| charset=iso-8859-1 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Turkic (Chuvash) / East Iranian (Ossetic, Pamir) Note the high semantical stability of all lexical items | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Links |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| http://www.geocities.com/indo_european_geography/turkic_east_iranian_correspondences.html?200819 - this posting is a mirror | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Introduction by the author enstnew at mail ru. External amedments in this posting are shown in blue |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
A short table. Maybe you guys (mates, fellas) think differently, but
I think this short article is paramount. It attempts to
demonstrate that Turkic are Indo-European languages. Note that
all correspondences are rather regular, and most lexical items are
semantically simple and historically stable. Conclusion: the Turkic
languages could be a lost "satemized" branch of the Indo-European
family, although highly modified and not looking like its western
counterparts. [Incidentally, *satem (hundred) is *Ser
or similar in Proto-Turkic.] The whole matter could have something
to do with the spread of | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Posting introduction |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
A little statistics. Presuming that all Swadesh 200 words were
analyzed and came up negative, of the 120 total listed "Eastern
Iranian" words 41 are members of Swadesh 200 list, or 20.5%. Of 41
"Eastern Iranian" Swadesh 200 list words, 40 are present in the
Ossetic language, or 20.0%. The remaining 79 non-Swadesh words can't
be used for Swadesh canonical analysis. The presumption affords a
most conservative estimate, if it is incorrect, the % of common
words would increase.
The 91% per millennium conservation rate, accepted for the
Indo-European languages, does not seem to be applicable to the
Türkic group. There are other coefficients floating around, ranging
down to 83%. Being explained by higher plasticity of flexitive (IE)
vs. agglutinative (Türkic and Ossetic), agglutinative languages are
much more conservative than IE-an because of a fixed system of
unchangeable roots. On the other hand, the societal mobility and
fluidity of the nomadic states brought them in long symbiotic
contacts with a multitude of other languages, which can tentatively
be corrected for by typological and statistical analysis of the
constituent admixtures. A tentative conservation rate change from
91% to 95% per millennium for nomadic societies would effectively
double the estimated duration of geographical separation. The table
illustrates 91% and 83% assumptions, both results contradict a known
history. The Swadesh analysis reflects the admixture effect, not
accounted for in the linguistic tree model
V.I.Abaev eyeballed the presence of patently Turkic words in Ossetic (presumably connected with consequences of the Mongolo-Tatar conquest, in conformance with the official doctrine) at approximately 10%. The Swadesh analysis demonstrates an additional layer of approximately 20%, in the primeval lexicon of the Swadesh 200 vocabulary, for a total of 30% Türkic bases in the undifferentiated Ironian+Digorian Ossetic vocabulary. V.I.Abaev underestimated (or falsified) the Türkic component by a factor of 3. V.I.Abaev also eyeballed the undifferentiated Indo-European portion in the Ossetic as totaling 20%, and allowing for an even split between non-Iranian and Iranian fractions, the Ossetic Iranisms constitute approximately 10%. The ratio of Türkic to Iranian lexicons in the Ossetic vocabulary is 3:1. V.I.Abaev, a prominent Iranist, also noted that the agglutination, morphology, semantics, syntaxis, and phonology of the Ossetic language are not compatible with the Iranian languages. A 40-50% of Ossetic vocabulary V.I.Abaev attributed to the languages of the Caucasian family (variously Adyg and Nakh groups or Adygo-Nakh group). In light of the properties of the Ossetic language, its attribution to the Iranian branch appears more than tenuous, and borders on blunt falsification. The Russian/Slavic and Chinese lexemes, in the present very limited selection, are strikingly similar and parallel each other. The ubiquity of the 2-way and 3-way parallels points in a direction that not only the Slavic family is a result of a part of the Baltic people immingling with the western outreaches of the Türkic people, but that the modern Chinese family is a result of a part of the Sono-Tibetian people immingling with the eastern outreaches of the Türkic people. The results are strikingly similar with the analysis of the Mongolian, Tungus, Korean, and