Lith.) burtininkas, (Rus.) moguschestvo (могущество); OPers. magush “magician”; Arm. mag (մագ); Az. məcu(si), Tr. büyü(cü); Est. maagi, Fin. maagikko, Hu. buves (buvesz); Mong. bö’e; Jap. mahōtsukai 魔法使い; Kor. masul 마술, masulsaga 마술사가; Ch. moshu shī 魔術師. The word bogus for wizardry and magic lurked in the Eng. folk speech before showing up in the far away America, Cf. bogus, boss, OK. The standing “IE” claim that the word did not exist in the A.-Sax. is obviously false, not only it did exist, but the wealth of the derivatives shows that it was an innate word long before the claimed “late 14th c.” magic, the 12th c. OPers. borrowing magi, and the Bible's magi. It carried the bifurcated semantics of the power and occult noted by G. Clauson (G. Clauson, ETD, 1972, 324). It is doubtful that the old Gmc. languages did not have the word in their vocabularies, Cf. macht “power”, and the slew of derivatives. The Lat. semantics “learned magician” relays the notional aspect of the original “sage, wizard”. The Türkic title boyar for the members of the State Council, of the Bulgarian/Hunnic origin, may also be a derivative of the word bögü with the suffix -ar “man”, boyars were powerful high dignitaries endowed with prophetic powers of the wizards, Cf. the legendary Merlin. Both the m- forms and b- forms are found both on the Eurasian far west and on the far east, attesting to a parallel, likely recursive, numerous, and asynchronous, penetration of kindred groups spanning the width of the Eurasian continent. The traces of the nomadic pastoralists appear in the Mesopotamia in the 4th to 2nd mill. BC, in the Europe at least in the 4th mill. BC, and in the Far East ca. 2000 BC, plenty of time to disseminate cultural influences, including the Indo-Aryan migrants before their long-range anabasises, and the European Corded Ware populace. It was an international word long before the modern times, and in modern times it gained even a wider distribution, then and now across the linguistic families across Eurasia. The awing Eurasian scatter points to mobile carriers spreading the terms, the complimentary m/b allophones point to the source with systemic m/b alteration. The carryover of the bifurcated semantics of the power and occult, and the systemic m/b alternation are components of a paradigmatic transfer case definitively attesting to their origin from the Türkic milieu. See bogus, boss, might, OK.
English mengir (aka menhir) (n.) “upright monumental stone” ~ Türkic meŋgü (mengü) “memorial monument, stela”, from meŋü, beŋü “memorial”; commonly of stone, but mostly of perishable materials. Cognates: Breton menhir , Welsh maen hir, Cornish medn hir. The phonetic and semantic concurrence is perfect. No “IE” etymology; the offered folk-type Breton etymology men “stone” + hir “long” is dubious in light of the Tr. meŋgü. England has numerous balbal alleys lined up with mengirs, exactly like the kurgan burials across Eurasian steppes, hence the Welsh, Cornish, and Breton lexicons; the “Breton” word may be an Alanian word of the Amorican Alans, who moved into Brittany in the 5th c. AD, and kept their Kurgan burial traditions with kurgans and stelas. Alternatively, the Brits of Brittany were Sarmatians, or Scythians, or even Cimmerians engaged in the construction of kurgan cemeteries adorned with meŋgü stelas. The dictionary spelling meŋgü reflects a particular phonetical form (actually, a range of forms: meŋgü, meŋi, meŋkü, meŋü, beŋgü, beŋkü, extracted from different sources), the phonetical articulation of the menhir falls neatly in this dialectal roster. Mengir belongs to the transfer paradigm of the mortuary tradition, along with lexemes alms, cairn, coffin, curse, God, grave, hall (e.g. Walhalla), hell, mound, pyre, tomb, tumulus.
English monastery ~ Türkic religious prayer formula manastar “forgive my sins”. Cognates: LGk. monasterion “monastery”, monazein “live alone” from monos “alone” + suffix -terion “place of something”; LLat. monasterium. The concept of monasticism was brought to the European scene “from the east”, naturally with its own terminology, which is visible in the numerous examples of the Gk. religious terminology of the Türkic origin. Most of that terminology is either left hanging, or assigned impossible explanations (See Yu.N. Drozdov, 2011, On Christianity). The word monastery is a good example, in Türkic it is not a word, but a formulaic phrase that is next to impossible to randomly reproduce with any word in any language, let alone reproduce with specific religious monastic-related meaning using the lexicon from the time of the incipient Christianity. The “IE” etymology is clearly artificial, with suffix -terion “place” magically transforming into the verb zein = “live”. Other religious terms mechanically carried from religion to religion are Adam (Türkic adam = man [generic word]), Eve (Türkic eve = engender, birth-giving woman [generic word]), Hell (not in English, but in Gk., Rus. ad, Türkic ada “calamities and suffering” [generic word]) leave no doubt that the Biblical creation account follows the archaic Türkic religious concepts, the echoes of which have survived to this day. In the centuries before our era, Türkic has already syncretized Buddhism with Tengriism, that is evidenced by the heavy load of Skt. Buddhist religious terms in the Old Türkic Dictionary (1969), which includes 208 of them. Some of these terms, in addition to the authentic Türkic terms, also found their way into the incipient Christianity.
English pyre (n.) “immolating fire” ~ Türkic bur- (v.) “fire, bake, boil”, bu (n.) “steam, vapor, fragrance”. Cognates: A.-Sax. fyr “fire”, waelfyr “funeral pyre, deadly fire” (Tr. öl bur “death-fire”); Lat. pyra “pyre”; Gk. pyr “funeral pyre; sacrificial altar, fire (place)”, for other cognates see fire. Other than p-/f- alteration, the A.-Sax., Eng., Lat., and Gk. forms are identical, and originate from the same source with the Türkic bur- (v.) and bu “steam” (early Akkadian na-piš-u “breathing, inhale, scent” (loanword stem paš/piš, 28-24 cc. BC)). With the advent of Christianity, the ritual of sending the soul of the deceased to the Almighty with a fire smoke (A.-Sax. wudurfec “smoke from a funeral pyre”, wudur “odor, breath”) for reincarnation was suppressed, its terminology waned, and was re-imported back in a new form, from the lands where the old A.-Sax. ritual had survived, under the same name, and was viewed as an exotic tradition. Pyre belongs to the transfer paradigm of the mortuary tradition, along with lexemes alms, cairn, coffin, curse, God, grave, hall (e.g. Walhalla), hell, mengir, mound, tomb, tumulus. See boil, fire, grave, tomb, tumulus.
English sin (n.) “transgression” ~ Türkic sın- “break, trespass”, a reflexive derivative of the verb sı:- “break, destroy”, used both literally and metaphorically. A homophonous sibling verb sıŋ- “sink, absorbed, digested, swallowed by earth” adds extra ominous flavor, a noun sin means “grave”, a noun cin (jin) means “evil spirit”; the terms are generic and not religious, but are used in religious lingo, i.e. sınyuk čaxšaputluğ “break commandment(s)”, siŋdür- “cause to be absorbed, drawn in”, sınsı (adj.) “beguiling but harmful”. Dialectal allophonic forms syn, suin, tsuy, sü (Ar.) “sin” are found in Buddhist and other religious literature. Cognates: A.-Sax. synn “moral wrongdoing, offense against God, misdeed”, OFris. sende, ONorse phrase verð sannr at “found guilty of”, OSw. sundia, MDu. sonde, Gmn. Sünde “sin, transgression, trespass, offense”, possibly cognate to Lat. sons “guilty, criminal”; Ch. tsui 罪. The “IE” “reconstructions” also cite Goth. sonjis, ONorse sannr “true” ~ Türkic čïn (chyn) (n.) “truth”, “true” (adj.), like if “black” could be same as “white”. The “IE” etymologies do not make sense neither for “sin”, Lat. sons < Tr. cin, nor for ONorse sannr < Tr. čïn, essentially suspending them up in the thin air, nor are they capable to explain the origin of the Ch. allophone.
English testament (n.) “will, assertion” ~ Türkic tutsuğ (n.) “will, testament”. Cognates: Lat. testamentum “last will”, testis “witness”; it is a household word for most languages that once were within the sphere of the Roman Catholicism. The Türkic tutsuğ is a derivative of the verb tutuz- “entrust”, a form of the verb tut- “keep, hold, grasp, seize, guarantee”. The tut- is a majority form, a minority has it dut-, and it is a pure incidence that testament is not a destament; the breakdown between the t- forms and d- forms is fairly well established, suggesting what group of tribes introduced the word into the Roman religious lingo. The metathesis of -ts- to -st- ( tutsuğ > testis) and the shift of tu- to te- probably resulted from adaptation of the foreign term to the local language; some dialectal form with rounded ü tütsüğ may imperceptibly merged ü to e [Clauson viii papa.10]. The unequivocally identical semantics and fairly eidetic phonetics unambiguously attest to the genetic connection, possibly from a Buddhist or Manichaean religious vocabulary. Notably, the word testament belongs to the host of late Turkisms in the early Christian argot [Drozdov, 2011], assimilated probably in the first centuries AD. The “IE etymology” came up with perplexingly complicated complex of three words starting with a first root tri- (as in the “third person”) to concoct a phrase “third person standing by” to somehow imitate the uncooperative phonetics. In lieu of the Old Testament, we have Old third person standing by. In the contest of “IE” philological ingenuity, this compound deserves an undisputed prize place.
English tomb (pronounced toom) “burial place” ~ Türkic tumlu “tomb”. Cognates: Du tombe, Dan. tomben; Ir. tuama; OFr. tombe, It. tomba, Sp. tumba, LLat. tumba “tomb”, all Romance are late arrivals; Gk. tymbos “kurgan, cairn”; Azeri türbə, Turk. türbe; Mong. tuun “tomb”. The Türkic tumlu with allophones tublu, tumlu, tuplu is a noun derivative of the verb tobul-/tomul-/tupul-/tübül- “dig, breach, crack, punch”, which allows directional type derivatives: tubluqa (tumluqa) “into the burial” (OTD 586). The verb tobul-/tomul-/tupul-/tübül-, in turn, is a derivative of the verb tom- “throw”, with its allophones. The attested consonantal dispersion b/p, the vowel alteration o/u/ü, and systemic m/b alternation point to the deep time depth and dialectal dispersion. The Gk. semantics is identical with the Türkic semantics, and since the Greeks did not bury their deceased in kurgans, clearly indicates a lexical borrowing. The LLat. borrowing is probably via Burgund pre-Christian lexicon of Savoy and Provence. The “IE” speculation of the tomb being a derivative of “to swell” and linked with “thigh” does not fit neither semantically nor phonetically nor historically, since the “IE” burial tradition does not build kurgans. Notably, the synonymic grave parallels the spread and timing of the tomb, its origin comes from the Türkic kör “grave”. The terms tomb and grave belong to the most conservative class of the words. Tomb belongs to the transfer paradigm of the mortuary tradition, along with lexemes alms, cairn, coffin, curse, God, grave, hall (e.g. Walhalla), hell, mengir, mound, tumulus. See mengir, tumulus, grave.
English torah (n.) “religious law” ~ Türkic tör, töra, törü (n.) “teaching, law”, cognate of the verb törü “created, born, plant (set up), initiate”. Other meanings are “custom, common law, base law, accepted order, rules”. In addition to the native töra, törü, Türkic has borrowed allophones darm, darma, tarma, etc., apparently fr. religions that syncretized with Tengriism. The Hebr. torah reportedly is a verbal noun from Semitic horah “he taught, showed”, a phonetically dubious etymology. Lat. form is Torah fr. Heb. In Türkic, tör is a throne place in a dwelling, the place opposite the door facing east and accordingly the throne is also facing east, a heart of the dwelling is tör. The Tör “law” is a meaning derived from the place where the rules are set. One of the speculations on the origin of the term “Türk” connects it with the notion that the term is an ideological supraethnic term alluding to a society that adheres to the Tör, with plural possessive suffix -k. The term Tör was used in the runiform coin legends on the Central Asian coins half a millennia earlier than the appearance of the term “Türk” in the Chinese and Greek annals. Another meaning of the form törü is “state”, essentially meaning “of the law, of the rule”. The runiform inscriptions for initial t use the grapheme þ later known as interdental voiced th in the Germanic runiform script. Notably, the Germanic term Thör ~ Þör for a Supreme Deity and a lawgiver is phonetically and semantically identical with the Türkic Tör depicted Þör in the inscriptions. Notably, the Sl. form tvorit (творить) “create” carries a prosthetic -v- in the first syllable after t- and before -o; usually it is added in front of the Türkic loanwords beginning with vowel. The Türkic term Tör/Thör/Þör belongs to impressive group of the Türkic words used in the Hebr. Bible and its translations: Adam, alms, amen, cherub, Eden, Eve, God, sin, tomb. These religious terms constitute a paradigmatic transfer via Hebr. and directly to Eng. via A.-Sax. (i.e. God, sin, Þör, tomb), attesting to genetic connections. With time, the original A.-Sax. Tör/Thör/Þör conflated with the Hebr. torah. See Adam, alms, amen, cherub, Eden, Eve, God, sin, tomb.
English tumulus “ancient burial kurgan, burial mound” ~ Türkic tumlu “tomb”. In essence, the Lat. tumulus is an allophone of the English tomb and Tr. tumlu. “IE” cognates are unknown: etymology jumps fr. Lat. tumulus straight to derivative of unattested PIE for “to swell” and straight to “thigh”, thus specifically recognizing a kurgan-type of the tomb; it does not fit neither semantically nor phonetically nor historically, since the “IE” burial tradition does not build kurgans. The “IE etymology” correctly connects tumulus with tomb, which in case of the Türkic Tengrian burial tradition is synonymous with (not necessarily ancient) “burial kurgan”, also called “tumulus”, “mound”, and “barrow”. The notion of the kurgan grave is preserved in the Gk. tymbos “kurgan, cairn” and Mong. tuun “ (kurgan) tomb”. Tumulus belongs to the transfer paradigm of the mortuary tradition, along with lexemes alms, cairn, coffin, curse, God, grave, hall (e.g. Walhalla), hell, mengir, mound, tomb. See tomb, grave.
English ulan “young man, usually with military connotations” and clan “people related by blood or marriage” ~ Türkic oglan, uhlan, ulan, oğla:n (ğ = silent g) “offspring, son, boy”. The root ög- is “mother”, og (ok) is “clan, inheritance” lit. “arrow” and metaphorically “family, tribe, familial branch, stock” with semantical extensions, la:n is an ancient Türkic suffix forming names of living creatures. The ulan is an obvious recent (Middle Age) borrowing from Türkic, but the clan comes from the same word, only from the Early Classical Time, “likely via Etruscan”. The obsolete reference to the Etruscan is based on the 20th c. reading of the Etruscan inscriptions, where oglan means “son”, and before the concept of the Kurgan waves. In the last 3,000 years had developed a slew of forms and meanings for oglan/ulan: “son” and its derivatives “offspring, youth, young man, hero, strongman, warrior, rider, cavalryman, militiaman, descendant, clan of descendants, clan, family, stock”, and possibly hundreds more semantic derivatives in different linguistic families.
English vampire (n.) “ghostly corpse drinking blood of living” ~ Türkic ubyr (n.) “ghostly being,
warlock”, lit. “devourer” fr. the verb ob-/op-/-/öp-/up- “gulp, suck in, devour edaciously”.
Instead of the more dramatic drinking blood, the Türkic version devours living beings, it belongs to
the times with undifferentiated reality, myths, religion, and folklore, when prototypes of the
religious good and bad angels actively participated in both religious mythology and minstrel
legends, Cf. “Kuban. Chulman Tolgau”
that ascends to the Bronze Age. The magic of incapacitating an ubyr vampire with a wooden
stake through his chest at the dark of the night later transformed into silver stakes during
daylight hours. The Türkic equivalent of ubyr from the word ič “drink” is ičgek
“drinker, vampire”,effectively they are synonymous. The root of the second member of
the Türkic idiom aša- ič- (asha- ich-) “eat and drink” has been preserved in the A.-Sax.
ðicgan and ge-ðicgan (with -ch-) “drink” (and “eat”), in a case of paradigmatic
transfer. Neither of the terms ubyr or ičgek has been recorded in the A.-Sax.
vocabulary. However, the Eng. references to narrated blood-sucking ghostly corpses date to 1196.
Cognates: Gmn. Vampir (18th c.), Fr. vampire (18th c.), Hu. vampir, OCS
opiri, Sl. upyr (упырь) “vampire”, objora (обжора) “glutton”, Serb. vampir,
Bulg. vapir, Uig. öbur
“wetnurse” (V. Radloff, “Probing a Dictionary of Turkic vernaculars (Die Sprachen der nördlichen
türkischen Stämme)”, v. 1-4. SPb., 1893-1911, I (1893), 1782 on), Tr. “edacious, glutton” (V.
Radloff, ditto). The prosthetic anlaut v- apparently originated in the Bulgarian/Sarmatian
milieu, it was systemically inherited by the Sl. Turkisms, or was added at Sl. internalization of
Türkic words starting with vowel. No “IE” parallels, the origin of the western forms is ascribed via
Hu.; some perverted attempts (M. Vasmer and others) tried to ascend the preceding Sl. form fr. the
later western form, such speculations are emblematic at a certain stage of the “IE” historiography.
The Hu. origin, with Bulgaro-Slavic phonetics, alludes to the post-Honfoglalás
time of the Hungarians' move to Pannonia (9th c. AD), an unlikely scenario for a word that is a part
of a myth cast millennia before; a likelier scenario would bring some allophonic form of this word
to the British Isles with the A.-Sax. milieu, it would live there with the myth till the later days,
when it would conflate with the allophone of the fashionable literati. The geographical distribution
and lexical traits are peculiar: mythological content and semantics are specific to the western,
Sarmatian area, in stark contrast with the eastern Karluk (Uig) and Oguz (Tr.) area, attesting to
the local western origin. The same is attested by the specifically Sl. reflexes found in Hu. and
further west. The western prong of the path parallels the path of the word Yule and similar
linguistic relicts. As a part of the ancient genesis myth, the vampire mythological image and
lexeme constitute a case of paradigmatic transfer positively attesting to their Türkic origin. See
eat, Yule.
93
English bazaar, an international word that spread throughout Eurasia and beyond, from Türkic baz/boz “to be loud, to scream” that in addition to bazar, generated an extensive family of semantically related words in Türkic and Slavic languages. The English flea market, Gmn. der Lausemarkt, Fr. marché aux puces are calques of the Türkic phrase bit bazary “flea market”.
English bodega, also boutique, “small shop of any sort” ~ Türkic butïq (butiq) “branch, limb, offshoot”. See boutique, bud.
English boutique, also bodega, “small shop of any sort” ~ Türkic butïq (butiq) “branch, limb, offshoot”. Cognates: A.-Sax. buttuc (buttuk) “end, small piece of land”, lit. “appendix (land)”, OHG buode, MHG bude; OFr. botica, Sp. bodega; Sl. (Russ.) budka (будка), (Ukr., Blr., Pol.) buda (буда), “small building”; speculated unrelated cognates OFr. apotecaire, Lat. apotheca, apothecarius, Gk. apotheke “barn, storehouse”. In a small-town entrepreneurial world, boutique was an appendix to the residency, a supplementary business, and the semantics of the word “branch, offshoot” is “appendix”, first used in the literal sense in France, attested as a Burgund Vandal “Wanderer” word botica from the Provence and Savoy. The A.-Sax. “appendix (land)” corroborates the original meaning of “offshoot”. The “IE etymology” ascends to nonsensical apotheca fr. apo- “away” + tithenai “put”. The “IE etymology” reverting to apoteca is unsustainable on phonetical grounds and unsustainable semantically: the obvious coexistence of the boutique and apoteca phenomena in France, and apoteca elsewhere in Europe, and the semantic incongruence since apoteca could at the same time be boutique if it was an appendix to a doctor's or a barber's home, and since apoteca was a specialty store like a tailor or shoemaker store, versus the boutique being a general convenience store, all that makes the “IE” attempt unsuitable. The Spanish version of botica is bodega, a form also adopted in English. See bodega, bud.
English cash “money box” ~ Türkic kečä “box”, a derivative of case “box”. The English semantic transition from cash “money box” to “money, coin, cash” is a late development, now universally borrowed from English as an international word. See case, cashier.
English cashier “money clerk” ~ Türkic kečä “box”, a derivative of case “box”. The English semantic transition from cash “money box” to “money, coin, cash” is a late development, now universally borrowed from English as an international word. The Turkish kasiyer “cashier” is a good example of re-conflation and reincarnation, an innate Türkic compound of two Türkic words kečä “box” and er “man” was re-imported into Turkish with a novel semantics “cashier”. See case, cash
English chapman (n.) “trader, peddler” ~ a compound of Türkic čıp (chip, chyp) (adj.) “slim (branch, twig)” and man “man”, see cheap and man respectively. The prime meaning of the word čıp is “twig, stem” that ultimately has produced metaphorical “abscess” (čïpqan, for resemblance to berries on a twig) and “slim” (quality of twig), the čıp “slim” is the base for Eng. chip (v., n.) “fleck, bit” and adjective cheap “slim (price, bargain)” that blossomed in the west, as attested by a constellation of derivatives in A.-Sax., see cheap. Cognates for cheap are few, and besides Türkic languages, where apparently it is a relict of the western Türkic languages represented by few archaic examples confined to Gmc. group, with a jaunt to Lat. Cognates for -man are widespread among Türkic languages, also with a detectable tendency for the concrete determinant -man “man” to disperse from the western Türkic languages, see man. Chapman follows the model of A.-Sax. ancorman, hierdeman, woruldman, and the Tr. ataman “leader”, lit “father-man”, dušman “enemy”, hetman (getman) “title”, müsülman “Moslem”, etc. Distribution of both component terms is peculiar, čıp/cheap within Türkic and NW European languages, and -man/man the same groups plus eastern “IE” languages (Cf. brahman), in all instances both components are oddities within the family of the “IE” languages, with spotty apearance contrasted with the distribution of the “IE” synonyms. That attests the non-IE origin for both components, and corroborates the Türkic origin for both of them. See cheap, man.
English cheap (adj.) “inexpensive, bargain” ~ Türkic čıp (chip, chyp) (adj.) “slim (branch, twig)”. The prime meaning of the word čıp is “twig, stem” that ultimately has produced metaphorical “abscess” (čïpqan, for resemblance to berries on a twig) and “slim” (quality of twig), the čıp “slim” is the base for Eng. chip (v., n.) “fleck, bit” and adjective cheap “slim (price, bargain)” that blossomed in the west, as attested by a constellation of derivatives in A.-Sax. Eastern Türkic languages retained numerous words for “cheap”, with local predominance: arzen, ıŋğay/ıŋtay/oŋoy/oŋtoy, kolay, oŋday/oŋdöy, ucuz/uci:z; the abandance of terms and forms attests that the notion of “inexpensive, bargain” is relatively late necessity caused by developed trade and competition, the linguistic inventions responding to that need originally were colloquial, and the western “cheap” belongs to that group of innventions. Besides the commercial terms “bargain, purchase, sale, price (deop ceap “high price”, chapman (trader), market, trade or deal (traffic in something)”, A.-Sax. used the stem ceap for a slew of other trade-related subjects: cattle, goods, possessions, property, rich, wealthy, gain, purchase money, purchase slave, bribing, market price, compensation, tollbooth, etc. The wealth of semantic extensions indicates an absence of corresponding local lexicon, an advent of a new social structure, and a new social model based on free trade. The concurrence of phonetic (čıp - cheap), semantic (slim/thin - slight/little), and semantic overtones (cheap - flimsy, cheap - stingy, cheap - tasteless, cheap - slim/thin on morals) leaves little room to doubt the Türkic origin. The “IE” etymological appeal to Lat. caupo (with ch-) “petty tradesman, huckster” leads to nowhere, explaining one unknown with another, a euphemism for “of unknown origin”, clandestinely implying a non-IE origin. Historical background also rules out the early Lat. origin, since the early (2nd c. AD) Goths bordered and intermingled with the Greeks, not Romans, and extensively used Gk., and not Lat., as a source of cultural borrowings. The presence in A.-Sax. of two synonyms, both ascending to Türkic speech, also rule out a Lat. origin: undeor lit. “un-dear” ~ Tr. terim “dear” + -an (negation) expressing “cheap” and ceap (with ch-) expressing the same “cheap”. The Gmc. allophones for “trade” are confined to Gmc. languages, with an oddbll stray borrowing into Lat.: A.-Sax. ceapian (with ch-), OHG. coufon, Goth. kaupon. Notably, Sl. languages used for “trader” a direct borrowing fr. Tr., gost (гость), an allophone of Tr. göster “visitor, stranger”, pointing to a path separate from the Gmc. and Lat. paths. The evolution of the term cheap from bargain trading to barter and eventually to monetary exchange quite obviously developed in the European arena and within the Türkic milieu. That is attested by the nearly excusive propagation of the term čıp in the western arena, contrasted with the presence of only archaic value of “slim (branch, twig)” in the eastern Türkic languages, and by exclusive use of the Türkic nomenclature and values for the monetary exchange (peneg “small coin” - penny, sheleg “unbroken, whole, interchanged” - shilling, manat - money, kı:z cost; Cf. Sl. tanga “bundle of pelts” (used as money) - denga (деньга) “money”, kuna “monetary fine for murder” - kuna (куна) “small silver coin”, pul “fraction, divided” - pul (пул) “small copper coin”). The western and eastern exchanges overlapped, for example, Khazars (7th c.) collected 1 shilling (sheleg) traditional tax from households within borders extending from the Avar Kaganate in the west to the Horezm in the east. They inherited that taxation system from the Bulgars, who inherited it from the Huns. The Eng. cheap, chapman, and gold (al(tun) “gold” - Goth. gulþ “gold”, with prosthetic anlaut g-) belong to the trading paradigm that includes a whole system of commercial and monetary terms, reputably ascending to the Huns, but in reality extending for another half a millennia to the Sarmat times of the 2nd c. BC with paradigmatic transfer of the first, most basic commercial terms. Some of these commercial terms penetrated OFr. and LLat., pointing to the Vandal/Burgund source. See chapman, gold, guest, money, penny, sale, shilling.
English cost (v., n.) “toll, price” ~ Türkic kı:z “rarity; costly, expensive”. Cognates: OFr. cost “cost, expenditure”; the suggested unrelated semantically and flawed phonetically Lat. constare “stand at” is clearly a dubious attempt. The traces of the semantics of “rarity; costly” can be observed in the A.-Sax. word cost applicable to the herb costmary Tanacetum vulgare emphasized to be used sparingly. The origin of the word is clearly non-IE, attested by complete absence of any “IE” cognates, while semantically the word belongs to the group of Turkisms with retail trade-connected semantics and mostly confined to OFr. and adjacent Romance languages. Like other late Turkisms in OFr., the origin of the modern cost is likely connected with the Burgund (Bulgar) nomadic Vandals, later the Provence and Savoy, and whence OFr. and VLat. The auslaut -t may be an archaic Türkic plural indicator, assimilated as a part of the stem. While the modern Eng. cost is limited to the trade-related field, the A.-Sax. word cost has at least four unrelated separate meanings, pointing to a homophonic origin of the word from four separate independent languages; almost all derivatives in the A.-Sax. are from a notion “choice” (ceosan), attesting to its innate endemism.
English gain (v., n.) “obtain something desirable” ~ Türkic gänč (gənch), gänǯ (gənj), genǯ (genj), kenǯ (kenj), kaznak “treasury, riches, booty”, exemplified in modern Turkish with truncated semantic field as ganimet “booty, loot, trophy, prize, plunder”; ultimately from a noun derivative conveying a semantic notion of “procreation, expansion” gen-/ken- of the adverb and noun gen, ken “behind, after” with suffix -č (č), Cf. keŋürüš (kengürüsh) “increase, gain”. The differences in spelling may reflect less the dialectal pronunciation and more the transcriptions with Middle Eastern scripts. The synonymous kaznak ascends to the verbal root kaz- “dig” with rich trail of derivatives, the “acquire” and “cauldron” are main themes; it is clear that it is related to the gänč only by conflation. A third root ka:n- “satisfied, satiated” may, other than being another form of gen-/ken-, have also conflated with the notion of gen-/ken- “produce, generate”. Essentially, gain means “harvest”, it is not a result of production but rather of a collection, that explains the suffix -č (č) in all gänč allophones. Cognates: A.-Sax. cennes “generate, produce, product”, cennan “produce”, gegaeð “gain”, the ME gaignage “profit from agriculture” is a later semantic expansion in the agrarian environment, Goth. geigan “gain”, the form ga-geigan attests the root form geg-; OFr. gaaigne “gain, profit, advantage, booty, prey”, gaaignier “to gain”; Chinese 獲 hou (Pyn.) “received” semantically relate to gain and echo phonetically. The semantics of the word reflects the lifestyle of the Türkic mounted tribes in the pre-industrial age, sufficiently documented by historians and chroniclers from the incipiency of writing, and geographically from the Mediterranean to the Yellow Sea. All allophonic phonetic forms have two forms ge-, ke- in the anlaut, with the second consonant variously -n- or -g-, or both. Both the phonetic form and semantic nuance are well preserved from the earliest documented originals long predating the late European records. The allophonic Chinese form ca. ge, gei > hou may reflect a form of Türkic gänʒ from the Zhou times.
English gold (n.) “heavy yellow chemically inert precious metal” ~ Türkic altun “gold”. The Türkic altun consists of the root al “orange (color, adj.)”, and adv. and adj. suffix -tun. The suffix -tun (-tün) is an inactive relict, found in archaic forms: altun ~ al “orange, lower, take, sift”, otun/udun/utun/ütün “bad, spoiled” ~ öd/öt/üd/üt “hole, fire”, qatun/xatun “mother-queen” ~ ka “family, vessel”, tütün “smoke” ~ tü “color, hue”. The root al “orange” is seen in Gmc. and Sl. forms, and its allophone ar in Skt., Av. and OPers. Cognates: A.-Sax. gyld, gild, OSax., OFris., ONorse gull, OHG gold, Goth gulþ (gulth), A.-Sax. gold, Gmn. Gold, MDu. gout, Isl. gull, Du. goud, Dan. guld; Balto-Sl. (Latv.) zelta, (OCS) zlato, Rus. zoloto; Skt. hiranyam, Av. zaranya, OPers. daraniya. All “IE” forms have an Ogur-type prosthetic anlaut consonant, in standard modifications of g-, j-, h-, d-, z-. The suggested unattested “IE” proto-forms *ghel and *gulth, conceived in the same Ogur-type form, are variations on the motive of the Türkic al, with semantically parallel notion “to shine”, the unattested concoctions contrast with the reality of the real and still active Türkic root. Distribution of the variations on the theme -al- is consistent with the “IE” languages emanating west and east at around or after 2000 BC from the N. Pontic area, they were spreading in three basic flavors, -al-, -or-, and gol-, which in Türkic languages would be interchangeable with gul.
English inch (n., v.) “small length, 2.5 cm” ~ Türkic ınča, yınča, anča “less, small”. Ultimately a denoun derivative fr. the noun in/i:n /en/yi:n “burrow, warren”, a cognate of the Eng. inn “lodge”. The metaphorical form ınča/anča relays a notion of smallness, quietness, only, but, and the like, it is not attested to be connected with a notion of some fraction. As a unit of measurement, the Türkic “small” can be used universally, to length, volume, weight, etc. Unlike the suggested Lat. un “one”, semantically ınča expresses a measurement directly. Numerous allophones and meanings attest to the primeval origin of the word ınča. According to G. Clauson, ınča: was the original archaic form (EDT 172); the word was formed with an equative suffix -ča that endures in the European languages, including the Lat. form. The notion of the word ınča/anča is reflected in its derivatives: yinč- “slight, delicate, thin, slim”, inčkä, jïnčkä “thin, slim, narrow”, yinčge:, yinčür- “slight, thin, slim, delicate”, yinčgä, yinčkä “barely visible, thin, narrow” (Ogur forms), and the like. The concurrent existence of the i- and yi- forms attests to an early dialectal split into Ogur (pervasive, with prosthetic semi-consonant) and Oguz (minority). The form a- (anča) overlaps a wide swath including Kipchak, Khakass in the north and Kashgar in the south: ančağ/ančak “only, only just, but, particularly”, ančakına “very little”, etc. The best illustrations are the expressions that ring an Anglo-Türkic bell: ınča: munča, lit. “less or more” (Eng. idiom “more or less”) and ınča: bunča, lit. “less or bunch”, with many other idioms with similar and extended semantics. The Sp. is not far behind: the favorite expression mucho dinero is an allophone of the munča tanga. The expression ınča (spelled anča) yeme kutluğ kıvlığ meaning “am I not so fortunate” is lit. “less (inch) so God-given” in a word-for-word rendition of the Türkic phrase. The form ınča (vs. the form anča) is best known fr. Uigur records, including the Uigur Christian records. Cognates: A.-Sax. ynce “inch”, yndse “ounce (unit of weight)”; Celtic (OIr.) inis “small island”, (Gaelic) innis ditto, (Welsh) ynys ditto, (Breton) enez ditto; Lat. uncia “ounce”. The A.-Sax. ynce “inch”, recorded in Romanized form with y- and -ce- for -ča (-cha), relays exactly the Türkic ınča with pharyngeal vowel -ı-/-ï-, eventually it shifted closer to the front as is articulated in the modern pronunciation. The English inch is peculiar to English, it is not found in any other Germanic language. The Celtic forms are notably closer to Eng., the Lat. form is more remote. Originated fr. the same phylum, the Lat. and Eng. allophones reached their destinations via different independent paths, as attested by the phonetic peculiarities. All forms stress the semantics of the smallness. The “IE etymology” connects ynce/inch with the peculiar to Lat. uncia “twelfth (part)”, a derivative of un “one”, with etymologically inexplicable semantic jump from “one” to “twelfth”. The Türkic etymology does not need any artificial semantic jumps, it naturally extends the notion of “small” to any object, including the Eng. small length and the Lat. small volume/weight, explaining both the Lat. and Eng. idiosyncrasies. The Türkic etymology is also consistent with other Türkic measurement terms found in Anglo-Türkic monetary triad (the word shilling was first record is in the Gundobad's (474? - 516) Burgundian Code, after Burgunds extended to Savoi in 438) and at times in Lat.: money, pence, shilling, inch. See bunch, money, much, pence, shilling.
English money “currency” ~ Türkic manat, “money”. Manat is one of allophonic forms ultimately derived from mün “monetary wealth, capital”. A.-Sax. had an elaborate monetary lexicon that attests to a tradition of market economy way before the Norman invasion: mynet “coin, money”, mynetcypa “money-changer”, mynetere “minter, coiner”, mynetian “to coin”, mynetisen “coinage”, mynetslege “minting, coinage”, mynetsmiððe “mint”, minte “mint”, etc., all transparent cognates of the mün and manat. The late OFr. monoie “money” belongs to the same lexicon, but apparently originated with the Burgund Vandals via a separate path. The term money belongs to the cluster of the Türkic monetary terms in English that was shared in the Central and Northwestern Europe for one and a half millennia, since the Hunnic times. Due to the late emergence of the monetary coins, the reverse origin (from Europe to Asia) may be suggested, but the absence of the primary source word and cognates in the pre-Hunnic European languages, and the converging attestation of the Türkic-based monetary terminology precludes that. The semantic and phonetic congruence does not leave any doubts on the unity of the origin. The word does not have cognates in either Lat. nor Gk., but Lat. has moneta “mint”, definitely connected with a notion of money, and reportedly coming from the title (not a surname, as asserted by some etymological experts who assign surnames to the Gods) of the Roman goddess Juno, whose prototype the Gk. Hera was a daughter of Saturn and had nothing to do with money. These early mythological stories are perfectly confusing for the experts, and citing them may help the wellbeing of the etymologists, but does not help the “IE” etymology. Besides being generic for “money”, manat is a modern unit of currency in the Azerbaijan and Turkmenistan. The semantic and phonetic match that ascends to the Türkic primary base mün does not leave any chances for random coincidences, especially so considering the Anglo-Türkic triad of money - penny - shilling ~ manat - peneg -sheleg. See means, mint, penny, shilling.
English penny “smallest unit of currency” ~ Türkic peneg, “small coin”. Cognates: A.-Sax. (OE) pening, penig, OSax. pending, OFris. panning, ONorse penningr, OHG pfenning, MDu. pennic, Dan. penge, Sw. pänning, Gmn. Pfennig; the Goth. recorded term is independent skatts, apparently reflecting the skins of the pelts in pelt money. The term penny belongs to the cluster of the Türkic monetary terms in English, Germanic, and now international lexicon. The semantic and phonetic congruence does not leave any doubts of the unity of the origin, the English form penig and the Türkic form peneg are absolutely identical. No “IE” etymology, predictably “of unknown origin”. See means, mint, money, shilling.
English sale (n.) “opposite of buying” ~ Türkic sal- (v.) “move, dispense”. The stem sal- conveys a notion of outward motion in numerous ways, of which “give” and “dispense” is but an one facet, represented by translations “expel”, “draw (something) aside”, “bring (carry, bear) to”, “send”, “spend”, “release”, “move”, “hurl”, and more. A trade idiom “move the goods” lit. and metaphorically reflects the sal-/sale as a notion of outward motion. Ultimately, the verbs sal- ( “move, dispense”, passive) and sat- (“trade, sell”, causative) are derivatives of sa:- “count”. The eastern Türkic languages did not invent, nor they needed to invent, a word expressing a noun “sale”, normally formed by morphological modification of the stem sat- (e.g. satïɣ “trade”), while the western languages did that using the building blocks of the Türkic languages. The eastern Türkic languages continued to use idioms like sat- al- (Cf. alimony), sat- ber- (Cf. to bear), lit “trade take, i.e. “to buy”, “trade bear to, i.e. “to sell” (satıp al- “to buy”, satıp ber- “to sell”). The western Türkic languages, probably in a course of amalgamation with alien languages that required to come up with a stand-alone noun, used the form sal- with a prime meaning “give” and a secondary notion of “give away, sell”, as a noun with emphasis on “trade”. Cognates: A.-Sax. sellan, syllan (inf.), salde, sealde, selest (conj.), asellan, forsellan (deriv.) “give, furnish, supply, sell”, sala “sale”, sealdnes, selen “giving, grant, gift”, Sw. salu, Dan. salg, OHG sala “sale”. All cognates belong to Gmc. branch, are used by a miniscule fraction of the “IE” languages, with no “IE” cognates outside the confined examples, they are obvious non-IE lexemes originated fr. a common source. A.-Sax. examples use “give” and “sale” interchangeably, the “sale” is an extension of “give”, continuing the Türkic course in an instance of paradigmatic transfer. Phonetically, A.-Sax. examples demonstrate a degree of the stem dispersion sal-, seal-, sel-, syl-, sall-, etc., natural for lexemes adopted by different alien vernaculars. The “IE etymology” is funny, it ascribes to the root sal- a meaning “grasp, take”, exactly opposite to the meaning of “sale”, i.e. “give away” presented by the A.-Sax. language. For the cognate word salary, “IE etymology” offers an origin from “salt”, and similar nonsense for other cognates, see salary. The limited spatial distribution allows to conjecture that the Gmc. forms evolved in the 2nd c. BC, when the Sarmat nomadic wave reached the north-central Europe and amalgamated with the local farming populations. That was probably an opportunity to create, outside of the Türkic morphological and grammatical norms, the separate noun sale and the verb sell. An originally single root, functionally distinguished by morphological markers and grammatical use, stratified into two independent words, first documented in the Goth. lexicon. However, our knowledge of the western Türkic languages is so minuscule that it leaves a possibility that the tip of the iceberg at our disposal does not cover the western area at all, leaving a possibility for the Türkic sal- to form the lexemes sell and sale with their precise meanings still in the Türkic Sarmat milieu. The linguistic pair sell and sale rose to great social prominence during the Industrial Era, with the emergence of mass production and mass distribution economies. Although not a direct allophone, sale belongs to the commercial paradigm that includes roots sal- and sat-; that paradigm also includes the word satïš, best known for the Gujarati cast and clan name Satïš “trader” in the far-away India. See salary, satisfy, sell.
English shilling (n.) “one twentieth of a pound” ~ Türkic sheleg (n.) “unbroken, unconvertible, unexchangeable “non-ambulant” coin”. The term shilling belongs to the cluster of the Türkic monetary terms in English, Germanic, and now international lexicon (i.e. shilling in Austria, New Zeeland, Somalia, Tanzania, Uganda, etc.). Cognates: A.-Sax., OSax., OFris., OHG, Dan., Sw. skilling, ONorse skillingr, Du. schelling, Gmn. Schilling, Goth. skilliggs; OCS skulezi, Pol. szelang, Sp. escalin, Fr. schelling, It. scellino; first record is in the Gundobad's (474? - 516) Burgundian Code, after Burgunds extended to Savoi in 438. The Russian Primary Chronicle under the year 885 noted that Radimiches (Slavic group) paid Khazars a tribute of one shilling per household; thus before the advent of the Varangians the eastward distribution of the term reaches the Volga river. The semantic and phonetic congruence does not leave any doubts of the unity of the origin, the form shilling comes from the nomadic Vandalic tribes. The word can't be sanely etymologized from the “IE” languages, predictably it is “of unknown origin”, and neither the Vandals nor the Khazars surely were not renowned Latin rhetoricians. The shilling is a component of the Anglo-Türkic triad of money/penny/shilling ~ manat/peneg/sheleg. The very existence of the triad constitutes a case of a paradigm transfer, and saliently attests to a common source within the Türkic phylum. See means, mint, money, penny.
English tariff (n.) “tax, charge” ~ Türkic tarïɣ (n.) “tax”, initially mostly in kind, later also in money, fr. tarïɣ “grain”. The Türkic taxing system for dependent population and usually for settled traders, farmers, and transit goods developed extensive vocabulary to enumerate different obligations, different dependencies, and different native languages: bert, čatipa, qalan, qatïl, salïɣ, tütün are a sampling documented in the OTD; tütün is a chimney tax (tütü “smoke”), tarïɣ is tax in grains (tarïɣ “grain”), and it is used in paired adjectival idioms to specify what kind of tax, like aš tarïɣ “tax in kind”, lit. “feeding tax”. Supposedly, the path to the English adopted form is It. tariffa, MLat. tarifa “list of prices, book of rates”, via Arabic ta'rif “information, notification, inventory of fees to be paid”. No “IE” cognates, and apparently the ancient Gmc. people used different words for august impositions (A.-Sax. gafol, Gmn. Steuern conflict with Türkic phonetics, and generally speaking, the European taxing terminology is of relatively recent origin).
English tavern “public house - road restaurant, bar, inn, or any combination thereof” ~ Türkic
tavar. The cognates are limitless: OFr. taverne “shed made of boards, booth, stall”, “tavern,
inn”; Lat. tabernaculum “tent”, taberna “hut, cabin, booth”, “hut, shed”; Arabic
dabbar “small cattle”; Russ. tovarnik “shed, barn, stowage”, the Russ. fem. form of
tovarisch is tovarka, with fem. suffix -ka, it points exactly where the
male form came from; Scand. die Waare/de Waare “goods”, which produced A.-Sax. waru
and Eng. ware
“manufactured goods, goods for sale” ~ Sw. vara, Dan. vare, OFris. were, MDu.
were, Du.
waar, MHG, Gmn. ware, all meaning “goods”. The Türkic word apparently filled in a huge
lacuna in the social and economic life of the Eurasia, its derivatives are spread everywhere in the
Eurasia, and now are disseminated across the globe. The dictionary entries just for the Türkic term
include:
1. article of commerce, sales
2. possessions, property, goods, acquisitions
3. supply train (military, with spillover to civilian), base camp
4. herd driven for sale
5. goods of processed leather
6. goods and tabor (train of wagons, “tabor” is a derivative of “tavar”) with goods,
fortified camp, fortified convoy stopover
7. money, as an adjective of the word “tavar”
= goodies for sale
8. related to supply train convoy and to its goods, an adjective
The derivatives pop out in most unexpected circumstances, for example the Biblical Tabernacle comes
from a tent (yurt) used as a sales stand to display and sell goods carried by the convoy train, it
is a cousin of the word “tavern”. The Russ. tovarisch, popularized after the Russian
revolution, is a derivative to denote members of the convoy's cohort. The feeble “IE” etymologies all
pull in different directions, coming up with individual and unrelated phonetical siblings for each
derivative on ad hoc basis, frequently with the help of the unattested inventions, like *traberna,
from trabs “beam, timber”. Try to merge the Lat. “beam, timber” with the Arabic “herd of
small cattle for sale” and the Hanseatic League “base camp, convoy”.
English toll “payment, fee” ~ Türkic tölač “compensation, fee”, from the verbal stem töla-,
töle:- “pay, pay off”. Ultimately töle:- may be a metaphoric form of semantically
connected tüle:- “shed (hair, skin)” and a base for tölük “strength, power”.
Cognates: A.-Sax. (OE) toll, toln, ONorse tollr, OFris.
tolen, OHG zol, Gmn. Zoll; LLat. tolonium “custom house”, Lat. telonium
“tollhouse”; Gk. teloneion “tollhouse”, telones “tax-collector”, telos “tax”.
The original general European sense was “payment exacted by authority”, “charge for right of
passage”, while in Türkic the verb töla- is a generic word for payment for service, for
payment that you owe, for payout. A.-Sax. has an extensive set of derivatives, attesting to
long-established fiscal order: tollere, tolnere
“tax-gatherer”, tollsceamol (tollshemol) “treasury”, tollscir (tollshir)
“taxing district”, tolsetl “place of toll or custom”; Cf. the Austrian city Tuln was a
toll collection point. Apparently, the Gk. merchants learned the term through their wallets, paying
for ferries and safe passage on the way, and that particular semantics gained hold on the Southern
European scene, but is likely irrelevant to the Gmc. domains in the Northern Europe. The Latins used
the Gk. word. The “IE etymology” ultimately derives toll from an unattested PIE *kwel-
“to roll, to move around, wheel”, which does not make much sense either semantically nor
phonetically; the “IE” languages do not have a key underlying cognate of toll in a verbal form
“to pay”, leaving the term an isolated and queer case. The Türkic etymology is transparent and
obvious.
94
English abode (n.) “dwelling” ~ Türkic oba (n.) “dwelling”. Oba is a denoun adjectival derivative of the verb abï- “hide, conceal”, i.e. “shelter”, oba extends its semantics from a “dwelling” to a “country”, “homeland”. Allophonic forms of oba is oma (the Gothic Oium), with m/b alteration, and opa with b/p/v/f alteration. Cognates: A.-Sax. hof “enclosure, court, dwelling, building, house, hall, temple, sanctuary”, Norse opphold, Dan. ophold, Sw. boning, Gmn. Aufenthalt; Lat. habitatio, It. abitazione “home”; Sl. (Blg.) obitel (обител), (Blr.) abitsel (абіцель), Slv. obydlie. Rus. obychno (обычно) “habitually”; Dagur obo, EYu. owo, WMong. obugan “kurgan, grave mound” (metaphorical for “final dwelling”); Manchu muhun (< *obuhun) “burial kurgan of nobility” (metaphorical for “final dwelling”), Jurchen bo “house”. The word is genetically related with the toponym Europe (Evropa ~ ev “home” + opa “home, country” > “homeland”). The A.-Sax. and Lat. allophones have a prosthetic anlaut h-. The eastern terms refer to dwelling in literal and metaphorical contexts. The distribution indicates that all European cognate forms for abode, including It., passed through the Gmc. channel. The eastern terms directly point to the Kurgan eastern waves as a linguistic source, connecting the west with the east. The “IE etymology” is patently faulty, on purely phonetical grounds it rightfully connects abode (n.) with OE verbal noun abide “dwell” in its “remain, wait, delay, remain behind” aspects, since a temporary stopping place along a pastoral route is also an oba, to remain, take rest, and wait. However, it then confuses abide with the unrelated semantics of the noun “wait”, a proposition that irrationally turns “wait” into “dwelling”, and would not feasibly create a slew of “dwelling” cognates across Eurasia and in the Gmc., Sl., and It. languages. See Europe, habitat, world.
English ashlar “connecting slab, brace” ~ Türkic aslïq- “to connect”, ašla- “to brace”. Ultimately fr. as-/aš- “suspend, hang”, via asıl- “join, hung, suspended” that has peculiar semantic extensions “crucified, executed, precipitous; advantage, profit, interest; pend (pendant, suspend), attach, stick; cook (suspend over fire)”. While the Eng. ashlar is a narrow trade term, its unexpected Eng. cognates derived from as-/aš- are ubiquitous: assign, assassin, assassinate, etc. There is also overlap and possible conflation with derivatives of aš- “enlarge, increase, more”. Cognates: this uncommon term is shared by few northern Germanic languages, without any dialectal modifications, tentatively pointing to English as a source language for recent borrowings. In English, the word belongs to the class of words that at a late date (13th c.) popped up from nowhere, and other than Türkic do not have cognates in non-Germanic European languages. No “IE” etymology. The loss of unaccented anlaut vowel is a typical phonetic modification. The English semantics developed from “connecting slab, bracing slab” to “"large, flat stone block” to “tall and lank” (1817, American English). Probably, the spread of the Roman arch construction method replaced the previous stone bracing method and for a time retired the term. Nowadays the term is narrowly used for pre-cast concrete rectangular blocks.
English barn “grain/fodder storage shed” ~ Türkic barın- “to shelter, lodge”, hence “shelter, lodge”, ambar (anbar) “grain/fodder storage shed”, ultimately a derivative fr. the verb bar- “go, leave”, in this context “leave, flee to shelter”. Cognates: A.-Sax. bernhus, berenhus, A.-Sax. bereærn, beretun; Sl. ambar, onbar; Chagatai, Crimean, Kuman, Tat., Turk. ambar; Pers. ambar; all “barn”. The “IE etymology” is convoluted: A.-Sax. bereærn ascending to bere “barley” and aern for “house”: bereærn “barley house” fr. bere “barley” + aern “house” << ONorse rann, Goth. razn “house”, A.-Sax. rest “resting place”, sealtærn “saltworks”; there neither bere, nor aern/rann/razn/rest are classed as “IE” words. The A.-Sax. beretun is no better, -tun is “town, settlement” in Celtic, it is neither “IE” nor a “storage shed”, nor an “animal pen”. The distribution in Türkic and Pers. throws a destructive curveball into already convoluted “IE etymology” using non-IE vocabulary, bernhus is a transparent compound of barın “shelter” + hus (koš/quš/xüžə) “house, hut”, i.e. barınkoš “bernhus”. The attested forms barn and ambar offer a common root, a perfect attested semantic meaning, and immediate phonetical proximity. See house, hut.
English board (n.) “flat length of timber, plank” ~ Türkic batğa:, batɣa (n.) “board”, apparently a deverbal noun/adjective derivative from the verb bat- “descend and disappear” formed with verbal adjectival suffix -ɣa/-ga, alluding to shaving of almost all material in making a thin board from a whole log. Cognates: A.-Sax. bord “board, plank”, “table”, “shield”, “ship”, “side of a ship”, ONorse borð, barð “plank”, Du. bord, boord “board”, Goth. fotu-baurd “foot-board”, OHG bart, Gmn. Bord “board”, Brett “plank”; MLat. bordus, It., Sp. bordo, OFr. bort “beam, board, plank”, “side of a ship”; Gk. pittakion “board”; Syriac petqa “board”; the distribution of the cognates is most peculiar; the Syriac form is eidetic with the Türkic form, complete with the suffix -ɣa/-ga, it probably expanded to Greece together with the utilitarian innovation: it was a generic board particularly used for cutting felt and pelt patterns for hats. With a spread of writing its semantics expanded to “writing tablet”, and in Türkic, eventually to “document”. The exceptional proximity of the Türkic and Syriac forms tends to indicate a path from the Middle East to Greece, a path separate from that of the Gmc. and Romance forms. The Gk. and Syriac forms constitute authentic cases of paradigmatic transfer, making the Gmc. cases appear as a secondary borrowing fr. an intermediary. A non-IE loan-word in the European languages, the “IE etymology” dreamed up a specifically Gmc. unattested phantom roots for “cut” and “border”, failing to acknowledge the Eastern Mediterranean cognates. The derivative notions connected with plank-built boats “ship”, “side of ship”, “tables”, “shields”, “borders”, “boardinghouses”, etc., were already seeded in the example of the A.-Sax. polysemy; the Romance forms are attested much later; at all times the spectrum of the derivative meanings is as wide as the use of the boards, they overlap and are inextricably entangled.
English bucket (n.) “vat, container, bucket” ~ Türkic but “vat, container, bucket”. See vat.
English burg “dwellings within fortified enclosure” ~ Türkic barq “building, estate, structure, dwelling”, hence balïq “fortified enclosure”, also dwellings within a balïq. Cognates are distinctly limited to the northwestern Europe: A.-Sax. burg, burh, OFris. burg, ONorse borg, OHG burg, buruc, Gmn. Burg, Goth. baurgs, all denoting “fortified enclosure” with excursions to “tower”, “fortress”, “castle”, “wall”, “citadel”, and the like. The differences between a tower ~ Tr. tura and burg ~ Tr. barq in English parallel those in Türkic, the first is a self-contained fortified dwelling, the second is a fortification containing dwellings, a girded place, see gird. In the Eurasia, barq/balïq and its allophones, including the western burg, are the most popular toponymic components. In both cases, the semantics varies with location, some types of balïqs and burgs may have other forms, which discriminate them according to the local specifics of the Sprachbund. The change from barq to burg and borough, and their local phonetics and spellings are local western innovations; the phonetical correlation with liquid -r-/-l- is observed for other words. See bark, castle, gird, tower.
English castle ~ Türkic kishlak (kashlyk) “winter quarters, winter village, winter fort/fortifications”. Cognates: Fr. castel, Lat. castrum/castellum “fort/fortified village”, forming -caster and -chester in place names, the “castle” was used to translate Gk. kome “village”.
English cemetery “land used for burials” ~ Türkic semäklä- (v.) “bury, burial rites”. Cognates: Tr. semäklägaü “to bury”, OFr. cimetiere “graveyard”, LLat. coemeterium. OE had licburg “cemetery” of Gmn. origin. The “IE” etymologies bring “dormitory” (Gk. κοιτώνες/koitones), “family, domestic servants” (OCS semija (семья)), “wife” (Lettish sieva), “bed, couch” (*PIE *version), “members of a household”, “measure of land” (A.-Sax. hiwan, higid), “cradle” (Lat. cunae), “propitious, gracious” (Skt. Sivah), all obviously unrelated to the acts of funerals. Given that funerals were one of the most persistent activities in the life of the families for dozens of millenniums, the burial terminology must be most resistant to modifications and cultural influences, including newly introduced religious lingo. In the European literature, the record on cemetery ascends to the early Christian writers, while a Gk. apparently unrelated version referred to “sleep of death”.
English court “area surrounded by walls” ~ Türkic qur- (v.) “arrange, build, line up, gather, stretch”, qur (n.) “sash, belt”. The modern use of “belt” for “encirclement” is a paradigmatic extension of the Türkic qur- “belt”, Cf. beltway, green belt. For cognates, etymology, distribution, and history see gird. See curtain, garden, gird, guard, and yard.
English curtain “barrier” ~ Türkic qur- (v.) “arrange, build, line up, gather, stretch”, qur (n.) “sash, belt”. For cognates, etymology, distribution, and history see gird. See court, garden, gird, guard, and yard.
dash 2
EDT 556, 557 1 taš (? d-) outside, exterior, courtyard, foreign country 1. A. внешняя /наружняя
сторона, часть > dash-->
OTD 539 TAŠ II 1. внешний вид, облик; наружная, внешняя сторона-->
EDTL v.3 164 даш (n.) 'внешняя сторона (часть)’ >> appearance, elegance-->
dash 2 (n., adj., adv.) “appearance, elegance”~ Türkic daš (dash), taš (tash) “outer, outside, appearance, far”.
...
English eave (n.) “roof overhang” ~ Türkic ev “dwelling place: house, roof, residence, shelter, etc., incl. motherland (fatherland in Gmc. languages)”. The root ev and its allophones ob/op/üw/iv etc. are most productive, they lay at the base of a range of semantic extensions and derivatives in a spectrum of languages, incl. oba/habitat/obitel (обитель)/abbey; during the Late Antique and Middle Ages, numerous European polities carried the part oba for “country, homeland”: Taksoba, Dulo-oba, Asupa (As-oba), Altyn Oba, etc., it is still a most popular toponymic component in Azerbaijan. The word eave is a semantic extension of the notion “roof”. Cognates: A.-Sax. efes “edge of a roof”, metaph. “edge (forest)”, OFris. ose, OHG obasa “porch, hall, roof”, ONorse ups, Gothic ubizwa “porch”, Gmn. Obsen “eave”, oben, über “above”. The “IE etymology” is artificial and feeble, confusing cause and effect and coming up with unattested “*proto-word” for one of the effects as a suggested cause; on the positive side, it intimates that the word ev for a “shelter” may be a derivative of a notion “above”. Demonstratively, there is no “IE” “*proto-word”, each European language developed its own expression for the “roof overhang” and its far from being universal extension “porch”. Expressly, the ev “roof” with its allophones is limited to the Gmc. NW and the Türkic Eurasian steppe belt.
English Europe (n.) “large peninsula of Eurasia” ~ Türkic ev “home” + opa “country” > “homeland”. Oba is a denoun adjectival derivative of the verb abï- “hide, conceal”, i.e. “shelter”, oba extends its semantics from a “dwelling” to a “country”, “homeland”. Allophonic forms of oba is oma (the Gothic Oium), with m/b alteration, and opa with b/p/v/f alteration. Cognates: too many to list, see samples at abode, habitat, world; Lat. Europa, Gk. Evropi (Ευρώπη). The “IE etymology” is “of uncertain origin”, but numerous incredible speculations abound, suggesting Gk. “broad face” + “face”, a Semitic Phoenician name of princess Europa in Gk. mythology that leaves etymology unexplained, Phoenician ereb “evening” and hence “west”, Semitic Akkadian erebu “to go down, set"” (sun) and hence “west”, and probably quite a few more. The name has a long history, and definitely passed early Gk. milieu: it was first recorded in the Homeric hymn to Apollo (522 BC or earlier) as a geographic name. In comparison with all other suggestions, the Türkic etymology offers a closest phonetic and sound semantic match. See abode, eave, habitat, world.
English habitat (n.) “abode” ~ Türkic oba (n.) “habitat”. Oba is a denoun adjectival derivative of the verb abï- “hide, conceal”, i.e. “shelter”, oba extends its semantics from a “dwelling” to a “country”, “homeland”, or tribes or clans of the abode (principality), figuratively also “tomb”, “kurgan” for the final dwelling of a deceased. Allophonic forms of oba are oma/ömə (the Goth. Oium), with m/b alteration, opa with b/p/v/f alteration, and uba/uva with o/u (ö/ü) alteration. These forms abound during Late Antique and Middle Ages: Aepa (Ay-opa), Altyn Oba, Asupa (As-upa), Duloba (Dulo-oba), Europe (Evropa ~ ev “home” + opa “country” > “homeland”), Hinuba (Hun-oba), Kara Oba, Kemi Oba, Kul Oba, Lietuva (Liet-uva ~ Lithuania), Obaly, Taksoba, Tonuzoba, Ufa. To the same host belong the first compound appellation for Suei, the present Swedes: Soebies (Σωηβοι, Σουηβοι) ~ Su-ebi, Suebi (Su-ebi), Suevi, Suovi (Su-evi, Su-ovi); the presence of the determinant oba is attested by alternate forms with suffixes -an (abstract derivative) and -ty/dy (adverbial/adjectival suffix): Sueones (Swedes) and Suedi (Swedesh); in all these appellations the part Su/Sue/Sw stands for “water”. The “IE etymology” on purely phonetical grounds connects habitat “abode” with semantically unsuitable Lat. habere “have, hold, possess” derived from unrelated root, that also conflicts with the Sl. cognate obitel (обитель) “abode”, and the Mong. cognate obo “abode”. See abode, Europe, world.
English home (n.) “domicile, residence, abode” (Sw N/A, F179, 0.09%) ~ Türkic qoš/quš/xüžə (n.) “house”, see house. The Eng. house is a structure, the home is a place. The word home is an allophone of the word house, derived from the allophone qom of the basic Türkic base qo/qon “coach, migrate”, see come. The Türkic attested form qom is allophonic with the Türkic quš and qöč “(mobile) home”, the initial syllable qo “reach a destination point, stop” links together the ken of polysemantic multilingual derivatives. Semantic stratification apparently occurred still in the Türkic milieu, since Gmc. languages nearly uniformly retained a formed phonetic and semantic notion “home”; otherwise, the Gmc. origin would shrink to a very compact spread, an unsustainable proposition. The Türkic attested form qom “place to stop”, “reach a destination point, stop” metaphorically is synonymous with the notion “home”, Cf. idioms “home on”, “home in” i.e. “direct on a target”.It also carries a related notion of “hideout”, “hide” (treasury, conceal, bury). Cognates: A.-Sax. ham “home”, husa “member of a household”, hamlet (14th c.) “small village”, OFris. hem “home, village”, ONorse heima “home”, heimr “residence, world”, Goth. haims “village”, Dan hjem, MDu heem, Gmn. heim “home”, Icl. heima, Yid. היים (heym); Kurd. xane, Taj. xона (xona) (both are allophones of qon “stopover, camp”); Basque hasiera “home” (allophone of house/quš). The conception home and its Gmc. cognates does not correspond to any single word in most of the “IE” languages. For “house”, the “IE etymology” suggests the usual “of unknown origin”, but the allophonic word home, however, was inexplicably awarded with a PIE pedigree fr. some invention *(t)koimo-, which happened to be eidetic to the Türkic attested form qom allophonic with the Türkic house/quš. The form with final -m- (ham “home”) parallels the form come derived from the same polysemantic root qon-/qom- “stopover”. The cousins home/qom are one member of a remarkable case of a paradigmatic transfer, where the single polysemantic syllable qo- “come to a destination”, “leave (something), put, put down, abandon, give up”, “all, together” had developed three momentous streams of derivatives, each with its own rainbow of forms and meanings. Besides heavily seeding Gmc. family, they seeded the Slavic, Romance, Fennic, Ugric, Iranian, and Mongolian families, reaching to the isolate Basque language. Their distribution allows to time their spread in time, and suggests the temporal seniority of the Celtic languages. The commonalities between Gmc., Romance, Mongolic, Fennic, and Sl. groups excludes a any hypothesized “IE” etymology. The universal spread of the traced steppe lexicon may be timed by the Corded Ware period of the 3rd mill. BC and the subsequent return of the C. European refugees back to the C. Europe ca. 1500 BC. See come, coach, house.
English house (n.) “home”, hut (n.) “small crude dwelling” (Sw N/A, F253, 0.06%) ~ Türkic qoš/quš/xüžə “house ~ hut”. The nomadic notion “house, home, hut” reflects the mobile economy and mobile lifestyle, it is intrinsically connected with the notion “coach” (v., n.) “drive, ride a coach”, “carriage” expressed by the Türkic köch “ride a coach”, “coach, carriage, wagon, mobile home”. Coaches were mobile homes, yurts were transportable stationary homes. In today's lingo it is a coach and RV. Ultimately, the form qöč is a trade word derived fr. the base qo/qon “coach, migrate”, see come. Cognates: A.-Sax. ham “home”, husa “member of a household”, A.-Sax., ONorse, OFris. hus, Goth. hus (gudhus, lit. “god-house”), Du. huis, Gmn. hof, Haus, Icl. haz, Yiddish hwyz (הויז); Romance kasa/casa; Sl. kosh, khata (кош, хата): (Bulg.) къща (kushta), (Bosn., Croat., Serb.) kuca, kућа (kucha), (Macedonian) kуkа, (Sloven.) hiša (hisha), (Ru., Eastern European) khata (хата) “home”, koshevoi (кошевой) “boss, head of the mobile nomadic clan on a pasturing route”, OCS kochevati (кочевати) “rove, migrate”; Kuchean (“Tokh. B”, Tarim) koškiye “hut”, kwaspo “village”; Hu. haz; Mong. qos, qosilig, Kalmyk xoš (hosh, khosh). Türkic has verbal derivatives semantically related to the notion of shelter, movement, and rest, qöši-, qöšit- “conceal, hide, shade”, kösül- “stretch (legs, etc.)”, and those have synonymous -l- counterparts qöli-, qölit- “conceal, hide, shade”, kölül- “stretch (legs, etc.)”. That explains the basis for the suggested “PAlt. proto-word” *kul'o “enclosure”, q.v. The Gmc., Sl., Romance, Kuchean, and Hu., Mong. forms clearly ascend to the common origin, within the “IE” paradigm the equivalency of the Gmc. (hus) and Romance ((casa) forms is well established. The “IE etymology” suggests the usual “of unknown origin”, probably because “IE” languages have so many different roots, like the Lat. domum “house”; the hypothesized origin from hide unwittingly ascends to another Türkic stem qoy/quy “inside, bosom”, a deverbal derivative of the stem qon-/qom- “place to stop”, see come. A.Dybo (Dybo A.V., 2007, 808): English “house ~ hut”, with all corresponding ancient and modern Gmc. cognates, Romance “kasa/casa” with all corresponding ancient and modern cognates, Sl. “kosh, khata” and other cognates, Mong. “qos”, Kalmuk “xoš (hosh)”. According to A.Dybo, the word possibly ascends to a “Proto-Altaic” *kul'o “enclosure”, but that hypothesis is superfluous with the attested basic stem qo/qon “coach, migrate, stopover, place to stay”, of which the unattested “*kul'o” would have been an allophonic derivative. The form with final consonant -t- (hut, khata) parallels the form qöts of the Baraba, Chulym, Tobol, and Kuman languages, qötü “roof, shelter”; the form with final -m- (ham “home”) parallels the form come derived from the same root qon-/qom-, see home. The ubiquitous Eurasian distribution of cognates points to a Eurasia-wide spread, and the commonality between Gmc., Romance, Mongolic, Fennic, and Sl. groups excludes a tepidly hypothesized “IE” etymology. Notably, in contrast with other European languages, the Celtic languages, that left N. Pontic on a circum-Mediterranean anabasis in the 6th-5th mill BC, did not carry to the W. Europe any phonetically house-related terms of the pastoral migrations and camps. That stratifies temporally the Celtic Kurgan migration from the earliest Kurgan Wave migration of the nomadic pastoralists to the C. Europe dated at 4400-4300 BC. The universal spread of the subject steppe lexicon may be timed by the Corded Ware period of the 3rd mill. BC and the subsequent return of the C. European refugees back to the C. Europe ca. 1500 BC. See come, coach, hide.
English inn (n.) “lodge, public lodging” ~ Türkic i:n (n.) “lair, den, hole, cave, nest, hiding place, burrow”. Cognates: none discovered, no credible “IE” etymology. Ultimately, the European in and en, in- and en- and em-, are allophones of the Türkic in/en (n.) “bottom, descent” that gained usage as grammatical prepositions with a directional notion “inside” (Romance, Gmc., but not Balto-Sl.) and “encompassing” (Romance, Gmc., but not Balto-Sl.) respectively. The phonetic homophony and semantic match between inn and i:n are impeccable.
English key “lock opener” ~ Türkic kilit “key”, dialectal kirit, a derivative of stem kelbir- “enter, pass through, get in”, kilit (with -i-) causative form of the base verbal stem kel-, kei- “to come” lit. “let in” (Cf. Sl. kalitka with -a-), kiritla- is “to lock”. There is also a ring of the verb kil- “do, make, act”, something like a causative “operator (device)”. All these words are conveying notions of “entry, entrance”; a synonym of “key” is a deverbal noun derivative ačqïč “key” lit. “opener” fr. the stem ač- “open, open up”. Cognates: A.-Sax. cæg, OFris. kei “key”, supposedly “of unknown origin, with no certain cognates”; Lat. clavis, Gk. klηis/klαιs (κληΐς/κλᾱίς); Sl. klüch (ключ) “key”, kalitka (калитка) “small gate”; Arab. iqlid; in contrast to the Gk. and Arab. forms, the Türkic synonyms are transparently etymologized with the Türkic base verbs. The Sl. form klüch has a bifurcated semantics, “key” and “natural spring”, the Türkic stem kir- also has a bifurcated meaning of “break through”, a figurative name for a natural spring, attesting that the Sl. cognate of the Gk., Lat., and Arab. forms is a paradigmatic transfer of bifurcated semantics from the Türkic linguistic family; the forms for key in Sl., Lat., Arab., and Gk. point to the same source with dialectal form kilit/kirit, likely derived from a precursor of the form kir- recorded late in the 10th c. Besides near perfect phonetic proximity and perfect semantic concordance, the Fris. word may suggest either Cimmerian or Sarmatian origin, allowing for another peek at their languages. Notably, for centuries in the 11th-14th cc. the Bulgarian smiths from the Sarmatian lands west of Urals were mass-producers of warding locks for the North-Eastern European market, demonstrating traditional design and metalworking craftsmanship.
English port (n.) “harbor” ~ Türkic bar- (v.) “part, disappear, go, walk, die (metaph.), begin”. The form port is a deverbal noun from the verb bar- “part, depart”, grammatically “parting”, formed with the suffix -t, like the words gift, unit, Celt, etc. A semantic relict of the verb is the Eng. par “ongoing (price, standard, etc.”, an idiom expressing an average or the usual status (amount, number, etc.), a relict “of unknown origin”; the semantics of the “going, ongoing” is a reflex of the verb's sememe “go”. Ditto parcel, which came directly from the form of the verb bar- without substantiation with the suffix -t. A.-Sax. expanded semantics of port to mean “city”, Cf. “town with a harbor”, “entrance”, portgeat “city gate”, portweall “city wall”. Another extension is the “fracture, make into parts” portian “to bray (in a mortar)”; these extensions can't be attributed to Lat. loanwords. With usual phonetic variations, the verb formed derivative nouns part “separate, depart”, portion “parcel”, port “exit, entryway”, portal ditto, particle “part of a whole”, departed “deceased”, and so on. Another set of cognates is comprised of the terms connected with travel, i.e. far, fare, forward, faraway, far-off, etc., these siblings of the root bar- refer to the distance and travel means related to some type of outward motion. This cluster was conflated, in practice and etymologically, with the cognates of the verb ber- “bear” that describe status: fare, welfare, warfare, confer, etc. Etymologically the two fare words are no more than homonyms, one referring to status (bar- “depart”), the other to delivery (ber- “to bear, give”), see bear, fare. Cognates: A.-Sax. faran “to journey”, fara “travelling companion, comrade”, faru “journey, expedition, companions, baggage”, OSax., OHG, Goth. faran “travel” , OFris., ONorse fara ditto, Du. varen ditto, Gmn. fahren ditto; Lat. porta “gate, door”; Av. peretush “passage, ford, bridge”. The b/p/f alteration is regular, it is typical for the East European or West Eurasian palatalized pronunciation independent of the linguistic family association; the alternation of the vowels is stochastic and also regular. The form part, depart, departed is a calque of the Türkic formulaic epitaph “(I, he) departed (from family, friends, etc.)” barım, bardı: written in the Sogdian and Türkic runiform scripts; it is an instant of a huge paradigmatic transfer complex. Both Türkic verbs, the bar- and ber-, relay some type of motion, their initial distinctions did not survive internalization by numerous diverse vernaculars, leading to phonetic and semantic crossovers, Cf. Skt. para- “carry” fr. ber- “carry” vs. Av. pere- and Lat. porta fr. bar- “go”. The variety of forms and articulations attest to the long temporal paths, likely originated in the Corded Ware culture (R1a) of the 3rd mill. BC; that is corroborated genetically and closely linked with the Pit Grave stage of the Kurgan culture. The westward dissemination was split by the Globular Amphora culture (R1b), creating conditions for observed fossilized p-/f- split; the eastward dissemination brought the palatalized p- forms into the South-Central Asia. The paradigmatic transfer of phonetic and semantic patterns makes obvious the genetic connections between all these, prima fascia confusing, lines of the siblings. See bear, depart, fare.
English soap (n.) “washing cleanser” ~ Türkic soqun-, suqun- (v.) “wash, rub in”; sabïn, sabun, sovun, supanü (Chuv.) (n.) “soap”. The verb soqun- “wash, rub in” is a deverbal derivative from the verb suk- “insert, enter”. The link attests to the initial meaning “rub in”, the meaning “wash” is one of its semantic extensions. Cognates: A.-Sax. sape “soap, ointment”, WFris. sjippe, OHGmn. seiffa, MLG sepe, Gmn. seife, Icl. sapu, Du. zeep, that ends the listing of the Gmc. cognates; LLat. sapo “coloring ointment”, an obvious loanword; Romance: It. sapone, Fr. savon, Sp. jabon, Rum. sapun; Celtic: Gaul soap, Scottish siabann, Welsh sebon; Balto-Sl.: Latv. ziepes, different fr. Lith. word, Lith. and Sl. use the same non-IE word; Gk. sapoúni (σαπούνι); that ends the extent of “IE” W. European sampling; Basque xaboi; Fennic: Fin. saippua, Hu. szappan (sapan), Mari shabon; Eastern Europe and Asia: Chuv. supanü, 40+ other Türkic cognates, Taj. sobun, Gujarati sabu, more Asian “IE” traces, Mong. savan, Ch. 皂 zao, 肥皂 feizao (zaofei), Jap. 石けん, せっけん sekken. Cognates demonstrate malleability of the vowel and second consonant in transition between languages and language families, further obscured by incompatible spelling conventions. The o-/u- ambiguity, inherent to the Türkic family, was propagated by the further spread of the word. The distribution obviously rules out an “IE” origin: Chuvash, for example, is a geographical isolate not bordering on any non-Türkic or “IE” language that uses the root sup-, ditto the Mong., Mari, Ch. and Jap. words. The appearance of the LLat. word sapo also attests to its guest status within the “IE” family. Hu. is a recent migrant to the C. Europe. The Jap. form, completely identical to the Türkic form, and incompatible with the native Kor. form, attests that the word was brought to the Far Eastern China and Japan by the Türkic-speaking migrants, probably the Zhou Scythians. It could have reached Japan in its pristine form under a Chinese influence, Cf. Ch. and Jap. spelling using the same character. The distribution of the word is highly peculiar, it clearly is either a legacy of the ancestor language or a cultural borrowing across the linguistic families. The word belongs to the small and exclusive group of the very few ancient international cultural words with a span across the entire Eurasia, on a backdrop of its very few authentically native Eurasian synonyms. That warrants that the unattested PIE and PG “reconstructions” *soi-bon-, *saipon are patently bogus vis-à-vis the attested lexemes and etymology. Under the “IE” guise the “reconstructions” unwittingly imitate the attested western Türkic form of the Chuv. word without leading to and rather obfuscating etymology. The non-phonetic base of the “IE” and PG “reconstructions” is, however, valid: the practical use as a dyeing ointment, medicinal ointment, and a soap is attested by historical testimonies and by the linguistic etymology ultimately ascending to the base root and the notion “rub in”.
English stair (n.) “stepped ramp” ~ Türkic satu/šatu (shatu) (n.) “stair”. Cognates: A.-Sax. stæger “flight of steps”, “single step”, stigan “climb”, ON, OFris. stiga, MDu. stighen, OHG stigan, Gmn. steigen, Goth. steigan “climb”; Skt. stighnoti “mounts, rises, steps”. The need for stairs in Türkic stationary dwellings is testified by the Türkic-OSl. word terem present in all OSl. annals, it stands for a multi-story palace with its legendary balcony, terem was later supplanted by synonymic dvorets “palace”, but still in the 17th c. the Russian Czars lived in the terem. In addition to the terems, stairs must have had other utility uses in Türkic life. The form satu comes from the Middle Asia, precisely what Türkic form morphed into English stair is in question, but the presence of the same word from Albion to Hindustan with the Türkic in-between allows to expect something closer to the Frisian form; Skt. had to carry it from the Eastern Europe of the 15th c. BC. The “IE etymology” quite amusingly piles up on top of “of unknown origin” everything from unattested *conjectures to delirious cognates “place”, “suddenly”, and “walk”.
English tower (n.) “tall and narrow structure” ~ Türkic tura “fortified dwelling, fortress”; turag “asylum, refuge, den”, from verbal stem tur- “live, dwell”. The tur/tura has a number of other generic meanings: place, dwelling, house, cattle pen, stopover, village, settlement, and is best known from the toponym Turan in Avesta, formed with abstract noun suffix -an to derive nouns from concrete nouns, lit. “dwelling place”. English has retained that abstract suffix for denoun and deverbal adjectives, Cf. terranean, diluvian. A consonant form tu: uryny “birthplace” is semantically identical and also sounds like Turan. Obviously, every place where Türkic-speaking people lived was called in native languages a “dwelling place”, and could not be used as a distinct toponym. Consequently, the toponym Turan started as an exonym. Naturally, the people of Turan were called Turks, likely another exonym, Cf. exonyms Dagestani and Tatar to designate “locals, aliens”, a majority of whom were Türkic-speaking, or the Indians for Amerindians. The Avestan record was not the earliest documentation of the stem tur-, it was first recorded in the Assyrian inscriptions of the 23rd-20th cc. BC for the Turuk nomads, but it attests to the influence of the Türkic lexis on the Iranian languages in the pre-Avestan time. Cognates and speculations: Gmn. Turm “tower”; OSl. terem, Russ. türma (тюрьма) “prison”; also Lat., Fr., Sp. forms, Lat. turre, OFr. tor, 11th c.; Sp., It. torre “tower” “possibly from a pre-IE Mediterranean language”; that unwittingly imply that the Türkic and the English (Gmc.) substrate was the pre-IE Mediterranean language, i.e. that the English's substrate predates the Gk. in Europe. Among Türkic derivatives is türma “jail, dungeon”, from tür- “emplace” > Russ. türma (тюрьма) “prison”, a late cultural borrowing from the Tatar languages. Another Türkic meanings for türma is “grave mausoleum, grave”.
English vat (n.) “vat, container” ~ Türkic but “vat, container, bucket” (OTD 129). Cognates: A.-Sax. fæt “vat, container”, OSw., ONorse fat, OFris. fet, MDu., Du. vat, OHG faz, Gmn. faß, Sl. badiya, all “vat, container”. Here v/b, a/u are clearly allophones, as much fluid in Türkic languages as they are in other languages; the semantics is unmistakably perfect; like many other Türkic words, vat was lurking in the English language until recorded in the 12th c. No “IE” cognates or etymology for vat whatsoever. Clearly cognate of English bucket (n.), from Anglo-Fr. buquet “bucket, pail”, and diminutive A.-Sax. buc “pitcher, bulging vessel”; among the nomads, buckets traditionally were of leather and in forested areas also of wood. Unlike vat, bucket is claimed to descend from a unattested PIE *bhou- “to grow, swell”, an apparent nonsense. Like the vat, bucket was lurking in the English language until recorded in the 13th c.
English world (n.) “earth in its entirety” ~ Türkic аbïl (n.) “village, settlement”. Abïl is a denoun adjectival derivative of the verb abï- “hide, conceal” with innumerable derivatives, of which habitat, (Sl.) obitel, and (Mong.) obo are but a few examples. Abïl has produced allophonic derivatives like “village” and “world”. Cognates: A.-Sax. woruld, worold, OSax. werold, OFris. warld, ONorse verold, OHG weralt, Du. wereld, Gmn. Welt; Sp. Avila (settlement's toponym). The transition from the semantics “village, settlement” to aweld “land, possession, settled area” is documented in the form (Svi)aweld(i) “land, possession, settled area of Swedes” and numerous similar compounds of the Gmc. sagas (e.g. Danaweldi etc.). The loss of the unaccented anlaut a- and introduction of the prosthetic -r- are, like the word world itself, inner Gmc. innovations that produced a string of allophones dutifully listed in the “IE” etymologies. The b/v/w/f alterations are regular allophonic dialectal variations. The “IE etymology” connects the world with unattested PGmc. *wer “man” found in the compound werewolf, plus another unattested PGmc. *ald “old, age”, an incredible unsubstantiated proposition. It also ascribes to the original Gmc. form aweld the semantic extensions of much later times, like the “animal world”, “human existence”, “affairs of life”, “long period”, “human race”, “mankind”, “humanity”, etc., not ever mentioned in the primary Gmc. sources. Transition from аbïl to aweld to welt to world is documented, transparent, and does not need any unattested asterisked sobriquets, although the forms аbïl and aweld are separated by at least 2-3 millennia and 9000 km. The much greater transition from aweld to world was much more dynamic, it took only about 500 years, because it fell on diverse alien ears. See abode, habitat.
English yard (n.) “court” ~ Türkic yer (n.) “earth, land, ground, terrain, territory, place,
landed property”, yerde
with the denoun locative suffix -da/-dä/-de/-ta/-tä/-te “on the grounds, in the place, in the
property”, and the like.
The word and the anlaut semi-consonant could also ascend to the verb qur- (v.) “arrange,
build, line up, gather, stretch”,
qur (n.) “sash, belt”, denoting an enclosed space, that root produced the word “court” formed
with the same locative suffix -ta. The court and yard are largely synonymous
denoting enclosure. Phonetically, the anlaut consonant is symptomatic of Ogur languages, versus the
anlaut vowel symptomatic of Oguz languages; -y is a semi-consonant typical for some Ogur
languages, selected from a lineup of d-/g-/y-/j-. The phonetic difference between the
court and yard points to separate origin paths, and likely considerable temporal
separation. For cognates, etymology, distribution, and history see gird. See
court, curtain, earth, garden, gird, guard.
95
4.8 Cooking and food
acid alimentation bake beer blend boil booze bouillon cabbage cake cannabis chaff cook curd fire
food herb jam jelly juice kitchen loaf mead menu oat savory (26)
Cooking and food; Preliminary note.
Etymological synopsis of Eng. and some Gmc. and European cooking terms ascending to the Türkic stems
is depicted in the following table. All Türkic terms, shown in italics, are attested. In its
entirety, the Gmc. cooking terminology ascends to the Türkic languages. Other European languages
have spotty distribution of the Türkic cognates. Numerous native, demonstratively non-IE origin
words survived in different European languages. In Asia, status is also motley. Manifestly, even
among “IE languages” the “IE” terms are far from being predominant. The “IE etymology” offers a
jumble of different invented roots tailored to various misclassified “IE forms”, at times quite
ridiculous, systemically circular and ubiquitously devoid of a prime notion. All Türkic primal stems
have bifurcated semantics that refers to two aspects of a phenomena:
1) “vapor (fragrance)” and “boil” for basis “steam”,
2) “dry” and “cook” for basis “hot ashes”,
3) “churn” and “boil” for basis “skim”,
4) “shine” and “bright” for basis “inflame”.
The Türkic notion of “churn” was used metaphorically for “boil”, it created two independent lines of derivatives, one connected with a mechanistic turbidity, and the other with turbidity in boiling liquids. The now lost A.-Sax. sod, soden, seoðan “cooking, boiling, seethe” are cognates of the surviving sodden “wet, saturated”, lit. they denote “soak, decoct”. It had as widespread use as the surviving A.-Sax. coc- “cook”, with derivatives healfsoden, simsoden “half-cooked” lit. “half-watered, half-soaked”, niðsoden “newly-boiled”, etc. The notion ya- “inflame” developed derivative “(cook on) flame” and “bright, shine” which stratified into a b-line and an h-line. A.-Sax. has form byar- (Cf. bierhtu) “ and hyar- (Cf. hierste) “fry, roast”. The Cooking and Food selection lists only immediate members of the kitchen processes, a wealth of other food-related lexemes, like animal names, cooking utensils, etc., are listed in other categorical groupings. Taken as a finite set of lexical traits, the selection provides a statistically infinite example of paradigmatic transfers with probability value indistinguishable from a hard 1. The English cooking lexicon corroborates genetic conclusions that the Kurgan migrations of the early and latter times were familial affairs, with women carrying the cooking lexicon.
Scherbak
Animals cognate list
104
English sundry (adj.) “mixed” ~ Türkic sandrı:-, sandırı:- (v.) “mix up, confuse” related to mental conditions of becoming or being “mixed up, scatter-brained, insane, hallucinating, raving” (EDT 836). The sandrı:- is a derivative of a verb san- “reckon, think, deem, meditate, reflect, suppose, conjecture, count”, a reflexive derivative of the verb sa:- “reckon, count” that among others produced the noun sa:ğ “intellect”, see think. An alternate origin (EDTL 160) is suggested fr. a root say- (v.) “puncture”. 5+ homophonic roots say left a fair latitude in asserting an original root. One of alternate articulations sound as say-, suylan, sayqla, saygak, sayaq (EDTL v.7 158), with -n-/-y- alternation. Semantics denotes a sizable collection of diverse small things, thus “mixed”. A range of semantic applications includes “craziness, insane, quarrel, row, rave, mix up, scatter-brain, hallucinate, confused, incoherent, stray (speech), nonsense, slander, snitch”, and the like. A semantic shift in Eng. retained the notion of “mixed things” vs. the Tr. predominant use of “mixed mind”. In contrast, its Sl. counterpart pomeshatsya (помешаться) retained the root mesh-/mes- “mix” for a Sl. calque of “going, being mentally insane” along with a “pile of mixed (smth.)”. Suitable phonetics and crisp semantics makes it impossible to ascribe a phonetic and semantic match to fortuitous coincidence. For a 6-morpheme word, a chance match is conservatively in the range of P = 0.16 (for phonetics, reducing the number of phonemes to ridiculously low number 10 in each language) X 0.001 (for semantics, allowing for 1000 semantic fields in each language, with ludicrously exaggerated 10 synonyms in each field) = 0. 00000001, or 1 chance out of 100 mln 6-morpheme words (All 10,000-word dictionaries on the Earth for all 6,000 Earthly languages contain only 60 mln words, and only a small fraction of them has 6 or more morphemes). That probability is vanishingly small, while its opposite, the probability that these two words are one and the same word, is overwhelming, P = 0.99999999. Cognates: A.-Sax. syndrig, syndrige “separate, apart, special, peculiar”; Mari shoya, shoyak (n.) “lie”; Mong. (Oyrat) say- (v.) “puncture” (~ Chuv. suy- “lie, lying”); Chag. sayiγ “delirium, gibberish”, Osman. sayïkla- (v.) “delirium, gibberish”. Distribution: From Albion to Mongolia across Türkic Eurasian Steppe Belt and across linguistic borders. On top of perfect phonetics and traceable coherent semantics the “IE etymology” suggests phonetically close but semantically neologistic candidates. Instead of “mixed” are proposed neologistic semantic extensions “separate, peculiar, exceptional” etc., with some extremes as far off as “far away”, “without”, and “broken”. It is impossible to breach a semantic gap, but a phonetic conflation is possible, i.e. the A.-Sax. variations synder-, sundor-, sunder- “peculiar, special” sound close to sundry. An etymology of the second, apparently peculiarly Gmc. word (incompatible “cognates” must be dismissed) is an independent subject, related to exceptional, privileged position or a state of prominency; it is unrelated to the A.-Sax. lexeme, which used the stems mix and blend (Tr. bulɣa-) for sundry “mixed”. See blend, sane, sanity, say, think.
1) “vapor (fragrance)” and “boil” for basis “steam”,
2) “dry” and “cook” for basis “hot ashes”,
3) “churn” and “boil” for basis “skim”,
4) “shine” and “bright” for basis “inflame”.
The Türkic notion of “churn” was used metaphorically for “boil”, it created two independent lines of derivatives, one connected with a mechanistic turbidity, and the other with turbidity in boiling liquids. The now lost A.-Sax. sod, soden, seoðan “cooking, boiling, seethe” are cognates of the surviving sodden “wet, saturated”, lit. they denote “soak, decoct”. It had as widespread use as the surviving A.-Sax. coc- “cook”, with derivatives healfsoden, simsoden “half-cooked” lit. “half-watered, half-soaked”, niðsoden “newly-boiled”, etc. The notion ya- “inflame” developed derivative “(cook on) flame” and “bright, shine” which stratified into a b-line and an h-line. A.-Sax. has form byar- (Cf. bierhtu) “ and hyar- (Cf. hierste) “fry, roast”. The Cooking and Food selection lists only immediate members of the kitchen processes, a wealth of other food-related lexemes, like animal names, cooking utensils, etc., are listed in other categorical groupings. Taken as a finite set of lexical traits, the selection provides a statistically infinite example of paradigmatic transfers with probability value indistinguishable from a hard 1. The English cooking lexicon corroborates genetic conclusions that the Kurgan migrations of the early and latter times were familial affairs, with women carrying the cooking lexicon.
| Lexeme | Prime Notion | Second Notion | Derivative | Notion | Eng. Cooking Derivative | Eng. Other Derivatives | Allophone | European Derivatives |
|---|---|---|---|---|---|---|---|---|
| bu | steam | turbulence | bula- | boil (lit. steamed) | bullion | fart, fog, murky, mist, purge | ||
| bu | steam | turbulence | bug | bake | ||||
| bu | steam | turbulence | bïš-/pïš- | boil | popina, peptein, pech, poeth, kepti | |||
| bu | steam | turbulence | par | virtuve, varit | ||||
| kok- | ash, fire | dry | cook | concoction | cökene, Küche (Gmc.) | coquere, coquina, kuhnya | ||
| kan- | skim (boil) | churning | qatna- | boil | kitchen | |||
| su, so | moisture | water | süd | soak | boil | soak, sodden | sop, sip | sok, sökkva |
| ya- | inflame | shine | yaru- | bright | fry | bread | frigere, phrygein, bhrjjati, birishtan |
English acid (n.) “sour”, acidify (v., n., adj.) “turn sour” ~ Türkic ačïɣ (adj.) “sour, bitter”, аčï-, acı:- (achi-, aji-) (v.) “turn sour”. Türkic allophones and spellings for “turn sour” and derivatives come in a slew of forms: ajy, ačıkh, ačy, aši, aččyk, ajyg, ahyy, aji, ačuu, and more. The range of the notions expressed includes ferment, ache (wound), aggravate (disease), hurt, grieve, lament, condole, unbearable, heavy, angry, cruel, anger, bitterness. Of 44 European languages, Türkic leads with combined 27 (61%) languages, with ač- 16 (36%) languages and syr- (Gmc. < Tr.) with 11 (25%) languages, matching a level of 50.6% R1a/b demographic presence in Europe. Sl. with kisl- is a second runner-up with 13 (30%) languages. Hence, the Sl. (Hg I) was a dominant language of the Old Europe, a predecessor of the Hg J vernaculars. The remaining 4 languages march to their own tunes with 3 distinct native words, incl. Gk. oxy. NW Gmc. sore, soere, syra, etc. are allophonic derivatives of the Türkic sïr- (v.) “sore, hurt, strip skin”. Cognates: A.-Sax. aeced, eced “acid, vinegar”, acan (v.), ece, aece “ache, suffer pain”, eceddrenc “acid drink”, ecedfaet “vinegar-vessel”; Ir. aigeadach, Welsh asidig “acidic”; Gmn., It., Galician, Rum., Catalan, Alb. acid, acido “acid”; Fr. acide “sour”; Yid. asidig (אַסידיק) “acidic”; Lat. acidus “sour, hot (sharp)”, acere “sour”; Gk. οxino (οξινο) “acidic” (s/h alternation); Basque azido “acid”; Kurd. asid, asidik “acid, acidic”; Gujarati esida, esidika “acid, acidic”, Punjabi aisida “acid”; Mong. ačug, učuɣ, Kalm. atag, atsag “bitter” (< Tr.); Kor. akki- “bitter, pity” (< Tr. аčïn- “sympathize, grieve”, аčï- “bitter”); Vietnam. axit “acid” . On a complimentary side for syr- q.v. are Ch. suan (酸), Kor. san (산) “acid”. Distribution spans Eurasia from Atlantic to Pacific. Far Eastern languages picked up most prominent semantic essence; Gmc. languages carried both substantive and metaphorical notions and idioms (Cf. “sour relations”, “bitter fight”). Given the host of attested Türkic cognates, it would be ludicrous to accuse the entire Türkic linguistic family of borrowing from Lat. or Fr. Or Ch. fr. Gmn. Reality must sink in. A faux “PIE proto-root” *ak- “sharp, pointed” is a patented nonsense, due to be gently rescinded. While the Türkic innumerable grammatical forms descend from the verbal stem аčï-, A.-Sax. verb apparently was a derivative of a noun or an adjective. Both English and Türkic have uncounted number of derivatives with many literal and metaphorical semantics, extending to chemistry, attitude, character, appearance, culinary, and so on: acid, acetone, acete (oil), etc., Cf. metaphorical acid (smile, comment, tone). A degree of internalization in N. European languages points to the Corded Ware period. The word has a widespread usage in the Middle East, Caucasus, and Central Asia as a noun derivative ačika/adjika, a staple hot spice in every household of all imaginable languages reached by the Türkic horses. Eidetic phonetics and parallel use in Eng. and Türkic of both forthright and negative metaphorical meanings present a formidable case of paradigmatic transfer, a positive attestation of genetic heritage from a Türkic milieu. See ache.
English alimentation (n.) “nourishment, provision ” ~ Türkic alım (n.) “take, receive (debt, payment, tax)”. Ultimately a deverbal noun fr. al- “take, receive, capture”. It matches a synonymous berim fr. ber- “bear (v.)”, see bear (v.). The suffix -m denotes “me”: “my take”. The key verbal notion “take” is wittingly or unwittingly obscured with a secondary semantic derivative, a concrete noun “food”. Nowadays alimentation is an international word. Cognates: A.-Sax. alaeccan “take, catch”, aelmes, aelmesse, almysse “alms, almsgiving”, aelmesfull “charitable”, aelmesriht “right to alms”, +21 more “alms”, alaenan, alene “lend, grant, lease”, alaedan “bring, grow”; Fris. alimentaasje “alimentation”; OIr. alim “I sustain (by taxes, nourishment, etc.)”, aldım “I have taken, received”, alımın (“debt”) aldı: (“took”) “he took (collected) debt (levy)”, morphologically with Türkic agglutinated suffixes -m, -ın, dı:, Ir. ailiunais “alimony”; Lat. alimonia (-monia action suffix) “support, sustenance”, alere “nourish”; Mong. al “take”, Tungus-Manchu ali, aliw “take”; Even. al, ali “take, take away”. Distribution Eurasian-wide, from Atlantic to Pacific. No “IE” connections. Etymology is described as an “oddball among “IE” languages”, effected by a myopic disregard of the Eurasian spread. The Lat. “food, sustenance” is a semantic derivative for receipts in kind, widely used prior a switch to a monetary tax. It reflects a system of dependents and allotments that was inherited by the Roman and other societies, Cf. Sl. meaning “allot a table” (поставить на стол) to give a right to collect taxes in kind, a princely prerogative also expressed by A.-Sax. “right to alms”. The Celtic carryover of the prime root complete with Türkic morphology and syntax attests to a presence of the word in the 6th-5th mill. BC N. Pontic prior to the Celtic anabasis to the European Iberia. The A.-Sax. word predate the Lat. word, that is attested by its incompatibly rich internalization. Under a hypothesis of Saxons being another form for the Saka Scythians, the A.-Sax. lexical forms may be reflexes of the original Scythian speech. Conflated with its Lat. sibling, the word has survived from A.-Sax. into English. The dual semantics of the primary “take, receive, capture”, “(provide with) food, support, sustenance”, and the carryover of the morphological components from the Türkic vocabulary, constitute an indelible case of paradigmatic transfer. That attests to biological and linguistic common genetic inheritance from the Türkic phylum. See alimony, alms, bear (v.).
English bake (v.) “cook” ~ Türkic bukač/buka:č, buqač/baqač, bukač/baka:č (n.) “baking pot, ovenbake”. Ultimately a derivative of an oldest surviving stem bu, bug/bu:ğ, bus, burs, mug (n., v.) “steam” or close allophones. Besides “steam”, the root bu, bug/bu:ğ denotes fog, cloud, vapor, evaporation, suffocation, smoke, etc., Cf. Eng. mist, mizzle, see mist. Grammatically, bu- is a verb, bug is a deverbal noun formed with a suffix -k/-q/-ɣ. A synonymous sister line with suffix -š forms an alternate series biš-, bïš-, pïš- (bish-, bysh-, pysh-) “cook” with overlapping semantics centered around “fog”. The stem is now found across Eurasia in all kinds of applications. A concrete noun for pot cooking is no older than an earthenware, but it ascends to a timeless fog and similar weather actions. An initial form for a “baking pot” was probably somewhat simpler than the form baka:č before the suffix -č (-ch) was invented. Türkic has a triplet of stems associated with cooking, they became active kernels in creating corresponding European, Indo-European, and other derivatives, see Cooking and food; Preliminary note q.v. These are qatna- “boil”, kok- “cook (on fire or smoke)”, and bu “steam” with derivatives for “boil”. Their respective Eng. derivatives are “kitchen”, “cook”, and “bake”. Cognates: A.-Sax. bacan “bake” (all A.-Sax. forms are with /-k-/, suffix -an forms denoun verb “to steam”); ONorse baka, MDu. backen, OHG bahhan, Gmn. backen; Welsh poeth “cooked, baked, hot”; OCS pech (печ, печь) “stove, to roast”, bus, busenets (бус, бусенец) “drizzle”; Gk. phogein “to roast”; Skt. pakvah “cooked”; Akkad. na-piš-u “breathing, inhale, scent”; Komi bus “dust, powder”, Udmurt bus “fog, steam”; Mong. bug “steam”, Kalm. bug “demon of fog”. Distribution from Atlantic to the Far East is consistent with the extent of the Eurasian Steppe Belt with its fringes in Europe and South-central Asia. An “IE etymology” ascends the word to “bath” in a sense of heat cooking, via faux “proto-words”, a “PG” *bakan “bake” and a “PIE” *bhe-, bheg- “to warm, roast”. These ersatzes are not needed as they are unwittingly eidetic to the attested Türkic buk- “baking pot” and bu “steam”. Both ersatzes are phonetically-driven, semantically spurious absurdities waiting to be rescinded. An oldest record is Akkadian ca 28-24 cc. BC with a loanword stem paš/piš. A.-Sax. forms abacan, beceð, baeceð, boc, bocon point to a long period of independent grammatical development and illustrate a fluidity of the stem vowel. The Celtic cognate may attest to a presence of the word in the 6th-5th mill. BC N. Pontic prior to the Celtic trek to the European soil. The Gmc. cognates likely ascend to the Corded Ware times' amalgamation of the Türkic Kurgans and European refugee natives. Within the trio “boil”, “cook”, and “steam”, bake is a member of a paradigmatic transfer case attesting to a genetic origin from a Türkic vocabulary. See boil, cook, kitchen, mist.
English beer (n.) “ale brew” (Sw N/A, F1264, 0.01%) ~ Türkic bor, bo:r, bura, boza, begni: (n.) “wine”, boza, buza “beer”. The terms, bor “wine” and buza “beer” are semantically overlapping, one or another is areally predominant, depending on staples available. The terms are derived from an undifferentiated root bo-/bu-, primeval bu “steam, vapor, boiling, churning”. An alternate is a couple bor “white”, boz “gray”, both related to a white color of chalk, and specifically to a fermented white residue left at making cheese from kumis, later for the same with grains. In the first case, the s/r split is non-etymological, its semantic and phonetic diffusion mobile, in the second case it is etymological. A meaning of either one is rather a vague “fermented”, a concrete name refers to a process, color, or an implied feedstock. In many cases the ambiguity has survived into modern times, especially so for wine. Cognates: A.-Sax. beor “beer”, breowan (v.) “brew”, breowlac (n.) “brewing”, OFris. biar, bjoor, bier, Du. bier, OHG bior, LG beer, Gmn. bier “beer”, MDu, MLG busen “booze” (< buz, see booze), Icl. bjor, Sw. buska (< buz); “a WGmc. word of much-disputed and ambiguous origin”; Rus. burluk “lees, sediment” (< Tr. borluk ditto); Gk. brytos (βριτος) “brew”; MPers. (3rd c. AD) bör “wine”; Hu. bor “wine”; Mong. bor “wine”; Uigur bor, por “wine”, borluk “vineyard”; Crimean borla “grape, vineyard”; an origin fr. bor “white (cediment)” adds cognates Kor. morä, mosä “sand (white)”; Mong. bor “dust (white)”, buza “wine”, bozu, božu, bozo “lees, sediment, pulp”, Kalm. bor tser “plaster, gypsum”, Bur. bor “clay”; Manchu buraki “dust, sand”. Distribution extends across a span of Eurasia. “IE etymology” rates a source as of an “ambiguous origin”. The ambiguity notwithstanding, an “IE etymology” bravely offers conclusive origins from a faux “PIE root” *po(i)- (v.) “drink”, “PG root” *beuwoz-, *beuwo- “barley”, “PWGmc. root” *beur, “PG root” *beuza “beer”, “PIE root” *bhews-, *bews- “dross, sediment, brewer's yeast”. All reverse engineered to order. All rooted in linguistic partisanship of deliberate dilettantish myopia easily complemented by yet many more “proto-words” from an PIE proto-reconstruction bag. All pure nonsense. Türkic masses knew of fermented kumis drinks at least from a 3rd mill. BC, millenniums before a coming of the Indo-Aryans to Mesopotamia. Beer was popular in ancient Egypt and Mesopotamia, and the Guties (aka Goths) “tribes” surrounded sedentary Mesopotamian polities. Fermented grain drinks could not escape to be added to the boozer repertory. The Scythian boozers are known from a 9th c. BC. The Gmc. tribes were late learners of the bor “beer”, they knew it as ale. The duo of bor “wine, beer” and buza “beer” constitutes a case of paradigmatic transfer, indelibly attesting to a lexical origin from a Türkic milieu. See boil, booze.
English blend (v., n.) “combine, add together” ~ Türkic bula- “stir, stew, steam” (v.), bula-, bele-, bulɣa- (v.) “stir, mix, roil”. The term originated from a boiling steaming action, see boil. Other meanings are “boil, cook, cook in steam, vex, annoy, sadden, harm, stir discontent, stir unrest, smear”, and more. There is a semantic overlap, a gray zone of semantic conflation, dispersion, and contraction. On top of the polysemous bula-, bulɣa-, numerous derivatives refer to types of mixing actions as independent verbs: bultas- “blunge, shake, loose (integrity), mixture, blend (n.), slipslop”; bulnuq- “blunge, mix up”, etc. In bVlnd suffix -n- marks a deverbal noun result, -t forms an abstract noun. The notion “mix” has created a socially salient linguistic base for unrest and rebellion. Out of 40 European languages, only Gmc. 5 (12%) use allophones of bl-, the other 35 languages mostly use constructs of mix. The archaic Gmc. languages were ignorant of a word “mix”, a positive evidence of a non-“IE” origin. Cognates: A.-Sax. blandan, blondan “blend, mix, mingle”, ONorse blanda, OSax., OHG blantan, OFris. blenda, Goth. blandan, MHG blenden “blend”; Gmn. blendling “bastard, mongrel”; Lith. blandus “turbid, troubled, thick”, OCS blesti (блести) “go astray”, bludit (блудить) “get lost”, Rus. bulga, bulgachit (булга, булгачить) “commotion, alarm”, Bulg. bolašekčija “laundress”, Serb. bulog, buloga “unrest, revolt, riot”, bulandisati “mistaken”, Pol. bulany “foment unrest”; Pers. bulɣaq “unrest”; Osset. bulğaq “quarrel”; Mong. bulɣa- (v.) “muddle, smirch, befoul, foment unrest”, Kalm. bulngir, bulngr “dirty, muddled, mud, sediment, murk”; Tung. bula “bog, mire”. Distribution extends from Atlantic to Pacific. From a focus “mix” semantic range emanates in all directions, reflecting social, spatial, and associative needs of the native developments and hosting languages. However, the hosting languages avoid Europe at all costs. An “IE etymology” is pure mechanistic nonsense: “to shine, flash, burn”, “bleach”, “blind, blunder, dazzle”. Most generously, these suggestions are outmost figurative derivatives or phonetic strangers of the base meaning “mix”. The PIE conjectures blend a pile of derivatives and truncate them to an unattested *b(h)lend-. A peculiar distribution of the phonetics and semantics in the Eurasian steppe belt and the Northern Europe goes unaddressed. At one time bulɣa- “mix, rebel” was suggested for an endonym of the Bulgars, a derisive term no scholar should have suggested and no ethnicity would adopt as an endonym. The phonetics, the Bulgar's self-appellation As (Sl. Yas, Yass), the allophonic form Balkar, and Bulgars initial Caucasus location in proximity to the Balkh, point to the Bulgar and Balkar being allophones of Balkh. The Orkneys bland “buttermilk (kumis) diluted with water”, ONorse blanda “diluted hot whey” (Türkic bulɣama), Sl. boltanka (болтанка) “soup or drink with suspended ingredients”, burda (бурда) “suspicious drink mixture”, etc. relay the applications of the blending. A wide semantic field of the Türkic verb is echoed across linguistic borders in numerous Northern European reflexes. See bake, boil.
English boil (v.) “boil, bubble up, seethe” ~ Türkic bula- (v.) “boil, steam, simmer (food)”, a passive denoun verbal derivative (suffix -l, -la) fr. bu/bu: “steam” with precise meaning “to steam (cook)”. In addition to a systemic “of unknown origin” an “IE etymology” employs an arsenal of magic science tools: “uncertain”, “probably”, “perhaps”, “but possibly” and “of echoic origin”. It firmly relies on a circular logic, with a straight face asserts a ridiculous progenitor “bubble”, and climaxes with an absence of any sane etymology. The root bu- (v.) and buɣ (n.) “steam” with deverbal noun suffix -ɣ/-q/-w, in different vernaculars is realized in a documented spectrum of 25+ articulations: bu, bu:, buu, buɣ, bu:q, buh, buv, buw, buqu, buğu, buwï, buhu, buğum, buaq, boğ, bog, boğu, bıwaq, bïw, pu, рu:, puw, pav, muɣ, mug. The last two semantically and phonetically coincide with the Lat. reflex moveo “move, stir”, providing a traceable link to an ethnic source for a notion “move, motion”. It comes from a Karluk branch, some Uigur ancestors blessed us the word “move”. Semantically close are derivatives bur- (v.) “evaporate, smell” and bus-, bu:z- “smoke, foggy, turbid, ice” with their own lines overlapping the primal bu. Invariably, internalization and dissemination of that variety had to produce further dispersion of the forms and semantic extensions. Türkic has a triplet of stems associated with cooking that became active participants in creating corresponding European and Indo-European siblings, see Cooking and food; Preliminary note q.v. These are qatna- “boil”, kok- “cook (on fire or smoke)”, and bu “steam” with derivatives for “boil”. Their respective derivatives are “kitchen”, “cook”, and “bake”. Out of 40 European languages 21 (52%) use cognates of bu “steam”, another 8 (20%) use cognates of qatna- “boil”, for a total of 29 (72%) of Türkic extracts. That matches well a level of the 50.6% R1a/b demographic presence in Europe. The other 19 (48%) languages use their own 6 basic words with no notable domination. Cognates: A.-Sax. byl, byle “boil”, Gmc. wallen, brodeln “boil, seethe, swirl, stir, bubble”; Scotts goil (b/g alternation, Cf. cloud < bulut), Welsh bervi “boil”; OFr. bolir “boil”, Fr. bouillir, It. bollire, Port. ferver, Rum. fierbe, Sp. hervir “boil”; Lat. bullire “to seethe, boil”; Gk. vrasmos (βρασμος) “boil”; Balto-Sl. (Lith.) virti “boil”, (OCS) par (пар) “vapor, steaming”, (Rus.) par (пар) “steam”, parit (парить), varit (варить) “boil, to steam, sweat, condensate” (and parit “soar, glide”), parnik (парник), parnaya (парная) “greenhouse, sweat room”, burlit (бурлить) “seethe”, bus, busenets (бус, бусенец) “drizzle, mizzle”, Maced. vrienie (вриење), Slovak varit “boil”, Serb. bugija “vapor”; Alb. vlim “boil”; Dravid. bey, ve “boil, cook”; Hindi bhaap (भाप) “steam”; Hu. forral “boil”; Mong. butslah (буцлах) “boil”, Kalm. bug “demon of fog”; Nenets, Aleut, Fin., Eng., Rus. parka “sweat coat, heavy jacket”. Distribution extends from Atlantic to Pacific. Respective “IE” etymology is a farce. The Lat. bullire is a derivative form of the Türkic passive bula- “boil” in causative form with suffix -ur/-ir, ditto notions vapor, evaporation “steam, vaporization” (funny, “of unknown origin”). E. European and Gmc. forms may use initial and prosthetic v/w. The Celtic forms are likely the oldest, before the Celtic circum-Mediterranean 6th-5th mill. BC migration from the N.Pontic to Iberia. Next in time is probably Alb. Mong. l.-w. may be a product of Zhou Scythians, ca. 2nd mill. BC. If Gk. had its own term, it would not need a l.-w. The Gmc. forms ascend to the Cored Ware time, and Hindi to the 2nd mill. BC. A component of the trio “boil”, “cook”, and “steam”, boil is a member of an ubiquitous paradigmatic transfer case indelibly attesting to a genetic origin from a Türkic vocabulary. See bouillon, breath, fart, purge, purl, pyre, vapor.
English booze (v., n.) “strong drink” (n.), “drink a lot” (v.) ~ Türkic buza, boza (n.) “intoxicating beverage”, buxsum “millet drink, booze”. Like most of other internalized “IE” Türkic words, etymologically booze goes under a tag “of unknown origin”. In practice that tag is frequently synonymous with “Türkic”. A more specific synonym would state “Anglo-Saxon” or “Sarmatian”. Ultimately a derivative fr. buz- (v.) “crush, rampage, misbehave”, (n.) “misbehaviour, rampaging” (МК 1 485//OTD 130) originated from a boiling steaming action, see boil. In the eastern Türkic languages buz is attested as a verb, in the western Türkic languages buz is attested as a noun. Either branch has no obstacles to use the stem with an appropriate verbal or a noun suffix. Western Türkic languages tend to refer to grain drinks: millet, wheat, barley, rice, buckwheat, oats, all malts. Eastern languages tend to refer to wines. A complimentary and overlapping Türkic bor, bo:r, bura “wine” turned into A.-Sax. beor, Eng. beer, see beer. Few more relevant terms were internalized in various Eurasian languages, Cf. Sl. braga “malt” Cf. brewery. Cognates: A.-Sax. bescenean (/beshen-/) “to booze”, ME bouse, MDu. busen, buisen, buysen “drink heavily”, MHG busen “inspire” ?; Ir., Scots booze; Sl. buzit (бузить) “drink heavily, misbehave”, “misbehave, rampage, amuck”, mezga “pulp (usually grapes, apples)” (b/m alternation, suffix -ka/-ga/-qa); Catalan beguda “drink, consume”; Basque booze “drinking”; Pers. buzä, boza “millet, drink”; Ar. buzə, buza, boza “millet beer”; Mong. buza “wine”; bozu, božu, bozo “lees, sediment, pulp”. Distribution spans across Eurasia. An “IE etymology” is basking in myopia and falsehood. With an attested vocabulary of a solid paradigmatic transfer case, there is no need for any faux “PG” *beuza “beer” nor a faux “PIE” *bhews-, *bews- “lees” nor for boldly invented faux “PSl.” *mezga “malt”. Eng. morphology attests to a long-time internalization. The Sl. bifurcated buzit (v.) < buza (n.) < Tr. buz (beer, alcoholic drink) parallels the Türkic verb/noun bifurcated semantics. The Scythian boozers are known from 9th c. BC. Since such an essential word is unknown in the older Balto-Slavic languages, apparently the European booze is of a late distribution, after 2nd c. BC (Sarmat time). The Near Eastern spread starts with Neo-Persian Sassanid period (3rd–7th cc. AD), The Egyptian Arabic spread was brought over by Mamluks (ca 13th c. AD). See beer, boil.
English bouillon (n.) “clear meat broth” ~ Türkic bula- (v.) “boil”. Ultimately a denoun verbal derivative fr. bu/bu: “steam” meaning “to cook in steam” with a reflexive deverbal noun suffix -an. The o/u in Türkic are interchangeable, both forms bula- and bola- mean “boil”, and can be used in the same village or across a continent. The stem has numerous derivatives associated with boiling action, lit. and metaphorical, like an A.-Sax. wealhat “boiling hot, red-hot”, wielm “boiling, swelling”, see boil. It has a raster of semantic extensions, some very remote: “to be agitated”, “rage”, “toss”, “well”, “bubble”, “seethe”, “foam”, “be hot”, “swarm”, “flow”, “rise”. Most extensions echo semantic extensions of the original Türkic bu/bu: and bula-. Semantic extensions further develop into independent words that connect bula- “boil” with something rising as a steam, i.e. a wall or a village, Cf. Lat. vallum (< bul), vicus, and then vicar “head of a village”, religious “secondary priest”. Forms carry a passive voice marker -l for liquid not boiling but being boiled. A combination of a stem + passive suffix makes the case a grammatical paradigm transfer of a formed passive denoun verbal derivative fr. bu/bu: “steam”, valuable for detecting genetic connections. An Anglo-Saxon's broð, broth ascends to an allophonic Türkic form bur- “steam plumes”, see bore, wrinkle. A synonymic A.-Sax. kitchen word for “boil” was sioð(an), seoð(an) “to seethe” and sod(en) “to soak” fr. the Türkic saɣ- (v.) “soak in, absorb”, see soak. A word bouillon came via French, from OFr. bolir, which is English boil and Türkic bula-. Of the 44 European languages, 16 (36%) share a Türkic base bor, 10 (23%) share a Türkic base bol- , 10 (23%) share a Türkic base qat- “kitchen”, and 3 (0.7%) share a Türkic base qap- “alight, engulfed in flames”. The other 6 (14%) languages use their own 5 basic words. 39 (89%) of European languages use Türkic-derived words for “boil”, far in excess of a 50.6% R1a/b demographic presence in Europe. Cognates: A.-Sax. byl, byle, weal-, weall(an) “boil”, wielm “boiling, swelling”, Gmn. wall(en) “boil”; Scotts goil (b/g alternation, Cf. cloud < bulut), Welsh berwi “boil” (< bur-); Balto-Sl. (Lith.) virti “boil”; (OCS) par (пар) “vapor, steaming” (< bur-), (Rus.) par (пар) “steam”, parit (парить), varit (варить) “boil, to steam, sweat, condensate” (and parit “soar, glide”), parnik (парник), parnaya (парная) “greenhouse, sweat room”, burlit (бурлить) “seethe”; OFr. bolir, boillir “boil”, Port. ferver, Rum. fierbe, Sp. hervir “boil” (< bur-); Lat. bullire “boil” (causative suffix -ur/-ir); Gk. vrasmos (βρασμος) “boil” (< bur-); Alb. vlim “boil”; Dravid. bey, ve “boil, cook”; Hindi hbhaap (भाप) “steam” (< bur-); Hu. forral “boil” (< bur-), Mong. butslah (буцлах) “boil” (< bu); see boil for extended cognate listing. Cited cognates demonstrate variety of guest sources, and their respective paths and periods. Distribution spans across Eurasia. An “IE etymology” correctly associates bouillon < boil but myopically dead-ends at Lat. without extending even to a nearest Gk. prototype. It incorrectly cites unrelated Lat. bulla “bubble” as a cognate source (bubble and boil are equidistant fr. bu “steam”) and unrelated puyl “bag”, bule “buttocks”. There also is no need for inventions of faux “PIE” *bew- “swelling”, *bhel- “blow, inflate, swell” (< Tr. buq “swelling”). The A.-Sax. root weal- has numerous allophonic forms and spellings, weal-, wael-, wel-, wiel-, hwel-, weall-, waell-, wyll-, the word was not formalized neither phonetically nor in script. It carries phonetic ambiguity expected from a mixture of dialectal kins. Use in Romance languages of suffix -ur/-ir constitutes a case a grammatical paradigm transfer. Retention of the Celtic forms attests to the presence of the root words in the 6th-5th mill. BC N. Pontic prior to the Celtic trek to the Iberia. The OFr. form likely entered French from Burgundia, later Provence and Savoy, and had an initial suffix -än of reflexive instrumental mood: bülän (bulən with rounded u) > bouillon “decocted”, reflected in the French spelling. Numerous evidence of paradigmatic transfer indelibly attests to a genetic origin from a Türkic phylum. See boil, bore, soak, wrinkle.
English cabbage (n.) “head of lettuce” ~ Türkic (OTD) qabaq, qabaɣ, qapaq, käwä, kabïy (n.) “pumpkin”. Ultimately fr. kap “cap, cup, vessel, face, head” with diminutive suffix -aq, fr. qa (n.) “vessel, tankage”, see cap and cup. Shift of application from “pumpkin” to “cabbage” is attested by idiom bal qabaq lit. “honey pumpkin” extending to “honey cabbage” ~ “honey (little) head”. Generally, names of plants and animals are portable, within and between languages. Qabaq has a store of homophones that may participate in paradigmatic transfer cases for other meanings. A secondary meaning is “gourd” extending to bottle, basket, container, and up to “wine-bottle” and “tavern”. A corollary of qabaq are qulaq and qırč, qırčın that refer to the haulm (halm, above ground) part of tuberous plants. Qulaq “ear” and qırč “sprout” are proper metaphoric epithets for a cole-type cabbage, Cf. A.-Sax. cole, Fin. kaali, Gmc. kürbis. Few “IE” etymologists would accept that ordering coleslaw in a restaurant they speak a broken Turkic and ask for slaughtered ears. As an assertion of some later days contacts, the cabbage reportedly is of Fr.-Burgundian provenance. Of 42 European languages, 22 (52%) share a Türkic base qab-, 13 (31%) share a base col-, of the remaining 7 languages, 3 (7 %), 2 (7 %), and another diverse 3 (7 %) use their own 4 bases. Taken separately, the 52% alone matches a 50.6% R1a/b demographic presence in Europe. Accounting for both qab- and col- increases the match to a predominant 83%. Adding Gmc. kür- makes the match Pan-European or Pan-Turko-European if you will. Cognates: A.-Sax. cawel, cawl, caul, cal, cole “cabbage”; Gmc. terms kürbis et al. incl. A.-Sax. cyrfet derivate from “gourd”, Cf. Karachai kar “pumpkin”; Ir. cabaiste “cabbage”; MFr. caboche/caboce “head” (dialectal), chou “cabbage”, It. cavolo “cabbage”, Lat. caput “head”; Balt. (Latv.) kaposti, (Lith.) kopustai “cabbage”, Sl. kapusta (капуста) “cabbage”, Rus. kabak (кабак) “tavern”; references of loanword qabaq in Pers., Finno-Ugrian, Caucasian, and Sl. languages (Doerfer G., 1967, Bd. III, No. 1419); references of loanword qabaq in Mong. (Cl. TE 307/EDTL v. 1980, v. 5, 163) A well-defined areal distribution (15°C median, -2°C min, 26°C max) extends from the most-eastern Asian steppes to the belt south of the Baltic Sea. No adult “IE” etymology. On top of a somewhat honest “of uncertain origin”, the “IE etymology” offers an origin from Lat. *kaput “head” via a faux “PIE root” *kaput- “head”. It is unwittingly eidetic to the attested Türkic kap- “face, eyelid, cover” originated fr. a Türkic kap- “cover, roof, top”. A spare “IE etymology” offers a faux compound ca- (?) + boce “hump, bump” with a line-up of most loony cognates. None works. Among 44 European languages, the Türkic kap- “cover” holds a priority with 18 (41%) languages, matching a 50.6% R1a/b demographic presence in Europe. A 14 (32%) languages Sl. gol-, golov- originated fr. a Türkic kol, ko:l “cone, hill, hillock”, i.e. “top, tip” that echoes the kap- “cover” for a notion “head”. Together, they practically cover entire Europe to the Urals, of most of which the poor Romans never heard. There is just not enough room for any proprietary “IE” paradigm. An “IE etymology” is using the notion “head”, making it a circular logics closed loop, see cap and cup. Notably, the English cabbage, like the Provence caboce, preserved not only the stem related to “head”, but also an allophone of the Türkic archaic diminutive suffix -aq “little head”. The A.-Sax. forms point to a word internalized in a series of incremental steps. The Fr. chou bridges col and qab-, pointing to internalized origin of the first two forms. The Türkic quartet qab-/kap-, col-, kürb-, and gol- present across European vernaculars constitutes a paradigmatic transfer paradigm, indelibly attesting to an origin from a Türkic linguistic phylum. See cap, cup.
English cake (n.) “sweet pastry”, “small flat mass” (Sw N/A, F1432, 0.01%) ~ Türkic ka:ğut, kawut “ground grain mixed with melted butter and sugar”, kek “flat, round loaf of bread”. Ultimately a derivative of kak, ka:k “dry” with its numerous siblings, “parch, sear, bake, roast”, and definitely related to Lat. coquere “cook”, see cook, see Cooking and food; Preliminary note. Ka:ğut, kawut refers both to a flour ingredient and its products, including cakes and halva. An underlining term probably ascends to the times of the early campfires, oldest haplogroups, and prehistoric demographics. The secondary form kawut grew its own line of derivatives with an extended semantic following. In England (until early 15c.) supposedly a “flat, round loaf of bread”, but A.-Sax. allophones attest to much deeper internalization and better variety. In the European 44 languages, cake and tort proliferate, 18 (41%) of languages use versions of cake, matching a level of the European 50.6% R1a/b demographic presence in Europe. 17 languages (39%) use versions of tort, the remaining 2 groups of 2 languages and 5 individual languages use 7 of their own words. Undoubtedly, most of the spread was by loanwords across linguistic barriers, Cf. Eng. cake and Sl. keks (кекс). Nowadays it is a truly international word. Cognates: A.-Sax. ceace, cece, cecel, coecil, ceig, cycel, cyceli “cake”, ONorse kaka, MDu. koke, Du. koek, OHG huohho, Gmn. kuchen “cake”; Ir. caca , Welsh cacen, Scots ceic “cake”; Balto-Sl. (Latv.) kuka, Rus. keks (кекс) “cake”; Fin. kakku, Est. cook “cake”; Rum. gogoašă “doughnut, follicle, cocoon” (< Tr. “kek, cook” + aš “food, eats”); Lat. coquere “cook”, Maltese kejk “cake”; Khalaj, Pers. kavut “cake, sweets (type)”; Ar. sawiq “cake”; Sum. uk-uk “burn”. Distribution spans from Atlantic to the end of the Eurasian Türkic Steppe Belt, stopping at the Far Eastern languages. The pretentious “IE” reconstructions, a la “PG” *kako, WGmc. *kokon- “cake” and “PIE” *gog “ball-shaped object” are beyond contempt. These ersatzes are not needed, unwittingly they are eidetic to the attested Türkic lexemes with a Sum. concordance. The word belongs to a massive cluster of food-related paradigmatic transfer case, indelibly attesting to a genetic origin from a Türkic lexicon. See cook, Cooking and food; Preliminary note.
English cannabis (n.) “hemp” ~ Türkic kenevir, kendir, kentir, kenaf (n.) “hemp”. The root ken (n.) generally refers to plants, vegetation, Cf. kenbe: “plant, vegetation”. The term kenevir refers to hemp seed, and by extension to a hemp plant. Besides “hemp”, the basic term kendir covers a range of utilitarian plants: Trachomitum, Apocynum cannabinum, Hibiscus camnabinus, at times Linum, and their fiber. A part -vir may stand for -urï “seed”, or be a denoun noun-forming grammatical element, etc. Besides medicinal use the hemp fiber found numerous vital applications for cloth, bast shoes, packing, etc. Nowadays it is universally known as a Scythian word cannabis, after Herodotus' spelling κανναβις (Herodotus IV 74). It is one of at least 21 Scythian words recorded by Classical authors recognizable as Türkic forms. Synonymous with the words “hemp” and kenevir is a secondary meanings of a word meŋ. Cognates: A.-Sax. haenep “hemp”, Fris. himp, ONorse, OIcl. hampr, hamp, OHG hanaf, Gmn. hanf “hemp”; Irish cnaib, Scots corcach, Welsh cywarch “hemp”; Balto-Sl. (Litv.) kanapes, (Lat.) kаnере, kаnuре, kаnаре, (OPrus.) knарiоs, (Sl.) kendyr, konoplya, konop- (кендырь, конопля, коноп-), “hemp”; It. саnаро, Rum. сinерa, Lat. саnарis, саnnарus “hemp”; Gk. cannabis (κανναβις) “hemp”; Hu. kender “hemp”; NPers. kanab, kenaf “hemp, hemp fiber”; Skt. čanas “hemp”; Mordv. (Erzya) kаnх, (Moksha) kаntf, Mari kǝne, kyne “hemp”, kandara, kändyra “rope”, Komi kön (in köntus “hemp seed”, tus “seed”), Udm. kenəm “hemp” (but Komi, Udmurt рiš); Sum. kunibu “hemp” (Cf. kenbe: q.v.); Oset. gaen, gaеnаe “hemp”; ММонг. genjir “hemp”, WMong. künjid “sesame”, ganjuga “saddle thongs”, Kalm. kenchr “strawmat, rug”; Baoan kencir (宝片) “hemp”; Türkic, Kuchaean (“Tokh. B”) kuncit “sesame”, EYugur kenjer “hemp”, Uz. kanap, kenaf “hemp”, Salar gamju “whip”, Chuv. kantra “lace, rope”, Turk., Gagauz kenevir “hemp, hemp seeds”; references to Mong., Kurd., Taj. cognates (Doerfer G., 1967, Türkische Elemente im Neupersischen. Ğim bis kaf, Bd. III, No 1647). Distribution is Eurasia-wide across all imaginable linguistic borders with appendages reaching Europe on one end and Tungus on the other end. Of 42 European languages 42 (100%) are using some form of hemp/cannabis, a clear popularity of a Türkic word in European languages. There were unsuccessful attempts to create faux “Altaic” pedigree. Ditto with attempts to sow enough doubt to create “IE”, “PG”, and “Iranian” (Persian) etymological versions, some supported by some faux “proto-words”. A trio of Celtic terms demonstrates how drastically a single word can change its form in a course of 8 millennia time from a 6th mill. BC in N.Pontic to a 2nd mill. AD literate period. No etymological antics could have predicted their final forms nor could have traced them to their kendir origin. A most consistent eidetic parallelism between the Fennic-Uralic forms and Türkic forms suggests that at least a generic ken “plants” could have existed in the Y-DNA N (NOP) branch (ca. 35 mill. old), a parental branch of the Y-DNA R haplogroup (ca. 25 mill old). European cognates probably date to a series of Kurganic westward waves that started ca. 7 mill. ago. There are human bacterial studies that suggest that Kurgan migrations were driven by epidemic events. An anlaut k-/h- alternation is peculiar to the Gmc. group, it may be an inheritance of the 3rd mill. BC Corded Ware period. A Celtic wedge that split Corded Ware into two islands retained its original anlaut k-. The Lat. and Gmc. forms suggest two independent paths. The Sum. word is an oldest literate record. The medicinal trio cannabis, valerian and theriac constitutes a case of paradigmatic transfer, it attests to a Türkic origin of the word. See herb, theriac, valerian.
English chaff (n.) “worthless, rubbish, residue (seed covering or anything)” ~ Türkic čö:b, čöp (chob, chop) (n.) “worthless, rubbish, sediment, dregs, residue”. A standing etymology rates the word “of uncertain origin”, positively attesting to a non-European origin. Ultimately fr. a notion “leaf” in its endless forms. Among the closest are Алт. cöbre, cöbïrga, Khak. sobïra “bark”. The variety of forms probably ascends to an out of Africa times, when leaves were one of few implements used by people. Only one name for an implement has survived: a “broom”. The others, “petal”, “bark”, “cabbage”, “chunk”, “scrap” etc. are probably aged neologisms. The anlaut consonant is recorded as č, y, j, g, k, q, s, x, the second consonant is more modest: b, p, v, y/j; in Far Eastern languages -b- may be elided. Phonetic dispersion and variety of applications (way beyond various scrap flecks) does not lead to a semantics of a root čö- but points to a local articulation č-, a great time depth, and a primeval origin of the base word possibly preceding Neolithic toolmakers. There is a homophonic connection with Türkic čöp “chop” semantically very distant from čö:b “chaff, leaf, bark”, see chop. Cognates: A.-Sax. ceaf, caef (cheaf, chaef) “chaff”, Fris., Icl. kaf “chaff”, MDu. kaf (n.), kappen (v.) “chaff”, Dan. kappe (+ avner “chaff”), Sw. kappa “to chop, cut” (+ agnar “chaff”), Gmn. kaff “chaff” (+ spreu); Ir., Scots chaff; ONFr. choper; Alb. kashtë “chaff”; Maltese karfa “chaff”; Est. kesi “chaff”; Mong. kebek, qavursun, yayursu(n), yuyursu(n), yuursu “chaff”, Khalka xeveg “bran”, guurs(an) “stem, stalk”, xuurs, xuurc “bran, straw”, Ordos ğursu “straw”, Bur. guurha(n) “stem”. Distribution spans from Atlantic to Pacific. No “IE” links whatsoever, the “IE etymology” does not reach even the Lat. With an absence of the “IE” cognates across “IE” languages the “IE” “reconstructions” of PG and PIE “proto-words” are ludicrously flagrant. Different phonetic forms indicate different paths to English and Germanic. Phonetics of A.-Sax. form and the respective Gmc. forms allow numerous interpretations: the A.-Sax. -c-- transmits phonemes -k- and -ch-, the value of-ea- is unclear, the -ff- and -f- may indicate a range of phonetic values across different vernaculars. Concordant phonetics and semantic constitute a case of paradigmatic transfer, indelibly attesting to an origin from a Türkic milieu. See chop.
English cook (v., n.) “prepare food by heating” ~ Türkic qoɣur- (v.) “frying, roast”, qaɣur- (v.) “parch, sear, bake, roast”, kok- (v.) “smoke-ize, ash-ize, sear-ize, char-ize” ~ “fire smoke, (cook food) over ashes, lit. “smoke-burn”, “on ashes, ash-burn”, “heat”. The roots kok-, qoɣ-, and qaɣ- are genetically related, their semantic fields are distinctly overlapping. The term ultimately comes fr. a notion “dry” for dry grass and firewood for campfire cooking, still active and productive, with a variety of phonetic forms and a wide range of derivatives. Semantic development follows dry (combustible) > burn > cooking (parch, sear, fry, bake, roast). Some forms are not readily traceable even for native speakers: quru-, qur- “cook, bake”. The cooking-related derivatives line up as kok- q.v., ka:g- “parch”, qoq-, ko:ğ-, xox- “sear, burn”, qoɣur- q.v., qaɣur- q.v., qaɣrul-, qavrul- “fry, roast”, kağurğa:n, kakurğa:n “bake, roast, cook”, qaqlan-, qaqlat- “smoked”, etc., and on to concrete products, Cf. kağurma:č “shawarma” (k- > sh-), qaɣurma “fried (meat)”, Cf. cook ~ cookie, fry ~ fries. A most notable and probably one of the oldest is inlaut alternation -ɣ-/-ğ- > -v-/-w-: qav-, qaw-, kov-, kow- regular for Türkic languages. A wealth of forms allows to trace the word across numerous native and hosting languages. A Türkic triplet of cooking stems created corresponding European and Indo-European derivatives, see Cooking and food; Preliminary note q.v. These are qatna- “boil”, kok- “heat, cook (on fire or smoke)”, and bu “steam” with derivatives for “boil”. Their respective derivatives are “kitchen”, “cook”, and “bake”. Cognates: A.-Sax. ge-cocnian (v.), coc (n.) “cook”, OSax kok, OHG choh, cochon Gmn. kochen, Sw. kock “cook”; Rus. kavardak (кавардак) “soup (type), pottage” (< Tr); Lat. coquere “cook, prepare food”, VLat. coquus (n.) “cook”; Mong. qag “dry”, qagari “fry”, qaur-, qauru-, qaɣur- “cook” (< Tr), Khalkha hagd “dry grass”, qаw “withered, dry”; Pers. xofk, xofke “dry” (+kavurdak “soup (type)”, with kav-); Kor. gamum (가뭄) “dry”; qаq “dry”, also echoed by Finno-Ugrian languages (G. Doerfer III, No 1397); Sum. uk-uk “burn”. Distribution spans from Atlantic to Pacific across linguistic barriers. No sane “IE” etymology. It derives cook (v.) from cook (n.), probably on an assumption that restaurants were there before housewives were invented. By a factor of thousands to one housewives outnumbered cooks at any historical time. In reality, cooking is as old as campfires, ca. 400 mill. years ago. Cooking had proper names for the act, they changed with inventions of different ways and utensils to cook. The shallow “IE etymology” offers an absurd for the word “cook” (and “stove”) as a “PIE proto-root” *pekw- “to cook, ripen”. Unwittingly, that reconstruction ascends to the Türkic bu “steam” with allophonic pe-, i.e. of the Türkic biš-, bïš-, pïš- (bish-, bysh-, pysh-), Cf. bıšur- “boil, cook, maturate”. It is an early Akkadian na-piš-u “breathing, inhale, scent” (loanword stem paš, piš, 28-24 cc. BC). It is in Oscan popina “kitchen”, Gk. peptein “bake”, Lith. kepti “bake, roast”, OCS pech (печ, печь) “stove, to roast”, Welsh poeth “cooked, baked, hot”, Skt. pakvah “cooked”, Etruscan pazu, Hu. föz, Sum. peš “burn, cook”, Cf. Eng. pot. The Sum. word is an oldest literate record ca. 4th mill. BC, with reflexes across Eurasia. Motivation for a cook morphing from *pekw- could not have been etymological. An unstated premise of the “IE etymology” that before Lat. Gmc. people did not have native terminology for a crucial survival necessity is a preposterous proposition. It conflicts with systemic lexical contrast between Gmc. and “IE families. The Lat. coquere not leads but trails a Gmc./Türkic, and is not on an “IE” path, consistent with an abundance of other Turkisms in Latin. A Turkish kek “cake” is a reborrowing fr. Eng., where it is a semantic innovation from a coc “cook”. The cooking supergroup trio and all its members constitute a case of paradigmatic transfer, inextricably attesting to a genetic origin from a Türkic milieu. See bake, boil, broil, fry, kitchen, pot, sodden.
English curd (n.) “solid fraction of milk”, curdle (v.) “congeal to curds” ~ Türkic kurt, kurıt, ko:r (n.) “curd”. Ultimately a derivative of a verb kurı:- “cure (food), dry, parch”, a derivative of an adj., noun ku:r, kuruğ “dry”. That attests to a connection of the notions “dry” and “curd”. It comes as a dried cheese or as a beverage. Under Türkic morphology, the suffix -dd produces a deverbal noun (kurıt), and the final -l (-le under Eng. spelling conventions) in the verb forms a passive “curdled”. Cognates: A.-Sax. celdre, ceoldre, cealer “pressed curds”, crudan “press, hasten, drive”, Eng. yogurt “curdled milk” (< Tr, joz- “curdle, thicken” + gurt “curd”); Gaelic gruth “curd”; Afgan. kuards (كوردس) “cheese (type)”; Mong. xuru “cheese (type)”, Kalm. hursy “dry cheese”, Bur. xurhan “dry cheeselets”; Manchu xuru(t) (qurusun ?) “cheese (type)”. Distribution: ubiquitous in Eurasia across linguistic borders, a cultural hallmark also known as ayran (diluted beverage). No sound “IE” etymology, a myopic ken. An idea of a metathesis of crud is a baby talk. So is also etymologizing of yogurt as jog-urt instead of jo-gurt. There is no contention on the Türkic origin of yogurt. A general absence of the word curd in the Gmc. branch and in the “IE” family at large points to a relatively recent directional addition separate from the bulk of the Gmc. Turkisms. In contrast, the Celtic form may ascend to the 5th-4th mill. BC, unless it is also a later acquisition. The reasons for such a small Western European footprint are apparent: local languages had their own developed lexicons, partially kindred to a Türkic base (Cf. A.-Sax. meolc “milk”, an allophone of memeleki, lit. “that of the breast (breast milk)”, molcen “kumis, yogurt”), see milk. The A.-Sax. forms with inlaut -l- need more etymological scrutiny. Demographic and societal interplay retained native terminology, and have preserved the “curd” of the Sarmatian nomadic Wendeln's “Wonderers” lexicon. Notably, the ko:r “curd” is a form of the western Türkic languages, the intermediate Sprachbund has undifferentiated “curd, yeast, leaven”. The eastern Türkic languages use the ko:r for “yeast, leaven”. That cline attests to the western Türkic demography of the Sarmatian Wendeln of the 2nd c. BC. The bulk of the Türkic-based European “milk” lexicon was probably introduced by the previous Y-DNA R1a/R1b Kurgan waves. Based on a semantic affinity, the word crudd “solids, coagulated substance” was probably a local adaptation of the internalized alien curd. Otherwise it is lacking any etymology. It can't be used as a base for the preceding “curd”. See curdle, milk.
English fire (n.) “burn, flame, blaze”, (v.) “bake, incinerate, combust” (Sw N/A, F522, Σ0.03%) ~ Türkic ört, öt, o:t (CT, R1b), virt, vut (Chuv., R1a ) (n.) “fire, burn, lit up, ignite”, ot- (v.) “strike, light (a fire)” . Semantics of different forms largely overlaps, especially for the base notions, while some meanings are peculiar to certain forms, e.g. “light, ray” is o:t. An oldest artifact ascending to the earliest times is called otïq “firestriker”. It sports an oldest deverbal suffix -q, an oldest testament to agglutination. The anlaut consonant v, w, f, p, h, etc. is prosthetic in respect to the CT version, but with temporal priority of R1a in respect to R1b it was rather elided on the road to a CT. So may be a consonant -r-, replaced with accentuated -ö- or long -o:-. The final -t had survived in all three (or four) demic branches. A second notion of the word is “fiery” and/or “fearless”, also retained in the Gmc. vocabularies. English has a wide field of derivatives, now most obsolete but illuminating: fyrdesne “warrior”, fyrbrync “conflagration”, fyrbeta “fireman”. Most diagnostic is a compound waelfyr “deadly fire”, an allophone of the Türkic öl virt, ört “deadly fire” (öl “death”, virt, ört “fire”). All cognates are allophones of a fundamental notion of burning with fire. 40 European languages use 12 roots to express “fire”, showing that there is no native “PIE” word for it. Roots came from all directions and origins. Of the 40 European languages, 10 (25%) share a base ca. fire, 9 (23%) share a base og-, Cf. Sl. ogon огонь), Lat. ignis “fire”, 5 (13%) share a base tu-. The other 16 (40%) languages use their own 9 words. Such pattern shows that words came from 12 distinct sources, 2 of them are Türkic, fire q.v. and og-. 48% of the European languages share Türkic-originated roots, matching a level of 50.6% R1a/b demographic presence in Europe. Accounting for a synonymous pyre would slightly impact the ratios but not the overall picture, see pyre. Cognates: A.-Sax. fyr, fier, fyrcynn (+ bəl, bəlfyr) “fire, pyre, funeral fire, bonfire”, fyren, fyrenful “of fire, fiery”, ad “pyre, fire, flame, Hell”, atendan “kindle”, ada: “danger, devil, injury”, OSax., OFris. fiur, Fris. fjuur, fjoer, ONorse fürr, MDu., Dan. fyr, Du. vuur, OHG fiur, LGmn. füer, Gmn. feuer “fire”; Sl. (Czech) pyr “hot ashes”, Rus. ochag (очаг) “hearth” (< Tr. vočak, votčak), vatra “hearth, bonfire”; Lat. pyra “funeral pyre”, Rum. vatra “hearth, bonfire”; Gk. pyr (πυρ) “funeral pyre; sacrificial altar, fire (place)”; Hu. forro “hot”, vatra “hearth, bonfire”; Umbrian pir “fire”; Pers., Av. atar- “fire, flame” (sacral lingo); Arm. hur “fire”; Skt. pu; Hett. ur-, uar- “burn”; Hitt. pahhur “fire”; Mong. ör, hör “flame, heat”, örbid “flare up, ignite, burn”, odčin, očin “spark”; Evenk. orumna “flare up (flame); Kor. pur, pul “flame, heat”; Sum. ud, utu, tab “fire”. Distribution spans from Atlantic to Pacific across linguistic barriers. All languages have figurative “get inflamed, fervor, barrage”, etc., including for love and desires. An “IE etymology” suggests two independent sources for “fire”, with roots egni and per. Of these roots, however, one, egni, is an allophone of a Türkic og- shared both east and west. The other is an allophone of Türkic ör-, ür- (v.) with a prosthetic f-/p- identical with Eng. “fire”. They display a Türkic origin. Another “IE” speculation, of animate and inanimate nouns, proposes an oddball attribute particular to some languages, it can't be credibly applied across linguistic borders. There is no need for fact-obscuring baby talk like “PG proto-word” *for, “PWG proto-word” *fuir, *fuïr, “PIE proto-word”*pehwr, *perjos, *paewr- and their ilk. The myopic fantasies are waiting to be quietly rescinded. The “PIE” egni “fire” is attested in Sum. ag, ang (v.) “burn”, Cf. Hu. eg-ni (v.) “burn” and Türkic yak- “ignite, burn down”, oksu “fire”. The Sum. word, an oldest on record, is a derivative and not a prime form, it attests a parental status of the prime word with reflexes scattered wide in Europe and Asia, overlapping the “IE” family as a partial case in space and time. The triplet of synonymic terms related to fire constitutes a case of paradigmatic transfer, inextricably attesting to a genetic origin from a Türkic milieu. See ad, ignite, hell, pyre.
English food (n.) “nourishment, sustenance” (Sw N/A, F696 0.01%) ~ Türkic apat (Chuv.) “food, eatable”. Ultimately an allophonic form of CT ye:- “eat, feed” with oblique tense participle suffix -p (Cf. CT yep) and active tense suffix -at/-ut. A single vowel root a-, e-(ye-), i- “eat” forms long semantic lines related to eating, food, and linked notions: CT asa-, aša-, ašla-, je-, ji-, jiš-. Related to asa-, aša- /a:sha/ “eat, feed”, aš, a:š /a:sh/ “food”, a:č, a:c /a:j/ “hunger, hungry”. In the form “food” and its Gmc. siblings a root had evaporated, leaving only traces of former morphological elements: apat > fVt > food, see fodder. A synonym liv, lev “food, delicacy” related to good living, see live. Of the 40 European languages 12 (30%) have retained some visible connections to the base root, 3 (7%) others use Türkic synonymous alim-, see alimony. The balance 25 (63%) use a cornucopia of native and borrowed terms, mostly unique and none capable to be nominated as an “IE”. Cited cognates come in two distinct flavors, suitable and uncouth. Cognates: A.-Sax. ofett, foda, Eng. food “food”, et (v.) “eat”, Fris. iten “food”, ita “eat”, MDu. eten, Du. eten “eat”, OSw. etan “eat”, Sw. föda “food”, ONorse eta “eat”, OHG ezzan, Gmn. essen “eat”, Goth. fodeins “food”, itan “eat”; Ir. bia, Welsh bwyd “food”; Balto-Sl. (Latv.) ediens “food”, Baltic est, ist, emi, edu “eat”, Bulg. džimis “fruits”, Cz. jidlo “food”, Pol. jedzenie “food”, Slovak jedlo “food”, Rus. obed (обед) “eat, lunch, dinner”, Sl. isti, ests, jести, jėsti, jisti, jesc “eat”; Lat. edi “eat”; Gk. edo (εδω), esthio (εσθίω), estho (εσθω) “eat”; Alb. ushqim “food”; Arm. utem “eat” (< Tr. 1st pers. sing); Yid. esnvarg (עסנוואַרג) “food” (< esn “eat”); Hu. elelmiszer “food”, gyümölcs “fruits”; Basque janari “food”; Skt. atti “eat”, ye:k “demon” lit. Tr. “devourer”; Mong. ide-, ideh- “eat, gnaw, erode (acid), guttle”, asara “eat” (< Tr., Cf. Gmn. essen), Evenk. žew-/žep- “consume, to have eaten”; Tung. žepti- “eat”, Manchu žе- “eat”; Chinese chi (吃) “eat”; Chuv. si- “eat”. Distribution spans from Atlantic to Pacific. There is no room for parochial reconstructions of the “PG”-type *fodo, “PIE” *peh-, and their airy ilk. The “IE etymology” tends to confuse and conflate notions of “food” and “pasture”, quite contrasting concepts where “food” came many millennia before any domestication. A pile of perfunctory surrogate “IE cognates” Lat. pasci “feed”, pascare “graze, pasture, feed”, pabulum “food, fodder”, panis “bread”,Gk. pateisthai “feed”, pastor “shepherd”, “feeder”, OCS pasti “feed cattle, pasture cattle”, Russ. pishcha (пища) “food”, Gmn. obst “vegetables”; Av. pitu- “food” etc. are perfectly irrelevant. Holding uncouth conjectures as facts is beneath science. English and Türkic both have two genetically connected complimentary forms to express “eating” and “feeding” notions, respectively Eng. eat and food (feeding), and CT ye, aš and an outlier apat, see eat. The base forms have extraordinary distribution, food/apat from Atlantic to SE Asia, and eat/ye from Atlantic to Pacific, indicating that once they belonged to two separate Sprachbunds. Unlike the eat/ye, which carries salient hallmarks of a continent-wide Kurgan spread, the food/apat is much more localized, with no apparent presence in the eastern Türkic languages. That points to a western form of the food/apat, with attested presence in the N.Pontic refuge (3rd-1st mill. BC, not a N.Pontic glacial refuge of 13th-9th mill. BC), and spread eastward and westward. As suggested by particular phonetic forms in the Gmc. languages, the form food/apat was shared by the Corded Ware - Sarmatian Kurganians' areas. A presence of the form food/apat in Celtic languages may push its attested presence in the N.Pontic to the 6th-5th mill. BC, to the time of the Celtic circum-Mediterranean migration from the N.Pontic. A presence of two synonymous Türkic forms for “food” in Celtic (bia, bwyd < apat, OIr. alim “sustain me (with food)” < al- “take”) tends to suggests an earlier date. It could be a much later acquisition from the Central Europe area when Globular Amphora culture dissected Corded Ware area before a Celtic westward retreat. A presence of the second word, alim , in Central European Lat. alimonia, Fr. aliments, and Rum. alimente “food” points to ingrained internalization there. A paradigmatic transfer case of two synonyms from the Türkic to the European languages indelibly attests to a genetic origin from a Türkic milieu. See alimony, alimentation, eat, fodder, live.
English gluten (n.) “sticky protein” ~ Türkic yelïm “glue, jelly, paste” (n.), yelimle:- (v.) “to glue”. Ultimately fr. ö:l “damp, moist” (Cf. oil “liquid hydrocarbon”) via öli- “moist, damp”, öli:ge: “sticky”, gelim “glue, jelly, paste” (Ogur), to OSax. klei “glue” > “gluten”. The Ogur counterpart gelim of the eastern Oguz Türkic form's recorded yelïm is visible in the A.-Sax. lim, (be)lim and other European forms. The MFr., Lat. gluten “glue, beeswax” is a denoun derivative of glu-, with an inherited abstract noun suffix -t- and deverbal nominal suffix -en. Semantics indicates an early period, when brans and clays were used for adhesives, long before an invention of the hoof and fish glues necessary for handicrafts and construction of recursive composite bows. The proto-form for yelïm and gelim probably ascends to the term for stickiness recoded as öli:ge: and other derivatives, which in turn ascends to the öli- q.v. Cognates: A.-Sax. lim “anything sticky, lime, mortar, cement, gluten”, (be)lim “glue”, (aeg)lim “eggwhite”, [lim]ceale (keale) “plaster”, claeg “clay”, cliða “poultice plaster”, clæman “smear”, OSax. klei, OFris. klai, MDu clei, Dan klæg “clay”, OHG kliwa “bran”, ONorse kleima, OHG kleiman “cover with clay”, Gmn. kleie “glue”; OIr. glenim “stick, adhere”; OFr. glu “birdlime”, MFr. gluten ; LLat. glus, gluten “glue, beeswax”; Gk. gloios (γλοιος) “sticky (matter)”; Balto-Sl. (Lith.) glitus “sticky”, glitas “mucus”, (OCS) glina “clay”, glenu “slime, mucus”, Rus. kley (клей) “glue”; Pers. lajan “ooze, slime”, lajuj “obstinate”; Mong. deleŋ “moist, tit, udder”; Manchu delen ditto; Tungus (Even, Lamut) delŋa “tit”. A Eurasian distribution spans from Atlantic to Pacific. No credible “IE” etymology. The “PGmc.” and “PIE” etymologies do link the notions of glue and clay. They concoct fictitious “proto-forms” of some conflated forms for glue and clay, failing to credibly trace an origin to its sources. An absence of cited cognates from the eastern “IE” languages and the presence of the OIr. cognate attest to the propagation of the term to Europe prior to the split of the “IE” languages into the western and eastern fractions, prior to 2,000 BC. The OFr. and LLat. forms are late borrowings, probably from the Gothic-Vandalic-Burgund milieu of the Late Antique period. In the European languages the form yelïm has produced words jelly, glue, clay, and lime. The form ö:l in the European languages has produced the words olive and olive oil, their etymology makes clear that the oil was primary, and the olive oil, olive tree, oiled, glue, etc. are secondary. “Gluten” has derivative terms like “glutamic (acid)”, “glutamate (salt)” etc. The cluster containing oil, clay, gluten, etc. constitutes a case of paradigmatic transfer profoundly attesting to its origin from a Türkic phylum. See jelly, glue.
English herb (n.) “non-woody leafy plant” ~ Türkic irvi: (n.) “long tapering plant”, arpa: “barley”, arpağa:n “wild oat, wheat oat”. Possibly a derivative of a prime notion yer “earth, earthly”, Cf. A.-Sax. erd, eard, eorð, eorðe, heorð “earth, earthly”, see earth. Suffix -ğa:n indicates similarity, Cf. Tr. -lig- “possessive, like”. A wide semantic spread points to an initial generic character of the word, which over time was adopted for a shifting variety of concrete nouns. The forms recorded during Middle Ages probably were used at least 5-6 millennia earlier, and were changing with time. Cognates: A.-Sax. gaers, wort “herb, grass”, erbe “non-woody plant, leafy vegetable”, Fris. krud, Dan. urt, Du. kruid “herb”, Sw. ört “herb”; Gmn. kraut “herb”, erbse “pea”, Icl. jurt “herb”; Ir. fear “grass, herb”, eorna “barley”, Welsh perlysiau “herb”; Sl. verba (верба) “woody shrub (pussy-willow)”; OFr. erbe, Fr. herbe “grass, herb, plant fodder”, Rum. iarba “herb”; Lat. herba “grass, herb, herbage, turf, weeds”, Sp. yerba, Port. herva, It. erba; Gk. albi (αλφι, αλφη); Alb. barishte “herb”; Pers. arba; Afgan orbušah; Fin. yrtti; Mong. arbai “barley, oat, rye”; Manchu arfa “barley”; no Skt./Av. cognates. Distribution is truly Eurasian. An “IE etymology” asserts a primacy of herba with an Ogur anlaut consonant h-, a dubious assertion for an Eurasian spread. “IE” linguists tend to recite that “IE forms” like Gk. and Lat. are random coincidents with Türkic forms. There is no justification for a primacy of Lat. form to probably much older Gmc., Baltic, Fennic, Gk., Mong., etc. forms. Wild grasses were used for food for a long hunter-gatherer period. The assertion is humiliated further by brazen claims of faux PWG *gras, PG *grasa “grass”, fr. faux “PIE proto-word” *gʰreh- “grow, become green”. A.-Sax. gaers reflects an Ogur articulation with an anlaut consonant g-, an allophonic A.-Sax. wort reflects an Oguz articulation with a typical Gmc. prosthetic anlaut w-. The Eng. allophonic form erbe echoes a Gmc. erbse and a Sl. verba. Semantic furcation continues to the present, herb- refers to a botanical class of plants (herbarium, herbicide, herbivore, etc.) while herbs is for medicinal and savory plants. A conflation with the Lat. form herba is a late (19th c.) development. Differences in articulation reflect different paths, different sources, and very different timeframes. A first appearance of the word in Europe may be connected with the first Kurgan waves ca. 4400-4300 BC, and then a spread in Europe with later Kurgan waves. Phonetic and semantic affinity attests to a common genetic origin, while the distribution and timing point to independent paths (grass < gaers < aers < arpa: with western Ogur prosthetic anlaut g- vs. Oguzic form erbe < arpa:). See earth, see other plant-related words of Türkic origin: cannabis, caragana, derrick, elm, juice, laber, tree, valerian, wormwood.
English jaggery (n.) “brown sugar” ~ Türkic yaɣïz (n.) “burnt (color), dark”. Ultimately a metaphorical reference to the wet earth's brunneous yaɣïz (< yaɣ) color in opposition to a kö:k “(blue) sky” color (Clauson EDT, 909). It probably ascends to a pre-domestication hunter-gatherer time, fossilized as a hue of the horses (Türkic) and deer (Mong.) and as a generic name for a particular hue, see hue. It apparently came to Hindustan as a name for a brown sugary product of obscure source (Bengal?) but under a Türkic name. First recorded in Avesta (post 3rd c. AD), it was picked up in Skt., Urdu, and Ar. (typ. as sakkar), and in new times reached British Isles via Indo-Port. (< Kannada) as “brown sugar”. Interpreted as allophones, jagara and sakkar bear distinct etymological histories. Cognates: Indo-Portuguese jagara, jagra “brown sugar”; Fr. jagre “brown sugar”; Scots seagaraidh “brown sugar”; Serbo-Croat. jaggeri (јаггери) “brown sugar”; Kannada sarkare (ಶರ್ಕರ ) “sugar”, Hindi, Urdu sakkar (शर्कर, شکر), Skt. sarkara (शर्कर) “sugar”, Av. yaɣïz “brown sugar”; Mong. dajir, dagir “deer”; Jap. jagari, jaggari (ジャガリ, ジャッガリ) (+kokuto 黒糖) “brown sugar”. Distribution spans from Atlantic to Pacific across linguistic barriers. “IE etymology” stops at Hindi, Urdu, Skt., equates etymologically lexemes jaggery and sugar, and comes up for sugar with a faux “PIE proto-word” *korkeh “gravel, boulder” defined as attested “akin to OGk. “pebble” kroke (κροκη)”, see akin. It demonstrates a willful myopia, and translates Skt. sharkara “sugar” and jaggery “brown sugar” as “grit, gravel”. The earliest word jaggery belongs to Avesta, q.v., listed among Avestan-Türkic parallels (Laude-Cirtautas, 1961, 102-103; Studia Turcica. Bp., 1971). Attested evidence makes speculative identifications superfluous. The phonetic and semantic match leave no doubts on the genetic origin from a Türkic lexis. See akin, hue.
English jam (n.) “syrupy preserve of boiled fruit” ~ Türkic jem (n.) “food”, jemiš (jemish) (n.) “fruits”. Ridiculously, under “IE etymology” the word is either rated “of unknown origin” or is deduced from a series of unrelated notions. Ultimately fr. je-/ye- (v.) “eat” jem/yem (n.) “food, edible” (MK III 144). Jemiš is a deverbal noun derivative of je-/ye- (МК II 12), -miš is a suffix to create objects of action (like “fruit”) from specific verbs (like “eat”). Of the 42 European languages, 20 (48%) share a base je-/ye-, 9 (21%) diverse languages use versions of “marmalade”. The other 13 (31%) languages use their own 13 different words. Such pattern shows that they came from 13 distinct sources, one of them (Rus.) also Türkic. 50% of the European languages share Türkic-originated root, matching a level of 50.6% R1a/b demographic presence in Europe. Cognates: Fris. jam “jam”, Du. jam “jam”; Scots jam “jam”, Welsh jam “jam”; Balto-Sl. (Lith.) uogiene “jam”, (Ukr.) džem (джем) “jam”, Czech, Slov., Serb., Macedonian džem (џем), Bulg. džimiš “fruits”; Rum gem “jam”; Maltese gamm “jam”; Basque jam; Yid. klem (קלעם) “jam”; Hu. gyümölcs; Mong. žeme “venery, quarry, venison”, ide-, ideh- “eat, devour, gnaw, nibble”, Bur. zemehen “slaughter fest”, Manchu že “eat”, Evenk žew, žep “consume”, Tungus žepti “eat”. Distribution: Eurasian spanning from Atlantic to Pacific. There is no credible candidate for a Pan-European etymology, no common pan-European word. No sane “IE” etymology. A largest non-Türkic-derived group carries a term atypical for its all four European linguistic branches. Suggested “IE” progenitors are “press” for an explicitly boiling process with no pressing whatsoever, Persian or Hindi “garment, robe” related to pajamas, an alternative form of “jamb” (i.e. doorjamb), “dioscorea” climbing vine plant, and an alternative form of a word iam “yes”. None of them relate to fruits or sweets or tasty substance. Connection between Eng. jam “fruit preserve” and Türkic jem “sweet preserve of crushed fruit” is direct both phonetically and semantically, vividly attesting to an origin from a Türkic milieu. See yammy.
English jelly (n., v.) “sticky substance, gelatin” ~ Türkic yelïm, ilim (n.) “glue, jelly, paste”, yelïmla- (v.) “glue, stick, attach”. Ultimately, likely from Türkic ö:l “damp, moist” (Cf. oil “liquid hydrocarbon”) via öli- “moist, damp”, öli:ge: “sticky”, yelïm “glue, jelly, paste”. A synonym of yelïm is yap- (v.) “glue, stick, attach”: yel and yap- could be allophones with -l-/-p- grammatical suffixing or alternation. Alternations of the initial consonant y-/zh-/j-/ch-/0- are regular and systemic, reflecting an Ogur anlaut consonant and an Oguz absence of it. The alternation -e-/e-/-i-/i- is also regular. Of the 45 European languages 42 (93%) share a Türkic word, mostly with Ogur (R1a) prosthetic anlaut g-. 3 (7%) languages use diverse native words. A cultural loanword flooded nearly entire Europe across all of its linguistic borders, by far exceeding a level of 50.6% R1a/b demographic presence in Europe. Such universal deluge could have occurred only in the commercial, post-Industrial Revolution's times, but the Europe was already well primed by a sequence of early nomadic Kurgan waves. In some languages an ice-cream jelly graduated to a lowly jelly, gelado, etc. Cognates: 42 European forms q.v.; Mari, Chuv. silem “glue”; Mong. jilsün “glue (fish)”; references of loanword yelïm in Pers. (Doerfer G., 1967, Bd. IV, No. 1889). Distribution spans across entire Eurasia, from Atlantic to the Far East. No credible “IE” cognates. Suggested “IE cognates” OFr. gelee “frost, jelly”, geler “congeal”, of supposedly Lat. gelu, gelare “frost, freeze” refer to a homophonic Türkic notion “chill” of the word ye:l (v., n., adj.) “wind, windy”, see chill, yell. A semantically unrelated Lat. pruinae “frost” is way out of the cognate field. The Türkic form is a direct semantic match and a close allophonic form of the European offsprings, The forms jelly, glue, and gluten are allophones describing the same properties of the substance. To derive the “glue” and “jelly” from two different etymological sources solely on phonetic resemblance is unsustainable. See chill, glue, gluten, yell.
English juice (n.) “sap, plant liquids” ~ Türkic yu:sı, jü, yu (n.) “juice”. Ju “juice” is a member of a semantic cluster “sap, juice - marrow - fat”. An attested final -s is an articulation of simulative c (/yu:dj/) that results in a notion “juicy juice”, Cf. saksı “suck” fr. sak-, saɣ- “suck”, see suck. “Juice” is allophonic with yülüк “marrow, sap, juice” and few other semantic extensions. Ju “juice” is genetically inseparable from su, suv “water”, with allophonic alternate anlauts s-, č-, ğ-, d-, h-, ǯ- in various vernaculars, Cf. A.-Sax. sund “water”, sundhelm “covering of water, sea”. The Türkic stem jušil- (jushil), passive of juš- (jush), means “drip” (v.), “dribble” (v.), and points to a semantic origin of the notion juice: it was a sap collected from plants, a hunter-gatherer term, not a fluid pressed out of something. All kinds of conflations, substitutions, semantic transpositions and shifts impacted lexical development. Of 42 European languages, 6 (14%) share a Türkic base ju-/yu-, 21 (50%) diverse languages use versions of Türkic sak-/sok-, Cf. “suck”, “soggy”. The remaining 15 (36%) languages use 6 different native words. A Türkic origin adds to 64%, matching a level of 50.6% R1a/b demographic presence in Europe. That the sok- predominates over ju- by a factor of 4 tells that it was ingrained in Europe long before the ju- came to the same arena. That morsel should bear some diagnostic and historical value. Cognates: ME. jus, juis “juice”, Dan., Sw., Norw. juice; Ir. su, Scots sugh, Welsh sudd “juice” (lit. Tr. “water”); Balt. (Lith.) juše “fish soup”; OCS jucha “broth, soup”, Rus. yushka (юшка) “broth, soup”; OFr. jus “juice, sap, liquid”, Sp. jugo “juice”, Lat. jus, ius “broth, sauce, juice”; Skt. yus- “broth”; Basque zukua “juice”; Fin. ydin “marrow”; LKondomian juluk “sap under (tree) bark”; Saha sumə “juice”; Mong. ǯiluga “marrow”; Tungus ilge, irge “brain”; Chinese ji (Pyn. zhi) (汁) “juice”. Distribution extends from Atlantic to Pacific, but its scatter is not impressive. The ME jus supplanted native siblings wos, sea, seaw, saep “ooze, sap”. The spread and time depth of the distribution point to the origins predating by a millennium the mounted European Scythians (8th c. BC): the Chinese ji “juice”is likely a reflex of the “Scythian” Zhou component in the Chinese language, ca 1700 BC. Eidetic Sl. yushka and Skt. yus- point to a presence of the word in the E. Europe prior to the Aryan southeastward departure ca. 2000 BC. The presence of Celtic su- “water”-based lexicon for “juice” in Europe, the Ir. su, Scots sugh, Welsh sudd attests to its presence in WEurope from 2,800 BC. And attests to its presence in the E. Europe as far back as 6th-5th mill. BC, before a Celtic departure from the N.Pontic on a circum-Mediterranean migration. The Celtic su- “water” corroborates that Celts carried their Türkic language around Mediterranean, across Europe, and back to Anatolia. Its classification as an “IE” is a pre-Nazi fraud. That also explains a wide proliferation in the archaic Europe of the su-based lexicon among diverse local vernaculars. The European parallel eidetic copies of two Türkic words for “juice”, one with a stem complete with an original suffix, present a spectacular case of a paradigmatic transfer. That is an indelible evidence of a genetic origin from a Türkic milieu. See other plant-related words: cannabis, caragana, derrick, elm, herb, laber, tree, valerian, wormwood.
English kitchen (n.) “cooking room” (Sw N/A, F1196 0.01%) ~ Türkic katna:-, kayna:-, qayna:-, kayın- “boil, cook”. Ultimately fr. a verb kan- “boil”; according to G. Clauson (citing kanak), a stem kan- underlies various allophones of qatna- for “boil”. Literally and metaphorically, the prime meaning of the stem kan- means churning, exaltation, agitation, and such for “boil”, hence, among others, the term qayïn for (n.) “cursed”. Probably initially the stem kan- was describing a membrane underlying the skin of a pelt, and a process of its removal. Hence the meanings “cream”, “skin on the milk”, “churning” and “boiling”. That development is attested by a line-up of derivatives. The form qayna- also denotes “bustle”, a suitable epithet for “cook”. The roots qatna- and qayna- had conflated in use (EDTL, v. 5, 204), and may have conflated with forms of qaɣ- and kok- connected with heat cooking. Kok-, qoq- (v.) is “smolder, (cook food) over ashes”, lit. “on ashes, ash-burn (heat, smoke), qaɣur- (v.) is “parch, sear, bake, roast”. The roots qaɣ-, kok- ascend to a notion “dry grass”, i.e. to the times when a cooking fire was associated with dry grass. A trio qoq-, qop, qoz refer to smolder, smoldering fire. The noted cluster is a base of 37 European forms for “kitchen”, from Gk. kouzina to Est. köök, expressed in batches of forms randomly scattered among diverse languages. Those are a group of kuč-, kuz-, kuh- (16), koč- (9), kok- (6), kun- (3), ceg-, cid-, cist- (3, with /k-/), and keit- (1). They all are a part of the lexical mosaic. The last two, Celtic and Fin., are likely the oldest relicts that survived for millennia experiencing greatest phonetic drifts, least leveling, greatest displacement, and least representation. A bit hazy etymological picture greatly contrasts with the explicit clarity of the European forms. Of the 43 European languages 38 (88%) use versions derived from the Türkic roots, q.v. The other 6 (14%) languages use 5 native words. Such stark uniformity points to universal dissemination from a single focus predating by far the classical times of Gk. and Lat. Some of the dissemination went on as late as 18th c. A cognate term often refers both to a room and a type of cooking. Among eastern Türkic languages the form qatna-, qatïn-, closest to the Eng. form, is an oddball leaning to the phonetic form qay-. In the eastern Türkic languages the regular stem for “kitchen” comes from a notion “food” aš, ašlık, attesting to separate linguistic paths. Türkic has a triplet of stems associated with cooking that became active participants in creating corresponding European and Indo-European derivatives, see Cooking and food; Preliminary note q.v. These are kok- “cook (on fire or smoke)”, qatna- “boil”, bu “steam”, and ay- “flame”. Their respective derivatives are “cook”, “kitchen”, bake”, and “fry”. Cognates: A.-Sax. cyčen, cyčene “kitchen”, cyčenðenung “kitchen duty” (with initial /k/), Fris. koken, Dan., Norw. kjøkken, MDu. cökene, Du. keuken-, Sw. kök, OHG chuhhina, Gmn. küche “kitchen”, (ge)kochtes “cooked”; Ir. cistin, Scots cidsin, Welsh cegin; Sl. kuchnia, kuhinja, kuhnya (кухня); Lat. coquina “kitchen”, coquo (v.) “cook”, coquere, coquus (n.) “cook”, Sp. cocina , Port. cozinha, Fr. cuisine; Gk. kouzína (κουζίνα); Alb. kouzina; Yid. kikh (קיך); Fin. keittiö, Est. köök, Hu. konyha; Maltese kčina “kitchen” (+ 13 more); Pers. kavur- “parch, sear” (Doerfer III, 1554); Mong. gugur- “burn” (+ fraud, wrong(ed), qagari- “roast”. A spread of the base roots extends from Atlantic to Pacific, while historical distribution of the form “kitchen” does not extend beyond W. Europe (Cf. Hindi rasoee रसोई). Thus the term postdates the Aryan southeastward migrations of the ca. 2000 BC. It is an European innovation. It filled a preceding lexical gap for a “cooking room” in the Corded Ware lexicons since the mobile Kurgan populations of the time did not have any portable “cooking rooms” but overflowed with terms for cooking. A Türkic ašlïq lit. “foody (room)” came with stratification of the Türkic societies and a rise of stationary centers of power. Confusion is apparent at examination of the myopically suggested “IE” cognates. The roots qaɣ- and kok- are close enough to confuse “IE” etymology, it cites the stem qatna- for a derivative of a stem kok-. An “IE etymology” traces two superficial points, OFr. and Lat., without poking into much deeper origins and spread of the word. That myopia is not sustainable, a demeaningly misleading candidate for an Aesop collection. Symptomatic with the “IE” etymologic methodology, in support of circular logics the choice of cognates is exceedingly selective. Only cases that conform to an “IE” concept are admitted. That leaves a bulk of conforming non-IE terms and non-conforming “IE” terms outside of the “IE” paradigm's purview. European languages have traces of native cooking forms incompatible with a generic “IE” thesis, Cf. Icl. eld(hus) “kitchen”, Latv., Lith. virtuve, and compare Rum. bucatarie vs. Kor. bu-eok (부엌)), Oscan popina. The Celtic Welsh accurately renders the base qaɣ-, kok-, attesting to the existence of the root word in the 5th mill. BC N. Pontic Türkic phylum prior to the Celtic circum-Mediterranean migration to Iberia. A bulk of the “IE” “kitchen” cognates nearly uniformly ascends to the Türkic verbal stems katna:-, kok- “boil, fire or smoke (cooking)” and siblings. Variations between cognates are traceable to variations in the Türkic vernaculars, attesting to a tangled case of paradigmatic transfer, an indelible evidence of a genetic origin from a Türkic archaic milieu. See bake, boil, cook, fry.
English loaf (n.) “baked bread” ~ Türkic lavaš (n.) “baked bread, thin wheat cake”, traditionally flat and rounded. Ultimately fr. a compound liv aš, liv-i aš-у either “ritual food” or “(ritual) food”. Interpretive translations of textual evidence vary. As a part of a paired compound, liv is held as synonymous with aš “food”. The liv aš is interpreted as “offering, sacrifice food, holy food”, as a semantic interpretation of a paired “food food” with liv taken as “food”, or “kind of grain food” with liv standing for Ch. li “kernel of grain”. Forms with prosthetic anlaut consonant k-/h- point to a primary Ogur form kl-/hl- (Cf. hlaf, hlaifs, hleb) and a secondary Oguz l- form, pointing to a much earlier origin than a presumed origin of latter times. A primal word may refer to food as generic for “sustenance, alimony, support”, thus to “life, life support”, and eventually cohere to concrete nouns “life” and “grain”. A flavor of ritual would develop as a tribute to times specific to Uigur religious practices. European languages have two leading forms for “bread” (< “brew”, see booze), the pan and lav. The lav furcated to denote baked food like loafs of bread and traditional generic grain filler like noodles. The last are phonetically related, Cf. Türkic laqša/lakča (laqsha/lakcha), Chuv. läškä (ləshkə) “noodle”. Cognates: A.-Sax. hlaf “baked bread”, hläf “loaf, bread, food”, OFris. hlef, ONorse hleifr, OIcl. hleifr, OHG hleib, Goth. hlaifs, Sw. lev, Gmn. laib “loaf, bread”; Ir. blewynna, Welsh blewynna, mlewynna, Scots laif “loaf”; Balto-Sl. (Lith.) klepas, blynas, (Latv.) klaips; (OCS) levash, levaha, levada, blin (леваш, леваха, левада, блин) “baked pancake”, lapsha, loksha, lohsha (лапша, локша, лохша) “noodle”, hleb “loaf, bread”, Ukr. laksha “noodle”, Cz. livanec “pancake”, chleb “loaf, bread”; Arm., lavash; Ossete lawyz, lauz, lawsi “pancake bread”; Fin. leipä, Est. leib “loaf, bread”; Heb. lawsh or lush “hamur” ~ “pulp, dough”, Yid. latke (לאַטקע) “pancake”; Ar. lawsh (لواش); Ch. yilì, gliǝр (粒, 籽粒) “grain (kernel)”. Distribution extends from Atlantic to Pacific across linguistic borders. Etymological analysis asserts a Türkic origin for lavaš and hence for its cognates. The OCS cognates are attributed to Chagatai, Azeri, Turkish sources. The Sl. form hleb is undeniably consistent with Gmc. and Ogur idiosyncrasies. Still, the “IE etymology” stands at “of uncertain origin”, with no credible “IE” etymology. A suggested Lat. homonym libarе “libation” and all its extensions are versions of a Gk. leibo (λείβω) “pour” unrelated to “baked bread”. Other “IE” suggestions are even further away from reality. On purely phonetical grounds they are superficially identified with allophones of lavash. The Celtic forms blew-, mlew- are peculiar, the anlaut b- may correspond to habitual Gmc. prosthetic anlaut w-/f-. The root and the term may ascend to the times of the Celtic departure from the N. Pontic on a 5th mill. BC circum-Mediterranean voyage to Iberia. Since at that time agriculture had not reached the E. Europe yet, the subject is likely bread of wild millet grass that had survived into Lith. and OCS as blyn, blin. The Ch. word may be a random phonetic coincidence, the notion of a grain seed is a phonetic guess, but it also may be a cultural gift from the 17th c. BC “Scythian” Zhou Kurganians of the W. Eurasia. The Heb. form was recorded in Aramaic in Talmud, it is dated by 600 AD, it is close in time to the oldest European Goth. form for lavash. The Early Middle Age Heb. word may be a cultural or a demic influence of the Khazar connections. The N. European Sprachbunds use prosthetized and non-prosthetized forms, pointing to separate Ogur and Oguz Kurgan waves likely of different times. The form with R1a Y-DNA Ogur prosthetic consonant was probably used by some local tribes, it coexisted with allophones of lav- brought over by later R1b Y-DNA migrants. A semantic development of the Goth. term links the transition of the notion “noodle” to the notion of “baked bread”. That is also traceable in Sl. branch. Etymology of the terms loaf and bread were extensively debated and speculated on by the “IE” linguists after a 1868 publication of the Societe de Linguistique de Paris stipulated a Türkic origin for the forms for loaf. An exclusively NW development from loaf to helpings had produced a Gmc. Sprachbund term “bread”. Paradigmatic transfer of the form and meaning to Gmc. and other languages attests to its innate Türkic origin. See booze.
English mead (n.) “fermented honey drink” ~ Türkic mir, mïr, ba:l (n.) “honey”. The origin of the word is not clear, it should belong to the dusky hunter-gatherer times. Origin(s) should come from a forested area with attested historical bee presence and tradition of apiculture. Complementary to the term mir- for “honey” is a Türkic term arı, harı for “bee” (< par- “to fly, soar”? used for flying insects). There is a prominent m-/b- bifurcation corresponding to a west/east divide respectively. The m- fraction furcates into final -d-/-t- and -l-. The Celtic is of the line -l-, thus mVl and bVl are likely the oldest cognates. Suffixes -l and -r are still active and productive, but their archaic practice may be different from the modern one. 44 European languages are divided into three groupings: -d- 14 languages (32%), -l- 13 (30%), “honey” 11 (25%). The other 6 languages (13%) have two members in the Fennic group, and the rest are unique local words. The “honey” is a stand-alone group independent of the form mir, of unknown origins. Its initial h- may be a Gmc. prosthetic consonant to a root on-. Cognates: Gmc. (A.-Sax.) medu, (ONorse) mjöðr, (Dan.) mjød, (OFris., MDu.) mede, (Gmn.) met/metu “mead”; Celtic (OIr.) mil, mid, (Welsh) mel, fel, medd, (Scots) mil, (Breton) mez “mead”; Balt. medus, meddo “honey”; OCS medu, Sl. med/miod/mjod; Fin. mesi (< *mete?) “honey”, mehiläinen (*mekše?) “bee”, Mordvin puromo (< bur, mur?), Mari pormə (< bur, mur?) “bee”; Gk. meli, beli (μελι, βελι) “honey”, methy (μεθυ) “wine”; Alb. mjal “honey”; Rum. baloš “honey”; Arm. melr “honey”; Skt. madhu “honey, honey drink, wine”, Av. maδu; Kuchean “Tokhar B” mit “honey”; Ar. ary (< Tr.?), easal, asal (عسل) “honey”; Pers. ary (< Tr.?) “honey”; Hittite milit “honey”; Mong. bal “honey, wax”; Chinese mi, miet, mbir (蜜) “honey”; Kor. pel “bee” (< bal); Japanese mitsy (蜜) “honey”. Distribution spans Eurasia across linguistic borders. An outstanding lexical uniformity across Eurasia suggests an origin from a focal point, spread by cultural exchange, probably as a commodity of significant value. Speedy dispersion and adaptation of the product points to a staple in demand and widespread lexical borrowing. A best candidate for such focus is a temperate forested strip west of the Urals. The lands east of the Urals and south of the forest belt were not familiar with honey till the Early Modern times. Some languages that have the word had never adopted a use of the product. Naturally, the “IE etymology” lays a greatest but most dubious claim to preeminence. A cacophony of “reconstructions” blind to attested reality attempt to create a made-to-order myopic myth. The oldest historical traces refer to Burtases, Bulgars, and Khazars, probably including Bashkirs, as active exporters of honey. Later, they are followed by Suvars, Kipchaks, and Oguzes. The oldest lexical trace probably belongs to the Celts ca, 5th mill BC, they carried honey lexicon to Iberia and on to Europe. The Celts were likely preempted in Europe by the early Kurgan waves. In Türkic, mir and mil are dialectal clones of r/l alternation. The same with m/b alternation to bal, typical for the eastern Oguz linguistic subfamily. The same with mir and mis, miz., a rare few. The same with z/d alternation, miz and mid. The -r/-z/-s/-θ/-δ/-d alternation suggests a phoneme -r interpreted differently by hosting languages, and paths of adoption. Peculiarity of the word forms carries valuable diagnostic traits. The Chinese mi is likely a reflex of the “Scythian” Zhou component in the Chinese language, later passed on to Japan. Honey foraging precedes by far the appearance of horse nomadism, the word must have existed long before the Sredny Stog and Samara Eneolithic cultures of 7,000-5,000 BC in the temperate forested strip west of the Urals. Eventually, the product and the word had to be spread with the Kurgan nomadic waves.
English menu (n.) “dishes making up a meal” ~ Türkic meŋ, beŋ (n.) “food, feed, bait; lure”, meŋilä-, müŋila- (v.) “munch, savor”. The word meŋ, beŋ is an allophone of eŋ/aŋ, both denoting food and wild game. Dialectal adaptations may bear slightly differing meanings. A paired tautologic compound of two synonyms, an idiom eŋ meŋ “feed food” is typical for Türkic expressions.. Türkic has 15+ terms for “food” and 9+ terms for “eat, munch”, apparently a result of long history and numerous amalgamations. One of secondary meanings of meŋ is “hemp” aka kenevir nowadays universally known as cannabis, after Herodotus' spelling κανναβις (Herodotus IV 74). It has its own trail of meŋ, beŋ cognates. A homophone of meŋ is “brain”, see brain. Of the 42 European languages 32 (76%) use versions of meŋ for “menu” and 29 (69%) for related “munch”. A second runner-up for “munch” is Sl. with 4 (10%) languages. The other groups of 10 and 13 languages respectively use their own different words. A European dominance of the meŋ-derived lexicon is overwhelming. A stark uniformity of the term across European languages is a late development, cultural borrowings as late as 18th c. Cognates: A.-Sax. mocchen “munch”, Eng. munch “chew”, Gmn. mampfen, mummeln “munch”; Ir. bia, baoite, beatha “bait, food, feed”, Scots biathadh, biadh, biadhadh “bait, food, feed”, Welsh abwyd, bwyd, bwydo “bait, food, feed”; Lat. mand(ucare), It. mang(iare), Rum. manca “munch”; Fr. manger, machez “munch”, menu de repas “menu”, lit. “food to serve”; Arm. muyk (uույք), “eat”; Pers. bangi, bäŋ, bǝŋ, beng “hemp, stunned, stupefied”; Skt. bhanga- “hemp”, Av. baŋha “hemp”; Mong. meŋ “bait”, Kalm. meŋ “bait; lure”; Uig. mäŋilä “eat well”; many references to hypothetical “restored Proto-Altaic cognates”. Distribution spans Eurasia across linguistic borders. The forms meŋ, beŋ show two separate paths to the W. Europe, one a Celtic b-path (b- > b-/bw-/f-) ascending to the N.Pontic of the 5th mill. BC, the other multiple overland Kurgan m-paths, plus an Aryan farmers' b-path of a post-2000 BC migration to the Indian Peninsula. There is a discernible east-west split of semantic flavors, tending to a hunting “bait, lure” in the east and generic “eat, food” in the west. European terms consonant with meŋ and related to food are all genetically connected. Contrary to the IE-centered etymologies, they didn't originate from Lat. minutus “small”, have no business with “minute”, and not a grain of attestation. The suggestion is ludicrous, jumping from a surrogate to a surrogate: “diminish” > “small” > “detail” > “list” > “menu”. Under current “IE etymology” the Pers., Av., and Skt. cognates are held as “cultural words of unclear origin”. A historic Fr. phrase (11th c.) menu de repas “meal menu”, lit. “food to serve” was likely a cultural consequence of the western Hunnic times that stimulated a budding of the European roadway taverns and commerce, possibly a linguistic inheritance of the Provence Burgund aka Bulgar. A likely scenario for the emergence of the term menu is that individual pastoralists, having lost their horse cattle and their pasturing routs as their means of livelihood, switched from production to service. They created “nations of small proprietors” in France (Savoy, Provence), England, and other Early Middle Age principalities now heavily loaded with R1b Y-DNA haplogroup. Unbeknown to its users, the phrase menu de repas was a tautologic composite, repeating the word food twice. Tautology is a common event in linguistic amalgamations (Cf. whole gamut, see gamut, shagreen leather, see skin, etc.). For largely illiterate European clientele signage remained graphic for many centuries, a tradition that extended well into the 19th c. Menu meant an illustration posted on the tavern facade. To attract hungry clientele, menu on the private eatery meant “food”, not a “list” or “diminished”. The phrase is not a “small offered”, “detailed offered”, “diminished dishes, portions, service, choice” or the like. In the Fr. phrase the word menu means “food” (edibles), and the word repas means “kind of food” (as dishes, portions, service, choice, offerings). The word fossilized not earlier than a spread of paper, eventual printing, and basic literacy. Two millennia younger than the Lat. “diminish”, the term menu became associated with a printed list of dishes served, and then extended to the notion “list of choices” in eateries, computers, and other modern applications. The Türkic word is suitable phonetically, is to the point semantically, and fits a historical panorama. Menu belongs to a host of Türkic words of likely Burgund Wendeln “Wonderers” extraction connected with convenience store and eatery: band, bouillon, bodega/boutique, case/cash, glut, jar, tambourine. That lineup allows to visualize a transition from a nomadic pastoralism to a service economy driven by an absence of sufficient pastures in confining conditions. Of a large topical cluster, menu belongs to a paradigmatic transfer case attesting to its origin from a Türkic lexicon. See band, bouillon, boutique, brain, case, cash, gamut, glut, jar, munch, skin, tambourine.
English oat (n.) “grass cereal” ~ Türkic ot, öt (n.) “grass”, ötmak (n.) “bread, cake”. An “IE etymology” stands a routine “of uncertain origin”. Second meanings of ot are generic “medicinal grass, poison” +7 more meanings. Over 8 millenniums, the two meanings survived to modernity. An other form popular in Europe is ov-, an allophone of ot. Notably, both forms echo a generic forms for “food”, e.g. Türkic/Eng. ot/ate “oat” ~ ye/eat “eat”, Skt. av-, ov- “oat” ~ avasam “food”. That extended to modernity. A reason for the phenomenal linguistic longevity was an advent of horse domestication and pastoral economy, and a superior nourishment of oats in respect to grasses. That factor extended to the industrial times and on. Oat consumption and lexicon started with people eons before a horse feed. New items on the hunter-gatherer menu had to gain new names distinct from a generic “food”. At some time, with available morphological means, a generic “food” gained a form of concrete noun “grass cereal”. Of the 44 European languages 34 (77%) use versions of ot, öt. A second runner-up is a peculiar zob with 3 (7%) languages, oddly uniting Hu., Bosnian (aka Pecheneg), and Croat (aka Kangar). The other 7 languages use 6 their own different words. A dominance of the ot-derived lexicon is overwhelming, far exceeding the 50.6% R1a/b demographic presence in Europe. Cognates: A.-Sax. ate “oat”, Fris. oat, Dan. havre, Dutch haver-, Sw. havre “oat”, ONorse eitill “nodule”, Gmn. hafer, OPrus. aviža “oat”; Balto-Sl. (Lith.) aviža, (Latv.) auza, avena, (Sl.) oves (овес) “oat”, otava (отава), trava (трава) “grass”, otrava (отрава) “poison”, Cz. oves, Slvt. ovos, Sloven. ovseni, Pol. owies “oat”; Yid. out (אָוט) “oat”; Fin. kaura, Est. kaer “oat”; Lat., It., Sp. avena, Fr. avoine, Rum. ovaz “oat”; Gk. aigilops (αιγιλωΨ ) “wild oats”, “sty in eye”; Basque olo “oat”; Skt. avasam “food”; Mong. ovyos (овъёос) “oat” (< Rus,?), otačy “healing grass” (Cf. Tr. otçı “eye healer”); Manchu oqto “medicine”. Distribution spans from Atlantic to Pacific across linguistic borders, with some semantic clines. Positively no “IE” etymology. The fantasies of “PG” faux *aito, *aitra “swelling, gland, nodule, matter”, the “PIE” faux *heyd-, *hoyd- “swell, tumor, abscess” and the like, together with its myopic etymological quasi-science, belong to a dust bin of the European history. Phonetics of the word comes in distinct groupings. The Gmc. group is notable for a prosthetic anlaut t h- typical for Ogur articulation, the Sl. replaced alveolar stop t with a labiodental fricative v typical for Eastern European vernaculars, etc. Phonetic distribution allows to project two main paths, one from the Kurgan steppelands to the northern Atlantic and Baltics, the other form the 3rd mill. BC N. Pontic to the S. Europe, Baltics, and Hindustan. A paradigmatic transfer case for notions “food” and “medicinal grass, poison” attest to a genetic origin from a Türkic phylum. See food.
English savory (adj.) “delicious, pleasing in taste” ~ Türkic sev-, suv-, sӧv-, sav-, soy-, (v.) “like, love, savor, fondle, desire”, sevü, sevi (n.) “love”. Synonymous with amra, amran- (v.) “to love”, amïraq, amraq (adj.) “beloved, dear, friend”, a member of a pared sev- amra-, sev- amran- “to love”, see Amor. In Europe, love was intimate and pleasant: 44 languages use a record 18 different roots. Sl. (+Gmc.) lead with lyu-, le-, 13 (30%) languages, confirming that it was a dominant Old Europe language. A runner-up is a popular in Europe Türkic amr-, q.v., 8 (18%) languages becides “savory”, mostly of rousing Romance creed. It failed to supplant the ingrained native lexicons to reach a 50.6% R1a/b demographic presence in Europe. The remaining 23 languages use a bouquet of 16 different native words to express their passions. Cognates: A.-Sax. swaec, swaecc, swaecce “flavour, taste, smell, odor, fragrance”, smaec, smack (n), smaeccan (v.) (b/m alternation) “taste”; Scots saoraidh, Welsh sawrus “savory”; OFr. savore “tasty, flavorful”, savereie “culinary flavoring herb” (< Port. ?); Sp. cebiche (s > c), seviche “delicacy” (“of uncertain origin”); Lat. sapio, sapor (n.) “taste, flavor”, sapere (v.) “flavor”, dubious satureia “savory (plant)” (< OFr. “a foreign word in Lat.”); Gk. sophos (σοφος) “flavor” (> Lat. sapio); Catalan sajolida “savory” (b > j, Cf. soy- q.v.); Pol. czaber, Belarusian chaber (чабер) “savory”; Alb. shije “savory”; Lith. skonis “savory”; Mong. seb “peaceful” (not antagonistic), sedkl amrh “bliss” (< Tr. sev- amra-, q.v.), Kalm. sedkl “heart, soul, thought”; Manchu-Tungis sebže “glad”. Distribution: “savory” spans across entire width of Eurasia, from Atlantic to the Far East. Distribution is akin the “taste”, see taste. That contrasts sharply with the Europe-locked native synonymous gusto and vkus spread across 19 European languages. An “IE etymology” stops dead at OFr. savore (14th c.). It mechanistically suggests a totally unrelated sapient “wise” as a cognate of “tasty, loved”. In a circular logic mode it appeals to anachronistic and unrelated LLat. calque satureie “pot herb” of OFr. savereie “herb”, and to anachronistic Ar. zaʿtar (زَعْتَر). A string of incongruities clumsily attempts to cook up congruent phonetics and semantics of “savory”, a deverbal adj. derivative of the attested Türkic verb sev- “like, love, savor”. There is no need for the “IE” unsavory etymological drivel. That kind of heroic linguistics needs to be gracefully retracted. The dominant forms sev- and luv- for the same notion “love” eerily echo each other, reminding us that they belong to the same genetic stock of Hgs. I and R separated in time and space. The Eng. sw- and Türkic sev- are indeed allophones, as are cebiche and seviche, archaic sophos, surviving seb, sedkl, sebže, etc. The vowel and second consonant are notoriously fluid, -e-, -o-, -a- etc. and -v-, -w-, -b-, -y- etc., but generally follow a sound structural pattern. The Celtic congruence attests to an existence of the word root and its semantics at the times of the Celtic departure from the N. Pontic before a horse was domesticated on a 5th mill. BC circum-Mediterranean voyage to Iberia. The Ancient Gk. word attests to its existence ca. 1st mill. BC. Ditto for the IE-claimed PIt., albeit Celts disembarked and were disseminating still in the 3rd mill. BC. A flood of Zhou “Scythians” to the Far East unfolded in the early 2nd mill. BC, that's a terminal point to the Far Eastern attestations. The first Kurganian's cairns (proto-kurgan structures) are dated by a Khvalynsk period, of the Kurganians' westward migrations of early 5th Millennium BC. Gastronomical love was rolling toward Europe. By that time, Europe was already hosting their much remote pre-Kurgan genetic ancestors for about 4 millenniums. Their presence had already materially changed some of the face of Europe. The accurate phonetic and semantic transmission of the notion “love, delicious” in its many aspects constitutes a case of paradigmatic transfer, distinctly attesting to its origin from a Türkic lexis. See Amor, taste.
4.9 Animal names (38)
Animal Names; Preliminary note. Of 62 Türkic animal names compiled and analyzed by A. Scherbak, 1961, English has retained about 20 names, or ca. 1/3. They belong to temporally different layers, pointing to positively early records (ca. 4000 BC, Cf. Sum. bar-bar - “wolf”), tentative early (before 2000 BC, Cf. Türkic börü, Skt. wrkas - “wolf”) and late (before 1st c. AD, Cf. äshgäk - ass, koyan- coney, sabur - sable). Dating can be deduced from areal distribution, semantic differentiation, and phonetic divergence. Older cognates have wider geographic and linguistic distribution and phonetic divergence. Later cognates are more compact geographically, more cohesive phonetically, and more species-speciated. The 1/3 fraction is consistent with a rough assessment that about 1/3 of the Gmc. lexicon comes from a non-IE linguistic substrate, and considerably higher for Eng. When the Türkic nomenclature has clinal differences, English cognates tend to belong to the NW part of the cline, but in few instances the nearest cognates border on a Tungus-Manchu area, expected for the Enisei Kirgizes (aka Khakasses). That corroborates an observation on extensive Enisei Kirgiz parallels in English. Reference to Khakass is eponymic, it reflects an available literary base, and not the ethnic paths that brought their forms to English. Practically all Türkic names for animals carry traces of generic origin, semantic divergence and speciation. All Türkic terms are attested. Some names are remarkable for outstanding stability of their stems traversing temporal, spatial, and linguistic differences. Few Türkic names of unknown origin have not passed to English, they may serve as terminal points of the splits. Of 62-species Türkic animal lexicon three species, the horse, cow, and sheep, take ca. 40% of the descriptions. That reflects a relative importance of those species in the life of the Türkic people: horse 20%, and cow and sheep at 10% each (Scherbak 1961). The remaining 59 species each takes on average 1% of descriptions. That indirectly attests that a half of the Türkic horse nomadic economy was supported by species suitable only for stationary animal husbandry, covering demographically a half of the Türkic-speaking population.
European languages have a spotty distribution of the Türkic stems. Numerous native and demonstratively non-IE origin words survived in different European languages. A status in Asia is motley too, even among the “IE languages” the “IE” terms are manifestly not predominant. In most instances, etymological attributions misrepresent an origin. Türkic terms are notoriously ascribed either to a linguistic family of the dictionary, or to some secondary intermediary source. As a rule, claimed intermediary cognates are certifiable loanwords. The “IE etymology” invariably offers an incoherent jumble of roots tailored to various misclassified “IE forms”, at times quite ridiculous, systemically circular and ubiquitously devoid of a prime notion. The Türkic stem bu, for example, with allophones bo, bü, bö, (v-, w-), initially designated a generic “wild animal”. It diverged into “wild steppe animal”, “wild forest animal”, and “wild tundra animal”, and speciated into concrete nouns within each environmental zone. It had produced steppe derivatives Eng. bull, Tr. buqa, Sl. byk “uncastrated adult bovine male”, adjective bovine, genus Bos, Sp. burro, etc. Forest derivatives Eng. wolf, Tr. böri, Sl. volk, etc. “wolf, wild forest animal”. Tundra derivatives Tr. buɣu, Mong. buga, Manchu buho, Tungus buhu, bəün “deer, elk, maral “wild forest and tundra animal”. The stem culminated with a royal name Boris, which in the Türkic societies still carried its semantic meaning. On the other end of the Eurasia, in Yakutia the bur became a generic “male” for deer, moose, and the like tundra mammals of the Cervidae family. The origin of the notion “ferocious, feral” for “wild” may be a derivative of the notion bu/bur for “steam”, still reflected in the idiom “(a person) reached a boiling point”, i.e. became ferocious/furious, ready to explode, and the like expressions. The Türkic stem aŋ “animal”, especially “wild animal”, has produced a whole legacy of names starting or ending with aŋ (an, en, on, un, äŋ, etc.) with determinants of the type “ferocious”, “white”, “motley”, “beautiful”, “N-years-old”, etc., spread across Eurasia including Europe (Cf. animal “animal”, coney - kuyan, hare - horan, kuyan - horan).
The names come undifferentiated, colloquial, loanwords, exotic, supplanted, and euphemistic, making them fairly transparent and traceable. Taken as a finite set of lexical traits, animal names provide a statistically infinite example of paradigmatic transfer with probability value indistinguishable from a hard 1 “absolute confidence”. A tabulation of cited substrate cognates is below, there is plenty of room for more: birds, fish, insects.
|
|
Animals cognate list
| No | English | Türkic | No | English | Türkic |
| 1 | animal | aŋ | 21 | goose | kuš, qaz |
| 2 | argal | arkar | 22 | hare | horan |
| 3 | ass | äshgäk | 23 | hawk | haw |
| 4 | beetle | bit | 24 | hoopoe | üpüp |
| 5 | bitch | bi | 25 | horse | ars |
| 6 | bull, bovine, etc. | buqa | 26 | lamb | -la:n |
| 7 | cat | kädi | 27 | mare | ma |
| 8 | cattle | katıl | 28 | moose | mus |
| 9 | chattel | čatïl | 29 | mouse | muš |
| 10 | cob | kev- | 30 | owl | aba(qulaq) |
| 11 | cock (rooster) | kök | 31 | ox | öküz |
| 12 | coney, cony | koyan | 32 | puppy (dog) | papak |
| 13 | cow | koy, kälä | 33 | pussy (cat) | päsi |
| 14 | crow | qarɣa | 34 | sheep | sip, čip |
| 15 | dog | dayğa:n | 35 | steer | tor- |
| 16 | duck | öndek | 36 | tick | tik- |
| 17 | elk | elik | 37 | whelp | bala:p |
| 18 | frog | baqa | 38 | wolf | börü |
| 19 | gnat | yenč- | 39 | ||
| 20 | goat | käči | 40 |
English animal (n.) “beast” ~ Türkic aŋ, äŋ, eŋ, ag, aɣ, av (n., 18+ forms) “animal (wild), game”; -aŋ, -eŋ suffix denoting a wild animal. Semantics of the word aŋ covers generic lexicon connected with procurement of food: game fauna, hunt, hide (hunting), encircling, etc., see food. It can form speciated names, Cf. aangič “duck (kind)”, anɣyt “coot (kind)”. The Türkic suffix determinative -aŋ, -laŋ, Ch. 狼 (-laŋ) is most significant, it concatenates with determinant forming a term from nominal, verbal, etc. notions, Cf. koyan “coney” (qoy (n.) “cow or sheep”), yavan “asp” (ava (interj.) “awful, grief”), arslan “lion” (ars- (v.) “roar, cry”). The word hunt (h- aŋ -t) is formed with a prosthetic h- and an abstract suffix -t, like the words gift, unit, Celt, etc. The root aŋ has produced a line of derivatives: aŋčı: “hunter”, aŋčılıq “hunting”, aŋzaq (adj.) “gaming, hunting”, aŋta “lie in wait”, aŋzıra- (v.) “animalize”, aŋzı- (v.) “grow wild, animated”, etc. Temporally, separation of aŋ > av (CT) occurred “very early” (EDTL, v. 1, 152), av practically supplanted aŋ in CT, but derivatives of both (+ many others, q.v.) have survived to the present. The Lat. agglutinated suffixes -im- (m.?, “me”?), -al (adj.), Cf. Lat. -alis, serve to concatenate word animal (n.), a term developed many millenniums after the notion aŋ. In the word aŋ the notions “instinct, soul” and the like are temporally a long way from a notion “food” buried in the notion “food, game” long before a first domestication of animals (Clauson EDT, 166). The notion “soul” is a remote incarnation of a humble “food”. Of 44 European languages, Türkic leads with a combined an- and dier- in 20 (45%) languages, close to a level of 50.6% R1a/b demographic presence in Europe. It is followed by the Old Europe Sl. with 15 (34%) languages. The remaining 10 (23%) languages march to their own tunes with 7 native distinct words. Cognates: A.-Sax. Anglo- < angle “catch (fish)”, hunt “catch” (prosthetic h-); Ir. ainmhi “animal” (b/m), Welsh anifeil (b/f); Lat. animalis “animal” (> Catalan, Fr., Galician, Port., Rum., Sp., Corsican, It. > Basque, Eng., Maltese), animale “living being” (but Gk. zoo (ζωο) ditto), animus “basic impulses and instincts”; Gmn. animiert “animated” (but Gmc. dyr-, dier-, tier- “animal” < Tr. tirig “tarry, live, alive”, see tarry); Fin. hangas “trap” (prosthetic h-), Saami angas “trap”; Mong. ang, an(g) “animal, animals”, “wild animal”, “game”, “hunt”, “trophy”, “chase”, angla- (v.) “hunt, chase, catch”, anah “watch, watch for, beware, watchful”; Tung. аŋ “wild animal, game”, aŋan “fence (corral)”; Tung.-Manchu (Negid.) аŋа “net (fishing)”, (Nanai, Oroch., Orok., Ulch.) aŋga ditto; Kor. anh, аn “fenced in, enclosed”. Distribution: extends across much of the Eurasia, from Atlantic to Pacific, supplanting rarely the ingrained native terms. “IE etymology” proposes hot air for a tangible commodity of “food” and “game (edible)”: faux “PIE proto-roots” *ane- “breathe”, *henh-, *henhmos “breathe”, faux “Proto-Italic” *anamos “breathe”, and a line-up of unrelated “cognates” with airy pedigrees, the Gk. “wind, breeze”, “basic impulses and instincts”, OArm. “person”, Arm. “wind”, OFris., Eng., Norw. “breath”, Skt. “air, wind”; Kuchean (aka Tochar. B, agglutinative) “self; soul”. That kind of a clueless “IE” ad hock etymologizing has nothing to do with etymology, it needs to be gracefully disposed of. False loyalty-driven claims of alien lexicons breed disinformation in conflict with scientific objectivity, methods, and objectives. Some suggestions are counterproductive: OArm. “person” is a “creature”, Gk. “basic impulses and instincts” is “wild”, both are synonymous with “animal”. Celtic forms attest to a presence of the word in the N.Pontic before the 6th-5th mill. BC Celtic departure on a westward circum-Mediterranean anabasis. In the 2nd mill. BC Lat. carried the same lexicon from the same general area. Gmc. forms come directly from a Türkic milieu of the 3rd mill. BC Corded Ware-Battle Axe symbiosis. Mong. polysemants closely follows the Türkic polysemants. The NW and Far Eastern languages repurposed a cardinal word for different utilitarian uses. The Anglo - angle correspondence puzzled early philologists, the Türkic aŋ “catch” clenches a conclusion. In many cases the notion “animal” is unexpressed, the “hunt, chase, catch, trap” refer to an “animal (incl. fish)” with or without direct reference. The Old Europe Sl. languages have preserved their own native term, adopting pertinent loanwords from the SW and NW cultural vocabularies at various historical stages. All European languages formed motley vocabularies drawn from neighboring Sprachbunds, which in turn amalgamated Sprachbunds of the previous epochs with their specific demographic breakdowns, and so on. At the end, ordinarily only typology and morphological elements have survived across millennia, with very rare exceptions of local typological pidginization. The combined weight of evidence, historical developments, geography, phonetics and semantics attest to a genetic origin from a Türkic linguistic cradle ascending to the times when aŋ “game” was a “food”, hence “hunt”, hence “animal”. See food, tarry.
English argal, argali (n.) “semidesert wild sheep, Ovis ammon” ~ Türkic arkar (n.) “semidesert wild sheep”. Ultimately a deverbal noun fr. arɣï-, erɣï- (v.) “to career, run with fast career”, ïrɣï- (v.) “jump, leap”, formed with frequentative suffix -ɣï. The verb is homophonic with a derivative arɣa- “weave” of the same root and echoing semantics. The noun is generic, specific to certain types of sheep, goats, or even antelopes. Cognates: Eng., Rus. argamak, arɣamaq (аргамак) “fast horse”, refer to argamak; Mong., Bur. argali (аргаль) “argal”, Kalm. arhl (арһл) “argal”. Spotty presence and distribution across Eurasia, from Atlantic to the Far East. In spite of ample etymological sources, an “IE etymology” stops at Mong. which does not have an underlying root. There is no need for a faux “Proto-Türkic word” *arkar either. The attested arkar and its Türkic etymology work just fine.
English ass (n.) “donkey” (Sw N/A, F652, 0.01%) ~ Türkic eš(äk), äš(käk) (n.) “ass”. “IE etymology” confesses that “most “IE” words for “ass”' are loanwords”, but is shy to name the source. Ultimately a deverbal noun/adjective derivative fr. eš- “run, hurry, amble”, lit. “ambler”; suffix äk, -käk connotes habitual action. A secondary semantics of “plod, trail, follow, escort” is more realistic. A first record of ass for “donkey” comes fr. Sum. ansu (dated anywhere from 4500 BC to 2000 BC). It corroborates indicators that donkey was first domesticated in Central Asia, that it came to Mesopotamia with horse nomadic tribes noted in 3rd mill. BC. It corroborates a remarkable longevity of the Türkic stems and some Türkic lexicon in Sum. language. The early Assyrian records list few names of the neighboring horse nomadic tribes, see Introduction. Of 45 European languages, 29 (65%) use allophones of as-; another 8 (18%) use a base -mar- (see mare), i.e. 37 (83%) use Türkic roots. That more than matches a level of the 50.6% R1a/b demographic presence in Europe. The other 7 (16%) languages use their own 4 basic words with no notable domination but peculiar Balkan forms. Cognates: A.-Sax. assa, esol, assal, assald “ass”, OSax., OHG. esil, Du. ezel, Goth. asilus, Gmn. esel “ass”; OIr. asan, OCornish asen, Gaelic asal “ass”; Balto-Sl. (Lith.) asilas, (OCS) osl, (Sl.) osel, (Rus.) osel, ishak (ишак) “ass”; Lat. asinus, It. asino, Sp. asno, OFr asne, Fr. ane “ass”; OGk. ous, onos (ουoς) “ass”; Arm eš “ass”; Sum. ansu “ass”; Mong. elžigen, iljig “ass”; Manchu əyhen, eiχen ejiχen “ass”; Tungus əyhe “ass”; Türkic forms with Ogur-type prosthetic anlaut consonant: Kaz., Gagauz yäšäk “ass”. The term is spread from Europe to Asia and Pacific. Ominously, “IE cognates” are absent on the Asian side with their own non-IE forms, Cf. Hindi, Urdu gadha. An “IE etymology” asserts an origin fr. Lat. asinus and PWG faux *asil fr. Lat. That asinine (< Lat. asininus “of ass”) etymology suggests a Sum. daughter being 4000-1500 years older than its own Lat. grandmother, and Lat. cousins in Mong., Manchu, etc. Under the “IE” etymology the Celtic and Gmc. forms are Lat. daughters (1st mill. BC) and not a product of Celtic arrival to Iberia and a Corded Ware culture (3rd mill. BC) respectively. The Celtic departure in a westward circum-Mediterranean movement from the N. Pontic falls on a 6th-5th mill. BC, and their presence in Mesopotamia roughly coincides with a rise of Sum. civilization. An absurd of the upside-down “IE etymology” does not fit attested historical sequence of genetics and archeology. The bogus etymology is waiting to be gracefully rescinded. In many cases internalized word has a Türkic verbal passive suffix -l (-il, -el) as a part of the stem, Cf. A.-Sax., Balto-Sl., Gmc. forms. The A.-Sax. and Lat. forms demonstrate parallel and independent paths: assa (male), assen, eosele, assmyre (female, see mare) vs. Lat. asinus, asellos. The ultimate Türkic etymological origin (Clauson EDT 260) suggests that the tribes of the A.-Sax. circle or their Kurgan predecessors have been instrumental in spreading their terms for donkey to Lat. and Western Europe. A salient semantic and phonetic concordance presents a case of paradigmatic transfer, an indelible attestation of an origin from a Türkic linguistic milieu. See Introduction, mare.
English beetle (n.) “encrusted insect” ~ Türkic bit (n.) “louse, insect, bug”, bitla- “delouse, search-kill bugs”, böcek (böjek) “insect, beetle, bug”. The bit- and böc- are either allophones or closely related. A.-Sax. used to have its own insect nomenclature, eventually largely supplanted: ceafor, wibba, wicga, wifel (weevil), ymel. From its dawn, insect infestation was a curse of humanity and related vocabulary was most prominent and enduring. Competing with ingrained terms, of 45 European languages, only 5 (11%) adopted allophones of the Türkic bit-, all of them exclusively Gmc. The other 40 (89%) use their own 19 (!) native words, of which only 6 (13%) adopted Lat.-derived versions. There is no trace of an “IE family” in Europe or elsewhere. Echoing a poet, “there's no IE, we only dream of it”. Gmc. and Balt.-Sl. do share some roots, Cf. Balt. vabole vs. weevil, Sl. veblitsa “intestinal worm”. Cognates: A.-Sax. bita, bitela, bitle, bityl, bytylle, budda (dial.), butor “beetle”, bitel “biting (delouse)”, Dan., Norse bille, Icl. bjallan, Gmn. beetle; Serb. bitpazar “flee market (bazaar)”; Mong. boe(sun) “louse, bug”, Kalm. bi- “spider, scorpion” (< Tr. bi “tarantula”, biyt “louse”, bitla- “delouse”). Distribution spans across Eurasia from Atlantic to the Far East. There is no sane “IE” etymology. Ridiculously, “IE etymology” connects beetle “bug” with a bite, rather than with the Türkic bit “bug” or böc/böcek (böj, böjek) “beetle”, apparently finding it to be a shorter and innovative diversion. The “IE etymology” offers a faux “PG proto-word” *bitan “split” and its precursor “PIE proto-word” *bheid- “split” also related to biting. And using a Türkic denoun verbal suffix -le, -la it dreams up faux “PG” ersatzes *bitulaz, *bitilaz “biter” extendable to Faroese bitil “little bit”. All that nonsense is perfectly parochial, it does not extend to Mongolia nor even to a very “IE” Serbia. Instead of dispersing knowledge it dissipates faux and deceit. An alternation -t-/-c- (/-j-, -dj-/) is regular. A Gmc. exclusivity points to an amalgamation of a Corded Ware period, dating internalization to a historically defined period. An unusual phonetic dispersion of the A.-Sax. forms points to numerous paths spread in time from diverse sources and eventual leveling. A contrast of bita, bitela with budda also points to parallel lexical paths. A tentative connection between bit and böc- (böj-) is a corollary to the bit “beetle” etymology. A path böcek (böjek) > büj > budj > Ang-Sax. budda > beetle appear sound, considering a ready interchangeability of ö/ü and o/u in Türkic languages and the fluidity of the the affricate j. The suffix -ek is a Türkic diminutive marker: böc- (böj-) > böcek (böjek). Phonetic, semantic, and morphological match attests to a case of paradigmatic transfer and makes an origin from a Türkic linguistic phylum inescapable.
English bitch (n.) “female dog” (Sw N/A, F974, 0.01%) ~ Türkic bi, biči “mare”. An “IE etymology” asserts a staple “of unknown origin”, explicitly implying a non-IE origin. That does not stop good entrepreneurs from inventing “IE” utopian reality. The root bi belongs to an allophonic set ma-, ma:, me:, ba-, ba:, be:, bi for a notion of feminity. It has produced an uncounted number of natural and “IE” offsprings, incl. attested Eng. woman, mistress (+ miss), maiden, wife, etc., Türkic bike, biyke “mistress”, biyče “wife”, madä, biykeš “maiden”, etc. The initial b- can be articulated as m-, v-, w-, p-, f-, and be prefaced by a prosthetic vowel. Variations reflect areal articulations, helping with etymological tracing. The Eng. bitch and Türkic biči are eidetic and largely generic, attesting to a generic nature of the original term. For a notion of “feminity”, of 44 European languages 15 (34%) use versions of Türkic bi-, falling short of matching a level of 50.6% R1a/b demographic presence in Europe. That is because cumulatively 17 (39%) languages use their own non-supplanted native words: three groups totaling 8 (18%) languages use 3 of their own terms, as many as 9 other languages use their own distinct words. A second-largest group is Sl., it uses versions of a base žen- by 12 (27%) languages, apparently representing linguistic content of the Old Europe (4th mill. BC). The present landscape is far from reflecting historical dynamics, it does not account for many past changes, languages, and ethnic prejudices. A pattern of lexically noting sex is limited to its practical significance, mainly for domesticated animals and humans. Cognates: A.-Sax. bicce, bice “bitch”, maeden, maegden “female” (< Tr. ma, madä “female”), maedenclid “female child, girl”, maeg “female relative, wife, woman, maiden”, maere, mare, mere “fem. horse”, biccen, bicgan, byccen “fem. goat” (male Tr. ərkak, ər “male”), baarg “fem. hog, swine” (male Tr. kaban); ONorse bikkjuna “female dog (hound)”; Lapp pittja “bitch”; Mong. baytsan “farrow” (mare, cow), Bur. baltakan “farrow” (mare, cow); Tungus be, morin, muran “mare”, Manchu morin “mare”, məhən “pig (fem.)” (Tr. fem. donguz). Distribution spans from Atlantic to Pacific across linguistic barriers. Terms are recycled, reshaped, and reinvented, combining inertia and innovation, forming a continent-wide overlapping terminological continuum. In light of a continuum of geographically distributed evidentiary mass a proposed faux “PIE proto-word” *dheh-mhn-eh “the one nursing, breastfeeding” is laughable and not needed. The surviving common Türkic “bitch” is kančık “bitch (dog)”. Unlike its European counterpart, without negative connotations it also is generically applied to any female animal. The connection between Türkic on one end, ONorse in the middle, and Eng. on the other end is tangible: the ONorse bikkjuna is a compound of bi (female animal) + kjuna (parent), of which Eng. preserved the root bi (female animal) with suffix -itch/-tch, and Türkic preserved the root kaŋ (father, parent) with suffix -čık. The Eng. suffix -itch/-tch corresponds to the Tr. abstract noun suffix -ich/-ish, bitch is an abstract noun of bi, where bi is either a concrete noun for a female horse, or a generic for femininity, it works either way. The Tr. suffix -čık (-chık) is a compound of a diminutive denoun suffix -č and a diminutive marker -ık, a la “a second (smaller) part” of the base kaŋ (father, parent). All three forms express the same “animal mother” using their own unique forms with common morphological markers, each language had to come up with a way to form a word discriminating a notion “bitch” from “mare”. The Lapp form also ascends to the root bi with the female gender marker -a/-ja (ya), it is morphologically an ONorse form, and probably an allophone of an alternate ONorse form (without a surplus root for “parent”). Notably, the ONorse had a phrase bikkju-sonr “son of a bitch”, a precursor of the Eng. expression, using bikkju instead of a native “IE” word tik for “bitch”. A Sl. allophone of the tik is suka (сука), the pair attests that the Northern Europe had its own “IE” terminology, later supplanted by the Türkic lexicon. The Sl. form has negative connotations unnatural for its Tr. counterpart. The trio constitutes a complex paradigm, documented in disjointed but overlapping segments that together refute the assertion “of unknown origin”, and instead supply sufficient ammunition for a convincing conclusion on a Türkic origin. See mare.
English bull (n.) “bovine male”, “uncastrated adult cattle male, steer” ~ Türkic bilä, buqa, büqa, bïqa “uncastrated adult bovine male”. Türkic buqa could be a derivative of the stem bug- “bend”, as allusion to a notorious aggressive posture of the bulls. Fossilized lexical relicts attest to a period of undifferentiated metonymic use of the word for large animals: A.-Sax. bucca “buck, he-goat, male deer”; WMong., Dagur bugu, bog “deer”; Manchu buka “ram”, buhu “deer”, bukun “antelope”, and also male “beast”, “buffalo”, “goat”, “saiga”, “argali”, “wild goat”. Eurasia has two leading areal terms for “bull”, buC and Tor, where C stands for a choice of few consonants: -q/-g/-l/v-/f- and their siblings, and T may sound like t-/s-/ts-/th-. A -v- form has survived in derivatives, buvasamak and its allophones. Geographical distribution of the two is very pronounced, the buC is contiguous in the Northern Eurasia, and Tor is contiguous in the South-Western Eurasia. The -l form (bul, vol), as opposed to the -k form (buqa, bika), is shared by the western and eastern branches. It may serve as a diagnostic tracer. Few outliers complete the picture, Cf. Fin. sonni, Hindi saand (सांड), Icl. naut “bull”. Cognates: A.-Sax. bulluc “male calf, bullock”, ONorse boli, WFris. bolle, MDu. bulle, Du. bul, Gmn. Bulle “bull”; Balto-Sl. (Latv.) bullis, (Lith.) buliukas “bull”, (Sl.) vol (вол) “castrated bull”, byk, bugai (бык, бугай) “bull”; Gujarati, Punjabi balada (બળદ, ਬਲਦ), Telegu bul (బుల్) “bull”; Hu. bika “bull”; Est. pull “bull”; Thracian bolinthos (βολινθος) “wild bull, bison”; Albanian buall “buffalo”; Mong., Kalm. buh, buha (бух) “bull”; Tungus-Manchu (Evenk.) buk, buka “bull”; Jap. buru (ブル) “bull”. Distribution: the metonymic use extends across much of the Eurasia. Direction of borrowing is indicated by a generic term of the parental languages becoming varietal term in the recipient languages. “IE etymology” came up with myths in conflict with the mass of the Eurasian evidence: faux “PG” *bullon- “bull”, “roar”, “PIE” *bhel- “blow, swell”, utterly incredible mechanical constructs. With the wealth of attested material there is no need for pitiful self-serving tales. The international form buC was spread by mobile animal husbandry entrepreneurs who also propagated the complimentary term for castrated adult cattle male, the ox, the Türkic öküz “castrated adult bovine male”, see ox. Geographical distribution of the pair buC and ox is identical. In the Tor area, a counterpart for castrated bull is a borrowing from the buC zone: Gk. bodi (βόδι), Lat. bovis, hence “bovine”, q.v. Similarly, the Tor forms spill beyond zonal borders, Cf. A.-Sax. steor “bullock”, Eng. steer. The form buC was probably already widespread within the contiguous “pre-Kurgan” archeological cultures noted for their animal husbandry economies: Khvalynsk (6000 BC on), Samara (5500–4800 BC), Sredny Stog (4500-3500 BC), and their areal extensions. In the unabated Türkic mother language, the Eng. homophonic bull “steer” and bull “document” were clearly distinct: buqa “bull” and bola “cord”. The OCS adjective voloyu (волоуи) from vol (вол) has a Türkic suffix modifier -yu, attesting to its Türkic origin. The simultaneous propagation of bull and ox presents a case of paradigmatic transfer, indelibly attesting to an origin from a Türkic vocabulary. See ox.
English cat (n., v.) “cat” (Sw N/A, F1214 0.01%) ~ Türkic kädi, kədi “cat” (+pïšïk, muš, mïčïk, čätük + a dozen more). Feral or domesticated, cats are cats. Etymology is embryonic, stopping at ethereal PG. Türkic words for “cat” are pairs mö:š, ma:čı: and kädi, četük. These forms are predominant in Europe, across Eurasia, and some beyond. Etymology for the forms mö:š, ma:čı: is shared by cats and mice, donkeys and lions, see A. Scherbak's etymology for mVš-related forms (Scherbak, 1961, 129), see mouse, moose. The mV-/bV- (m-/b- alternation) is a primordial generic for “animal” or certain classes of animals, like “fur animals”. An imitative miaul (Türkic (v.) mujav-) points to an initial mö:š for “cat” (Scherbak, q.v.), later extended to include “mouse”. It speciated to “cat-mouse” and “cat”. Speculatively, “cat” and its name came from Africa to the Near East, and then spread to Mesopotamia (7th mill. BC), Greece (ca. 5 c. BC), England (ca. 3 c. BC) and from Mesopotamia on to Eurasia reaching China (7th mill. BC). That implies that an epithet was coming with an object. That is a faulty presumption in conflict with a situation on the ground. Of 44 European languages, allophones of kädi “cat” use 32 (73%) languages, allophones of muš “mouse” for “cat” use 24 (55%) languages, either one is easily matching a level of 50.6% R1a/b demographic presence in Europe. The m- forms for “cat” are allophonic with the claimed “*IE” base mü:š for “mouse”: “*mus- an old *IE name of the mouse”. When, how, and from where it became *IE is not elucidated. *IE etymology cites this base for all *IE cognates for the word “mouse”, while the same m- base for “cat” either escaped or was ignored by the *IE-enchanted linguists. The aberrant dichotomy does not perturb neither *IE etymologists nor the *IE etymology. Cognates: A.-Sax. catt, catte (ca 700), OFris. katte, ONorse köttr, Du. kat, OHG kazza, Gmn. katze, Goth. katts; OIr., Gael. cat, Welsh kath/gath/chath, Breton kaz; OFr. chat (12th c.), Lat. catta (ca. 75 AD) (but feles, felis, faeles ca. 2nd c. BC, Cicero), LLat. cattus, It. gatto, Sp. gato (but Rum. pisica, mata; pisica is an allophone of mü:š with m-/b-/p- alternation, Cf. Az. pišik); Gk. katta, gata (καττα, γατα) (ca 350 AD); Balto-Sl. (Lith.) kate, (OCS) kotuka, kotela, (Pol.) kot, (Rus.) kot, koška; all “cat”; *IE group west Arm. katu (կատու), Icl. köttur; Latv. kakis; *IE group east Gujar. keta (કેટ), Punjab kaita; unknown classification Basque katu; Uralic family Fin. katti, Est. kass, NSami gadfe “female ermine, stoat”; Kartvelian family Georg. kata (კატა); Semitic family Ar. qat (قط), qitt (m.) “cat”, mashia (ماشية) “cattle” < muš “animal”; Afroasiatic family Berber kadiska; Nilo-Saharan family Nubian kadis; disputed family Jap. kyatto (キャット), Kor. goyang-i (고양이); Sino-Tibetan family Burmise kyaung; Ch. mao (猫); Amerindian Maya mis, mees; Türkic family Turk. kedi; all “cat” except as noted. Distribution: wide Eurasian spread across familial borders, cognates for “cat” parallel that for the muš “mouse (+ cat)”. Nomenclature is unidirectional, the “mouse” name is widely applied to cats, while the “cat” name is never applied to mouse, a profound trait. The Coptic šau “tomcat”, Sum. saa, sua “cat”, Sum.-Akkadian. gullum “cat” rule out Mesopotamia as a focus of Anatolian-Gk.-European spread. Any claim on *IE or Gmc. etymological origin is unsustainable for both kädi “cat” and muš “mouse (+ cat)”. An *IE claim is bare without any support. A faux “PG proto-word” *kattuz “cat” is not needed and should be gracefully rescinded. An appeal to PUralic origin does not help either, Uralic falls way short for disseminating the word to the Eurasian scale. A suggestion of a Wanderwort status does not help either, all words carry a legacy. The Mayan word attests to a historical primacy of muš (at least 10,0000 YBP) in respect to a later “cat”. The R1a demic migrations from Central Asia to Europe (southern route) dated ca 9,000 YBP, and near simultaneous Afroasiatic migrations (Y-DNA Hg. E1b1b) to the Near East can't be even remotely asserted as a prime source for cat, kädi “cat”. Neither a Lat. origin (ca. 75 AD) of the Gmc. “cat” can be credibly asserted. The overland R1b migrations started in 4th mill. BC. That made the undifferentiated Türkic muš “mouse (+ cat)” a European staple preserved to the present. On that background, a spread of speciated alternate kädi “cat” suggests the same source as for the muš “mouse (+ cat)”, an innovation driven by subsequent R1b demographic flows. The R1b Celtic circum-Mediterranean trip from the E. Europe is a good candidate for seeding Middle East, Africa, and finally Europe in the 4th -3rd mill. BC. The Lat. native feles was colloquial, anemic, and supplanted by a regular kädi “cat”. Phonetics of the early anlaut c- could be k-/ch-/ts-, with a European tendency toward k-/h-. The k-/č- alternation parallels that of the form čat- “chat”, with Gmc. forms for “chat” coming with anlaut k-. Like the cat's imitative miaul, the čat- (v.) “chat” is imitative “sound, noise”, concordant with an animal naming practice. Conflated, it created parallel articulation cat - čat fossilized in the modern vernaculars, q.v., in the Türkic čät(ük) with a diminutive suffix -uk, and its cousins OFr. chat, Welsh chath. The same process formed Eng. cattle vs. chattel. Thus, an only viable source are the Türkic R1a/b Kurganians, consistent with temporal, geographical, and mobility ranges. Eastern Türkic languages have preserved a tautological pair četük - mü:š “cat - mouse” attesting to a period of undifferentiated semantics when the term mü:š “mouse” could designate either “cat” or “mouse”. Numerous other Türkic names for animals had such well-documented indefinite undifferentiated period. This unique linguistic trait either escaped or was ignored by the *IE-dazzled linguists. The pair četük - mü:š “cat - mouse”, its distribution as relict of its undifferentiated period, make this phenomenon a paradigm in its own right. Distribution of the members of the pair “cat - mouse” is an evidence of a paradigm transfer, a transfer systemic in its progression, with particular content propelled toward ones or the others vernacular clusters. A third member associated with the Türkic pair is a term for “rat”, a component of undifferentiated “mouse”, saqïrqan, sïqïrqan (+ buzaɣu tïlï, jamlan), also found in Europe (Cf. *IE Romance Fr. souris; unknown affiliation Basque sagu, Finno-Ugrian Hu. (s)eger, all “mouse”) and beyond (Cf. Uralic shingere “mouse”, Dravidic (s)agar “mouse”, and the oldest on record Sum. (s)egir “rat”). The paradigm does not end there, the word kök (Eng. cock “rooster”) implying maleness also belongs there: kök (küvük) čätük “male cat”. The evidence of paradigmatic transfer is striking in its many manifestations, for example, the Romance branch for “cat” has “cat” form in some languages, “mouse” form in other languages, and a “rat” in third languages. It is a linguistics dice game, with a same level of predictability. The cat-mouse-rat case of paradigmatic transfer indelibly attests to a genetic origin from a Türkic lexical fund. See chat, moose, mouse, pussy.
English cattle “group of domesticated bovine animals” ~ Türkic katıl- (v.) “mingled, grouped, packed, bundled”, metaphorical for collective “cattle, herd”. The word is related to two close forms, älä “cattle” (Shcherbak 1961, pp. 97, 122) and qatar- (v.) “pasture, drive cattle”. Ultimately derivatives fr. ka- (v.) “pack, pile, heap” formed with suffixes passive -ıl, -l, imperative -ar, -r, denoun verb -lä. The collective notion katıl- “herd”, “cattle” is a direct reflection of the notion “mingled, grouped”, it is a commixture of the animals. Türkic has an allophonic stem čat-, probably once one and the same word with kat-, qat-, with nearly identical semantics “converge, join, gather, assemble”, and accordingly identical capacity for parallel derivatives. Probably, initially the difference was strictly dialectal, and semantic shades developed when dialectal forms were absorbed into various Türkic Sprachbunds. The spellings cattle and chattel, from parallel derivatives katıl- and čatıl- (chatıl-), are carryovers from archaic phonetic differentiation, see chattel. An accent on “bovine” defines a narrow meaning of the word cattle, to separate it from small ungulates, but may cover flocks. An expanded term refers to other large animals of subsistent pastoralism, like yaks, horses, camels, llamas, etc. A semantic abundance of the stem katıl- (13 primary meanings on record, may be more at closer inspection) may seem to confuse the picture, but etymological intricacy of the quiz is readily resolvable if homophones and their derivatives are not piled together but explicitly separated. A popular euphemism katıl- “copulate, mate” is one of metaphorical meanings. A homophonic verb katıl- “to be strong, intensify in strength” is unrelated to the notion of “mingled”, it is a derivative fr. a homophonic verb kat- “harden, get stronger, intensify, fortify ruggedness”, for kotas, kotuz, kotoz “yak, mountain bull” lit. “strong, rabid (bull)” also used generically for a concrete noun “herd (of yaks)”, extended to generic “herd (of bulls, cows, and oxen in the plains)” and thus to “cattle”. Homophones “mingle” and “strong, rabid”, both referring to the cattle animals, probably have conflated to result in a merged colloquial notions of “herd”, “cattle” irrespective of the cattle type. For millenniums cattle was used as a unit of exchange, Gmc. and Sl. languages used allophones of cattle for “coin, wealth, property, treasury, tax” and the like. Cognates: A.-Sax. sceatt “money”, MEng. schat “cattle, treasure”, OSax., OFris., ODu. skat “coin, wealth”, OIcl. skattr “tax”, OHG skaz ditto, Goth. skatts “dinar, money”; OCS skot (скотъ) “cattle”, Rus., Sl. skot (скот) “cattle, property, money, tax”, Rus. kodla (кодла) “pack, herd”, skotnitsa (скотьница) “treasury”; OFr. (13th c.) catel, chatel, cheptel “cattle, goods, wealth, possessions, property, profit”; Gk. ktenos (κτηνος), zoon (ζωον) “cattle, animals” (vs. Lat. pecu, pecus, boves “cattle”, pecunia “money” and Ar. mashia (ماشية) “cattle” (< muš “animal”), see mouse); Pers. кälä “cattle (+ “cow”)”; Oset. sk̔ætt “barn”. Distribution of the root kat- “mingled” spans across Eurasia, from Atlantic to the Far East, practically across all Türkic languages, some still with an archaic aspirated form qat-. Distribution of the derivative katıl- is not addressed. An Eng. word related to cattle is one in a line-up of 8 other Türkic words for “cattle”; statistically it had 1 in 9 chances to reach Eng. in a particular form. Of 44 European languages only 2 (5%), Eng. and Rus., retained allophones of kat- “cattle”, “skot”, close to a statistical expectation. Direct connection kat- = “cattle” is cited only for MEng., Sl., OFr., Gk., and an outlier Pers., while most references name an anachronic secondary extended semantics, “property”. A Gmc.-Sl. prefix s- to the root kat- confuses etymologists, it conjugates the verb to a past participle, i.e. a perfect tense, Cf. do vs. done, Rus. delat vs. sdelat (делать vs. сделать). The IE-focused etymologies provide a myopic listing of cognate sources, resulting in a curtailed perspective. The “IE etymology” ascends catel to MLat. capitale “property, stock” with circuitous allusions to “principal, chief”, “fee, pecuniary”, and with a punch line “originally of movable property, especially livestock; began to be limited to “cows and bulls” from late 16th c.” Etymologically, katıl- “drive cattle together” is immeasurably closer for a notion “cattle” than millenniums later “property” or “payment”. Phonetic dissonance, semantic anachronism, and a dominant role of pastoralism in historical evolution make the “IE” hypothesis untenable, especially so in the presence of the attested katıl-. That line of verbal equilibristics is completely unsustainable. The “IE” fantasy needs to be quietly rescinded. A presence of two geographically distant allophonic forms katıl- and кälä “cattle” has a diagnostic quality, attesting that the initial form had wide circulation leading to phonetic differentiation, a western katıl- and an eastern (Uig., Uz. < Karluk) кälä. Celtic forms use undifferentiated “animal, beast, cattle” ascending to a base stem bu-/bo-/bü-/bö- (v-/w-) “wild animal”, Cf. Ir. beithígh, beithíoch, bolachta “beast, cattle”, Welsh wartheg, gwartheg “animal, cattle”. These reflexes probably are the oldest documented forms for “cattle”, a heritage of the 5-6th mill. BC Kurgan lexicon carried via an African route, see bull, see Animal Names; Preliminary note. Sources of the early English have not preserved records for cattle. As a unit of exchange (aka money) herds practically disappeared in the A.-Sax. society, replaced by Türkic lexis-denominated money, see money, penny, shilling. Instead, they preserved a slew of A.-Sax. related words: aeht, ceap (with ch- or k-), feoh, hriðer, neat, and orf. Incidentally, Türkic has or- (v.) “strand”, something bunched together, that is an only word that could have developed into orf, from Türkic-type possible articulation orb, orw, orv, orm, orp. Only orf refers to cattle as a collective for animals, the others were used to designate property (aeht), exchange equivalent (aeht, ceap, feoh), or obligations (aeht, feoh, neat). The word cattle was first recorded in 13th c., ascribed to Anglo-French catel “property”, a typical secondary metaphor in the societies where “cattle” is “property” and “property” is both “cattle” and “land, house, etc.”. The origin of the ONFr. catel, OFr. chatel is probably connected with the Burgund and/or Alan horse nomadic tribes settled in the Gaul. Their kindred tribes must have brought a version of the word to Britain. But like numerous other Turkisms (e.g. bash, boss, bother, derrick...), the word was lurking in Eng. till it reached official documents or an attention of grammarians. Finally, statistical assessment of a chance match for the pair cattle = katıl- returns vanishingly small probability, 1/1,000,000, i.e. it would take ca. 1,000,000 of 10,000-word dictionaries to locate a single language where cattle is called katıl, well in excess of 6,000 earthly languages. The assessment assumes semantic field of12 words for cattle, to match the Eng. semantic space (cattle, clowder, flock, fold, herd, kine, pack, pod, pride, school, shoal, warren). See Animal Names; Preliminary note, Supplementary Note; Chance paradigm, bash, boss, bother, bull, chattel, derrick, mouse, money, penny, shilling.
English chattel (n.) “private movable property” ~ Türkic čat- (v.) “converge, join, gather, assemble”, with passive verbal suffix -l- (-al/-äl). An allophone of cattle, see cattle. The spellings cattle and chattel, from the parallel derivatives katıl- and čatıl- (chatıl-), are carryovers from an archaic phonetic differentiation. The stem čat- forms čatïl “assembled, collected, driven into a crowd” that produced concrete notions of “herd” with a flair of coerced grouping and “private property”. The notion of coerced movement “drive (chattel)” is expressed by both allophonic stems čat- and kat-/qat-, probably once one and the same word, with nearly identical semantics “mingle, group, converge, join, gather, assemble”, and accordingly identical capacity for parallel derivatives, Cf. čatïla- “cat, catter” (whip (v.), whipper), i.e. coerce by flogging, drive chattel and/or cattle by flogging. Probably initially phonetic difference was strictly dialectal, and semantic shades developed when dialectal forms were absorbed into various Türkic Sprachbunds. Cognates: all cognates of cattle “livestock”, see cattle; A.-Sax. not recorded, Eng. cattle “livestock”, cat, catter “drive (cattle, chattel) with a whip, whipper”, chat “converse (at a gathering)”; OFr. (13th c.) chatel “cattle, goods, wealth, possessions, property, profit”. Distribution for a colloquial allophonic form of cattle is areal and limited. A suggested LLat. cognate capitale “property” is unsuitable semantically and phonetically, a suggested A.-Sax. scytel “dart, arrow” for “recursive movement” is unsuitable semantically. Examples of small and large shuttling movements permeate Türkic history from the earliest records, Cf. Huns westward move to Ordos to replace As-Tokhars (3rd c. BC), then their move eastwards to Altai, Aral, and finally to Pannonia (4th c. AD); Enisei Kirgiz move to Mongolia (9th c. AD) and then to Pamir; Oguz move to Aral and then to Anatolia, Hungarians move to Pannonia (9th c. AD); these few mighty examples are for the migration of the entire state, with all their “chattel” property, repeatedly driving dependent (~ allied) tribes and cattle to the new homelands. Use of chattel as a group appellation to the slaves (1640s) was not a rhetorical figure of speech, it was a millenniums-old barbaric practice of the settled civilized world, unacceptable in the nomadic world that did not know slavery and had to tend daily to their faunal property. The dating of the OFr. word suggests Burgund and/or Alan source of horse nomadic tribes who settled in the Gaul. See cattle, chat.
English cob (n.) “workhorse, harness horse” ~ Türkic kev-/gev- (v.) “chew, chaw, cud, quid”, kevsa- “chew, ruminate”. “IE etymology” is fuzzy on origins, replete with infantile speculations, and is only positive on “of a disputed origin”. The root kev- lends itself to polysemy, with extensions “blab”, “gnaw”, etc. The form cob is a truncated Lat. caballus “horse, gelding”, Gk. kaballes (καβαλλης) = ergates hippos (εργατης ιππος) “workhorse, nag” (Hesychius, 5th-6th c. AD, a list of oddball words), an allophone of the Türkic käväl, keväl, kewäl “racehorse”. That is an indisputable unsung fact. Forms with suffix -š (gə:wüš-, gə:wüše-) relay a frequentative mood. Semantic transition to “ruminant” could only happen after horses became a part of a household and people were feeding horses in off-pasturing times. Next were transitions to “horse” and “galloper”, which proceeded to kevel, käbäl “cavalry” that during Late Antique times became an international word. Of 44 European languages, for “horse”, 16 (36%) use versions of kev-, 9 (20%) languages use versions of mare, 4 (9%) use versions of equa. The other 15 (34%) languages use 13 of their own distinct expressions. For “chew, ruminate” 10 (23%) use a Sl. allophone jev- of the Türkic kev- and 8 (18%) use a Gmc. allophone kauw- of the Türkic kev-, for a total 18 (41%); 9 (20%) use Romance mas-, and other 16 (36%) languages use 12 of their own distinct expressions. The Türkic kev- is a dominant European term, approximating a level of the 50.6% R1a/b demographic presence in Europe. Cognates: Fris. kogje “chew”, Dan., Norw. hoppe, OIsl. hofr, OHG huof “horse”; OIr. cogain “chew”, Ir. capall, Scots cagnadh “chew”, Welsh ceffyl “horse”; OOccitan cavalier “horseman”; Lat., VLat. caballus “horse, gelding”, It. cavallo, Sp. caballo, Fr. cheval “horse”, OFr. chevalier “horseman”; Gk. q.v., Kavaleis, Kavilies (Καβαλεις, Καβηληες) “ethnic group along Meander River (Maιandros, Μαιανδρος) in Thrace”; OCS kushat (кушать) “eat”, kobyla “mare”; Latv. keve “mare”; Lith. kumele “mare” (m/b alternation); Fin. hеро, hevonen, Est. hobu, hobune “horse”, Hu. gebe “mare”, “nag (female horse)”, “old skinny workhorse”; Pers. kаvаl “racehorse”; Skt. čaphas “hoof”; Mong. kebi-, kewhə “chew, ruminate”. Distribution ranges from Atlantic to the Far East, across linguistic borders. Naturally, a relative value of the words “chew” and “horse” was changing in response to the demands of the times; “horse” climaxed in the 19th c. right at a threshold of the 20th. To its honor, the “IE etymology” did not dive into any faux “proto-words”, substituting instead some vain speculations like “a Wanderwort of “some” people in Asia Minor or by Danube river” (Vasmer II, 269).Mastering a horse by 5th mill. BC was so successful that it allowed a massive westward demographic movement to W. Europe in 4th-3rd mill. BC and by a 3rd mill. BC a major population replacements by waves of mounted R1b Kurganians. Their example sparked waves of emulations and amalgamations across Eurasia. Their domination was stopped only by firearms of the 2nd mill. AD. A non-IE origin of the word is beyond any doubts. Routinely interchangeable terms for horse repeatedly conflated during their lifetime across numerous host languages. Most of the Eurasian languages' horse-related diverse and fractured lexicon ascends to the Türkic vocabulary. See cavalry, horse, mare.
English cock (rooster) (n.) “adult male bird, usually chicken”, “penis” ~ Türkic kök, kü:g “male, mating”. Kök is extremely polysemantic and popular, with exceedingly wide range of metaphoric applications; dictionaries list 9-10 semantic nests and a few spellings, but still fall short of inventorying all nuances and shades, especially in adjectival form. Ultimately probably a derivative of the verb kö-/kü- “protect, cover (a herd)” in respect of leading a herd. In a mating aspect kök implies a male gender analogous to Eng. “tom” in “tomcat” applied to mammals and birds (Cf. kök četük “tomcat” (see cat), erkäk “man, husband”). Modern languages supplanted kök with synonymous erkek, a compound of er- “man” and kök, semantically a less unclear word (see -er). The notion of mating is extended to phallus, Cf. the most popular Rus. lexeme huy (хуй) “penis”, an allophone of a Kazakh form küy, an allophone of kök with the same meanings. The notion of phallus reflects the notion of maleness, not of a chicken, since the birds do not have penises. The notion of phallus extends to prongs of the latches and buckles (Cf. kök “latch”, köklet- “buckle”, cock (n.) “striker of a gunlock trigger”, cock (v.) “arm the striker”). Cognates: A.-Sax. cocc “male bird”, ONorse kokkr, OFr. coc (12th c.) ditto. Distribution: Eurasian but very private, does not cross linguistic borders. It appears that Eng./OFr. is an only exception. The “IE etymology” suggests “of echoic origin”, evidently with only the roosters in its myopic field of view. “Echoic” is as much language-specific as any other lexeme, it is not an escape hatch for linguists. Like other OFr. Turkisms, the OFr. word is probably of Alan or Burgund (Provence, Savoy) origin. The cock is a case of an unadulterated transfer paradigm that with certainty attests to a genuine genetic heredity (identical phonetics, semantic maleness, cockiness, penis, latching) from a Türkic phylum. See dick.
English coney, cony (n.) “hare” ~ Türkic kuyan, qoyan (n.) “hare”. Both coney, cony and hare are allophones of the Türkic kuyan, from a lineup of 17+ distinct forms. Ultimately fr. qoy “sheep” and homophonic with its diminutive form qoyun with suffix -n, -un “wild” related to specific animals, see . Homophonic with a deverbal noun derivative of the verb quy- “spooked, frighten, scared”. Synonymous with CT tovšan “hare”. G. Clauson (EDT, 1972, 678) offers his take on the “proto-form” *kodan. A. Shcherbak (1961, 136) offers his opinion on the “proto-form” *kothɣan. Both lead to a hypothetical form qot-. The attested forms contain -s-/-r-/-n-/-y- plus eastern -t- alternations. These mental exercises are irrelevant to the attested forms kuyan and horan, the last a Chuv. form preserved in the Mari language. From kuyan comes the Coney Island “Jack Rabbit Island”, and plenty of Türkic Kuyans, starting from the eastern Hunnic tribe Kuyan. It was one of the 24 original Hunnic tribes which eventually became a dynastic clan of Huns and Syanbi, Kuyans in the Bulgarian royal line, Kuyan Hill in Kyiv. Among Uezhi/Uechji “Tocharians” the kuyan “Jack Rabbit” also stood for a Milky Way, it was a Scythian qayan, and is still living in the Russified word Kuyanchik “My Little Rabbit” that a mom calls her little boy. Kuyan is also a popular toponym, semantically identical to the Coney Island. The forms hozan, hoa'n, hodan, hotun, allophones of hare (s/r/d alternation) belong to the eastern areas, including Tuva and Khakass languages, the Khakass with the most Turkisms encountered in Eng. Distribution in Europe is peculiar, a majority ascends to an Old Europe layer, while a layer of the “guests” includes Lat., Gk., Celts, and Hungarians. Of 44 European languages, 13 (30%) languages use versions of Old Europe Sl. zajets, 12 (27%) use versions of Türkic hare and 5 (11%) use versions of Türkic allophonic kuyan, 10 (23%) use versions of lebre of Old Europe Mediterranean. The other 5 (11%) languages use 4 of their own distinct expressions, including “guests” Gk., Hu., Lith. (+ oddball Lat.). Statistical review of the two native Old Europe Sprachbunds, the Türkic “guests” and the other “guests” to W. Europe allows to visualize specific demographic flows. Cognates: A.-Sax. hasu, hara “hare”, Fris. hazze, Du. haas, Norw., Sw. hare, Icl. heri, MHG heswe, Gmn. hase; Ir. giorria “hare”, Scots gearr, Welsh cannu, ceinach; Lat. canus, cascus “hare” (but Romance lepre); Mong. godoy- “protruding (hare tail)”, Bur. godo harayha “go hare” i.e. “jump out, hare's leaping gallop”, Tuv. hoduš (“hare”) dəər “darting hare”. Distribution - across Eurasia with fragments in Apennines and Celtic NW Europe. Türkic vernaculars had a relatively limited success in supplanting engrained native terms. On the opposite side of Eurasia a Yakut allophone of kuyan/coney is kuobah, possibly ascending to the Yakuts' Saka ancestors. The known distribution of the kuyan allophones allows to confidently trace the form coney to the Sarmatian area of western Urals mountains and the Caspian-Aral basin, the Scythian N. Pontic area, with the likely dating related to the Sarmat migration of the 2nd c. BC, starting as early as Corded Ware period. Since the Latins brought the word (q.v.) to the Apennines, “IE etymology” jumped up with focused fantasies of faux “PIE” *khs-en- and “PG” *haso. Unwittingly, the Türkic suffix -an in *khs-en- stands for “wild”, “wild animal”. That juvenile etymology is sorely not needed for an Eurasian-wide span of the attested words and abundance of forms testifying to their wide use in numerous Türkic and neighboring vernaculars. A pretentious myopia needs to be discarded. The word offers numerous possibilities for tracing and diagnostics. The Ir. and Welsh forms came from different vernaculars (s/r/n alternation) suggesting separate paths and timeframes besides a Mediterranean route. Isolated European forms prod to investigate their sources, they are markers with precious historical values. Systematically ignored Far Eastern connections need to be etymologically elucidated. The oldest available lexicons of predominantly R1a vs. R1b populations need to be quizzed in search for traces of dialectal differences. The case of coney and hare is a case of paradigmatic transfer, a partial case in an extensive ensemble of systemic transfer of the animal-related lexicons. The paradigmatic transfer case of the stratified hare-related lexicon indelibly attests to a genetic origin from a Türkic linguistic sphere. See hare.
English cow (n.) “female bovine” ~ Türkic qoy, qoyn, qon (n.) (k-, q-) “cow or sheep”, esp. “ewe”. Türkic has 3 (or more) generic stems to designate large herbivores, koy/kon/kot, sai/sag/sVr, and ud/uδ + a generic kev- (v.) “ruminate”. In modern Türkic languages, sai/sag and ud/uδ designate cows, and koy/kon designate sheep (and rabbit koyan/kuyan, Cf. coney, Coney Island). Via an s/k alternation, sVr is reflected in kVr, Cf. Tr. sy:r, si:ir vs. Sl. krava, Icl. kyr. The origin of both forms comes from Türkic syɣyn, syɣun “deer, wild cow”, hence the Türkic syɣyr, syɣur “cow, bull” related to Evenk. siru “deer, stud bull”. The koy/kuy refers either to cow or sheep or a few more meanings of an archaic allophone kod/koδ (Clauson EDT 678), suffix -an, -aŋ stands for “wild (animal)”, see animal. It is in reverse in Eng., where koy, kon designate cows, and sai, sag designate sheep, see sheep. Such discrepancy points to a very early time of the split. This transposition points to a time when terms were fluid, and it is typical for the east/west-like divide. During the endless hunter-gatherer times of chance opportunity, an object was food, aka prey, and terminology loose. Even with more advanced economies and universal literacy, thousands of creatures do not have names, and go under monikers like “sperm whale” etc. The uniformity of the Gmc. terms for cows indicates a settled phylum with established tradition of cow husbandry. Of 44 European languages, 14 (32%) languages use versions of Old Europe Sl. krav- “cow”, 14 (32%) use versions of Türkic bo- “bull”, 10 (23%) use versions of Türkic ko- “cow, ruminate”, and the remaining 6 (15%) languages use 5 of their own distinct words. Türkic terms are used by 24 (55%) European languages, matching a level of 50.6% R1a/b demographic presence in Europe. Cognates, re “cow”: A.-Sax. cu “cow”, OFris. ku, ko, Dan., Sw. ko, ONorse, Icl. kyr “cow”, OIcl. hjortr “deer”; Norw. ku, MDu. coe, Du. koe, OHG kuo “cow”, hiruʒ “deer”; LGmn. koh, koo, kau, Gmn. kuh; Scots coo “cow”, Breton саru “deer”, Cimr. саrw “deer”; OPrus. kurwis “ox”; Balto-Sl. (Lith.) kаrve, (Latv.) guovs, govs; (CSl.) krava (крaва) “cow”, (Rus.) govyadina (говядина) “beef”, Pol. karw “ox”, Polab. korvo “cow”; Arm. kov (կով) “cow”; Lat. bos, vacca, ceva “cow”, cervus “deer”; Gk. keraos (κεραος) “horned”; Pers. gav (گاو) “cow”; Skt. go (ग) “cow”, carvati “chew, ruminate”; Hu. gulya “cattle”; Sum. gu, gud “ox”, gur “oxen”; Ch. ngu, ngo “ox”. Cognates, re “sheep”: A.-Sax. sceap, scep, OSax. scap, OFris skep, MDu scaep, Du. schaap, MLG schap, OHG scaf, Gmn. schaf, Rus. yarka (< Tr. sarka), Mong. honi(n) (< Tr. kon-), Manchu honin (< Tr.), Tungus konin (< Tr.), CT sapik, sapïk, Bashkir hapïk, Chuv. surah. Distribution: cows and sheep could only be grown with local pastoralism, a role substantially diminished with a switch to migratory economies (4th-3rd mill. BC to present). Except for few ethnicities, e.g. Wallachians, Vlachs, their orbits were limited to safe zones and highlands. Genetics pulls linguistics from acuminate maze of k/s split, graphically depicting the split ranges of k-area into ancestral eastern zone east of Lake Balkhash with R1a Hg. and scattered remnants in a Caspian-Aral area, W. Urals, W. Europe and spattered Alat/Kalash/Khalajes. The s-area, which splits the k-area, is predominantly associated with the R1b Sarmatian-type tribes, it extends from the E. Europe to Kashmir. The first is known for h-articulation of the CT s, a so-called Horezmian dialect; the second is held as CT, Cf. Bashkir hïw, hyw “water”, hapïk “sheep” vs. CT su, suv, suw “water”, sapik “sheep”. Neither one was ever genetically stratified: lingo-genetic relationships depended on demographic compositions where a language, and not our modern knowledge of genetics, identified populations that started as R1a but converged to R1a/R1b mixtures. With time, density and range of the R1a Hg. dissipated more, while the relative density of the R1b Hg. held more cohesive. In a reverse west-to east movement a Sl. influx to the E. Europe brought along a considerable fraction of Slavicized R1a to supplement the local Türkic-lingual R1a populace. The *IE etymology trod a same path from its inception, feeding the same twigs into its own furnace. It devised roundabouts of faux “PG proto-words” *kwon, *ku, *gwou-, *kuz and “PIE proto-words” *kwom, *gwows “ox, bull, cow”, etymologically leading to nowhere. Unwittingly, those creations imitate attested Türkic originals. Such relicts must be disposed of to proper historical archives. Prior to a domestication of horses, Eurasians must have used a range of their own terms, Cf. yak, agelada (αγελαδα), etc. Mobility led to an explosion of exchange, trading horses for cows, sheep, etc. A spread of new terminology supplanted a smolder of the old ones. In essence, that was internationalization of replacement terms. Neither migrants nor their hosts knew a true origin of the words. Only original languages had retained some primeval traces, i.e. kev- “ruminate”. Gmc. terms parallel those of the Türkic pair koy, kon and sai/sag. A third Türkic term, the ud, uδ in Oguz articulation and tentatively gud/guδ in Ogur articulation (Cf. Sum. gud “bull”, Tofalar gudaa “bull deer, pricket”) is connected with milk and milking, e.g. English udder and Sl. udoi, doit (удой, доить) “milk (yield), to milk”. Few luminaries (M. Vasmer, V. Machek, A. Matzenauer) nescient of the Türkic origin of the underlying kev-/gev-, kevsa- (v.) “chew, ruminate”, its Mong. clone kewhə “chew, ruminate”, and other clones way beyond any Skt. reach, rightly noted the Skt. “ruminate” as a base for “cow”. However, their *IE-focused myopia stopped them dead right there. The Türkic word in Skt. attests that by the start of the Indo-Arian migration (ca. 2000 BC) the word was already a staple in the European Cored Ware aka Battle Axe zone. The Sum. and Skt. departed N.Pontic respectively in 5-6th mill. BC and 2nd mill. BC. The Sl. (Hg. I) and Latv. (Hg. N) ancestors from the opposite sides of the Eurasia met in E. Europe ca. 2nd-1st mill. BC, joining there the R1a/b Türkic Kurganians. Those four groups belong to the same “cow” phylum as the Gmc. and Türkic, and differ from the Lat. bov-, OIr. bo, and Basque behi. The last terms are shared between Pyrenees and Apennines, a post-2800 BC R1b Celtic playground. They are allophones of the Türkic boğa “bull”, a heritage from the 5-6th mill. BC Kurgan lexicon via the southern African route. The Arm. “cow” also belongs to the N.-E. European Kurgan phylum, possibly of post-N.Pontic Balkan-Phrygian or of Anatolian origin. That matches the ca. 30% Arm. R1b Y-DNA fraction of the Türkic Kurganians and explains Armenian Turkisms. A parallel advancement of the Türkic terms mirrors other similar linguistic evidence of the Kurgan migrations. The paradigmatic lexical transfer case of the related notions caw, sheep, bull, ruminate, udder provides indisputable linguistic evidence corroborating testimony of history, archeology and genetics leading to genetic origin from a Türkic phylum. See animal, bull, coney, sheep, udder.
English crow (n.) “black bird, Corvidae”, (v.) “call of crow” ~ Türkic qarɣa, karga (n., v.) (+garga, kargan, xarga, xerxi, etc.) “crow”. “Crow” is a derivative of kar-, gar-, xar-, xĕr-... “distinct call of crow + noun/adj. suffix -ga., an alt. root kak, ka:k. A synonymous Mong. qoŋ- /qong-/ “crow” found its way into some Türkic languages, and was disseminated in C. Europe by Gmc. languages. The term karga generally covers crows, ravens, and rooks (+3 extended meanings), and have synonymous monikers. Since the terms have speciated, cognates are trifurcated. Gmc. cognates closely follow the Türkic variety. Gmc. and OCS forms are closest to Chuv. and Khakass forms xarga, xerxi. They also share malicious verbal semantics: “gloat, portend, curse”, etc. The base root comes in varieties kar-, kr-, and Ør-, pointing to separate paths from common sources. Of 44 European languages, 22 (50%) languages use versions of Türkic kar-, kr-, 16 (36%) use versions of Uralic var-, and the remaining 6 (15%) languages use 6 of their own distinct words. The Türkic lexical contribution is consistent with a level of 50.6% R1a/b demographic presence in Europe. The Uralic var- (Hg. N) is notable for its high prominence. It endowed all Old Europe dominant Sl. languages (Hg. I) with a term for “crow”. Although Hg. N is ancestral for the Türkic Hg. R, its term did not survive to the Hg. R stage. Cognates, re crow: A.-Sax. crawe (n.), crawian, crawan (v.) “crow”, OSax. kraia, WFris. (v.) krie, Du. (v.) kraai, kraaien , OHG hruoh, chraja, Gmn. kräke (n.) krähe, krähen (v.) “crow”; Russ. karkat (каркать) (v.) “to crow; to portend misfortune; to dwell on negatives”, Sl. Bulg. grachene (v.) (grach “rook”, kr-), Bosn., Croat. kreštanje, kreketati ~ graktanje, graktati (v.) (kr-), Pol. krak- (v.) (kr-), Slovak, Sloven., Serb. grak- (грактати), krek- (крекетати) (v.) (kr-); Balt. (Latv.) kurnet, kerkt (kar-) (v.), (Lith.) krauklys (n.), groti, krank- (kr-) (v.) “crow” (+ (n.) varna); Lat. cornix “crow”; Gk. korone (κορωνη) “crow”; Fin. kurnuttaa (kar-) (v.), Est. krooksuma (v.) (kr-) (vs. kaaren crow, kar-) (n.), vares, kiremine (v.), kirema (n.) “crow”, Hu. karogas (kar-), krakogas (kr-) (v.) “crow”; Ar. ghurab (غراب) “crow”; reference to Pers. cognate; Mong. kheree “crow, raven”; OBulg. garga “crow”; re raven: A.-Sax. hræfn (Mercian), hrefn, hræfn (Northumbr., WSax.), hræmn, hremm “raven”, ONorse hrafn, Dan. ravn, Du. raaf, OHG hraban, Gmn. rabe “raven”; Lat. corvus “raven”; Gk. korax, korone (κοραξ, κορωνη) “raven”; OCS kruku “raven”; Mong. kheree “raven”; OBulg. garvan “raven”; re rook: A.-Sax. hrok, ONorse hrokr, MDu. roec, Du. roek, MSw. roka “rook”; Mong. kheree “rook”. Distribution extends from Atlantic to the Far East. The very distribution of the forms for crow, raven, and rook makes an “IE” origin unfeasible, and “IE” etymologies incredulous. Cognate congruity provides overwhelming evidence against chance harmony in a spectrum of diverse linguistic families. Qarɣa can be rated as a Wanderwort, sowing seedling wherever it passes. The immense volume of the derivatives allows to trace a single source growing into constellations of words and meanings. The mass of phonetic versions, haphazard modifications and elisions attests to millenniums of dispersions and internalizations. An “IE etymology” came up with a hive of faux “protos-”, i.e. a “PG proto-word” *khrokaz “European crow, rook”, “possibly imitative”, a “PG proto-word” *krawo “to crow?” from *krahana “to crow”, a “PG proto-word” *kreana from imitative “PIE proto-word” *gerh- “cry hoarsely” which is “related to croak”; a “PG proto-word” *khrabanaz “raven”, again “from a PIE root imitative of harsh sounds”, a PWG *hrabn “raven” from a “PG proto-word” *hrabnaz “raven?”, a “PG proto-word” *khrokaz “rook” “possibly imitative of its raucous voice”. All that hyper-ingenuity is not needed, though likely was not intended to clutter the issue. The result, however, obscures a direct connection and can mislead naive dupes into believing that PIE or “IE” had anything to do with the etymology of the word. In reality, development of the word strictly follows the tomeito and tomato law both in semantic and phonetic aspects. To get to the present, the word was shaped by many distinct vernaculars, and travel by many distinct paths. Furcation is visible in the nominal vs. verbal lines, in kar- vs. kr- vs. hr- vs. Ør- lines, in anlaut elisions (e.g. rook), in retention, replacement, or loss of suffix -an alluding to animal (e.g. kаrɣаn “crow”), and few other corroborating markers. An absence of an accented -a- in kar- points to hosts bent to anlaut consonant clusters. Some looming prongs can be associated with concrete sources, Cf. Tr. dial. хаrɣа vs. Gmc. hrok, hruoh, hræfn, hræmn, hraban, the lat three with Tr. dialectal instrumental verbal suffix -an, paralleling that of kargan, Cf. Tuva qarɣan “crow”. Gk. and Lat. forms point to a separate path from a kar- source. A European form kuak- (v., < kak, ka:k) “crow” without -r- in the root is used in areas with past Gmc. presence, Cf. Alb., Czech, Slovak, Dan., Du., Norse, Sw. kuak, kvak-, kvæk-, kwak-, kvek-, kväka. It also extends to a frog cry. Its origins may be connected with formation of the Gmc. people in Scandinavia prior to their migration to the continental Europe and amalgamation with the Celtic people. The forms kar- and kr-, and occasionally kuak-, with their allophones, display a variety of Türkic suffixes. Under the weight of evidence, a Türkic origin is undeniable.