Japanese languages; the Türkic lexemes are not only absorbed as loanwords into the substrate languages, they constitute a superstrate embedded and comingled with the substrate languages. A fine example of this linguistic symbiosis, that defies a Christmas-tree linguistic model, is the Türkic interrogative particle “ku“ (qoy/ğoy/quy/ku/ko/kam/kim/kem) from the verb “qoy-“ “put“, which became imbedded in the Slavic “k-to, glyadi-ko, skaji-ka“/who, look, tell me, with many derivatives and reflexes), and Chinese interrogative morpheme “hu“, also illustrated by precisely identical adaptations by other unrelated linguistic branches, whose only common denominator was an ancient symbiotic relationship with Türkic-lingual peoples. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Notes
on Evidence of Genetic Relatedness between East Iranian and Turkic peopless
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
"Exceptionally high frequencies of M17 are found among the Ishkashimi (68%) (one of the Pamir
languages of the Southeastern Iranian language group in Ishkashimi
district of Badakhshan Province in Afghanistan, the total number of
speakers is ca. 2,500. Ishkashimi-speaking people definitely can't
be selected, other than a joke, as adequate representatives of
linguistically Indo-Iranian peoples that exceed 1 billion population),
the
Tajik population of Khojant (64%), the Kyrgyz (63%), [and
Southern Altays (53%) -- my addition], but are
likely "due to drift, as these populations are less diverse, and are
characterized by relatively small numbers of individuals living in
isolated mountain valleys."[3] [...] Haplogroup R1a is also common among some Mongolic- and Turkic-speaking populations, such as the Bonan (26%, Mongolic), Dongxiang (28%, Mongolic), Uyghur (28%, Turkic), Kazan Tatar (24%, Turkic), Salar (17%, Turkic), Tuvan (14%, Turkic) peoples. The gene has proven to be a "diagnostic Indo-Iranian marker," and
"is likely to represent traces of an ancient population migration
originating in southern Russia/Ukraine," where it may have been
driven by the domestication of the horse around 3,000 B.C.; its
distribution and age are "consistent with the inferred movements of
these people, who left a clear pattern of archaeological remains
known as the Kurgan culture, and are thought to have spoken an early
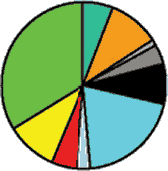
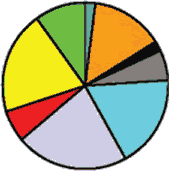
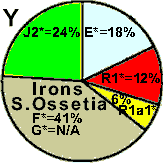
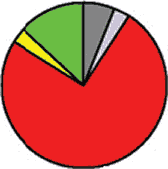
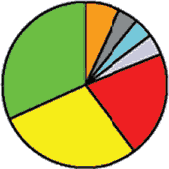
Indo-European language".[3]" This data is difficult to explain by secondary gene absorbtion, because any such hypothesis would require a mechanism explaining why this supposed absorbtion is not only present, but so exceptionally high precisely with these particular groups, which is not found in any other instances. The M17 gene presence in Bonan and Dongxiang can be explained by assuming they passed from Turkic to Mongolic languages. Note that the population of Khojant (the main city in the Pamir mountains) must have necessarily been of Pamir stock (especially Shugni, Rushani, and Yazgulami), which obviously began speaking Tajik only during the recent historical past. Aside from the quasi-scientific spin, the results of the cited study indicate that there is a strong affinity between a handful of Ishkashimi population and Tajik population living in Khojant, and populations of Kyrgyz and Altai states. The graphical picture of Ossetic constituent divisions is shown below. Figure 1 (Excerpts) Y-SNP haplogroup frequencies
It is clearly visible how grossly dissimilar are paternal lineages of the Ossetian Ironians and Digorians. Of the predominant haplogroups, Haplogroup G (red) may have originated in India or Pakistan, and has dispersed into central Asia, Europe, and the Middle East; Haplogroup F (gray) , well preserved in Ironians, contains more than 90% of the world’s population, it was in the original migration out of Africa, or else it was founded soon afterward; Haplogroup I (green) is a European haplogroup, it is almost non-existent outside of Europe, suggesting that it arose in Europe prior to the last Glacial Maximum; Haplogroup J2 (yellow) originated in the northern portion of the Fertile Crescent and later spread throughout central Asia, Mediterranean, and south into India, this lineage is found within Jewish populations. Comparison of the Ossetic graphs with the Persian graphs shows a somewhat relative similarity only between Isfahan dwellers and Ironians. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Based on Mark Rosenfelder's outstanding database |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||