English dog (n., v.) “domestic Canis, hound” (Sw N/A, F766 0.01%) ~ Türkic tayğa:n, dayğa:n “dog, hound”. No “IE” or any other etymology, within the “IE” paradigm the origin of the dog “remains one of the great mysteries of English etymology”. Ultimately fr. taya:- “prop, bolster, support”. The phonetic path is dog < dayg < daygan/taygan; the -t- and -d- are interchangeable dialectal variations: dayg <=> tayg. The suffix -an (-aŋ) is most regular in Türkic animal names, as a stand-alone word it designates “wild, wild animal”; suffix -gan is denominal noun suffix. In Türkic, tayğa:n is not a generic for “dog”, it is a type of powerful and swift dog used in hunting. That a lopeared variety of Enisei Kyrgyz hound dog would turn into an oddball generic term for a “dog” in few European languages is not predictable by any laws of “IE” etymological lawgivers. Cognates: A.-Sax. dogga, docga (dokga) “dog”, Dan. dogge; Scots dug “dog”; Fr. dogue “dog”, believed to be loanwords fr. Eng; references to loanwords in some more languages. Distribution: SE Türki (ca. 13th c.), and NC Kırgız plus spots in W. Europe. No “IE” claims for priority. The A.-Sax. dogga for a powerful breed of canine replaced an old Gmc. hund. A Türkic encircling hunt tradition was continued by the A.-Sax. and English aristocracy, together with its peculiar lexicon. The A.-Sax. form attests that the final -n was elided still in the Türkic milieu, probably because the suffix -an was felt as unneeded extension of a perceived root dog. Etymology of tayğa:n, dayğa:n probably ascends to the allophones for tuğ-/duğ- “emerge, born, rise, inchoate” (Clauson EDT 464) and puppy ta:y meaning a baby of an animal (Clauson EDT 566). That may allude to the early times of dogs domestication, when a puppy was a toy, Cf. Eng. doll and Türkic döl/tö:l “newborn, baby”. Two more words may have conflated with tayğ, dayğ due to their phonetic and semantic proximity, doğ- “go straight, cut through” (Clauson EDT 464) and doki- “strike, knock” (Clauson EDT 467), bolstering the form dogga, where the suffix -ga makes it equivalent to the semantics of the English adjectival dogging (i.e. relentlessly pursuing). See doll.
English duck (n.) “waterfowl, Anatidae” ~ Türkic öndek, ördek, ürdek “duck, drake”. Öndek and ördek are allophones, with r/n alternation. Ultimately fr. a homophonous stems ö:r-, ö:n- (v.) “rise, sprout, ortho-” (see ortho-) and ö:r, ö:n (n.) “height, high, high ground”, with deverbal noun suffix -daq/-däk and r/n alternation. The root ön-, ör- is polysemantic, covering dozens of semantic clusters, including “top”, “hill” “throne”, etc. It is most familiar to the Eng. speakers as on (adv., adj., prepos.) (Sw N/A, F26 0.73%) “on, on top”, etc. The prime notion of the word is “rising”, a notion “duck, drake” is a metaphoric extension, i.e. “(bird which) rises (from water)” (Clauson EDT 205). Grammatically, dek is a multifunctional word in its own right, i.e. a noun “end, outside”, a verb “touch”, a postposition “till, down to”. Hence it can be used as a modifier, reversing “up, rise” to “down, dive”, i.e. “dives (into water)”. Eventually, after elision of the unaccented part ön- (ör-/ür-) “rising” from the Tr. öndek “duck”, A.-Sax. turned the remaining suffix -dek into an A.-Sax. duce “duck”, dufan “to duck”, and then to the Eng. duck and to to duck, i.e. “dive”, see duck (v.). The “drake” is also a direct allophone of the Türkic öndek/ördek (Tat. ürdek) “drake, duck”. Modifications are in conflict with widely promulgated etymological laws, but work nicely in a world of reality. Of 44 European languages, 18 (41%) languages use barely recognizable versions of Türkic ön(d)-, ör(d)-, 11 (25%) use versions of Balkan's pa-, pat-, 7 (16%) use versions of Sl. kach-, and the remaining 8 (18%) languages use 6 of their own distinct words. The Türkic lexical contribution is not far from a level of 50.6% R1a/b demographic presence in Europe. The terms' connections with native branches are loose, terms are easily borrowed from alien languages. Cognates: A.-Sax. enede “duck, drake” (< öndek), duce “duck”, dufan (v.) “dive, duck”, WFris. duke (v.) “dive”), Dan. dukand, dykand “sea-duck”, MDu. duycker “diver”, Du. duiken (v.) “dive”, Sw. dykfagel “diver, diving bird, plungeon (sea fowl)”, dyka (v.) “dive”, Icl. önd “duck”, Cf. Tr. öndek, LGmn. düker “diver”, Cf. (ön)deker, duken (v.) “dive”, Gmn. tauchen (v.) “dive”, Scots duik, duke, dook “duck”, dook, douk (v.) “bathe” (< Eng.), Lat. onus “load, burden” (< Tr. “rise, lift”), hence legal Lat. onus probandi, lit. “lift, carry evidence”; Mong. örüne, hörüne (n., prosthetic h-) “west, western” (sunset side), hör-, höru- (v.) “dive”; Manchu furi- (v., prosthetic f-) “dive”; Tungus huriwki (n., prosthetic h-) “duck”, huri-, hur- (v., prosthetic h-) “dive”. Distribution extends from Atlantic to the Far East, way beyond a reach of “IE” or Gmc. etymologists. The very distribution of the forms for duck makes an “IE” origin unfeasible, and “IE” etymologies incredulous. An “IE etymology” came up with a host of faux “protos-”, i.e. “PG proto-word” *dukaa “dive, bend down”, *dubana “dive”, “PIE proto-word” *aneti- “a root of a noun “duck” in most Indo-European languages”, “PIE proto-word” *dhewb- “deep, hollow”, a prototype for “PG proto-word” *dukan. It even invented a faux A.-Sax. word *ducan “dip, dive, duck”. Absurdity of these “hypotheticals” is a modest farce. The Tungus and European versions of the prime word are equidistant from the source. The New Lat. onus (1626), a clone of the Türkic önüs, of the Türkic stems ö:r-/ö:n- with further Türkic derivative önüslüg “related to ascent”, is used in the ecclesiastical Lat. It must have been popularized by the discourses of the early Christian time when other Türkic words and idioms were popping up in the ecclesiastical Latin and Greek, and may have been recycled even earlier. The notion “burden” derives from the notion “hump, swelling” of önüš, örüš (n.) “ascent, rising (protuberance, hump, swelling)”. The circuitous but traceable chain of semantic and phonetic transformations led to the cognates enede and onus in the A.-Sax. and Lat respectively. See duck (v.), ortho-.
English elk (n.) “deer, moose” ~ Türkic el, elik (n.) “doe of deer, chamois (goat antelope)”, serna (chamois) “roe-buck, goat, deer”. The forms el and elik are synonymous. Since el is a noun, a denoun noun suffix -ik is a redundant later modification. European forms attest that the superfluous suffix predates a cradle of the European forms of the Corded Ware time, 3rd mill. BC. In the European usage, the consonant -k lost its suffixing function and is treated as a part of the root. Of 44 European languages, astonishing 38 (86%) languages use versions of Türkic el-, and the remaining 6 (14%) languages use 6 of their own distinct words. The Türkic lexical contribution exceeds a level of 50.6% R1a/b demographic presence in Europe. Whether via native Türkic or, say, Nenets, all those European languages unlikely received the word directly from the original language, especially so with its internationalized Eurasian distribution. Cognates: A.-Sax. elh, eloh, eola, eolc, eolh, elch “elk”, ONorse elgr, OHG elaho, MHG elch, LGmn. elk, elch “elk”, elen “gazelle”; Ir. eilc, Welsh elc; Lat. alces; Sl. olen (олень) “deer”, Rus., Pol. los (лось) “moose”; Lith. elnis “stag”; Gk. elafos (ελαφος), alke (αλκη) “moose”; Arm. elnik (եղնիկ) “doe, hind”; Agnean (Tokh. A, Tuhsi) yäl, Kuchean (Tokh. B, Tuhsi) ylem “gazelle”; Mong. ili, il “young deer”, elti “deer, doe”. Distribution extends from Atlantic to the Far East. An “IE etymology” is funny, it cites phony PGmc. *elkh-, *elhaz, *algiz, a faux “PIE proto-word” *helkis, *holkis, and a faux “PIE proto-word” *olki- to come up with a root for the Balto-Sl. forms, which are allophones of the Türkic losh (Sl. loshad, los (лошадь, лось) “horse, moose”. The fakes are unwittingly parroting the real Türkic el/elik. Mong. forms retained the shape of the acquisition time, ca. 1st mill. BC (amalgamation at the Hunnic time). The animal names are mostly non-specific, in different environments the same name is used for a variety of vaguely similar species. Notably, the word elik expanded from doe to its kid, which in the Türkic milieu did not discriminate between animal and human offsprings. That trait was paradigmatically calqued to Eng., where kid is a “young of a goat” and a kid “child”. see child. A further semantic extension from the kid to “grow a kid” gave elik a form elikli with notions of “to grow”, “to grow up”, and also “grown”, “fed (nourished)”, “bring up an orphan (by adopting/feeding them)”. Neither Gmc. nor a putative “IE” could seed the width of Eurasia with a northern term for an animal, nor could they paradigmatically transfer an archaic lexicon of elk and child. The Türkic source of European terms is inescapable. See child.
English frog (n.) “leaping tailless amphibian” ~ Türkic baqa, baga, maqa, maγa “frog” (b/m alternation). In both languages a secondary meaning is a hoof pad, a case of definitive paradigmatic transfer. A transition baqa <=> frog is traced via intermediate forms: baga (Tr.) ~ béka (Hu.) ~ broga (Welsh) ~ vors (Du.) ~ frøen (Dan.) ~ frosch (Gmn.) ~ frog (Eng.). Ultimately, baqa may ascend to an echoic pak, Cf. Uig. pak-pak “frog's call” (Scherbak, 1961, 153). In that case, baqa is a Tele word, since Uigurs are first known as members of the Tele confederation (toward the end of the 1st. mill. BC) that extended from the eastern Urals in the west to beyond Baikal in the east. In some Türkic languages baqa serves as a generic word for amphibians (frogs, tortoises) and a base for adjectival determinants. To a generic echoic ba- denoting wildlife points reduplicated baba aka baqbaq (n.) “froglet, tortoise”, Cf. Tr. кики, guguk “cuckoo”, Lat. cuculus ditto. The final suffix -a in baqa denotes a carrier of process. The correspondence of the anlaut f-/b- is best exemplified by the Eng.-Türkic pairs fart/burut-, feel/bilin-, fire/bur-, first/bir, etc. At some time the form included -r- (like the Welsh broga), absent in languages adverse to stems with consonant clusters. A.-Sax. synonyms point to a process of an elastic amalgamation from a range of languages: fenyce, pade, tosca, yce. Cognates: A.-Sax. forsc, frocga, frogga, frosc, frox “frog”, ONorse froskr, frauðr, Norse frosk, MDu. vorsc, Sw. groda, frosch, Icl. froskur, Gmn. frosch “frog”; Lith. varle “frog”; Serb. baga, bagljv “frog”, “hoof malady”, bagav “limping”; Lat. varde (an echo of verde “green” ?); Gk. bagos (μπαγος), vatrach (βατραχος) “frog”; Rum. baga, broasca, furcuta “frog”; Cat. granota “frog”; Hu. beka “frog”; Alb. bretkocë “frog”; Pers. qorbaɣe “frog”, baha, bahə “tortoise”, baka:nak, baka:yak “hoof frog”; Ar. baka:nak, baka:yak “hoof frog”; Beng. bena “frog”; Mong. baha “frog”; Bur. baha “frog”; Evenk baγa “frog”. The modern Türkic form qurbağa (Azeri, Turkish) includes an adjective qur “harm, damage”, semantically making it “bad toad”. Traces of the adjectival qur are observable in the compounds Icl. froskur, Alb. bretkocë, Gurj. dedakum, Fin. sammakko, Hindi mendaka (m/b alternation). Distribution: modern spread of baga allophones is immense, from Atlantic to Saha (Yakutia) and Manchuria. Two related forms dominate European languages, Gmc. f-/fr- and Sl. žab- forms, with f- and ž- articulating an alien anlaut b-. Combined, the f-, 12 (27%) languages and žab-, 12 (27%), add to 24 (55%) of 44 European languages, matching a level of 50.6% R1a/b demographic presence in Europe. A third major group is Romance ran- with 9 (20%) languages. Two small groups of 4 (9%) and 3 (7%) languages form 3 Celtic + 1 Sl., and Baltic groups respectively. The other mixed bag of 5 languages share 4 native terms. The breakdown shows unexpected loose connections with native branches and linguistic amalgamations. Terms are easily borrowed from alien languages. Neither Gmc. nor a putative “IE” could seed the width of Eurasia, nor could they paradigmatically transfer a Türkic archaic pair of frog and hoof frog, nor to seed Mong., Bur., or Evenk languages. An “IE etymology” is risible, citing phony PGmc. *fruþgo “frog” and a faux cognate “PIE proto-word” *preu- “hop, jump” mechanically associating unrelated Sl. and Skt. pseudo-homophones with notion “amphibian” firmly linked to the term baqa in its astonishing array of articulations. There is no need for myopic pretentions nor for faux A.-Sax. “obscure expressive suffix” -gga. A Türkic source for the paradigmatic European terms frog and hoof frog is inescapable.
English gnat (n.) “kinds of biting insects, flies, gnats, mosquitoes” ~ Türkic yenč-, yanč-, yənč- (v.) “gnaw, crunch, crack, fracture, knap”, all directly related to “bite”. The word is polysemantic, also carrying notions “reproach, rebuke, upbraid” and “oppress” (+ dozens of other notions), see nag. Dispersed Gmc. phonetics and semantics allows to detect and trace its trails within the Gmc. branch. Ultimately fr. a verb ye- “eat”, see eat. It is suffixed with a deverbal noun result -n- (eat > a bite, crunch, grind) and a diminutive denominal suffix -č/-ča (> stab, prick). Internalization yenč- > Gmc., Balto-Sl. gnat dropped the weak initial ye-, articulated -č as -t or -s, and added typical for Gmc. languages a habitual prosthetic anlaut g-/h-/k-. Two more allophonic forms developed their own lines via n/r/s alternations: yer- and uyaz/öyäz (r/s alternation) “biting insect”. A third related line is yem- “break”. Since gnats existed from the dawn of times, wide phonetic dispersion points to a primordial common origin supplemented by layers of amalgamations that developed into speciated terms like mus- (mosquito), kom- (komar), etc. All of them relay a notion “bite”, Cf. mando, comer, yank related to “eat”. Europe is dominated by three forms, mosk-, gnat, and komar with 13 (30%), 10 (23%), and 9 (20%) languages in Romance, Gmc. + Celtic, and Sl. branches respectively. Two of those derive from a Türkic lexis, the Gmc. gnat < yenč- and Sl. komar < kämür “gnaw, swallow, suck out (a bone)”, thus the Sl. komar is lit. “sucker, eater”. The remaining 12 languages use 10 (23%) of their own native words incl. a Lat. oddball culicem. The breakdown allows to stipulate a late Romance and Sl. cultural dispersion. The Gmc.-Türkic word is an old Kurgan's Corded Ware time, “guest” to the W. Europe. Its ethnic lexical cohesion of exclusively Gmc. points to a tightly knit Gmc. community with admixture of Celtic. Cognates: A.-Sax. gnæt, gneat “gnat, midge, mosquito”, gnagan “gnaw”, hienend “accuser”, hienan (v.) “oppress”, hienðo “annoyance, oppression”, Du. knagen “gnaw”, Norse, Dan. knutt “gnat”, Norse, Sw. nagga “gnaw”, Sw. knott “gnat”, LGmn. gnatte, Gmn. gnitze “gnat”; Balto-Sl. (Latv.) ods, knišļi “gnat”, (Sl.) gnus, gnida (гнус, гнида) “gnat”; Mong. nuruu “gnat” (< yer- q.v.). Distribution: N.W. of W. Eurasia + Türkic Steppe Belt + an echo in the Far East not yet scrutinized etymologically. The extent of the Eurasia is also filled by an abundance of names for “biting insect” in every language. The “IE etymology” cops out by suggesting an echoic origin: “probably imitative of gnawing”. Atypically, the Lat. culex “gnat” does not participate in this “PIE” enterprise, attesting to a non-IE origin. In parallel, suggested are “perhaps literally” a “biting insect” faux “PG proto-word” *gnattaz, *gnattuz and faux “PIE proto-word” *ghnehdhn-, *ghnehd- “gnaw, scratch” from a faux “PIE proto-word” *ghen- “gnaw, bite, scratch, grind”. These strained regressions are not needed. The attested material is fits phonetically, semantically, and morphologically with no “imitative” and “perhaps” clauses needed. The Gmc. prosthetic g-/k- is a reflex of a typical Ogur articulation with a prosthetic anlaut consonant, yen- > gen-. The Sl. form transitioned Ogur guyaz > gnus > gnatte, gnæt. Verbal forms gnaw (with allophones) are denoun derivatives of the noun gnat in OSax., ONorse, Sw., MDu, OHG. Via Sw., Norse, they are linked to a lacking rational etymology metaphoric derivative verb nag “annoying quetching”, Cf. Sw. gnaga, naga “gnaw”. Puzzling individually, a complex of forms' connections fits a historical context, the Gmc. insularity, and usual adaptations from a Türkic lexis. The polyfurcated word presents a crisp multi-prong case of paradigmatic transfer, indelibly attesting to its origin from a Türkic phylum. Way more connections are open for studies. See eat, nag.
English goat (n.) “caprine” ~ Türkic käči (kəchi), geči (gechi), äčkü (ächkü), eške (eshke) (n.) “goat”. This is a case where “IE” etymology, or at least some of it, admits an origin “from a substrate language”, i.e. a non-IE origin. The unnamed “substrate language” turns out to be Türkic, that was recognized based on timing of its spread in Balkan and Caucasus enclaves. Forms are bifurcated, an Ogur-type with consonantal anlaut k- and Oguz-type without it. Ogur-type forms are few, ca. 2-3, while Oguz forms number 8+, attesting to their wide areal and ethnic distribution. Goat herds were predominantly females, and males needed a determinative. Unlike A.-Sax., which had retained a notion “bull” bucca, biccen for goats, the Türkic lexis is speciated. Internalizations of k- to g-, -č- to -t- are regular. Of 44 European languages, 30 (68%) use allophones of the Ogur-type ca-, attesting to a “guest” status into languages that did not practice goat husbandry. The remaining 6 (14%) use their own native terms. Cognates: A.-Sax., OSax. get “goat”, A.-Sax. gat, get, gaet, gaete (f.), gatbucca (m.) (bucca “bull”), gotwoðe “goatweed” (woðe “weed” < Tr. ot “grass”, with prosthetic w-), ONorse geit “goat”, OHG geiz, Goth. gaits, MDu. gheet, Dan. gjed, Du. geit, MLG. hoken “goatling”, Gmn. geiß “goat”; Celtic gabhar “goat”; Sl. koza (коза) (f.), kozel (козел) (m.) “goat”; Lith. ožys, ožka “goat”; Lat. caper “goat”; Gk. kacika, kačik (κασικα, κατσικ), aka osteon (οστέον) “goat”; Alb. keth, kedhi “goatling”; Hu. kecske (kechke) “goat”; MPers. аzаk “goat” (Pers. chäpesh), Cf. Bashkir hïpra “castrated goat”; Skt. aja, asthi “goat” (ajas, сhagаs “billy-goat”); Mong. išige, ešige “she-goat” (~ eške); Manchu gucha “goat” (~ geči); Tr., Crimean, Chag., Chuv. kätši, kädžä, kаčаgа “she-goat”. Distribution: across Eurasia from Atlantic to Pacific, across linguistic borders. In spite of the “substrate language” assertion, “IE etymology” came up with “PIE proto-word” *ghaid-o- “young goat”, “PWG proto-word” *gait, and a “PG proto-word” *gaits. Neither one is enlightening, verifiable, needed, or a good substitute for the constellations of attested originals. A suggested origin from attested summons like či či, čik čik, etc. is backwards: unless it is imitative, a call comes after an animal is named; in that theory, a goat did not have a defined “IE” name. A. Scherbak (Scherbak 1961, 116) asserted that the form käči and the second Türkic form äčki are allophones, with äčki spread across N. Eurasia, and käči in the south. Both forms are authentic Türkic, and can't be classed as loanwords. A corollary is that Gmc. and Manchu forms are authentic versions of the Türkic käči. Türkic allophones are close to the Gmc. forms, they bridge Manchu and Gmc. The uniformity of the Gmc. forms points to a common source that is related rather to an authentic käči than to a synthetic *ghaid-o-. The Hu. form is an allophone of the Tr. käči. It is unlikely that Celts carried goats to Iberia on their circum-Mediterranean anabasis traced by R1b Y-DNA dating. Likelier, the Bashkir, Celtic, Pers., and the Lat. forms with inlaut -p- ascend to some E. European Sprachbund of the 3rd mill. BC. Compounds like gatbucca and gotwoðe constitute cases of paradigmatic transfer, indelibly attesting to the origins from a Türkic lexis. See bull, weed.
English goose (n.) “aquatic bird” ~ Türkic kuš, qaz, qa:z (n.) “goose, duck, bird”. A “IE” etymological idea of “probably imitative of honking” is empty without specificity: there are as many ways to reproduce “honking” as there are languages. A ku for generic “bird” ascends to Sumerian, 5th-4th mill. BC, it is found across Eurasia and way beyond, Cf. Ku Bird of American Southwest Yaquis, Cherokee Dagul'ku goose. It is unlikely that Almighty shaped Germans of clay or of European aborigines, more realistic would be some diverse bands of W. Europe aborigines of the “Kiling Fields” times fled and hid in safe lands. They amalgamated a their Sprachbund from floating around lexical chunks, a potpourri of Corded Ware, Battle Axes, Kurganians, and such. There would be no “PG” or “PIE”, as there is no “proto-” for a soup or any other mixture. The Türkic kuš is a generic and a specific term, a generic “bird” and a specific “goose”, Cf. genus solanum of order solanales, “tomato”. For that reason, a specific genus is wobbling: a “goose” in one language corresponds to a “swan” in another, etc. Of 44 European languages, astounding 43 (98%) use allophones of the Türkic kuš, attesting to a universal acceptance of an alien term in a dozen of mutually incomprehensible but etymologically traceable articulations (anseris, china, gandz, gans, gæs, ge, hanhi, oie, etc.). The remaining 1 (2%) language uses its own native term, the Alb. pate “goose” (gate “heron”). Not too good for the “PG” and “IE” etymology. Cognates: A.-Sax. gos “goose”, OFris. gos, ONorse gas, OHG gans, Gmn. gans “goose”; OIr. ge “goose”, geiss “swan”, Scots geadh, Welsh gwydd “goose”; Sl. gus (гусь) “goose”, Pol. ges; Balt. (Lith.) zasis “goose”; Lat. anser “goose” (< hans ~ Fin., Est. hani < kuš), avis “bird” (< auca “bird”) , It. oca, Sp. ganso “goose”, Fr. oie; Gk. khen, china (χŋνα) “goose”, Fin. hanhi, Est. hani “goose” (< FU -ku “bird”), Fin. kotka “eagle”, Fin.-Ugor. -ku “bird”, Hu. kacsa /kasa/ “goose” (< kuš); Skt. hansi (f.), hamsah (m.) “goose, swan”; Mong. (Kalm.) guži “bird (kind)”; Tungus gus, gusi-ken “sea eagle”; Sum. -ku “bird”; references to loanwords in Pers., Caucasus, and Nenets languages. Distribution: across Eurasian width and height, across linguistic families. On a Eurasian scale, any “IE” claims and pretensions on origins are futile, any improvisation baseless. Misinformation of the type PG, PWGmc. *gans- “goose”, PIE *ghans-, *ghhens “goose” should be gracefully retracted. The spread of the term may ascend to the Hg. NOP time, the Eurasian spread to the Hg. R1a/b time, the European spread to the 4th-3rd mill. BC, diverse individual languages adopted the word during historical times. The fluidity of vowel and instability of the consonants highlight stochastic nature of vocalizations in time and space. The equivalency of kuš and gos “goose” can't be denied. The near perfect phonetic and perfect semantic concordance does not leave any room for doubts of a European spread via Türkic channels. See duck (n.), owl.
English hare (n.) “coney” ~ Türkic horan, kuyan, küik (n.) “coney”, with dialectal variations. An “IE etymology” stands a routine “of uncertain origin”. Both coney, cony and hare are allophones of the Türkic kuyan. G. Clauson (EDT, 1972, 678) offers his take on a “proto-form” *kodan, with -d- > -r- transition; A. Scherbak (1961, 136) offers his opinion on the “proto-form” *kothɣan with apparent -th- > -r- transition; A. Dybo (EDTL vol. 9 140) - *gejik. Those scholastic exercises are irrelevant to the attested forms kuyan/koyan, horan, hasa and ceinach. The Chuv. form horan is preserved in the Mari language, the form horan is still active in its historical NW area. Modern English prefers the hare version of the old Chuv. form, whereas historically, the versions of the modern form kuyan dominated. Of a deverbal noun derivative kuyan fr. the verb quy- “spooked, frighten, scared” comes the Coney Island “Jack Rabbit Island”, and plenty of Türkic Kuyans, starting from the Eastern Hunnish tribe Kuyan, one of the 24 original Hun tribes which eventually became a dynastic clan of Huns and Syanbi, Kuyans in the Bulgarian royal line, Kuyan Hill in Kyiv. Among the “Uezhi/Uechji” Tocharians the Kuyan “Jack Rabbit” also stood for Milky Way, it was a Scythian qayan, and it is still living in a Russified word Kuyanchik “My Little Rabbit” that a mom calls her little boy. Kuyan is also a popular toponym, semantically identical to the Coney Island; in local vernaculars they all could be hor- instead of koy-. On the opposite side of the Eurasia the Yakut allophone of kuyan, coney is kuobah, possibly of the Yakuts' Saka ancestors. A corollary to the verb quy- “spooked” is tavggi- “run” for tavïshkan “hare” that marks a 3rd year in Türkic animal cycle calendar. The pair coneyy - hare indicates amalgamation of two independent languages with local languages, each one distinguished by its own path in time and space. Of 44 European languages, 14 (32%) languages use versions of Türkic hare, 13 (30%) use versions of Old Europe-Sl. zayats, 11 (25%) use versions of Gk. lagos (λαγος), and the remaining 4 (9%) languages use 4 of their own distinct words. Combined, the Türkic hare and coney add up to 19 (43%) of 44 European languages, not far from a level of 50.6% R1a/b demographic presence in Europe. Cognates: A.-Sax. hara, haer “hare”, OFris. hasa, MDu. haese, Du. haas, OHG haso, Gmn. Hase “hare”; Ir. giorria, Scots gearr, Welsh ceinach “hare” (with k-); Mari horan “hare” (< OChuv.); OChuv. horan, Khakass hozan “hare” (r/s alternation). The known distribution of the allophones horan and kuyan allows to confidently trace the form hare to the Sarmatian area of the western Urals mountains and the Caspian-Aral basin, with a likely dating related to the Sarmat westward migration of the 2nd c. BC. No viable “IE” connections. “IE etymology” offers a simplistic blend of attested Gmc. forms into a phantom WGmc. “protoform” with an inexplicable quirk addition of a noun suffix -an (*hasan-), which is a typical Türkic marker aŋ (an, en, on, un, äŋ, etc.) denoting “animal”. It might create a comfortable bubble for the faithful, but disinformation hurts etymology. Its further allusions to Skt. sasah, Afghan soe “hare” are unrelated cognates of synonymous Sl. form zayats (заяц) “hare”. Gmc. forms point to a third, separate source(s) on the -s- side of the -s-/-r- divide, i.e. the Oguz (CT) -s- in lieu of the Ogur -r-. That is a mighty diagnostic distinction that points to an Oguz presence in the Gmc. areas. The Welsh form may be a Celtic relict hailing from the 3rd mill. BC. Coney and hare with their bouquet of links and parallels constitute a case of paradigmatic transfer, a partial paradigmatic transfer case in an extensive ensemble of systemic animal-related lexicon of Türkic genetic origin. See coney.
English hawk (n.) “buzzard” ~ Türkic haw, ab, av, a:v, aw (n.) “hunt”. Ultimately fr. ay “moon” and “circular aura around moon” which created a notion ebir (n.) “circle”, öwür- (v) “encircle, bend”, Cf. aura, overture. Its derivatives named circular structures, like a corral, settlement, and an encircling hunting circle formed during battue hunt. The word hawk is a denoun noun derivative of aw articulated with a prosthetic anlaut h- and final agglutinated locative suffix -q (qı:/-qi:) “hunting grounds”. The anlaut h- articulation is typical for the vernaculars of the Aral-Caspian area, Anglo-Saxons, and Germanic languages (Cf. Gmn. herr vs. Türkic, Eng. er “man”), widely spread by Ogur-type languages. A specifically Ogur form haw is cited for Kumyk language (EDTL v.1, 62). Two thousand years ago Kumyks were called (Caucasian) Huns and Masguts (Gk. Massagets), confederated of the Hunnic refugees from a Chinese onslaught of the 1st c. BC and the Aral area Masguts. Jointly, they moved to the Caucasus in the 2nd c. AD. The word hawk is a Hunnic relict supplanted by a slue of other names including Scythian, like čaɣrï, qarɣuj, tegälgüč and their versions. Among 44 European languages the allophonic forms hawk and falc- dominate, with 23 (52%) languages, matching a level of 50.6% R1a/b demographic presence in Europe. The surviving Old Europe's Sl. languages trail far behind, with 12 (27%). The other 9 (20%) languages use 6 of their own native words. Cognates: A.-Sax. hafoc, hafuc, heafoc “hawk”, OSax. habuc, Mercian heafuc, ONorse haukr, Fris. hauk, MDu. havik, Sw. hök, OHG habuh, Gmn. habicht “hawk”; OIr., Scots sebac, Welsh hebog “hawk”; Rus. kobec “hawk”, oblava “battue hunt”; Latv. javturis “hawk”; It. avvoltoio “hawk” (vs. Lat. accipiter), Galician gabian; Alb. gjeraqinë (false cognate); Gujarati hoka “hawk”; Fin. haukka “hawk”, Hu.heja “hawk”; Mong. küjkünek “hawk”; Tungus (Evenk.) geki, (Even.) gaqbn, Udege gaxi, geaxi, Jurchen giaxun, giaxunun “hawk”; Tungus-Manchu (Negid.) gexin, Oroch. gaki “hawk” (Far East ref. A. Dybo EDTL v. 9, 151). Distribution: Eurasian from Atlantic to Pacific. In the modern Eastern Europe, the word has a very sporadic distribution. Any asterisked “PG” or “PIE” claims are ludicrous, either ignorance or malice. The “IE etymology” hypothesis on the hawk's origin from hypothetical “proto-words” is a total nonsense. No *habuk, *habukaz, *kopugos etc. are needed or can be validated to be a science. A hypothetical “IE proto-word” *kap- “grasp” is a total nonsense, since the kap-/qap- (v.) “seize, grab” is an attested Türkic word and not a whimsy “reconstructed” hypothetical “proto-word”, see cap and cup. Except for Alb., which is an allophone of the Türkic qarɣuj, all others have preserved the primal root ab/aw “hunt” with or without prosthetic anlaut consonant, and most have retained the locative suffix -q of the original. Cohesion of Celtic forms attests to its existence in the E. Europe prior to the Celtic circum-Mediterranean anabasis traced by R1b Y-DNA dating. The migrants from the Aral-Caspian area had to carry the peculiar derivative hawk of the word haw “hunt” northwestward to Europe, and not eastward to impart it on the remote Asian populations. Since the word is so deeply ingrained and internalized in the northwestern Europe's Germanic languages, and not in the other European linguistic branches, it can be suggested that the massive demographic movement was a result of a severe draught at the turn of the 2nd mill. BC, when the Aral area was nearly totally depopulated. That would have seeded the word among the descendents of the Corded Ware archeological culture. See cap, capture, cup.
English hoopoe (n.) “distinct bird (family Upupidae)” ~ Türkic üpüp, hüthüt (n.) (Uigur, Khakass), üpgük (Chigil), and other close variations. Onomatopoec imitative of the hoopoe up-up ((oop-oop) cry. All cognate forms carry allophones of üp. Cognates: Du. hop “hoopoe”, Nw. (hær)fug(len), Sw. (här)fag(eln), Gmn. (Wiede)hopf ; Lat. upupa, Fr. huppe, Rum. pupaza; Gk. epops (εποψ); Arm. hopop (հոպոպ); Ar., Uzb. hudhud; all “hoopoe”. N. European languages start with a prosthetic consonant f-/h-, reflecting Ogur pronunciation. Various “IE” languages have a variety of onomatopoeic forms, dissimilar and independent of the üpüp form: Sl. dud- (udod, dudek), Ir. fonsa, Latv. dzeguze, Lith. kukutis, Pers. šanasar, etc., unrelated to the “IE” Mother Tree. Such uncouth dissension undermines a trust into routine etymological assertions of onomatopoeic origins.
English horse (n.) “equine, stud, mare” (Sw N/A, F1688 0.004%) ~ Türkic ars (n.), ars- (v.) “call, loud cry of wild animal”. “IE etymology” declared a routine “of unknown origin”. That reality did not preclude creation of faux “PIE proto-words”, nor its annual production. Ultimately a derivative fr. the verb ars- “neighing, cry”, its denoun verbal derivatives arsla- “neigh, cry” and arslanla:- “roar, holler”, Cf. Tatar kürše, Azeri (hön)kür(mək), Uzb. (qich)qir(moq), Turk. komšu, Turkmen gonšy “neighing”, Cf. khoros (χορος), choir and quire, also “of unknown origin”. The term horse (n.) alludes to a call of that animal. An anlaut h- is prosthetic, a common trait for Gmc. branch's version of Ogur (~ Hg. R1a) vs. Oguz (~ Hg. R1b) articulation of words with an initial vowel, Cf. Clark Hall 1916, 142 “h is often wrongly prefixed to words, as in Cockney English”. Naming animals by their calls or other particulars is nearly universal, Cf. mus, muis for “cat”, see cat. An or- “cry” is an allophone of ars- “cry”, widely popular at European languages for noisy elements: orate, oration, orchestra, organ (musical), etc. The ars- is used for animals, and its synonym or- for humans. The ars has a trail of adjectival meanings: “wild”, “fierce ”, “toothy”, etc., of a base notion “wild”, probably a speciation of a suffix -lan “wild (animal)”, Ch. laŋ (狼) “wild animal, animal, wolf” supplanted by native Ch. (Austronesian ) vocabularies, Cf. arslan “lion”, kaplan “tiger”, qulan “horse (type)”, jïlan “snake”. Suffixes -an-/-aŋ and -lan/-laŋ are typical for animal names. Another related verb is sïrla- “neighing (foal)” for high pitch calls, also an allophone of ars- with Aral basin's s/h alternation. Cognates: A.-Sax., OFris., NFris., OSax. horss “horse”, WFris. hoars, ONorse hross, MDu. ors, Du. ros, hors, Dan hors, Sw. russ, hors, Icl. hross, hors, OHG hros, Gmn. roß , ross “horse”; Rus. slon (слон) “elephant” (< ars), Ruslan (Руслан) “pers. name”; Lat. ursus “bear”; Gk. arkouda (αρκουδα) “bear”; Fin. varsa “foal”, Hu. oroszlan (/oroslan/) “lion”; Pers. pars “lion”; Mong. arslan “lion, winner (fight)”, arsaleng, erseleng “lion (varicolored)”; Manchu arsalan “lion”, Solon arsala “lion”; Tr. arslan “lion, kitten”, ars, as “weasel, ferret”. Distribution: Gmc. forms are limited to NW Europe, with scattered echoes of names ar-, ars-, or- for wild animals. Türkic forms are spread fr. E. Europe to Pacific. The versions ors, orosz- (< ars) demonstrate a prosthetic nature of the anlaut h-. Amending the “unknown origin”, “IE etymology” fabricated faux “PIE proto-words” *krsos “horse” and a *kers- “run” fr. attested Lat. currere “career (v.), run”. “IE” etymological myopia unwittingly left out that the Lat. currere is a derivative of the attested Türkic root küra- “run”. Türkic languages are not known for their fluency in Lat., it is the other way around, in Lat., like in other European languages, Türkic-rooted words are immensely popular. Küra- belongs to a lineup of 10 verbs for “run”: eš-, jarïs-, juv-, jügür-, etc., each with its own flavor. The other invention, the *krsos, is a mechanistic distortion of the attested hors “horse”. Both attempts should be gracefully retracted, along with the rating “of unknown origin”. Etymology allows to diagnose and trace the events. A likely period of internalization was the Corded Ware period. Various western and central European refugees fled to the Eastern Europe, amalgamated there with the westward flow of the Battle Axe horsed nomads, and to a degree absorbed their culture, technology, lactose tolerance, and genetic markers. Uniformity of internalizations shows, 1st, that the internalization was a compact event; 2nd, for the Corded Ware migrants horse and its name were unknown; 3rd, they were surrounded by people who passed on to them their word ars-. They had no older forms to supplant. That was a time before the Aryan SE outmigration. Before the “IE” linguistic family was invented was a Hindustani goda, guda “horse”. Long before the European turned into Indo-European to account for the Aryan migration that brought some Corded Ware linguistic element to the Hindustan peninsula. Internalization was so ingrained that the later demographic encounters, with the Sarmatian Wendelns (2nd c. BC) and Western Huns (4th c. AD), did not uproot the ingrained word with a common Türkic generic synonym at. By the 1st mill. BC, A.-Sax. had developed its own speciated vocabulary, attesting to breeding and utilitarian use of the horses: eh, eoh, eos “charger ”, wicg “steed”. Some of them could have come from Saxon Celtic language. Probably more terms have escaped attention of grammarians. Numerous other European languages have developed native European terms, supplanted with later replacements. The phonetic fidelity with precise semantics, and a weight of inherited morphological elements indelibly attest to a Türkic origin of the word, probably acquired 5 mill. ago and carried along ever since. See cat.
English lamb (n.) “young sheep” ~ Türkic -la:n, suffix forming animal names. The -lan stands for an abstract noun “animal”. “IE etymology” asserts an innate Gmc. origin “with no certain cognates outside” Gmc. languages. A phonetic -n-/-m- alternation is routine, but its depiction is confusing, unsettled till Middle Ages, Cf. Gk. μπ ~ b, β ~ v and/or b. Romans had to switch fr. Gk. to Lat., and the poor A.-Sax.'s from went from Orkhon-type (without m) to Futhark (with m) and on to Roman (with m). Retroactive phoneticizing is severely conjectural. In most cases, a determinant can be explicated from semantically similar examples. Words with element -lan are ubiquitous across Türkic languages and geography, see below. Grammatically, the suffix -lan serves as a postposition noun in a determiner-noun pair like the “red fox”, “gray fox”, “prairie fox”, etc. An eldiri: “lamb-skin” articulates a truncated “lamb” with a prosthetic anlaut e- and diri for “derma”, see derma. A herdsmen practice was to cull male lambs for food, and retain productive females. Of 44 European languages, 13 (30%) use versions of Old Europe-Sl. yagn-, 12 (27%) use versions of Türkic -lan, and the remaining 19 (43%) languages use 13 of their own distinct words. Besides Sl. and Türkic, there is no uniformity in Europe, no shared “IE” lexis. Aside from the native lot, Türkic swings a confined share compatible with a level of 50.6% R1a/b demographic presence in Europe. Cognates: A.-Sax. lamb, lamp, lemb, lomb, lomber “lamb”, ONorse, OSax., OFris., Goth. lamb, MDu., Du. lam, MHG lamp, Gmn. lamm “lamb”; Ir. elit “deer”, Welsh elain “roe deer”; Sl. olin, olen, elen, yeleni “deer”, lan, lani, alnii, lane, etc. “doe”; OLith. elenis, Lith. elnis, alnis “deer, moose”, Latv. alnis “moose”; Gk. elaiphos (ελαιφος) “deer”, ellos (ɛλλoς) “fawn”, atlant (ατλαντ) “giant, large”; Arm. eln, elin “doe”; Pers. kalan “large”; Fin. eläin, -läimet “animal”, hirvieläimet “deer”, Est. loom, Hu. allati “animal”; Türkic arslan “lion”, bulan, kaplan “tiger, lion, leopard”, kulan “kulan”, kulun “colt”, sirtlan “hyena”, tulan “three-year old sheep”, etc.; Mong. tulan “five-year old sheep”, unaga(n) “foal”, keüken “barren”, Bur. dagan “2-year foal”, hyazalang “4-year mare”; Tungus morikan “foal”; Manchu arsalan “lion”, ərsələn “lioness”, unahan “foal”, muhashan “bull”; Ch. laŋ (狼) “wild animal, animal, wolf”. Distribution: Eurasian from Atlantic to Pacific across linguistic borders. An “IE etymology” totally gave up on “IE” etymology, , i.e. it conceded to a non-IE origin. The pronounced northern bent and Fennic generic semantics suggest a Fennic origin, Cf. Est. hirved, Fin. hirvieläimet “deer”. That is corroborated by the Türkic generic suffix -la:n as an apparent reflex of the elided Fin. postposition/suffix -läimet. The northern term for “animal” and specifically for the northern deer spread as a concrete noun “deer” across many incompatible vernaculars, adopting appropriate forms and semantics related to the notion of “deer”. Short of a miracle, a chance coincidence of such phenomena across many incompatible vernaculars is impossible. The areal Fennic-Türkic amalgamation was documented for the 2800 BC Central Siberian area between the Kurganians carrying metallurgical technology from the Carpathian area and the local hunter-gatherers. The amalgamation was confirmed biologically. The Seima-Turbino metallurgical province extended from the Baltic Sea to Mongolia (Chernykh E. 2008, Chikisheva T. 2010). The connection provides a link and a possible dating for the transfer of the suffix/postposition -läimet, -lan, from agglutinative Fennic to agglutinative Türkic and then on to the Zhou Ch. in the east and Gmc. languages in the west. The standing etymology asserts “common to the Gmc. languages, with no certain cognates outside of them”. The movement of the “Zhou Scythians” also reached a Far Eastern northern belt. The assertion does not even look beyond its myopic horizon, the reason for an absence of cognates among the eastern “IE” languages, and a diagnostic significance of that absence. The assertion is misleading and obfuscating, it hurts entire “IE” paradigm, negating its chances to grow into a credible science. It fails to diagnose an emergence of the now European word to the time after a 2nd mill BC departure of the Indo-Aryan farmers from the Eastern Europe. The word is straddling the noun/postposition/suffix development and recycling of agglutinated suffixes into lexemes. An origin via Türkic milieu is supported by a complex of independent indicators. See derma, sheep.
English mare (n.) “female equine” ~ Türkic ma:, me:, ba:, be:, bi, biyä, bisi, biči (n.) “mare”; mor, morin, muran (n.) is one of numerous appellatives for a generic “horse” synonymous with “mare”. “IE” corpus asserts “perhaps it is a word from a substrate language”, and thus of a non-IE pedigree. Just in case, asterisked sobriquets are propagated. The “IE etymology” ends up with a false linguistic assertion of “no known cognates beyond Germanic and Celtic”. A base notion of ba-/ma-, bi-/mi- etc. is “female”, applied to mammals including humans, Cf. biči ~ bitch “horse (Tr.), dog, woman (Eng.)”. Its derivatives number in hundreds. A case for extending be: to me: and ma: is straightforward, G. Clauson cites 63 indexed m-/b- alternations, and at least as many non-indexed m-/b-'s. Dialects that were not able to pronounce i>-b- by assimilation used instead and still use the nasal -m-. Whether a record on m-/b- transition was noted by medieval literature is strictly fortuitous (Cf. Balkar vs. Malkar, at times within a single family. The alternation is not registered by the speakers or listeners themselves, a la tomahto vs. tomaito or Yo:k vs. York in the USA). Notably, Horezmian is specifically singled out for propensity to -m- for -b-. A fluidity of the vowels presupposes routine -a-/-e-/-i- alternations. The use of mare as presumed generic for “horse” points to a preference for mares. Since a notion “female” in Türkic is also expressed by the words tiši: and küŋ (Goth. qina, Eng. quim), there are parallel lines expressing femaleness, incl. related to horses. Cognates: A.-Sax. maere, mare, mere “mare”, OSax. meriha, OFris. merrie, ONorse merr, Icl. merin (f.) (vs. Sl. (m.) merin), Du. merrie, OHG meriha, Gmn. mähre “mare”; Ir., Gael. marc, Welsh march, Breton marh “horse”; Sl. merin (мерин) (m.) “gelding, horse” (across most of the Sl. languages); Alb. pela (m-/b-/p- alternation); Basque behor; Bengali bisala; Est. mära; Fin. tamma; Georg. pashatis (m-/b-/p- alternation); Pers. mädiyän; Gujarati mara, mare (માર); Ch. muma (母马), ma (马) “horse”; Kor. ammal (암말); Lao ma (ມ້າ); Burmese myinn; Mong. gü morin “mare”, mor (морь) “horse”, baytsan “farrow mare”, Bur. baytakan “farrow mare”; Manchu geo morin “mare”; Tungus be, gek muran, əktə morin “mare”; Tadjik modien; Kazakh bïe, bye, Oguz madän, mädän; all “mare” except as noted. Now, can you believe “no known cognates beyond Germanic and Celtic”? Distribution: Eurasian-wide, across linguistic borders. The uninitiated dictionaries unwittingly contravene the “IE” august scholars. Cited examples show that the stem for the mare or generic horse is shared by diverse linguistic families far exceeding the reach of the “IE” spread, but consistent with the reach of the mobile Türkic pastoralists riding and trading their horses across Eurasia from Baltic (Finn., Est.) and Atlantic (Basque) to Pacific (Ch., Kor., Mong. etc.). Some languages too remote from the steppes (Indochina) must have borrowed from their northern neighbors. The m- form's (mare etc.) association with Horezm is consistent with other indicators for connections of the Gmc. forms with the Ural-Aral, or Sarmatian, area. The spread of the ma/ba “horse” paradigm is consistent with the “Scythian” spread of advanced bronze casting metallurgy and horse husbandry technology from the Central Asia eastward (Juns, Zhous) and westward/southwestward (Scythians, Saka). Notably, the Indo-Aryan farmers did not carry a horse culture to Hindustan, it was brought in and remained a property of the Indo-Sakas and Indo-Scythians. The Celtic (Ir.) marcra and capall and beithíoch “horse” correspond to Türkic ma:/ba: “mare” and qavčï (v.) “assault, rush, attack”. A prototype for the term for cavalry < cavalleria that supplanted the Late Antique Lat. equites came fr. the Türkic kobyla marked by distinct Türkic morphology, see cavalry. The Welsh reflexes geffyl/ceffyl are a part of that picture. Tracing the layering of the Lat. with Celto-Italic and Celto-Türkic terminology must be a separate saga in itself. The Pers. aspa and Lat. ecus “horse, mare” are obviously incompatible with with the Türkic and Gmc. ma/ba, they are confined to comparatively limited linguistic archipelagos. Since the Sl. horse-related terminology is entirely of Türkic origin, and the aspa/ecus-type terms entirely missing there, the PIE languages did not have aspa/ecus terminology. Then that terminology is a cultural injection from some external source. It would be a task for the “IE” linguists to find the source where their chargers borrowed it from. See cavalry.
English moose (n.) “elk” ~ Türkic mus, müs, muŋuz, müŋüz (n.) “horn”, i.e. “horned”. Türkic forms are numerous: mu:s, mi:s, muos, müs, mü:s, müz, mü:z, pü:s, mıjıs, mijiz, mojuos, müjıs, müjız, müjüs, münüs, etc., with more variations and anlaut b- counterparts. Such wealth of forms helps with tracing a particular ethnic origin. Cognates cover Eurasia and Americas, pointing to the origin beyond the 15th-13th mill. BC migration of the Native Americans. Türkic forms are widely dispersed geographically and phonetically, attesting to a very long history and vernacular diversity. They also have a number of synonym terms for the moose, Cf. Eng. moose and elk. The Amerindian forms should also be widely dispersed. There is a salient divide within the Gmc. group in the distribution of the allophones of the elk and moose, attesting to different acquisition paths from different sources. The words with anlaut m- are complemented by numerous allophones with delabilized anlaut b-, pointing to a secondary origin of the b- form and various parallel developments. The -s in mus is a suffix marker of duality -(a)z, a predecessor of the Türkic and Eng. plural suffix -s. Numerous forms also have an inlaut suffix -n-/-ŋ- (müŋüs and the like). Cognates: Fennic (Est.) poder “moose”, (Mari) püčö, (Udmurt) pujey “deer”; Amerindian (Algonquian Narragansett) moos, (Abenaki) moz, (Penobscot) muns, (Ojibwa) mooz, (Unami Delaware) mo:s “moose”; Mong. mögeresün “horn, cartilage”; Tung. motï “moose”; CT bulan “moose”, Bashkir, Tatar mïšï, pošï, Chuv pašï, “horn, horned”, Tuv., Sakha, bisasir (m.), bur (f., s/r alternation) “moose”. The cited cognates are only a tip of an iceberg, they only represent the entries echoing the surviving forms for the moose. They represent probably only 5-10% of the relevant terms, which over millenniums and in melting pot environments have developed a wealth of alternative terms and applications. Distribution: covers Eurasian and American temperate northern belt around the globe. The standing etymology basks in myopia, it asserts a recent acquisition of a millennium-old term that started its existence in the Old World and probably existed at the Hg. NOP time, a father of Hg. O and a grandfather of Hg. R time. The shameful “etymology” of the word, which suggests its Amerindian origin in English (17th c.), is ludicrous, it shocks with its utter myopia and close-minded scholarship. Notably, the Algonquian and another dozen tribes' Y-DNA is predominantly R1, not yet discriminated for subclades (disputed R1b), thus bridging a 10,000-year gap to the much later R1 nomadic Kurganians. We should celebrate the echoes of ancient voices in our own time. A semantic origin from “stripping bark for food in winter” is no less ludicrous, it should be a last of all possibilities. The appellation “horned” for the moose is not unique, it is calqued, for example, in the Sl. moniker for the moose sohatyi (сохатый) “horned”, fr. suk (сук) “branch stub”, Cf. Eng. ard “scratch plough”, a plough possibly fortified with horn. What could we call the language that first used a moniker “horned” for the moose or its ilk can't be asserted. The whole Earth's human population was small, and there were no Türkic languages then. But it was definitely a Kurgnians' Türkic language that spread the Fennic word far and wide and delivered it to the distant foggy Albion. There is no other viable alternative to carry that cultural element to the most far-flung ends of the Eurasia.
English mouse (n., v.) “miniature rat” ~ Türkic muš, müš (mush, müsh) (n.) “mouse (+ cat)”, aka čačkan, sïčgan (10+ more) “mouse”. CT кälämuš “field mouse” (кälämä “field”), Azeri mïšovul “squirrel”; sïčgan is a Manchu-Mong. loanword adopted with a Türkic suffix. Ultimately onomatopoetic, from a cat's miaul suggested by A. Scherbak (Scherbak, 1961, 129): muš is an allophone of piš, a call for cat (piš-piš, pis-pis, and the like), via dialectal p-/b- and b-/m- alternations. It explains most of the Eurasian words for cat and mouse, and even dogs, squirrels, etc., and down to a muscle, see cat, muscle. Suffix -gan, -kan, -an, -vul, -ul refers to animals, -k forms deverbal nouns. Traces of undifferentiated semantics for the peculiar lexical pair cat - mouse are spread across Eurasia and linguistic families. Of 44 European languages, allophones of muš “mouse” use 24 (55%) languages, matching a level of the 50.6% R1a/b demographic presence in Europe. None use allophones of cat for mouse. The other 20 (45%) languages use 11 different terms, including 5 unique terms. For “cat”, allophones of kädi “cat” use 32 (73%) languages, exceeding the level cited above, while 9 (20%) use allophones of muš for “cat”. Only 3 languages use their native 2 forms, one of them is an oddball Lat. Of a combined body of 88 European languages, the Türkic muš and kädi are internalized by 56 (64%) European languages, making them predominant across Europe. Compared with the spread of the muš “cat”, the cat “cat” is more colloquial, with a peculiar distribution. The stem cat forms Eurasian animal names outside of a feline line, Cf. katıl- “cattle”, see cattle. A large variety of the forms for muš and kädi attests to a greater antiquity in respect to the word četük “cat” (Clauson EDT 402). In the Türkic northwestern languages muš is a standard word for “cat” (Clauson EDT 765). The connection between the form muš for “cat” and its European forms for “mouse” is certain, Cf. A.-Sax. mus, mase, Gmc. mus, Sl. mïš (мышь), etc. “mouse”. The missing link between the two appears in the adjectival undifferentiated form sıčğan muš, where sıčğan is a generic word for both “rat” and “mouse”, lit. “mousy (ratty) cat” (Clauson EDT 796), uluğ sıčğa:ti “large mouse” for “rat”, and Sıčğan a year of Rat. Adjectival expression clarifies a reference to a “mouse”, corroborating undifferentiated semantics when generic muš was any small mammal, “cat”, “mouse”, “rat”, etc. A modern science made the Gk. allophone of the Türkic muš an international word, e.g. myalgia, myotrophy, myocardium, myotome, myasthenia, and many more. Cognates: A.-Sax. mys, mus, mase, mie “mouse, muscle”, OFris., ONorse, MDu., Dan., Sw. mus, Du. muis, Gmn. maus; Yid. moyz (מויז); Balto-Sl. (Lith.) muse, (OCS) mysu; (Rus.) mysh (мышь); Lat. mus, musculus; Gk. mys (μυς) “mouse, muscle”; Skt. mus “mouse, rat”, OPers. mush; Semitic family Ar. maws (الماوس); Kartvelian family Georg. mausi (მაუსი); Jap. (disputed family) mausu (マウス); Kor. mauseu (마우스); Saha michar, küdäk (~kädi “cat, mouse”); all “mouse” except as noted. Distribution, for muš “mouse”, spans across linguistic borders, from Atlantic to Pacific, for muš “cat” from Atlantic to Sayans (Teleut mıjık) (Clauson EDT 765). Muš practically flooded Europe, supplanting numerous native terms. Areal distribution is typical for local Sprachbunds; Gmc. languages belong specifically to a northwestern Sprachbund. An “IE etymology” is a joke. It's a brazen disinformation in every aspect. It is a case of a circular logics. In exhorting “IE” paradigm numerous cognates conflicting with the “IE” premise were omitted. There is no need for lunacies like “PG” and “PIE” *mus- “an old “IE” name of the mouse”. The fact of the European phenomenon cat = mouse screams against that. A Türkic muš does the job for both cat and mouse. An ubiquitous supersedure of the native terms with Sprachbund terms is palpable. Ancient Greeks have not used undifferentiated term muš, knowing the difference between speciated mys, pontiki (ποντικι) “mouse” and gata (γατα) “cat”. The undifferentiated semantics of the Skt. word attests that at the time of the Indo-Aryan outmigration from Eastern Europe ca. 2000 BC the word mus has not yet differentiated between the “mouse” and “rat”. Real etymological quest should be not an untestable speculation on how exactly all those diverse masses of illiterate “PIE” folks had pronounced words 5,000-years ago, but where the loanwords came from, their etymological history. The Fr. and Basques adopted late versions of sıčğa:n/sıčan, probably in the first half of the 1st mill. AD, likely from the nomads of the Alan or Burgund circle. The “IE” Celts preserved their own distinct Ir., Scots luch, Welsh llyg(oden) “mouse”, unaware of their “PIE” language status. The mü:š/mačı: is ages older than sıčğa:n/sıčan. That allows to assess the temporal frames of the supersedures. The Far Eastern languages adopted mü:š/mačı: probably via Zhou Scythians of the early 2nd mill. BC, roughly contemporaneously with the migration of the Indo-Aryan farmers to the south-central Asia. Then Eastern Türkic languages adopted sıčğa:n/sıčan of the Far Eastern languages. Since safety could be found much closer to the Eastern Europe and Western Asia than India and China, both migrations must have been driven by inclement environmental changes, not to escape their immediate neighbors. The eastern Türkic languages retained četük for “cat” and sıčğan for undifferentiated “mouse” and “rat”; the northeastern Türkic languages adopted undifferentiated küskü: for “mouse” and “rat”, and called “rat” uluğ küske, a calque of uluğ sıčğa:ti “large mouse” (Clauson EDT 750). A semantic bifurcation “mouse, muscle” is a paradigm attested among the Türkic languages: a calque of muš, a sıčğanak “muscle” is a diminutive form of sıčga:n, lit. “little mouse”. This paradigm was transferred to Lat. (musculus), Gk., and Anglo-Sax., reliably pointing to ultimately Türkic origin of the word. Aside from the old Türkic metaphoric “little mouse” neither the Türkic, nor the European “IE” languages have a common word for “muscle” (Clauson EDT 796). The ubiquitous terminology of the “cat - mouse” paradigm converges multi-faceted evidence, adorning paradigm with lexical opulence, spectacular distribution, the salient metaphor of mice and muscle, the ambiguity of the term muš, its prominent stakes in the raster of the Eurasian linguistic families, a precious relative dating capacity, and a romantics of past human endeavors. The paradigm does not end there, e.g. the word kök (Eng. cock “rooster”) implying maleness also belongs there, see rooster. Skt. borrowed mus “mouse, rat” as a paradigm, together with a Türkic küsä, küskä “rat, field mouse”, Cf. Skt. kača, kačika “weasel”. Pers. borrowed muš “mouse” as a paradigm, together with yap- for “bat” fr. Türkic yap “web, membrane”, Cf. Pers. shab-pare, shab-parak, and shab-kur “bat”. The paradigm extends to the archeological and biological evidence, and to the social impacts on the host peoples. It includes peculiar nomadic traditions of: an accent on pedigree and seniority; supremacy of customary law; parliamentary system of collective governance; prime status of feminine and maternal side (prejudicedly labeled “matriarchate”); respect for individual rights unavoidable in fluid nomadic societies in contrast with sedentary societies of entrapped serfs; tradition of exploring natural resources, be it alien nations, game, forest, steppe, or whatever is open for mining; and relentless self-reliance. Not all host societies adopted alien traditions equally, but elements of them still dominate modern societal mentality and order. Because “mouse” is a secondary, adjectival form, it allows to peek into its past and future, serving as a powerful linguistic lens. The eidetic Eng. and Kirgiz forms for “mouse” are consistent with the noted clustering of numerous other Eng. lexical parallels; the terms Kirgiz, Khakass, and Enisei Kirgiz refer to the same descent in different phases; it is a case of a Kirgiz-Eng. general trend of paradigmatic transfers. See cat, cattle, muscle, rooster.
English owl (n.) “hooter, bird of prey” ~ Türkic abaqulaq, apalak, qoburta (n.), etc., from the stem aba-/obu- etc., with various prosthetics and suffixes in different Türkic languages. The abaqulaq is a moniker compound of aba < jap, qob- “wool, felt” + qulaq “ear”, a reference to their horned ear tufts that hide their ears. Ogur-type articulation adds a prosthetic consonant y- > japa-, yaba-, forms like apalak “felt-like” elide a syllable, forms like jabaqu qulaq duplicate the syllable qu. In some languages it is truncated to jaba, čaba etc. lit. “tufty”. A great owl has a separate Türkic name ü:gi:/ö:gi:/ü:ki:. Judging from its narrowly confined clustering in Europe, it is a second form of the same japa, qobu- (b > w > g articulation). Such peculiar exclusivity offers a tracing potential. Cognates: A.-Sax. uf, ule “owl”, WFris. ule, Dan. ugle, MDu. uil, ONorse ugla, Norw. ugle, Sw. uggla, Icl. ugla, OHG uwila, Gmn. eule “owl”; Latv. upis “eagle-owl”; Lat. ulula; Pers. yapalaq; all “owl” unless noted. Some suggested cognates do not belong to this class: Sl. sova “owl”, Cz. upet “to wail, howl”, Av. ufiieimi “call out”; Sum. bagialu “owl”. Distribution covers nearly entire width of the Eurasia east from Atlantic. Half of European languages use 2 words, the Türkic owl or Sl. sova, 12 (27%) and 10 (23%) languages respectively; the other half uses 12 native words between all of them. “IE etymology” suggests an origin of the word from “imitative of a wail or an owl's hoot”, citing Lat ulula “owl” and ululation in support. Unwittingly, ululate, ululation is a Türkic derivative, it comes from a word yel (n.) “wind, howl (demonic)”, Cf. wail, yell, yawl, yowl, see howl, lull, ululate, yell. The folk or “imitative” use could be true in some isolated instances, but that is irrelevant. Thus a myopic approach does not hold a water. The universal use compound terms like abaqulaq “owl” q.v. preclude a simplistic approach. Linguistic experts (M. Räsänen, K. Menges et. al.) buttressed that point with semantic extensions of the first member of the compound, the Türkic “tuft” q.v., with explicit “heavily tousled hair”, “curly, shaggy”. Imitation may in fact be a primordial origin of the Türkic word, but that remains etymologically unsubstantiated. Once the daily “tufty ear” for the “owl” had spread, for both native speakers and aliens its original meanings was supplanted, leading to further conflations and folk etymologies. If Sumerian bagialu “owl” is related to the Gmc. ugle, that suggests an existence of the word in the 3rd. mill. BC, separately from, and prior to, the Corded Ware period. The Gmc. auslaut ending with -l/-la is a reflex of the Türkic adjectival suffix -l/-il, making it something like “owling bird”. Unless they are recent calques, the Hindi, Urdu form ullu “owl” parallels that of the Lat. and its Gmc. allophones, possibly attesting to its presence in the Eastern Europe at the time of Indo-Aryan southeastern migration early in the 2nd mill. BC. The alternate Pers. form cuğd, the Hindi, Urdu choghd (and buum) “owl” are reflexes of the Türkic ü:gi: with Ogur prosthetic anlaut consonant, a time of acquisition could range from the 2nd-1st mill. BC to recent. The Türkic origin of the compound word is indisputable, the word “owl” came from a Türkic ornate lexicon. See howl, lull, ululate, yell.
English ox (n.) “castrated bull, steer” ~ Türkic öküz, hokiz (n.) “castrated bull”. Ever since B.Münkacsi in 1905 suggested an *IE origin, the subject never went totally cold. Unlike most *IE-centered researches, ox broke through an *IE systemic myopia, and brought extensive investigation of cognates outside of the *IE paradigm's world. That largely extinguished the issue of the *IE pretentions, but not a production of asterisked “IE reconstructions”. The term öküz also denotes “bull”, “horned cattle”, “steppe dweller”, contrasting “ruffian, good, truthful”, and more. The notion “ox” is used as a generic for “bull” with connotations of “working bull, castrated bull”. Of 44 European languages, the Eng.-Türkic ox with 14 (32%) languages and a Sl. vol with 14 (32%) languages are two equal majorities. A next group is Romance bov- (< Tr. bug- “bull”) with 9 (20%). The other 7 (16%) languages use 3 different terms, one of them unique unique. Combined, the Türkic-derived ox and bull add up to 23(52%) of 44 European languages, not far from a level of 50.6% R1a/b demographic presence in Europe. Cognates: A.-Sax. oxa “ox”, OFris. oxa, WFris. okse, ONorse oxi, MDu. osse, Du. os, Gmn. ochse, Goth. auhsa “ox”, faihu “cattle”; Welsh ych “ox”; Lat. peku, pecus “cattle” (< Tr. buqa, büqa “bull”, b > p); Hu. ökör “cow, horned cattle”; Skt. uksan (उक्षन) “bull”, pasu “cattle” (~ Lat.), Av. uxšan “bull”; Agnean (Tokhar. A) ops “ox”; Kuchean (Tokhar. B) okso “ox, bull”; Mong. (Mong.) üker, ükür , hüker “bull, cow, horned cattle, cattle”, üхэр “bull, ox, cow, slow animal”, (Mongor.) fuguor “bull” (> Tung. hukur “cow”); Tung. hukur “cow, horned cattle”, Tung.-Manchu (Evenk) hukur (uku, ukun, ukur, hukul, əkun) “cow, horned cattle”, (Even) hӧkən, hӧkӧn “cow”, (Solon.) wxwr “cattle”, uxur (uɣur, ukur, ukuru) “bull, horned cattle”; Jap. beko “bull”; Chuv. vakar “ox”. Distribution: Eurasian from Atlantic to Pacific across linguistic borders. Distribution manifestly include cognates way beyond an *IE reach, positively excluding *PIE or *IE origins. Still, the *IE etymology fabricated figmentary “*PIE proto-words” *uksen “ox”, *uks-en- “male animal” and “*PG proto-words *uhso, *ukhson “ox”, practically parroting the ubiquitously attested Türkic forms. With a wealth of cognates scattered across Eurasia such clannish ingenuity is not needed, science is supposed to account for reality. Two more words indirectly relate to the ox and a direction of borrowing: Tor/tor and diva. Both words relate to bovine animals. One is a Türkic torpak, torbok “young bull” (bull calf), up to 2 years, -aq is a diminutive suffix. The other is a Türkic düvä, tüvä, genetic “female”, usually in a context of animals. The first, tor- is identical with the OGk. legendary tavros (ταυρος) “bull”, which found a great popularity in Europe, Cf. Eng. steer, Sw. tjur, Dan tyr “young bull”. The other is identical with diva “female”, Cf. Eng. diva, divine, divinity; A.-Sax. gyden, gydenu “goddess”, gydenlic “virgin” (g- prosthetic); Lat., It. diva “goddess”, Skt. devi “goddess”; this one rose to a sacramental level in church and theater. The common origin of the Eng. and Türkic lexicon is evinced by the paradigmatic transfer of the semantically kindred quartet of bull, ox, steer, and diva, an indelible evidence for a common origin from a Türkic milieu. See bull, steer.
English puppy (n.) “whelp, pup, cub” ~ Türkic papak, pebek, bäbek (n.) “mammal young”, “kids, children” (Sevortyan 1978, EDTL v. 2, 95-97). An “IE etymology” declared a routine “origin obscure”. That did not preclude production of the “PIE proto-words”, nor impacted their output. The form bäbek/papak is a western palatalized version of the CT bebe, beba, bäbä (n.) “baby, child”, see baby; -q/-k is a “rare” archaic diminutive suffix also widespread in Sl; -an is instrumental suffix (> baban). Ultimately fr. ba- (v.) “attach, bind”. A line of the type bab- refers to close relations, “puppy” is an extension of the notion “baby”, Cf. bebe, beba, bäbä “baby, child”, baba, babay “father, grandfather, old man”, paired ana baba “parents, mom and dad”, see father, papa. Among 44 European languages relative distribution between puppy and baby is most peculiar. 23 (52%) languages switched to Türkic “baby” vs. only 6 (14%) switched to “puppy”. 8 (18%) languages retained an Old Europe-Sl. ditya “baby”, and 13 (30%) retained their own native terms for “baby”. For “puppy”, 17 (39%) languages switched across linguistic borders to a Türkic kö-/ku- (Cf. Tatar köček “dog”), 10 (23%) retained Old Europe-Sl. shchenok “puppy”, 5 (11%) retained Teutonic valp “puppy”, 4 (9%) retained Teutonic hund- “dog”, and only 2 (5%) retained their own native terms. A main difference is in retention of the native terms, a conservative 30% for the “baby” vs. 5% for the “puppy”. Any adherence to IE, any trace of “IE” are non-existent. Here, there is no “IE” in Europe. Cognates: OFris. bobba “child”, ME baban (early 13c.), babi, babe (14th c.) “infant”; Welsh baban “baby”; A.-Norman pupus “child, boy”, pupulus “little boy”, pupille “orphan”; Serb. bebe, beba “child”, Bolg. bebe “child”, Bosnian beba “baby”; Lat. pupa, pupaa “doll, puppet, girl”, pupillus “orphan, minor”, It. bambino “baby”, OFr. poupee “doll, toy, puppet”; Alb. bebe “child”; Fin. pentu “puppy”; Mong. büӧbai, buubaj, büübei, bübei “doll, crib”, pubai “crib, cradle”; Tungus-Manchu (Evenk) bə, bubə, bəbə “crib, cradle”, bə-, bəbə- (v.) “put the baby in the cradle”, “swing (cradle), lull, lullaby”, bebev- (v.) “swing”, bəlu- “lull, swing”, (Even) bəbə, bäba “crib, sitting cradle”, “child (over 3 years)”, bəbə-, bəbət-/bəbəč- “swing, lull, dandle”, (Negid.) ba-ba “lullaby”, bəbə- (v.) “swing (cradle), lull”, (Orok.) bəbə “lullaby”, bəbə- бэбэ- (v.) “lull”; (Nanai) bə, bəbə- “lullaby, lull”. All cited examples are homogeneous, their forms and meanings directly or metaphorically ascend to a notion “infant, baby, child”. Distribution: Eurasian from Atlantic to Pacific across linguistic borders. Distribution exceeds by far an *IE reach, positively excluding *PIE or *IE origins. The “IE etymology” goes haywire, on top of “origin obscure”, and armed with a record 30% of retained native European terms for “baby”, it suggests a stochastic slew of homophones. A myopic guesswork is in a full bloom. The pearls are: bub “probably imitative of the sound of drinking”, “PG proto-word” *babo “father, brother, close male relation”, “OE proto-word” *baba “boy, child”, Gmn. bübbi “teat” (“Pennsylvania Gmn.”, 17th c. Du.), Fr. poupe “poop”, an “old woman”, “father”, “sissy”, and so on. All that cacophony falls on the top of the attested Welsh (Hg. R1b) baban and Türkic (Hg. R1b) bäbek, papak, pebek. The R1b is a leading haplogroup among Türkic Kurgan ethnicities, and among the Welsh Cymrys the R1b S145 stands at a whopping 45%. Whether the Du. and Welsh Cymrys and the Cimbri of the Cimbric War are one and the same with the annalistic Cimmerians, kicked out of the Black Sea area by the 8th c. BC Scythians, is a long-standing debate of the pre-DNA and previous to the post-IE era. The super-conservative retention of the native terms for “baby” by European vernaculars bodes well for the retention of the term “baby” by the Celtic and Türkic vernaculars. The English synonymic quadruplet series puppy, baby, doll, and whelp constitutes a massive case of paradigmatic transfer from a speciated semantic layer, attesting to the common genetic origin from the Türkic milieu's native languages. See baby, band, doll, father, papa, whelp.
English pussy, puss (n., v.) “domesticated fem. cat” ~ Türkic pïshïk, päsi (n.) “cat”. Türkic has 4 basic native forms for “cat”, pïšïк, pəsi, mäčə, kədi. The form pïshïk, päsi is an allophone of the form muš, müš for “cat”, with m/b alternation. The origin of the muš is likely onomatopoetic, from the cat's miaul; its CT synonym is an alternate base name for a “cat” četük, lit. “chatting, chattering, noisy”, see cat. A semantically identical etymology was suggested by A. Scherbak (Scherbak, 1961, 129): a call for cat (piš-piš, pis-pis, and the like), via dialectal p-/b- and b-/m- alternations. This suggestion allows to explain most Eurasian words for “cat” and “mouse” and even dogs, squirrels, rabbits, and other small mammals, the likes of pisi, pishik, pushuk, mïsïk, mishik, möshük, meche, mush, besai, etc., and segregate them from the remaining Eurasian words that don't fall under the suggested echoic etymology, see mouse. Also traditional is its metaphorical use for female genitalia and generic females that took semantically uniform different forms expressing vulgar and endearment meanings in different languages, Cf. LGmn. puse, Fr. chat, see Eve, ewe. The related Ir. pus “lip, mouth” may express the most archaic euphemism ascending to the time of Celtic departure on their circum-Mediterranean anabasis in 5th mill. BC. Etymologically, it is irrelevant whether muš or piš or čat has a priority, each one has its own Sprachbund distribution, and over time different Sprachbunds intertwined and overlaid, creating an impressionistic-type diffusion with elements blended at a distance but distinct at a close range, both for the primary and the secondary meaning. Of 44 European languages, the Eng.-Türkic pussy takes a prime seat with 23 (55%) languages, and allophones of Türkic cat use another 8 (18%) languages, for a combined 32 (73%), exceeding by far a level of 50.6% R1a/b demographic presence in Europe. The remaining 12 (27%) languages use a variety of 11 their own terms. The allophones of cat use such diverse languages as Pol., Hu., and Icl., in addition to Manchu and Tung. Cognates: Puss is a conventional name for a “cat” from Gmc. languages to Afghanistan; it is pisica “cat” in Rum., a loan of the Türkic pïshïk, and a secondary word for “cat” in numerous cases, Cf. Lith. puz, LGmn. puus, Sw. katte-pus; Ar. bassa (بَسَّة); Pers. pishi. The Manchu kəsikə and Tung. koška, kərkə (r/s alternation) “cat” scream against a widely advertized “IE” *PIE reinventions. The Tung.-Manchu either invented “IE” family and *PIE language, or the IE's paratrooped there from Europe. Within Türkic languages, the p- forms congregate in the Aral - Horezm area, Cf. Az., Turkmen pishik, Kara-Kalpak pishik, pichik, Turk. päsi, Uz. pishik, pushuk, pshïk, Tat. päsi. Distribution spans from Atlantic to Mongolia. Contrary to the “IE” assertions, it is not specific to linguistic families or even to specific braches within linguistic families, it crosses both classifications. Such geographical peculiarity is consistent with the other Turkisms in Eng. and in the Gmc. branch. The ubiquitous terminology of the “cat - pussy - mouse” paradigm is a case of paradigmatic transfer with convergence of multi-faceted evidence attesting to a genetic origin either from or via a Türkic linguistic community. See cat, Eve, ewe, mouse.
English sheep (n.) “ovine” ~ Türkic sıp, šïp, sıpa (n.) “ungulate colt, cattle”. Conflicting with a material of the Türkic languages, a standing etymology declares “of unknown origin” and “no known cognates outside Gmc.”. Originally one of generic terms for “ungulates”, “cattle, herd”, for a young colt of horse or donkey and other unspecified lesser animals, in at least the Az., Khakass, Ottoman, Kipchak, and Uigur languages. The first three of them point to the Aral-Caspian basin, consistent with numerous other Türkic-Gmc. lexemes. As “cattle”, it extends to “property” etc. The anlaut s- or š- is vernacular. Cognates: A.-Sax. sceap, scep “sheep”, ceape, ceapy “cattle, herd, sale”, OSax. scap, OFris. skep, MLG schap, MDu. scaep, Du. schaap, OHG scaf, Gmn. schaf “sheep”; Ch. sib-kan, pyn. tiangan (天干), Tr. šïpqan “animal cycle”; Tr. sïp basï (geogr.) “animal head”, sïpaqur “feedbag, morral”, sïp aqurï “trough”. Distribution: from Albion to Ottoman to Uigur and China. The term covered most of the Eurasia. No *IE connection, no following outside a Türkic milieu and the Gmc. group. European distribution is chopped. An ethnically largest group is Sl. ov- with 11 (25%) languages, it shares ov- with an ethnically motley tail of 8 (18%) largely Romance group of languages incl. Lat. Allophones of sheep are used by a splinter of Gmc. group with 8 (18%) languages. The remaining 17 (39%) languages use 13 diverse versions of their own vocabularies. Predominant is a motley group; Sl. is a dominant group, followed by Gmc. with its Türkic-Gmc. sheep, followed by Romance group. There is no *IE trace in Europe, the myopic “IE” “reconstructions” are a nonsense flying in the face of attested material. Undifferentiated origin, local idiosyncrasies, and substitutions of a brand name for a generic name are frequently observed phenomena in the terms for animals. Numerous terms are recycled in a seemingly random order, Cf. cat, mouse. A shift from a particular small hoofed animal to another one is a reasonable evolution. A phonetic shift from the original sıp, šıp to sheep, ship, shep etc. is also a credible fortuity. Gmc. languages are not uniform neither phonetically nor terminologically, Cf. Dan. faar or Goth. lamb “sheep”. The Türkic animal name sıp for a Gmc. sheep presents a credible alternative to the positively erroneous assertions “of unknown origin” and “no known cognates outside Gmc.”. There is no puzzle, just a lack of linguistic attention. The term neatly falls into the overall lineup of the English animal names of the Türkic origin, corroborating its genetic origin from a Türkic archaic milieu. See cat, mouse.
English steer (n.) “young bull, castrated” ~ Türkic tor-, torpak (n.) “1 to 2 years old bullock”. Tor is a marker of young age, it is akin to “halfling youth”. It is applied to other animals, Cf. torlan “foal”, torum “camel calf”, torbah “maral calf”, etc. It denotes a male, vs. a female tana. In some southern and western languages tana and/or tor lost a gender clarity to düvä (Cf. diva, goddess) and kačar/kašar respectively, or turned into a generic “young cow”, see ox. It may be a derivative of dӧre-, tӧre- “beget, birth”, it is congruent with it and its derivative turtu, turtam “kins, kindred”. It is homophonic with törü “law” (Cf. Torah “given, law”). It echoes a deverbal noun derivative of tür- “gore” (with ü/ö > o alternations), especially so with its secondary meanings “stab, pierce”, “horn, thrust, poke, shove”, and “chase”. Due to the Gk. mythology, from a very utilitarian and vernacular term it exploded to an international fame, Cf. Taurus constellation, Taurus (astrology), Tauri and Tauride (Crimea), Toreador bullfighter, torero, etc. Due to its heavenly station, the Tor “bull” under its Gk. moniker extends to nearly every Earthly language. Of 29 European languages two groups use allophones of tor and buq- “bull” (the others are semantically confusing between homophones steer “bullock” (n.) and “drive, direct” (v.)), 10 (34%) and 6 (21%) respectively. Combined, they add up to 16 (55%) of 29 languages, matching a level of 50.6% R1a/b demographic presence in Europe. The Sl. group is split between forms vol- and buq-, with a native Sl. form vol- accounting for 5 (17%) languages. Remaining 8 (28%) languages use their own 8 native terms. There is no trace of an “IE” presence in Europe. Cognates: A.-Sax. steor, styr “steer, bullock, young cow”, tarse “male falcon”, toren, torendan “tear”, torn “anger”, torngemot “battle”, OSax. stior “bull”, Fris. stjoer “steer”, MDu., Du., Gmn. stier “steer”, Dan. tyr “steer”, Sw. tjur “steer”, ONorse stjorr “steer”, Goth. stiur “bull”; Scots stiuir “steer”; Yid. stirz “steer”; Lat. taurus “bull”, stottorum “steer”, Galician tauro “bull”; Gk. tavros (ταυρος) “bull”; Alb. drejton “steer”; Est. tüürid “steer”; Hindi steeyar (स्टीयर) “steer”, Gujarati stiyarsa (સ્ટિયર્સ) “steer”; Mong. toroi “piglet” (~ Tr. torai, torapai “(wild) piglet”, Cf. torlan, torum q.v.). Distribution: typical Türkic Eurasian-wide Steppe Belt to Mongolia plus a W. European scatter. An “IE etymology” suggests a faux “PG proto-word” *steuraz and a “perhaps” а faux “PIE proto-word” *steu-ro, both “steer”. Reducing the word to a mechanical construct is ludicrous. “IE etymology” stripped a multi-layer, multi-aspect phenomena to a caricature. Clinging to the vernacular s- may help to distract attention but raises questions on reasoning. In the presence of the attested original there is no need for such “reconstructed” hypotheses. Shoving anlaut st- down uninitiated throats, “IE etymology” does not trouble to address an absence of the initial s- in otherwise unconnected Gk., A.-Sax. (torngemot), Dan., Sw., Lat., and Est. forms. And the abnormality of the “IE” Staurus vs. Taurus implies Gk. and other freaks' sloppiness. It does not bother to substantiate a need for hypotheticals, analyze correlation with similar applications and etymological sources for the synonyms “ox” and “steer” that differ only by age. And the relationship between tor (m.) and diva, divine (f.), q.v. All those *IE breaches score for the Türkic tor and its kins. A Gmc. version “steer” comes in two flavors, with and without prosthetic anlaut s, i.e. steor vs. tyr. The Gmc.-Sl. prefix s is grammatically a verbal marker of perfect tense also fossilized in deverbal nouns, Cf. Sl. dat (дать) “give”, sdat (сдать) “give away, surrender”. A randomness of distribution indicates that the Ø/s split occurred still at the time of the Türkic/non-Türkic symbiosis, i.e. during a Corded Ware period. The Gk. term is a result of a Scythian-Gk. amalgamation, Cf. Herodotus 4.108. In some southern dialects of the Khorezmian, the word tana became a general name for young cows, paralleling that of the tor. That word is prolific in the Amerind family throughout N. and S. America in all 11 branches, attesting to its and a parallel kuna “woman” presence back to 13-15 mill. ago. A paradigmatic transfer case for the animal terms bull, ox, steer, cow, etc. is an indelible attestation of a genetic origin from a Türkic vocabulary. See bull, cow, ox.
English tick (n.) “tiny blood-sucking parasitic insect with barbed proboscis” ~ Türkic tik-, dik- (v.) “sting (bite), jab, punch, stick, insert, embed”, tikti (v., adj.) “stung”. A standing etymology first declares “of unknown origin”, and then proceeds to compose “IE proto-words”. There is no “IE” linguistic unity, 44 European languages use 27 different bases, and except Sl. and Gmc., they are systemically Sprachbunds of a single or very few languages. A Gmc. group of Gmc.-Türkic tic- with 6 (14%) languages leads along with the Old Europe Sl. group of 6 (14%) languages. The rest, incl. Lat., are isolated minority languages. The retention of native appellations is outstanding. Cognates: A.-Sax. ticla, ticia (n.) “tick (insect)”, stingan (v) “sting (/(s)tiŋ/) with prosthetic s-”, MDu. teke, Du. teek, OHG zecho, Gmn. zecke “tick”; Fr. tique, It. zecca “tick”. Distribution: a verb is ubiquitous, a noun sporadic across Eurasia; a compact isle in W. Europe. No *IE or any other etymology whatsoever. A fictitious “PG” *tikko, *tigo, WGmc. *tik- is a ludicrous imitation of the attested tic-. The A.-Sax. ticla retained a Türkic denoun verbal suffix -la. The Gmn. form probably reflects a Türkic form δik- with an interdental th (runic þ), variously transcribed as t and d. The phonetic and semantic match is perfect, the phonetic and semantic eidos makes the connection tick = tik- indisputable. On a continental scale, the insects' terminology tends to be areal; eastern Türkic languages have a different set of names. Two Türkic words, tiki and tik-/dik-, likely related, constitute a case of paradigmatic transfer to the Eng. tick “sound” and tick “insect”, an irrefutable evidence of a genetic connection with a Türkic lexis. See tick (sound).
English turkey “turkey” fowl ~ Türkic turuhtan “a kind of “fowl”. Cognates: Gmn. truthahn, Yid. terkey “turkey”; Ir. turcaí “turkey”; It. tacchino; Corsican turchia “turkey”; Fin. turkki “turkey”. The first part turuh is probably turuğ, turuɣ expressing a notion of stationarity, immobility, a derivative fr. a verb tur- “stay, remain”. The second part is an inchoative suffix -tan/-tän/-dan/-dän. Confusion between “turkey” and Turkey probably was initially based on plain consonance and was not caused by “imported to Europe by Turkey merchants through Turkey”. The closeness of Türkic and Gmn. forms and contrast with independent It. form attest to that. Any “IE etymology” is inapplicable because turkey/truthahn is not a staple in “IE” languages, it is obviously an alien guest, and secondly because any attempts to connect a pre-18th c. name with the country of Turkey that did not yet exist, are rather artificial scheming. An ethnic moniker Turk (Byzantine Greek Tourkos (Τούρκος)) showed up during Middle Ages, probably after centuries of post-8th c. AD Byzantine - “Scythian” encounters. At that time no Türkic entity or tribe used or knew of the Byzantine term reportedly See tower.
English whelp (n.) “young, puppy” ~ Türkic bala: (balu:), mïlа (n.), bala:p (adv.) “nestling, puppy, baby”. An expert elucidation for the origin is a routine “of unknown origin”, emended with “PG” and “pre-Gmc.” “reconstructions”. Ultimately fr. a verb bal- “attached, bound”, a passive form of ba- (v.) “attach, bind”. An archaic suffix -p (bala:p) forms denoun adverbs. Both the Türkic and Eng. nouns have a derivative verbal form with semantics “bear, birth, birthing” now expressed in Eng. with a phrase “give birth” instead of the concise and meaningful whelp which may still be active as a trade term. A synonymic form bebe, beba, bäbä (n.) “baby, child” is likely an allophonic deverbal noun derivative of the same word ba- (v.) “attach, bind”, see baby. A synonymic Eastern European (preserved in Chuv.) allophonic version of bebe/beba/bäbä “baby” is bäbek, papak, pebek “kids, children” (Sevortyan 1978, EDTL, 95-97), it produced the western version, the Eng. “puppy”, see puppy. Cognates: OSax. hwelp, ONorse hvelpr, Norw. (Nynorsk) kvelp, Du. welp, Gmn. hwelf, welpe “puppy” of dogs and carnivores (Cf. Baloo of Rudyard Kipling). The phonetics is interesting: Gmc. forms are palatalized, a hallmark of Eastern Europe phonetics. Suffix -p forms denoun adverbs like “lovely”, “swell”, “puppy” (metaphoric construct fr. noun bala: “puppy”) etc. The notation “rare” for the adverbial suffix -p stands for its archaic nature or a western provenance in the eastern sources. Without a record in an authentic runic form, what phoneme the ancient Gmc. scribes tried to convey with the Romanized anlaut symbol wh-/hw-/hv-/w- can only be presumed, almost definitely it is little related to a modern phonetic practice, Cf. kvelp. In Türkic bala: (balu:) is widely used including lovely foals, slave girls, children, etc., just like a “puppy” in modern English. No *IE etymology. The English quadruplet whelp, baby, doll, and puppy is a case of paradigmatic transfer attesting to the common genetic origin from the languages of the Türkic milieu. See baby, band, doll, puppy.
English wolf (n.) “Canis lupus” ~ Türkic börü, böri: (n.) “wolf”. Türkic has 3 main terms for “wolf”, börü is most common (+kurt, kashkï). The ultimate origin of the form börü is probably bö/bü for larger mammals, see notes above. Etymological analysis of böri “pushes back into a distant past the era of emergence and spread of the bӧ:ri core in Türkic languages” (EDTL v. 2 220). Bory is attested in a Scythian term Borysthenes “Dnieper” ~ “Wolf River”, bory “wolf”; also translated as “bear” ~ “Bear River”, ten, than “river, water space, body of water” (Herodotus IV 9, 10, VI 53); Danube Bulgarian Buri-chai ~ Dnieper ~ “Bear River”, chai “river”. Transition fr. börü to western vl, vk, vlk > wolf is readily explainable by alternations b-/v-/w-/f- and liquid r-/l-. A complimentary -l- form bülčäk, bilcik, böltürük “wolf cub” illuminates a path to vl- forms, Cf. böri vs. wulf (b/w, r/l alternation). A Sakha mölbör “bear” and merdäk “bear cub” may have preserved elements of Sakha's ancestral Saka anlaut m- articulation. Börkä is “escape, flee”; in some Türkic languages an allophonic form barıs, a version of bars, designates leopard and extends to lion and tiger, see Boris. The Sl. (Hg. I) Old Europe version vl, vlk became a dominating form in Europe. A notion bör “grey” conflated with the prime notion to produce a synonymous concrete paired noun grey wolf (tales, poetry). By the 3rd mill BC European forms were phonetically bordering on the Asian bridge forms. Similar forms without a labial b- produced versions of a form lup- attested by Sabinian, Lat. lupus, Gk. lukos (λυκος), and so on. An Ir. alp “wolf” designates something large, giant, Cf. Tr. alp “formidable, terrible, solemn”, It. Alps. The older recorded Akkadian, Skt., Av., and Sogd. forms are closer to the Türkic börü than the later recorded European forms. Of 44 European languages, the pan-European-Türkic böri takes a prime seat with 29 (66%) languages, exceeding by far a level of 50.6% R1a/b demographic presence in Europe, attesting to millenniums of internalizations and a loss of native forms. The Gk.-Romance lyk-/lup- use another 11 (25%) languages. The remaining 4 (10%) languages use their own 4 terms. Cognates: A.-Sax., OSax. wulf, ONorse ulfr, OFris., Du., OHG, Goth. wulfs, Gmn. wolf, Cf. Gmn. Herr Wolf vs. Tr. Er Böri “proper name” (Clauson EDT 356); Ir. buralo; Balto-Sl. (Lith.) vilkas, (Latv.) vilks, (OCS) vlk, vluku, (Rus.) volk, birük (волк, бирюк); Alb. ulk; Hu. far(kas); Osset. beräɣ, beræg, EOsset. biräɣ, biræg (< Tr. böri); Lat. ferus “wild” (“large wild animal of northern woods”; OPers. vǝhrka (m.), vǝhrka:- (f.) (< Tr. böri); Skt. vrkah,vrka, wrkas (वृक), Av. wəhrko, vǝhrka-; Sogd. wurk, wurka; Kuchean (aka Tochar. B, agglutinative, in Brahmi script, ca. 800 AD) walkwe; Sum. bar-bar “wolf”; Akkadian (28-24 cc. BC) barbaru “wolf or leopard”, a reduplication of börü; Danube Bulg. vereni (“wolf” in 12-cycle animal calendar); Mong beltereg (< Tr. böltürük “wolf cub”); all wolf unless noted. Distribution: from Atlantic to Baikal, across linguistic borders. Börü is used from Europe to Saha (Yakutia) and Uiguria in phonetically close forms. A phonetic uniformity within each of the three areas, the Europe, steppe Eurasia, and SC Asia is impressive. Each zone lacks synonyms, a trait atypical for non-domesticated animals and developed vocabularies. Due to its geographic and ethnic extent, the Türkic vocabulary is comparatively most diversified both phonetically and semantically more vaguely speciated. Possibly brought over to Europe as early as 9.5 mill. BP by the carriers of Hg. R1a overland migrants, börü and its versions were guests, amplified by numerous migratory waves of the R1a/b groups. At the time, majority of the W. European population belonged to Hg. I, a Sl. haplogroup then disseminated across W. and C Europe. The Celtic buralo attests to a presence of the word in the E. Europe prior to the Celtic departure on a circum-Mediterranean path ca. 5th-4th mill. BC. Form börü is used in Sogd., Skt., and Av., the last two attest that the form was in common use in the E. Europe of the 3rd mill. BC. The final -k of the Kazakh, Kirgiz, and Tuvan forms is paralleled by the auslaut suffix -k of the Balto-Sl., Skt., Av., and Sogd. forms. Rus. has preserved both the Tr.-Sl. Old Europe version volk and a CT version birük. Genetics absolutely decimated the old Gmc. self-adoring notion of a primacy of the Gmc. form, pushing it into a minor and later category of linguistic borrowers, Cf. the faux surrogates “PG proto-word” *wulfaz, “PWG proto-word” *wulf, “PIE proto-word” *wlkwo-, *wlkwos “wolf”, and the like. With widely attested ancestor, no substitutes are needed. “IE etymology” unwittingly cites ancient Hyrcania as a supporting argument, equating it with OPers. Varkana “wolf-land” (< böri). Attempts to bring böri into “IE” paradigm claiming Pers. origins via a Türkic-Osset. channel have waned. Hyrcania was a land of nomadic tribe suitably called Iirks, Yiyrks, yrkae/Hyrcani/Gircani “nomadic Scythians”, lit. “nomads” (Pliny 6.XIX). They are Yörük in Turkey, Yürük in Turkmenistan, Mazandarani in Iran, likely the same as Dahae (+ Tuhsi, Tokhars, Yuezhi, Dügers, and Digors). Located by SE end of the Caspian Sea, they see-saw between Oxus (Amudarya) and Parthava. In Gmn. Iirkischen means “Irish”, pointing to the origin of the epithet Irish as “nomads, pastoralists”. The term Hyrcania is not limited to the pre-673 BC Akkadian Partukka or 247 BC Parthia, there are a Hyrcanian forest, Hyrcanian Sea, and a Hyrcania fortress in a Judean desert. A Pers. “wolf” is gorg (گرگ), possibly an iteration of some form of böri. Idiosyncratic internalizations attest to temporally different acquisition paths from different sources. The entire harebrained “IE” version does not hold water at any angle. Versus the faux “reconstructions”, the attested European and Asian forms are equidistant from the Türkic forms. A bit less myopic and a bit more objective analysis should have included the Türkic cognates as Eurasian most spread geographically. See Boris.
English acorn (n.) “nut of oak tree” ~ Türkic yaɣaq “large hard-shelled seed”, yekel (Chuv.) “acorn”. Cognates: ONorse akarn, Goth. akran, Du. aker, LGmn. ecker, Gmn. Ecker “acorn”; Sl. jelud (желудь). The Sl. form remotely resembles an intermediate form from the eastern Türkic to the European Chuv. to Sl. to Gmc. The “IE etymology” derives acorn from impossible phonetical associations: “open land”, “field”, “acre” “fruits and vegetables”. With the cousins acorn - yekel, there is no need for stretched imagination.
Old English ad (n.) “heap, funeral pile, pyre, fire, flame” ~ Türkic öt “fire, flame”; Türkic ada “calamities and suffering”. The Azeri and Turkish preserved a form öd. The A.-Sax. word ad, adwylm “whirlpool of fire” did not survive into the modern language, and accordingly is not explicated etymologically; after 1200s it was replaced with the synonymous word fyr “strong fire, torch”, attested in the post-Norman invasion time, an allophone of the Türkic bur- “fire”, “fiery”. The semantic and phonetic match of the ad/öt/öd is perfect, and it leads to understanding of the Gk. and Sl. word ad for “hell”, which apparently was borrowed as a physically fiery or suffering place from Türkic to Gk. and then to Slavic (see monastery). In Gk. and Sl. languages, the word adis (αδης) and ad (ад) stand for “hell” without a notion of a fire, obviously a loanword for a religious concept. The Tengriism theology did not have a concept of the “hell” employed in Christianity, did not have a term for it, and accordingly initially had to find a native word to relay a new concept, while the Gk. had the word kólasi̱ (κoλαση) for “inferno, hell”. The spelling with the long ā, definitely not in the arsenal of the Anglo-Saxon scribes, is a clear attempt to render the Türkic word with the rounded ö. On top of the obvious phonetic parallelism, the semantic parallelism is not less striking, demonstrating a near perfect paradigmatic transfer of two Türkic words related to fire, via two spatially and temporally independent paths, into the incipient and matured Christian word. The Türkic idiom ada tuda lit. “inferno total” without any religious connotations has survived in a paradigmatic transfer mode in the modern idiom total hell. See fire.
English anguish (n.) “extreme distress” ~ Türkic özak (adj.) “narrow”. The syllable öz comes in numerous flavors, öd, öδ, öz, üz, making the Goth. form aggwus just another attested dialectic form. The attested link is Türkic özak “narrow” > Lat. angustus “narrow, tight” > OFr. anguisse, anguissier “choking sensation, distress, anxiety, rage” > English anguish “suffer great pains or distress”. Apparently, the semantic fork happened still in the parental dialect, and Lat. acquired both meanings, literal and figurative, as a case of paradigmatic transfer. The Türkic özak (adj.) is a derivative of öz (n.) “valley, pass between mountains”, hence a narrow passage, narrows. The semantic of “narrow” is preserved in Goth. form aggwus, A.-Sax. enge “narrow, painful”, MDu. enghe, Balt. (Lith.) ankshtas, Lat. angustus, Sl. uzkii, vuzkii, Arm. anjuk, Skt. aihus, aihas, Av. azah- “need”. The “IE etymology” does not dig to the base stem of the “IE” forms, stopping at a limited sampling of allophonic forms. See anger, narrow.
English antler “horn” ~ Türkic anten “horn”. English has derivatives such as antenna (insect), antenna (radio); no sentient PIE etymology, no similar word exists in any other Romance language, while Türkic shares this primordial base with all Gmc. languages. In the “IE” paradigm, Gmn. Augensprossen “antlers”, lit. “antler-sprouts” is linked with the unattested Gallo-Romance cornu *antoculare “horn in front of the eyes”, from Lat. ante “before” + ocularis “of the eyes”, which incidentally also includes the Türkic base ant, and cooks etymology incompatible with a word that was needed 50,000 years ago.
English anvil “incus” ~ Türkic andal (Bashk.) “anvil”. Cognates: MDu. anvilt, OHG
anafalz, Du. aanbeeld, Dan. ambolt; Gk. amoni
(αμόνι); Jap. anbiru (アンビル), all “anvil”. For such a pinpointed meaning, the commonality of
the origin is obvious. The Celtic forms, the Ir. inneoin, Welsh einion must be a
loanword, since their departure on the circum-Mediterranean path took place before the Metal Age in
the Eastern Europe; it appears to be a borrowing from the Romance group. Ditto the Jap. word, since
it is different from the Far Eastern lingo and from the eastern Türkic örs, örsün, ürdün.
98
English apt (adj.) “quick, resourceful”, aptitude (n.) “ability” ~ Türkic yapt (n.) “construction, action”, a noun derivative from a verb yap- “construct, make, do” + abstract noun suffix -t. Cognates: Middle Fr. aptitude, LLat. aptitudo, aptus “joined, fitted”. The original Lat. aptus “joined, fitted” retained semantics of the Türkic yapt (n.) “construction, action”, a case of paradigmatic transfer. The “IE etymology” derives the Lat. form from an unattested *PIE *ap- “to grasp, take, reach”, essentially identical with the actual Türkic yap- “make, do” and yapt “construction, action” that does not use any ingenious imagination to come up with etymology. Numerous English derivatives are built on the stem apt, not on the Lat. aptus, corroborating the Türkic origin: aptly (adv.), aptness (n.), apt (adj.), and derivatives of aptitude (n.). The Fr. aptitudee probably incorporated into the pre-Norman English lexis already equipped with numerous forms of apt- derivatives.
English arch ~ Türkic arca, from the Türkic root arca “back, behind”. Cognates: OFr. arche “arch of a bridge”, Lat. arcus, PIE unattested base *arqu- “bowed, curved” (The logics behind the mechanism of the insane unattested cognates is “arrow” = “bow”: Goth. arhvazna “arrow”, A.-Sax. earh, ONorse ör, hence arrowed = bowed, i.e. if we see an arrow, it is linguistically a bow, i.e. the arch).
English ard “scratch plough” ~ Türkic or “scratch plow”. The Türkic stem is a verb or-
“rip (harvest), scythe”, leading to the original semantics for the or “ripper”, the other
semantic meaning of the verb or- is “cut”, which makes the or “cutter”, a tool for
cutting. Cognates: ONorse arðr, Sw. arder, Sl. oralo. No “IE” etymology; the
“IE” terminology for plows and scratch plows comes from numerous different independent sources. The
common Gmn.-English-Slavic-Türkic term is specific for the Northern and Eastern Europe. The
direction of borrowing is fairly apparent, the absence of this word at the numerous Slavic and Gmn.
neighbors (other than Türkic) indicates that Slavs or Germans gained this word from another area.
The Slavic and Gmn. migrations to Central Asia and Siberia can confidently be excluded, while the
Kurgan excursions to Northern Europe are well-established, thus a most plausible scenario is Türkic
=> Gmc. and Türkic => Slavic, with likely Gmn. <=> Slavic exchange, given the early history of
Slavic expansion, driven by progressive farming technique.
99
English ardent (adj.) “passionate” ~ Türkic arzu “desire, striving” (n.). Cognates: OFr. ardant “burning, hot; zealous”, Lat. ardere, ardentem (nom. ardens) “glowing, fiery, hot, ablaze, passionate”, ref. OE æsce, unattested “IE” *as- “to burn, glow”, PIE root *as- “to burn, glow”. This fanciful etymology operates with imagined ashes, flames, and burning established on unattested linguistic “facts”, while ignoring or ignorant that the actual attested Türkic words ataš (atash) “fiery red” and atašluɣ (atashlug) “fiery” provide attested sources for the English “ash”, used in the “IE” concoction, without manufacturing asterisked shams. The etymology ardent ~ arzu is sustainable on its own, without any extended equilibristic. A great semantic distance lays between the ashes and passions.
English Augean (stables), metaphoric “filthy” ~ Türkic aqür “horse stables” (n.). The English word came from Gk. via Lat. and probably via French folklore, the Gk. form is Afɣeías (Αὐɣείας), Lat. Augeas or Augeias, English Augean. The Gk. borrowing must be of Scythian origin, it associates the Scythian stables aqür (or close allophone) with the Scythian Herakles = Tr. Her + Ak + es = Man + White/Noble + Gk. ending -(l)es. Although the English application is not ancient, the timing of its Gk. borrowing arises to the earliest Gk. folklore. The numerous Gk. etymologies try to explain the name from the Gk. allophones and link the story with numerous Gk. mythologies, somehow all unrelated to the connotation of “stables”, while the clone of the Türkic word is obvious.
English aught (n.) “something, nothing, zero” ~ Türkic ot (adj.) “grass, weed”, metaphorically “useless, nothing”, lit. “useless (vegetation), weeds”, Cf. semantically identical metaphor “fluff”. Cognates: none outside of the Türkic belt; A.-Sax. awiht, aught “little, nothing, something”. Both the Türkic ot “nothing” and öte:- “perform, fulfill” survived in A.-Sax. and into Eng., breeding confusion among literati (Shakespeare, Milton, and Pope) and etymologists. The A.-Sax. spelling indicates that the acute semantic distinction between the unrounded -o- and rounded -ö- endured into A.-Sax., but was lost in the OE transition to English, creating phonetically eidetic but semantically distinct homophones (Cf. aught “nothing” fr. ot (n,) vs. ought “should” fr. owe/oye- (v.) “owe, must do”). For the aught, the “IE etymology” dreams up unrealistic scenarios with virtual soubriquets “ever”, “vital force, life”, “eternity”, “thing”, “anything”, “weight”; all that fanciful equilibristics is not needed. In contrast, for the ought, the same “IE etymology” suggests neither “IE” nor any other etymology whatsoever. See oath, ought, owe.
English aurora (n.) “dawn light, glow, blaze” ~ Türkic jaru- (v.) “illumine” (as of dawn aurora). The form jar-/yar- is widely used in Sl. languages, e.g. zarevo (зарево) “dawn aurora”. In Lat. the form jaru- (v.) “illumine” turned into the allophone aurora, presently an international word, with a derivative Aurora, the Roman goddess of dawn. The supposed “IE” cognates (Gk., Lith., Skt., Lat.) fr. unattested PIE *ausus- “dawn” and *aus- “to shine” conflict with the absence of cognates in Gmc. and Sl. branches, and rely on phonetic reflections of the disparate notions of “dry”, “kindle”, “burn”, “south wind”, “east”; the Gk., Skt., Lith. eos, usah, ausra “dawn” appear to ascend to the E.European Sprachbund of 2000 BC, after the s/r split; hence no reasonable “IE” cognates. The anlaut semi-consonant j-/g- is a trait of the Ogur languages, while the Oguz languages start with the vowel ya-, hence the jar- vs. yar- forms. See jar (v.).
English axle (n.) “shaft” ~ i:k (n.) “axle”. The Türkic i:k is an allophone of ok “arrow”, pointing to its origin; it also means “spindle, distaff, pivot”, and the like. Cognates: OSax. ahsla, A.-Sax. eax, eaxl, ONorse öx(ull), OHG ahsala; Dan., Du. as, akse, Icl. öxull; Ir. ac(astóra), Welsh echel; Lat. axis “axle, pivot”, Gk. axon “axis, axle, wagon”; Skt. aksah; Balto-Sl. (Lith.) aszis, (Sl.) os- (ос-: ось, осовина); Fin. akseli, while Est., Hu. and Mong. have a different word, Est. telje, Hu. tengely, and Mong. tenxleg (тэнхлэг) connected with the Türkic teleg “wagon”. The form with auslaut -l includes the Türkic denominal adjective suffix -l/il (ikil), attesting that initially the word had an adjectival notion of “stemmed, shafted”, later fossilized into noun. The various phonetical renditions of the first consonant attest to its character incompatible with the limited phonetics of the European alphabets; in modern dictionaries the underlying ok “arrow” is rendered as oq, ox, and oɣ. The word is patently non-IE, unlike Türkic, the “IE” concocted “proto-word” does not have a proto-object to be etymologically derived from. The “IE” version of the word had obviously (i.e. Skt.) already formed by the 2000 BC migration of the Indo-Aryans from the Eastern Europe. The Welsh peculiar form may indicate that circum-Mediterranean Celts at the tome of departure from the N. Pontic (~4000 BC) already had wagons and their distinct vernacular.
English barley ~ Türkic arpa “barley”, urba (Chuv.) “barley”. Cognates: A.-Sax. bere “barley”, bærlic with Türkic suffix -lig/-liɣ/-lik/-lan “like”, ONorse barr, Gmn. Erbse “pea”; possible cognate of Lat. far “coarse grain”. The semantics is accurate, and phonetical transition via the Gmn. form appears to be reasonable. No attested “IE” cognates. See herb.
English bag (v., n.) “flexible container” ~ Türkic bag (baɣ) (n.) “sheaf (of goods), bale, bundle”, a concrete nominal derivative with the deverbal suffix -g fr. the verb ba:- “bind, bond, tie, belt”, which overlaps with the verb bele:- “to bale, wrap” fr. a second form of ba-. Cognates: A.-Sax. baelg (winbaelg “wine canteen”), A.-Sax. bagge, ONorse baggi, MDu. puyl “bag”; links to Scandinavian vernaculars is the (un)educated depth of the etymological luminaries. The Eng. poke “bag, purse” is also an unrecognized cognate, apparently carried over by a group with palatalized vernacular, it is concordant phonetically and precise semantically. We can only be amazed that the same bags used on the Silk Road are used in our daily life; the modern Eng. phonetics even retained the nuance of the phonetic value of -a- conveyed in Arabic transcription with a long -a:-. Another word taken from the camel back, yuk “sheaf”, took hold in the Slavic language as vieuk, a sheaf, and was actively used in figurative and direct meaning during the early years after the fall of the Former USSR to carry goods from the decadent West to the goods-starving East. The Slavic version in its form has a prosthetic anlaut v-, probably derived from a Türkic dialectal w-. The A.-Sax., Du. and Lat. have inlaut -l-, like Lat. bulga “leather canteen, bag”, a cognate of Eng. bulge, a concrete deverbal noun derivative of the verb bele:- agglutinated with the same deverbal concrete suffix -g: beleg “wrapped”. No “IE” cognates, etymologists can't even come up with asterisked *bag to make a case for an “IE” bag. See bulge.
English barge (n.) “boat type” ~ Türkic barq (n.) “construction, constructed object”.
Türkic notion barq (n.) is a generic term for anything built, any structure, mostly
buildings, for example a sepulture, in this case lit. “craft”. Cognates: A.-Sax. barð
“barque”; OProvenčal barca, MLat. barga; Hamito-Semitic group's Egyptian bari
“boat”, Gk. baris (βαρισ)
“Egyptian boat”. No “IE etymology” whatsoever. The A.-Sax. form precedes that of the LLat., it can't
be borrowing, and suggest independent path possibly connected with the Burgunds; OProvenčal and
MLat. time and place attest to Burgund origin of Provencal and Late Lat. words; the Egyptian and Gk.
forms are probably of Kipchak Mamluk if not of earlier origin. Apparently, for seafaring non-nomadic
people, the semantically contracted Türkic barq
(n.) “constructed object” was predominantly associated with water craft structure. The verb barge
(v.) “crash into, strike, thrust, shove”, an allophone of the Türkic stem bart (adv.) with
the semantics “sudden intervention” on purely phonetical homophony is asserted within the “IE
etymology” to be a late innovation stemming from the noun barge “boat” that ultimately ascends
to the Türkic barq, confusing the verb barge with semantically incompatible noun
barge “small vessel” and its verbal derivative barge “transport by barge”. Undoubtedly,
the sea-fairing people around Mediterranean had a developed boat terminology for a long time, but
the Celtic newcomers with their spread across Western Europe along river routs (2nd mill BC) were
disseminating far and wide their own sail technology and boat terminology to the local populations,
making them good candidates for initial seeding of the word barq in the Northern Africa along
their circum-Mediterranean migration route attested by the dating of the R1b haplogroup, and then in
Europe. See
bark, barge (v.).
100
English bark (n.) (barque) “small ship” ~ Türkic barq (n.) “construction, constructed object”. Cognates: the earliest “IE” cognate is LLat. barca “small ship”, but another cognate cited is Egyptian bari and Gk. baris “Egyptian boat”, of Hamito-Semitic group. In Türkic, the notion barq (n.) is used as a generic term for anything that is built, any structure, mostly buildings, but for example a sepulture. Apparently, for seafaring people semantically contracted the Türkic barq (n.) “constructed object” to be predominantly associated with water craft structure. No “IE etymology” whatsoever. Three homophonic meanings for English bark (n.) “ship”, “woody covering”, and “dog bark” point to adoption of the words together with associated semantics from the non-native languages . See barge (v.), barge (n.).
English berm (n.) ~ Türkic bürma (n.) “fold, pleat” (OTD 133), a deverbal noun fr. the verbal base bür- (aka pür-) “constrict, tighten forming folds”, “fold” with numerous further derivatives. Cognates: ODu. baerm “edge of a dike”, Fr. berme. The Türkic noun is of the verbal stem. The English orthography -er reflects the Türkic phonetics -ür with ü as u in “mule”, the articulation of the English -e- in berm closely mimics articulation of the Türkic phonemes u and ü, demonstrating amazing continuity of the distinct phonetical peculiarities across time and space, and frustrating students who work on mastering English. The combination -aer- in Du. points to the attempts to render the same Türkic vowel ü with available means. The term brim (n.), related to the folds of the surf, appears to be a derivative of the Türkic verbal stem bür-, or a development of the berm (n.), semantically it extended to an “edge of a fold”. Another phonetically and semantically viable derivative is the word “surf”, which does not fit into “IE” etymologies: a Türkic derivative of the verbal stem bür-, in conjunction with the word su for water, is a compound süpür- “sweep”, with connotation of “wet sweep”, the süpür- is allophonic with the surf, and the surf is also rated “of obscure origin”. In labialized phonetical version, the bür- ~ berm would produce pleat, verbal form plait, probably reflecting the alternate migration route and great time difference of its origin. Accepting that the Cimmerians and Sarmats were Eastern European Uralics, and the Scythians were their remote migrant kins from the South Siberia, the word berm would belong to the Sarmatian languages. With no “IE” etymology, the word is rated “of obscure origin” by the uninquisitive cloistered “IE” linguists.
English bill (n.) “shafted weapon with hook-like cutting blade head” ~ Türkic bilä- (bulə-) (v.)
“to sharpen”, balta/baltu/baldu/baltir “battle ax”. Cognates: OE bil,
OHG bihal, ON bilda “hatchet”, OSax.
bil “sword”, Gmn. Bille, Du. bijl “ax”; OIr. biail “ax”. Suggested
unattested PIE root
*bheie- “to cut, to strike” is a mechanical variation on Gmc. phonetics. The distribution
exclusively in Gmc. and OIr. and incompatibility with other “IE” roots attest to a non-IE origin. The
ON form bilda phonetically matches the Türkic balta/baltu/baldu/baltir
and bridges the the semantics “sharpen” > “sharp” ~ “ax, hatchet”, indicating the line of
development. The loss of unaccented auslaut -ta (bilda > bil) is reasonable,
considering the distance, timespan, and transition as a loanword into “IE” lexis.
101
English blade (n.) “cutting edge” ~ Türkic baldu, balta “ax, hatchet”. In English, a second meaning applies to anything that resembles blade, like a leaf or grass, shoulder blade, skate blade, spade, etc. Cognates: A.-Sax. blæd, OFris. bled, OSax., Dan., Du. blad, ONorse blað, Gmn. blatt, Hu. balta, Arm beran, Basque pala, Sum. bal. The presence of the word in Sumerian, along with other Türkic-Sumerian words in English (Cf. bat ~ pata ~ badd) corroborates the Türkic path to English and the circum-Mediterranean path of Kurgans via Caucasus and Mesopotamia (Basque, Celtic). In the “IE” family, only Gmc. languages have cognates of this Türkic and Sumerian word, and its Scandinavian-Baltic (OFris., ONorse, OSax.) focus points to the Scythian-Sarmatian conveyance to the northwestern Europe. The “IE etymology” does not offer any attested cognates, and dances around derivative meanings of grasses and leafs; the suggested “IE etymology” of “to thrive, bloom” is beyond any criticism. It is quite possible that the prehistorical meaning was based on sharp flat implements obtained from nature, like the cutting edge of reeds, we have no way to ascertain that, but the oldest attested form in Sumerian was already both specific and arose in the Neolithic society. A contracted form lad, with dropped anlaut b-, produced derivatives like Eng. leaf, Gmn. Laub, Welsh llafn, Ir. lann, Sl. lezvie (лезвие), etc., the Celtic forms (Ir., Welsh, Basque) neatly fit into genetically-established circum-Mediterranean path of the Kurgans.
English bog (n.) “slop, mire, wet spongy ground” ~ Türkic bög- (v.) “collect, gather (water etc.)”, bögtür (n.) “bog, slop, mire”, deverbal noun fr. causative of bög-, boɣ- (active), bögül- (pass.) “obstruct, squeeze, choke, dam (flow)”. The general notion of the stem bög refers to the dynamics of runoff, slop, the flow of water, drain, etc., and it is metaphorically used as a model for movements of people etc., both in positive (drain) and negative (dam) applications, of which Gmc. languages carried the positive notion. Other Türkic cognates carry semantics of 1. slime, slime mold, mold; 2. quagmire, 3. tie, bind, bond, 4. asphyxiate, choke. Cognates: Gael. and Irish adj. bog “soft, moist”, bogach “bog”. The “IE etymology” links bog (n.) with bow (v.) “bend”, which is semantically unsustainable, although the bow derives from the Türkic fairly homophonic buq- “bend, bow” (OTD p.125); otherwise for bog the “IE etymology” can't come up with a credible suggestion outside of unattested *reconstructions presenting non-evidentiary nonsense. The Celtic form with the deverbal noun suffix -ch parallels other most basic nouns formed with this suffix, Cf. gench, see gene; the Celtic form allows to date this suffix to 6th-5th mill. BC, their circum-Mediterranean departure date, and attests to a paradigmatic transfer of the compound base + suffix. The Celtic term must have made an anabasis of a half-way around the known world of the 3rd mill. BC, around Mediterranean Basin and all the way to Ireland and Albion. See bow, gene.
English bong (n.) “dull resonant sound, loud blow”~ Türkic böŋ (böng) (n.) “sound of a fallen object”. Cognates: Scandinavian word, ONorse banga “to bang”. Undoubtedly of echoic origin, but the echo is limited to the Türkic and Scandinavian/Gmn. world, the rest of the world had heard some other echo.
English boss (n.) “overseer” ~ Türkic boš (bosh) (adj.) “free, unencumbered, yeoman”, from
bošu- “freed, get freedom”, a derivative of bu “steam, vapor,
fragrance”. Cognates: MDu. baes, Du. baas
“master”, early Akkadian na-piš-u “breathing, inhale, scent” (loanword stem paš/piš,
28-24 cc. BC). The term is clearly from Middle Age society, supposedly “of unknown origin”. In US
the word gained popularity to distinguish a bonded slave from a free supervisor and then as a
substitute for “master”. The s/sh alteration and adjustment of vowels are normal in dialectal
forms, probably the phonetic version bos formed in the original Türkic environment. No
“IE” parallels.
102
English bow (n., v.) ~ Türkic buq-/bük- (v.) “to bend, bow” (OTD p.125), with numerous derivatives. Cognates: A.-Sax. bugan “to bend, to bow down, to bend the body in condescension”; Du. buigen, MLG bugen, OHG biogan, Gmn. biegen, Goth. biugan “to bend”, ONorse boginn “bent”, the Gmc. source is unquestionable, the etymology is quite transparent and singular; Skt. bhujati “bends, thrusts aside”. The Skt. bhujati in India can't predate the arrival of the Indo-Aryans in the South-Center Asia from the Central-Eastern Europe at about 1600 BC (3600 ybp), and thus derives from the same source as the Gmc. version, although Gmc. version likely appeared by overland route at quite different time, and was popularized by the mounted Türkic Kurganians. The OE form bugan is precise match of the Türkic buqan, where the suffix -an forms the noun result of a verb, the object of action from base intransitive verb “a bent one (n.)” (OTD 650). Notably, the OTD has a notation that the noun suffix -an is rare, within the predominantly eastern Türkic languages covered by the dictionary, pointing that it was picked up by the dictionary due to the influences of the westerly branches onto the easterly branches. The suffix -an has allomorphs -en and -in (-ïn), found in Du., MLG, Gmn., and ONorse. We can be absolutely sure that the Goth., OE, Du., OHG, MLG, Gmn., and ONorse did not pick up bugan from the Ottoman Türkic, they had it millenniums earlier.
English box (n.) “container” ~ Türkic boɣ “container, travel pouch packed for transportation of things”, from the verb boɣ- “squeeze, choke”. Cognates: LLat. buxis; the Gk. pyxis “boxwood box” does not make sense as a generic name, it appears that pyxis is intended to be a linguistic ploy to lead to the box. One can visualize multitudes for millennia on squeezing their belongings into multitudes of boɣs attached to their saddles, with each of their 3-5 pack horses festooned with boɣs from head to tail, then how come that OED has no clue and derives the name of such life-sustaining utensil from an adjective of a box tree? The word box/boɣ should have been a must lexicon not only within the nomadic society, but also among all the pedestrian polities that hired nomadic armies millennia after millennia, dealing daily with them and their boɣs. Would we get the name of the dog from the adjective of a dog tree? Or a name of a paradise from a paradise flower? That way can be produced etymology for half of the English, and any second-grader could do OED with his brains turned off. And still, OED has a rundown on box, leading over a circuitous path from where to nowhere, but staying firmly within the infertile “IE” light spot.
English brute (adj., n.) “brutal, bestial, crude” ~ Türkic börü (böri) “wolf”. Cognates: MFr. brut “coarse, brutal, raw, crude”, Lat. brutus “heavy, dull, stupid”, with connotation “of lower animals”. The notion of the Türkic börü (böri) is “forest predator”, and in different languages designates a wolf or a bear, usually wolf in western languages, but the Scythian name Borusthenes (Βορυσθένης) for the Dnieper river is variously rendered as “Wolf River” and “Bear River”, and after it was named the city Borusthenetai (Βορυσθένηται), the later Olbia (Ολβία Ποντική). The name Borusthenes outlived Herodotus by 15 centuries, in the 10th c. AD Bechens called Dnieper Baroux (Βαρουχ), according to Constantine VII Porphyrogenitus. While the MFr. could receive their form from the Burgunds, the Lat. form is much older, and points to a Türkic path directly into Latin. The noun brute is Eng. innovation. See Boris.
English bud “incipient leaf or flower”~ Türkic buqüq “inflorescence, process of budding, node”,
budaq, butiq “offshoot”. Cognates: Du. bot, Gmn. Beutel “bud”; OSax. budil
“bag, purse”; OFr. boter “push forward, thrust”; the OSax. budil is semantically
dubious, except as a derivative. The buqüq - bud semantic and phonetic match does not leave
any room for doubts and speculations. The “IE” attempts to etymologize are pitiful: “bag”, “purse”,
“beetle”, all semantically off-course. The nonuniform phonetic is consistent with numerous
contributing dialects and blurred concept of budding and offshoot. See boutique, bodega.
103
English burl (n.) “purlish bulge (on a tree)” ~ Türkic bu:, bu:r (n.) “steam”, bu:r-, bü:r-(v.) “evaporate, twist”, urnï (n.) “bulge”, bu:r- is a verbal denoun derivative of bu: “steam”, anything swirling, burnï is a noun denoun derivative of burun “nose, protuberance”, anything akin to nose, burl is a passive form of bu:r- “steamed” i.e. “whirled”; the Türkic notion “steaming” is expressed with the Eng. form of bula- (v.) “boiling” to convey a chaotic movement. The Eng. purl and burl are two allophones of the same word that went through different paths before rejoining in English language; purl is a palatalized version of burl; the terms survived as different concrete nouns from the same notion. In Eng., the noun burl in the context of a tree burl appears to be a conflation of the phonetically indistinguishable Türkic notions of “whirl” (see whirl) and “bulge”, i.e. “whirling bulge”. Cognates: Eng. purl “swirled flow”; OFr. bourle “tuft of wool”, LLat. burra “wool”; the OFr. and LLat. cognates are concrete derivatives of the above bu:r- (something burled, purled, whirled, swirled, twirled) conveying a notion of “boil (n.)”, if not something else; Sl. burlit (бурлить). lit. “stirred, agitated” in respect to whirled form, the ending -it/-ить is a reflex of Türkic suffix -ti/-di, Sl. burya (буря) “blizzard, twister”. No “IE” connection, no “IE” distribution, any “IE” “reconstructions” are absurd. Besides Türkic, the word is peculiar to a handful of European languages with peculiar semantic and phonetic distribution. Figuratively, anything salient and purlish in shape can be called burl. The semantic and phonetic match is near-perfect. See boil, purl, whirl.
English cab (n.) “compartment” ~ Türkic qab/qap (n.) “shell”, fr. qa (n.) “vessel”, qa- (v.) “place, place in order, place together”. Cognates: nothing serious listed, the closest are derivatives cabriolet “light, horse-drawn carriage”, Fr. cabriolet “small cab”. However, English has numerous cognates: cab, capsule, cabin, cabaret (little tavern), cabana (tent, cover), cabbie, cabinet, caboose, taxicab, cabriolet. The “IE etymology” turns to improbable suggestions: “leap of a kid”, “wild goat”. Like English, Türkic has numerous cognate derivatives: qabaq “door, gate cover, cap”, qabirčaq “box, casket, chest, trunk”, qabučaq “tree hollow”, qapuluɣ “closed, locked”, etc. Russian also has numerous cognate derivatives: kapkan (капкан) “trap”, каплак (kaplak) “type of hat”, каптан (kaptan) “wagon”, каптурга (kapturga) “ammo bag”, kapterka (каптерка) “closet, shelter”, etc. It would not take too much effort to locate plenty of Balto-Sl. and Gmc. cognates expressing aspects of “shelter”, “box”, “compartment”. See cap.
English caginess, cageyness “cautious and watchful, wariness” ~ Türkic kuyım, qïjïm (n.) “phobia, horror, fear, panic”, ultimately fr. kuy-, quj- “spook, shy”. The form kuy-, quj- is in turn a version of the form kud-, qud-, which abandons with “IE” cognates, Cf. caution (n., v.) and a host of its cognates, including the Lat. version cautio. The English derivatives of the stem are cagy, cagey, caginess, cagily, predictably “of unknown origin”, with no “IE cognates”. The Eng. root cag- has not produced any verbs, except for caution, the corresponding verbs and verbal compounds descend from totally different roots: watchful, wary, leery, etc. That attests to the word's origins from different sources and relatively short internalization time. The forms kuy-, quj-, kud-, qud-, belong to the series that also contains forms gorg-, gӧrg-, ɣorɣ-, qorqu-, qoruq-, ürk-. The survived forms reflect Ogur and Oguz specifics, with and without anlaut prosthetic consonant (Cf. gӧrg- vs. ürk-). The well-developed cognate lines are abundant on the European and Asian scenes. The oldest on record appears to be the Oguric form qorq “fear” documented as the part Gorgon “terrifying” in the Gk. name Medusa Gorgona written by Hesiod around 750 - 650 BC, which attests to the existence of the myth preceding the appearance of the European Scythians on the European scene, commonly dated by the 8th century BC. The form qïjïm is but one form of many derivatives of the stem qorq that include a form korkul- “be afraid” with an adje stctival suffix -l, of which the suffix -ly in the English cagily is a direct reflex. See cage, care, Gorgon, scare.
104
(Skip) (English Acorus calamus “sweet flag, calami, marsh plant type” ~ Türkic igir “acor”. Cognates: Lat. Acorus calamus “wetland reed endemic to S.Siberia, M.Asia (Caspian, Aral), India etc.” The Lat. name is a modern concoction.
English can (n.) “container” ~ Türkic kanata (Turkish kodes) (n.) “jug, can, container”. Cognates: OE canne “cup, container”, OSax, ONorse, Sw. kanna, MDu. kanne, Du. kan, OHG channa, Gmn. Kanne; LLat. canna “container, vessel”. The “IE” suppositions fr. Lat. canna “reed”, “reed pipe”, “small boat” do not make sense, thus the recognition that “the sense evolution is difficult”. Definitely so. The semantic and phonetic match of the European and Türkic words make any superficial phonetical resemblance with reeds, pipes, and boats irrelevant.
English candle (n.) “wax lamp” ~ Türkic kandil (n.) “oil lamp”. Cognates: OE candel “lamp, lantern, candle”, MIr. condud “fuel” (claimed cognate Welsh cann “white” is unrelated), Lat. candela “a light, torch, candle made of tallow or wax”, candere “to shine”; Skt. cand- “to give light, shine”, candra- “shining, glowing, moon”; the claimed cognate Gk. kandaros “coal” is unrelated. The claimed Slavic cognate chad “smoke, soot” could not be derived from the Lat. or Etruscan. Candles were common from early times among Romans and Etruscans, but unknown in ancient Greece (where oil lamps sufficed). The idea of early ecclesiastical borrowing from Lat. is preposterous, people in general, and English in particular were using lamps long before Christianity, and for example Etruscans were never given a chance to become ecclesiastical Christians. The Skt. cand- points to Nostratic spread, according to the genetic tracing Skt. migrated to Indian subcontinent ca 1500 BC via Eastern Europe and Caspian area.
English car (n.) “wheeled vehicle” ~ Türkic köl- (v.) “to harness (animals to cart)”. All western
European cognates have a rhotacised form with -r, pointing to a single source leading to the
Celtic arrival in Iberia 2800 BC: A.-Sax. cræt “cart, wagon, chariot”, ONorse kartr,
ONFr. carre, Gaul. karros, OIr., Welsh carr, Breton karr “cart, wagon”;
Lat. carrum, carrus, originally “two-wheeled Celtic war chariot”; the eastern European
cognates have a form with -l: Rus. odnokolka, dvukolka, koleya,
prikol (одноколка, двуколка, колея, прикол) “one horse cart,
two-horse cart, grooved track left by cart, tie/harness something”. In agglutinated languages, the
word köl- and its allophones (e.g. car-) was just one of many, because the nature of
agglutination makes innate derivatives from the names of the animals or harnesses by attaching the
same suffix to the various stems; that matter is supported by numerous synonyms for harnessing, e.g.
Icl. beisla, belti, nýta, virkja, where belti is a verbal derivative of the Türkic
bel
“belt” with a locative suffix -ta/-te/-ty
denoting a notion of “belt it, rope it, harness it”. The word köl-/car- has a long trail,
e.g. A.-Sax. (OE), ONorse, etc., and was still productive in the 20th c. in Russia, showing one or
two horses are harnessed into a carriage. Obviously, the term car has nothing to do with the
unattested *krsos from the PIE unattested root *kers- “to run”, it is a form still
widely used as a noun derivative of the verb “to hitch, harness (animals to cart, boat to pier)”
that probably was around long before the wheel came around. The animals were first hitched to drag
sledges and stretchers, which required a word for harnessing, and it was later transferred to the
wheeled transport. Modern English sports the words carriage, chariot, cart, carrier, carry,
caravan, caravanserai, and a host of other derivatives connected with transportation, formed of
the modest original verbal stem köl-. See belt, harness.
105
English caragana (n.) “pea tree” ~ Türkic qaraqan (n.) “caragana”, shrub with edible peas and leaves (OTD 425), now used as decorative shrub and pharmaceutical ingredient. The medicinal properties of the plant may have been a prime reason for its being carried from its native Central Asia to around Eurasia. The part cara/qara does not necessarily stand for “black”, it is exceptionally polysemantic term, and include a meaning “strong”; the part qan does not necessarily stand for “Khan”, it is exceptionally polysemantic term, and medicinally includes a meaning “blood”; it can be imagined that the generic name of the plant denotes “blood medicine”. See other plant-related words: cannabis, derrick, elm, juice, herb, laber, tree, valerian, wormwood.
English case (n.) “box” ~ Türkic kečä (kecha) (n.) “box”. Cognates: Provenčal caissa; Dan. kasse, Du. kader, Icl. kassi, Gmn. Kasten; MFr. caisse, It. cassa, Sp. caja, Cat. caixa (kaisha), Lat. capsa; Gr. koutí; Basque kutxa; Est. kast; Balt. (Latv.) kaste; Bosn., Bulg., Croat, Serb. kuti-, Slov. škatla (shkat-); Tamil kasu; Skt. karsha; Sinhalese kasi; Ch. he 盒 , hezi 盒子.With the semantics “box”, the word is truly international, formerly Eurasiatic, and presently of the whole world. Reportedly, the present form cash originated in Burgundy (Provence), from those nomadic Burgund (Bulgar) Vandals, it went into French, and then to English. More likely, the same word in slightly different allophones widely circulated across Eurasia, re-conflating and reincarnating in different allophonic forms. The Lat. form stands out, pointing to a path separate from the Burgundian form. Obviously, borrowing from Lat. to Dravidian, Sinitic, Fin., and other diverse languages from diverse linguistic groups can be positively excluded. The only inescapable conclusion can be only that the Eurasiatic steppe nomads spread the word around the steppe belt. The English semantic transition from cash “money box” to “money, coin, cash” is a late development, now universally borrowed from English as an international term. See case “occurrence” cash, cashier.
English case (n.) “instance, occurrence, set of circumstances” ~ Türkic qaza (n.) “destiny, fate, predestination, fortune, lot, luck”. Cognates: Ir. gcas, chas, Welsh achos; OF cas, Lat. casus “chance, occasion, opportunity, accident, mishap, a falling, befall”, Rom. caz, Sp., Cat. cas, “casualty”; also suggested Skt. sad- “a falling”; Balt. (Latv.) gadi-; Basque kasu; Arm. chacnum “a falling”; Mong. hereg; Kor. gyeong-u. All these notions of “what is/may/will be happening” ascend to the root qaza “destiny, fate, predestination, fortune, lot, luck”, the cognate of the English case “what befalls one, state of affairs”, and are unrelated to the homophonic notion of “box, container”, and its derivative “cash”. The terms kazak (qazaq, Cossak) and khazar (qazar), formed with synonymous suffixes -aq and -ar, synonymously denote a freelance fortune seeker, i.e. a mercenary; the word Kazakh is just another spelling of the same word, invented in the Stalinist Russia for entirely for political reasons to discriminate it from what in English is spelled as Cossak, sold in the Russian historiography as vaguely denoting none other but the Slavic mercenaries; the suffixes -aq and -ar produce synonymous derivatives. The notion of “a falling” may or may not be applicable, depending on semantics “fall” vs. “befall” in the respective languages, the difference is of the same scale as “fate” vs. “box”. The geographical panorama of the distribution of the word “case” is striking, formerly Eurasiatic, from Atlantic to the Pacific and across different linguistic families. Also notable is the parallel spread of the notions case “box” and cash, derived from a different Türkic stem kečä. See case “box”, cash.
English casualty (n.) “effect, result, injury” ~ Türkic közün- “appear, show up, appear in view, be seen”, lit. “be gazing, be eyeing” Essentially, the verb köz- is synonymous with “to be”, like many Türkic verbs also conveying a specific property of the generic semantics, namely the property of initiation, of coming into view. G. Clauson suggested that etymologically köz- is a second form of kör- “eye, gaze”, and közün- is a reflective form of köz- “be eyeing, be gazing” in now extinct English mighty tool of passival reflexive form were the objet is the subject (See passival reflexive form above). The passival reflexive form közün- found wide acceptance in the European languages, producing reflexes such as “cause”, “case (event, situation)”, “casual”, “casualty”, etc. The “IE etymology” reaches the closest notion of “casual” and ascends it to the LLat. casualis “by chance”, Lat. casus “chance, occasion, opportunity; accident, event”, and Lat. cas-, past participle stem of cadere “fall, sink, settle down, decline, perish”, obviously leading to the unenvoked Türkic köz- of the same semantics. Unlike the myopically curtailed “IE” etymology, the Türkic etymology leads to the base word, tracing lexical development from its inception over many millennia. See case, casual, cause.
English category (n.) “conceptual division” ~ Türkic qatïɣ (adj.) “property of hard, tough, strong, harsh, cruel, violent”. Cognates: MFr. categorie, LLat. categoria, Gk. kategoria “category, prediction, accusation”. The “IE etymology” expounds on the Gk. kategoria as a compound of kata “down to” + agora “public assembly”. It is obvious that the path from the “public assembly” to “conceptual division” is long and tenuous, while the direct Greek borrowing from the Türkic of the concept “something with property of XXX” with its intact phonetics is verbatim and consistent with other direct Türkic loanwords in Greek (eg. ache akhos, sinew neuron, guest xenos, etc.) and with the genetic picture of the reverse migration of the sedentary farmers from the N.Pontic to the Central Europe and Balkans during the 2nd mill. BC. See ache, sinew, guest, etc.
English cave (n.) “underground hollow” ~ Türkic kovı: (n.) “cave, underground hollow”, Cf. kovı:, qovï “hollow”, yığa:č, kuv ağač “hollow tree”, kovuk “hollow”, koğuš “large room” (alt. form, interchangeable), ku:y, kaba “cave” (alt. forms, interchangeable)); a secondary notion of kovı: “cave” is “surrounded”, i.e. a passive form of the notion “box”, whereas “box” is “surrounding, enclosing” something, and “cave” makes something “surrounded, enclosed”. The second notion allows derivatives of the “enclosed” type, like “container”, “bag” and “box”. The kovı: allophone ku:y has a sibling o:y- “hollow out”, with its own world of derivatives; of these two, it is impossible to tell which one was a prime and which one is a secondary. Allophones and derivatives of the Türkic kovı: occupy a substantial place in the Romance and Gmc. “IE” vocabularies in Europe, attesting to a long period of internalization, Cf. concave, cove, coffin, and cave in, and have cognates in the “IE” Asian vocabularies. Cognates: A.-Sax. cofa (cova?) “cave, den”, hordcofa “(hoarding) closet”, caven (v., 15th c.) “to hollow out”; OFr. cave; the notion of cave is a “large hollow in the terrain”, and not a “pile”; languages use other terms for small non-inhabitable cavities, like “pit” or “hollow”; ditto for the man-made subterranean structures (Cf. A.-Sax. eorðscrafu “earth hollow”, lit. “scooped (scratched) earth”, the scrafu is discordant with cofa). The enterprising “IE” etymologists suggest an unattested PIE root *keue- connected with cumulus “accumulation, pile”, a manifestly looney proposition. The weird “IE” mechanics notwithstanding, the phonetic and semantic equivalency of the attested terms cofa, kovı:, and kaba for the same terranean feature is obvious. Not any less obvious is the importance of the caves in the historical and pre-historical past, even now people still live in caves across Eurasia, and continue to use terms for them that probably hail 40,000 years back. The word “coffin” is a derivative of cofa/cave, burials in essence are artificial caves, cavities delineated by protective structure (Cf. synonymous A.-Sax. grafan “to dig, dig up”, Goth., OHG graban “to dig”, and A.-Sax. graef “cave, grave”; Cf. tomb, tumulus fr. Tr. “to dig”, grave fr. Tr. gür “ditch, cave”). The cave is one illustration of the disservice the ideologically “IE” linguists provide to the historical and linguistic disciplines with disinformation via stretched linguistic machinations. The Skt. form kupah “hollow, pit, cave” attests to the presence of the term “cave” in the Eastern Europe before the 2000 BC outmigration of the Aryan farmers to the Indian subcontinent. See cavern, cavity, coffin, concave, cove, grave, tomb, tumulus.
English cavern (n.) “cave, chamber” ~ Türkic kovı: (n.) “cave, underground hollow”, see cave. Cognates: A.-Sax. cofa (cova?) “cave, den”, etc.; OFr. caverne (12th c.), Lat. cavea, cavus “cave, vault, cellar, hollow”; Skt. kupah “hollow, pit, cave”; probably corresponds to the A.-Sax. eorðscræf “earth hollow”, lit. “scooped (scratched) earth”. The adaptation of the modified form of cofa was assisted by near synonymy of the A.-Sax. cofa and its modified form caverne See cave, cavity, coffin, concave, cove.
English cavity (n.) “pit (natural or artificial)” ~ Türkic kovı: (n.) “cave, underground hollow”,
see cave. Cognates: A.-Sax. cofa (cova?) “cave, den”, etc.; Lat. cavea, cavus
“cave, vault, cellar, hollow”; Skt. kupah “hollow, pit, cave”; an indigenous Eng. innovation
(13th c.) fr. cave, an allophone of the Türkic kovı: “cave”, from the heritage of
Türkic substrate lexicon with the known A.-Sax. source. Ultimately an element of the Eurasian Steppe
Belt lexicon carried by the Aryan farmers (Skt.) to the Indian subcontinent starting at about 2000
BC. See cave, cavern, coffin, concave, cove.
106
English Celt/Kelt (n.) (ethnonym, proper name) ~ Türkic kel- (v.) “arrive, come”.
The ethnonym Celt/Kelt does not have “IE” etymology, the closest that comes to pseudoetymology is a
word in the Hebrew Bible naming a hand tool. The semantics of the word celt/kelt in respect
to the Celts/Kelts was lost. The Türkic verb kel- with agglutinated suffixes makes a
semantic cluster of numerous grammatical forms, transmitting a meaning connected with arrival; the
suffix -t produces an abstract noun (“arrival”), and with the suffix -tï (-ti;-tu, -tü;
-dï, -di; -du, -dü) it produces predicate adjectives in analytical form (newcomer); other Türkic
grammatical mechanisms would also lead to the form Celt/Kelt. The first to call
Celts/Kelts was Hecetaeus of Miletos (550 – 476 BC), who noted that in the N. Pontic area Kelts
were neighboring Scythians in the west. Herodotus (484 – 425 BC) mentions Kelts in the N.
Pontic and Iberia. From then on, the ethnonym Kelts was used interchangeably with the
ethnonym Gauls, Caesar (102 – 44 BC) stated that Gauls called themselves Kelts;
the allophony of the two forms is obvious. Strabo (63 BC – 24 AD) identified Kelts
with Scythians, i.e. with nomadic horse pastoralists. The transfer of the of the term Kelts
on the NW people now called Celtic was initiated by Edward Lhuyd (1707), following a logical
sequence deduced from the sources and current observations. The generic exonym Celt
“newcomer” clenches well with the individual tribal names, and may apply to the tribes without
immediate ethnic connection. The transition from an exonym to ethnonym is a commonplace occurrence.
107
English chagrin (n.) “grief, vexation” ~ Türkic qadɣur- (n.) “grieve, sorrow”. Cognates: Eng. grief “sorrow”, grave (adj.) “very bad”, Sl. gore (горе) “grief, vexation”, Lat. gravus, gravare “grief, vexation”. Supposedly “of unknown origin”, supposedly no “IE” cognates, which allows “IE etymology” to drop the ball and resign. Palatalization of laryngeal consonants and contraction of consonants is a known phenomena in the western Türkic dialects, hence q- > ch, dɣ > g. Another known phonetic change is d/r alteration, which tentatively would independently produce English grief and grave (adj.), Sl. gore (горе), and Lat. gravus, gravare from dialectal forms of same Türkic stem qadɣur-.
English chalk (n.) “limestone, chalk” ~ Türkic (Chuv.) chol (n.), OT tash, Yak. tash, Tuv. dash; MM. chilaun, Khalh. chulu:, Dag. cholo: “stone”. Cognates: A.-Sax. cealc “chalk, lime, plaster, pebble”; Ir. cailc, Welsh sialc, calch; Lat. calx “limestone, lime (crushed limestone), small stone”; Gk. khalix “small pebble”. Gmc. languages uniformly have a phonetically different word, variations of krit. The Chuv. anlaut ch- corresponds to eastern Türkic t-/d-, thus chol ~ tash; the Mong. forms close to the English chalk point to the Ogur Hunnic word in the Mong. lexicon, likely ascending to the Syanbi period ca. 150 AD. In light of the Mong. clones, the “IE” supposition of chalk origin from “IE” root for “split, break up” is fishy. The silent -l in the constructs -al- and eal- apparently indicates a quality of the vowel rendered -a- and -ea-, which is rather specific and likely has not changed from the original form; the auslaut -k is probably a reflex of the Türkic suffix -ɣ/-k/-g, which among other functions produces nouns, along the line chä- + -k (-ɣ/-g).
English chip (n.) “fleck, bit” ~ Türkic čïp (chip, chyp) (n.) “twig, wand, thin flexible branch”. Cognates: A.-Sax. cipp “piece of wood”, A.-Sax. forcippian “to pare away by cutting”, cipp “split small piece of wood”, Du. kip “small strip of wood”, OHG kipfa “wagon pole”, ONorse keppr “stick”; Lat. has cippus “post, stake, beam”, all allophones and derivatives of the Türkic čïp. The original stem čïp had numerous uses in the animal husbandry household: frame of wagon cover, structural frame of yurt and its roof, wattle fencing for corrals, etc.; accordingly, Türkic has numerous derivatives and allophones: čïbïq, čïbïqla, čïbïrt (v.), čubuq, etc.. Gmc. languages preserved the original stem meaning and its utilitarian derivatives. Naturally, in wooded zone semantics changed from that of the forestless steppes; semantic expansion took place in line with the needs of the time, from wagon parts to fast food and micro schemes, and the old Türkic “twig” keeps marching across the globe and penetrating into our brains, eyes, and hearts.
English chunk (n.) “compact mass, lump”, chunk (v.) “lump side by side” ~ Türkic sïnuq, sïŋuq (adj.) “broken, shattered, destructed”, sïn-/sïŋ- (v.) “break, cleft, split”, fr. verb sï- “break, cleft, split”. The allophonic forms čoŋ “chunk, lump” and šınuk “broken, shattered, destructed” are also phonetically suitable candidates. No cognates are listed, none outside Türkic languages; no “IE” connections, no “IE” etymology, no English etymology, spuriously suggested “American English origin”. However, European cognates are in plain view: MHG schenken “pour portions (in glasses)”, Sl. shinkovat (шинковать) “cut (into pieces, chop cabbage)”, (Pol.) szynkowac “pour (drinks in tavern), (Russ.) shinkar “tavern holder, pourer in tavern”, all with a notion of separating a whole into smaller parts. The distribution in English, American, Gmc., southern and northern Sl. excludes an American origin, and points to a common ancient adaptation, spread across the Hunnic territories. The reflexive form sïn-/sïŋ- of the verb sï- has a metaphorical meaning “break (the rules, transgress, trespass)”, which produced the Eng. sinn “transgression”. This word, and its nearly exclusively Gmc. cognates synn, sende, sannr, sundia, sonde, Sünde, sons (Lat.) and Ch. tsui 罪 should also be included in the cognate list. The exclusive presence in Eng. of both lit. and metaphorical meanings presents a case of paradigmatic transfer, credibly attesting to a common genetic origin, and thus attesting to the source of the cognates for the languages that have retained only one, the lit., meaning of “break”. Such distribution also attests to a time gap between the lit. and metaphorical meanings, since the religious notion of “sin, transgression, guilt, evil deed” originated in the Buddhist milieu, and was widely spread by the Buddhist missionaries west and east in the few centuries before and after our era. See sin.
English cloud (n.) “visible atmospheric water vapor” ~ Türkic bulut (n.) “cloud”. The Türkic bulut ultimately ascends to the root bu: “steam, fog, mist”, with noun/adjective nominal suffix -l (after vowels) that usually forms intransitive or passive derivatives, i.e. bul “steaming, fogging, misting”, and deverbal suffix -ut/-it that usually forms active nomen actiones, abstract and concrete nouns; both suffixes are rare in the eastern languages, pointing to their western provenance. The development of the word bulut is illustrated by the verb bulutlan- “to be cloudy, overcast” with animation suffix -lan, where bulut forms the verbal root “to cloud”. Cognates: A.-Sax. baelc, weolcan (with -ch-) “cloud”, Du. wolk, Sw. moln, Gmn. Wolke; Est. pilve, Fin. pilvi, Hu. felhő; Sl. oblak, oblako (облак, облако); Mong. üül. This cluster of cognates demonstrates nearly all possible alternations: b/p/f/v (disguised as w)/m, including the Türkic peculiar and thus diagnostic m/b alternation. The A.-Sax. forms point directly to their origin as allophones of bul, the articulation -c- /ch/ is echoed in the Sl. -chen/-chno marking a habitual action. The Sw. demonstrates exclusively Türkic m/b alternation (Cf. Malkar vs. Balkar), the Sl. demonstrates a typical Sl. prosthetic anlaut vowel for loanwords. The Mongolian version with a silent b- may reflect the Eastern Hunnic vernacular, sounding something like wyool. The suffixes are specific for each variety: Tr. -ut (with version -it), Gmc. -kan/-k/-ke/-n, Fennic -ve/-vi/-ho, Sl. -ak/-ako; that attests that in each case the words were internalized into the local vernacular. That the Sl. takes the auslaut syllable as an suffix is attested by derivatives that replace the A.-Sax. -c/-c- or Sl. -ak/-ako with -chen/-chno, e.g. oblachen, oblochno (облачен, облочно) “clowdy”. The distribution of the cognates is peculiar: northern Eurasia all the way down to Mongolia. The root bul-/wol-/mol- is obviously non-IE. The roots used in the balance of the “IE” family are variations of nub-, sky-, and vad-, obviously connected with sky and water, obviously of an areal provenance, and obviously all of different origin. The root nub- is shared by suspects that found an Eastern European refuge from the “killing fields” that between 4500 and 4000 ybp almost completely annihilated European populations marked by the Y-DNA haplogroups E, F, G, J, I, and K. The refugees trekked back to Europe at about 3,500 ybp (Klyosov A., Tomezzoli G., 2013). The “IE etymology” is so purblind that it practically does not exist, the offered clod “lump of earth or clay” is semantically vacuous, unsuitable, and is unsustainable because it is based purely on phonetic consonance. An analysis of transition from the weolcan to cloud may afford insights on the amalgamation processes within the English language. It appears that weolcan passed through some other language or languages with very different phonetics, was re-introduced back to English, and supplanted the old form.
(Skip) English chute (n.) “fall of water” > “cataract, narrow passage for cattle” ~ Türkic čüm- (chum) (v.) “dive”. Cognates: OFr. cheoite, Fr. chute “fall”. The “IE etymology” runs amok: Lat. cadere “case, event, befall”.
English coal “carbonized fossil fuel” ~ Türkic kül/köl “ashes, (hot) coals”. Ultimately, fr. the verbal stem kül-/köl- “bury, cover underground”, with the suffix -ür (-yur, -ür; -r; -ar, - är; ïr, -ir) it is an adjectival participle “buried, underground”, hence an allophonic derivative kömür “coal”, and the derivative kül/köl “ashes”. The köl also has connotations of dark, black, shadow, it creates derivatives and paired words like kölägä, köligä “shadow”, köm kök “very blue”. Cognates: OFris. kole, ONorse kol, MDu cole, Du kool, OHG chol, Gmn. Kohle, with -l/-m dialectal variation. The “IE etymology” is funny, it uses two concoctions to muddle through and get nowhere: A.-Sax. (OE) col “coal”, via unattested PGmc. *kula(n), via unattested PIE *g(e)u-lo- “live coal”, which harkens back to the Türkic kül/köl “(hot) coals”. The Türkic word is alive and kicking, and does not need any hallucinated asterisks.
English cock (latch) (n., v.) “pivoting part, latch” ~ Türkic kök (n., v.) “fastener, thong, suspender” and the like fasteners with pivoting action. The transition from yurts, horse saddles, and carts to cars and guns has extended the use of latches and suspenders, adjusting semantics to modern gun cocks, cock valves and verbs cock (the gun). Türkic has four main meanings for kök, and English has no less, confusing etymology with homophones of diverse provenance and conflations. With the Türkic mechanical device kök synonymous with English mechanical device cock and Gmn. mechanical device hahn, the common origin unrelated to chicken, cockroaches, and cockney motherland is obvious. See cock (rooster), Cockney.
English cockney (n.) “nonstandard native dialect of east end of London” ~ Türkic köken (n.)
“motherland, native place, ancestral land”. Hence, the Eng. “domestic (language)”.
Köken is a derivative of the polysemous stem kök-/gök- conveying basic notions “root”,
“sky”, and a dozen of others; the notion “root” developed semantic derivatives “root, origin”,
“latch, thong, cock” (Cf. “cocked handgun”), with immediate further derivatives “tie, buckle”,
“establish”, “graze (on green)”, “thunder, thundering”, some of which (“root”, “grazing”, “tie,
latch”) express the notion “motherland, native place, ancestral land”, and further on “base”,
“origin, kinship, genealogy”.
The suffix -en in köken
probably is a Türkic archaic plural marker, standing for “roots”, with few other, apparently less
likely, options. Phonetic variations on the theme kök-, like its siblings gök-, kük-,
kü:g, küy-, and more, express a wealth of adjacent and distant literal and metaphorical notions
(Cf. Sl. khui (хуй) “penis” from Türkic kü:g/küy “horny (sex), sexy”). Semantic and
phonetic conflations, with seemingly kök-derivatives emanating from various siblings, make
the whole cluster of siblings and their direct and conflated derivatives one large lexical family.
The earliest reference to the English Cockney
is a “mythical luxurious country, first recorded in 1305”, a clear reference to the “ancestral
land”. No “IE” or any other etymology. Phonetic folk etymologies are “milksop, simpleton; effeminate
man; hence: Londoner” and “spoiled child, milksop; cock's egg; runt of a clutch”; all folk
etymologies date from late Middle Ages, a thousand years after the collapse of the substrate
language; the semantics of “domestic (language)” as an echo of “motherland” is a relict from the
forgotten past. See cock (latch), cock (rooster).
108
English cold (n.) (Sw181) “low temperature” ~ Türkic xaltarä (v.) “to freeze”, hel “winter”.
The Old Türkic has a rich trove of 22 words directly connected to cold, compared with 5 in English
(cold, cool, chill, frigid, nip, the first three are allophones). The Bashkir, of the Oguz stock,
form is halqïn, the suffix -q- makes denoun intransitive verb, the suffix -ïn
forms deverbal noun/adjectives and concrete nouns. The forms xaltarä
“to freeze”, hel “winter”, and čil “wind” are cited for the Chuv. language, of the
Ogur, or r-, stock. The xaltarä/halqïn are allophones of the CT salqïn
with an array of semantic shades: “coolness, cold, icy, wind, breeze” with neutral or positive
connotation, as opposed to the tun/ton/dun/don with negative connotation, Cf. Herodotus “icy
Tanais”. The Chuv. form hel “winter” in the Oguz CT is qiš (qish). Ultimately fr.
čil (chil) “wind”, vocalized ye:l in CT, without a prosthetic anlaut consonant in lieu of
a semi-consonant, and with “usual phonetic changes” and few vowel variations.
In Eng. the common form ye:l has produced words “yell” and “howl”, paradigmatically
transferring the second meaning of the wind's distinct “howl”, see howl, yell. In warmer
climates, the notion “wind/blow” was associated with “coolness”, and in northern climates “cold” and
“chill” were associated with “freeze” and “snow”. The mechanism of metaphoric semantic extension,
especially in the northern area with continental climate like the northern Urals, fr. “wind” to
“howl” and fr. “wind” to “chill, cold” is identical; the sound of wind may have created the
onomatopoetic name ye:l
for the “wind”. A semantic extension of the prime notion “wind” was the Türkic form salqïn,
which under the k/s
split bifurcated into the sal-
and kal- forms, with s- articulated s-/š-(sh-)/č-(ch-) and k-
articulated
k-(c-)/g-/h-/x-/j-/č-(ch-). The k/s split probably originated in the vicinity of the Aral
area, known for its h- propensity, at first with an s/h split, later h-
branched into numerous allophones. The furcation is readily visible across all cognates. The notion
of the inflicted cold has been preserved in the A.-Sax. and OE semantics for chill
“feel cold, grow cold” (see chill). Cognates: A.-Sax., WSax. ceald (with ch-
, cheald) “cold, cool, coldness”, ciele (with ch-) “cold, cool, coldness” ,
ofcalan (with ch-, ofchalan)
“chill down”, Anglian cald, OFris., OSax. kald, ONorse kaldr, OHG, Gmn.
kalt, Goth. kalds “cold”, Du. hаl
“frozen (soil)”; Balto-Sl. (Lith.) šaltas “cold”, šaldyti “freeze”, šalnà
“frost”, (OCS) hlad- (хладъ-) “cold” , (pro)hlada
“cool (place, air, etc.)”, (n.) hlad, hlod “coldness”, (v.) (o)hlad(it)- “cool down”,
minor variations across Sl. languages, slana (слана)
“frost”; Lat. gelidus “cold”, gelare “freeze”, gelu “frost”, glacies
“ice”; Skt.
hladate “refresh”, (pra)hladas “cool down”, jаḍаs “cold, stupefied” , the Skt.
forms are barely distinct fr. the Sl. forms both in phonetics and semantics; Av.
sarǝta- “cold”; Hu. szel (/sel/) “wind”; Ossetian sald
“cold”; Mong. salki(n), Khalkha salxi, Kalmyk sälkn, Ordos salxin,
Monguor šarki, Buryat halxi(n) “wind, windy”; Kor. sallaŋ “cool (wind)”. The
Türkic allophones of the form sal- dot the Eurasian map: Altai, Balkar, Bashkir, Chagatai,
Chuvash, Karakalpak, Kazakh, Khakass, Kipchak, Kirgiz, Kumyk, Lobnor, Nogai, Sakha, Sary Uigur,
Tatar, Tofalar, Turkish, Turkmen, Tuvan, Uigur, Uzbek, and more (Dybo 2013, 203). In light of the
western Gmc. and Romance cognates, a much massaged thesis about Mong. origin of the form
sal-/hal-
must be rejected. Formally, the Lat. gelare phonetically and semantically is a clone of the
Türkic xaltarä, i.e. xalt- + -ar- + -ra ~ “snow and ice” + adjectival suffix, i.e. “snowy,
icy” + directional suffix, i.e. “into snow”. With an unbridled perspective, a cognate list is
macroscopic, extending from Atlantic to Pacific, and with an endless listing of the Türkic and
related allophones.
European and “IE” languages use both forms, kal-
and sal- (e.g. OCS, Lith., Ossetian, Av. sal-), even in a single language (e.g. OCS),
attesting to the different trunks of the sources at the base of the Indo- and the European groups
and individual languages.
At least 14 European etymologists explored the origins of the Gmc. cold
within the myopic bounds of the “IE” field, nescient of the magnificent Eurasian span and the
existence of the world beyond their grail. The “IE etymology” suggests unattested “PIE” *gel-/*gol-
and PGmc.*kal-/*kol-, *kaldaz for “cold” (-az apparently accentuates the Gmn. -z
articulation of the suffix -d/-ed, an allophone of the Türkic, Skt. -ti and Sl. -t
(ть)) , and separately PGmc.*kal- for “chill”, essentially ending up with the Türkic
attested stem sal-
and hal-. Since the “IE” migrations fr. the E. Europe started in the 2nd mill. BC, the Lat.,
Gmc., Balto-Sl., and Skt. forms can be dated to 3rd mill. BC, and Celtic forms can be dated to as
early as 5th mill. BC. To explain the acute k/s dichotomy observed among the canvassed “IE” languages, the putative focal PIE language was adorned with a putative phoneme ks. Of the
cognates (q.v.), none expanded their reach beyond their areal theater, neither from the west to the
east, nor from the east to the west. Only the nomadic Kurgans reached and amalgamated on both ends
of the Eurasia, and could endow their neighbors. The form xaltarä/halqïn echoes the form
katur- “freeze”, fr. the verb ka:d- “freeze” and noun ka:d “snow-storm, blizzard”;
the underlying notion of the stem ka:d- is “harden”, hence the metaphoric “freeze”.
Also, xaltarä and hel echo the Türkic ka:r “snow” (like in Kar Sea
“Snowy Sea”) with -r-/-l- alternation typical for the Chuv. language.
Notably, all four roots, for “wind/blow”, “freeze”, “winter”, and “snow” could have ended up with
the allophones
chill and cold. The Celtic forms for “cold, chill, cool”, which blend both the semantics
and phonetics, appear to ascend to the stems ka:r “snow” and ye:l
“wind” (e.g. cwl): Ir., Gaelic fuar
, Welsh oer, oer hoer, cwl (coul). That implies that the derivative “cold” from the notion
“wind” evolved after the Celtic departure from the Eastern Europe ca. 5th-4th mill. BC, and
cwl is a later acquisition. The etymological chain auspiciously parallels the spread of metals
across Eurasia (Cf. Seima-Turbino Metallurgical Province), which brought typologically similar
bronzes to Mesopotamia and China. Eng. has 3 words derived from the Türkic words for the notion
“cold”, namely cold (q.v.), tomb, and soggy, exhibiting a case of paradigmatic transfer, attesting
to a common linguistic and cultural origin. See
chill, earth, howl, ore, soggy, tomb, yell.
English color (n.) “hue”~ Türkic kula: “color of the horse’s coat”. The specific coloration may vary, but frequently of a dun hue. Cognates: Dan., Sw. kulör, Du. kleur, kulör; OLat. color, colos; Balto-Sl. (Latv.) krasu, Ukr. kolir; Gr. hroma (χρώμα); Gujarati kalara, Heb. qalyr; Ch. cai (tsai) 彩; Jap. kara カラー; Kor. keolleo 컬러, all referring to “color”. There is nothing like an “IE” “proto-word” across groups of the “IE” languages. The cognates of “color” walk all over Eurasia. Except for Ch., other forms alternate -r- and -l-. The Türkic form refers to a typical color of the horse hue, conceptually it is a generic term. The semantics, phonetics, and distribution favor a common origin provided by mobile nomadic people. The suggested PIE unattested proto-word *kel- phonetically parrots the Türkic kula:, but semantically is unsuitable.
English cork (n.) “hard outer layer”, “bark of the cork oak” ~ Türkic kairy (n.) “bark (tree)”, ultimately fr. köy-, küy- “burn”, discerned in all dialectal forms for bark: qadiz, qaz, qasïq, qas, kabyk, with a notion of “burnt, dried, seared”; the development produced parallel words for “skin, hide, pelt”: kön, qandir, qas, qasïq, qasuq, qaz, qoɣis, quiqa. Cognates: Eng. crust; Lat. quercus “oak”, cortex “bark”, Sp. alcorque “cork sole”, Sl. kora (кора) and its allophones. These Türkic forms for bark are from Oguz languages, a matching kairy of the European Ogur form agrees with the English form. Association with oak dates back to the time when oak bark was a known material for various applications, possibly imported from the nomadic Türkic suppliers. Not even a hint on “IE” etymology. The Türkic word for “cork” is polysemantic, its another meaning, preserved in English, is crust. See crust.
English cove (n.) “recess (small bay, inlet, niche, grotto, concave)” ~ Türkic kovı: (n.) “cave, underground hollow”, see cave. Cognates: A.-Sax. cofa (cova?) “cave, den”, etc.; Lat. cavea, cavus “cave, vault, cellar, hollow”; Skt. kupah “hollow, pit, cave”; the identity of the “cave” and “cove” is fairly obvious and accepted without reservations, but somehow for their origins the “IE etymology” postulates different sources, a miracle of twin siblings coming fr. unrelated parents. For the “cave” the “IE etymology” suggests a looney unattested PIE proto-root *keue- for cumulus “accumulation, pile”, while for the “cove” it suggests another unattested PG proto-root *kubon “tent, hut, shed, pigsty”. Go figure. In contrast, the near perfect phonetic and semantic equivalency of the attested terms cofa, kovı:, and cove for a kindred terranean feature is obvious, the cove is an indigenous Eng. semantic innovation (16th c.) fr. cave, an allophone of the Türkic kovı: “cave”, recycled fr. the heritage of Türkic substrate lexicon with the known A.-Sax. source. The metaphorical adjectival derivative notion of “concave” fr. OFr. concave (14c.), Lat. concavus, also an allophone of the Türkic kovı: on the theme of “cave”, had earned its own independent life. See cave, cavern, cavity, coffin, concave, grave, tomb, tumulus.
English crock (n.) “soot” ~ Türkic kurun (n.) “soot, crock, greave”,
ultimately intransitive/passive deverbal noun fr. the verb kur- “fix, set in order, organize,
set up”, the same verb that formed the word kurgan,
alternatively mound (mount, mountain) from the Türkic root men-/min-/mün- “ascend,
climb on, mount, ride (a horse)”. Cognates: Eng. greave “soot”, A.-Sax. hrum
“soot”, hrumig, behrumig “sooty”; OFr. greve “shin, armor for the leg”, lit. “coating”
as metaphorical fr. “soot coating”, of likely Burgund nomadic origin via Provence and Savoy, defined
as “of unknown origin”. On purely phonological grounds, the “IE etymology” confuses homophones
crock “soot” and
crock “pot, vessel”, another non-IE word of probably Semitic origin (Arabic gaurab
“stocking”) that reached NW Europe and found in Gmc. and Sl. languages (Ru krujka (кружка)
“drinking cup”; it is obvious that the two words are unrelated, as are the identical homophones for
“foolish talk” and “decrepit”. Absent the A.-Sax. proto-English form, the genetical connection
between the kurun
and crock would remain unsuspected and probably unknown. The phonetical transition from
hrum
to crock is less than obvious, although the precise semantics of the quadruple sequence
kurun ~ hrum ~ crock ~ greave makes that phonetical transition certain beyond any doubts.
Possibly, crock and greave
came to Eng. via separate paths from two remotely related languages. See mound, gravy.
109
English crop (n., v.) “harvest” ~ Türkic körpä: (n.) “harvest” related to second chance arrivals (late crop, newly fresh grass, newborn, sprout, soft), körpälä- “use new harvest” (v.). A specificity of the Türkic word has not survived into Eng., it was lost on the way. The Türkic word refers to new and fresh arrivals: grass, animal and human offspring, fruits, and their property like the lamb meat and skin, in lit. and metaphorical (soft, mattress, etc.) senses. Cognates: OE cropp “head or top of a sprout or herb”, OHG kropf, ONorse kroppr, Du. krop, Sw. kropp “body, trunk”, Icl. kroppur “body hump”. All allophones are confined to the Gmc. group. The metathesis örp - rop (Cf. curd - crud) must have taken place at an early transition. No credible “IE” etymology, not even “of unknown origin”. Some surmises are ludicrous: “crap”, “group”, “body, trunk”, PG *kruppaz “body, trunk”, PIE *grewb- “warp, bend, crawl”; concrete derivatives and uses are reverse projected as base stem. A chance phonetic and semantic coincidence for such pinpointed appellative, with only 4 Eng. synonyms (crop, glean, harvest, reap), is exceedingly small.
English crust (n.) “hard outer layer” ~ Türkic kairy (n.) “crust”. Suggested cognates: Eng.
cork; A.-Sax. hruse “earth” (probably, “surface crust”), ONorse hroðr “scurf”,
OGmn.
hrosa “ice, crust”; Latv. kruwesis “frozen mud”, OFr. crouste; Lat. crusta
“rind, crust, shell, bark”; Gk.
krystallos “ice, crystal”, kryos “icy cold, frost”; Skt. krud- “make hard,
thicken”, Av.
xruzdra- “hard”. These cognates appear to conflate different subjects and different
etymologies based on varied superficial resemblances: crystal, earth, ice, mud, cold, frost, all of
them could not have turned to “crust”. The absence of a common “IE” word points to the “IE” linguistic
borrowing. Türkic has numerous forms for crust: qadiz, qaz, qasïq, qas, kabyk, all from the
Oguz languages, and a matching kairy
with the European Ogur form, which agrees with the English form. The Türkic word for crust is
polysemantic, its another meaning, preserved in English, is cork. Geographical spread of the
words meaning “crust” points to the movements of the Türkic mounted nomadic tribes across Eurasia,
the presence of the Skt. word indicates a period older than the post-2000 BC migration from the
Eastern Europe, or a later borrowing, as indicated by the more easterly form with inlaut d.
The surviving records indicate that most of the 42+ Türkic languages use the same word in different
dialectal forms, pointing to long periods of independent development. The semantic and phonetic
difference of the European crust
vs. cork indicates that borrowing of these two words were independent, allochronic, and
probably from quite different, both from the Ogur dialects (because of auslaut -r). See
cork.
110
English cue (n.) “prompt, stimulus information for action, discriminative stimulus, actor's line that initiates action” ~ Türkic kü (n.) “signal, notification, bruit, yell, noise”. Ultimately fr. the stem ke:g-/ke:/küg/kü: “rumor, fame, reputation”. The cue “signal” is homophonous with cue/queue (n.) “line up, ordered sequence”, metaphorical “tail”, an allophone of the Türkic quδ (quδruq) “tail”, with confused and unsettled Eng. spelling, Cf. “a cue line”. The base notion of the cue “signal” is “initiation”, Cf. cue ball “initial ball, initiating ball”, cue stick “initiating stick”. Gyrating direct and metaphorical semantics, and the malleable spelling and misspelling conventions make a plain etymology gaudy. There are even more pertinent threads: the Eng. cue, clue, clew “initial evidence that gets the ball rolling, given hint, perceived hint”, Eng. on cue “on a signal”, and then the clew “ball of yarn or thread” that starts cloth and the queue “in sequential order”, i.e. “in a cue line”. Cognates: Ch. hao/jiao 叫 “call”, i.e. cognates practically non-existent outside the Türkic Eurasian spread. The “IE” myopic etymology is quite spurious: citing Shakespeare, it runs cue “signal” not to the, but from the Q/q notation and the cue in the actor's lingo, and ultimately from the Lat. quando “when, perplexity” or “a similar Latin adverb” fr. a totally irrelevant hypothetical faux “PIE proto-root” *kwo- of relative and interrogative pronouns. The last is an unwitting allophone of the Türkic interrogative pronoun ki/ke/kim/kem, Cf. Eng. who, Sp. que. The real Lat. cue is signum, tessera. The line of the faux “IE etymology” does not connect the Shakespeare's cue with the “cue stick”, the “initial evidence”, or a “ball of yarn”. In essence, it is a mild non-self-deprecating way of expressing “We don't have a clue”. The trio of the cue “signal”, queue “tail”, and the pronouns que/quando/who indelibly attests to the descent from the real, attested Türkic lexicon. Tracing references and dates for the word queue tends to lead to the Vandal/Burgund source and time. See queue.
English curb (n.) “edge” ~ Türkic kır (n.) “edge”. Kır is a ridge surrounding plain or steppe, with extensions to “plain, steppe”, “piedmont”, and “edge”, and few edgy semantic extensions. It is a perfect phonetic and semantic match for curb, semantically way better than the unrelated suggested “IE” homophonic curve, in turn an allophone of the Türkic qarvï (adj.) “bent, crooked”. Cognates: OFr. courbe “edge. limit, restrain”. The origin of the Fr. version is probably Burgund, and the peculiarity in English suggest an origin from the same Vandalic-Burgund millieu, 1st mill. AD.
English curve (n., v.) “bend” ~ Türkic qarvï, karwı: (adj.) “curved, bent, arched”, ultimately probably a cognate of the verb kar- “pile up behind an obstacle”, like “swell” (of the tide). Cognates: Du. krom, Dan. krum, Gmn. krümmt; Ir. cuartha, Welsh crwm; Lat., It., Port., Sp. curv- “crooked, curved, bent”; Sl. kriv- (крив-) “crooked”; Hu. görbe, Fin. käyrä “crooked”; all are obvious cognates of the Türkic qarvï. The distribution of the word, geographical and within incompatible linguistic groups, points to its origin from a single source and penetration via separate paths, one circum-Mediterranean via Iberia to the Apennines, and the other overland to the Northern Europe. No “IE etymology” beyond the Lat. cognate. The phonetic monotony of the allophones and Celtic cognates point to a single source not older than 6th-5th mill. BC. Reference to unstrung recurved bow is typical Türkic expression; the fact that Celts did not bring a recurved bow to the Western Europe concurs with archeological dating of its later invention.
English dam (n., v.) “terrestrial barrier to contain water” ~ Türkic da:m (n.) “obstruction, embankment, wall”. The Türkic noun dam (n.) is very polysemantic, centered around the notion of barrier with extensions to walls, buildings and parts of buildings (foundation, wall, roof), kurgan grave tumuli (see tumulus), sheds, prisons, and the like, and the notion of latching. Ultimately a deverbal noun derivative fr. the verb to-/tu- (also tï-, Cf. tïd “detain, restrain”) “obstruct, block” with a vast trail of phonetic derivatives and semantic applications. A deverbal verbal derivative dula-/tula- narrows semantics to a concrete verb “stem, staunch” for water and the like applications. The root comes in two forms, with initial d- and t-. The anlaut t-/d- transition is attested still in the Türkic milieu; the first vowel wobbles, mainly between -u- and -o-; the form tu- is likely a prime (EDTL v. 1980, 292). The verbal counterpart dam- is connected with liquid leakage and is basically “drip” with physical and metaphorical extensions, with weak and vague genetic connection between the verbal and noun notions. Cognates: A.-Sax. (for)dem(man) “dam up”, dimhus “prison”, lit. either “walled house” or “dark house”, OFris. damm, ONorse dammr, MDu. dam, Gmn. Damm “dam”; Ch. dang擋 “block, obstruct”; Kor. daem 댐 “to dam”; Jap. damu ダム “dam”. As a cultural word, it grew to become international. Etymology: the routine “of unknown origin”, even no attempts to connect with any “IE” phonetic simile. The Türkic origin is obvious, both phonetic and semantic matches are undisputable. The initial d- connects the origin with the 10th -13th cc. records of the Caspian basin (Azeri, Ottoman, probably Khakass listed as Central Asian Tefsir); the earlier attributions can be only conjectured. This association is consistent with the other Eng. Turkisms with links to the Caspian basin. See berm, dike, tumulus.
English dash (n.) “appearance, look” ~ Türkic daš/taš (dash/tash) (n.) “appearance, look, outer, external”. The form daš- as opposed to taš- is used in the Aral-Caspian basin, typical for the Az., Tkm., and also the Tuv. language. The notion of exterior is a semantic extension of the notion “outside” as opposed to “inside”, its other extensions are courtyard, foreign country, ant the like. Cognates: A.-Sax. dafen, dafn “fitting, suitable, proper (appearance, look)”, other related forms dafenian, dafenlic, daflic, dafniendlic, dafenlicnes express propriety or suitability. The A.-Sax. inlaut -f- apparently reflects an attempt to render the phoneme -š- using the available Romanization toolbox. None other cognates outside Türkic languages. The Eng. dash (v.) “move quickly” and dash (v.) “break into pieces, broken” may appear to be chance homonyms, when in fact they are faithful reflexes of the Türkic semantic furcation, see dash “break”, dash “move”. The word is a most powerful case of the Türkic-English paradigmatic transfer, with absolutely perfect phonetic precision and rigorous semantic accuracy. It is statistically incontrovertible attestation of the Türkic genetic origin. See dash “break” and its Supplementary Note, dash “move”.
English derrick (n.) “lumber frame for a simple crane” ~ Türkic direk, tirek (n.) “support, prop, column”, derek, terek (n.) “tree”. The forms for “support” are obvious interchangeable allophones of the form for the “tree”. Besides a routine generic use, it is known as a trade term in architecture and nautical application translated as “punt-pole”, “boat-pole” (mast) and the like. Semantically, derrick belongs to the host of other trees that are not plants, like scaffold, coat tree, family tree, tree diagram, etc., its closest meaning is “lumber, timber structure”, and it must be as old as the use of tree trunks for structural elements in constriction and mechanical equipment. The late folk etymology ascending to a 17th c. popular hangman with name like Diederik, Dietrich, Theodric is plainly wrong and rather silly. As a hoist, an erected lumber framework served many more needs than as a part of gallows in the noble British art of hanging people. As a trade term it found its way to America, together with a slew of other lurking words with absent records for their use in England. In search for the PIE cognates, the Pers. form diraxt “tree” is closer to derrick than the hangman's names. The word derrick became popular with the popularity of oil and oil wells beginning in the 19th c. Nowadays, derrick is a trade term for a hoist tower of a drilling rig, water storage tower, mining tools and structures, and the like with or without a use of lumber, but with historical memory of their lumber origin. The derivation from the originally Türkic term is obvious, the phonetics and semantics are perfect, the import of Türkic laborers from the 5th to 15th centuries must be excluded, the Norman source must also be reasonably excluded, and that leaves the Anglo-Saxons as latest viable source. Probably, the mysterious origin of the word rig is an elision of the derrick after connection with the tree had been long forgotten, Cf. Dan., Norse, Sw. rigge, rigga “equip, rig, harness”. In that case, the phantom “PIE” *reig- “bind” is not needed. See other plant-related words: cannabis, caragana, elm, juice, herb, laber, tree, valerian, wormwood.
English dike (n.) “levee” ~ Türkic dık- (v.) “erect, stand straight, dam”. Cognates: Du. dyke, dike “standing barrier”, Sp. dique “levee, upright wall, vertical rock stem protruding to the surface”. No parallels in Indo-Iranian languages, PIE, or even in the *PIE. As a straightly erected structure, erected posture, standing and protruding, the Türkic dık- is found in popular appellations that refer to exaggerated masculinity (see dick). No “IE” etymology. The triad dike - dick - cock is a case of a paradigmatic transfer, a transfer of an identical set of properties of a particular object. The triad assertains the Türkic linguistic genesis. See cock (rooster), dick.
English din (n.) “noise” ~ Türkic daŋ/duŋ/tоŋ “noise”. Cognates: A.-Sax. dyne, ONorse dynr, MLG don, Dan. don, Sw. dan “noise”; Welsh dwndwr; Sp. dinar “pound, make noise”; Skt. dhuni “roar”. “IE” languages have hundreds unique expressions for “din”, with clearly no single “proto-word”. The onomatopoetic origin is more then probable, all unique words for “din” probably echo peculiarly unique perception of noise in different societies. The Türkic dVn-type word is confined to Gmc, Celtic, Sp., and Skt., repeating a common distribution pattern of Türkic layer in the “IE” languages. The stand-alone form, and phonetical and semantic concordance attest to a common origin from a source that extended from Atlantic to South Asia.
English dingdong (n., v., adv.) “bell's sound” ~ Türkic daŋ doŋ “sound”. Obviously onomatopoeic, obviously without parallels in “IE” languages, obviously modern loan-word acquisition by some European languages, and obviously an allophone of never formalized Türkic daŋ doŋ reported by M.Kashgari (10th c., taŋ toŋ) and recorded in Khakass (daŋ doŋ). Notably, the word parallels numerous English cognates of Khakass words with forms closest to the English forms. Khakass is a modern name for the people known as Enisean Kirgizes from the turn of the eras, they destroyed Uigur Kaganate and expanded their control over area centered at the Pamir mountain range. The modern Kirgizstan is named after descendents of the Enisean Kirgizes. Prior to the Russian colonization of Siberia in the 17th c., the Enisean Kirgizes remained a dominant ethnicity in the forest-steppes from lake Balkhash to lake Baikal. Dingdong is a variation on other English-Türkic cognates of din, ding, and dong, all onomatopoeic Türkic words. See din.
English dune (n.) “sand ridge” ~ Türkic döŋ/töŋ, düŋ/tüŋ, dön/tön, dün/tün “bulgy, protruding, dune, hill” (EDTL v. 1980, 279-281; Murzaev 1977, 47-48). The word is extremely polysemantic, the prime notion is “fold, bend” (i.e. not straight), which produced extension “bulgy, protruding” (upwards), which became a base for the notion “dune, hill” and a cluster of other concrete nouns and a verbal notion “turn” with its own numerous extension lines. Among the most important semantic extensions are: “bulge”, “hill”, “stump”, “pillory”, “cape”, “(swamp) islet”, “bush”, “rude”; the notion “dune, hill, small hill” is one of the prime nouns. Accordingly, various portions of this semantic spectrum can be found in numerous languages across Eurasia. Cognates: A.-Sax. dünlendise “mountainous”, dünlic “of a mountain, mountain-dwelling”, dünhunig “honey from lowland, open country”; OE dün “down, moor; low hill, low mountain”, Eng. down, MDu. dunen “sandy hill”, Du. duin, Gmn. Tumbe “grave, pit, cave”; Celtic dun “hill, citadel”, OIr. dun “hill, hill fort”; Welsh din “fortress, hill fort”; second element in place names London, Verdun, etc., traced to pre-insular Celtic [Cambridge Dictionary of English Place-Names] before Anglo-Saxon migration; Lat. tumulus “hill, rising, hillock”, tombe “grave, tombstone”, It. tomba “grave”, Rum. tumul “burial mound”; OGr. tumbos “mound, hill”; Rus., Bulg. tumba “roadside pillar”; Hu. domb “hill”, Mansi tomi “hill”; tumb in the toponymy of the Northern Urals; Arm. tumb “mound, fill”; Pers. tomp, tomb, tom, tum “hill”. Notably, the A.-Sax. words düniendlic (dünondlic) and dünlic have preserved the Türkic adjectival suffix -lic “-like” (Tr. -lig/-liɣ/-lik/-lan “like”). The Türkic, A.-Sax., and Eng. have parallel bifurcated semantics of “low” (down) and “low hill” (dune), with the Eng. “low hill” extending to “citadel”, “hill fort”, and eventually to town, that bifurcated semantics continues to the present. The non-English Gmc. words tend to mean “sand bank”, the Celtic cognates tend to mean “hill”. The “IE” speculations unwittingly but correctly link dune and down, but otherwise blunder on who borrowed from whom without a clue of the source or the early records and distribution. Distribution covers most of the Eurasia across various linguistic barriers. The Celtic trace points to their circum-Mediterranean migration of the 6th-5th mill BC. It is obvious that the well-ingrained A.-Sax. forms and the Celtic forms came via temporally and spatially distinct paths. The European words may ascend to the R1b Y-DNA haplogroup Kurgan waves of the 4th-2nd mill. BC, to the amalgamations of the 3rd mill. BC Corded Ware culture, or even to the migrants of the R1a Y-DNA haplogroup ca 8th-6th mill. BC. The cluster of the dune, alms, grave, mengir, mound, tomb, and tumulus constitutes a salient case of paradigmatic transfer from the Eurasian Türkic nomadic milieu, from the times much older than Lat. and OGk. cognates on the far fringes of the Eurasia. See alms, grave, mengir, mound, mount, tomb tumulus.
English dung (n., v.) “feces” ~ Türkic tuŋ (n.) “excrement, feces”, tuŋ (v.) “soil, mire”. The base root was not found in the records, but records have preserved a derivative noun/adjective tuŋra “excrement/feces, filth, dirty, mud” formed from the root base tuŋ and a “rare” deverbal suffix -ra, pointing to the original verbal base “to shit, soil”. The absence of the main entry tuŋ/duŋ and the presence of the derivative form tuŋra point to the severely underrepresented in the eastern sources western vernaculars. The notion of the noun tuŋ is largely adjectival “soiled, dirty, filthy”, the terms like the dung are concrete noun deverbal derivatives. The Eng. semantics of specifically “animal feces” is a semantic contraction. Besides the Türkic, all cognates are limited to the Gmc. languages, unshared by the rest of the “IE” linguistic groups. Cognates: A.-Sax. dung “manure, fertilizer”, OFris, OSax dung, OHG tunga “manuring”, tung “cellar covered with manure”, ONorse dyngja “manure heap”, Gmn. dung, Sw. dynga “dung, muck”, Dan. dynge “heap, mass, pile”; Lith. dengti “to cover”. The notions of feces and soiling predate by many millennia the utility of farming, manure, manuring, and of using dung as a heating and insulating element in a farming environment. The “IE” attempt to etymologize dung as “covering” is out of sync, out of gumption, utterly feeble, and out of reason with a claim of an unattested “PIE proto-word” of “covering”. A cited as a cognate OIr. dingim “I press” has an unequivocal Türkic form with an agglutinated suffix -im “me, I”, it appears to be a derivative of the Türkic verb taŋ-/daŋ- “tie up” denoting “constrict” translated as “pressing”, and beyond a phonetic resemblance definitely has no connection with the notion of “poop, dung”. Notably, there are two Türkic names for “swine”, lağzı:n and toŋuz/doŋuz, Tat. duŋgz, OBulgar Doxs (Dokhs, Дохс) as recorded in the 8th c. Bulgar Khans' Nominalia for the native names in the 12-year cycle calendar. The part duŋ “soiled, dirty, filthy” may be a solution for the lingering etymological puzzle, reflecting a Near Eastern pre-Islamic influence on the traditional names in the calendar. The name toŋuz/duŋgz (Oguz articulation) may reflect the tradition of rating swine an unclean animal, Cf. Hebraic tradition ascending at least to 6th c. BC. Of the pharmacopeia of the 16 Türkic closely synonymous words and forms that refer to different attributes of the feces (Cf., e.g., dung on the snow), English has inherited an abridged lexicon of the words dung, shit, and poop, an authentic case of paradigmatic transfer unequivocally attesting to the common linguistic origin. The word turd, not mentioned in the sources, may also be a viable candidate for the Türkic origin, it refers to a particular type of a natural extrusion. See shit, poop.
English duration (n.) “continuing in time” ~ Türkic dur-/tur- (v.) “auxiliary verb marker of duration or permanency of an action”. The Türkic auxiliary verb dur-/tur- modifies an action “to last or to last for some time”, it is equivalent to the Eng. compound be -ing as in the “is walking”, “is looking”. The base dur-/tur- is a polysemantic verb “get up, rise; stand; be, reside; dwell; stay, stop for a time; intention, willingness to do something” and some more totaling at least 14 meanings, plus an adverb for “continuity of action or state”, usually in a form turur (modern western) or tur, turu (modern eastern), plus a simulative suffix, and some more totaling at least 6 grammatical functions. Essentially, the dür-/tür- semantics forms a notion “prolonged state” in various grammatical forms. The form tur- tends to refer to a beginning stage, the form dur- tends to refer to a finishing stage of the named action. For mobile languages, the notions “western” and “eastern” are very fluid in time and space. The status of an auxiliary verb lends it to borrowing and subsequent innovations. Cognates: ðurg, ðurh (prep.) “during (time), through”, trum “firm, fixed, secure”, trumlic “durable”; MLat. duratio “duration”, durus “hard”, OFr. duration “duration” (14th c.); Bulg. durdisvam “(you) stop”; Serb. durmadan “continuously”, dur!, dura! “stop!”, durun orda “stay there”; Gk. ntourma (ντουρμα) “enduring”; Alb. dur!, dura! “stop!” The exclusive status within the “IE” family makes it an obvious loanword. The Serb. “stay there” is almost eidetic with Türkic phrase. The suggested “IE etymology” ascending to the notion “tree” and its property “hard” is more than dubious, considering the real Türkic attested terek “tree” vs. a faux invention *dreu- based on mechanical phonetic manipulations, and the minor role of the form tree/*dreu- among the “IE” family. In contrast, the Türkic dur-/tur- offers the base for duration and anything durable, “firm, solid, steadfast”, in addition to the reflexes of the downstream derivative lines developed from the attested 14 verbal meanings. The thin link connecting the Middle Age “duration” with the extreme minority of the European vernaculars suggests a recycling from the Burgund lexicon or of their horse nomadic kins. A late arrival to Europe, the root dur-/tur- otherwise has a real Eurasian-wide distribution. Unlike the “PIE proto-root” with neither place, nor time, nor the physical users of the faux antecedent word, the Türkic word has attested place, time, and real people behind it. Moreover, the Türkic word comes as separate offshoot surrounded by numerous allophonic offshoots (i.e. tir-, tür-/dir-, dür- etc.) with complimentary notions. A significant size of the sibling cluster atteststhat “...most likely existed a diffused connection of most of them (words), that is, their simultaneous coexistence. ...Among the Turkic verbs with grammatized functions, the tur-/dur- holds a special place by its universality, expanse, and diversity of its grammatical application.” (EDTL v. 1980, 299). See endure, duress, durable.
English dust (v., n.) “particles, fallout” ~ Türkic doz (n., v.) “dust”. Cognates: A.-Sax. dust, OHG tunst, Gmn. Dunst, Dan. dyst, Du. duist; Ir. dusta, deannach, Welsh dwst, ddwst, nwst, Hindi, Gujarati dhuḷa, all obvious allophones of the Türkic doz and allophonic form toz. Dust and its allophones occupy a minuscule part in the “IE” family, attesting that the word is a foreign guest there. The distinct notion of “dust” includes notions for suspension, volatility, small particulate that were used in the “IE etymology” to create an artificial paradigm of “IE” reality and a dubious “proto-word”; these notions also are inherent to the Türkic doz (n.) and doz- (v.). The particular distribution of allophones with pinpointed semantics in the NE fringes of Europe, across the Eurasian steppe belt, and in the eastern fringes also attests that the word “dust” is a guest among the “IE” languages, where across the Romance and Balto-Sl. languages is used the form of the type pulp, pulv, extending also to the Fennic languages. The presence of the Türkic form in Celtic languages attests to its age reaching to the 6th-5th mill. BCEastern Europe. The form doz (with d-) is recorded in the Kipchak milieu.
English dye (v., n.) “stain, color” ~ Türkic dava, dawa: (n.) “stain, color”.
Cognates: A.-Sax. deah, deag “color, hue, tinge”; Ir. dath “color”, Lith. dažai
(dajai); Mong. budag (будаг); the cognate distribution is profound, peculiar to the
Anglo-Celtic, Türkic, and Mong. and Lith. outliers with known Türkic historical presence. The origin
of the Türkic dawa:
is the name for the tamarisk plant, its fruit was used to extract dye, the plant was possibly also
used for medicinal purposes, hence the second notion “drug” in the form daıva. The “IE
etymology” came up with a random semantics “secret”, based on chance and poor consonance.
111
English ea (n.) “river” ~ Türkic aq- (v.) “flow, leak, outpour”. Cognates: A.-Sax. ieg “island”, Goth. ahua “river, waters”, giutan “pour” (Tr. causative akıt- “pour”), ONorse Ægir “sea-god”; Hitt. (ca 2000 BC) akwa- “drink” (Gmc. -an verbal infinitive marker, -ba marker of adjectival adverb of manner). The English aqua “solution, decoct”, aqua- “involving water” also are the Lat. derivatives of the Türkic aq- (v.); in English, the aqua and aqua- are not substrate stems, they were borrowed from Lat. and grew to become innate words. The forms with consonant -b-/-f-/-p- are allophones of the same stem, e.g. Rum. ape, Pers. ab, af, Skt. ap “water”. The presence of the -b-/-f-/-p- allophones in Europe (Rum.) and in Asia (Pers., Skt.) are consistent with N.Pontic serving as a refuge for European refugees from the carnage inflicted during the 3rd mill. BC on the old European farming populations marked by Y-DNA haplogroups G2a, E1b-V13, I1, I2, and R1a (older migrants), from where ensued the subsequent migrations to the south-central Asia (Pers., Skt.) and back to Europe (Rum.). The other Türkic synonymous stem tök- (v.) “pour, pour out, strew” also attests to the same migration pattern, it was widely adopted in Sl. tok, tek “flow”, Balt. (Latv., Lith.) teku “flow”, Skt. takti, takati “to stream”, Av. tachaiti “to flow, run”; the circum-Mediterranean path of Kurgans (Celts) via Caucasus and Africa to Iberia at 2800 BC is attested by the preserved Ir. tech-, techim “run”. The nearly parallel spread of these two linguistic markers parallels the migration of the genetic markers and provides solid corroborating testimony on the pattern of linguistic development started in the 3rd mill BC, but with roots attested in the 6th mill. BC (the start of Kurgan circum-Mediterranean migration, marked by dolmens, cairns, and kurgans).
English elm (n.), Lat. Ulmus campestris ~ Türkic ilmä, əlmə “elm, Ulmus campestris tree”. The word elm has an uncanny resemblance with the Türkic names alma:, elma for the apple and karagach trees and the like, and in the Modern Times added a potato plant. That semantic fluidity is historically typical for the Türkic names for flora and fauna, leading to crossover results in different Türkic and amalgamated languages. Amalgamation also affects phonetics, əlmə/alma may turn into apple with lm/ml transposition and m/b/p alternation. The alternation is also known to apply to the phonetics within the Türkic family. Cognates: A.-Sax. elm “elm”, elmrind “elm-bark”, Dan. elm, ONorse almr, OHG elme, Gmn. ulme, Du. olm, iep; OIr. lem, Gaul. leam(han), Welsh llwy(fen); Cz. jilm, Rus. yabloko (яблоко) “apple”; Lat. ulmus, Fr. orme, It. olmo, Catalan om; Taj. em; Fin. jalava, Est. jalakas, Hu. szilfa; Georgian telavi (თელავი); Jap. erumu エルム; Uz. ilm, Kazakh ğılım. Distribution across linguistic families and across Eurasia attests that no “PIE” or “PG” origin can be sanely suggested. The m/b/p alternation extends to m/b/p/w/v/f alternation, there are sz/j (y)/ğ prosthetisations, and a fluid anlaut vowel. The extent of the spread of the word points to its dispersion by the Türkic horse nomadic pastoralists as the only viable option, the “IE” farmers were not roving around and venturing too far. The Romans never ventured into Siberia to share their lexicon with various Siberian tribes. The semantic fluidity shown for the Türkic languages points to a word for a generic notion of a large salient tree. The same root is in the name of the river and lake Ilmen, of the western Siberian Southern Urals Ilmen Mts, a Manchu clan, and a family name in Turkey and Russia. Notably, there is a linguistic parallel with the ash tree name, also found in the NW Europe and in Central Asia, Cf. Eng. ash-tree, A.-Sax. aesc (əsh) “ash-tree”, aescen “of ash-wood”, aescrind “ash-tree bark”, and Kirg. (former Enisei Kirgizes, Khakasses) jazuu “elm”, an another node between the Gmc. and Khakass languages. See other plant-related words: cannabis, caragana, derrick, juice, herb, laber, tree, valerian, wormwood.
English engine (n.) “device, contraption” ~ Türkic ıyın-, ïjïn- (v.) “strain, exert vigorously”. Ultimately from the notion yı:d “scent, odor, smell, stink” and its derivative yı: “to sweat” associated with exertion. In metaphorical idiomatic form, this peculiar association still holds in English, Cf. sweat of the brow “diligent labor”, sweat it out “endure physical exertion”, etc. An alternate form is ıg-. The part -ın- is a reflective suffix “self, yourself”. The connection between ıyın in its nominal and verbal forms and the LLat. ingenium “battering ram war engine” is sound both phonetically and semantically. Cognates: A.-Sax. higian “exert oneself, strive”, OFr. engin “war machine” (12th. c.). The anlaut h- in the A.-Sax. articulation, and -n- in the Fr. articulation (Cf. A.-Sax. elboga, eleboga, elnboga “elbow”, see elbow), are of prosthetic nature. The CT root ıy-/yı- in the A.-Sax. has the form ıg-, a valuable diagnostic trait. As a source for the engin “war machine”, the “IE etymology” suggests a homophonic Lat. ingenium “congenital, inborn, innate” and its Fr. counterpart engin “skill, cleverness, trick”, either of which offer only a phonetic similitude. The LLat. lexicon is inapplicable to the Roman technology since outside of the scholarly circles by the Middle Age the Lat. was a dead language. Semantically, the “IE etymology” offers a term basically equivalent to “invention”, a result of talent or skill, which conflicts with the European practice of naming war machines, Cf. catapulta Gk. “pelting penetrator”, aries Lat. “ram (sheep)”, etc. Such abstract generic term in 12th. c. world could cover anything, from toothpaste to hot air balloons, being applied to the contraption a thousand years old. Also, the native Lat. ingenium ultimately ascends to the Türkic root gen-/ken- “new, child, baby”, unwittingly recycled into a faux “PIE proto-word” *gen(e)-yo-. It is easy to visualize that for millennia, leverage and strain were the the only machines known among various societies, the names for the new devices were derived from the common verbs and nouns of the day, Cf. Ch. invention cross-bow nu 弩 “hack (strike downward)” vs. its Türkic name koğuš “(from a) groove” (vs. from a finger). After the Roman battering ram had been used by the army for 12 centuries, it is hard to imagine that in the Middle Age arose an urgent need to rename the old contraption. To foreign lands the old machine had to come along with its old Lat. name arius. Renaming the common old arius to a strange ingenium could only happen on a foreign soil, like the Lat. horae becoming clock on the English soil. The OFr. engigneor “engineer” and its derivatives are normal extensions for an agent noun tending to the machine, Cf. Fr. coucher “driver of a coach”. The timing of the word and its distribution suggests its provenance from the Burgund Vandals or their kins. See elbow, gene, kin.
(Skip) English enigma (n.) “riddle” ~ Türkic tanığma: (n.) “riddle”, a deverbal derivative of tanï- “know, familiar”. Cognates: Lat. aenigma “enigma”, ainos “fable, riddle”, Gk. ainigma (αίνιγματα), “riddle”, “IE etymology” asserts the word “of unknown origin”. The paucity of cognates also make very weak cognate suspects the Welsh ddirgelwch; Arm. hanelukn (հանելուկն); Mong. negen (нэгэн), Heb. tmua (תְמוּהָה), which to a some degree all ring consonant with the Türkic tanığma:. The Türkic tanığma: derives from the verb tanı “know”, the deverbal suffix -g (-ɣ, -g; -ïɣ; -ig; -uɣ, -üg; -aɣ, -äg) makes it a noun/adj. “knowledge, understanding, knowing, knowable”, and the negation suffix -ma- turns it to the opposite “unknowing, puzzling”. This is quite an impressive practical path from tanı to tanığma:, and this is exactly what a random Türkic listener unfamiliar with the word would hear: “something unknown” (n.). Notably, Gk. does not have a known suffix -ma, and the suggested Gk. root ainos (aίνος) “tale, story” without the Türkic -ma does not have a grammatical mechanism to turn into ainigma (αίνιγματα). Chances for accidental phonetical coincidence are next to nil: even doubling or tripling the number of potential synonyms (English: riddle, conundrum, mystery, brain-teaser, problem) makes the semantic field extremely narrow (say, 15 out of 100,000 dictionary is 0.00015; 15 out of 200,000 dictionary is 0.00008, etc.), the chance phonetical coincidence is also vanishingly small, something on the order of 7 trailing zeroes, and the product of the two is one chance out of 100 billion 6-phoneme words. The only realistic path is that the Greeks learned the word from a Scythian sage like Anacharsis, in whose language tanığma is a staple word, and the English inherited it with the rest of its Türkic substrate. The anlaut t- in the documented form may indicate that it is a relict of its Ogur origin with an initial consonant.
English ether (n.) “hypothetical medium” ~ Türkic esir, äsir, (n.) “ether, space”. Ultimately a deverbal noun derivative fr. the verb es- “stretch, extend, expand, spread” formed with the substantiatable noun suffix -ïr/-ir, essentially “spread, endless, limitless”. An alternate articulation may have been a homophonic jaz-/yaz- “spread, vast”. Cognates: A.-Sax. aeðm “air, breath, breathing, vapor, blast”, Cf. Gk. atmos “vapor, steam”; Lat. aether “the upper pure, bright air”, Gk. aither (ειθερ) “upper air, bright, purer air, sky”, Arab. asir “ether, space”. Apparently, the word first came to Europe with the Greeks, was independently carried to Europe by the Anglo-Saxons, and spread to the Arabs during the Arab Enlightenment period. The “IE etymology” suggested an origin from semantically unrelated Gk. aithein “to burn, shine”, an allophone of the Türkic isi:- “hot, burning”. No cognates across “IE” family, no “IE” etymology.
English ewe (n.) “female sheep” ~ Türkic eve (n.), generic for “engender, birth-giving (woman, cat, etc.)”. The semantic and phonetic congruence leaves no doubts that ewe “mama sheep” is the same word as the eve “birth-giving (mama)”, see Eve. The association of the word ewe with sheep is purely fortuitous, driven by the economic significance of the sheep in the life of the particular Eurasian pastoralists, Cf. Türkic compounds ana mächä “mama cat” and ata mächä “papa cat”, Tuv. ava hoi “mama sheep”, and the like; under a slightly different economy, the ewe would be associated with, say, llamas or deer (like the Welsh cognate below). Hence the “IE” etymological speculations of the of PIE *owi- “sheep” is unsustainable, the allophones like the unattested owi- are derivatives of the prime notion eve, ava “mama”, as opposed to the aba, ata “papa”. Notable is a distinction common for the Türkic and the languages that use cognates of ewe: the words denoting the “sheep” in the majority of the Türkic languages at the same time denote females, independently or in combination (Shcherbak, 1961, 111), and so does the ewe. The Heb. etymology for Eve suffers a similar malady, see Eve, some linguists see the trees and miss the forest. The semantic extension from the “mama sheep” to generic “sheep” is natural, since the flocks of sheep were and are nearly exclusively female, with lambs and rams on as-needed basis. Cognates: A.-Sax. eowu “mama sheep” (aka “female sheep”, since mamas are predominantly female), OSax. ewi, OFris. ei, MDu. ooge, Du. ooi, OHG ouwi, “female, generic sheep”, Goth. aweþi “flock of sheep”; OIr. oi, Welsh ewig “female deer, hind”; Lat. ovis; Gk. ois; Balto-Sl. (Lith.) avis "sheep," (OCS) ovica; Skt. avih. The etymological terms ewe and sheep are essentially synonymous, since all languages with pastoral economy have separate terms for rams. The Welsh term stands out as denoting a female of entirely different nature, pointing to a possible deer-breeding economy. Notably, the “IE” textbook examples of OFris., Du., OIr., and Gk. forms, aside of the anlaut consonant, are phonetically closer to the Türkic terms for “sheep” koy, hoy, and the like, than to the “PIE reconstruction” *owi-; hence they may in fact confuse the “mama, female” with “sheep”. The ewe “mama” unites the terms ewe, Eve, and Adam into a separate complete paradigm that came to English via two separate and independent paths. See Eve, Adam.
English feeling (n.) “physical or emotional sensation” ~ Türkic bilig, bilin- (minnir-) “become aware, understand, become acquainted, delve, get to know, recognize”; “knowledge, feeling, advice, instruction, guidance”. Ultimately fr. the verb bil- “know, understand, perceive”, with verbal suffixes -ig and -in, noun/adjective and reflexive respectively. In both languages the underlying prime notion is “to know, perceive”. Cognates: A.-Sax. filnes, felan “feeling, feel, perceive, touch” with a notion of “perceive through senses of not any special organ”, OSax. gi/ge-folian, OFris. fela, OHG vuolen, Du. voelen, Gmn. fühlen “feel, touch”, all “to feel”, ONorse falma “to grope”; Lat. palpare “feel by touching, touch”. Derivatives of the root bil- “to know, to learn” are ingrained into Gmc. languages. In Türkic languages, the notion feeling is an extension of the notion to know, expressed by four roots, bil-, sez-, tartil-, tuj-, with a flake tartil- being fr. the tart- “pull, guide”. This evolution is common to Gmc. and Sl. languages, with Sl. chuvstvovat (чувствовать) “feel” being a derivative of chu- (чу-) “to get wind of, smell, hear”, i.e. “perceive”. The Lat. sensum “to feel” appear to be an allophonic derivative of alternate Türkic root sez- “to come to know, to learn, to feel”, while the Lat. palpare “feel by touching, touch” may ascend to the synonymic Türkic root bil-. The “IE etymology” suggests “perhaps ultimately imitative”, essentially resigning to a no meaningful etymology. The Türkic dialectal form minnir- is an allophone of bilin- with m/b alteration. Türkic allophones include pilik (labial plosive), bilis (-g > -s), bilim (-g > -m), bilik (-g > -k), bili/bilü/belü (Kipchak, truncated form first noted by Herodotus for Sarmatians and then by Kashgari for the NW languages (Bulgar). These forms provide sufficient evidence for flexibility and consistency to make the transition of plosive labial b- to fricative labial f- (biling > feeling) credulous. The Gmc. forms are consistent in transitions b-/v-/f-, the Lat. is a stand-alone with the transition b-/p-; that points to different paths and timing. Another utilization of the root bil- with the semantics “able” produced the suffix -able in English innovations like suitable and doable, the last a compound of two roots, the tü “do” and bil- “able”. The Eng. Latinisms -able, -ible came fr. the Lat. Türkisms from the same word bil- “able”, the Lat. -abilis, -ibilis. See feel.
English fissure (n.) “narrow depression, slit, groove, cleft” ~ Türkic öz/özi: (n.) “fissure, cleft (mountain)”. Cognates: OFr fissure, Lat. fissura; all Gmc. forms are derived from Lat., and are outside of the substrate level. The loanword nature in Lat. is beyond doubts, even if the lonely attested Skt. form bhinadmi has any relation with Lat. fissura and findere: the rest of the “IE” languages are free from cognates. The prosthetic anlaut f- and the Türkic participle suffix -ur with the deverbal form of the attested stem öz form the Lat. fissure with precise semantics and credible phonetics: “split, cleft” (substantiated participle).
(Skip) English flask (n.) “canteen” ~ Türkic baklaga (n.) “water bag”. Cognates: A.-Sax. flasce “flask, bottle”; LLat. flasconem “water bag”. One “IE” etymological theory suggests an unattested proto Gmc. *fleh- “flax”, another theory suggests a metathesis of the Lat. vasculum “small vessel”, that's the end of the “IE” phonetic digs.
(Skip) English galimatia
(n.) “nonsense” ~ Türkic ɣalät, ɣalet (adj.) “erroneous”. Cognates: none outside Türkic languages;
no “IE” connections, no “IE” etymology; fr. Fr., of routine “of unknown origin”. Galimatia
happened to be a favorite of the famed Sinologist/Turkologist Otto J. Maenchen-Helfen, although he
never boasted that he picked it up from the Türkic lexicon. The French could have picked it up from
the Alans (Amorica) or Burgunds (Provence/Savoy). The Amorican Alans could also bring it directly to
the English soil.
112
English garden (n.) “yard adjoining a house” ~ Türkic qur (n.) “sash, belt”, karta (Chuv.) “fence”, qur- (v.) “arrange, build”; among the verbal derivatives are the relevant “fence in, gird, surround, block, enclose”. The word qur/qur- is extremely polysemantic, some of its notions are believed to be among the most old words of the lexicon; the words cairn and kurgan are derivatives of the verb qur-, see cairn. Numerous English words ascend to the primordial verb, semantically garden is a specialized enclosure. Based on indirect indicators, it is possible that Türkic internalized qur/qur- from the Mong. languages (Sevortyan 2000, EDTL, v. 6, pp. 154). On the other hand, the absence of semantic correspondences with Tung. and the demographic predominance of the Huns within the Syanbi state suggest that the Mong. cognates are internalized Hunnic words. That is especially notable in the archaic nature of the Mong. semantics: “string (a bow)”, “braid yurt grates”, “set up yurt”. Prior to the Hunnic period, future Mongols lived in stationary villages and bred pigs, the traits incompatible with the pastoral nomadism. The word was borrowed by the Sl., Pers., Mong., Caucasian, and other languages across Eurasia and linguistic families. Cognates: A.-Sax. geard “garden, yard, enclosure”, gierd, gerd, ierd “yard (measure)”, the vocalizations for the notions “garden”, “yard (enclosure)”, and “yard (measure)” were likely identical, i.e. articulation ierd was a garden and a yard; gyrdan “to gird (sword), encircle, surround”, gyrdel “girdle, belt, zone (encircled by belt)”, gyrdelhring “girdle, buckle (belt ring)”, gyrdweg “fenced-in road” (Cf. beltway, the qur “belt” replaced with a Türkic synonymous bel “belt”); OFris. garda, OSax. gardo, Goth. gards, OHG garto “enclosure, yard, garden”, Norse Gardariki, Garðaríki “country of (fenced-in) cities”, these denoted a notion of “enclosure” that could be a garden, a walled city, or an orchard; Welsh iard “yard (enclosure)”, OFr. jardin (13th c.) “enclosure”, including garden, ONFr. gardin “(kitchen) garden, orchard, palace grounds”; VLat. hortus gardinus “greens, vegetable enclosure”. Various Middle Age European phonetic knock-offs were a fashion craze. For more cognates, etymology, distribution, and history see gird. The word yard with its allophones is semantically and phonetically near equally close with with the allophones of garden and earth (with elided -g), see earth, yard.To sway the origin one way or another would require a close inspection. The distribution from Mongolia to Atlantic, particularly among the 3rd mill. BC Corded Ware descendents, and across linguistic families attests to the spread of the polysemantic word by the eastward and westward Kurgan waves. The dating can be pinned to the 5th-4th mill. BC (Celtic Welsh), 3rd mill. BC (Gmc., Sl.), 2nd mill. BC (Zhou period, Tung./Mong.). A paradigmatic transfer of distinct semantic notions (Cf. gird, belt “belt”, garden, court, yard “enclosure”) attest to the common genetic origin from the Türkic milieu. See court, curtain, gird, guard, and yard.
English gist (n.) “epitome, digest” ~ Türkic öz/göz “essence” (Oguz/Ogur),, with extensions özet/gözet (Oguz/Ogur) (n.) “epitome, knowledge, mind, intellect”. The polysemantic word with 13 principal meanings is a derivative of the verb ö- “awe”; besides the “essence”, English also inherited the semantics “breathe”, “spirit, ghost”, “desire”, and “other”, essentially homonyms because their connection with the the underlying “awe” borders on imperceptible. The cognate siblings, initially distinguished by various suffixes, grew to diverge in vocalization and eventually by spelling, which further impacted vocalization: giz-/iz-/gis-/is-/ges-/ess-, gas-, gaes-, gaed-, ghos-, gus-, oð-, etc. The anlaut g- is prosthetic, corresponding to the Ogur articulation, Cf. geoc/ioc “yoke”. Cognates: A.-Sax. gesen, guttas (with z/d alternation) “guts”, lit. “core, essence, internals”, but see gut, gastgemynd “thought”, compound with mynd “mind” instead of hygd, ditto, see mind, gastgehygd ditto, a compound of “blow (~ breathe)” and a European hygd “thought, mind” q.v., i.e. “a strike of insight”, -ge- is a prefix, gastcyning “soul’s king, God”, a compound of “blow (~ breathe)” and a Türkic kengu “king”, gastsunu “spiritual son”, a compound of “blow (~ breathe)” and a Türkic soŋ “offspring“, gistung/gitsung, gad/gaed (with z/d alternation) “desire”, Goth. gaidw “desire”, oðer “other” (apparently with z/d/th alternation); Eng. essence “essence”; Lat. essentia “essence”; Gk. ousia “essence”. Two apparent facts are notable. First, a paucity of the European and “IE” cognates in spite of the exceptionally wide semantic range, even within the fraternal Gmc. group. That positively indicates a non-IE origin and thus negates any and all PIE speculations. Secondly, a pronounced Oguric articulation, typical for the Cockney-type vernacular, with minor Oguzic deviations. Thirdly, the high degree of internalization is impressive, the A.-Sax. family of cognates exceeds 30 lexical clusters, with numerous variations in articulation and with phonetic alternations. That attests to the A.-Sax. historical line of development at least commensurate with the Gk. internalization. Fourth, numerous compounds consisting of either two Türkic words or of a Türkic and Gmc./European/local word, Cf. q.v., also attest to the temporally long period of amalgamation. Fifth, of the 13 basic semantic fields of the word in the Türkic languages, English has retained 5 fields plus the parental word ö- “awe”. That degree of retention could only happen under a considerable demographic pressure of the native Türkic speakers, especially in view of the numerous native non-Türkic synonyms competing for survival, and high degree of the actually supplanted lexicon. Sixth, under the PIE paradigm, every semantic tree grows from its own seed, with its own faux “PIE proto-word” mechanically extracted by phonetic resemblance from some other unrelated modern lexeme. The suggested “IE etymology” is utterly unsuitable, fr. Lat. iacet “it lies”, iacere “to lie, rest”, via a Fr. idiom cest action gist “the essence of the action is”. OFr. gist en “essence in”, ultimately equates the noun “essence” with the verb meaning “to lie, to throw”, an uncanny proposition. Unwittingly, the “IE” proposition is using a phrase with same Türkic word göz (n.) “essence” complete with the Ogur prosthetic anlaut g-. The OFr. form allows to suggest a path from a Burgund-Provence source independent of the A.-Sax. path. The transition göz > gözt > gist is marked with suffix -t, a Türkic active marker for intrans. verb bases. Of the “IE” languages this marker is actively used by the Balto-Sl. and Skt. languages. In the Gmc. languages it remains a forgotten inactive relict from the olden days, Cf. Goth. iddja, Sl. idya/ida/iti/idu/isi/issti and Balt. eiti/iet/eit of the Türkic verb base i-/e- “go”. In terms of the paradigmatic transfer, the word öz/göz duly deserves a slot on the prize pedestal, indelibly attesting to the Türkic genetic origin. See awe, gut, mind.
English glue (n., v.) “cement” ~ Türkic yelïm “glue, jelly, paste”. Cognates: A.-Sax. lim “anything sticky, lime, mortar, cement, gluten”, (be)lim “glue”, ceale (keale) “plaster”, claeg “clay” cliða “poultice plaster”, clæman “smear”, OSax. klei, OFris. klai, MDu clei, Dan klæg “clay”, OHG kliwa “bran”, ONorse kleima, OHG kleiman “cover with clay”, Gmn. Kleie “glue”; OFr. glu “birdlime”; OIr. glenim “stick, adhere”; LLat. glus, gluten “glue, beeswax”; Gk. gloios “sticky matter”; Balto-Sl. (Lith.) glitus “sticky”, glitas “mucus”, (OCS) glina “clay”, glenu “slime, mucus”. Ultimately from Türkic ö:l “damp, moist” (Cf. oil “liquid hydrocarbon”) via öli- “moist, damp”, öli:ge: “sticky”, gelim “glue, jelly, paste” (Ogur form) to glu “glue”, and OSax. klei “glue”. The Ogur counterpart gelim of the recorded eastern Türkic form's yelïm (Oguz), saliently visible in the A.-Sax. lim, (be)lim, is visible in the above European forms, and the semantics indicate an early period, when for adhesives were used brans and clays, long before the invention of the hoof and fish glues necessary for construction of the composite recursive bow. The proto-form for yelïm and gelim probably ascends to the term for stickiness recoded as öli:ge: and other derivatives, which in turn ascends to the öli- “moist, damp”, a denoun verbal derivative of the ö:l “damp, moist”. The absence of the cited cognates from the eastern “IE” languages and the presence of the OIr. generic cognate attest to the propagation of the term to Europe prior to the split of the “IE” languages into western and eastern halves, prior to 2000 BC. The OFr. and LLat. forms attest to late borrowing, probably from the Gothic-Vandalic-Burgund milieu of the Late Antique period. The form yelïm has also produced in the European languages the words jelly and gluten. The PGmc. and PIE etymologies link the notions of glue and clay, but fail to trace the origin to its base, instead coming up with some conflated forms for glue and clay as fictitious “proto-forms”. See jelly, gluten.
(Skip) English glut (n.) “overabundant” ~ Türkic oglït-, oɣlït- (v.) “increase”. The stem is og (n.) “family, tribe”, with an suffix -l- it is an adjective ogl- “familial, related to family”, an suffix -ït modifies it to various verbal cases (causative, passive, active ), creating a notion of “increase” (Cf. oglan = son, offspring > gain in size of family). The notion of “overabundance, satiation” is the expansion of the meaning “increase”, reflected in the notion “satiate, eat to satiation”. Cognates: Eng. glut, Sl. glot- (glot + at > глотать), OFr. gloter , Lat. gluttire “swallow, gulp down”. Most of the Sl. and Gmc. languages do not have the stem glt-. The “IE” etymologies are not satisfactory. The stem glt- in association with throat and swallowing appears only in a sprinkling of the European languages belonging to separate branches and centered in the Slavic area, with Eng. and Lat. being distant outliers, obviously pointing to independent borrowing from a single and ancient source long after the branches had formed; the balance of the European branches use allophones of the word faryng (pharynx) for “throat”. A best candidate for introduction of the word glut appear to be the nomadic tribes of the Vandal Sarmat circle, who ensconced in the area of modern Poland in the 2nd c. BC, and later migrated to the Savoy-Provence area between Rome and Gallia. The loss of the unaccented anlaut o- is theoretically consistent with the truncated and contracted forms of the western Türkic languages, Cf. Kashgari's observations.
English good (n.) “pleasing, valuable or useful”, (adj.) “with desirable or positive qualities” ~ Türkic kut (ɣut, qud, qut, xut (hut)) (n., adj.) “heavenly favor, good fortune, happiness, good fate”. A prime notion of the kut (ɣut, qut) is a “life force”, or “spirit”, endowed by the Almighty Heaven. A blurry notion of the kut must have preceded by many millennia the more crystallized notion of the Tengri “Heaven, God”. The notion “good” perfectly conveys the substance of kut connected with anything materially good that spiritually comes your way, it is both desirable or positive and pleasing, valuable or useful, it is a good (fortune). The long list of A.-Sax. and Türkic meanings are fairly eidetic. Cognates: A.-Sax. god “good”, goddead “good work, benefit”, godddond “doer of good”, godian (v.) “better (improve)”, godlar “good teaching”, godlic “goodly, excellent”, etc., ONorse goðr, Goth. goþs, OHG guot, Du. goed, Gmn. gut; Ir. cuí, coir, ceart; OCS godu (v.) “please”, Russ. godnyi (adj.) “good”, gotitsya (v.) “be good”; Hu. kedv “pleasant”, kedvel “prefer”, kedves “dearly, kindly”; Mong. qutug “happiness”; Manchu xutu (hutu) “good luck”; Sum. had (hul) “rejoice, pleasure”; Akkadian hadu ditto. The paradigmatic transfer is manifested by the Türkic and Gmc., and particularly Eng., polysemantic bifurcation of the word kut (ɣut, qut) and its allophones into notions “god” and “good”, and its grammatical use as a noun, verb, and adjective, Cf. Türkic quta- (qutan, qutad) (v.) “become lucky, be blessed” and A.-Sax. godian (v.) “better (improve)”. Notably, Ir. did not preserve the native form for “god”, and substituted it with an allophone dia of the Lat. word. The Welsh, in contrast, has preserved the native form for “god” but not the form for “good”. Taken together, the two words conform to the Türkic bifurcation paradigm. The connection between Gmc. and particularly Eng. with Hu., Mong. and Manchu does not fit into any “IE” scheme, and throws the “IE” “reconstructions” *ghedh- and PGmc. *godaz, and the entire “IE etymology” into shambles. Irregular comparative and superlative (good, better, best) reflect a widespread “IE” pattern in words for “good”, Cf. Sl. xoroshiy, luchshe, samyi xoroshiy (хороший, лучше, самый хороший), Lat. bonus, melior, optimus, attesting that within the “IE” family the notion “good” is a guest. A consensus on the loanword status is corroborated by the selection of the "base words" in the Swadesh List, such an important word as "good" is prominently not included on the list, while the complimentary "bad" is saliently included. The word kut must have evolved long before 5th mill. BC, when appeared first Tengrian kurgans marked by Tengrian ritual of sending the deceased off to Tengri for reincarnation. The Kurgan migrants to Sumer brought along the name for Tengri that we know in Sumer phonetics as Dingir and in Sumer cuneiform writing of the 4th mill. BC. A similar timeframe is indicated by the attested presence in the Celtic languages, which left the Eastern Europe before the 4th mill. BC. The phonetic and semantic match leave no doubts on the Türkic origin of the Gmc. term. The term kut is extremely polysemantic, in addition covering “happiness, blessing, grace, wealth, luck, success, happy lot, dignity, majesty, true state of being, bliss”, and probably another lot not found in the dictionaries. See give, God, my.
English greave (n.) “soot” ~ Türkic kurun (n.) “soot, crock, greave”. Ultimately, the word is intransitive/passive deverbal noun fr. the verb kur- “fix, set in order, organize, set up”, the same verb that formed the word kurgan, alternatively mound (mount, mountain) from the Türkic root men-/min-/mün- “ascend, climb on, mount, ride (a horse)”. Cognates: Eng. crock “soot”, A.-Sax. hrum “soot”, hrumig, behrumig “sooty”; OFr. greve “shin, armor for the leg”, lit. “coating” as metaphorical fr. “soot coating”, of likely Burgund nomadic origin via Provence and Savoy, postulated as “of unknown origin”. On purely phonological grounds, the “IE etymology” confuses homophones crock “soot” and crock “pot, vessel”, an another non-IE word probably of Semitic origin (Arabic gaurab “stocking”) that reached NW Europe and is found in Gmc. and Sl. languages (Ru krujka (кружка) “drinking cup”. It is obvious that the two words are unrelated, as are the other homophones for “foolish talk” and “decrepit”. Absent the A.-Sax. proto-English form, the genetic connection between the kurun and greave would remain unsuspected and probably unknown. The phonetic transition from hrum to greave and crock is less than obvious, although the precise semantics of the quad sequence kurun ~ greave ~ hrum ~ crock makes that phonetical transition certain beyond any doubts. Possibly, crock and greave came to Eng. via separate paths from two remotely related languages. See mound, gravy.
English hash (n.) “chopped mix dish”, “minced” ~ Türkic aš (ash) (n.) “food, dish (generic)”, aša (v.) “eat”, uša:- (usha-) “chop, crush, crumble”. Specifically, ash is a Tatar and others dish of finely chopped meat and vegetables. Cognates: A.-Sax. aes “food, dish (generic)”, aðecgan “eat”, Gmn. essen “food, meal (generic), eat”; Latv., Lith. est, esti “eat”, Alb. ushqim “eat”; Pers. eš “soup, porridge”; Hu. eszik “eat”; Gujarati, Hindi ahara, aahaar આહાર, आहार “food”; Az. ərzaq “food”. A curious series of cognates associated with the hashing tool may ascend to the stone chopping blade. The word aš may be its derivative: A.-Sax. æces, æx “chopper, axe, hatchet”, OSax. accus, Northumbrian acas, OFris. axe, ONorse ex, Gmn. axt, Goth. aqizi “chopper”; OFr. hache “ax”, Fr. hacher “chop up”; Gk. axine, Lat. asctia. The prosthetic h- points to the Ogur-family dialect, like the Sarmat, Hunnic, and Bulgar vs. the modern Tatar, the inlaut h- (Gujarati, Hindi) points to the s/h alternation typical for the Caspian-Aral area articulation. The “PIE etymology” links the two together without a due attention to the Eurasian cognates. Herodotus reported a Scythian dish called “asxi/aschi”, a precursor for the modern “hash/ash” (Herodotus IV 23). The simultaneous presence of the word in the Gmc., Gk. and Romance attests to numerous paths from related sources, probably starting at the Neolithic time.
English heap (n.) “pile of objects on top of each other, great number, multitude” ~ Türkic
kip/kep (n.) “pile of clothing, clothing as household or trading stuff” (Tuv., Sakha, Kirg.). A
derivative fr.
kop- (qop-) “stand up, rise up”, ultimately a deverbal derivative of
the verb ka:- (qa-) “pack, pile”. A passive form with a suffix
-l is ka:la:- (qa:la:-)
with a synonymous form sal-, a precursor of the verb sa- “count”, see sanity.
The pair points to the origin of the verb sa- from counting pebbles, to the monumental
k-/s- divide at the root of the Eurasian speech and the kentum (centum)/satem origin as a
consequence of the front/rear sound harmony. Cognates: OSax. hop, OFris. hap, Sw.
kippa, Norse, Dan. heap, MLG hupe, Du. hoop, Gmn. Haufe; Sl. kipa,
Balt. (Lith.) kaup(as), Lat. chupa; Hu. kepe, kupac; Sum. kapa; Ch.
ke 砢, all “heap”. Nowadays, the western Turkish and Bosnian have allophonic forms küme
and kamara respectively. At the turn of the eras the Oguzes (Turkish) and Kangars (Bosnians)
occupied an area around the lake Balkhash. The Enisei Kirgizes, Sakha (offshoot of the Saka 塞
tribes), and Tuvinians (Tuba, Tabgach 拓拔, 拓拔雲碌), located to the north-east of Balkhash in the Altai
and Dzungaria highlands, with their respective allophonic forms kep, kip, and hep,
share the form with the Gmc., Slavic, and English. A chance correspondence between the Gmc., Slavic,
Chinese, and English forms on one hand and Tuv, Sakha, Kirg., Sum. forms on another hand is excluded
because of the extremely narrow semantic field. We see that the north-eastern tribes (in respect to
the steppe belt) in Asia share the word with the north-western tribes in Europe, and with the
Sumerians in the center and to the south. To make things even more interesting, the Lat. shares the
form grumus with Icl. hrúga, Balt. (Latv.) greda, Sl. gruda, and
Turkish/Bosnian küme/kamara, with the European forms ascending to Neolithic times in
reference to a pile of rocks (cairn), and in Lat. and Icl. case pointing to the Celtic
origin, while the Celtic forms use semantically equivalent and temporally as old notions Ir.
carn, cairn, Welsh domen, with underlying reference to a pile of rocks (cairn). No
“IE etymology” for either “heap” nor “cairn”, these most ancient words are infiltrators into the
“IE” languages. See cairn.
113
English herd (n.) “troop of animals” ~ Türkic orda, ordu “gathered, corralled, fenced-in (n.)”,
kert (Chuv.) “herd, flock”.
Ultimately fr. a verb or- “put, place, lay, deposit” and its derivatives orun (n.)
“place” with 28 other direct and extended meanings, orut (n.)/orut- (v.) “corral,
cattle yard, fenced terminal (n.), stopover, camping, settle in place (v.)” formed fr. or-
with suffixes -un and
-ut respectively (Cf. bat and ban “bath”, see bath, put). The word
orda/ordu (n.) is a derivative of the verb orut-
(v.) formed with the oldest deverbal noun suffix y (-ï)/-a/-u (phonetic versions of the same
suffix): orut-a > orta > orda and orut-y > orty > ordy “corralled, cattle-yard'ed,
fenced-in (n.)” (EDTL v.1 467on, with references). The o/u and d/t
alternations are regular and should be expected. The o-/u- vs. ö-/ü- articulation was
also noted (Clauson EDT 112). The alternations provide a diagnostic trace. Temporally, the
notion “corral, corralled” is the oldest, connected with the early domestication of the horse and a
transition from hunter-gathering to producing pastoralism. That particular notion was disseminated
to the Corded Ware populations and fossilized there. In the course of 5,500 years-long practice of
nomadic pastoralism, the term extended and speciated, by the tumultuous Antique and Middle Age
periods to designate a “center”, “palace”, “fortress, fortification”, “gathering, assembly”, “army,
troops”, “coach”, and dozens more concepts. The elegant etymological solution is complicated by
alternate etymological paths of the semantic, phonetic, and morphological nature. A second basic
notion of or-/ur- is “dig”, it forms the notions “pit”, “rampart”, and “moat”, see ard.
As a residence, the word extends from burrow to palace. A deverbal noun formed with the locative
suffix
-da/-ta is the word orda “lair” (den) leading to the notions “center”, “palace”, etc.
q.v. The parallel presence of the synonymic element or-/ur- in Türkic and Mong. points to the
Hunnic source and time of about 3rd mill. BC if not earlier. A third
basic notion of or-/ur- “harvest”, “set up, place”, “strike” survived to the 10th c. with a
wide range of idiomatic meanings. In the sense “arrangement”, the word extends from “set up” to
“place, center” to “army, troops” and attributes of power. A fourth notion is carried by the Chuvash
allophonic verb ker- “close in, block”, also “stretch” and “bark (dog)”.
It is an an allophone of the or-/ur-, and reflects on its semantic line. All three idiomatic
meanings of the verb ker- describe hunting practice: stretch line of hunters to encircle, and
block escape with the help of the dogs. That hunting method eventually led to turning prey into
permanently corralled herd animals and into managed herds. In the hunting context, the forms ker-
and or-/ur- may have conflated with the synonymous word es-/uz- “lengthen, stretch,
surround, block” or its tentative Oguric forms ges-/guz-/ger-/gur-/her-/hur-. Apparently,
extermination of the wild horses of Europe beyond a viable economic hunting level allowed only the
Asian steppe hunters to continue a thread that ended up in the early breeding and domestication of
the horses. The earliest horse domestication is dated by 3,500 BC within the Botai culture. Allowing
about 1000 years from corralling to domestication, the corralling lingo of the Botai hunters
developed by ca. 4,500 BC, and that would be the first notion expressed by some allophones of the
ker-/or-/ur-
ascending to the earliest times of the encircling hunting practices for a variety of large and small
prey. The traces of the early idiomatic extensions are found in the related derivatives: ordu:
“center, place”, “capital, palace”, orna- “place, locate”, оrnaɣliɣ “hard, strong
(place, palace)”, оrnatmaq “fortification (thoughts)”, оru “pit, dungeon”, oruŋu,
uruŋu “banner”, oruŋut, uruŋut “leader, head”, oruq “road, way”, оrtaq
“friend, fellow”, ortuluq “friendship, fellowship”. In the context of the military camp, the
last two fall under the notion “troops”. Since hunting aspect had completely faded with its lexicon,
and the Mongol state became the only superpower state on the planet, the existing Türkic word
ordu/orda in its specific meaning of military and administrative center came to the front and
became an international word way beyond the empire's borders. A lowly digs of an animal den turned
into a power center of the human daily reality (Sevortyan, ibid). The notion “palace, center,
administrative center, army/troops, fortress” is a secondary/tertiary concrete noun at the
etymologic pinnacle sticking out in the eyes of etymologists, viewed as a root base. It postdates
even the preceding notion of the “center” as an administrative/military rowing encampment. A term
for controlled animal mass turned into horde, a coherent mass of human invaders. The initial
h- of the horde can't be ascribed to the Sl. influence, the prosthetic initial h-
is a typical trait of the Ogur languages and of the A.-Sax. and other Gmc. languages. Türkic has
three more synonyms, ör/ür, ögür, and sürüg “herd” with numerous extended meanings:
“tame, domesticated person, friend, fellow of a group/troop”, etc. The ör/ür “herd” is a
particular reflex of the articulation or/ur, excluding of an erroneous script reading. These
synonyms also retain the notion of “bark (dog)”, corroborating their common origin and hunting
practices. The A.-Sax. survival of or- lexicon is eidetic to the survival in the Türkic, it
comes in two distinct flavors, with and without the prosthetic h-, and shows amalgamation of
the Oguric, Oguzic, and local streams:
Without an initial h-:
or “ore” < or- “dig”, see ore, ora “border, bank” < or “moat,
rampart (concrete digs)”, orceard, ortgeard, orcyrd “orchard , garden” (lit. dug over
earth/yard) < or- “dig” + yer “earth, land, ground”, orcerdweard “gardener” <
or- “dig” + yer “earth, land, ground” + aɣtur- “watch”; compounds - sceapheord
“flock of sheep”, sceapheorden “shed”, sceaphyrde “shepherd” < sıp “colt,
smaller animal” + ordu “army, horde”, see sheep. The A.-Sax. cognate or/ora
parallels semantically both notions of the Türkic primary concept “dig” and even allows to time the
semantic extension to the brass by the early Chalcolithic time, the time when nomadic pastoralists
learned of the metallurgy and started spreading that technology far and wide across Eurasia.
With an initial h-:
heord, hierd, hyrd, hyrwd “herd, flock, swarm, keeping, care, custody”, heordung
“guard, watch” < ordu “army, horde”; compounds - gafolheord “taxable swarm (of bees)”
(gafol/give, heord/horde) < kiv “give” + ordu “army, horde”, see give.
The Lat. fraction is not much less impressive. The Lat. ordo, ordinem “row, line, rank,
arrangement” is semantically and phonetically congruent with the A.-Sax. branch and the Türkic
family without any faux “PIE proto-roots”, but comes via a different path and at a different time,
possibly via Gallo-Italic amalgamation of the 3rd-2nd mill. BC. Cognates: A.-Sax. heord,
ONorse
hjorð, Goth. haírda, Sw. hjord, OHG herta, Gmn. Herde “troop,
flock, swarm”; Balt. (Lith.) kerdžius “shepherd”, OCS čreda; Skt. sardhah, Hu.
csorda (chorda), Tr. ordu “corralled, troop”. It is generally accepted that herd
and horde is the same word, since phonetics is the same, and horde is a polysemantic
word with one of the meanings “troop, group, crowd”, the same as the herd. The articulation
kert appears to be an isolated case among Türkic languages, finding it in the Balt. and OCS
allows to speculate that that is a form of the Sarmatian Bulgars, who from the 2nd. c. BC coexisted
with local Baltic and Fennic tribes. The form with anlaut consonant is also typical for the Gmc.
languages. The “IE etymology” blinds on a dubious OCS čreda “line, line-up”, a derivative of
the Türkic
čar “braid, braiding”, čars “crackle”, and the Skt. allophone sardhah “herd,
troop” ascends to the Türkic deverbal noun sürüg “herd, troop” fr.
sür- “lead, proceed”. The supercharged “IE” paradigm obfuscates the obvious Türkic origin and
corrupts honest etymological effort. At best, the Skt. word was brought to the Hindustan after 2000
BC by the Indo-Arian migration of the European farmers, or likelier it was brought there directly by
the uncountable waves of the Türkic herders before and after the Indo-Arian migration. See ard,
bath, give, ore, put, sheep.
English hide (n.) “pelt, skin” ~ Türkic qoyqa, quyqa, kuyka:, kuyğa (n.) “pelt, skin”. Cognates: A.-Sax. hyd, ONorse huth, OFris. hed, MDu. huut, Du. huid, OHG hut, “pelt, hide”, Gmn. Haut “skin”; A.-Sax. hydan “to hide”; Ir. cheilt/chur/chun (v.) “to hide”, Welsh chuddio/guddio/kuddio (v.) “to hide”.These North European cognates carry a mark of a local Sprachbund. The Türkic term is a compound of a stem qoy/quy “inside, bosom” which produced the English hide, the verb qoy-/quy- means “placed inside, in the bosom”, and with the noun-producing suffix -qa (-ɣa/-qa/-gä/-kä) forms quyaɣ “armor, cuirass, shell”. The numerous and various synonyms of hide in different European languages, like the Türkic words and the English hide, uniformly have a connotation of hiding, translated into a constellation of idioms. The transitions g/k/q to h, and of semi-consonant y to th/t/d are consistent with similar observed linguistic modifications, they may be a result of assimilation into an alien linguistic system, or a local development within the Turkic family under an influence of an alien linguistic system. The same root qoy/quy for hidee (v.) transpires in the Ir. and Welsh forms for “to hide”, suggesting two separate paths, one overland, and the other the Celtic circum-Mediterranean. The “IE etymology” is feeble, addressing only a selected selection of samples suitable for the task, and strenuously resorting to random, unsuitable, and far-fetched cognates, like “eyebrows” and “clouds” and “guts” that ascend back to the Türkic form for the notion “inside, bosom”. See gut, hide (v.)
English hole (n.) “openning, perforation, aperture” ~ Türkic (Tuv.) khoolay (holai) (n.) “hole (vent opening in yurt)”, an allophone of CT deverbal oluk (olok, oluq) “hollowed, hole”, fr. the verb oy- “peck, make hollow”. The “IE etymology” appeals to PGmc. unattested proto-form *hul, and to unrelated “IE” “conceal”, a clear admission of the non-IE origin. The Türkic derivatives show a deverbal origin of the noun and the stem transition between oy- and ol-, with further split to ol- and hol- forms. The form oy- was frozen in time and co-exist with the form ol- (oyuk and oluk) in the eastern languages. The Tuv. form with prosthetic h- demonstrates an Ogur affinity and is closest to the Gmc. forms and to the faux PGmc. proto-form; it may be a Khak. (Enisey Kirgiz) inheritance in Tuva, consistent with other peculiar Khak.-Gmc. affinities. The Anat. oyuk/hoyuk “scarecrow” (i.e. hollow image) also retained both anlaut o- and ho-. Cognates: A.-Sax. hollow, OSax., OFris., OHG hol, MDu. hool, ONorse holr, Gmn. hohl “hollow”, Goth. us-hulon “to hollow out”. The salient traces of the verb oy-/ol-/hol- “make hollow” are abundant in Türkic and English: Türkic oyuk/oluk “trough, gutter, groove”, oy “pit, indentation”, oytur- “to hollow”, olun “stem, trunk, tube (stem), cylinder (stem)”; the A.-Sax. hol “hollow, depressed, cave, hole, den, perforation, aperture”, holc, holca, holg “hole, cavity”, hollan, holdlan (v.) “hollowing” (active and passive), holing “hollow place”. Two A.-Sax. words attract special attention: holinga, holunga adv. “in vain, without reason”, formed with Türkic suffixes, deverbal noun result -n/-ïn/-in and deverbal adjectival suffix -ga/-ɣa/-gä, semantically paralleling the Türkic “scarecrow” (i.e. hollow image). This A.-Sax. construct belongs exclusively to the Türkic milieu; and the holecerse “plant”, with its Türkic sibling olun “stem (hollow stem of a plant)” that attests that semantic extension from hollow to hollow stem has occurred at the very early stage in the life of the Türkic languages. English has a plethora of derivatives, from hollow to hull, all deverbal forms of the notion “to hollow something”. Notably, the round shape of the hollow also developed metaphorical semantics “round, circle”, Cf. Eng. wheel; Sl. kulich (кулич) “round loaf”, kalach (калач) “ditto, usually with a hole in the center”, koleso (колесо) “wheel”; Heb. challah, halla, (חלה ,אל) /χa'la/) “braided bread”that originally implied roundness, circle, and denoted hollowness, halal (האַלאַל ,חלאל) “clean, ritual”, the Heb. words with no native etymology refer to the ritual elements, a patently cultural borrowing. The Yiddish forms khale, koylatch and koilitsh corresponding to the Heb. challah, halla attest to a Jewish-Khazar (Ashkenazim) origin and a Slavic intermediary, with a timeframe of 7th-11th c. of the word's migration to the Central Europe and on to Palestine. Chances of its Biblical origin are exceedingly slim. The presence of the Yiddish and Heb. cognates makes a mockery of any attempts for “IE” etymology. The wealth of the parallel Türkic and English derivatives attests to an unambiguous case of paradigmatic transfer and a common genetic origin.
English hue (n.) “color, color of horse, fur” ~ Türkic tü (adj.) “color of horse, fur”.
The notion “hue” is an extension of the notion “fur”, “black hue” is synonymous with “black fur”,
except for the novel semantic extension to other objects. The Türkic notion “fur” takes forms
tü:g, tük, tüy that do not carry the specific notion “hue”. Cognates: A.-Sax. diag
“hue, tinge”, , -fah, -haef, haewen“-hued”, Sw. hy “complexion”, Goth. hiwi
“appearance”. The phonetic spread attests that there was no normalized form well into the Middle
Ages. The form diag is an obvious allophone of the Türkic base form
tü:g, tük “fur”, it provides an indelible testimony on the common genetic origin. The second
consonant -l- (-fealu) in the Türkic languages forms an adjective “furry, hairy”. The
h/t anlaut alteration must be connected with dialectal variability and consonantal development
of the Türkic languages. The other articulations may ascend to local roots or to local
vocalizations. No credible “IE” etymology, the suggested versions of the faux “PIE proto-words” relay
to semantically discrepant non-animal skin, complexion, and such.
114
English jar (n.) “cylindrical vessel” ~ Türkic yart (jart), bart “vessel, bowl-shaped vessel, goblet”, also “liquid measure (half)”. Ultimately fr. the verb yar-/jar- “split, split in half”, Cf. yarty/jarty “half”, yarimaspi “(lit. half-eyed) squinted”. The auslaut t- is a causative suffix. Semantics and recorded usage point to retail trade lingo. A homophonic verb ya:r- (ja:r-) “to light, illuminate”, suggests a semantic dubbing of the jars as a lantern or candle-holder, see candle. Cognates: Provenčal jarra, Sp. jarra, It giarra “vessel”; MFr jarre “liquid measure”; Arabic jarrah “earthen vessel”; Pers. jarrah ditto. No “IE” etymology, no “IE” distribution, positively a loanword in the “IE” family. Distribution of the word points to two separate paths, a northern path to England and a Burgund Vandal path via Provence; a separate path runs to the Mesopotamia. The spread of the word with both meanings, “vessel” and “measure”, supports a Sarmatian source, both paths originating in the Baltic region. A suggested dubious Arabic origin should have been validated by examining native etymology and distribution within the Semitic family. See candle.
English jelly (n., v.) “sticky substance, gelatin” ~ Türkic yelïm, ilim (n.) “glue, jelly, paste”, yelïmla- (v.) “glue, stick, attach” . Ultimately, possibly from Türkic ö:l “damp, moist” (Cf. oil “liquid hydrocarbon”) via öli- “moist, damp”, öli:ge: “sticky”, yelïm “glue, jelly, paste”. A synonym of yelïm is yap- (v.) “glue, stick, attach”: yel and yap- could be allophones with -l-/-p- alteration. Alternations of the initial consonant y-/zh-/j-/ch-/0- are regular and systemic, reflecting an Ogur anlaut consonant and an Oguz absence of it. The alternation -e-/e-/-i-/i- is also regular. Suggested “IE” cognates: OFr. gelee “frost, jelly”, geler “congeal”, supposedly Lat. gelu, gelare “frost, freeze”. Since the Türkic form is a direct semantic match and a close allophonic form of the European offsprings, the semantically unrelated Lat. “frost” is way out of the cognate field. The forms jelly, glue, and gluten are allophones describing the same substance. To derive the “glue” and “jelly” from two different etymological sources solely on phonetic resemblance is unsustainable. See glue, gluten.
English jig (n.) “jerking or guiding device, contraption” ~ Türkic jig (n.) “spindle, shank”. English spelling comes in two flavors, jig and gig, reflecting Ogur anlaut consonant; in Oguz version the word starts with semi-consonant or vowel yig-, the Oguz version is ig/ik. In Türkic languages, both Ogur and Oguz forms are active and randomly commingled, reflecting individual historical admixture composition and vocal peculiarity of each language. The granular distribution carries a diagnostic value. No “IE” or any other etymology whatsoever. English usage: jig saw, jig (lure), jig (dance), jigger (bartending), gig (show business), etc., all without intelligible etymology. The words jig/gig and derrick belong to the line-up of technological terms inherited by English in the process of paradigmatic transfer, indelibly attesting to the common genetic origin. See derrick.
(Skip) English joke (n.) “jape” ~ Türkic älik, elik, elük, elü:g, elö:g (n.) “joke, jape, gibe”. Ultimately, a derivative of a tentative base el-/il- or elü:- (matching tentative Ogur form jel-/jil- or jelü:-) with semantics conductive for “mockery, flout, carousal” and the like, exclusive of the notions “say, language, people”. Such a notion may be provided by the diffuse verb al-/a:l- “tricky” full of negative and positive connotations. The suffix -ik/-ük forms deverbal nouns/adjectives. Cognates: A.-Sax. gliw “glee”, gliwian (v.) “carouse, jest”, gliwere “buffoon”, with numerous semantic and phonetic extensions and compounds; the suggested Gmc. cognates are semantically not related: “language”, “people”, “say, utter”, “confession”; Lat. iocari, iocus, Fr. jeu, Sp. juego, Port. jogo, It. gioco, all modern Romance forms uniformly carry initial j-; Mong. eleg “joke”, elegle- “to joke”. The “IE etymology” deadlocks at Lat. iocus “joke, sport, pastime”; semantically, that is accurately paralleled in the A.-Sax. gliw. The suggested modern Romance words are congruent with the Eng. “joke” only phonetically but grossly conflict semantically, they mean “game, sport”, positively nothing like a “joke”.The nominal and verbal Mong. forms are indistinguishable from the Türkic words neither semantically nor morphologically, suggesting that they were absorbed in the Hunnic epoch at the turn of the eras (Syanbi period). The Türkic form elük belongs to the Oguz branch, a corresponding Ogur form has an anlaut consonant: jelük, which produced the English joke, furnishing one more evidence linking English with the Ogur vernaculars of the Sarmats. The inlaut liquid -l- elided in the Romance milieu. The Lat. and Lat.-derived forms indicate an independent path without an anlaut consonant: Lat. iocari, iocus. The word could not have disappeared from the Roman times to the advent of the modern linguists, but as with many other words, the vernacular of the populace remained a separate world from the world of the literature that serves as a linguistic mine for the linguists. Not only the time barrier separates the English word from the Lat., the true cognates of the English joke are notably absent from the English traditional donor languages, including its main French contributor, which provides most of the Lat.-derived lexicon, and Italian and Spanish, which are closest to the Roman vernacular. These hurdles exclude a chance of direct Lat. connection, supporting a thesis of two independent borrowing paths. Türkic has retained an allophonic form for “joke”, šaka (shaka), in the Oguz branch; if elük/jelük is more archaic, the šaka (shaka) form may have been an intermediary for the Eng. and Lat. forms: jelük/šaka > jaka > iocari, iocus ~ joke. See haze.
English junk (n., v.) “ruins, ruined remains, worthless stuff” ~ Türkic yanč- (yanch) (v.) “crush, trample”, yunčï- (yanchi) “get worse”, deverbal derivatives of extremely polysemantic siblings yan- (v.) “crush, crack”, yun- (v.) “get bad (condition)”, with deverbal adjectival derivative yunčığ “bad (condition), weak, ruined”. A similarly sounding Türkic synonymous ček (check) “rubbishy goods”, the phrase ček čük, ditto, may have conflated with the phonetics of yunčï-/yunčığ. Cognates: Gmn. Dschunke. It is an Eng. loanword from a nautical lexicon: “old refuse from boats and ships”, “discarded articles of any kind”, “old cable or rope”. No claimed “IE” etymology, no presence across “IE” branches; obvious guest from alien linguistic families. A European etymology on solely phonetical homophony, without a trace of a faux “IE proto-word”, ascends to unrelated Fr., Lat. junc/iuncus “reed”, and thus a stipulated etymology “of uncertain origin”. The close phonetics and exact semantics validate the Türkic origin, the articulated anlaut j- vs. CT y- points to Ogur dialectal source consistent with other words of the Aral basin origin; same with the Gmc. form with articulated anlaut consonant. The contraction of the type -nčığ to -nk also points to the Eastern European dialects with contracted finals of Ogur-type. Considering a separation by at least 2-3 millennia and at least 5000 km geographical distance, some phonetic variation is normal.
English knack (n.) “talent, ability, capacity” ~ Türkic qan-, ka:n-, (v.) “happen, occur, meet a desire”. A deverbal noun derivative with a suffix -k/-g suggests a version with Türkic suffix -k/-g/-ɣ signifying derivative nouns and adjectives using grammatical mechanism lost in the modern Eng. The recorded and much later Türkic model for the word is qanïɣ (kanığ) with the similar suffix -ïɣ “satisfaction, satiation” from the verb qan-. Cognates: A.-Sax. can, con “can, be able to; learn, know”, MEng. knak, late 14c.; the Gmn. knacken “to crack” is an unlikely plausible metaphorical synonym, if it is in fact the same word. The Eng. 18c.-19c. slang nacky “ingenious, dexterous” is just another interpretation of the meaning “talent, ability, capacity”. See can for cognates of the verb. No “IE” etymology, no “IE” cognates, the word is clearly a member of non-IE linguistic family. The word belongs to a cluster of Turkisms connected with activity of doing something: ability, result, intention, etc. See can, do, keen.
English know (v.) “cognize, recognize, perceive” (Sw N/A, F15, 1.00%) ~ Türkic köni, göni (n.) “verity, truth”, köŋül, göŋül, köngül, göwün, kölün (n.) “consciousness, thought, mindset, memory, meditation, conviction”. Ultimately derivative of the verb kön-/gön- “right (something), make things right” with a rich trove of derivatives, of which the notion “know” is just an one lesser facet. The Türkic single notion “know” has more than 20 distinct synonyms, of which 10 with unrelated stems each with its own pleiad of conjugations, declensions, and derivatives. Besides “know”, Gmc. languages propagated numerous carryover meanings connected with the Türkic base kön. Cognates: A.-Sax. cnawan “know, perceive”, tocnawan “know, acknowledge, recognize, distinguish, discern”, cnawlaec “knowledge”, cnawe “conscious”, etc., all opposed to “believe”, OHG chnaan “know”, irknaan “recognize”, Gmn. können, kennen, erkennen, Goth. kann “know”, kannjan “make known”; Ir. gnath “known, famous”; Fr. connaitre “perceive, understand, recognize”; Lat. agnoscis “recognize”, cognoscere “get to know, recognize”; Gk. gnos (γνωσ) “knowledge”, gnosiz (γνωις) “cognition”. The line-up of the cognates is remarkable in that on one hand, the Gmn. können and the Türkic könen-, i.e. a verbal derivative of the verbal root kön-/gön- denoting in the modern Türkic languages “enjoy, rejoice, achieve prosperity” in parallel with the meaning “know”, are exactly identical phonetically and rigidly connected semantically. On the other hand, the Gmn. können is universally recognized as a cognate of all the words listed in the line-up. This is an indelible attestation of the common origin. Unwittingly, the suggested faux “PIE root” *gno- “to know” is an allophone of the real and attested Türkic root kön-/gön- which underlies the Türkic semantic of “to know”. The presence in English of the nearly synonymous pair deem and know constitutes a case of a paradigmatic transfer, an indelible testament to the common origin from the Türkic linguistic milieu. See deem.
(Skip) English laber (OE) (n.) “thistle” ~ Türkic läbär (Chuv.) (n.) “thistle”. Cognates: A.-Sax. laber, leber “rush, reed”, OHG leber. The term is not attested in the eastern Türkic languages, but a name for a particular plant is unlikely to stabornbly survive for millennia; it is likely a Sarmatian word carried from the Eastern Europe to the northeastern Europe. The non-IE origin is obvious. See other plant-related words: cannabis, caragana, derrick, elm, juice, herb, tree, valerian, wormwood.
English leather (n., v., adj.) “tanned animal skin”~ Türkic eldiri (n.) “hairless pelt, goatling- or lamb-skin”. Eldiri is a compound of el “kid, lamb” and diri “derma”, see derma, elk. The English form with interdental voiced th is likely a form elðiri, with Goth. þ: leaþer; scholars with European and Arabic alphabets do not spell th, they are replaced with substitutes like d, t, s, and the like; it could be exclusively a western areal articulation. Cognates: A.-Sax. leðer (in compounds only) “hide, skin, leather”, ONorse leðr, OFris lether, OSax. lethar, MDu., Du. leder, OHG ledar, Gmn. leder; OIr. lethar, Welsh lledr, Breton lezr. No “IE” cognates whatsoever, all cognates are confined solely to the Gmc. group, Türkic languages with their outskirts. The suggested unattested PIE concoctions *lethran (Gmc.) and PIE *letro- do not ascend to any “IE” etymology, they are mechanical manipulations of the Gmc. forms. The loss of the initial e- is specific to the Gmc. languages. Among compounds, stands out the A.-Sax. leðercodd “leather bag”, a compound of two Türkic reflexes eldiri “leather” + qod (v.) “lay, put, deposit”, lit. “leathern storage”, a form not encountered in the Asian written sources. The root let-/leth- could be a loanword from an unknown N. Pontic source that timewise ascends to the 6th-5th mill. BC Celtic circum-Mediterranean departure and entered northern European vernaculars via separate Celtic and much later Gmc. paths; that would explain the Türkic prosthetic e-, consistent with Türkic systemic aversion to the initial l-. At the same time, the endured pinpointed semantic and phonetic congruity unambiguously attest to a common genetic provenance. All languages have retained derivatives connected with the storage utility of the lather bags, a main and enduring technological advance. See derma, elk.
(Skip) English leak (n.) “discharge of a fluid” ~ Türkic liš (lish) (n.) “saliva, moisture, sputum”. Cognates: OE leccan “to moisten”, Goth. leithu, Cimr. lliant, MDu. leken, ONorse leka; Balt. (Latv.) ieliet, (Lith.) pilti; Pol. lać (lach), Sl. lit (лить); Lat. libarе, Gk. leívo (λείβω), all “to pour”, with a base stem le-/li-, all are derivatives of the Türkic liš “moisture”, with few allophonic variations. The term leak is a derivative of a verb “to pour”, which has a very particular distribution in Europe. The noun leak is developed from the verbal stem le-/li- “to pour” with the Türkic suffix -ïg/-ïɣ, which produced the ONorse cognate leki “leak”, A.-Sax. leccan, and the English leak. Other terms connected with water also have Türkic stems: Lat. aqua, Pers. apa are derivatives of the Türkic verbal stem aq- “to flow”; the Eng. water and Gmc. Wasser are cognates of the Türkic noun stem su/suv “water”, with the Sl. voda (вода) apparently germinating from the Gmc. form. The Sl. tok (ток) “current” and potok (поток) “stream” are reflexes of the Türkic tök- “to pour”. As a group, all these semantic siblings with particular distribution present a case of paradigmatic transfer, and attest to a common genetic origin.
English luck (n.) “fortune, lot” ~ Türkic аlïč (alych) (n.) “fortune, lot”.
Cognates: A.-Sax. lac “play, gift, present, booty, sacrifice, offering”, lacdaed
“munificence”,
lacgeofa “generous giver”, lactian “present, bestow”, laclic “sacrificial”, all
semantic derivatives of a notion “fortune, lot”, i.e. fortunate to gain something, MDu luc,
gheluc, Du. geluk, “good fortune”, MHG g(e)lücke, Gmn.
glück “fortune, good luck”. Etymology: “of unknown origin”. Positively no “IE” etymology. All
cognates are limited to Gmc. group, a positive indication of the loanword into the “IE” family and of
the Türkic origin. The phonetic and semantic match are very congruent. Gmc. forms differ from the
Oguz forms by a prosthetic anlaut g-/dh-, which is a fairly common pattern for the Ogur forms
of the Oguz/Ogur allophonic counterparts. In the transcription of the A.-Sax. Ogur words, the
prosthetic g- at times looks like the prefix ge-: geoldəg < geol + dəg “Yule-day”,
where geol is the Oguz yul “road, road of fate, fate”; geolean < geole + an
“reward for past deed”, where geole is Oguz öl
“death”, -an is a denoun adjectival suffix, lit. “posthumous”, etc. At internalization by the
Gmc. languages, the unaccented initial vowel is systematically elided, Cf. Goth. liutei
“deceit, hypocrisy”, liuts “hypocritical” fr. alta- (v.) “deceit”, alta:ğ (n.)
“deceit”, allïɣ “deceitful, hypocritical”.
115
English mallet (n.) “hammer” ~ Türkic maltu/baltu (n.) “axe”. The conventional contracted translation does disservice to the forms and semantics. The oldest attestation of the word is the Sum. balaq “axe”, followed by the Assyro-Babylonian pilaqqu “axe”. The Türkic sister form balqa “hammer” and balta/palta/baltu “axe” attest, first, that “axe” was a specific term derived from a root bal; secondly, that semantics also covered a “hammer”: “hammer ax, forester's ax, wooden hammer, boilermaker's hammer, sledgehammer”; thirdly, that semantics also covered a “club”: “mace, long handle mace, a type of club”. The Tuv. bala “pestle”, Kipchak balčala- (v.) “smash, crash”, Mong. balba- (v.) “beat, bash, punch, smash” point to the Stone Age mundane implements and utility of bal up to and including the Sumer time. What started as a stone hammer grew to Chalcolithic and Iron Age tools. The connection of the root bal for “hammer” with “milling/grinding” is indelibly traced across Eurasia. The tools and their names spread far and wide along and across Eurasia and across linguistic families. The observed cognates run from the Gk. πελεχυς (pelekys) “poleax” to the pra-Tungus pal(u)qa “hammer”, Manchu folxo/folgo “hammer”, and from the Nenets helüka “club, mace” to the Skt. paraçu, parçu “axe”. Scholars myopically attending to the “IE” paradigm came up with their own line-up of cognates: Eng. mallet 14th c., OFr. maillet “mallet, small wooden hammer, door-knocker”, Goth. malan “grind”, Lat. malleus “hammer”, milium “millet”, mola “millstone, mill”, molere “to grind”; Gk. mylos “millstone”; Balt. (Lith.) malu “to grind”; OCS mlatu, Russ. molot “hammer”, OCS meljo “to grind”; Arm. mal(em) “crush, bruise”; Hitt. mall(anzi) “(they) grind”; the listing should have included Pers. putk “hammer”, Fin. petkel, petkele “hewing ax”, Mordvin petkel, petkol “pestule”, and quite a few more. Unlike the m/b pair munča/bunča “much/bunch”, only the m- form is accounted for as a European “hammer”, unwittingly pointing to a forked Mediterranean path and to the Stone Age technology. The phonetic spectrum of the anlaut b/m/p/f/h alternation and aspects of pestle, hammer, ax, and hammer-ax combination (poleax) are Eurasian ubiquity. With the Sum. trace, there is little doubt that Celts also started their circum-Mediterranean anabasis with a later supplanted word bel. Experts starting from G. Ramstedt (1916), who traced the spread of the word and its forms, are unanimous in the Türkic origin. See bunch, much.
English mammal (n.) “nourished with breast milk” ~ Türkic mämäli, məməli (n.) “mammal, nourished with milk”. Ultimately fr. məme, meme, mamu: “breast”. Cognates: A.-Sax. mamme “breast, teat”, Lat. mamma “breast” (and obviously teat). On the Türkic side, mama, mamma, mamu:, meme are listed for Az., Ottoman, Turkm., and Teleut; others (like Gagauz) happened not to be documented, but use it nevertheless. Like other sexual lexemes, for puritanical reasons “breast, teat” was excluded from the dictionaries. Still, the listed spread extends from Mediterranean to Manchuria. Notably, the term meme is used exclusively for women, the terms yelin and yazɣuq (mare's nipples) are used exclusively of animals, and the term emig (fr. em- “suck”, Sl. allophone vymya (вымя), exclusively for animals) is used for both women and animals; such developed and specialized lexicon is peculiar for Türkic languages. The term mamme came to Eng. as a transfer paradigm of mamme and “udder”, one referring to the human's milk secretory organ and the other to the animal's organ; the udder is a derivative of the Türkic term, ud (uδ, ut-, ut-) “cow”, the term ascending from the period of domestication, because it is a noun derivative of the verb ud- “follow, join, be fealty” (Cf. Sl. doit, udoi (доить, удой) “to milk (an animal), milk (yield from animal)”). Eng. and Tr. retained the mamme and ud part of the paradigm, while Sl. retained only the ud part of the paradigm, it later invented a calque mlekopitayuschee (млекопитающее) “fed with milk” for the western “mammal”. More than that, the Eng. “cow” (with k-) and Sl. “korova” (cow) also belong to the same paradigm, since both terms are derivatives of the Türkic göres- (v.) “gore”, and lit. mean “horned (animal)” The paradigmatic transfer genuinely attests to the Türkic origin of the lexemes constituting it. The “IE etymology” shy away from mentioning languages that use allophones of meme for “breast, teat”, and is circumspect to its origin, diplomatically suggesting “perhaps cognate with mamma”. The etymological failure is embarrassing and demeaning for the entire “IE” theory. Probably, the Eng. synonymous teat (A.-Sax. titt “nipple, breast”, surprisingly of male gender) belongs to the “IE” family, considering its distribution pattern. For the Lat. mamma, since the Romans failed to spread their term to many peoples within their own empire, chances are really slim that they managed to do it to the Tuvans in a remote Mongolia. Rather, they obtained it as a loanword from the local Celtic, Scythian, or Sarmat peoples, independently of the Saxes. Linnaeus recycled the ancient term for a class within the animal world. See cow, gore, mama, milk, mother, udder.
(Skip?) English marasmus (n.) “bodily degradation”, generic “extreme degradation” ~ Türkic maraz (n.) “blackout, dark (night, extreme darkness”. Cognates: A.-Sax. mare “nightmare”, MDu. mare, ONorse mara, OHG mara, MLG mar, Gmn. mahr “nightmare, incubus”; OIr. morrigain “demoness of the corpses”, lit. “nightmare queen”; Sl. mrak, mrok (мрак, мрок) “darkness”, (Bulg., Serb.) mora, (Czech) mura, (Pol.) zmora “nightmare”; Gr. marasmos (n.) “wasting away, withering, decay”, marainein (v.) “quench, weaken, wither”; Gujarati mare “mare”; Sogd. mrz, mrrz “navvy, laborer”,far Ch. meng 梦 “dream”; Kor. agmong 악몽 “nightmare”; Jap. akumu 悪夢 ditto. Unless the eastern forms were derived fr. the Türkic ming “brain”, Jap. form truncated. The word is obviously an adaptation of a Türkic metaphor for darkness, sinister menace, and nightmare. A chance coincidence of corroborating phonetics and sinister semantics across the width of the Eurasia is most unreal. See mind.
English mere (n.) “Moon's dark areas” ~ Türkic mürän (n.) “river, stream”, bürüŋ (n.) “river cataract”. Ultimately fr. the verb bür- “twist, spin” with deverbal noun suffix -än, a derivative of the noun bu, bur “steam, steaming”, Cf. to bore, burl, burrow, See burl. Apparently, initially a name for dangerous precipitous streams, obviously in the mountainous conditions, it grew to include terrifying bodies of water, like lakes and seas. The b/m alternation is regular among the Türkic languages. Ubiquitous among Anglo-Saxons (about 40 derivatives), and in parallel with the synonymous sea, the word faded in the Middle Age English, and was resuscitated in the 18th c. to designate the lunar “seas”. The parallel ubiquity of the mere and sea, along with numerous other synonyms for sea, attests to the process of convergence and melding by numerous distinct vernaculars during the extent of the tumultuous Old English period. Both dominant terms, the mere and the sea, originated within the Türkic milieu, see sea. Cognates: A.-Sax. mere, maere “sea”, WFris. mar, Du. meer, Norw. mar, Gmn. meer; Ir. fharraige, Breton mor, Gael. mhuir, Welsh mor; Sl. more (море); Fin., Est. meri, Hu. tenger, all “sea”; WMong. mören, Dagur mur “river, stream”. Any claims to an “IE origin” and “PIE proto-words” are doomed by the spread of the word across linguistic families and continent-wide vast geography. In addition to the two dominant words, A.-Sax. used 17 other synonyms for the “sea, ocean”: brim, ear, egor(stream), fifel(stream), fifel(waeg), garsecg, geofon, haef/heaf-, haf (Gmn. haff), haern, holm, hranmere, lagu, waegholm, wael, waer/waere/wer, woruldwaetar, a good portion of them must be the European natives. The synonymic abundance attests to undifferentiated use of many of them, and to the bounty of relatively independent sources with their own unique histories. That the sea won at the end attests to the presence of numerous demographic minorities whose lexicons have completely faded, and of the presence of two demographic majorities, one of which supplanted the lexis of the other. That the archaic mere was resuscitated attests that it continued a low intensity existence, probably supported by the influence of the European Latinisms. Among other European synonyms stand out the Basque, Alb., Gk., and Arm. forms with emphasis on the element -ts-. The Hu. tenger is a reflex of a third Türkic synonym tengiz, an attested Sum. word which survived for 6 millenniums. The Celtic relict forms reflect the archaic m/b alternation, Cf. anlaut fh- vs. mh-, i.e. b- vs. m-. Apparently, Slavs never had access to a sea, their more must have been a borrowing from their neighbors. The A.-Sax. dominant duo of the mere and the sea is an indelible evidence of a paradigmatic transfer from the Türkic linguistic milieu. The form mere flooded the European languages, it probably came to Europe with the first Kurgan waves, the form sea probably came with the later Sarmat waves culminating ca. 2nd c. BC, and the form tengiz probably came last with the Huns of the 4th c. AD, Cf. the name of the Attila's son Dengiz “Sea”. See bore, burl, sea.
English mist (n.) “fog, condensed vapor, fine spray” ~ Türkic muz (n.) “mist, steam, fog”, an allophone of bu: “steam, fog, mist” that underlies both “IE” and non-IE terminology for “steam” and “vapor” and their derivatives, with dialectal m/b alteration. The base forms of these allophones are bu:, bug, bus, pus, muz and complementary forms with -r for -s and -z, bur, pur, mur (Cf. fart, bullion, purge, murky, fog). Cognates: A.-Sax. mist, wælmist “mist of death”, MLG mist, Du. mist, Icl. mistur, Norse, Sw. mist, all “mist”; Gk. omikhle, OCS migla, mgla (мгла) “hazy, dim, dark”; Skt. mih, megha “cloud, mist”. The A.-Sax. “mist of death” is a compound of two Tr. allophones, öl- “die, killed” + muz “fog” > wælmist, it is a paradigmatic transfer of two Tr. words, with the prosthetic w-/v- in the anlaut, also typical for the Sl. Turkisms, and apparently back -ə- for the front rounded vowel -ö-, unless -æ- coded -ö-. The “IE etymology” offers Lat. micturire “desire to urinate” with a stress on “desire”, a somewhat obnoxiously ingenious idea that connected “fog” with desirously urinating two-legged mammal world, a philological bunk version. That idea can't fill the void fabricated by dodging cognates across the largest Eurasian area. The Gmc. forms employ denoun adverbial suffix -tï, -ti; -dï, -di needed to form adverb misty, while the Sl. adopted form mgla for the same adverb misty formed with the “rare” denoun adverbial suffix -l, -la, -lä; that suffix is rated “rare” because it is a western areal suffix, and a “guest” in the records on eastern languages. The suffixes constitute another, independent evidence of the paradigmatic transfer, this time with morphology and not lexicon. The calculated probability of non-accidental concurrence of semantic, phonetic, lexical, and morphological match is expressed by a number with dozens of trailing 9s: 0.999..., i.e. an infinitesimally close to 100% statistical confidence factor, way beyond a slightest doubt. The processes of linguistic diversification and amalgamation, driven by migrations and amalgamations, enrich every individual language in its own unique way by allowing to use and reuse allophones for semantically distinct purposes (Cf. fart and purge). See boil, booze, breath, bullion, cloud, fire, fart, fog, purge.
English mountain (n.) “elevated landmass” ~ Türkic men-/min-/mün- (v.) “ascend, climb on, mount, ride (a horse)”. The notion “mountain” developed as a semantic extension of the notion “climb, ascend” of the Türkic stem mün-, a dialectal modification peculiar to the northwestern part of the steppe belt, it largely supplanted the native terms. The common “IE” stem for “mountain” is hor-, and the hor- has no connection to the notions of climbing, climbing on, mounting, or riding (a horse). The Common Türkic stem for “mountain” is tag/dag, not present in the A.-Sax. Instead, A.-Sax. has munt (heahmunt “high mountain”) and beorg (heahbeorg “high mountain”) “mountain” or rather “hill, ridge, cone”. It is apparent that the two A.-Sax. non-IE synonyms originated from two unrelated sources, Türkic and Gmc. respectfully. And Eng. has lost its Gmc. synonym for the word mountain. Cognates: A.-Sax. munt “mountain”, OFr. montaigne, Lat. mons “mountain”. For a family boasting ca 450 “IE” languages, a dozen cognates within the family is a pittance, a loanword obviously and by definition. The term munt entered Eng. as a singular extremely well developed word with numerous derivative applications, extensively syncretized with the local Central European terminology (Cf. foremunt “promontory”, heahmunt “high mountain”, muntaelfen “mountain elf”, etc.). Its parallel occurrence in the Central European A.-Sax. and Mediterranean Lat. points to separate paths from the same vernacular area, first denoting prominent mountainous landmarks (Cf. foremunt “promontory”), and then extending as a specific generic term “mountain”. The notion of “mount, ride (a horse)” was lost for a time (A.-Sax. used rid(an) “ride” for mounted riding and any other movement on the road), and re-entered Eng. from another source. Notably, the Gmc. beorg grew to become “mountain”, the bulk of its semantics uses Türkic burial kurgan equivalents: mound (allophone of munt), tumulus (Türkic tumlu “tomb”), hill, barrow, burial place. See mount , montage, tomb.
English ocean (n.) “limitless sea” ~ Türkic ӧkän, ӧgen, ögän (n.) “river, spring, brook, channel”. The word is a form of the root ӧg/ӧn/ӧz with identical range of semantics, best known for the Oguz form ӧgüz, largely “river”, with 7 other semantic clusters, including “stream”. The verbal form is ӧz- “to flow”. The word came to Europe with the Greek mythology as οkeanos/Ogenus (ωκεανος/Ὠκεανος/Ὤγενος), a great river or sea surrounding the flat disk of the Earth as opposed to the enclosed Mediterranean sea. The anthropomorphic Ogenus/Okeanos was a father of all earth's rivers. It is obvious that the Türkic ӧgen “river” and the Gk. Ogen “river” is one and the same word. The European etymology declares the term as “of unknown origin”. It may be reasonably surmised that both the alien word, and the alien myth that brought the word to Europe, were echoes from the same alien depths of the Turkic folk epos. By the Herodotus' time both were internalized deep enough to be held as a Greek native. Herodotus believed that Homer, or even one of the earlier Greek poets, just invented the name. In addition to the prime form ӧg/ӧn/ӧz, Türkic languages use forms ӧgen/ӧnen/ӧzen with an instrumental denoun noun suffix -en, and with a synonymous suffix -üz q.v., and with other local preferences for similar suffixes, creating a much wider spectrum than the forms documented in the Greek myths. The variety of the forms has a diagnostic value, it allows to better pinpoint the ethnic origin of the word. Cognates: A.-Sax. egor “flood, high tide”, egorhere “flood, deluge”, egorstream “sea, ocean”; Ir. aigean, Gael. cuan, Welsh cefnfor “sea, ocean”; Lat. ocean(us) “river or sea”; Gk. ogen(us) ditto; Sl. uzen (узень) “arm of a river”; Hu. ӧzӧn “stream”; Chuv. var “stream”. The roaming nomadic pastoralists of the steppes might have had some vague idea that the dry land is surrounded by limitless waters, and used a their familiar word for “river” in their nightly tales. The A.-Sax. lexicon has its own path parallel with the Gk. path; same with the Sl., Hu., and Chuv. paths. The Celtic path attests to the existence of the word prior to the Celtic circum-Mediterranean departure ca 6th-5th mill BC. The Chuv. var corresponds to the CT ӧz-, with a prosthetic v- and r/s alternation. Türkic has a whole family of homophonous words with unrelated semantics, Mong. has inherited those unrelated homophones, likely in the centuries during the Hunnic Ordos period ca 3rd c BC. Of the numerous strains, a particular strongest variety ӧg/ӧgen had spread to the European lands, and on to the rest of the Eurasia, making the ocean an international word. There is a funny industry of the “IE” published etymological masterpieces confined to the PIE paradigm within the Family Tree model that came up with the “PIE proto-words” of the type “*ō-kei-ṃ[h1]no-” and some Vedic dragons to shape a sectarian alternative to the Gk. ωγεν but not the Türkic ӧgen. The trio sea, mere, and ocean constitutes a case of paradigmatic transfer from the Türkic linguistic milieu, indelibly attesting to the origin from a common source, albeit by many different times and paths. See mere, sea.
English omen (n.) “foretelling sign, important or bad” ~ Türkic yama:n, yabal (adj.) “bad, evil, not good”. Ultimately fr. stem yam (n.) “trash, mote, speck”, yama- (v.) “fix, patch, clean, wipe”. Cognates: Lat. omen “foreboding” from OLat. osmen. The Türkic yaman/aman has two opposite meanings, “bad, not good”, “evil spirit, ghost” and “outstanding, unusual, good”, “magician, conjurer, magic formula”, Cf. Ar. religious amin “benevolence, mercy”. An element of mysticism is carried by the notion of the spirit and such. The negative meaning is being or linked with a derivative of the stem. The Türkic bifurcated literary semantics points to the derived semantic of foreboding “bad omen” and “good omen” leading to consequent bad or other events. “IE” etymology: Lat. omen “foreboding” from OLat. osmen “of unknown origin”. No “IE” cognates, the word pointedly does not belong to the “IE” family. The Lat. transparently used the Türkic word.
(Skip non-substrate) English onus (n.) “burden, task” ~ Türkic önüš, örüš (n.) “ascent, rising (protuberance, hump, swelling)”. Önüš and örüš are allophones, with r/n alternation. Ultimately fr. homophonous ö:r- (v.) “rise, sprout, ortho-” (see ortho-) and ö:r (n.) “height, high, high ground”, with r/n alternation. The notion “burden” derives from the notion “hump, swelling” as a most prominent or heaviest part. Cognates: A.-Sax. enede (enedek?) “drake, duck”, Lat. onus “load, burden”, hence legal Lat. onus probandi, lit. “burden of proving”. The “drake” is an allophone of the Türkic ördek/öndek (Tat. ürdek) “drake, duck” from the “rising”, i.e. “(the bird which) rises (from the water)” (Clauson EDT 205). The Tr. ördek/ürdek “duck” eventually, after abandoning the part ör-/ür- “rising”, turned the remaining adjectival suffix -dek to became the A.-Sax. duce “duck”, dufan “to duck”, and then the Eng. duck and to duck i.e.“dive”, see duck. The suffix -dek is accidental in the eastern languages pointing to its western provenance, its adjectival function shows up in the undoubtedly Türkic word beliŋdek “terrifying, frightful” fr. beliŋ “panic, terror”. The circuitous but traceable chain of semantic and phonetic transformations led to the enede and onus cognates in the A.-Sax. and Lat respectively. The Türkic derivative önüslüg “related to ascent” is probably a model used in the ecclesiastical Lat. This word is definitely not a late borrowing from Turkish, it must be an innate in Lat., probably popularized by the discourses of the early Christian Church time when other Türkic words and idioms were popping up in the ecclesiastical Latin and Greek, and maybe popular even earlier. Possible contributing source: Tengriist (Arian in the Christian lingo) converts that rose in the hierarchy of the early Christian Churches. See duck, ortho-.
English ore (n.) “mined mineral” ~ Türkic öre: (oro:, oru:) (n.) “pit (in the ground)”. Cognates: A.-Sax. ar, aer, ora “ore, brass, copper”, Du. oer, Low Gmn. ur “ore”, ONorse aurr “gravel”; Gk. orykto (ορυκτό) “ore”; Mong. ord(on) “mineral deposits”; Sum. urudu “ore copper)”; Heb. arad “bronze”. The rest of the European languages use derivatives related to “mine, mineral” (ma-/mi-), apparently from the “IE” lexicon, and Balto-Sl. related to “rude, crude, rubble” ruda ((руда, could stand for Heb. arad too). The Türkic öre: not only has various phonetic forms and semantic meanings, it also has phonetic siblings that may have originated and conflated with the notions of “pit, mine pit”: yer “earth” (A.-Sax. eorþe, where initial e- may stand for y- > yorthe), ur- “strike, hit”, i:r- “breach, notch”, for example yeri would be genitive of yer, “of the earth”. The Mong. cognate may precede the Hunnic period (3rd c. BC), ascending to the Zhou period (16th c. BC) and to the time when the first pastoral migrants brought bronze technology to the sedentary Far East (21-20th cc. BC). The gap between a “pit” and a “pit product” is easily covered by agglutination. The “IE etymology” derives ore from the A.-Sax. clone eorþe of the Türkic yer for “earth”, and then makes an unexplained semantic jump to the Gmc. form ar for “brass, copper, bronze”. The Gmc. ar is clearly an allophone of the Eng. ore and Tr. öre:, which in the first copper mines was both “ore” and “copper (ore)”. The alternate Gmn. erz for “ore” is likewise transparent, “ore” is both “ore” and “earth”, “of the earth”. Neither one is IE's. The distribution of the cognates, Gmc., Gk., Türkic, provides a strong argument in favor of the Türkic origin. In the Urals, the river Or, and cities Orenburg and Orsk named after the river, are located in the vicinity of the 3rd mill. BC ancient copper-mining area of the Seima-Turbino Metallurgical Province, the mines were worked into our era. Between the Gmc. and Türkic ore, the term extends across the entire width of the Eurasia. The Eng. ore and earth, and the Gmn. ar and erz constitute an indelible case of paradigmatic transfer from the Türkic milieu with a datable timestamp ascending to the 3rd mill. BC Copper Age. See earth.
English ortho- (prefix) “straight, right, proper” ~ Türkic örti- (v.) “rise, sprout, ortho-, at
right angle”, extended form of the synonymous verb ö:r-.
Neither EDT nor OTD note an interdental t-, but for different reasons, leave a possibility
that Türkic languages had both örti- and örthi-. The notion of the verb örti-
is distinct from other Türkic words for the “rise” that the riser, whatever it may be, is
maintaining contact with its starting point, and connects at a right angle; that distinction was
carried on to the receptor languages, i.e. orthogonal projection and the like. Due to its use in
religious, scientific and technical fields, now this word has a global circulation, appearing in
nearly every language (e.g. orthodox, orthochromatic, orthodontia, and orthogonal). The root cognate
of the European dissemination is Gk. orthos (ορθώς)
“straight, true, correct, regular” via LLat. orthogonius “right-angled”. A general English
lexicon has some 70 words starting with ortho-, with specialized lingo the count would be in
many hundreds. That shows that the frequency listing seriously underestimates actual frequency of
words that form compounds. The corresponding Romance spelling, and the spelling in the most of the
European languages is orto-, since neither the Lat. alphabet, nor most of the European
languages have interdental th in their phonetics. While the form ö:r- is common among
Türkic languages, the form örti- is peculiar to Kazakh, Kirgiz, and a dialectal province in
Anatolia, that allows to shed some light on the origin of the Gk. source. More light can be shed
using the dental fricative th as a rare phoneme tracer, since the great majority of the
European and Asian languages lack it, and have difficulties enunciating or distinguishing it. M.
Kashgari lists 9 Türkic groups with th: Oguz, Kipchak, Suvar, Chigil, Kanchak, Argu, Kashgar,
Yagma, Yamaki. Bashkort and Turkmen also have it, they also have retained their cohesion, preserving
the age-old phonetics. Of those, the Türkic tribes of the Aral basin, Horezmians, Bukharians, and
tribes known under collective name Alans have it documented in the coin legends with a prototype of
the letter þ. Of those, Oguz, Kipchak, Suvar, and Alan are tribal conglomerates, the rest are
rather ethnic groups. On the other end, while most of the Europe lacks the
th sound, it is present in Goth. and A.-Sax., and in a great arc on the European periphery:
English, Swedish, Norwegian, German, Celtic Welsh, Basque, Spanish, Catalan, Portuguese, Greek,
Gascon, Uralic Sami, Uralic Mari, Albanian, Sardinian. The Iberian languages were influenced by the
Celts, nomadic Vandals, and Alans, and then by Semitic languages that also have th. The heavy
dosage of R1a and R1b Y-DNA haplogroups in Greece that parallels that of the northwestern Europe,
and the timeframe of the Greek migration make a sufficiently strong statement on the possibility
that the Gk. adopted or inherited the term orthos from the nomadic Scythians, who played a
salient cultural role in the records of the Classical Greece, it is also consistent with a tentative
Scythian stop-over in the Aral basin on their way from the Altai to the N. Pontic. The “IE” etymological illusion suggests some fictitious form for not any less fictitious notions of “high,
steep, lofty”, attesting that in tune with G.Doerfer's sour observation, with loose linguistic
methodology, a proto-word can be restored in any language, from Akkadian to Eskimo (G. Doerfer,
1963, Türkische und monlgolische elemente im Neupersischen, 96). It is very unlikely that any
other linguistic group on the Earth can produce a veritable case with such perfect phonetics and
pinpointed semantics with natural origin in sprouting plants and branches.
116
(Skip?)
English pan (n., v.) “flat container” ~ Türkic ban (n.) “pan, writing tablet”.
The Türkic verb buta:-/butï:-
“prune” via derivative “board” (Cf. batğa:, Gk pittakion “board, writing tablet”, Eng.
board)
buta-, butaqla--, butï-, butïqla-
turned not only into “flat dish”, and also into “writing tablet” and outlet (branch) store butik,
among others. Cognates: ONorse panna, OFris. panne, MDu. panne, Du. pan,
OLG panna, OHG phanna, Gmn. pfanne, Icl. pönnu, Yid.
pan; Welsh (sos)ban, badell, phadell, Ir. pan; Lat. patina “shallow pan,
dish, stewpan”; Gk.
pan, patane (παν, πατάνε)
“plate, dish”;; Balto-Sl. (Latv.) panna, (Pol.) panew, (Czech) panve; Finn.
pannu, Hu. pan; Gujarati pana (પાન); Ch. pan 盤 “dish”,
ban 板 “board, plank”; Kor. beom 범 “pan”. Since cooking appeared much earlier than
writing, the prime notion of the term was “flat container, dish”, and was later recycled for
“writing tablet”. The source for the Ch. writing were Zhou Scythians, hence the original source for
the notion “flat container, dish” was the pan/ban “board, plank”, which in turn is a
derivative of the verb buta:-/buti:- “prune”, and the proliferation of the term from Atlantic
to Pacific across the steppe belt and into the Eurasian European fringe is natural. Probably,
dissemination of the notion for “dish” was carried by the females, butik store by traders,
and “writing tablet” by males. Notably, the parallel semantics of “flat dish” and “board, writing
tablet” originated from a pruned chunk of tree branch travelled far and wide, from Greece to China.
The pan “flat container” is unrelated to pan
derivative of “panorama”. See butik.
English pole (n., v.) “stake, rod, pillar” ~ Türkic bal- (v.) “linked, attached”. The form bal- is a passive form of the verb ba- formed with a suffix -l, an equivalent to the Eng. compound be + (verb)-ed, -en, -n., i.e. “is linked, was attached”, it carries a notion of a link between two or more terminals expressed in a verbal/adjective or noun function. The relict verb ba-/ma- “wrap, bound, bind, bind up, tie, tie down, tie up” is fairly straightforward, its origin of (baby) wrapping stays pretty compact. Its history spiraled from a verb to a noun and on to denoun verbs and deverbal nouns, gaining extended meanings on the way. The oldest known and straightforward form is badı “he tied up (horse)”, it attests that derivatives of ba-/ma- were involved in the nomadic pastoral economy. The most popular surviving form of the archaic ba- is the noun baɣ/baq and its verbal form baɣla-/baqla-, formed with deverbal noun marker -ɣ/-q and denoun verbal marker -la. The attested m/b/p alternation demonstrates a wide dialectal spread, Cf. the ancient forms man- vs. ban- “to put on a belt, to girdle” formed in reflexive aspect “self, me, selves, us”; Cf. the anlaut p- formed initial pay-, pu-, pula “to tie”. Palatalized articulation b > p is typical for the Eastern Europe. The passive form bal- “linked, attached” defines a connection between two terminal points, one to which the subject it tied to, the other the subject that is tied by the link. A form bal as a noun naturally extends the semantics to “pole, stake, rod, terminal, hitchrack, hitch”, which spread across Eurasia due to its role in the nomadic Polar star mythology. The Polar star myth could have evolved only after a domestication of a horse, after which it could have spread among the Eurasian nomads as a visual description of a celestial compass, so crucial for traversing the endless featureless steppes, and in the process of demographic amalgamation could have reached various alien hunter-gatherer and farming populations. The Polar myth depicts the Polar star as a permanent immovable hitchrack stake around which circle two horses tied to the ring on the top of of the post. The ability to locate the Polar star by vectoring two prominent stars of the Big Bear constellation, and thus to locate the cardinal direction to the North, opened a new page in the history of navigation. The notion of a celestial center around which rotates at least the entire celestial sphere, if not the entire universe, opened a new page in the history of cosmology. That cosmogenic picture then entered etiologies of numerous myths and religions. The term pole also extended its semantic field from a horse tie-in point to geocentrism, sports, electromagnetism, societal and intellectual polarization, etc. Cognates: A.-Sax. pal “pole, stake, post”, OFris., OSax. pal “stake”, MDu. pael, Du. paal, OHG pfal, ONorse pall “pole”; Lat. palus “stake”, “sky, heavens”, “end of an axis”, Rum. balama “door hinge”; Rus. becheva, bichevka (бечева, бичёвка) “string, tie”; Gk. polos (πόλος) “pivot, axis (sphere), sky”; Alb. rez-baglama “door hinge”; Serb. bağlama “door hinge”, baglya “sheaf of hay or straw”; Mong. baɣla- “bind in bags”, “tie in knots”, “form groups” (notion “tie, bond”), Kalm. baɣ 'batch (goods)’, “unit as a whole”, “bag”, “bundle”, “group”. Most of the internalized words have preserved their celestial connection, pointing to the times when the initial celestial tale had not yet developed flowery tales of the second, third, etc. generation, in various languages. Also salient is the element of connection, tying, bonding. The “IE etymology” unwittingly offers a series of unattested “PIE proto-words” leading to the Türkic bal-/pal-: “*pakslo-, suffixed form of root *pag- “fasten””, Cf. attested Türkic baɣ “fasten ”, or “*kwol- “turn round””, or “*kwel- “revolve, move round”” (with *kw turning into Gk. p-). The “IE” bumbling does not make any sense: the mythological axis, pole, or stake is one and the same, an immobile center of the celestial rotation in respect to the stationary Earth, thus only one word is needed to describe the center. That also makes unnecessary the invention of a dreamed-up *kw turning into Gk. p-. It is unlikely that the nomads of the 3,500 BC Botai steppes saw the Earth other than flat and the sky other than its flat cover. The very etymological notion of an axel of a sphere is screamingly asynchronous, off by at least 5,000 years. As late as 1888, a traveler could poke his head through the edge of the sky, Cf. the Flammarion engraving. There was no celestial sphere for the lay people. Instead of celebrating that English had preserved one of the oldest datable words, the “IE etymology” obfuscates the issue by veiling it in grotesque hides. The word pole is indigenously English, it came with the languages of the English ancestors, via a path completely separate from Gk. and Italic paths, it was so ingrained in the ancestral languages that a supposition of its acquisition from an alien Gk. or Italic languages is unsustainable. The absence of the word in the Celtic group attests that it was not a household term at the time of the Celtic departure from the Eastern Europe ca 5000 - 4000 BC. That makes the Corded Ware period a likely acquisition period of the word, complete with the celestial myth of a pole stake with two circling horses on the ropes, the notion of the Polar star singularity, and a navigational method, as one indivisible complex. With time, the stars that served as the the Polar star were changing, but each generation was endowed with its own permanent Polar star surrounded by its own satellite horses. The Türkic origin of the prime myth is beyond question, and so is its prime lexicon.
English pot (n.) “cooking vessel” ~ Türkic badïr, batïr, patır (n.) “bowl, pot”. Ultimately a derivative of the verb bat- “immerse in water” with deverbal noun suffix -ïr, Cf. batım, batığ “deep”, lit. “deep (dish)”, a small cousin of “bath”. Cognates: A.-Sax. pott, OFris. pott, MDu. pot; Ir. pota, phota, bhota, Welsh pot, bot, pot, potiau, botiau “pot”; Sl. badiya (бадья) “shallow pail”; OFr. pot “pot, container”; LLat. potus “drinking cup”; Skt. patra “bowl”; Sogd. p'ttr “bowl”; Mong. badir; Ch. bao 煲 “bowl, pot”; Kor. bun 분 “pot”. The “IE etymology” states “of uncertain origin”, but emphasizes Skt. and Sogd. cognates, while G. Clauson presumptuously and falsely asserts a foreign origin. The distribution of the word makes the “uncertain origin” quite certain: the word belongs at least to the Neolithic times, and likely way older; it traveled circum-Mediterranean route from the Pontic steppes with the Celtic Kurgans of the 4000-2800 BC, and overland with Neolithic Kurgan waves and later Scythians (OFris.) and Sarmatians to the future Gmc. area, and ca 2000 BC with Indo-Aryans to Hindustan (Skt.), and ca 1000 BC it repopulated the S.Urals/Aral area with Timber Grave Kurganians, where ca 1000 BC they agglomerated with farming migrants from the Afganistan area (Sogd.). The late Vulgar Lat. and Fr. probably received it from the Burgundian Bulgars. The who and how the word propagated is quire clear, only the Türkic tribes could have spread it from Mongolia to Atlantic. To survive the long distances and immense timespans, the word had to be carried along the migratory routs by the the fairer sex. The Buddhist context of the Skt. and Sogd. is consistent with lore that Buddhism originated from the Saka people. All other semantic extensions are local innovations. See bath.
English purse (n.) “handbag” ~ Türkic bursaŋ (bursoŋ, bursuŋ) (n.) “monk community”. The stem of the term is burs, ultimately a contracted form of the Skt. buddha sangha “Buddhist congregation”, the -aŋ/-oŋ/-uŋ is a 2nd pers. possessive suffix. Cognates: ONorse posi “bag”, OFr. borse, MLat. bursa, LLat. bursa, Romance bursa, bolsa, all “purse”; Ukr., Sl. Bulg. bursa “religious school”; Ch. fosen, bvyr-sag “Buddhist monk congregation”, apparently a Turkism. The spread and history of the term are intimately connected with the Türkic languages. The word has historical and semantic aspects, see bursary for historical background. Semantic transition went from the original “Buddhist congregation” to “seminary” (Sl, Ukr., Bulg. bursa “seminary”), to “stipend” for seminary students, to “seminary treasury” (Eng. bursary, bursar “treasury, treasurer of a college”), and on to the purse as a “money bag” (OFr.). The timeline for the purse must be different from bursary, its timing (12th c.) points to a Burgund source (OFr. purse “money bag”), while the same form in Sl. is its precursor “seminary”, and the form that entered Europe (sometime between 2nd c. BC and 4th c. AD) was bursaŋ “monk community”. The conjunction point of the two meanings (“seminary” vs. purse “treasury”) points to Bulgars, whose Western Wing (Kutragur, Kutigur) was identified with the Burgund nomads in the west, and the Eastern European territory of the Western Wing continued as the first Eastern European Viking/Sl. state (9th c.) that fossilized word bursa meaning only a “seminary”, and not a “purse (treasury)”. The suggested “IE” origin fr. Gk. byrsa “hide, leather” is a screaming contravention with the extant records, either a fortuitous coincidence, or a secondary derivative. The bursa “purse” or “seminary” is used by a miniscule fraction of the “IE” languages, no “IE” cognates outside the confined examples. The OFr. and MLat., and likely Gk. examples are a late borrowing, they are obvious guests of the distant Buddhist world to some members of the “IE” family, the “IE” etymology is not applicable. The story of the bursary and purse constitutes a paradigmatic transfer that involves a span of Eurasia fr. China to Atlantic, and a timeframe fr. the 2nd c. BC (on the outside) to the 12th c. AD. The Türkic origin is attested by functional and semantic continuity, and transparent phonetic correspondence. The paradigmatic transfer, with a peculiar distribution consistent with the other European ancient Turkisms, and with ingrained relicts of probably Manichean terminology of the Indian Buddhist origin, renders the demographic transfer of the organized religious schooling and the Türkic origin incontestable. The purse paradigm is a part of a much larger paradigmatic transfer connected with Manichean and Buddhist practice via Manichean terminology. See abyss, bode, bursary, mantra, monastery, sin, testament, Yule.
English queue (n.) “line up, ordered sequence, tail” ~ Türkic quδ (quδruq) (n.) “tail”. The denoun noun suffix -ruq reflects a blind tendency to package words into conventional morphology, probably typical for bilingual affiliates. Not infrequently, the newly suffixed form drives the concise original form out of existence. The queue “ordered sequence”, with unsettled and confused Eng. spelling, is homophonous with cue (n.) “signal”. Its original meaning “tail” was supplanted by a metaphorical “ordered sequence”, with the “tail” relegated to a metaphorical use. For the queue, English still has two spellings, queue and cue. Cognates: Lat. coda, cauda “tail”, an allophone of quδ, q.v., OFr. (12th c.) cue, coe “tail”, metaphorical “penis”, Fr. queue “tail”. The Lat. cauda supplanted a native synonym crinis, the A.-Sax. used a native taeg, teag “tie, cord, band, thong, fetter” for the “tail”, an allophone of the Türkic taŋ- “tie”. In reality, the claimed Lat. coda, cauda “of uncertain origins” is probably misleading LLat. case, a way beyond the Classical Lat. period. References and dates for the word queue tend to lead to the Vandal/Burgund source and time, during the early Middle Ages. The trio of the cue “signal”, queue “tail”, and cauda “tail” indelibly manifests the descent from the real, attested Türkic lexicon not encumbered by the faux late “IE” hypotheticals. See cue.
English quilt (v., n.) “sewn together” ~ Türkic köbül-, kübil-, kübül- (v., n.) “quilted”. The verb kübil- “sewn together” is a passive form of the verb kübi:- “sow together, quilt (v.), oversew”, and the like. Ultimately a denoun verbal derivative fr. küb/güb (n./adj.) “thick, puffed” applied in particular to stuffed garments, pillows, and soft stuffed armor. The phonetic difference with elided inlaut -b- may have been engendered by numerous plausible causes, like assimilation, contraction, temporal (2 or more thousand years difference) or spatial (half a globe away distance) separation, or inaccurate renditions (-w- rendered as -b-), etc. Cognates: practically none, Lat. culcita “mattress, pad”, OFr cuilte, coute “quilt”, “of unknown origin”. Synonymous with the Lat. stragula “curtain, quilt, matting, bed” and its A.-Sax. form strael, phonetically much further away from its Lat. counterpart than kübil- and quilt. The near total absence of the “IE” cognates and the presence of the native European terms attest to a status of cultural borrowing. The first quilts probably were fur coats made of pelts, with fur on the inside or outside. The quilting technique of sowing garments was expanded to many other utilitarian uses besides blankets and mattresses. The oldest textile quilt was found in Mongolia, application-type quilt masterpieces were found in the Ardjan and Pazyryk kurgan burials of the 1st mill. BC. The close phonetics, identical semantics of a pinpointed semantic field, and the Türkic oldest textile quilts, like the bounty of other Türkic lexemes in English, make the Türkic origin most inescapable.
English sack (n.) “bag, enclosure, pouch” ~ Türkic sag, sagdak (n.) “quiver bag”, “hunting bag”. Ultimately the root saɣ/sag and its synonymous version with a denominal noun suffix -dak that reflects a tendency to package words into conventional morphology, probably typical for bilingual affiliates. The basic notion of the sag is “to sag”, “an assortment of equipment suspended from the belt”, a journeyman's practice widely known from the nomadic graves' innumerous gravestones. The origin of the word likely points to the hunting economy, prior to the nomadic pastoralism stage with its more developed technology and signal quiver bags. Inescapably, semantics had to build up from the Stone Age realities to the Classical and Middle Age realities, from the belt pendants to the pastoral extraction of milk and then to the nomadic cavalry warfare times. The signal derivative verbs like the “take”, “to milk”, “squeeze”, “pick, pluck”, “pocket” arose fr. the prime notion “wring, gouge”. The main notion of the eastern cognates is “to milk”. The Classical and Middle Age realities coincided with a blossoming of the written literature and made the nomadic quiver one of the most ubiquitous words. Numerous homophones offer alternate versions of the genesis (ref. Sevortyan 2003, ESTJA, v. 7 150 and related entries), some more pertinent than the others. A gradual development was taken as a single slug of history, each semantic branch came from its own providential root with its own disjointed linguistic seed. Cognates: A.-Sax. sac, sacc, saec, sacu “sack”, WSax. sacc, Mercian sec, OKentish sæc “large cloth bag”, “sackcloth”, MDu. sak, OHG sac, ONorse sekkr, Goth. sakkus “bag”; OFr. sac, Sp. saco, It. sacco “bag”; Etruscan, Lat. saccus “bag”; Gk. sakkos “bag”; Heb. saq “cloth bag”; Mong. saga “pull over”, sahu “to milk”, Kalmyk sa:xo “pull closer, pull over”, “to milk”, Manchu savadaq, qorumsava “quiver bag” (-g/k- > -v-). Cognates depict a living picture of development and migrations. Some derivatives are really wayward: Cf. sakak “pendulous, hanging (chin), Adam’s apple” and its derivative saka:l “beard, sagged, hanged” and, unexpectedly, semantics of “gills”. The westward spread of the word from the Steppe Belt is consistent with the spread of the Kurgan nomadic tribes and the tribes of the Scythian and Sarmatian circle, and with the distribution there of the other terms of nomadic origin. The Heb. saq matches exactly the Türkic sag/sak in phonetics and semantics, and could ascend to the time when Scythians dominated Palestine in the 7th c. BC, because it was later mentioned in the Torah story of Joseph (Genesis xliv) written in the 5th c. BC. The Mong. and Tungus cognates precede by far the Hunnic period (3rd c. BC), ascending to the Zhou period (16th c. BC) and to the time when the first pastoral migrants brought bronze technology to the sedentary Far East (21-20th cc. BC). Nearly every host language has synonyms of the sag/sak, in the A.-Sax. case they were faetels, faetel “sack, bag, pouch” and cilic “sack-cloth”. That is an indicator of amalgamation and demographic processes. Notably, three Türkic semantic meanings survived into English, sack “bag, sack”, sack “squeeze out, discharge”, and suck “suction, nurse”. Initially separated by eons in time, they were paradigmatically transferred and internalized still in the A.-Sax. period, attesting to their common Türkic genetic origin. See suck.
English sage (n., adj.) “wise” ~ Türkic sag, sağ (ğ may be articulated silently) (n., adj.) “wise, talented, foresighted”. Ultimately fr. the stem sag- “mind, intelligence, acumen”, a deverbal noun fr. sa:- “think, conceive, regard, count”. The notion “count, numerate” is an extension of the prime notion “think, hold, regard”, Cf. “think, held as reliable” vs. “count as reliable” vis-a-vis “count tables, votes”, etc. This calque formation of two unrelated notions is widespread among vast Eurasian languages. Cognates: A.-Sax. hyge, hygd “mind, thought, reflection, forethought”, hygecraeftig, hygefaest, hygefrod “wise, prudent”, Goth. handugs “clever, wise”, Lat. sagax “sage, sagacious, astute”, OFr. sage “wise, knowledgeable, learned, shrewd, skillful”; Hitt. sak(ah)hi “to know”; plus all the Türkic languages. The A.-Sax. anlaut h- is an articulation of the initial s- typical for the Horezm area, consistent with the other Khakass terms from the Aral-Caspian basin, an embodiment of the s-/k- furcation aka satem-kentum split. The Lat. sagax carries practically the whole semantic load of the Türkic sag: astute, discerning, discriminating, intelligent, keen, knowing, piercing, sagacious, sharp, shrewd, and the like. It is semantically overlapping with the Türkic term yarlïqa- “councilman”, the English earl, the title of the Gutian ruler of Akkad of the 21st c. BC, see earl. By the “IE” etymological theory sage comes from Lat. sapere “have a taste, have good taste, be wise”, from an unattested PIE base *sap - “to taste”. The standing doctrine inexplicably omit the pertinent Lat. form sagax. From the unattested PIE *sap “taste” to the “wise” lays quite a semantic distance that needs a scholarly leap, even the notions “seasoned” and “wise” are semantically quite distant. The “IE etymology” for sap “plant juice, sapwood, fool, spade” is completely irrelevant to the sage “wise”, the conjecture is obviously pure nonsense in all respects. If of all “IE” languages only the ancient Lat. has it, then by definition it is a loanword to the “IE” languages. The Türkic sag is real, universal, and does not need any asterisks. The synonymous Gk. soph ascends to the 6th c. BC, and could be a medium that brought this Türkic word to the Lat. sagax and on to the western “IE” languages. A mysterious phonetic vacillation -g/-k > ph (f) > -g/-k may reflect the Türkic allophonic form sa:v. See earl, sagacity.
(Skip?)
English sapphire (n.) “gemstone type” ~ Türkic sepahir, sabarir (n.), generic for “mountain crystal,
Moon Stone”. Cognates: Lat. sapphirus; Gk. sappheiros (σάπφειρος) “blue stone”;
Heb. sappir “sapphire”, ultimately not of Semitic origin; Skt. sanipriya
“dark precious stone”. The “IE etymology” runs from Lat. from Gk. from a Semitic source but ultimately
not of Semitic origin. Indian possibility: Skt. sanipriya “dark precious stone” with either a
semantic shift or etymologically confused with Sani + priyah
“Saturn precious stone”. The Gk. “blue” and Skt. “Saturn” both appear to be local semantic
adaptations based on homophony. The name has been internationalized via trade routs, and etymology
must be sought along the the caravan trade routs.
117
English satyr (n.) “deviant” ~ Türkic satïr (adj., adj. n.) “rootless, kinless (man)”. M. Kashgari defined sa:tir as “a term of abuse”, a kinless and thus at least odd. Ultimately a deverbal derivative satir “vendor” of the stem sat- “trade, sell”, i.e. “hawker, peddler” with derisive connotations. Cognates: A.-Sax. saetere, saetnere “waylayer, robber, seditious”, saetian “lurk, lurking”; Lat. satyrus, Gk. satyros “lecher”, Heb. se'irim “monster”. In every case, the term refers to some peculiar personality. The European (IE) etymology asserts the standard “of unknown origin” and cites senseless hypotheses. The European mythology depicts a weird being, with horse tail and ears, or a part-man part-goat, Heb. Bible mythology depicts a hairy monster. In these cases the origin is also weird, from a forest or a desert. The A.-Sax. version is more realistic, referring to an unexpected calamity, closer to the Türkic pungent portrayal. The modern English may have borrowed the word from the Lat. and Greek, but it did not have to: the English substrate already had it, shared it with Gk., which passed it to Lat. It was successfully adopted into Gk. as a “strange-man”, “oddball-man”, which eventually gave us satire and satyr, words supposedly “of unknown origin”.
(Skip?) English sconce (n.) “small fortification, shelter” ~ Türkic quč- (quch-) (v.) “clinch, clamp, embrace, envelop, hug”. The Türkic nominal derivatives are qučam, qučaq “bundle, armful, pile”. Cognates: OHG schanze “bundle of sticks”, Du. schans “earthwork”; Sl. kucha (куча) “pile”; Balt. (Latv.) kaudze “pile”, (Lith.) kaupas “pile”. No “IE” cognates, the etymology is a brave “of uncertain origin”. The Gmn. and Du. forms mark a path from an armful to a bundle of sticks and then to shelter, something like a hut, wigwam, and palisade. Ditto the Sl. form, which matches a perfect phonetic reflex quč-/kucha with a perfect Gmc. semantics. A suspected Fr. connection implies a Burgund input. Further development, in the modern times, is ensconce “sit tight, settle, entrench”. The difference between the Sl. and Gmc. forms indicates quite different paths, much older for Gmc. and relatively recent (turn of the eras, pre-Balto-Slavic dispersion) for the Balto-Slavic. The Lat. form is also close phonetically and semantically: sconce “candlestick with a screen”, an obvious semantic extension of “small shelter”, “small palisade”, probably from the same source as the Gmc. form. The Gmc. transition from k-/q- to sk-/sq- is consistent with other prosthetic anlaut s- modifications. The auslaut -nch shows up in the Türkic complimentary verb qun- “grab”, with a participle suffix -ča > qunča “grabbed” that would make a perfect transition to the notion of quč- “grabbed, clinched, clamped, embraced, enveloped, hugged”, which allows to propose that the Old Türkic quč- and the Gmn. forms are derivatives of the same base qun- “grab”, with Balto-Slavic a later extension of the Türkic form.
English sea (n.) “turbulent body of water with swells of considerable size” ~ Türkic si (n.) “water, moisture”. Presently the Common Türkic is using allophones of dingez for the “sea”, while the notion “water, moisture, liquid” is expressed by an allophonic su. All surviving cognates associated with water, moisture, and juices that start with su-, so-, si-, sog- and the like attest to historically much wider phonetic spread. The stem si is found in numerous derivatives from the notion “water, moisture”, i.e. siba-/siva- “irrigate”, sıbızğu: “pipe”, sid-/sit-/siδ- “urinate” (see seat), siŋ- “water sinking into soil” (see sink), sidük “urine”, sı:k “shallow”, siŋir/siŋür “pour”, sığ- “fill (a sac)”, sığıt “weep”, siŋir “vein”, sirkä “vinegar”, sıvık “liquid, runny”, sibak “baby cradle urine draining hose”, sıčra- “gush”, sil- “smear”, sïč- “poop”, sıčğa:k “diarrhea”, etc. Phonetically, the form si- seems to be cited more for the Aral-Caspian basin and Khakass language. Cognates: A.-Sax. sæ “sheet of water, sea, lake”, OSax. seo, OFris. se, MDu. see, Goth. saiws “lake”, Du. zee “sea”, Dan. sø “sea” or “lake”, ONorse sær “sea”, Gmn. See “sea” or “lake”. The Gmc. phonetic spread fairly well matches the Türkic spread. The “IE etymology” rates the word by a routine “of unknown origin”, which means that there is a better than 50% chance of it being Türkic. Some technical innovations also denote a Türkic trail: Cf. Lat. sipho, Gk. siphon (σιφόνι) “pipe, tube (for drawing wine from a cask)” vs. Türkic sibak “draining hose” and sıbızğu: “pipe”. The Lat. and Gk. words are also rated with “of unknown origin”. No “IE” cognates whatsoever; the A.-Sax. woruldwaetar (n.) “ocean, sea” was supplanted by the Türkic allophone for sea. Probably, si became a specific generic term for large bodies of water, and was transferred to “sea” with the Gmc. westward migration toward the ocean. The distinction between “sea” and “lake”, salten or fresh is entirely conventional, depending on the environment. The distance between the “sea”, a “royal seat”, and the “urinate” is much less conventional, and barely palatable; it is dismissible but not disprovable. See seat, sink.
English seat (n.) “place for sitting on” ~ Türkic čıj-/čij- (čıž-/čiž-) (chij with -j- as -j- in jest, -g- in gel) (v.) “sit”. A separate noun ast “bottom, lower surface, beneath” is an appropriate equivalent to the noun “butt, bottom, behind” (as in sit “rest on butt”) in static applications. For semantic, phonetic, and historical details on the verb čıj-/sit see sit. The noun seat is an obvious derivative of the verb čıj-/sit, it is attested fr. the 3rd mill. BC, i.e. the latest time when Skt. and Sl. shared the common Eastern European territory. (Cf. Sl. sidenie (сиденье), Skt. asana, Sp. asiento, Tr. asan “seat” (n.)). Cognates: A.-Sax. setl, steall, sess, seld, A.-Sax. sadol “saddle”, ONorse sæti, OHG saze, sezzal, MDu. (ge)saete, Goth. sitls, stol, Dan. sæde, stol, Du zit, zetel, stoel, Sw. säte, sitt, Icl. sætið; OIr. suide “seat, sitting (remaining in one place)”, Welsh sedd “seat”, eistedd “sitting”, Ir. shuío(chán); Balto-Sl. (Latv.) sedekli, (Lith.) sedyne, (Sl.) sid(enie) (сиденье), sed(alische) (седалище);; Lat. sedess “seat”, sedere “sit”, Fr. siege (sij); Hindi., Gujarati sıṭa; Fin. istuin, Est. asukoht, iste, Hu szek (sek); Taj. čoj (ҷой) “place”, Ch. zuo(wei) 座位, Jap. shito; all “seat” except as noted. Phonetic changes are the same as with sit, see sit. Eurasian languages have three predominating versions for the notion “seat”, one derived fr. čıj- “sit”, second derived fr. ast “beneath” (stool etc., with elided anlaut vowel), third derived fr. ast “beneath” with epizodically elided -t (eistedd, asukoht, asana); that etymology explains nearly all forms in the languages within or bordering on the Eurasian steppe belt. The trailing -l (setl, sitls, stol, etc.) is a passive verbal marker (“to be sited on”), it can be retained in deverbal nouns. The modern Türkic word olur- “sit” with a sense of “settle temporarily, occupy” initially applied specially to rulers (Clauson EDT 150), it is the form that survived to the present; it is a dignified form of the archaic inelegant verb čıj-. Notably, the range of the Türkic semantics “seat” (concrete noun, throne, place, investiture, rear end, support, legitimacy) is closely retained by the European and some Asian languages. See sit.
English sector (n.) “section, arc, division, parcel off” ~ Türkic čektür- (chektür-) (v.) “parcel off, separate”, “separate with markers” (imp.). A gambling term, lit. “draw (one of a number of objects used in casting l ots)” extended to anything to be parceled, functionally synonymous with “cut something into parts, chop”. Ultimately a form of the verb ček- (chek-) “pull, draw” with numerous remote metaphorical extensions. Cognates: A.-Sax. tyge “tug, pull” (t- ~ č-), OCS sěšti (сѣщи) (s- ~ č-) “chop off, hack, cut”, Lat. secare “to cut”. The cited minute distribution within the “IE” family attests to a guest status there, especially so for such a cardinal notion as “cut”. The “IE etymology” dead-ends at the Lat. cognate, without delving any further, with a faux “PIE root” *sek- “to cut”, an unwitting allophone of the Türkic ček-. The Lat. claimed conjugation of *sek- to secare and then to sectus and on to sector also parrot the Türkic conjugational agglutination, eidetic enough to assert that all cited Lat. forms are originally Türkic down to morphological elements save for č- > s- alternation. The “IE etymology” also uses the stem *sek- “to cut” to produce a PIE the word “sex”, apparently via secondary notions of “division” or “to sever”, demonstrating an art of bivalent stunt equilibristics. Since the notion “sex” is way off the sector “section, arc, division, parcel off”, an incredible double stunt does not cut it but rather exposes blunt artificiality of the pseudoscientific manipulations. See sex.
(Skip) Gmn. Schabracke “horse blanket” ~ Türkic “cheprak” - “horse blanket”. Same word in Yiddish, Polish, Byelorussian, Ukrainian, Russian. The Gmc. form uncharacteristically replaced the unvoiced -p- with a voiced -b-, a reverse of the typical phonetic shift, probably assimilation of the combination -pr-.
(Skip) English sepia (n.) “reddish shade of brown” ~ Türkic sepi- (v.) “to tan”, i.e. to grow reddish-brown quite plausibly draws on the ink fluid of the cuttlefish, but then the “IE etymology” stumbles down from the Greek and Lat. sepiaa “cuttlefish” to the sepein “rotten”, a dubious proposition. More likely, the mollusks were not born rotten, but gained their name from the color of the extracted pigment, and the term for the color came from the Türkic derivative sepi (adj.), a loanword with proper semantic and phonetics. Numerous Türkic-Greek parallels attest to the close cultural exchanges between the Türkic Scythians and the Greeks, as described Herodotus.
English shade (n., v.), shadow (n., v.) “unilluminated area caused by obstructed light” ~ Türkic čadar, čadïn, čadïr, čatïn, čatïr (n.) “shade”. The form čatïn is rare, it is cited by G. Clauson just once, in a phrase kün čatın “sunshade” (kün “sun, day”) in reference to ča:tır “tent”, while ča:tır is cited both as “sunshade” and “tent” (G. Clauson, 724). The connection between “shade” and čadïn/čadïr is so obvious, it should have taken a deliberate effort of an etymologist to miss it. Linguistic sources accentuate shading paraphernalia, the derivatives of the notion “shade”: tent (shater), hut, parasol, umbrella, sunshade, etc. As a “shade”, the word is synonymous with köli:-/göli:-/köši:- “shady, shaded, cool”, i.e. shaded from sunlight, vs. casting a shadow. The physical sunscreen “shade” does not invoke an image of a ghost. As a “shadow”, the word is synonymous with köli:ge:/göli:ge: “cast a shadow”, i.e. an inseparable companion like a ghost. Cognates: A.-Sax. scead “shade, shadow, shed (shelter), protection”, OEng. sceadwe, sceaduwe, OSax. skado, MDu. scade, schaeduwe, Du. schaduw, OHG scato, Gmn. Schatten, Goth. skadus, Kentish ssed; OIr. scath, OWelsh scod, Breton squeut “darkness”, Gaelic sgath “shade, shadow, shelter”; Sl. (OCS) tenya (тѣня), Rus. ten (тень), Pol. сiеn, Lower Lusatian sen, all “shade/shadow” Rus. seni (сени) “entrance portico”; Gk. skot(os) “darkness, gloom”; Alb. kot “darkness”; OFr. (12th c.) tente “tent, hanging, tapestry”, MLat. tenta “tent”, Cf. tent “shading cover”, Skt. chattra “parasol”. Sl. has retained the notion of “tent” shater (шатер) “pavilion”, a derivative fr. the forms čatïr/čadar/čadïr. The Cmc. anlaut digraph sc-/sk-/sch-/ss- attempted to transmit the Romanized phonetics of /tʃ/ (/ch/) that corresponds to the Türkic č- /tʃ/ (/ch/). The palatalized articulation is typical for the Eastern Europe vernaculars. Ditto for Sl. č-/t- alternation. The Sl. palatalized auslaut -n probably reflects the form čatïn with elided inlaut -t-: čatïn > tatïn > ten/сiеn/sen, with dialectal peculiarities. The Sl. forms may have been influenced by the Türkic tuman “fogg, too many”, see big, mickle, which produced the Sl. tma “darkness”. The phonetic differentiation between “shade” and “shadow” is peculiar to Eng. and Du., attesting to its recent innovative origin. Generally, with the exception of the Eng. and Du., the Gmc. and Sl. semantics is a contracted copy of the Türkic semantics, typical for internalized lexemes. No “IE” parallels, cognates are focused to Europe, to the Gmc., Celtic and Sl. There is some murky “IE” etymology. There are unjustified speculations of Persian, of some Iranic language, or of Chinese loanwords. There are the unattested “PIE” *skot-wo-, *skoto- “dark, shade” mechanically extrapolated from the extant Gmc., Celtic, and Gk. versions, while the Sl. “proto-form” ostensibly ascends to the Türkic-derived attested tma, and the OFr. is ascribed to the attested Lat. tendere “stretch”. All conjectures are equally contradictory. The oddity of the Gmc. shade/shadow and the Sl. ten/сiеn/sen was noted in the “IE” studies, the accidental difference in forms and intertwined semantics for Gmc., and the absence of the Sl. ancient examples of the form ten for Sl. The cited as Uigur form čadïn/čadïr, a tentative source of the Sl. ten, may have migrated from the eastern Central Asia to the Aral-Caspian area when Uigur groups fled from the territories threatened by China and in the first centuries AD came to dominate the Horezm area. The evidence of an earlier Uigur presence there is lacking, but Uigur ancestors may have participated in the return of the Timber Grave nomads during re-population of the Horezm area at the turn of the 1st mill. BC. The Türkic fuzzy duality of two semantic tinges overlapped and reeled in different languages, it was carried to the A.-Sax. and the modern Eng. The metaphorical connection with the shade following like a ghost was also carried to the A.-Sax. and the modern Eng. Distribution is peculiar, the continental-size modern internalized forms are overlapping the continental-size original forms, replacing them as a part of the general language replacement across the Eurasian continent. The OFr. and MLat. forms are probably a legacy of the Burgund lexicon. The Sl. and Gmc. forms attest to much older internalization and independent paths. The diagnostic presence of the Lower Lusatian form (Serbian enclave) suggests the origin from the Kangar vernacular, a legacy of the Bajanak (Pecheneg) westward migration fleeing from the conquest of the Aral-Caspian area by the Oguz migrants (Oguz Yabgu state) ca. 750 AD, if not the earlier migration of the same Kangar Union tribes fleeing in concert with the Avars from the conquest of the Aral-Caspian area by the First Türkic Kaganate (550s). The Gk. form may be a legacy of the Gk./Scythian times, the Alb. form may be a legacy of the Byzantine-time Gmc. tribes that intermittently populated Adriatic seaboard. The Skt. cognate, unless it is a late loanword, attests to the existence of the word prior to the departure of the Indo-Arian farmers from the Eastern Europe ca. 2nd mill. BC. The phonetic and semantic homogeny, semantic duality, and the accompanying image of a ghost are the traits of the paradigmatic transfer case, attesting to a common origin from the Türkic milieu. See big, mickle.
English sling (n.) “pebble-hurling strap weapon” ~ Türkic salïŋu, salŋu (salyngu, salngu) (n.) “sling”, a deverbal noun derivative fr. sal- “move violently” with reflective gerund abstract suffix -ingü, lit. “be moving (hurling) violently”. The spread of the Türkic word sal- as a component of the term for “sling” is most impressive, it extends across linguistic families and most of the Eurasian landmass. Türkic vocabulary has also preserved terminology for the ancient weapon's appurtenances, attesting to the sling munitions complex: kerzü “rolled sling balls”, küvlük “rolled clay sling balls”, tïš “tooth”, i.e. an iron release trigger”. Cognates: Dan. slynge, Du. slinger, Norse slynge, MLG slinge, Gmn. Schlinge; Fr. sangle; Latv. linga; Slvk. slichka (slučka); Geor. slingi (სლინგი); Gujrati slinga (સ્લિંગ); the Türkic terminology is uniform in deriving from the root sal-, but otherwise diverse in its forms; the native “IE” terminology is peculiar to nearly every language, no common “PIE” “proto-word”; the A.-Sax. term liðere, liðera (leather) for the sling is an allophone of the Türkic word eldiri for “leather”; in addition to the common allophones of the “sling”, the Gmc. languages, like most of the European languages at large, have their own peculiar native terms for the sling. Notably, most of the Gmc. and other languages retained the peculiar Türkic phoneme -ŋ- (-ng-) spelled as -ng- and the suffix -ingü as a part of the root. The perfect phonetics and semantics of all cognates positively attest to the common origin ascending to the root sal- and the initial form of the type salïŋu, salŋu. See tooth.
English socket (n.) “receptacle” ~ Türkic sok-, suk- (v.) “insert, thrust, fill up, stuff, hide”;
the sok- and suk- have overlapping topologies and semantics (the other semantic is
unrelated “beat, crush”, see sock (beat)), and “it is simply a matter of judgment which verb
is involved”.
The notion of the “receptacle” ultimately ascends to the stem suk- (sok-) that stands for
index finger (n.), thrust (with an index finger) (v.), and in a passive form
“thrusted, indented” (n., adj.); the attested terminal points are suk (sok) “index finger”
and forms suğut
and suktu: “inserted, stuffed” with suffix -ut for abstract nouns and active concrete
nouns which form the notion of “socket, receptacle”. Unlike the fuzzy distribution, the meaning of
the sok-, suk- “insert, stick in” is very definitive, it in particular it reflected a unique
method of coupling, widely used by archeologists to trace archeological cultures: socketed vs.
tongued type spearheads, arrowheads, and axes; the socketed types were found at documented
Sarmatians (200 BC) and Guties (2200 BC), at Scythian-type Zhous in China (1600 BC), and at a
nomadic mummy in the Tarim basin (1300 BC); the artifacts are reliably identified with the Eurasian
horse nomads and Sarmatian kurgan burials. Apparently, outside of the Türkic phylum, only English
has a cognate. It is obvious that the forms socket, suğut, and suktu: are semantically
identical and phonetically close allophones, the Eng. word comes complete with a version of the
Türkic suffix -ut, it is a paradigmatic transfer reliably attesting to the origin of the
word. The bifurcated semantics of the Eng. sock “beat” and sock “indentation”,
transferred paradigmatically with the Türkic sok-, render independent evidence from a
different angle attesting to the elaborated multifaceted transfer paradigm. The “IE etymology” blunders into unrelated homophonous fields: “spearhead”, “plowshare”, “hog's snout” “pig”, “swine”,
“sow”; the “IE etymology” is clearly an etymological hogwash attesting that “a study by an acute and
powerful intellect in an exigency of a hard case would discover any curious, narrow, hidden sense
preferable to the plain, obvious, and rational meaning” (US Supreme Court, 1925). The word and
notions sock (hosiery) and sock (beat) are etymologically related to socket, it
is an indentation to hide a foot in, or to catch wind to indicate its direction, and the word
sock has a list of valid cognates leading the “IE etymology” absolutely nowhere, “perhaps from
Phrygian or another Asiatic language”, i.e. patently non-IE source. See sock (stocking), sock
(beat).
118
English stop (v., n.) “halt”~ Türkic to:- “to close, block”. Ultimately fr. an adj./adv. to “much”, and its utilitarian verbal form toδ-/tod- “satiated” with passive suffix δ-/d-. Suffix -p forms deverbal analytic nouns to:- > top “closer, block”. Semantically identical, the Gmc. forms differ by a prosthetic anlaut s-. That anlaut s- regularly shows up in the N. European or Gmc. and Sl. forms of the words (see crunch “crackle” Lith. skrudeti “crack, flake”, Latv. skraustet “creak, rattle”; sconce “fortification”, Du. schans “earthwork”, OHG schanze “bundle of sticks”, Sl. kucha (куча) “pile” fr. Türkic qučaq “bundle, armful, pile”). The word evolved and then emanated from the Gmc. phylum, and now is an international word. Cognates: A.-Sax. -stoppian (for-stoppian “stop”, Eng. stopper “plug”, OSax. stuppon, WFris stopje, OHG stopfon “plug up, stop up”, OLFrankish (be)stuppon “to stop (the ears)”; It. stoppare, Fr. étouper “stop by plugging”; Skt. stambh (caus. stabhayati स्तभायति), stha (caus. sthapayati स्थापयति) “stop”. The It. form, without a Lat. precedent, points to a loanword status. The Fr. word, without the initial -s, may have passed from Burgund, and gained a Mediterranean prosthetic anlaut e- on the way. The Skt. forms attest to the presence of the word in the 2nd mill. BC among the demographically mixed Indo-Aryan farmer migrants from the Eastern Europe. With no “IE” “proto-word” across a predominant majority of “IE” languages, the word is a loanword status within the family. The “IE etymology” is confused and divided. The utilitarian use as “stopper” likely propagated the word along Eurasia before it reached international spread in the modern times. Türkic offers a morphologically, phonetically, and semantically sound etymology where the “IE” has none.
English suture (n.) “cord of sheep intestines, thread” ~ Türkic sač (sach) (n.) “hair”, saču: (n.) “hem”, saču:la:- (v.) “sewtogether, to hem”. The hair, including human, was used for thread from the Paleolithic times, hence the related derivative terminology. The phonetic spectrum of the recorded Türkic articulations provides sufficient material to relate to the multitude of the other forms, including Gmc.: čač/ča’č/čaš/čäš/češ/če”š/čəčč; hse’əš/hüs; sač/sač"/sas/saš/seč/səč/səs/ssya/süs; šaš/šeš/šəš; tsats/t'aš. Like in English (“to thread”), in Türkic the stem sač- can be used as a verb (sačan-). Cognates: A.-Sax. seam, ðeodnes “suture”, seamere, seamestre “tailor, seamster”, seamsticca “stick used in weaving”, Eng. (15th c.) sutura “fibrous joint”, Dan snoet “spun (yarn)” Icl. snúa; Ir. chasadh “spin (yarn)”; Lat. sutura “a seam, a sewing together”, sutus “sewn”, Gk. syrrápto (συρράπτω) “suture”; Balt.-Sl. (Lith.) sukti, (Latv.) sukt, (Sl.) such “spin (yarn)”, (OCS) sukati, suku (съкати, съку) ditto; Skt. sutram “thread”; Mari suse “hair”; Mong. tsatsag, sasag “tassel, fringe”. “IE etymology” does not connect the spinning etymology, which in most cases is a derivative of the local form of the stem. In particular, Eng. sew does not have a suitable etymology, and lends itself to a tentative derivative from the same stem sač-: A.-Sax. siwian, siowian “to stitch, mend, patch, knit together”, ONorse syja, Sw. sy, Dan. sye, OFris. sia, OHG siuwan, Goth siujan, Lat. suere “to sew”; Skt. sivyati “to sew”; OCS šijo “to sew”, šivu “seam”; Latv. siuviu, siuti “to sew”. The OE, Gmn. and Goth. versions related to suture preserved the Türkic instr. case suffix -an: sewan “to thread”. The A.-Sax. had two homophones spelled seam, one related to transportation and apparently of the local origin, and the other an allophone ascending to the Türkic linguistic phylum related to weaving, stitching, and tailoring. In the European alphabetizations, the first consonant is spelled mostly s-, but the A.-Sax. form ðeod- points to an interdental consonant. The other non -s- renditions corroborate transmissive inaccuracies, just the Türkic approximations include č, h, š, ts, and the A.-Sax. ð- belongs to the same cluster. The first vowel and second consonant also vary fairly widely, altogether attesting to a deep timeframe and wide dispersions. The -č- (ch)/-k- alternation of the second consonant is regular for the Eastern European languages. The consonance of the A.-Sax. ðeod-, and the Lat. and Skt. sut- attest to their origin in close proximity, pointing to the lingoes of the focal Corded Ware (3rd mill. BC) communities. The “IE etymology” is not serious, it dead-ends at Lat. suere “to sew”, i.e. too late, too shallow, and too partial for the manifested spread and depth of the common source.
(Skip) English swill (n.) “slop, animal feed of refuse” ~ Türkic ašbar (ashbar) (n.) “slop, animal feed of refuse”. The compound ašbar is a combination of aš (n.) “food” and bar- (v.) “bear” with semantic shades of “spew out, refuse”, see bear (v.) “carry”. Cognates: A.-Sax. swilian, swillan (v.) “gargle, wash out” is semantically identical. Ultimately, ašbar and swill/swilian (Gmn. schwelgen) ascend to Türkic aš, aša- “food, eat”, with contraction of the anlaut a- and alternations sh to s, b to w, and liquid r to to l, all within the realm of the Türkic-Gmc. assimilations. The r/l shift probably occurred under an influence of the jibed A.-Sax. swelgan “to swallow, devour, imbibe” with a related but opposite semantics. Cf. A.-Sax swelg “abyss, bottomless pit, void”, swelgend “whiripool, vortex, abyss”, swelgan “ingest”, where metaphorical “ingest” lit. “fall into abyss”. The “IE etymology” deduces swilian directly from the Eng. version swallow of the A.-Sax. swelgan “ingest” which, besides a metaphorical and contrary semantics, does not have a credible “IE” etymology. The suggested “IE” alternate of an invented “Iranin” *khvara- alludes to the -s-/-h- Caspian-Aral area alternation while leading to the very same etymological dead end. Besides the Gmc. branch, there are no cognates across the “IE” family, the swallow is an obvious guest within the that family. The Türkic origin for the Gmc. forms appears to be more germane and credible than the incoherent “IE” versions. See bear (v.).
English tab (n.) “account, bill, check” ~ Türkic tap- (v.) “receive, acquire”, with a collection of Türkic verbal and substantive equivalents covering everything from earning (serving) to hand over and entrust. The word tap is popular in Eng., Cf. “draw from”, “tapped phone”, etc. Ultimately fr. the noun/verb tab-/tap- “strike, spank lightly”, and its semantic extension “trace, footprint, mark, scar, blot, stain, smear, patch”, see step, tap (attain), tap (stroke). The first consonant wobbles between d- and t-, the first vowel wobbles between -a-/-e-/-ə-, the second consonant wobbles between -b-/-p-/-v-/-w-. Phonetic alternations create semantic overlaps and somewhat fuzzy semantic fields and may help with ethnic diagnostics. Keeping track of the accounts is as old as are the caravans, caravanserais, and eateries, the tab “account” could ascend to that time. Archeologically, sustained trade relations are detectable from the mid of the Neolithic. The attestation is late, 19th c., hence the “colloquial”, the “recent origin”, and the confused conflation with “tag, tablet, tabula”, and such. No cited cognates within the purview of the “IE” etymology, a routine assertion “of uncertain origin”, but the Ch. tuo 托 “owe” and Kor. daejo 대조 “check” are semantically and phonetically close, matching the Eng. semantics of the type my tab “my account, how much I owe”. The “IE etymology” gives “American English colloquial, probably from tabulation or of tablet or tabloid”. That does not account for the forms like keep tabs on “follow the account”, tab “file tab”, or the “attached ear” to locate account or open a can. A suggested ultimate etymology from the Lat. tabula “small flat slab or piece” is essentially an unsustainable dead-end etymology (the Lat. “tab” is libellus). Likelier, before surfacing in the New World, the word was lurking in England for nearly two millenniums, Cf. the fate of bash, bother, boss, chill, derrick, doll, ok, and dozens more late comers. The Türkic etymology fits the phonetics and semantics. See step, tap (attain), tap (stroke).
English tablet (n.) “writing board” ~ Türkic tü:b (n.) “substrate (flat), beneath, support”. The semantic span of the Türkic tü:b is exceedingly wide, covering numerous aspects of the root, its substance, function, and appearance: “root (plant), foundation, basis, bottom, beneath, support, substrate (flat), very flat, ancestry”, and further semantic derivatives. The notion of a (very) flat substrate surface apparently formed in conjunction with a complimentary word for a rough substrate surface. The derivative notion of the flat substrate is undoubtedly millennia younger than the prime notion of a plant root. The flat substrate meaning is the most consequential, known in the words “tablet (writing surface)”, “table (furniture)”, “table (tabulation)”, etc.; the secondary major meanings are tubular (cylindrical) shape expressed in the words “tube”, “tub (bathtub)” and impression on a flat surface “type (print)”, “type (precursor)”, “typing”, “typography”; numerous other meaning are expressed as semantic calques, like “the root of the problem”, “family roots”, “at the root of”, etc. The oldest use of the tü:b is Sum. tup (4th mill. BC) and Akkadian tupp (3rd mill. BC) for the substrate of the cuneal writing and then of any writing. With the art of writing the word spread out around the western Eurasia, creating there allophones in practically every impacted language. The notion of the (wooden) board was a function of the materials available, the earliest Sum. tup was a clay tablet, and it remained clay well into the New Era. As a cultural influence, the word tü:b may be classed as the most consequential cultural borrowing of all times prior to the invention of a computer. Evidence suggests that the tablet “board” originating fr. tü:b “root, substrate” was borrowed via literary sources, the A.-Sax. used beme, bieme “tablet, trumpet”. Notably, that use parallels that of the Türkic tü:b “substrate, tube”. Cognates: Sum. tup, Akkadian tupp, Elamite, Hurrian tuppi; MGk. tabla (ταβλα) “board”, tipus (τιπωσ) “seal impression”; Umbrian tafle “on the board”, Lat. tabula “board, table (spreadsheet)” tipus “seal impression”, MLat. tabuleta diminutive of “table”; OFr. tablete (13th c.) diminutive of “table”; Eng. table (furniture, spreadsheet), Du. tabel “table (spreadsheet)”, Gmn. tafel “board, table (spreadsheet), table (tabulation)”; Sl. (Serb.) tavlia “board”, (Pol.) tabela “table (spreadsheet)”, (Russ.) tabel, tablitsa (табель, таблица) “table (spreadsheet)”, tablo (табло) “display panel”; Sp. tableta, It. tavoletta. The list can be significantly expanded, since directly and indirectly these terms were relatively recently disseminated by Lat. as a lingua franca of the European science. There is no special need to prove that the Türkic languages were not influenced by the Lat., or that the Sum. form was identical with the Türkic forms, these facts speak for themselves. Notably, in numerous instances the Türkic polysemantic meanings were transferred paradigmatically, with the prime meanings of root, writing board, and tube, Cf. Lat. tuber “root”, tabula “board”, trumbа “pipe”. The “IE etymology” is unable to come up with PIE “proto-words” even for scattered words, much less for the entire se, mantic series, its verdict is “of uncertain origin”, a capital debacle for so culturally powerful borrowing that opened the gates of civilization. See dip, tuber.
English taco, taquito (n.) “flat bread” ~ Türkic toqüč (n.) “flat bread”. Ultimately fr. an one meaning of the verb toqa-/toqï- “dinge/batter” from the polysemantic range of “dinge/batter, full/satiate, rough/knock, sprag (door stop etc.)” numbering at least 8 distinct meanings. That relevant action is for the dinging of dough to make flat a clump of it. The Sp. etymology derives the word taco from “plug, wadding”. That happens to be one of the Türkic meanings of toqa (sprag, q.v.). That is a case of paradigmatic transfer from the Türkic to Spanish as key cultural loanwords of two separate meanings of the same word. The suffix -üč in toqüč is a diminutive suffix, with its allophone in the Sp. taquito. Türkic has 15 names for flat bread, it is still a popular form of daily staple in the Eurasian areas near the steppe belt. The chances of one of the 15 names taking root in the areas of cultural or genetic amalgamation hover at only around 7%; for two words it is by orders of magnitude less. In English this word has not been registered until well into the 20th c. as a cultural borrowing.
English tad (n.) “slight amount”, toddler (n.) “yearling” ~ Türkic dad, tad (n.) “toddler (male)”. Appellatives dede/de:de/dada belong to the terms of kinship for male line seniority ranked from 1 to 10. The number 1 is dad/father, and the number 10 is a male child from one month to two years. The first and second consonants wobble between t and d, and the vowel wobbles between -a-/-e-/-ə/-i-/o- and a few more, see dad. A few euphonious words may have conflated semantically: tut- (v.) “cherish, protect, keep, carry”, a derivative of the tut-, tutun- (v.) “stutter, stammer, stumble”, tat, tata, tada (n.) “small (space, distance)”, and probably more. Cognates of the type dada for the terms of kinship are dispersed across Eurasia and across linguistic families, mostly designating “dad”. They do not provide a conclusive pinpointing diagnostics. The notion “toddler”, in contrast, has a very limited distribution and thus carries a significant diagnostic value. Also helpful are semantic extensions expressing various aspects of a phenomenon “toddler”, like the smallness, stuttering, stumbling, stammering, etc. Tell-tale semantic extensions are visibly concentrated within the Gmc. group, they point to the depth of time and internalization. Cognates: A.-Sax. tealt (-eal- = -o-? = -ə-?) “unstable, precarious”, tealtlan, tealtrian (eal = o? = -ə?) “totter/dodder, shake, stumble, waver”, the tade, tadi “toad” and the Eng. tadpole “of unknown origin” may be semantic extensions of the same tad/tat “small” in parallel with the padde, pade “toad, frog” (from Türkic baga) and frocga “frog” (also an allophone of baga), Du. touteren “tremble”, NFris talt, tolt “unstable, shaky”; Ir. toltar, Scots tolter, Welsh tolter, toller, “unstable, wonky”, Cornish tat “father”; Balto-Sl. (Lith.) tete, tetis, tetytis, tevas, (Latv.) teta, tevs “father”, (OPruss.) thewis “pop, dad”, thetis “grandfather”, (Sl.) tata, tyatya, tato “father”, dyadya “uncle”, tetya “aunt”; Lat. tata “father” (a Romance oddball, Cf. It., Sp., Fr. padre, pere); Gk. τεττα (Iliad 4, 412), τατα “father (vocative only)”; Skt. tatas “son, father”; Alb. tate “father”. Besides Türkic, the notion “toddler, son” is cited only for A.-Sax. and Lat. Cognates demonstrate a predominance of the notion “father”, the other notions of “brother”, “uncle”, “aunt”, “son”, “toddler” are secondary. Moreover, the secondary terms, even when they were initially internalized, in the majority of cases were eventually supplanted by the local terms, and have survived only for concrete applications or as synonyms/extensions of the local terms. A scant presence of the tad/toddler in the A.-Sax. indicates that it was introduced by a demographic minority, and lingered to the present only because it had filled a certain semantic gap. Its cognates, however, are spread across Eurasia in a rainbow of articulations. The Gmc. cognates point to a distribution of the base word in the Northeastern Europe and amalgamation within the Corded Ware (3rd mill. BC) archeological culture. The Celtic forms ascend to the Celtic Kurgans arrival to Europe in ca 2800 BC, 800 years before the time of the Aryan migration, and point to the base word existence at the time of the Celtic departure from the N. Pontic area in the previous millennia, i.e. to the period around 5,000 BC. Its presence in Skt. points to its existence in the N. Pontic area at the time of the Aryan departure ca 2000 BC. The carryover of the base word complete with its semantic terms “father”, “son”, “toddler” constitutes a case of paradigmatic transfer that indelibly attests to the word's Türkic origin. So also does the thematic constellation of the paradigmatically transferred Türkic terms of kinship complex. A complex clenches diagnostic material on the sources and dating beyond any isolated lexemes. See ethel, dad, father, papa, uncle.
English tale (n.) “narration” ~ Türkic tele/tili/dili (n.) “language, tongue, speech”. Ultimately a derivative of te:-/de:- “utter, say” as opposed to “speak”, which is söy-, with an intermediate derivative til, tïl (n.) “tongue (anat.)”, its derivative verb tili “tell, order” and its derivative noun tili “speech”. The denoun verb til-, tïl- lit. stands for “to tongue”, Cf. Eng. verb to mouth “speak, say” fr. the noun mouth. An opinion that tell, tale, and talk are forms of one and the same root is an accepted premise of the “IE” etymology. Besides til “tell, speech”, Türkic has söy- “say, saga”, and ay- “speak, say, declare”, where the “declare” is lit. “hear me” with oratio recta, Cf. Lat. audire “to hear”, see say, saga tell, audio. The Eng. semantic transposition between tell and say is not necessarily extending to the cognates in other linguistic families, each one with its own history of internalization and semantic development. Cognates: A.-Sax. talu “story, tale, telling”, tyn “teach”, Fris. (fer)tell(ing) “tale”, Du. taal “speech, language”, Dan. tale “speech, talk, discourse”, ONorse tal “tale”, Gmn. (er)zähl(ung) “story”; Welsh dyweder, dywedwch “say, tell”; Lat. dico “say, speak, tell”, Sp., It. dice “say, speak, tell”, Port. dizer “say, tell”; Gk. dieg (διηγ) “recount”, diegoumai (διηγούμαι) “tell recite narrate”, diegou (διηγου) “tutor”; Latv. teikt “say, tell”; Kurd. di(beji) “tell”, dirok “story, tale”; Punjabi daso “tell”; Fin. tietää, Est. teatama “tell”; Ch. shua 说 “say, tell, talk”; Kor. tel 텔 “tell”. Ironically, the suggested unattested faux PIE root *del- “to recount, count” as a base for the tell, tale, and talk reverts back to the Türkic verb tili-/tele-/dili-. A signal absence of the southeastern Indian/Iranian cognates points to the absence of the word in the native European vocabulary, the Aryan migrants of the 2nd mill. BC came to use the native southeastern terms. The Chinese shua “say, tell, talk” is likely a reflex of the Scythian Zhou component in the Chinese language, ca. 2nd mill. BC. Lastlyly, an etymological confusion on a secondary homophonic notion of a number and numerical counting is a completely separate issue. The “IE etymology” suggests the same faux PIE root *del- “to recount, count” for enumeration and for the tale, which conflicts with the mankind's universal practice of independent terms for speaking and enumerating. Neither could the notion of numbers appear concurrently with the notion of speaking or be its semantic extension. The unwitting confusion apparently arose out of the auditory proximity between the Türkic tel-/til- “speech” and töle:- “pay”, töl- “toll, payment, fee”, see toll. In that context, talu is not a “number” per se, but a price, i.e. talu seofon as “number (or numbering) seven” is impossible, but the “rate of seven (coins)” is viable. Thus a teller is a toll collector. The distribution of the root te:-/de:- covers most of the Eurasia from Atlantic to Pacific, and across linguistic families. In the A.-Sax., the word tale appears as a paradigm, with a synonymous saga, thus the same stories are variously called saga or tale (tal), or even both (Cf. Saga “Ynglinga tal”, lit. “Saga Ynglinga tale”, complete with the Türkic noun locative conjugation suffix -ga, “Tale on Yngling”, “Story on Yngling”. Snorri did Ynglings Saga and Thjodolf did Ynglinga tal. In a Ch. rendition the Ynglinga saga would be called “Ynglinga shua”. The Eng. quartet tale “narration”, tell “narrate”, say “utter, state”, and saga “story”, constitutes an indelible transfer paradigm with a transposition of the Türkic duplex til “utter, state” - söy “narrate”, an irrefutable evidence of the genetic connection. Notably, the transfer paradigm transplanted not only the basic phonetics and semantics, but also preserved the semantic subtlety between the tell “story, account, record, news” and say “speak, utter, express”. The subtlety is apparent in the idioms “tell apart” “tell off” vs. the impossibly awkward “say apart” “say off”, or in the Türkic savaš- “say (words), i.e. argue” vs. the Eng. inexplicable idiom “words were said”, i.e. “argue”. To miss this striking paradigm would have taken a diligent etymological effort. The evidence for the genetic origin from the Türkic milieu is indelible. See audio, saga, say, tell, toll.
English tambourine (n.) “drum” ~ Türkic tümrüg/tümrük, dümrüg, tümri:, dümri:, tümrü:, dümrü: (n.), aka küvrüg (n.), “hand drum with side zills”. A prospective ultimate origin comes from the likes of the primal verb tVn/tVb/tVm “clap, kick”. Homophonic with a Türkic tambur (n.) “a kind of lute”. Such homophony is typical for initially undifferentiated generic words that acquire concrete meanings while spreading among different populations, Cf. mö:š, ma:čı: shared by cats and mice, a generic agach/ığač “tree” and the concrete Gk. acacia (ακακiα), bo:y “body” and the concrete boy, see boy, cat, mouse. A connection with the Türkic word tabor “encirclement”, for mobile fortifications used in the nomadic warfare, is superficial. Although both the drum and tabor are circular, these two were apparently etymologically confused. Cognates: Cf. Türkic tawil, tovïl, tovul, towïl “drum”; Ar. tabi, Pers. tabir ditto; Cf. Türkic tümrü:či “tambourine player”, and a word-formation of tokığu: “drum-stick” fr. tokı:-/dokı:- “strike, tackle” (see touch); Cf. the Sum. dub “kick”, a-dab “drum”, Etruscan taφu “beaten”, OIr. taflu “drum”, A.-Sax. tunne “drum, cask”, Hu. dob “drum”, taps “clap”, Chuv. tapta “trample”. All the above forms appear to be genetically related. The A.-Sax. -nn- clearly stands for -m-, the word tunne describes anything that has a drum shape, i.e. a cask, barrel, tun. The very Eng. word drum is an another allophone of the A.-Sax synonymous allophones, a scholarly tympan and a folksy timbrel “hand drum”. A term “drum” is widely used as a metaphor for a phrase “cylindrical vessel”, for example in machinery. Otherwise, the innate A.-Sax -drum/-dre/-der serves only as a non-substantive morphological adverbial suffix: sundrum “singly”, wundrum “wonderfully”. The spotty modern distribution, predominantly in the Gmc. branch in addition to the Türkic family, signals a status of a guest within the “IE” family. A recent reincarnation comes from the Fr. tambourin “long narrow drum used in Provence”. Provence was a kingdom of Burgunds, they may have modified a drum, but they used their Old Türkic name rendered as tambur. The OFr. (11th c.) forms tabor, tabur “drum” suggest that in the combination -mb-, the phoneme -m- is prosthetic. Even the oldest recorded Sum. word (ca. 4th mill. BC) must be eons younger than the times when drums became ubiquitous. The Celtic word ascends to about the same time, of the Celtic migration from the N. Pontic area on their circum-Mediterranean route to Iberia. Ultimately, the Fr., the OFr., and the A.-Sax. forms ascend to the attested Türkic base forms, and in their historical anabasis descend from the Türkic phylum. See boy, cat, mouse, touch.
English tire, tyre (n.) “hoop” ~ Türkic ter-, tir- (n.) “wheel, wheel hoop”. Ultimately fr. the verb tägir- “rotate, circle, twirl” and its later versions devir-/täwir-. The final -ir is an imperative case suffix, it had survived in most cases, and is articulated -z in some cases. The root ter-/tir- is a deverbal noun fr. the verb daŋ-/devir-/dola-/dür-/täg-/taŋ-/tawər-/tiar-/tigir-/tiw-/tüör-/tür-/ebir-/egir-/evir- “spin, roll”, devir/täräläk/teger/teker/tewir/teyir “wheel” and “wheel hoop (tire)”. The first consonant wobbles between d-, t-, and null, with rare oddball excursions. The most significant phonetic shift is at the second consonant, from the majority's -ŋ-/-g-/-ğ-/-k-/-q- to homorganic -v-/-w-, which turned into -y- and completely elided in the case that resulted in articulation tire, tyre. A suggestion of the direction -g- > -w- and not the other way around may be too presumptive. The present immense phonetic spread is just a sampling from the sources available, more forms may yet to be collected. An abundance of ethnically defined material provides for an ethnical diagnostics. The Türkic noun “wheel” is a grammatical extension of the verb tägir-, it applies to anything round rotating around an axis. The kernel verb is quite polysemantic, is has 6 general semantic fields, namely “rotate” (+ “turn” “fold” “return/returned”), “overturn, overthrow, subvert”, “botch, destroy”, “pervert/perverted”, “stitch up”, and “overáge/overáged, older”, plus metaphorical extensions, plus a series of localized colloquial meanings, many with noun/adjective complements. Accordingly, it produced a rich progeny, with the utility of some applications changing with time. The 20th c. made a modest colloquial “wheel hoop (tire)” to grow to an international “tire” now used across the globe. Cognates: A.-Sax. (root tev-) towriðan “twist apart, distort”, towtol “spinning implement”, toweraft “twist”, toweard “facing, approaching, impending, future” (Cf. turn (of a century), Eng. toward, towards), towendan “overthrow, subvert, destroy”, (root tär-) ðrawan “turn, twist”, ðurhðrawan “twist through”, ðraestan “writhe, twist”, hwearf, hweorfan “turn” (hweorfan has 17 allophones, from agengehweorfan to ymbhweorfan), hwearft “circle, revolution”, hwierfan “turn, change, convert, return, wander” (hwierfan has 10 allophones, from aehwyrfan to wyrfan), Eng. twist “spin, wind, twist together”, twirl, whirl “twisting, spinning turn(s)”, Fris. draai “turn”, ONorse hvirfla “rotate, spin”, hvirfill “circle, ring”, hverfa “turn around”, Goth. hvairban “wander”, wairþan “turn into”, Dan. vride, tur “twist, turn”, Du. draai “turn”, Sw. vrida “turn, twist”, Gmn. werben “convince, woo (i.e. change of mind, turn around)”; Ir., Gael. tionndaidh “turn, convert”, Welsh tro, thro, dro “turn, twist, bend, change”; Balto-Sl. (Lith.) vartyti “turn, rotate”, versti, verčiu “turn”, (Latv.) värtit “roll, revolve”, (Sl.) vorotit, vratit (воротить, вратить) “turn, reverse”; Lat. verto, vertere “turn”, Rum. torsiune “twist, torsion”, Port. torçao, virar “twist, turn”; Gk. diastrefo, desimo (διαστρεφω, δεσιμο) “twist, bend”; Skt. vartayati “rotate, circle, twirl”, vartate, vartati “rotate, roll”; Punjabi vari (ਵਾਰੀ) “turn”; Fin. vuoro “turn”; Arm. t’ek’um (թեքում) “bend”; Geor. ts’armartva (წარმართვა) “bend”; Ch. zhuan 转 “turn”; Kor. teuwi 트위 “twist”; Jap. tsuisuto ツイスト, tan ターン、“twist, turn”. Successive offsprings continue expanding phonetics by eliding the initial te- and starting with initial v-/w-; adding prosthetic initial consonant h- or prefix s- (Cf. swirl vs. whirl and twirl), etc., adding native suffixes and compounding words. Semantic meanings also kept expanding with concrete and metaphorical extensions. Such lexical flexibility posed insurmountable hurdles for the dogmatic “IE” etymologists, who had to invent special pleading faux “PIE proto-words” for each phonetic and semantic phenomenon, not unlike the primacy of the Greek eternal element aether found only in the heavens, Cf. swirl “of uncertain origin” and the whirl from wharf from “PIE root *kwerp- “turn, revolve”. In this example, the Gmc. *k- is a prosthetic consonant specific to the Gmc. branch and not to the entire “PIE” fiction, -wer- is Türkic tever- “turn, revolve” with abraded initial te- and with the Türkic imperative suffix -er-, and the final -p (or -l) is the Türkic passive suffix. All elements are attested, and there is neither a room for the phantom “PIE” inventions nor any need for them. Within the Türkic milieu also went on a stochastic developmental process similar to the Gmc. stochastic development. The modern recorded versions for the “wheel” with t- articulation, in addition to the expected teyir-/tewir-/teger-/teker-, are təgərmi, tӧŋgelek, tӧŋgülӧk, and the like, modified by the local versions of the additional agglutinated suffixes. Like the Gmc. examples, the unchangeable old suffixes are perceived as a part of the root, and require new conjugational and declensional suffixes. A Türkic tire-/tirä-/dire- (v.) “brace, support” may have conflated with the homophonous appellations for the “wheel” as a concrete appellation for the “wheel hoop”. That possibility would further narrow linguistic choice to specific populations. In the OT, the denominal derivatives of the verb tire:-/dire:- are widely used to refer to bracing implements like breastplate bracing and supports, and probably reflect times when brace plates were riveted to the rim, with the appearance of metals they became tire-iron plates that survived to the 20th c. Even deeper etymological roots for the Eng. term tire may lay in the term tir (n.) for “tree” and “lumber”, since tire- (v.) is a denoun verbal derivative of the tir (n.), see derrick. Lumber strip tires were used since Neolithic times, prior to the metals. Nearly all populations were using carts and tires and had established native vocabulary for that. Without auto parts stores along the pastoral routs, all repair parts had to be carried along. Scythians living in wagons had to use lumber or metal tires, Alexander Macedonian army used them, Chinese used them to deliver heqin tribute to the Huns, Eastern Huns used them to become Western Huns, Chingiz-khan army used them, the millennia of the Kurgan waves to Europe used them. The word has no “IE” connections, no English etymology, the “IE etymology” does not list cognates, the “IE etymology” (“attire”) is incredulous. Outside Türkic languages, cognates have particular distribution paralleling that of the numerous other Turkisms, and besides the “wheel” and “tire” and “time”, they should be inspected for the “turn”, “fold”, “overturn”, and all other meanings carried by the versions of the root tägir- and their deverbal noun derivatives, q.v. The meaning “tire”, due to the effects of our age presently used not by millions, but by billions, would predictably be a champion of the cognate lineup. A number of the daughter forms, like their Türkic predecessor, in addition to the notion “rotate, twirl” still carry the metaphoric notion of “time”, q.v. Such paradigmatic transfer carryover provides an indelible evidence of the genetic origin from the Türkic milieu. See derrick.
(Skip) Gmn. (n.) Tasse ~ Türkic tas/taz(n.) , Ital. tazze, French tasse, all “low cylindrical bowls”.
English theriac/theriacum (Theriacum Andromachi) (n.) “snake antidote” ~ Türkic tiryak (n.) “snake antidote”. Ultimately a deverbal noun derivative from the verb tara- “scrape, scratch (insect bite itch)” formed with a “rare” deverbal noun suffix -yaq/-yäk. The verb conveys a primary notion “disperse”, of which “scrape, scratch (itch)” and “comb” are secondary but prevalent meanings, maybe a result of accretion of two homophonous notions. The first vowel shifts between -a-/-u-/-y- (-ï-)/-i-, that and the “rare” among the eastern Türkic languages suffix -yaq may guide to a specific ethnic origin. The noun bears a wide cluster of meanings: “antidote, opium, narcotic, drug addict, heavy smoker, drunkard, maniac, quarrelsome, etc. I.e., it is a generic Türkic word widely passed across Eurasia with a single meaning, apparently in high demand by the consumers. Among the host languages were the Gk. (1st c. AD), Lat., Gmc., and numerous languages of the China, Persia, and India. Apparently, the antidote concoction was a trade commodity routinely carried to all ends by the trade caravans. Theriac was in use till the 20th c.Cognates: A.-Sax. ator, at(to)r, atr, atorcyn “poison, venom”, atorlaðe, atterlothe “antidote”, aetrian “to poison”, atorlic “poison-like”; Gk., Lat., Pers. theriac or close allophones, “antidote”; Ar. diryaq, tariaq, teryab “antidote”, Skt. tarksya “antidote”. The A.-Sax. words are well-internalized, the initial a-/ae- is a prefix “on”, i.e. “on-tor” etc. The A.-Sax. notion “poison” is a semantic back-formation of the notion “antidote”, it complemented the native terms clufðung, lybb, unlybba, mandrine. The suggested “IE etymology” fr. the Gk. “pertaining to animals”, “wild animal, beast" is too fanciful, unsuitable and unsustainable. The Gk. and Scythian amalgamated in the N. Pontic area (Cf. Herodotus IV 108), hence the Greek Türkisms. The Skt. form shows that the word was around long before Mithridates (2nd c. BC); probably it is millenniums older and was one of the remedies from the exploration of the poppies. The trio cannabis, valerian and theriac constitutes a case of paradigmatic transfer that attests to the word's Türkic origin. See cannabis, herb, valerian.
(Skip) English thread
~ Türkic “telu” “bowstring, to stretch”, Gmn. “Draht” ~ “wire”. Cognates: Eng. “thread”,
Gmn. “Draht”, Mong. “tele”, Hotan “ttila”, New Pers. “tel”, Kurdish “tel”,
Ossetian “tel”, Khal. “tele”, Buryat “telür”, Kalmyk “tel-”, Evenk “telbe-”,
Japanese “turu/tsurú”, etc. (Dybo A.V., Chronology of Türkic languages and linguistic
contacts of early Türks, Moscow, 2007, 806).
The Türkic is so far the only language where the word can be etymologized, which excludes all
branches of Indo-European and Tungusic families. The Eurasian spread of the word is amazing.
119
English tool (n.) “implement, means to accomplish some act” ~ Türkic tol-, dol- (v.) “completed, filled, full, fulfill, perform”. Derivatives tulum (n.) generic for “equipment, mechanical contrivance”, tolɣa- (tolga-) (v.) “to wind, wound (coil around), don, attach, squeeze, grasp”. The verb tol-/dol- “completed, filled, full, fulfill, perform” is a derivative fr. the verb to-/do- “stop, block, close”, see stop. The verb tolɣa- is formed with Türkic verbal suffix -ɣa/-ga. The Türkic derivatives favor the path tolɣa- (v.) > tol/tool: Türkic has derivatives tolɣaq (n.) “vise”, tolumlan- (v.) “to arm”, “to don armor”, tolumlüɣ (adj., adv.) “armed, equipped”. A likely etymological chain is Tr. tol (n.) “completion” > tolɣa- (v.) “action for completion” > Eng. tol/tool “implement to accomplish”; a direct transition from the Tr. tol (n.) “completion” > Eng. tol/tool (n.) “implement to accomplish” appears to be less possible. Semantics is mostly known as war implements like generic “weapons, military equipment”, with concrete applications like the “bow and arrows and military equipment”, “skin container, inflated skin used as a float” (tolku:k), etc., plus some traces from weaving. The initial consonant t- is fairly stable, the first vowel is indiscriminately -o-/-u-. Deverbal noun derivatives are mostly formed with instr. suffix -ma and deverbal noun suffix -g/-ig. Cognates: A.-Sax. tol “tool”, ONorse tol “tool”, Dan. (værk)tøj, Sw. (verk)tyg, Icl. tol, Gmn. (werk)zeug “tool”; Welsh teclyn; Pers. tulum “tool”, mainly in a military context; Fin työkalu, Est. tööriist; Mong. tökhöörömj (with instr. suffix -ma)). A loanword in Pers. The European cognates are all within the Gmc. branch, a testament to a non-IE origin. A suggested A.-Sax. word tawian “prepare” with a distant echo of phonetical resemblance is semantically unrelated. See stop.
English top (n.) “upper part” (Sw 76, F739 0.01%) ~ Türkic töpü (n.) “top”.
All Türkic recorded forms are bi-syllable, a single-syllable Gmc. versions show an internalization
process. The initial consonant t- is very stable, the first vowel is wobbling between
-ö-/-o-/-e-/-ä-/-ə-/-ü-, the second consonant wobbles between consonants homologous with
-b-, and the last vowel is most flexible. There are multiple speculations on the fancied
“proto-form” of the creationist model. The semantics and semantic extensions of the English and
Türkic words are nearly identical, except for the idioms top off as “finish” instead of
“full, to the brim”, top drawer, top gun, and topless, which appear to be late
American innovations. Türkic also used the word töpü for crown (anat.), pate, head, hill,
etc., the word numbers a total of 7 distinct semantic clusters. Notable is a correspondence töp
(tö:p) “upper part” – tüb (tü:b), tüp (tü:p) “bottom part”, typical for Türkic innate
archaic word-forming for similarities and contrasts, see deep. Notably, the stem is used in
the Buddhist lingo, tope - “dome-shaped shrine erected by Buddhists” (Cf. Tilla tapa ,
lit. “Golden Hill”), and in Native American, tepee - “Native American conical tent”, these
two terms are now international words in their own right. The first Buddha was a Türkic Saka extract
Shakyamuni (6th c. BC), of the Kurgan tradition, hence the Türkic term tope in Indian
tradition. Cognates: A.-Sax. top “top”, tobeadan
“elevate, exalt”, tobigend “bowing down, tottering” (lit. “over the top”, “genuflect”),
OFris.
top, NFris. top, tap, tup “top”, ODu. topp, Du. top, Sw. topp, Icl.
toppur, LGmn. topp, OHG, Gmn. zopf “top”; Rum. tepsan “pate”; Lith.
topas, Latv. tops “top”; Serb. tepe, tepeluk, tepa, tepaluk “top ornaments on
female headdress”; Gk. τεπες “highest”; Alb. tepe
“hill”; Basque tontor; Ossetian č'оpp “top”; Gujarati toka; Bengali
tapa; Ch. tou “top, head, hair”; Kor. tob; Jap. toppu “top”; Mong. deed
“top”, doba “hill”. The “IE etymology” is attesting to a non-IE provenance. Besides the deep
connections in Gmc. branch, there are no “IE” connections outside the Gmc. phylum, and the specs of
Romanic words “are probably borrowed from Gmc.”, while distribution screams against that.
Distribution: is spread wide across Eurasia and across linguistic families. The “IE” languages
generally do not have at all a so generic word for the upper part of anything. On dubious phonetic
homomorphy the “IE etymology” suggests a ludicrous “tuft of hair” as a precursor for the top,
with a faux PG
*tuppaz “braid” and a faux PIE *dumb- “tail, rod, penis”. That makes top a
metaphorical extension of a concrete tuft, and expressions like “on top of a rock” lit. “on
top of a braid, tail, rod, penis”. Such widely publicized etymological equilibristics is beneath
contempt. In Türkic etiology, “top” was especially important and everyday word, because of the
etiology of the upper world (aka heavens), and the mandatory use of mountaintops for sacral
ceremonies. Each tribe needed to know and use a local sacral mountain. That ritual tradition is
shared by Amerindians, pointing to its origin to be older than 13th-15th mill. BC. The exact
phonetics and semantics validate the Türkic origin: even for a 3-letter word a chance coincidence of
phonetics and semantics appear to be out of question, considering a slew of identical semantic
derivatives in two languages. The effect of paradigmatic transfer is reflected by consistent
transfer of semantic fields to the host languages: top and hill, upper part and bottom part,
elevate, exalt, etc. That the dispersed notions associated with the specific phonetic expressions
radiate from a focal point indelibly connected with the Türkic phylum. See deep, tip, tub, tube.
120
English tor (n.) “stony top, rocks on a hill” ~ Türkic tur-, dur- (v.) “be, stand (upright), stay”. Among Türkic verbs with grammatical functions, the verb tur-/dur- holds a special place in extent, wealth, and its grammatical diversity. The overlapping semantic fields of the tur- vs. dur- have diverged since the Stone Age with areal speciation forming complimenting flavors connected with tur- for beginning and dur- for finishing, e.g. “sand up” vs. “sit down”. The concrete notion tur- “stand (upright)” is a progeny of the flavor “rise, arise” from the beginning field. It is one semantic application from a polysemantic cluster numbering about a hundred applications. The flavor of stability (“sit down”) is reflected in the complimenting notions “durable”, “duration”, etc. A linguistic re-blending caused by millennia of migrations and amalgamations leveled the spatial distribution. As a transitional result, both forms spread across the Türkic milieu, leaving behind faint traces of the old areal speciation. The word tor belongs to the cluster that formed the notions “rock”, “hill”, “pile”, “tower”, and the like. The initial consonant t- and the second consonant -r are very stable, the first vowel is wobbling between -o-/-u-/-a-. Cognates: A.-Sax. torr “tower, rock”; Gael. torr “lofty hill, mound”, OWelsh twrr “heap, pile”; Lat. torus “tor” (n.). The Lat. turris “high structure” is obviously related to “tower”, and descend from the Türkic tura “tower”. In the Celtic Welsh and Lat., this is likely a part of the lexicon that the Celts carried during their circum-Mediterranean migration, the A.-Sax. word was likely brought over independently 2500 years later by the Sarmatian nomads fleeing an assault of their eastern kins. The parochial “IE” “etymology” of “possibly from a pre-Indo-European Mediterranean language” transparently implies a status of a guest within the “IE” family; the assertion “Mediterranean” reflects a mental myopia of the linguistic roamers. See durable, duration, duress, tower.
English toilet (n.) “potty, stool, commode” ~ Türkic tölet, tölit (n.) “seat, cushion”. In Türkic, tölet is documented as a generic term without specific application, but a homophonic derivative dölük means a more specific “rubbish pot”, pointing to a metaphoric origin of the term. In both forms the -et and -ük are suffixes modifying the base root töl-/döl- “completed, filled, full”, a passive form of to:- “stop”. The term toilet became an international word in the 20th c. with the invention in America (USA) of a porcelain plumbing lavatory cleaned by a water flow. Cognates: A.-Sax. not recorded, MFr. toilette “cloth, clothes bag”, a derivative of OFr. toile “cloth” and Lat. tela “web, net, warp of a fabric”, a signally dubious model: bypassing the Türkic “seat, cushion” a long distance separates “cloth bag” from a most primitive latrine. The semantic jump fr. MFr. “clothes bag” to “lavatory” is quite tenuous, and combined with the American vernacular origin is totally improbable, attesting to etymological conflation of “cloth bag” with “potty” based on phonetical fortuity; the metaphorical use of speculative toilette “dressing, clothing” for the toilet “potty” would be quite credible, but given the direct Türkic match the etymology does not need to appeal to a simile. The Türkic origin is direct, the Lat. origin appears to be a result of a folk-like etymology. Like other words related to private bodily functions, dictionaries tend to skip this word, making the path obscure. The word was probably introduced by the Burgund nomads, and regained legitimacy in England from the Norman lingo.
English total (n., v., adj.) “full, complete extent” ~ Türkic tutuš, tuduš, tütas, totosh (adj.) “complete, all”. The Türkic forms are ultimately deverbal nouns fr. a deverbal verb form in -a fr. the polysemantic verb tut-/dut- “seize, grasp, capture, catch”. The form in -uš/-as/-osh is connoting reciprocity. The word tut- “seize, catch” appeared in the sole surviving Hunnic phrase of the 4th c.: Süčy tiligan, Pugu'yu tutan “Army commander would order (to march, go), Pugu would (be) taken” (see take). The bridge to the extended semantics of totus (Lat. entire) runs from the tut-/dut- as a service verb to express a notion “completely” (e.g. “completely honest”) fr. a notion “solid” (e.g. “solid ice, whole thing”). The total, from the stem tot-/tut-, may be one of the oldest, judging by the extent of the functions the stem is conveying and the number of paired idioms like the tut- qap- “seize capture” with the stem qap- “capture”. Cognates: OFr. (14th c.) total; Lat. totus “all, all at once, the whole, entire, altogether”, tota (summa) “totality” (Cicero), (ex) toto “totally” (Cicero), MLat. totalis “entire, total”. The Lat. examples demonstrate declinable internalized root tot-, entirely identical with the Türkic root in phonetics and semantics. Romance languages use versions of tot-; the -l is a regular Türkic verbal passive suffix, seen in Lat. and OFr. examples, and many Eurasian languages. The “IE etymology” rates Lat. tot- as a “word of unknown origin”. Total belongs to the raft of 32 Türkic words denoting a concept “all”, along with all, entire, and gamut, each one endowed with its own unique path. The word, together with its derivative semantics, migrated from the Eastern Europe to the Apennine peninsula with its Latin predecessors, or with Etruscans from the Asia Minor, rejoining during the Middle Ages its A.-Sax. synonyms on the British Isles. However, the high proportion of R1b (ca. 60%) and a small proportion of R1a (ca. 3%) points to the overland Kurgan waves that settled in the Apennines as we know it today, and they were the most likely carriers of the Türkic lexicon there, eventually spread with the Lat. language. See all, entire, gamut, omni-, take.
English tree (n.) “tall wood plants” (Sw51, F1389, 0.01%) ~ Türkic terek (teräk, derek) “tree”. This must be among the oldest known words of shared vocabulary. Ultimately it is likely a concrete deverbal noun derivative of tire:- “prop up, support, erect” with a suffix -ek/-eg/-ig/-äg “standing, stander”. Other potential candidates are tir-/dir- “live”, tirig/dirig “alive”, tur-/dur- “stay, stationary”, ter-/der- “collect (firewood)”, and a conflation of these terms for a concrete noun. The polysemantic word comes in 26+ articulations (da:rek, derek, dirak, täräk, terek, teyek, terai, tierak, tirek, tirek, tırak, tӧrek, toɣraq, etc.) and 12 semantic clusters (“tree, fruit tree, poplar, poplar grove, 7 listed poplar varieties, aspen, willow, pine, fir, date palm, pole, shelf (many types), wardrobe, roost, shrub, tall (height), flower”), and some more. Of 44 European languages, 21 (48%) of mostly Sl., Gmc., and Celtic languages use Türkic ter- “tree”, approximating a level of the 50.6% R1a/b demographic presence in Europe. 8 (18%) Romance languages use versions of arb-; a Gmc. group of 5 (9%) languages use versions of bam-; and a Fennic group of 3 (7%) languages uses pu-. A remaining 7 (16%) languages use 7 their own native terms. Some European languages must have preserved their original synonyms for “tree” with a repurposed semantics. Cognates: A.-Sax. treowu, treow, OSax trio, ONorse tre, Goth. triu “tree”; OIr. daur, Welsh derwen, Gaulish deruos “oak”; Balto-Sl. (Lith.) derva “wood, pine”, (OCS) drievo (дриево) “tree, wood”; OFr. tre “tree”, Fr. dervee “oak”, Occitan drouille ”oak wood”; Romance - none; Gk. drys “oak”, drymos “brush, thicket”, doru “beam, shaft of a spear”; Alb. drusk “oak”; Skt. dru “tree, wood”, daru “log, wood”; Pers. dirext, daraxt, diraxt, tarak “tree”; Kalm. terəg “poplar, aspen”. Distribution: Eurasian-wide, across linguistic borders, with portable semantics applied to local woody variety. Distribution stops at a Far Eastern threshold; a heavily forested area had its own native terms unshakable to the newcomers. Unlike in Europe, the Zhou “Scythians” who penetrated all the way to Pacific did not supplant the native “tree” terms. Semantic portability pokes fun into attempts to rigidify “IE etymology” for fauna and flora, Cf. a terek “aspen” in Kipchak and Lobnor is a tireh “fir” in Sakha, Cf. cat, mouse. That casts a doubt on a flimsy linguistic paleontology of the “IE etymology” that suggests a separate faux “PG proto-form”, and a faux “PIE proto-form” *drew-o- “firm, solid, steadfast” and *deru- “oak”. Unwittingly, the invented “PIE root” is eidetic with the Türkic dur-/tur- (v.) “withstand, endure”, see duration. The alleged “reconstructions” are ludicrous, they conflict with a mass of attested forms and semantics, conflict with an obvious presence of the term at a Stone Age; it presupposes a largely deciduous environment, and extends an utilitarian quality to the forests surrounding pit-houses. The presence of numerous incongruent words for the “tree” in the “IE” languages, the attested terms in the Türkic languages, and the influence of the Steppe Belt on the sedentary neighbors and neighboring migrants suggests a linguistic development unrelated to the “IE” conundrum. An elision of a first vowel and a truncation or replacement of the suffixes is consistent with the linguistic tendencies in the NW Europe, while numerous words with vowel -e- in originally widely spread languages attest to its initial presence. In the 2nd mill. BC the word migrated from the Eastern Europe to India; Pers. forms are eidetic with the Türkic terek/derek, see derrick. The presence in English of the complimentary forms, tree, derrick, and acacia, constitutes an incontestable case of paradigmatic transfer, indelibly attesting to a common origin from a Türkic phylum. See acacia, cannabis, caragana, cat, derrick, duration, elm, juice, herb, mouse, valerian, wormwood.
English tuber (n.) “root” ~ Türkic tü:b (n.) “root”. The semantic span of the Türkic tü:b is exceedingly wide, covering numerous aspects of the root, its substance, function, and appearance: “foundation, basis, bottom, beneath, support, substrate (flat), very flat, ancestry”, and further semantic derivatives. The most consequential meaning is the flat substrate, known in the words “tablet (writing surface)”, “table (furniture)”, “table (tabulation)”. The secondary major meanings are tubular (cylindrical) shape expressed in the words “tube”, “tub (bathtub)” and impression on a flat surface “type (print)”, “type (precursor)”, “typing”, “typography”; numerous other meaning are expressed as semantic calques, like “the root of the problem”, “family roots”, “at the root of”, etc. The oldest use of the tü:b is Sum. tup (4th mill. BC) and Akkadian tupp (3rd mill. BC) for the substrate of the cuneal writing and then of any writing. With the art of writing the word spread out around the western Eurasia, creating allophones there in practically every language. As a cultural influence, the word tü:b may be classed as the most consequential cultural borrowing of all times prior to the invention of a computer. Evidence suggests that the tuber “root” originating fr. tü:b “root” was re-borrowed via literary sources, joining the Gmc. flat vessel tubbe “tub” of the same origin from the Türkic tü:b. Cognates: OE tub (15th c.), OHG zubar, MLGmn., MDu, MFlemish tubbe “tub”, Gmn. zuber “tub”, Lat. tubus “tube”, asserted to be “of uncertain origin”, plus all the above allophonic derivatives and semantic extensions “table”, “type”, etc. Gmn. has another semantically close Turkism tasse, an allophone of the Türkic tas/taz “washtub”, the pair constitutes a case of paradigmatic transfer. The Gmn. forms with anlaut z- ascend to a second form of tü:b with a voiced d- and typical Gmn. phonetic drift d-/z-. The absence of tü:b in A.-Sax. is consistent with the absence of clay tablets as a writing media in the tradition of the runic writing and the A.-Sax. demographic composition. In the Gmc. milieu have survived only the utilitarian word for the tub; most of the rest were introduced via Sum. and later intermediaries, some came via direct paradigmatic transfers fr. Türkic, others came as calques of idiomatic expressions, and others remained locked only in the Türkic circulation. The “IE etymology” invented a special PIE asterisked clone *tubh- “root” of the real tü:b “root”, and an underlying root *teue- “to swell”, phonetically likening a root with a thigh. That fantasy is totally unnecessary, by creating a bypass route it diverts from the real source of many sloppily explained and unexplained linguistic processes. See tablet.
English udder (n.) “bovids' mammary gland” ~ Türkic ud/uδ (n.) “bovine, cow”. The term ud/uδ is a component of the bovine-connected generic quintet buqa, koy/kon, öküz, sai/sag, and ud/uδ that made the Eng. bull, cow, ox, sheep, and udder respectively, see bull, cow, ox, sheep. The udder (late spelling) is formed by agglutination of a (rare) aorist (past tense) participial suffix -er to form nouns and noun/adjectives “milking” and the like. The use of verbal suffix attests the previous presence of a verb ud-/uδ- in the past and possibly in some modern languages, as attested by Sl. verb doit, udoi (доить, удой) “to milk, milk (yield)” and Tr. milk-processing lexicon uδïtma “cottage cheese”, uδïš- “to coagulate (milk)”, uδït-“to make cottage cheese”. Cognates: A.-Sax., OFris. uder, ONorse jugr, OHG utar, Gmn. Euter, “udder”, MDu. uyder, Du. uijer; Sl. doit, udoi q.v.; Lat. uber, Gk. outhar, Skt. udhar; Sum. gud “bull” in Ogur articulation with a prosthetic initial consonant, all “udder” except as noted. The distribution is consistent with with the bulk of other Tr. - Gmc. cognates, with the mass of cognates spread across Tr. - Gmc. phylum, and the balance on the fringes of the Steppe Belt; the Lat., Gk., and, ONorse peculiarities attest to independent paths. The transfer of the bovine paradigm, the phonetic and semantic match indelibly attest to the genetic connection. See bull, cow, ox, sheep.
English vacuum (n.) “void” ~ Türkic evük- (v.) “separate (from house)”. The verb evük- is a denominal derivative of the noun ev (eb/ef/ev “house”), which allows morphological formation of contrasting derivatives, “be in, reside, stay” and “be out, not reside, not stay”. Cognates: Lat. vacuum, vacuus, vacare “empty space, vacant place, void”; science made this word international. No “IE” cognates outside of Lat. The European forms come with elided and retained initial e-: vacuum, vacation, evacuate, evict, evoke, all with a primordial notion of “separate out”; the initial connection with “house” is long lost except where the “house” is a clause. The “IE etymology” appeals to unrelated Lat. vanus and Gk. kenon, uses a bogus PIE *eue- that is a manufactured clone of the real Türkic ev and evük-, and draws on phonetically unrelated samples as cognates; it leaves the stem vac- in suspension. See vacation, evacuate, evoke, evict.
English valerian (n.) “plant, a kind of parsley”, Heracleum sibiricum ~ Türkic pultäran, baldïran (n.) “a kind of parsley”, fr. baldïr “early, early (plant)” + -an collective suffix. Türkic baldïr also means “protrusion, cliff outcrop”, which with certain grammatical suffixation can echo the Lat. valere “to be strong”, and a notion “alien, adopted”, which echoes another A.-Sax. name for parsley wudumerce “wild parsley, wood-mint”. Cognates: A.-Sax. petersille “parsley”, OFr. valeriane, Lat. valerianus (adj.), Valerius (pers. name), valere “to be strong”. The “IE etymology” leads to OFr. valeriane, Lat. Valerianus, and personal name Valerius, valere “to be strong”, or to the Gmn. and Scand. forms pointing to connection with the saga-hero Wieland. Either suggestion would not pass a muster explaining the Türkic pultäran of the widely dispersed Balkars, Chuvashes, Tatars, and Altaian Kipchaks untouched by a Roman influence. Alternatively, the Gmc. version of baldiran, e.g. the A.-Sax. peter-, conflated with Lat. valerianus or OFr. valeriane, all of them ultimately of the Türkic origin, irrespective of the origin of the Lat. homophonic verb valere. The Türkic-based etymology is direct and credible, it points to two independent paths leading to the Lat. and Gmc. forms, and it parallels the Scythian cannabis (κανναβις) (Herodotus IV 74), an allophone of the OT kenevir “hemp”. The eastern Türkic languages have another name for “valerian”, qamsun, qamatzun, which appears to be a derivative of the verb qamsa “move, come in motion”, semantically echoing the Lat. semantics of valere “to be strong”. Such phonetic and semantic similarities on the opposite ends of the Eurasia need a miracle to be incidental. See other plant-related words: cannabis, caragana, derrick, elm, juice, herb, laber, tree, wormwood.
English woe (n., interj.) “evil, misfortune” ~ Türkic aba, ava:, ay, uvy (interj.) “oh, what a
misfortune”. Cognates: A.-Sax. wa, wea “woe”,
euwa, wa, wea (interj.) “woe!”, wealic “woeful”, ONorse verri, Sw. värre,
Goth. wai (interj.), OFris. wirra, OHG wirsiro, OSax. wirs, Goth.
wairsiza “worse”, OCS, Rus. uvy (interj.); Lat. vah, vае (interj.), Gk. οα,
ουα, ουαί (oa, ova/oua, ovə/ouə, ovai/ouai) (interj.), Av. avoi, vауoi (interj.) “oh,
what a misfortune”; Yidysh wei, wei-wei; Central Asian, Caucasus wai, wai-wai “oh,
what a misfortune”. The “IE etymology” is mute, in spite of the popularity of the expression in the
King James Bible “voe to you” and the idiom “my voes to you” i.e. “if you only had my problems”. The
phonetic link between woe and
ava:/uvy is clearly seen in numerous dialectal forms. Goth., with both wai
(interj.) and wairsiza “worse” demonstrates a transition from interj./noun to comparative of
“bad, evil” using native morphology. The Av. form attests to the antiquity of the idiosyncratic form
dating as early as the end of the 3rd mill. BC, before the migration of the future Indo-Iranians to
the South-Central Asia. See worse.
121
English voucher (n.) “receipt from a business transaction”, “summon into court to warrant title to property” ~ Türkic vučuŋ, bıčığ, bıčğa:s (n.) “receipt, voucher, warrant”. Ultimately, a deverbal noun derivative fr. bič- “cut” (per G. Clauson). The word is most remarkable: Türkic (probably, still Zhou nomads) word has cognates in Eng., Fr., Gallo-Romance, Lat. vocitare, vocare, and Chinese 憑證 buchun, po-čhuŋ ditto, pyn. píngzheng (v.) “make up, compensate”. Türkic has allophone vučuŋ/bučuŋ, indicating a western (like Ogur Sartmatian or Hunnic) and eastern (like Zhou, Tokhars/“Uezhi”, proto-Huns) phonetics. The word could not have existed before the Zhou “Scythians” brought writing over to the future China ca. 16th c. BC, hence it appearance in Europe postdates the appearance there of a writing and an arrival of some kind of the literate “Scythians” there. Likely, it was brought to Europe with the western Hunnic state ca. 4th-5th cc. The words vouch and voucher lurked somewhere in the English folk language until they popped out sometime in the 17th c. See vouch.
(Skip) English wake (n.) “wave behind boat” ~ Türkic vak (n.) “wave behind boat”. Cognates: A.-Sax. wacu (n.), wæcnan, wæcnian, awæcnan, onwæcnan, awoc, awacen, awakien, awacian, awacode (v.), ME awecchen, aweccan (v.), OSax. wakon, OFris. waka, Goth. wakan, ONorse vaka, OHG wahta (n.), wahhen (v.), Gmn. wachen (v.), MDu. wachten, Du. waken, Dan. vaage; Lat. vegere, vigere “vigor”; Skt. vajah (n.) “vigor”, vajayati (v.); Kor. byongɣan “vigil”; Türkic Chuv. vak-, văran-, Turkm. oya-, Karachai, Kumyk oyaw, Tatar uyaw “alert, wake”. The base semantic of the word wake is “to become, to be alert”. It is apparent that the base stem is uy-/oy, which in the case of the western Sprachbund attained a prosthetic anlaut v-/w-, and in many languages transformed the semi-consonant -y- into a variety of consonants -c-/-d-/-h-/-g-/-yg-/-ɣ-/-k-, with -c-/-h- (-ch-)/-g-/-k- predominating in the west (vak-, vaka, wah-), and -d-/-h-/-yg-/-ɣ- taking hold in the east (oyg, od-, uh). Most of the eastern languages retained the initial root uy-/oy (Azeri, Turk., oy(an), Skt. vay(ah), Uigur uy(ag)). The Kor. version demonstrates a spread from Atlantic to Pacific. English is unique in that it recycled the Türkic suffix a- denoting result of action named by the stem (vak “alert” > vaka “be alert, alerted”) into a prefix (wake “alert” > awake “be alert, alerted”), that transition probably came during initial adjustment to the novel flexive morphology typical for the incipient “IE” languages. Notably, the A.-Sax. forms awacan and awaclan differ by the Tr. adjectival suffix -l-, which makes these two forms “to awake” and “awaken (adj.)”, instead of misinterpretable “to awake” and “to awake”. The semantic extension from the raw notion of “alert, alertness” to the process of alertness (vigil) and consequences of alertness (wake) occurred before the migratory fractionation, since the daughter languages carry those meanings (wake 1. aftermath, outcome, 2. vigil, 3. funerary feast). The vacillations between the transitive and intransitive forms are the product of the linguistic development, that problem could not have arised in the languages with morphological means of instinctively producing transitive verbs. The “IE etymology” is practically non-existent, the wacky PGmc. *wakwo leads nowhere, and explains nothing. Modern derivatives: vigil, watch, wake (boat), wake (funerals), wake (outcome), etc.
English wax (n.) “bee wax” ~ Türkic auz, avus, awus “bee wax”, fr. a:v (n.) “hunting, game”, a:v- (v.) “surround, swarm” with archaic deverbal noun suffix -s/-z. The obvious difference between au/avus/awus and the Du. wass, with its numerous allophones, is the prosthetic anlaut w-. A derivative verb evze:- “flurried, confused, distressed” from auz, avus graphically illustrates the perils of dealing with swarms of bees. Semantics of the Türkic word points to the hunter-gatherer time, when hunting included any side prospecting like hives; a prospecting as supplemental sustenance continued well into modernity. English inherited a quad of bee-related terms, apian, bee, mead, and wax, of which three, bee, mead, and wax came as a paradigmatic transfer, unconditionally testifying to the linguistic and ethnic genetic connection. The focal word in the quad is “honey”, which sports Türkic allophonic forms ba:l and mır, with a consensus that they are related to the respective “IE” lexicon, see mead. A separate consensus formed for the “wax”, with its own etymology divorced from that for “honey”, a situation typical for the spotlight-oriented “IE” linguistics. Cognates: A.-Sax. weax “bee wax”, OSax., OHG wahs, ONorse vax, Du. wass, Sw. vax, Gmn. Wachs; Balt. (Lith.) vashkas, (Latv.) vasku, OCS vosku (воску); Hu. viasz, Fin. vaha, Est. vaha; Ch. la “wax”; Xak. la:v “sealing”. The European forms uniformly start with a prosthetic v-/w-, typical for the Eastern European, and particularly Sl. and Gmc. allophones, it is v-/w- + auz, avus; the Ch. form sports a prosthetic anlaut l-, the Ch. form was apparently re-imported as the Xak. la:v for a concrete noun, paralleling that of the archaic auz, avus. Some phonetic peculiarities include a loss of initial unaccented a-, the s/h alteration typical for the Aral area (Horezm, Bashkort) visible in Uralic languages (Hu., Fin., Est.), and ks/sk metathesis. None of the “IE” etymological theories that connect wax with avus and separately la with avus delve into a mechanism that connects the English wax on the Atlantic coast with the Ch. la on the Pacific coast. Within the “IE” paradigm, the extent of well-defined areal distribution has no meaningful explanation. Neither do the “IE” etymological theories offer the initial etymological origin for the “reconstructed proto-words”. Neither is noted, addressed, or explained the phenomena of the paradigmatic transfer of the triplex bee, mead, and wax. The trend of the Middle Ages, when the same entity governed both fact and fantasy, managed to endure into the 21st c. To fit into the “IE” paradigm, the family tree-based comparative linguistics has to offer numerous “proto-words” for diverse language families. Or to switch to a different model where all “proto-words” except for one would be obvious loanwords from other families. It can be reasonably suggested that for some very long time, the bee wax was a commodity in demand across Eurasia connected by established trade routs, and it came with its own lexicon that gained the same popularity as today's words computer and democracy. See apian, bee, mead.
English while (n., v., conj.) “period”, “spend a period”, “at the same time” ~ Türkic äwwä, ävväl, evväl (adv.) “at first, before, in the beginning” (adv.), “before, in front of” (postposition). Ultimately a derivative of the verb e:v- “hurry”. See awhile. Contrary to the “IE” verbose nonsensical etymology, while is an elision of awhile, an allophone of the äwwäl. It has nothing to do with the suggestions of phonetically and semantically unrelated notions for “rest”, “bed”, “joy”, quite distant from the real semantics of the “time interval”. Such etymological equilibristic is obviously disingenuous. An extant Ar. homophonic synonym would be a more reasonable suggestion if its derivation fr. an Ar. root could be established, an impossible wish. Since the word time is a form of the Türkic timin, the two separate notions of time and awhile/while always co-existed, without a need to convert the word awhile into the word time. Likewise, the notion of “rest” is a derivative of the notion “period”, expressing “rest for a while”, “lounge for a while”. The form while is a natural oral contraction of the non-accented anlaut vowel, a derivative of the form awhile (adv.). See awhile, time.
English whip (n., v.) “lash” ~ Türkic yip (n.) “cord, string”. Cognates: None besides Türkic languages, only English; no Gmc., European, or “IE” cognates. The phonetic and semantic match is perfect. An idea of pre-historical borrowing fr. English into the bulk of the Türkic languages is a non-starter. No “IE” etymology, not a whiff of suggestion. This word belongs to the lexical cluster of Turkisms that was inherited by English independently fr. other Gmc. languages, and may be a useful marker for linguistic and demographic tracings. The connection with a fox-hunting leads exclusively to the Türkic nomadic ethnology, and sheds light on the origins of the British aristocracy and the peculiar British traditions of freedoms, justice, parliamentarism, bag of wool, and Queens. English did good enlarging the simple nest yip/whip “cord” into a flowery constellation of 30 forms, from whippletree to whiplash to whipper, whipsaw, whipping cream, and far beyond.
English wormwood (n.) “herb (Artemisia)” ~ Türkic armuti (Chuv.) (n.) “wormwood herb (Artemisia)”. Ultimately a derivative fr. arem/ärïm (Kazan-Tatar, Bashkort), a form of the CT verb arï- “clean, cleanse, removal”, with ut “grass”. The obvious phonetic difference between armuti and worm, wermod is the prosthetic anlaut w- typical for Gmc. (and Sl.) forms of the stems starting with vowel. Cognates: A.-Sax. wermod “wormwood, absinthe (alcoholic drink)”, OSax. wermoda, Du. wermoet, OHG werimuota, Gmn. Wermut “wormwood”; Lat. artemisia. The Lat. word appears to be a debased arem/armuti. In the eastern Türkic languages armut is “pear”, a frequent case of recycling floral/faunal terms. The herb is used for medicinal purposes, specifically to treat hawks, disinfect, as an aphrodisiac, and to add bitter taste (vermouth). The “IE etymology” is routine “etymology is unknown”; western distribution is limited exclusively to the Gmc. linguistic branch. Reference to the hawks and Türkic semantic shift typical for flora and fauna terms corroborate the Türkic origin. A.-Sax., in parallel with the native wermod and suðernewudu, also use dan “educated” Lat./Gk. sufficiently consonant loanword abrotonum. In English, until Middle Ages, the word lurked as a “folk word”. See other plant-related words: cannabis, caragana, derrick, elm, juice, herb, laber, tree, valerian.
English wrinkle (n., v.) “crease” ~ Türkic burki: (burqï) (n.) “wrinkle”, burqar-, burkur- (v.) “wrinkled, winced”. Ultimately fr. bur-/bür- (v.) “twist, wind round, screw” with a deverbal noun/adj. suffix -q “wrinkled”, see bore. Cognates: A.-Sax. wrinclian “wind”, then OE (ge)wrinc(l)(od) “wrinkled, crooked, winding”, Dan. [w]rynke, Sw. [w]rynk, Norse [w]rynke, Gmn. [w]runz(lig); Rus. morschina (n.), morschitsya (v.) (морщина, морщиться) “wrinkle, to wrinkle” with b/m alternation. The semantic difference (“wind, coil” vs. “wrinkle”) and difference in articulation with preserved or elided initial b-/w- and the Türkic adjectival suffix -l “wrinkled” points to separate Gmc. paths; still another path leads to the Sl. form. The Türkic-origin word parallels native A.-Sax. synonyms hnycn(ed), rif(lan), rump(en) “wrinkle”. The “IE” version of a faux “PGmc. proto-word” *wrankjan, pandered from the A.-Sax. attested lexicon, unwittingly ascends to the attested Türkic verb bur- (bür-) q.v. That misleading hypothetical speculation is not needed. Semantic and phonetic patterns may help to pinpoint specific ethnic origins. See bore.
(Skip) English yacht “watercraft” ~ Türkic yaɣ- (v.) “come (rain), fall (luck), pour (sand), approach”, the notion of movement. Cognates: ONorse jaga “to drive, to move to and fro”, Norw. jaght, OHG jagon “chase”, MLG jacht, “chasing ship” fr. “chase”. See jag.
English yield (n., v.) “income, proceeds (per period)” (n.), “give, pay, hand over” (v.) ~ Türkic
ılkı:/yılkı: (n.) “yield (per period), litter, offspring”. A derivative of
ıl: (Oguz)//yıl
(Ogur) “period, year”, initially connected with annual yield from the herds and fields and later
expanded to tolls, rents, and taxes. Not only ıl: and al-, algı are synonymous in
respect to the “alms, offering, payment” without religious overtones, and with the A.-Sax.
alle(gan, -fan) “yield”, it was even suggested that the verbal il- was a second form of
al- “take, capture, accept” (Clauson EDT 125). Essentially, yılkı:
is an adj. “annually, continuous (something)” that narrowed the implied “something” to “annual
growth”, “yield”, “pay” and a litany of domestic animals' litter. Cognates: A.-Sax. alle(gan,
-fan) “yield”, WSax. gield(an) (v.), Anglian geldan (v.) “pay”, OSax. geldan
(v.) “be worth”, ONorse gjaldo “repay, return”, MDu. ghelden, Du. gelden
“worth”, OHG geltan, Gmn. gelten “worth”, Goth. (fra)gildan “(re)pay,
(re)quite”; Balto-Sl. (OCS)
žledo (jledo), (Lith.) geliuoti “pay”. The anlaut consonant g- in the western
forms (gield, geld, gjald-, gheld, jled-) is consistent with the phonetic peculiarity
of the Ogur languages. The survival of both forms (gield etc. and yield) in the
historical records indicates that they were brought over and used by at least two linguistically
distinct groups. Probably, the Ogur form gıl- was a first source, later supplanted by the
Ogur form yıl-. The auslaut -d/-t probably is a relict of the 3rd. sing. verbal marker
of the verb yıltı “(he) pays” that in the eastern languages was recorded only in the nominal
form yılkı: with a nominal suffix -ki. No “IE” connection, no cognates outside of the
northern European NGmc. and Balto-Sl. groups. Distribution, besides the Eurasian spread of the
Türkic languages, is peculiarly limited to the NW Europe. The antiquity of the word is attested by
numerous and far-flung semantic extensions reaching into all matters associated with payments, from
secular to religious: “money, reward, render; worship, serve, sacrifice, worth, cost, repay,
concern”. In extreme cases it is the Gmc. gold, gelt, geld “metal, coin” and “money”
respectively, the modern Wall Street “y/p ratio”, and the A.-Sax. godgeld, godgield
“offering”, a compound of god + gield in a colloquial phonetic form of the Türkic
kut “spirit” + yılkı: “yield, income”. The metaphoric semantics of yield (v.)
“cede, concede” is a late colloquial innovation. In tracing etymological links without understanding
the core meaning of the yield “give, pay, hand over”, the surviving semantic derivatives
distract, rather than help. Still in the Türkic milieu, the phonetically and semantically similar
forms of
yıl- and al- have probably conflated, expanding their respective semantic reach, that
is expressly visible in the term for gold, which straddles the stem yıl in the west
and stem al- in the east. The proximity of the stems yıl-, ıl- and al- in the
derivative forms
gold (western) and altun (eastern) makes etymological attribution of the ultimate
source equally viable. See alms, gold.
122
1
English above (adv., adj., prep., n.) “over” (Sw N/A, F1914, 0.00%) ~ Türkic up-, op-, ob- (v.) “up,
rise, go up”. A most salient expression of up- from the days of the animal freight horsepower
is the command to get up and move on, cited for the 11th c. Khakas and the Middle Age England (17th
c.). The Türkic verbal stem reached us in a number of verbal conjugations and derivatives:
infinitive deverbal verb opla- “rise up to attack”,
opra:-/opran-/apra-/ofra-/ofran-/ipre-/ipren- “grow up in age, to age”, oprat-
“over-aged, weary” causative of opra:- with the same phonetic changes as opra:-,
passive opul- “upped”, deverbal noun opu “upsurge”, deverbal noun/adj. obuz, opuz
“hump, humpy”, deverbal adj. opraɣ, opraq “up in age, aged”. A linguist would have to make an
effort to miss the connection between derivatives and the root verb. Two other Türkic verbs are
similar to up-, one is a:ğ- “rise, climb, ascend” (Cf. high) and the other
a:š- (Cf. astir) “cross over” without implicit implication of rising. That nuanced difference
makes above and over synonymous, both imply rising. Cognates: A.-Sax. bofan, bufan,
bufon, beufan “over, above”, versions aboven, aboun, abow, abufan, onbufan, OSax., OHG
oban, Gmn. oben, Du. opper, boven; Skt. bhavagra. The forms, diverged by
different host vernaculars and independent development, reconvene in a new milieu, bearing close
semantics but widely differing forms, mostly featuring a loss of the initial vowel. The contrast
with the forms for allophonic above is more pronounced. Typically, some of the divergent
forms stabilize by their semantic shade, grammar function, and expanding utility. The semantic
overlap of the forms abufan, bofan, bufan and their siblings with the forms ofer, ofor
and their siblings variously expressing the same notions “over” and “above”, and their phonetic
similarity point to their common origin ascending to the same Türkic verbal notion up-, op-, ob-
“up, rise, go up”. That observation is further supported by the similarity in the wide phonetic
dispersions and limits in geographical/ethnic localizations. The distribution of the cognates is
typical for the Türkic siblings, the N.W. Europe plus the Türkic steppe belt, extending from
Atlantic to the Pacific and within the borders of China. Peculiar on the Türkic side, the word
over had gained incompatibly larger distribution than the geographically confined above;
that trait may help to illuminate the underlying historical processes. The “IE etymology” confuses the
semantically unrelated directional prefixes/prepositions Gk. epi “at, near”, its Lat.
allophone ob ditto, Gk. opi- “behind”, Oscan op, Lith. ap- “about,
near”, OCS ob “on”, Skt. api “also, besides”, Av. aipi “also, to, toward”,
Hittite appizzis “younger” i.e. supposedly “(those) behind” with the A.-Sax. deverbal adverb
up, uppe “up, upward”, the cognate of the Gmc. allophones OSax., OFris., up
“up, upward”, ONorse upp, Dan., Du. op, OHG uf, Gmn. auf “up”, Goth.
iup “up, upward”, uf “on, upon”, OHG oba, Gmn. ob “over, above, on, upon”
that expressly pinpoint an upward move or position. Such inapt mechanistic wiles are unsustainable.
Notably, a related Türkic bava, baba (n.) “upper point, top” offers a real and viable
alternative for the origin of the “above”, without scholastic equilibristics, it suggests a
conflation of the noun notion “top” with the verbal notion “up, upward”, i.e. the typical Türkic
emphatic pleonasm. Tautology is a common event in linguistic amalgamation (cf. shagreen leather,
whole gamut, etc.). The terms above, over, and papa/baba are intrinsically connected.
Internalized into the European syntax as bava with an action prefix a- “on” (Cf.
alive, asleep, aback, afoot, etc), it is semantically identical with the action notion “above”. The
phonetic connection with the papa/baba is striking, statutorily papa/baba relays the
very same semantics of “upper, above, top”. Of the two etymological scenarios, one for both over
and above being expressions of up-, op-, ob-, and the second for above deriving
separately from bava, baba, the evidence tends to lean in favor of the first scenario due to
consistent overlapping. The second scenario, based on the paucity of the vestigial evidence, suggest
a reborrowing from the Corded Ware vernaculars back into the Türkic milieu. G. Clauson (Clauson
EDT) cites 40 instances of reverse reborrowing of Turkisms back into Türkic. In this
hypothetical case the bava “father, upper” returned with a narrowed sense of “upper” as
opposed to baba
“father”. The common origin of the Eng. and Türkic lexicon is evinced by the paradigmatic transfer
of the semantically kindred quartet above, over, high, and papa, an indelible
testament to the common origin. See high, over, papa.
EDT 299bedü:- (grow, increase)
(Skip) English abundant (adj.) “in great quantity” ~
Türkic abadan (adj.) “plentiful, crowded, numerous, populous”. Ultimately fr. the stem bedü:-
(v.), bedük (adj.) “big, great”, Cf. oğla:n bedü:di:
“clan grew big”, see clan. Cf. English “be abundant” ~ Türkic “abadan bol” “be (become)
plentiful, crowded, populous”. The Türkic form is echoed in the A.-Sax. blaed “prosperity,
riches, success”, Cf. blaeddaeg “day of prosperity”, see day, blaedgifa “giver
of prosperity”, see give. Cognates: OFr. (12th c.) abonder, (14 c.) abundant
“plenty”, Lat. abundans, abundare, abundo “plenty”; Pers. abad, abadi “populous,
flourishing”. The A.-Sax. anlaut bl- (blaed) corresponds to the Türkic b- (bedü:-).
The anlaut a- of A.-Sax. speech marks the verb as momentary, a single event: abedü:-
(v.), Cf. abide, arise, awake, ashamed; in Romance it is directional to/from like in acculturate,
abandon; the Greek negation a- can't apply. The modern Türkic abadan with anlaut a-
is probably a re-importation of the Europeanized forms to follow the European literary usage. The
European persistent inlaut -n- is probably an effect of the Romance articulation with
prosthetic -n- instead of the forms aboder, abudant , abudans, abudare,
abudo, probably under the influence of the semantically similar Türkic precursor bunča
“so many, so much”, the base for the Türkic bandur- and Eng. bundle. A closer phonetic
and semantic cognate is hard to imagine. Statistically, the probability of the same 3-syllable word
with the same semantics randomly appearing in two unrelated languages is vanishingly small, see
example for a single syllable “bad”. As a paired compound, probability of retaining the same
expression that seems to preserve intact is even smaller by orders of magnitude. See bad, be,
clan, copious, day, give.
2
English agaze (adj.) “peering, staring” ~ Türkic ög- (v.) “perceive, realize, see”, ögse- (v.)
“eyeing, penetrate, perceive”.
Ultimately a derivative fr. a verb ö- (Eng. spelling awe) “perceive, think,
understand, see”, noun ög “mind, thought, perception”, see awe. The word numbers 5
semantic clusters, EDTL lists four of them. Ignoring a visual perception, EDTL lists
13 of 16 total meanings. A notable feature of the word is that the notion “perceive, perception”
seamlessly conflates mental and optical aspects, an integral mental and ocular perception, Cf.
idioms “yes, I see it” and “yes, I realize it”. Apparently, by the time the word reached A.-Sax. and
Scandinavian dictionaries, its semantics swaged down to a notion of fear and horror. Still, possibly
from religious sources, Eng. inherited notions of overwhelming feeling of wonder, admiration, and
profound respect. An optical aspect of one semantic offshoot developed the noun ög into a
pleiad of terms for vision: eye, oko, oculus, ocular, oculist, agaze, gaze, gazer, and more. A
second offshoot produced mental “admiration”, a third - mental “fear, terror”, a fourth - mental
“aware”. In spite of a thousands-years presence in Europe and extensive borrowings, the spread of
ö/awe remains scattered and localized, covering only 11 (25%) of the European languages. The
other 33 (75%) of the European languages use 22 of their own terms mostly expressing notions of
scare and admiration. Best internalized is A.-Sax., it developed numerous semantic extensions.Cognates:
1. awe: A.-Sax. aege, ege, oga, oht “awe, fear, terror, dread, influence”, egeful,
egesful “awe, awful, inspiring awe”, egelic “terrible”, egesa, egis- “awe, fear,
horror, peril, monstrous thing, monster, horrible deed”, OHG agiso “fright, terror”, Goth agis
“fear, anguish”; 2. eye: A.-Sax. agmore “eye socket”, aesmael “microphthalmia”,
andeages “eye to eye”, an-eage, an-(a)gede “one-eyed”, eage, eahe, ea “eye,
aperture, hole”, eagecee “eye-ache”, eaghyll “eyebrow”, OSax. aga “eye”, WSax.
eage “eye, eye area, aperture, hole”, Mercian ege, OFris. age, WFris. each,
MDu. oghe, Du. oog, Dan. øie, Sw. öga, ONorse auga, agi, Norse
Bokmal øye, Norse Nynorsk auga, OHG ouga, Gmn. auge, Goth. augo
“eye”; Scots ee “eye” (but Irish awe, Welsh parchedig “revere”, ofn
“fear”); Lith. akìs “eye”; OCS око (oko) “eye”; Arm akn (ակն) “eye”; Lat.
oculus “eye”; Gk.
osse (οσσε) “eyes”, ops (οψ) “eye (poetic); face”; Skt. akši “eyes”, Av. aši
“eyes”. The original conceptual notions “perceive, think, see” had largely devolved to critical
conc. tangible concepts: fear, eye. Distribution: available information is too curt, but it
still points to a Eurasian spread: Atlantic on the western edge, Uigur on the east, and Osman,
Chuv., Vogul (Mansi, Ugric), Chag. in between (VEWT 368, 569, EDTL 501). The “IE
etymology” displays a highest degree of incompetence, it completely misinterpreted every possible
element, and replaced very substantial attested evidence with asylum-quality fantasies. The
IE-suggested arsenal of “IE” bravery – “fear, fright, terror, anguish” for a notion ö/awe
“perceive, think, admiration” is rather emotional than linguistic. Faux “reconstructions” of the
type “PGmc. proto-word” *agiz- “fear?”, *agaz “terror, dread”, “PIE proto-word”
*agh-es- “pain, grief”, “PIE proto-word” *hegh- “upset, afraid”, and “PIE proto-root”
*okw- “see” are not needed except for a misleading patriotic propaganda. Falsifications float on
the surface: a falsely cited attested Gk. akhos “pain, grief” is an allophone of a Türkic
aɣrï “sick”, the “PIE proto-root” *okw- “see” is an allophone of the attested Türkic
ög-/og-“see” addressed in very this article. A wealth of the attested material and a case of
paradigmatic transfer of the notions awe and ok “see, eye” with their numerous
siblings (Cf. awesome, awful, awing, awe-inspiring, etc.) indelibly attest to a genetic origin from
a Türkic linguistic phylum. See awe, eye, ogle.
3
English agile (adj.) “spry, adroit” ~ Türkic ačïl-, aǯïl-, ačïl-, ačal-, (v.) “open up, open;
blossom, bloom”.
A root ač- (~ /ædʒaɪl/) is very polysemantic, numbering 16+ semantic clusters with ca. 50
meanings. Old Türkic usages define specific applications of a general term. The forms ač-/aǯ-
are semantically indistinguishable from the form
aq-, and probably reflect genetic connection and dialectal variation. An overall notion of
the stem is “start an action”, “set in motion”. The stem ač-/aǯ- with passive suffix
-al/-il denotes activity exemplified by English concrete verbs “open, open up, pave the way;
untie, detach; dispel, dissipate, disperse, fork (point); resolve (problem), decide, assoil; check
out; distinguish, discern”. Notionally, adj. parallels modern English pairs “sleepy” < “sleep”,
“runny” < “run”. The form
agl- predominates in Europe, out of 44 European languages it is used by 20 (45%) languages,
compatible with a level of 50.6% R1a/b demographic presence in Europe. That single group is
linguistically motley, of all significant linguistic branches. The remaining 24 European languages
use 13 of their own native terms. Such lopsided distribution attests to the agl- “guest”
status in Europe, and no “IE” connection.
Cognates: ONorse aka “to drive”; MIr. ag “to fight”, (but Welsh ystwyth
“agile”); MF agile, Lat. agilis “nimble, quick”, agere “move, drive”, fr.
agere (fr.
ag-) “do, set in motion, drive, urge, chase, stir up”; Gk. agein “lead, guide, drive,
carry off”, efkíniti (ευκίνητη) (fr. ευκ-) “agile”; Skt. aja- “drive”;
Finno-Ugric, Komi-Zyryan az “cleft”, Mansi-Vogul äs “indentation”; Mong. аčа
“furcate”, Kalm. ats ditto; Manchu ača “join”, аčаn, ačabun “joint”.
Distribution: from Atlantic to Pacific across linguistic borders. Across linguistic borders, the
original extended semantics found new specific extensions and applications. A Lat. “PIE” root ag-
is a routine allophone of the Türkic ač- articulated with local phonetic tools, no “PIE”
prefix is needed, Cf. ač-, ag-, ak-, efk-, aj-, az-, äs-, ats-. A shared stem's forms and
notions point to a time layer possibly ascending to the 6th mill. BC, before the departure of the
Celtic Kurgans on their circum-Mediterranean path. A Türkic genetic origin indelibly stands out.
4
English akin (adj.) “close, similar” ~ Türkic jaqïn, yakın, yağu:k “close, near, relative” (adj.,
adv.).
A derivative of the verb yak- (yaq-) “approach, come close, near”, with extensions “ajoin,
join”. An “IE etymology” derives akin fr. kin,
a Türkic allophone of kun/kün “relative”, see kin. Either etymology is perfectly
viable, a difference is in direct inheritance vs. later adaptation to the areal vernacular. For the
“near, relative”, 44 European languages use about 30 different native terms. There is no
Pan-European or “PIE” word, the word is positively an “alien guest” in Europe and outside of the
Eurasian Steppe Belt. Cognates: A.-Sax. kin, akin “near, relative”; Scots akin
ditto; Basque akin ditto; Pers. yaqïn ditto (Doerfer IV, 1527); Mong. (d)aga
“follow”; Tung. (d)aga “near, next”; Mansi-Vogul jayu “approach”, jayuk
“vicinity”; Kor. gakkaun (가까운) “near”; CT yakın “near,
relative”, Chuv. yakın, yahaŋ ditto. Distribution: from Atlantic to Pacific, across
linguistic borders, with few puny islets in W. Europe. Chuv. and CT words sound nearly identically,
pointing to a fossilized primordial form. Since the notion
kin, relative ascends to the earliest human concepts, so must be the word. The Türkic word
likely morphed to an A.-Sax. routinely prefixed form, at least in the minds of speakers. A presence
of numerous A.-Sax. native synonyms (freonhealdlic, maeg-, and (ge)sibb) and nearly
complete absence of the European cognates favors a direct continuity from the Türkic original. A
Heb. יְהוֹיָקִים (Yehoyakim “created by Yahve/Yahwe”, lit. “by Gods”), Cf. Joachim,
turned into Sl. name Yakim, supposedly a baptismal name, but suspiciously close to jaqïn,
yakın “kin”, its Sl. traditional interpretation is “mentally or physically infirm”, a far cry
from kins and Yahves. Rather, a casual naming followed a custom of calling relatives yakın/yakım.
A tendency of the Sl. speakers to use local sobriquets in lieu of the alien words, a predominance of
the Türkic languages in the Eastern Europe before a start of Sl. migrations there starting in the
6th c. AD, and a christianizers' tendency to use names palatable for the receptors, makes far-flung
associations dubious, especially so in respect to the minds of the 10th c. recipients. Whether
A.-Sax. or Sl., the effect of leveling does it job. See kin.
5
English all (n., adj.) “full or entire extent” (Sw N/A, F37, Σ0.78%) ~ Türkic alɣu, alku:, alqu (n.,
adj.) “all”.
“IE etymology” abstrusely rates as “no certain connection outside Germanic”, “of uncertain origin”.
Other recorded forms are alaj, aley, aleyi, aleysi, alajı, etc. The Türkic verbal stem is
al- with numerous lines of meanings. Among them are “capture, gain, take, take away, receive,
select, choose, receive in exchange, borrow, barter, buy, catch, marry”. In that line a base is
“taken, entire, aggregate”, with a linguistic utility salient as intensifier and action. That allows
its wide use in derivatives and paired expressions mirrored in English “all-American, all-inclusive,
all-over, altogether, all-dressed”, etc. Another line is “horizon, space” with as many applications:
what is grasped by an eye, open, extensive, wide, vast (plain, valley), or a small spot on a body.
Another line is “multitude”: crowd, army, population. Another line is “size”: widen, increase (size,
volume), spacious, empty, entire, pasture, valley. Abstract notion has unlimited utility. The Türkic
alqu complete with a suffix -qu/-ɣu/-ɣü/-kü is but an example of grammatic and semantic
utility, it forms nouns, instr. of action, subjects of action, adj., participles “all, whole,
everyone” etc. With a web of its phonetic and semantic connections, the word illustrates a use of
the Türkic languages in Europe ca. 3rd-2nd mill. BC.
Cognates: A.-Sax. eall (so spelled), WFris. al “all”, OFris., ONorse allr,
Norw. all, Goth. alls, Du. al, Sw. all, Icl. öll, all-, allur,
OHG
al, Gmn. all ; Ir. uile, Welsh oll, all-, holl “all, at all (entire
extent)”, Scots a; Balto-Sl. (Lith.) aliai “all, each, every”; Rus. elan (елань)
“bare, open”; Gk. ola (oλα); Fin. ala “free space, territory”; Tung.-Manchu, Evenk.
jalan “meadow, field”; Nanai. n'ala “lowland (flooded)”; all “all” except noted. A
spectrum of cognates it too large to list. Distribution: From Atlantic to Pacific, across
linguistic barriers. A. Dybo listed 22 Türkic synonyms for “all” (Dybo. A., 2013, EDTL v. 9 16).
Unfortunately she skipped one, the
all, a most popular and etymologically most attractive. A synonymous Eng. gamut is an
allophone of the Türkic qamiɣ “accumulate” (see gamut). A synonymous Eng. entire
ascends to the A.-Sax. ðurh, an allophone of the Türkic tür/dür “roll up, cumulate”
(see entire). The Lat. omn- and Arm. ameny (ամենը) are allophones of the Türkic
om(qu)- “gathered”, grammatically analogous to alqu (see
omni-). Romance languages use versions of the Türkic tut-/tot- “hold, grab”
etymologically rated also as “a word of unknown origin”. A Hunnic phrase, first deciphered by
Shiratori in 1902, said at a capture of Luoyang in 328 in the future China, contains tut
“take, capture” (see total). Balto-Sl. languages use vse (всё, все-) “all”. That could
have been a relict of the Old Europe vernaculars if a derivative vsegda (всегда) “always” did
not carry a Türkic directional suffix -ta/-da. Still, vsegda could be an Old Europe
word used with Türkic grammar. That is supported by the Lat. root bis “twice, doubly”.
OHindi, OPers., and Av. use other synonyms. Eastern “IE” languages have their own vocabulary
unconnected with the western “IE” languages, attesting to a non-IE origin of the popular European
forms. The “IE etymology” cheerfully states “no certain connection outside Germanic”, and parallels
with a suggestion of a hypothetical PG improvisation *allaz on the theme of all, and a
super hypothetical *h2el- for a super hypothetical “PIE
proto-word”. The Türkic family's collection of 23 words express the notion “all” in both omnis
(Lat. “entire”) and
totus (Lat. “each one”) semantic meanings. The 23 are comprised of derivations of about 12
Türkic native and about 11 internalized words. The native words convey notions “existing (be),
gathered/taken, covered, accumulated, remaining, equal/exactly, repleted (to the top), pressed (to
the limit), throughout, sound (good), finished, filled”, unequally dispersed across a surviving
Türkic geography. The abundance of lexical material, its peculiar distribution in the
Sprachbunds' pockets, and the traits of the transmitted material allow to narrow possible
demographic sources. Specifically demographic, and not geographic, sources because a likelihood is
very small for the mobile nomadic populations that the present location of the source population is
identical with that of the pre-literate time. The genetics, and to a degree archeology, would be in
position to corroborate linguistic projections. The all is not a loanword, it is a substrate
word that keeps living on. The distribution of the stem al- in Europe and across the Türkic
Eurasian belt covers geographically, albeit not demographically, most of the Eurasia. The Celtic
examples predate the origin of the word to the Celtic departure from the Eastern Europe ca. 5th-4th
mill. BC. Distribution, combined with etymological information on the original sources and
final destinations, attests to diverse temporal and geographical paths of different synonyms.
Grouping of the destinations enables visualization of different paths. The Türkic etymology fits
perfectly semantically, phonetically, and in application. As a cluster, the synonymous quartet
all, entire,
gamut and total originate within the same Türkic source, with the all and
entire attested in the A.-Sax. They constitute an authentic case of paradigmatic transfer from
the Türkic milieu. See
entire, gamut, omni-, total.
6
English analogue, analog (n., adj.) “similar or equivalent in some respect” ~ Türkic jaŋla
“similar”, anlayu (adv.) “so, this way”.
Ultimately a gerund form of a denominal verb fr. an (n.) “that” ( “that-ing” (n.)), i.e. Eng.
be (v.) > being (n.) > “being” (v.) > “being-ing” (gerund (n.)); quotation marks show
theoretical equivalent construct example; or in Türkic an “be” > anla “being” >
anlayu (gerund (n.) “similarity”. However unpalatable, this is the grammatical explanation
given (G. Clauson, EDT, 272). Not to be confused with homophonic neologism analogue, analog
“continuous, not discrete” vs. “digital, discrete, not continuous”, which developed from the same
source via slide rule mechanistic calculators. Cognates: A.-Sax. angeld, angilde “rate
(proportion) of compensation, price to currency (proportion)”, angelic “like, similar”; Fr.
analogue (adj., n.); Lat. analogus (adj.); the origin is claimed to be fr. Gk.
analogon, fr. ana “up to” +
logos “ratio”. The A.-Sax. cognates are precise semantically, start with an-, and
differ enough phonetically not to be immediately connected with Türkic or Gk. “proto-word”. A second
part geld, gilde denotes “pay, payment”, i.e. proportional, commensurate pay. Some fussiness
and polysemy of the A.-Sax. an- and its allophones tend to sully a clear picture. The Gk.
origin of the “IE etymology” may sound reasonable enough, but raises numerous problems: could a
multitude of pastoral tribes scattered over much of the Eurasia, and broken into uncounted pastoral
routes, adopt and spread this Gk. compound, and furthermore, reduce it to a most basic semantics of
the “similar, such type”? The hypothetic Gk. ana “up to” is incompatible with the attested
A.-Sax. part an- of the compound angeld. The A.-Sax. native form angelic
“analogous” conflicts with the Gk. analogon “analogous”. Scholarly etymology seems to be too
scholarly to be realistic. The Greeks, on the other hand, could pick up the expression in the
N.Pontic, where they cohabited with the Kurgan nomads, or during the Herodotus' time, when according
to Herodotus (Herodotus IV 108, 109, 120) some of them were bi-lingual. Either way, a chance
coincidence is too remote to inspire any confidence, in both cases the substance is elementary, but
a scholarly path to it goes through intricacies of compounding or inexplicably complex (in the
European terms) agglutination. Rather, the same simple Türkic word expressing similarity could be
brought over to the British Isles, and a millennium+ later conflated with the borrowed scholarly
usage. The Türkic origin appears to be more feasible and credible than a promulgated Gk. origin.
7
English any (adj., adv., pron.) “whatever (one, some, every, or all, every)” ~ Türkic ne: (adj.,
adv., pron.) “what, whatever”, ne:ŋ “any, at all”.
The ne: is multi-functional and polysemantic, with primal functions of interrogation “what”
and negation “no”. As negation, it is a precursor of all European, Indo-European, and other negation
allophones: no, ne, ni, nein, nyet, etc. (see
no). As “what”, it fills a large spectrum of grammatical needs besides interrogation, largely
identical to the Eng. “what”: relative pronoun, pronoun adjective, exclamation, adverbs in oblique
cases, forms idiomatic expressions and negative pronouns. The form ne:ŋ (neng) may
be a dialectal variation, or morphologically a denominal noun fr. ne:. The Eng. any is
an allophone of ne: with a function of indefinite pronoun serving as adjective (“any time”)
and adverb (“any more”), essentially a synonym of “whatever, however, whosoever” (“whatever time”,
“however more”) in respect to animate and non-animate objects. Cognates are confined to the Gmc.
group, so any pretensions to an Indo-European pedigree are baseless: Gmc. group is a tiny fraction
of the “IE family”. Cognates:
A.-Sax. ænig “any, anyone”, OSax. enig, OFris. enich, Saterland Fris.
eenich “some”, WFrisian iennich “only” ONorse einigr, Du. enig, Gmn.
einig “any, some”, LGmn. enig “some”; all “any” except as noted; it appears that a
majority of the Gmc. group retained the form ne:ŋ with an auslaut -g and a prosthetic
vowel. An “IE” etymological conjecture that any is connected with a numeral one is based
on purely phonetic consonance, its corporality contravenes semantically the very ambiguity of notion
any (“some, all”). It has no supporting attestations, and bears no credibility. No faux “PGmc.
proto-root” *oi-no- “one, unique”, faux “PGmc. proto-word” *ainagaz “one”, faux “PGmc.
proto-word” *ainaz “one” etc. inventions are needed. An idea that any was born in late
12th c. on Eng./Gmc. soil is preposterous, functionally it is no different than the all which
is rightfully presumed to ascend to an early human vocabulary. In a daily usage, the form ænig
“any, anyone” may have conflated with the ambiguity of the forms ænes “once” and æn
“once, at some time”, but a converse is as much possible, that ænes and æn are also
conflated allophones of the ne:. The form ne:ŋ has no connection to the Eng. none,
which is a contraction of “no one”. In contrast, the Türkic origin demonstrates functional and
semantic continuity, and credible phonetic correspondence. The Eng. all, some, no and any
constitute a paradigmatic transfer case. The last two ascend to the same root with the same semantic
spectrum and grammatical functions. See all, no, some.
8
English archaic (adj.) “antique, antiquated” ~ Türkic ürke, ürde (adv.) “once, of old”.
According to an “IE” etymology, “a Greek verb of unknown origin”. Ultimately fr. the verb er-,
a form of “be” in motion, Cf. Eng. are “be, pl.”, see are. In phonetic versions it
survived with anlauts e-/i-/ü- (a- in Gk.), and formed a derivative ür “once, of old,
past, before, formerly” and “long ago, for a long time”. That root produced a word ürke
formed with a deverbal noun suffix -gä, -kä, -qa (Cf. Ürük ~ Uruk “old city” in Sumer),
leading to the Gk. temporal notion of archaic “extremely old”. The flavor of archaism is
carried by a cluster of sibling offsprings: erken “indefiniteness, being, while, while
being”, ürkänč “for a long time”, irig “mouldering, decayed”, irig “tough,
hard”, etc., all of them with a context of time. Türkic has 9 stems carrying the notion “archaic” (ašnu,
burun, ïlik, etc,), hence visibility of the ürke is an order of magnitude less than that
of the European “archaic”, where it is a unique linguistic component. Nowadays
archaic is an international word. Cognates: A.-Sax. ord “source, beginning”,
oreald “very old” (or + ald, paired), Fr. archaique, Gk. arkhaios (αρχαιος)
“ancient”, arkhe (αρχη) ditto; Mong., Manchu
er (< erte) “early, early-ish”; Manchu erte “early”, erin “time”; Tungus
erde ditto, Nanai erin, erku “time”, Ulchin. erun “time”, Oroch. eru > eu
“time”; Kor. il, ileun (이른) “early”; Osm. er “early
morning”, erken “previous, previously, old”, erki “early”. Distribution: spans
the width of Eurasia from Atlantic to Pacific with excurses to Gk. and on. The “IE etymology” stipulates arkhe as “beginning”, and suggests the origin of the Gk. “beginning” fr. a phrase
arkho “I am first”. That whirl is little credible. A suggested faux “PIE” *hergh- is
eidetic to the attested ürke and is sorely not needed; that stipulation is especially ironic
for a case “of unknown origin”. The meaning of the arkhaios is “in the beginning, from the
beginning, once”, etc., i.e. preceding any following events. A cited Gk. phrase eimai protos
(ειμαι πρωτος) “I am first” is transparently composed of 3 Türkic components, ič “I”, (y)im
“am”, bir “protos, first”, and it has nothing to do with any archaism. “IE” languages do not
know arkhe “beginning”, that attests to its loanword status in the Gk., then European-wide
acquisitions. That rules out a speculation that a loanword originated fr. the Gk. for “I am first”,
and disallows a primary status for the Gk. word, see first. The sense archaic “what is
old, behind us” is a natural application of the ürke “once, of old” and of the arkhe
“in the beginning, initially”, Cf. Az. arxamızda “behind us”. The Türkic origin is supported
by phonetic and semantic authenticity, and by indelibly Türkic morphology. See are, first.
9
English arrogant (adj.) “with overbearing pride” ~ Türkic ö:r- (v.) “rise, sprout”,
orı: “rise, stand out”.
The base lexeme ö:r- is best known in the form ortho-
(orthodontic, orthodox, orthogonal, etc.). The connection between ö:r-/orı: and
arrogant is attested by the A.-Sax. noun compound orgelword “arrogant speech”, where
the stem
orgel lit. means “(unduly) stand out”, see orate, ortho-. The A.-Sax. -g-
corresponds to the Türkic deverbal noun suffix -q-/-k-; -l is an adj. suffix, thus
orgel ~ arog(ance). Semantically, orgel belongs to a host of other A.-Sax. words (total
17) for the notion “arrogance”, of which one, haughtiness, has survived into English. The
only other survival is the Türkic/A.-Sax. arrogance. Türkic-based etymology is direct and to
the point: “stand out”. Of 44 European languages, 32 (73%) use the term arrogance; the other
10 (27%) languages use their own 8 words, incl. Lat. superbus. Such lopsided breakdown
attests to a pervasive modern borrowing. The word is a “guest” in Europe and “IE” family. Cognates:
A.-Sax. orgel(word) “arrogant (speech)”, ONorse hrokr “excess, exuberance”; Scots
ardanach “arrogant”, Welsh drahaus “arrogant”; ONFr. rogre “aggressive”, OFr.
(12th c.) arrogance, Lat. arrogantia.
Distribution: typical for Turkisms, for ö:r- a Eurasian Steppe Belt plus fringe
appendages crossing linguistic barriers. Paths to Europe run via Central Europe (orgel) and
Scandinavian (hrokr) and Apennine (arrogo) peninsulas. Synonyms: The ortho-
and orgel are kins and a part of a huge synonymic family with A.-Sax. members anmedia,
baelc, belg, bieldo, bogung, dyrstignes, gielp, mod, modignes, oferhygd, ofermodignes, prut,
prutscipe, prutung, toðundenes, upahafennes, wiðerweardnes, wlenc. They are derivatives of the
stems belg, bog, dyrstig, gielp, hygd, med, mod, prut, toð, haf, weard, and wlenc, all
expressing related notions. A word prut survived as pride, but without a negativity of
“arrogance”. The forms
belg (baelc, belg, bieldo, and probably bogung) “marked, notable” are
allophones of the Türkic belgü “mark, sign, trait”, see Belgi. The bog (with
three spellings) “bough, twig, branch, offspring” is practically synonymous with the Türkic ö:r-
(v.) “rise, sprout” and butïq “branch, offshoot”. It appears to be an allophone and semantic
calque of the last, see boutique. The dyrstig appears to be standing for “standing
(withstanding)”, i.e. “not retreating” and thus “bold”. It is a derivative of the Türkic tur-
“stay, remain”. The
gielp stands for “boast, glory”. It is an allophone of the Türkic küle:-
(güle:-) “praise” with a passive suffix -l “praised, glorified” and adverbial suffix
-p. A non-Türkic hygd stands for “mind”, the hygd, med, and mod
are calques expressed in different languages. The med and mod stand for “mood”,
allophonic with a Türkic ming “mind”, see mind. The toð is “tooth”, an
allophone of the Türkic tiš (tish) “tooth”, see tooth. A wlenc (with -k)
“stately, splendid, lofty, magnificent, rich” is semantically and phonetically close to a Türkic
ulug “great”. The unexplored A.-Sax. Turkisms may need their etymologies detailed. A non-Türkic
prut is “pride”. A non-Türkic upahafennes apparently stands for “uplift, upheft
(up-heft)”. A non-Türkic weard stands for “toward”. A brief review of the A.-Sax.
non-Türkic terms for “arrogance” shows that they are all metaphoric extensions of some other notion,
united more by expressed negative attitude than by a prime notion of each stem. They likely were ad
hoc terms used by demographic minorities, that was a reason for their extinction. An “IE etymology” claims an origin fr. Lat., via a semantically impossible inverse meaning “toward asking, proposing”,
alleged synonymic with “stretch out (the hand)”, and alleged synonymic with “straight line”. That
concoction is patched together by some dubious phonetic and morphologic echoes. A mundane reality
would not fuse with a mystical “PIE root” *reg- “straight, rectilinear”. Disjointed analogies
are unsustainably tenuous. Philological manipulations would not accommodate the A.-Sax. orgelword,
nor would they explain the phonetics of the A.-Sax. and ONorse “arrogance”. A developmental chain
ö:r-/orı: > orgel- > arrogant is consistent semantically, morphologically, and
phonetically, leaving little room for uncertainty. It punctuates three distinct paths from Central
Asia to Europe. The modern Eng. form is likely an upgrade of the native A.-Sax. orgel-
conflated with an OFr. (12th c.) arrogance. See Belgi, butique, mind, orate, ortho-, tooth.
10
English astute (adj.) “savvy, sharp, shrewd” ~ Türkic asurtɣuq, asırtku:, asırtğuk (adj.)
“assertive, intelligent, clever”. Ultimately fr. ası “usefulness”, a denoun verb with a
suffix -ra fr. a noun ası; -t- is a deverbal abstract suffix; -ɣuq, -ku:,
-ğuk is instrumental suffix.
Although the form and semantics are unequivocally asserted (EDT 252), near-homophonic forms and
deserving semantics raised several alternatives: 1. us “intelligence, sense”; articulated as
as/us/yus by different Türkic languages; 2. asra- feed, nourish; 3. ası- ~
asır- protrude, project, bulge, jut.; 4. “weasel”. In all cases, the final asurt-, asırt-
“assertive” is positively attested, its semantic origin might be questioned. The form us is
singled out as “purely western” (EDT 240). A denotation “weasel, cunning, shrewd, wriggler”
is specifically referenced as attested in Chuv. and in European calques “what a weasel”. A base root
is a denoun noun asur/asır. The inlaut suffix
-t- denotes a spatial aspect, in this case an abstract notion from a concrete subject. The
suffix -ɣuq forms nouns/adjectives from the root base, functionally it is synonymous with
-lïɣ/-lig “poss., like” forming abstract notions. Duplication of the abstract suffixes indicates
that the first suffix have had lost its functionality and was treated as a part of the root. The
species ermine and weasel are of one and the same genus Mustela, the meanings “cunning, shrewd” and
“intelligent, clever” are metaphoric extensions of the as/us “ermine, weasel”. A base word
may precede metaphors by many millennia, illustrating precarious ways of semantic development.
Cognates: 17th c. Fr.
astucieux, Lat. astutus “crafty, wary, shrewd; sagacious, expert”, from astus
“cunning, cleverness, adroitness”; Re.: “usefulness”: Mong. asuɣ, asig “usefulness,
benefit, gain”, aysi- “help, defend”, Khalka asig “usefulness”; Manchu aisi, ajisi
“usefulness, profit”, asak- “drive, pursue”, aysila “usefulness, help”; Tung. asa-,
asakta “drive, pursue”, Nanai hasa, hasasi “drive, pursue”. A different base semantics
carries different cognates. Distribution: a form is carried across much of the Eurasia;
meaning may be more confined. The Lat. form may be closer to the original notion of as/us,
attesting to parallel independent development in the western and eastern Türkic milieus. No
“IE” cognates whatsoever. Given the spread of phonetically linked cognates from Atlantic to Pacific, and
the known absence of the “IE” cognates, the unscholarly etymology “of uncertain origin” is a most
anserine or dishonest verdict.
11
English bad (adj.) “not good”, “wicked, evil, vicious” (Sw N/A, F217, 0.07%) ~ Türkic bäd (bəd), bat
(adj.) “bad, wretched”, bä:d- (bəd-) (v.) “bad, spoiled, weak”.
No “IE” etymology, “a mystery word with no apparent relatives in other languages”. Oops, there are
some relatives. The Eng.
bad has a remarkable fate, it is a Sum. agrarian word for bad soils, bad “hard soil”;
a Türkic, and then Eng. bäd “bad, not good, wicked, evil, vicious”. A similar Sum. allophonic
form is bai “bad”. The Farsi bad has the same meaning. The Türkic bä:d- (stem),
be:de:r (imp.), be:dme:k (inf.) refers to condition: “(eyesight went) bad”, “(food)
spoiled”. The verb fossilized without a denoun suffix (-la) attests to an archaic primacy of
the verb; nouns and adjectives are deverbal derivatives. A Türkic notion “bad” is expressed with 7
roots in 18+ articulations; some notions are speciated. Cognates: A.-Sax. baedan (v.)
“spoil, defile”, cited with a Türkic abstract suffix -an “spoiled, defiled”, EDan. bad
“damage, destruction, fight”, Norw. bad “effort, trouble, fear”; Tajik bad “bad”;
Pers. bad “bad”, bad budan “be bad” (budan < Tr. buol- “be”), Sum.
bad (w ~ b) “uncultivated land”. Distribution: “relatives” are spread across
Eurasia, overlapping Eurasian Kurgan territories extending to the British and Persian fringes.
Archaic origin is demonstrated by a presence in Sum. at least a millennium before the Indo-Arian
migrants' appearance in the Zagros area. The unfortunate myopic and arithmetically inept linguists
discount Pers. eidetic word as a pure chance coincidence. Given a pinpointed semantics of the word,
with generous allowance for 10 synonyms in either English and Persian 10,000 word dictionaries, a
probability of a same word appearing by random chance in 3 unrelated languages is miniscule, on the
order of P33 = 0,0000001. The “IE etymology” blunds perplexed, a
“mystery word” with “no relatives” is bestowed with a speciated semantics “effort, trouble, fear”,
“damage, destruction, fight” personifying a concise “bad”, and is ornamented with a faux “PGmc.
proto-word”
*bad- and a faux “PGmc. noun” *bada-, i.e. what O. Maenchen-Helfen called galimatia.
A mix of fantasy and myopia needs to descend back to Earth. Till 18th c. Eng. used comparative and
superlative forms badder (-iro, ra, -re), baddest (est-, esta-) incompatible with the Türkic
grammar or Gmc. suffixes. A Gmc. comparative suffix is shared with Pers. allophonic -tar, badder
vs. badtar. The Persian bad must have come from a Türkic or Sumerian, consistent with
known direct link from the Babylonian, Akkadian, and Assyrian milieu to the Persian. The future
Persians alternatively could pick it up from the same N. Pontic source as the future A.-Sax., before
a later Indo-Aryan southeastern migration. In the Sumerian script, the lexeme “bad” is homophonic,
it portrays incompatible notions of “bad” and “shelter”. The notion of “bad” covers specific
applications of die, kill, hunter, sad, depressed, unravel, defeat, obscured, dark (bad), hardship,
uncultivated (bad4). The notion of “shelter” covers trust, certainty (bad), shelter (a2-bad3),
fortification (bad3), overhead, top, wall, parapet (bad3-si) (PSD
2014). A Türkic tool of contrasting bifurcation is also observed in Sumerian, with phonetically
close but distinct forms describing contrasting subjects, Cf. guest vs. host. The fuzziness of the
Sumerian terms illustrates a process in motion, where initial terminological vagueness gradually
develops specific derivatives to take shape for speciated applications. The word
bad already was with us (some of us, not all of us) for 5000 years, probably in millenniums
to spare. Sumerians arrived to lower Mesopotamia from the N.Pontic steppes via Caucasus 5000 - 4500
ybp, carrying primarily R1b haplogroup with mainly an R-M269 subclade and its downstream L23
subclade, bringing with them their N.Pontic language. At least 1000 years before the Indo-Iranian
migration into the S.Caucasus, they have provided us with the best-documented 5000-year old lexeme
bad of the early Kurgan steppe culture (A. Klyosov, Ancient History of the Arbins, Bearers of
Haplogroup R1b, from Central Asia to Europe, 16,000 to 1500 Years before Present//Advances in
Anthropology, Vol.2, No.2, May 2012, pp.87-105, ISSN Print: 2163-9353, ISSN Online: 2163-9361,
Full Text (PDF 1,419KB).
| Supplementary Note There were linguists who asserted that miracles do happen, and cited Persian and English bad as an example. There were linguists who trusted their peers and recited the same example. And there were non-linguists who trusted the trusting linguists and were repeating the same truism orally and in writing. Probability of the same word bad appearing by random chance in 2 or 3 unrelated languages: To ensure at least one coincidence in 2 independent languages would require 1/0.00002 = 50,000 of
2-language sets, for a total of 50,000 languages (rounded). |
12
English Belgi (adj.) “ethnic name” ~ Türkic belgü, belgü:, belgö: (n.) “mark, sign, trait”, belgülüg
(adj.) “marked, notable”.
A deverbal noun/adjective suffix -gü/-ɣu denots instrument or subject of action. Opposite of
belgülüg “notable” is belgüsiz “unknown”, that helps to understand the semantics of
Belgi. Ultimately fr. a polysemantic verb bele:- “smear, smudge, dirt, soil”, a denoun
verbal derivative for a notion “mix”. The achromatic bele:- sired a rich progeny, the Eng.
bald, black, blanch, blank, bleach, bleak, blear, blaze, pale, etc., see black, and other
cited heirs. A name derived from a social status provides material for supporting cognates.
Typically, high status titles tend to expand geographically beyond demographic borders, Cf. earl
fr. yarlïqa- fr.
yar-. Cognates: Wallah, Wallach, Vlah “outsider, non-indigenous person”, Boloh “son of
Atilla, aka Djilki “Horse”, ca. b. 490 AD”, Boarix “Hunnic queen, widow ruler, ca. 520-535 AD”,
Wale, Welsh, Belgæ “ethnic name”; Balto-Sl. bel (бел) “white”; Mong. belge “notable”,
Kalm. belgǝ “designation, mark, sign”, belǝg- “denote, foretell”; Tung.-Manchu
bǝllǝy “amulet”, Evenk. bilki- (v.) “divine”, bilisǝk “diviner, witch-doctor”;
Nenets belga, balgi “mark, marker, designation”; Hu. belyeg “stamp, badge” (~ Tr.
baj “цель, мишень”); Nakh, Ingush bilgalo “label”; Kabardin bergala “label”.
Distribution: Eurasian-wide across linguistic borders. The tribe of Belgi (Belgae)
appeared on the European scene as ethnologically Türkic Sarmatians, of the Vandal variety (Wanderers
< wendeln “to wander”), mounted and mobile horse pastoralists leading a collection of
supposedly Celtic and Gmc. agrarian subjects, all known under an exonym Belgi (Belgae) after
a ruling tribe of a nomadic confederation. As Vlahs etc., they are noted in Rumania, Greece,
Albania, Bulgaria, Yugoslavia, Macedonia, the future Belgium, and British Wales (Cambria,
Cimmerians); and a Balkan Hunnic principality Walachia. An alternate (“IE”) etymology descends from
an A.-Sax. cluster belg
“bag, purse, leathern bottle, pair of bellows, pod, husk, belly (v.), anger, arrogance”, belgan
(v.) “angry, offend, provoke”, belgnes “injustice”, all not much help for an endonym but may
had been helpful for the locals. A PIE etymological version picks up on belg “belly”, creates
an unattested faux “proto-word” *bhelgh- “to swell, bulge, billow”, and ends up at its
starting point dead end while unwittingly appealing to a Türkic stem bel “waist”. Hardly the
Italians, English or French would ever call themselves with an endonym “Bloated”. The Türkic
semantics of Belgi “marked, notable” is appropriate, it parallels that of the German
“strong, manly” from the Türkic erman “manly” formed with a prosthetic anlaut g- and a
suffix -man “very, main, most”, lit. “very man”, appropriate for an exonym that fossilized as
an endonym complementing the old native name Deutsch. See black, earl.
13-
(Skip)
English bogus (adj.) “phony, sham” ~ Türkic bögüš (n.) “understanding, comprehension,
misunderstanding, miscomprehension”.
“IE etymology” rated “origin is unknown”. Quasi-scientifically, it is explained as a “folk speech”. A
nominal suffix -s/-š
expresses negation (OTD 661, 663), i.e. “misunderstanding, miscomprehension”; it is “rare”
(in eastern languages, thus a guest from the western languages). Ultimately fr. bögü:, bögö:
“magic, sage, wizard, sorcery, witchcraft”, a derivative of bög- “collect, gather”, in this
case in reference to accumulated knowledge (Cf. bögü/mögü “wise, sage”, see magus, Cf.
earl fr. yarlïqa- fr. yar- “split, cleave”) or more remotely a community
gathering. The suffix -s/-š turns the root base of the word on its head, i.e. a “real, true”
to “sham”. Articulation -s/-š-/z as opposed to -r is connected with the s/r
alternation separating Oguz/Ogur languages, -s is of the “eastern” Oguz type, -r is of
the “western” Ogur type, Cf. CT -lar (pl., -r-type) vs. Sp. las (pl., -s-type).
The connection with magic forces and magician tricks is attested by a documented Eng. expression
(19th. c.) (tantra)bogus (ref. Buddhist Tantra) for strange objects used in parallel with
appellation “the devil”, besmirching the dignified progenitor bögüš to a notional aspect of
sorcery and witchcraft. Bogus is one of a host of words that appeared in English from
nowhere. Cognates: almost none listed; but since the word is connected with a notion of
comprehension, Türkic cognates abound: bögtačï “beneficial”, bögtäg “blessing”,
bögü “wise”, and so on; Nigerian (Hausa) boko (v.) “fake”; ..... Suggested etymologies
are bizarre, speculative, and introverted. The phonetic precision and perfect semantic connotation
of “not real” allows to assert that on the English soil, a lurking Türkic substrate word survived
unnoticed for millennia. On the Sl. and Iranian soil, the mystical Türkic bögü: without
negation -s/-š became an oldest local word bog (бог) for the Almighty. In one form or
another, the word bögü: covers Eurasia from one end to another, nearly always in reference to
supernatural context. See magus.
13
English bold (adj.) “fearless and daring, fast, quick” ~ Türkic bol (adj.) “courageous, brave”.
“IE etymology” suggests a “perhaps” origin and a semantic cacophony, v.i. Ultimately fr. a root bol
“be, exist” with numerous applications. If the word evolved in a post-grammatized time, a suffix
-d/-t/-th (+r) is probably a 3rd pers. past tense marker -ti > balti (Goth.
-thei) “braved”, or a truncated version of a number of a d-type attested adj. suffixes
like -däm, -täm etc. On top of bol, Türkic also has a store of phonetically distinct
synonyms starting with b- with incompatible roots: baš (bash), ba:tir, berk,
böke, and their allophones. There is no “Pan-IE” term in Europe. Of 44 European languages a
largest is a motley group of 6 (14%) languages; the Eng. bold is used by 4 (9%) languages;
the remaining 34 (77%) languages use their own 23 native terms. Such breakdown of the term bold
attests to a “guest” status in Europe. Cognates: A.-Sax. beald, bield, bilde, byld,
WSax. beald, Ang.
bald “bold, brave, confident, strong”, ONorse ballr “frightful, dangerous”, OHG
bald “bold, swift”, Goth. balthei “boldness”; Chuv. palt “fast, quick”.
Distribution: The root bol “be” (various articulations) is ubiquitous across Eurasia. A
spread of bol “brave” is not specifically denoted; ref. L. Budagow, Calcutta Dictionary of
the Old Uzbek language (EDTL v. 2 185). An “IE” etymology is solidly inept: conjectural “perhaps”
with a faux “PGmc. proto-form” *balthaz, a faux “PIE proto-word” *bhol-to-, a faux
“PIE proto-root” *bhel- (v.) “blow, swell”, a faux “PGmc. proto-word” *budla, *buþla
“house, dwelling”, a faux “PIE proto-word” *bhew-, *bhuh- “grow, wax, swell”.
All that berserk is crowned with an apotheosis of “related to build”. A “bravery” ends up with a
swell and a hut. Go figure. The word shows up in names such as Archibald, Leopold, Theobald. The
Goth. form is closer to the Türkic original than some Türkic vernacular forms. Chuvash language is
distinct by palatalization, in contrast with the “Common Türkic”, hence the initial -p.
14
English callous (adj., v.) “indurate, hardened”, (n.) “hardening (skin)” ~ Türkic kalŋuk “scurf,
scale”, qalïn, qalïŋ “thick layer”.
“IE etymology” rated: “PIE source uncertain”. A derivative of kalnu:-, qalnat- (v.) “solidify
or thicken”, kalın (adj.) “solid, dense, rigid”, and derivatives kalna:d-, kalna:dti:
“thickened”. Ultimately fr. kal, qal (adj.) “coarse, shameless, stupid, crazy, insane,
rabid”, and “wild, savage, mad”. Cognates: A.-Sax. hreof, hrief, hrifðo, sceorf, scruf,
scurf “scurf”, Dan. hjerteløs, Du.
harteloos, Norse hardhudet; OIr calath, calad “scurf, scale”, Ir.
(fuarc)hroíoch, Welsh caled, greulon “hard”; Lat. callus, callum, callosus, Fr.
calleux, “hardened”; Balto-Sl. (Latv.) ciets, (Lith.) surambėjęs, (Sl.)
kor-, kr-, kvr- (кор(явый), кр(епкий), квр(гав) “gnarled”; Est. kalk, Fin. kova;
Arm. kosht (կոշտ); Georg. gulk- (გულქ-),
all “callous” except as noted. Distribution: extends across the width of the Eurasia from
A.-Sax. and Fr. to Shor and Teleut (aka Tele). A parallel spread of physical and
psychological notions carried to nearly all host languages implies that they have developed fairly
early, along with phonetic adaptations, suggesting the dates of the Kurgan Waves, 4th-3rd mill. BC,
and even the 6th-5th mill. BC in case of the Celtic migration. An “IE etymology” is lost between two
trees: it confuses Lat. calor “heat” with calluses. It suggests an unneeded faux “PIt. word”
*kaln/so- “hard” with OCS, Rus., Serbo-Croat. kaliti, kalit (калить) “heat treatment,
temper, case-harden”, an absurd proposition for a horn-like callosity. Given the Celtic original,
Lat. and “PIt.” had a ready-made word to imitate. There is no room to play any “IE” fantasy game. A
transition -r- <> -l- clearly demarcates the European part from the Asian part, explaining
the forms har-, hjer-, gre-, chro-, kor-, kr-, kvr- and the like, and the forms kal-,
cal-, kalk-, kov- , ciet- and the like. The k-/h-/g- transitions parallel those of the
kad- > get-, got-, gat-, gis-, gad- vs. kiv- > give-, kut > god, and have a congruent
areal distribution, see get, God, give. The A.-Sax. forms come from two related vernaculars,
apparently they encountered local (European) homophones, Cf. semantics “scurf, rough, scabby” vs
“belly, womb”, “rain”. The hr- forms may be likened with the Aral-Caspian vernaculars. The
A.-Sax. semantics follows the diffusion of the Türkic examples, attesting to an origin from diverse
sources, by far exceeding a confined Lat. semantic field. See get, give, God, hard.
15
English chalant (adj.) (we better know it as a nonchalance n., nonchalant adj.,
nonchalantly adv.) “unconcerned, careless” ~ Türkic čalaŋ (chalang),
čalıŋ (chalyng) “blank, void, barren, bare, naked, blabber, chatter”, lit.
“bare of (dress, feeling, etc.)” signifying outer and inner emptiness, Cf. “wasteland” čalaŋ yer,
lit. “empty earth”.
The final -t is probably a rudiment of archaic pl. -ng > -nt.
A forked semantics is due to two unrelated homophones of completely different bases that formed
notions “naked” and “talk” respectively. The notion “naked” is ultimately a derivative of the verb
yal-/čal “bare, naked” with a prosthetic č- typical for the Ogur-type languages. The
notion “talk” is a derivative of the verb čal- “knock, strike, play”, Cf. cello (chello),
cellist (chelist) not etymologized in any “IE” language. Each of the two homophones had its own
areal distribution without much cross-interference. Cognates: v.sup. examples; none cited
outside of Türkic languages; of 44 European languages, 22 (50%) use Fr. expression, attesting to a
status of an international loanword. Distribution: Peculiar to the Eurasian belt of the
Türkic languages + Fr. + scattered loanwords in Europe. The Fr. idiom ne pa is a double
negation: ne “emphatic negation” (Türkic +etc.), pas (pa) “agglutinated
negation” (m- > b- > p-), equivalent to agglutinated Türkic ne ...ma..., Cf. ne
jatmaz “not laying”. No “IE” parallels, no decent “IE” etymology. An attempt to link
chalant to a Lat. calere “be hot” not only does not fit, it unwittingly ascends to a
still another Türkic root, a passive form yal- “blazed, burned, shined” of the verb ya:-
“blaze, burn, shine”, Cf. Sl. kalit (калить), nakal (накал) “heat, glow” ~ Lat. calere.
The English/French form chalant has preserved the original Türkic grammatical formant -t,
inexplicable within the “IE” paradigms, but useful for genetic diagnostics. The very peculiar and
diagnostic word probably was brought to French with the Burgund lexis carried by the Sarmatian
migration of the 2nd c. BC and/or the Gaulic Alans of the 4th c. AD. Such peculiar word widely used
in modern European languages, with its pinpointed semantics, a faintest European trace, and a
salient presence in Türkic, constitutes an indelible case of paradigmatic transfer, vividly attests
to its Türkic genetic origin.
16
English colossal (adj.) “enormously large” ~ Türkic qolusuz, kolusuz “immeasurable, countless”.
According to a standing “IE etymology” a “Gk.” kolossos, popularized by Herodotus, comes from
an “of unknown origin”. Ultimately, qolusuz comes fr. qolu/kolu that refers to some
measurement, count, number, like in “countless”. А Türkic negation suffix -suz in Eng. is
rendered by an A.-Sax. suffix -less, like in “clueless”. The word had been internalized in
Europe to a degree that only 6 (14%) of 44 European languages use terms other than a Türkic
qolusuz. The 6 can't be ignorant of a version of “colossal”. A.-Sax. term corresponding to
qolu, kolu was (ge)rim “number, counting, reckoning” (e.g. geargerim, wintergerim
“years-number”, dogorgerim “days-number, time”, etc.). Cognates: Fr. colosse,
Lat. colossus, Gk. kolossos (κολοσσός) “colossal” (+ wide international spread). An
oddball within the “IE” languages, a status of a loan-word is obvious. The phonetic and semantic match
is near-perfect, with possible r/l alternations. The r/l alternation is likely an
areal phenomena, like the A.-Sax. salo, salu “dusky, dark”, ONorse sölr “dirty yellow”
vs. the Tr. sary “light yellow, grayish color, pale, dirty white”, see sallow. Chances
of a pre-historical borrowing from an European language into a primal core of the Türkic languages
is infinitesimal. European languages lack a native root like the Türkic semantically suitable
word-forming root qolu, kolu. The Türkic word entered European languages complete with its
word-forming suffix -suz > Gk. -sos > Lat. -sus, making the Türkic origin of
the word undeniable.
17
English copious (adj.) “abundant”, copacetic “abundantly satisfactory” ~ Türkic köp, qop (adj.)
“copious, abundant”, fr. köp-, köb-, qop (v.) “much, plentiful, large, lush, very”.
There is no European or “IE proto-word”. For the notion “copious, abundant” each European language
had developed its own expressions. Because semantic field width is extremely narrow, chances that
precisely the same word would arise independently in unrelated languages are nil. Cognates:
A.-Sax. ceapeadig? “rich, wealthy”, Fr. copieux “abundant”, Lat. copia
“abundance, ample supply, profusion, plenty”, copiosus “plentiful”; Lith.
gausus “abundant”; Est. külluslik “abundant”; Hu. kiados “copious”.
Distribution: Peculiar: nearly every Eurasian Türkic language, and few islands in the W.
Europe. The “IE etymology” offers a Lat.-based faux compound of com- “with” + unattested
*op- “work” (Cf. opus) i.e. comopus as a linguistic ingot for further
conditioning. That would imply a miracle with Uigurs and Enisean Khakasses independently reinventing
a Lat. invention. The “IE etymology” is dubious. An abundance of loose European expressions, plus the
fact that Romans failed to seed their supposed invention among their immediate neighbors while
purportedly successfully seeding a compound to the far-off Eastern Siberia, make the attempt for the
“IE etymology” a non-starter. The Türkic origin is straight-forward, it gives a root and an organic
semantics of the concept. English could have received this Turkism and the abundant via
French, but the A.-Sax. cognate points to a direct infusion from a Corded Ware Türkic milieu.
18
English coy (adj.) “quiet, modest, shy” ~ Türkic köy-, kön-, koy-, kon- (v.) “soften, turn tame,
obliging”.
Ultimately fr. a verb ko- “leave, lay”. The Türkic word ultimately ascends to the semantics
“bosom”, the verbal form would be “to bosom, to hug, to pacify”. A homophonic coy “sheep”
echoes the nature of the animal. A common origin of the European forms, including Lat., is
undeniable. An A.-Sax. spelling is muddled with Romanization, but fairly consistent with modern
Eng., OFr., and Sl. forms. Cognates: A.-Sax. (s)ceoh, (s)coh (cheoh, choh) “shy,
timid”, Eng. quiet, OFr. coi, quei “quiet, still, placid, gentle”, Lat. quietus
“resting, at rest”; forms of Sl. languages are all prefixed with po- to indicate settling
into a stable position, and with s- to indicate completed action: (po)koi, (spo)koi(nyi),
(spo)koy(stvie) (покой, спокойный, спокойствие) “rest”, “quiet”, “tranquility”; Lith. kuklus
“coy, humble, modest”, Tr. ko:y, koyun, ko:n “bossom” (Clauson EDT 674, 678);
reference to a Mong. cognate.
Distribution: Eurasian Türkic Belt with few European isles and a trace in the Far East. An
“IE etymology” stops at Lat. with few novel decorations: a faux “PIE root” *kweie-“rest, quiet”, a
few local variations on coy, a neologism decoy, military abbreviation for company.
Except for a faux “PIE root”, all modifications are credible. A Lat. form is not traced to its
origin. It is utterly unlikely that Lat. had produced Türkic cognates. Morphing of consonants to a
semi-consonant -y- is widespread within Türkic languages, -n > -y is a regular
transition. Both Tr. rounded -ö- and unrounded -o- are attested; G. Clauson attests to
the forms köñ and koy-. A choice of Türkic articulations carries a diagnostic value
for particular sources. A Türkic origin is etymologically well attested.
19
English damp (adj.) “slightly wet”, dampness “wetness” ~ Türkic dum “wet, wetness”, dymly (adj.)
“damp”.
Ultimately fr. a substantive and verbal root dum, dum- “damp, wet, moisture, soggy, liquid
(adj.) evaporation, drop (as drop by drop), stuffy, stale, dim, sink, descend (downstream)”, a
deverbal verbal derivative fr. the verb du-/tu- “stop, block”, see dumb. A suffix
-p forms deverbal analytic nouns, “dampness” from “to be damp”, that form probably survived from
the Türkic milieu times. The word belongs to the cluster that includes dampness, cold, smoke, and
dimness, with linguistic traces generously left across Eurasia. In Europe, of 44 European languages
only 3 (Eng., Fris., Tatar) (7%) use allophones for “damp”, positively attesting of a “guest” status
in W. Europe. That excludes any claims on an “IE” pedigree, the claims are blatantly false.
Cognates: OHG damph, MLGmn. damp; Gmn. dampf “vapor” (but Gmc. native
feucht, with allophones); ONorse dampi “dust”, + numerous cognates listed in dumb.
No “IE” cognates, a faux ouverture “PG *dampaz” is an improvisation on the original theme
dum. A derivative adjective dymly “wet, soggy” is recorded in the westerly areal of the
Türkic languages, it must belong to the ancestors of a vague class called Scythians, Sarmats, and
eventually Türks. This is one of the numerous English words that popped up unannounced from the
depths of the country folk speech. See dumb.
20
English dear (adj.) “precious, valuable, costly, loved, beloved” (Sw N/A, F599 0.02%) ~ Türkic terim
(adv.) “a royal title or form of address” (G. Clauson G., 524, 549); dӧre- tӧre- (v.) “create,
produce, progeny”; tö:r “honorary” .
A standing etymology is a routine “ultimate origin unknown”, “a word of unknown etymology”. Since
“dear” can be an adj., a noun, an adv., and an interj., it carries a semantic range. According to G.
Clauson citing Pelliot, the most plausible explanation of the word
terim is teŋrim (with elided -ŋ-, Cf. Thor) “my goddess”, “my lady”, “my
princess”, “my deity”, where besides the Almighty Tengri, teŋri is a generic for god and
deity. The Eng. “My Lord” and “My Lady” are exact equivalents of the Türkic terim. A simpler
and less strained connection is with the verb ter- (te:r-, de:r-) “collect, gather” and its
noun derivatives alluding to treasures, treasury, gems, and the like, Cf. tergü “delicacy”,
terkak “stash”, terim (n.) “harvest, fruits”, terkan “provincial ruler”. In
that context, terim alludes to precious, esteemed, and dear, i.e. “my dear (valuable,
pricy)”. A notion “collection, treasure” (n.) comes from a sense of “harvest, fruits” (Sevortyan
1980, v. 3, 205), corroborating a semantic development “collect” (v.) > “collection” (harvest,
group, etc.) > “treasure” > “precious, dear”. That alternative is supported by the modern Turkish
semantics, which agrees with the modern Eng. semantics. It would not be anomalous for the word
terim paronymously carry a flavor of of both interpretations. Corollary to terim are the
forms dӧre- tӧre- connected with creation, progeny, and status title. The range of forms and
meanings may all ascend to a single primal word. The modern Turkish reflexes are değer “worth
it”, değerli “worthy”,
değmez “not worth it”, etc. (ğ is silent, i.e /deer/, /deerli/, /demez/
respectively). The transition t/d is regular, -m in the form terim is a 1st
pers. possessive suffix preserved in the Gmc. languages as a preposition my, mein. The
homophonic Türkic der-, ter- (v., n.) for sweat and labor, ultimately derived from
harvesting, should be excluded, they confuse etymological tracing connected with treasure and value
(Ir. dir, Pruss.
darge, dargel (name), Latv. deru, Lith. deriu, dereti). Cognates:
A.-Sax.
deore, diere, OSax. diuri, ONorse dyrr, OFris. diore, MDu. dure,
Du.
duur, OHG tiuri, Gmn. teuer, all “dear”; Ir. daor, drud “dear”, dir
“proper”, dire “duty, due”, Scots ghradhach, Welsh drud, ddrud “dear”;
Balto-Sl. (Latv.) dargs “dear”, (OCS) drag “dear”; Rum. draga “dear”; Pers.
geran, gerani “dear”, geranbaha “precious”; Skt. a-drtas “respectable, estimable”;
Mong. tölgü, tölgi “destiny, fate” (< Tr. törkö, ditto); all “dear” except as noted.
Distribution: spans Eurasia from Atlantic to the Far East. Cognates are mostly limited to
Gmc. group, a positive indication of a loanword status within the “IE” family. In spite of “unknown
etymology and origin”, “IE etymology” dives down to a codified 3rd mill. vocalizations asserting
faux “PG” *deurja-, *diurijaz “precious, dear, expensive”. Precise articulation within motley
human hordes of motley origins, ethnicities, cultures, geography, and genetics is sold as a science.
On a backdrop of a complete ignorance in all related matters the achievement is more then miraculous
to be taken seriously. The A.-Sax. form
deorlice (adv.), the modern form dearly (adv.), have retained not only the Türkic
suffix -lik (“like”), but more auspiciously, the original meaning of God, Godly, Goddess
(Tengri, Teŋri, Thor) derisively misinterpreted as a “household god”, i.e. unauthorized minor God of
the 1st-2nd mill. AD from banned and persecuted beliefs. The innovation dearth (n.) is among
semantic extensions, it is formed with a Türkic deverbal abstract noun suffix -t, Cf. ber-
“to bear, convey” ~
bert “tax, return”, see bear (v.). Its cognates OSax. diurtha “splendor, glory,
love”, MDu. dierte, Du. duurte, OHG tiurida “glory” are directly connected with
the original appellation “My God, My Goddess”, “My Precious, My Esteemed”. The English innovation
deary (n.) (diminutive) is an allophone of the adv. form teri. The ultimate etymology
comes directly from the “treasure” and from the Türkic appellation Tengri (Teŋri) for “God”:
Teŋri > teri, a crasis of teŋri in the form teŋrim (Pelliot, Clauson), applied in
Türkic parlance to royals and other dignitaries. The notion of “worthy, pricy, valuable, costly,
expensive” is a semantic extension carried to the modern languages, this process is exemplified by
recent extension of “God” to “Lord”, “Redeemer”, “Prince”, “All-Merciful”, “Exalter”, etc. Dear
is probably the only dear case of the word Tengri/Teŋri entering and enduring in English. A
presence of the Celtic terms daor and dir attests to the existence of these terms
prior to the Celtic circum-Mediterranean migration of the ca. 4000-2800 BC from the N. Pontic area.
They present a case of paradigmatic transfer of both terms, an evidence to an origin from a Türkic
phylum. A weight of converging evidence is insurmountable. See bear (v.), Thor.
21
English dumb (adj.) ~ Türkic dumur- (v.) “atrophy, degeneration”.
An “IE etymology” ascends to a level of “perhaps”. Ultimately fr. a verb dum- “submerge (in
water), dim, suffocating, sink”, a deverbal derivative verb fr. du-/tu- “stop, block, cover”
formed with a very multipotent verbal suffix -ur. Its nominal form is dum “dampness”.
Lost in articulation but retained in spelling suffix -p forms deverbal analytic nouns, i.e.
“dimness” fr. “dim”. Corollary notions are ubiquitous dü, duman, düman “fog, foggy”. A notion
“atrophy, degeneration” is a semantic extension of the base notion, Cf. doom, dim, dull.
Cognates: A.-Sax.
dumb (adj.) “silent, unable to speak”, (v.) “mute”, dumbian. adumbian “mute, dumb,
peaceful”, MEng. “foolish, ignorant” (synonymous with chump, block), OSax. dumb, Goth.
dumbs “mute, speechless”, OHG thumb “mute, stupid”, Gmn. dumm “stupid”; Sl. (Rus.,
Bulg./Bolg., Serb., Pol., Ukr.) tuman (туман) “fog, murky”; Balt. (Latv.) dumjš
“stupid”; Pers. du:d, du:dman “fog”; Av. dunman “fog”, dvanman “cloud”; Kalm.
tumn, tumŋ “fog”; Nenets (Kamassian) tumen, toman “fog”; Tr. duma:n “cataract
(eye)”. Distribution: notions “dumb” and “atrophy” are peculiar to Türkic and Gmc. languages;
the notion “fog” covers a width and meridian of the Eurasia. The ONorse dumbr is eidetic with
Türkic form. Türkic suffix -an, -n is a deverbal noun marker, Cf. Gmc. -an, -en ditto.
The “IE etymology” invents some “proto-forms”: a faux “PWGmc. proto-word” *dumb “dumb, dull”,
a faux “PGmc. proto-word” *dumbaz “dumb, dull”, a faux “PIE proto-word” *dheubh-
“confusion, stupefaction, dizziness”, a faux “PIE proto-root” *dheu- “dust, mist, vapor,
smoke”. All these will be corroborated once reverse-verified against attested records of the
Proto-period in the Proto-homeland land. The related notions of “defective perception or wits” is
not serious, with no cognates across other “IE” brunches, and with semantic and phonetic breaches.
Unsupported material belongs to dustbins. Unwittingly, the IE-cited meanings “mist, vapor, smoke”
are the meanings of the Türkic related noun dum, Cf. Türkic, Rus./Sl. tuman “fog”,
dym “smoke”. Related to dementia, from the same Türkic dumur “atrophy, degeneration”. See
dementia.
22
English durable (adj.) “long lasting, withstanding” ~ Türkic durağan (adj.) (-ğ- ~ aspirated
or silent) “fixed', stable”, from the root dur-/tur- (v.) “last for some time” of a base
notion “stay”.
In an “IE” etymology, a presence of a Lat. allophone serves as an inviolable proof of origins from a
Lat. ingenuity. A reality depicts a different picture. Of 44 European languages a largest is a
motley group dur-/tur- of 25 (57%) languages from 9 branches, starting from Tatar and ending
at Irish (a Lat. native is exegi). That matches a 50.6% R1a/b demographic presence in Europe.
Such scatter is typical for the “guest” Wanderworts. The remaining 19 (43%) languages, incl.
Lat., use their own 15 native terms. Such breakdown also attests to the dur-/tur- “guest”
status in Europe. Cognates: A.-Sax. trym-, trum-, trim-, trymian, trymman “strengthen,
fortify” (< tur-), trumlic “firm, durable, substantial, sound”, trymnes
“firmness, solidity”, tryms, trymes “solidness (coin)”, un-trymig, un-trymmig, un-trymig
“impair, weaken”; Lat.
durabilis “durable”, from the same Türkic root and with the same semantics, a compound of 2
Türkic roots dur- and -bilä. Unwittingly, Lat. dur is a clone of the Türkic
dur- (v.) for “withstand, endure”. Thus no “IE etymology” for the stem dur-/dura-, together
with the Lat. ingenuity it unwittingly defaults to the Türkic etymology. Distribution: the
root dur-/tur- is one of most potent Türkic roots, it is spread across the width and much of
the height of the Eurasia. Development of the relevant A.-Sax. lexicon indicates that it is
significantly older than the Lat. one; relatively, the Latins were latecomers. The Türkic adjectival
suffix
-bilä “ability” became a Lat. -abilis, -ibilis > Eng. -able, -ible, it is used
after stems ending with -a/-i, thus -abilä/-ibilä. It forms adjectives expressing
likeness, reciprocity, proximity; instrumental(ity), temporality, and is equivalent to the Türkic
adjectival suffix -ɣan/-gän/-qan/-kän for general tense participle. See able, endure,
duration, duress.
23
English eligible (adj.) “entitled” ~ Türkic ele:-, elge:- (v.), eleg (n.) “sieve, strainer, screen”.
Ultimately, the verb ele- is a denoun derivative from the word el “arm, forearm”, Cf.
Eng. compound elbow, lit. el “arm” + bük- (v.) “bend”, see
elbow. The el numbers about 15 semantic clusters including metaphorical “conduct”,
i.e. govern, rule, lead. Eleg is a deverbal instrumental derivative in -g/-ɣ/-k fr. a
verb ele-/elɣe-/älgä-/eɣle- (attested metathesis elɣe-/eɣle-/ekle-) “sift, select,
pick out” with numerous semantic extensions. Reflexes of the prime notions “select” and “rule”
formed the offshoot “eligible, entitled” (EDTL v. 1 260). The same root has produced the Eng.
elegant, elegy, elegiac, etc. Cognates: A.-Sax. elboga, elnboga “elbow”, elbowelc,
aelc “each, any, all, every, each (one)” (< eleg), elcora, elcra, elcran, elcor, elcur
(adv.) “else, elsewhere, otherwise”, elcian “put off, delay” (< eleg), elcung
“delay, elciend “procrastinator”; Fr. eligible “fit to be chosen”, LLat. eligibilis
“that may be chosen”, Lat. eligere “choose”; Mong. еlgеg (v.) “disperse, dispel (in
the wind)”, elesün “sand, dust”, elgeg (n.) “sieve, coarse sieve”; Kalm. elgǝG,
еlχǝ- (v.) “disperse, dispel”, elsŋ “sand, dust”; Chuv. ala- “disperse, dispel”,
Teleut älgäk “sand, dust”, Osm., Cuman äläk “sand, dust”, MTurk. älkä- (v.)
“sift”, Turk. älgäk “sieve, coarse sieve”; Kor. elgemi, elgimi “sieve, coarse sieve”.
Distribution: versions of eleg proliferate across Eurasian families and languages like
stars in a night sky. Like the English “to handle”, the Türkic elïg is a derivative from
elïg “hand”, thus elïg (n.) is “hand, arm” and “ruler, suzerain”, and
elïg (v.) has a constellation of derivative meanings related to ruling, one of which is “be
eligible”, which matches exactly the original meaning recorded in English: “fit or proper to be
chosen”, supposedly from Fr. from LLat. from Lat., and then hitting a dead end. Thus, in this
particular meaning, we have a chain of semantic shifts: hand (Tr.) => handle (Tr.) => govern (Tr.)
=> eligible to govern (Tr.) => chosen to govern (Lat.) => fit to be chosen (Fr.) => eligible (Eng.).
No “IE” parallels, no murky “IE” etymology. In Sl. a parallel sequence produced a calque rukovodit
(руководить) (v.),
rukovodstvo (руководство) (n.), lit. “lead with hands (govern)” (v.), “govern by gesturing
with hands” (n.). It is a small philological word after all. See elbow, Table 3a.
(Skip) Old English enge (adj.) “narrow, tight” ~ Türkic özak (adj.) “narrow”. Cognates: A.-Sax. nearu (n.) “distress, difficulty, danger; prison, hiding place”, nearu (adj.) “narrow, constricted, limited; petty; causing difficulty, oppressive; strict, severe”, Fris. nar, OSax. naru, MDu. nare, Du. naar “narrow”; the semantic of enge “narrow” is preserved in MDu. enghe, Balt. (Lith.) ankshtas, Lat. angustus, Sl. uzkii, vuzkii, Arm. anjuk, Skt. aihus, aihas, Av. azah- “need”. The attested link is Türkic özak “narrow” > Goth. aggwus “narrow” > A.-Sax. enge “narrow, painful”, with Sl. forms intermediate between Türkic and Goth. The Türkic özak (adj.) is a derivative of öz (n.) “valley, pass between mountains”, hence a narrow passage, narrows. With its original meaning of the Türkic öz “narrow pass”, the word spread to the South-Central Asia at about 1600 BC, and with the Kurgan or Sarmatian waves to the NE Europe and SC Europe (Lat. angustus “narrow, tight”). The syllable öz comes in numerous flavors, öd, öδ, öz, üz, making the Goth. form aggwus and Sl. uzkii, vuzkii just another attested dialectic forms belonging to separate linguistic branches. The “IE etymology” does not find the base stem in other Germanic languages and classes it “of unknown origin”. See anger, anguish.
(Skip) English entire (adj., n) “full, complete extent” ~ Türkic türə, törə, düs, tüs (adj.) “all, entire”. The word entire formed with a prefix en- “in, within” ascends to the A.-Sax. ðurh, ðruh, ðurg (prep.) “thorough, through, entire”, a derivative of the verb tür-/dür- “roll up, cumulate” to form with suffix -k/-g/-h nouns and adjectives, Cf. türk “mature, at a maximum, zenith” homophonous with the ethnonym Türk. The bridge to the extended semantics of omnis (Lat. entire) runs through the notion of “cumulate” via a notion of “crimp”. The alternation tür/tüs reflects the Ogur (tür, Northwest) vs. Oguz (tüs, Khakas, Tofalar) articulation. The verb tür-/dür-“ is not an alien element in Eng., in addition to the above entire, thorough, through, it produced other Eng. words with superlative connotations: durable, duration, duress, truth. Cognates: ðurh; Goth. þairh “through”; OFr. entier “whole, unbroken, intact”; Lat. integer, integrum “completeness”, an utter paucity. The Türkic and Gmc. “through” and “all” are still synonymous, Cf. “see through” and “see (it) all”. The Lat. form with the root teg- “touch”, integ- “untouched” appears to be an extremely long shot to phonetically produce the root ður- and semantically the notions “thorough” and “entire”. The claimed origin of the “IE” unattested teg- fr. VLat. source and rating of “perhaps of imitative origin” also raise questions of a serious conflict, and that is aside from the existence of the attested underlying Türkic verb teg-/deg- “touch”, see touch. Nether the VLat. nor the stem teg- represent the “IE” family. The teg-/deg-“touch” has no “IE” cognates across the “IE” family, it is an obvious guest there, the “IE” pedigree is implausible other than internalizing it with the prefix en-. It is hardly explainable that the “IE etymology” ignored the rich A.-Sax., Goth., and Eng. vocabulary based on the stem ðurh “entire”, and suggested an etymology of suppositions and canards. Since the synonymous triplet all, entire, and gamut correspond to the same source as a bundle, with all and entire attested in the A.-Sax., they constitute an authentic case of paradigmatic transfer from the Türkic milieu, see all for further details. The Türkic etymology fits fairly perfectly semantically, phonetically, and in application; the ðurh and þairh are not loanwords, they are substrate words shared between the Gmc. branch and the Türkic family. The distribution of the stem tür- in Europe and across the Türkic Eurasian belt covers geographically, albeit not demographicly, most of the Eurasia. The absence of the Celtic native forms postdates the forging of the semantic extension to after the Celtic departure from the Eastern Europe ca. 5th-4th mill. BC. The distribution of the stem tür- , combined with etymological information on the original sources and final destinations, attests to its own temporal and geographical paths. The grouping of the destinations enables visualization of different paths. See all, gamut, omni-, total.
24
English false (adj., adv.) “deceptive, delusive” ~ Türkic al-/äl-, yal-, ar- (v.) “deceitful, false,
lie/lies”.
“IE etymology” is rated as “of uncertain origin (“but see “fail” (v.)”)”. The “fail”, a Gk.
sfallein (σφάλλειν) “mistaken” is unrelated to the subject. In the archaic Türkic culture,
lying was among the greatest human sins, so the word “fail” had grave connotations, see sin.
Vestiges of that attitude still survive prominently in the British culture, to much lesser degree in
the American culture, and fairly well in the modern Türkic cultures. Of 44 European languages a
largest is a motley group (C)al- of 32 (73%) languages from nearly every European branch,
starting with Tatar and ending at Scots. That matches a 50.6% R1a/b demographic presence in Europe.
Such scatter is typical for the “guest” Wanderworts. Such forced breakdown also attests to
the
-al- status of a “guest” in Europe. The remaining 13 (30%) European languages use their own 9
native terms. Cognates: A.-Sax. aleogan “lie, deny, deceive, be false, unfinish(ed)”,
lyge “lie, falsehood”, Goth., OHG. liugan, lugi “lie”, Du. valsch, Dan. falsk,
Gmn.
falsch; OFr. fals, faus, Fr. faux;; Ir. logaissi “falsehood”; Lat.
falsus, fallere “deceived, erroneous, mistaken, deceive, disappoint”; OCS alïr (алыр, алырь)
“deceit, trick”, Sl. lgat (лгать) “deceive, lie”, Rus. falsh (фальшь) (< Gmn.
falsch “false”; Pers. ul/al “trick, deceit”, qallabiy “cheat, counterfeit, false,
coiner of false money”,
qalb “counterfeit”, kolah sar “swindle, cheat”; to ; Hu. a:l- “deceitful,
false, lie”; Mong. aldaɣa/aldaa “mistake, blunder”. Distribution: Eurasian wide, way
beyond A.-Sax. and Lat. reach. That positively excludes an “IE” origin. The A.-Sax. grammatically
well-developed word shows deep internalization of the root al-, with and without a prosthetic
anlaut vowel. That points to internalization much older than the Lat. internalization. In English,
the Türkic stem yal-, al-, ar- turned into two semantically close but separate forms,
lie/liar and false originated from Türkic derivatives formed with various suffixes and
expressed with dialectal phonetic variations. The forms with Lat. and Gmc. anlaut f- indicate
that the word came into circulation from the a source with an Ogur-type (R1a Y-DNA Hg.) prosthetic
anlaut consonant. The forms lie/liar, in contrast, point to the Oguz origin, without a
prosthetic consonant and some in contracted form with elided unaccented anlaut vowel. Somewhere on
the way, the Türkic prosthetic anlaut consonant usually expressed as d-/g-/j- turned into
typical for the Eastern Europe vernaculars voiceless labiodental fricative f-, shared by the
Sl., Romance, and Gmc. vernaculars, Cf. face yü:z, father atta, fissure öz/özi:,
A.-Sax. aid
fula(est) < yӧlä, etc. The word does not have “IE” parallels, and etymological
conjectures come to the routine “of uncertain origin”. See face, father, fissure, lie, sin.
25
English full (adj., n., v.) “replete, filled” (Sw182, F597, 0.02%) ~ Türkic ye:l-, jel-, yeldi: (v.)
“eat, eaten”.
The ye:l- is a passive of a prime form
ye:- “eat” denoting a speciated “full, filled, satisfied, sated”. It is a prime meaning of a
very polysemantic word that numbers about 12+ semantic clusters addressing various aspects of a food
intake: satiated, covetous, consume, crunch, gnaw, etc. Gmc. languages internalized Türkic ye:l-
with their habitual initial prosthetic consonant f-/v- as a generic “full, fill”. Sl. and
Romance did that with an initial prosthetic consonant p-. Together that grouping includes 30
(68%) of the European languages, exceeding a 50.6% R1a/b demographic presence in Europe. Among
European branches, the Sl. group predominates with 13 languages, pointing to a linguistic
homogeneity of a pre-2000 BC, i.e. pre-IE, Old Europe. The remaining 14 (32%) languages use their
own 9 native terms. An A.-Sax. adj. full “full, filled” attests that a non-speciated notion
“fill” had already existed in the A.-Sax. lexus in an undifferentiated form full and as a
verb fyllan “fill”. Collectively, European Turkisms point to an original Oguric-type
articulation marked by a prosthetic (in respect to Oguric) initial consonant.
Cognates: A.-Sax. metaphorical ful/full serves as a prefix/preposition intensifier
“very, super”, fulbrecan “very broken”, fulhar “very hoary”, fullbryce “super
breach”,
fullclaene “very pure (clean)”, fulaest, fylst (n.) “help, aid, support”, fultum
(n.) “help, aid”, fullaestan (v.) “help, aid, support”; among other metaphorical extensions
are “entirely, completely, fully, fill, quite, exactly, precisely”, specifically A.-Sax. ful,
full (adj.) “full, filled”; OSax. full, OFris. ful, Du. vol, OHG fol,
Gmn. voll, ONorse
fullr, Goth. fulls, with a similar dispersed spectrum of polysemantic meanings; Bulg.
džimis “fruits”; Hu. gyümölcs “fruit”; Mong žeme “carrion”, ide-, idǝh
“eat, corrode, devour, gnaw, exploit, take bribes, embezzle money”, Bur. zemeheŋ “gift (when
animals are slaughtered)”, zegeŋ “wolverine”; Tung. žepti- “eat”; Manchu žе-
“eat”, Evenk žew-, žep- “eat up”; Chuv. si- “eat”. Distribution: Eurasian-wide,
across linguistic borders. A semantic dispersion is confusing only when etymology is inventing
mystical ghosts lurking in an neverland, like the mechanistic “PG” *fulljanan “fill” or “PIE”
*pele- “fill”. Mysticism only but distracts from tracing a real chain of semantic extensions.
The origin, the paths, the timing are fairly clear, albeit not unequivocal, since the Hunnic-time
events overlay a long chain of prior events that were depositing upon the same turf their own
Turkisms. A notion “fill” is a derivative of the notion “full”, a result of apophonic development.
See eat, edacity.
26
English gentle (adj.) “tender, delicate” ~ Türkic yinč- (adj.) “slight, delicate, thin, slim, bow,
bend”.
Ultimately fr. yi:n (n.) “body, flesh, limbs, body part, skin”, with diminutive denoun suffix
-č. A prime notion is “thin, narrow”. It is extended by additional 16 clusters from “small,
barely noticeable”, to “quiet”, to “graceful, gentle”, “wise”, and to “excellent, good”, among
others. The Eng. anlaut g- /dʒ-/ in gen- is conventionally depicted as y-
(Eng.) or j- (Gmn.); in any case gen- is articulated /ˈdʒɛn-̩/, not /ɡen-/ in Eng. and
/dʒin-/ in Türkic. Clusters of the root yinč- include all Eng. relevant terms: 9. “genteel,
gainly, gracile”, 10. “gentle”, 11. “refined, elegant”, 12. “gentle, noble, honorable”, 14. “artful,
wise”. The “gentle” and “noble” are innate semantic properties of the Türkic yinč-. A massive
semantic and phonetic match can't be a result of a chance coincidence: the notion “gentle,
gentleness, nobility” is very narrow and a corresponding probability is astronomically small. Chance
coincidences for two or more notions are limitlessly small (geometric progression). Listing of ways
to articulate yinč- in Türkic is excessively large, 28+ forms (EDTL v. 1 364,
VEWT 203) That
attests to antiquity of the term and its ethnic diversity. Only 4 (9%) European languages use
versions of
gentle (Port., It, Maltese, Eng.; native Lat. are leves, mitis). Cognates: Eng.
inch, Tr. yınča, anča “inch, small, less”, Eng. needle, Tr. yi:ne, igine,
igne: “needle”, see knee for more cognates; OFr. gentil, jentil “high-born,
worthy, noble, of good family; courageous, valiant; fine, good, fair”, Fr. “nice, graceful,
pleasing, fine, pretty” (< Lat.); Lat. gentilis “same family or clan” (unrelated extract),
MLat. “noble or good birth” (unrelated extract); no cognates outside of Tr. and of Lat. loanwords (<
Tr.); false Lat. cognates v.i. Distribution: ubiquitous across Türkic Steppe Belt, a “guest”
status in W. Europe. A myopic “IE etymology” is lost between two trees, its horizon lays within two
trees' circle. Its suggested etymology for the whole range of internalized loanwords (gentle,
gentile, genteel, gens, jaunty) is claimed to descend fr. a notion gens, gentis “race, clan”,
*gene- “beget, birth” that ascend to a totally unrelated Türkic ge:nč, ke:nč (n., adj.)
“young (sprout), new, child, baby”, see gene. The gen- “tender, delicate” should not
be confused with the identical Romanized rendition of another root ge:nč, ke:nč “gene,
genesis”. In the popular standing etymologies these homophones are routinely confused and conflated.
That myopic and mechanistic approach makes a mockery of the “IE” philology. Philological myopia and
illiteracy are inexcusable results of preconceived partiality. Numerous derivatives of the stem
yi:n convey connotation of material weakness, as opposed to a stiffness of hard materials. Thus
metaphorical “flesh” as a material is a prevailing notion with adjunct expressive secondary notions
of “bow, bend”, with further semantic and morphologic extensions. An Ogur form of the Oguz yinč-
is jinč-, ginč-, and other dialectal versions with anlaut consonant specific to Oguric
branch from a lineup h-/k-/g-/d-. The morpheme y- may be Oguric with expressed
articulation or Oguzic with nearly undetectable articulation. The semantics of “flexibility”
propagates into notions of “joint”, “flexible”, and the like (Cf. Lat., Eng. genu “knee” and
its “IE” cognates). The semantics of “bend” propagates into notions of “bowing” (Cf. LLat.
genuflectere “bend the knee” and its “IE” cognates). The semantics of “delicate” (gentle,
gentleman, genteel) propagates into notions of “detailed, discernable, refinement, crisp,
clear”, with an ultimate notion of “keen, discerning, wise”. Such expansion of the material property
of the object “flesh” opens gates wide for concrete and especially for abstract uses, of which
gentle is but one of the most direct derivatives. Most of the European synonyms for gentle
are derived from stems other than the Oguric gen-. They are relicts of the Old Europe,
pre-IE, i.e. pre-2000 BC languages (Cf. Sl. nežen (нежен), laska (ласка) “gentle touch,
fondle” with 7 (16%) languages). Like hundreds Turkisms in Eng., the roots gen- and
tend- entered European languages as a paradigm, as allophones of the Türkic yi:n and
tut- with their pinpointed semantics, see tend. As a paradigm they attest to a common
origin from a Türkic phylum. See gene, tend.
27
English grey, gray (adj.) “intermediate achromatic color” ~ Türkic ğır, kır (adj.) “grey”.
The “IE etymology” cheerfully states “no certain connection outside Germanic”, i.e. a mysterious
origin within myopic “IE” horizons. The Türkic root ğır, kır is but one of at least eight
extant roots for the notion “grey”, a few of which, including “grey”, demonstrate an extended period
of various undifferentiated semantics when one word named a range of colors and other traits: hue,
pale, blue, green, brownish, roan, ashen, pale yellow, etc. These notions were areal and portable,
changing their contents under local conditions, and fossilized with codification of languages.
Domestication of horses, switch to producing breeding, and extensive trade (5th mill. BC) brought
about an explosion of related terminology. Distribution of European synonyms shows that
“grey” was an innovation and a “guest” for the European languages: 24 (55%) languages use versions
of the form “grey”, matching a 50.6% R1a/b demographic presence in Europe. The Sl. languages are a
single substantial European group with its native term, numbering 10 (23%) languages. The remaining
11 (25%) languages use their own 6 terms, few of them formed from alternate Türkic synonyms.
Cognates: A.-Sax. har, græg, Mercian grei, ONorse grar, OFris. gre,
OHG grao, MDu. gra, MIcl. harr, Du. graw, Gmn. grau “grey”; Gk.
gri (γκρί); Arm. gorsh (գորշ); Basque, Sp. gris; Fin. harmaa; Hu.
szürke; no Balt. or Sl. connections; Gujarati gre; Tuhsi (aka Tokhar) kır
“grey”; references to cognates in Nanai languages; all “grey” except as noted. Distribution:
from Atlantic to Far East and North; Sl. reached Pacific, while Türkic reached Atlantic.
Distribution of “grey” is spotty within “IE” languages and crosses numerous linguistic family
barriers, attesting to a “guest” status within the “IE” family. No “IE” connections, the PIE
dictionaries cite a “PIE proto-form” that is a slightly distorted mirror of the Türkic ğır.
IE-invented faux “PGmc. proto-forms” *grewa- *grewaz are not needed, and are rather shady;
suggested as “cognates” notions “see, glance, watch, look”, “shine” are unrelated. A reality does
not need any substitution. The Türkic origin of the Gmc. forms is beyond doubt. Numerous Gmc.
derivatives exceed by far the narrow semantics of the Türkic ğır “grey”, attesting to a long
period of independent evolution. The Türkic ğır also has a meaning “dirt” (Cf. grease,
grime, grunge, and related grim, gruesome), one of these two meanings produced the other
as a metaphor. Türkic and Eng. also actively use “grey” in naming animals, Cf. a common idiom “grey
wolf”, compounds grey hen, greyhen “grouse”, greyhound “grey hound”, greywacke
“sandstone type”, etc. The entire compound greyhound is an allophone of the Türkic compound
ğır aŋdï- where hound (n.) is an allophone of the Türkic aŋdï- (v.) “lurk, waylay,
watch for (game, beast)”, i.e. lit. “grey ambusher” formed with a typical Gmc./Aral-Caspian
prosthetic anlaut h-. Locations of the form ğır as opposed to kır are centered
around the Caspian-Aral basin (Turkmen, Azeri, Tuhsi/Tokhar), consistent with numerous other English
Turkisms. Türkic and Eng. words carry in parallel both notions “grey” and metaphoric
“silver-haired”, an indelible case of phonetic and semantic paradigmatic transfer.
28
English hard (adj.) “firm, strong, difficult” (Sw N/A, F321, Σ0.05%) ~ Türkic qart, gart (adj.)
“hard”, (n.) “dried, hardened (crust)”.
The word numbers 5 semantic clusters, in the n./adj. and verbal forms. Of those, “scab, crust
(wound)” i.e. hardened, dried, and “hard”, “bark, cork” are prime, the “old” (< kar- “grow
old”) and “wise, seasoned” are either secondary or homophones. The opposite is also viable (kar-
(v.) “grow old” > kart n./adj.). Türkic has at least 24+ internalized words for “hard”,
although a number of roots is much smaller. A synonymous Türkic
kat- (v.), katı: (adj.) “hard, firm, tough, strenuous” may have developed as an
allophone of qart, gart (n.) and emerged to gain a universal distribution with an
overwhelming variety of forms: qarča- (qarcha-), qurč (qurch), kat, katığ, ɣayät, ɣayet, qat-,
qataɣ, qatïɣ, qatɣï, qatqï, qatïɣ, ked, keδ, qadaɣ, qadïɣ, qadïr, kej, ket, qattïh, xatϊɣ.
A.-Sax. has at least four deeply ingrained native synonyms for the notion “hard”, pointing to an
extensive linguistic amalgamation of disparate languages. Cognates: A.-Sax. hard, heard
“hard, strong, solid, firm”, heardian, hierdan, hyrdan (v.) “harden, become hard”, OSax.,
ODu. hard, ONorse harðr, OHG harto, Goth. hardus “hard”; OKimr. сrаff
“strong”; Gk. kratos “strength”, kratys “strong”; Sl. (Ru.) et al. krepko, krepkiy
(крепко, крепкий) “firm, strong”; Skt. kratu (क्रतु) “hard?”, Av.
xratuno “hard?”; references of non-Türkic Far Eastern languages are cited. Distribution:
extending from Atlantic to the Far East. European distribution is bent to native terms: of 44
European languages, 13 (30%) use their own 11 words. 11 (25%) Sl. languages use 2 words. The Türkic
qart is used by 9 (20%) languages, Romance group numbers 5 (11%) languages, Celtic group uses 3
(7%) languages. Atypical for Europe lexical segmentation with a large proportion of home-grown terms
points to early fossilization, likely ascending to the 3rd - 1st mill. BC. A complete absence of the
“IE” cognates outside of the Northwestern European Gmc. and Sl. groups plus a Gk. outlier attests to a
“guest” status within the “IE family”. An unstoppable “IE etymology” contributed its own fantastic
appropriations: faux “PGmc. proto-form” *hardu- “hard”, faux “PWGmc. proto-form” *hardı
“strong, powerful”, faux “PGmc. proto-form” *harduz, faux “PIE proto-form” *kort-us
“strong, powerful”, faux “PIE proto-form” *kret- “strong, powerful”. Fortunately, none of
that nonsense is needed, the attested lexicon, a mass of its derivatives, and its wide spectrum of
cognates provide ample testimony to the initial development of the notion “hard”. It allows to
visualize a process of borrowing and internalization by an alien lexical machinery and spelling
conventions. The A.-Sax. spelling heard, hierd, hyrd points to alternate articulations of the
vowel and hence to diverse paths for internalization. All cognates reflect a history of migrations
and influences from the peoples of the Steppe Belt. Besides defining physical properties, all
languages, starting with Türkic, have metaphoric meanings of difficulty: “extremely, very, hard,
strenuous, strong, intense, vigorous, violent, harsh, severe, stern, cruel”, and the like. The
nominally Cimmerian (OKimr.) form dates to 3rd c. BC at the latest, it may have amalgamated
vernaculars of allied nomadic tribes of the Scythian circle of the Cimmerian union. The pinpointed
semantics and the retention of the polysemantic spread make the semantics and phonetics perfect
without a need to appeal to unattested delusive “PIE proto-forms”. The English trio of grammatically
similar hard, bold and sharp constitutes a case of paradigmatic transfer, inextricably
attesting to a common origin from the Türkic milieu. The trio probably ascends to a Corded Ware
period (3rd mill. BC), millenniums before the Anglos joined with the Saka Saxes, and Anglo-Saxon
community had congealed. See bald, sharp.
29
English hilarious (adj.) “super-humorous”, hilarity (n.) “glee” ~ Türkic gülčir-, külčir-, külsir-
(v.) “smile, chuckle, laugh”, güleryüz (adj.) “smiling”.
An “IE etymology” asserts a dubious “probably” confidence level, v.i. Ultimately fr. gül-, kül-
“laugh, laugh at, smile”. Dialectal allophones and developed derivatives point to an antiquity of
the verbal stem. Of five Türkic terms related to laugh, four paradigmatically transferred to Eng.:
gül- as
hlæ- “laugh, hilarious”; jer- “jeer”; elük “joke”; qatɣur- “cackle,
cachinnation, gag”. The four Türkic words complemented and supplanted a related native
European lexicon of the faded A.-Sax. terms. A motley group (gül-) of 13 (30%) European
languages dominates (Romance 5, Celtic 2, Gmc. 4, Fin. 1, Tatar 1). A runner-up Sl. group (vesel-)
of 9 (20%) includes Hu., Luxembourg, Romance; a second Sl. grouping (smech-) of 5 (9%) stands
separately. A combined Sl. fraction is a second majority group, consistent with a thesis that Sl.
(Y-DNA Hg. I, a splinter of Hg. G) was an oldest European language, the language of Old Europe. A
side Romance group includes 3 (7%) more languages. The remaining 14 (32%) languages use 12 of their
native, distinct, and all European, words. Aside of gül-, there is no shared Pan-European or
“IE” word in Europe. Any claims to an opposite are self-delusions. Cognates: A.-Sax.
hlagol “laughter-prone”, hleahtor “laughter”, hleahterlic “ridiculous”, and many
more; Ir., Scots gaire “laugh, smile”, Welsh
gwen, gwenu “smile, grin, shine”; Lat. hilaris, Gk. hilaros (ιλαρος) “cheerful,
gay, merry, joyous”, hilaos (ιλαος) “graceful, kindly”. Distribution spans Eurasian
Steppe Belt, was spilled to Gk., and independently carried to A.-Sax. A stray suggestion of an
origin fr. a faux “PIE proto-root” *selh- “reconcile” ~ Lat. solari “console” is
hilarious. Under the “IE” paradigm, a Gk. source with a known adj. and no known nominal or verbal form
is not helpful, leading from one unknown to another. A source of the Gk. word was attested by
Herodotus IV 108, 109, 120: “Gelons were Greeks from long ago, they speak partly in Scythian, and
partly in Hellenic”. A Roman holiday related to Cybele, Hilaria, was a big deal with joy and
pomp. Cybele, an Anatolian mother goddess said to be a Phrygian goddess, was worshipped on mountain
tops like the Türkic Tengrian rites. The celebration was also a family day of joy. The recorded
verbal stems link an Anatolian source with the records of the eastern areas of the Eurasia where no
Phrygian influence has been documented. The Celtic forms point to an independent path with -r
articulation of the r/l split, and an Ogur-type source vernacular. The Türkic etymology is a
phonetic and semantic match. A paradigmatic transfer of the Türkic lexical quartet, v.s., testifies
to a common genetic origin from the Türkic milieus of very different geographies and periods. See
laugh, cackle, jeer, joke.
30
English ideal (adj.) “extremely good, perfect” (Sw N/A, F256, Σ0.05%) ~ Türkic idil, edil (adj.)
“good”, fr. stem idi:, edi, eδi, “very, superb” + pass. adjectival suffix -l.
Ultimately fr. a verbal stem ed-, et-, id- “do, make, create, organize, put in order,
ornament, adorn” conveying generic notions “act” and “improve”, both with wide semantic spectrums,
plus 7 other semantic clusters from “correct, re-do” to “respect, honor”. In turn, it is a
derivative fr. an asserted verb e-, i- “force to be, implement, do”. The adjective idi:
“very, extremely” in passive form idil, edil accurately conveys the notion expressed by a
modern expression “made ideal”, in Türkic idilmak, i.e. “make idyllically good”. A Türkic
tendency of forming paired compounds of two synonyms is most helpful in identifying semantic load of
a pertinent word, Cf. compound bïš- etil-
(bïš- = etil-) “ripen, matured”, i.e. “done”. A Türkic peculiarly bifurcated method of
creating opposites from the same stem developed synonymous edgü: “good” and antonymous
etet- “bad going, difficulty”, with their own trees of derivatives. European distribution is
outstanding and peculiar: of 44 European languages, 40 (91%) use variations of the form
i/e-d/t-il-; only 3 languages use their own terms (Scots, Welsh, Lat.). That is due to a recent
spread and universal borrowing precipitated by an absence of the notions “idea, ideal” in all
European languages. That is except for various Türkic languages of numerous ethnic groups in Europe,
too many to list, and not all traceable. Cognates: A.-Sax. ed-wit “reproach”,
(ge)edbyrdan
“regenerate” (do + ber- “bear”), edcolnes “cooled” (do + hel “cool”),
(ge)edcennan, edcenning “regenerate, regeneration” (do + ke:nč “young (sprout)”),
(ge)edciegan “recall” (do + qol- “call), edcierr “return” (do + kel
“come”); the listing of A.-Sax.-like compounds runs for a page+; Irish idealach “ideal”,
Welsh ddel[frydol] “ideal”; Icl. [i]tilvalið “ideal”, OHG. ita-wıč, id-weitjan
“reprove, blame”, Goth. iddja “went” (< id- “move”), idreiga, idreigon
“repentance, repent” (id-), id-weit “reproach”; LLat.
idealis “idea”, Lat. idea “idea” (> ideal, vs. Lat. native ratio); Gk.
idea (ἰδεα) “notion, pattern”, idaniko (ιδανικο) “ideal”; Fin. ihanteellinen
“ideal”; Tatar idil “ideal”; no citations for Far Eastern and N. Siberian cognates. A paucity
of cognate listings is precipitated by the “IE etymology's” myopic horizons and pure ignorance of
the standing false claims. Distribution: From Atlantic to the Far east. Pre-modern rise of
the European forms probably started in the Corded Ware period expanding to the N. Europe. By the
turn of the eras via Gk. intermediaries it reached Mediterranean, and started a European spread from
a printing period. Defying any IE-linked origin, amusingly the “IE etymology” used to derive reflexes
idea (n.), ideal (adj., n.), idyl (adj.), etc. from different sources, in the
case of
ideal from unrelated optical Gk. eido (εἰδω) “(I) see” and Lat.
idea “vision, mental picture”, leading to a dead end. The Gk. form might ascend to a Tr.
cognate
edlä- (v.) “pay attention, be attentive”. Semantically, “IE etymology” is not viable since it
is ascribed to an unrelated notion that is lacking an essence of excellence and pleasantry
associated with the notion of “good” innate to the word ideal and the words idyl, idyllic.
See idyl.
31
English idle (adj. +v., n.) “inactive” ~ Türkic ytla (adj.) (Chuv.), edligsiz, etigsiz (adj.) (CT)
“inactive, useless, wasteful”.Standing
“IE” etymology is a dubious “word of unknown origin”. A polysemantic root ed-/et- carries a
raster of 9 semantic clusters conveying a prime notion “do, act”. Ultimately, all allophones ascend
to the Türkic verb edla-/eδlä- “use, apply”. The word “idle” comes in two distinct forms,
Western and Eastern (Clauson EDT 36). The Western, yt-la, probably a primeval word
from the east, is formed with obsolete ancient adj., adv. suffix -la. The Eastern,
ed-lig-siz, reflects a canonized Türkic grammar in CT format. That format probably evolved in
the west and extended to the east in best traditions of mixing and amalgamation. Of 44 European
languages, largest groups with 6 (14%) languages each are a Romance and a motley group incl. Eng.
Four groups bear from 4 to 3 languages each, and the remaining 20 (45%) languages use their native
18 terms. Such nativistic breakdown points to an antiquity of the surviving terms. On top of the
“unknown origin”, there is a Pan-European disunity instead of a Pan-European linguistic unity or a
“Pan-IE” language. Disunity also shows up in comparing ed-
“inactive” with ed- “do”, two derivative notions of the same root. The “do” has 13 cognates
vs. 6 for “inactive”. A need for a speciated notion “do” was twice greater than a need for a casual
notion “idle, lazy” of a daily routine. Cognates: A.-Sax. idel “empty, void; vain;
worthless, useless; not employed”, OSax. idal, OFris. idel, ODu. idil, Du.
ijdel, OHG ital, Gmn. eitel; Sl. delo, dela (дело, дела) “job, task,
occupation”, delat (делать) “do, deal”, all “idle” except as noted. Sources do not cite
Türkic cognates outside of the Türkic phylum. Distribution: Türkic Eurasian Belt; incursion
into Gmc. isle with few radiating waves. Typical for the loanwords, only a small semantic selection
of the original semantics was transferred to and internalized by the receptor languages. The
territory fr. Urals to Sarmatia and Iberia likely used the “western” term, later supplanted by the
“eastern” CT form and then largely displaced by an influx of post-600AD Sl. vernaculars. The early
carriers originated fr. Y-DNA Hg. R1a (Ogur-type languages), presently centered around Itil/Volga
river. They later admixed with waves of Oguz-type tribes of Hg. R1b (aka Sarmats). Unlike the
eastern Türkic languages that produce form “inactive” as a negation of the active form (edligsiz,
with negation suffix -siz), the Chuv. form reversed the meaning fr. “do” to “idle”. In that
respect, the western Chuv. form stands out vs. the eastern Türkic languages. Since no W. European
vernacular retained any elements of the negation -siz, their loanwords ascend to the
Chuv.-Bulg. vernaculars. Phonetic and semantic cohesion indelibly attest to a Türkic genetic origin.
See ideal, idyl.
32
English idyl, idyll (adj.) “pleasant” ~ Türkic idil, edil (adj.) “good”.
Ultimately fr. stem idi:, edi, eδi, “very, superb” + adjectival suffix -l, a
derivative of a stem ed-/et- “do, make, create, ornament, adorn, put in order, organize”
conveying generic verbal notions “act” and “improve”, both of wide semantic spectrum. The adjective
idi: “very, extremely” in passive form idil, edil accurately conveys the notion expressed
by a modern expression “made ideal”, i.e. “make perfectly good”. The Türkic peculiar bifurcated
method of creating opposites from the same stem developed fairly synonymous
edgü: “good” and antonymous etet- “bad going, difficulty”, with their own trees of
derivatives. The alterations e-/i- and -d-/-t- are largely random, predicated by vast
spread of the areal linguistic variety, randomness of amalgamation processes between kindred
languages, and a vast semantic spectrum covered by the applications, Cf. more examples of
translations: “copulation, marshal, prosper, succeed, thrive”, etc. Cognates: Lat.
idyllium, Gk. eidyllion are semantic extensions of the paradise quality; in that sense it
is now an international word. The word is used nearly exclusively in the form idyllic, like
“ideal scenery” for a picnic or crime, an adjective with the Türkic adjectival suffix
-lic/-lig/-liɣ, carrying the same semantics of “good, superb”. Amusingly, the “IE
etymology” derives two reflexes, ideal (adj.) and idyl (adj.) from different sources, in the case
of ideal from Gk. and Lat. idea “vision, mental picture”, and idyl from some
kind of “shape”. The Lat. and Gk. examples may be scholarly conflations of phonetically similar
derivative extensions, since they are ascribed to the semantically unrelated Gk. word eidos
and suffix -eidos “form” and “similar in form” (e.g. ellipsoid) respectively. Defying
any “IE” link, the suggested notions lack an essence of excellence and pleasantry associated with the
notion of “good” innate to the words idyl, idyllic. The cherry-picking of “IE” “cognates”
profoundly illustrates the absence of the term in the overwhelming majority of the “IE” languages,
clearly attesting to the non-IE origin of the word. See ideal.
(Skip, too messy, ALAZ
etc.EDTL v.1 132 недомогающий etc., + 136 AЛAШA/ALAŠA слабый, немощный, +ilek, iylek + AϓÏR +++)
’ILLAT [ a.] болезнь, недомогание (QBN 43.,)
33-
English ill (adj.) “sick”, (n.) “bodily disorder” ~ Türkic ilek, iylek (n., adj.) “sick”.?
Ultimately fr. an archaic adj. i:g and its extensive lineup of allophonic forms that in some
particular case drifted to -l- via -y-/-v-/-w-/-š-/-Ø- (i.e. ia- > i-Ø- > ıl, ılı-,
Cf.
egle, eyle, eile). The i:g, in turn, is ultimately a contracted form of a verb a:ŋ-
(i.e. ŋ (ng) > g) with a notion of downward infirmness:
“hang over, slide to the side, lean to one side” (EDTL v. 1, 86). The anlaut a-
wobbled to i-, ı, e-, yı, etc. This incredible transformation chain is supported by an
incredible variety of phonetic forms that came to literate times. Here is a documented partial
sampling with a- form: аɣаr, aɣir, aɣır, еɣir, aır, а:r, а’r, awır, avır, awur, аur, o:r,
u:r, ıar, yıvаr. With
i- form: i:g, igli, ığlı, igili, inli, ilek, iylek. In modern Eng. ail, ill and
evil. The suffix -ek is a deverbal adj. and denoun diminutive suffix, -en is
reflexive suffix. There are no laws for stochastic events. Without a documented trail of allophones
no linguist versatile in systemic phonetic “reconstructions” would reconstruct a sound change ail
and ill to a parental a:ŋ-. Semantics of ilek/ilen reflects a notion of
“demise, ruin” which comes in a number of concrete effects, “sick” is one effect, “evil, bad,
hurtful, hard/heavy, unfortunate, difficult, topple” etc. are among the others. A fuzziness of the
term is reflected in the Gmc. lexis, which finds a range of translations with notions of negative
event or status. Numerous Gmc. forms carry traces of the parental form аɣ-. Cognates:
A.-Sax. eglan, eglian “afflict, trouble”, egle “hideous, painful”, yfel, ebol,
eofel, evel “bad, ill, evil, wicked, wretched”, OSax. ubil, OFris. evel, Saterland
Fris. eeuwel “bad, vicious”, MEng. eyle, eile “hideous, painful”, evel, ivel, uvel,
evilty “evil”; ONorse illr, illa, ilt “bad, sick, evil, hard”, Norw. ille, Dan.
ilde, Icl. illur, MDu. evel, Du. euvel “bad, vicious”, Goth. agljan
“distress”, aglus “difficult”, agls “shameful, disgraceful”,
agliþa “distress, affliction, hardship”, us-agljan “oppress, afflict” ubils
“bad, vicious”, OHG ubil, LGmn. övel, Gmn. übel “bad, vicious”; OFr. ulcere
“sore”; Lat. ulcus “sore”; Gk. hélkos (ελκος) “wound, ulcer”; Skt. arsas (अर्शस),
Hindi ars (अर्श) “hemorrhoids”; Hittite huwapp-, huwappa “evil”,
huwappi “mistreat, harass”; Mong. aɣla-, uyila-, ula-, ukila-/ihilah “cry”. A fuzziness
of the term brings about other cognates related to the cluster of negative derivatives, such as
a:ɣï/a:wï “crying, groaning”, agri/awrï “pain” (Cf. aggravate, Agrippa “painful
birth”), awï “poison” Cf. A.-Sax. ifeg, ifegn “(poisonous) ivy”, aɣsa- “limp”
Cf. Mong. asag “limp”, а:ɣdar- “knock over, overturn”, aɣsa “snap upset”,
а:ɣna- “festinate” (Cf. agony, Gk. agon (αγων) “contest”), and the like, each with
further possible cognates in neighboring languages. Distribution is spread along the Steppe
Belt with excursions into neighboring areas. “IE etymology” invented a special pleading cornucopia of
“IE” or PG “protoforms” for each word encountered in the European languages, the likes of *upo,
*up, *eup “down, up, over”, *upelos “evil”, *olcos,*elkos, *h1elk-
“wound, illness, ulcer”, *azljaz “trouble, plague, afflict” and *agh-lo-, *agh-
“depressed, afraid” and *agilo “awn” for a single “ail”, *ubilaz, *upelo-, *wap- “bad,
evil” and *h1upelos, *h1wep-,
*h1wap- “treat badly” for “evil”. That listing
is probably incomplete, the mill keeps rolling. A patriotic clownage was keeping rambling on. That
quasi-scientific nonsense must be retrieved with self-deprecation. An entire semantic theme is based
on few allophones of a base root modified with a constellation of agglutinated suffixes. They define
a grammatical quality of the root (noun, verb, adj.) and define the word's semantics. They play
critical role in analysis of lexical clusters with markers of family, branch, ethnicity, and timing.
The markers carried by key lexemes, the -an, -l, -le, -t,-ta, -ur, attest to their Türkic
origin as much as the -ed, -ing, -ery, -full attest to their Eng. origin. Paradigmatic
transfer of the allophonic ill, ail, evil is a separate line of attestation to their Türkic
origin. See aggravate,
agony.
33
English jolly (adj., v., n.) “festive” ~ Türkic yol (n.) “road, way”, metaphorically a winter
holiday “road, way (of fate)”.
The term jolly is positively traced to the winter solstice holiday Yule, then dumbfoundingly
rated “of unknown origin”. An evolution of the word is one of most fantastic and romantic tales of a
linguistic discipline, ascending to a very dawn of the human speech. It started with a notion “rip”,
like in “ripping weeds”. Ripping plants to cut a path became a metaphorical “way, road” (+ 9 more
semantic clusters). A metaphorical “road” turned into a metaphorical “fate” (+ 4 more conc.
meanings: life, happiness, dole, luck). A metaphorical “fate” turned into a metaphorical “festivity
of fate”, metaphorical “festive”, and metaphorical “joy, jolly”. The notion “jolly” is but a single
branch in its bush of metaphorical branches, it includes such unpredictable derivatives as “shave”
(rip the hair, a Stone Age technique of shaving), “visit (happy or successful, or for successful
market trade)”, “send”, “ambassador, messenger”, “guide”, “strip (of something)”, etc. Semantic
ruster extends from Atlantic to Pacific, in Europe its limbs had showed up with first written
records as a millenniums-old sacred religious tradition of personal and communal fate. Cognates:
A.-Sax. geol, geola, Ang. giuli, ONorse jol “jolly”, jol “solstice
feast, “Christmas”, “Yule-tide”, Gmn. Yule, Eng. jolly “festive”, Yule
“solstice feast”, Yule log “log burned at solstice rites”, Goth. jiuleis “solstice
feast” ; OFr. jolif; Fr joli “festive”, semantically extended to “pretty, nice”, It.
giulivo “festive”, Lat. gaudium “joy, delight”, gaudere “rejoice”; OPers. Yalda
“solstice celebration”, a Syriac (Aramaic) term, a Pers. own New Year, Nowruz, falls on the
vernal equinox; Mong., Tungus, Manchu ǯol
“way, road”; Mong. ǯol “luck, happy journey”, ǯulga “rip, pluck (way)”; Evenk
nul “scrape”. Distribution: From Atlantic to Pacific, across linguistic borders. The
spread of the term as a solstice religious celebration attests that in the 1st mill. BC, it was
already an international word, it was a time of a solemn pledge to behave to obtain a successful
year. The linguistic association of the religious rites with the notion “celebration” must have been
an annual affair, it came embedded in the Gmc. and/or Norse traditional religious rites. The word
complemented the native terms for “joy, gladness”, Cf. Goth. faheþs (faheths) “joy,
gladness”, laikan “leap for joy”, A.-Sax. lac (lak) “play”. The word has survived due
to the winter solstice holiday Yol (or
Yul) Teŋri ~ “Fate (gift from) Tengri” ~ “Fate (from) God” (Irk Bitig, “Book of
Omens”, 7th-9th cc. AD), celebrated with spruce, music, dances, and gift exchanges (in Europe
adapted and rechristened to anthropomorphized Christmas, but still dedicated to God). In some
Türkic-populated areas the holiday is still active. Its propagation is sufficiently well described
in ethnological literature; it is a traditional Persian celebration that ascends to Mithraistic
traditions of the incipient Persia (6th c. BC). In the Pers. form, a Türkic locative directional
suffix -da/-ta inflects to the “road to (fate, fortune, etc.)”. The initial g- vs.
j- or y- stands for the same initial semi-consonant sound, and reflects different
attempts to render its phonetics in a Roman alphabet. In Europe, a first significant cultural
amalgamation can be dated to the Corded Ware period, ca 3rd mill. BC. The latest immediate source
was likely a superimposition of either Sarmatian (2nd c. BC) or Hunnic (4th-5th cc. AD) phylum. The
accented vowel -o- vs. -u- betrays different vernacular sources for the Northern vs.
Gmc. forms, possibly the westerly Sarmatian Ases (Alans) vs. the easterly Huns. The word complements
a mass of Türkic terms paradigmatically transferred to European sacral lingo. See Yule.
34
English keen (adj.) “sharp, eager, great (desire)” ~ Türkic qïn- (v.) “desire, be exited, love,
copulate”.
Per “IE etymology”, “no cognates outside Gmc., and “somewhat obscure” original meaning”. A phonetic
twin verb qa:n-, ka:n- (v.) “satisfy, meet a desire” is semantically as close as to be a
cousin, probably originating from the same forbear “to be satisfied, satiated” to express nuances of
the satiation process. The noun and verbal meanings of the Eng. keen “sorrowful lament” and
“lament of grief” respectively, fiercely relay the same type of vivid emotion. The word is a
record-breaker in Europe: 31 different terms for a notion “keen” is used by 44 European languages,
or on average 1.42 terms per language, and that includes 3 languages that use Türkic qïn-
(Eng., Fris., Tatar). There is no whiff of Pan-European or “IE” word for “keen” in Europe.
Cognates: A.-Sax. cene “audacious, keen”, cenlice “keenly”, cenðu
“ardentness”, Du. koen “audacious”, Gmn.
kühn “audacious”; Ir caoin “lament, cry, weep”, Gael. caoin(eadh) “cry”; Kalm.
kinh “diligent, conscientious”; Khakas hïn- “ardent, inflame, desire, copulate”.
Distribution: Türkic Steppe Belt reaching Atlantic and Far East, across linguistic barriers.
No “IE” etymology, no “IE” cognates, the word is a clear “guest” from a non-IE linguistic family. The
“IE etymology” confuses keen with its semi-homophone can (v.) “able to” (see can),
jumbling the issue to a folly. It bravely and futilely cites allophones of can and know
to come to keen. It confuses metaphoric extensions, like a sharp (adj.) or a bold,
boldly (adj., adv.), with a prime notion “desire” (v.). Semantically, there is little difference
between a “sharp desire” and “acute desire”, a “bold desire” and “ardent desire”, but etymologically
there is a sea of a difference that should not be waved off. In spite of “obscure meaning”, the “IE
etymology” suggests a mechanistic approach: a faux “PGmc. proto-form” *koniz with unrelated
semantics “knowledgeable, skilful”, a faux “PIE proto-form” *gneh “know”, cognates “can”
“cunning”. There is no need to appeal to a faux “PG” *koniz “bold, brave”, see bold,
and fictitious “PIE” *gneh- or *gno- “to know”, see know. That screaming
nonsense is not needed, reality of passion exceed infantile imagery. All cognates uniformly transmit
the notion of “eager (effort), ardent (action)”. The Eng. keen is ascribed to a 13th c., but
the A.-Sax. examples attest to an internalization from much earlier times. The recorded examples
from the Middle Age usage reflect a peculiar for the Middle Age life accent on violence totally
absent in the Eng. semantics and the Türkic originals. The Eng. and Ir. meaning of “sorrowful
lament” corroborates the antiquity of the mourning ritual and its name. The surviving examples
present semantics of a generic nature, where the powerful, learned and smart are but various shades
in different aspects. All Gmc. cognates are dialectal versions of the Türkic word. A misguided
appeal to a fictitious “PG” *kan- is just another way of citing the attested Türkic qan-.
Numerous English and other's semantic extensions (e.g. “sharp”, fig. and lit., etc.) are later
innovations. The Celtic forms attest that the word was already around at the time of a Celtic
departure ca. 5th-4th mill. BC for a circum-Mediterranean migration toward Iberia: ardent
lamentation was a key part of a burial ritual. The Türkic etymology is accurate phonetic and
semantic match. The word keen belongs to a large cluster of English Turkisms connected with
characterization of some activity: ability, result, intention, etc. They constitute a massive case
of paradigmatic transfer unconnected with the homophones used to build a fictitious “IE” etymology.
They attest to an undistorted origin from a Türkic linguistic field. See bold, can, know.
35
English kilter (kelter) (n.) “in good condition, in order” ~ Türkic kel- (v.) “deliver, bring, make
available, come, come about, appear, arrive, serve, as to (cond. mood), come (aux. verb)”.
An “IE” line of etymology is a routine “of unknown origin”. Ultimately a derivative fr.
ko:-, qo:- “leave” with a passive marker –l “left”.
With agglutinated suffix ür/ur, the form keltür-, keldür- attains a mood of intention
or willingness to act: “something good gonna happen”, “something good gonna come”, etc. In English,
the
kilter/kelter is only used idiomatically: “something out of/off kilter/kelter” i.e.
“something is not going to happen”, “something is not right”, etc. The Eng. expression is traced to
the 1600s, but must be millenniums older. Cognates: A.-Sax. cwelan “die” lit. “leave”,
cwellan “kill” lit. “overcome”, cwellere “murderer” lit. “overcomer, queller” (quell
“overcome”), Gmn., Du.
quellen “gush, outpour”; Scots kilt “proper way of doing something, knack”; Kuchean
(aka Tokhar B) kel- “bring”. A descendent line includes the ethnonym Kelt/Gaul/Celt, a
Türkic moniker “newcomer” apparently given by the ingenuous Iberian folks of the 3rd mill. BC to the
newly arrived remote kins, see Celt/Kelt. Distribution: Türkic Steppe Belt; scattered
reaching to Atlantic and toward Far East, across linguistic barriers. No “IE” cognates whatsoever.
Pretentions on “IE nativity” using homophonic “skirting”, “tucking”, “sloping, tilting” from
different sources are pitiful attempts. A paucity of cognates in Gmc. languages indicates an
independent path similar to other exclusively English-Türkic correspondences, likely from late
Sarmat vernaculars, possibly via Anglo-Saxon transmission. Celtic allophone attests that at a time
of ca. 5th-4th mill. BC Celtic departure on a circum-Mediterranean anabasis toward Iberia the word
and its notion had already existed. Semantic and phonetic likeness is perfect, a Türkic origin is
beyond doubts. See Celt/Kelt.
36
English many (adj., n.) “great amount or extent” ~ Türkic miŋ, biŋ (adv.) “many, much, big”, munča
(muncha, adv.) “many, huge number”.
An “IE etymology” falsely asserts a Gmc./PIE origin. Ultimately equative form of bu:/mu:
“this” via dialectal m/b alteration, and its oblique form bu:n/mu:n. The -čais
a denoun adj. suffix, Cf. Türk, Türkic ~ Türk, Türkča, see much. Munča has a clone
bunča, in Türkic languages they produce numerous grammatic and semantic derivatives, and English
has a fair dole of them. The word is most archaic, it follows an invention of the numerals 1 “bir”,
2 “eki, iki”, and then came a “many” because a 3 “uč” has not been invented yet, see first, prior.
With time,
miŋ grew to also denote a largest known specific number of 1,000 (troops, etc.). The root
mun- is noted for a root vowel instability. In Europe, mun- “many” is a most popular
record-breaker. Of 44 European languages, 28 (64%) languages use variation of the Türkic root
mun-. A Sl. group of 6 (14%) languages is dominant with their native root vel-
“large”, corroborating that for ca. 40,000 years the Y-DNA Hg. I Sl. was an Old Europe's language.
Allowing for an anlaut v-/w-/p- alterations would increase the total of the Sl. eminence. The
remaining 10 (23%) languages use their own native terms; compared with Sl. vel-, all others
are newcomers. The linguistic breakdown across all linguistic borders clearly demonstrates a “guest”
status of the Türkic allophones in Europe. There is no whiff of a common Pan-European or an “IE”
word in Europe. Cognates: A.-Sax.
manig, manega, monig “many”, OFris. manich, Du. menig, OHG manag, Goth.
manags, Gmc. mangen, menig, manch; OIr. menicc, muid; Welsh mynych
“frequent” is probably a derivative of an archaic form; Romance forms
multis/multi/molti/molts/forcha/macho, Rum. bimbaše, bombašir “major (rank)”; Gk.
mrimrasis (μριμρασης) “major (rank)”; OCS munogu “many”, Bolg. bimbašyja, bumbašir
(n/ŋ > m) “major (rank)”, Serb. bimbaša (n/ŋ > m) “major (rank)”; Alb.
bimbaš “major (rank)”; Fin. moni, monet, Est. muti, monigi, mitugi; Hu.
menyi “how much?”; Caucasus (Balkar, Karachai, Kabardin, Abazin, Ubykh, Osset., Shaps)
min, ming; Dravidian pala “many” (p-/b-/v-/m- alternation), munduru
“three”; Nenets (Kamasin) muŋ “1,000”; Mong. minɣan “10,000” (< Tr., first borrowing
period, Clauson, JRAS 1959, The Turkish numerals, 311), mingan, minqan, mingɣan, minga(n)
“big, 1,000”, Bur. myanga(n) ditto, Mong., Mongor. minhan, minhän ditto; Tungus-Manchu
bïnɣan, mïnɣan “big, 1,000”; Kor. manheun (많은); Ch. bu
shao (不少) “many”,
muiwan “10,000”, mangü “eternal” (< Tr.); Jap. mono (もの)
“things”; all “many” except as noted. Distribution: with some exceptions, covers most of the
Eurasia across linguistic borders. Predictably, a sane “IE etymology” is non-existent. Instead, it
suggests “perhapses”, faux “reconstructions”, and a Lat. translation “copious” of many for
the linguists unfamiliar with a foreign word many. That is a faux “PGmc. proto-form”*managaz,
a faux “PWGmc. proto-form” *manag, and a faux “PIE proto-word” *menegh-, and a kind
suggestion of a mysterious “N. European substratum word also borrowed in Uralic” (myopically, the
Mong., Tungus-Manchu, Kor., Jap, Ch., Nenets, etc. are omitted). All that constitutes an
etymological self-mockery. Some of the host languages have preserved their own archaic synonyms,
attesting to the loan-word status of the munča/many allophones. The m- forms attest to
different paths and times. Probably, the version
munča settled in Europe separately from bunča, and in view of its geographical spread
also much earlier than bunča, pointing to the Kurgan Culture waves from a N.Pontic. If that
supposition is correct, more m-version lexicon of the b-version words may be found in
the Romance languages. The Cat. forcha and Ch. bu shao apparently ascend to the
dialectal form
bunča, carried over by the circum-Mediterranean Kurgans to Iberia and overland Zhou Kurgans
to Ordos and beyond. The Celtic and Romance forms, like the OIr. menicc (menich) and Sp.
mucho, ascend to the Bell Beaker spread from Iberia. The Welsh mynych is probably an
authentic archaic
munča. Gmc. and other N. European forms are of much later provenance, they ascend to the
fairly late spread of the Sarmat vernaculars. A thesis that Eng. pronunciation was altered from
manig to
many by an influence of any appears superficial and unjustified in light of many
examples of dialectal adaptations by numerous languages with incompatible phonetics and linguistic
typology. See
bunch, bundle, first, much, prior.
37
English massive (adj.), massif (n.) “salient formation” (n.) ~ Türkic basɣuq, basquq (masɣuq,
masguk) (n.) “massive”.
Ultimately a deverbal n., adj. of a very polysemantic verb ba:s-, ma:s- “press”
(+“suppress, overcome, seize (rape)” with 10 semantic clusters; a short listing lists 10 common
suffixes. Polysemantics is extremely extensive, numbering well in excess of 100 conc. meanings with
limited number cited. Türkic “massive” is a “salient formation” based on lit. and met. “mountain,
plateau”, and also for “lump, clew”, etc. Depending on a dialect, the Türkic bas- and mas-
are interchangeable (m/b alteration) and in mixed societies can be used in parallel. Nowadays
“massive” is an international word, a neologism in many languages, with typically half a dozen of
native synonyms; etymologically, a modern presence is irrelevant. A historical trail is pretty thin;
an “IE” trail stops at Lat. Cognates: A.-Sax. festnes “massiveness, firmness,
stability, fastness, stronghold, firmament” (m/b/f alternation, -t- ~ Tr. abstract
noun suffix); OFr. massif “bulky, solid”, masse “lump” (+heap, pile, ingot, bar,
crowd, large amount), Fr. massif “bulky, solid”, Cf. Massif Central, plateau in France; Sp.
meseta “plateau”; Lat. massa “lump (dough etc.)”; Gk. maza “mass, lump, ball” (but
native bala (μπαλα) “ball”), massein (μασσειη) (v.) “knead” (but native zymono
(ζυμώνω) “knead”); Sl. massiv (массив) “something huge, gromada (громада)
“sth. great”,
great ≈ gromada”, Rus. baskak “collector (tax)”, Pol. basalluk “type of
whip”; Ar. bas “press (debt collection)”; Mong. basu “oppress, affront, throw, crush”,
basa “do it!, more!”; Tungus-Manchu basala, basalla “kick”; Kor. matta, maža, mažin
“beat, break”; OTr. basym “bundle, clew”. Distribution: From Atlantic to Pacific,
across linguistic barriers. The receptors' semantics is a tiny fraction of the Türkic native
semantic spectrum, a minimal number of conc. applications. An unstoppable “IE etymology” suggests a
“probably” origin fr. a faux “PIE proto-root” verbal construct *mag- “knead, fashion, fit”
infinitely remote from the notions “plateau, massif”. A hypothetical “PIE proto-root” *mag-
(v.) “soften, make soft” is an opposite of a majestic “salient formation”. On the Türkic side
nothing soft can be detected; quite the opposite, the ba:s-, ma:s-“suppress,
overcome”, basɣuq, masɣuq “massive” are rigid and aggressive, terribly large and scary. The
faux “IE etymology” can't stand. A Türkic-Gk.-Lat. trail to Europe is acknowledged from the
Herodotus times (Herodotus IV 108, 109, 120), way prior to the upcoming Sarmatian, Hunnic, Bulgar,
Avar, and Kipchak invasions, and the prior massive nomadic invasion waves up to the Celtic times of
the 3rd mill. BC, millenniums prior to the Gk. and Lat. appearance on the W. European scene.
Truncating history to a flush period of a second-grade state, and turning it into a center of
universe is degrading to the scholars and their science. Based on a primitive phonetic consonance
idea of the origin fr. the Gk. maza (μᾶζα) “dough”, Lat. massa “kneaded dough, lump”
is semantically unsuitable. Even an alternate flush idea of the mass as a derivative of the
Lat. mateola, LLat. matteola “mallet” is semantically much closer, since it ultimately
reverts to an underlying Türkic word baš/maš/mas “head” at the end of a cudgel.
See ambush, bust, push.
38
English matt, matte (adj.) “dull, opaque, lackluster, darkish” ~ Türkic bat, mat, pus (adj.) “matt,
opaque”.
A deceptive “IE etymology” is incoherent, of “perhaps” variety. The form matt is an
articulation of bat- (v.) “immerse in water” (m/b alternation) denoting adj. notion
“muddy, cloudy; turbid” and a n. “mud, dregs, silt (in water)”. A suffix -ka (-ɣa, -qa) forms
nouns: batka, batxu, matka, matɣa, patka “smudge, dirt, feces (in water)”. The ma- and
ba- are interchangeable (m/b alteration), depending on a dialect, and in mixed societies
can be used in parallel; Kor. pa-. The notion “matt, matte” is an oddball in Europe,
typically overshadowed by numerous native synonyms. As a neologistic loanword, recently it widely
spread in Europe, taking a status of a most popular notion: of 44 European languages 24 (55%)
languages use it. The other 20 (45%) languages use 15 of their native synonyms. With a delay in
millenniums, the Türkic word became a staple European word. Cognates: A.-Sax. maðelig
“turbulent, tumultuous”, smitan, (be)smitan “smear, daub, soil, pollute, defile” (prefix
s-), smitte “smudge, smut”, (ge)smittian (v.) “befoul, pollute”, OHG bi-smıčan
“smear”, Gmn.
schmutz “mud, dirt”, Goth. (ga)smeitan (v.) “smear”; OFr. (15th c.) mat “matt,
dull, opaque, lackluster, darkish”, “withered, dull surface or finish”; Lat. madere
“wet”; Rus.
batkak (баткак) “swamp, mud, puddle”; Serb. batisati “vanish (water)”; apparently,
these are the only traces of ethnically Türkic “matt” presence in Europe; Pers. batlaq, bodaq
“swamp, marsh”, batau “east (best sunlit)”; Mong. bagta- (v.) “lodge”; Tung. (Gold.)
pa-, pago- “drop, end (level)”; Kor. ppažida “immerse”. Distribution: The core
meaning “bath” is spread across Eurasia from Atlantic to Pacific. Distribution of derivatives
like
mat, batka is ever noted, if any. “IE etymology” suggests a “perhaps” Lat. madere
“wet, drunk” that ascends to the Türkic prime root bat- and not to a faux “PIE proto-word”
*mad- “wet, drunk”, OR an unrelated chess term mate that is a novelty millenniums younger
than the old bat-. Neither the suspects Ar. nor Heb., nor mat “pad” are realistic.
Childish guess-game pseudo-analyses are neither serious nor sustainable. The A.-Sax. words predate
an appearance of the OFr. and LLat. versions by millenniums, they could only come from a Saka/Saxon
side of the A.-Sax. compact, they can't be accused of being late borrowings. A Türkic genetic origin
is unassailable. In reality, no standing etymology exists whatsoever, whoever goes by etymological
dictionaries is going to miss this pearl... See bath.
39
English mental (adj.) “of mind”, mentation (n.) “rational synthesis” ~ Türkic meŋtä (mengtə)
(adj.) “of mind” (lit. “of brain”).
An “IE etymology” positively and falsely asserts an “IE” origin, v.i. Ultimately from a constellation of
forms for “brain”: meji/meŋä/meŋi etc. with noun locative suffix -ta/tä/-da/-dä/-δa/-δä
conveying “place of” or “of initiating place”, i.e. “from brain” or “of brain”, and a passive suffix
-l: men-ta-l. The noun root meŋ/beŋ (m/b alternation) comes in basic and
possessive forms typical for the names of body parts and organs. Etymologically, the m- form
is held as a prime, the
b- form as a later development, Cf. Sl. mozg (мозг) vs. Eng. brain. A
complementary Türkic synonymous noun is men with a variation ben (m/b
alternation) expressing “conviction of”. A corresponding mental/emotional state is expressed with
the same locative or possessive suffix: mentä (adj.) “with superior mentality”, i.e. “clever,
smart, wise, brainy”, Cf. Gmn.
Minne “love”. The word men comes with a constellation of dialectal forms: mendä,
mentä, mindä, mintä with men/ben alternation. These Türkic forms of “mind” and “brain” in
nominal and verbal application are intricately connected to the English “mind”: meji, meŋä, meŋi
and men, min, ben, bin. Half of the European languages use a version of the Türkic men-
across linguistic barriers: a motley collection of 25 (57%) languages, matching a 50.6% R1a/b
demographic presence in Europe. It is a de-facto Pan-European term of a Türkic origin. The other 19
(43% ) European languages use their own 13 native terms. A similar breakdown holds for a more
dispersed notion “mind”, with corresponding 16 (36%) languages. Cognates: A.-Sax. mynd,
myne, gemynd “memory, remembrance”, mod “mind, mood”, maenan “mean, signify,
intend, mention”,
brægen “brain”, ONorse minni “mind”, Goth. muns, gamunds “thought”, gaminþi,
ga-maudeins “remembrance”, Gmn. verstand (m/b alternation), meinung “mind”,
vernunft (m/b) “reason” (but geist, geistig “wit” < Tr. us- “think,
suppose”); Ir. meabhrach. Welsh meddyliol “mental”, meddwl “mind”; Sl. (Bosn.,
Croat., Serb., Maced.) mentalni(a) “mental”; LLat. mentalis “of mind”, Lat. mens
“mind, brain”, Romance (Cors., Galic., It., Port., Rum., Sp.) mente, minte “mind”; Gk.
myalo (μυαλο) “mind”; Alb. mendor “mental”; Skt. matih “mind, thought”; Ar.
bein “mind, head”. The germinal m- forms and the later b- acquisitions run in
parallel and randomly intermix, leaving behind a dating trail, see brain. Distribution:
is predominant in Europe, spread across Eurasia, and across linguistic barriers, stopping at Far
East. While in an “IE” textbook a “brain” and its 40 scions come from “of uncertain origin”, its twin
brother m- is ignorantly rooted in a bag of faux inventions ascending to a faux “PIE root”
*men- “think”. The “IE etymology” fails to connect the two articulations tied by the Türkic
hallmark m/b alternation. The faux “PIE” *men- is a dead-end mechanistic construct, an
unattested clone of the attested Türkic meŋä, meŋi, men “brain”. That nonsense needs a gentle
wipeout. A notion “think” is also a slightly sullied copy of a Türkic notion saq-, saqan-,
see think. Its coincidence with a name of a great thinker C. Sagan (-an is a deverbal
noun suffix, think ~ thought, thinking) is a pure fortuity; the naive reconstructions of his
name are typical fantasies. In reality, we do not even know if Gmc. languages even existed as such
in the 3rd mill. BC, or if vernaculars were not a series of mutually unintelligible Sprachbunds of
different provenance that coalesced millenniums later. We still have their traces attested in
Scandinavia, Germany, and vicinities, and in our daily lexicon. Gmc. forms with ancient prefix
ge-/ga-/gi- are an innovation forming intensive meaning or collective nouns. The auslaut
-d/-t reflects a Türkic dialectal form of a deverbal locative or abstract noun suffix. An
abundance of phonetic variations points to a lengthy parallel existence of both -ŋ- and
-n- forms, a reduced g in ng is a routine dialectal
articulation. A presence of the Skt. cognate indicates an existence of the m- form word
earlier than 2000 BC. The diversity of the A.-Sax. root forms attests to a long history of
diversification and amalgamation. Dictionaries certainly do not include all deviant or archaic forms
and semantic variations. A Gmc. meinen “think” is a derivative of the prime notion “brain”,
abundantly traceable to its Türkic root. See brain, mentality, mind, sane, sanitary, sanity,
think.
41
English mickle (adj., n.) “large number, amount or extent” ~ Türkic mi:g, mig, big (n., adj., adv.)
“big, thousand”.
See big. The Türkic mig has numerous allophonic forms. Most important variation is an
m/b alteration, big/mig, the other forms are min, mi:n, pin, mi:g, bi:g, müg, ben, bog.
The form mig/mi:g or the like are recorded elsewhere except Ottoman and Chuvash. The
Eng.-related form is most frequently encountered in Khakas, Horezmian, Chagatai, and Koman (aka
Couman). An adjectival suffix -le in mickle is a form of the Türkic adjectival suffix
-al/-el (-la/lä), “rare” in the eastern languages, but regular in the Gmc. cognate forms. In
Türkic, “big” is an archaic precursor of a “thousand”, similar to the “dark” and “fogg” (Sl. tma
(тьма) and tuman (туман) respectively), and a semantic extensions of
tuman to “ten thousand”. The compound form tuman contains the stem man (ban)
for a “thousand”. A literary example for the allophonic form bog cites case identical to the
Norse form: Khakas bog kiši: “big man”, Norse bugge “great (man)”, with
interchangeable o/u typical for Türkic languages. Altaists suggest a “Proto-Altaic” *mana
“much, many, big” and a “Proto-Türkic” *bang “big”, which lead to big independently of
the Altaistic school.
Cognates: A.-Sax. micel (mikel), mycel (mykel), miccl-, micl- “big, great, intense,
much, many, long, loud”, etc., mara “bigger, greater”, micelaete“greedy”,
miceldoend “going big”, micellic “great, splendid, magnificent”, micelmod
“magnanimous”, micelnes “greatness, size, multitude, abundance, magnificence”, micelu
“largeness, size”, +dozens more, OSax. mikil, ONorse mikill, OHG mihhil, Goth
mikils “great, intense, big, long, much, many”; MIr. mag, maignech “great, large”; MWelsh
meith “long, great”; Lat. magnus “great, large, much, abundant”, major “greater”,
maximus “greatest”; Gk. megas “great, large”; Arm.
mets “great”; Skt. mahat- “great”, mazah- “greatness”; Av. mazant-
“great”; Hitt. mekkish “great, large”, Mong. (kh)emjee “amount, extent”, Khalka
mandah “grow, enlarge”, mantgar “big, large”, Bur. mandagar “big, massive”,
mantan “big, huge”. According to the G. Clauson's EDT, the initial vowel
was -ı- (-y-), at a very early date in all Türkic languages it became -i-;
a supposition that an initial semantics was “thousand” is little credible. More likely, the term
mig “big” gained meaning “thousand” both much later and in a fairly confined area.
Distribution: The Eurasian-wide distribution of the word attests to its presence in this form in
the N. Pontic prior to the Celtic Neolithic circum-Mediterranean departure at 6th-5th mill. BC, and
prior to the Gk. and Aryan migrations of the 2nd mill. BC. The parallel presence in the NW Europe of
the forms mig and big points to independent temporal and spatial migration paths. An
“IE etymology” suggests a faux “PGmc. proto-form” *mekilaz from a faux “PIE proto-word” *meg-
“great”, a self-promoting propaganda that does not respect reality or enlighten etymology. That
belongs to a dust bin. The presence of the suffix -č (-ch) in Eng. much and bunch
attests to an etymology other than that suggested by the tormented “IE” version that derives the
modern form much from mickle. The presence of the triplet “big”, “bunch”, “much”
constitutes an authentic case of paradigmatic transfer incontestably attesting to a common genetic
origin from a Türkic milieu. See big, bunch, might, much.
39
English moist (adj.), moisture (n.) ~ Türkic mayıl, banıl (adj.) “liquified, watery, fluid, pulp”..
“IE” etymologically rated “of uncertain origin”, “etymology uncertain”. Ultimately fr. a notion
“deteriorated, worn out” expressed by a range of forms: may-, bayï- (Kipchak), mayïl-,
bayïl-, bayïla-, mayïq-, mayïh- (Khakas etc.), mayïš- (M. Kashgari). The labial
consonants b ~ m are interchangeable. An equivalency of mayıl and banıl, with
-n-, -y- transition, is stated by EDT (Clauson EDT 772) as passive deverbal
noun/adjective derivatives of may-/*ban-. In conc. application “over-ripen (fruit)”, banit
“molasses, syrup, must (fermenting juice)”.
Cognates: A.-Sax. must “must, new wine”, mos, moss “bog, marsh”, A.-Norman
muster “moist or wet”, Goth. midja “fluid, watery” (in midja-sweipains “flood,
deluge”); Sl. mochit (мочить) “wet”, mokrota (мокрота) “liquified, fluid”; Latv.
mitris “watery”; OFr. moiste “damp, wet, soaked”, Lat. mucidus (/mutsidus,
mukidus/?) “slimy, moldy, musty”, mucus (/mutsus, mukus/?) “slime”; Lat. mustum
“must (fermenting juice), molasses, syrup”, musteus “as new wine”; Skt. phanita
“molasses, syrup”; Kuchean (aka Tocharian B)
panit “molasses, syrup”; Mong. muudsan “deteriorated”. Distribution: from
Atlantic to the Far East. For such a prominent phenomenon, an absence of competent etymology is
quite telling. A nature of a notion “water” allows to suggest its “out of Africa” provenance, and in
fact Hamito-Semitic languages have
moi, mai for “water”, staking a terminus for a dashed trace of Hamito-Semitic > Dravidian >
Türkic > A.-Sax. > English. A similar initial path would apply to Lat., if the moi, mai is
related to mucus and the water is related to slime: Hamito-Semitic > Dravidian
> Türkic > Lat. It appears that no sane follower of “IE” jingoism would suggest a Lat. loanword into a
primeval vocabulary of the Hamito-Semitic linguistic family, it is rather a Corded Ware legacy. The OFr. form may have originated independently from the Burgund or Alan vernaculars of the mid-1st
mill. AD; the inlaut -s- may have originated there, or it reflects the Lat. /ts/. But the
modern Fr. form moite “moist” is congruent with the A.-Sax. form and its cognates. In Türkic,
the Hamito-Semitic/Dravidian word carries the traits of a loanword: a stand-alone root, concrete in
lieu of generic semantics, minimal derivative development. Historically, numerous Türkic tribes were
in early contact with Hamito-Semitic and Dravidian languages: Guties (3rd - 2nd mill. BC), Scythians
and Cimmerians (1st mill. BC), and their other contemporaries. Türkic tribes are also known for
their unequaled mobility over continent-scale long distances and their amalgamation with numerous
local populations generally, and European populations specifically.
40
English much (adj., adv., n.) “great amount or extent” ~ Türkic munča (muncha) (adv.) “extreme
degree, so many, so/thus, such a number of”.
Ultimately an equative form of a pron. mu:/bu: “this”, with two case forms, a basic case
bu and all other cases bu:, mu:; -n- (and -l-) is archaic suffix; the
-ča is an adv. equitive suffix. The bo ~ bu are the oldest forms of demonstrative
pronouns. The munča is a clone of bunča via dialectal m/b alteration. Its
development into much mirrors that of the bunch in respect to grammatical development,
semantic expansion, and phonetics, see bunch. It reached A.-Sax. in an archaic form ca.
mungu, menigdu < Tr. müngü with a “rare” (i.e. archaic) suffix -gü that forms a
notion “collective number”, Cf. idiom “a number of times” i.e. “many times”. Cognates:
A.-Sax. manig “many, many a, much”, menigu, menio, meniu, menego, menigu, mengeo,
mengo, mengu, menigu “multitude”, (ge)mang “multitude, troop, crowd”, meni, menig,
manig “many”, (ge)mana “community, company”, manlaru “host, troop”, manigfeald,
manigfealdlic “manifold, numerous”,
ma “more”, + few more; menigdu “band (of people)”, menigu, menio, meniu
“multitude”; Dan. meget (but Du. veel “much” < Sl. vel- “big”), Sw. mycket,
Norw. mye, Icl. mikið, Goth. manags “much”, mais “more”, OHG. mer
“more” (but veel < Sl. “big”), manag “much”; Ir. bhfad “much”, Scots moran
(but Welsh llawer); Sl. (Bolg., Bosn., Croat, Rus., etc.) mnogo, mnojestvo “much,
multitude” (but Slov., Slk. vela, veliko “big”); Port., Rum., Sp., Tatar mucho, muito,
mult, munča; Fin. paljon “much”, Est. palju “much”; Gk. poly (πολυ) “much”;
Brahmi bho, bhola:r, ро, pola:r, polar (~ Tr. bu, bular “this”); OMong. mun (
pron.) “he”, mut ( pl. pron.); mön ( pron.) “self, exactly”. Distribution:
Spans Eurasia fr. Atlantic to the Far East. The version munča settled in Europe much earlier
than bunča, pointing to a Kurgan Culture waves from the N.Pontic. An “IE etymology” bravely
fabricated a few faux “proto-words” based on deliberate myopia and ignorance: a faux “PGmc.
proto-word” *mekilaz “?” of a faux “PIE proto-root” *meg- “great”, a faux
“PWGmc. proto-word” *mikil “?” of a faux “PGmc. proto-form” *mikilaz “great, many,
much” of a faux “PIE proto-root” *megh- “big, great”. Reality is absent in “IE” context. An
astonishing mass of attested material is traced to their sources across Eurasia, it does not need
any marvel sprinkling. The origin of the word is traced down to its bone, a gray area had swaged
down to a primacy of b- vs. m- argued on a base of attested relicts. Tracing of the
m- form may have a deep diagnostic value. See bunch, bundle.
41
English murky (adj.), murk (n.) “unclear, clouded” ~ Türkic mürkï (adj.) “dim, stupid, gloomy,
bleak”.
Ultimately a particular metaphorical extension of a verb bür- “tighten, strap, tie” for an
action “cover” in a sense of “tuck, envelop” expressing befogging optical effects with the notion
“dim, darken”. A substance of the metaphor may relate to a mental state: darkened, murky, gloom.
Türkic cognates include
bürün- “wrap”, büriš “folder”, bürkür “overcast”,
maraz “dark night”, etc. On the European scene, mürkï “murky” occupies a salient
space: of 44 European languages, a motley group of 10 (23%) languages use versions of the Türkic
mürkï. The English form had preserved the stem mür- with front rounded u, the
Türkic adjectival suffix -kï, and an intact semantics of “dimly, indistinct”, whether it is
an obscured light or blurred reasoning. Cognates: A.-Sax. murc, mirce (murk, mirke)
“murkiness, darkness, murky, dark, black”, OSax. mirki “dark, ONorse myrkr, Dan
mǿrk “darkness”; Balto-Sl. (Lith.) markstyti “flash”, (Latv.) mirklis “glance”,
acumirklis “blink, moment”, (OCS) mraku, (Serb.-Croat.) mrak, (Rus.) mrak
(мрак) “fog, darkness”, merknut, mertsat (меркнуть, мерцать) “fade, flash, blink”,
burka (бурка) “cloak” (< Tr. ditto); Gk. amorbos (αμορβος) “unblemished” (=“dark”? “not
sad”?); Skt., Vedic markas “obscuration, cloudiness”, i.e. “murky”; Mong. büri-, büreh
“cover, wrap (furniture), upholster”, bürheh, bürke-“cloudy, overcast, cover, wrap up,
darken, blacken”, Mongor buri- “cover, etc.”; Tungus-Manchu (Evenk.) bürküle- “cover
(a frame of a chum)”, Ulch., Nanai, Manchu, Mongor. büri- “cover, tighten (drum), envelop
(fruit trees)”. Distribution: From Atlantic to Pacific, across Eurasia and linguistic
barriers. A dubious “IE etymology” tends to connect the origin with some notions of “glance”, “blink”,
“blink (timing)”. Hence the vision aspects with a “PIE” phantom *mer- “flicker” in a sense
of “intermittent flash” with a suggested derivative “morning”. It suggests (or claims) few faux
“reconstructed proto-words”: faux “PGmc. proto-words” *merkwjo- “darkness”, *merkuz
“dark”, and faux “PIE proto-words” *mer- “flicker”, *mergw- “flicker, darken, dark”
without coordinating those with the attested Mongolian, Tungus, etc. siblings. If that was for real,
it would move the “IE” origins from a W. Eurasia to the E. Eurasia Far Eastern end, a new hypothetic
“IE” Motherland. Hopefully the locals would greet their induction into a rubbery “IE” family. The Eng.
and Sl. semantics is directly reflective of the ultimate notion “befogged”. The array of the
cognates illustrates fluidity in articulation of the root vowel, e.g. murc, mirce, mǿrk, mrak,
etc., attesting to diverse paths and deep age of internalization. A suggested Gk. cognate appears to
be unfit. An abundance of derivative cognates evinces a paradigmatic transfer case from a common
genetic provenance. See fog, mist.
42
English old (adj., n.) “aged” (Sw N/A, F261, Σ0.06%) ~ Türkic olut (adj.) “mature, stout”.
Pinpointed as a Khak. (aka Enisei Kirgiz) form (M. Kashgari I 52, EDT 130). The
olut is an adjectival derivative of a noun/adjective ul/ül/ol/öl “base, foundation,
bottom” and the underlying verb ul-/ül-/ol-/öl- (v.) “obsolete, wear out, grow unusable”. A
deverbal suffix -ut/-t forms abstract noun category from the verbal base: “obsoleteness,
weariness, fatigue”. Notions of age, previous, and initialness are already contained in the basic
noun and verbal lexemes, with various derivatives formed by agglutinated suffixes, like ulug/uluɣ
“large, great”, ulus “nation, state”, ulam “support”, or oldrum “crippled,
incapable of standing up” fr. oldur- “to sit” (lit. “come down”) fr. ol/ul/u:l “base,
down under, down”, alt/ald
“bottom, lower side”. A peculiar areal (Aral basin) and ethnic (Khak.) stratification delivers
diagnostic data prized for historical studies: the form alt “bottom”, “lower part/side, base”
is specific to the modern southwestern Oguz languages including Turkmen, and the form al/a:l
with semantically contrasting “forehead”, “front”, “front part/side”, ald- “grow”, is
specific to the modern non-Oguz languages. The notion “old, aged” belongs to the first group; at
some past, some of the group leapfrogged the Ogur family area to jump from the northeastern to the
southwestern areas. Thus a semantic bifurcation is observed, and a semantic and phonetic dispersion.
Which of the above listed base root forms, and some more forms, was an ancestor form diversified
later can't be positively determined. Cognates: A.-Sax. ald, eald, ield, Anglian
ald, WSaxon eald “aged, antique, primeval, elder, experienced”, OFris.
ald, Goth. altheis, Du. oud, Gmn. alt “old, aged”; Ir. aois,
Welsh
oed, “old, aged”; Lat. altus, Sp. alto “high” also belong to the same field
with adjectival semantics of “up” and “down”, reflected by a series of Eng. cognates of the type
alto, contralto, altimeter, altitude, etc.; Fennic (Fin.) ala-, ali- “under, below”,
ala “down”, alta “down below, at the base (of something)”, (Mordvin) alo “down
below”, aldo “(coming) up”, “at the bottom”, (Mari) ül, üla “(what's) below”, “under”,
(Udmurt) ul, ulyn ditto; Mong. uldaŋ, ula “sole (shoe bottom), underside”; reference
to Tungus cognates.
Distribution: traceable fr. Enisei (3rd century BC) to Aral to NW Europe to Albion;
independently fr. Eastern Europe via Africa to Iberia (ca. 2800 BC). European distribution, though,
is at insignificant 3rd place: 7 (16%) languages out of 44 European languages (Turkic, Eng., Gmn.,
Yid., Du., Fris., Luxembourgish), behind a Sl. Old Europe group with 12 (27%) languages, and a
largely Romance group with 10 (27%) languages. No credible “IE” etymology, no “IE” cognates, the word is
clearly a “guest” from a non-IE linguistic family. An “IE etymology” fabricated its own Munchhausen
legend: faux “PGmc. proto-forms” *althaz “grown up, adult”, *aldaz “grown-up”, and
faux “PIE proto-root” *al- “grow, nourish” (apparently after
alimony (n.) “payment”, alimentation (n.) “nourishment, provision” from Türkic alım
(n.) “sustain (by taxes, nourishment, etc”), and a faux “PIE proto-word” *heltos “grown,
tall, big”. An appeal to a fictitious althaz is a primitive two-decker fantasy on a theme of
an attested Türkic alt, a blend of Ogur ald- (v.) “grow” and Oguz semantic notion
“old, aged” (adj.). That “IE” nonsense is not needed, a mass of attested material across Eurasian
space indelibly attests to a genetic origin from a Türkic milieu, and provides specific addresses to
follow. An idea that identical semantics and phonetics could independently arise in two unrelated
linguistic phylums is unsustainable. A species of the “IE languages” has no stem uniformity for the
old, attesting a range of non-IE sources. In the European languages predominate stems sen-
“senior”, vek- “viejo”, and
ant- “ancient”, they are drastically different from the Eastern “IE languages”. The NW
European and Türkic languages stand out even from the field of the European “IE languages”,
projecting a rigorous distinction and unbroken commonality on a Eurasian scale. The N. Europe most
popular toponymic element
olden is an allophone of the Türkic olen, with suffix -en to form adv. of time
olen > olden, with a balïq for burg. A Türkic allophone of the
Oldenburg is Oldenbalïq, Oldenbalkh. Its Sl. calque Starigrad (Стариград) “Old
Fort” is a compound of an E. European (tentatively Corded Ware culture) apparently non-IE root
star- (Icl.
storr-, Skt. sthir- “big”). A Sl. derivative grad (град), gorod (город) is an
allophone of the Türkic qur- “to gird”. It apparently came via a Gmc. lexicon, see gird
(girt). The single-syllable base root ol- has numerous homophones in every language,
including Türkic, making it vulnerable to etymological confusion with semantically unrelated
notions, like alm- “provisions”, etc., and folk etymologies. The Eng. duplex old and
age constitutes a transfer paradigm of two related Türkic words, an irrefutable evidence of the
Türkic genetic connection. See age, burg, gird.
43 Moved
English other (adj., pron.) “second (adj.), alternate (pronoun)” (Sw N/A, F173, 0.09%) ~ Türkic
ötrü/ötürü (adj., pronoun) “then, following, after”; adır- “separate, detach”, adın- “other”;
özge:/özgä “other, different”. The base word denotes “separate, separation” and comes in a raster of
phonetic forms: ad-, at-, ay-, ayyr-, az-, üz-, which form downstream derivative lines. The
lines are semantically eidetic, but further vary in the selection of modifiers and ranges of
concrete meanings. Ultimately fr. a polysemantic verbal stem ad-/at- (öt-, öz-), one of its
meanings is “odd, strange, foreign” which also produced the Old English ad “pyre” and its Gk.
and Sl. allophones adis (αδης) and ad (ад)
“hell”. As a result of divergent conventional Romanizations and unsettled spelling conventions,
probably the spelling with -t- does not reflect the soft -t- closer to an interdental
voiceless -th-, and the spelling with -z- (özge:) similarly masks an interdental
voiced -th- (Cf. spelling öδrün- “chosen, detached” with -δ-).
Semantics of the Eng. word is identical specifically and concordant basically. Since the base notion
is “separation”, cognates should cover that notion. Cognates: A.-Sax. other “second,
alternate, after this”, “the other”; OSax. athar, OFris. other, ONorse annarr,
OHG andar, Gmn. ander, Goth. anthar, Dan. andet, Du. anders, Sw.
andra, all meaning “other”; Sp. otra, Catalan altre; Balt. (Lith.) antras;
Sl. drugoi (другой); Maltese ohra; Lat. alter; Skt.
antarah “other, foreign”; Pers. yzir, digar, Taj. digar “other”; Udi (Lezgic)
ha(n) “separately”; Nanai padi “detached”; Kor. pagi “detached”; Igbo (Nigeria)
ozo “detached”; Nenets ha “part of”; Tungus (Even) ha “part of”, (Oroch) ha
“part of, some”. The OSax. and Sp. forms demonstrate direct connection between ötürü (ötrü)
and forms athar, otra. The stem öz/o:z- alludes to something other, and lends itself
to conflation öz ~ ot ~ oth. The ONorse, Gmn., and Goth. have a prosthetic -n- before
fricatives, pointing to a separate dialectal origin. Distribution of the cognates far exceeds
the myopic boundaries of the “IE” etymology, spreading from Atlantic to Pacific. The striking phonetic
dispersion attests to the primeval times of its birth, and millenniums of development under
incompatible conditions. Any notion that the word originated with any dead or alive European
language is absurd waiting to be rescinded. The “IE etymology” connects the word other with the
Lat. compound of unattested *al- “beyond” + unattested adjectival comparative suffix *-tero-,
a sorcerously long shot that would not have produced either the Slavic drugoi, nor the Skt.
antarah, nor the prosthetic -n > nn- before fricatives in the Gmc. and Skt. The
phonetic and grammatic match between the European, Eurasian (Türkic), and Hindustani forms points,
first, to a common source, and second, to major dialectal variations within the common source. The
pronounced commonality between the Gmc. and Hindustani forms attests to a common origin from the
within of the 3rd mill. BC Corded Ware culture, brought over to the Hindustan at ca 1500 BC. The
Türkic origin is validated not only by the near-perfect phonetics and perfect semantics, and
prodigious distribution, and traceable links to the underlying notion, but also by the scholars
whose independent studies focused on these Türkic word(s). See ad.
44
English prior (adj.) “earlier in time” ~ Türkic bir (n.) “one”; bir, birin, birinč “first, at
first”, burun, burïn “earlier”, see first.
An oldest, simple generic form bir had survived in Europe, while in Türkic it developed from
a cardinal/ordinal bir/first to bildir: bir > bir-yïl-dïr > bildir “at
first, earlier, in the past, past year” (yïl “year”) (EDTL v.2 ). The notion burun
“before, in front” is homophonic with a burun “nose”, conflating forms and meanings: both are
in front of something. That leads to burun as a second form of birin < bir. The
trail of the Türkic bir extends to 27 (64%) European languages, exceeding a 50.6% R1a/b
demographic presence in Europe. A second, mostly Romance group, numbers 13 (30%) languages. The
remaining 5 (6%) languages use their own native terms. There is no trace of a shared Pan-European or
“IE” word in Europe. Cognates: A.-Sax. for “before”, prior (adj.) “earlier,
before, at first”, (n.) “title, first”, beforan (be + for + an), Du. voor,
Dan., Norse før, Sw. före, Icl. fyrir “before”, Gmn. vor “earlier”; Ir.
roimh “earlier”, Welsh brior, mhrior “earlier”; Lat. prior “of old, first”; Gk.
prin (πριν) “earlier”; Balto-Sl. (Latv.) pirms “earlier”, (Lith.) prieš, (Sl.)
pre-, pred- (пре-, пред-, прежде, прежний, предыдущий, перед, etc.) “earlier”, pora (пора)
“pont in time”; Osset. burunqï, burunɣï “first, earlier”; Kurdish (Kurmanji)
beri “earlier”; Pers. bir “one”; Bengali purbe “earlier”, Hindi, Gujarati
purva “earlier”; Sakha marïn, maɣïn, mağïn “earlier” (b/m alternation).
Distribution: points to Eurasia-wide spread, across linguistic barriers. A commonality
between Gmc., Celtic, and Balto-Sl. groups excludes a suggested “IE etymology” from a Lat. prior.
A fantasy of faux “PIE proto-ghosts” *per-, *prai-, *prei-, *pri , *pro with shadow semantics
“forward, before, beyond”, hence “first, before, in front of” is superfluous. The fictions are
twisted reflexes of the real Türkic bir “first” adjusted for particular articulations.
Taxonomically the Lat. and Eng. forms are on the same level. The Welsh forms brior and
mhrior reflect an univocal Türkic feature of m/b alternation. Parallelism of the forms
prior and for reflects local articulations. A common origin of bir, for, fyr, pr-
to express the ordinal notion “first, first in line, at first” is beyond doubts. The ordinal “first”
was used as pre- and post-positions (Cf. A.-Sax. forwost “first, leader, head”) that have
developed into prefixes in languages with typology that allowed contamination of the roots with
prefixes, i.e. that did not rely on a primacy of the root in every derivative. “IE” languages have a
spectrum of genetically unconnected stems for cardinal “one” (Cf. one and ek) vs.
fairly uniform with the ordinal “first”. The ordinals are allophones of the Türkic bir “one”
added to the line-ups of the native synonyms for the notion prior. A peculiarity of the
European forms for the notion “first”, other than those derived from the Türkic bir “one”, is
that they tend to derive not from a native cardinal for “one”, but from the native words for
“outset”, “beginning”, and the like, alluding that the native Sprachbunds did not have a word for
“first” (Cf. Ir. an gcéad, Welsh gyntaf, Basque lehen). Except for few
metaphoric expressions, practically all related “IE” forms for the notion “before” ultimately ascend
to the Türkic cardinal “one”. European languages have developed numerous derivatives and
applications using cognates of bir “one”, attesting to a long history of internalization,
further amplified by an innovation of prefixes. As a result of Indo-Europeanization, first of the
European languages, and then of the internationalization of the European vocabularies, these words
occupy a prominent place in the dictionaries of the world's languages. A degree of internalization
by the time of the initial written records attests to exceedingly deep roots. The acquisition dates
may precede by far the Corded Ware period, the earliest may ascend to the times of the first Kurgan
waves. The paradigmatic transfer of the complex first, second, and ilk, and of the
integral morphological elements, unimpeachably attest to their Türkic origin. See first.
45
English sallow (adj.) “dusky, dark, dirty, grayish color” ~ Türkic sarı/saru/sary/sarığ, saz (adj.)
“pale, dirty white, light yellow, grayish color; bile”.
A clumsiness of the “IE” etymological claims led to a “probably” status of the “IE etymology”:
“probably originally a borrowing from some other language”. Ultimately, the word denotes a bile, a
liquid content of an animal stomach, it is a second meaning of the Türkic word, Cf. apricot
both “color” and “fruit”. The form saz “pale”, viewed as a root base for the form sar-,
is represented in an idiom daŋ sa:zı “yellow (~sallow) dawn” recognizable in Eng. and Türkic,
see dawn. The Türkic form intersects two conc. meanings from a nomenclature of pasturing, for
grass (yellow, dry) and for emaciated; a conc. term for a salt marsh grass is sarɣan < sarı.
An ONorse
sölr “dirty yellow” unveils a path of a phonetic transition between sar and sol.
The r/l alternation is likely a Gmc. areal phenomena. A.-Sax. used two major clusters of
metaphoric extensions related to yellowness and soiling: sun, soil, and their derivatives. They form
their own cognate lines, Cf. A.-Sax. sol “mud, wet sand”, “sun” vs. Lat. Sol, solar
“solor loft” (aka Lat.
solarium), A.-Sax. solate “sunflower” vs. Lat. girasol, Sl. solntse (солнце)
“sun”, etc. A notion “dry” intersects at a single point (withered) with the color-focused
semantic field, it is a conc. metaphoric extension. Sarı was a most popular Türkic color
name, it was widely used as endonyms, from antiquity (Sary As, Sarir, Saragur, Saryg, possibly
Sarmat) to Middle Ages (Sarysün, Kuman, Kipchak, Akkoyunly, Ak Nogaj, where Sary, Ku, and Ak overlap
as synonyms) and to modernity (Sary Yogur, Sary Uigur). Classical authors list an inventory of
nomadic tribes in the Caspian basin with names starting with allophones of sar under
different spellings. With a rise of the Khazar Kaganate a part of their lands became known as
Saksin, lit. Saka's (Saxon) Province. No Pan-IE cognates, the European notional semantics is riveted
to the Gmc. languages. Cognates: A.-Sax. sear “withered, barren”, salo, salu
“dusky, dark”, salubrun “dark brown”, saluneb “dark-complexioned”, salupad
“dark-coated”, salwed “darkened”, etc., har “hoar, hoary, grey, old”, harung
“hoariness, age” (s/h alternation), Eng. sorrel (adj.) “reddish brown”, OHG salo
“dirty gray”, ONorse sölr “dirty yellow”, MDu. salu “discolored, dirty”; Ir. сiаr
“dusky”, harr “gray, gray-haired”; MFr. sorel (from sor) “yellowish-brown”; OCS
solovoi, solovyi “cream-colored”; Hu. sarga “yellow”; Mari sare “yellow”; Nenets
sar “grayish-yellow”, sarg “golden-yellow”; Mong. sira “yellow”. Distribution:
from Albion to the Far East and Arctic ocean, across linguistic barriers. Distribution of the
cognates is consistent with the body of the substrate Turkisms: Türkic, Gmc., Balto-Sl., and spotty
outlier languages like Lat. On top of the “probably originally a borrowing”, the “IE etymology”
built sandcastles of faux “proto-words”: faux “PGmc. proto-word” *salwa- “dark, dirty”, faux
“PWGmc. proto-word” *salu “?”, faux “PGmc. proto-words” *salwaz “?”, *salh
“?”, *salhaz “?”, *salho
“?”, *salhijo “?”, faux “PIE proto-root” *sal- “dirty, gray”, faux “PIE
proto-words” *solh “?”, *shlk-, *shlik “?”. That cacophony of fantasies
on top of a wealth of historically attested forms and meanings is not needed; reverse unverifiable
hypotheses are not scientifically defensible. An initial semantics of imprecise dirty hue, a kind of
tawny, is retained in all phonetic forms. The MDu. soor “dry” and OHG soren “to
become dry” reflect similarity with withered color. A Sl. idiom pojeltet (пожелтеть) “turn
yellow” for “dry (withered foliage)” exemplify a range of metaphoric semantics. The Fr. forms
indicate an independent path. OFr. preserved a lighter hue sorel “yellowish-brown”, the Eng.
sorrel accentuated a darker hue “reddish brown”. Ir. has preserved an h-version of the
h-/s- alternation. Later, after a re-population of the Aral basin ca. 1000 BC, it became typical
for the Horezm area vernaculars. A.-Sax. has the same form, either from Celtic or from Khakass of
Horezm. The first may be due to an A.-Sax./Celtic amalgamation still in the Upper Pannonia area. An
appeal to the Lat. is woefully anachronistic: it conflicts with the developed nature of the A.-Sax.
lexicon. Before our era, Lat. was confined to a tiny area down the Apennine peninsula, without a
chance to culturally influence the A.-Sax. From a historical perspective, Lat. can only be a
receptor for a basic object like the sun. Two transmission lines are discernable, one
circum-Mediterranean arriving at Iberia ca 2800 BC, which eventually produced the Ir. h-version,
and probably later an overland s-version, which produced Gmc. and Sl. s-versions with
a darker hue, and the Sl. s-version with a lighter hue, Cf. Sl. ser (сер, серый)
“gray, gray-haired”. The Fr. lighter hue may have been introduced by the Burgund Vandals,
semantically it is closer to the Tr. sary. An absence of the cognates in the eastern portion
of the “IE” languages suggests a spread of the word after the 2000 BC southeastward departure of the
Indo-Aryan farmers, but before the westward reverse outflow of the European farmers that started ca.
1500 BC. The case of paradigmatic transfer from the Türkic phylum is indelible, Gmc. languages
internalized almost intact both the phonetics and the peculiarly fuzzy semantics.
46
English sane (adj.), sanity (n.) “sound mind” ~ Türkic san- (v.) “think, reflect, realize, cognize,
contemplate”.
Etymologically “IE” rated as “a word of uncertain origin”, with a second deck suggesting “IE” “perhapses”. The stem san- is a derivative of a verbal stem sa- “count, reckon”, but
it may be a reverse, with sa- being a contracted derivative of
san-, see heap. With agglutinated suffixes the stem san- produces active and
passive verbs, nouns, adjectives, and any other grammatical form, for example verbal infinitives
with a suffix
-mak/-maq ≈ “make”. A noun san denotes “thought, meaning, essence”, “number,
quantity”, “rank, reputation, fame” and others; their downstream reflexes are also cognates of the
same Türkic root. In the European hierarchy the Türkic san- stands at the top: of 44 European
languages it is used by 18 (41%) languages; next is a partial Old Europe Sl. group with 6 (14%)
languages. The other 20 (45%) European languages use their own 16 native terms. There is no
Pan-European or a “PIE” word, the word is a “guest” in Europe and outside of the Eurasian Steppe
Belt. Cognates: A.-Sax. sann, sinnan, sunnon, þencan “meditate upon, think of, care
about”, þencendlic (thencendlic) “thoughtful”, OSax. þenkian (thenkian), OFris.
thinka (þinka), Eng. think, ONorse þekkja (thekkja), Goth. þagkjan (thagkjan),
Gmn. sinnen “meditate”; Welsh cyn(hemla); Sl. san “rank”, samchiy (самчий)
“head boss”; Lat. sanus “of sound mind, rational, sane”, sanitatem “healing”; Ar.
shan “fame”; Ch. shaŋ, shan (声) “reputation, fame, rank”; Jap.
san (さん) “rank, title”; Chuv. sum “number, count” (Cf. sum “amount”).
Distribution: From Atlantic to Pacific, across linguistic barriers. The “IE etymology” gets it
backward in deriving sane and sanity form a Lat. sanitas “health, sanity”,
sanus “healthy, sane”, and then expanding to “soundness of mind” and “health-giving”
sanitorius, see sanitary. The Lat. “healthy” is an interpretation of the Türkic san-
that found its way to the Gmc. languages and on to English independently of the meanings sane
and sanity. A derivative insane was initially developed in Lat. For a “word of
uncertain origin” the myopic “IE” etymologists fancied real miracles: unattested “IE reconstructions”.
I.e. the faux “PIE proto-words” *seh-no- “?”, *seh- (v.) “tie”, Lat. satis
“enough” for “satisfy”, and an apotheosis with sane < Lat. sanus “healthy; sane”. Thus
a circle is complete: sane < sane. Results are commensurate with underlying anopia. An
s-/th- alternation is specific to most of the Gmc. languages. A possible source may reside in
the Black Sea/Caspian basin Türkic languages' peculiarities, or an initial phoneme transcribed as
s- in Romanized transcriptions. Either way, the san- “think” and Eng. think are
indeed allophones. Attempts to generate separate independent etymologies are mislead and misleading.
A form þencendlic
demonstrates the process of dentalization, when dentalized words branch off phonetically and
semantically. In Eng., sane and sanity, and mind form a cluster that ascends to
the matching Türkic cluster of san- “think” and ming “brain”. The cluster constitutes
a case of a transfer paradigm, a positive attestation of a genetic connection with a Türkic milieu.
See heap, mind, sanitary, think.
47
English sanitary (adj.) “healthy” ~ Türkic esen/asan/esän (adj.) “healthy, uninjured, smart,
reasoned”.
“IE etymology” does not delve into an origin of the term, it dryly refers to a Lat. source sanitas
“health” as a god-send gift. The word is a derivative variation of san- (v.) “think, reflect,
realize, cognize, contemplate” of a stem sa- “count, reckon”, with a prosthetic vowel e-,
Cf. special ~ especial. The word is polysemantic with 8 semantic clusters, each with its own
trail of meanings: 1. health, 2. calm, 3. flourishing, 4. greetings, 5. smart, reasoned, 6. free, 7.
untouched, loyal, 8. true, authentic, credible (EDTL v. 1 307). In Gmc. languages, the
Ogur-type prosthetic e- has gained a sense of collective and/or habitual action, it forms
A.-Sax. ge-, OSax. gi-, OHG. ga-, gi-. That function was largely lost
millenniums ago. The prosthetics survived in Türkic, Cf. Stanbul ~ Istambul, Smirna ~ Izmir, etc.
Its traces in the Oguz-type languages are demonstrated by the relict pairs bir-/ber- “bear,
carry” ~
ebir-/eber- “circle, evade”; tüz/düz “level, flat, even”, tö:z “root, basis,
origin (of low level)”, diz čök-/diz/tiz “genuflect (of low level)” ~ ediz, edüz
“tall, elevated, top (of high level)”; kir/qir “dirt, trash” - egir/ekir “swamp
plant”, etc., Cf. Goth. ga-arman “pity”, ga-bairan “bear”, ga-biugan “bend”,
etc. Due to a dominating role of Lat. in scholarly terminology, the alien esän is a
dominating term of the European lingo, used by overwhelming 36 (82%) of the European languages. The
other 8 (14%) languages use 3, mostly Gk. ygeion- (υγειον-) “hygiene” terms. Now the
sanitary is an international word. The Lat. semantics “healthy” is an interpretation of the
Türkic san-.
Cognates: A.-Sax. sund, synto, (ge)sund, (ge)synto “sound, health, soundness,
uninjured, welfare”, sundfulnes “health, prosperity”; Yid. (zay ge)zunt, (zeit ge)zunt
“(be) healthy, (be) well”, Gmn. (ge)sund(heit) “health” (lit. “healthhood”); since with few
exceptions all European cognates but and incl. Lat. are borrowings, there is no point in enumerating
European forms. From the range of the Türkic lexemes, v.s., follow the Lat. sanitas “health”,
sanus “healthy, sane”; MPers. a:sa:n “worthy, dignified”, NPers. asatiy “easy”,
asani “easy, easiness”, asayef “ease, comfort, convenient”; Ar. shan “fame”;
Agnean (Tokhar. A), Kuchean (Tokhar. B) a:sa:m “worthy, dignified” (< Tr. dial esem);
Mong. esen, əsən “healthy, calm; tranquil, peaceful”; Ch. shaŋ, shan (声)
“reputation, fame, rank”; Jap. san (さん) “rank, title”. There is a deficit of ethnological
citations. Distribution: From Atlantic to Pacific, across linguistic barriers.
Distribution
is similar to that of the “sane” of the same root, see sane. “IE etymology” deadlocks at Lat.,
which is a “guest” loanword. The Türkic origin is confirmed by the Eng. sane/Lat. sanus
“of sound mind, rational, sane”, allophones of the Türkic san-. The Eng. cognates sane,
sanity, etc., belong to the same stem san- as the Türkic form esan. The “IE”
etymology gets it backward in deriving sane and
sanity form the Lat. sanitas “health, sanity”, sanus “healthy, sane”, and then
expanding to “soundness of mind” and “health-giving” sanitorius. The Türkic san- found
its way to Gmc. languages and on to Eng. independently of the Lat. path. The Gmc.-Yid. words are
likely a late addition carried by a Judaic sliver of Türkic migrants after a fall of the Khazar
Kaganate (10th c. AD). The Türkic etymology is perfect phonetically and semantically, it has a rich,
long and detailed historical trail. In Eng., sanitary belongs to the cluster of sane
and sanity, and mind, a cluster that ascends to the matching Türkic cluster of san-
“think” and ming “brain”. The cluster constitutes a case of a transfer paradigm, an
inexorable attestation of the genetic connection. See mind, sane, sanity, think.
48
English sapient (adj.) “sagacious, wise”, like in Homo Sapiens ~ Türkic savan, saban (adj.)
“prophetic, wise”, sa:včı: (n.) “prophet”.
Ultimately fr. a noun root sav/sab (n.) “word, speech” and a “rare, obscure” polyfunctional
suffix -an, here instrumental, lit. “with word”. The word sav/sab is a derivative of
the root sa- “count, reckon, think”. A form leading to “wise” is savčï/sawčï “prophet,
messenger” produced with a nomen agentes suffix -čï/-či (-chy, -chi), a personal noun with
semantics “speaker, teller, talker, informant”, Cf. A.-Sax. secga “sayer, informant”, formed
with a Türkic “rare” alternate adjectival suffix -ɣa/-gä/-qa, Cf. bilgä, ögä “wise”,
qïsɣa “short”. A synonymous suffix allows to trace an origin of a word to a particular Türkic
vernacular. The “speaker, informant” extended to “foreteller”, and then to “prophet, messenger”,
leading to the adjectival “prophetic, wise”. The verbal version of sav/sab has numerous
allophones: savla-, söyle-, söle-, süle-, sülä-, söy-, suy-; each form has its own trail of
derivatives, ultimately fr. the verb
sa:-/say- “think”. The A.-Sax. secga may be interpreted as sek- or sech-,
in the second case it is outright identical with the Türkic savčï/sawčï, Cf. pairs
calic/chalice, cyld/child, cypa/chapman, ceosan/choose, cist/chest, and a host of others. The
ultimate base sa- can be articulated sä-/sə- and the like, Cf. articulation of the
element in the forms sayla-/saila-/saylə-/seyle-/seiyle-/suyla-/šayla- “discuss”, also Cf.
articulation /sey/ of the Eng. say “utter”, see say. Cognates: A.-Sax. sefa
“mind, understanding, insight”; OSw. sebban “perceive, note”, OHG seffen; Fr.
savant “learned man”, Sp. se, sabe “know”, sabia/sabio “wise”, Lat. sapere
“wise”, sapientem
“wise” (palatalized sap of sab); Fin. saa “get, obtain, receive”; Hu. szo
(=so) “voice, sound, speech, word, argument, talk”; Mansi säw “word, sound”, Khanty
saw “sound, singing”; Tung. sä “know”; Kor. sän “account”, sjem
“counting up, reckoning”. Distribution: Eurasian-wide, from Atlantic to Pacific, across
linguistic borders. No viable claim on any European or “PIE” origin. A “guest” status within the
“IE” family and the westward migration of the Corded Ware tribes, who repopulated Europe after roughly
3500 ybp (1500 BC). A suggested “IE etymology” with unattested “PIE proto-roots” *sapp “liquid
in a plant” or *sep- “taste, perceive”, together with their faux “PG roots”, stands as far
from being realistic as it can get. The presence of the cognates within the “IE” family is sporadic,
outside of the Gmc.-Lat. circle no “IE” cognates are cited whatsoever. The Sp. se, sabe are
unaltered originals of the Türkic sa-/sä-/sə-/sab-, pointing to a path independent of the
Lat. path, evidently directly from the Visigoth-Alanic vernaculars. For “wise”, Türkic has at least
7 other words (bilgä, biliglig, bögu, bögülüg, dana, jïnčkä, öga), which tend to demonstrate
the weight afforded to wisdom in Türkic societies and an amalgamated history of the Türkic. The
Türkic root forms sav/sab/sag/sai have a flavor of suffixed derivatives of once one-syllable
primal form
se/sa that may ascend to a Hg. NOP, older than the haplogroups R1a and R1b. Notably, English,
Gmc. and Lat. preserved the Türkic substrate form with the Türkic suffix -аn/-än, attesting
to the origin of the word; the ending -t, -s, etc. are individual modifications. The Türkic
origin is also confirmed by the Eng. sane/Lat. sanus “of sound mind, rational, sane”,
allophones of the Türkic san- (v.) “think, reflect, realize, to be aware, contemplate” that
also ascend to the same prime verb sa:-, say- “think”. See sage, sane, sanity, savant,
say.
49
English savvy (adj., v., n.) “knowledgeable, astute” ~ Türkic savan (adj.), savčï/sawčï (n.)
“prophetic, wise”, see sapient, savant.
Tracing its origins, an “IE etymology” comes to absurd end, v.i. Ultimately fr. a verbal stem sa-
“count, reckon” and its derivative noun sav/sab “word, speech”, which developed forms with
semantics “in the know, wise”, and accordingly a “speaker, teller, talker, informant”, leading to
“prophet, messenger”; -an is instr. suffix. The notion “know” is an essence of “savvy”.
Cognates: Sp., Galician sabe “know, grasp, (adj.) shrewd” (< saber “know”),
Corsican sape “know”, Fr. savoir, sçavoir “know” (but Fr. connaitre “know” ≈
Dan., Sw., Gmn., Eng. ken-, thus a “guest” in Fr.). Given the contrasting high gist of the
notion “know” and a nonsense of the suggested “PIE origins”, a paucity of the European cognates must
be duly appreciated as accidental “guests” in Europe that came to Iberia with a sea breeze (ca. 2800
BC) and spread along the western coast. Another hint is given by a mysterious word se that
ousted the expected sabo. That “mystery” is a sa-, v.s., a root of the noun sav/sab
“word, speech”, v.s. Aside of habitual myopia and a common ignorance, there is nothing mysterious
there. Everything falls into its place, the geography, the timing, the migrations, and philology.
Distribution: the root distribution is Eurasian-wide, from Atlantic to Pacific, across
linguistic borders, with a peculiar slight shade of a trace in the W. Europe, see sapient.
The “IE” etymologies invoke a West Indies pidgin, and a Fr. savez, and a Sp. sabe
“know”, and a “taste, flavor” like in a veggie soup, and a faux VLat. *sapere “ wise,
knowing”, turning a soup into a potato salad. Except for a dubious borrowing from the West Indies
pidgins, that mushy salad is too far away and not too far from the truth, since the Sp., Lat., and
Fr. forms are derivatives fr. the Türkic prime notion sav/sab (v.) “word, speech” which
produced savan, saban, intermediates savez, sabe, the Lat. sapere, and a
sidekick subject form savvy. See sapient, savant, say.
50
English sharp (adj., n.) “pointed, incisive (edge)” ~ Türkic šarp (sharp) (adj.) “sharp, peak, steep
incline”.
The form šarp/sarp is a distinct allophone of more popular forms sivri:, süvri:, süwri:,
subı “sharp, pointed, tapering”, 16+ unique forms. A range of phonetic dispersion is
impressive, attesting to antiquity of the word's origin and its Eurasian spread. The form šar-
, with an adverbial suffix -p, is cited for Kipchak and Chuv. languages. A preserved Türkic
use carries a metaphoric notion of “difficult, hard, inaccessible” with further semantic extensions
like “acerbic (taste)” (Cf. “sharp cheddar”), “strong” (Cf. “strong poison”), “rough”, “biting” (Cf.
“rough vinegar”, i.e. biting vinegar). Metaphoric extensions parallel the Eng. usage, Cf. “sharp
mind”, “sharp dispute”, “sharp criticism”, “sharp image”. The Eng. form is akin to the Chuv.
palatalized forms šür/šüre/šövör. Other Türkic languages vocalize in a non-palatalized form
sVr-. Siblings of the Türkic sar-, shar- dominate in Europe, out of 44 European languages
they are used by 17 (39%) languages, approaching a level of 50.6% R1a/b demographic presence in
Europe. The Old Europe Sl. group's
ostr- is used by 12 (27%) languages, and a largely Romance third group covers 10 (23%)
languages. Each group is quite uniform. Only 2 European languages use their own words. A strong
uniformity and conservatism point to well-ingrained terms that ascend to a very early Stone Age
time, overlaid by an oversized influence of the R1a/b migrants. The Sl. ostr- (Y-DNA Hg. I)
is an inheritance fr. its parental type G Hg., a migrant from the Middle East to Europe.
Cognates: A.-Sax. scearp “sharp, prickly, cutting edge, pointed, acute, active, shrewd,
keen, severe, biting, bitter”, OSax. scarp, OFris. skerp, Dan. skarp, Du.
scherp, ONorse skarpr, Gmn. scharf, scharp “sharp”; MIr. cerb “cutting”,
Ir. cearb, gear “cutting, keen”, Welsh siarp; Latv. skarbs “sharp”; Sl. (Rus.)
serp (серп) “sickle”, ščerba (щерба) “notch”, osetr (осетр), sevrüga, shevrüga,
shevriga, (севрюга, шеврюга, шеврига) “sturgeon” (< Tr.), Pol. szczerba “gap, dent, jag,
chip, nick, notch”; Lat. acerbus “tart, bitter”, scalpellum “sharp knife” (now an
international word); Alb. harb “rudeness” (< “cut”); Hu. hirtelen “sharp something”,
söreg “beer”; Kuchean (aka Toch. B) kärpye “rough”; Mong. sibüge, shivegei, shigbei
“awl”. The Türkic kerai “razor” and kertük “scar” (s/k alternation) appear to
be conc. noun allophones of the same notion “sharp”. Distribution: From Atlantic to Far East,
across linguistic barriers. No distribution across “IE” family, positively attesting to a non-IE
origin, despite any claims. A myopic “IE etymology” manages to cover only its targeted domain of the
universe, and comes up with unrealistic solutions with a sand of chimeric “reconstructions”. Those
are a faux “PGmc. proto-word” *skarpaz “cutting” and faux “PIE proto-root” *sker-
“cut” and *(s)kerb- “cut?”, a pale echo of of attested diversity. That approach reeks of past
ages. No reasonable “IE” etymology, the focused NW European distribution is peculiar and parallels
other European NW Turkisms. The Gael. forms have matching cognates in Türkic and Sl. Phonetics and
semantics are matching and overlapping. Celtic cognates attest to lexical inherence ascending to a
6th-5th mill. BC, a time prior to the Celtic departure from the N.Pontic kurgan area.
51
English short (adj.) “little length” (Sw33, F940 0.01%) ~ Türkic qïrt (adj.) “short”.
The word is a derivative of a verb ïr- “notch, break, smash, scrape, strip”, and a cognate of
the kırk- “shear” and
qïruq “destroyer”, among many others. An adjective is formed with a suffix -t (after
r-), -tï:, -ti: retained in “IE” cases, with -t/-d/-z alternation in Gmc. and
Skt. Türkic bifurcated verbs qïr- “notch” and qïs- “shorten, reduce” originated and
subsequently re-internalized fr. a single form under a historical r/s split. The English
curt and short, precursors of curtail, shirt, shorts, etc. are synonymous allophonic
forms, likely re-internalized from sister vernaculars. Cognates: A.-Sax. sceort, scort
“short, not long, not tall, brief”, scortnes
“shortness, small amount”, ONorse skort “shortness”, skorta “short of”, OHG scurz
“short”; OIr. cert “small”, MIr. corr (korr) “stunted”; Balto-Sl. (Lith.) skursti
“stunted”, (OCS) kratuku (кратку), (Rus.) korotkiy (короткий) “short”; Lat.
curtus “short”; Skt. krdhuh “shortened, small”; Mari, Chuv. карсаk “hasty
coney, hare”'; Mong. kirsa “marten” (lit. “quick”); Tung. karsan ditto; Manchu
harsa ditto; Az.
kare- “shorten”, Tur. karsmak “constrict, contract”, карса “fast, in a moment”,
карсаk (qарсаq) “hasty, quick”. Distribution: From Atlantic to Far East, across
linguistic barriers. Semantic range revolves around notion “short, narrow (length, time, reaction)”,
and the like. Distribution of the word is symptomatic, consistent with the bulk of the
substrate Turkisms in the “IE” languages. The Eurasia-wide distribution of the word attests to its
presence in this form in the N. Pontic prior to the Celtic Neolithic departure on a
circum-Mediterranean voyage ca. 6th-5th mill. BC, and prior to the Aryan SE out-migrations of the
2nd mill. BC with an offshoot to the Indian subcontinent. An “IE etymology” asserts that “short” is
connected with “cut” (see
qïs-, q.v.), and devises an unattested “PIE proto-root” *sker- “cut”, a faux clone of the
real Türkic qïr- with some implied Gmc. accent, as opposed to the Ir., Sl., Lat., Skt.,
Türkic, Mong., Tung., etc. forms. Versus the real Türkic “notch, break”, the “IE
etymology” offers its
semantic cousin “cut”. An alternate “IE” etymological suggestion for “short” comes from a cluster of
the Eng. break, brief, Gothic -maurgjan, OCS bruzeja, Gk. brakhys, Lat.
brevis “short/shortened”, etymologically unrelated to the word short. That fountain of
ingenuity is not needed, a reality has an upper hand. A reality that all languages are products of
amalgamation is not guiding a creativity of the myopic “IE” etymology. Other than a digraph
sc-/sk- to convey a phoneme /sh/, the initial s- in the ONorse and Lith. forms may
indicate an ancient Gmc./Sl. perfect tense prefix marker s-. Remarkably, in spite of the
extraordinary temporal, geographical, and migrational distances and paths, the 7,000-years-old OIr.
form cert (kert) encountered its 2,000-years-old sibling A.-Sax. form sceort, scort
(short) and coexists with the modern Türkic sibling form qïrt in still nearly eidetic
forms and proper semantics. The word presents an extraordinary case of paradigmatic transfer of
authentic compounded root-suffix pair, indelibly attesting to its origin from the Türkic phylum.
Being a No 33 member of the Swadesh list, the word is included in the canonical compilation of basic
linguistic concepts believed to cover the most stable lexemes of the human vocabulary, and is
proving to be so. See carve, curt, cut.
52
English sodden (adj.), soddenness (n.) “wet, saturated” ~ Türkic su, suv, suw (n.) “water”, (adj.)
“watery, damp, wet”, sud “spit”.
A form su, typical for the eastern Türkic languages, and its variations so, šu, šıv, suğ,
are forms of suv that carries extended semantics of “water, aquiferous basin”. Derivatives
suluk-, sulik-, sulan-, silik, selik “watery, water-like, wateriness” etc., indicate a very old
phonetic dispersion. The Eng. root
sod is notable for its use in wet cooking, it belongs to a rich collection of Turkisms in
English cooking lexicon, where nearly entire terminology consist of the Türkic derivatives: bake,
boil, broil, cook, fry, and kitchen, see Cooking and food; Preliminary note q.v.
That is drastically different from the modern Türkic terminology, Cf. corresponding Turkish culinary
fırında pişirmek, kaynatmak, kavurmak, pişirmek, kızartmak, mutfak respetively. Of 44 European
languages, the Old Europe Sl. vod- takes a precedence with 26 (59%) languages. A Romance
group
ag- follows with 9 (20%) languages, and a Türkic group u-, su- follows with with 5
(11%) languages. Only 3 languages use their own native terms. “Water” is one of very few terms that
can be held as Pan-European; at the same time it is not an “IE” word. Cognates: A.-Sax.
sod, soden, seoðan “cooking, boiling, seethe”, soden, gesoden “boiled”, seoþan
“cook, boil, seethe”,
healfsoden, simsoden “half-cooked” lit. “half-watered, half-soaked”, niðsoden
“newly-boiled”, sypian “sip”, soc “sucking” (< Tr. süg “milk” fr. su
“water”), see suck, milk, Eng. sip “drink slow”, sop “soak, sop” (< Tr. suv
“water”), suck “suckle” (< Tr. saɣ- “suck”), WSax. supan “sip” (< Tr.
syp “water drop”), see sip, sype wetting”, sodan, sopplan “soak, sop”;
WFris.
sean, Du. (ge)zoden “seethed, boiled”, zode “swampy”, Sw. sjuden, Icl.
soðinn, LGmn. saden, söddt, Gmn. (ge)sotten; Mong. usun, husu “water”,
usubki “watery”, Mongor fudzu “water”, Ugur χsun “water”. Distribution: the
roots su-, sod- are nearly invisible in Europe, while spanning Eurasia from Atlantic to
Pacific. A European spread may include Tatar, Ir., Scots, Latv., Alb., and Basque. That is
predicated by a thesis that if the anlaut s- is primeval, it is routinely lost in
internalizations, su- > u-. If it is prosthetic, a u- form is primeval (EDTL v. 7
350). Both schemes ultimately lead to the Atlantic seaboard's sodden. A.-Sax. examples
illustrate how deeply ingrained was the Türkic lexicon. A myopic “IE etymology” proposes faux “PGmc.
proto-forms” *sudanaz, *seuþana “seethe; boil”. Those assertions lead from nowhere to
nowhere, and trace nothing. It is a typical propagation of a past philological nonsense. The now
lost A.-Sax. sod, soden, seoðan etc. are cognates of the surviving sodden “wet,
saturated”, they denote action “soak, decoct”. That comes along a widespread use of the surviving
A.-Sax. coc- “cook”, a paradigmatic transfer case. A paradigmatic transfer of the entire
Türkic cooking lexicon attests that Anglo-Saxons migrated to British Isles not as a force of male
conqueror-knights, but as families with their wives, who were the carriers and disseminators of the
Türkic-based kitchen lexicon. In addition to sodd, Eng. has other derivatives of the su
“water”. A variety of the Eng. forms points that words originated at a variety of linguistic sources
and found their way to the British Isles. See bake, boil, broil, cook, fry, kitchen, milk, sip,
sop, suck.
53
English sorrel (adj.) “light brownish color” ~ Türkic sary (adj.) “pale, dirty white, light yellow,
grayish color”.
An “IE etymology” suggests a “probably” origin, semantically diverse look-alikes, and straight-face
funny assertions. The term covers 13 semantic clusters, 9 of them related to colors (yellow, blond,
sorrel, etc.). Some of them are very specific, Cf. “yellowish with light tail and mane”; there a
“dark tale” may stand for another military division. The color scheme of the times was driven mostly
by a horse and pasture hues, hence the term sary. Articulation includes sal- (Cf.
homophonic Eng. sallow “grayish”, see sallow), xar-, say-, sai-, saz- (r/s
alternation), and various suffixes. Semantic range covers colors (yellowish, whitish, grayish,
reddish), hue (hair, skin), shade, and reaches substances (butter, yolk, jaundice), postures
(malice, manner), etc. The word is widely used in anthroponymics, v.i. European attention reaches
Frankish times (fr. 480s AD), which ascends to the Hunnic Europe times (ca 370 - 470 AD) and to the
Hunnic migration times (53BC - ca 150 AD) which brought Hunnic confederation back to the Eastern
Europe, Caucasus, and eventually to the W. Europe. Sary was a most popular Türkic color name,
for pale yellow and achromatic pale gray. It was widely used for endonyms, from antiquity (Sary As,
Sarir, Saragur, Saryg, possibly Sarmat) to Middle Ages (Sarysün, Kuman, Kipchak, Akkoyunly, Ak
Nogaj, where Sary = Ku = Ak) and to modernity (Sary Yogur, Sary Uigur). Classical authors list an
inventory of nomadic tribes in the Caspian basin with names starting with allophones of sar
under different spellings. Cognates: A.-Sax. sere, sear, searian “withered”, Du.
zuring “sorrel”, MDu. soor “withered, dry”, Dan. (skov)syre “sorrel” lit. “forest
syre, sorrel”, Norw. (eng)syre lit. “meadow syre, sorrel”, Sw. syra,(ängs)syra, harsyra,
lit. “pasture, meadow, rabbit sorrel”, OHG soren “withered, dry”; Ir. harr “gray,
gray-haired”; Sl. ser- “gray, grayish”; MFr. sor, sorel
“yellowish-brown”; Hindi zarad (ज़रद) “yellow”; Fin.
suolaheinä “sorrel” lit. “salt hay”, Hu. sarga “yellow”, (vörös)sarga
“red-yellow”; Mari sare “yellow”; Mong. sira “yellow”, šara “bow (epithet)”;
Kalmyk šar, Buryat šara “yellow”; Nenets sar “grayish, yellow”, saryg
“golden-yellow”; Kor. sigi (시기) “yellow”. Distribution:
Linguistic and geographic spread exceed by far a reach of the “IE” languages. Within the “IE” family,
cognates crowd only a Gmc. branch, and stay away from crossing branch boundaries, attesting to a
“guest” status within a family. The claimed “IE” origins fr. “probably Frankish”, “of Germanic
origin”, “or some other Germanic source”, “perhaps a diminutive form in French”, are all cloistered,
myopic and bogus. None of the suggested “IE” entities even existed when the word found an
international distribution. An unstoppable “IE etymology” proposes faux “PGmc. proto-words”
*sauza-, *sauzaz “dry”, *suraz “sour” (?!), and a faux “PIE proto-word” *saus-
“dry, parched”. The nonsense leads from nowhere to nowhere, traces nothing, and is a classical game
of sparrow blind shooting. There can't be an “IE etymology” for non-IE lexemes, not a trace of “IE
etymology” in sight. The notion “withered” is a semantic extension based on similarity with withered
color; the Sl. idiom pojeltet (пожелтеть) “turn yellow” ≈ “dry (foliage)” exemplify a
derivative semantics across numerous languages. The Ir. anlaut h- reflects the s-/h-
alternation typical for Aral-Caspian basin and now typical among the Bashkirs. Eng. has preserved a
darker hue, sorrel “reddish brown”, Fr. preserved a lighter hue sorel
“yellowish-brown”. Two transmission lines are discernable, one Celtic circum-Mediterranean coming to
Europe ca 2800 BC, which eventually produced the Irish h-version harr “gray,
gray-haired” and its Gmc. siblings, and another, probably later, overland s-version, which
produced Gmc. and Slavic s-version with darker hue, and Slavic s-version with lighter
hue, Slavic ser “gray, gray-haired”. A Fr. lighter hue may have been introduced by the
Burgund Vandals, semantically it is closer to the Tr. sary. See sallow.
54
English subliminal (adj.) “unconscious (perception)” ~ Türkic sumlï- (v.) “gibber,
blather”, sumlïm (n., adj.) “alien language”.Semantics
of the word sumlï- is “unclear speech”, “speaking in tongues”, or simply babble. A
conventional, but not supported by any evidence, “IE etymology” suggests “an apparent” origin from
“below threshold”, from sub “below” + Lat. limen “threshold”, Cf. limit
“boundary, frontier”. That may sound attractive, but in light of the M. Kashgari's 10th c. records,
the etymological references to the 18th c. publication that reportedly first used a compound word do
not make sense. The attested Lat. sublimis is a precursor for the
sublime (17th c.), as in a Sublime (Awed) Porte for the Ottoman Court. It means
“imposing, elevated, stately, eminent”, Cf. sublimity (n.) “awed”, “high moral or
intellectual”. The Lat.
sublimis stands in a glaring conflict with notions of “unconscious (perception)” or “below
threshold”. A chance coincidence of phonetics and semantics between the Eng. subliminal and
Tr. sumlï-, sumlïm is rather out of question, thus a “below threshold” belongs to a host of
folk etymologies.
English sundry (adj.) “mixed” ~ Türkic sandrı:-, sandırı:- (v.) “mix up, confuse” related to mental conditions of becoming or being “mixed up, scatter-brained, insane, hallucinating, raving” (EDT 836). The sandrı:- is a derivative of a verb san- “reckon, think, deem, meditate, reflect, suppose, conjecture, count”, a reflexive derivative of the verb sa:- “reckon, count” that among others produced the noun sa:ğ “intellect”, see think. An alternate origin (EDTL 160) is suggested fr. a root say- (v.) “puncture”. 5+ homophonic roots say left a fair latitude in asserting an original root. One of alternate articulations sound as say-, suylan, sayqla, saygak, sayaq (EDTL v.7 158), with -n-/-y- alternation. Semantics denotes a sizable collection of diverse small things, thus “mixed”. A range of semantic applications includes “craziness, insane, quarrel, row, rave, mix up, scatter-brain, hallucinate, confused, incoherent, stray (speech), nonsense, slander, snitch”, and the like. A semantic shift in Eng. retained the notion of “mixed things” vs. the Tr. predominant use of “mixed mind”. In contrast, its Sl. counterpart pomeshatsya (помешаться) retained the root mesh-/mes- “mix” for a Sl. calque of “going, being mentally insane” along with a “pile of mixed (smth.)”. Suitable phonetics and crisp semantics makes it impossible to ascribe a phonetic and semantic match to fortuitous coincidence. For a 6-morpheme word, a chance match is conservatively in the range of P = 0.16 (for phonetics, reducing the number of phonemes to ridiculously low number 10 in each language) X 0.001 (for semantics, allowing for 1000 semantic fields in each language, with ludicrously exaggerated 10 synonyms in each field) = 0. 00000001, or 1 chance out of 100 mln 6-morpheme words (All 10,000-word dictionaries on the Earth for all 6,000 Earthly languages contain only 60 mln words, and only a small fraction of them has 6 or more morphemes). That probability is vanishingly small, while its opposite, the probability that these two words are one and the same word, is overwhelming, P = 0.99999999. Cognates: A.-Sax. syndrig, syndrige “separate, apart, special, peculiar”; Mari shoya, shoyak (n.) “lie”; Mong. (Oyrat) say- (v.) “puncture” (~ Chuv. suy- “lie, lying”); Chag. sayiγ “delirium, gibberish”, Osman. sayïkla- (v.) “delirium, gibberish”. Distribution: From Albion to Mongolia across Türkic Eurasian Steppe Belt and across linguistic borders. On top of perfect phonetics and traceable coherent semantics the “IE etymology” suggests phonetically close but semantically neologistic candidates. Instead of “mixed” are proposed neologistic semantic extensions “separate, peculiar, exceptional” etc., with some extremes as far off as “far away”, “without”, and “broken”. It is impossible to breach a semantic gap, but a phonetic conflation is possible, i.e. the A.-Sax. variations synder-, sundor-, sunder- “peculiar, special” sound close to sundry. An etymology of the second, apparently peculiarly Gmc. word (incompatible “cognates” must be dismissed) is an independent subject, related to exceptional, privileged position or a state of prominency; it is unrelated to the A.-Sax. lexeme, which used the stems mix and blend (Tr. bulɣa-) for sundry “mixed”. See blend, sane, sanity, say, think.
56
English sure (adj.) “certain” (Sw N/A, F115, 0.15%) ~ Türkic sürek (adj.) “sure, relax, safe”.
The Türkic verbal stem sür- “lead, drive out, expel” is one of most productive polysemantic
stems with notions “lead, chase, be engaged into, produce, perform/execute, pull, drag, live, rip,
draw/pull off”. Modern Turkish has over 100 derivative bases; among those are notions of latching,
locking, bolting, slider, continuity, duration, sustainability, etc. A noun is formed with a suffix
-k/-g: sürük, sürüg “flock, herd, cloud (~ “many”)”; an rk/kr metathesized form is
an areal European variety, sure, sûr >
sicuro, sigur “security”. Etymologically, a notion “drive out, away” is most popular, EDT
cites it 35 times (EDT 844); it denominates “safety”. Cognates: A.-Sax. orsorg,
orsorglic, orsorgnes “safe; secure, safely, unconcerned; security, prosperity” (+ in modern
terms “insurance”), OHG ursorg ditto; It. sicurta “security” (< Tr., VEWT 420),
OFr. sur, seur “safe, secure”; Lat. securus “safe, secure, free from care” (but native
salus); Mong. sür “masculine, courage, bravery”, sürü- “drive (cattle)”, sürüg-
“herd”,
sürdü “frighten”, Kalm. sürχə “drive (cattle)”. Distribution: Eurasian-wide,
from Atlantic to Mongolia. An interchangeability of u/o in Gmc. and A.-Sax. parallels their
interchangeability in Türkic. The “IE etymology” ascends to Lat. see “free from” + cura
“care”, which conflicts and ignores the attested A.-Sax. orsorglic etc. forms fr. or- +
sorg + lic, where or- is a prefix “out of”, equivalent to Lat. ex-, sorg is
“safe”, and
-lic is a Türkic suffix -lig/-lan “like, attribute”. The cognates sorg and
securus “certain, sure, safe” in Lat., OHG, and A.-Sax. point to at least two independent
paths to Lat. and Gmc. The “IE” etymological attempt is a fabrication, it dead ends at Lat., uses the
Türkic stem
qorq, and is obviously misleading. See care, Gorgon, scare.
57
English tart (adj.) “sharp or acid, sour taste”, “harsh” ~ Türkic tarqa, tarka:, talka: (adj.)
“bitter, sour”, lit. and metaphorically “green unripened fruit” (МК I 427).
Under “IE” paradigm, etymological gap is noted as unexplained: fr. nowhere to Gmc., or “fr. some
Indo-European language” (Clauson EDT 539). The preserved semantics of “green unripened fruit”
(Khakas) points to the origin of the notion “tart”. Ultimately a derivative fr. a polysemantic verb
taru:-, daru:- “constrict, tighten”, a reference to a tart effect of cramped jaws at biting a
sour fruit. A final t- in tart is an inherited deverbal noun abstract suffix -t.
A tautological idiom ačïɣ tarqa vividly reduplicates a meaning with two synonyms, an “acidic
tart” is transparent in Türkic and Eng. An overwhelming majority in Europe uses versions of Türkic
tar-, 31 (70%) languages. A Romance minority 7 (16%) use synonymous Türkic acer- a la
Lat. acerbus, and the remaining 7 (14%) languages use their own 5 words. There is no trace of
any “IE” presence; there is no point in listing all of many European versions of the Türkic
tar-. Cognates: A.-Sax. teart “sharp, rough, severe”, teartlic, teartlice
“sharp, rough”, teartnes “sharpness, roughness, hardness”; Scots tairt “tart;
tartness”, Du.
tarten “defy, challenge, mock”, Gmn. trotzen “defy, brave, mock”; Ir. toirtín,
Scots tairt, Welsh darten “tart, tartness”; Fin. tarttu- “grab, catch”; Alb.
thartë “sour, acid, sharp”; Pers. talx “tart”; Mordv. targa- “pull”, Mong.
tarqa- “spread, scatter”, Kalm. tatxa “pull, drag”; OTr. tat- (v.) “taste,
try”.
Distribution: From Atlantic to Mongolia. A tight confinement of the western cognates is
striking and telling. Some metaphorical verbal extensions may be false cognates: “cramped jaws” may
be expressed in many ways. A plea for a Pers. origin (< daru “medication”) is debunked: “in
the (Pers.) southwestern languages, where the form daru is mainly widespread, a Pers. daru
“medication” is not known” (EDTL v. 3 159). The word is badly confused etymologically with
unrelated homophones to manufacture “PG” and “PIE” pedigree as cognates or a derivative of the verb
“tear”, qualified with a “but the gap in the record is unexplained”. Another version of the “IE” confusion comes from the line of the torte, tort, tortilla “flat bread” which, as an
attribute of food and taste, might have conflated with the A.-Sax. “tart” (adj.) with the tart
(n.) “small pie”, a Lat. cognate. A third line of etymological confusion is connected with the word
torture “suffering”, where sharp taste is addled with a sharp pain. If used emphatically, that
association mirrors the reduplicative idiom above forming a conventional emphatic jingle. A
connection between a nominal for a sour-taste fruit, and an adjective is typical. A second consonant
-l- in the Khakas and Pers. tends to culturally link those vernaculars. A wealth of phonetic
and semantic dispersion of the root tar-, dar-, the equal role of the transitive and
intransitive verbs typical for an oldest lexicon, a developed derivative field, and its presence in
all branches of the Türkic linguistic family attest to its native long history, and positively
exclude a supposition of a loanword status “from some Indo-European language”, v.s. The triplet in
Eng. of the Türkic lexemes
acid, tart, and ache constitutes an authentic case of paradigmatic transfer,
unequivocally attesting to a common Türkic linguistic origin. See acid, ache.
58
English thick (adj.) “dense” ~ Türkic sik/sïq (adj.) “squeezed, pressed”.
Ultimately fr. a verb sik-, sïq- “squeeze, press, compress, distress, depress” (+10s more), a
derivative of a prime verb sï- “break” with a suffix -k/-q denoting a result of
action. Cognates: A.-Sax. þicce “thick, dense”, OFris. thikke, Saterland Fris.
tjuk, Dan. tyk,, OSw. thikki, Sw tjock “thick”, ONorse þykkr (thykkr),
Norw. Bokmal tykk, Norw. Nynorsk tjukk, Faroese tjukkur, Icl. þykkur,
OHG dicchi, Gmn. dick; OIr. tiug, Gael. tiugh “thick”, Welsh trwchus,
drwchus “thick”; Mong. shyka-, siqa- (v.) “press, oppress”. Distribution: From
Atlantic to Mongolia. Distribution amply attests to a non-IE origin. The spread areal is
limited to Türkic, Mong., Gmc., and Celtic phylums and lands saliently marked by the Y-DNA
haplogroups R1a and R1b, megalithic and earthen kurgans, and nomadic archeological evidence of many
epochs. In the quasi-scientific etymologies, the native Türkic word is veiled by unattested faux
“PGmc. proto-words” *thiku “thick (?)”, *þekuz “thick”, faux “PWGmc.
proto-word”
*þikkwi “?”, and faux “PIE proto-forms” *tegu- “thick”, *tegus “thick”. A faux
“PIE” *tegu- “thick” is asserted instead of attested straightforward Türkic adj.
sik/thik/thïq with perfect phonetics and semantics. That nonsense is myopically played without
crediting the Türkic and Mong. duly attested material and duly attested Eurasian spread. A confusion
between the initial s-/th- (and at times
t-/d-) probably lays in the absence of grapheme for th- in the receptor languages. The
Celtic native words attest to the existence of the word in the N. Pontic before the proto-Celtic
southwest departure in the 6th-5th mill. BC and their arrival to Iberia in 2800 BC, 7000-6000 years
before it was first recorded by the immortal M. Kashgari. Celtic migrants may have been instrumental
in spreading the notion and the word in the NW Europe.
59
English twat (adj., n.) “obscenity, abusive term” ~ Türkic tat (adj.) “obscene, abusive term”.
An “IE etymology” stands as of “unknown origin”. On one hand, there is no direct connection. On
another hand, there is a common Eurasian word of obscene, abusive nature phonetically identical with
the subject word. The Türkic term tat became an international word long before our era, it is
found in early Chinese annals, in South-central Asia, in the Eurasian steppe belt, it became widely
known in Europe as an epithet
Tatars, which lit. means “alien folks”. A homophone is a Türkic tat (n.) “corrosion”,
which points to its generic origin as a product of spoilage, ca. “garbage, refuse, waste”. As an
obscene term for alien people, it was applied to insiders and outsiders of the Türkic societies,
hence the tat Uigurs are “the wayward Uigurs, non-Moslems”, Kerulen Tatars are
“oddball refugees, escapees”, Persians are tats because they are foreigners. Semantically, in
ethnic aspect, it parallels another widely known epithet Kushan/Kashan meaning “subject
population, slaves”, also widely applied to diverse alien people in Europe and Asia. The term tat
became a marker of a Türkic presence, a presence in all areas ever populated by the Türkic people.
The Eng. twat (n.) means “stupid incompetent fool”, and also obscene for “female genitals” as
a derisive euphemism for “no good, garbage”. Cognates: A.-Sax. taetteca “tatter,
shred”, ðwit “cuttings”, ðwitan (v.) “cut, whittle, cut off, cut out”, (a)ðwitan
(v.) “disappoint”,
twaefan (v.) “separate from”, twaeming (v.) “parting, division, separation”, tweon
(v.) “doubt”; Mong. tatai “disgusting!” Distribution: for both appellative and
abusive, ubiquitous across Eurasia. No “IE” etymology. The cited A.-Sax. native examples are phonetic
variations of the Türkic tat, and echo the Türkic entirely negative semantics as something of
a splinter nature, separate and alien, shreds of or from a whole. The term does not have a Türkic
etymology other than a descriptive definition, while the A.-Sax. examples may lead to its prime
roots rendered ðwit- to imply shavings, refuse, waste. Millenniums later, the word has passed
through numerous hands and re-entered English as an ethnonym Tatar, Tatary, synonymous with a
negative Huns and still earlier negative
Scythians, a concrete appellation for concrete people, and an echo of the Sax, Saxon, Saka,
Sekler, etc. See bode, bud, calm, tor.
60
English worse (adj.) “comparative of bad, evil, ill, opposite of better” (Sw N/A, F623 Σ0.02%) ~
Türkic uvy, uva, ava: (interj.) “oh, what a misfortune”, see voe.
An “IE etymology” myopically claims its own, i.e. Gmc., origin. Ultimately fr. an onomatopoetic root
uv/uɣ/u “howl, thunder, boom”, present in all native derivatives (uva, uvulda-, uwïlda-,
u:l-da-, uvvuldy-, uvut, uwut). Cognates: A.-Sax. wiers, wiersa, wierse “worse”,
wierslan “to get worse”, wierrest “worst”,
wierslic “bad, vile, mean”, OSax. wirs, ONorse verri, Sw. värre, OFris.
wirra, OHG wirsiro, Goth. wairsiza “worse”, OCS uvy (interj.), voi
(вой) (howl of wind, animals); Gk. oa, ουa, ουαί (oa, ova/oua, ovə/ouə, ovai/ouai)
(interj.), Lat. vah, vае (interj.), Goth. wai (interj.), Av.
avoi, vауoi (interj.) “oh, what a misfortune”; Yiddish wei, wei-wei, Central Asian,
Caucasus
wai, wai-wai “oh, what a misfortune”. Distribution: No references outside of the
Türkic Eurasian-wide milieu, which is certainly inaccurate, v.s. A link between woe and
uvy is clearly seen in numerous dialectal forms, some complete with an intact denoun adverbial
suffix -r/-ra/-rä. Between worse and uvy it is seen clearly via intermediate
forms: Türkic uvy (interj.) > Goth. wai (interj.) > Goth. wairsiza “worse” >
OSax. wirs (interj.) > A.-Sax. wiersa, wyrsa (interj., adj.) > English worse
(adj.). An “IE” attempt to invent etymology with unattested “PGmc. proto-word” *wers-izon-
(v.), “PIE proto-word” *wers- (v.) “confuse, mix up” is plain silly given the crisp
transmission trail. The Yiddish and Central Asian forms became internationally known due to their
intensive use in the modern movie industry that plays on ethnic and regional idiosyncrasies. In the
form voe in the sense of “bad, misfortune” the word was popularized by the King James Bible's
“voe to you” and the expression “my voe to you” ~ “if you only had my problems”. The Av. form
attests to the antiquity of the idiosyncratic form dating as early as the end of the 3rd mill. BC,
before the migration of the future Indo-Iranians to the South-Central Asia. See voe.
61
English young (adj., n.) “early, early period, development or growth, new, youthful” (Sw N/A, F507,
0.02%) ~ Türkic yangï: (adj.) “young, new”.
Ultimately fr. yan
“kind, type” to form an adjectival determinant for a noun pair like a “young boy”. The form
yangï: is one of many: yaŋï, yeni, yengi, jaŋï, jaŋɨ, yana:, yaña, yagi:, jagi; jaga:, yaga,
yagı, yağı, yegi, yegi:, yača:. Of all the Türkic forms, the form yangi: “young” of the
south-central Uzbek form of the Uigur-Karluk (aka Qarluq) linguistic branch appears to be closest to
the Eng. and to a Gmc. branch in general. Two synonymous notions young and
new have developed fr. the archetype and eventually established their specific spheres of
application, young and new vs. young or new., Cf. “new baby” vs. “young
baby”, “(court) news” vs. “juvenile (court)”. The semantic duality had fossilized with an advent of
a literacy; some receptor languages know one or the other form. Cognates: A.-Sax. gegoð,
geoguð “young”, OSax., OFris. jung, ONorse ungr, MDu. onc, OHG jung,
Goth. juggs “young”; OIr.
oac, Welsh ieuanc “young”, newydd “new”; Lat. juvenis “young”, LLat.
nova “new”; Balto-Sl. (Lith.) jaunas, OCS junu, Rus. junyj (юный) “young”,
novyj (новый) “new”; Pers. nou “new”; Skt. yuva “young”; Hu. gyenge “weak”;
Mong.
žaŋgi “news, notification” (< Tr.); Ch. yan 秧 “young”; Sum. genna “young,
small” (ca. 4th mill. BC); all “young” unless noted. A cognate new, news elided a prosthetic
anlaut semi-vowel, a la (ja)nue and the like, Cf. Eng. new /noo/. In Europe, the
Türkic
yan- “young” prevails, it numbers 23 (52%) languages, matching a 50.6% R1a/b
demographic presence in Europe. A Sl. Old Europe mlad- “young” is second, with 12 (27%)
languages, it is a dominating European native word. A minor n- “new” 3rd group with 4 (9%)
uses a truncated Türkic form. A context of n- “new” < Tr. yan- “young” covers 42 (93%)
European languages, leaving only 3 languages to use their own native terms. An oldest attested
cognate of the n- form is a Hittite newash “new”, ca. 17 c. BC. The Türkic yangï:
is a true Pan-European non-IE neologism fr. allophones of same Türkic (ya)ngï:.
Distribution: practically all major languages across Eurasia, starting with Sum. Distribution
attests to a common vocabulary of the migrants marked by a Y-DNA haplogroup R1b (male, Celtic,
pastoral) and R1a, warrior, later turned into brahman caste (male, Aryan, farming). The distribution
of the word across Eurasia, and the presence of the Celtic and Skt. cognates attest to a continued
presence of the word in the E. Europe no later than the 4th-3rd mill. BC (Celtic migration) and
3rd-2nd mill. BC (Aryan migration). Forms with an anlaut semi-consonant (j, y) are affiliated
with the Ogur subfamily, forms staring with vowel are affiliated with the Oguz subfamily. Gmc., Sl.,
and Lat. forms are closer to the Türkic yangi:. Celtic forms are closer to those of the NE
Türkic phylum:
yača:, yaga. The Lat., Skt., and possibly Welsh forms present a third variety distinguished
by an inlaut prosthetic voiced labiodental fricative v. The Ch. cognate is probably an
acquisition, via Mesopotamia as attested archeologically, from the “Zhou Scythians” of the ca. 1750
BC Shang period. The Mesopotamian Sum. cognate ascends to a 5th mill. BC, an earliest documented
example. The “IE etymology” invented hypotheticals, faux “PGmc., PWGmc. proto-words” *juwunga-,
*jungaz “young?”, *neuja- “new, young”, and faux “PIE proto-words” *yeu-, *yuwn-ko-
“force, vigor”, *hyuhnkos, *hyuhen- “young”. Unsustainable semantically and canny
phonetically, they are tortured embellishments tailing a tortured root. The attested forms yangi:
and young do not need any decorations. Independent of the Romanized spellings, the real
yangï: and young are phonetically eidetic forms. One Yangi was an early monarch of the
Early Period of Assyria (Azuhinum) ca. 2500 BC, he must have started as a young or new ruler vs. an
old one, Cf. Eng. idiom “baby Bush”. The Türkic and English phonetics and semantics are pinpointed
and perfect, leaving no room to question a common origin. The trio young, new and old
constitutes an authentic case of paradigmatic transfer, incontestably attesting to a common genetic
origin from a Türkic milieu. See old.
62
English yummy (adj.) “delicious” ~ Türkic em- (v.) “suckle”, em, yem, ye:m, de:m (n.) “food,
edibles”, yemiš (n.) “fruit, pome”.
An “IE” etymological line follows a non-Carnegie “How to fool friends and influence dupes”. An origin
of the word em-, em “suckle, food” ascends to a notion “female” represented in numerous
aspects: 1. suckle (baby), 2. female genital organ, 3. breasts, 4. nipple, 5. nursing bottle, 6.
senior (woman), 7. mother, female, 8. crawl, 9. curled up, 10. vertex, pate, 11. caress, 12. ingest,
eat, feed, etc. A two-phoneme root is expressed in 7+ forms (em-, äm-, im-, iem-, iäm-, ӧm-, ap-,
etc.) and morphologically extended into numerous notional lines (ämit, ämyiz, ämi, ämčäk, äminjäk,
and so on). It is indelibly connected with the notions süt “milk”, su, suv “water”,
and em- (v.) as a protagonist for “milk”. The first two demonstrate that in primordial times
any liquid was called by a generic su that stood for many aspects of liquid, including
notions “suck” and “suckle”. The third term em, initially synonymous with the with a generic
su, referred to an aspect “mothering” connected with “suckling” of liquid from human and animal
mammal glands. There is an uncanny connection of e- (ye-) in em- with e-
“eat”, then m- stands for the above list of m- aspects; that connection can't be
validated nor denied. A specific notion “milk” in some forms elided an anlaut vowel, retaining the
root me-, mi-, mjǫ-, mu-, me-, mo-, etc., added a passive suffix -l, and a deverbal
noun suffix -k/-q/-γ etc. Reflexes of those transformations are scattered across a
geographically large area of Eurasia; some languages had an aversion to anlaut vowels, others - to
anlaut consonants, adding or eliding a first morpheme. Those lexical developments are relatively
recent, within a last 10,000 years; a sequence of developments is fairly clear: “suckle” (v.) >
“meal, milk” (n., product) > “food, feed” (objective). A uniform distribution of the suffix -l
(mVl-) points to a European spread from a single source. A form yemiš also carries a
semantics “balm, balsam, fragrant, fruity”, concordant with the semantics “yummy”. A Türkic
adjectival participle of yem is yemy/jemï (pronounced yemmee), or yummy,
is identical to the Eng. form, which is a contracted adjectival form of yemiš. From a notion
“suck breast milk” the word has progressed to “food, nourishment”, and on to “yummy”. Cognates:
A.-Sax.
medren “maternal, mother’s side”, gemedren “of the same mother”, melc, meoloc,
meoluc, mylo, meolc “milk”, meluhus, mealchus “meal-house” (< Tr. meme, memeleki
“milk, food”, lit. “breast milk”), meolcliðe, mealcliðe “milky”, meolcan “to milk (~
meal)”, OSax.
miluk “milk”, OFris. melok, Fris. molke “milk”, ODu. miluk, ONorse
mjolk, Goth. miluks “milk”, OHG. miluh “milk”; Sl. mleko, moloko (молоко)
“milk”; Lat.
mulgere (v.) “milk, extract” (but “milk” (n.) lac); Gk. amelgo (αμελγω) “milk”
(< Tr. em-, äm-); Fin. ime “suck, feed (breastfeed)”; Hu.
em- “suckle (archaic)”; Khanty em-, emi- “suckle”; Nenets nimne- “suckle”;
Mong.
em-kü, üm-kü “swallow”, mölkü “crawl”, Bur. bülxü “creep”; Tung.-Manchu
(Solon.) imi- “drink”, (Barguz.) um “drink”, (Manchu) omı “drink”; Amerindian
(Kanienkeha) onon:ta “milk”; Cf. jam (n.) “fruit preserve” (Ogur prosthetic j-);
every named cognate has its em-, äm- Türkic counterpart. Distribution: From Atlantic
to Pacific. The m- form “milk” predominates in Europe with 23 (52%) languages, from a conc.
“breast milk, suckle” to a generic “milk”, matching a 50.6% R1a/b demographic presence in Europe.
Aside fr. a Romance lac “milk” with 10 (23%) languages, only 11 European languages use their
own 8 native terms for “milk”. Typical for copied lexemes, only the lacking words are borrowed by
other languages, a bulk of relevant terms stays with Türkic source languages, with some scatter in
close neighborhoods. With a childish approach, adults of the “IE etymology” have pronounced a
verdict that the word “yummy” is a “baby talk”, a not too enlightening proclamation betraying an
absence of any sensible “IE” etymology. It takes a ton of myopia to be that simplistic on the term of
human mothering and suckling, of the most primordial times and innumerable applications. For the
Eng. cognate “jam” it offers a cornucopia of origins, like a jamming fruit into a preserve,
unrelated to tasty fruits or tasty substance. See jam.
1
English above (adv., adj., prep., n., interj.) “over” (Sw N/A, F1914, 0.00%) ~ Türkic up-, op-, ob-,
kop- (v.) “up, rise, go up”.
A most salient expression of up- from the days of an animal freight horsepower is a command
to get up and move on, cited for the 11th c. Khakas and the Middle Age Eng. (17th c.). The root
ob- in a form ubyr (n.) “devourer” < (v.) “gulp, suck in, devour” gave the Eurasian folks
a “vampire”, Cf. “gulp up, swallow up”, see vampire. The Türkic verbal stem reached us in a
number of verbal conjugations and derivatives: infinitive deverbal verb opla- “rise up to
attack”, opra:-, opran-, apra-, ofra-, ofran-, ipre-, pren- “grow up in age, to age”,
oprat- “over-aged, weary” causative of opra:- with the same phonetic changes as opra:-,
passive opul- “upped”, deverbal noun
opu “upsurge”, deverbal noun/adj. obuz, opuz “hump, humpy”, deverbal adj. opraɣ,
opraq “up in age, aged”. The (probably prosthetic) k- form extended base semantics to
conc. applications: “get up, let go”, “rise (moon)”, “resurrect”, “get away, break off”. A linguist
would have to make an effort to miss a connection between derivatives and the verbal root. Two other
Türkic verbs are similar to up-, one is a:ğ- “rise, climb, ascend” (Cf. high)
and the other a:š- (Cf. astir) “cross over” without implicit implication of rising. That
nuanced difference makes
above and over synonymous, both imply rising. Cognates: A.-Sax. aboun, abow,
abufan, aboven, bofan, bufan, bufon, beufan, onbufan “over, above”, up, uppe “up,
upward”, OSax.
oban “over, above”, OSax., OFris. up “up, upward”, Dan. oven, op “over, up”,
Du.
opper, boven “over, above”, op “over, up”, OSax., OHG uf (adv., < ob-, up-)
“up”, oban, obana (v.) “up, over, above” (ob- + -en, Tr.-Gmc. suff. en), Gmn.
oben, auf (adv.) “up”, Sw. ovan, Icl. ofan “from above” (ob- + -en), Goth.
iup “up, upward”, uf “on, upon”; all Gmc. forms expressly pinpoint an upward move or
position; Sl. (Ukr.)
kopa “pile (wheat)”, (Bolg.) kopa “pile”, ditto Serb, Croat., Slov., Czech, Pol.,
etc.; Latv. kaра, kaре “dune, long high berm”, kарuоlе “pile”, Lith. koроs
“dune(s)”; Pers.
kopa “pile”; Skt. bhavagra “above”; +Dravidian pai “upper part”, Mong. obuɣa
“pile, heap, stack”; Sum. pad “above, uncover, find”; references to “IE” and Dravidian
cognates.
Distribution: Distribution is typical for the Türkic siblings, from Atlantic via a Türkic
steppe belt to Far Eastern Mongolia extending to the borders of China; isles in N.W. Europe. Wide
phonetic dispersions; forms are rather colloquial, specific to geographic and ethnic areas. An “IE
etymology” boldly rigs a perfectly transparent Türkic word ob-, up-. It concocts a Rube
Goldberg-type faux compound of a- = on “on” + b “be” = Türkic bu “be”, +
*ufan “over, high”. Essentially, that philological equilibristics invents a new “IE” word
*ufan “over”. There, the *uf is an OHG articulation of the Türkic ob-, up-, and
the -an is a Türkic verbal suffix carried over to Gmc. That Rube Goldberg machine-type
concoction does not fly. The falsifiers' position is demeaning, its inapt mechanistic wiles are
unsustainable. The internalized forms, diverged by different host vernaculars and independent
developments, reconvene in a new milieu, bearing close semantics but wobbling phonetically, mostly
featuring a loss or addition of an initial vowel. The semantic overlap of the forms abufan,
bofan, bufan and their siblings with the forms ofer, ofor and their siblings denoting the
same notions “over” and “above”, and their phonetic similarity attest to their common origin
ascending to the same old Türkic verbal notion up-, op-, ob- “up, rise, go up”. Typically,
divergent forms stabilize by their semantic shade, grammar function, and expanding utility. On the
Türkic side, the meaning
over had gained larger distribution than a geographically confined above. That trait
may help to illuminate underlying historical processes. A related Türkic bava, baba (n.)
“upper point, top” offers a real and viable path for the origin of the “above”. Tautology is a
common product in linguistic amalgamations, it suggests a conflation of the noun notion “top” with
the verbal notion “up, upward”, i.e. a typical Türkic emphatic pleonasm (cf. shagreen
leather, whole gamut, etc.). The terms
above, over, and papa/baba are intrinsically connected. Internalized into the European
syntax as bava with an action prefix a- “on” (Cf. alive, asleep, aback, afoot, etc.),
it is semantically identical with the action notion “above”. The phonetic connection with the
papa/baba is striking, statutorily papa, baba relays the very same semantics of “upper,
above, top”. Of the two etymological scenarios, one for both over and above being
expressions of up-, op-, ob-, and the second for above deriving separately from
bava, baba, due to consistent overlapping the evidence tends to lean in favor of the first
scenario. The second scenario, based on a paucity of the vestigial evidence, may suggest a
reborrowing from the Corded Ware internalizaions back into the Türkic milieu. G. Clauson (Clauson
EDT) cites 40 instances of reverse reborrowing of Turkisms back into Türkic. In this
hypothetical case the bava “father, upper” returned with a narrowed sense of “upper” as
opposed to
baba “father”. The common origin of the Eng. and Türkic lexicon is evinced by the
paradigmatic transfer of the semantically kindred quartet above, over, high, and
papa, an indelible testament to a common origin. See gamut, high, over, papa, shagreen.
2
English as (adv., anaphora) “like, same, equal” (Sw N/A, F71, 0.26%) ~ Türkic eš, oš, aš, oks, okš
(adj.), osna- (v.) “as, similar, like, equal”, as-, a:s-, aš-, (v.) “weigh (scales)”.
No European or “IE” etymology, no rational suggestions. A primary function is indicative particle
“here”, + functions: “clarifying word, this, just this, now, nowadays, so, true, very, actually,
like, alike, akin, similar”. An ultimate origin fr. a word as- “hang, suspend”, i.e. an
adder. Suffixed forms number 24+ (VEWT 368), with suffixes -aš, -al, -el, etc. A
prosthetic consonant -k-, -ɣ-, -v-, -χ- and -s-/-k- alternations affect a shape of the
word. It has numerous semantic derivatives, one of which is “to weigh”, with its own numerous
derivatives, one of which is an “equal” of a balance scale equilibrium or a conc. state. A device
and its terminology ascend to a Stone Age trade, weighing as an essential component of life. The
forms eš and osna- are allophones of as-, aš- with a single progenitor.
Socially, notion “equal” expanded to meanings of “one’s equal”, “friend”, “comrade”, and utilitarian
“unequal”, “greater”, “increase”, etc., the terms of comparison and appraisal. A wealth of Türkic
synonyms for “equal” numbers an impressive 38. Related forms are oɣsa-, оɣsatï, оqsadi, oqsatï,
oqša-, osna-, osnadï, ošadïɣï, ošatïɣï, oxsa-, xsat “as, like, compared, resembling (+ so, thus,
such)”. A number and a semantic raster of candidate derivatives is mind-boggling, especially in
utilitarian and trade relations: assay, assess, asset, assimilate, assize, assort, assume, etc. The
Eng. pair as and so are complementary semantic twins, they respond to a “how (like
what)?” and a “how (degree)?” respectively. They are easily compounded and conflated, Cf. “so as”,
“just as”, “just so”, Cf. A.-Sax. eall swa , eallswa, ealswa, alswa “quite as, just as” =
“all, totally as”. An Eng. internalization caused some newer conflations and confusions. The Eng.
so, an A.-Sax. swa, appear to be a handy one of those. It is phonetically a mirror of
oš, semantically overlapping and complimentary to it, the so as rings as a reduplication
jingle. Unlike the oš, the so does not have its own known historical trail.
Cognates: A.-Sax. (*o)swe “as, so”, se, seo, selfe, sua, swa, swæ “in this way, so
as, consequently, just as”, OSax., MDu., OHG so, OFris. sa, Fris. as, Dan.
saa, Du. als, Sw. sa, ONorse sva, Goth. swa, -þwa, swah “so, just
so, also, thus”, swa-ei, swa-swe “so that, so as”, swa-lauþs “so great”, swa-leiks
“such”; Scots as; Tatar os- “as, so”, šul “just this, that”; OLat.
suad “so”, Rum. asha! “so!”; Gk. hos “as, like, such”; Fin. ase- “hang
in, on (v.)”, asema “place”, asu- “reside”; Hindi accha (adj.) “(so) good”;
Mong. asa- “rise”, “impose” (< “hang (v.)”), “inflame” (hang over fire), ilje- “look”,
Bur. aha- “accost, badger” (< “hang (v.)”); Evenk asaktaža- “annoy” (< “hang (v.)”);
Manchu fasi- “hang, choke”, Oroch. hasi- ditto; Kor. ič- “pay attention to...”,
atta “snatch”; Kipchak šol “just this, that”. A loss of initial o- (oš- > š-, s-)
and articulation with -l- is documented still in a Türkic milieu. Distribution:
Eurasian Steppe Belt, Far East, with a teeny isolated isle in a NW Europe. Isolation offers valuable
diagnostic possibility. The word probably belongs to a host of unrecorded Turkisms that for
centuries lurked below surface, reportedly ca. 1200 AD it seemingly popped up as from a nowhere.
Gothic words vigorously refute that, the Goths, with their language and R1b-L238 haplogroup (TMRCA
ca. 4300 ybp), came to Scandinavia ca. 750 BC as a splinter population. Beyond L238 Hg lay older
parental sources. An “IE” supposition of equivalency with A.-Sax. alswa “quite so”, Gmn.
als “than” is patently wrong. As is not a “worn-down form of Old English alswa”,
it is a root oš in all its majesty. The alswa is a late A.-Sax. compound consisting of
the A.-Sax. al, ael, eal, eall “all, every, entire” + A.-Sax. se, seo, sua, swa, swae,
swe, (sama, same, selfe). In that compound the A.-Sax. al, eal “all” is an allophone of
the Türkic al(gu) “all”, and the A.-Sax. swa is an allophone of the Türkic oš
“as, so”, see so. The “IE” etymological fast one with alswa is a case of an
anti-etymology. Instead of parsing a word into its components, it looks at one of its compounds and
subs an unrelated part for an examined word. The word alswa is precisely that, it is a
compound of two attested Türkic roots, with fuzzy semantics, phonetics, a history on the Türkic
side, and a dim history on the Eng./IE side. An absence of a native European source attests to the
word origin from a non-IE source and a “guest” in Europe and in the “IE” family. A paradigmatic
transfer of two Türkic words,
as and so, indelibly attests to their origin from a Türkic community. See so.
3
English 'd (< would, or the would is an expansion of phonetical wud/ud) (v.)
“conditional modal verb”~ Türkic 'yu, conditional suffix applied to nouns and pronouns. If a
literature on the topic exists, it is imperceptible. Ultimately, an allophone of a Turkish suffix
-dıy, diy, -duy, -düy and its siblings from about a hundred Türkic vernaculars. Conditional
suffix follows immediately after a root, and can accumulate a tail of more agglutinated suffixes.
Cognates: A.-Sax. wolde, past tense of willan “to wish, desire, want”, ONorse
vilja, OFris. willa, Du. willen, OHG wellann, Gmn. wollen, Goth.
wiljan “to will, wish, desire”, Goth. waljan “to choose”. The accuracy of thee cited
cognates may be presumptuous. These are presumed cognates, since there is no set of linguistic
“laws” other then individual “laws” designed specifically for individual words, which would predict
regular phonetic change for a semantically contrasting word. Notably, the A.-Sax. dictionary does
not have a conditional modal verb to express the conditional would, leaving room for
speculative guesses as to how those folks expressed the conditional case. The closest are Du. zou,
(d/z alternation?), Nw., Sw. sku(lle) (sk = š < d?), appearing as allophones of
the 'yu with a vernacular consonant. An “IE etymology” stipulates that the English conditional
wud/ud is a derivative of the will “wish, desire, want” via A.-Sax. wolde, past
tense of willan “to wish desire, want”. That suggests that prior to the Middle Ages the
ancestors of the English did not have a way to express a conditional proposition. That allegation
appears to be impossible, considering realities facing English ancestors in the previous
millenniums, and the numerous languages they encountered prior to the Middle Ages. Semantically,
functionally, morphologically, and phonetically the similarity of the Eng. 'd and Tr. 'yu
(> -dıy) is striking, the use of the Türkic conditional suffix 'yu is documented from
328AD to the present. Actually, the Hunnic phrase said at the capture of Luoyang in 328 in the
future China, contains three English cognates:
tili “tell, order”; tut “take, capture”; and 'yu “would, 'd”, like in
“He would like” ~ “He'd like”. In English, the conditional would divorced the verb, and
migrated to the noun/pronoun, while in Türkic it remained faithful to the verb, but both have that
suffixal for 'yu , a “'ud ~ 'd”. The wud/ud/'d form is probably ancestral to the
'yu form, as is asserted for the phenomenon of consonant -y- transition among the Türkic
languages. The transition may be a result of the Türkic vernaculars spreading to the east and
amalgamating with the eastern languages they were encountering at each migration cycle. In English,
prior to being apostrophized, the conditional provision was expressed as a suffix, integral with the
stem, a la sheele for “she will”, and without any form of the will expressed.
Likelier, the conditional suffix has already long existed, inherited from the Türkic substrate, in
the forms and variations innate to the vernaculars of the Burgund, Vandal, and other European
Sarmatian tribes. See would.
4
English early (adv.) “early on” (Sw N/A, F865, Σ0.02%) ~ Türkic er, ertä, erte: (adv.) “early, in
the morning”, modern Oguz Turkish erken, ilk “early”.
Ultimately
ertä- comes fr. the verb ert- “pass”, in the sense that the night had passed, a
deverbal verbal derivative of the er- “be, follow”, a precursor of the Eng. are, see
are. The
er also means “early”, the same as its twice-removed derivative ertä-. Both English
and Türkic words are formed by the same agglutination mechanism, with different suffixes. The Eng.
adverbial suffix -ly is a form of the Türkic adverbial suffix -la/lä. The root of both
words is Türkic er or its allophone, the English adverbial suffix -ly is conveyed in
Türkic with temporal locative suffix -tä (-ta/-tä/-da/-dä/-δa/-δä) “when early, at an early
time, in the morning”, the suffix corresponds to the modern Oguz Turkish -ken/k. The Türkic
er also means “morning” and “tomorrow”, possibly as a derivative of the notion
erï- “disappear, dissipate (of night, darkness)”, Cf. Av. ayar “day”. That peculiarity
is retained in the Gmn., where morgen also denotes “morning” and “tomorrow”. Cognates:
A.-Sax.
aerlice “early”, aerra, aerre aer, aeror, ere, erer “soon, before (in time)”,
superlative
aerest “earliest”, OSw., OFris., OHG er, Du. eer; Gmn. eher “earlier”,
ONorse
ar, arliga “early”, Goth. air “early”, airis “earlier”; Fennic languages
erte is widely spread expressing the same notions; Gk. eerios “at daybreak”; Av. ayar
“day”; Mong.
erte “early”, Manchu erde “early”, erin “time”, Nanai erin, erku “time”,
Oroch. eru, еu “time”; NKor. ir, Kor. il (일) “early”,
ilda (일다) “be early” (il< ir). Distribution: across Eurasia
from Atlantic to Pacific. A standing “IE etymology” comes in two flavors, a first only shyly
recounts Gmc. cognates without fibbing, a second bravely dreams up some faux “proto-words”, a “PG”
*awiz and a “PIE” *howis. The first is useless, the second is ridiculous given the
dispersion from the Pacific to Atlantic and Arctic, and across numerous linguistic families. The
bearing of etymological ineptitude can't be trivialized, it is symptomatic of the entire system of
faux paradigms and faux fixes. Leaving an origin with A.-Sax. essentially kills a subject of
etymology. The A.-Sax. intricate grammatical development and nearly exclusive Gmc. distribution in
Europe attest to a long history of internalization, probably from the Corded Ware culture period. A
perfect semantics and close phonetic correspondence leave no doubts about a Türkic origin. Borrowing
of such basic word from a Gk. or Av. into Gmc., Manchu, or Kor. can be confidently excluded. See
are.
5
English far (adv., adj., n.) “very distant” (Sw N/A, F458, 0.03%) ~ Türkic ıra:- (v.), jïraq, ïraq
“far, distant, stay away”.
Ultimately fr. a verbal root ır- (ïr-) “withdraw, leave, depart” identical with a noun
root ır (ïr) “there, that side, left, north”. Various internalizations, including
Türkic, are articulated with a prosthetic anlaut consonant f-, p-, h-, d-, y-, jy-, etc.
Particular traits allow diagnostic tracing to particular ethnicities. Among 44 European languages
the word is marginal: 8 (18%) languages (Eng., Fris., Scots, Basque, Dutch, Lux., Yiddish, Tatar),
behind an Old Europe Sl. with its 12 (27%) languages and on a level with a motley Germ.-Romance
group of 8 (18%) languages. A majority of 16 (37%) languages use their own native terms. Of the
last, 7 (16%) languages stayed with their own native terms but in the past colloquially used
Türkic-derived “guest” forms. A good 34% of the 44 European languages were exposed to or adopted
Türkic-derived terms. There is no Pan-European or a common “IE” term. Cognates: A.-Sax.
feor, feorr, fi(e)ra, fyrra “far, remote, distant”, feornes “distance”, feorrung
“removal, departure”, OSax. fer, OFris. fer, fir, ONorse fiarre, OHG ferro,
fer, Goth. fairra “great distance, long ago”, Icl. fjar; OIr. ire
“farther”; Lat. per “through”; Gk. pera (περα) “across, beyond”; Alb. pera
“far”; Arm. herru (հեռու), Gujarati dura (દૂર),
Skt. parah “farther, remote, ulterior”; MMong. irada “downstream” (da-
directional suffix, Cf. Eng. to “direction of”); Hitt. para “outside of” (16th c. BC
or later). Distribution: Eurasian Steppe Belt fr. Atlantic to Far East, with an isle in a NW
Europe. An “IE etymology” offers a mind-boggling sequence of “Proto-Germanic” stand-alones arising
from “Proto-IE” stand-alones equipped with a universal word perr loaded with an
indiscriminate pile of semantic meanings: “forward, through, in front of, before, early, first,
chief, toward, against, near, at, around”, and a wide range of other extended meanings at times
semantically overlapping with the notion of “distant”. Likewise are the faux “PGmc. proto-words” *ferro
“great distance”, *ferera- “far, remote, distant” a faux “PIE root” *per- “through,
forward (+“in front of, before, first, chief, toward, near, against, across, beyond”, etc.)”. The
myopic “IE” etymology does not delve into complexity of the “IE/PG” links to attested Hitt., Mong.,
Arm., and Ir. originals and a wealth of the attested Türkic originals and derivatives. During N.
European Corded Ware period, Armenians were either Balkan Phrygian migrants or ingenious isolates of
the Armenian Plateau. In either case Arm. chances to learn a Gmc. *ferro were slim to none.
Ditto with Gmc. to learn the Arm. herru. At any angle. the myopic etymology does not hold
water. Given a pre-eminence afforded there to the Lat. and Skt. underlying the postulated “IE” Family
Tree model, the applicability of the Lat. cognate to the notion of “distant” in time and space is
questionable, more likely it belongs to the “IE” semantic pile of indiscriminate “through”, “chief”,
et al. That kind of etymological ingenuity leads from intractable to nowhere. It only serves to fill
in gaps with some mucky mortar. The attested lexical base forms two sets, one with an anlaut
prosthetic consonant, and the other without a prosthetic consonant, starting with a vowel. The OIr.
ire without a prosthetic consonant attests to the form in circulation in the N. Pontic area
before the Celtic circum-Mediterranean departure in the 6th-5th mill. BC. The Türkic ıra:-
ascends to that time and beyond. The Gujarati form is consistent with the historically known
Ogur-type-speaking Ephthalite Gujars migrating to Malwa (8th c. AD), an area later named Gujarat
after them, hence the peculiar prosthetic d-. The Arm. form is consistent with the flows of
Ogur-type speaking nomadic Huns, Masguts (Masagetae), Kayi, Suvars, and the tribes known under
sobriquets Agvan and Alban migrating to SW Caucasia in the first 3 centuries of our era. The
f-/p- prosthetic consonants are consistent with the N. Pontic area being a staging platform for
so called “IE languages'” southward migration to the Indian subcontinent (Skt.) and Iranian plateau
(Hitt.) starting ca 2000 BC, Scythian migrations toward Jutland and Scandia, and Sarmats' migration
to the north-central Europe in the last centuries BC (Gmc. languages). Of these migrations, the
Scythians, Huns, and Ephthalites (Avesta's Turanians) tentatively had dominating R1a Y-DNA
haplogroup, and the Sarmatian tribes had dominating R1b Y-DNA haplogroup. An antiquity of the word
is attested by indifference of the verbs to transitivity. The consistency of the allophonic forms
and semantic precision attest to a common origin of the word and its continuous proliferation. The
phonetic and semantic concordance attests to a Türkic origin, preceding the Corded Ware period and
likely preceding by far the Celtic departure on their pedestrian anabasis.
6
English ha, hah, ha-ha (interj.) (Sw N/A, F405, 0.03%) “laugh, guffaw” ~ Türkic qatur (ɣatur),
qatɣur- (v.) “guffaw, hijinks”.
Ultimately fr. a root qat- “laugh” with suffixes ur, ɣur-. The population of the
“OEurope” and the rest of the Europe in their many vernaculars definitely had numerous expressions
for “laugh, guffaw”, but a population replacement of the 4th mill. BC by the horse-mounted Kurgan
people wiped out and marginalized the previous European populations together with their numerous
vernaculars. For 2 millennia, many Türkic languages covered Europe, spreading their lexicons and
introducing new terminology that took hold across Europe. The Türkic qatur, ɣatur, qatɣur- in
whatever allophonic forms, prefixes and suffixes of the time, is found in most European languages:
in OE, OFr., Gk, Lat., Balt., Sl., etc. An advent and spread of the “IE” languages to Europe in the
1st mill. BC was a process of infiltration. It gradually absorbed and digested the internalized
Türkic lexis, and brought to us remnants of the former common European lexicons, of which the ha,
hah, ha-ha is one of the most prominent members.
7
English hey (hei, hai, ai, he, heh) (interj.) “call to get someone's attention, hello (greeting)”
(Sw N/A, F84 0.22%) ~ Türkic ay (interj.) “call to get someone's attention”.The
word is most polysemantic, prime meanings are “say, sound, clarify” + a range of others. A notion
hei “call” probably got stuck as a most effective call. Synonymous with its allophone at
“name, call”. Cognates: Sw., Norse, Icl., Dan., Du., Gmn.
hei; Ir. hug; Pol. hei; Balt. (Lith.) ei, (Latv.) hey; Lat.
eho “hey”, ai(i)о “speak! assert!”; Gk. eia,; Hu hey; LAv. ad “tell,
say”; Mong.
аjа, ajas “sound, sounds” (+ “pronunciation, accent, rhythm, melody, tone”), aji(lad)-
“tell, say”; all hei “call” except as noted. Distribution: Eurasian Steppe Belt fr.
Atlantic to Far East, with fragments randomly scattered in the neighborhoods. An “IE etymology” tends
to confuse the Türkic cognates of ay “call for attention” with the cognates of ay “cry
of grief”, which are semantically and in intonation completely different. The “IE etymology” also
boldly refers to a fuzzy notion “natural expression” that reeks by pre-literate times when a cause
and effect were one and the same. That does not jibe with semantically identical calls with
completely different phonetics, used by a wide variety of languages.
8
English how (adv.) “in what manner” (Swadesh 15, F60, 0.34%) ~ Türkic qala, qalai, qalï (ɣalï,
ka:yu:) (adv.) “how”.
Ultimately fr. an interj. root qa adopted fr. a suffix. An adverbial suffix -lï (Eng.
-ly, Cf. light ~ lightly) also points to the root
qa-, which leads to numerous semantic precursors. A complex of forms of a kayu circle
(kač, kačan, kah:, kalti:, ka:nı, ɣaltï, qalï, qaltï, xalï, etc.) ascend “to an earlier stage
in the language when different suffixes were in use” (G. Clauson, ETD 632). That allows to
single out archaic forms and recognize them among various cognates. The form kayu (ka:yu:)
phonetically and semantically is virtually indistinguishable from how. There is no common
“IE” term, but instead there is a Pan-European Türkic qa-. Of 44 European languages, an
overwhelming 36 (82%) languages use Türkic qa in a range of articulations: ka-, co, cu,
cia, ho, etc., some with elated elements but still readily recognizable, Cf. kak, jaki, yak,
etc. A remaining 7 (16%) languages use their own 6 native terms. If any of them falls into a “IE”
category, it is a grim existence. Cognates: A.-Sax. hu, OSax. hwo, OFris., MDu.
hu, Saterland Fris. wo, WFris. hoe, Du. hoe, Dan. hogyan, Sw. hur,
LGmn. ho, wo, wu, Gmn. wie, Goth. hvaiwa, Icl. hvernig “how”; Ir.
conas, Scots ciamar, hoo, foo (but Welsh sut); Latv. ka, Lith. kaip;
Sl. kak (как), kako, jak “how”, koli (коли) “if”; Romance como; Hu. hogyan;
Kurd. čawa; Pers. ce (in ce tour), Taj. hel; Mong. herhen; Tatar
kali; all “how”. Distribution: Eurasian Steppe Belt fr. Atlantic to Far East, with
exceptional presence across nearly entire Europe. On the “IE” market the Türkic qa-
“how” is being sold as a faux “PGmc. proto-word” *hwo “how” and a faux “PIE proto-root”
*kwo- “stem of relative and interrogative pronouns”. That helps to fool few curious and millions
of innocent: “Science knows better”. It does if it does not play on quasy-patriotic “me too”.
Transition from Romance/Türkic initial k-/q- to voiced h- is the same as for Romance
casa to Gmc. house. A Gmc. h-/w- transition is attested, it is a recent colloquial
event. The Gmc. wie, wei now stand out, but initially are known with an anlaut h-.
Ultimately all “IE” forms for how ascend to the allophones and variations of the Türkic
qalï, with laryngeal initial consonant, still preserved in the Türkic, Ukrainian, etc.
languages. With the attested Türkic qalï/ɣalï/ka:yu:, there is no need for the half-baked *hwo-
and *kwo-, it is absurd to reinvent a faux allophone when there is a massive series of
attested forms. The form kayu: with alternative form xayu: “how” was recorded in
Khakas (11th c.), adding to other Eng.-Khakas phonetic clones. The Scythians, relayed in Herodotus
IV, 131, 132 (5th c. BC), sent a message to Darius (recorded in Gk. prose) that is heavy on qalï.
A chain translation fr. Scythian to Pers. to Gk. to archaic poetic Türkic reads (Gasanov Zaur, 2002,
Royal Scythians):
Qali, Qali, qarğa qahqa qal ı masanız,
Qali, qaraqu qarima küliməsəniz,
Qali, qurbağa çülimənə qalimasaniz,
Qalti, çuramlarla qartlanmiş qarşibolmassiniz.
In translated Herodotus' rendition it reads:
Qali, qaraqu qarima küliməsəniz,
Qali, qurbağa çülimənə qalimasaniz,
Qalti, çuramlarla qartlanmiş qarşibolmassiniz.
(If) How, (If) you the Persians) how birds to the sky (would) not rise,
(If) How mice underground (would) not hide,
(If) How frogs to a bog (would) not jump,
Then arrows shall turn you back.
That is a real documented Türkic “how” from millenniums long past. The text contains an embedded
signature, Kolaksai (< qali), of the Scythian leader; the sai (tai) refers to the clan
ties, see tie. A Türkic origin of the word is way beyond doubts.
(If) How mice underground (would) not hide,
(If) How frogs to a bog (would) not jump,
Then arrows shall turn you back.
9
English in (prep.) “toward the inside” (Sw N/A, F13, 1.15%) ~ Türkic in-/en- (v.) “descend, come
down”, in/en (n.) “bottom, descent”.
Ultimately fr. a noun i:n “lair, den” for an underground lair of a wild animal, fr. a suff.
-in, -en, a verbal-nominal word-form with subject matter. Or a vice-versa. That word has
survived for millenniums from its first surfacing, Cf. Eng. inn “den, lodge”. The i-
and e- forms (and a-/ä-/ə-) are eidetic, they had a parallel and overlapping
existence, and produced differentiated crisscrossed derivatives. The notion “descend, in” has more
than 15 semantic derivative clusters, some quite ludic like see a dream, achieve, leave, dusk,
nightfall, etc. In addition, the verbal root in-/en- forms descending notions (ini/ene-),
like parturiate, younger (brother, sister), young, etc. Those derivatives found a wide distribution
in the Tungus-Manchu languages, attesting to fairly late (Zhou time, 2nd mill. BC) extensive marital
connections with the Türkic ethnos. The Eng. in is a grammatically universal preposition,
adverb, and adjective, with a wide spectrum of semantic meanings: inside, inward, within, incoming,
happening, among, about, during, etc., basically a movement from outside to inside. The directional
in, on, and
at are notoriously confused in daily life, adding vernacularly to the semantic spectrum. The
Türkic form in, en, i (+ yn) spread like a fire across Europe, of 44 European
languages a motley mass of 19 (44%) languages adopted it, making it a predominant common European
term. A Sl. Old Europe follow with v “in” and its allophones with 11 (25%) languages. The
remaining 12 languages, incl. Lat., use their native 11 terms. Cognates: A.-Sax. in
“in, to, for; into, upon, on, at, to, among (temporal); in, at, about, towards, during (purpose)”,
(wicung) inn, “(guest)chamber”, OFris., Du., Gmn., Goth. in, ONorse i; OIr. in,
Welsh yn-; OCS on- “in”, inde (инде) “in somewhere” (< Tr. in with
directional -ta), Sl. (OCS), (Serb/Croat) indje (и̏ндjе), (Czech) jinde, (Pol.)
indzie, all with leading semantics “in, into, toward inside”; Gk. en, Lat. in;
Mong. enel (passive) “down and under, afflicted”; Manchu, Negidal, Orok, Nanai ina,
Evenk ena, mostly “nephew”, with various other in-laws, and with a compliment of other
related derivatives, like a “younger brother/sister of the husband”, related to the Türkic ini
“junior”. Distribution: From Atlantic to Pacific, across linguistic barriers. A direct
comparison of Eng. cognates is muddled, because similar phonetic forms are semantically conflated,
any type of movement in any direction is thrown in the same phonetic pile without regard to its
meaning. There is no sensible “IE” explanation for the origin of in. The ideas of the faux
mechanistic constructs “PIE proto-root” *en and/or “PG” *in “in” are not needed to
simulate the attested Türkic originals. These tales need to be rescinded as an abuse of science.
That leaves no “IE” etymology, the word came from nowhere, both grammarians and curtailed-purview
etymologists act as confused observers. A similar “IE” etymological cacophony surrounds the origin of
on (prep.). The Türkic etymology offers semantic explanation for both in (prep.) and
on (prep.), with further extensions to adv.s and adj.s. Both prepositions have clear and
discrete semantic meanings, i.e. aiming to a lower/inside status vs. aiming to a higher status. The
presence of the Old Celtic cognate suggests an existence of the word at the time of the Celtic
departure from the N. Pontic ca 5000- 4000 BC, and may imply that the counterpart on also was
in existence. A Gmc. convergence of the European cognates points to the Corded Ware hub as a source
of the European internalization. A healthy half-dozen of the Eng. directional prepositions
irrefutably lead their origin from the Türkic milieu. The Türkic origin is an only realistic
outcome. See and, at, be, on 1, on 2, till (prep.), to.
10
English less (adv., adj.) “smaller comparative of adjectives and adverbs” (Sw N/A, F759 0.01%) ~
Türkic es- “smaller of comparative of adjectives and adverbs” (adv.).
On a background of 22 Türkic synonyms and cognates, the form es- suggests a pinpointed ethnic
origin. Ultimately fr. the root es- a depreciatory derivative “winnow, reduce, lessen,
diminish”, Cf.
eske “old, dilapidated”. Another aspect of the negative notion is “bad, evil, nefarious”,
etc., Cf.
esiz “bad”. The initial l- could either be prosthetic, or alternately a part of
original elided with time, or natural under an influence of the A.-Sax. native lytel
“little”: lytel/laes are more palatable than lytel/aes. The notion apparently came
from a process of winnowing, thus also “tremble, shake”, blowing off the chaff from the grain,
reducing bad and keeping good. The same root is producing a contrasting notion of “healthy,
flourishing”, Cf. esen “healthy”. The Eng. “less” is a comparative of “little”, but is not
connected genetically with it. Like the Türkic es-, the A.-Sax. laes “less” is
dubbing as leas “vain, worthless”, an evil of “false, faithless, untruthful, deceitful”. A
bridge between the Türkic es “smaller” and Eng. less “smaller” is provided by the
A.-Sax. essian “to waste away, blow away”, laesian (v.) with a native homonym “graze”.
Cognates: A.-Sax. essian “waste away”,, laes (adv., n.) “less, lest”,
laessa (adj.) “less”, laest (superl.) “less”, lesu, lysu “evil, false”, OSax.
les “less”, OSw., OFris. les, lessa; Balt. (Lith.) liesas “thin”; Ar. agal
“earlier” (< Tr.); Mong. esin “beginning, origin” (< Tr., ~ “earlier, before (time)”); Shor
äzä /əzə/ “earlier”. Distribution: From Atlantic to the Far East, across linguistic
barriers. Cognate distribution exclusively across the Gmc. and Balt. area points to the
internalization at a Corded Ware period (3rd -2nd mill. BC). The Aryan migrants to the southeast did
not know the word. No credible “IE” cognates whatsoever. An unstoppable “IE” etymology came up with
uncorroborated mechanistic imitations of the Gmc. cognates in a line of faux ersatzes, a faux “PGmc.
proto-forms” *laisizan “small?”, *laisiz “smaller, lesser, fewer, lower”, and faux
“PIE proto-root” *leis- “small” with “PIE proto-word” *leys- (v.) “shrink, grow thin, become
small, gentle”. The suggested irrelevant attested ONorse hlass, hlaða “to stack” (Cf. Sl.
kladka (кладка) “masonry”), lesa “read, collect, gather”, ODan. læsæ ditto are
random phonetic resemblances incongruent with the notion “smaller”. Etymological value of these
assertions is zero. The “reconstructions” do not cite any “IE cognates” from “IE” sister languages, do
not address an origin of the invented root, know nether geography nor time, and in a circular logics
lead from nowhere to nowhere. A prosthetic anlaut l- distinctly appears to be a dialectal
Eastern European innovation. The Balt. (Lith.) form preserved the original semantic of es-:
“reduce”, from “scatter, winnow” by blowing. The Türkic original is attested, near perfect
phonetically, perfect semantically, and is corroborated by second meanings preserved in parallel in
both vernaculars. The paradigmatic transfer of the phonetics and complimenting semantic meanings
“reduce”, “evil”, and “blow” indelibly attest to a common genetic origin from a Türkic milieu.
11
English OK (interj.) “expression of positive, agreement, approval” ~ Türkic ok, ök (oq, ök)
(emphatic positive) “verily, very, exactly”.
An “IE”-rated “origin disputed”; speculations abound, most uterly uncouth, duly enumerated by
Wikipedia. In Russia, a Türkic origin is a common knowledge, due to an education force of a smiling
adage “bread yok, meat yok, vodka ok”, lit. “bread - none, meat - none, vodka - yes”. It is used
derisively in the vast territories of the Eurasia, in the areas of Ukraine, Russia, and generally of
Russian-speaking folks, the areas where the Russian supplants native languages. For centuries, it
was a descriptive reflection of reality. Reality wobbled, adage was eternal. The OK, O.K., (okeh,
okay) is one of the few words that repatriated back to England from America. Now an
international word, in the 19th c. “from a nowhere” it appeared in the USA, and since generated a
few etymological anecdotes, some of them recited in etymological dictionaries. A folk etymology is
standing for “oll korrect” giving a deserving credit to American ingenuity. Before surfacing in the
New World, the pre-American Türkic had to be lurking in England for at least two millenniums. The
OK is a member of a pair ok/yok, positive/negative respectively. Cognates: A.-Sax.
ac, aec with a long list of lose interpretations “but, but also, moreover, nevertheless,
however, because, for (?), and (?), unless, except”, aht, eaht, awiht (n.) “good”; these are
fairly consistent with a vaguely emphatic use of the interj. particle, any theme accented with an
emphasis; they can also be used as interrogative emphasis; Goth. ak “but, however (after
negative clauses)”; OHG. oh “but, however”, Yid. ö “yes, agreeable, affirmation”;
Mong.
ug “immediately, main, rational”. A closer examination would recover many more cognates
scattered across Eurasia. Distribution: Nowadays international and global. Interjections are
very enduring, retaining their forms, with somewhat lose spelling, over recorded periods across
various host languages (Cf. aha, aga “bingo!”). Some lexical meanings preserved in particles
ok and yok point to semantic directions of their grammatization: i.e. oq “fast,
quickly, immediately”, etc. Literary examples cite a negative version yok; a nearly
homophonic jingle ok of the inseparable pair may be omitted from the sources. It could be
expected that in the last 2+ millenniums such an abstract interjection would experience semantic
drifts and expansions, and develop colloquial nouns, verbs, adverbs, and adjectives. The form
aht, eaht displays grammatization: -t is a Türkic abstract noun suffix, see give,
gift, port. The OK is remarkable for its endurance, international spread, and its
particular identification with the American culture. A collection of Eng. interjections common with
Türkic languages is extensive; probably more have escaped attention of dictionaries. Together, they
constitute a tangible paradigmatic transfer case that attests to a common genetic origin from a
Türkic phylum. See give, gift, hey, not, port, quite, uh, voe, worse, yah, yeah, yep, yes.
12
English on 2 (adv., prep., postp.) “move on, along, effectual, make progress” ~ Türkic ö:n-, ön-,
öŋ-, ün-, yöne-, yün- (v.) “appear, grow, sprout”.
An “IE etymology” offers indiscriminate approaches. A base notion is rooted in sprouting of
vegetation, its 15 semantic clusters all reflect different aspects of sprouting: grow, rise, etc.,
some with quite remote meanings. It is distinguished by a common trait of attachment to a starting
point, Cf. ortho-. The homophones
on 1 “on a surface, on date” and on 2 “move on, come on, be effective, lights (are)
on” can be held as a single word only by equating them, a surreal proposition. That is an unviable
case. The ö- and ü- are routinely interchangeable; ditto the -n and -ŋ.
A length of the vowel had lost its semantic meaning at archaic times, if it ever bore it. It is
etymologically irrelevant. An exhaustive phonetic listing would include more irrelevant variations.
An excessive attention to particulars of articulation, complicated by diverse transcriptions only
distract from a substance. In Türkic, a semantic distinction between spoken on 1, on 2, and
in is readily apparent, the difference between on 1 < ö:n, öŋ (n.) and on 2 < ö:n-,
ön- (v.) is in suffixation, denoun suffixes vs. deverbal suffixes, Cf. the on 1 “top”:
denoun verb öŋger “carry (on top, in front)”, denoun noun öndün “(in) front”; the
on 2 “grow, sprout” deverbal verb önla “grown”, deverbal noun önbek “harvest,
crop”. In “IE etymology” phonetic forms (on 1, on 2, in) are semantically conflated.
Direct comparison of cognates is muddled because relevant and irrelevant lexemes are thrown into a
single etymologic pile irrespective of the meanings. According to the “IE etymology”, on is a
universal preposition, adverb, and adjective, with a generous spectrum of semantic meanings: be
above or below smth., be in smth., be with smth., be during smth., be about smth., etc., in other
words be anywhere inside or outside of smth. The sense “move on, along, effectual, make progress”
does not figure in. There is no etymological explanation to such distortion, the homonym on 2
comes from nowhere. In the following cognate listing any entry that does not denote the substance of
“move on, along, make progress” is a disqualified false cognate. By that criteria, most of the
habitually cited “cognates” are irrelevant false cognates. Cognates: A.-Sax. on, an,
NFris. a “on, in” (~ “move”?), Saterland Fris. an “on, at” (~ “move”?), WFris. oan
“on, at” (~ “move”?), Dan. ӧge, pa, Du. aan “on, at, to” (~ “move”?), Sw. a
“on, at, in”, pa, ONorse upp a:, Norw. pa, Faroese a “on, onto, in, at”,
Icelandic a “on, in”, LGmn. an “on, at” (~ “move”?), Gmn. an “to, at, on”,
Goth. ana (=in, on, upon, at, over, to, into, against) (~ “move”?); OCS na “above,
upon” (with up direction, instead of “move”); Balto-Sl. (Lith.) nuo “down from” (down
direction, instead of “move”); Lat. an-; Gk. ana (ανα) “on (move?), upon (move?)”;
Alb. në “in”; Av. ana “on” (without direction or continuation); Mong. ӧndei-
“rise”; Tungus (Even) ӧn “rise (of water), tide, increase”. Note: 1. phonetics has
little to do with one-syllable words; practical use defies any conventions; a “wrong” use is right
if it is conventionally used and clearly understood; 2. Etymological confusion is misleading;
outwardly similar words have utterly different origins. Distribution: extends across Eurasia
and linguistic families. A similar “IE” etymological cacophony surrounds the origin of in
(prep.), see and, at, be, en-, in. The root ön, öŋ, ün is popular: in addition to the
notion “grow”, it carries unrelated notions “front”, “face”, “sneak”, and at least 4 others formed
with agglutinated suffixes; one of those, öŋŋö, is a precursor template for “another”. An “IE
etymology” is totally amuck: it treats distinct notions as a random collection of accidental forms.
There is a method to that craziness: centuries of internalizations brought an element of havoc into
vernaculars of diverse ethnic groups. The eastward stampede exodus from the Central European
“killing fields” zone reshuffled not only the ethnicities and geography, but the languages as well:
to survive, escapees had to adjust to realities they had encountered. The ensuing fossilized
confusion lead to etymological jokes a la “on, an unstressed variant of an in, on, into”
and such indiscretionary assertions. To replace meaningful on, in, etc. with a meaningless
faux “PGmc. proto-word” *ana “on” (+ at?) and a faux “PIE proto-root”*an-, hen-
“on” (on the table? or move on?) is an intellectual disgrace for the preachers and the
flock. A move on is never same as “on (the table),
upon (inspection), onto (the table), in (the mouth, guts), into (city, water,
music)”. The myopic assertion is an etymological disinformation at its best. It is fairly clear that
the Lith.
nuo rather belongs to the Sl. notion of niz (низ) “bottom” than to the European on
“make progress”. The Dan. form is allophonic with -n-/-g- alternation, and is ethnically
diagnostic. The prepositions' complex originally had clear and discrete semantic meanings, i.e. move
to a higher status vs. move to an inside status, or a progress from one status to a stronger status,
get better, improve, heal, etc. The timing of the internalization likely ascends to the amalgamation
of the Corded Ware period, when functional parts of the alien words were extracted and
re-grammaticized to the local vernaculars. While the links connecting many substrate Turkisms are
inferred from the phonetic and semantic similarity, directional indicators provide a third element,
the precise words that were the first building blocks for creation of the abstract directional
indicators. The Türkic etymology offers semantic explanation for both on (prep.) and in
(prep.), with further extensions to adverbs and adjectives. In every case, an origin from a Türkic
linguistic milieu is independently traceable and vividly demonstrable as ascending to its own
distinct root. See and, at, be, en-, in, on 1, ortho-, till (prep.), to.
13
English once (adv.) “previous time, before” (Sw N/A, F336, 0.04%) ~ Türkic öŋ “first, before,
previously, once”.
A myopic “IE etymology” asserts its own “IE” original, *oi-no-, a homophonic counterfeit
parachuted down from the blue sky. Ultimately fr. n./adj. öŋ “one, first, fore” and its
derivative öngü, öŋkü “first”, synonymous with bir (n.) “one”; bir, birinč
“first”, see first. With the öŋ and eŋ fairly homophonic and nearly synonymous,
a conflation into a formulaic beginning for the daily recitations of the tales and legends is quite
reasonable: a derivative form fr. öŋ to aen (ən), to aenes (ənes), and then to
once /wuns, uans/, see eŋ (prefix). The suffix -ce, asserted “to retain the breathy -s-”,
is likely an internalized reflex of ordinal -č, Cf. birinč “first”. The English
version is unique in Europe, which has its own 28 unique ways to say “once”, plus 6 dead words
related to Lat. There is no Pan-European or a common “IE” term, like an ubiquitous Türkic word öŋ
“one”. Without a single inherited European stem, “once” is either a random innovation, or a “guest”
from another linguistic family as asserted herein. A chain öŋ “first, once” > on, un
“first, one” > öŋč ~ anes “once” is clearly visible. There is no need for patriotic
romanticizing. 70% (31) of European languages use variations of öŋ for “once”, exceeding a
50.6% R1a/b demographic presence in Europe.
Cognates: A.-Sax. æne, anes “once”; it straddles both öŋ and eŋ; Sl. 12
languages; Gmc. 9; Romance 5 (but Lat. iterum); Tatar 1 (but all other European and
non-European Türkic languages are not represented); Mong. ӧmïne, emüne “first, in front” (ŋ
> m), öŋge “frontal side”; Manchu f'an “frontal side”, outer, frontal properties:
“appearance”, “looks”, “color (faces)”, “blush” “color" (horses)”.
Distribution: extends across Eurasia and across linguistic families, from Atlantic to
Pacific. On a globe map, a footprint of qualified European languages is miniscule compared with the
root öŋ in all other languages. Omitting that the Türkic öŋ underlies “one” and all
its derivatives does not help the “IE” cause, it rather wrecks the whole “IE” paradigm by
repercussions of being caught unawares. The “IE etymology” stipulates “one” (A.-Sax. ane “one”)
as a base for once, ignoring that one lacks a time dimension needed for the notion of
a past point in time. In reality,
one is a semantic derivative of a base notion “front, front side of smth.”, and a component
in a base notion “front” that comprises 8 semantic clusters, each with its own trail of meanings.
Thus, the base cluster (No. 1) “front” carries 9 meanings, i.e. 1.1. front; 1.2. front side; 1.3.
what is ahead; 1.4. front as first of smth.; 1.5. ahead, forward; 1.6. facade; 1.7. plaza, open
space; 1.8. space in front of smth.; 1.9. smth. in opposite direction. The No 1.4, “first of smth.”,
is not a number, it is a location. The notion “first, one” belongs to a cluster No 3 with 4
meanings, i.e. 3.1. beginning; 3.2. initial, first; 3.3. before, long ago (=once); 3.4. what was
before. The No 3.2 “initial, first”, is a location and time, it is a number, a generic cardinal 1
“one, first”, a precursor of cardinals 2, 3, and so on. The level of the formed notions points to
the timing and horizons of their conception. The Türkic origin is supported by two additional
independent counts of evidence. A secondary meaning of öŋ (postpos.) “before, in front”
became a base for the Goth. ana (prep.) “on, upon, over (on)”, A.-Sax. an (prep.)
“on”, OHG.
ana (prep.) “on”, attesting to a paradigmatic transfer (i.e. transfer of two independent
meanings of the same word). Also, a secondary meaning of eŋ, yaŋ “front, face” (eŋäk,
yaŋaq) became a base for the Goth. ana-siuns “visible” (lit. “seen front”), Anglo-Sax
an-sien “face” (lit. “seen front”), attesting to a second and separate paradigmatic transfer of
two independent meanings of the same word. Thus, we observe totally unrelated to the notion of
once
multi-faceted paradigmatic transfers of a complex of three meanings expressed by two sibling words (öŋ
and eŋ). It is apparent that the modern form once had conflated three incompatible
independent notions of “on one occasion”, “as soon as”, and “at a previous time”, each one with its
own etymological history. The etymology of “one occasion” and “soon” must be traced separately from
the “previously”. In a short period since 1200-1300 AD, the spellings and pronunciations have
changed, confusing undiscerning “IE” linguists equipped only with a pre-packaged recipe looking for a
problem. Considering at least 4,000 years of independent development and the traversed distances,
and that the word must have been in daily use in reciting old legends, the semantic and phonetic
match with the Türkic synonyms is as perfect as it gets. See on 1, on 2, en-.
14
English over (adv., adj., prep., n., prefix) “above, excess, ultra-, super-” (Sw N/A, F118, 0.15%) ~
Türkic up-, op-, ob- (v.) “up, rise, go up”.
The notions “over” (adv.) and “above” (adv.) came from a single common source. They are close
semantically and phonetically. It is a tomeito vs. tomato case. Parallelism of the
o ~ u and p/b plus the Gmc. f/v/w alternations in the root served as a basis for
slight semantic differentiation in individual Türkic languages and their Eurasian heritage. The
Türkic verbal stem reached us in a number of verbal conjugations and derivatives: infinitive
deverbal verb opla- “rise up (to attack)”, passive opul- “upped”, deverbal noun opu
“upsurge”, etc.
A most salient expression of up- from the days of the animal freight horsepower is a command
to get up and move on, cited for the 11th c. Khakas and the Middle Age England (17th c.). A linguist
would have to make a successful effort to miss the connection between the base root and a host of
forms and derivatives. Cognates corroborate a parity of terms. Cognates: A.-Sax. 1.
up, uppe, ufa, 2. ofer, ofor, yfera, yferra, 3. ufane, ufon, ufan, OSax.
obar, OFris. over, Fris. boppe “above”, Dan. øverst “over”, over
“above”, Du. opper “above”, ONorse yfir, Norse
ovenfor, Sw. ovan, ovanför “above” (not “over”), över “over”, OHG ubar,
Gmn. über, Goth. ufar “over, above”, Icl. yfir “over”, ofan “above”;
Latv. virs, pari, par, Lith. virš, viršuje; Arm. verin (Վերին);
Gujarati upara; Fin. piriste; all “over” except as noted. The A.-Sax. Group 1. has no
suffix, Group 2. has Türkic caus. suffix -ar, Group 3. has Türkic (and now also Gmc.) verbal
suffix -en, all internalized, transparent and apparent. Semantics randomly jumps between
“over” and “above”. Distribution: From Atlantic to Pacific, extending across Eurasia and
across linguistic families. A myopic “IE etymology” comes up with ornate solutions for a
non-existent problem. It asserts a faux “proto-history” with faux “PGmc. proto-form” *uberi
(?) and faux “PGmc. proto-word” *uber “over”, a faux “PIE proto-root” *uper “over” and
a faux “PIE proto-word” *uper “a comparative form of *upo”, plus “PGmc. proto-word”
*bufan- as a compound of a be “by” = “near, in, by, during, about” and a “PGmc.
proto-word” *ufan- “under” from a faux “PIE proto-root” *upo “under” which in some
loving eyes turns miraculously fr. a dubious “up from under” into “over”. A pile of asterisked
nonsense is asserted against an overwhelming mass of attested lexemes traceable from a root to
derivatives. Attempts to reinvent a reality infringe not only on philology, but also on a history of
relevant populations. To create a myth, “IE etymology” also confuses semantically unrelated
directional prefixes/prepositions with the A.-Sax. deverbal adverb up, uppe “up, upward”: Gk.
epi “at, near”, its Lat. allophone ob ditto, Gk. opi- “behind”, Oscan op,
Lith. ap- “about, near”; OCS ob “on”, Skt. api “also, besides”, Av. aipi
“also, to, toward”, Hittite appizzis “younger” i.e. supposedly “(those) behind”. Those
homophones are confused with the cognates of the Gmc. allophones, the OSax., OFris., up “up,
upward”, ONorse upp, Dan., Du. op, OHG uf, Gmn. auf “up”, Goth. iup
“up, upward”, uf “on, upon”, OHG oba, Gmn. ob “over, above, on, upon” for an
upward move or position. The apotheosis of the confusion comes when an upward motion is derived from
the faux “PIE root” *upo “under” with diametrically opposite semantics. Scholastic wiles
result from loose criteria and selective sampling. Much of the confusion is brought upon by the
widely dispersed phonetics. Words, diverged by different host vernaculars and independent
development, reconvene in a new milieu, bearing close semantics but widely differing forms, Cf.
ofer/ufa/yfera/up. Typically, some of the divergent forms stabilize by their semantic shade,
grammar function, and expanding utility. The A.-Sax. ofer, ofor, an oddball form within the
Gmc. languages, provides a shining example of such a path. In the Clark-Hall 2011, Anglo-Saxon
Dictionary (about 20,000 words) they occupy 4 pages of continuous listings numbering more than
350 entries, or above 1.75% of the total dictionary material. Few of these derivatives have survived
into Eng., Cf. oferaet “overeat”, ofercuman “overcome”, etc. The ofer/ofor
forms, compared with the distinct yfir, allow to visualize a demographic relationship of the
contributing populations: the form yf-, with the initial semi-consonant, appears to carry a
linguistic imprint of the Ogur languages. Its modest proportion points to a minor influence of the
candidate Ogur populace in the original Anglo-Saxon composition formed long before the advent of the
Ogur Huns in the 4th c. AD. Two other Türkic words are similar to up-, one is a:ğ-
“rise, climb, ascend” and the other is a:š- “cross over” without implication of rising. The
A.-Sax. ofer is a reflex of a Türkic causative form, synonymous with the base form
up-/op-/ob- with -f-, like a homophonic form ubak/ufak “small”. The A.-Sax. -f-
forms ofra-, ofran- are concordant with the records on the A.-Sax. pronunciation, Cf.
contrasting Gmc. forms. The presence of an A.-Sax. completely unrelated homonymous word
ofer “boar”, of the native European origin attests that the ofer “over” is a
homophonic non-native word. A semantically identical form ver- and its allophones are a
version of the ofer, over, yfir with elided initial vowel or semi-vowel, Cf. Arm, Latv. and
Lith. forms vs. ONorse and A.-Sax.
yfera. A review of the real and claimed cognates spotlights the ancient folk's and the
modern confusion in numerous aspects starting with notional and overlapping semantics and ending
with origins and conflations. The semantic overlap of the forms ofer, ofor and their siblings
with the forms abufan, bofan, bufan and their siblings variously expressing the same notions
“over” and “above”, and their phonetic similarity attest to their common origin ascending to the
same Türkic verbal notion up-, op-, ob- “up, rise, go up”. That observation is further
supported by the similarity in the wide phonetic dispersions and limits in geographical/ethnic
localizations. In spite of the clearly observable overlap, parallelism, and similarity, the confused
“IE etymology” ascribed different origin and different “PG” and “PIE” roots. Those are respectively
*uberi, *uper “over”, and super-confused “PG” compound of *ufan- “over/high” imagined
with a prefix a- “on” and a prefix be- “by” to arrive at abufan “above”. A
concocted “PIE proto-word” is absent. Such mechanistic wiles are unsustainable. Afterword: A
related Türkic bava, baba (n.) “upper point, top” offers a real and viable alternative for
the origin of the “above”. Without strained equilibristics, it suggests a noun notion “top” with a
verbal notion “up, upward”, i.e. a typical Türkic emphatic pleonasm. Tautology is a common event in
linguistic amalgamation (cf. shagreen leather, whole gamut, etc.). The terms above, over, and
papa, baba are intrinsically connected. Internalized into the European syntax as bava
with an action prefix
a- “on” (Cf. alive, asleep, aback, afoot, etc), it is semantically identical with the action
notion “above”. Due to consistent overlapping, the phonetic connection with the papa/baba is
striking: statutorily, papa/baba relays the very same semantics of “upper, above, top”, an
equivalent of the Gmc. über. Of the two etymological scenarios, one for both over and
above being expressions of up-, op-, ob-, and the second for above deriving
separately from bava, baba, the evidence tends to lean in favor of the first scenario. The
second scenario, due to the paucity of the vestigial evidence, suggest a reborrowing from the Corded
Ware vernaculars back into the Türkic milieu. G. Clauson (Clauson EDT) cites 40 instances of
reverse reborrowing of Turkisms back into Türkic. In this hypothetical case the bava “father,
upper” returned with a narrowed sense of “upper” as opposed to baba “father”. Tracing of the
word
upon would likely lead to the same source, directly and without a need to appeal to a compound
up+on or similar machination: the on is a suffix similar to the suffix -er in
over. A common origin of the Eng. and Türkic lexicon is evinced by the paradigmatic transfer of
the semantically kindred quartet above, over, high, and papa, an indelible
testament to a common origin. See above, gamut, leather, papa, skin.
15
English quite (adv., interj. emph.) “positive degree, extent, reality” (Sw N/A, F538, 0.02%) ~
Türkic ked, keδ, gey, key (emphatic particle) “very, quite (good)”, qudur “very, over” (Chuv.), Cf.
“good”, “couth”.
No sane “IE” or any other etymology whatsoever, not even a standard refrain “of unknown origin”. In
contrast, albeit its allophone “good” is IE-rated as “a word of uncertain etymology”, it is supplied
with canny “IE reconstructions”. The Eng. quite is an etymological mystery, confused with an
unrelated and late MLat. sleepy homophone quietus “quiet, calm” with an opposite semantics.
Both quite and ked serve to emphatically qualify nouns, verbs and clauses, they are
incipient for extremely good or exceptional degree of being positive and above an average. The form
ked also has a few homophones, two of them surfaced in English, Cf. ked, keds (to shoe,
shoes, sheepticks). Quite is quite an oddball in the “IE” Europe: 28 out of 43 languages (65%)
use their own native words, the other 15 (35%) languages use 5 different words with no domination.
Cognates: A.-Sax. cuð “excellent, noted, famous”, cost, ceosan “excellent”,
uncuð “lacking”, OFris., OSax. god “good”, ONorse goðr, MDu. goed, OHG
guot, Gmn. gut “good”, Goth. godei “goodness, virtue”, goþs “good”; Sl.
(Rus.) godnyi (годный) “suitable”. Distribution: spans Eurasia with an European Gmc.
isle. Besides incongruent semantics, q.v., an “IE etymology” came up with a MLat. word as an ancestor
of the millennium older A.-Sax. and Goth. cognates. For a cognate “good” it produced a faux “PG
proto-word”
*goda- “fitting, suitable”, and “PIE proto-words” *ghedh- “unite, associated,
suitable” and *gno- “know”. Allusions to Anglo-Norman, Spanish, and French are semantically
no better. With an attested and widely spread Türkic harbinger there is no need for incoherent
pseudo-scholarly fantasies. Beyond contempt for a semantic incongruity stands a suggestion of a
connection with a phonetically resembling but semantically unrelated quit “cease, stop, clear
of something” and the like homophones. G. Clauson cites a phrase that sounds reasonably close in
both languages: bu: key dür “be quite good”, lit. “be quite durable, reliable, strong”
(Clauson EDT 700). There, the ked and key are allophones, with -d > -y
regular transition in Türkic languages. A Türkic inheritance is impeccable. The trio of sibling
derivatives “quite”, “good”, and “couth” (+ uncouth) constitutes a case of paradigmatic transfer
attesting to an origin from a Türkic phylum. See be, couth, durable, good.
16
English so (adv. emph.) “such, to such degree” (Sw N/A, F32, 0.64%) ~ Türkic ӧš-, os-, aša- (emph.
adv.) “(degree) excessively, very”.
Ultimately they ascend to a base notion “to grow” originally concerning plants, with extended prime
semantics “increase” “multiply”; “rise”; “swell”; “accustom, get used”. Further semantic derivatives
of ӧš-/os- are ӧša- “so, thus, such”, “this way”, “that”, “that one (mentioned)”, “as,
like, similar, resembling, compatible”. A unison of ӧš- and so may be coincidental,
but prospect of chance coinciding vs. chances of habitual aphesis are despairingly small. The basic
form ӧš- grew into the A.-Sax. swa with elided unpronounceable ӧ and a rich
throve of meanings carried on from their Türkic ancestors. Among further semantic offshoots is a
noun ӧsüm formed with suffix -(a)m/-äm to denote a degree, an abstract noun, or object
and result. It grew to express Eng. “same” and “some”, Cf. gleam/glitter/Helios < Türkic yal-
“shine”, seam/sew < Türkic sok-, suq- “sew”, see same, some.
The prosthetic g- (gleam) and h- (Helios) point to Oguzic articulation with an initial
consonant/semi-consonant. In applications, the emphatic ӧš-/oš- fused with demonstrative
pronouns bu and ol: ošbu “this”, ošol “that”. The
first is a pattern for the A.-Sax. swa “so” with š and b pronounced s
and w
respectively, peculiar to the E. European and Gmc. articulations. A form eš-, phonetically
nearly identical with ӧš-, is held as an independent lexeme.
Its semantics denotes “same, the same”. A form ӧz, phonetically nearly identical with ӧš-,
is also held as an independent lexeme. It has a meaning of a personal pronoun “self, own”, echoing
the demonstrative pronouns of the ӧš- “that”, “that one”, “same” and “some”.
They signal that they may have originated and diverged from a single lexeme. The Eng. pair so
and as are allophonic twins, forms of the same verb oš-, they respond to a “how
(degree)?” and a “how (like what)?” respectively. They are easily compounded or conflated, and
fuzzily used, Cf. “so as”, “just so”, “just as”. The dispersion of the A.-Sax. spellings and
semantics attests to vague emphatic notions open for producing derivational innovations and
scholarly confusions. Reflexes of the A.-Sax. dispersion are still notable in the modern Eng., with
about 13 distinct functions and meanings listed. Cognates: A.-Sax. swa, swæ, sua,
se, seo, selfe “in this way, so as, consequently, just as”, OSax., MDu., OHG so, ONorse
sva, Norw. Nynorsk so, Dan. saa, sa “so”, Sw. sa, OFris. sa, WFris.
sa “so”, Du. zo, LGmn. so “so”, Gmn. so, sehr,; all “so”, Goth. swa,
-þwa “as, like, such”; Ir. sin “that”, Gael. sin “that”, Welsh cyn “so”,
Scots sae “so”; Rus. aj (аж) “so (much)”; OLat. suad “so”, Rum. asha!
“so!”; Gk. hos “as, like, such”; Alb. sa “how much, so, as”; Hindi accha (adj.)
“(so) good”; Urdu so (سو) “hence”.
Relevance of some cited “cognates” needs to be verified. Distribution: Extends fr. Albion to
Mong. border. European distribution is confined to the Gmc. branch with few excurses, demonstrating
its “guest” status and non-IE provenance. Instead of explaining traceable etymological process, an
“IE etymology” conjectures an imaginary phonetic proto-form with indigestible semantic mix. Among
them are a faux “PGmc. proto-forms” *swa, swe “so”, and faux “PIE proto-forms” *swo- *swe
“so” (“PIE reflexive pronominal stem”), i.e. imaginary calques of the attested ӧš-, os-. The
Gk. form hos, with a prosthetic aspirate, synonymous with os- and “so” corroborate the
original form os-. The proposed cognate
selfe stands out from the norm, likely it is an erroneous translation or interpretation as a
reflex of the form ӧs-, ӧš-. A strong presence in the Celtic languages points to its
existence in the Türkic linguistic milieu of the N. Pontic, at least with inchoate semantics, prior
to the Celtic Kurgans' departure on a circum-Mediterranean voyage from the Eastern Europe to Iberia
ca. 5th-4th mill. BC. A colloquial interjection in the native Türkic form is preserved in the
Rumanian ot asha! “like this!, like so!”. The Hindi word parallels numerous other Turkisms:
grhas “house”, ghira “encircle”, sari “wrap”. Its presence in the original Hindi,
if accurate, points to its existence on the European scene prior to the Indo-Aryan migration to the
Indian subcontinent ca. 2000 BC. Functionally, the adv. so/aša (asha) is mirrored in the
ubiquitous Christian religious term amen “like this!, like so!, so be it!” of the Türkic stem
amin with the same semantics, see amen. The eidetically close semantics and phonetics,
concordance with peculiarities of the Gmc. articulations, and an absence of credible alternatives
attest to a common origin from the Türkic linguistic milieu. Carryover of the semantic and phonetic
components as a process of paradigmatic transfer attests to the origin from the Türkic phylum. See
amen, as, gird, same, sari, some.
17
English until (prep., conj.) “up to a time” (Sw N/A, F326, 0.04%) ~ Türkic anta, antada “till that”
(adv., postpos.).
No “IE” origin, no realistic “IE” or related etymology. The status is partially but crisply formulated
by the citations from EDTL v. 1, 148, 149, 456: 1. “Along with
an in a demonstrative-spatial sense some Türkic languages use a palatal parallel en...
as a basis for... əne, əнə and so on...” (148); 2. “(With the forms an, ana) is
completely homogeneous Mong. form ene as a demonstrative pron. “this”, “he”, “she”, “it”...,
or “this”, “this one”” (148). 3. “...Finnish... etta “this”... Türkic inčä “so””
(149); 4. “...anarï, aŋrï “to there”” (157); 5. “The adverb anda
coincides with similar forms in other languages with a wide distribution area. Compare “IE” an indicative
particle “there”, “on the other hand”, OPers. and “here”, Goth. an “so as”, “and so”…;
Av. antar, OPers.
antar “inside”, “between”…; adverb anda “in that”, “between this”, “under this” -
partly answering to a question “where?”, occasionally to a question “where to?”, “under”, “between”;
in a Hittite language anta “there”, “to that”… Compare andai, andan” (456). Under “IE” paradigm, the attribution is rated as a convergence of Türkic, Mong, Tungus, Finno-Ugrian, Korean,
and “IE” lexical roots (EDTL v. 1, 149). The convergence claim is ridiculous. Reality attests to a
prime root, its numerous derivatives, and a trail of loanwords in numerous unrelated languages.
Reality suggests that words are borrowed as much as utensils, starting from stone implements and
reaching today's rocketry. An oldest attestation comes from 16th c. BC Hittite in a derivative form
anta “there” composed of a demonstrative pronoun root an “that (object)” and a
directional suffix -ta. Unless Hittites spoke Türkic, morphologically mature words are
loanwords. Hittite has enough Turkisms to attest its Türkic nature, some of it myopically classed by
“IE” enthusiasts as “IE” lexis just because some Hittite words were carried to some European languages:
akwa- “drink”, ammuk “me”, hanti “opposite”, huwapp- “evil”, ko
“this”, nash “us”, genu “knee”, kir “heart”, pahhur “fire”,
mekkish “great, large”, mall(anzi) “(they) grind”, para “outside of”,
sak(ah)hi (v.) “know”, shakiya- “declare”, uk “I, me”, wesh “we”, and more
(examples plucked from present work). The anlaut an is a demonstrative pronoun, vaguely
translated as “look there, over there, that, that one, here, there, look here”. The part til
corresponds to a Türkic directional suffix -ta, Cf. Sl. do (до) “till, before, up to”,
Eng. “to (the end), till (finished)”. Morphology of antada: tada is a double locative
in respect to time and place of the adverb “then”, a form of ol “that”, Cf. antın, andın
“from there”. A.-Sax. had 17 ways to say “until”, of them only one surely and one possibly ascend to
the Türkic words that survived to modern Eng. The others, originally native, sunk into an abyss of
time, but may have survived elsewhere. A best surviving European form is a native Sl./Old Europe
directional prep. do-, synonymous with Eng. to /tu, too/ and Du. tot. Sl.
passed on its word to Alb. and Ir.; one way or another, they all are patterned after a Türkic
demonstrative an- with directional ta-. There is no Pan-European or a common “IE”
term. European majority are 21 languages that use their own 14 native terms. Cognates:
A.-Sax.
hwonne (< Tr. ane), ðenden (adv.) “until” (< ane-), til
(Northumbrian) “to” (locative), OFris. til “to, til”, Sw. intill, Dan. indtil, til,
ONorse til “to, until”, Gmn. zu “to” (< tu, du < ta), Goth. und “unto,
until, up to” (< anta), unte “until” (< anta), (f)ande “until, until
that” (prosthetic f-); Sl. togda (тогда) “then” (-da =directional); Ir. ann
“there”, Scots an sin “there”; Hu. amig “until”; Fin. etta “that”; OPers., LAv.
ana “that”; Bur. ene “this”, ede “those”; Tung. ädu “here”; Kor. i
“this”; Hittite
andan “to there” (=Tr. “from there” ~ “until”); + a host of Türkic inflected forms.
Distribution: From Atlantic to Pacific. Crosses linguistic barriers. Forces to note overlap
between Türkic and numerous Eurasian languages, including members of the “PIE paradigm”. Undercuts a
dogma of the “PIE” paradigm in temporal, geographical, and ethnological aspects. Raises questions of
where, when, by whom, and a scientific visibility issue. In Europe, the relevant lexical components
are oddball “guests” incompatible with local lingoes. The “IE etymology” is totally incoherent. For
the attested demonstrative pronoun an “there, that” seeded across entire Eurasia it
promulgates a faux “PGmc. proto-form” *und-, a version of attested anta, and a faux
“PIE proto-form” *nti- from a faux “PIE proto-root” *ant- “front, forehead”, a clone
of attested anta. It asserts that the “two syllables (i.e an and til) have the
same meaning”, i.e. that the an “there, that” and the directional suffix -ta ~ til
together form a dysfunctional tautological compound. It cites the attested OHG biaz, Gmn.
bis “until” as a calque of another dysfunctional tautological compound of a OHG bi “by,
at, to” + zu “to”. Thus, it asserts that one nonsense is buttressed by another indigestible
nonsense. In reality, the biaz, bis “by to”, i.e. “on a way to” makes as much sense as the
synonymous Türkic anta “on a way to, till that”. English etymology offers a dubious
interpretation of un- “as far as, up to” instead of a simple demonstrative “there, that”
combined with a directional -ta > til “to” forming a notion “that to (tomorrow, Monday,
arrival, i.e. a target of action)”. A faulty interpretation is a misinterpretation. Confusing the
notions “this, that” with an “up to” i.e. “busy, occupied with, capable of” with a notion “as far
as” is utterly uncouth. In a presence of attested parental lexicon that objective to create an
alternate reality is unsustainable: the language of the invading Gothic nomads stands in stark
contrast with the preexisting European vs. Near Eastern lingoes. Aside from the unsuitable Goth.
tils and the Gmn. ziel “end, limit, point aimed at, goal” (locative), all cognates offer
allophonic variations of antada and a contracted part till. Uniformity of the
contraction till points to its early Gmc. internalization. The origin of the final -l
lays in the Türkic adjective and adverb-forming suffix -l: anta > antal >> antil, intill, indtil,
until “then”. There is no need to appeal to exotic inventions and figments. Directly or
indirectly, the enduring Eurasian source is indisputably Türkic.
18
English yet (adv., conj.) “til (now), withal, even” (Sw N/A, F332, 0.04%) ~ Türkic yet- (v.)
“reaching (smth.), leading (to)”.
Etymologically rated “of unknown origin, (but) perhaps...” with “perhaps” leading yet to unstoppable
“IE” figments, v.i. Semantics of the word denotes “in process (from) to”. A horse domestication (ca.
4th mill. BC) lent semantic accent fr. generic to specific “leading the horse(s)”. A late derivative
notion “pour” relates to metallurgy. The EDT cites the matching Türkic semantics: “sufficient”,
“insufficient”, “catch up”, “reach”, “lead”, “overtake”, “extend”, “come”, “arrive”, “join”, “fasten
on”, all variations of the same “lead to, reach a” in the form yet-. A fuzziness of the
Türkic notion, carried over to Eng. and other languages, allowed to develop a huge trail of semantic
extensions, Cf. “reach, be sufficient, grab, catch up, reach an age, live, reach adulthood,
maturity, comprehend, understand, advance, come (time, season), reach maturity, ripen, grow...”, and
derivatives, for example yetik formed with a suffix -k: “attained, sufficient, came of
age, ripen, experienced, informed, knowledgeable, connoisseur, far-sighted, wise, developed, nimble,
dexterous, grown, overgrown...”, and later “pour”. Examples illustrate a penetrating depth of the
word, its role in the language, and subsequent extensions. In A.-Sax. and Eng., that role is
extensive, but incompatibly humbler. A doublet form of yet is er- “reaching” with its
own set of derivatives like eriš “reach, comprehend, mature”, etc. A verbal yeŋ (with
nasal ŋ) “win, overcome” is semantically so close to yet as to suggest a root ye-
modified with deverbal active, causative suffix -t and a subject, definition suffix -ŋ.
In Eng., articulation of g as /j/ is routine, hence the spellings get-, jet-, yet-
could all have produced /jet/ of the basic Türkic form. Alternate spellings could include dge-,
-ge, d. An Eng. yon bridges the notions yet and yeŋ. Of 44 European
languages, the word yet, with all its semantic wealth, is marginal; it is used by only by 3
(7%) languages (Eng., Fris. Tatar), attesting to its “guest” status in Europe. A Sl. Old Europe
language predominates with allophonic likes of eshcho “yet” with 11 (25%) languages. The
remaining 30 (68%) languages use 16 of their own terms. There is no Pan-European or a common “IE”
term.
Cognates: A.-Sax. giete, gieti, giety, gieta, gita, get, git, gyt, gyta, giet, giety,
gieta, gita, get, git, gyt, gyta, giet “as yet, even”, get, gieta “till now, thus far,
earlier, at last, also”, “yet, still, besides, further, again, moreover”, geotan, gietan
“flow, pour”, OFris. ieta, WFris. jit, jitte “scatter, shed, pour”, Dan. endnu,
Du. ooit “ever”, gieten “pour, cast, mould”, Sw ända, gjuta “pour,
cast”, Norse enda, Goth. ith (iþ), MHG ieuzo, Gmn. jetzt “now”,
gießen “pour, cast, mould”; Ir.
ach, Scots yat “yet, pour”, Welsh eto; Sl. (Ru., Czech, etc.) escho/ješte
(еще/ješte), Lat. sed “but”, nondum “not yet”; Fin., Latv., Est. vel, vielä;
Av. aiti, Gk. eti (ετι); Mong. od- (од-), židkü- “strive, strain”; Kor. ajig
(아직); all presumably “yet” unless noted otherwise. Distribution:
From Atlantic to Pacific, across Eurasian linguistic barriers. A short form and numerous allophones
induced an “IE” etymological confusion that connected unrelated phonetic and semantic expressions for
various pronominals and conjunctions, with no credible etymology. On top of “unknown origin”, among
“IE” figments are a faux “PGmc. proto-form” *juta “yet?”, “PWGmc. proto-form” *geutan,
“PGmc. proto-form” *geutana “flow, pour”, “PGmc. proto-form” *getana “get” (see get),
and a faux “PIE proto-form” *ghewd- “to”, and more of the same. Somehow there came notions
*hyew-,*hoyu “long time” and a faux“ PGmc. proto-form” *ta “to, towards” fr. a faux “PIE
proto-form” *do and an exact mirror of a Türkic attested directional suffix -ta “to,
towards”. All that unattested and/or unrelated mass of nonsense is not needed, it can't substitute
for the real, well-documented forms and meanings. A consistency of the Celtic forms with the later
forms suggests that the word originated at a dawn of a horse husbandry, before 4000-3000 BC. Baltic
forms for yet are a calque of the Türkic semantics, Latv. vel, Est. veel, from
the verbal root for “lead”. The MHG form illustrates a transition of yet (Tr.) ~ ieta
(Fris.) to escho (Sl.) and ieuzo (Gmc.), probably via separate paths. The forms eti
(Gk.) and aiti (Av.) suggest independent sources. A variety of Gmc. forms indicate numerous
historical paths. Scandinavian forms uniformly have a prosthetic inlaut -n-. The Goth. ith
points to an interdental consonant in the source form, rendered with -t, -d, and -z in
a later diverse phonetics. The interdental consonant is also consistent with the Gmc. regular
transition -t-/-d- > -z-. The Eng. word preserved a full semantic spectrum of the Türkic
original, i.e. comparison (“not done yet”), contrariness (“nice yet affordable”, “shut yet
leaking”), sufficiency (“light yet filling”), superlativity (“minimal results yet”), process (“not
yet coming”), timing (unspecified future “results still coming yet”, indefinite “events yet to
come”), simultaneity (“nice yet expensive)”, repetition (“yet again”). They all are reflexes of the
base notion in space and time, “lead to, reach a”. There is no room for “PG” or “PIE” material. A
myopic “IE etymology” never extended beyond its minute “IE” interest's horizons. The unique and
eidetic phonetics, invariable notion of transition, and parallelism in semantic applications make
this short word one of prime cases of a lexical continuity across millennia and entire continent.
The word indisputably originated in, and was disseminated by, numerous Türkic lexical streams.
19
English yuck, ugh (excl.) “expression of disgust” ~ Türkic ye:k (yek) (n., adj.) “repugnant,
unpleasant, vile, bad”, also “glutton, (constantly) devouring”, also “demon, devil”.
Ultimately fr. a verb ye- “eat”, also lit. “devour (food, people)”, a prototype of a
legendary ubyr “vampire”, see vampire. The notion “disgust” is an attribute of the
notion “eat”, extended as a generic term to denote many emotional shades: “disgusting, despicable,
bad, hated, evil”, and on to mystical “evil spirit, Šeytan, Šaytan” ~ Demon, Satan, etc. Its more
expressive and apparently much later form is yakša “demon” lit. “gluttonous, desirous to
englut”. Cognates: For a cognate line “eat” see eat; Du. jak, bah “disgusting”,
Dan., Lux. yuck, Scots, Ir. yuc, Welsh iwch; Fr. (be)urk; Lith. juk;
Skt. ye:k “demon” lit. Tr. “devourer”; Mong. žigsi- “disgusted, scared, hate, not to
love” (denoun verbs), žekere- “be, become cold (attitude)”, žikir- “shiver from cold”,
jikip- “cold, scare shiver, tremble with horror”. A paucity of “disgust”-type cognates is
predicated by myopic targeting of research, and obsolete efforts targeted to jam reality into
preconceived frames like an “Altaic family”.
Distribution: From Atlantic to the Far East, across linguistic barriers. No claimed “IE” etymology, not even “of uncertain origin”. The stray suggestions of “echoic origin” and the like are
not too enlightening; they boil down to a veiled “we have no clue”, and that's sincere. Minutest
presence in European languages, but see eat, v.s.; an obvious “guest” from a “surprise”
linguistic family. Probably every language, starting from a baby age, had its own excl. for “yuck”.
That made the excl. terms deeply ingrained, changeable only with major ethnical cataclysms. That
paints a picture of how a bulk of Gmc. languages adopted a Türkic term as a baby talk. Unlike the
western yuk, yuck, the Skt. Buddhist terms (< Tr.) are roughly datable to a period of 6th c.
BC to 5th c. AD, see Table 2b. In recent English the adjectival “devil” also expressed
notions of “bad, vile, unpleasant, repugnant”, a relict of once popular beliefs. A variety of
spellings and reasons for disgust attest that the word survived on a level of a kitchen talk, deep
inside the folk speech and way under radars of the grammarians. As a notion “Demon, Satan”, the word
belongs to a host of religious terms subsumed or adopted with the advent of the Christianity: the
Tengriist faith syncretized various beliefs of various ethnicities, keeping them in the background
of ongoing religious beliefs. The ample semantic raster produced by the root inextricably attests to
an origin from a Türkic lexical phylum. See eat, kick, sin, Table 2b, Torah, vampire.
Replaced with amendments version 9/21/2022
English as (adv.) “like, to the same degree” (Sw N/A,
F71, 0.26%) ~ Türkic as-, aš-, (v.) “weigh (on scales)”, eš “similar, like (adj.)”.
The origin of the word is “to hang, suspend”, with uncounted semantic derivatives, one of which is
“to weigh”, with its own numerous derivatives, one of which is “equal” of a balance scale, equal
refers to a static equilibrium. The device, and its terminology, ascends to the Stone Age
technology. The form eš is likely an allophone of aš-, conflated with other meanings
of eš, it is an oddball in the prime semantics of the word eš. The notion “equal”, in
turn, expanded to the notions “unequal”, “greater”, “increase”, etc., leading to the terms of
comparison and appraisal. Socially, the term expanded to the meanings of “one’s equal”, “friend”,
“comrade”, etc. The number of candidate derivatives is mind-boggling, especially in trade relations:
assay, assess, asset, assimilate, assize, assort, assume, etc. A litmus test on the origin is the
use by the “IE etymology” of the faux “PIE proto-words” combined with the Lat. prefix ad- “to
(directional)” assimilated to a-/as-, or a claimed LLat. origin. Not surprisingly, some of
the “PIE proto-words” turn out to be identical with the real attested Türkic words. The Eng. pair
as and so are complementary semantic twins, they respond to a “how (like what)?” and a
“how (degree)?” respectively, they are easily compounded and conflated, Cf. “so as”, “just as”,
“just so”. Cognates: none listed. Supposition of equivalency with A.-Sax. alswa “quite so”,
Gmn. als “than” is patently wrong, since the
alswa is an A.-Sax. compound consisting of the A.-Sax. al, ael, eal, eall “all, every,
entire” + A.-Sax. se, seo, sua, swa, swae, swe, (sama, same, selfe). In that compound the
A.-Sax. al “all” is an allophone of the Türkic algu “all”, and the A.-Sax. swa
is an allophone of the Türkic oš “so”, see so. The “IE” fast one with alswa is a
case of an anti-etymology: instead of parsing a word into its components, it looks at one of its
compounds and subs an unrelated part for the examined word. The word alswa attests to
precisely that, it is a compound of two attested Türkic roots, with fuzzy semantics, phonetics, and
history on the Türkic side, and even fuzzier history on the Eng./IE side. The absence of the
European cognates attests to the word from a non-IE source being a “guest” in Europe and in the “IE” family. See so.
131
(Skip) English awhile (adv.) “undetermined short period between two events” ~ Türkic äwwäl (adv.) “at first, before, in the beginning” (adv.), “before, in front of” (postposition). Cognates: A.-Sax. hwile, hwil, OSax. hwil, OFris. hwile, OHG hwila, Goth. hveila, Gmn. Weile, all “space of time, while”. The Türkic phonetics is a little vague, since we do not know if the ancient phonetics had both -vv- and -w-, and the record has it both äwwäl (əwwəl) and ävväl (əvvəl); the Türkic semantics exactly matches the English usage, referring or alluding to a period between two events: event one - äwwäl - event two. The “IE etymology” has awhile as a derivative of while, via A.-Sax. ane hwile “(for) a while” (13th c.), and via an unattested PIE *qwi- “rest” connects it with notions of rest (Lat. quies, OGS pokoi (покой), ONorse hvila “bed”, hvild “rest" and joy (Av. shaitish, OPers. šiyatish “joy”), not serious propositions quite distant from the real semantics of the “time interval”. Such etymological equilibristic is obviously disingenuous. Since the word time is a form of the Türkic timin, the two separate notions of time and awhile always co-existed, and never needed to convert the word awhile into the word time. The form while (n., v.) is a natural oral contraction of the non-accented anlaut vowel, a derivative of the form awhile (adv.). See time.
English early (adv.) ~ Türkic er, ertä (adv.) “early, in the morning”, modern Oguz Turkish erken, ilk “early”. Ultimately ertä- comes fr. the verb ert- “pass”, in the sense that the night had passed, a deverbal verbal derivative of the er- “be, follow”, a precursor of the Eng. are, see are. The er also means “early”, the same as its twice-removed derivative ertä-.Both English and Türkic words are formed by the same agglutination mechanism, with different suffixes. The Eng. adverbial suffix -ly is a form of the Türkic adverbial suffix -la/lä. The root of both words is Türkic er or its allophone, the English adverbial suffix -ly is conveyed in Türkic with temporal locative suffix -tä (-ta/-tä/-da/-dä/-δa/-δä) “when early, at an early time, in the morning”, the suffix corresponds to the modern Oguz Turkish -ken/k. The Türkic er also means “morning” and “tomorrow”, possibly as a derivative of the notion erï- “disappear, dissipate (of night, darkness)”, Cf. Av. ayar “day”. That peculiarity is retained in the Gmn., where morgen also denotes “morning” and “tomorrow”. Cognates: A.-Sax. aerlice “early”, aerra, aerre aer, aeror, ere, erer “soon, before (in time)”, superlative aerest “earliest”, OSw., OFris., OHG er, Du. eer; Gmn. eher “earlier”, ONorse ar “early”, Goth. air “early”, airis “earlier”; Gk. eerios “at daybreak”; Av. ayar “day”; Mong. erte “early”, Manchu erde “early”, erin “time”, Nanai erin, erku “time”, Oroch eru, еu “time”; NKor. ir, Kor. il 일 “early”, ilda일다 “be early” (il< ir); erte expressing the same notions is widely spread in Fennic languages. The A.-Sax. intricate grammatical development and nearly exclusive Gmc. distribution in Europe attest to the long history of internalization, probably from the the Corded Ware culture period. The standing “etymology” comes in two flavors, one only shyly recounts Gmc. cognates without fibbing, the other bravely dreams up faux “proto-words”, “PG” *awiz and “PIE” h2ówis. The first is useless, the second is ridiculous given the dispersion from the Pacific to Atlantic and Arctic, and across numerous linguistic families. The perfect semantics and close phonetic correspondence leave no doubts about a Türkic origin. Borrowing of such basic word from a Gk. or Av. into Gmc., Manchu or Korean can be confidently excluded. See are.
English far (adv., adj., n.) “very distant, very much” ~ Türkic ıra:- (v.), jïraq, ïraq “far, distant, stay away”. Cognates: A.-Sax. feor, feorr, fi(e)ra, fyrra “far, remote, distant”, feornes “distance”, feorrung “removal, departure”, OSax. fer, OFris. fer, fir, ONorse fiarre, OHG ferro, fer, Goth. fairra “great distance, long ago”, Icl. fjar, OIr. ire “farther”; Lat. per “through”; Gk. pera (πέρα) “across, beyond”; Alb. pera “far”; Arm. herru (հեռու), Gujarati dura (દૂર), Skt. parah “farther, remote, ulterior”, Hitt. para “outside of” (16th c. BC or later). The line-up presents two sets, one with a prosthetic consonant recorded as f-/p-/h-/d-, and the other starting with a vowel and without prosthetic consonant. The peculiar Gujarati form is consistent with the historically known Ogur-type-speaking Ephthalite Gujars migrating to Malwa (8th c. AD), the area later named after them Gujarat, hence the peculiar prosthetic d-. The peculiar Arm. form is consistent with the flows of Ogur-type speaking nomadic Huns, Masguts (Masagetae), Kayi, Suvars, and the tribes known under sobriquets Agvan and Alban migrating to SW Caucasia in the first 3 centuries of our era. The remaining f-/p- prosthetic consonants are consistent with the N. Pontic area being a staging platform for “IE” languages' southward migration starting ca 2000 BC to the Indian subcontinent (Skt.) and Iranian plateau (Hitt.), Scythian migrations toward Jutland and Scandia, and connected Oguric Sarmats' migration to the north-central Europe in the last centuries BC (Gmc. languages). Of these migrations, the Scythians, Huns, and Ephthalites (Avesta's Turanians) tentatively had dominating R1a Y-DNA haplogroup, and the Sarmatian tribes had dominating R1b Y-DNA haplogroup. The OIr. form without a prosthetic consonant attests to the form in circulation in the N. Pontic area at the time of proto-Celtic departure in the 6th-5th mill. BC, and the Oguz Türkic form ıra:- also ascends to that time. The consistency of the allophonic forms and semantic precision attest to the common origin of the word and to its uninterrupted proliferation. The “IE” etymology, in contrast, offers a mind-boggling sequence of Proto-Germanic stand-alones arising from a Proto-IE stand-alones equipped with a universal word per loaded with an indiscriminate pile of semantic meanings: “forward”, “through”, “in front of”, “before”, “early”, “first”, “chief”, “toward”, “against”, “near”, “at”, “around”, and a wide range of other extended meanings only partially overlapping with the notion of “distant” except for asserted phonetic consonance. Given the pre-eminence afforded to the Lat. and Skt. underlying the postulated “IE” Family Tree model, the applicability of the Lat. cognate to the notion of “distant” in time and space is questionable, more likely it belongs to the “IE” semantic pile of indiscriminate “through”, “chief”, et al. The phonetic and semantic concordance attest to the Türkic origin, likely ascending to the Corded Ware period.
English gamut (n.) “complete extent or range” (adv.) ~ Türkic qamu, qamuɣ (adv.) “whole, altogether”. The best expression of the Eng. meaning of gamut is a tautological idiom “the whole gamut”, i.e. “the whole whole” that refers to any matter or affair except music. Türkic has an identical tautological idiom alqu qamaɣ “all gamut”. Ultimately a derivative of the verb qam-/kam- “put down, knock down, lower” that blossomed into numerous derivatives, ending with the Eng. gamut, come, common, commons, commodity, gamma, etc. Their cognates in Gmc. languages are very close: Dan. gamut, kom, commons, gamma, Du. gamma, kom, commons, Gmn. gamut, kommen, gemein, commons, gamma, etc. Qamuɣ is a guest in the MPers. adopted as hamag “all” but not found in other Iranic languages. The Lat. notion gamma, homophonous with the Gk. letter named after Semitic name for “camel”, somehow also came to stand for the notion omnis (entire). The word come, for example, ascends to the verbal derivative kamit- “fall, drop, come down”, and originally carried the notion “come down” directly connected with a notion “lower”. The concrete musical noun gamma is a late semantic extension (MLat.) in a figurative sense for the “entire musical scale or range” gamma ut, first recorded in the 1620s. The narrow professional term could not sire the ubiquitous notion “all, entire” in the whole Gmc. branch, it would have been adopted only as a specific musical trade term. The conventional anecdotal etymology links gamut with syllables in a Lat. hymn for St. John the Baptist's Day, a purely concrete musical derivative application fossilized in popular encyclopedias. In contrast, in English the word gamut developed into a spectrum of noun, adverb, and adjective applications. No “IE” cognates across the “IE” family, an obvious guest within the “IE” family. Since the synonymous triplet all, entire, and gamut correspond to the same source as a bundle, with all and entire attested in the A.-Sax., they constitute an authentic case of paradigmatic transfer from the Türkic milieu, see all for further details. The Türkic etymology fits perfectly semantically, phonetically, and in application. The gamut is not a loanword, it is a substrate word shared between the Gmc. branch and the Türkic family. The distribution of the stem kam- in Europe and across the Türkic Eurasian belt covers geographically, albeit not demographically, most of the Eurasia. The absence of the Celtic native forms postdates the origin of the semantic extension to after the Celtic departure from the Eastern Europe ca. 5th-4th mill. BC. The distribution, combined with etymological information on the original sources and final destinations, attests to diverse temporal and geographical paths of different synonyms. The grouping of the destinations enables visualization of different paths. See all, entire, omni-, total.
(Move-Skip)
English ha, hah, ha-ha (interj.) “guffaw” ~ Türkic qatur (ɣatur) (v.) “guffaw,
hijinks”. The population of the “OEurope” and the rest of the Europe in their numerous vernaculars
definitely had numerous expressions for “guffaw”, but the population replacement of the 4th mill. BC
by the horse-mounted Kurgan people wiped out and marginalized the previous European population,
together with their numerous vernaculars. For 2 millennia, many Türkic languages covered Europe,
spreading their lexicon and introducing new terminology that took hold across Europe. The Türkic
qatur/ɣatur, in whatever allophonic forms of the time, is found in most European languages: in
OE, Greek, Lat., OFr., Balt., Slavic, etc. The advent and spread of the “IE” languages to Europe in
the 1st mill. BC was a process of infiltration, it gradually absorbed and digested the Türkic lexis,
and brought to us remnants of the former common European lexicon, of which the
ha, hah, ha-ha
is one of the most prominent members.
132
(Move-Skip) English hey (hei, hai, ai, he, heh) (interj.) “call to get someone's attention, hello (greeting)” ~ Türkic ay (interj.) “call to get someone's attention”. Cognates: Lat. eho, Gk. eia, Sw., Norse, Icl., Dan., Du., Gmn. hei; Balt. (Lith.) ei, (Latv.) hey; Pol. hei; Hu hey; but Ir. hug. The “IE etymology” tends to confuse the Türkic cognates of ay “call for attention” and cognates of ay “cry of grief”, which are completely different in intonation and semantics; the “IE etymology” refers to natural expression, but that does not jibe with semantically identical calls with completely different phonetics, used by wide variety of the languages.
English how (adv.) “in what manner” (Swadesh 15, F60, 0.34%) ~ Türkic qala, qalai, qalï (ɣalï, ka:yu:) (adv.) “how”. The adverbial suffix -lï (Eng. -ly, Cf. light ~ lightly) points to the root qa-, which leads to numerous semantic precursors. A complex of forms of the kayu circle (kač, kačan, kah:, kalti:, ka:nı, ɣaltï, qalï, qaltï, xalï, etc.) ascend “to an earlier stage in the language when different suffixes were in use” (G. Clauson, ETD, 1972, 632), that allows to single out archaic forms and recognize them among various cognates. The form kayu (ka:yu:) is virtually indistinguishable from how phonetically and semantically. Cognates: OSax. hwo, OFris., MDu. hu, Du. hoe, Dan. hogyan, Gmn. wie, Goth. hvaiwa, Icl. hvernig “how”; Ir. conas; Latv. ka, Lith. kaip; Sl. kak (как); Romance como; Hu. hogyan; Taj. hel; transition from Romance/Türkic initial k-/q- to Gmc. voiced h- is the same as for Romance casa to Gmc. house. Ultimately all “IE” forms for how ascend to the allophones and variations of the Türkic qalï, with laryngeal initial consonant, still preserved in the Türkic and Ukrainian languages. With the attested Türkic qalï/ɣalï/ka:yu:, there is no need for the unattested Gmc. *hwo- and the unattested PIE *kwo-, it is absurd to reinvent a faux allophone when there is a series of attested forms. Notably, the form kayu: with alternative form xayu: “how” was recorded in Khakass (11th c.), adding to other Eng.-Khakass phonetical clones. The Türkic origin is beyond doubts.
English in (prep.) “toward the inside” (Sw N/A, F13, 1.15%) ~ Türkic in-/en- (v.) “descend, come down”, in/en (n.) “bottom, descent”. Ultimately fr. a noun i:n “lair, den” for an underground lair of a wild animal. That word has survived for millenniums from its first surfacing, Cf. Eng. inn “den, lodge”. The i- and e- forms (and a-/ä-/ə- forms) are eidetic, they had a parallel and overlapping existence, and produced differentiated crisscrossed derivatives. The notion “descend” has more than 15 semantic derivative clusters, some quite ludic like see a dream, achieve, leave, dusk, nightfall, etc. In addition, the verbal root in-/en- forms descending notions (ini/ene-), like parturiate, younger (brother, sister), young, etc. Those derivatives found a wide distribution in the Tungus-Manchu languages, attesting to fairly late (Zhou time, 2nd mill. BC) extensive marital connections with the Türkic ethnos. The Eng. in is a grammatically universal preposition, adverb, and adjective, with a wide spectrum of semantic meanings: inside, inward, within, incoming, happening, among, about, during, etc., basically a movement from outside to inside. The directional in, on, and at are notoriously confused in daily life, vernacularly adding to the semantic spectrum. Cognates: A.-Sax.in “in, to, for; into, upon, on, at, to, among (temporal); in, at, about, towards, during (purpose)”, (wicung) inn, “(guest)chamber”, OFris., Du., Gmn., Goth. in, ONorse i; OIr. in, Welsh yn-, OCS on-; Gk. en, Lat. in; Sl. (OCS) inde (инде) “in somewhere”, (Serb/Croat) indje (и̏ндjе), (Czech) jinde, (Pol.) indzie, all with leading semantics “in, into, toward inside”; Mong. enel (passive) “down and under, afflicted”; Manchu, Negidal, Orok, Nanai ina, Evenk ena, mostly “nephew”, with various other in-laws, and with a compliment of other related derivatives, like a “younger brother/sister of the husband”, related to the Türkic ini “junior”. A direct comparison of Eng. cognates is muddled, because similar phonetic forms are semantically conflated, any type of movement in any direction is thrown in the same phonetic pile without regard to its meaning. There is no “IE” sensible explanation for the origin of in. The ideas of the faux mechanical constructs “PIE proto-root” *en and/or “PG” *in “in” are not needed to simulate the attested Türkic originals. These falsehoods need to be rescinded as an abuse of science. That leaves no “IE” etymology, the word came from nowhere, both grammarians and curtailed-purview etymologists act as confused observers. A similar “IE” etymological cacophony surrounds the origin of on (prep.). The Türkic etymology offers semantic explanation for both in (prep.) and on (prep.), with further extensions to adv.s and adj.s. Both prepositions have clear and discrete semantic meanings, i.e. aiming to a lower/inside status vs. aiming to a higher status. The presence of the Old Celtic cognate suggests an existence of the word at the time of the Celtic departure from the N. Pontic ca 5000- 4000 BC, and may imply that the counterpart on also was in existence. The Gmc. convergence of the European cognates points to the Corded Ware hub as a source of the European internalization. A healthy half-dozen of the Eng. directional prepositions irrefutably lead their origin from the Türkic milieu. The Türkic origin is the only realistic outcome. See and, at, be, on 1, on 2, till (prep.), to.
English less (adj., adv.) “smaller comparative of adjectives and adverbs” (Sw N/A, F759 0.01%) ~ Türkic es- “smaller of comparative of adjectives and adverbs” (adv.). Ultimately fr. the root es- a depreciatory derivative “reduce, lessen, diminish”, Cf. eske “old, dilapidated”. Another aspect of the negative notion is “bad, evil, nefarious”, Cf. esiz “bad”. The origin of the notion apparently came from the process of winnowing, blowing off the chaff from the grain, reducing bad and keeping good. The same root is producing a contrasting notion of “healthy, flourishing”, Cf. esen “healthy”. The Eng. “less” is a comparative of “little”, but genetically is not connected with it. Like the Türkic es-, the A.-Sax. laes “less” is dubbing as leas “vain, worthless”, an evil of “false, faithless, untruthful, deceitful”. The bridge between the Türkic es “smaller” and Eng. less “smaller” is provided by the A.-Sax. essian “to waste away, blow away”, laesian (v.) with a native homonym “graze”. The prosthetic anlaut l- came about naturally under the influence of the A.-Sax. native lytel “little”, lytel/laes more logical than lytel/aes. Cognates: A.-Sax. laes (adv., n.), laessa (adj.), laest (superl.) “less”, lesu, lysu “evil, false”, essian “waste away”, OSw., OFris. les; Balt. (Lith.) liesas “thin”. The Balt. (Lith.) form preserved the original semantic of es-: “reduce”, from “scatter, winnow” by blowing. Near perfect phonetic correspondence and perfect semantic and grammatical correspondences. The prosthetic anlaut l- distinctly appears to be a dialectal Eastern European innovation. All preserved forms are confined exclusively to the Gmc. and neighboring languages. No credible “IE” cognates whatsoever. All of the suggested cognates, like the “PG proto-word” *laisizan (??), “PIE proto-word” *leis “small”, the attested ONorse hlass, hlaða “to stack” (Cf. Sl. kladka (кладка) “masonry”), lesa “read, collect, gather”, ODan. læsæ ditto, are either incredible uncorroborated faux mechanical imitations of the Gmc. cognates, or random phonetic resemblances incongruent with the notion “smaller”. In contrast, the Türkic original is attested, near perfect phonetically, perfect semantically, and is corroborated by the identical second meanings preserved in parallel in both vernaculars. Cognate distribution exclusively across the Gmc. and Balt. area points to the internalization within the Corded Ware period (3rd -2nd mill. BC), without spreading to the Aryan migrants to the southeast. The paradigmatic transfer of the phonetics and uniquely complimenting semantic meanings “reduce”, “evil”, and “blow” indelibly attest to the common genetic origin from the Türkic milieu.
(Skip) English 'd (contracted of would, or the would is an expansion of phonetical wud/ud) (v.) “conditional modal verb”~ Türkic 'yu, conditional suffix applied to nouns and pronouns. Cognates: A.-Sax. wolde, past tense of willan “to wish, desire, want”, ONorse vilja, OFris. willa, Du. willen, OHG wellann, Gmn. wollen, Goth. wiljan “to will, wish, desire”, Goth. waljan “to choose”; these are presumed cognates, since no set of linguistic “laws” other then individual “laws” designed specifically for individual words would predict regular phonetical change for a semantically contrasting word. Notably, the A.-Sax. dictionary does not have a conditional modal verb to express the conditional would, leaving room for speculative guesses as to how those folks expressed the conditional case; the closest are Du. zou, Nw., Sw. sku(lle), appearing as allophones of the 'yu with prosthetic consonant. The “IE etymology” stipulates that the English conditional suffix wud/ud is a derivative of the will “wish, desire, want” via A.-Sax. wolde, past tense of willan “to wish desire, want”, which suggests that prior to the Middle Ages the ancestors of the English language did not have a way to express a conditional proposition. That allegation appear to be impossible, considering the realities facing English ancestors in the previous millennia, and numerous languages they encountered prior to the Middle Ages. Semantically, functionally, morphologically, and phonetically the similarity of the Eng. 'd and Tr. 'yu is striking, the use of the Türkic conditional suffix 'yu is documented from 328AD to the present. Actually, the Hunnic phrase said at the capture of Luoyang in 328 in the future China, contains three English cognates: tili “tell, order”; tut “take, capture”; and 'yu “would, 'd”, like in “He would like” ~ “He'd like”; in English, the conditional would divorced the verb, and migrated to the noun/pronoun, while in Türkic it remained faithful to the verb, but both have that suffixal for 'yu “'ud ~ 'd”. The wud/ud/'d form is probably anscestral to the 'yu form, as is asserted for the phenomenon of consonant/-y- transition among the Türkic languages; the transition may be a result of the Türkic vernaculars spreading to the east and amalgamating with the eastern languages they were encountering at each migration cycle. In English, prior to being apostrophized, the conditional provision was expressed as a suffix, integral with the stem, a la sheele for “she will”, and without any form of the will expressed. Likelier, the conditional suffix has already long existed, inherited from the Türkic substrate, in the forms and variations innate to the vernaculars of the Burgund, Vandal, and other European Sarmatian tribes. See would.
English ok (interj.) “expression of positive, agreement, approval” ~ Türkic ok/ök (oq/ök) (positive, emphatic) “verily, very, exactly”. OK (O.K., okeh, okay) is one of the few words that repatriated back to England from the America. Now an international word, in the USA it appeared “from nowhere” in the 19th c., and since generated a few etymological anecdotes, some of them recited in detail in the etymological dictionaries, with a folk etymology of standing for “oll korrect” giving a deserving but misplaced credit to the American ingenuity. Before surfacing in the New World, the pre-American Türkic had to be lurking in England for nearly two millenniums. It is also a member of the pair ok/yok, positive/negative respectively. They are used somewhat derisively in the vast territories of the Eurasia, in the areas of Ukraine, Russia, and it is a popular idiom of the Russian-speaking folks in the Türkic republics who use elements of the local language, especially when something need to be emphasized: the “bread yok, meat yok, vodka ok”, lit. “bread - none, meat - none, vodka - yes”, always said without agitation and with a slight smile. Cognates: A.-Sax. ac, aec with a long list of lose interpretations “but, but also, moreover, nevertheless, however, because, for (?), and (?), unless, except”, these are fairly consistent with the emphatic use of the particle, complementing any theme with an emphasis, they can also be used as interrogative emphasis; Goth. ak “but, however (after negative clauses)”; OHG. oh “but, however”. The literary examples cite the negative version yok; the nearly homophonic jingle ok of the inseparable pair is missing from the literary sources. It can be expected that in the last 2+ millenniums such an abstract interjection would experience some semantic drift and expansion, and develop colloquial nouns, verbs, adverbs, and adjectives. At the same time, interjections are very enduring, retaining their forms, with somewhat lose spelling, over recorded periods across various host languages (Cf. aha, aga “bingo!”). The OK is remarkable for its endurance, international spread, and its particular identification with the American culture. The collection of Eng. interjections common with Türkic languages is extensive; probably more have escaped an attention of dictionaries. They constitute a tangible paradigmatic transfer case that attest to the common genetic origin from the Türkic phylum. See hey, not, quite, uh, voe, worse, yah, yeah, yep, yes.
English on 2 (prep., postp.) “move along, make progress” ~ Türkic ö:n-, ön-, öŋ-, ün-, yöne-, yün- (v.) “grow, sprout”, appear”. An exhaustive phonetic listing would include even wider variations, largely irrelevant for the context. The ö- and ü- are routinely interchangeable; ditto the -n and -ŋ. The length of the vowel had lost its semantic meaning in the archaic times, if it ever bore it, and save for some areal discriminatory significance is etymologically irrelevant. An excessive attention to the particulars of the articulation, complicated by transcriptions in numerous incompatible scripts and vernaculars, only distracts from the substance. The word's base notion is rooted in sprouting of vegetation, and all 15 of its semantic clusters reflect different aspects of sprouting: grow, rise, etc., some with quite remote meanings. The base notion is distinguished by a common trait of attachment to a starting point, Cf. ortho-. In Türkic, the semantic distinction between spoken on 1, on 2, and in is readily apparent. The difference for on 1 < ö:n, öŋ (n.) and on 2 < ö:n-, ön- (v.) is in suffixation, the denoun suffixes vs. the deverbal suffixes, Cf. the on 1 “top”: denoun verb öŋger “carry (on top. in front)”, denoun noun öndün “(in) front”; the on 2 “grow, sprout” deverbal verb önla “grown”, deverbal noun önbek “harvest, crop”. In English, a direct comparison of cognates is muddled, because phonetic forms (on 1, on 2, in) are semantically conflated, etymologically any type of movement in any direction is thrown into the same phonetic pile without regard to its meaning. In the “IE” etymology, on is a universal preposition, adverb, and adjective, with a generous spectrum of semantic meanings: be above or below something, be in something, be with something, be during something, be about something, etc., in other words be anywhere inside or outside of something. There is no sensible explanation to such fuzziness, no etymology, it just appeared from nowhere. Cognates: Du. aan, Gmn. an, Goth. ana, Gk. ana, Lat. an-, OCS na “above, upon” (with up direction), Dan. ӧge; Av. ana “on” (without direction); Balto-Sl. (Lith.) nuo “down from” (down direction); Mong. ӧndei- “rise”; Tungus (Even) ӧn “rise (of water), tide, increase”. It is fairly clear that the Lith. nuo rather belongs to the Sl. notion of niz (низ) “bottom” than to the European on “make progress”. The Dan. form is allophonic with -n-/-g- alternation, and is ethnically diagnostic. Distribution extends across Eurasia and linguistic families. A similar “IE” etymological cacophony surrounds the origin of in (prep.), see and, at, be, en-, in. The Türkic etymology offers semantic explanation for both on (prep.) and in (prep.), with further extensions to adverbs and adjectives. The complex of these prepositions originally had clear and discrete semantic meanings, i.e. move to a higher status vs. move to an inside status, or progress from one status to a new stronger status, get better, improve, heal. The timing of the internalization likely ascends to the amalgamation of the Corded Ware period, when functional parts of the alien words were extracted and re-grammaticized to the local vernaculars. While the links connecting many substrate Turkisms are inferred from the phonetic and semantic similarity, directional indicators provide a third element, the precise words that were first building blocks for creation of the abstract directional indicators. In every case, the origin from the Türkic linguistic milieu is independently traceable and vividly demonstrable as ascending to its own root. See and, at, be, en-, in, on 1, ortho-, till (prep.), to.
English once (adv.) “previous time, before” (Sw N/A, F336, 0.04%) ~ Türkic öŋ “before, previously”. With the öŋ and eŋ fairly homophonic and nearly synonymous, a conflation into a formulaic beginning for the daily recitations of the tales and legends is quite reasonable: a derivative form fr. öŋ to aen (ən), to aenes (ənes), and then the same transition to once. With a dangling possibility of other intermediate forms, and phonetic diffusion inherent to verbal recitations, precise reconstruction of the transition is impossible. But the phonetic and semantic match of the putative start for the attested intermediate and end points clinches a viable conclusion. The English version is unique in Europe, which has its own 28 unique ways to say “once”, plus 6 words of the dead Lat., and that count discounts numerous allophones within different branches. Hence, there is no “PIE proto-word” for the European languages, like a word “one”, even though numerous European languages use it in an idiomatic form. Without a single inherited European stem, “once” is either a random innovation, or a “guest” from another linguistic family. In that regard, Türkic is the largest contributor to English, and it positively has a phonetic and semantic clone to form the word “once”. Cognates: A.-Sax. æne, anes “once”; it straddles both öŋ and eŋ. The “IE etymology” offers “one” (A.-Sax. ane “one”) as a base for once, an accidental conjecture because one lacks a time dimension needed for the notion of a past point in time. It alludes to a notion “for the first time”, “one time (vs. many times)”, not “Once upon a time”. The Türkic origin is supported by two additional independent counts of evidence. The second meaning of öŋ (postpos.) “before, in front” became the base for the Goth. ana (prep.) “on, upon, over (on)”, A.-Sax. an (prep.) “on”, OHG. ana (prep.) “on”, attesting to a paradigmatic transfer (i.e. transfer of two independent meanings of the same word). Also, the second meaning of eŋ, yaŋ “front, face” (eŋäk, yaŋaq) became the base for the Goth. ana-siuns “visible” (lit. “seen front”), Anglo-Sax an-sien “face” (lit. “seen front”), attesting to a second and separate paradigmatic transfer of two independent meanings of the same word. Thus, we observe totally unrelated to the notion of once multi-faceted paradigmatic transfers of a complex of three meanings expressed by two sibling words (öŋ and eŋ). It is apparent that the modern form once had conflated three incompatible independent notions of “on one occasion”, “as soon as”, and “at a previous time”, each one with its own etymological history. The etymology of “one occasion” and “soon” must be traced separately from the “previously”. In the short time since 1200-1300 AD the spelling and pronunciation have changed, confusing undiscerning “IE” linguists equipped with a pre-packaged recipe looking for a problem. Considering at least 4,000 years of independent development and the traversed distances, and that the word must have been in daily use in reciting old legends, the semantic and phonetic match with the Türkic synonyms is as perfect as it gets. See on 1, on 2, en-.
English other (adj., pronoun) “second (adj.), alternate (pronoun)” (Sw N/A, F173, 0.09%) ~ Türkic
ötrü/ötürü (adj., pronoun) “then, following, after”; adır- “separate,
detach”, adın- “other”; özge:/özgä “other, different”.
The base word denotes “separate, separation” and comes in a raster of phonetic forms: ad-, at-,
ay-, ayyr-, az-, üz-, which form downstream derivative lines. The lines are semantically
eidetic, but further vary in the selection of modifiers and ranges of concrete meanings. Ultimately
fr. a polysemantic verbal stem ad-/at- (öt-, öz-), one of its meanings is “odd, strange,
foreign” which also produced the Old English ad “pyre” and its
Gk. and Sl. allophones adis (αδης)
and ad (ад) “hell”. As a result of divergent conventional Romanizations and unsettled
spelling conventions, probably the spelling with -t- does not reflect the soft
-t- closer to an interdental voiceless -th-, and the spelling with -z-
(özge:) similarly masks an interdental voiced -th- (Cf. spelling
öδrün- “chosen, detached” with -δ-). Semantics of the Eng. word is identical
specifically and concordant basically. Since the base notion is “separation”, cognates should cover
that notion. Cognates: A.-Sax. other
“second, alternate, after this”, “the other”; OSax. athar, OFris. other, ONorse
annarr, OHG andar, Gmn. ander, Goth. anthar, Dan. andet, Du.
anders, Sw. andra, all meaning “other”; Sp. otra, Catalan altre; Balt.
(Lith.) antras; Sl. drugoi (другой); Maltese ohra; Lat. alter; Skt.
antarah “other, foreign”; Pers. yzir, digar, Taj. digar “other”; Udi (Lezgic)
ha(n) “separately”; Nanai padi “detached”; Kor. pagi “detached”; Igbo (Nigeria)
ozo
“detached”; Nenets ha “part of”; Tungus (Even) ha
“part of”, (Oroch) ha “part of, some”. The OSax. and Sp. forms demonstrate direct connection
between ötürü (ötrü)
and forms athar, otra. The stem öz/o:z- alludes to something other, and lends itself
to conflation öz ~ ot ~ oth. The ONorse, Gmn., and Goth. have a prosthetic -n-
before fricatives, pointing to a separate dialectal origin. Distribution of the cognates far
exceeds the myopic boundaries of the “IE” etymology, spreading from Atlantic to Pacific. The striking
phonetic dispersion attests to the primeval times of its birth, and millenniums of development under
incompatible conditions. Any notion that the word originated with any dead or alive European
language is absurd waiting to be rescinded. The “IE etymology” connects the word other with the
Lat. compound of unattested *al- “beyond” + unattested adjectival comparative suffix *-tero-,
a sorcerously long shot that would not have produced either the Slavic drugoi, nor the Skt.
antarah, nor the prosthetic -n > nn- before fricatives in the Gmc. and Skt. The phonetic
and grammatic match between the European, Eurasian (Türkic), and Hindustani forms points, first, to
a common source, and second, to major dialectal variations within the common source. The pronounced
commonality between the Gmc. and Hindustani forms attests to a common origin from the within of the
3rd mill. BC Corded Ware culture, brought over to the Hindustan at ca 1500 BC. The Türkic origin is
validated not only by the near-perfect phonetics and perfect semantics, and prodigious distribution,
and traceable links to the underlying notion, but also by the scholars whose independent studies
focused on the subject Türkic word(s). See ad.
133
English over (adv., adj., prep., n., prefix) “above, excess, ultra-, super-” (Sw N/A, F118, 0.15%) ~ Türkic up-, op-, ob- (v.) “up, rise, go up”. A most salient expression of up- from the days of the animal freight horsepower is the command to get up and move on, cited for the 11th c. Khakass and the Middle Age England (17th c.). Parallelism of the o ~ u in the root vowel served as the basis for semantic differentiation in individual Türkic languages. The Türkic verbal stem reached us in a number of verbal conjugations and derivatives: infinitive deverbal verb opla- “rise up (to attack)”, opra:-/opran-/apra-/ofra-/ofran-/ipre-/ipren- “(grow) up (in age), to age”, oprat- “over-aged, weary” causative of opra:-, passive opul- “upped”, deverbal noun opu “upsurge”, deverbal noun/adj. obuz, opuz “hump, humpy”, deverbal adj. opraɣ, opraq “up in age, aged”. A linguist would have to make an effort to miss the connection between derivatives and the base root. Two other Türkic words are similar to up-, one is a:ğ- “rise, climb, ascend” and the other is a:š- “cross over” without implicit implication of rising. That nuanced difference makes above and over synonymous, both imply rising. The A.-Sax. ofer is a reflex of a Türkic causative form, synonymous with the base form up-/op-/ob-, and with -f- like a homophonic form ubak/ufak “small”. The A.-Sax. -f- forms ofra-/ofran- are concordant with the records on the A.-Sax. pronunciation, Cf. contrasting Gmc. forms. The presence of an A.-Sax. completely unrelated homonymous word ofer “boar”, of the local European origin attests that the ofer “over” is a non-native word. Cognates: A.-Sax. ofer, ofor, ufa, ufane, ufon, ufan, yfera, yferra, up, uppe, OSax. obar, OFris. over, ONorse yfir, OHG ubar, Gmn. über, Goth. ufar “over, above”, Dan. øverst, Du. opper, Norse ovenfor, Sw. ovan, ovanför, boven, Icl. yfir; Arm. verin (Վերին); Latv. virs, pari, par, Lith. virš, viršuje; Gujarati upara; Fin. piriste. The semantically identical form ver- and its allophones are a version of the ofer/over/yfir with elided initial vowel or semi-vowel, Cf. Arm, Latv. and Lith. forms vs. ONorse and A.-Sax. yfera. A review of the real and claimed cognates spotlights the ancient folk's and the modern etymological confusion in numerous aspects starting with indistinct and overlapping semantics and ending with origins and conflations. The “IE etymology” confuses the semantically unrelated directional prefixes/prepositions Gk. epi “at, near”, its Lat. allophone ob ditto, Gk. opi- “behind”, Oscan op, Lith. ap- “about, near”, OCS ob “on”, Skt. api “also, besides”, Av. aipi “also, to, toward”, Hittite appizzis “younger” i.e. supposedly “(those) behind” with the A.-Sax. deverbal adverb up, uppe “up, upward”, the cognate of the Gmc. allophones OSax., OFris., up “up, upward”, ONorse upp, Dan., Du. op, OHG uf, Gmn. auf “up”, Goth. iup “up, upward”, uf “on, upon”, OHG oba, Gmn. ob “over, above, on, upon” that expressly pinpoint an upward move or position. The apotheosis of the confusion comes when the upward motion is derived from the faux “PIE root” *upo “under” with diametrically opposite semantics. Such scholastic wiles result from loose criteria and selective sampling, they need to be recsinded. Much of the confusion is brought upon by the widely dispersed phonetics. The forms, diverged by different host vernaculars and independent development, reconvene in a new milieu, bearing close semantics but widely differing forms, Cf. ofer/ufa/yfera/up. Typically, some of the divergent forms stabilize by their semantic shade, grammar function, and expanding utility. The A.-Sax. ofer, ofor, an oddball form within the Gmc. languages, provides a shining example of such a path. In the Clark-Hall 2011, Anglo-Saxon Dictionary (about 20,000 words) they occupy 4 pages of continuous listings numbering more than 350 entries, or above 1.75% of the dictionary material. Few of these derivatives have survived into Eng., Cf. oferaet “overeat”, ofercuman “overcome”, etc. The ofer/ofor forms, compared with the distinct yfir, allow to visualize a demographic relationship of the contributing populations: the form yf-, with the initial semi-consonant, appears to carry a linguistic imprint of the Ogur languages. Its modest proportion points to a minor influence of the candidate Ogur populace in the original Anglo-Saxon composition, which formed long before the advent of the Ogur Huns in the 4th c. AD. The semantic overlap of the forms ofer, ofor and their siblings with the forms abufan, bofan, bufan and their siblings variously expressing the same notions “over” and “above”, and their phonetic similarity point to their common origin ascending to the same Türkic verbal notion up-, op-, ob- “up, rise, go up”. That observation is further supported by the similarity in the wide phonetic dispersions and limits in geographical/ethnic localizations. In spite of the clearly observable overlap, parallelism, and similarity, the confused “IE etymology” ascribed different origin and different “PG” and “PIE” roots, respectively *uberi, *uper “over”, and super-confused “PG” compound of *ufan- “over/high” with a prefix a- “on” and a prefix be- “by” to arrive at abufan “above”, with a concocted “PIE proto-word” absent. Such inept mechanical wiles are unsustainable. Notably, a related Türkic bava, baba (n.) “upper point, top” offers a real and viable alternative for the origin of the “above” without scholastic equilibristics, it suggests a conflation of the noun notion “top” with the verbal notion “up, upward”, i.e. the typical Türkic emphatic pleonasm. Tautology is a common event in linguistic amalgamation (cf. shagreen leather, whole gamut, etc.). The terms above, over, and papa/baba are intrinsically connected. Internalized into the European syntax as bava with an action prefix a- “on” (Cf. alive, asleep, aback, afoot, etc), it is semantically identical with the action notion “above”. The phonetic connection with the papa/baba is striking, statutorily papa/baba relays the very same semantics of “upper, above, top”. Of the two etymological scenarios, one for both over and above being expressions of up-, op-, ob-, and the second for above deriving separately from bava, baba, the evidence tends to lean in favor of the first scenario due to consistent overlapping. The second scenario, due to the paucity of the vestigial evidence, suggest a reborrowing from the Corded Ware vernaculars back into the Türkic milieu. G. Clauson (Clauson EDT) cites 40 instances of reverse reborrowing of Turkisms back into Türkic. In this hypothetical case the bava “father, upper” returned with a narrowed sense of “upper” as opposed to baba “father”. Tracing of the word upon would likely lead to the same source, directly and without a need to appeal to a compound up+on or similar machination, the on is a suffix similar to the suffix -er in over. The common origin of the Eng. and Türkic lexicon is evinced by the paradigmatic transfer of the semantically kindred quartet above, over, high, and papa, an indelible testament to the common origin. See above, high, papa.
English quite (emphatic particle: adv., interj.) “positive degree, extent, reality” ~ Türkic ked (emphatic particle) “very, quite”. Both quite and ked serve to emphatically qualify verbs or clauses, asserting extremely good or exceptional degree of being positively above average. The form ked has few homophones, one of them surfaced in English, Cf. Keds® (shoes). Cognates: A.-Sax. cuð “excellent, noted, famous”; apparently no other cognates, the closest is the Türkic original also depicted keδ with an interdental -δ. No “IE” or any other etymology whatsoever, not even a standard refrain “of unknown origin”, the quite lives as a complete etymological mystery. The suggestion of a connection with a phonetically resembling but semantically unrelated quit “cease, stop, clear of something” and the like homophones is beyond contempt for semantic incongruity. G. Clauson cites a phrase that sounds reasonably close in both languages: bu: key dür “quite good”, lit. “be quite durable” (Clauson EDT 700),, in that case ked and key are allophones, with -d > -y regular transition in Türkic languages. The Türkic inheritance is quite solidly tangible. See be, durable.
(Skip) English sure (adj.) “certain” ~ Türkic sürek (adj.) “sure”. The Türkic verbal stem sür- “lead” is one of most productive polysemantic stems with notions “lead, chase, be engaged into, produce, perform/execute, pull, drag, live, rip, draw/pull off”, with over 100 derivative bases in modern Turkish. Some derivatives have the notions of latching, locking. bolting, slider, continuity, duration, sustainability. Cognates: A.-Sax. orsorg, orsorglic, orsorgnes “safe; secure, safely, unconcerned; security, prosperity”, OHG ursorg ditto; OFr. sur, seur “safe, secure”, Lat. securus “safe, secure, free from care”. The “IE etymology” ascends to Lat. se “free from” + cura “care”, which not only conflicts with, but also ignores the A.-Sax. orsorglic form fr. or- + sorg +lic, where or- is a prefix “out of”, equivalent to Lat. ex-, sorg is “safe”, and -lic is the Türkic suffix -lig/-lan “like”. The parallel presence of cognates sorg and securus “certain, sure, safe” in Lat., OHG, and A.-Sax. points to at least two independent paths to Lat. and Gmc. The interchangeability of u/o in Gmc. and A.-Sax. parallels their interchangeability in Türkic. The “IE” etymological attempt dead ends at Lat., uses the Türkic stem qorq, and is obviously misleading. See care.
English until (prep., conj.) “up to a time” (Sw N/A, F326, 0.04%) ~ Türkic anta, antada “till that” (adv., postpos.). The morphology making antada: tada is a double locative in respect to time and place of the adverb “then”, a form of ol “that”.. Cognates: Sw. intill, Dan. indtil, and the Türkic languages. No “IE” connections, no realistic “IE” etymology. English etymology offers a compound of un- “as far as, up to”, cognate of OFris., OSax., Goth. und “up to, as far as”, which in turn is an allophone of the underlying Türkic an(ta), and till - an allophone of the -ta, with cognates A.-Sax. til (Northumbrian) “to” (locative), ONorse til “to, until”, Dan til, OFris. til “to, til”, Goth. tils “convenient”. Aside from the unsuitable Goth. tils and the Gmn. Ziel “end, limit, point aimed at, goal” (locative), all cognates offer allophonic variations of antada and their contracted part till. The uniformity of the contraction till points to it developed in the early Gmc. internalization. The origin of the final -l lays in the Türkic adjective and adverb-forming suffix -l: anta > antal >> antil, intill, indtil, until “then”. There is no need to insert a Goth. und and other figments.
English yet (adv.) “til (now), withal, even” (Sw N/A, F332, 0.04%) ~ Türkic yet- (v.) “lead, reach”. Cognates: A.-Sax. gyt, giet, gieta “as yet, even”, get, gieta “till now, thus far, earlier, at last, also”, OFris. ieta, Goth. ith (iþ), MHG ieuzo, Dan endnu, Norse enda, Sw ända; Ir. ach, Welsh eto; Lat. sed; Sl. (Ru., Czech, etc.) escho/ješte (еще/ješte), Av. aiti, Gk. eti (ἔτι); Mong. od- (од-); Kor. ajig 아직. The MHG form illustrates the transition yet (Tr.) > ieta (Friz.) > ieuzo (Gmc.) > escho (Sl.). The forms eti (Gk.) and aiti (Av.) demonstrate a separate independent furcation. Scandinavian forms uniformly have a prosthetic inlaut -n-; the variety of Gmc. forms indicate numerous historical paths. The Goth. ith points to an interdental consonant in the original form, in the later alien phonetics rendered with -t, -d, and -z. The interdental consonant is also consistent with the Gmc. regular transition -t-/-d- > -z-. The semantics of the word originated in the act of leading (a horse from and to), and the like, implying movement by both parties. The consistency of the Celtic forms with the later forms suggests that the word originated at a dawn of the horse husbandry, before 4000-3000 BC. Baltic forms for yet are a calque of the Türkic semantics, Latv. vel, Est. veel, from the root for “to lead”. The short form and numerous allophones induced an “IE” etymological confusion that connected unrelated phonetic and semantic expressions for various pronominals and conjunctions, with no initial etymology. Notably, the English word preserved the full semantic spectrum of the Türkic original, implying comparison (“not done yet”), contrariness (“nice yet affordable”, “shut yet leaking”), sufficiency (“light yet filling”), superlativity (“minimal results yet”), process (“not yet coming”), timing (unspecified future “results still coming yet”, indefinite “events yet to come”), simultaneity (“nice yet expensive)”, repetition (“yet again”), they all are reflexes of the base notion in space and time, “lead to, reach a”. The EDT cites the matching Türkic semantics: “sufficient”, “insufficient”, “catch up”, “reach”, “lead”, “overtake”, “extend”, “come”, “arrive”, “join”, “fasten on”, all variations of the same “lead to, reach a” in the Oguz form yet-, while the A.-Sax. forms with a prosthetic g- belong to the Ogur form. Remarkably, in English the Ogur form yielded to the Oguz form, pointing to the prevailing demography. The unique and eidetic phonetics, invariable semantics of a transition process, and parallelism in semantic applications make this short word one of the prime cases of the lexical continuity across millennia and entire continents.
English yuck, yuk, ugh (excl.) “expression of disgust” ~ Türkic ye:k (yek) (n., adj.) “bad, vile, unpleasant, repugnant”, also “demon, devil, (constantly) eating, glutton”, ultimately fr. a verb ye- “eat”, lit. “devourer (of people)”, a prototype of a legendary vampire. Its more expressive and apparently much later form is yakša “demon” lit. “gluttonous, desirous to englut”. Cognates: Skt. ye:k “demon” lit. Tr. “devourer”. Unlike the semantic extension yuk, yuck, the Skt. Buddhist terms of Türkic origin are roughly datable to the period of the 6th c. BC to 5th c. AD, the last is the reasonable terminal date when the Buddhist term could penetrate European vernaculars. In recent English the adjectival “devil” also expressed notions of “bad, vile, unpleasant, repugnant”, a relict of the popular beliefs leading to the Dark Ages. No attested cognates, no claimed “IE” etymology, not even “of uncertain origin”, the stray suggestions on “echoic origin” and the like are not too enlightening statements expressing the absence of the “IE” etymology. No presence across “IE” branches; obvious a guest from alien linguistic families. The variety of spellings and reasons for disgust attest that the word survived on the level of a kitchen talk, deep inside the folk speech and way under radars of the grammarians. Etymologically, the word belongs to the host of the religious terms subsumed or adopted with the advent of the Christianity; the Tengriist faith syncretized various beliefs of various ethnicities, keeping them in the background of purely religious beliefs. See eat, kick, Torah, sin.
Start 6/25/2019 Stop
133
Chuvash-Germanic lexiconChuvash is a relict of a language that is reputed to be an archaic branch of the Türkic, or a remnant of the Ogur branch, or a language of Suvars/Sibirs, or a Turkified Fennic Mari language with idiosyncrasies befitting a language adopted from a different linguistic group. In case of Suvars/Sibirs, they were conquerors of the Bactria in 140 BC. The Y-DNA genetic markers point to a blend of Türkic and Fennic males, with predominant haplogroups R1a (32%), N3 (18%), and N2 (10%) (N3, N2 nomenclature per YCC 2002 convention, aka N-TAT and N-P63 respectively). These markers corroborate the Chuvash Türkic ancestry related to the Aral basin, Huns, and Ogurs (R1a), and to the Ugro-Fennic population (N3, N2), i.e. the archaic branch of the Türkic languages, Suvar ancestry, and a linguistic influence of the Fennic population. A proportion of R1b (4%) is insignificant, attesting to a minor admixture of the Siberian (Kipchak) population. A minor component of the haplogroup C (2%) from the Far Eastern populations (Mongols, Tunguses) contravenes the speculation of the Chuvashes' Far Eastern origin. Genetically, Chuvashes are far remote from their R1b cousins populating the Central and Western Europe, pointing to very deep roots of their common lexicon, predating the Corded Ware period of the 3rd mill. BC, and possibly ascending to the language of the parental haplogroup R1.
Being a stand
out branch within the Türkic family, Chuvashes are endowed with their own Türkic-Germanic
correspondences that defy chance coincidence. In their non-conventionality, they are quite
selective, they chose to solely ally with the Germanic branch, apparently ignoring the Romance,
Indo-Iranic, and every other “IE” branch. What turn of the fate gave them a chance of such peculiar
selection is not clear. Both Chuvashes and Germanic people were member tribes in the Western Hunnic
confederation, but that does not warrant neither a cultural borrowing of the basic vocabulary, for
example words “do” and “child”, nor a close geographical location stipulated for the English
language. The Chuvash - Germanic correspondences add a credence to the suggestion that Chuvashes are
associated with the Suvars, who were attested both in the Central and in the Eastern Europe. We have
a fairly good Suvar chronology that begins with Sumerian inscriptions of the 23rd. c. BC. Chuvashes,
representing an archaic branch of the Türkic people, could not belong to the Sarmatian wave of the
2nd c. BC that is a likely candidate for most of the Germanic-Türkic correspondences. Most of the
words shown in Table 6. “Türkic–Germanic correspondences” also have English correspondences
and are included in Table 4.
134
| No | English | Chuvash | Cognates |
|---|---|---|---|
| 1 | acorn | jěkel | Gmn. Eichel “acorn” |
| 2 | asp | äväs | A.-Sax. æps, Gmn. Espe “asp” |
| 3 | barley | urba | Gmn. Erbse “pea” |
| 4 | cheerful | xatär | A.-Sax. hador, Gmn. heiter “cheerful” |
| 5 | child | papak, pebek | Eng. baby |
| 6 | defense | xüte | Gmn. Hut, Eng. hood, hat, Sw. hatt “defence” |
| 7 | do (v.) | tu | Gmn. tun, Eng. to do, Du doen “to do” |
| 8 | fast, quick | palt | Eng. bold, Gmn. bald “fast, soon” |
| 9 | fence | karta | Eng. garden, Gmn. Garten |
| 10 | food, eatable | apat | A.-Sax. ofett, Gmn. Obst “vegetables” |
| 11 | freeze (v.) | xaltarä | Gmn. kalt, Eng. cold “cold” |
| 12 | good, fine | xitren | A.-Sax. cytren “beautiful” |
| 13 | herd | kěrt | Eng. herd, Sw. hjord, Gmn. Herde “herd, flock”, Goth. haírda |
| 14 | kindred | xajmatläx | Gmn. Heimat, (OHG heimoudil), Got haimoþli “homeland” |
| 15 | otter | ätär | Eng. otter , Gmn. Otter |
| 16 | parsley | pultäran | Gmn. Baldrian “valerian”, Lat. Valeriana, Tr. baldiran |
| 17 | poppy | mäkän | Gmn. Mohn “poppy” |
| 18 | sow-thistle | pěčen | Gmn. Vesen “siftings, bran” |
| 19 | stick up (v.) | čak(k) | Gmn. Zacke “tooth, jag” |
| 20 | thistle | läbär | A.-Sax. laber, leber “rush, reed”, OHG leber |
| 21 | top | tärä | Eng. tor “stony top”. Lat. torus |
| 22 | tremble (v.) | čětre | Gmn. zittern “to tremble” |
| 23 | wake | vak | Gmn. Wake, Eng. wake, Sw. vak “wake” |
| 24 | wormwood | armuti | Gmn. Wermut “wormwood” |
| 25 | superfluous | ytla | Gmn. eitel, Eng. idle, Dt ijdel |
At their core, the leading hypotheses on the substrate of the English language, and by extension of the Germanic languages as a group, turned out to lead nowhere. They were not able to demonstrate continuity in the morphological and lexical aspects, they were not able to attest continuity in the phonological aspect, and they were not able to present instances where the English and suggested substrate language use the same word in the same grammatical function and with the same semantics.
The concept of the Türkic substrate does all of the above. In addition, it supports the existence of genetic connection between the Futhark alphabet and the Türkic alphabets, although its mechanism is yet to be analyzed, it demonstrates the common Türkic origin of the Latin and English linguistic building blocks, and it reflects the known development of the English language. It does not sue for political ends, nor does it mimic the fresh wave of the neutral-looking studious panegyrics to the “IE” extraordinarity. Historically, the Türkic-IE relationship is a yawning gap. A huge complex of disciplines, from archeology to theology, bear grains illuminating interactions, with linguistics sorely trailing in depth and width. A close inspection of mutual linguistic infusions would flag out a cultural and trade road far preceding the Silk Road.
The Türkic substrate concept is based on accumulated knowledge on the movement of the Kurgan
people in the pre-historical and historical times, it is consistent with the findings of the
archeology, genetics, and historical records. Moreover, it corroborates their findings, adding the
linguistic aspect to the body of multi-discipline evidence. Composed in the 20th c. and widely
popularized mantra on the Iranian-linguality of the Scythian and Sarmatian Kurgans (Scytho-Iranian
Theory) stubbornly remained unsupported by contiguous disciplines, including linguistics, it
remained infertile in its insights, and conflicted with the historical, ethnological, and biological
records. Reverting back to the 2000-years old original concept of the Türkic-linguality of the
Scythian and Sarmatian Kurgans restores concordance with the historical records, harmonizes the
linguistic aspect with the other disciplines, allows a better understanding of the historical
developments, and serves as a productive base for understanding of the substrate languages across
Europe. Pinning down the Türkic portion of the substrate allows a deeper insight into the heritage
from the times preceding and synchronic with the Kurgan waves.
135
In respect to morphology, the review of the modern English suffixes demonstrated that proportion of the suffixes inherited from the Türkic substrate stands at 63%, and in the Old English that proportion stood at 69%; the trend is consistent with the known development of the English language. Modern English is a product of perpetual creolization, pidginization, and blending of the linguistically incompatible mother languages, which in turn were products of perpetual creolization, pidginization, and blending. The mother languages came ingrained with linguistic typology, equipped with supremely developed morphology and lexis. The loss of the substrate morphological structure is expressed in the reduction and contraction of the morphological elements, and in concomitant increase in the number of lexemes required to fill in the semantic void created by the morphological contraction. Studies of modern creole languages highlighted their proclivity for marginalizing morphological structures of the substrate languages in integrating substrate lexemes into the new pidgins. English does not stand out, it presents a handy example of that common morphological trend.
The review of the word usage frequency in modern English demonstrated that proportion of the Türkic substrate vocabulary in the modern English is no less than 30%. Results were obtained using the standard experimental method of independent testing that examines random subsets of data for statistical validation of reliability and results. The method produces repeatable and predictable outcomes independent of the researcher. The test for the 800-word vocabulary returned 36.65%. That means that about 1/3 of the passage spoken or written in modern English ascends to the Türkic substrate. Accounting for the Türkic-derived morphological units in the same text would quite significantly boost that rough estimate.
The review of the modern English lexical units versus the Latin and the Türkic demonstrated that the Türkic substrate is present in the Latin, Sanskrit, and English, while the phonetical differences point to separate and independent paths leading to the Latin and English. In the English substrate layer, the Latin Turkisms conflated and superimposed on the English Turkisms, in the end producing modern English words with roots in Old English, Latin, Latin via French, and ultimately in Türkic.
The substrate-derived English lexis is consistent with the migrations outlined by the archeology and genetics, it carries the marks of the migrations, and in some cases allows to draw suggestions about location and time of their earlier presence. Within the framework of the “Indo-European homeland”, such cases allow to corroborate postulations of the “Circumpontic” hypothesis (Merpert, 1974, 1976) and “Kurgan theory” (Gimbutas, 1964, 1974, 1977, 1980) about the importance of the Eastern Europe in the evolution of the “Indo-European” languages, without their fancied allusions to the “Indo-Europeans”, but with evolutionary perspective on the migratory processes that had the Eastern Europe as one of the staging stations on the way from Asia to the Atlantic.
The waves of the Gimbutas' “Kurgan theory” are specific episodes pertaining exclusively to the
Eastern Europe/Central Europe scenery, they are an incomplete part of the overlooked general
migratory processes with the preceding waves leading to the Eastern Europe, with the parallel paths
traversing Anatolia to reach the Balkans and Iberia, and with recurring reverse migrations. Having
such omissions, the partial picture is inevitably faulty, and the confusion between separate
migratory events in opposite directions and a millennium apart is not surprising. The horse was
domesticated in the Northern Kazakhstan, the overlooked wave that brought domesticated horse to the
Eastern Europe created conditions underlying the Gimbutas' “Kurgan theory”. Similarly, the migration
stipulated within the “Anatolian” (or Neolithic Gap”) theory (Gamkrelidze and Ivanov, 1980, Renfrew,
1987, Safronov, 1989, Gray and Atkinson, 2003) is only a specific episode of the Eastern European
parallel path traversing Anatolia to reach the Balkans and Iberia, the partial picture is inevitably
faulty, and results conflict with Anatolia's role as a migratory corridor for particular migrants at
a particular time. Within a larger framework, having accounted for the ample reverse migrations, and
freed from the parochial biases of the “Indo-European homeland”, the theories' data is largely
consistent with the linguistic and migratory processes.
136
The term “substrate” in linguistics refers to an indigenous language that in the process of diffusion and convergence contributes features to the language of the later migrants. The defining characteristic of the language is its grammatical structure, in this case the Germanic grammatical structure, initially inherited and relatively recently elided by English. The Germanic grammatical structure suggests that it was inherited from the substrate language. That raises a question on the substrate-adstrate relationship within the Germanic languages, opens a gate for a possibility of relexification of the Germanic and English languages on the “IE” substrate base, and requires a close study. The Relexification Hypothesis stands in opposition to the Substrate Hypothesis.
The well-developed “IE” Theory was exploited far beyond its capabilities. The “IE” Theory happened not to have a key definition what exactly constitutes the “IE” linguistic family, where are its boundaries, what are the criteria defining what is and what is not IE. Personal intuition substitutes for defined criteria. Consensus does not extend beyond the name “Indo-European linguistic family”, its contents are sorely undefined. The large proportion of English words that straddle credible “IE” and Türkic cognates may be indicative of what the base definition of the “IE” linguistic family should be. The present study enumerated a mass of lexical elements shared by the Türkic family with with various branches of the “IE” languages, and languages of a far-flung spectrum of various linguistic families across Eurasia. By peeling off Turkisms, the study sieved, indirectly and to a certain degree, the innate lexical bodies of the compared languages, a small step toward winnowing unadulterated picture of the mother tongues. The linguistic theory that brought over under a single roof geographically close languages of difference provenance can delve into the sieved material without a burden of circular reconstructions and malleable laws. Science celebrates resurgent facts that dislodge stale models and hypotheses, and open gates for new paths. The study is not refuting the “IE” paradigm, but is rather attesting to symbiotic relations between different human conglomerates composed of diverse human trunks.
It took about a century and a half to correlate dinosaurs with the birds. To save dinosaurs from the birdy onslaught, ideologists and scientists came up with theories, doctrines, and proofs. The contention within and without evolutionary biology continued till a series of dinosaurs came to light, forcing, save for a few stalwarts, a conclusion of the dispute. That moment opened gates for explosive exploration of the bird ancestry on the levels deemed impossible just a few decades earlier. Research shed a new light not as much on the birds as on the dinosaurs, giving them polychromatic colored instead of daub scales, boisterous physique and lifestyle, and turning terrible into cute. Connecting English with its ancestors promises nothing less, to bring colors to replace daub, make philology alive and boisterous, and knit history with language.
At the end of the 5th c. AD, Saxonia was located in the heart of the Europe, at the junction of Germany, Poland, and Czechia (Bohemia), adjacent, and probably a part, of the core Hunnic lands. It can be speculated that after the contraction of the Hunnic Empire, Saxonia came into being as a splinter of the Hunnic state, and possibly populated by a splinter Hunnic tribe lead by a splinter of the Hunnic dynastic clan Dulo. In support of this speculation can be cited vestiges of populations scattered in the nearby mountainous areas who connect their ethnic and historical origin with the Huns, the few literary references of the Huns remaining in that area, and details from the history of the Hungarian migration Honfoglalás to Pannonia and their interface with the local Türkic populations west of Pannonia. Tacitus located Saxes in Holstein, surrounded in the north by Angles in Schleswig and in the south by Angles in the basin of r. Weser, extending to Elbe (Angeiloi), in one continuous arc. Angles and Saxes fell under Hunnic supremacy at the turn of the 5th c., and two generations later started their expansion. They carried their Germanic language with the imbedded Türkic substrate not only to the British Isles, but to the Bohemia area, where their traces waned with time, and to the middle course of r. Elbe, where their traces survived into the present.
The continuity of the Celtic movement from the Iberia to the Central Europe and their eventual
retreat to the northwestern fringes of the Europe is still unclear; the extent, details, and most
cardinally the composition of the Celtic migrations across Europe are blurred, and since English has
a notable Celtic layer, understanding of its origin or origins would help in understanding
linguistical processes. The Scandinavian spill into the continental Europe brought along to the
continental Europe their language and genes, of which the Y-DNA Hg I was a major component.
Clarification of the early Scandinavian demographic, linguistic, and genetic impact on the
Anglo-Saxon and British Isles area may impact the historical picture of the English language
development. The distinct Anglo-Saxon language, perpetuated by the English language, has spread far
and wide, first by colonial expansion, and lately as an international lingua franca. English
preserved the language of the Eurasia, England preserved the Anglo-Saxon democratic traditions of
the Eurasia, and they made them a heritage of the whole world. Numerous examples across Eurasia
played out the same scenario: a relatively small group of nomadic horse breeders imposed themselves
as ruling elite on an alien sedentary society, eventually adopting its language and creating a
common syncretic religious ideology to cement their rule. Almost universally, the mechanism of the
conquest was a peaceful marital union between the conquering and conquered elites. Invariably, the
amalgamation of the languages reflects demographic and social situation, and creates a common lingua
franca. Examples are plentiful, starting from Zhou in China and ending with Norman conquest of
British Isles. In most cases, the new polities became known under the conquerors' name, like
Tokhars, Kushans, and Russians. In few cases, a double name includes both names from the previous
cycle of amalgamation, like As-Tokhars, or both names from the latest compact, like Indo-Scythians.
The Anglo-Saxons amalgamated on the continent, they migrated to the British Isles under a double
name where the part Saxon appears to be a cognate of the names Scythian, Saka, Esgel, Eseg, and
more; these non-native renditions reflected a stem depicted at times as S'k with a glottal stop, but
it was probably closer to the syllable syc- in the word syconium, with the
semi-consonant -y- like in the word eyes. The plural form of the ethnonym may attain
native suffixes -aɣut/-an/än/-ɣut/-güt/-lar/-lär/-s/-t or local plural markers, creating
forms like Sykan (Saxon) and Saklar (Sekler). Traces of these processes have survived
in the folklore of the tribes around Jutland and in the Norse sagas.
137
The blending of OE and Norman Romance is familiar to all students of English as a matter of fact, loanwords from Norman entered English and underwent phonetical changes without much to do about it, they did not originate a new linguistic law on phonetical adaptation that serve to discriminate between compliant and incalcitrant transformations, and to dismiss incalcitrant words as unrelated to the Norman; A.-Sax. turf and OFr. tourbe neatly occupy their appropriate spots on the descent tree without a need to conform to some linguistic law. In other words, no reconstructed OFr. form *tourbe is needed to arrive at turf, and any other allophone would be acceptable as long as the semantics proves a genetic connection. Going from the attested into unattested, however, requires conformance to the phonetical laws, and the semantically sound Türkic turan, turfan, or turmaq may be dismissed as gross noncompliants in spite of the convergent historical, archeological, and biological evidentiality. The resolution of the conundrum seems to be obvious: glotto-transformations are the consequence of the interplay of the historical, demographic, and linguistic factors, and not the other way around.
A comparative study of the western Türkic forms preserved in the European and especially in the Germanic languages may be helpful in resolution of ongoing linguistic problems, like the numerous occurrences of inconclusive translations from different alphabets, which may be confirmed using cognates in the European, Germanic, and western Türkic languages.
On the European arena, English stands out among the European languages. Few other European languages loom likewise. A most interesting subject is connected with the English – Chinese overlap, encountered in the present review of the English Turkisms. Here, examples of the English – Türkic – Chinese correspondences, in a very inexhaustible review, number about 30 out of 800 words, or about 4%. Some of them may be of Chinese origin, of the Austro-Asiatic family, but the majority are positively of the Türkic origin, because they belong to the category of the daily vocabulary older than the state of China, Cf. bĕn “I, me”, err “boy”, pan “dish”, ganche “coachman”, and such. Some of them may be random coincidences, because Chinese words are very short, which greatly increases a probability of chance coincidences, and that has to be validated statistically. Some of them may be late acquisitions, like the Buddhist fosen “bursa/purse”. The balance of the 30 words present an opportunity to peek at the linguistic contribution of the Zhou Scythians to the Chinese language. And since the sample of 30 words is but a random selection of a small part of the Chinese Turkisms that happened to reach English, a more comprehensive comparative review may be quite enlightening in terms of linguistic permeation ascending to the pre-historic times.
The review of the Türkic substrate in English allowed to discern some trends and make some predictions which underlying logics may or may not be consequently validated. One such prediction is that on closer examination, Latin would have more Turkisms with m-dialect than with the b-dialect. The specific testing results of this particular prediction, and other hypotheses may be helpful in archeology, genetics, linguistics, and Eurasian history. Another prediction follows an indicator that consistently exposes linguistic links between English and the languages of the Caspian-Aral basin. In numerous aspects, that agrees with the Edda messages about progenitor Ases. Directly and indirectly, the Türkic tribes of the Caspian-Aral basin interacted symbiotically for millennia with the sedentary population of the Sogd on economical, political, familial, and cultural levels, had to absorb some of the Sogdian lexicon, and had to carry some elements of the Sogdian lexicon to the NW Europe. A close examination of the Türkic-Sogdian links in the Germanic languages may expose some elements of the native Bactrian linguistic phylum prior to the later influences. Still another indicator consistently exposes linguistic links between English and Kirgiz languages, which at the Anglo-Saxon time still was on the level of Enisei Kirgiz. That unanticipated connection may shed a light on the little-known pages of the Eurasian history.
REFERENCESGadjieva English gabble
Adji Murad, 2002, Кipchaks and Оguzes. Medieval History of the Türkic
People and the Great Steppe, News, Moscow, 78, ISBN 5-88149-076-2 (in Russian)
Agasyoglu F., 2000. Azer halgy (sechmə jazylar), Baku
Alinei, M., 2001, European dialects: a window on the prehistory of Europe//Lingua e stile,
XXXVI, pp. 219-240.
Alinei M., 2004, Interdisciplinary and linguistic evidence for Paleolithic continuity of
Indo-European, Uralic and Altaic populations in Eurasia, with an excursus on Slavic ethnogenesis//Quaderni
di semantica, No 26.
Allentoft M.E. et al., 2015, Population genomics of Bronze Age Eurasia Nature 522, 167–172
(11 June 2015) doi:10.1038/nature14507
Balkan K., 2000, Relations between the Language of the Gutians and Old Turkish//Journal of
Erdemir, c. VI
Bichurin N., 1851, Collection of information on peoples in Central Asia in ancient times,
Printing house of military schools, Sankt Petersburg, 1851 (Reprint)
Bikkinin I., 1994, Turkic Borrowings In English, PhD thesis,
Turkic
Borrowings In English (in English)
Caferoğlu A., 1968, Eski Uygur Türkčesi Sözlüğü //Türk Dil Kurumu Yayınlarından, Issue
260. Istanbul
Cambridge Dictionary of English Place-Names (CDEPN), 2004, Ed. V. Watts, Cambridge, CUP, ISBN
978-0521362092
Chemodanov N.S., 1962, Place of Germanic languages among other Indo-European languages,
Moscow, USSR AofS
Chen Sanping, 1998, Some remarks on the Chinese "Bulgar"//Acta Orientalia Academiae
Scientiarum Hungaricae, v. 51, No. 1/2 (1998), pp. 69-83
Chernykh E.N., 2008, Eurasian “steppe belt”: at the origins, Journal “Nature”, 2008. No 3,
pp. 34-43 (In Russian)
Chikisheva T., 2010, Dynamics of anthropological differentiation in South-Western Siberian
population in Neolithic - Early Iron Age, Professorial dissertation, Novosibirsk, 2010
Clark-Hall, J. R., 2011, A Concise Anglo-Saxon Dictionary, Wilder Publications, ISBN
978-1617201875
Clauson G., 1972, (EDT), ED of pre-13th c. Turkish, Oxford
Dialects of Türkic languages, 2010, Ed. A.B. Dybo, Eastern Literature, Moscow
Drozdov Yu.N., 2011, Türkic-lingual Period Of European Historyry, Moscow, Yaroslavl, Letter,
ISBN 978-5-904729-20-2 (in
English)
Doerfer G., 1963, Türkische und mongolische elemente im Neupersischen, I (1963), 96
Doerfer G., 1981, The conditions for proving the genetic relationship of languages//The
Bulletin of the International Institute for linguistic sciences, Kyoto, Sangyo University v. II, No.
4 September, 1981
Dybo A.V., 2007, Chronology of Türkic languages and linguistic contacts of early Türks,
Moscow
Dybo A.V., Starostin G.S., 2008, In Defense of the Comparative Method, or The End of the Vovin
Controversy//Aspects of Comparative Linguistics 3, p.139, Moscow, RSUH
Dybo A.V., Ed., 2010, Dialects of Türkic languages, Eastern Literature, Moscow
Dybo A.V., 2013, Etymological Dictionary of Türkic languages (Этимологический словарь тюркских
языков), v. 9, Astana, Prosper Print, ISBN 978-601-7340-32-2
Feist, S., 1932, The Origin of the Germanic Languages and the Europeanization of North Europe.
Language (Linguistic Society of America) 8 (4): pages 245–254. doi:10.2307/408831.
http://jstor.org/stable/408831
138
Forrer E., 1934, Neue Probleme zum Ursprung der indogermanichen Sprachen.“ Mannus”, B. 26.
Gimbutas M., 1994, The Civilization Of The Goddess, ed. Joan Marler Harper, San Francisco,
1994, ISBN 978-0062508041
Gimbutas M., 1980, The Kurgan wave migration (c. 3400-3200 B.C.) into Europe and the following
transformation of culture, Journal of Near Eastern Studies 8, pp. 273-315.
Haak W.et al., 2015, Massive migration from the steppe was a source for Indo-European languages
in Europe, Nature 522, 207–211 (11 June 2015) doi:10.1038/nature14317
Hall J.R.C., 1916, A concise Anglo-Saxon dictionary, Macmillan, New York.
Hatice Mergen et al., 2004, Mitochondrial DNA sequence variation in the Anatolian Peninsula
(Turkey)//Journal of Genetics, v. 83, No. 1, April 2004
Hawkins J.A., 1990, Germanic languages//Major Languages of Western Europe, ed. Bernard
Comrie, Routledge, ISBN 0-415-04738-2
Herodotus, 1942, The Persian Wars, Transl. G.Rawlinson, Modern Library, New York
Johanson L. Csató, Johanson E.A., The Turkic Languages, Routledge, 1998
Kashgari M., 2005, Divan Lugat at Türk (11th c.), Almaty, Daik Press
Klyosov A., 2010, The principal mystery in the relationship of Indo-European and Türkic
linguistic families, and an attempt to solve it with the help of DNA genealogy: reflections of a
non-linguist//Journal of Russian Academy of DNA Genealogy, v. 3, No 1, pp. 3 - 58, ISSN
1942-7484, 2010
Klyosov A., 2012, Ancient History of the Arbins, Bearers of Haplogroup R1b, from Central Asia to
Europe, 16,000 to 1,500 Years before Present, Advances in Anthropology 2012. Vol.2, No.2,
DOI:10.4236/aa.2012.22010,
http://file.scirp.org/Html/19567.html
Lambton A., 1954 – 1992, Persian Vocabulary (PV), Cambridge, University Press, ISBN 0 521
09154 3
Lopatinsky L.G., 1891, Abkhaz name for Balkars//Note on the Adyge people in general, and in
particular on Kabardians//Collection of materials for description of the Caucasus places and
tribes. Tiflis, 1891, v. 12 5
Maspero, H., 1978, Az ókori Kína. (The ancient China), Gondolat, Budapest
Malov S.E., 1952, Türkic Enisei writings: texts and translations. Moscow-Leningrad.
Mongait A.L., 1974, Archaeology of Western Europe. Bronze and Iron Ages, Moscow, Science
Mukhamadiev A., 1995, Turanian Writing//Problems Of Lingo-Ethno-History Of The Tatar People,
Kazan, Academy of Sciences, pp. 37, 46on
Mukhamadiev A., 2005, Ancient coins of Kazan, Kazan, Tatar Publishing house, ISBN
5-298-04057-8
Murzaev E.M., 1977, Two toponymic subjects//Soviet Turkology, 1977, No 2 pp. 47-48
Old Türkic Dictionary (OTD), 1969, eds. Nadelyaev V.M., Nasilov D.M., Tenishev E.R., Scherbak
A.M., Science Publishing, Leningrad
Oxford English Dictionary (OED),
1989, ed. E. S. Weiner, Oxford
University Press, ISBN 0-198-61186-2
Pennsylvania Sumerian Dictionary (PSD), 2006-2014, Babylonian Section of the University of
Pennsylvania Museum of Anthropology and Archaeology, Philadelphia, Open access
http://psd.museum.upenn.edu/epsd1/index.html
Polomé E.C., 1990, Types of Linguistic Evidence for Early Contact: Indo-Europeans and
Non-Indo-Europeans//Markey-Greppin (eds.) When Worlds Collide 267-89.
Popper K.R., 1963, Conjectures and Refutations, the Growth of Scientific Knowledge,
Routledge, London
Prokosch E., 1939, A Comparative Germanic Grammar, Philadelphia, University of Pennsylvania,
Linguistic Society of America, ISBN 99910-34-85-4
Räsänen M., Versuch eines etymologischen wörterbuchs der Türksprachen, Helsinki, 1969 (Gmn.)
Rosenfelder M., 2002, How likely are chance resemblances between languages?
http://www.zompist.com/chance.htm
Scherbak A.M., 1961, Names of domesticated and wild animals in Türkic languages, Linguistic
Institute, USSR Academy of Sciences
Sevortyan E.V., 1974, (EDTL), Etymological Dictionary of Türkic languages, Science, Moscow. 1974-2003
Shuke G., 2010, Were the Latvians Türks? Phenomenon of Türkic substrate's presence in Baltic
Languages, Daugavpils, 2010, ISBN 978-9984-49-046-5
Smirnitsky, A., 1998, Lectures in the history of the English Language (the Middle and the New.
English Periods), Dobrosvet, Moscow
Steinbauer D. H., 1999, Neues Handbuch des Etruskischen, St. Katharinen
Stetsyuk V., 2003, Research on Prehistoric Ethnogenetic Processes in Eastern Europe, Lvov
Sturluson Snorri, 1842, The Younger Edda, Transl. G. W. Dasent, London, William Pickering
Terentiev V.A. The oldest Turkic borrowings in the languages of Europe // Soviet Soviet
Turkology, 1990, No. 4, pp. 69-73 (Терентьев В.А. Древнейшие тюркские заимствования в языках
Европы // Советская тюркология, 1990, № 4, с. 69-73
Trubetzkoy N., 1923, Der Turm von Babel und die Zusammenführung von Sprache (The tower of Babel
and the merging of languages)//Eurasian Chronicle, Berlin, Bk. 3, pp. 107–124, Reprinted in
Trubetzkoy 1995, pp. 327–338)
Trubetzkoy N., 1928, Proposition 16. Actes de 1er Congrès international de linguistes, 17–18,
Leiden, A.W. Sijthoff’s Uitgevermaatschappij.
Trubetzkoy N., 1995, History. Culture. Language (Istorija. Kul’tura. Jazyk). Moscow:
Progress, Univers.
Uhlenbeck C.C., 1957, The indogermanic mother language and mother tribes complex // American
Anthropologist, Philadelphia, v. 39, no. 3, 385-393
Vasmer, Max, 1953-55, Russisches etymologisches Wörterbuch, Heidelberg
Velden, Von den, F., 1912, Über Ursprung und Herkunft der indogermanischen Sprachen und anarische
Sprachreste in Westeuropa.
Bonn
Velden, Von den, F., 1917, Neue Wege zur Ursprache der alten Welt.
Bonn, Georgi
http://babel.hathitrust.org/cgi/pt?id=njp.32101073641712;view=1up;seq=5
Velden, Von den, F., 1920, Der Ursprung der nichtgemein-indogermanischen Bestandteile der
germanischen Sprachen//Anthropos
14/15, 1919/20, pp. 788-792
Vennemann T., 2003, Languages in prehistoric Europe north of the Alps//Languages in
Prehistoric Europe, eds. Alfred Bammesberger & Theo Vennemann, Heidelberg, C. Winter
Vorontsov V.A., 2009, “Song of Igor's Campaign” In the light of true historicism, Kazan,
Intelpress
Watts V.E., Gelling M., Insley J., 2004 Cambridge Dictionary of English Place-Names (CDEPN),
Cambridge University Press, ISBN 9780521362092
Wiik K., 2008, Where did European men come from?//J. Genetic Genealogy, 4, pp. 35 - 85
Yablonsky L.T., Pejemsky D.V., Suvorova A.N., 2010, Paleoanthropology of Southern Urals
population in Late Sarmat time (Pokrovka-10 burials)//Establishment and development of Late
Sarmat culture (from archeological and natural sciences materials), Proceedings, Center for Study of
Sarmatian History and Culture, No. 13, Volgograd, pp. 143-183
Zarathustra, 2002, Zarathustra. The doctrine of fire. Ghathas and prayers, Moscow,
Eksmo-Press
Zuev Yu. A., 1960, Ethnic History Of Usuns, Kazakh Academy of Sciences, Alma-Ata, v. 8, 12